通过 Markdown 改进 RAG 文档处理
通过 Markdown 改进 RAG 文档处理
作者:Tableau
原文地址:https://zhuanlan.zhihu.com/p/29139791931
通过 Markdown 改进 RAG 文档处理 https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw
https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw
如何将 PDF 转换为 Markdown 以获得更好的 LLM RAG 结果
Markdown 是一种轻量级、易读的格式化文本语言。许多人可能通过 GitHub 的 README.md 文件熟悉 Markdown。
以下是一些基本的 Markdown 语法示例:
# Heading level 1
## Heading level 2
### Heading level 3This is **bold text**.This is *italicized text*.> This text is a quoteThis is how to do a link [Link Text](https://www.example.org)This text is code| Header 1 | Header 2 |
|------------|------------|
| table data | table data |
Markdown 正在成为大语言模型(LLMs)的流行格式。
Markdown 具有一些重要优势,例如[1]:
-
为标题、表格、列表、链接等提供结构
-
添加粗体或斜体等排版强调元素
-
易于编写且人类可读
-
已经广泛使用,例如在 GitHub 和 Jupyter notebooks 中
Markdown 不仅在 LLM 输入文档的上下文中有用,它也是像 ChatGPT 这样的聊天机器人格式化其响应的方式。注意 ChatGPT 的响应如何以大号粗体字呈现标题,并对关键词使用粗体文本。

在本文中,我们将在 LLM 和检索增强生成(RAG)的背景下探讨 Markdown。
比较 PDF 库
我们首先测试两个生成纯文本的流行 PDF 阅读器库。然后我们将尝试两个专门为 LLM 设计的新 PDF 阅读器,它们可以生成 Markup。
为了比较不同的 PDF 阅读器,我将使用 Docling 技术报告 2408.09869v3.pdf 作为我的输入 PDF 文件[2],该文件采用 CC BY 4.0 许可。
FILE = "./2408.09869v3.pdf"
PyPDF
PyPDF 是一个免费开源的 Python 库,我们可以用它来轻松读取 PDF 文档。
以下是如何使用 PyPDF 来从 PDF 文件中提取文本:
# pip install pypdf
from pypdf import PdfReaderreader = PdfReader(FILE)
pages = [page.extract_text() for page in reader.pages]
pypdf_text = "\n\n".join(pages)
输出的 pypdf_text 是一个包含提取文本的字符串。
Docling Technical Report
Version 1.0
Christoph Auer Maksym Lysak Ahmed Nassar Michele Dolfi Nikolaos Livathinos
Panos Vagenas Cesar Berrospi Ramis Matteo Omenetti Fabian Lindlbauer
Kasper Dinkla Lokesh Mishra Yusik Kim Shubham Gupta Rafael Teixeira de Lima
Valery Weber Lucas Morin Ingmar Meijer Viktor Kuropiatnyk Peter W. J. Staar
AI4K Group, IBM Research
R¨uschlikon, Switzerland
Abstract
This technical report introduces Docling , an easy to use, self-contained, MIT-
licensed open-source package for PDF document conversion. It is powered by
state-of-the-art specialized AI models for layout analysis (DocLayNet) and table
structure recognition (TableFormer), and runs efficiently on commodity hardware
in a small resource budget. The code interface allows for easy extensibility and
addition of new features and models.
1 Introduction
Converting PDF documents back into a machine-processable format has been a major challenge
然而,我注意到 PyPDF 提取的文本有一些问题:
-
标题除了被换行符包围外,与文本格式没有区别
-
文本高亮,如粗体文本,都丢失了
-
页码在换行符上(就像标题一样)
-
表格没有被正确提取
以下是真实 PDF 表格与 PyPDF 提取的表格的比较:

