DeepSeek开源周 Day01:从FlashMLA背后原理回顾KV Cache
FlashMLA
今天DeepSeek开源周第一天,开放了FlashMLA仓库,1小时内星标1.6k!

FlashMLA 是一个高效的 MLA 解码内核,专为 Hopper GPU 优化,适用于可变长度序列。该项目目前发布了 BF16 和具有 64 块大小分页 kvcache 的功能。在 H800 SXM5 上,使用 CUDA 12.6,内存受限配置下可达 3000 GB/s,计算受限配置下可达 580 TFLOPS。
Github仓库地址:https://github.com/deepseek-ai/FlashMLA
这里提到两个比较关键的功能就是BF16精度计算以及Paged kvcache缓存技术
好巧不巧,近期DeepSeek 发布了一篇新论文,提出了一种改进版的注意力机制 NSA,即Native Sparse Attention,可以直译为「原生稀疏注意力」;但其实就在同一天,月之暗面也发布了一篇主题类似的论文,提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。注意机制最近这么火爆的背景下,不妨我们趁机复习下Kv Cache相关概念以及相关注意力机制模型。
KV Cache简介
这部分主要参考LLM推理算法简述,可以快速回顾下KV Cache概念,关于更多LLM推理算法讲解大家可以阅读https://zhuanlan.zhihu.com/p/685794495。
LLM 推理服务的吞吐量指标主要受制于显存限制。研究团队发现现有系统由于缺乏精细的显存管理方法而浪费了 60% 至 80% 的显存,浪费的显存主要来自 KV Cache。因此,有效管理 KV Cache 是一个重大挑战。
什么是KV Cache?
Transformer 模型具有自回归推理的特点,即每次推理只会预测输出一个 token,当前轮输出 token 与历史输入 tokens 拼接,作为下一轮的输入 tokens,反复执行多次。该过程中,前后两轮的输入只相差一个 token,存在重复计算。KV Cache 技术实现了将可复用的键值向量结果保存下来,从而避免了重复计算。如下图所示,展示了有无 kv cache 的流程:
- Without KV Cache 每次需要计算全 Wq(X), Wk(X), Wv(X),每次需要计算全量 Attn
- With KV Cache,第一步计算完整 A t t n Attn Attn,将 K V KV KV 保存成 K V _ c a c h e KV\_cache KV_cache
- With KV Cache,第二步,取第二步的 Next Token 计算 Q K V QKV QKV,将 [ K V _ c a c h e , K V ] [KV\_cache, KV] [KV_cache,KV] 联合,计算出 Q K V QKV QKV
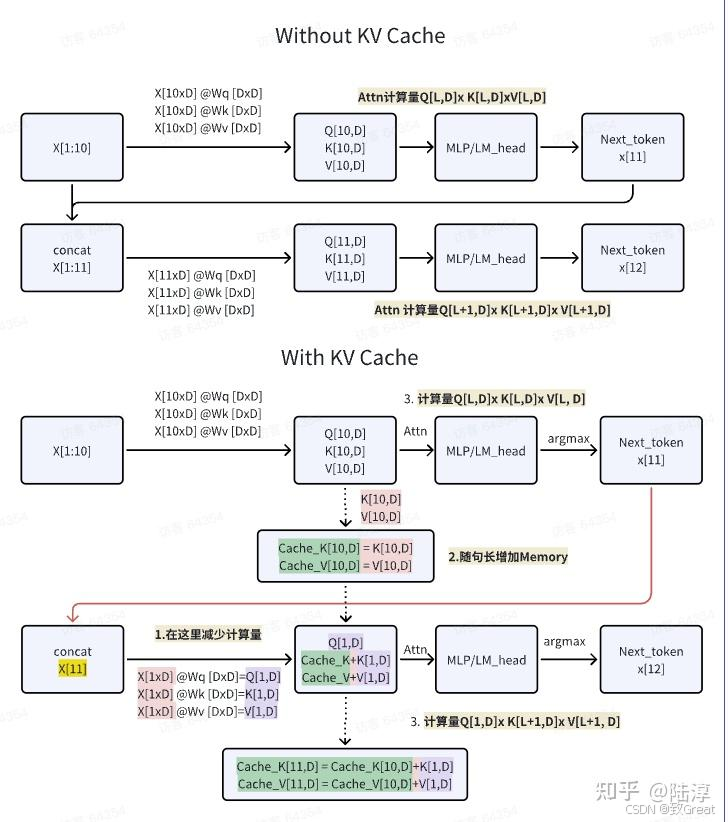
图片来源:陆淳,https://zhuanlan.zhihu.com/p/685794495
如何优化KV cahce?
KV cache的峰值显存占用大小计算公式:2 x Length x batch_size x [d x n_kv_heads] x Layers x k-bits,由此我们可以看出影响KV cache的具体因素:
- k-bits: 数据类型,FP16 占2个bytes。(量化)
- 2: 代表 Key/Value 两个向量现
- Length: 输入输出序列的长度(循环队列管理窗口KV,减少长度kv)
- Layers:模型层数
- d x n_kv_heads:kv维度(MQA/GQA通过减少KV的头数减少显存占用)
- batch_size : KV Cache 与 batchsize 度呈线性关系,随着 batch size 的增大,KV cache 占用的显存开销快速增大,甚至会超过模型本身。
- 操作系统管理:现GPU的KV Cache的有效存储率较低低 (page-attention)

