【数据结构】哈希 ---万字详解
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到log_2
N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好
的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个
unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是
其底层结构不同。因为unordered_set与unordered_map使用方式类似,我们着重见介绍unordered_map,unordered_set见文档。
unordered_map(文档)
- unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
- 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_map实现了直接访问操作符(operator[]),它允许使用key作为参数直接访value。
- unordered_map是单向迭代器
接口
unordered_map容量相关
- bool empty()const (检测unordered_map是否为空)
- size_t size()const (获取unordered_map的有效元素个数)
unordered_map的元素访问
- operator[] (返回与key对应的value,没有一个默认值)
- 注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,将key对应的value返回。
unordered_map的查询
- iterator find(const K& key) (返回key在哈希桶中的位置)
- size_t count(const K& key) (返回哈希桶中关键码为key的键值对的个数)
unordered_map的修改操作
- insert (向容器中插入键值对)
- erase (删除容器中的键值对)
- void clear() (清空容器中有效元素个数)
- void swap(unordered_map&) (交换两个容器中的元素)
unordered_map的桶操作
- size_t bucket_count()const (返回哈希桶中桶的总个数)
- size_t bucket_size(size_t n)const (返回n号桶中有效元素的总个数)
- size_t bucket(const K& key) (返回元素key所在的桶号)
使用
#include <iostream>
using namespace std;
#include <map>
#include <set>
#include <unordered_map>
#include <unordered_set>
void test_unordered_set()
{unordered_set<int> us;us.insert(4);us.insert(2);us.insert(1);us.insert(5);us.insert(6);/*us.insert(6);us.insert(6);*///可以去重 不能排序unordered_set<int>::iterator it = us.begin();while (it != us.end()){cout << *it << " ";++it; }cout << endl;
}
void test_op()
{unordered_set<int> us;set<int> s;const int n = 1000000;vector<int> v;v.reserve(n);srand(time(0));for (size_t i = 0; i < n; ++i){v.push_back(rand());} size_t begin1 = clock();for (size_t i = 0; i < n; ++i){us.insert(v[i]);}size_t end1=clock();size_t begin2 = clock();for (size_t i = 0; i < n; ++i){s.insert(v[i]);}size_t end2 = clock();size_t begin3 = clock();for (size_t i = 0; i < n; ++i){us.find(v[i]);}size_t end3 = clock();size_t begin4 = clock();for (size_t i = 0; i < n; ++i){s.find(v[i]);}size_t end4 = clock();size_t begin5 = clock();for (size_t i = 0; i < n; ++i){us.erase(v[i]);}size_t end5 = clock();size_t begin6 = clock();for (size_t i = 0; i < n; ++i){s.erase(v[i]);}size_t end6 = clock();cout << "set:(insert)" << end2 - begin2 << endl;cout << "unordered_set:(insert)" << end1 - begin1 << endl;cout << "set:(find)" << end4 - begin4 << endl;cout << "unordered_set:(find)" << end3 - begin3 << endl;cout << "set:(erase)" << end6 - begin6 << endl;cout << "unordered_set:(erase)" << end5 - begin5 << endl;
}从运行结果可以看出unordered_set容器增删查的效率比set快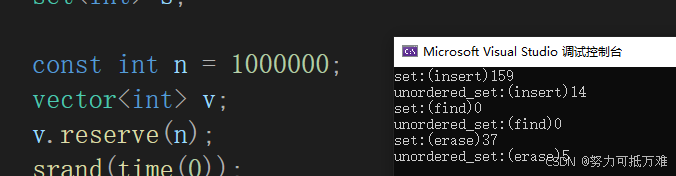
相关OJ题
- 重复n次的元素
- 两个数组的交集I
- 两个数组的交集II
- 存在重复元素
- 两句话中不常见的单词
底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
哈希是一种映射的对应关系,将存储的数据根存储的位置使用哈希函数建立出的映射关系,方便我们进行查找。在查找字符串中只出现过一次的字符中就可以创建一个256的int数组,去统计次数,因为字符总共只有256种,这里就建立了字符(char)与字符的值(int)的映射关系(直接定址法:映射只跟关键字直接相关或者间接相关)。 其次计数排序也是统计次数,建立类似的映射,进行排序。
1,2,5,9,1000000,888888,23存起来,方便查找,怎么存?(不使用搜索树)
如果每个值直接进行映射,那么我们要创建一个100w大小的数组,空间浪费十分严重。基于这个原因,哈希引申出一些映射的方式进行补救。
除留余数法(最常用)