来自文档[2]的原始 PDF 表格与 PyPDF 提取的文本对比。作者提供的图片。
我怀疑任何人或 LLM 都无法使用这个变形的表格做出任何正确的陈述。
Unstructured
链接:http://Unstructured.io
流行的开源库 unstructured 对于 PDF 文档的处理与 PyPDF 类似。
以下是如何使用 Unstructured 来从 PDF 文件中提取文本:
# pip install unstructured[pdf]==0.16.5
from unstructured.partition.pdf import partition_pdfelements = partition_pdf(FILE)
unstructured_text = "\n\n".join([str(el) for el in elements])
输出格式和问题与 PyPDF 类似。
Unstructured 将上面的表格提取为单行,这也不是我们想要的:
CPU Thread budget TTS native backend Pages/s Mem pypdfium backend TTS Pages/s Mem Apple M3 Max (16 cores) 4 16 177 s 167 s 1.27 1.34 6.20 GB 103 s 92 s 2.18 2.45 2.56 GB Intel(R) Xeon E5-2690 4 16 375 s 244 s 0.60 0.92 6.16 GB 239 s 143 s 0.94 1.57 2.42 GB (16 cores)
PyMuPDF4LLM
PyMuPDF4LLM 是一个专门设计用于提取 PDF 内容并将其转换为 Markdown 格式以用于 LLM 和 RAG 用例的 Python 库。
PyMuPDF4LLM 是开源的,采用 AGPL-3.0 许可。
以下是如何使用 PyMuPDF4LLM 来从 PDF 文件中提取 Markdown 文本:
# pip install pymupdf4llm==0.0.17
import pymupdf4llmmd_text = pymupdf4llm.to_markdown(FILE)
在下图中,我使用 print(md_text) 生成上面的图像,使用 IPython.display 中的 Markdown(md_text) 生成下面的图像。