在bf16格式下的13B模型中,我们只有大约10G的空间来存储kv cache。
KV Cache 的引入也使得推理过程分为如下两个不同阶段,进而影响到后续的其他优化方法。
-
预填充阶段 (Prefill):发生在计算第一个输出 token 过程中,计算时需要为每个 Transformer layer 计算并保存 key cache 和 value cache;FLOPs 同 KV Cache 一致,存在大量 GEMM (GEneral Matrix-Matrix multiply) 操作,属于 Compute-bound 类型计算。
-
解码阶段 (Decoder):发生在计算第二个输出 token 至最后一个 token 过程中,这时 KV Cache 已存有历史键值结果,每轮推理只需读取 KV Cache,同时将当前轮计算出的新 Key、Value 追加写入至 Cache;GEMM 变为 GEMV (GEneral Matrix-Vector multiply) 操作,FLOPs 降低,推理速度相对预填充阶段变快,这时属于 Memory-bound 类型计算。
解码中的KV Cache
我们下面用一个例子更加详细的解释什么是KV Cache,了解一些背景的计算问题,以及KV Cache的概念。
无论是encoder-decoder结构,还是现在我们最接近AGI的decoder-only的LLM,解码生成时都是自回归auto-regressive的方式。也就是说,解码的时候,先根据当前输入 i n p u t i − 1 input_{i-1} inputi−1,生成下一个token,然后把生成的token拼接在 i n p u t i − 1 input_{i-1} inputi−1 后面,获得新的输入 i n p u t i input_i inputi,再用 i n p u t i input_i inputi 生成 t o k e n i + 1 token_{i+1} tokeni+1,依此选择,直到生成结果。
比如我们输入“窗前明月光下一句是”,那么模型每次生成一个token,输入输出会是这样(方便起见,默认每个token都是一个字符)
step0: 输入=[BOS]窗前明月光下一句是;输出=疑
step1: 输入=[BOS]窗前明月光下一句是疑;输出=是
step2: 输入=[BOS]窗前明月光下一句是疑是;输出=地
step3: 输入=[BOS]窗前明月光下一句是疑是地;输出=上
step4: 输入=[BOS]窗前明月光下一句是疑是地上;输出=霜
step5: 输入=[BOS]窗前明月光下一句是疑是地上霜;输出=[EOS]
(其中[BOS]和[EOS]分别是开始和结束的标记字符)
我们看一下在计算的过程中,如何输入的token “是” 的最后是hidden state如何传递到后面的类Token预测模型,以及后面每一个token,使用新的输入列中最后一个时刻的输出。
我们可以看到,在每一个step的计算中,主要包含了上一轮step的内容,而且只在最后一步使用(一个token)。那么每一个计算也就包含了上一轮step的计算内容。
从公式来看是这样的,回想一下我们attention的计算:
α i , j = softmax ( q i k j T ) \alpha_{i,j} = \text{softmax}(q_i k_j^T) αi,j=softmax(qikjT)
o i = ∑ j = 0 i α i , j v i j o_i = \sum_{j=0}^{i} \alpha_{i,j} v_{ij} oi=j=0∑iαi,jvij
注意对于decoder的时候,由于mask attention的存在,每个输入只能看到自己和前面的内容,而看不到后面的内容。
假设我们当前输入的长度是3,预测第4个字,那么每层attention所做的计算有:
o 0 = α 0 , 0 v 0 o_0 = \alpha_0,0 v_0 o0=α0,0v0
o 1 = α 1 , 0 v 0 + α 1 , 1 v 1 o_1 = \alpha_{1,0} v_0 + \alpha_{1,1} v_1 o1=α1,0v0+α1,1v1
o 2 = α 2 , 0 v 0 + α 2 , 1 v 1 + α 2 , 2 v 2 o_2 = \alpha_{2,0} v_0 + \alpha_{2,1} v_1 + \alpha_{2,2 }v_2 o2=α2,0v0+α2,1v1+α2,2v2
预测完第4个字,放到输入里,继续预测第5个字,每层attention所做的计算有:
o 0 = α 0 , 0 v 0 o_0 = \alpha_{0,0} v_0 o0=α0,0v0
o 1 = α 1 , 0 v 0 + α 1 , 1 v 1 o_1 = \alpha_{1,0} v_0 + \alpha_{1,1} v_1 o1=α1,0v0+α1,1v1
o 2 = α 2 , 0 v 0 + α 2 , 1 v 1 + α 2 , 2 v 2 o_2 = \alpha_{2,0} v_0 + \alpha_{2,1} v_1 + \alpha_{2,2}v_2 o2=α2,0v0+α2,1v1+α2,2v2
可以看到,在预测第5个字时,只有最后一步引入了新的计算,而 o 0 o_0 o0 到 o 2 o_2 o2 的计算部分是完全重复的。
但是模型在推理的时候可不管这些,无论你是否只是要最后一个字的输出,它都会把所有输入计算一遍,给出所有输出结果。
也就是说中间有很多我们不需要的计算,这样就造成了浪费。
而且随着生成的结果越来越多,输入的长度也越来越长,上面这个例子里,输入长度是step0的10个, 每步骤,直接step5到15个。如果输入的instruction是规范型任务,那么可能有800个step。这个情况下,step0就变得有800次,step1被重复了799次——这样浪费的计算资源显然不可忍受。
有没有什么方法可以重利用上一个step里已经计算过的结果,减少浪费呢?
答案就是KV Cache,利用一个缓存,把需要重复利用的时序计算结果保存下来,减少重复计算。
而 K K K 和 V V V 就是需要保存的对象。
想一想,下图就是缓存的过程,假设我们第一次输入的输入长度是3个,我们第一次预测输出预测第4个字,那么由于下图给你看的是每个输入步骤的缓存,每个时序步骤都需要存储一次,而我们依旧会有些重复计算的情况。则有:

kv_cache下标l表示模型层数。在进行第二次预测时,也就是预测第5个字的时候,在第l层的时候,由于前面我们缓存了每层的 k k k, v v v值,那层就不需要算新的 o 3 o_3 o3,而不再算 o 1 o_1 o1, o 2 o_2 o2。因为第l层的 o 0 o_0 o0, o 1 o_1 o1 本来经过FFN层之后进到 l + 1 l+1 l+1层,再经过新的投影变换,成为 l + 1 l+1 l+1层的 k k k, v v v值,但是是 l + 1 l+1 l+1层的 k k k, v v v值就已经保留了!
然后我们把本次新算出来的 k k k, v v v值也存储起来。
c a c h e 1 = [ ( k 0 , v 0 ) , ( k 1 , v 1 ) ] cache_1 = \left[ (k_0, v_0), (k_1, v_1) \right] cache1=[(k0,v0),(k1,v1)]
c a c h e 2 = [ ( k 0 , v 0 ) , ( k 1 , v 1 ) , ( k 2 , v 2 ) ] cache_2 = \left[ (k_0, v_0), (k_1, v_1), (k_2, v_2) \right] cache2=[(k0,v0),(k1,v1),(k2,v2)]
然后我们再做下一次计算出的结果:
c a c h e 3 = [ ( k 0 , v 0 ) , ( k 1 , v 1 ) , ( k 2 , v 2 ) , ( k 3 , v 3 ) ] cache_3 = \left[ (k_0, v_0), (k_1, v_1), (k_2, v_2), (k_3, v_3) \right] cache3=[(k0,v0),(k1,v1),(k2,v2),(k3,v3)]
这样就节省了attention和FFN的很多重复计算。
transformers中,生成的时候传入use_cache=True就会开启KV Cache。
也可以简单看下GPT2中的实现,中文注释的部分就是使用缓存结果和更新缓存结果
Class GPT2Attention(nn.Module):......def forward(self,hidden_states: Optional[Tuple[torch.FloatTensor]],layer_past: Optional[Tuple[torch.Tensor]] = None,attention_mask: Optional[torch.FloatTensor] = None,head_mask: Optional[torch.FloatTensor] = None,encoder_hidden_states: Optional[torch.Tensor] = None,encoder_attention_mask: Optional[torch.FloatTensor] = None,use_cache: Optional[bool] = False,output_attentions: Optional[bool] = False,) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:if encoder_hidden_states is not None:if not hasattr(self, "q_attn"):raise ValueError("If class is used as cross attention, the weights `q_attn` have to be defined. ""Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`.")query = self.q_attn(hidden_states)key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)attention_mask = encoder_attention_maskelse:query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)query = self._split_heads(query, self.num_heads, self.head_dim)key = self._split_heads(key, self.num_heads, self.head_dim)value = self._split_heads(value, self.num_heads, self.head_dim)# 过去所存的值if layer_past is not None:past_key, past_value = layer_pastkey = torch.cat((past_key, key), dim=-2) # 把当前新的key加入value = torch.cat((past_value, value), dim=-2) # 把当前新的value加入if use_cache is True:present = (key, value) # 输出用于保存else:present = Noneif self.reorder_and_upcast_attn:attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)else:attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)attn_output = self.c_proj(attn_output)attn_output = self.resid_dropout(attn_output)outputs = (attn_output, present)if output_attentions:outputs += (attn_weights,)return outputs # a, present, (attentions)
总的来说,KV Cache是以空间换时间的做法,通过使用快速的缓存存储,减少了重复计算。(注意,只能在decoder结构的模型可用,因为有mask attention的存在,使得前面的token可以不用关照后面的token)
但是,用了KV Cache之后也不是立刻万事大吉。
我们简单计算一下,对于输入长度为 L L L,层数为 L L L,hidden size为 d d d的模型,需要缓存的参数量为
2 × L × s × d 2 \times L \times s \times d 2×L×s×d
如果使用的是半精度浮点数,那么每个值所需要的空间就是
2 × 2 × L × s × d 2 \times 2 \times L \times s \times d 2×2×L×s×d
以Llama2 7B为例,有 L = 32 L = 32 L=32, L = 4096 L = 4096 L=4096,那么每个token所需的缓存空间就是524,288 bytes,约524k,假设 s = 1024 s = 1024 s=1024,则需要占用536,870,912 bytes,超过500M的空间。
这些参数的大小是batch size=1的情况,如果batch size增大,这个值是很容易就超过1G。
注意力相关模型
笔者之前回顾了一些注意力机制相关模型:从MHA、MQA、GQA、MLA到NSA、MoBA,写了下面一篇文章来解读这些注意力模型,
注意力机制进化史:从MHA到MoBA,新一代注意力机制的极限突破!
这里为了节约篇幅,只提一下模型简介,具体原理可以阅读上面综述。
MHA:Multi-Head Attention
论文标题:Attention Is All You Need
论文链接:https://arxiv.org/pdf/1706.03762
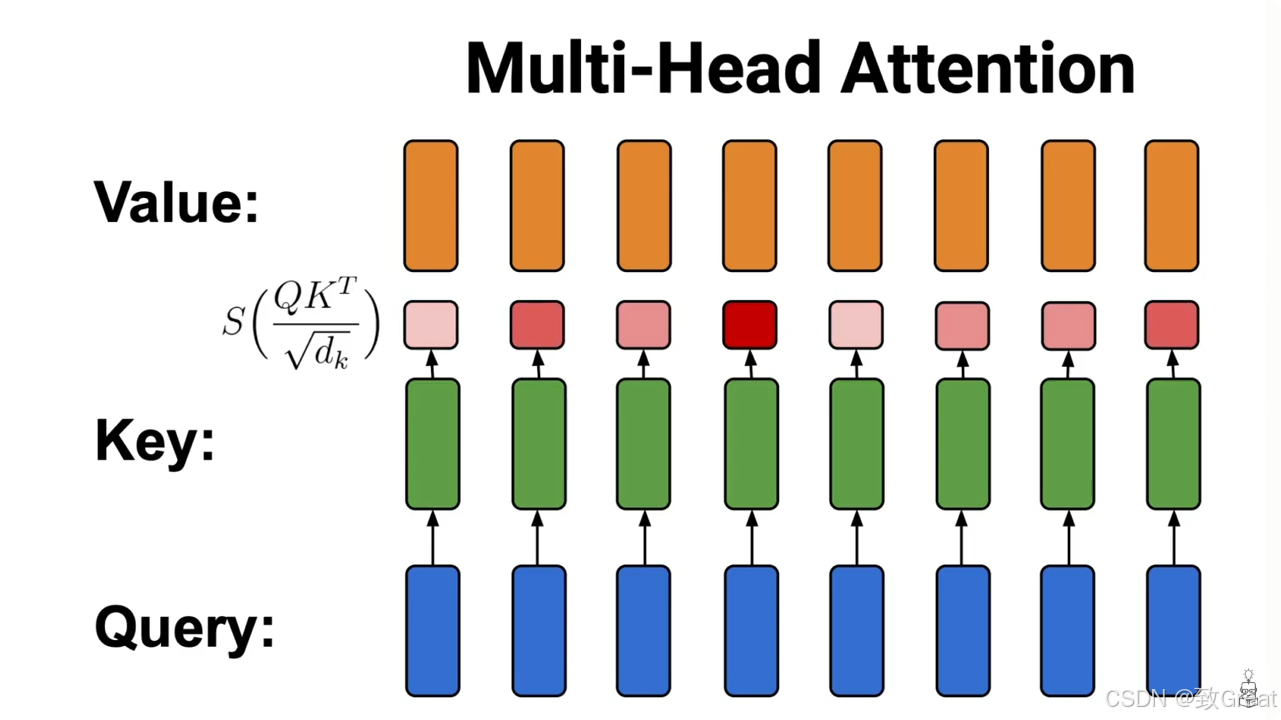
MHA在2017年就随着《Attention Is All You Need》一起提出,主要干的就是一个事:把原来一个attention计算,拆成多个小份的attention,并行计算,分别得出结果,最后再合回原来的维度。