不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
现在我们要存11,就会发生冲突了,这种冲突叫做哈希冲突。(不同的值映射到了相同的位置)哈希通过映射关系进行查找,效率非常高,但是哈希最大的问题就是如何解决哈希冲突?这里就引入了很多种方法来解决哈希冲突。
哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列
闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有
空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置
呢?
- 线性探测(从发生冲突的位置开始,依次向后探测,直到找到下一个空位置为止)
- key % 表大小 + i (i = 0,1,2,3,4,...)
- 二次探测(按2次方往后找空位置)
- key % 表大小 + i^2 (i = 0,1,2,3,...)
线性探测
插入
- 通过哈希函数获取待插入元素在哈希表中的位置如果该位置中没有元素则直接插入新元素
- 如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
删除
- 采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素,可能会影响其他元素的搜索。
- 比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
enum State{EMPTY,EXITS,DELETE};线性探测的实现
#include <iostream>
#include <vector>
using namespace std;
enum State
{EMPTY,EXITS,DELETE
};
template<class T>
struct HashData
{T _data;State _state=EMPTY;
};template<class K>
struct SetOfT
{const K& operator()(const K& key){return key;}
};
//unordered_set<K> ->HashTable<K,K>
//unordered_map<K,V> ->HashTable<K,pair<K,V>>
template<class K,class T,typename KOfT>
class HashTable
{
public:bool Insert(const T& d){KOfT koft;/*if (Find(koft(d)))return false;*///闭散列哈希表不能满了再增容//因为如果哈希表快满了的时候插入数据,冲突的概率很大,效率会很低//快接近满的时候就增容//因此提出负载因子的概念=表中数据个数比上表的大小//一般情况下,负载因子越小,冲突的概率特低,效率越高//但是控制的太小,会导致大量的空间浪费,以空间换时间/*if (_tables.size()==0||_num * 10 / _tables.size() > 7){*/// //第一次会出现除0的问题// //1.开两倍大小的新表// //2.遍历旧表的数据,重新计算表中的位置// //3.释放旧表// size_t newsize = _tables.size() == 0 ? 10 : 2 * _tables.size();// vector<HashData<T>> newtables;// newtables.resize(newsize);// for (size_t i = 0; i < _tables.size(); ++i)// {// if (_tables[i]._state == EXITS)// {// //计算新表中的位置并处理冲突// int index = koft(_tables[i]._data) % newtables.size();// while (newtables[index]._state == EXITS)// {// ++index;// if (index == newtables.size())// index = 0;// }// newtables[index] = _tables[i];// }// }// _tables.swap(newtables);//}if (_tables.size() == 0 || _num * 10 / _tables.size() > 7){HashTable<K, T, KOfT> newht;size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;newht._tables.resize(newsize);for (auto& data : _tables){if (data._state == EXITS){newht.Insert(data._data);}}_tables.swap(newht._tables);}size_t index = koft(d) % _tables.size();while (_tables[index]._state == EXITS){++index;if (index == _tables.size())index = 0;}_tables[index]._data = d;_tables[index]._state = EXITS;++_num;return true;}HashData<T>* Find(const K& key){KOfT koft;size_t index = key % _tables.size();while (_tables[index]._state != EMPTY){if (koft(_tables[index]._data) == key){if (_tables[index]._state == EXITS){return &_tables[index];}else if (_tables[index]._state == DELETE)return nullptr;}++index;if (index == _tables.size())index = 0;}return nullptr;}bool Erase(const K& key){HashData<T>* ret = Find(key);if (ret){ret->_state = DELETE;--_num;return true;}else{return false;}}
private:vector<HashData<T>> _tables;size_t _num=0; //有效数据的个数
};
void test_HashTable()
{HashTable<int,int, SetOfT<int>> ht;ht.Insert(4);ht.Insert(14);ht.Insert(24);ht.Insert(5);ht.Insert(15);ht.Insert(25);ht.Insert(6);ht.Insert(16);
}线性探测的问题

