LLM架构解析:词嵌入模型 Word Embeddings(第二部分)—— 从基础原理到实践应用的深度探索
本专栏深入探究从循环神经网络(RNN)到Transformer等自然语言处理(NLP)模型的架构,以及基于这些模型构建的应用程序。
本系列文章内容:
- NLP自然语言处理基础
- 词嵌入(Word Embeddings)(本文)
- 循环神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU)
- 编码器 - 解码器架构(Encoder - Decoder Architecture)
- 注意力机制(Attention Mechanism)
- Transformer
- 编写Transformer代码
- 双向编码器表征来自Transformer(BERT)
- 生成式预训练Transformer(GPT)
- 大语言模型(LLama)
- Mistral
1. 简介(Introduction)
词嵌入(Word embeddings)是自然语言处理(Natural Language Processing,NLP)领域的一个基础概念。它们本质上是一种将单词转换为连续向量空间中的数值表示(即向量)的方法。其目标是捕捉单词的语义含义,使得具有相似含义的单词具有相似的向量表示。
这篇博客文章涵盖了词嵌入从基础到高级的各个重要方面,确保读者能够全面理解这一主题及其在自然语言处理(NLP)和大语言模型(LLMs)背景下的演变。

词嵌入(Word Embeddings)
定义:词嵌入是单词的密集、低维且连续的向量表示,它捕捉了语义和句法信息。
特点:
- 密集:与独热编码(One-Hot Encoding)等稀疏表示不同,词嵌入是密集的,这意味着它们的大多数元素都不为零。
- 向量空间:单词被定位在一个向量空间中,从而可以进行数学运算和比较。
- 降维:为了提高计算效率和便于可视化,向量空间通常会被降维到较低的维度。
- 语义相似性:具有相似含义的单词具有相似的嵌入。

示例
如果“国王(king)”由向量 v k i n g v_{king} vking表示,“王后(queen)”由向量 v q u e e n v_{queen} vqueen表示,这些向量之间的关系可以捕捉到性别差异,例如 v k i n g − v m a n + v w o m a n ≈ v q u e e n v_{king} - v_{man} + v_{woman} \approx v_{queen} vking−vman+vwoman≈vqueen。

词嵌入的必要性
虽然上述内容确实有一定道理,但为什么我们要有足够的动力去学习和构建这些词嵌入呢?
- 对于语音或图像识别系统而言,所有信息已经以丰富的密集特征向量的形式存在,这些向量嵌入在高维数据集中,比如音频频谱图和图像像素强度。
- 然而,当涉及到原始文本数据时,尤其是像词袋模型(Bag of Words)这样基于计数的模型,我们处理的是单个单词,这些单词可能有它们自己的标识符,但无法捕捉单词之间的语义关系。
- 这会导致文本数据产生巨大的稀疏单词向量,因此,如果我们没有足够的数据,由于维度灾难(curse of dimensionality)的影响,我们最终可能得到效果不佳的模型,甚至会出现数据过拟合的情况。

词嵌入是如何使用的?
- 它们被用作机器学习模型的输入。
获取单词 -> 给出它们的数值表示 -> 用于训练或推理。 - 用于表示或可视化在用于训练它们的语料库中任何潜在的使用模式。
让我们举个例子来理解词向量是如何生成的。我们选取在某些条件下最常使用的情感,将每个表情符号转换为一个向量,而这些条件将作为我们的特征。

2. 词嵌入(Word Embeddings)基础
2.1 理解向量和向量空间
在自然语言处理(Natural Language Processing,NLP)和词嵌入(Word embeddings)的背景下,理解向量和向量空间是基础的,因为它们构成了表示单词及其关系的数学基础。
什么是向量?
向量是一种既具有大小(长度)又具有方向的数学对象。简单来说,向量可以被看作是一个有序的数字列表,它表示空间中的一个点。例如,在二维空间中,一个向量可以表示为:

其中 v 1 v_1 v1和 v 2 v_2 v2是该向量在两个维度(例如, x x x轴和 y y y轴)上的分量。
在自然语言处理中,单词在多维空间中被表示为向量,其中每个维度捕捉单词含义的不同方面或特征。
什么是向量空间?
向量空间是一种由一组向量组成的数学结构,这些向量可以相加,并且可以与标量(数字)相乘,从而在同一空间内生成另一个向量。向量空间由其维度(例如,二维、三维等)来定义,维度指的是指定该空间内任何一点所需的坐标数量。
在词嵌入的背景下,我们处理的是高维向量空间,通常具有数百甚至数千个维度。每个单词都被映射到这个空间中的一个唯一向量。


向量如何表示单词
当我们在向量空间中把单词表示为向量时,目标是捕捉单词的语义含义。具有相似含义或出现在相似上下文中的单词,在向量空间中应该彼此靠近。训练词嵌入的过程是基于单词在大型文本语料库中出现的上下文来学习这些向量表示的。
例如,“国王(king)”和“王后(queen)”这两个单词可能由在向量空间中彼此靠近的向量来表示,因为它们共享相似的上下文(例如,皇室、领导地位)。
向量空间中的运算
向量空间允许我们执行各种在自然语言处理中很有用的运算:
- 加法和减法:
通过对向量进行加法或减法运算,我们可以探索单词之间的关系。例如,著名的类比:

这个运算展示了如何通过根据“男人(man)”和“女人(woman)”之间的差异来调整“国王(king)”的向量,从而推导出表示“王后(queen)”的向量。
-
点积:
两个向量的点积提供了一种衡量它们之间相似度的方法。如果两个单词向量的点积很高,这意味着它们是相似的,并且共享上下文。 -
余弦相似度:
余弦相似度是一种常用的衡量两个向量之间相似度的方法,计算为它们之间夹角的余弦值。在比较单词向量时,这特别有用,因为它有助于对向量的大小进行归一化,只关注它们的方向。

向量空间的可视化
虽然自然语言处理中使用的向量空间通常是高维的(远远超出我们直接可视化的能力),但通常会使用主成分分析(Principal Component Analysis,PCA)或t分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)等技术将维度降低到二维或三维。这种降维使我们能够可视化单词彼此之间的位置关系,揭示出语义相关单词的聚类。

单词/词义嵌入的t-SNE投影。绿色标签显示了“dogychairman”的两种词义嵌入,而黄色和红色标签显示了这两种词义的最近邻居。
2.2 向量嵌入的类型
向量嵌入是一种将单词、句子和其他数据转换为数字的方法,这些数字能够捕捉它们的含义和关系。它们将不同的数据类型表示为多维空间中的点,在这个空间中,相似的数据点会聚集得更近。这些数值表示有助于机器更有效地理解和处理这些数据。
单词嵌入和句子嵌入是向量嵌入中最常见的两种子类型,但还有其他类型。一些向量嵌入可以表示整个文档,以及为匹配视觉内容而设计的图像向量、用于确定用户偏好的用户画像向量、有助于识别相似产品的产品向量等等。向量嵌入帮助机器学习算法在数据中找到模式,并执行诸如情感分析、语言翻译、推荐系统等任务。

在各种应用中,通常会使用几种不同类型的向量嵌入。以下是一些例子:
- 单词嵌入:将单个单词表示为向量。像词向量(Word2Vec)、全局词向量(GloVE)和快速文本(FastText)等技术,通过从大型文本语料库中捕捉语义关系和上下文信息来学习单词嵌入。
- 句子嵌入:将整个句子表示为向量。像通用句子编码器(Universal Sentence Encoder,USE)和跳过思想向量(SkipThought)等模型,会生成能够捕捉句子整体含义和上下文的嵌入。
- 文档嵌入:将文档(从报纸文章、学术论文到书籍等任何文档)表示为向量。它们捕捉整个文档的语义信息和上下文。像文档向量(Doc2Vec)和段落向量(Paragraph Vectors)等技术就是为了学习文档嵌入而设计的。
- 图像嵌入:通过捕捉不同的视觉特征,将图像表示为向量。像卷积神经网络(Convolutional Neural Networks,CNNs)和预训练模型(如残差网络(ResNet)和视觉几何组网络(VGG))等技术,会为图像分类、目标检测和图像相似度等任务生成图像嵌入。
- 用户嵌入:将系统或平台中的用户表示为向量。它们捕捉用户的偏好、行为和特征。用户嵌入可以用于从推荐系统到个性化营销以及用户细分等各个方面。
- 产品嵌入:在电子商务或推荐系统中,将产品表示为向量。它们捕捉产品的属性、特征以及任何其他可用的语义信息。然后,算法可以使用这些嵌入,根据产品的向量表示来比较、推荐和分析产品。
嵌入和向量是同一回事吗?
在向量嵌入的背景下,是的,嵌入和向量是同一回事。它们都指的是数据的数值表示,其中每个数据点都由高维空间中的一个向量来表示。
术语“向量”仅仅是指具有特定维度的一组数字。在向量嵌入的情况下,这些向量在连续空间中表示上述任何一种数据点。相反,“嵌入”专门指的是将数据表示为向量的技术,这种表示方式能够捕捉有意义的信息、语义关系或上下文特征。嵌入旨在捕捉数据的底层结构或属性,并且通常是通过训练算法或模型来学习的。
虽然在向量嵌入的背景下,“嵌入”和“向量”可以互换使用,但“嵌入”强调的是以有意义和结构化的方式表示数据的概念,而“向量”则指的是数值表示本身。
在这篇博客文章中,我们主要关注的是词嵌入(Word Embeddings)。让我们更详细地讨论一下这个内容。
2.3 词嵌入如何表示含义
词嵌入是自然语言处理(Natural Language Processing,NLP)中的一个强大工具,因为它们能够以一种捕捉单词语义含义以及单词与其他单词之间关系的方式来表示单词。与独热编码等传统方法不同,独热编码将单词视为相互独立且没有关联的实体,而词嵌入则以紧凑、密集的向量形式对有关单词上下文和用法的丰富信息进行编码。
词嵌入中的含义概念
词嵌入背后的核心思想是,出现在相似上下文中的单词往往具有相似的含义。这基于语言学中的分布假设,该假设指出,出现在相同上下文中的单词往往具有相似的含义。
例如,考虑“猫(cat)”和“狗(dog)”这两个单词。这些单词经常出现在相似的上下文中(例如,“猫/狗正在玩球”)。因此,它们的嵌入在向量空间中应该彼此靠近,这反映了它们相似的含义。
通过上下文捕捉含义
词嵌入通常是通过分析单词在大型文本语料库中出现的上下文来学习得到的。学习过程涉及将每个单词映射到高维空间中的一个向量,使得这个空间的几何结构能够捕捉单词之间的语义关系。
- 共现统计:
词嵌入通常源自共现统计,其中每个单词的向量是基于在文本中频繁出现在其附近的单词来学习的。例如,在词向量(Word2Vec)模型中,嵌入的训练方式是让具有相似共现模式的单词拥有相似的向量表示。 - 上下文相似性:
出现在相似上下文中(即被相同的一组单词所包围)的单词会被赋予相似的向量表示。例如,“国王(king)”和“王后(queen)”可能经常出现在相似的上下文中(例如,“_统治着王国”),这使得它们的嵌入在向量空间中彼此靠近。
2.4 嵌入中的几何关系
词嵌入的真正强大之处在于嵌入空间中向量之间的几何关系。这些关系对不同类型的含义和语义信息进行了编码。
- 同义性和相似性:
具有相似含义的单词,其嵌入在向量空间中彼此靠近。例如,“快乐(happy)”和“愉快(joyful)”这两个单词可能由彼此靠近的向量来表示,这表明了它们的语义相似性。 - 类比和语义关系:
词嵌入的一个迷人特性是它们能够通过向量运算来捕捉类比关系。一个著名的例子是这样的类比:
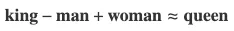
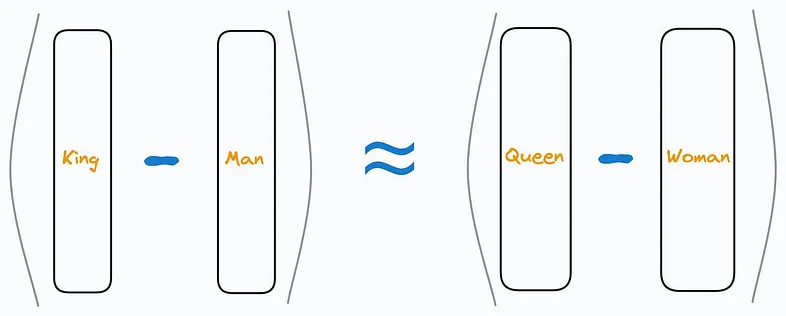
这意味着“国王”和“男人”之间的向量差与“王后”和“女人”之间的向量差相似。这种运算表明,嵌入能够捕捉诸如性别、皇室,甚至是地理关系(例如,“巴黎 - 法国 + 意大利 ≈ 罗马”)等复杂的语义关系。
- 层次关系:
一些嵌入还能够捕捉层次关系。例如,在一个训练良好的嵌入空间中,“狗(dog)”可能会靠近“动物(animal)”和“猫(cat)”,这反映了“狗”和“猫”都是“动物”的一种这样的层次结构。 - 一词多义性和上下文含义:
虽然传统的词嵌入在处理一词多义(具有多种含义的单词)方面存在困难,但像上下文嵌入(例如,双向编码器表征来自变换器(BERT)、基于语境的词向量表示(ELMo))这样的较新模型已经推进了这一概念。在这些模型中,一个单词的嵌入会根据它出现的上下文而发生变化,这使得模型能够捕捉像“银行(bank)”(例如,河岸与金融银行)这样的单词的不同含义。
2.5 密集表示
词嵌入被称为密集表示,是因为它们将一个单词的含义浓缩到相对较少的维度中(例如,100 - 300 维),其中每个维度捕捉单词含义或上下文的不同方面。这与独热编码等稀疏表示形成对比,在独热编码中,每个单词由一个大多为零的长向量来表示。
例如,考虑在三维空间中“猫(cat)”和“狗(dog)”的以下词嵌入:

