Elasticsearch 高级
Elasticsearch 高级
建议阅读顺序:
- Elasticsearch 入门
- Elasticsearch 搜索
- Elasticsearch 搜索高级
- Elasticsearch高级(本文)
1. nested 类型
1.1 介绍
Elasticsearch 中的 nested 类型允许你在文档内存储复杂的数据结构,比如一个用户可能有多个地址,或者一个博客文章可能有多个标签等。nested 类型可以让你索引这些复杂数据,并且允许你对嵌套的数据进行查询。
1.2 添加 nested 文档
向商品映射中添加 nested 类型的字段 attr_list
- attr_list 表示商品属性
- attr_list 有两个字段:color、memory
PUT /items/_mapping
{"properties":{"attr_list":{"type":"nested","properties":{"name":{ "type":"keyword" },"value":{ "type":"keyword" }}}}
}
由于添加了字段,所以需要对 items 索引进行更新,但是建议先删后加:
DELETE /items
PUT /items
{"mappings" : {"properties" : {"brand" : { "type" : "keyword" },"category" : { "type" : "keyword" },"commentCount" : { "type" : "integer", "index" : false },"id" : { "type" : "keyword" },"image" : { "type" : "keyword", "index" : false },"isAD" : { "type" : "boolean" },"name" : {"type" : "text","analyzer" : "ik_max_word","search_analyzer" : "ik_smart"},"price" : { "type" : "integer" },"sold" : { "type" : "integer" },"stock" : { "type" : "integer" },"updateTime" : { "type" : "date" },"location" : { "type" : "geo_point" },"attr_list":{"type":"nested","properties":{"name":{ "type":"keyword" },"value":{ "type":"keyword" }}}}}
}
在实体类上添加属性:
// 商品属性
@ApiModelProperty("商品规格")
private List<Spec> attr_list;@Data
public static class Spec {private String name;private String value;
}
向索引添加文档,可以添加单个文档也可以批量添加文档,添加文档时指定商品属性:
@Test
void testAddDocument2() throws Exception {// 商品idLong id = 317578L;// 根据id查询商品Item item = itemService.getById(id);// 转为ItemDocItemDoc itemDoc = BeanUtils.copyBean(item, ItemDoc.class);ItemDoc.Spec spec_1 = new ItemDoc.Spec();spec_1.setName("大小");spec_1.setValue("60*40");// 再设置一个新规格ItemDoc.Spec spec_2 = new ItemDoc.Spec();spec_2.setName("颜色");spec_2.setValue("白色");itemDoc.setAttr_list(List.of(spec_1, spec_2));// 使用esClient添加文档IndexResponse response = esClient.index(i -> i.index("items").id(id.toString()).document(itemDoc));// 打印结果String s = response.result().jsonValue();log.info("添加文档结果:{}", s);
}
查询文档:GET /items/_doc/{id}
1.3 搜索 nested
查询商品颜色是白色的商品:
GET /items/_search
{"query": {"nested": {"path": "attr_list","query": {"bool": {"must": [{ "term": { "attr_list.name": { "value": "颜色" } } },{ "term": { "attr_list.value": { "value": "白色" } } }]}}}}
}
"nested":这是一个嵌套查询,用于查询嵌套对象。它允许你在嵌套对象中执行更复杂的查询。
"path": "attr_list":指定了要查询哪个嵌套对象字段。在这个例子中,嵌套对象的字段名是attr_list
1.4 聚合 nested
先按商品属性名称聚合,再按属性值聚合:
GET /items/_search
{"size": 0,"aggs": {"attr_aggs": {"nested": { "path": "attr_list" },"aggs": {"attr_name_aggs": {"terms": { "field": "attr_list.name", "size": 10 },"aggs": {"attr_value_aggs": {"terms": { "field": "attr_list.value", "size": 10 }}}}}}}
}
1.5 Java Client
1.5.1 nested 查询
将 “查询商品颜色是白色的商品” 的 DSL 转为对应代码:
@Test
void testNested() throws Exception {SearchRequest.Builder builder = new SearchRequest.Builder();builder.index("items");builder.query(q -> q.nested(n -> n.path("attr_list").query(q1 -> q1.bool(b -> b.must(a -> a.term(t -> t.field("attr_list.name").value("颜色"))).must(a1 -> a1.term(t -> t.field("attr_list.value").value("白色")))))));SearchRequest build = builder.build();SearchResponse<ItemDoc> response = esClient.search(build, ItemDoc.class);// 解析结果List<Hit<ItemDoc>> hits = response.hits().hits();hits.forEach(hit -> {ItemDoc source = hit.source();log.info("查询结果:{}", source);});
}
1.5.2 nested 聚合
将 “先按商品属性名称聚合,再按属性值聚合” 的 DSL 转为对应代码:
@Test