从文档[2]中 PyMuPDF4LLM 提取的 Markdown 输出。作者提供的图片。
与之前的 PDF 阅读器相比,现在标题使用 Markdown 清晰地格式化。总的来说,输出非常干净。提取的文本中不再有随机的页码。
然而,PyMuPDF4LLM 没有正确解析表格示例:
Thread native backend pypdfium backend
CPU
budgetTTS Pages/s Mem TTS Pages/s MemApple M3 Max 4 177 s 1.27 103 s 2.18
6.20 GB 2.56 GB
(16 cores) 16 167 s 1.34 92 s 2.45Intel(R) Xeon
E5-2690
(16 cores)
Docling
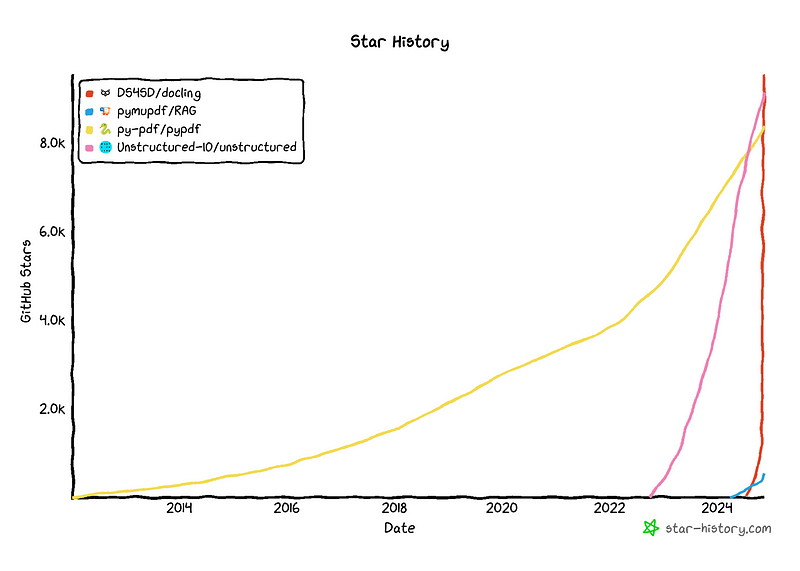
Docling 目前是 GitHub 上的热门仓库。图片由作者使用 https://star-history.com 创建。
IBM 最近发布的 Docling 可以解析文档(PDF、DOCX、PPTX、图像、HTML、AsciiDoc、Markdown)并将它们导出为 Markdown 或 JSON 格式,用于 LLM 和 RAG 用例。
Docling 是开源的,采用 MIT 许可。
以下是如何使用 Docling 来从 PDF 文件中提取 Markdown 文本:
# pip install docling==2.5.2
from docling.document_converter import DocumentConverterconverter = DocumentConverter()
result = converter.convert(FILE)
docling_text = result.document.export_to_markdown()
docling_text 的输出与 PyMuPDF4LLM 的输出类似。然而,Docling 在提取我们的示例表格方面做得更好:
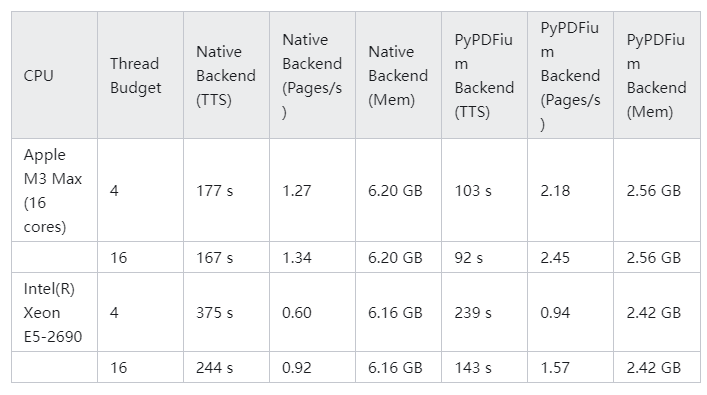
因为输入到 LLM 的表格已经是 Markdown 格式,当我们在 RAG 用例中将这些数据输入到 LLM 时,LLM 可以简单地向用户重现相同的表格,并且它将以人类可读的格式呈现。
Docling 具有出色的表格提取功能的原因是它包含了专门用于表格结构识别的 AI 模型[2]。
基于我的 PDF 文件的结果,Docling 产生了迄今为止最好的结果。 输出的 docling_text 完美地以 Markdown 格式呈现,可以用于下游的 LLM 任务。
处理速度
然而,使用 Docling 有一个缺点,那就是处理速度。我使用 timeit 计算了每个库处理我的 9 页 PDF 示例文件的平均处理速度。
虽然 Docling 给出了最好的结果,但它处理文件也花费了大约 38 秒。另一方面,PyPDF 非常快,只需 461 毫秒。
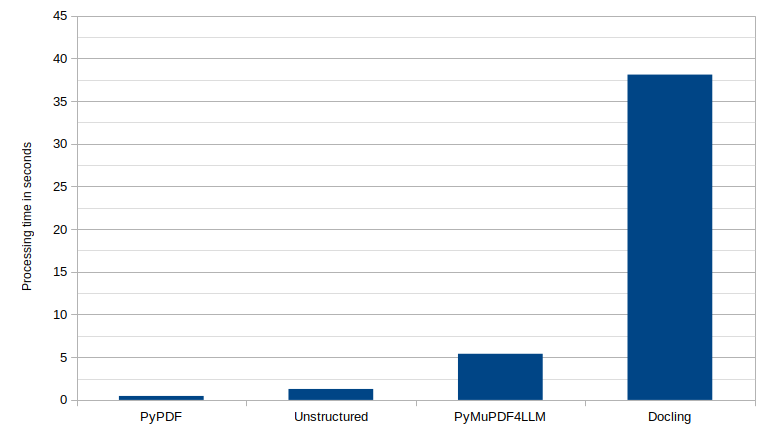
处理 9 页 PDF 文件的时间。PyPDF:461 ms,Unstructured:1.28s,PyMuPDF4LLM:5.4s,Docling:38.1s。作者提供的图片。
分块
在 RAG 上下文中处理 Markdown 的一个重要优势是我们可以使用标题将文档分成连贯的片段。
在读取 PDF 文档并将其转换为 Markdown 后,我们可以使用 LangChain 的 RecursiveCharacterTextSplitter 根据特定的 Markdown 语法进行分块。
LangChain 在 Language.MARKDOWN 中定义了这些默认分隔符:
separators = [# First, try to split along Markdown headings (starting with level 2)"\n#{1,6} ",# End of code block"```\n",# Horizontal lines"\n\\*\\*\\*+\n","\n---+\n","\n___+\n","\n\n","\n"," ","",
]
使用 langchain_text_splitter,我们现在可以使用Markdown 特定的分隔符对我们的 Markdown 文件进行分块:
# pip install langchain-text-splitters==0.3.2
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters.base import Languagetext_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.MARKDOWN,chunk_size=1000,chunk_overlap=100,
)
documents = text_splitter.create_documents(texts=[docling_text])
print(documents[1].page_content)
在 https://langchain-text-splitter.streamlit.app 有一个 LangChain 各种文本分割器的在线演示,你可以尝试使用。
当我比较基本 PyPDF 输出上的 RecursiveCharacter 文本分割器与 Docling 输出上的 MARKDOWN 文本分割器时,Markdown 分割器明显更胜一筹。
向 Markdown 添加元数据
我们可以对 Markdown 文件做的另一件好事是添加 YAML front matter 元数据。
YAML front matter 必须放在文档的开头,所有元数据都包含在三个破折号之间。
以下是可以添加到我们文档中的 YAML front matter 示例:
---
title: document title
filename: document filename
tags: keyword1 keyword2 keyword3
description: summary of the document
---
我们可以从 PDF 文件中提取这些元数据(Docling 的元数据提取功能“即将推出”),或者我们可以使用 LLM 生成必要的元数据。
Anthropic 最近发布了他们称为上下文检索的想法,其中每个文档块都包含一个由 AI 生成的块上下文的简短摘要[3]。
同样,我们可以将 YAML front matter 元数据添加到每个块中。这将为 LLM 提供关于每个块的额外信息,并提高 RAG 检索性能。
