实现Django和Transformers 构建智能客服大模型(模拟订单系统)
一、环境安装准备
#git拉取 bert-base-chinese 文件#创建 虚拟运行环境python -m venv myicrplatenv#刷新source myicrplatenv/bin/activate#python Django 集成nacospip install nacos-sdk-python#安装 Djangopip3 install Django==5.1#安装 pymysql settings.py 里面需要 # 强制用pymysql替代默认的MySQLdb pymysql.install_as_MySQLdb()pip install pymysql# 安装mongopip install djongo pymongopip install transformerspip install torch#安装Daphne: pip install daphne#项目通过 通过 daphne启动daphne icrplat.asgi:application二、构建项目及app模块
#创建app模块
python3 manage.py startapp csicrplat├── README.md
├── cs
│ ├── __init__.py
│ ├── __pycache__
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── icrplat
│ ├── __init__.py
│ ├── __pycache__
│ ├── asgi.py
│ ├── common
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
├── myicrplatenv
│ ├── bin
│ ├── include
│ ├── lib
│ ├── pyvenv.cfg
│ └── share
├── nacos-data
│ └── snapshot
└── templates三、相关代码
####################################views.py####################################@csrf_exempt
def send_message(request):if request.method == "GET":text = request.GET.get("message")# 输入验证if not text or len(text) > 512:return JsonResponse({"status": "error", "message": "无效的输入文本"})try:# 加载 BERT 模型和分词器path = "/Users/jiajiamao/soft/python/space/bert-base-chinese"model_dir = "/Users/jiajiamao/soft/python/space/csBotModel/"model_path = os.path.join(model_dir, "cs_bot_model.pth")# 初始化 tokenizer 和 modeltokenizer = BertTokenizer.from_pretrained(path)model = BertModel.from_pretrained(path)logging.info("*****************初始化tokenizer和model successfully")# 初始化训练类 任务分类 3 (label: 0,1,2)trainer = TrainModel(tokenizer, model, output_size=3)# 加载 训练trainer.train_dataloader()# 加载训练好的模型trainer.load_model(model_path)# 调用模型进行推理predicted_label = trainer.predict(text)print(f"Predicted Label: {predicted_label}")# 根据预测结果生成回复if predicted_label == 0:response = "请登录您的账户,进入订单管理搜索订单号可以查看订单状态。"elif predicted_label == 1:response = "您可以取消订单,请提供订单号。"elif predicted_label == 2:response = "请登录您的账户,提交退货申请。"else:response = "抱歉,我不明白您的问题。"return JsonResponse({"status": "success", "response": response})except Exception as e:return JsonResponse({"status": "error", "message": str(e)})else:return JsonResponse({"status": "error", "message": "无效的请求方法"})################################CsBotModule.py################################import torch.nn as nn"""定义模型类 CsBotModel
"""