MQA:Multi-Query Attention
论文标题:Fast Transformer Decoding: One Write-Head is All You Need
论文链接:https://arxiv.org/pdf/1911.02150
MQA就是减少所有所需要的键值缓存内存消耗的。
Google在2019年就提出了《Fast Transformer Decoding: One Write-Head is All You Need》提出了MQA,不过那时候主要是针对的人不多,那是大家主要还是关注在用Bert也开始创新上。
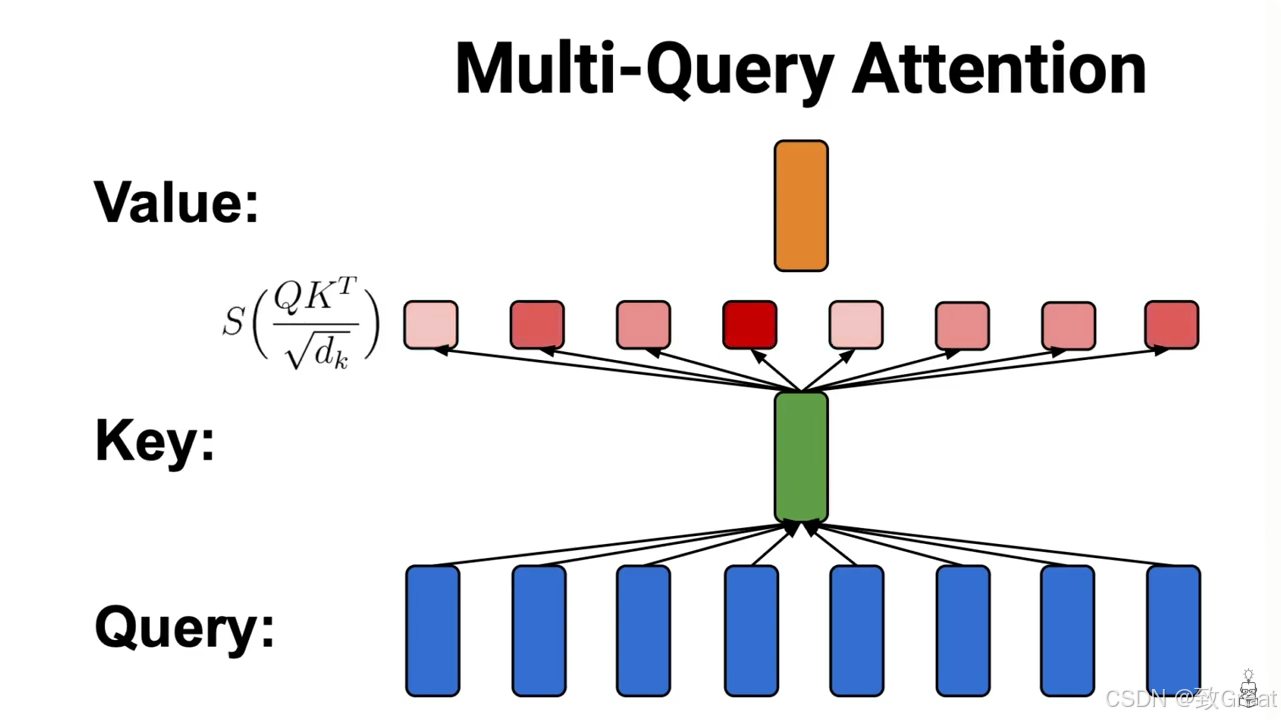
MQA的做法其实很简单。在MHA中,输入分别经过 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV的变换之后,都切成 8 8 8份( n n n=头数),维度也从 d m o d e l d_{model} dmodel降到 d h e a d d_{head} dhead,分别进行attention计算再拼接。而MQA这一步,在运算过程中,首先对 Q Q Q进行切分(和MHA一样),而 K , V K, V K,V则直接在在线变换的时候把维度压到 d h e a d d_{head} dhead(而不是切分开),然后返回每个Query头分别和一份 K , V K, V K,V进行attention计算,之后最终结果拼接起来。
简而言之,就是MHA中,每个注意力头的 K , V K, V K,V是不一样的,而MQA这里,每个注意力头的 K , V K, V K,V是一样的,值是共享的。而性别效果和MHA一样。
GQA:Grouped Query Attention
论文标题:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
论文链接:https://arxiv.org/pdf/2305.13245
既然MQA对效果有点影响,MHA存储又有不下,那2023年GQA(Grouped-Query Attention)就提出了一个折中的办法,既能减少MQA效果的损失,又相比MHA需要更少的存储。
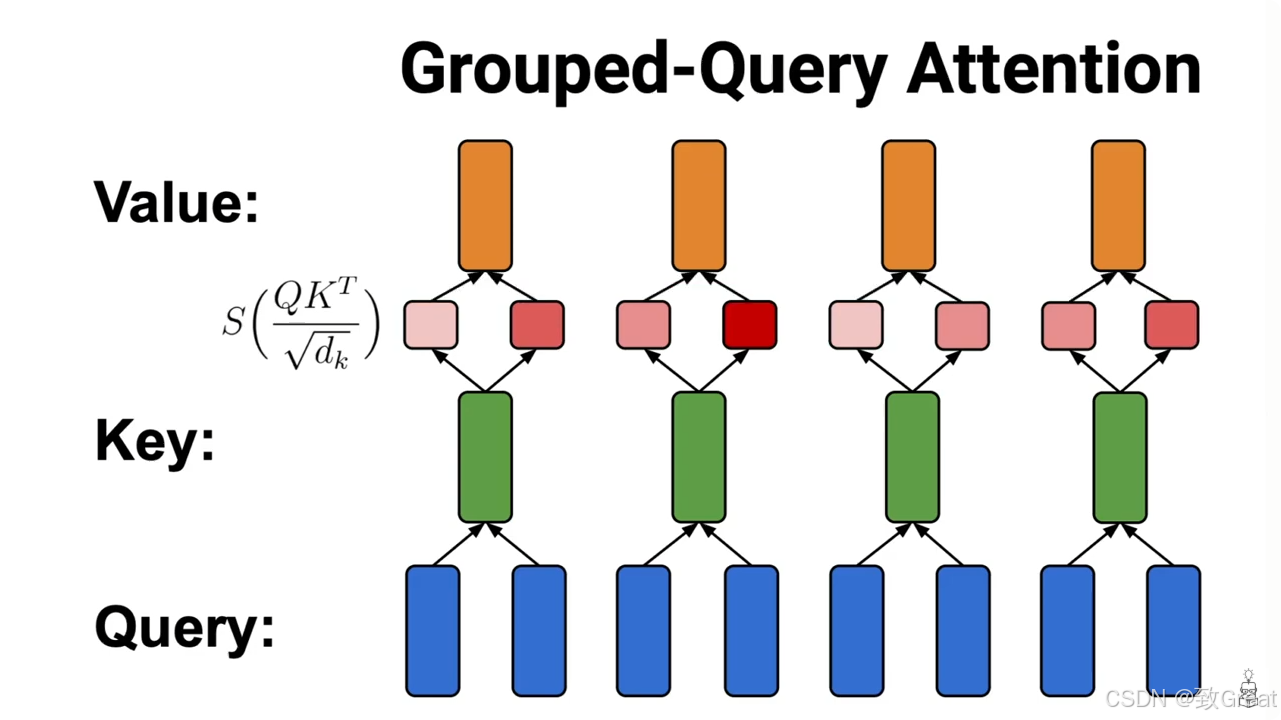
GQA是, Q Q Q 还是按原来MHA/MQA的做法不变。只使用一套共享的 K , V K, V K,V就能效果不好吗,那就还是多个头。但是要不要太多,数量还是比 Q Q Q的头数少一些,这样相当于把多个头分成group,同一个group内的 K , V K, V K,V共享,同不group的 Q Q Q所用的 K , V K, V K,V不同。
MHA可以认为是 K , V K, V K,V头数最大时的GQA(有几个Q就有几个K,V),而MQA可以认为是 K , V K, V K,V头数最少时的GQA(K的头数只有1个)。
MLA:Multi-head Latent Attention
论文标题:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
论文链接:https://arxiv.org/abs/2405.04434
MLA(Memory-efficient Latent Attention) 的核心思想是将注意力输入 h t h_t ht 压缩到一个低维的潜在向量,记作 c t K V c^{KV}_t ctKV,其维度 d c d_c dc 远小于原始的 h n ⋅ d h h_n \cdot d_h hn⋅dh 维度。这样,在计算注意力时,我们可以通过映射将该潜在向量恢复到高维空间,以重构键(keys)和值(values)。这种方法的优势在于,只需存储低维的潜在向量,从而大幅减少内存占用。