让我们从 Docling documents 向每个块添加元数据:
metadata = """---
title: Docling Technical Report
filename: 2408.09869v3.pdf
description: This technical report introduces Docling, an easy to use, self-contained, MIT licensed open-source package for PDF document conversion.
---"""for doc in documents:doc.page_content = "\n".join([metadata, doc.page_content])
现在我们可以将这些块移动到向量数据库中。每个块都以 Markdown 格式精美呈现,并带有额外的元数据。
例如,看看 documents[19].page_content 中的表格有多漂亮。如果没有额外的元数据,表格块将孤立存在,没有任何上下文。
---
title: Docling Technical Report
filename: 2408.09869v3.pdf
description: This technical report introduces Docling, an easy to use, self-contained, MIT licensed open-source package for PDF document conversion.
---
| CPU | Thread budget | native backend | native backend | native backend | pypdfium backend | pypdfium backend | pypdfium backend |
|-----------------------|-----------------|------------------|------------------|------------------|--------------------|--------------------|--------------------|
| | Thread budget | TTS | Pages/s | Mem | TTS | Pages/s | Mem |
| Apple M3 Max | 4 | 177 s | 1.27 | 6.20 GB | 103 s | 2.18 | 2.56 GB |
| (16 cores) | 16 | 167 s | 1.34 | 6.20 GB | 92 s | 2.45 | 2.56 GB |
| Intel(R) Xeon E5-2690 | 4 16 | 375 s 244 s | 0.60 0.92 | 6.16 GB | 239 s 143 s | 0.94 1.57 | 2.42 GB |
总之,这是如何使用 Docling 为 RAG 准备 PDF 文件:
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters.base import Language
from docling.document_converter import DocumentConverterdef process_file(filename: str, metadata: str = None):"""read file, convert to markdown, split into chunks and optionally add metadata"""# read file and export to markdownconverter = DocumentConverter()result = converter.convert(filename)docling_text = result.document.export_to_markdown()# chunk document into smaller chunkstext_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.MARKDOWN,chunk_size=1000,chunk_overlap=100,)docling_documents = text_splitter.create_documents(texts=[docling_text])if metadata:for doc in docling_documents:doc.page_content = "\n".join([metadata, doc.page_content])return docling_documents
结论
在本文中,我比较了四个不同的用于读取 PDF 文件的 Python 库:PyPDF、http://unstructured.io、PyMuPDF4LLM 和 Docling。
前两个库生成纯文本输出,后两个库生成 Markdown。
通过使用 PyMuPDF4LLM 或 Docling 并将 PDF 转换为 Markdown,我们获得了更好的文本格式,减少了信息丢失,并获得了更好的表格解析。
使用 Markdown 语法,我们可以获得更好的文档分块,因为标题可以轻松指导分块过程。
使用 YAML 的 front matter 语法,我们可以向每个块添加额外的元数据。
Docling 在输出质量方面是明显的赢家。然而,Docling 的每个文档的处理时间也是最长的。
参考引用
[1] PyMuPDF (2024), RAG/LLM and PDF: Conversion to Markdown Text with PyMuPDF, Medium blog post from Apr. 10, 2024
[2] C. Auer et al. (2024), Docling Technical Report, arXiv:2408.09869, licensed under CC BY 4.0
[3] Anthropic (2024), Introducing Contextual Retrieval, Blog post from Sep. 19, 2024 on anthropic.com
[4] Unstructured Data Isn’t Just for Embeddings: Hidden Structure can Improve RAG