class CsBotModule(nn.Module):"""nn.Module:所有神经网络模型的基类。自定义模型需要继承 nn.Module 并实现 __init__ 和 forward 方法。@:param bert_model 预训练的 BERT 模型(例如 BertModel 或类似的 Hugging Face 模型)@:param hidden_size:BERT 模型的隐藏层大小(通常是 768 或 1024)@:param output_size:输出层的大小,表示回复的分类数量或生成回复的维度。假设:你有一个 BERT 模型,它的输出维度是 768(即 hidden_size = 768)。你正在做一个文本分类任务,共有 5 个类别(即 output_size = 5)。那么:输入一个句子,BERT 会将其转换成一个 768 维的向量。self.fc 会将这个 768 维的向量映射到一个 5 维的向量。这个 5 维的向量可以经过 Softmax 函数,得到每个类别的概率分布。"""def __init__(self, bert_model, hidden_size, output_size):#调用父类(nn.Module)的构造函数,确保 PyTorch 能够正确初始化模型super(CsBotModule, self).__init__()# 加载的 BERT 模型,用于提取输入文本的特征。(它会将输入的文本(比如句子)转换成固定长度的向量表示# (通常是 768 维或 1024 维,取决于 BERT 的版本)。)self.bert = bert_model# 一个全连接层(线性层),将 BERT 的输出映射到最终的输出空间(它的作用是将输入数据从一个维度映射到另一个维度。)#hidden_size 是 BERT 模型的输出维度(比如 768 或 1024),也就是 BERT 提取的特征向量的长度。# output_size 是你希望模型最终输出的维度。比如:如果是分类任务,output_size 就是类别的数量。如果是回归任务,output_size 就是输出的数值维度。self.fc = nn.Linear(hidden_size, output_size)"""forward方法用来定义数据如何通过模型传递,最终返回分类结果@:param input_ids:输入的 token ID 序列(经过 tokenizer 处理后的输入)。这是输入文本经过分词和编码后的表示。它是一个张量(Tensor),形状通常是 (batch_size, sequence_length)。每个 token(词或子词)被映射成一个唯一的 ID,input_ids 就是这些 ID 的集合。@:param attention_mask:注意力掩码,用于指示哪些 token 是有效的(1)或填充的(0)。它的作用是告诉模型哪些位置是真实的 token(值为 1),哪些位置是填充的 token(值为 0)。BERT 会根据这个掩码忽略填充部分。"""def forward(self, input_ids, attention_mask):# 获取BERT的输出outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)pooled_output = outputs.pooler_output # 使用[CLS]的输出向量# 全连接层生成回复logits = self.fc(pooled_output)return logits################################TrainModel.py################################import logging
import osimport torch
import torch.nn as nn
from torch.optim import AdamW
from cs.CsBotModule import CsBotModule"""PyTorch和Transformers库中的模块。torch是PyTorch的核心库,nn是用来构建神经网络的模块,BertTokenizer和BertModel是BERT模型和它的分词器,AdamW是用来优化模型的。
"""
class TrainModel:"""#初始化模型 创建一个 CsBotModel 的实例@:param model:预训练的 BERT 模型。@:param hidden_size=768:BERT 模型的隐藏层大小(BERT-base 的隐藏层大小为 768)。@:param output_size=tokenizer.vocab_size:输出层的大小,设置为 tokenizer 的词汇表大小,表示模型需要生成词汇表中的每个 token 的概率。"""def __init__(self, tokenizer, model,output_size):self.tokenizer = tokenizerself.model = model# self.csBotModule = CsBotModule(self.model, hidden_size=768, output_size=self.tokenizer.vocab_size)self.csBotModule = CsBotModule(self.model, hidden_size=768, output_size=output_size)"""训练循环将模型设置为训练模式。清空梯度。输入数据并得到模型的预测值。计算损失值。通过反向传播计算梯度。使用优化器更新模型参数。打印当前轮次和损失值。通过多次循环,模型会逐渐拟合数据,损失值也会逐渐降低,最终达到我们需要的效果。"""def train_dataloader(self):logging.info(f"*********************训练加载器开始处理")""" 损失函数的作用是衡量模型的预测结果与真实结果之间的差距CrossEntropyLoss:交叉熵损失通常用于分类任务中。比如,模型需要预测一张图片是猫还是狗,交叉熵损失会根据模型的预测概率和真实标签,计算出一个数值。这个数值越小,说明模型的预测越准确。"""criterion = nn.CrossEntropyLoss()logging.info(f"*********************加载损失函数 衡量模型的预测结果与真实结果之间的差距")"""优化器 AdamW优化器 :优化器的作用是根据损失函数的值,调整模型的参数。