void testNestedAggs() throws Exception {SearchRequest.Builder builder = new SearchRequest.Builder();builder.index("items2");builder.size(0);builder.aggregations("attr_aggs", a -> a.nested(n -> n.path("attr_list")).aggregations("attr_name_aggs", a1 -> a1.terms(t -> t.field("attr_list.name").size(10)).aggregations("attr_value_aggs", a2 -> a2.terms(t -> t.field("attr_list.value")))));SearchRequest build = builder.build();SearchResponse<ItemDoc> response = esClient.search(build, ItemDoc.class);Map<String, Aggregate> aggregations = response.aggregations();Aggregate attrAggs = aggregations.get("attr_aggs");//解析结果NestedAggregate nested = attrAggs.nested();Map<String, Aggregate> attrNameAggs = nested.aggregations();Aggregate aggregate = attrNameAggs.get("attr_name_aggs");aggregate.sterms().buckets().array().forEach(bucket -> {String key = bucket.key().stringValue();Long docCount = bucket.docCount();log.info("属性名:{},属性值数量:{}", key, docCount);Map<String, Aggregate> aggregations1 = bucket.aggregations();Aggregate attrValueAggs = aggregations1.get("attr_value_aggs");attrValueAggs.sterms().buckets().array().forEach(bucket1 -> {String key1 = bucket1.key().stringValue();Long docCount1 = bucket1.docCount();log.info("属性值:{},属性值数量:{}", key1, docCount1);});});
}
2. 同义词
2.1 设置同义词
搜索中同义词的需求:在搜索时输入一个关键字,包含关键字同义词的文档应该也可以搜索出来。
比如:输入“电脑”,会搜索出包含 “计算机” 的文档,输入 “黑马” 搜索出 “黑马程序员”、“传智播客” 的文章。
elasticsearch 的同义词有如下两种形式:
-
单向同义词:
heima,黑马=>黑马程序员,黑马、传智播客箭头左侧的词都会映射成箭头右侧的词。
输入箭头左侧的词可以搜索出箭头右侧的词。
-
双向同义词:
马铃薯, 土豆, potato双向同义词可以互相映射。
输入 “土豆” 可以搜索出 “potato”,输入 “potato” 可以搜索出 “土豆”
怎么设置同义词?
首先在同义词加到 synonyms.txt 文件中,synonyms.txt 文件在 es 的 config 目录下。
在 synonyms.txt 中加入:
中国,中华人民共和国,china
heima,黑马=>黑马程序员,黑马、传智播客
...
2.2 定义同义词分词器
在设置索引映射时自定义同义词分词器 my_synonyms_analyzer,并且用于 “title” 字段的搜索。
PUT /test_index
{"settings": {"analysis": {"filter": {"my_synonym_filter": {"type": "synonym","updateable": true,"synonyms_path": "synonyms.txt"}},"analyzer": {"my_synonyms_analyzer": {"tokenizer": "ik_smart","filter": [ "my_synonym_filter" ]}}}},"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word","search_analyzer": "my_synonyms_analyzer"}}}
}
参数说明:
my_synonym_filter是自定义的词汇过滤器;my_synonyms_analyzer是自定义的分析器,my_synonyms_analyzer包含并引用了my_synonym_filter;updateable指示能否动态更新,必须为true才能动态更新同义词;synonyms_path指示同义词文件的位置;my_synonyms_analyzer分析器里用ik_smart的分词器,my_synonyms_analyzer 的分词流程是原始文本先经过ik_smart分词的结果再用 my_synonym_filter 处理;mappings.properties.title.search_analyzer指示title字段在搜索时使用my_synonyms_analyzer分析器。
2.3 测试
先向 test_index 索引中添加数据:
POST /_bulk
{"index": {"_index":"test_index", "_id": "5"}}
{"title": "china你好"}
{"index": {"_index":"test_index", "_id": "4"}}
{"title": "中国你好"}
{"index": {"_index":"test_index", "_id": "6"}}
{"title": "中华人民共和国你好"}
{"index": {"_index":"test_index", "_id": "7"}}
{"title": "China你好"}
{"index": {"_index":"test_index", "_id": "8"}}
{"title": "这是一匹黑马"}
{"index": {"_index":"test_index", "_id": "9"}}
{"title": "黑马是中国良心培训机构"}
{"index": {"_index":"test_index", "_id": "10"}}
{"title": "黑马程序员是中国良心培训机构"}
{"index": {"_index":"test_index", "_id": "11"}}
{"title": "传智播客一所IT培训机构"}
搜索关键字 “china”:
GET /test_index/_search
{"query": {"match": { "title": "china" }}
}
分析查询到的结果,会发现,查询到的结果只有包含关键字的值,很显然同义词并没有生效,此时就要开启同义词生效,执行 POST /test_index/_reload_search_analyzers。
3. 自动补全
3.1 介绍
当在搜索框输入字符时提示出与该字符有关的搜索项,这个效果就是自动补全。
Elasticsearch 如何实现自动补全?
要实现上述自动补全的需求需要完成两个功能:
- 拼音搜索
- 前缀搜索
3.2 拼音分词器
3.2.1 安装拼音分词器
与 IK 分词器一样,拼音分词器也有插件,在 GitHub 上有 elasticsearch 的拼音分词插件。
地址:https://github.com/medcl/elasticsearch-analysis-pinyin
找到与 Elasticsearch 版本一致的插件下载包。
安装方式与IK分词器一样,分三步:
- 解压 elasticsearch-analysis-pinyin-7.17.7.zip
- 上传到虚拟机中 elasticsearch 的 plugin 目录
- 重启 elasticsearch
- 测试
测试
POST /_analyze
{"text": "黑马程序员","analyzer": "pinyin"
}
3.2.2 自定义分词器
默认的拼音分词器会将每个汉字单独分为拼音,而我们希望的是每个词条形成一组拼音,需要对拼音分词器做个性化定制,形成自定义分词器。
elasticsearch 中分词器(analyzer)的组成包含三部分:
character filters:在 tokenizer 之前对文本进行处理。例如删除字符、替换字符tokenizer:将文本按照一定的规则切割成词条(term)。例如 keyword,就是不分词;还有 ik_smarttokenizer filter:将 tokenizer 输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
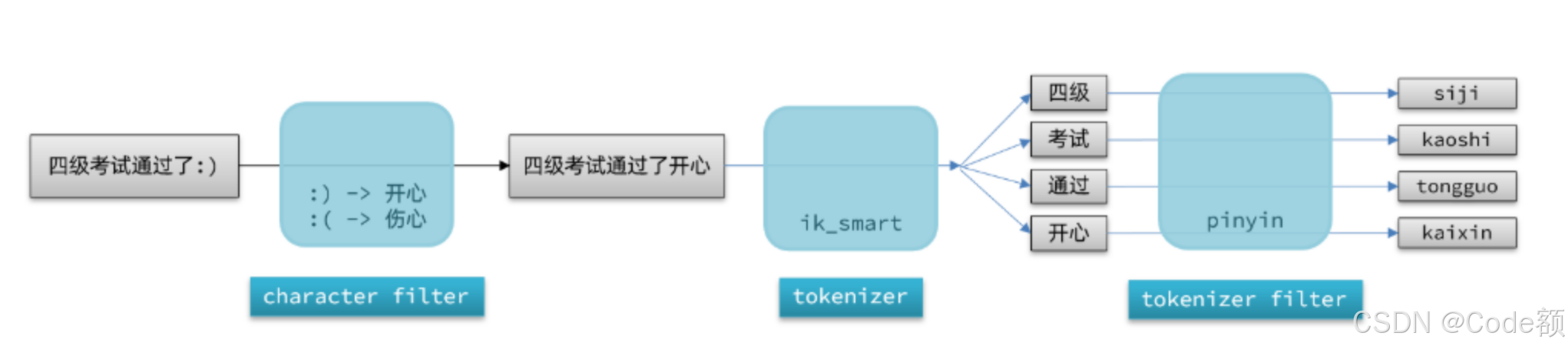
声明自定义分词器的语法如下:
PUT /test_index2