这一过程可以用以下公式描述:
- c t K V c^{KV}_t ctKV 是低维的潜在向量。
- W D K V W^{DKV} WDKV 是一个压缩矩阵(down-projection matrix),用于将 h t h_t ht 的维度从 h n ⋅ d h h_n \cdot d_h hn⋅dh 降维到 d c d_c dc(其中 D 代表“降维”)。
- W U K W^{UK} WUK 和 W U V W^{UV} WUV 是两个向上投影矩阵(up-projection matrices),分别用于将共享的潜在向量映射回高维空间,以恢复键(K)和值(V)。
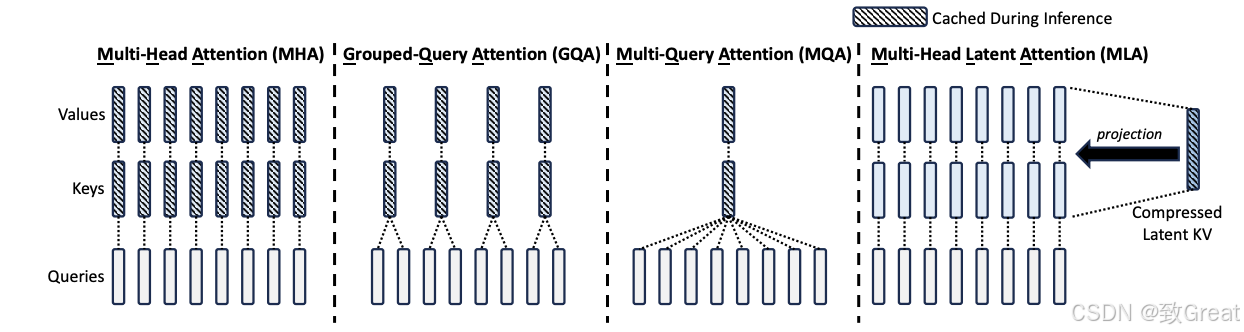
多头注意力(MHA)、分组查询注意力(GQA)、多查询注意力(MQA)和多头潜在注意力(MLA)的简化示意图。通过将键(keys)和值(values)联合压缩到一个潜在向量中,MLA在推理过程中显著减少了KV缓存的大小。
NSA:Native Sparse Attention
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
论文地址:https://arxiv.org/abs/2502.11089
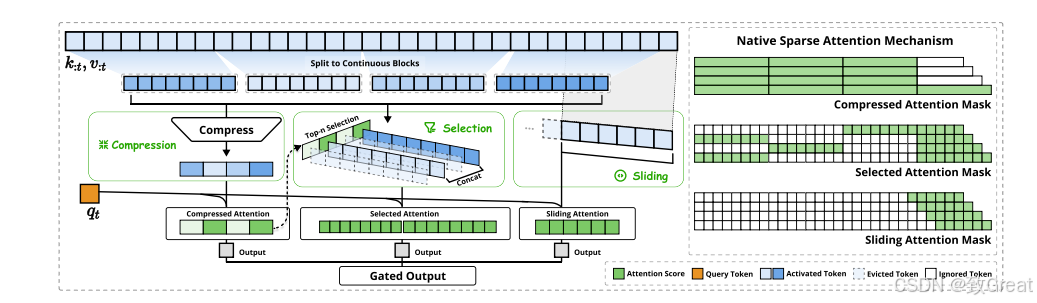
NSA的技术方法涵盖算法设计与内核优化。其整体框架基于对注意力机制的重新定义,通过设计不同的映射策略构建更紧凑、信息更密集的键值对表示,以减少计算量。同时,针对硬件特性进行内核优化,提升实际运行效率。
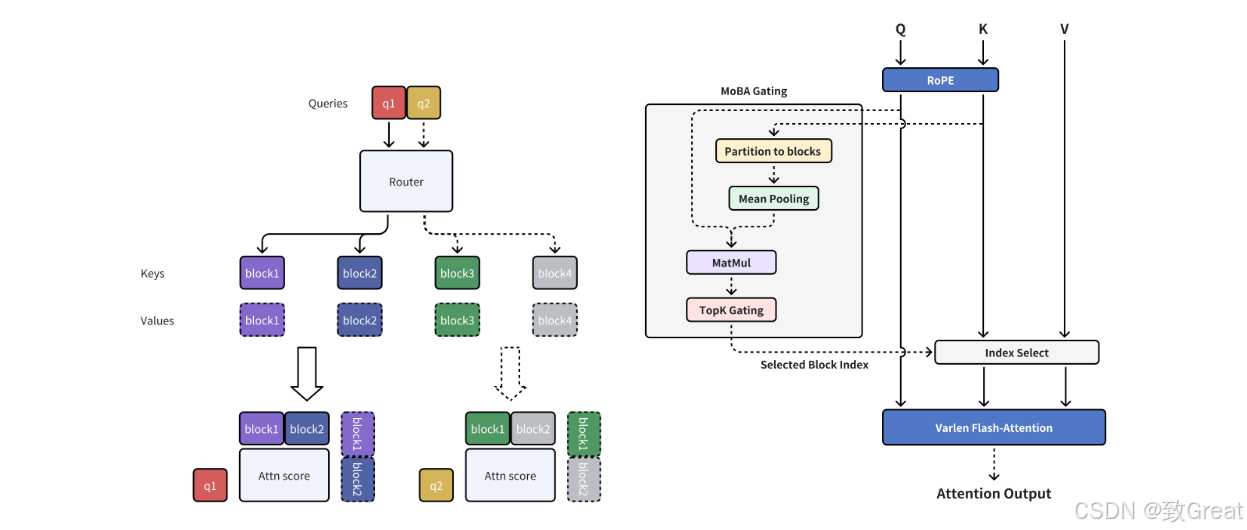
MoBA: Mixture of Block Attention for Long-Context LLMs
论文标题:Mixture of Block Attention for Long-Context LLMs
论文地址:https://github.com/MoonshotAI/MoBA/blob/master/MoBA_Tech_Report.pdf
它基于MoE原理,应用于Transformer模型的注意力机制,通过将上下文划分为块,并采用门控机制选择性地将查询令牌路由到最相关的块,提高LLMs效率,使模型能处理更长更复杂的提示,同时降低资源消耗。
Page Attention
论文标题:Efficient Memory Management for Large Language
Model Serving with PagedAttention
论文地址:https://arxiv.org/pdf/2309.06180
在 vLLM 库中 LLM 服务的性能受到内存瓶颈的影响。在自回归 decoder 中,所有输入到 LLM 的 token 会产生注意力 key 和 value 的张量,这些张量保存在 GPU 显存中以生成下一个 token。这些缓存 key 和 value 的张量通常被称为 KV cache,其具有以下特点:
- 显存占用大:在 LLaMA-13B 中,缓存单个序列最多需要 1.7GB 显存;
- 动态变化:KV 缓存的大小取决于序列长度,这是高度可变和不可预测的。因此,这对有效管理 KV cache 挑战较大。该研究发现,由于碎片化和过度保留,现有系统浪费了 60% - 80% 的显存。
为了解决这个问题,该研究引入了 PagedAttention,这是一种受操作系统中虚拟内存和分页经典思想启发的注意力算法。与传统的注意力算法不同,PagedAttention 允许在非连续的内存空间中存储连续的 key 和 value 。具体来说,PagedAttention 将每个序列的 KV cache 划分为块,每个块包含固定数量 token 的键和值。在注意力计算期间,PagedAttention 内核可以有效地识别和获取这些块。
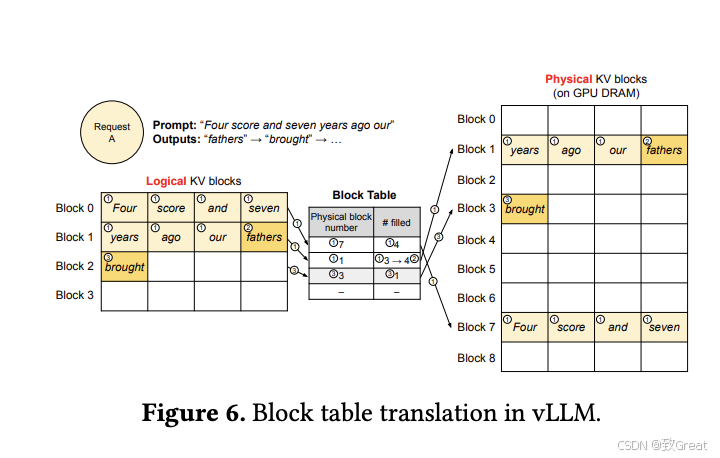
https://arxiv.org/pdf/2309.06180
具体来讲,Paged Attention 将每个序列的 KV Cache 分成若干块,每个块包含固定数量token 的键和值。在注意力计算期间,PagedAttention 内核可以有效地识别和获取这些块。因为块在内存中不需要连续,因而可以用一种更加灵活的方式管理 key 和 value ,就像在操作系统的虚拟内存中一样:可以将块视为页面,将 token 视为字节,将序列视为进程。序列的连续逻辑块通过块表映射到非连续物理块中。物理块在生成新 token 时按需分配。在 PagedAttention 中,内存浪费只会发生在序列的最后一个块中。这使得在实践中可以实现接近最佳的内存使用,仅浪费不到 4%。
FlashAttention
论文标题:FlashAttention: Fast and Memory-Efficient Exact Attention
with IO-Awareness
论文地址:https://arxiv.org/pdf/2205.14135
此前针对Transformer类模型的优化工作致力于减少FLOP从而优化计算速度,忽略了显存IO访问上的优化。
attention计算所带来的O(n^2)复杂度的矩阵对HBM的重复读写是制约模型推理的一个主要瓶颈。
如下图所示GPU SRAM的读写(I/O)的速度为19TB/s 和GPU HBM 的读写(I/O)速度 1.5TB/s 相差十几倍,而对比存储容量也相差了好几个数量级。从图中可以看出Flash Attention的计算是从HBM中读取块,在SRAM中计算之后再写到HBM中。
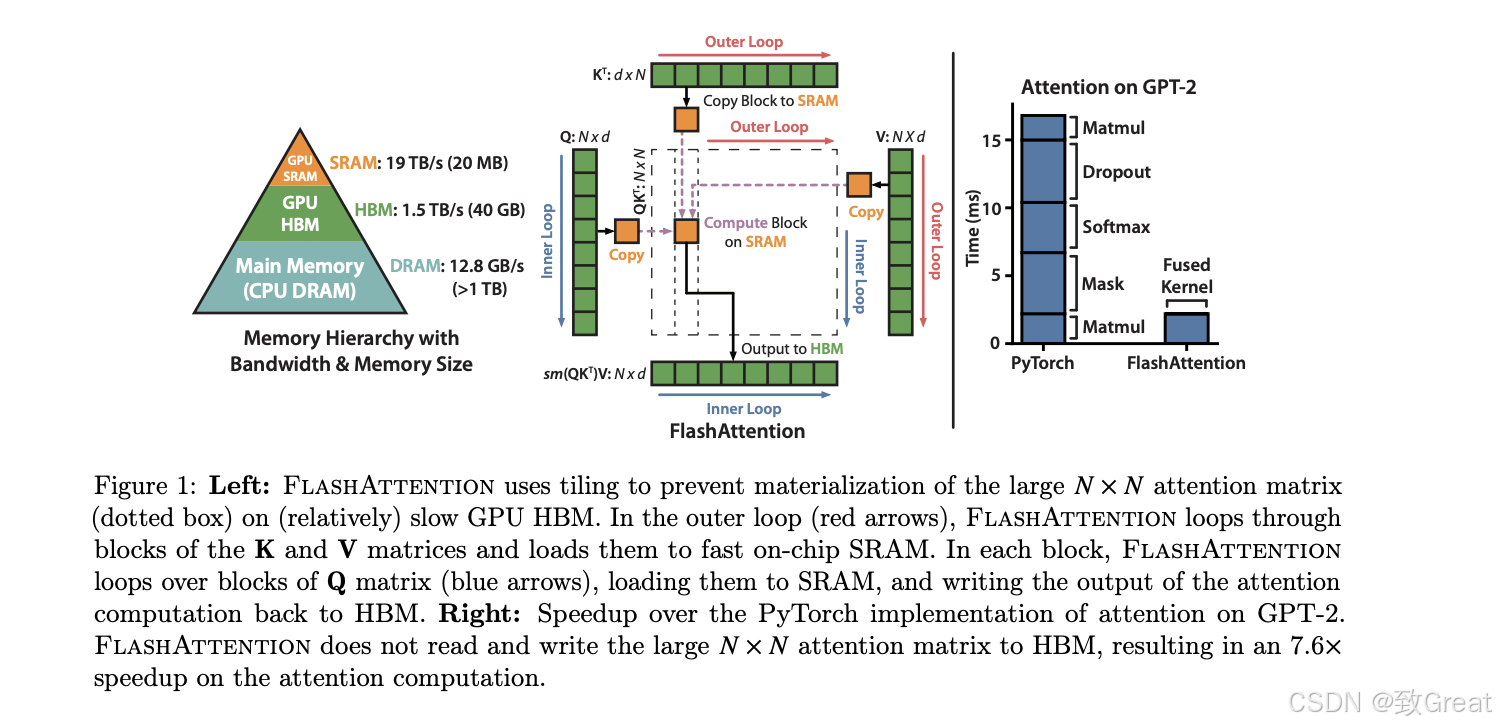
要解决这些问题,需要做两件主要的事情:
- 在不访问整个输入的情况下计算 softmax
- 不为反向传播存储大的中间 attention 矩阵
为此 FlashAttention 提出了两种方法来分布解决上述问题:tiling 和 recomputation。
- tiling - 注意力计算被重新构造,将输入分割成块,并通过在输入块上进行多次传递来递增地执行softmax操作。
- recomputation - 存储来自前向的 softmax 归一化因子,以便在反向中快速重新计算芯片上的 attention,这比从HBM读取中间矩阵的标准注意力方法更快。
由于重新计算,这虽然导致FLOPS增加,但是由于大量减少HBM访问,FlashAttention运行速度更快。该算法背后的主要思想是分割输入,将它们从慢速HBM加载到快速SRAM,然后计算这些块的 attention 输出。在将每个块的输出相加之前,将其按正确的归一化因子进行缩放,从而得到正确的结果。
参考资料
- LLM(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能
- LLM推理算法简述
相关文章:

DeepSeek开源周 Day01:从FlashMLA背后原理回顾KV Cache
FlashMLA 今天DeepSeek开源周第一天,开放了FlashMLA仓库,1小时内星标1.6k! FlashMLA 是一个高效的 MLA 解码内核,专为 Hopper GPU 优化,适用于可变长度序列。该项目目前发布了 BF16 和具有 64 块大小分页 kvcache 的功…...

java23种设计模式-工厂方法模式
工厂方法模式(Factory Method Pattern)学习笔记 🌟 定义 工厂方法模式属于创建型设计模式,定义一个创建对象的接口,但让子类决定实例化哪一个类。将类的实例化操作延迟到子类,是面向对象设计中"开闭…...

数据驱动未来!天合光能与永洪科技携手开启数字化新篇章
在信息化时代的今天,企业间的竞争早就超越了传统产品与服务的范畴,新的核心竞争力即——数据处理能力和信息技术的应用。作为数据技术领域的领军者,永洪科技凭借其深厚的技术积累和丰富的行业经验,成功助力天合光能实现数字化升级…...

【C++设计模式】工厂方法设计模式:深入解析从基础到进阶
1. 引言 在软件开发的世界里,设计模式如同巧妙的建筑蓝图,为解决常见问题提供了行之有效的方案。工厂方法模式作为一种广受欢迎的创建型设计模式,以其独特的优势在众多项目中得到广泛应用。它不仅能够为对象的创建提供通用且灵活的方式,还能有效隐藏实现细节,提升代码的可…...

Vue 3 + Vite 项目中配置代理解决开发环境中跨域请求问题
在 Vue 3 Vite 项目中,配置代理是解决开发环境中跨域请求问题的常见方法。通过在 Vite 的配置文件中设置代理,可以将前端请求转发到后端服务器,从而避免浏览器的同源策略限制。 1. 创建 Vue 3 Vite 项目 首先,确保你已经安装了…...

2.3 变量
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 变量是用来存放某个值的数据,它可以表示一个数字、一个字符串、一个结构、一个类等。变量包含名称、类型和值。在代码中…...