它是模型的“教练”,帮助模型一步步改进,最终让损失值降到最低。@:param 需要优化的是self.csBotModule这个模型的所有参数。比如,模型中的权重、偏置等参数@:param lr=5e-5 每次调整的幅度是0.00005 目标是让损失值降到最低!"""optimizer = AdamW(self.csBotModule.parameters(), lr=5e-5)logging.info(f"*********************加载优化器 每次调整的幅度是0.00005")epochs = 10 # 增加训练轮数#定义训练数据dataList = [{"text": "如何查询我的订单状态?", "label": 0},{"text": "我可以取消订单吗?", "label": 1},{"text": "如何进行退货操作?", "label": 2},{"text": "我的订单在哪里?", "label": 0},{"text": "订单支付失败了怎么办?", "label": 1},{"text": "我的订单显示已发货,但还没收到。", "label": 2}]logging.info(f"*********************定义训练数据 {dataList}")logging.info(f"*********************开始数据预处理")input_ids, attention_masks, labels = self.preprocess_data(dataList, max_len=512)logging.info(f"*********************训练轮数为 {epochs} 轮。")for epoch in range(epochs):# 将模型设置为训练模式。在训练模式下,模型会启用Dropout等特性,并计算梯度用于反向传播logging.info(f"*********************进入训练模式")self.csBotModule.train()# 在每一轮训练开始时,我们需要清空优化器中的梯度。梯度就像是模型在“学习”过程中积累的“历史记录”,# 如果不清理干净,新的一轮学习就会被旧的数据干扰,导致训练效果变差。logging.info(f"*********************清空优化器中的梯度")optimizer.zero_grad()# 这里是将处理好的数据(input_ids和attention_masks)输入模型,模型会根据这些数据计算出预测值(outputs)。# 换句话说,模型试图通过这些输入数据来“猜”出正确答案。logging.info(f"*********************计算出预测值")outputs = self.csBotModule(input_ids, attention_masks)# 计算模型的损失值(loss)。criterion是损失函数,这里使用的是CrossEntropyLoss(交叉熵损失),# 它用于衡量模型的预测值(outputs)与实际标签(labels)之间的差异。损失值越小,说明模型的预测越接近真实值logging.info(f"*********************计算模型的损失值")loss = criterion(outputs, labels)# 进行反向传播,计算损失的梯度。这一步会从损失值开始,沿着模型的每一层,逐层计算各参数的梯度。#可以把它理解为模型在“反思”自己哪里做错了,并找出改进的方向logging.info(f"*********************进行反向传播")loss.backward()# 根据计算出的梯度,使用优化器(这里用的是AdamW)更新模型的参数,从而让模型在下一轮训练中表现得更好。logging.info(f"*********************优化器 更新模型的参数")optimizer.step()#这行代码是记录当前训练的状态。Epoch表示当前是第几轮训练,# Loss表示当前轮的损失值。通过这个信息,你可以观察模型的训练进展,看看损失值是否在逐渐减小logging.info((f"*********************Epoch {epoch + 1}, Loss: {loss.item()}"))# 检查目录是否存在,如果不存在则创建model_dir = "/Users/jiajiamao/soft/python/space/csBotModel/"os.makedirs(model_dir, exist_ok=True)# 保存模型model_path = os.path.join(model_dir, "cs_bot_model.pth")self.save_model(model_path)"""数据预处理分词和编码 1.分词后的文本被转换为词汇表中的索引(ID)input_ids[101,1963.......] 例如:['如', '何', '查', '询', '我', '的', '订', '单', '状', '态', '?']分词后,分词器会将每个分成的词转换为其对应的索引 例如: '如' 可能对应索引 101 2.生成注意力掩码(Attention Mask):attention_masks注意力掩码用于区分实际文本和填充部分。实际文本部分为1,填充部分为0。 