机器学习的一百个概念(9)学习曲线
前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
引言
在机器学习领域,模型性能评估是一个永恒的话题。当我们构建模型时,常常会遇到一系列问题:模型是否充分学习了数据中的规律?是否需要收集更多数据?模型复杂度是否合适?为了回答这些问题,我们需要一个强大的分析工具,这就是学习曲线(Learning Curve)。🔍
学习曲线是机器学习从业者的必备分析工具,它直观地展示了模型学习过程中的性能变化趋势,帮助我们深入理解模型行为,指导模型优化方向。本文将全面探讨学习曲线的概念、原理、应用以及实践,帮助读者掌握这一强大的分析利器。💪
学习曲线的定义与作用
什么是学习曲线?
学习曲线是一种可视化工具,用于展示模型性能随训练过程变化的趋势图。它通常以下面两种方式之一呈现:
- 训练集大小为横轴:展示模型在不同训练样本数量下的性能表现,帮助评估数据量对模型性能的影响。
- 训练迭代次数为横轴:展示模型在训练过程中性能的变化趋势,用于监控模型收敛情况。
纵轴通常是某种性能度量指标,如准确率(Accuracy)、误差率(Error Rate)、损失值(Loss)等。关键的是,学习曲线同时展示了模型在训练集和验证集上的性能,这两条曲线之间的关系是我们诊断模型问题的重要依据。📈
学习曲线的核心作用
学习曲线在机器学习中扮演着多重角色:
- 模型状态诊断:通过曲线形态识别模型是处于过拟合、欠拟合还是理想状态
- 数据需求评估:判断增加训练数据是否能提升模型性能
- 学习动态观察:监控模型在训练过程中的学习进展
- 模型选择指导:为模型复杂度的调整提供依据
- 计算资源规划:帮助评估继续训练的边际收益,优化计算资源分配
通过学习曲线,我们可以更科学地认识模型的学习行为,而不是凭经验或猜测进行模型调整。这是实现数据驱动决策的重要工具。🧪
学习曲线的数学原理
基础数学表达
从数学角度看,学习曲线本质上是描述性能指标随训练条件变化的函数关系。假设我们用 E E E表示模型的性能指标(如误差),用 m m m表示训练样本数量,则学习曲线可表示为:
E = f ( m ) E = f(m) E=f(m)
对于不同的数据集,训练集误差 E t r a i n E_{train} Etrain和验证集误差 E v a l E_{val} Eval都是样本数量 m m m的函数:
E t r a i n = f t r a i n ( m ) E_{train} = f_{train}(m) Etrain=ftrain(m)
E v a l = f v a l ( m ) E_{val} = f_{val}(m) Eval=fval(m)
理想情况下,随着 m m m的增加, E t r a i n E_{train} Etrain会逐渐增大(因为更多数据使模型更难"记住"所有样本),而 E v a l E_{val} Eval会逐渐减小(因为更多训练数据提升了泛化能力),最终两者趋于接近某个值。这个值近似于模型在该问题上能达到的最佳性能,也称为不可约误差。🧮
偏差-方差分解视角
学习曲线的行为可以通过偏差-方差分解(Bias-Variance Decomposition)更深入地理解。预测误差可分解为三个部分:
E r r o r = B i a s 2 + V a r i a n c e + I r r e d u c i b l e E r r o r Error = Bias^2 + Variance + Irreducible\ Error Error=Bias2+Variance+Irreducible Error
- 偏差(Bias):反映模型假设与真实规律的差距,通常与欠拟合相关
- 方差(Variance):反映模型对训练数据扰动的敏感度,通常与过拟合相关
- 不可约误差:数据本身的噪声所导致的误差,无法通过模型改进消除
当训练样本增加时,一般来说方差会减小(模型变得更稳定),而偏差几乎不变。这就解释了为什么增加数据量对高方差(过拟合)的模型更有效,而对高偏差(欠拟合)的模型帮助有限。📐
学习曲线的典型形态
学习曲线的形态多种多样,但有几种特征形态特别值得关注,因为它们对应着常见的模型问题状态。理解这些典型形态,可以帮助我们快速判断模型状况。🔬
理想学习曲线
理想的学习曲线具有以下特征:
- 训练误差随样本增加而平稳上升,最终趋于稳定
- 验证误差随样本增加而持续下降,最终趋于稳定
- 两条曲线最终收敛到接近的误差值,且该值较低
- 两条曲线之间的间隙(gap)较小
这种情况表明模型复杂度适中,既能充分学习数据中的规律,又不会过度拟合训练数据的噪声。模型具有良好的泛化能力,增加更多数据对性能提升有限。✅
欠拟合模型的学习曲线
欠拟合(高偏差)模型的学习曲线表现为:
- 训练误差较高,且随样本增加迅速趋于稳定
- 验证误差也较高,与训练误差较为接近
- 两条曲线早期就几乎平行,增加数据后几乎不再变化
- 两条曲线之间的间隙小
这种情况下,模型复杂度不足,无法捕捉数据中的重要规律。即使给予更多数据,模型表现也难以显著提升,因为模型本身表达能力有限。📉
过拟合模型的学习曲线
过拟合(高方差)模型的学习曲线表现为:
- 训练误差非常低,几乎接近零
- 验证误差明显高于训练误差
- 两条曲线之间存在显著的间隙
- 随着样本增加,间隙可能逐渐缩小,但仍然明显
这种情况表明模型过于复杂,不仅学习了数据中的真实规律,还"记住"了训练数据中的噪声。增加更多训练数据通常有助于改善这种状况,因为更多数据可以帮助模型更好地区分真实规律与随机噪声。📈
从学习曲线诊断模型问题
学习曲线的一个关键应用是帮助诊断模型存在的问题,并指导改进方向。下面我们详细探讨如何利用学习曲线进行问题诊断。🔍
诊断流程
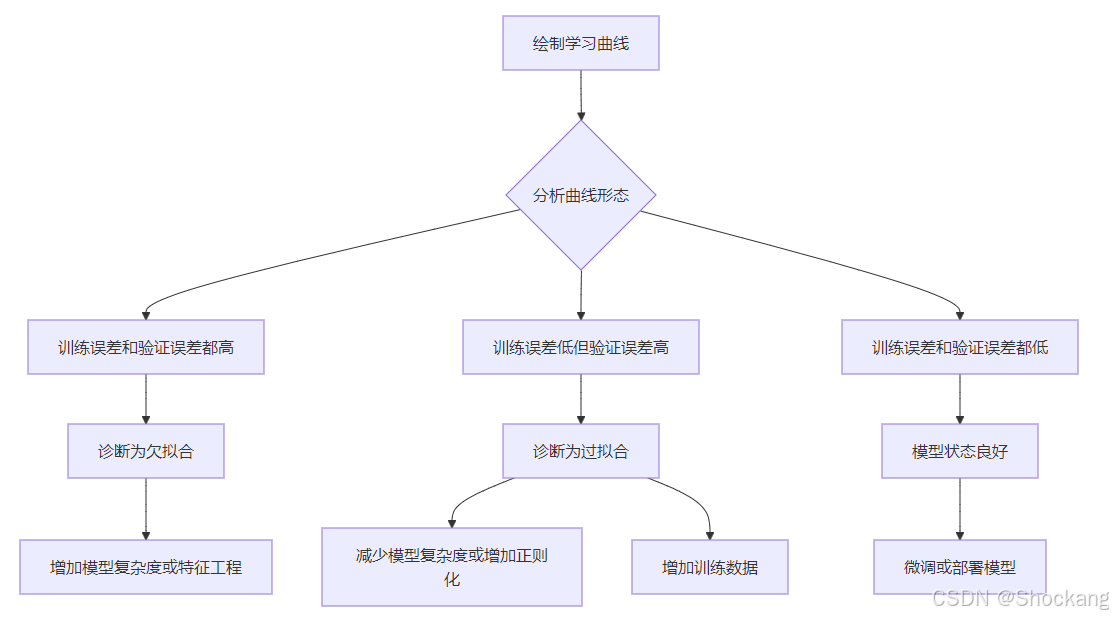
欠拟合问题的诊断与解决
当学习曲线显示训练误差和验证误差都较高且接近时,我们面临的是欠拟合问题。这表明模型太过简单,无法捕捉数据中的复杂模式。🔎
解决方案:
- 增加模型复杂度:使用更复杂的模型结构,如从线性模型升级到非线性模型
- 增加特征数量或复杂度:添加更多相关特征,或创建特征交互项
- 减少正则化强度:如果使用了正则化技术,可以适当降低正则化参数
- 模型架构变更:尝试完全不同的模型类型,如从决策树转向神经网络
需要注意的是,仅仅增加训练数据通常对欠拟合问题帮助有限,因为问题不在于数据不足,而在于模型表达能力不足。🛠️
过拟合问题的诊断与解决
当学习曲线显示训练误差很低但验证误差明显较高时,我们面临的是过拟合问题。这表明模型过于复杂,"记住"了训练数据中的噪声。🔍
解决方案:
- 增加训练数据:更多的训练样本有助于模型区分真实模式与噪声
- 减少模型复杂度:使用更简单的模型结构,如减少神经网络层数或节点数
- 应用正则化技术:如L1/L2正则化、Dropout、早停等
- 特征选择:移除无关或冗余特征,减少模型需要学习的参数
- 数据增强:通过创建合成样本扩充训练集,同时保持数据分布
过拟合是机器学习中最常见的问题之一,尤其是在数据有限但模型复杂的情况下。学习曲线是检测和监控过拟合的有力工具。🛠️
理想状态的确认
当学习曲线显示训练误差和验证误差都较低且接近时,表明模型达到了相对理想的状态。此时模型既能有效学习数据模式,又具有良好的泛化能力。🎯
后续可能的操作:
- 微调超参数:通过网格搜索或随机搜索进一步优化模型性能
- 模型集成:尝试组合多个模型提升性能
- 部署与监控:将模型部署到生产环境,并持续监控其性能
- 尝试更先进的模型:如果有更高性能要求,可以尝试更先进的算法或架构
即使模型状态看起来理想,我们也要警惕数据分布偏移(Data Drift)的问题,即生产环境中的数据分布可能随时间变化,导致模型性能下降。👍
学习曲线在实际应用中的决策指导
学习曲线不仅是一种诊断工具,更是指导实际机器学习项目决策的重要依据。下面我们讨论学习曲线如何帮助我们在实际项目中做出更明智的决策。🧭
数据收集策略
一个常见的问题是:我们是否需要收集更多数据?学习曲线可以帮助回答这个问题:
- 如果验证曲线仍在下降且与训练曲线有明显间隙,增加数据可能带来明显收益
- 如果验证曲线已趋于平稳,即使与训练曲线有间隙,增加数据可能收益有限
- 如果两条曲线都已平稳且接近,增加数据几乎不会带来额外收益
这种分析可以避免不必要的数据收集成本,或者证明额外数据收集的价值。💼
计算资源分配
学习曲线还可以帮助评估继续训练的价值,指导计算资源分配:
- 当学习曲线显示性能仍在明显改善时,值得继续投入计算资源
- 当学习曲线趋于平稳时,可能需要改变策略而非简单地继续训练
- 在早期停止训练可以节省计算资源,尤其是在大规模模型训练中
在资源有限的环境中,这种指导尤为重要,能够帮助团队将计算资源用在最有价值的地方。⚙️