这些向量彼此靠近,反映了“猫”和“狗”的相似含义。
2.6 词嵌入中含义的应用
词嵌入捕捉含义的能力在自然语言处理中有广泛的应用:
- 相似性和相关性:嵌入用于衡量两个单词的相似程度,这在信息检索、聚类和推荐系统等任务中非常有用。
- 语义搜索:词嵌入使搜索引擎更加智能,能够理解同义词和相关术语。
- 机器翻译:嵌入有助于在不同语言之间对齐单词,从而实现更准确的翻译。
- 情感分析:通过理解上下文中单词的含义,嵌入提高了情感分类的准确性。
2.7 词嵌入中的上下文概念
词嵌入通过分析在大型文本语料库中与目标单词紧密相邻出现的单词,利用上下文来捕捉单词的含义。其核心思想是,出现在相似上下文中的单词往往具有相似的含义。
- 上下文窗口:
在训练词嵌入时,通常会使用一个上下文窗口来定义围绕目标单词的单词范围,这些单词被视为目标单词的上下文。例如,在“猫坐在垫子上(The cat sat on the mat)”这样的句子中,如果目标单词是“猫(cat)”,且上下文窗口大小为 2,那么上下文单词就是“这(The)”和“坐(sat)”。
上下文窗口的大小会影响嵌入的质量。较小的窗口关注更接近的单词,能够捕捉更具体的关系,而较大的窗口可能会捕捉更一般的语义关系。 - 上下文相似性:
训练过程会调整单词向量,使得具有相似上下文的单词最终拥有相似的向量。例如,“猫(cat)”和“狗(dog)”可能具有“宠物(pets)”、“动物(animals)”、“家(home)”等相似的上下文。因此,它们的向量在嵌入空间中会彼此靠近。 - 上下文相关嵌入:
像词向量(Word2Vec)和全局词向量(GloVe)这样的传统词嵌入会为每个单词生成一个单一的向量,而不考虑其上下文。然而,像基于语境的词向量表示(ELMo)和双向编码器表征来自变换器(BERT)这样的较新模型会生成上下文相关嵌入,其中一个单词的向量会根据其上下文而发生变化。
例如,在双向编码器表征来自变换器(BERT)中,“河岸(river bank)”和“金融银行(financial bank)”中的“银行(bank)”这个单词会有不同的向量,这反映了它们在这些上下文中的不同含义。这使得能够对单词及其含义有更细致入微的理解。
为什么上下文很重要
上下文至关重要,因为如果没有上下文,一个单词的含义往往是模糊的。同一个单词根据其周围的单词可能会有不同的含义,而理解这一点是自然语言理解的关键。
- 消除歧义:
上下文有助于消除具有多种含义(一词多义)的单词的歧义。例如,“树皮(bark)”这个单词可能意味着狗发出的声音,也可能意味着树的外皮。上下文(例如,“狗大声地叫(The dog barked loudly)”与“树的树皮很粗糙(The tree’s bark was rough)”)有助于确定正确的含义。 - 同义词和相关单词:
具有相似含义或在相似上下文中使用的单词将具有相似的嵌入。例如,“快乐(happy)”和“愉快(joyful)”可能会出现在相似的上下文中,如“感觉(feeling)”或“情感(emotion)”,从而导致相似的嵌入。 - 捕捉细微差别:
通过利用上下文,嵌入可以捕捉含义上的细微差别。例如,“大(big)”和“巨大(large)”可能具有相似的嵌入,但上下文可能会揭示它们在使用上的细微差别,比如“大机会(big opportunity)”与“大量(large amount)”。
3. 词嵌入技术
在自然语言处理(Natural Language Processing,NLP)中,词嵌入的生成是理解语言语义的核心。这些嵌入,即单词的密集数值表示,捕捉了语义关系,并使机器能够有效地处理文本数据。已经开发出了几种生成词嵌入的技术,每种技术都为语言的语义结构提供了独特的见解。

让我们来探讨一些主要的方法:
3.1 基于频率的方法
3.1.1 计数向量化器(Count Vectorizer)
在收集用于分布式单词表示的单词数据时,可以从对一系列文档中的单词进行简单计数开始。每个单词在每个文档中出现的次数总和就是一个计数向量。计数向量化器(CountVectorizer)通过计算每个单词出现的次数,将文本转换为固定长度的向量。现在,这些token被存储为一个词袋模型(Bag-of-Words)。

代码示例
from sklearn.feature_extraction.text import CountVectorizer# 示例语料库
corpus = ['This is the first document.','This document is the second document.','And this is the third one.','Is this the first document?',
]# 初始化计数向量化器
vectorizer = CountVectorizer()# 拟合并转换语料库
X = vectorizer.fit_transform(corpus)# 将结果转换为密集矩阵并打印
print("Count Vectorized Matrix:\n", X.toarray())# 打印特征名称
print("Feature Names:\n", vectorizer.get_feature_names_out())
输出:
Count Vectorized Matrix:[[0 1 1 1 0 0 1 0 1][0 2 0 1 0 1 1 0 1][1 0 0 1 1 0 1 1 1][0 1 1 1 0 0 1 0 1]]
Feature Names:['and' 'document' 'first' 'is' 'one' 'second' 'the' 'third' 'this']
局限性
- 由于词汇量较大,导致维度较高。
- 忽略单词的语义含义和上下文。
- 不考虑单词顺序。
- 生成稀疏的特征矩阵。
- 在捕捉长距离单词关系方面能力有限。
- 无法处理同义词,将每个单词视为不同的个体。
- 在处理新文档中的未登录词(OOV)时存在困难。
- 对文档长度敏感,可能会引入偏差。
- 罕见词可能会引入噪声,且没有有意义的贡献。
- 除非进行处理,否则频繁出现的词可能会主导特征空间。
- 对所有词赋予同等重要性,缺乏区分能力。
- 对于大型语料库,资源消耗大,可能存在可扩展性问题。
3.1.2 词袋模型(Bag-of-Words,BoW)
词袋模型(BoW)是一种文本表示技术,它将文档表示为一个无序的单词集合以及这些单词各自的频率。它忽略单词的顺序,捕捉文档中每个单词的频率,从而创建一个向量表示。
这是一种非常灵活、直观且最简单的特征提取方法。文本/句子被表示为一个唯一单词计数的列表,由于这个原因,这种方法也被称为计数向量化。要对我们的文档进行向量化,我们所要做的就是计算每个单词出现的次数。
由于词袋模型是根据单词的出现次数来衡量单词的重要性。在实际应用中,像“is”“the”“and”这样最常见的词没有什么价值。在进行计数向量化之前,会先去除停用词(在本系列博客中介绍过)。
示例

词汇表是这些文档中唯一单词的总数。
Vocabulary: [‘dog’, ‘a’, ‘live’, ‘in’, ‘home’, ‘hut’, ‘the’, ‘is’]
代码示例

局限性
- 忽略单词顺序和上下文,丢失语义含义。
- 高维度、稀疏的向量可能导致计算效率低下。
- 无法捕捉单词之间的语义相似性。
- 在处理一词多义(多个含义)和同义(相同含义)方面存在困难。
- 对词汇量大小和选择敏感。
- 无法捕捉多词短语或表达。
- 常见词(停用词)可能会主导表示。
- 需要大量的预处理(分词、去除停用词等)。
- 不适合需要对语言进行细致理解的复杂任务。
3.1.3 词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)
词频-逆文档频率(TF-IDF)是一种数值统计量,用于评估一个单词在文档中相对于一组文档(或语料库)的重要性。基本思想是,如果一个单词在某个文档中频繁出现,但在其他许多文档中不常出现,那么它应该被赋予更高的重要性。
在语料库D中,文档d中术语t的TF-IDF分数是通过两个指标的乘积来计算的:词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)。
-
词频(TF)
词频(TF)衡量一个术语在文档中出现的频率。为了防止偏向较长的文档,通常会用文档中术语的总数对其进行归一化。
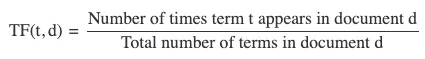
-
逆文档频率(IDF)
逆文档频率(IDF)衡量一个术语在整个语料库中的重要性。它会降低在许多文档中出现的术语的权重,并增加在较少文档中出现的术语的权重。

在分母中加上“+1”是为了防止在术语未出现在任何文档中的情况下出现除零错误。 -
结合TF和IDF:TF-IDF
对于文档d中的术语t,TF-IDF分数是通过将TF值与IDF值相乘来计算的:

重要性:有助于识别文档中的重要单词,常用于信息检索和文本挖掘。
代码示例
from sklearn.feature_extraction.text import TfidfVectorizer# 示例文本数据(文档)
documents = ["The cat sat on the mat.","The cat sat on the bed.","The dog barked."
]
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer()
# 拟合模型并将文档转换为TF-IDF表示
tfidf_matrix = vectorizer.fit_transform(documents)
# 获取特征名称(语料库中的唯一单词)
feature_names = vectorizer.get_feature_names_out()
# 将TF-IDF矩阵转换为数组
tfidf_array = tfidf_matrix.toarray()
# 显示TF-IDF矩阵
print("Feature Names (Words):", feature_names)
print("\nTF-IDF Matrix:")
print(tfidf_array)
输出:
Feature Names (Words): ['barked' 'bed' 'cat' 'dog' 'mat' 'on' 'sat' 'the']TF-IDF Matrix:
[[0. 0. 0.37420726 0. 0.49203758 0.374207260.37420726 0.58121064][0. 0.49203758 0.37420726 0. 0. 0.374207260.37420726 0.58121064][0.65249088 0. 0. 0.65249088 0. 0.0. 0.38537163]]