便于能够区分有效数据和填充数据例如:[1,1,1,1,0,0,0,0] """def preprocess_data(self, dataList, max_len=512):logging.info("*****************开始分词和编码")input_ids = []attention_masks = []labels = []for data in dataList:encoded = self.tokenizer.encode_plus(data["text"],max_length=max_len,padding="max_length",truncation=True,return_attention_mask=True,return_tensors="pt")# 提取编码结果input_ids.append(encoded["input_ids"])attention_masks.append(encoded["attention_mask"])labels.append(data["label"])logging.info(f"*****************提取编码结果 input_ids: {len(input_ids)},attention_masks: {len(attention_masks)},labels: {len(labels)}")# 转换为张量 使用 torch.cat 将列表中的张量拼接成一个大的张量。input_ids = torch.cat(input_ids, dim=0)attention_masks = torch.cat(attention_masks, dim=0)labels = torch.tensor(labels)logging.info(f"*****************转换为张量 input_ids: {len(input_ids)},attention_masks: {len(attention_masks)},labels: {len(labels)}")return input_ids, attention_masks, labels"""保存模型"""def save_model(self, path):torch.save(self.csBotModule.state_dict(), path)"""# 加载模型"""def load_model(self, path):self.csBotModule.load_state_dict(torch.load(path))self.csBotModule.eval()"""模型接收到一段文本后,先将文本转换成它可以理解的形式,然后根据训练好的知识,预测这段文本属于哪个类别,最后把预测结果返回给用户。整个过程就像模型在“读”完你的输入后,告诉你它认为的最可能的答案。@:param text: 前端输入 text """def predict(self, text):self.csBotModule.eval()with torch.no_grad():"""@:param max_length=512:将文本的长度限制在512个词以内。@:param padding="max_length":如果文本不够长,用填充符补齐到512个词。@:param truncation=True:如果文本超过512个词,截断超出部分。@:param return_attention_mask=True:生成一个注意力掩码,告诉模型哪些部分是真实文本,哪些部分是填充符。@:param return_tensors="pt":将结果转换为PyTorch张量,便于输入模型。"""encoded = self.tokenizer.encode_plus(text,max_length=512,padding="max_length",truncation=True,return_attention_mask=True,return_tensors="pt")# 开始分词和编码input_ids = encoded["input_ids"]#这是注意力掩码,帮助模型区分真实文本和填充部分。attention_mask = encoded["attention_mask"]""" 将编码后的文本和注意力掩码输入模型,模型会给出预测结果(outputs),通常是一个概率分布,表示每个类别的可能性。然后从模型的输出中找到概率最大的类别。torch.max会返回两个值:最大值和最大值的索引。这里我们只需要索引predicted,它表示模型预测的类别编号。"""outputs = self.csBotModule(input_ids, attention_mask)_, predicted = torch.max(outputs, dim=1)return predicted.item()四、启动项目
#通过 daphne 启动应用
daphne icrplat.asgi:application五、测试
保存和加载模型 文件
# 涉及到的数据都是 模拟的,可以改成动态数据epochs = 10 # 增加训练轮数dataList = [{"text": "如何查询我的订单状态?", "label": 0},{"text": "我可以取消订单吗?", "label": 1},{"text": "如何进行退货操作?", "label": 2},{"text": "我的订单在哪里?", "label": 0},{"text": "订单支付失败了怎么办?", "label": 1},{"text": "我的订单显示已发货,但还没收到。", "label": 2}]#接口传入 》》如何进行退货操作?》》生成结果如下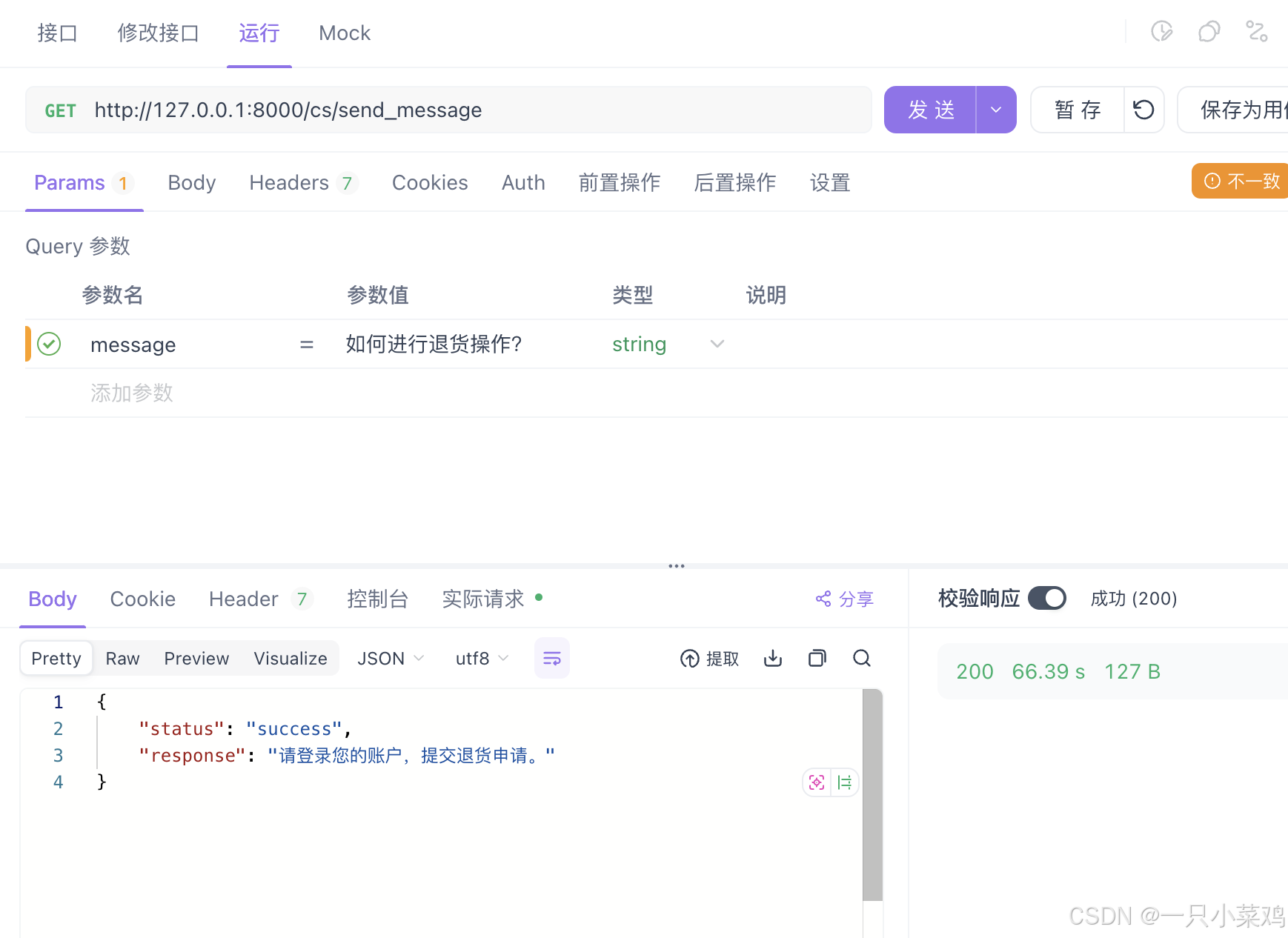
#接口传入 》》如何查询我的订单状态?》》生成结果如下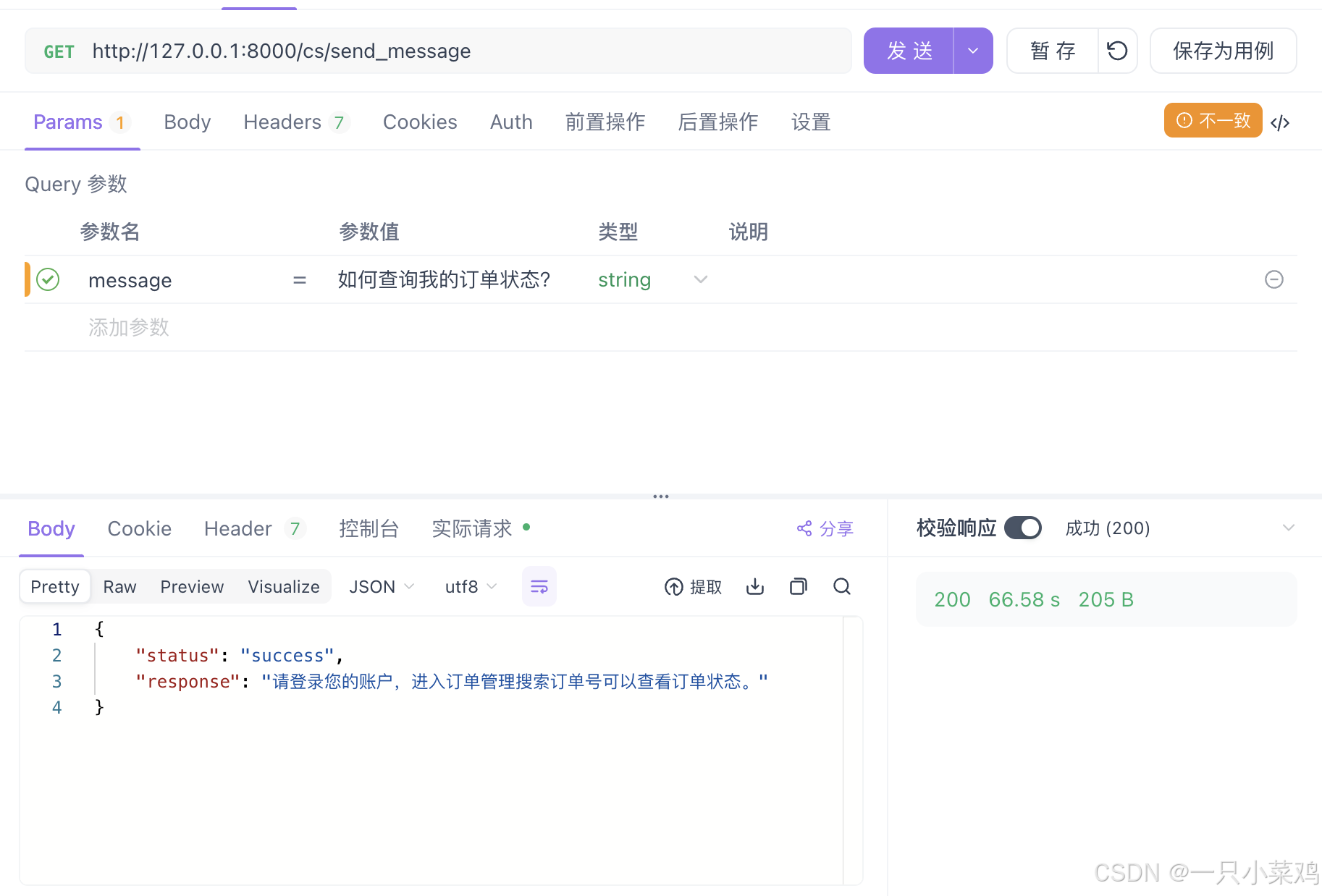
相关文章:
实现Django和Transformers 构建智能客服大模型(模拟订单系统)
一、环境安装准备 #git拉取 bert-base-chinese 文件#创建 虚拟运行环境python -m venv myicrplatenv#刷新source myicrplatenv/bin/activate#python Django 集成nacospip install nacos-sdk-python#安装 Djangopip3 install Django5.1#安装 pymysql settings.py 里面需要 # 强制…...