模型复杂度选择
学习曲线对模型复杂度选择提供了重要参考:
- 欠拟合模型的学习曲线通常指示我们需要增加模型复杂度
- 过拟合模型的学习曲线则表明我们应该减少复杂度或增加正则化
- 不同复杂度模型的学习曲线对比可以帮助找到"甜蜜点"
在实践中,可以绘制多个不同复杂度模型的学习曲线,并选择在验证集上表现最佳且学习曲线形态健康的模型。这比简单地比较最终性能更有指导意义。🎛️
特征工程决策
学习曲线也可以指导特征工程过程:
- 如果学习曲线显示欠拟合,可能需要创建更多复杂特征或特征交互项
- 如果学习曲线显示过拟合,可能需要减少特征数量或增加特征选择
- 通过比较添加新特征前后的学习曲线,可以评估该特征的价值
这种分析帮助我们系统地改进特征集合,而非基于直觉或试错进行特征工程。📊
使用Python实现学习曲线分析
Python以其丰富的机器学习库和可视化工具,是实现学习曲线分析的理想环境。下面我们将展示如何使用Python,特别是scikit-learn库,实现学习曲线的分析。💻
基本实现
首先,我们看一个使用scikit-learn实现学习曲线的基本示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_iris
from sklearn.svm import SVC# 加载数据
iris = load_iris()
X, y = iris.data, iris.target# 计算学习曲线
train_sizes, train_scores, valid_scores = learning_curve(SVC(kernel='rbf', gamma=0.1), X, y, train_sizes=np.linspace(0.1, 1.0, 10),cv=5,scoring="accuracy"
)# 计算平均值和标准差
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
valid_mean = np.mean(valid_scores, axis=1)
valid_std = np.std(valid_scores, axis=1)# 绘制学习曲线
plt.figure(figsize=(10, 6))
plt.plot(train_sizes, train_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, valid_mean, 'o-', color="g", label="Cross-validation score")# 添加误差条
plt.fill_between(train_sizes, train_mean - train_std, train_mean + train_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, valid_mean - valid_std, valid_mean + valid_std, alpha=0.1, color="g")# 添加图表元素
plt.title('Learning Curve - SVM')
plt.xlabel('Training Size')
plt.ylabel('Accuracy Score')
plt.legend(loc="best")
plt.grid()
plt.show()
这段代码首先使用learning_curve函数计算不同训练集大小下的性能指标,然后可视化结果。函数返回三个值:训练集大小、训练集得分和验证集得分。我们还添加了标准差区域,以显示交叉验证的变异性。🔧
高级可视化技巧
为了让学习曲线更具信息量和可读性,我们可以添加一些高级可视化功能:
def plot_learning_curve(estimator, X, y, title="Learning Curve", ylim=None, cv=5, n_jobs=None, train_sizes=np.linspace(.1, 1.0, 10)):plt.figure(figsize=(12, 8))plt.title(title, fontsize=18)if ylim is not None:plt.ylim(*ylim)plt.xlabel("Training examples", fontsize=14)plt.ylabel("Score", fontsize=14)train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, scoring="accuracy")train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)# 绘制训练集和测试集分数plt.grid(True, linestyle='--', alpha=0.5)plt.plot(train_sizes, train_scores_mean, 'o-', color="#ff7f0e", label="Training score", linewidth=2)plt.plot(train_sizes, test_scores_mean, 'o-', color="#1f77b4",label="Cross-validation score", linewidth=2)# 添加标准差区域plt.fill_between(train_sizes, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.2, color="#ff7f0e")plt.fill_between(train_sizes, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.2, color="#1f77b4")# 添加最佳性能标记和性能差距max_train = np.max(train_scores_mean)max_test = np.max(test_scores_mean)gap = max_train - max_testplt.annotate(f'Max train: {max_train:.4f}', xy=(0.7, 0.02), xycoords='axes fraction', fontsize=12)plt.annotate(f'Max test: {max_test:.4f}', xy=(0.7, 0.06), xycoords='axes fraction', fontsize=12)plt.annotate(f'Gap: {gap:.4f}', xy=(0.7, 0.10), xycoords='axes fraction', fontsize=12)plt.legend(loc="lower right", fontsize=14)return plt
这个增强版函数提供了更多信息:
- 自定义标题和轴标签
- 清晰的网格线
- 明显的颜色区分
- 标准差阴影区
- 最大训练/测试分数标注
- 训练-测试性能差距
这些增强使学习曲线更加信息丰富,便于解释和决策。🎨
比较多个模型的学习曲线
在实际应用中,我们经常需要比较不同模型的学习曲线,以选择最适合的模型:
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier# 定义多个模型
models = {"Logistic Regression": LogisticRegression(max_iter=1000),"Decision Tree": DecisionTreeClassifier(),"Random Forest": RandomForestClassifier()
}# 创建子图
plt.figure(figsize=(18, 12))for i, (name, model) in enumerate(models.items(), 1):plt.subplot(2, 2, i)train_sizes, train_scores, valid_scores = learning_curve(model, X, y, train_sizes=np.linspace(0.1, 1.0, 10), cv=5, scoring="accuracy")train_mean = np.mean(train_scores, axis=1)valid_mean = np.mean(valid_scores, axis=1)plt.plot(train_sizes, train_mean, 'o-', color="r", label="Training score")plt.plot(train_sizes, valid_mean, 'o-', color="g", label="Cross-validation score")plt.title(f'Learning Curve - {name}')plt.xlabel('Training Size')plt.ylabel('Accuracy Score')plt.legend(loc="best")plt.grid()plt.tight_layout()