{"settings": {"analysis": {// 自定义分词器"analyzer": {// 分词器名称"my_analyzer": { "tokenizer": "ik_max_word", "filter": "py" }},// 自定义tokenizer filter"filter": {// 过滤器名称"py": {// 过滤器类型,这里是pinyin"type": "pinyin","keep_full_pinyin": true,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
属性说明:
-
type: "pinyin":这指定了过滤器的类型为
pinyin,即使用拼音分词器。 -
keep_full_pinyin: false:控制是否保留完整的拼音形式。设置为
false表示不保留完整的拼音形式。 -
keep_joined_full_pinyin: true:控制是否保留连接的完整拼音形式。设置为
true表示保留连接的完整拼音形式,例如 “你好” 可能会被转换为 “nihao”。 -
keep_original: true:控制是否保留原文本。设置为
true表示保留原文本,这在某些情况下很有用,例如需要同时支持拼音和原文本的搜索。 -
limit_first_letter_length: 16:控制首字母的最大长度。例如,“你好” 的首字母形式为 “n h”,这个值控制了首字母的最大长度。
-
remove_duplicated_term: true:控制是否移除重复的词条。设置为
true表示移除重复的词条,这有助于减少索引大小。 -
none_chinese_pinyin_tokenize: false:控制是否对非中文文本也进行拼音分词。设置为
false表示不对非中文文本进行拼音分词。
测试自定义分词器:
POST /test_index2/_analyze
{"text": "黑马程序员","analyzer": "my_analyzer"
}
3.3 自动补全查询
3.3.1 completion
Elasticsearch 专门设计 completion 查询用于自动补全,completion 查询可以实现前缀搜索的效果,性能比前缀搜索更快。
completion 查询会匹配以用户输入内容开头的词条并返回,使用 completion 查询对文档中字段的类型有一些约束:
- 参与补全查询的字段必须是 completion 类型。
- 字段的内容一般是用来补全的多个词条形成的数组。
在 test_index2 索引中添加 suggestion 字段并且设置为 completion 类型:
PUT /test_index2/_mapping
{"properties": {"suggestion": { "type":"completion" }}
}
3.3.2 测试
更新原有文档,文档中指定了自动补全的内容:
POST /test_index2/_update/100
{"doc": { "suggestion": ["拉杆箱","托运箱"] }
}POST /test_index2/_update/101
{"doc": { "suggestion": ["拉杆箱","旅行箱","莎米特"] }
}
测试:
GET /test_index2/_search
{"suggest" : {"suggestion_suggest" : { "completion" : { "field": "suggestion", "size": 10, "skip_duplicates": true },"text" : "旅" }}
}
参数说明:
-
suggest:这是建议器的顶级对象,用于配置建议器。 -
suggestion_suggest:这是建议器的名称,可以自定义。它用于标识建议器。 -
completion:这是指定建议器类型的部分。在这里,我们使用的是
completion类型,它是专门为自动补全设计的建议器。 -
field:这是用于建议的字段名称。在这个例子中,我们使用名为
suggestion的字段,该字段应该已经被配置为completion类型的字段。 -
size:这个参数控制返回的建议数量。在这个例子中,我们设置了
size为10,意味着最多返回10个建议。 -
skip_duplicates:这个参数用于控制是否在返回的建议中跳过重复的条目。在这个例子中,我们设置为
true,意味着如果某个建议在多个文档中出现,只会返回一次。 -
text:这是用户输入的文本,用于生成建议。
3.3.3 Java Client
@Test
void testSuggest() throws IOException {SearchRequest.Builder builder = new SearchRequest.Builder();builder.index("test_index2");builder.suggest(s -> s.suggesters("suggestion_suggest", ss -> ss.completion(c -> c.field("suggestion").size(10).skipDuplicates(true)).text("拉")));SearchRequest request = builder.build();SearchResponse<Index2> response = esClient.search(request, Index2.class);Map<String, List<Suggestion<Index2>>> suggest = response.suggest();List<Suggestion<Index2>> suggestion_suggest = suggest.get("suggestion_suggest");suggestion_suggest.stream().forEach(suggestion -> {suggestion.completion().options().forEach(option -> {String text = option.text();System.out.println(text);});});
}/*** 测试自动补全模型类*/
@Data
public static class Index2 {//idprivate Long id;//nameprivate String name;private List<String> suggestion;}
3.4 拼音自动补全
3.4.1 创建自动补全字段
自定义分词器:
PUT /test_index3
{"settings": {"analysis": {"analyzer": {"completion_analyzer": { "tokenizer": "keyword", "filter": "py" }},"filter": {"py": {"type": "pinyin","keep_full_pinyin": true,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id": { "type": "keyword" },"name":{"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"suggestion":{ "type": "completion", "analyzer": "completion_analyzer" }}}
}
3.4.2 更新/新增文档
POST test_index3/_doc/100
{"id":100,"name":"RIMOWA 30寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4","suggestion": ["拉杆箱","托运箱"]
}POST test_index3/_doc/101
{"id":101,"name":"莎米特SUMMIT 旅行拉杆箱28英寸PC材质大容量旅行行李箱PC154 黑色","suggestion": ["拉杆箱","旅行箱","莎米特"]
}POST test_index3/_doc/102
{"id":102,"name":"拉菲斯汀(La Festin)612026 新款女士钱包 头层牛皮短款钱包 凯利黑","suggestion": ["拉菲斯汀","女包"]
}
3.4.3 测试
GET /test_index3/_search
{"suggest": {"suggestion_suggest": {"completion": {"field": "suggestion","size": 2,"skip_duplicates": true},"text": "la"}}
}
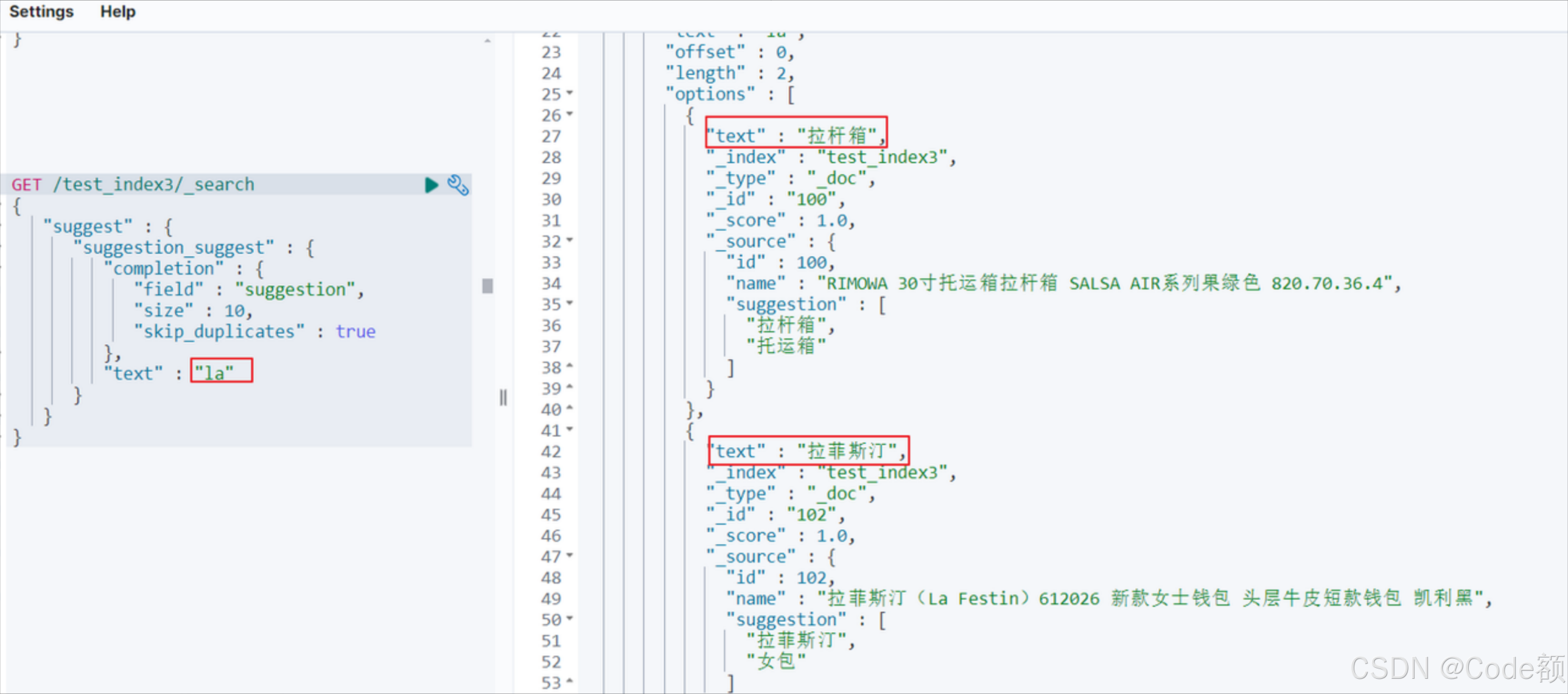
相关文章:

Elasticsearch 高级
Elasticsearch 高级 建议阅读顺序: Elasticsearch 入门Elasticsearch 搜索Elasticsearch 搜索高级Elasticsearch高级(本文) 1. nested 类型 1.1 介绍 Elasticsearch 中的 nested 类型允许你在文档内存储复杂的数据结构,比如一个…...
)
1--当「穷举」成为艺术:CTF暴力破解漏洞技术从入门到入刑指南(知识点讲解版)
当「穷举」成为艺术:CTF暴力破解漏洞技术从入门到入刑指南 引言:论暴力破解的哲学意义 “世界上本没有漏洞,密码设得简单了,便成了漏洞。” —— 鲁迅(并没有说过) 想象你是个不会撬锁的小偷,面…...

jdk 支持路线图
https://www.oracle.com/java/technologies/java-se-support-roadmap.html 按照路线图得知,在2025.09 发布openjdk 25,是一个LTS版本。...
 - 自录制gif演示)
VsCode启用右括号自动跳过(自动重写) - 自录制gif演示
VsCode启用右括号自动跳过(自动重写) - 自录制gif演示 前言 不知道大家在编程时候的按键习惯是怎样的。输入完左括号后编辑器一般会自动补全右括号,输入完左括号的内容后,是按→跳过右括号还是按)跳过右括号呢? for (int i 0; i < a.s…...