【沐渥科技】氮气柜日常如何维护?
氮气柜的维护是确保其长期稳定运行、延长使用寿命和保持环境控制精度的关键。以下是沐渥氮气柜的日常维护和定期保养指南: 一、日常维护 柜体清洁 定期用软布擦拭柜体表面和内部,避免灰尘堆积。避免使用腐蚀性清洁剂,防止损伤密封条或传感器。…...

数据安全之策:备份文件的重要性与自动化实践
在信息化高速发展的今天,数据已成为企业运营和个人生活中不可或缺的重要资源。无论是企业的财务报表、客户资料,还是个人的家庭照片、学习笔记,数据的丢失或损坏都可能带来无法挽回的损失。因此,备份文件的重要性日益凸显…...

windows下玩转vllm:vllm简介;Windows下不能直接装vllm;会报错ModuleNotFoundError: No module named ‘vllm._C‘
文章目录 -1. Windows下不能直接装vllm前言ollama vs vllmOllamavLLMvllm简介核心特点PagedAttention内存优化高效推理应用场景安装与使用-1. Windows下不能直接装vllm 我其实很久之前就意识到这个事儿,后来太久没搞就又忘了。 昨天忙活了半宿,得来的确实一个无法解决的报错…...

目录《Vue 3 + TypeScript + DeepSeek 全栈开发实战》
在快速迭代的软件开发世界里,技术的融合与创新始终是推动行业前行的不竭动力。今天,我们站在了前端技术与大数据搜索技术交汇的十字路口,手中的工具不再仅仅是编码的利器,更是解锁未来应用无限可能的钥匙。正是基于这样的时代背景…...

for...of的用法与介绍
一、定义 for...of 是 ES6(ECMAScript 2015)引入的一种用于 遍历可迭代对象(Iterable)的循环语句 二、语法 for (const item of iterable) {// 代码块 }参数: iterable:一个可迭代对象(如数组…...

快速使用PPASR V3版不能语音识别框架
前言 本文章主要介绍如何快速使用PPASR语音识别框架训练和推理,本文将致力于最简单的方式去介绍使用,如果使用更进阶功能,还需要从源码去看文档。仅需三行代码即可实现训练和推理。 源码地址:https://github.com/yeyupiaoling/P…...