相关文章:

通过 Markdown 改进 RAG 文档处理
通过 Markdown 改进 RAG 文档处理 作者:Tableau 原文地址:https://zhuanlan.zhihu.com/p/29139791931 通过 Markdown 改进 RAG 文档处理https://mp.weixin.qq.com/s/LOBOKNA71dANXHuwxe7yxw 如何将 PDF 转换为 Markdown 以获得更好的 LLM RAG 结果 Mar…...

Java学习总结-IO流
什么IO流? 以内存为主体。input:磁盘向内存输入内容。output:内存向磁盘输入内容。 IO流的分类:...

python发送qq邮件
1.发送邮件的前提是你的qq邮箱设置能够用程序访问 这个服务点打开 就在 设置->账号 中 可以找到 # 导入 smtplib 库,用于实现 SMTP 协议,可实现邮件的发送功能 import smtplib # 从 email.mime.multipart 模块导入 MIMEMultipart 类,用…...

使用Deployment运行无状态应用
使用Deployment运行无状态应用 文章目录 使用Deployment运行无状态应用[toc]一、工作负载资源与控制器二、ReplicationController、ReplicaSet和Deployment1. ReplicationController(已淘汰)2. ReplicaSet(ReplicationController 的增强版&am…...
跨平台应用程序项目实战教程 6 — 弹出框)
QT Quick(C++)跨平台应用程序项目实战教程 6 — 弹出框
目录 1. Popup组件介绍 2. 使用 上一章内容完成了音乐播放器程序的基本界面框架设计。本小节完成一个简单的功能。单击该播放器顶部菜单栏的“关于”按钮,弹出该程序的相关版本信息。我们将使用Qt Quick的Popup组件来实现。 1. Popup组件介绍 Qt 中的 Popup 组件…...
)
Design Compiler:库特征分析(ALIB)
相关阅读 Design Compilerhttps://blog.csdn.net/weixin_45791458/category_12738116.html?spm1001.2014.3001.5482 简介 在使用Design Compiler时,可以对目标逻辑库进行特征分析,并创建一个称为ALIB的伪库(可以被认为是缓存)&…...

2025高频面试设计模型总结篇
文章目录 设计模型概念单例模式工厂模式策略模式责任链模式 设计模型概念 设计模式是前人总结的软件设计经验和解决问题的最佳方案,它们为我们提供了一套可复用、易维护、可扩展的设计思路。 (1)定义: 设计模式是一套经过验证的…...

41. 评论日记
越复杂的结构越脆弱,你不能因为有智驾有只能,你就全交给它了,手机永久了还发热呢,你全交给它那你要死了也怪不了谁。 这年头的手机基本都有防水,但是你天天拿着这个在泳池里玩,哪天炸了我都只能说炸的响炸的…...

Python第七章09:自定义python包.py
# 自定义python包# 从物理上看,包就是一个文件夹,在该文件夹下包含了一个_init_.py文件,该文件夹可用于包含多个模块文件 # 从逻辑上看,包的本质依然是模块 # _init_.py 标识python包,没有就是普通文件夹࿰…...

基于大模型预测升主动脉瘤的多维度诊疗研究报告
目录 一、引言 1.1 研究背景 1.2 研究目的与意义 二、升主动脉瘤概述 2.1 定义与分类 2.2 发病原因与机制 2.3 流行病学现状 三、大模型技术原理及应用现状 3.1 大模型基本原理 3.2 在医疗领域的应用进展 3.3 针对升主动脉瘤预测的独特价值 四、术前大模型预测方案…...

Lua中table函数使用详解
目录 1. table.concat(list [, sep [, i [, j]]])2. table.insert(list, [pos,] value)3. table.move(src, a, b, dest [, dest_pos]) (Lua 5.3)4. table.pack(...) (Lua 5.2)5. table.remove(list [, pos])6. table.sort(list [, comp])7. table.unpack(list [, i [, j]])总结…...

如何在Windows上找到Python安装路径?两种方法快速定位
原文:如何在Windows上找到Python安装路径?两种方法快速定位 | w3cschool笔记 在 Windows 系统上找到 Python 的安装路径对于设置环境变量或排查问题非常重要。本文将介绍两种方法,帮助你找到 Python 的安装路径:一种是通过命令提…...
)
图形库 EasyX - EasyX 初识(EasyX 概述、EasyX 下载与安装、打开一个窗口、打开一个彩色窗口、绘制简易图形、输出文字)
一、EasyX 概述 EasyX 是一款专为 C 开发者设计的轻量级图形库,主要面向 Windows 平台,它有如下特点 EasyX 的 API 设计简洁直观,易学易用,绘图效果所见即所得 二、EasyX 下载与安装 1、EasyX 下载 官方网址:https…...