Android设计模式之模板方法模式
一、定义: 定义一个操作中的算法的框架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。 二、结构: AbstractClass抽象类:定义算法的骨架,包含模板方法和若干…...
)
纯个人整理,蓝桥杯使用的算法模板day1(dfs、bfs)
算法索引 dfs(深度优先搜索)bfs(广度优先搜索)迷宫树结构 dfs(深度优先搜索) 功能: 适合搜索所有的解 代码模板: class Solution{public void dfs(int[][] graph, int i, int j){i…...

【第34节】windows原理:PE文件的导出表和导入表
目录 一、导出表 1.1 导出表概述 1.2 说明与使用 二、导入表 2.1 导入表概述 2.2 说明与使用 一、导出表 1.1 导出表概述 (1)导出行为和导出表用途:PE文件能把自身的函数、变量或者类,提供给其他PE文件使用,这…...
)
Spring Boot事务管理详解(附银行转账案例)
一、事务基础概念 事务的ACID特性: 原子性(Atomicity):操作要么全部成功,要么全部失败一致性(Consistency):数据在事务前后保持合法状态隔离性(Isolation)&…...
3.2 个人所得税计算器(project))
(头歌作业—python)3.2 个人所得税计算器(project)
第1关:个人所得税计算器 任务描述 本关任务:编写一个个人所得税计算器的小程序。 相关知识 个人所得税缴纳标准 2018 年 10 月 1 日以前,个税免征额为 3500 元/月,调整后,个税免征额为 5000 元/月, 7 级超…...

在一个scss文件中定义变量,在另一个scss文件中使用
_variables.scss文件 : $line-gradient-init-color: linear-gradient(90deg, #8057ff 0%, #936bff 50%, #b892ff 100%); $line-gradient-hover-color: linear-gradient(90deg, #936bff 0%, #b892ff 50%, #f781ce 100%); $line-gradient-active-color: linear-gradient(90deg, …...
)
【计网】网络交换技术之电路交换(复习自用)
复习自用的,处理得比较草率,复习的同学或者想看基础的同学可以看看,大佬的话可以不用浪费时间在我的水文上了 1.电路交换定义 电路交换是一种通信方法,在通信开始之前,源和目的地之间建立一条专用的物理路径…...