Aliyun CTF 2025 web ezoj
文章目录 ezoj ezoj 进来一看是算法题,先做了试试看,gpt写了一个高效代码通过了 通过后没看见啥,根据页面底部提示去/source看到源代码,没啥思路,直接看wp吧,跟算法题没啥关系,关键是去看源码 def audit_checker(even…...

推理模型对SQL理解能力的评测:DeepSeek r1、GPT-4o、Kimi k1.5和Claude 3.7 Sonnet
引言 随着大型语言模型(LLMs)在技术领域的应用日益广泛,评估这些模型在特定技术任务上的能力变得越来越重要。本研究聚焦于四款领先的推理模型——DeepSeek r1、GPT-4o、Kimi k1.5和Claude 3.7 Sonnet在SQL理解与分析方面的能力,…...

【H2O2 | 软件开发】事件循环机制
目录 前言 开篇语 准备工作 正文 概念 流程 事件队列类型 示例 结束语 前言 开篇语 本系列为短篇,每次讲述少量知识点,无需一次性灌输太多的新知识点。该主题文章主要是围绕前端、全栈开发相关面试常见问题撰写的,希望对诸位有所帮…...
LVTTL(Low Voltage Transistor-Transistor Logic)电平详解
一、LVTTL电平的定义与核心特性 LVTTL(低压晶体管-晶体管逻辑)是传统TTL(5V)的低电压版本,工作电压通常为3.3V,旨在降低功耗并适配现代低电压集成电路,同时保持与TTL的逻辑兼容性。其核心特点如…...

Manus:成为AI Agent领域的标杆
一、引言 官网:Manus 随着人工智能技术的飞速发展,AI Agent(智能体)作为人工智能领域的重要分支,正逐渐从概念走向现实,并在各行各业展现出巨大的应用潜力。在众多AI Agent产品中,Manus以其独…...

批量测试IP和域名联通性
最近需要测试IP和域名的联通性,因数量很多,单个ping占用时间较长。考虑使用Python和Bat解决。考虑到依托的环境,Bat可以在Windows直接运行。所以直接Bat处理。 方法1 echo off for /f %%i in (E:\封禁IP\ipall.txt) do (ping %%i -n 1 &…...

网络安全之tcpdump工具
引言 wireshark是一款非常不错的抓包软件,在图形化界面占绝对统治地位;尽管其在字符界面下有些许选项可供使用,但终究不太方便,下面我再介绍一款NB的终端抓包工具 tcpdump 1、混杂模式 linux的网卡有混杂模式一说,当开…...

TMS320F28P550SJ9学习笔记8:I2C通信的结构体寄存器配置的了解
继续学习IIC通信的寄存器配置方式:尝试使用寄存器方式配置了解I2C a 没条件完整测试IIC功能,具体的修改与测试留在下文,这里只贴出全部代码,就不提供工程了 文章提供测试代码讲解、完整工程下载、测试效果图 目录 IIC通信引脚&a…...

TypeScript类:面向对象编程的基石
一、从现实世界到代码世界 想象你要建造一栋房子,首先需要一张设计蓝图——它定义了房屋的结构(几个房间)、功能(卧室/厨房)和特性(材料/颜色)。在TypeScript中,class就是这个设计蓝…...
自定义类型:结构体)
C语言学习笔记-进阶(10)自定义类型:结构体
1. 结构体类型的声明 前面我们在学习操作符的时候,已经学习了结构体的知识,这里稍微复习一下。 1.1 结构体回顾 结构是⼀些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。 1.1.1 结构体的声明 struct tag {member-…...
)
Java 大视界 -- Java 大数据在智能家居能源管理与节能优化中的应用(120)
💖亲爱的朋友们,热烈欢迎来到 青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而 我的博客 正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也…...
)
upload-labs-master通关攻略(9~12)
Pass-9 建立1.php <?php phpinfo();?> 上传时抓包 修改代码 在1.php后面加点号空格点号 放行后得到 Pass-10 将1.php放入 上传时抓包 修改代码 将1.php改为1.pphphp 上传后得到 Pass-11 将1.php改为1.png 上传时抓包 修改代码 ../upload/2.php%00 放行后得到 Pass…...
)
python语言总结(持续更新)
本文主要是总结各函数,简单的函数不会给予示例,如果在平日遇到一些新类型将会添加 基础知识 输入与输出 print([要输出的内容])输出函数 input([提示内容]如果输入提示内容会在交互界面显示,用以提示用户)输入函数 注释 # 单行注释符&…...

UI自动化测试 —— web端元素获取元素等待实践!
前言 Web UI自动化测试是一种软件测试方法,通过模拟用户行为,自动执行Web界面的各种操作,并验证操作结果是否符合预期,从而提高测试效率和准确性。 目的: 确保Web应用程序的界面在不同环境(如不同浏览器、操作系统)下…...