局限性
- 无法捕捉单词的上下文或含义。
- 对于大型词汇表,会生成高维度且稀疏的向量。
- 无法有效地处理同义词或一词多义。
- 可能会过度惩罚较长的文档。
- 仅限于线性关系,无法捕捉复杂的模式。
- 是静态的,无法适应新的上下文或不断演变的语言。
- 对于非常短或非常长的文档效果不佳。
- 对单词顺序不敏感。
3.1.4 N元语法(N - Grams)
N元语法是在文本分析中可作为一个单元共同使用的单词序列。像 “玛丽有一只小羊羔(Mary had a little lamb)”“玛丽有(Mary had)”“有一只(had a)”“一只小(a little)” 和 “小羔羊(little lamb)” 这样的表述就是二元语法(N = 2)。很多N元语法在数据中出现的频率可能不够高,因而用处不大,这会导致表示结果稀疏且缺乏意义。
类型
- 一元语法(Unigram):单个单词。
- 二元语法(Bigram):一对单词。
- 三元语法(Trigram):三个单词的序列。
重要性
能够捕捉文本中的上下文和单词依赖关系。
import nltk
from nltk.util import ngrams
from collections import Counter# 示例文本数据
text = "The quick brown fox jumps over the lazy dog"
# 将文本分词为单词
tokens = nltk.word_tokenize(text)
# 生成一元语法(1 - gram)
unigrams = list(ngrams(tokens, 1))
print("一元语法:")
print(unigrams)
# 生成二元语法(2 - gram)
bigrams = list(ngrams(tokens, 2))
print("\n二元语法:")
print(bigrams)
# 生成三元语法(3 - gram)
trigrams = list(ngrams(tokens, 3))
print("\n三元语法:")
print(trigrams)
# 统计每个N元语法的频率(用于演示)
unigram_freq = Counter(unigrams)
bigram_freq = Counter(bigrams)
trigram_freq = Counter(trigrams)
# 打印频率(可选)
print("\n一元语法频率:")
print(unigram_freq)
print("\n二元语法频率:")
print(bigram_freq)
print("\n三元语法频率:")
print(trigram_freq)
输出
一元语法:
[('The',), ('quick',), ('brown',), ('fox',), ('jumps',), ('over',), ('the',), ('lazy',), ('dog',)]
二元语法:
[('The', 'quick'), ('quick', 'brown'), ('brown', 'fox'), ('fox', 'jumps'), ('jumps', 'over'), ('over', 'the'), ('the', 'lazy'), ('lazy', 'dog')]
三元语法:
[('The', 'quick', 'brown'), ('quick', 'brown', 'fox'), ('brown', 'fox', 'jumps'), ('fox', 'jumps', 'over'), ('jumps', 'over', 'the'), ('over', 'the', 'lazy'), ('the', 'lazy', 'dog')]
一元语法频率:
Counter({('The',): 1, ('quick',): 1, ('brown',): 1, ('fox',): 1, ('jumps',): 1, ('over',): 1, ('the',): 1, ('lazy',): 1, ('dog',): 1})
二元语法频率:
Counter({('The', 'quick'): 1, ('quick', 'brown'): 1, ('brown', 'fox'): 1, ('fox', 'jumps'): 1, ('jumps', 'over'): 1, ('over', 'the'): 1, ('the', 'lazy'): 1, ('lazy', 'dog'): 1})
三元语法频率:
Counter({('The', 'quick', 'brown'): 1, ('quick', 'brown', 'fox'): 1, ('brown', 'fox', 'jumps'): 1, ('fox', 'jumps', 'over'): 1, ('jumps', 'over', 'the'): 1, ('over', 'the', 'lazy'): 1, ('the', 'lazy', 'dog'): 1})
局限性
- 高维度与稀疏性:维度高,且很多N元语法出现频率低,导致表示稀疏。
- 缺乏语义理解:只是简单的单词序列组合,不理解单词的语义。
- 忽略上下文:没有考虑到单词序列所在的更广泛上下文。
- 可扩展性问题:随着语料库增大,N元语法的数量会急剧增加,计算和存储成本高。
- 对噪声和稀有词敏感:稀有词或噪声可能会影响分析结果。
- 难以捕捉一词多义与同义词:无法区分同一单词的不同含义,也难以处理同义词。
- 跨语言泛化困难:不同语言的N元语法模式差异大,难以泛化。
- 难以捕捉长期依赖关系:对于长距离的单词依赖关系捕捉能力有限。
3.1.5 共现矩阵(Co - occurrence Matrices)
共现矩阵用于捕捉在给定上下文窗口内单词共同出现的频率。这些矩阵量化了单词之间的统计关系,为生成词嵌入提供了基础。
让我们通过一个简单的例子来说明共现矩阵的概念。假设我们有一个由以下三篇文档组成的语料库:
- 文档1:“敏捷的棕色狐狸跳过了那只懒狗(The quick brown fox jumps over the lazy dog)。”
- 文档2:“那只棕色的狗大声叫着(The brown dog barks loudly)。”
- 文档3:“那只懒猫安静地睡着(The lazy cat sleeps peacefully)。”
我们想基于这些文档中的单词,在窗口大小为1的情况下构建一个共现矩阵。这意味着我们考虑每个单词与其紧邻的相邻单词的共现情况。我们将忽略标点符号,并以不区分大小写的方式处理单词。
首先,让我们根据语料库中的唯一单词构建一个词汇表:
词汇表:[the, quick, brown, fox, jumps, over, lazy, dog, barks, loudly, cat, sleeps, peacefully]
接下来,我们创建一个共现矩阵,其中行和列代表词汇表中的单词。矩阵中每个单元格 (i, j) 的值表示单词 i 与单词 j 在指定窗口大小内共同出现的次数。
| the | quick | brown | fox | jumps | over | lazy | dog | barks | loudly | cat | sleeps | peacefully | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| the | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| quick | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| brown | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| fox | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| jumps | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| over | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| lazy | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| dog | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| barks | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| loudly | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| cat | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| sleeps | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| peacefully | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
这个共现矩阵捕捉了在窗口大小为1的情况下,每个单词与其他每个单词的共现频率。例如,“the” 行和 “lazy” 列的单元格值为1,表示在指定窗口大小内,“lazy” 与 “the” 在整个语料库中共同出现了一次。
这个例子展示了如何构建和利用共现矩阵来捕捉文本语料库中单词之间的统计关系,为各种自然语言处理任务(如词嵌入、情感分析和命名实体识别)提供有价值的见解。
共现矩阵在自然语言处理中的主要应用之一是生成词嵌入。通过分析语料库中单词的共现模式,共现矩阵可以捕捉每个单词周围的上下文信息。像词向量(Word2Vec)和全局词向量(GloVe)这样的技术利用这些矩阵来创建单词的密集、低维向量表示,其中向量之间的几何关系反映了单词之间的语义相似性。这使得可以进行单词相似度的度量、类比检测和语义搜索。

import numpy as np
import pandas as pd
from collections import Counter
from sklearn.preprocessing import normalize# 示例语料库
corpus = ["I love machine learning","machine learning is great","I love deep learning","deep learning and machine learning are related"
]# 对句子进行分词
corpus = [sentence.lower().split() for sentence in corpus]# 将句子列表展平为单个单词列表
vocab = set([word for sentence in corpus for word in sentence])
vocab = sorted(vocab) # 排序以保证顺序一致
vocab_size = len(vocab)# 初始化一个空的共现矩阵
co_occurrence_matrix = np.zeros((vocab_size, vocab_size))# 定义窗口大小
window_size = 2# 创建从单词到索引的映射
word2idx = {word: i for i, word in enumerate(vocab)}# 填充共现矩阵
for sentence in corpus:for i, word in enumerate(sentence):word_idx = word2idx[word]start = max(0, i - window_size)end = min(len(sentence), i + window_size + 1)for j in range(start, end):if i != j:context_word = sentence[j]context_idx = word2idx[context_word]co_occurrence_matrix[word_idx, context_idx] += 1# 将矩阵转换为DataFrame以便更好地可视化
co_occurrence_df = pd.DataFrame(co_occurrence_matrix, index=vocab, columns=vocab)# 对共现矩阵进行归一化
co_occurrence_normalized = normalize(co_occurrence_matrix, norm='l1', axis=1)# 将归一化后的矩阵转换为DataFrame以便更好地可视化
co_occurrence_normalized_df = pd.DataFrame(co_occurrence_normalized, index=vocab, columns=vocab)# 显示共现矩阵
print("共现矩阵:")
print(co_occurrence_df)# 显示归一化后的共现矩阵
print("\n归一化后的共现矩阵:")
print(co_occurrence_normalized_df)
局限性
- 高维度导致效率低下和存储问题:词汇表越大,矩阵维度越高,计算和存储成本增加。
- 极度稀疏:大多数单词对很少共现,导致矩阵中大部分元素为零。
- 捕捉深度语义关系的能力有限:只能反映单词的共现频率,难以捕捉深层次的语义联系。
- 上下文独立性:无法区分同一单词在不同上下文中的不同含义。
- 大规模语料库的可扩展性挑战:矩阵大小随语料库增大呈二次方增长。
- 偏向高频词:高频词在矩阵中占主导,对低频词或短语的表示不可靠。
- 表达能力有限:难以捕捉复杂的语言结构。
- 数据噪声:存在停用词和无意义的单词对,影响分析结果。
3.1.6 独热编码(One-Hot Encoding)
独热编码是自然语言处理(NLP)中表示单词的一种基本方法。词汇表中的每个单词都被表示为一个唯一的向量,除了对应于该单词在词汇表中索引位置的元素为1之外,其余所有元素都设置为0。
示例:给定一个包含10,000个单词的词汇表,对每个单词进行数值表示的最简单方法是什么?

你可以为每个单词分配一个整数索引:

我们的10,000个单词的词汇表,每个单词都被分配了一个索引。
那么,举一些例子:
- 我们词汇表中的第一个单词“土豚(aardvark)”的向量表示将是 [1, 0, 0, 0, …, 0],即在第一个位置为1,后面跟着9,999个0。
- 我们词汇表中的第二个单词“蚂蚁(ant)”的向量表示将是 [0, 1, 0, 0, …, 0],即在第一个位置为0,第二个位置为1,后面跟着9,998个0。
以此类推……
这个过程被称为独热向量编码。你可能也听说过这种方法被用于在多分类问题中表示标签。
现在,假设我们的自然语言处理项目正在构建一个翻译模型,我们想把英语输入句子“这只猫是黑色的(the cat is black)”翻译成另一种语言。我们首先需要用独热编码来表示每个单词。我们会先查找第一个单词“the”的索引,然后发现它在我们10,000个单词的词汇表中的索引是8676。

然后我们可以用一个长度为10,000的向量来表示单词“the”,其中除了位置8676处的元素为1之外,其他每个元素都是0。

我们对输入句子中的每个单词都进行这种索引查找,并创建一个向量来表示每个输入单词。整个过程有点像下面这个动图展示的这样:

展示输入句子“这只猫是黑色的(the cat is black)”中单词的独热编码的动图。
请注意,这个过程为每个输入单词生成了一个非常稀疏(大部分元素为0)的特征向量(在这里,术语“特征向量”“嵌入”和“单词表示”可以互换使用)。
这些独热向量是一种快速且简单的将单词表示为实数值向量的方法。
注意:
如果你想要生成整个句子的表示,而不仅仅是每个单词的表示,该怎么办呢?最简单的方法要么是将句子中各个单词的嵌入连接起来,要么是对它们求平均值(或者是两者的某种混合方式)。更先进的方法,比如编码器-解码器循环神经网络(RNN)模型,会按顺序读取每个单词的嵌入,以便通过多层变换逐步构建出句子含义的密集表示。
代码:
def one_hot_encode(text):words = text.split()vocabulary = set(words)word_to_index = {word: i for i, word in enumerate(vocabulary)}one_hot_encoded = []for word in words:one_hot_vector = [0] * len(vocabulary)one_hot_vector[word_to_index[word]] = 1one_hot_encoded.append(one_hot_vector)return one_hot_encoded, word_to_index, vocabulary# 示例
example_text = "猫在帽子里 狗在垫子上 鸟在树上(cat in the hat dog on the mat bird in the tree)"one_hot_encoded, word_to_index, vocabulary = one_hot_encode(example_text)print("词汇表:", vocabulary)
print("单词到索引的映射:", word_to_index)
print("独热编码矩阵:")
for word, encoding in zip(example_text.split(), one_hot_encoded):print(f"{word}: {encoding}")
输出:
词汇表: {'mat', 'the', 'bird', 'hat', 'on', 'in', 'cat', 'tree', 'dog'}
单词到索引的映射: {'mat': 0, 'the': 1, 'bird': 2, 'hat': 3, 'on': 4, 'in': 5, 'cat': 6, 'tree': 7, 'dog': 8}
独热编码矩阵:
cat: [0, 0, 0, 0, 0, 0, 1, 0, 0]
in: [0, 0, 0, 0, 0, 1, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
hat: [0, 0, 0, 1, 0, 0, 0, 0, 0]
dog: [0, 0, 0, 0, 0, 0, 0, 0, 1]
on: [0, 0, 0, 0, 1, 0, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
mat: [1, 0, 0, 0, 0, 0, 0, 0, 0]
bird: [0, 0, 1, 0, 0, 0, 0, 0, 0]
in: [0, 0, 0, 0, 0, 1, 0, 0, 0]
the: [0, 1, 0, 0, 0, 0, 0, 0, 0]
tree: [0, 0, 0, 0, 0, 0, 0, 1, 0]
稀疏独热编码的问题
我们已经完成了独热编码,并成功地将每个单词表示为一个数字向量。很多自然语言处理项目都采用了这种方法,但最终结果可能并不理想,尤其是在训练数据集较小的情况下。这是因为独热向量并不是一种很好的输入表示方法。
为什么单词的独热编码不是最优的呢?
- 缺乏语义相似性:独热编码无法捕捉单词之间的语义关系。例如,“猫(cat)”和“老虎(tiger)”被表示为完全不同的向量,没有显示出它们之间的相似性。这对于基于类比的向量运算等任务来说是个问题,在这些任务中,我们期望像“猫 - 小 + 大”这样的运算能得到类似于“老虎”或“狮子”的结果。独热编码缺乏完成这类任务所需的丰富性。
- 高维度:独热向量的维度与词汇表的大小成线性关系。随着词汇表的增大,特征向量会变得越来越大,加剧了维度灾难。这不仅增加了需要估计的参数数量,还需要指数级更多的数据来训练一个泛化能力好的模型。
- 计算效率低:独热编码的向量是稀疏且高维度的,其中大多数元素为0。许多机器学习模型,尤其是神经网络,处理这样的稀疏数据时会遇到困难。较大的特征空间也会带来内存和存储方面的挑战,特别是如果模型不能有效地处理稀疏矩阵的话。
3.2 静态嵌入
密集向量,或称为词嵌入,通过为单词提供更具信息量和更紧凑的表示,解决了独热编码的局限性。
- 降维:与向量长度等于词汇表大小不同,嵌入通常使用维度小得多的向量(例如,50、100或300维)。
- 语义接近性:密集向量将语义相似的单词在向量空间中放置得彼此靠近。例如,“猫(cat)”和“狗(dog)”的向量之间的余弦相似度会高于“猫”和“鱼(fish)”的向量之间的余弦相似度。
示例:
- 词向量(Word2Vec):通过根据上下文预测单词或反之来学习嵌入。
- 全局词向量(GloVe):使用矩阵分解来推导嵌入。
- 变换器(例如,双向编码器表征来自变换器(BERT)、生成式预训练变换器(GPT)):生成基于周围上下文捕捉单词含义的上下文嵌入。
独热向量存在的最重要问题是什么,而密集嵌入又是如何解决它的呢?
嵌入解决的核心问题是泛化能力。
泛化问题。如果我们假设像“猫(cat)”和“老虎(tiger)”这样的单词确实是相似的,我们希望有一种方法能将这种信息传递给模型。当其中一个单词很罕见时(例如“狮虎兽(liger)”),这一点就变得尤为重要,因为它可以借助一个相似的、更常见的单词在模型中所经过的计算路径。这是因为,在训练过程中,模型学习以某种方式处理输入“猫”,即通过由权重和偏差参数定义的多层变换来传递它。当网络最终遇到“狮虎兽”时,如果它的嵌入与“猫”相似,那么它将采取与“猫”相似的路径,而不是让网络完全从头开始学习如何处理它。对于你从未见过的事物进行预测是非常困难的——但如果它与你见过的事物相关,那就容易多了。
这意味着嵌入使我们能够构建更具泛化能力的模型——网络无需匆忙学习许多不同的方式来处理不相关的输入,而是让相似的单词“共享”参数和计算路径。
迈向密集、具有语义意义的表示
如果我们从词汇表中选取5个示例单词(比如说……“土豚(aardvark)”、“黑色(black)”、“猫(cat)”、“羽绒被(duvet)”和“僵尸(zombie)”),并检查由上述独热编码方法创建的它们的嵌入向量,结果会像这样:

使用独热编码的单词向量。每个单词都由一个大部分为0的向量表示,除了在由该单词在词汇表中的索引所决定的位置上有一个“1”。注意:并不是说“黑色”、“猫”和“羽绒被”具有相同的特征向量,只是在这里看起来是这样。
但是,作为说某种语言的人类,我们知道单词是具有许多层内涵和意义的丰富实体。让我们为这5个单词手工制作一些语义特征。具体来说,让我们将每个单词表示为在“动物”、“蓬松度”、“危险性”和“恐怖性”这四种语义属性上具有介于0和1之间的某种值:

为词汇表中的5个单词手工制作的语义特征。
那么,来解释几个例子:
- 对于单词“土豚(aardvark)”,我给它的“动物”特征赋予了较高的值(因为它确实是一种动物),而“蓬松度”(土豚有短鬃毛)、“危险性”(它们是小型的、夜行性的穴居猪)和“恐怖性”(它们很可爱)的值相对较低。
- 对于单词“猫(cat)”,我给它的“动物”和“蓬松度”特征赋予了较高的值(原因不言而喻),“危险性”特征赋予了中等的值(如果你养过宠物猫,就会明白原因),“恐怖性”特征也赋予了中等的值(试着搜索一下“斯芬克斯猫”的图片)。
根据语义特征值绘制单词
我们已经接近重点了:
每个语义特征都可以被看作是更广泛、更高维度的语义空间中的一个维度。
- 在上述虚构的数据集中,有四个语义特征,我们可以一次绘制其中两个特征,形成一个二维散点图(见下文)。每个特征是一个不同的轴/维度。
- 每个单词在这个空间中的坐标由其在感兴趣特征上的特定值给出。例如,单词“土豚(aardvark)”在“蓬松度与动物”二维图上的坐标是(x = 0.97,y = 0.03)。

在二维或三维轴上绘制单词特征值。
- 同样,我们可以考虑三个特征(“动物”、“蓬松度”和“危险性”),并在这个三维语义空间中绘制单词的位置。例如,单词“羽绒被(duvet)”的坐标是(x = 0.01,y = 0.84,z = 0.12),这表明“羽绒被”与蓬松度的概念高度相关,可能有一点危险性,而且不是动物。
这是一个手工制作的简单示例,但实际的嵌入算法当然会自动为输入语料库中的所有单词生成嵌入向量。如果你愿意,可以将像词向量(Word2Vec)这样的词嵌入算法看作是单词的无监督特征提取器。
像词向量(Word2Vec)这样的词嵌入算法是单词的无监督特征提取器。
词嵌入的维度是什么?
一般来说,词嵌入的维度是指单词的向量表示所定义的维度数量。这通常是在创建词嵌入时确定的一个固定值。词嵌入的维度表示在向量表示中编码的特征总数。
不同的生成词嵌入的方法可能会导致不同的维度。最常见的是,词嵌入的维度范围在50到300之间,不过更高或更低的维度也是可能的。
例如,下面的图展示了“国王(king)”、“王后(queen)”、“男人(man)”和“女人(women)”在三维空间中的词嵌入:

3.2.1 词向量(Word2Vec)
由米科洛夫(Mikolov)等人提出的词向量(Word2Vec),是谷歌推出的一种流行的基于预测的方法,它通过在上下文窗口内预测周围的单词来学习词嵌入。这种方法产生的密集向量表示能够捕捉单词之间的语义关系。
本吉奥(Bengio)提出的方法为自然语言处理研究人员提供了新的机会,他们可以修改该技术及其架构本身,以创建一种计算成本更低的方法。为什么呢?
本吉奥等人提出的方法从词汇表中选取单词,并将它们输入到一个具有嵌入层、隐藏层(多个)和一个softmax函数的前馈神经网络中。
这些嵌入具有相关的可学习向量,它们通过反向传播进行自我优化。本质上,由于这是一个浅层网络,该架构的第一层就产生了词嵌入。
这种架构的问题在于,在隐藏层和投影层之间的计算成本很高。原因比较复杂:
- 投影层产生的值是密集的。
- 隐藏层为词汇表中的所有单词计算概率分布。
为了解决这个问题,研究人员(米科洛夫等人在2013年)提出了一个名为“词向量(Word2Vec)”的模型。
词向量(Word2Vec)模型从本质上解决了本吉奥的自然语言模型(NLM)的问题。
它完全去除了隐藏层,但与本吉奥的模型一样,投影层对所有单词是共享的。缺点是,如果数据较少,这个没有神经网络的简单模型将无法像神经网络那样精确地表示数据。
另一方面,在有较大数据集的情况下,它可以在嵌入空间中精确地表示数据。同时,它还降低了复杂度,并且该模型可以在更大的数据集上进行训练。
词向量(Word2Vec)有两种神经嵌入方法:连续词袋模型(Continuous Bag of Words,CBOW)和跳字模型(Skip-gram)。

连续词袋模型(CBOW)和跳字模型(Skip-gram)的架构。示例句子——“想法可以改变你的生活(Idea can change your life)”。
3.2.1.1 连续词袋模型(Continuous Bag of Words,CBOW)
连续词袋模型(CBOW)在给定周围单词的情况下,预测一个单词出现的概率。我们可以考虑单个单词或一组单词。但为了简单起见,我们将取单个上下文单词,并尝试预测单个目标单词。
英语中大约有120万个单词,这使得在我们的示例中不可能包含这么多单词。所以我将考虑一个小例子,在这个例子中我们只有四个单词,即“居住(live)”、“家(home)”、“他们(they)”和“在(at)”。为了简单起见,我们假设语料库中只有一个句子,即“他们住在家里(They live at home)”。

首先,我们将每个单词转换为独热编码形式。此外,我们不会考虑句子中的所有单词,而只会选取在窗口内的某些单词。例如,对于窗口大小等于3的情况,我们在一个句子中只考虑三个单词。中间的单词是要预测的单词,周围的两个单词作为上下文输入到神经网络中。然后滑动窗口,并重复这个过程。
最后,通过如上述滑动窗口反复训练网络后,我们得到权重,我们使用这些权重来得到如下所示的嵌入。

通常,我们取窗口大小约为8到10个单词,并且向量大小为300。
3.2.1.2 跳字模型(Skip-gram model)
跳字模型(Skip-gram)的架构通常试图实现与连续词袋模型(CBOW)相反的操作。它试图在给定目标单词(中心单词)的情况下,预测源上下文单词(周围单词)。
跳字模型(Skip-gram)的工作原理与连续词袋模型(CBOW)非常相似,但在其神经网络的架构以及生成权重矩阵的方式上存在差异,如下图所示:

在获得权重矩阵后,获取词嵌入的步骤与连续词袋模型相同。
那么,对于实现Word2Vec,我们应该使用这两种算法中的哪一种呢?事实证明,对于维度较高的大型语料库,使用跳字模型更好,但训练速度较慢。而连续词袋模型更适合小型语料库,并且训练速度也更快。

3.2.2 全局词向量(GloVE,Global Vectors for Word Representation)
斯坦福大学的全局词向量(GloVE)通过利用共现统计信息来训练词嵌入,结合了基于计数的方法和基于预测的方法的优点。通过优化全局词-词共现矩阵,GloVE生成的嵌入能够捕捉局部和全局的语义关系。
GloVE是一种无监督学习算法,它通过分析文本语料库中单词的共现统计信息来获得单词的向量表示。这些单词向量捕捉了单词之间的语义含义和关系。
GloVE背后的关键思想是通过检查整个语料库中单词共现的概率来学习词嵌入。它构建一个全局词-词共现矩阵,然后对其进行因式分解,以推导出在连续向量空间中表示单词的单词向量。
这些单词向量因其能够捕捉单词之间的语义关系,在自然语言处理(NLP)任务中受到了广泛欢迎。它们被用于各种应用中,如机器翻译、情感分析、文本分类等,在这些应用中,理解单词的含义和上下文至关重要。
上下文理解使我们能够根据周围的单词来理解某个单词。
GloVE嵌入与其他嵌入技术(如Word2Vec和FastText)一起被广泛使用,显著提高了自然语言处理模型的性能。
GloVE词嵌入是如何创建的?
GloVE模型的基本方法是首先创建一个巨大的词-上下文共现矩阵,该矩阵由(单词,上下文)对组成,使得这个矩阵中的每个元素都表示一个单词与上下文(可以是一个单词序列)一起出现的频率。然后,其思路是应用矩阵分解来近似这个矩阵,如下图所示。
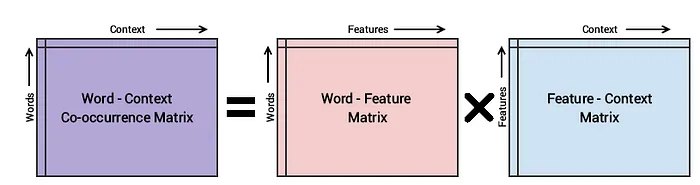
考虑词-上下文(WC)矩阵、词-特征(WF)矩阵和特征-上下文(FC)矩阵,我们尝试对WC = WF × FC进行因式分解,这样我们的目标就是通过将WF和FC相乘来从它们重构WC。为此,我们通常用一些随机权重初始化WF和FC,并尝试将它们相乘得到WC’(WC的近似值),然后衡量它与WC的接近程度。我们使用随机梯度下降(SGD)多次执行此操作,以最小化误差。最后,词-特征矩阵(WF)为我们提供了每个单词的词嵌入,其中F可以预设为特定的维度数。需要记住的一个非常重要的点是,Word2Vec和GloVE模型的工作方式非常相似。它们都旨在构建一个向量空间,其中每个单词的位置都基于其上下文和语义受到相邻单词的影响。Word2Vec从单词共现对的局部单个示例开始,而GloVE从语料库中所有单词的全局聚合共现统计信息开始。
3.2.3 FastText
Word2Vec的局限性
虽然Word2Vec在自然语言处理领域是一个具有变革性的方法,但我们会发现它仍然有一些改进的空间:
-
未登录词(OOV,Out of Vocabulary)问题:
在Word2Vec中,会为每个单词创建一个嵌入。因此,它无法处理在训练过程中未遇到过的任何单词。
例如,“张量(tensor)”和“流动(flow)”等单词在Word2Vec的词汇表中是存在的。但是,如果你尝试获取复合词“TensorFlow”的嵌入,就会得到一个未登录词错误。

-
词法问题:
对于像“吃(eat)”和“吃了(eaten)”这样具有相同词干的单词,Word2Vec不会进行任何参数共享。每个单词都是根据其出现的上下文单独学习的。因此,存在利用单词内部结构来提高处理效率的空间。

为了解决上述挑战,博亚诺夫斯基(Bojanowski)等人提出了一种名为FastText的新嵌入方法。他们的关键见解是利用单词的内部结构来改进从跳字模型中获得的向量表示。
对跳字模型的修改如下:
- 子词生成:
对于一个单词,我们生成其内部长度为3到6的字符n元语法。
-
我们取一个单词,并添加尖括号来表示单词的开头和结尾。

-
然后,我们生成长度为n的字符n元语法。例如,对于单词“eating”,可以通过从尖括号的开头滑动一个3字符的窗口直到到达结尾的尖括号来生成长度为3的字符n元语法。在这里,我们每次将窗口移动一步。

-
这样,我们就得到了一个单词的字符n元语法列表。

不同长度的字符n元语法的示例如下方所示:

- 由于可能存在大量独特的n元语法,我们应用哈希来限制内存需求。我们不是为每个独特的n元语法学习一个嵌入,而是学习总共B个嵌入,其中B表示桶的大小。该论文使用了大小为200万的桶。

每个字符n元语法被哈希为1到B之间的一个整数。尽管这可能会导致冲突,但它有助于控制词汇表的大小。该论文使用福勒-诺尔-沃(Fowler-Noll-Vo)哈希函数的FNV-1a变体将字符序列哈希为整数值。

-
带负采样的跳字模型:
为了理解预训练过程,让我们举一个简单的示例。我们有一个句子,中心单词是“eating”,需要预测上下文单词“am”和“food”。

-
首先,通过对字符n元语法的向量和整个单词本身的向量求和来计算中心单词的嵌入。

-
对于实际的上下文单词,我们直接从嵌入表中获取它们的单词向量,而不添加字符n元语法的向量。

-
现在,我们按照与一元词频的平方根成比例的概率随机收集负样本。对于一个实际的上下文单词,采样5个随机的负样本单词。

-
我们计算中心单词和实际上下文单词之间的点积,并应用sigmoid函数以得到0到1之间的匹配分数。
-
根据损失,我们使用随机梯度下降(SGD)优化器更新嵌入向量,以使实际上下文单词更接近中心单词,同时增加与负样本的距离。

-
3.3 上下文嵌入

上下文嵌入在学习单词之间的关系方面确实展现出了一些很有前景的成果。
例如,
多亏了它们的自注意力机制,这些嵌入能够生成具有上下文感知的表示。这使得嵌入模型能够根据单词使用的上下文动态地为其生成嵌入。因此,如果一个单词出现在不同的上下文中,模型将得到不同的表示。
下面的图片精确地展示了单词“Bank”在不同用法下的情况。
为了便于可视化,使用t分布随机邻域嵌入(t-SNE)将嵌入投影到了二维空间中。

全局词向量(Glove)与双向编码器表征来自变换器(BERT)在理解单词不同含义方面的对比
像全局词向量(Glove)和Word2Vec这样的静态嵌入模型,对于一个单词的不同用法会产生相同的嵌入。
然而,上下文相关的嵌入模型则不会。
实际上,上下文相关的嵌入能够理解单词“Bank”的不同含义:
- 一家金融机构
- 斜坡地形
- 一道长脊等等。
这里的不同含义取自普林斯顿大学的Wordnet数据库:WordNet。
因此,它们解决了静态嵌入模型的主要局限性。
3.3.1 自注意力机制
将静态嵌入转化为动态上下文嵌入


该图展示了单词“Apple”的含义是如何根据其在句子中的上下文而变化的。这是通过上下文嵌入实现的,在这种方式中,一个单词的表示会根据周围的单词进行调整。我们来剖析一下这个例子。
左侧:“我吃了一个苹果。”
- 句子:“我吃了一个苹果。(I ate an Apple.)”
- 上下文:在这里,“Apple”显然指的是水果。

以下分析展示了“Apple”的最终表示是如何受到周围单词影响的:
- “I”:表示说话者的代词。
- “ate”:表示进食动作的动词。
- “an”:用于修饰单个物品(通常为可数名词)的冠词,辅助限定上下文。
- “Apple”:这个单词本身,其含义受上下文影响。
- 结果:由于“ate”和“an”这两个单词,这里“Apple”的向量在很大程度上倾向于水果的含义。
右侧:“我买了一个苹果公司的产品。”
- 句子:“我买了一个苹果公司的产品。(I bought an Apple.)”
- 上下文:在这个上下文中,“Apple”更有可能指的是苹果这家科技公司,意味着购买了一部苹果公司的产品,比如iPhone或MacBook。

以下分析展示了上下文是如何改变单词含义的:
- “I”:同样是表示说话者的代词。
- “bought”:表示购买行为的动词。
- “an”:和之前一样的冠词。
- “Apple”:在这里,这个单词的含义转向了产品或品牌的语境。
- 结果:在这个句子中,由于“bought”所提供的上下文,“Apple”的向量转向了表示苹果公司或其产品的方向。
上下文很关键:单词“Apple”根据周围的单词会有不同的含义。在“我吃了一个苹果。(I ate an Apple.)”中,它表示水果。在“我买了一个苹果公司的产品。(I bought an Apple.)”中,它指的是苹果公司的产品。
上下文嵌入:这些嵌入根据上下文调整“Apple”的向量,从而更准确地理解每个句子中该单词的含义。这种方法有助于更自然地理解语言,捕捉到静态嵌入所忽略的细微差别。
现在我们需要像对“Apple”所做的那样,为每个独特的单词都进行这样的处理。