线性探测的思路就是如果我的位置被占用了,我就挨着往后去占别人的位置,可能会导致一片一片的冲突,洪水效应。
- 线性探测优点:实现非常简单
- 线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。如何缓解呢? 二次探测
开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中。
 开散列中每个桶中放的都是发生哈希冲突的元素。
开散列中每个桶中放的都是发生哈希冲突的元素。
开散列实现
template<class T>
struct HashNode
{HashNode(const T& data):_next(nullptr),_data(data){}T _data;HashNode<T>* _next;
};template<class K>
struct _Hash
{
public:const K& operator()(const K& key){return key;}
};//特化 HashTable<string,string,SetOfT<string>> ht;
template<>
struct _Hash<string>
{size_t operator()(string key){size_t hash = 0;for (size_t i = 0; i < key.size(); ++i){hash *= 131;hash += key[i];}return hash;}
};
//HashTable<string,string,SetOfT<string>,_HashString> ht;
/*struct _HashString
{
public:size_t operator()(string key){size_t hash = 0;for (size_t i = 0; i < key.size(); ++i){hash *= 131;hash += key[i];}return hash;}
};*/
template<class K,class T,class KOFT,class Hash=_Hash<K>>
class HashTable
{typedef HashNode<T> Node;
public:~HashTable(){Clear();}void Clear(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* _next = cur->_next;delete cur;cur = _next;}}}const size_t HashFunc(const K& key){Hash hash;return hash(key);}bool Insert(const T& data){KOFT koft;//增容 负载因子if (_num == _tables.size()){size_t newsize = (_tables.size() == 0 ? 10 : 2 * _num);vector<Node*> newtables;newtables.resize(newsize);for (int i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){size_t index = HashFunc(koft(cur->_data)) % newsize;Node* next = cur->_next;cur->_next = newtables[index];newtables[index] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//计算在表中的映射位置size_t index = HashFunc(koft(data))%_tables.size();Node* cur = _tables[index];//查找这个值在不在表中while (cur){if (koft(cur->_data) == koft(data)){return false;}else{//头插到表中cur = cur->_next;}}Node* ret = new Node(data);ret->_next = _tables[index];_tables[index] = ret;_num++;return true;}Node* Find(const K& key){KOFT koft;size_t index = HashFunc(key) % _tables.size();Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){return cur;}else{cur = cur->_next;}}return nullptr;}bool Erase(const K& key){KOFT koft;size_t index = HashFunc(key) % _tables.size();Node* cur = _tables[index];Node* prev = nullptr;while (cur){if (koft(cur->_data) == key){if (prev == nullptr){_tables[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;_num--;return true;}else{prev = cur; cur = cur->_next;}}return false;}
private:vector<Node*> _tables;size_t _num=0;假设总有一些桶挂的数据很多,冲突很厉害怎么解决?
- 针对单个桶:一个桶链的长度超过一定值,就将挂链表改为挂红黑树。(Java HashMap就是当桶长度超过8就改成挂红黑树)
- 针对整体,控制负载因子
 仿函数Hash将对应的key转成可以取余的整型,默认的仿函数直接返回key,因为有些类型的key直接就可以取余;如果是其他自定义类型我们就自己构造一个哈希函数,作为仿函数,传入Hash模板中。(常见字符串哈希算法)
仿函数Hash将对应的key转成可以取余的整型,默认的仿函数直接返回key,因为有些类型的key直接就可以取余;如果是其他自定义类型我们就自己构造一个哈希函数,作为仿函数,传入Hash模板中。(常见字符串哈希算法)
开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上:由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <=0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
unordered_set与unordered_map的模拟实现
哈希表的改造
- 模板参数列表的改造
- 增加迭代器操作
- 增加通过key获取value操作
#pragma once
#include <iostream>
#include <vector>
#include <string>
using namespace std;
namespace wxy
{template<class T>struct HashNode{HashNode(const T& data):_next(nullptr),_data(data){}T _data;HashNode<T>* _next;};//前置声明 两者如果相互依赖,就需要对其中一个进行前置声明template<class K, class T, class KOFT, class Hash>class HashTable;template<class K>struct _Hash{size_t operator()(const K& key){return key;}};// 特化template<>struct _Hash<string>{// "int" "insert" // 字符串转成对应一个整形值,因为整形才能取模算映射位置// 期望->字符串不同,转出的整形值尽量不同// "abcd" "bcad"// "abbb" "abca"size_t operator()(const string& s){// BKDR Hashsize_t value = 0;for (auto ch : s){value += ch;value *= 131;}return value;}};template<class K, class T, class KOFT, class Hash>struct HTIterator{public:typedef HTIterator<K, T, KOFT, Hash> Self;typedef HashNode<T> Node;typedef HashTable<K, T, KOFT, Hash> HT; //这里会往前找 找不到HashTable? 