【CXX】6.6 UniquePtr<T> — std::unique_ptr<T>
std::unique_ptr 的 Rust 绑定称为 UniquePtr。有关 Rust API 的文档,请参见链接。 限制: 目前仅支持 std::unique_ptr<T, std::default_delete>。未来可能会支持自定义删除器。 UniquePtr 不支持 T 为不透明的 Rust 类型。对于在语言边界传递不…...

【网络协议安全】任务10:三层交换机配置
CSDN 原创主页:不羁https://blog.csdn.net/2303_76492156?typeblog三层交换机是指在OSI(开放系统互连)模型中的第三层网络层提供路由功能的交换机。它不仅具备二层交换机的交换功能,还能实现路由功能,提供更为灵活的网…...

C语言每日一练——day_4
引言 针对初学者,每日练习几个题,快速上手C语言。第四天。(连续更新中) 采用在线OJ的形式 什么是在线OJ? 在线判题系统(英语:Online Judge,缩写OJ)是一种在编程竞赛中用…...
 ─── linux第17课)
文件系统调用(上) ─── linux第17课
目录 linux 中man 2和man 3的区别 文件内容介绍 C语言文件接口 示例: 输出信息到显示器,你有哪些方法 总结: 系统文件I/O 文件类的系统调用接口介绍 示例 open 函数具体使用哪个,和具体应用场景相关, write read close lseek ,类比C文件相关接…...

在 Spring Boot 中实现基于 TraceId 的日志链路追踪
1 前言 1.1 什么是 TraceId? TraceId 是一个唯一的标识符,用于跟踪分布式系统中的请求。每个请求从客户端发起到服务端处理,再到可能的多个微服务调用,都会携带这个 TraceId,以便在整个请求链路中进行追踪和调试。 1.2 日志链路追踪的意义 日志链路追踪可以帮助开发者…...

STM32 HAL库 CAN过滤器配置
之前在STM32 f407 CAN收发 基于HAL库和Cubemx配置_stm32f407can收发程序-CSDN博客这篇博文里写了一下配置CAN收发的方法,当时由于并没有使用过滤器的现实需求,所以就也没仔细研究。现在工作中确实需要用到过滤器了,有些项目中控制器和发动机E…...

C++ 控制结构与函数全面解析
引言 在 C 编程中,控制结构和函数是构建程序逻辑的关键要素。控制结构能够决定程序的执行流程,而函数则可以将代码模块化,提高代码的复用性和可维护性。本文将深入介绍 C 中的控制结构和函数的相关知识。 一、控制结构 1. if - else 语句 …...
的钢材缺陷识别系统)
基于django+pytorch(Faster R-CNN)的钢材缺陷识别系统
一、训练数据来源以及数据标注 数据来源于阿里云天池实验室公开数据集中的铝型材缺陷检测数据集APDDD 数据标注通过labelme进行标注,图片所有标注以转化为矩形标注,存放成json格式。 二、模型训练方式及结果 缺陷识别模型基于Faster R-CNN ResNet5…...

C++多态
多态 多态分为:静态多态(函数重载,运算符重载)和动态多态(派生类、虚函数) 二者区别:静态多态是在地址编译时绑定,而动态多态是在地址运行时绑定 动态多态的特点: 1.有继承关系 2.子类重写父类虚函数(就是跟父类行为函数名称一样,但是是作为子类的行为) 动态多态的…...

【一句话经验】ubuntu vi/vim 模式自动设置为paste
从centos过来,发现ubutun有些地方不习惯,尤其是vi的粘贴,默认自动进去了代码模式,导致每次粘贴必须得set paste,否则会出现问题。 解决办法非常简单,按照下面命令执行即可: cd ~ echo "…...

MongoDB 触发器实现教程
在传统的关系型数据库(如 MySQL)中,触发器是一种强大的工具,它可以在特定的数据库操作(如插入、更新或删除)发生时自动执行一段代码。然而,MongoDB 并没有原生内置的触发器概念。不过࿰…...

ESP8266 NodeMCU 与 Atmega16 微控制器连接以发送电子邮件
NodeMCU ESP8266 AVR 微控制器 ATmega16 的接口 Atmega16 是一款低成本的 8 位微控制器,比以前版本的微控制器具有更多的 GPIO。它具有所有常用的通信协议,如 UART、USART、SPI 和 I2C。由于其广泛的社区支持和简单性,它在机器人、汽车和自动化行业有广泛的应用。 Atmega1…...
问题 C: 【递归入门】组合+判断素数)
《算法笔记》8.1小节——搜索专题->深度优先搜索(DFS)问题 C: 【递归入门】组合+判断素数
题目描述 已知 n 个整数b1,b2,…,bn 以及一个整数 k(k<n)。 从 n 个整数中任选 k 个整数相加,可分别得到一系列的和。 例如当 n4,k=3,4 个整数分别为 3,7,12…...
)
重生之我在学Vue--第8天 Vue 3 UI 框架(Element Plus)
重生之我在学Vue–第8天 Vue 3 UI 框架(Element Plus) 文章目录 重生之我在学Vue--第8天 Vue 3 UI 框架(Element Plus)前言一、Element Plus 基础:从安装到组件革命1.1 安装与两种引入模式全量引入(适合快速…...

