数据结构——二叉树经典习题讲解
各位看官早安午安晚安呀
如果您觉得这篇文章对您有帮助的话
欢迎您一键三连,小编尽全力做到更好
欢迎您分享给更多人哦
大家好,我们今天来学习java数据结构的二叉树

递归很重要的一些注意事项:
- 1:递归你能不能掌握在于:你能不能想清楚第一层非递归 以及 递归结束的条件(也就是最后一层递归,有时候递归结束的条件可能有好几个这很常见)(结束的条件仔细想一下是否能够合并呢?return root,return null,下一层root啥也没干,root == null,是否能够合并呢?这个其实无伤大雅,但是能合并尽量还是合并一下)(这两个场景你能够想清楚,你基本思路就没什么问题)
- 2:递归有返回值的
- 2.1:如果有返回值,你大概率是要接收你下一层递归的返回值()(然后你进行整理完之后继续向上返回)
- 2.2:递归如果返回值是要叠加的,譬如求二叉树的高度的,这个返回值一定要接收。
1.1.判断两个二叉树是否相等
链接
public boolean isSameTree(TreeNode p, TreeNode q) {if(p == null && q != null || p != null && q == null){ //结构不一样不相等return false;}if(p == null && q == null){ // 看你俩只要同时为空就相等return true;}return p.val == q.val && isSameTree(p.left,q.left) && isSameTree(p.right,q.right);}1.2.相同的二叉树
相同的树
public boolean isSameTree(TreeNode p, TreeNode q) {if(p == null && q != null || p != null && q == null){return false;}if(p == null && q == null){return true;}return p.val == q.val && isSameTree(p.left,q.left) && isSameTree(p.right,q.right);}public boolean isSubtree(TreeNode root, TreeNode subRoot) {if(isSameTree(root,subRoot)){ //判断一开始就是否相等return true;}if(root == null){return false;}if(isSubtree(root.left,subRoot) || isSubtree(root.right,subRoot)){ //左边和右边一个相等就行//其实这个就是前序遍历,利用返回值return true;}return false;}1.3.翻转二叉树
翻转二叉树
public TreeNode invertTree(TreeNode root) {if(root == null){return null;}//交换节点TreeNode tmp = root.left;root.left = root.right;root.right = tmp;//翻转invertTree(root.left);invertTree(root.right);return root;}
1.4.平衡二叉树
平衡二叉树
补充知识点:
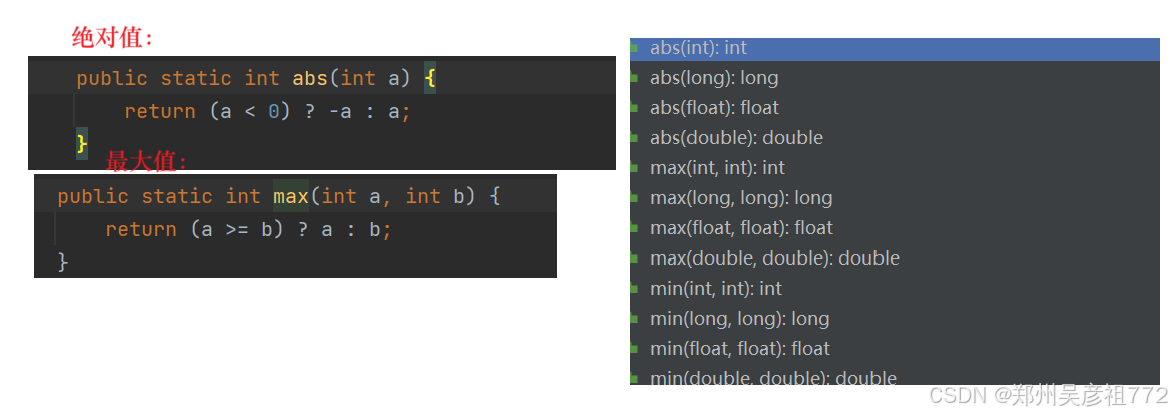
//更改的平衡二叉树,因为我们在算高度的时候每一颗子树的高度我们都算过,我们完全可以算整个树的高度//然后进行顺带算两边的高度差是否 <= 1,一次性算完int getHeight2(TreeNode root){if(root == null){return 0;}//左树高度和右树高度int leftHeight = getHeight2(root.left);int rightHeight = getHeight2(root.right);//两边高度差<= 1并且都大于0(任何一个高度为-1的时候,整个树的返回值就为-1(-1代表不平衡))// 只要有一个-1返回,那么之后都是返回-1,不平衡if(Math.abs(leftHeight - rightHeight) <= 1 && leftHeight >= 0 && rightHeight >= 0){return Math.max(leftHeight,rightHeight)+1;}return -1;}public boolean isBalanced(TreeNode root) {if(root == null){return true;} return getHeight2(root) >= 0;}1.5.对称二叉树
对称二叉树
public boolean isSymmetric(TreeNode root) {if(root == null){return true;}//我要看是否对称,肯定要两个节点进行比较,要两个变量return isSample(root.left,root.right);}public boolean isSample(TreeNode p , TreeNode q){//两边都是空的,就一个根,直接返回trueif( p == null && q == null){return true;}//一个为空另一个不为空,直接返回falseif( p == null || q == null){return false;}if(p.val != q.val){return false;}return isSample(p.left,q.right) && isSample(p.right,q.left);}