MacOS 安装open webui
open-webui 不是一个 Python 包,所以 pip install open-webui 会失败。它是一个独立的 Web UI 应用,通常通过 Docker 或 手动构建 来运行。 如何正确安装 Open WebUI? 你可以选择 Docker 方式(推荐)或 手动安装。 方法…...
之添加行拖拽排序功能示例9,TableView16_09 嵌套表格拖拽排序)
DeepSeek 助力 Vue3 开发:打造丝滑的表格(Table)之添加行拖拽排序功能示例9,TableView16_09 嵌套表格拖拽排序
前言:哈喽,大家好,今天给大家分享一篇文章!并提供具体代码帮助大家深入理解,彻底掌握!创作不易,如果能帮助到大家或者给大家一些灵感和启发,欢迎收藏+关注哦 💕 目录 DeepSeek 助力 Vue3 开发:打造丝滑的表格(Table)之添加行拖拽排序功能示例9,TableView16_09 嵌…...

开启ipv6与关闭的区别
在运行P2P CDN时,开启IPv6与关闭IPv6存在以下核心区别,需从技术、合规、运营等维度综合评估: 一、性能与效率 开启IPv6的优势 更大地址空间:IPv6支持海量设备接入,解决IPv4地址枯竭问题,便于P2P CDN节点扩…...

Redis + Caffeine多级缓存电商场景深度解析
Redis Caffeine多级缓存 Redis Caffeine多级缓存电商场景深度解析一、实施目的二、具体实施2.1 架构设计2.2 组件配置2.3 核心代码实现 三、实施效果3.1 性能指标对比3.2 业务指标改善3.3 系统稳定性 四、关键策略4.1 缓存预热4.2 一致性保障4.3 监控配置Prometheus监控指标 …...

Leecode Hot50
文章目录 矩阵Solution73. 矩阵置零Solution54. 螺旋矩阵Solution48. 旋转图像Solution240. 搜索二维矩阵 II二叉树二叉树的四种遍历结果Solution94. 二叉树的中序遍历Solution104. 二叉树的最大深度Solution226. 翻转二叉树Solution101. 对称二叉树Solution543. 二叉树的直径S…...

解决 Gradle 构建错误:Could not get unknown property ‘withoutJclOverSlf4J’
解决 Gradle 构建错误:Could not get unknown property ‘withoutJclOverSlf4J’ 在构建 Spring 源码或其他基于 Gradle 的项目时,可能会遇到如下错误: Could not get unknown property withoutJclOverSlf4J for object of type org.gradle…...
)
C++ 初阶总复习 (16~30)
C 初阶总复习 (16~30) 目的16. 2009. volatile关键字的作用17. 2010.什么是多态 简单介绍下C的多态18. 2011. 什么是虚函数 介绍下C中虚函数的原理19. 2012 构造函数可以是虚函数嘛20. 2013.析构函数一定要是虚函数嘛?21. 2015. 什么是C中的虚…...

TDengine 中的异常恢复
简介 本章主要介绍在 TDengine 执行命令过程中发生异常,如何手工终于执行的任务。可以终止连接,线上查询及终止事务。 如果一个事务 在一个复杂的应用场景中,连接和查询任务等有可能进入一种错误状态或者耗时过长迟迟无法结束,…...

二层框架组合实验
实验要求: 1,内网IP地址使用172.16.0.0/16分配 2,SW1和sw2之间互为备份 3,VRRP/STP/VLAN/Eth-trunk均使用 4,所有PC均通过DHCP获取IP地址 5,ISP只能配置IP地址 6,所有电脑可以正常访问ISP路由器环回 实验思路顺序: 创建vlan eth-trunk 划分v…...

IP综合实验
1.配置eth-trunk进行绑定 [LSW1]interface Eth-Trunk 0 [LSW1-Eth-Trunk0]q [LSW1]interface g0/0/2 [LSW1-GigabitEthernet0/0/2]eth-trunk 0 [LSW1-GigabitEthernet0/0/2]int g0/0/3 [LSW1-GigabitEthernet0/0/3]eth-trunk 0 [LSW1-GigabitEthernet0/0/3]display et…...
)
2025年信息系统与未来教育国际学术会议(ISFE 2025)
基本信息 官网:www.icedcs.net 时间:2025年4月18-20日 地点:中国-深圳 简介 2025年信息系统与未来教育国际学术会议(ISFE 2025)作为第二届粤港澳大湾区教育数字化与计算机科学国际学术会议(EDCS 2025&…...
)
nacos 外置mysql数据库操作(docker 环境)
目录 一、外置mysql数据库原因: 二、数据库准备工作 三、构建nacos容器 四、效果展示 一、外置mysql数据库原因: 想知道nacos如何外置mysql数据库之前,我们首先要知道为什么要外置mysql数据库,或者说这样做有什么优点和好处&am…...