从前端视角理解消息队列:核心问题与实战指南
消息队列(Message Queue)是现代分布式系统的核心组件之一,它在前后端协作、系统解耦、流量削峰等场景中发挥着重要作用。本文从前端开发者视角出发,解析消息队列的关键问题,并结合实际场景给出解决方案。 一、为什么要…...
配置参数说明)
Mysql配置文件My.cnf(my.ini)配置参数说明
一、my.cnf 配置文件路径:/etc/my.cnf,在调整了该文件内容后,需要重启mysql才可生效。 1、主要参数 basedir path # 使用给定目录作为根目录(安装目录)。 datadir path # 从给定目录读取数据库文件。 pid-file filename # 为mysq…...

Docker 安装成功后,安装 Dify 中文版本的步骤
Docker 安装成功后,安装 Dify 中文版本的步骤如下1: 克隆 Dify 代码仓库:在终端中执行以下命令,将 Dify 源代码克隆至本地环境。 bash git clone https://github.com/langgenius/dify.git进入 Dify 的 docker 目录: b…...
——响应相关)
Spring(4)——响应相关
一、返回静态页面 1.1**RestController和Controller** 想返回如下页面: 如果我们依旧使用原来的**RestController** 可以看到的是仅仅返回了字符串。 此时将**RestController改为Controller** 可以看到这次返回的是html页面。 那么**RestController和Controller…...

LPDDR5x电源使用Si电容对PI和PSIJ影响分析
SoC可能包含许多高速接口,其中LPDDR5X目前因为高带宽、低功耗、大容量等性能优势开始逐渐在AI计算、5G通信、视频处理等领域开始使用。LPDDR5X目前的速率高达8.533 GT/s,以及多个为这些接口供电的IO电压轨,而这些IO轨的PDN需要提供低阻抗&…...

[网络爬虫] 动态网页抓取 — Selenium 介绍 环境配置
🌟想系统化学习爬虫技术?看看这个:[数据抓取] Python 网络爬虫 - 学习手册-CSDN博客 0x01:Selenium 工具介绍 Selenium 是一个开源的便携式自动化测试工具。它最初是为网站自动化测试而开发的,类似于我们玩游戏用的按…...

MySQL数据库操作
目录 SQL语句 1、SQL的背景 2、SQL的概念 SQL的分类 SQL的书写规范 MySQL数据库 1、MySQL数据库的编码 (1)utf8和utf8mb4的区别 (2)MySQL的字符集 (3)MySQL默认编码为 latin1 ,如何更改…...

java之uniapp实现门店地图
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、后台实现1. 获取门店的经纬度2.api查询对应的sql 二 、小程序实现 前言 实现查询门店地址的功能,可以按照距离排序。使用技术:java…...

Git基本概念及使用
目录 一、git安装 二、git仓库基本概念 1. 远程仓库(Remote): 2. 本地库(Repository): 3. 分支(Branch): 4.本地库和远程库的关系 三、git仓库的工作流程 四、gi…...

游戏引擎学习第147天
仓库:https://gitee.com/mrxiao_com/2d_game_3 上一集回顾 具体来说,我们通过隐式计算来解决问题,而不是像数字微分分析器那样逐步增加数据。我们已经涵盖了这个部分,并计划继续处理音量问题。不过,实际上我们现在不需要继续处理…...

docker私有仓库配置
基于 harbor 构建docker私有仓库 1、机器准备 os:openEuler 、rockylinux mem:4G disk:100G 2、关闭防火墙、禁用SELinux 3、安装docker和docker-compose yum install docker-ce -y配置加速 vim /etc/docker/d…...

PostgreSQL 18新特性之虚拟生成列
PostgreSQL 12 提供了生成列(GENERATED ALWAYS AS STORED)功能,但是只能支持存储型的生成列,需要占用存储空间,更新成本高。 为此,PostgreSQL 18 即将引入一个新的增强:虚拟生成列。这种类型的…...

燃气对我们生活的重要性体现在哪里?
燃气在我们的生活中有 多方面的重要性 ,以下是燃气对我们生活的重要性的详细说明: 烹饪和热水供应 : 燃气是家庭烹饪的主要能源,能够快速、高效地加热食物,使家庭聚餐更加便捷和愉快。 燃气热水器能够在短时间内提供…...
)
简易分析 uni.chooseImage 拍照上传的基本知识点(附Demo)
目录 前言1. 基本知识2. Demo 前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 基本的介绍也可看官网:uni.chooseImage(options) 以下知识点主要用于学习了解,从实战中出发 1. 基本知识…...

私域流量时代的创新实践:以定制开发开源AI智能名片与S2B2C商城小程序源码为例的深度研究
摘要:在数字化转型的浪潮中,私域流量已成为企业获取用户、增强品牌影响力及实现销售转化的关键路径。本文首先概述了私域流量的概念及其重要性,随后通过分析故宫文创、B站跨年晚会及美妆品牌“完美日记”的成功案例,深入探讨了私域…...