《深度探秘:SQL助力经典Apriori算法实现》
在数据的广袤世界里,隐藏着无数有价值的信息,等待着我们去挖掘和发现。关联规则挖掘算法,作为数据挖掘领域的关键技术,能够从海量数据中找出事物之间潜在的关联关系,为商业决策、学术研究等诸多领域提供有力支撑。其中…...

AVR128单片机红外遥控8*8LED点阵屏显示
1)将接收到的红外解码信号用LCD液晶显示屏显示。 2)将接收到的5种红外解码信号分别控制88的液晶点阵屏MATRIX-88-GREEN (颜色可以自定)进行不同的显示:整行从上到下、从下到上轮流显示;整列从左到右、从右到左轮流显示;…...

前端Uniapp接入UviewPlus详细教程!!!
相信大家在引入UviewPlusUI时遇到很头疼的问题,那就是明明自己是按照官网教程一步一步的走,为什么到处都是bug呢?今天我一定要把这个让人头疼的问题解决了! 1.查看插件市场 重点: 我们打开Dcloud插件市场搜素uviewPl…...
)
【c++深入系列】:类与对象详解(中)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 不是因为看到希望才坚持,而是坚持了才能看到希望 那么上一篇博客我讲解了什么是类和对象以及类和对象是怎么定义的࿰…...

【Linux】远程登录时,使用图形界面报错:MoTTY X11 proxy: Unsupported authorisation protocol
1、问题描述 使用 MobaXterm 远程登录Ubuntu后,使用sudo权限运行图形界面程序报错: MoTTY X11 proxy: Unsupported authorisation protocol (gpartedbin:10518): Gtk-WARNING **: 22:01:34.377: cannot open display: localhost:10.02、查看SSH配置 修改 SSH 服务端配置,…...

作用域与上下文:JavaScript魔法森林探秘
在JavaScript的魔法森林里,作用域和上下文是两位神秘的守护者,它们掌控着代码的逻辑流向和变量的生杀大权。今天,就让我们一起踏入这片神奇的土地,揭开全局作用域、函数作用域和闭包的神秘面纱,看它们如何影响我们的代…...
充值成功逻辑和网络异常重试逻辑)
虚拟电商-话费充值业务(五)充值成功逻辑和网络异常重试逻辑
一、网络异常重试逻辑编写 如果在对接供应商的过程中出现了网络异常,我们需要做一个补偿机制,在任务类型枚举类:TaskTypeEnum中有一种业务状态码是针对远程调用失败的 步骤一:在对接供应商的方法:SupplierServiceImp…...

42.评论日记
怎么看待算命? 我能算到你今晚睡觉前会上一次厕所。 你可以选择相信我算的内容,也可以不信。 你也可以有感觉要上厕所的时候不去拉兜里。 也可以选择相信,早早的拿好纸做准备。 你今晚可能不止上一次,也可能今晚没吃没喝早早…...

MTK-GMS版本国内WIFI受限问题
MTK-GMS版本国内WIFI受限问题解决 文章目录 问题参考资料解决方案方案一 修改配置坑点 方案二 直接修改属性 问题 最近负责ROOM 产品,出现WIFI受限显示,但是网络是通畅的。 GMS 版本,在国外或者国内翻墙网络不会出现WIFI受限显示问题&#…...

C# System.Text.Json 中 JsonConverter 使用详解
总目录 前言 在 C# 开发中,System.Text.Json 是一个高性能的 JSON 处理库,广泛用于序列化和反序列化对象。当默认的序列化行为无法满足需求时,JsonConverter 提供了强大的自定义能力。本文将详细讲解 JsonConverter 的使用方法,帮…...

Leetcode 857 -- 贪心 | 数学
题目描述 雇佣 K 名工人的最低成本 思路 参考官方题解和这里。 代码1(正确) class Solution { public:double mincostToHireWorkers(vector<int>& quality, vector<int>& wage, int k) {int n wage.size();double res 0, totalq …...