Windows 10 ARM64平台MFC串口程序开发
Windows 10 IoT ARM64平台除了支持新的UWP框架,也兼容支持老框架MFC。使得用户在Windows 10 IoT下可以对原MFC工程进行功能升级,不用在新框架下重写整个工程。熟悉MFC开发的工程师也可以在Windows 10 IoT平台下继续使用MFC进行开发。 本文展示MFC串口程序…...
)
怎么使用pm2启动和暂停后端程序(后端架构nodejs+koa)
首先查看自己的pm2进程 pm2 list 或者 pm2 status 如果什么进程都没有,但是你确实有后端程序运行在服务器上,使用以下查看pm2程序的启动用户 ps aux | grep pm2就可以看到具体的用户和进行的信息 接着转换到你要操作的pm2的进程用户下 sudo su - …...

AI人工智能-Jupyter NotbookPycharm:Py开发
安装 命令: pip install jupyter 启动 命令: jupyter notebook 启动成功后,下面网址会默认自动打开当前用户的根目录。 其实这个页面显示的内容,是我们电脑目录C:\Users\当前用户\下的文件夹 我们平常做实验,希望在…...

uniapp-小程序地图展示
一、当前页面直接获取 <view class"map"><map id"myMap" style"width: 100%; height: 40vh;" :latitude"latitude":longitude"longitude" :markers"markers" :scale"scale" :show-location&qu…...

使用 Python 进行链上数据监控:让区块链数据触手可及
使用 Python 进行链上数据监控:让区块链数据触手可及 区块链技术正以前所未有的速度改变着各行各业,特别是在金融、供应链、物联网和智能合约等领域的应用,已经成为了一种新常态。然而,随着区块链网络的快速扩展和去中心化特性的不断强化,数据的可视化与监控变得愈发重要…...

CentOS 7 磁盘及分区管理笔记
一、查看磁盘信息 1. lsblk 命令 作用:列出系统中所有的块设备(包括磁盘、分区等)及其相关信息,如设备名称、大小、类型等。 命令格式:lsblk 示例: lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sd…...
)
python基础学习二(列表及字典的使用)
文章目录 列表列表的创建获取列表中的多个元素判断列表中元素是否存在列表元素的添加操作列表元素的删除操作列表元素的修改列表的排序列表生成式 字典字典的创建字典的常规操作字典的常用操作字典的视图操作字典元素的遍历字典的特点字典的生成式 列表 一个对象由id࿰…...

【NLP 50、损失函数 KL散度】
目录 一、定义与公式 1.核心定义 2.数学公式 3.KL散度与交叉熵的关系 二、使用场景 1.生成模型与变分推断 2.知识蒸馏 3.模型评估与优化 4.信息论与编码优化 三、原理与特性 1.信息论视角 2.优化目标 3.局限性 四、代码示例 代码运行流程 核心代码解析 抵达梦想靠的不是狂热…...
)
macOS Jdk1.8安装(目前主流版本的jdk)
Jdk1.8安装 1、jdk安装包下载链接2、下载安装包(根据自己是什么系统进行下载)3、下载完成之后双击安装包进行安装安装好之后查看查看安装的版本需要查看JDK的安装路径(一般在/Library/Java/JavaVirtualMachines)配置环境变量1、jdk安装包下载链接 jdk8下载链接 https://www.…...

树莓派5智能家居中控:HomeAssistant全配置指南
一、硬件选型与系统架构 1.1 树莓派5的硬件优势 2023年发布的树莓派5采用Broadcom BCM2712处理器(4核Cortex-A76架构),相比前代产品具有三大突破性改进: 接口升级:首次支持PCIe 2.0接口,可扩展万兆网卡或…...
如何配置Dubbo的服务提供者?)
Dubbo(22)如何配置Dubbo的服务提供者?
配置Dubbo的服务提供者是实现分布式服务架构的重要步骤。服务提供者负责将服务注册到注册中心,使得服务消费者可以发现并调用这些服务。下面以一个完整的Spring Boot项目为例,详细介绍如何配置Dubbo的服务提供者。 配置步骤 引入依赖:在项目…...

【通道注意力机制】【SENet】Squeeze-and-Excitation Networks
0.论文摘要 卷积神经网络建立在卷积操作的基础上,通过融合局部感受野内的空间和通道信息来提取有意义的特征。为了增强网络的表示能力,最近的一些方法展示了增强空间编码的好处。在本研究中,我们专注于通道关系,并提出了一种新颖…...
深度解析:从 RS232 仿真到设备互联的技术实现)
【SPP】蓝牙串口协议(SPP)深度解析:从 RS232 仿真到设备互联的技术实现
目录 一、SPP协议概述 1.1 SPP的定位与核心功能 1.2 协议栈层次(SPP 协议模型) 1.3 技术原理 1.4 用户需求 二、设备角色与连接模型 2.1 角色定义(DevA 与 DevB 交互) 2.2 角色动态切换 2.3 协议依赖关系 三、数据传输:从 RS232 到蓝牙的映射 3.1 控制信号仿真…...