怎么办 Node* _node;const HT* _pht;HTIterator(Node* node, HT* pht):_node(node), _pht(pht){}T operator*(){return _node->_data;}T* operator->(){return &(_node->_data);}bool operator!=(const Self& s){return (_node != s._node);}Self& operator++(){if (_node->_next){//当前桶还有数据,走到下一个节点_node = _node->_next;}else{KOFT koft;Hash hash;//如果一个桶走完了,找到下一个桶继续遍历size_t index = hash(koft(_node->_data))%_pht->_tables.size();++index;/*for (; index < _pht->_tables.size(); ++index){Node* cur = _pht->_tables[index];if (cur){_node = cur;return *this;}}*/while (index < _pht->_tables.size()){_node = _pht->_tables[index];if (_node)break;else++index;}if(index==_pht->_tables.size())_node = nullptr;}return *this;}};template<class K, class T, class KOFT, class Hash>class HashTable {public://友元声明 template<class K, class T, class KeyOfT, class Hash>friend struct HTIterator;typedef HTIterator<K, T, KOFT, Hash> Iterator;typedef HashNode<T> Node;size_t HashFunc(K key){Hash hash;return hash(key);}Iterator begin(){if (_num == 0)return end();for (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]){return Iterator(_tables[i],this);}}return end();}Iterator end(){return Iterator(nullptr,this);}~HashTable(){Clear();}void Clear(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* _next = cur->_next;delete cur;cur = _next;}}}pair<Iterator,bool> Insert(const T& data){KOFT koft;Hash hash;//增容 负载因子if (_num == _tables.size()){size_t newsize = (_tables.size() == 0 ? 10 : 2 * _num);vector<Node*> newtables;newtables.resize(newsize);for (int i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){size_t index = HashFunc(koft(cur->_data)) % newsize;Node* next = cur->_next;cur->_next = newtables[index];newtables[index] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//计算在表中的映射位置size_t index = HashFunc(koft(data))%_tables.size();Node* cur = _tables[index];//查找这个值在不在表中while (cur){if (koft(cur->_data) == koft(data)){return make_pair(Iterator(cur,this),false);}else{//头插到表中cur = cur->_next;}}Node* ret = new Node(data);ret->_next = _tables[index];_tables[index] = ret;_num++;return make_pair(Iterator(ret,this), true);}Iterator Find(const K& key){KOFT koft;size_t index = HashFunc(koft(key)) % _tables.size();Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){return Iterator(cur,this);}else{cur = cur->_next;}}return end();}bool Erase(const K& key){KOFT koft;size_t index = HashFunc(koft(key)) % _tables.size();Node* cur = _tables[index];Node* prev = nullptr;while (cur){if (koft(cur->_data) == key){if (prev == nullptr){_tables[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;_num--;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<Node*> _tables;size_t _num = 0;};
}unordered_set的模拟实现
namespace wxy {template<class K,class Hash=_Hash<K>>class unordered_set{public:struct SetOfT{const K& operator()(const K& key){return key;}};typedef typename HashTable<K,K,SetOfT,Hash>::Iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}private:HashTable<K,K,SetOfT,Hash> _ht;};void test_unorderedset(){unordered_set<int> s;s.insert(1);s.insert(5);s.insert(4);s.insert(2);unordered_set<int>::iterator it = s.begin();while (it != s.end()){cout << *it<< " ";++it;}cout << endl;}
}unordered_map的模拟实现
namespace wxy {template<class K, class V,class Hash=_Hash<K>>class unordered_map{struct MapOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename HashTable<K,pair<K, V>,MapOfT, Hash>::Iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> insert(const pair<K,V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}iterator Find(const K& key){return _ht.Find(key);}bool Erase(const K& key){return _ht.Erase(key);}private:wxy::HashTable<K, pair<K, V>, MapOfT,Hash> _ht;};void test_unorderedmap(){unordered_map<string, string> dict;dict.insert({ "sort", "排序" });dict.insert({ "sort", "排序" });dict.insert({ "left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余";dict["insert"] = "插入";dict["string"];for (auto kv : dict){cout << kv.first << ":" << kv.second << endl;}cout << endl;}
}
相关文章:

【数据结构】哈希 ---万字详解
unordered系列关联式容器 在C98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到log_2 N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好 的查询是,…...

Python Web 框架
Python 有多个强大的 Web 框架,每个框架都具有不同的特点和应用场景。根据开发者的需求(如开发速度、灵活性、功能等),可以选择适合的框架。以下是一些常见的 Python Web 框架: 1. Django 简介:Django 是一…...

大模型翻译能力评测
1. 背景介绍 随着自然语言处理技术的飞速发展,机器翻译已经成为一个重要的研究领域。近年来,基于大模型的语言模型在机器翻译任务上取得了显著的进展。这些大模型通常具有数亿甚至数千亿的参数,能够更好地理解和生成自然语言。 但是…...

深度学习中的前向传播与损失函数
目录 编辑 前向传播:神经网络的推理过程 什么是前向传播? 前向传播的步骤 数学表达 代码示例:前向传播 损失函数:衡量预测与真实值的差异 损失函数的定义 损失函数的作用 常见的损失函数 代码示例:损失函…...

MySQL 复合查询
实际开发中往往数据来自不同的表,所以需要多表查询。本节我们用一个简单的公司管理系统,有三张表EMP,DEPT,SALGRADE 来演示如何进行多表查询。表结构的代码以及插入的数据如下: DROP database IF EXISTS scott; CREATE database IF NOT EXIST…...
core API简单示例,并解决403权限验证问题,即何进行进行权限授权以及验证)
Java程序调kubernetes(k8s1.30.7)core API简单示例,并解决403权限验证问题,即何进行进行权限授权以及验证
简单记录问题 一、问题描述 希望通过Java程序使用Kubernetes提供的工具包实现对Kubernetes集群core API的调用,但是在高版本上遇见权限验证问题4xx。 <dependency><groupId>io.kubernetes</groupId><artifactId>client-java</artifact…...

Java安全—原生反序列化重写方法链条分析触发类
前言 在Java安全中反序列化是一个非常重要点,有原生态的反序列化,还有一些特定漏洞情况下的。今天主要讲一下原生态的反序列化,这部分内容对于没Java基础的来说可能有点难,包括我。 序列化与反序列化 序列化:将内存…...

火鸟地方门户系统V8.5系统源码+搭建环境教程
一.介绍 火鸟地方门户系统V8.5源码 系统包含4端: PCH5小程序APP 二.搭建环境 系统环境:CentOS、 运行环境:宝塔 Linux 网站环境:Nginx 1.2.22 MySQL 5.6 PHP-7.4 常见插件:fileinfo ; redis 三.测…...

深度学习:梯度下降法
损失函数 L:衡量单一训练样例的效果。 成本函数 J:用于衡量 w 和 b 的效果。 如何使用梯度下降法来训练或学习训练集上的参数w和b ? 成本函数J是参数w和b的函数,它被定义为平均值; 损失函数L可以衡量你的算法效果&a…...

Git常用命令
Git是一个优秀的代码版本管理工具,其常用命令包括但不限于以下这些: 一、初始化与配置 git init:在当前目录初始化一个新的Git仓库。git clone [url]:克隆远程仓库到本地。git config:配置Git的各种选项和变量&#…...

css预处理器scss/sass
一、css预处理器sass的诞生 众所周知css并不能算是一们真正意义上的“编程”语言,它本身无法未完成像其它编程语言一样的嵌套、继承、设置变量等工作,仅仅只能用来编写网站样式,如此一来代码就会百年的臃肿难以维护。为了解决css的不足&#…...

磁盘/系统空间占满导致黑屏死机无法开机的解决办法
文章目录 起因具体操作1.重启虚拟机,一直按CtrlShitf进入GRUP界面2.选“Ubuntu高级选项”并回车选择第二个,recovery mode3.4.命令查看磁盘情况5.查找和删除文…...

API 与 SDK 之间的区别
API 与 SDK 之间的区别 很多人在软件开发中经常会分不清 SDK 与 API ,今天就来浅谈一下两者之间的区别。 直白地说,SDK 包含了 API ,是一套完整的,能完成更多功能的工具包,无论你想获取什么样的信息,SDK …...