上下文嵌入通过提供基于上下文变化的单词表示,解决了静态嵌入的局限性。这些嵌入是由经过训练以理解单词出现的上下文的深度学习模型生成的。
- 上下文感知:一个单词的表示会受到其周围单词的影响,从而根据上下文产生不同的含义。
- 动态表示:单词根据其在不同句子中的用法会有多种表示形式。
- 增强的语义理解:上下文嵌入能够捕捉更复杂的关系和细微的含义。
这一领域的关键进展之一是基于语言模型的嵌入(ELMo,Embeddings from Language Models)的发展。ELMo会考虑整个句子来确定单词的含义。它在各种自然语言处理任务中显著提升了性能。
在ELMo之后,双向编码器表征来自变换器(BERT,Bidirectional Encoder Representations from Transformers)进一步拓展了这一概念。BERT会分析一个句子中所有单词之间的关系,而不是孤立地分析单个单词。这带来了更加精细的语言模型。
3.3.2 双向编码器表征来自变换器(BERT)
像BERT这样的变换器模型,使用注意力机制来衡量句子中所有单词的相关性。这在自然语言处理的特征提取方面是一个变革性的突破。它使得预测更加准确,对语言细微差别的理解也更加深入。
BERT是一个基于变换器的模型,它学习单词的上下文相关嵌入。它通过同时考虑一个单词的左右上下文来考量其完整的上下文,从而生成能够捕捉丰富上下文信息的嵌入。
from transformers import BertTokenizer, BertModel
import torch# Load pre-trained BERT model and tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
word_pairs = [('learn', 'learning'), ('india', 'indian'), ('fame', 'famous')]# Compute similarity for each pair of words
for pair in word_pairs:tokens = tokenizer(pair, return_tensors='pt')with torch.no_grad():outputs = model(**tokens)# Extract embeddings for the [CLS] tokencls_embedding = outputs.last_hidden_state[:, 0, :]similarity = torch.nn.functional.cosine_similarity(cls_embedding[0], cls_embedding[1], dim=0)print(f"Similarity between '{pair[0]}' and '{pair[1]}' using BERT: {similarity:.3f}")
3.3.3 基于语言模型的词嵌入(ELMo)
基于语言模型的词嵌入(ELMo,Embeddings from Language Models)是由艾伦人工智能研究所(Allen Institute for AI)的研究人员开发的。ELMo词嵌入在问答和情感分析任务中展现出了性能提升。其官方论文地址为:https://arxiv.org/pdf/1802.05365.pdf 。
ELMo在自然语言处理(NLP)的特征提取方面是一项重大进展。这项技术利用深度的、上下文相关的词嵌入来捕捉句法和语义信息,以及一词多义(即具有多种含义的单词)的情况。
与传统的词嵌入不同,ELMo会在周围文本的上下文中分析单词,从而带来更丰富的理解。下面是一个用Python编写的简化示例:
from allennlp.modules.elmo import Elmo, batch_to_ids# 初始化ELMo
options_file = 'elmo_options.json'
weight_file = 'elmo_weights.hdf5'
elmo = Elmo(options_file, weight_file, num_output_representations=1)# 示例句子
sentences = [['I', 'have', 'a', 'green', 'apple'], ['I', 'have', 'a', 'green', 'thumb']]# 将句子转换为字符ID
character_ids = batch_to_ids(sentences)# 获取ELMo嵌入
embeddings = elmo(character_ids)
ELMo的动态词嵌入是一项具有变革性的技术,它提供了细致入微的词表示,能够根据上下文反映单词的不同含义。这为更复杂的自然语言处理应用铺平了道路,提升了包括特征提取等在内的各种任务的性能。
在某些应用范围有限的用例中,训练一个自定义的嵌入模型可能会被证明是有益的。然而,训练一个具有良好泛化能力的嵌入模型可能是一项艰巨的任务。收集和预处理文本数据可能很繁琐,而且训练过程在计算上也可能非常耗费资源。
对于任何构建人工智能系统的人来说,好消息是一旦创建了嵌入,它们也可以在不同的任务和领域中进行泛化。一些可供使用的著名预训练嵌入模型如下:
- OpenAI的嵌入模型:
ChatGPT以及GPT系列大语言模型背后的公司OpenAI也提供了三种嵌入模型:text-embedding-ada-002、text-embedding-3-small、text-embedding-3-large。可以使用OpenAI API来访问OpenAI的模型。 - 谷歌的Gemini嵌入模型:
text-embedding-004(最后更新于2024年4月)是谷歌Gemini提供的模型。可以通过Gemini API来访问它。 - Voyage AI:
Voyage AI的嵌入模型得到了Claude系列大语言模型的提供商Anthropic的推荐。Voyage提供了几种嵌入模型,如voyage-large-2-instruct、voyage-law-2、voyage-code-2 。 - Mistral AI嵌入模型:
Mistral是Mistral和Mixtral等大语言模型背后的公司。他们提供了一个名为mistral-embed的1024维嵌入模型。这是一个开源的嵌入模型。 - Cohere嵌入模型:
Cohere是Command、Command R和Command R+等大语言模型的开发者,他们也提供了多种嵌入模型,如embed-english-v3.0、embed-english-light-v3.0、embed-multilingual-v3.0等,可以通过Cohere API来访问这些模型。
4. Word2Vec训练
4.1 Word2Vec是如何生成词嵌入的?
Word2Vec使用了一种你可能在机器学习的其他地方见过的技巧。
Word2Vec是一个带有单个隐藏层的简单神经网络,和所有神经网络一样,它有权重,在训练过程中,其目标是调整这些权重以最小化损失函数。然而,Word2Vec不会被用于它所训练的任务,相反,我们只会提取它的隐藏层权重,将其用作我们的词嵌入,然后抛弃模型的其余部分(这听起来有点“残忍”)。
你可能在无监督特征学习中也见过这种技巧,在无监督特征学习中,自编码器被训练用于在隐藏层中压缩输入向量,并在输出层中将其解压缩回原始向量。训练完成后,输出层(解压缩步骤)会被去掉,只使用隐藏层,因为它已经学习到了很好的特征,这是一种在没有标记训练数据的情况下学习良好图像特征的技巧。
4.2 架构
其架构类似于自编码器的架构,你取一个较大的输入向量,将其压缩为一个较小的密集向量,然后与自编码器不同的是,你不是将其解压缩回原始输入向量,而是输出目标单词的概率。
首先,我们不能将单词作为字符串输入到神经网络中。
相反,我们将单词作为独热向量输入,独热向量本质上是一个长度与词汇表相同的向量,除了表示我们要表示的单词的索引位置被赋值为“1”之外,其余位置都填充为“0”。
隐藏层是一个标准的全连接(密集)层,其权重就是词嵌入。
输出层输出词汇表中目标单词的概率。

这个网络的输入是一个表示输入单词的独热向量,标签也是一个表示目标单词的独热向量,然而,网络的输出是目标单词的概率分布,不一定像标签那样是独热向量。
隐藏层权重矩阵的行,实际上就是我们想要的词向量(词嵌入)!

隐藏层就像一个查找表。隐藏层的输出就是输入单词的“词向量”。
更具体地说,如果你将一个1×10000的独热向量与一个10000×300的矩阵相乘,实际上它只会选择矩阵中与“1”对应的那一行。

所有这些操作的最终目标是学习这个隐藏层权重矩阵,然后在完成后抛弃输出层!
输出层只是一个softmax激活函数:

这是该架构的一个高层示意图:

4.3 语义和句法关系
那么Word2Vec如何帮助回答我们在本文开头提出的问题呢?
从技术上讲,如果不同的单词在上下文中相似,那么当这些单词作为输入传入时,Word2Vec应该产生相似的输出,并且为了产生相似的输出,为这些单词计算的词向量(在隐藏层中)必须相似,因此Word2Vec的目的是为处于相似上下文中的单词学习相似的词向量。
Word2Vec能够捕捉单词之间多种不同程度的相似性,这样语义和句法模式就可以通过向量运算来重现。像“男人之于女人就如同兄弟之于姐妹”这样的模式可以通过对这些单词的向量表示进行代数运算来生成,使得“兄弟”的向量表示 - “男人”的向量表示 + “女人”的向量表示产生的结果在模型中最接近“姐妹”的向量表示。这样的关系可以针对一系列语义关系(例如国家 - 首都)以及句法关系(例如现在时态 - 过去时态)生成。

4.4 训练算法
一个Word2Vec模型可以使用层次softmax算法和/或负采样算法进行训练,通常情况下,只使用负采样算法。
传统上,预测模型是根据最大似然原理进行训练的,在给定前面单词的情况下,基于对所有词汇表单词的softmax函数来最大化下一个单词出现的概率。

然而,考虑到一个庞大的词汇集,这种训练过程在计算上是相当耗费资源的,因为我们需要在每个训练步骤中计算并归一化所有的词汇表单词。因此,许多模型提供了不同的减少计算量的方法。
这同样适用于Word2Vec模型,尽管该网络是浅层的,只有两层,但它的宽度极大,因此,它的每一种训练过程都提供了一种独特的减少计算量的方法。
4.4.1 层次softmax算法
为了近似估计模型试图最大化的条件对数似然,层次softmax方法使用哈夫曼树来减少计算量。
层次softmax算法对于不常见的单词效果更好。
很自然地,随着训练轮数的增加,层次softmax算法就不再那么有效了。
4.4.2 负采样算法
负采样算法通过只对N个负样本实例以及目标单词进行采样,而不是对整个词汇表进行采样,从而减少计算量。
从技术上讲,负采样算法忽略了独热编码标签词向量中的大部分“0”,并且只对目标单词和一些随机采样的负类别进行权重传播和更新。
更具体地说,负采样算法在对目标单词进行采样的同时,也对负样本实例(单词)进行采样,并在最大化目标单词的对数似然的同时,最小化采样得到的负样本实例的对数似然。

如何选择负样本呢?
负样本是根据一元词分布来选择的。
从本质上讲,选择一个单词作为负样本的概率与其出现的频率相关,出现频率越高的单词越有可能被选为负样本。
具体来说,每个单词被赋予一个与其频率(词频计数)的3/4次方相等的权重。选择一个单词的概率就是它的权重除以所有单词的权重之和。
4.5 实际方法
使用不同的模型参数和不同规模的语料库会极大地影响Word2Vec模型的质量。
可以通过多种方式提高模型的准确性,包括选择模型架构(连续词袋模型(CBOW)或跳字模型(Skip-Gram))、增加训练数据集、增加向量的维度数量,以及增加算法所考虑的单词窗口大小。这些改进中的每一项都伴随着计算复杂度增加的代价,因此也会增加模型生成的时间。
在使用大型语料库和高维度向量的模型中,跳字模型在总体上能产生最高的准确率,并且在语义关系方面始终能达到最高的准确率,而且在大多数情况下,在句法准确率方面也能达到最高。然而,连续词袋模型的计算成本较低,并且能产生相似的准确率结果。
总体而言,随着所使用单词数量的增加以及维度数量的增加,准确率也会提高。将训练数据的数量翻倍,与将向量维度的数量翻倍,所导致的计算复杂度增加程度是相当的。
4.5.1 子采样
一些高频词往往提供的信息较少。频率高于某个阈值的单词(例如“a”、“an”和“that”)可以进行子采样,以提高训练速度和性能。此外,常见的单词对或短语可以被视为单个“单词”,以提高训练速度。
4.5.2 维度
词嵌入的质量随着维度的增加而提高。然而,在达到某个阈值之后,边际收益将会递减。通常情况下,向量的维度被设置在100到1000之间。
4.5.3 上下文窗口
上下文窗口的大小决定了在给定单词之前和之后的多少个单词将被包含为该给定单词的上下文单词。根据作者的建议,对于跳字模型,推荐的值是10;对于连续词袋模型,推荐的值是5。
下面是一个上下文窗口大小为2的跳字模型的示例:

5. 部署词嵌入模型时的注意事项
- 在部署模型时,你需要使用与为词嵌入创建训练数据时相同的流程。如果你使用了不同的分词器,或者不同的处理空白字符、标点符号等的方法,最终可能会得到不兼容的输入。
- 在你的输入中可能存在没有预训练向量的单词。这样的单词被称为未登录词(OOV,Out of Vocabulary)。你可以做的是将这些单词替换为“UNK”,表示未知,然后单独处理它们。
- 维度不匹配:向量可以有多种长度。如果你训练的模型使用的向量长度为比如说400,然后在推理阶段尝试使用长度为1000的向量,你将会遇到错误。所以要确保在整个过程中使用相同的维度。
6. 如何选择嵌入模型?
自从ChatGPT发布以及被恰如其分地称为“大语言模型大战”的局面出现以来,在开发嵌入模型方面也出现了一股热潮。评估大语言模型和嵌入模型的标准有很多且在不断发展。对于“使用哪种嵌入模型?”这个问题,没有一个绝对正确的答案。然而,你可能会注意到某些嵌入模型在特定的用例(如摘要生成、文本生成、分类等)中效果更好。
OpenAI过去会针对不同的用例推荐不同的嵌入模型。然而,现在他们推荐在所有任务中都使用text-embeddings-3模型。
Hugging Face的多语言文本嵌入基准(MTEB,Multi-Task Evaluation Benchmark)排行榜会根据七个用例来评估几乎所有可用的嵌入模型,这些用例包括:分类、聚类、成对分类、重排序、检索、语义文本相似度(STS,Semantic Textual Similarity)和摘要生成。
另一个重要的考虑因素是成本。如果你处理大量的文档,使用OpenAI的模型可能会产生相当高的成本。开源模型的成本则取决于具体的实现方式。
7. 结论
词嵌入的发展历程已经从简单的独热编码演进到了先进的基于变换器的模型。从像Word2Vec和GloVe这样提供静态嵌入的方法开始,这个领域已经发展到了具有上下文嵌入的ELMo、BERT和GPT,从而能够更细致入微、更复杂地理解和生成人类语言。这种演进反映了在捕捉人类语言的复杂性方面的重大进步,最终成就了当代大语言模型和变换器的强大能力。
8. 检验你的知识!
8.1 问题及参考答案
- 你将如何解释两个词向量之间的余弦相似度,以及它对于这两个词之间的关系意味着什么?
- 预期答案:余弦相似度衡量的是向量空间中两个向量之间夹角的余弦值。余弦相似度接近1表明这些向量彼此接近,并且所代表的词可能具有相似的含义。余弦相似度为0则表明这些向量是正交的,这意味着这些词是不相关的。负的余弦相似度则表明这些词具有相反的含义。
- 讨论在捕捉一词多义(polysemy)和同音异义词(homonymy)方面,向量空间表示法的局限性。现代的嵌入技术是如何解决这些局限性的?
- 预期答案:像Word2Vec这样的传统向量空间模型会为每个词分配一个单一的向量,这无法捕捉一词多义(一个词有多种含义)和同音异义词(发音相同但含义不同的词)的情况。像上下文嵌入(例如BERT)这样的现代嵌入技术通过根据词的上下文为同一个词生成不同的向量来解决这个问题,从而有效地捕捉了不同的含义。
- 在训练词嵌入时,使用大词汇量和减少词汇量之间存在哪些权衡?
- 预期答案:大词汇量能让模型捕捉到更广泛的词以及词的细微差别,但会增加计算复杂度和内存需求。减少词汇量可以使训练速度加快并且降低资源使用量,但可能会遗漏重要的词或词的细微差别,导致对低频词的嵌入效果变差。
- 在哪些场景中,相较于使用全softmax方法,你更倾向于在训练词嵌入时使用基于采样的方法(如负采样)?
- 预期答案:当处理大型数据集和大量词汇时,更倾向于使用负采样,因为它通过只更新一小部分权重,显著降低了计算成本。当重点在于捕捉词之间的相似性,而非对整个词汇表的分布进行建模(就像在Word2Vec这样的模型中)时,负采样尤其有用。
- 在捕捉词的含义和上下文方面,BERT嵌入与Word2Vec嵌入有何不同?
- 预期答案:BERT嵌入是上下文相关的,这意味着它会根据周围的上下文为同一个词生成不同的嵌入。这使得BERT能够根据词在句子中的用法捕捉词的动态含义。相比之下,Word2Vec生成的是静态嵌入,其中每个词都有一个单一的向量表示,与上下文无关。
- 解释FastText是如何通过纳入子词信息来改进Word2Vec的。这对生僻词的嵌入质量有何影响?
- 预期答案:FastText通过将词表示为字符n元语法的集合来改进Word2Vec,这使得它能够通过组合子词的嵌入来生成词的嵌入。这种方法有助于为罕见词或未登录词生成更好的嵌入,因为即使在完整的词数据稀疏的情况下,它也可以利用子词信息来创建有意义的表示。
- 讨论层次softmax的使用及其对大型数据集训练效率的影响。
- 预期答案:层次softmax是一种在大词汇量情况下用于近似softmax函数的技术。它将词汇表构建成一棵二叉树,使得模型能够以对数时间而非线性时间来计算概率。通过减少所需的计算量,这极大地提高了训练效率,尤其是在处理非常大的数据集和大量词汇时。
- 解释为特定领域应用优化嵌入所面临的挑战,以及你将如何应对这些挑战。
- 预期答案:特定领域的应用可能需要能够捕捉该领域独特细微差别的嵌入,而通用的嵌入可能会遗漏这些。挑战包括特定领域的数据有限、词汇不匹配以及需要进行微调。为了应对这些问题,可以使用迁移学习,即对一个通用模型在特定领域的数据上进行微调,或者使用特定领域的语料库从头开始训练嵌入。
- 对于像情感分析这样的特定任务,你将如何评估词嵌入的质量?你会使用哪些指标?
- 预期答案:对于情感分析任务的词嵌入质量,可以使用内在指标和外在指标来评估。内在评估包括诸如词相似度或类比任务等。外在评估则涉及在下游任务(如情感分析)中使用这些嵌入,并使用诸如准确率、F1值或AUC等指标来衡量性能。在特定任务的上下文中,这些嵌入区分积极和消极情感词的能力至关重要。
- 讨论在评估词嵌入质量时,仅仅依赖诸如类比任务这样的内在评估指标可能存在的陷阱。
- 预期答案:像类比任务这样的内在指标通常测试的是嵌入的几何属性,但可能与下游任务的性能没有很好的相关性。它们可能会给人一种关于嵌入质量的错误印象,因为它们没有考虑到特定应用的具体要求。例如,在类比任务中表现良好的嵌入,在捕捉情感分析或命名实体识别所需的细微差别方面可能仍然会失败。因此,外在评估为特定任务的嵌入质量提供了更实际的衡量标准。
- 在低延迟环境中部署像BERT这样的上下文嵌入模型可能会面临哪些潜在挑战,以及你将如何缓解这些挑战?
- 预期答案:在低延迟环境中部署BERT存在挑战,因为它的规模大且计算复杂,这可能导致推理时间缓慢。缓解策略包括模型蒸馏(在保持性能的同时减小模型的规模)、量化(降低模型权重的精度),或者使用更高效的变体,如DistilBERT或ALBERT。此外,诸如缓存常见短语的嵌入,或者使用两阶段方法(即先由一个更简单的模型对输入进行过滤,然后再将其传递给BERT)等技术,有助于减少延迟。
- 在生产环境中部署词嵌入模型时,你将如何处理未登录词(OOV)的问题?
- 预期答案:处理未登录词的问题,可以使用纳入子词信息的模型,如FastText,它可以通过将未见过的词分解为已知的子词来生成其嵌入。另一种方法是使用像BERT这样的上下文模型,它可以根据上下文推断未登录词的含义。在某些情况下,你还可以设置一个备用机制,将未登录词映射到一个表示未知词的通用向量,或者通过字符级嵌入或哈希等技术来处理它们。
8.2 自主探究
- 应该选择哪种嵌入模型以及原因是什么。你将如何选择嵌入模型的规模?
- 什么是“维度灾难”,以及它与自然语言处理(NLP)有何关系?
参考文献
- https://medium.com/@vipra_singh/llm-architectures-explained-word-embeddings-part-2-ff6b9cf1d82d
相关文章:
—— 从基础原理到实践应用的深度探索)
LLM架构解析:词嵌入模型 Word Embeddings(第二部分)—— 从基础原理到实践应用的深度探索
本专栏深入探究从循环神经网络(RNN)到Transformer等自然语言处理(NLP)模型的架构,以及基于这些模型构建的应用程序。 本系列文章内容: NLP自然语言处理基础词嵌入(Word Embeddings)…...
)
marked库(高效将 Markdown 转换为 HTML 的利器)
文章目录 前言使用基本使用自定义渲染器例子 代码高亮 前言 最近尝试了一下通过星火大模型将ai引入到项目上,但是ai返回的数据可以显而易见的发现是markedown语法的,那么就需要一个工具,将类似这种的格式转换为markdown格式 Marked 是一个用…...

Vue3 + Element Plus + AntV X6 实现拖拽树组件
Vue3 Element Plus AntV X6 实现拖拽树组件 介绍 在本篇文章中,我们将介绍如何使用 Vue 3 和 Element Plus 结合 antv/x6 实现树形结构的拖拽功能。用户可以将树节点拖拽到图形区域,自动创建相应的节点。我们将会通过简单的示例来一步步讲解实现过程…...

在 Rocky Linux 9.2 上编译安装 Redis 6.2.6
文章目录 在 Rocky Linux 9.2 上编译安装 Redis 6.2.6Redis 介绍官网Redis 的核心特性高性能支持多种数据结构多种持久化机制复制与高可用2.5 事务与 Lua 脚本消息队列功能 Redis 适用场景Redis 与其他数据库对比Redis 的优势与劣势Redis 优势Redis 劣势 部署过程系统环境信息环…...

中和农信:让金融“活水”精准浇灌乡村沃土
2025年政府工作报告首提“投资于人”概念,并22次提及“金融”,强调要着力抓好“三农”工作,深入推进乡村全面振兴;一体推进地方中小金融机构风险处置和转型发展;扎扎实实落实促进民营经济发展的政策措施,切…...

4. 理解Prompt Engineering:如何让模型听懂你的需求
引言:当模型变成“实习生” 想象一下,你新招的实习生总把“帮我写份报告”理解为“做PPT”或“整理数据表”——这正是开发者与大模型对话的日常困境。某金融公司优化提示词后,合同审查准确率从72%飙升至94%。本文将用3个核心法则+5个行业案例,教你用Prompt Engineering让…...

cocos 图片上传与下载
创建一个场景 在 Cocos Creator 中,我们将从接口获取的图片 URL 列表动态创建图片节点并显示在页面上。使用 assetManager.loadRemote 来加载这些图片并显示。 目录结构如下 为按钮button和文本Lable挂载ts脚本 运行界面 图片上传测试 背景会变成上传的图片 以下是…...

Unity中的UI坐标和点击接口
默认已经知道UI中的基础知识,这里提供一些细节 📚️锚点和轴心点 锚点是根据父物体的确定的,锚点Anchor分为两种状态,Min Max 和 Min ! Max Min ! Max时会根据锚点进行自适应拉伸 参考文章:Unity 锚点 Anchors的通俗…...
,源码可白嫖!)
基于JavaWeb的二手图书交易系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 人类现已迈入二十一世纪,科学技术日新月异,经济、资讯等各方面都有了非常大的进步,尤其是资讯与网络技术的飞速发展,对政治、经济、军事、文化等各方面都有了极大的影响。 利用电脑网络的这些便利,发展一套二手图…...
)
人脸表情识别数据集的正确使用方法(Affectnet、RAF-DB、FERPlus数据集通用)
众所周知深度学习是个很玄学的东西,不同的数据集加载方式会训练出不一样的精度,导致无法复现论文精度。 这里分享下正确的加载数据集的方法: 拿RAF-DB数据集举例: ①准备好RAF-DB数据集,训练集和测试集放进同一目录&…...

【408--考研复习笔记】操作系统----知识点速览
目录 一、计算机系统概述 1.计算机系统的组成 2.操作系统的定义与作用 3.操作系统的发展历程 4.操作系统的基本特性 5.操作系统的结构 简单结构 分层结构 微内核结构 模块化结构 宏内核结构 6.用户接口 7.系统调用 8.处理机的工作状态 9.中断机制 10.特权指令与…...

Java常用异步方式总结
使用建议 完整代码见https://gitee.com/pinetree-cpu/parent-demon 提供了postMan调试json文件于security-demo/src/main/resources/test_file/java-async.postman_collection.json 可导入postMan中进行调试 Java异步方式以及使用场景 继承Thread类 新建三个类继承Thread&…...

算法设计学习3
实验目的及要求: 1.加强对结构体的应用。 2.熟悉字符计数排序。 实验设备环境: 1.微型计算机 2.DEV C(或其他编译软件) 实验步骤: 任务:要求使用自定义函数来实现 输入一段文本,统计每个字符出现的次数,按…...
(1))
OpenCV 图形API(或称G-API)(1)
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 引言 OpenCV 图形API(或称G-API)是一个新的OpenCV模块,旨在使常规图像处理更快且更便携。通过引入一种新的基于图的执行…...

解决Luckysheet在线预览编辑Excel、PDF.....无法在同一个界面创建多个luckysheet实列问题
luckysheet插件由于是实列挂载到windows.luckysheet实列上,导致同时只能使用一个luckysheet于是我们使用<iframe/>标签进行隔离: 1.每个<iframe>创建独立的浏览器上下文环境,避免多个Luckysheet实例共享同一JavaScript执行环境 …...

php8属性注解使用教程
简介 PHP 8 引入了 属性(Attributes)作为新的元数据机制,用于替代传统的 PHPDoc 注解,使得代码更具类型安全性和结构化。 基本语法 PHP 8 的属性(Attributes)使用 #[...] 语法表示,并可以用于…...