16、Python面试题解析:python中的浅拷贝和深拷贝
在 Python 中,浅拷贝(Shallow Copy) 和 深拷贝(Deep Copy) 是处理对象复制的两种重要机制,它们的区别主要体现在对嵌套对象的处理方式上。以下是详细解析: 1. 浅拷贝(Shallow Copy&a…...

BUUCTF-Web方向21-25wp
目录 [HCTF 2018]admin弱口令session伪造 [MRCTF2020]你传你🐎呢[护网杯 2018]easy_tornado[ZJCTF 2019]NiZhuanSiWei[MRCTF2020]Ez_bypass第一层第二层 [HCTF 2018]admin 打开环境,有三处提示,一个跳转链接,一个登录注册&#x…...
)
elementPlus 中表单验证方法(手机号、正整数、邮箱)
1、手机号验证 <el-form ref"formRef" :model"form" :rules"rule" label-width"100px"><el-form-item label"联系电话" prop"mobile"><el-input type"tel" v-model"form.mobile&q…...

阿里云 ACS:高效、弹性、低成本的容器计算解决方案
阿里云的 容器计算服务(Alibaba Cloud Container Service, ACS) 是一种 Serverless 容器计算 解决方案,提供高度弹性、低成本、易管理的 Kubernetes(K8s)容器运行环境。用户无需关注底层服务器资源,而是直接…...

启动Redis报错记录
突然启动Redis就报了个错:‘Could not create server TCP listening socket 127.0.0.1:6379: bind: 操作成功完成。‘ 查了下解决方案,应该是6379端口已绑定,服务没有关闭。 需要输入命令redis-cli 再输入shutdown 但又出现了新的问题&…...

springBoot统一响应类型2.0版本
前言: 通过实践而发现真理,又通过实践而证实真理和发展真理。从感性认识而能动地发展到理性认识,又从理性认识而能动地指导革命实践,改造主观世界和客观世界。实践、认识、再实践、再认识,这种形式,循环往…...

ubuntu离线安装Ollama并部署Llama3.1 70B INT4
文章目录 1.下载Ollama2. 下载安装Ollama的安装命令文件install.sh3.安装并验证Ollama4.下载所需要的大模型文件4.1 加载.GGUF文件(推荐、更容易)4.2 加载.Safetensors文件(不建议使用) 5.配置大模型文件 参考: 1、 如…...
数组声明和使用)
Unity游戏制作中的C#基础(4)数组声明和使用
一、数组的声明 在 C# 中,声明数组有多种方式,每种方式都有其适用的场景,下面为你逐一详细介绍: 1. 直接初始化声明 这种方式直观且便捷,在声明数组的同时就为其赋初值,让数组从诞生之初就拥有了具体的数据…...

自定义SpringBoot Starter
✅自定义SpringBoot Starter SpringBoot 的 starter 可以帮我们简化配置,非常的方便,定义起来其实也不复杂,我的项目中定义了很多 starter,比如business-job就是一个 stater,以他为例,介绍下如何定义 star…...
怎么办(解决方法)?)
电脑经常绿屏(蓝屏)怎么办(解决方法)?
一、排查系统与驱动问题 进入安全模式修复系统 强制重启电脑 3 次触发恢复环境,选择 疑难解答 > 高级选项 > 启动设置 > 重启,按 F5 或 5 进入带网络连接的安全模式3。 在安全模式下,尝试卸载最近安装的软件或更新,尤其…...

IO/网络IO基础全览
目录 IO基础CPU与外设1. 程序控制IO(轮询)2. 中断中断相关知识中断分类中断处理过程中断隐指令 3. DMA(Direct Memory Access) 缓冲区用户空间和内核空间IO操作的拷贝概念传统IO操作的4次拷贝减少一个CPU拷贝的mmap内存映射文件(m…...

DPVS-5: 后端服务监控原理与测试
后端监控原理 被动监测 DPVS自带了被动监控,通过监控后端服务对外部请求的响应情况,判断服务器是否可用。 DPVS的被动监测,并不能获取后端服务器的详细情况,仅仅通过丢包/拒绝情况来发觉后端服务是否可用。 TCP session state…...

前端基础知识
1. 变量和常量 1.1 变量 // 变量let name Jacklet age 20name lisiage 18 1.2 常量 // 常量const PI 3.14// PI 3.1415926 // error,常量不可重新赋值const articleList []const user {name: vue3,age: 10} 1.3 const 声明的数组和对象 因为数组和对象在…...
)
从零到一学习c++(基础篇--筑基期十一-类)
从零到一学习C(基础篇) 作者:羡鱼肘子 温馨提示1:本篇是记录我的学习经历,会有不少片面的认知,万分期待您的指正。 温馨提示2:本篇会尽量用更加通俗的语言介绍c的基础,用通俗的语言去…...

Linux 第三次脚本作业
源码编译安装httpd 2.4,提供系统服务管理脚本并测试(建议两种方法实现) 一、第一种方法 1、把 httpd-2.4.63.tar.gz 这个安装包上传到你的试验机上 2、 安装编译工具 (俺之前已经装好了) 3、解压httpd包 4、解压后的httpd包的文…...
)
C#与AI的交互(以DeepSeek为例)
C#与ai的交互 与AI的交互使用的Http请求的方式,通过发送请求,服务器响应ai生成的文本 下面是完整的代码,我这里使用的是Ollama本地部署的deepseek,在联网调用api时,则url会有不同 public class OllamaRequester {[Se…...

Sky Hackathon 清水湾的水 AI美食助手
这里写自定义目录标题 视频 视频 video...

基于SpringBoot的校园消费点评管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

企业财务数据分析-投资回报指标ROA
上一篇文章主要介绍了关于投资回报的核心指标ROE,其实还有一个比较关键的指标资产回报率指标(ROA),资产收益率是用来衡量企业盈利能力的重要财务分析指标。资产收益率越高,说明企业资产的利用效率越高,利用…...

PostgreSQL 支持字段类型
PostgreSQL 支持多种字段类型,以下是常见的主要类别和具体类型的简要概述: 数值类型 SMALLINT:2字节整数,范围 -32768 到 32767 INTEGER:4字节整数,范围 -2147483648 到 2147483647 BIGINT:8字节…...

Deepseek引爆AI热潮 防静电地板如何守护数据中心安全
近期,Deepseek的爆火将人工智能推向了新的高度,也引发了人们对AI背后基础设施的关注。作为AI运行的“大脑”,数据中心承载着海量数据的存储、处理和传输,其安全稳定运行至关重要。而在这背后,防静电地板扮演着不可或缺…...

【ARM】MDK如何生成指定大小的bin文件,并指定空区域的填充数据
1、 文档目标 解决MDK如何生成指定大小的bin文件,并指定空区域的填充数据 2、 问题场景 客户有这样的需求,客户本身的工程编译生成bin文件后,bin文件大小为200k。整体芯片的内存有512k。客户想要最终生成的bin文件可以达到512k的一个情况&a…...

开源基准测试模拟器:BlueROV2 水下机器人的控制
拜读An Open-Source Benchmark Simulator: Control of a BlueROV2 Underwater Robot 非常感谢Esben Uth的帮助。 本文介绍了在 Simulink™ 中实现的常用且低成本的遥控潜水器 (ROV) BlueROV2 的仿真模型环境,该环境已针对水下航行器的基准控…...