Lua的环境与热更
一、global_State,lua_State与G表 Lua支持多线程环境,使用 lua_State 结构来表示一个独立的 Lua 线程(或协程)。每个线程都需要一个独立的全局环境。而lua_State 中的l_G指针,指向一个global_State结构,这个就是我们常…...

java八股-分布式服务的接口幂等性如何设计?
文章目录 接口幂等token Redis分布式锁 原文视频链接:讲解的流程特别清晰,易懂,收获巨大 【新版Java面试专题视频教程,java八股文面试全套真题深度详解(含大厂高频面试真题)】 https://www.bilibili.com/…...
)
鸿蒙学习使用模拟器运行应用(开发篇)
文章目录 1、系统类型和运行环境要求2、创建模拟器3、启动和关闭模拟器4、安装应用程序包和上传文件QA:在Windows电脑上启动模拟器,提示未开启Hyper-V 1、系统类型和运行环境要求 Windows 10 企业版、专业版或教育版及以上,且操作系统版本不低于10.0.18…...

基于 FFmpeg/Scrcpy 框架构建的一款高性能的安卓设备投屏管理工具-供大家学习研究参考
支持的投屏方式有:USB,WIFIADB,OTG,投屏之前需要开启开发者选项里面的USB调试。 主要功能有: 1.支持单个或多个设备投屏。 2.支持键鼠操控。 3.支持文字输入。 4.支持共享剪切板(可复制粘贴电脑端文字到手机端,也可导出手机剪切板到电脑端)。 5.支持视频图片上传,可单…...
)
ESLint v9.0.0 新纪元:探索 eslint.config.js 的奥秘 (4)
从 v9.0.0 开始,官方推荐的配置文件格式是 eslint.config.js,并且支持 ESM 模块化风格,可以通过 export default 来导出配置内容。 // eslint.config.js export default [{rules: {semi: "error","prefer-const": "…...

电脑还原重置Windows系统不同操作模式
电脑有问题,遇事不决就重启,一切都不是问题!是真的这样吗。其实不然,主机系统重启确实可以自动修复一些文件错误,或者是设置问题,但是,当你由于安装了错误的驱动或者中毒严重,亦或是蓝屏,那么重启这个方子可能就治不了你的电脑了。 那么,除了当主机出现异常故障现象…...

图论2图的应用补充
图论1基础内容-CSDN博客 图的应用 4.1 拓扑排序 拓扑排序针对有向无环图的顶点进行线性排列的算法,使得对于任何来自顶点A指向顶点B的边,A都在序列中出现在B之前。这样的排序存在于有向无环图中,而对于非有向无环图则不存在拓扑排序。 拓扑排…...
算法及其Python实现)
非线性模型预测控制(NMPC)算法及其Python实现
目录 非线性模型预测控制(NMPC)算法及其Python实现第一部分:NMPC算法概述1.1 NMPC的定义1.2 NMPC的优点1.3 NMPC的应用领域第二部分:NMPC算法的数学模型2.1 系统建模2.2 目标函数与约束2.3 NMPC算法的求解第三部分:NMPC算法的实现与优化3.1 实现步骤3.2 Python实现3.3 设计…...

sql语句分类
SQL语句分类 SQL,英文全称为Structured Query Language,中文意思是结构化查询语言(属于编程语言的一种) DDL数据定义语⾔ Data Definition Language,数据定义语言,例如修改数据库中的表、视图、索引等对…...

<一>51单片机环境
目录 1,51单片机开发语言是C,环境keil 1.1,工程创建 1.2用什么把代码放进单片机里面 2,初识代码 1,51单片机开发语言是C,环境keil 1.1,工程创建 1. 创建项目工程文件夹,可以当作模板Template 2. 创建文件,取名main.c 3,编译,选择输出文…...

flutter 解决webview加载重定向h5页面 返回重复加载问题
long time no see. 如果觉得该方案helps,点个赞,评论打个call,这是我前进的动力~ 通常写法: 项目里用的webview_flutter 正常webview处理返回事件 if (await controller.canGoBack()) {controller.goBack(); } else {Navigator…...

折腾基本功:Redis 从入门到 Docker 部署
前面写过了两篇 “Redis” 相关的内容,今天补一篇“基本功”内容,让后续折腾系列文章可以篇幅更短、内容更专注。 前言 在日常工作中,我们构建应用时总是离不开一些基础组件,Redis 就是其中特别常用的一个。之前我写过不少文章&…...