plt.show()
通过这种方式,我们可以在一个图表中比较多个模型的学习行为,直观地看出哪个模型更适合当前问题。📊
学习曲线与网格搜索结合
学习曲线分析也可以与超参数调优结合,帮助我们更全面地评估模型:
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'C': [0.1, 1, 10, 100],'gamma': [0.001, 0.01, 0.1, 1]
}# 网格搜索
grid_search = GridSearchCV(SVC(kernel='rbf'), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X, y)# 获取最佳模型
best_model = grid_search.best_estimator_# 绘制最佳模型的学习曲线
plt.figure(figsize=(10, 6))
title = f"Learning Curve (SVM, RBF kernel, γ={best_model.gamma}, C={best_model.C})"
plot_learning_curve(best_model, X, y, title=title)
plt.show()
这种方法首先通过网格搜索找到最佳超参数,然后绘制该最佳模型的学习曲线,帮助我们验证最佳模型是否真的能够良好泛化。🔍
不同算法学习曲线的比较
不同的机器学习算法由于其内在特性不同,其学习曲线也展现出不同的特征。理解这些差异有助于我们选择适合问题特点的算法。下面我们比较几类常见算法的学习曲线特点。🔄
线性模型
线性模型(如线性回归、逻辑回归等)的学习曲线通常具有以下特点:
- 训练曲线和验证曲线通常较早收敛
- 两条曲线之间的间隙较小
- 如果问题本质上是非线性的,即使增加数据量,性能也会迅速达到天花板
线性模型适合处理特征间关系较为线性的问题,计算效率高但表达能力有限。如果学习曲线显示较早收敛且性能不理想,可能需要转向更复杂的模型或进行非线性特征变换。〰️
决策树与集成方法
决策树及其集成方法(如随机森林、梯度提升树)的学习曲线通常有这些特征:
- 单一决策树容易过拟合,训练曲线迅速接近完美,但验证曲线表现较差
- 集成方法(如随机森林)通常能够减轻过拟合,训练和验证曲线间隙较小
- 增加数据量对这类算法通常有明显效果,验证曲线会持续改善
这类算法对数据量的依赖较大,当数据足够时能展现出良好的性能。如果学习曲线显示验证性能随数据量增加仍在显著提升,通常值得收集更多数据。🌲
支持向量机
支持向量机(SVM)的学习曲线展示出以下特点:
- 核SVM对训练集大小非常敏感,小样本时容易过拟合
- 随着数据量增加,验证性能通常会显著提升
- 不同核函数的SVM展示不同的学习曲线形态:线性核较为平稳,RBF核在数据量小时更容易过拟合
- 正确设置正则化参数©和核参数(如gamma)对学习曲线形态有显著影响
SVM的一个显著特点是,当数据量较小而特征维度较大时,容易出现训练性能高但验证性能不佳的情况。如果学习曲线显示明显的过拟合趋势,可以考虑调整C和gamma参数,或增加训练数据。🔄
神经网络
神经网络,尤其是深度学习模型,其学习曲线具有独特的特点:
- 容量大的神经网络在数据量小时极易过拟合,训练曲线和验证曲线间隙巨大
- 随着数据量增加,神经网络的泛化能力通常持续提升
- 深度网络的学习曲线通常需要更多迭代才能稳定
- 适当的正则化技术(如Dropout、批归一化)可以显著改善学习曲线形态
神经网络的学习曲线通常还会展示出阶段性的性能提升,这反映了网络在不同抽象层次上学习表示的过程。对于深度学习模型,除了样本大小vs性能的曲线外,迭代次数vs性能的曲线也非常重要,用于监控训练过程和早停决策。🧠
无监督与半监督学习算法
无监督学习(如聚类、降维)和半监督学习算法的学习曲线也具有参考价值:
- 聚类算法(如K-means)的学习曲线可以显示不同数据量下聚类质量的变化
- 半监督学习的曲线可以展示标记数据与未标记数据比例对性能的影响
- 自编码器等无监督表示学习方法的学习曲线可以反映重构误差的变化趋势
这类算法的学习曲线通常需要结合特定领域知识来解释,比单纯的监督学习更为复杂。📊
算法选择启示
不同算法学习曲线的比较为算法选择提供了重要依据:
- 如果数据量有限且不易扩展,线性模型或正则化良好的模型可能是更好的选择
- 如果学习曲线表明增加数据有助于提升性能,且有能力获取更多数据,集成方法或深度学习可能更有优势
- 当多种算法的学习曲线形态相似但最终性能不同时,可以直接选择性能最佳的算法
- 当算法的学习曲线形态与问题特性(如数据量增长前景)匹配时,长期来看可能更具优势
理解这些模式有助于我们基于项目条件和约束做出更明智的算法选择决策。🔍
学习曲线与其他评估方法的结合
学习曲线虽然强大,但与其他模型评估技术结合使用时,能提供更全面的模型性能视角。以下我们探讨几种重要的组合方式。🔄
学习曲线与验证曲线的结合
学习曲线关注数据量对性能的影响,而验证曲线(Validation Curve)则关注超参数对性能的影响。两者结合使用可以形成更完整的模型调优策略:
from sklearn.model_selection import validation_curve# 验证曲线 - 分析参数影响
param_range = np.logspace(-3, 3, 7)
train_scores, test_scores = validation_curve(SVC(), X, y, param_name="gamma", param_range=param_range,cv=5, scoring="accuracy", n_jobs=-1
)# 绘制验证曲线
plt.figure(figsize=(10, 6))
plt.semilogx(param_range, np.mean(train_scores, axis=1), label="Training score")
plt.semilogx(param_range, np.mean(test_scores, axis=1), label="Cross-validation score")
plt.xlabel("gamma")
plt.ylabel("Accuracy Score")
plt.legend(loc="best")
plt.title("Validation Curve with SVM")
plt.grid()
plt.show()
首先使用验证曲线找到合适的超参数范围,然后使用学习曲线评估该参数设置下模型对数据量的敏感性,这种组合方法可以更系统地优化模型。📈
学习曲线与学习率调度的结合
对于迭代学习算法(如神经网络、梯度提升),学习曲线可以与学习率调度策略结合,监控训练过程并动态调整学习策略:
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import StandardScaler# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 带学习率调度的神经网络
mlp = MLPClassifier(hidden_layer_sizes=(100,),max_iter=1000,learning_rate='adaptive',learning_rate_init=0.01
)# 监控不同迭代次数下的性能
max_iterations = [10, 50, 100, 200, 500, 1000]
train_scores = []
test_scores = []for max_iter in max_iterations:mlp.set_params(max_iter=max_iter)mlp.fit(X_scaled, y)train_scores.append(mlp.score(X_scaled, y))# 使用交叉验证计算测试分数cv_score = cross_val_score(MLPClassifier(hidden_layer_sizes=(100,), max_iter=max_iter, learning_rate='adaptive'),X_scaled, y, cv=5).mean()test_scores.append(cv_score)# 绘制迭代学习曲线