5.Excel:从网上获取数据
一 用 Excel 数据选项卡获取数据的方法 连接。 二 要求获取实时数据 每1分钟自动更新数据。 A股市场_同花顺行情中心_同花顺财经网 用上面方法将数据加载进工作表中。 在表格内任意区域右键,刷新。 自动刷新: 三 缺点 Excel 只能爬取网页上表格类型的…...

基于RFID技术建筑物资材料智能管理解决方案
建筑行业仓库和物资材料管理面临诸多挑战,如工程设备重复利用的管理需求、物资出入库管理不规范、账物不符、物资丢失等问题。特别是在复杂多变的工地环境中,对物资进行科学规范的管理难度极大。上海岳冉基于RFID技术的建筑物资材料智能管理解决方案聚焦…...

详解CountDownLatch底层源码
大家好,我是此林。 今天来分享一下CountDownLatch的底层源码。 CountDownLatch 是 Java 并发包 (java.util.concurrent) 中的线程之间同步工具类,主要用于协调多个线程的执行顺序。其核心思想是通过计数器实现线程间的"等待-唤醒"机制&#…...
)
Python每日一题(9)
Python每日一题 2025.3.29 一、题目二、分析三、源代码四、deepseek答案五、源代码与ai分析 一、题目 question["""企业发放的奖金根据利润提成。利润(I)低于或等于10万元时,奖金可提10%,利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部…...

一阶谓词逻辑表示法、产生式表示法、框架表示法深度对比
前文我们已经深度学习了一阶谓词逻辑表示法、产生式表示法和框架表示法这三种知识表示方法,那么它们之间有什么异同点呢?接下来我们对它们进行深度对比。 首先,我得回忆这三种知识表示方法的基本概念和特点。 (1)一阶谓词逻辑(FOPL)是基于形式逻辑的,使用谓词、变量、量…...

Tomcat生产服务器性能优化
试想以下这个情景:你已经开发好了一个程序,这个程序的排版很不错,而且有着最前沿的功能和其他一些让你这程序增添不少色彩的元素。可惜的是,程序的性能不怎么地。你也十分清楚,若现在把这款产品退出市场,肯…...
‘ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。)
【算法day25】 最长有效括号——给你一个只包含 ‘(‘ 和 ‘)‘ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
32. 最长有效括号 给你一个只包含 ‘(’ 和 ‘)’ 的字符串,找出最长有效(格式正确且连续)括号子串的长度。 https://leetcode.cn/problems/longest-valid-parentheses/ 2.方法二:栈 class Solution { public:int longestValid…...

Python之变量与数据类型总结
前言 一、基本数据类型 1、整数(int) 2、浮点数(float) 3、布尔值(bool) 4、字符串(str) 二、复合数据类型 1、列表(list) 1.1、列表基础 1.1.1、列…...

【大模型基础_毛玉仁】5.3 附加参数法:T-Patcher
目录 5.3 附加参数法:T-Patcher5.3.1 补丁的位置1)键值存储体2)补丁设计 5.3.2 补丁的形式5.3.3 补丁的实现1)准确性2)局部性 5.3 附加参数法:T-Patcher 附加参数法:通过引入可训练的额外参数实…...

【19期获取股票数据API接口】如何用Python、Java等五种主流语言实例演示获取股票行情api接口之沪深A股实时交易数据及接口API说明文档
在量化分析领域,实时且准确的数据接口是成功的基石。经过多次实际测试,我将已确认可用的数据接口分享给正在从事量化分析的朋友们,希望能够对你们的研究和工作有所帮助,接下来我会用Python、JavaScript(Node.js&…...

RSA 简介及 C# 和 js 实现【加密知多少系列_4】
〇、简介 谈及 RSA 加密算法,我们就需要先了解下这两个专业名词,对称加密和非对称加密。 对称加密:在同一密钥的加持下,发送方将未加密的原文,通过算法加密成密文;相对的接收方通过算法将密文解密出来原文…...

Koordinator-Metric查询
以CollectAllPodMetricsLast()举例,看看koordinator怎样使用tsdb进行查询。 CollectAllPodMetricsLast() GenerateQueryParamsLast()传入metric采集间隔2倍时间调用CollectAllPodMetrics()func CollectAllPodMetricsLast(statesInformer statesinformer.StatesInformer, metr…...

LeetCode1两数之和
**思路:**懒得写了,如代码所示 /*** Note: The returned array must be malloced, assume caller calls free().*/ struct hashTable {int key;//存值int val;//存索引UT_hash_handle hh; }; int* twoSum(int* nums, int numsSize, int target, int* re…...

AOA与TOA混合定位,MATLAB例程,三维空间下的运动轨迹,滤波使用EKF,附下载链接
本文介绍一个MATLAB代码,实现基于 到达角(AOA) 和 到达时间(TOA) 的混合定位算法,结合 扩展卡尔曼滤波(EKF) 对三维运动目标的轨迹进行滤波优化。代码通过模拟动态目标与基站网络&am…...