Nginx 请求超时
Nginx 请求超时详解 在现代 Web 服务中,Nginx 作为一个高效的 Web 服务器和反向代理服务器,广泛应用于处理大量的 HTTP 请求。随着 Web 应用和服务的复杂性增加,Nginx 在处理客户端请求时,可能会出现超时问题。请求超时是指当客户…...

2022 年学习 Spring Boot 开发的最佳书籍
在我们之前的文章中,我们查看了学习 Java 编程的必读书籍我们在其中探索了一些您可以利用的资源来加快 Java 开发的速度。在此基础上,在用 vanilla Java 编写一段时间后,您将意识到组织文件和其他内容(例如设置 getter 和 setter、…...
)
JavaScript 前端面试 5()
十:new操作符 1:new操作符是什么 在JavaScript中new操作符是用于创建一个给定构造函数的实例对象 function Person(name,age){ this.name name; this.age age; } Person.protoype.sayName function (){ console,log(this.name) } cost person1 new…...

【Jenkins】显示 HTML 标签
需求 在 Jenkins 中显示 HTML 标签内容(例如格式化的文本、颜色、图标等)是一个常见的需求,如下,编译工程显示当前编译的分支: 但 Jenkins 默认会出于安全考虑(防止 XSS 攻击)转义 HTML 标签&a…...

DeepSeek R1模型提示语技巧:如何高效引导AI生成优质内容
文章目录 明确任务目标提供上下文使用结构化提示指定输出格式控制输出长度调整语气和风格提供示例迭代优化提示语避免歧义结合多轮对话总结 DeepSeek R1是一款基于大规模语言模型的AI工具,能够生成高质量的自然语言内容。为了充分发挥其潜力,用户需要掌握…...

UE5从入门到精通之多人游戏编程常用函数
文章目录 前言一、权限与身份判断函数1. 服务器/客户端判断2. 网络角色判断二、网络同步与复制函数1. 变量同步2. RPC调用三、连接与会话管理函数1. 玩家连接控制2. 网络模式判断四、实用工具函数前言 UE5给我们提供了非常强大的多人网路系统,让我们可以很方便的开发多人游戏…...

NGINX配置TCP负载均衡
前言 之前本人做项目需要用到nginx的tcp负载均衡,这里是当时配置做的笔记;欢迎收藏 关注,本人将会持续更新 文章目录 配置Nginx的负载均衡 配置Nginx的负载均衡 nginx编译安装需要先安装pcre、openssl、zlib等库,也可以直接编译…...
)
PyTorch torch.logsumexp 详解:数学原理、应用场景与性能优化(中英双语)
PyTorch torch.logsumexp 详解:数学原理、应用场景与性能优化 在深度学习和概率模型中,我们经常需要计算数值稳定的对数概率操作,特别是在处理 softmax 归一化、对数似然计算、损失函数优化 等任务时,直接求和再取对数可能会导致…...

【多模态大模型】端侧语音大模型minicpm-o:手机上的 GPT-4o 级多模态大模型
MiniCPM-o ,它是一款 开源、轻量级 的多模态大语言模型,目标是在手机等资源受限的环境中实现 GPT-4o 级别的多模态能力! 1. MiniCPM-o:小身材,大能量! MiniCPM-o 的名字已经暗示了它的核心特点:Mini (小巧) 和 CPM (中文预训练模型),最后的 “o” 则代表 Omnimodal …...

【Java 优选算法】模拟
欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎指出~ 模拟算法的思路比较简单,根据题目描述列出流程,找出规律,将流程转化为代码 替换所有的问号 题目链接 解法 直接根据题目给出条件模拟 示例,找出规律 1.先找出字符?,再…...

计算机网络复习
目录 1. 前言 2.五层模型 1.应用层 2 传输层 3.网络层 4. 数据链路层 编辑5. 物理层 3.UDP/TCP协议 UDP协议 TCP协议 4. HTTP/HTTPS协议 1. 前言 博主目前大四, 备战春招, 复习一下计网, 大家也可以看看我的文章. 共同学习, 如有不足之处欢迎指正. 2.五层模型 在计…...

应用层的协议-http/https的状态码
1xx:表示临时响应,需要操作者继续操作 2xx:成功,操作被成功接受并处理 3xx:一般是重定向问题 4xx:客户端的问题 5xx:服务端的问题 1xx: 100: 表示服务器收到客户端的第一部分请…...

文字语音相互转换
目录 1.介绍 2.思路 3.安装python包 3.程序: 4.运行结果 1.介绍 当我们使用一些本地部署的语言模型的时候,往往只能进行文字对话,这一片博客教大家如何实现语音转文字和文字转语音,之后接入ollama的模型就能进行语音对话了。…...

C++之类型转换
目录 C语言中的类型转换 隐式类型转换 强制类型转换 C中的类型转换 static_cast reinterpret_cast const_cast dynamic_cast 本期我们将学习C中类型转换的相关知识点。 C语言中的类型转换 在C语言中,也有过类型转换的情景。 隐式类型转换 隐式类型转换…...

【WSL2】 Ubuntu20.04 GUI图形化界面 VcXsrv ROS noetic Vscode 主机代理 配置
【WSL2】 Ubuntu20.04 GUI图形化界面 VcXsrv ROS noetic Vscode 主机代理 配置 前言整体思路安装 WSL2Windows 环境升级为 WIN11 专业版启用window子系统及虚拟化 安装WSL2通过 Windows 命令提示符安装 WSL安装所需的 Linux 发行版(如 Ubuntu 20.04)查看…...

【数据库】【MySQL】索引
MySQL中索引的概念 索引(MySQL中也叫做"键(key)")是一种数据结构,用于存储引擎快速定找到记录。 简单来说,它类似于书籍的目录,通过索引可以快速找到对应的数据行,而无需…...
提示词(Prompt)高阶撰写指南)
大语言模型(LLM)提示词(Prompt)高阶撰写指南
——结构化思维与工程化实践 一、LLM提示词设计的核心逻辑 1. 本质认知 LLM是「超强模式识别器概率生成器」,提示词的本质是构建数据分布约束,通过语义信号引导模型激活特定知识路径。优秀提示词需实现: 精准性:消除歧义&#…...

LabVIEW C编译支持工具库CCompileSupp.llb
路径:C:\Program Files (x86)\National Instruments\LabVIEW 2019\vi.lib\Platform\CCompileSupp.llb 1. 工具库概述 定位:LabVIEW内置的C语言编译支持工具库,用于处理LabVIEW与C/C代码的混合编程接口,涵盖编译器配置、代码生成…...

【安装及调试旧版Chrome + 多版本环境测试全攻略】
👨💻 安装及调试旧版Chrome 多版本环境测试全攻略 🌐 (新手友好版 | 覆盖安装/运行/调试全流程) 🕰️ 【背景篇】为什么我们需要旧版浏览器测试? 🌍 🌐 浏览器世界的“…...

整数二分算法
例题: 给定一个按照升序排列的长度为 n 的整数数组,以及 q个查询。 对于每个查询,返回一个元素 k 的起始位置和终止位置(位置从 0开始计数)。 如果数组中不存在该元素,则返回 -1 -1。 输入格式 第一行…...

【java】this关键字
在 Java 中,this 是一个特殊的关键字,它代表当前对象的引用。简单来说,this 指向当前正在调用方法或构造函数的对象。this 关键字的主要作用是解决变量名冲突、访问当前对象的成员变量或方法,以及在构造函数中调用其他构造函数。 …...