plt.figure(figsize=(10, 6))
plt.plot(max_iterations, train_scores, 'o-', label="Training score")
plt.plot(max_iterations, test_scores, 'o-', label="Cross-validation score")
plt.xlabel("Max Iterations")
plt.ylabel("Accuracy Score")
plt.legend(loc="best")
plt.title("Learning Curve by Iterations")
plt.grid()
plt.show()
这种方法可以帮助我们确定最佳迭代次数,避免训练不足或过度训练,并为早停策略提供依据。🔄
学习曲线与混淆矩阵的结合
学习曲线通常展示整体性能,而混淆矩阵则提供分类详情。将两者结合可以更全面地评估模型:
from sklearn.metrics import confusion_matrix, plot_confusion_matrix
import matplotlib.pyplot as plt# 获取不同训练集大小下的模型
percentages = [0.2, 0.5, 0.8, 1.0]
models = {}for p in percentages:# 获取一部分数据作为训练集n_samples = int(len(X) * p)X_subset = X[:n_samples]y_subset = y[:n_samples]# 训练模型model = SVC(kernel='rbf', gamma=0.1)model.fit(X_subset, y_subset)models[f"{int(p*100)}%"] = model# 绘制不同训练集大小下的混淆矩阵
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
axes = axes.flatten()for i, (name, model) in enumerate(models.items()):plot_confusion_matrix(model, X, y, normalize='true',ax=axes[i],display_labels=iris.target_names,cmap=plt.cm.Blues)axes[i].set_title(f"Training Size: {name}")plt.tight_layout()
plt.show()
这种组合分析可以揭示模型随训练集大小增加在不同类别上的表现变化,帮助我们了解哪些类别更难学习,以及数据增加是否对特定类别的识别有显著改善。🧩
学习曲线与特征重要性的结合
学习曲线也可以与特征重要性分析结合,了解特征对学习过程的影响:
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectFromModel# 训练模型并获取特征重要性
rf = RandomForestClassifier()
rf.fit(X, y)
importances = rf.feature_importances_# 按重要性排序特征
indices = np.argsort(importances)[::-1]
feature_names = [f"Feature {i}" for i in range(X.shape)]# 绘制特征重要性
plt.figure(figsize=(10, 6))
plt.bar(range(X.shape), importances[indices], align='center')
plt.xticks(range(X.shape), [feature_names[i] for i in indices], rotation=90)
plt.xlabel('Features')
plt.ylabel('Importance')
plt.title('Feature Importance')
plt.tight_layout()
plt.show()# 仅使用重要特征绘制学习曲线
selector = SelectFromModel(rf, threshold='median')
X_selected = selector.fit_transform(X, y)plt.figure(figsize=(10, 6))
title = "Learning Curve (RandomForest, Selected Features)"
plot_learning_curve(RandomForestClassifier(), X_selected, y, title=title)
plt.show()
通过比较使用全部特征和只使用重要特征的学习曲线,我们可以评估特征选择对模型学习效率和性能的影响。🔍
案例分析
通过实际案例深入理解学习曲线的应用价值,可以帮助我们更好地将理论应用于实践。下面我们分析几个典型场景下的学习曲线案例。🔬
案例1:图像分类中的学习曲线分析
在计算机视觉领域,特别是图像分类任务中,学习曲线对模型选择和优化至关重要:
# 假设使用MNIST数据集的例子
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import StandardScaler# 加载部分MNIST数据(为了计算效率)
X, y = fetch_openml('mnist_784', version=1, return_X_y=True, as_frame=False)
X = X[:10000] # 取前10000个样本
y = y[:10000]# 数据预处理
X = X / 255.0 # 归一化
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义不同深度的神经网络
models = {"1 Hidden Layer": MLPClassifier(hidden_layer_sizes=(100,), max_iter=300),"2 Hidden Layers": MLPClassifier(hidden_layer_sizes=(100, 100), max_iter=300),"3 Hidden Layers": MLPClassifier(hidden_layer_sizes=(100, 100, 100), max_iter=300)
}# 比较不同模型的学习曲线
plt.figure(figsize=(18, 6))
for i, (name, model) in enumerate(models.items(), 1):plt.subplot(1, 3, i)train_sizes, train_scores, valid_scores = learning_curve(model, X_train, y_train,train_sizes=np.linspace(0.1, 1.0, 5),cv=3,scoring="accuracy")train_mean = np.mean(train_scores, axis=1)valid_mean = np.mean(valid_scores, axis=1)plt.plot(train_sizes, train_mean, 'o-', color="r", label="Training score")plt.plot(train_sizes, valid_mean, 'o-', color="g", label="Cross-validation score")plt.title(f'{name}')plt.xlabel('Training Size')plt.ylabel('Accuracy Score')plt.legend(loc="best")plt.grid()plt.tight_layout()
plt.show()
案例分析:
- 随着网络深度增加,模型容量增大,小数据集上过拟合风险增加
- 更深的网络在数据量增加时性能提升更明显
- 当数据不足时,简单模型可能优于复杂模型
- 在图像任务中,预训练和数据增强可以改善学习曲线形态
这种分析帮助计算机视觉工程师在资源约束下做出明智的模型架构选择。📸
案例2:文本分类中的学习曲线
文本数据具有高维度、稀疏性等特点,学习曲线在NLP任务中展现出独特模式:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline# 加载20 Newsgroups数据集(部分类别)