基于 SpringBoot 的社区维修平台
收藏关注不迷路!! 🌟文末获取源码数据库🌟 感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多…...

maven项目添加第三方JAR包
项目开发过程中,不可避免的需要用到一些maven库(公共库、司库等)中没有的冷门jar包依赖,这时,可以将这些第三方JAR包安装到本地maven仓库中,实现项目依赖的一致性。具体步骤如下: 1、下载jar包 …...
)
C#:接口(interface)
目录 接口的核心是什么? 1. 什么是接口(Interface),为什么要用它? 2. 如何定义和使用接口? 3.什么是引用接口? 如何“引用接口”? “引用接口”的关键点 4. 接口与抽象类的区…...

c#和c++脚本解释器科学运算
说明: 我希望用c#和c写一个脚本解释器,用于科学运算 效果图: step1: c# C:\Users\wangrusheng\RiderProjects\WinFormsApp3\WinFormsApp3\Form1.cs using System; using System.Collections.Generic; using System.Data; using System.Tex…...

2025年嵌入式大厂春招高频面试真题及解析
以下是 2025 年嵌入式大厂春招高频面试真题及解析,结合真题分类和核心知识点整理: 一、C/C++编程基础 1.1 指针与内存 野指针的成因及避免方法(未初始化、释放后未置空) malloc与calloc的区别(后者自动初始化为0) 指针与数组的区别(内存分配方…...

【C++】nlohmann::json 配置加载技术实践:从基础到高级应用
一、nlohmann::json 库概况与核心特性 nlohmann::json 是 C 社区最受欢迎的 JSON 库之一,其设计理念简洁即美,通过单头文件实现完整的 JSON 解析、序列化和操作功能。 1.1 基本特性 nlohmann::json是一个现代C编写的开源JSON库,采用MIT协议…...

ngx_regex_init
定义在 src\core\ngx_regex.c void ngx_regex_init(void) { #if !(NGX_PCRE2)pcre_malloc ngx_regex_malloc;pcre_free ngx_regex_free; #endif } NGX_PCRE21 #if !(NGX_PCRE2) 就为假 条件不成立 ngx_regex_init 函数就成了空实现 NGX_PCRE2 被定义,则表示 Ngin…...

【前端扫盲】postman介绍及使用
Postman 是一款专为 API 开发与测试设计的 全流程协作工具,程序员可通过它高效完成接口调试、自动化测试、文档管理等工作。以下是针对程序员的核心功能介绍和应用场景说明: 一、核心功能亮点 接口请求构建与调试 支持所有 HTTP 方法(GET/POS…...

Lua中os模块函数使用详解
目录 os.clock()os.date([format [, time]])os.difftime(t2, t1)os.execute(command)os.exit([code [, close]])os.getenv(varname)os.remove(filename)os.rename(oldname, newname)os.setlocale(locale [, category])os.time([table])os.tmpname()总结 以下是 Lua 中 os 模块的…...

量子计算与经典计算的拉锯战:一场关于计算未来的辩论
在计算科学领域,一场关于未来的激烈辩论正在上演。2025年3月,D-Wave量子公司的研究人员在《Science》杂志上发表了一项突破性成果,声称他们的量子退火处理器在几分钟内解决了一个经典超级计算机需要数百万年才能完成的复杂现实问题。这一声明…...

MySQL 基础入门
写在前面 关于MySQL的下载安装和其图形化软件Navicat的下载安装,网上已经有了很多的教程,这里就不再赘述了,本文主要是介绍了关于MySQL数据库的基础知识。 MySQL数据库 MySQL数据库基础 MySQL数据库概念 MySQL 数据库: 是一个关系型数据库管理系统 。 支持SQL语…...

GPT模型搭建
GPT模型搭建 1. 章节介绍 本章节聚焦于从0搭建GPT模型,通过事先准备的基础代码,引导学习者逐步构建模型。旨在让程序员、软件架构师和工程师等掌握GPT模型搭建的核心流程,理解其关键组件与技术细节,为实际应用和面试做好准备。 …...
)
BUUCTF-web刷题篇(8)
17.EasyCalcS 查看源码,发现有段代码有php文件,即calc.php 经过代码审计之后应该要访问calc.php文件,打开后: <?php error_reporting(0); if(!isset($_GET[num])){show_source(__FILE__); }else{$str $_GET[num];$blackli…...