【C++习题】24.二分查找算法_0~n-1中缺失的数字
文章目录 题目链接:题目描述:解法C 算法代码:图解 题目链接: 剑指 Offer 53 - II. 0~n-1中缺失的数字 题目描述: 解法 哈希表: 建立一个hash表看哪个数字出现次数为0 直接遍历找结果࿱…...
)
分享一款内存马检测工具(附网盘链接)
DuckMemoryScan DuckMemoryScan是一款简单寻找包括不限于iis劫持,无文件木马,shellcode免杀后门的工具 功能列表 HWBP hook检测 检测线程中所有疑似被hwbp隐形挂钩内存免杀shellcode检测可疑进程检测(主要针对有逃避性质的进程[如过期签名与多各可执行区段])无文件落地木马检…...

vscode ctrl+/注释不了css
方式一.全部禁用插件排查问题. 方式二.打开首选项的json文件,注释掉setting.json,排查是哪一行配置有问题. 我的最终问题:需要将 "*.vue": "vue",改成"*.vue": "html", "files.associations": { // "*.vue": &qu…...

python数据分析之爬虫基础:爬虫介绍以及urllib详解
前言 在数据分析中,爬虫有着很大作用,可以自动爬取网页中提取的大量的数据,比如从电商网站手机商品信息,为市场分析提供数据基础。也可以补充数据集、检测动态变化等一系列作用。可以说在数据分析中有着相当大的作用!…...

洛谷 P1036 [NOIP2002 普及组] 选数 C语言
题目:https://www.luogu.com.cn/problem/P1036 题目描述 已知 nn 个整数 x1,x2,⋯ ,xn,以及 1 个整数 k(k<n)。从 n 个整数中任选 k 个整数相加,可分别得到一系列的和。例如当 n4,k3,4 个…...

CSS动画案例4
目录 一、介绍二、基础布局1. HTML2.CSS 三、交互效果1.设置中间图片的动画2.设置左右两侧每行内容的起始位置与动画3.设置左右两侧第二行与第三行的动画延时的时间4.icon划入时的效果 四、结束语 一、介绍 今天我们继续来看下一个CSS动画案例,这个案例主要是图片以…...

华为云云连接+squid进行正向代理上网冲浪
1 概述 Squid是一个高性能的代理缓存服务器,主要用于缓冲Internet数据。它支持多种协议,包括FTP、gopher、HTTPS和HTTP。Squid通过一个单独的、非模块化的、I/O驱动的进程来处理所有的客户端请求,这使得它在处理请求时具有较高的效率。…...

【C++】封装红黑树实现的map和set
前言 这篇博客我们将上篇博客实现的红黑树来封装成自己实现的set和map,来模拟一下库里的map和set 💓 个人主页:小张同学zkf ⏩ 文章专栏:C 若有问题 评论区见📝 🎉欢迎大家点赞👍收藏⭐文章 1.源…...

【SSM】mybatis的增删改查
目录 代理Dao方式的增删改查 1. 创建项目 $$1. 在sql.xml里增加日志代码以及user的mapper资源。 $$ 2. 在usermapper里引入接口。 $$3. 在测试类中引入以下代码,并修改其中名字。 $$ 4. 实例对象User.java里属性要与表中列严格对应。 2. 查询 1>. 查询所有 …...

macos下brew安装redis
首先确保已安装brew,接下来搜索资源,在终端输入如下命令: brew search redis 演示如下: 如上看到有redis资源,下面进行安装,执行下面的命令: brew install redis 演示效果如下: …...

鸿蒙修饰符
文章目录 一、引言1.1 什么是修饰符1.2 修饰符在鸿蒙开发中的重要性1.3 修饰符的作用机制 二、UI装饰类修饰符2.1 Styles修饰符2.1.1 基本概念和使用场景2.1.2 使用示例2.1.3 最佳实践 2.2 Extend修饰符2.2.1 基本概念2.2.2 使用示例2.2.3 Extend vs Styles 对比2.2.4 使用建议…...

【Linux】Linux2.6内核进程调度队列与调度原理
目录 一、进程管理中的部分概念二、寄存器三、进程切换四、Linux2.6内核进程调度队列与调度原理结尾 一、进程管理中的部分概念 竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务&#…...

MacOS使用VSCode编写C++程序如何配置clang编译环境
前言 这段时间在练习写C和Python,用vscode这个开发工具,调试的时候遇到一些麻烦,浪费了很多时间,因此整理了这个文档。将详细的细节描述清楚,避免与我遇到同样问题的人踩坑。 1.开发环境的配置 vscode的开发环境配置…...