categories = ['alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space']
newsgroups = fetch_20newsgroups(subset='all', categories=categories)# 创建文本处理流水线
pipelines = {"Naive Bayes": Pipeline([('tfidf', TfidfVectorizer()),('clf', MultinomialNB())]),"Linear SVM": Pipeline([('tfidf', TfidfVectorizer()),('clf', LinearSVC())])
}# 比较不同算法的学习曲线
plt.figure(figsize=(12, 5))
for i, (name, pipeline) in enumerate(pipelines.items(), 1):plt.subplot(1, 2, i)train_sizes, train_scores, valid_scores = learning_curve(pipeline, newsgroups.data, newsgroups.target,train_sizes=np.linspace(0.1, 1.0, 5),cv=3,scoring="accuracy")train_mean = np.mean(train_scores, axis=1)valid_mean = np.mean(valid_scores, axis=1)plt.plot(train_sizes, train_mean, 'o-', color="r", label="Training score")plt.plot(train_sizes, valid_mean, 'o-', color="g", label="Cross-validation score")plt.title(f'{name}')plt.xlabel('Training Size')plt.ylabel('Accuracy Score')plt.legend(loc="best")plt.grid()plt.tight_layout()
plt.show()
案例分析:
- 文本分类中,贝叶斯模型在小数据集上通常表现较好,但随数据增加性能提升有限
- 线性SVM在数据量增加时通常能显著提升性能
- 特征表示(如TF-IDF, word2vec等)对学习曲线形态有显著影响
- NLP任务中,数据质量与数据量同等重要,高质量数据可以改善学习曲线斜率
理解这些模式有助于NLP工程师在项目早期做出更合理的技术选择。📝
案例3:时间序列预测中的学习曲线
时间序列数据的特殊性使得其学习曲线也具有独特特点:
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
import pandas as pd# 生成模拟时间序列数据
def generate_time_series(n=1000):np.random.seed(42)dates = pd.date_range(start='2020-01-01', periods=n)ts = pd.Series(np.sin(np.linspace(0, 10*np.pi, n)) + 0.1*np.random.randn(n))ts.index = datesreturn tsts = generate_time_series(1000)# 特征工程:创建滞后特征
def create_features(ts, lag=5):df = pd.DataFrame(ts)df.columns = ['y']for i in range(1, lag+1):df[f'lag_{i}'] = df['y'].shift(i)df.dropna(inplace=True)return dfdf = create_features(ts, lag=7)
X = df.drop('y', axis=1).values
y = df['y'].values# 比较不同模型的学习曲线
models = {"Linear Regression": LinearRegression(),"Random Forest": RandomForestRegressor(n_estimators=100)
}plt.figure(figsize=(12, 5))
for i, (name, model) in enumerate(models.items(), 1):plt.subplot(1, 2, i)train_sizes, train_scores, valid_scores = learning_curve(model, X, y,train_sizes=np.linspace(0.1, 1.0, 5),cv=5, # 使用TimeSeriesSplit更合适,这里简化处理scoring="neg_mean_squared_error")train_mean = -np.mean(train_scores, axis=1) # 转为正MSEvalid_mean = -np.mean(valid_scores, axis=1)plt.plot(train_sizes, train_mean, 'o-', color="r", label="Training MSE")plt.plot(train_sizes, valid_mean, 'o-', color="g", label="Cross-validation MSE")plt.title(f'{name}')plt.xlabel('Training Size')plt.ylabel('Mean Squared Error')plt.legend(loc="best")plt.grid()plt.tight_layout()
plt.show()
案例分析:
- 时间序列模型的学习曲线通常受序列长度和季节性影响
- 线性模型在短期预测中学习曲线较早收敛
- 非线性模型(如随机森林)需要更多数据才能有效捕捉复杂的时间依赖关系
- 时间序列的学习曲线分析需要考虑数据的时间结构,常规交叉验证可能导致数据泄露
理解这些特点可以帮助时间序列分析师更好地权衡模型复杂度与可用历史数据长度的关系。⏱️
总结与展望
学习曲线作为机器学习中的重要分析工具,提供了独特的视角来理解模型的学习行为和泛化能力。本文全面探讨了学习曲线的概念、原理、应用以及与各类机器学习任务的结合。通过对学习曲线的深入理解,我们能够更科学地诊断模型问题、指导模型选择和优化、规划数据收集策略。🔍
关键要点回顾
-
学习曲线的定义与价值:学习曲线展示了模型性能随训练数据量或训练迭代次数的变化趋势,是诊断模型状态的重要工具。
-
数学原理:从偏差-方差分解角度,学习曲线反映了模型在不同数据量下偏差和方差的变化规律。
-
典型形态解读:理想、欠拟合和过拟合模型各自具有典型的学习曲线形态,通过这些形态可以快速诊断模型状态。
-
实践应用:学习曲线可以指导数据收集策略、计算资源分配、模型复杂度选择和特征工程决策。
-
实现技术:Python和scikit-learn提供了丰富的工具来计算和可视化学习曲线,可以与其他评估方法有机结合。
-
算法比较:不同类型的算法展现出不同的学习曲线特征,理解这些差异有助于算法选择。
-
案例分析:在图像分类、文本处理和时间序列预测等实际应用中,学习曲线分析能够提供独特的洞察。
未来发展方向
随着机器学习领域的不断发展,学习曲线分析也在持续演进:
-
超大规模模型的学习曲线:如何分析和解释大型预训练模型(如GPT、BERT)的学习曲线特性是一个重要研究方向。
-
自动化学习曲线分析:开发自动化工具,能够解读学习曲线并给出具体优化建议。
-
动态学习曲线:实时监控和可视化训练过程中的学习曲线变化,并据此动态调整训练策略。
-
跨模态学习曲线:研究多模态学习任务中不同模态数据对学习曲线的影响。
-
学习曲线与神经架构搜索:将学习曲线分析整合到神经架构搜索过程中,提高搜索效率。
学习曲线不仅是一种分析工具,更是连接理论与实践的桥梁。通过深入理解和灵活运用学习曲线,我们能够更加科学、有效地开发和优化机器学习模型,为人工智能的进步贡献力量。🚀
通过本文的学习,希望读者能够掌握学习曲线这一强大工具,将其灵活应用于实际机器学习项目中,做出更加科学的决策,构建更加高效的模型。无论是研究人员还是实践工程师,深入理解学习曲线都将为您的工作带来显著价值。🌟
相关文章:
学习曲线)
机器学习的一百个概念(9)学习曲线
前言 本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见[《机器学习的一百个概念》 ima 知识库 知识库广场搜索&…...