AI SEO内容优化指南:如何打造AI平台青睐的高质量内容
AI SEO内容优化指南:如何打造AI平台青睐的高质量内容 在生成式AI平台(如DeepSeek、Kimi、豆包、腾讯元宝等)主导的搜索新时代,内容优化已成为企业抢占流量入口的核心策略。本文将从内容创作、分发到效果维护全链路,解…...

无需预对齐即可消除批次效应,东京大学团队开发深度学习框架STAIG,揭示肿瘤微环境中的详细基因信息
生物组织是由多种类型细胞构成的复杂网络,这些细胞通过特定的空间配置执行重要功能。近年来,10x Visium、Slide-seq、Stereo-seq 和 STARmap 等空间转录组学 (ST) 技术的进步,使得生物学家们能够在空间结构内绘制基因数据,从而各类…...

B2B2C多用户商城系统:打造新零售电商生态的创新解决方案
在当今数字化时代,电商行业正以前所未有的速度蓬勃发展,而新零售作为电商与传统零售的深度融合,正逐渐成为市场的新宠。为了满足这一变革带来的多元化需求,B2B2C多用户商城系统应运而生,为商家和消费者搭建了一个高效、…...
:多模态 AI 如何工作?)
走向多模态AI之路(二):多模态 AI 如何工作?
目录 前言一、跨模态对齐(Cross-modal Alignment):AI 如何理解不同模态的关系二、多模态融合(Multimodal Fusion):AI 如何整合不同模态的信息三、多模态生成(Multimodal Generation)…...

MCP 实战:实现server端,并在cline调用
本文动手实现一个简单的MCP服务端的编写,并通过MCP Server 实现成绩查询的调用。 一、配置环境 安装mcp和uv, mcp要求python版本 Python >3.10; pip install mcppip install uv 二、编写并启用服务端 # get_score.py from mcp.server.fastmcp import…...
与栈(Stack):从基础到任务队列实战)
C#游戏开发【第18天】 | 深入理解队列(Queue)与栈(Stack):从基础到任务队列实战
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

2.5路径问题专题:LeetCode 64. 最小路径和
动态规划解决最小路径和问题 1. 题目链接 LeetCode 64. 最小路径和 2. 题目描述 给定一个包含非负整数的 m x n 网格 grid,从网格的左上角出发,每次只能向右或向下移动一步,最终到达右下角。要求找到一条路径,使得路径上的数字…...
)
办公设备管理系统(springboot+ssm+jsp+maven)
基于springboot的办公设备管理系统(springbootssmjspmaven) 系统功能主要有: 欢迎页账号管理 管理员账号管理系统账号添加密码修改 普通管理员管理 用户管理用户添加用户查询 资产类型管理资产信息管理资产档案管理资产报表...

蓝桥杯2024JavaB组的一道真题的解析
文章目录 1.问题描述2.问题描述3.思路分析4.代码分析 1.问题描述 这个是我很久之前写的一个题目,当时研究了这个题目好久,发布了一篇题解,后来很多人点赞,我都没有意识到这个问题的严重性,我甚至都在怀疑自己…...

数据库--SQL
SQL:Structured Query Language,结构化查询语言 SQL是用于管理关系型数据库并对其中的数据进行一系列操作(包括数据插入、查询、修改删除)的一种语言 分类:数据定义语言DDL、数据操纵语言DML、数据控制语言DCL、事务处…...

SQL Server:Log Shipping 说明
目录标题 SQL Server Log Shipping与Oracle归档日志备份对比分析一、SQL Server Log Shipping的日志截断机制二、Oracle归档日志备份对比三、关键配置对比表四、最佳实践建议 如何修改和查看SQL Server默认备份配置防止自动删除?一、查看现有备份配置二、修改备份配…...

Zephyr实时操作系统初步介绍
一、概述 Zephyr是由Linux基金会托管的开源实时操作系统(RTOS),专为资源受限的物联网设备设计。其核心特性包括模块化架构、跨平台兼容性、安全性优先以及丰富的连接协议支持。基于Apache 2.0协议,Zephyr允许商业和非商业用途的自…...

【大模型系列篇】大模型基建工程:基于 FastAPI 自动构建 SSE MCP 服务器 —— 进阶篇
🔥🔥🔥 上期 《大模型基建工程:基于 FastAPI 自动构建 SSE MCP 服务器》中我们使用fastapi-mcp自动挂载fastapi到mcp工具,通过源码分析和实践,我们发现每次sse请求又转到了内部fastapi RESTful api接口&…...