【Spark源码分析】规则框架- `analysis`分析阶段使用的规则
analysis分析阶段使用的规则 规则批策略规则说明SubstitutionfixedPointOptimizeUpdateFields该规则优化了 UpdateFields 表达式链,因此看起来更像优化规则。但是,在处理深嵌套模式时,UpdateFields 表达式树可能会非常复杂,导致分…...

Windows和Ubuntu系统下cmake和opencv的安装和使用
以下是在Windows和Ubuntu系统下分别安装CMake并使用C配置OpenCV实现读取图片并显示功能的详细步骤: Windows系统 1. 安装CMake 访问CMake官方网站(https://cmake.org/download/)。根据你的Windows系统版本(32位或64位ÿ…...

详解 Qt QtPDF之QPdfPageNavigator 页面跳转
文章目录 前言头文件: 自 Qt 6.4 起继承自: 属性backAvailable : const boolcurrentLocation : const QPointFcurrentPage : const intcurrentZoom : const qrealforwardAvailable : const bool 公共函数QPdfPageNavigator(QObject *parent)virtual ~QPd…...

设计模式之单例
单例可以说是设计模式中最简单的一种模式。但任何一种设计模式都是普遍经验的总结,都有值得思考的地方。所以单例也并不简单,下面让我们慢慢了解它。 单例顾名思义这个类只有一个实例。要做到这点,需要做到以下几点: (…...

笔记软件:我来、思源笔记、Obsidian、OneNote
最近wolai的会员到期了,促使我更新了一下笔记软件。 首先,wolai作为一个笔记软件,我觉得有很多做得不错的方面(否则我也不会为它付费2年了),各种功能集成得很全(公式识别这个功能我写论文的时候…...

前端入门指南:前端模块有哪些格式?分别什么情况使用
前言 在当今的前端开发中,模块化是提升代码组织性和可维护性的关键手段。随着前端技术的发展,出现了多种模块化方案,每种方案都有其独特的优势和适用场景。本文将详细探讨常见的前端模块格式,包括全局变量、IIFE、CommonJS、AMD、…...

Vue3 常用指令解析:v-bind、v-if、v-for、v-show、v-model
Vue 是一个非常强大的前端框架,提供了许多常用指令来简化模板的使用。Vue 指令以 v- 开头,用于对 DOM 元素和组件的行为进行控制。本文将介绍 Vue 中常见的五个指令:v-bind、v-if、v-for、v-show 和 v-model,并通过实例代码来演示…...

如何查看ubuntu服务器的ssh服务是否可用
你可以通过以下几种方法检查 Ubuntu 服务器上的 SSH 服务是否可用: 1. 使用 systemctl 检查 SSH 服务状态 首先,检查 SSH 服务是否正在运行: sudo systemctl status ssh如果 SSH 服务正在运行,你会看到类似以下的输出ÿ…...

redis面试复习
1.redis是单线程还是多线程 无论什么版本工作线程就是是一个,6.x高版本出现了IO多线程 单线程满足redis的串行原子,只不过IO多线程后,把输入/输出放到更多的线程里区并行,好处: 1.执行的时间更短,更快&a…...

【人工智能基础04】线性模型
文章目录 一. 基本知识1. 线性回归1.1. 基本形式1.2. 线性回归 2. 优化方法:梯度下降法2.1. 梯度下降法的直观意义2.2. 随机梯度下降法 3. 分类问题3.1. 二分类:逻辑回归-sigmoid函数3.2. 多分类问题--softmax函数 4. 岭回归与套索回归4.1. 基础概念什么…...

使用YOLO系列txt目标检测标签的滑窗切割:批量处理图像和标签的实用工具
使用YOLO系列txt目标检测标签的滑窗切割:批量处理图像和标签的实用工具 使用YOLO的TXT目标检测标签的滑窗切割:批量处理图像和标签的实用工具背景1. 代码概述2. 滑窗切割算法原理滑窗切割步骤:示例: 3. **代码实现**1. **加载标签…...

《装甲车内气体检测“神器”:上海松柏 K-5S 电化学传感器模组详解》
《装甲车内气体检测“神器”:上海松柏 K-5S 电化学传感器模组详解》 一、引言二、K-5S 电化学传感器模组概述(一)产品简介(二)产品特点(三)产品适用场景 三、电化学传感器原理及优点(一…...