浅谈Tomcat数据源连接池
目录 为什么需要JDBC连接池 Tomcat JDBC Pool 相关参数 1. 基本配置 2. 连接池大小控制 3. 连接验证与测试 4. 空闲连接回收 5. 连接泄漏与超时 Tomcat JDBC Pool 源码分析(tomcat 8.5.3) DataSourceFactory DataSource ConnectionPool Pool…...

Techub 财报解读:Circle 冲刺 IPO,但收入增长难掩利润困局
作者:Techub 财报解读 撰文:Yangz,Techub News 4 月 1 日,Circle 向美国证券交易委员会(SEC)提交 S-1 文件,计划进行首次公开募股(IPO),股票代码为 CRCL&…...

C++中的链表操作
在C中,链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。C标准库(STL)中提供了std::list和std::forward_list两种链表实现,分别对应双向链表和单向链表。此外&am…...

Vue2 生命周期
文章目录 前言🔄 Vue2 生命周期流程(8个核心钩子)📝 代码中典型用法示例一、您的描述验证二、完整生命周期代码示例三、关键阶段行为说明🔍 常见问题 前言 提示:以下是本篇文章正文内容,下面案…...

2007-2022年 上市公司政府补助数据 -社科数据
上市公司政府补助数据(2007-2022年)-社科数据https://download.csdn.net/download/paofuluolijiang/90028547 https://download.csdn.net/download/paofuluolijiang/90028547 政府补助是指政府为支持企业发展,提供的资金或资源支持。对于上市…...

设计心得——状态机
一、状态机 在设计一些与硬件交互或者游戏等开发中,经常会听到状态机(State Machines)这个字眼,而在设计模式(GoF)中,又经常听到状态模式这个概念,它们之间有什么联系和不同呢&…...

python match case语法
学习路线:B站 普通的if判断 def if_traffic_light(color):if color red:return Stopelif color yellow:return Slow downelif color green:return Goelse:return Invalid colorprint(if_traffic_light(red)) # Output: Stop print(if_traffic_light(yellow)) …...

Lua中协程相关函数使用详解
目录 1. coroutine.create(f)2. coroutine.resume(co [, val1, ...])3. coroutine.yield([val1, ...])4. coroutine.status(co)5. coroutine.wrap(f)6. coroutine.running()7. coroutine.isyieldable()协程状态转换示例总结 Lua 中的协程(coroutine)提供…...

代码拟有感
最近的日子像被按了0.5倍速播放键。腱鞘炎让手腕转动时发出咯吱声,尾骨的钝痛让久坐变成酷刑,落枕的脖子和酸胀的手臂组成了“疼痛交响乐”——这些隐秘的、持续的身体抗议,让原本枯燥的代码练习变成了一场生理与意志的拉锯战。 我盯着屏幕苦…...

《实战AI智能体》MCP对Agent有哪些好处
首先MCP为Agent提供了标准化的方式来接入各种工具和数据源,无论是本地运行的工具,例如通过stdio服务器,还是远程托管的服务HTTP over SSE服务, Agent都可以通过统一的接口与它们进行交互,极大扩展了第三方工具库。 例如,在金融领域,Agent 可以接入股票分析的MCP工具。当…...

maptalks获取所有图层并把图层按照zIndex排序
maptalks获取所有图层并把图层按照zIndex排序 获取所有图层 通过调用 map.getLayers() 可以返回当前地图上所有的图层集合。此方法会返回一个数组形式的结果,其中包含了地图上的每一个图层层级对象。 图层属性中的 ZINDEX 每种图层类型(如矢量图层、…...