Redis6数据结构之List类型
redis的List类型底层结构是双向链表,插入删除时间复杂度O(1)快,查找为O(n)慢。 应用场景:简单队列、最新评论列表、非实时排行榜(定时计算榜单,如笔记本日销榜单)。 常用命令: lpush将一个或多个值从左边…...

【视觉与语言模型参数解耦】为什么?方案?
一些无编码器的MLLMs统一架构如Fuyu,直接在LLM内处理原始像素,消除了对外部视觉模型的依赖。但是面临视觉与语言模态冲突的挑战,导致训练不稳定和灾难性遗忘等问题。解决方案则是通过参数解耦方法解决模态冲突。 在多模态大语言模型…...

[笔记.AI]初始向量
(借助 DeepSeek-V3 辅助生成) 初始向量的生成方式 在自然语言处理(NLP)中,初始向量是指模型在处理输入文本时,将每个 Token(如词、子词或字符)映射到高维向量空间的起点。这些初始…...
)
MySQL(一)
MySQL定义 ⭐ MySQL是一个“客户端——服务器”结构的软件 客户端:主动给服务器发起的数据,称为请求。 服务器:被动接收,给客户端返回的数据,称为响应。 客户端和服务器是通过网络通信进行的。 内存和硬盘的区别&am…...
虚数运算(结构体教程)(指针解法)(C语言教程))
(C语言)虚数运算(结构体教程)(指针解法)(C语言教程)
#include <stdio.h> //定义结构体 typedef struct {float realpart;float imagpart; }Complex; //初始化虚数 //传递值,和指针分开 void assign(const float real,const float imag,Complex* A){A->imagpartimag;A->realpartreal; } //虚数相加 //同样…...

大模型LLMs框架Langchain之工具Tools
写在前文: 下面是官方对工具的流程: 创建工具 创建工具时,必须指定参数:name、description、args_schema、return_direct 初始化环境 import asyncio from typing import Annotated, Listfrom langchain.agents import initia…...

让AI帮写个modbus slave小工具
工作中用到modbus,也下载过modbus poll和slave,试用期到了就要License,那不如让AI帮写一个简单的,够用即可。 步骤: 一、先安装python 1、windows电脑microsoft store搜索python安装 2、打开IDLE 2、选择菜单新建一…...

使用el-select回显时显示value,不显示对应的label
原因:后端传过来的是string类型 解决:向后端传过来的String类型的数据强制转换为Number类型 代码: <el-select clearable v-model"deviceinfo.Type" placeholder"请选择类型"><el-optionv-for"dict in ty…...

Spring IOC:容器管理与依赖注入秘籍
Java Spring 核心容器、IOC 一、IOC(控制反转)核心概念 基本概念 控制反转是一种将对象的创建、依赖关系的管理和生命周期的控制权从应用程序代码转移到外部容器的设计原则。在传统编程中,对象的创建和依赖关系是由程序自身控制的࿰…...

Cpp网络编程Winsock API
Cpp网络编程Winsock API 作者:blue 时间:2025.3.31 文章目录 Cpp网络编程Winsock API**1.服务端**(Server)1.1初始化网络库1.2创建套接字对象1.3设置ip和端口1.4将套接字对象与ip和端口绑定1.5设置套接字为监听状态1.6等待客户端…...

聊聊Spring AI的Chat Model
序 本文主要研究一下Spring AI的Chat Model Model spring-ai-core/src/main/java/org/springframework/ai/model/Model.java public interface Model<TReq extends ModelRequest<?>, TRes extends ModelResponse<?>> {/*** Executes a method call to …...

VUE3+Mapbox-GL 实现鼠标绘制矩形功能的详细代码和讲解
以下是如何使用 Mapbox GL JS 实现鼠标绘制矩形功能的详细代码和讲解。Mapbox GL JS 是一个强大的 JavaScript 库,可以用来创建交互式地图。下面将通过监听鼠标事件并动态更新地图图层来实现这一功能。 实现步骤 初始化地图 在 HTML 文件中引入 Mapbox GL JS 库&…...

Python数据类型-list
列表(List)是Python中最常用的数据类型之一,它是一个有序、可变的元素集合。 1. 列表基础 创建列表 empty_list [] # 空列表 numbers [1, 2, 3, 4, 5] # 数字列表 fruits [apple, banana, orange] # 字符串列表 mixed [1, hello, 3.14, True] # 混合类型…...

【Python】Browser-Use:让 AI 替你掌控浏览器,开启智能自动化新时代!
Browser-Use:让 AI 替你掌控浏览器,开启智能自动化新时代! Github地址: https://github.com/browser-use/browser-use/tree/main 在 AI 浪潮席卷的今天,我们是否想过让 AI 不仅仅是聊天、生成内容,而是能像人一样实际操…...

Proxmox配置显卡直通
1.查看显卡 lspci | grep VGA 2.修改grub 2.1备份grub cp /etc/default/grub /etc/default/grub.bak 2.2修改grub vi /etc/default/grub 如果是Intel的CPU GRUB_CMDLINE_LINUX_DEFAULT“quiet intel_iommuon” 如果是AMD的CPU: GRUB_CMDLINE_LINUX_DEFAUL…...

C# FileStream 使用详解
总目录 前言 在 C# 编程中,文件操作是常见的任务之一。FileStream 类是 System.IO 命名空间中的一个重要类,它提供了对文件的读取和写入操作的底层支持。本文将详细介绍 FileStream 的使用方法,包括如何创建、读取、写入文件,以及…...
)
C++编程语言:抽象机制:一个矩阵的设计(Bjarne Stroustrup)
第29章 一个矩阵的设计(A Matrix Design) 目录 29.1 引言 29.1.1 基本的 Matrix 用法 29.1.2 Matrix 的要求 29.2 一个 Matrix 模板 29.2.1 构造和赋值(Construction and Assignment) 29.2.2 下标和分片(Subscripting and Slicing) 29.3 Matrix算术运算(Matrix…...
)
Swift LeetCode 246 题解:中心对称数(Strobogrammatic Number)
摘要 在日常开发中,我们经常遇到一些关于对称性的判断,比如字符串回文、镜像翻转等。而 “中心对称数”(Strobogrammatic Number) 这个问题,本质上是考察一个数字在旋转 180 度后是否还是原来的样子。 这个问题看似简…...

网络安全等级保护测评
名词解释 网络安全等级保护测评 网络安全等级保护测评,是对信息系统进行的一种安全评估活动。它的目的是验证信息系统是否达到了国家网络安全等级保护制度所规定的安全保护要求。这个制度将信息系统按照重要性划分为不同的安全保护等级,每个等级都有相应的安全保护要求。 …...

项目复盘:websocket不受跨域限制的原理
主要还是因为: 1、WebSocket 是独立于 HTTP 的应用层协议,通过 HTTP 建立连接后,完全脱离 HTTP 语义约束。这意味着 不受 HTTP 同源策略限制 不需要预检请求 不依赖 CORS 头机制 2、建立连接时的握手请求仍使用 HTTP 格式,但…...

deep-sync开源程序插件导出您的 DeepSeek 与 public 聊天
一、软件介绍 文末提供下载 deep-sync开源程序插件导出您的 DeepSeek 与 public 聊天,这是一个浏览器扩展,它允许用户公开、私下分享他们的聊天对话,并使用密码或过期链接来增强 Deepseek Web UI。该扩展程序在 Deepseek 界面中添加了一个 “…...

AI原生应用爆发:从通用大模型到垂直场景的算力重构
2025年第一季度,中国AI产业迎来标志性转折点:DeepSeek-R1大模型月活用户突破3000万,通义千问QwQ-32B在医疗领域诊断准确率达三甲医院主治医师水平,京东AI虚拟模特单日生成商品图超200万张……这些数据的背后,是AI技术从…...

arcgis jsapi 4.31 调用geoserver 发布的wms服务
服务的调用我也测试了网络搜索的很多方法,均未奏效,后来还是通过对官网例子的研究,找到了解决方案,调试的过程是非常痛苦的,最大的问题就是调用后没有任何反应,也不会给你任何的错误信息,这是最…...

《筋斗云的K8s容器化迁移》
点击下面图片带您领略全新的嵌入式学习路线 🔥爆款热榜 88万阅读 1.6万收藏 文章目录 **第一章:斗战胜佛的延迟焦虑****第二章:微服务化的紧箍咒****第三章:混沌中的流量劫持****第四章:量子筋斗的终极形态****终章&…...

[笔记.AI]大模型训练 与 向量值 的关系
(借助 DeepSeek-V3 辅助生成) 大模型在训练后是否会改变向量化的值,取决于模型的训练阶段和使用方式。以下是详细分析: 1. 预训练阶段:向量化值必然改变 动态调整过程: 在预训练阶段(如BERT、…...
)
【学Rust写CAD】18 定点数2D仿射变换矩阵结构体(MatrixFixedPoint结构别名)
源码 // matrix/fixed.rs use crate::fixed::Fixed; use super::generic::Matrix;/// 定点数矩阵类型别名 pub type MatrixFixedPoint Matrix<Fixed, Fixed, Fixed, Fixed, Fixed, Fixed>;代码解析 这段代码定义了一个定点数矩阵的类型别名 MatrixFixedPointÿ…...

Linux进程间通信:【目的】【管道】【匿名管道】【命名管道】【System V 共享内存】
目录 一.进程间通信目的 二.管道 三.匿名管道 3.1用fork来共享管理管道 3.2站在文件描述符角度-深度理解管道 3.3内核角度 3.4管道样例 3.4.1测试管道读写 3.4.2代码 解决方案1:倒着关闭: 解决方案2: 只让父进程一个人指向写端 四…...

Python 自动化:节省时间,更智能地工作
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 时间是你最宝贵的资产。如果你花费数小时手动执行重复性任务,那么当 Python 可以为你完成这些任务时,你就是在浪费时…...

StarRocks的执行计划和Profile
文章目录 一、执行计划和Profile相关脚本二、如何分析查询1、概念了解2、Query Plan①查看 Query Plan②分析 Query Plan 3、Query hint4、Query Profile①启用 Query Profile②查看 Query Profile③分析 Query Profile 一、执行计划和Profile相关脚本 命令功能ANALYZE PROFIL…...

【设计模式】过滤器模式
过滤器顾名思义,定义一些过滤规则,将符合要求的内容筛选,就比如过滤不同大小或者不同颜色的水果,需要颜色和大小过滤器,筛选条件独立为对象,可以通过灵活组合形成过滤链条。避免大量使用判断语句。 案例代…...

Jenkins插件安装失败如何解决
问题:安装Jenkins时候出现插件无法安装的情况。 测试环境: 操作系统:Windows11 Jenkins:2.479.3 JDK:17.0.14(21也可以) 解决办法一: 更换当前网络,局域网、移动、联通…...
)
GO语言杂记(文章持续更新)
1、MAIN冲突 在一个文件夹下有两个go文件同时写了main函数,将会报错,main函数只能在main包中。 实则不然,有些环境下并不会报错。 2、gofmt命令---自动对齐 命令作用:将go文件代码自动缩进。 gofmt -w escapecharprac.go...

VUE如何前端控制及动态路由详细讲解
在Vue.js中,前端控制通常指的是通过Vue的响应式系统、组件化、路由、状态管理等技术来实现对前端应用的控制和管理 一、前端路由控制基础 使用 vue-router 管理路由,通过路由守卫和动态添加路由实现权限控制。 1. 安装和配置 npm install vue-router…...

【区块链安全 | 第九篇】基于Heimdall设计的智能合约反编译项目
文章目录 背景目的安装1、安装 Rust2、克隆 heimdall-dec3、编译 heimdall-dec4、运行 heimdall-dec 使用说明1、访问 Web 界面2、输入合约信息3、查看反编译结果 实战演示1、解析普通合约2、解析代理合约 背景 在区块链安全研究中,智能合约的审计和分析至关重要。…...