GUI-Guider 按钮按下 选项卡 右移动一个,到最右边停下
extern lv_ui guider_ui; // 在文件顶部添加// 在按钮事件中使用: lv_obj_t * tabview guider_ui.screen_tabview_1; // 替换为你的实际 TabView 名称 uint16_t current lv_tabview_get_tab_act(tabview); lv_tabview_set_act(tabview, current 1, LV_ANIM_ON); …...

让AI再次伟大-MCP-Client开发指南
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring原理、JUC原理、Kafka原理、分布式技术原理、数据库技术、JVM原理、AI应用🔥如果感觉…...

sql工具怎么选?
为什么大多数主流工具又贵又难用? 有没有一款免费好用的sql工具? 像大多人朋友常用的sql工具,应该都遇到过这种情况, 用着用着收到了来自品牌方的律师函, 或者处理数据经常卡死, 再或者不支持国产数据库…...

video标签播放mp4格式视频只有声音没有图像的问题
video标签播放mp4格式视频只有声音没有图像的问题 这是由于视频格式是hevc(H265)编码的,这种编码格式视频video播放有问题主要是由于以下两种原因导致的: 1、浏览器没有开启硬加速模式: 开启方法(以谷歌浏览器为例)&a…...
与VLOG无法打印)
问题解决:glog中的LOG(INFO)与VLOG无法打印
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 MotivationProcess glog版本为:https://github.com/google/glog/archive/…...

【第2月 day16】Matplotlib 散点图与柱状图
好的!以下是针对初学者的 Matplotlib 散点图与柱状图 学习内容,用简单易懂的语言和示例讲解: 一、散点图(Scatter Plot) 作用:展示两个变量之间的关系(如相关性、分布等)。 1. 核心…...

汽车 HMI 设计的发展趋势与设计要点
一、汽车HMI设计的发展历程与现状 汽车人机交互界面(HMI)设计经历了从简单到复杂、从单一到多元的演变过程。2012年以前,汽车HMI主要依赖物理按键进行操作,交互方式较为单一。随着特斯拉Model S的推出,触控屏逐渐成为…...

Vue 3 中按照某个字段将数组分成多个数组
方法一:使用 reduce 方法 const originalArray [{ id: 1, category: A, name: Item 1 },{ id: 2, category: B, name: Item 2 },{ id: 3, category: A, name: Item 3 },{ id: 4, category: C, name: Item 4 },{ id: 5, category: B, name: Item 5 }, ];const grou…...

06-Spring 中的事件驱动机制
Spring 中的事件驱动机制(ApplicationEvent 源码解析) 本小结主要总结Spring的事件,如果对于观察者模式比较熟悉的话,理解这个应该不难。 这块涉及的面试题相对简单,主要还是以日常使用为主。 另外在Spring的源码中也运…...
关于列表内置函数和多维列表)
Python学习笔记(8)关于列表内置函数和多维列表
列表访问计数 索引直接访问 index()#获得首次出现指定元素的索引 index(value,[start,[end]] #控制搜索索引范围 counr()#获得指定元素在列表中出现的次数 len()#返回列表长度 成员资格判断 incount()返回0,代表不存在 列表切片 slice[起始偏移量 start:终止…...

【算法学习计划】回溯 -- 递归
目录 leetcode 面试题08.06.汉诺塔问题 leetcode 21.合并两个有序链表 leetcode 206.反转链表 leetcode 24.两两交换链表中的节点 leetcode 50. Pow(x, n) 本篇文章将是我们回溯专题的第一篇文章,在这里我先浅浅讲一下什么是回溯 其实就是递归,只不…...

Unity中 JobSystem使用整理
Unity 的JobSystem允许创建多线程代码,以便应用程序可以使用所有可用的 CPU 内核来执行代码,这提供了更高的性能,因为您的应用程序可以更高效地使用运行它的所有 CPU 内核的容量,而不是在一个 CPU 内核上运行所有代码。 可以单独使…...

【从零实现Json-Rpc框架】- 项目实现 - 服务端主题实现及整体封装
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

JavaScript基础-移动端常用开发框架
随着移动互联网的发展,越来越多的应用和服务需要支持移动设备。为了提高开发效率和用户体验,开发者们依赖于一些成熟的JavaScript框架来构建响应迅速、功能丰富的移动Web应用。本文将介绍几款广泛使用的移动端开发框架,并通过具体的示例展示它…...

Tree - Shaking
Vue 3 的 Tree - Shaking 技术详解 Tree - Shaking 是一种在打包时移除未使用代码的优化技术,在 Vue 3 中,Tree - Shaking 发挥了重要作用,有效减少了打包后的代码体积,提高了应用的加载性能。以下是对 Vue 3 中 Tree - Shaking …...

VSCode历史版本的下载安装
VSCode历史版本的下载安装 文章目录 VSCode历史版本的下载安装VSCode安装下载历史版本地址查询VSCode历史版本的 commit id 安装参考资料 VSCode安装 Windows版本:Windows10VSCode版本:VScode1.65.0(64位User版本)本文编写时间&a…...

Websoft9分享:在数字化转型中选择开源软件可能遇到的难题
引言:中小企业数字化转型的必由之路 全球94.57%的企业已采用开源软件(数据来源:OpenLogic 2024报告),开源生态估值达8.8万亿美元。中小企业通过开源软件构建EPR系统、企业官网、数据分析平台等,可节省80%软件采购成本。…...

【无人机】无人机PX4飞控系统高级软件架构
目录 1、概述(图解) 一、数据存储层(Storage) 二、外部通信层(External Connectivity) 三、核心通信枢纽(Message Bus) 四、硬件驱动层(Drivers) 五、飞…...

新版本Xmind结合DeepSeek快速生成美丽的思维导图
前言 我的上一篇博客(https://quickrubber.blog.csdn.net/article/details/146518898)中讲到采用Python编程可以实现和Xmind的互动,并让DeepSeek来生成相应的代码从而实现对内容的任意修改。但是,那篇博客中提到的Xmind有版本的限…...

Windows查重工具,强烈推荐大家收藏!
我大家在用电脑的时候,是不是发现用得越久,电脑里的软件和文件就越多? 今天我给大家带来的这两款重复文件查找神器,简直就是电脑里的“清洁小能手”,能帮你把那些重复的文件和文件夹找出来。 Easy DupLicate Finder 重…...

数字孪生技术之争:UE、Unity还是飞渡DTS数字孪生平台?
作为深耕数字孪生内容创作的B站UP主,我们创作的内容广受数十万粉丝喜爱。后台私信经常提及两个问题:“这质感绝了!如此丝滑流畅是UE做的吗?”VS “请问用Unity能实现这个效果吗?” Unreal Engine凭借影视级渲染&#…...

【GCC警告报错4】warning: format not a string literal and no format arguments
文章主本文根据笔者个人工作/学习经验整理而成,如有错误请留言。 文章为付费内容,已加入原创保护,禁止私自转载。 文章发布于:《C语言编译报错&警告合集》 如图所示: 原因: snprintf的函数原型&#x…...

【Tauri2】013——前端Window Event与创建Window
前言 【Tauri2】012——on_window_event函数-CSDN博客https://blog.csdn.net/qq_63401240/article/details/146909801?spm1001.2014.3001.5501 前面介绍了on_window_event,这个在Builder中的方法,里面有许多事件,比如Moved,Res…...

修复SSL证书链不完整问题certificate verify failed unable to get local issuer certificate
文章目录 前言排查过程怀疑文章平台图片转存问题尝试使用 Python 代码下载图片使用 SSL Labs Server Test 验证猜想回顾 SSL 安装命令ACME 生成的证书 验证使用 [SSL Labs Server Test](https://www.ssllabs.com/ssltest/index.html) 验证文章发布平台转存验证 个人简介 前言 …...

管家婆财贸ERP BB102.采购销售订金管理
低适用版本: 财贸系列 23.8 插件简要功能说明: 采购订单/销售订单支持查询订金付款情况,联查下游付款/收款信息更多细节描述见下方详细文档 插件操作视频: 进销存类定制插件--采购销售订金管理 插件详细功能文档: …...

前端对接下载文件接口、对接dart app
嵌套在dart app里面的前端项目 1.前端调下载接口 ->后端返回 application/pdf格式的文件 ->前端将pdf处理为blob ->blob转base64 ->调用dart app的 sdk saveFile ->保存成功 async download() {try {// 调用封装的 downloadEContract 方法获取 Blob 数据const …...

牛客 简写单词
简写单词_牛客题霸_牛客网 主要是如何输入 #include <iostream> #include <string>using namespace std;int main() {string str;while(cin>>str){if(str[0]>a&&str[0]<z){cout<<char(str[0]-32);}else cout<<str[0];str.clear(…...

解决STM32CubeMX中文注释乱码
本人采用【修改系统环境变量】的方法 1. 使用快捷键 win X,打开【系统R】,点击【高级系统设置】 2. 点击【环境变量】 3. 点击【新建】 4.按图中输入【JAVA_TOOL_OPTIONS】和【-Dfile.encodingUTF-8】,新建环境变量后重启CubeMX即可。 解释…...
))
若依——基于AI+若依框架的实战项目(实战篇(下))
目录 前言 6. 设备管理 6.1 需求说明 6.2 生成基础代码 6.2.1 需求 6.2.2 步骤 ①创建目录菜单 ②添加数据字典 ③配置代码生成信息 ④下载代码并导入项目 6.3 设备类型改造 6.3.1 基础页面 需求 代码实现 6.4 设备管理改造 6.4.1 基础页面 需求 代码实现 …...

SpringBoot项目瘦身指南:从臃肿到高效的优化实践
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、问题背景 SpringBoot的"约定优于配置"特性极大提升了开发效率,但默认配置可能导致项目逐渐臃肿。典型的症状包括: 打…...

运筹帷幄:制胜软件开发
运筹学在软件开发项目中的作用主要体现在复杂系统建模、资源优化和决策支持中。通过数学建模、算法设计和数据分析,运筹学能够帮助开发团队更高效地实现软件需求,尤其是在涉及资源分配、路径规划、调度优化等场景时。 案例:电商物流配送系统的…...

代码随想录|动态规划|18完全背包理论基础
leetcode:52. 携带研究材料(第七期模拟笔试) 题目 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些…...
)
52.个人健康管理系统小程序(基于springbootvue)
目录 1.系统的受众说明 2.开发环境与技术 2.1 MYSQL数据库 2.2 Java语言 2.3 微信小程序技术 2.4 SpringBoot框架 2.5 B/S架构 2.6 Tomcat 介绍 2.7 HTML简介 2.8 MyEclipse开发工具 3.系统分析 3.1 可行性分析 3.1.1 技术可行性 3.1.2 经济可行性 3.1.3 操作…...

大语言模型中的嵌入模型
本教程将拆解什么是嵌入模型、为什么它们在NLP中如此重要,并提供一个简单的Python实战示例。 分词器将原始文本转换为token和ID,而嵌入模型则将这些ID映射为密集向量表示。二者合力为LLMs的语义理解提供动力。图片来源:[https://tzamtzis.gr/2024/coding/tokenization-by-an…...
)
运维之 Centos7 防火墙(CentOS 7 Firewall for Operations and Maintenance)
运维之 Centos7 防火墙 1.介绍 Linux CentOS 7 防火墙/端口设置: 基础概念: 防火墙是一种网络安全设备,用于监控和控制网络流量,以保护计算机系统免受未经授权的访问和恶意攻击。Linux CentOS 7操作系统自带了一个名为iptables的…...

Ubuntu 20.04 出现问号图标且无法联网 修复
在 Ubuntu 中遇到网络连接问题(如出现问号图标且无法联网),可以通过以下命令尝试重启网络服务: 1. 推荐先修改DNS 编辑 -> 虚拟机网络编辑器-> VMnet8 ->NAT 设置 -> DNS 设置 -> 设置DNS 服务器 DNS填什么 取决…...

联想M7400打印机怎么清零
一(粉盒加粉后清零): 开机,打开前盖; 按下 “清除返回” 键,屏幕显示 “更换硒鼓?是否”; 按 “开始” 键,屏幕无显示; 按下 “” 号键 11 次,…...

AIGC7——AIGC驱动的视听内容定制化革命:从Sora到商业化落地
引言:个性化视听时代的到来 2024年,OpenAI发布视频生成模型Sora,可生成60秒高清视频;中国团队推出的Vidu模型实现16秒镜头连贯生成。这些突破标志着AIGC正式进入高质量视听内容定制化阶段。据Gartner预测,到2027年&am…...