1.6.通过字符串构建二叉树
通过字符串构建二叉树
import java.util.Scanner;
class TreeNode{char val;TreeNode left;TreeNode right;public TreeNode(){}public TreeNode(char val){this.val = val;}
}// 注意类名必须为 Main, 不要有任何 package xxx 信息
public class Main {public static void main(String[] args) {Scanner in = new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseString str = in.nextLine();//创建二叉树TreeNode root = create(str);//中序遍历inorder(root);}}public static int i = 0;public static TreeNode create(String str){ //递归的第一层要素就是要知道什么时候结束// 首先我们遇到 “#” 就要返回 ,但是我们的i还是要先++ 后返回if(str.charAt(i) == '#'){//但是我们要考虑的是,我们就算是返回了,我们的遍历str的i还是要往前走i++;return null;}else{TreeNode root = new TreeNode(str.charAt(i));i++;root.left = create(str);root.right = create(str);return root;}
//最后你会发现其实这两个返回值可以合并成一个,//其实每次递归题大家都可以看一下}//中序遍历public static void inorder(TreeNode root){if(root == null){return;}inorder(root.left);System.out.print(root.val +" ");inorder(root.right);}
}
1.7.二叉树分层遍历:
二叉树的层序遍历
public List<List<Integer>> levelOrder(TreeNode root) {List<List<Integer>> list = new ArrayList<>();//别问 问就是OJ的测试用例让我这么干的// root = [] 预期结果[],所以下面返回的也是List而不是nullif(root == null){ //如果根节点都是null,就不用遍历了return list;}// 先把 根节点add进去队列里面Queue<TreeNode> queue = new LinkedList<>();queue.offer(root);//tmp.add(root);//这里不对呀,最后一倍一倍的增长。这个size也不对,看我下面如何修改while(!queue.isEmpty()) {//int size = tmp.size();List<Integer> tmp = new ArrayList<>();//这个可不敢放在一开始呀,不然又叠加了(ArrayList好一点)int size = queue.size();//计算上一次add进来的总和, 下面直接就是 size!=0,这完全就是要把上一次的全poll出去while (size != 0) { //和上一个的区别就在于,上一个层序遍历是一个一个出队列的,这个是一次性把上一次add进来的全部poll出去TreeNode cur = queue.poll();tmp.add(cur.val);// System.out.println(cur.val + " ");size--;//记得--;if (cur.left != null) {queue.offer(cur.left);}if (cur.right != null) {queue.offer(cur.right);}}list.add(tmp);}return list;}
1.8.二叉树的最近公共祖先
二叉树的最近公共祖先
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if(p == root || q == root){return root;}if(root == null){return null;}TreeNode leftRoot = lowestCommonAncestor(root.left,p,q);TreeNode rightRoot = lowestCommonAncestor(root.right,p,q);if(leftRoot != null && rightRoot != null){return root;} else if (leftRoot != null) {return leftRoot;}else{return rightRoot;}}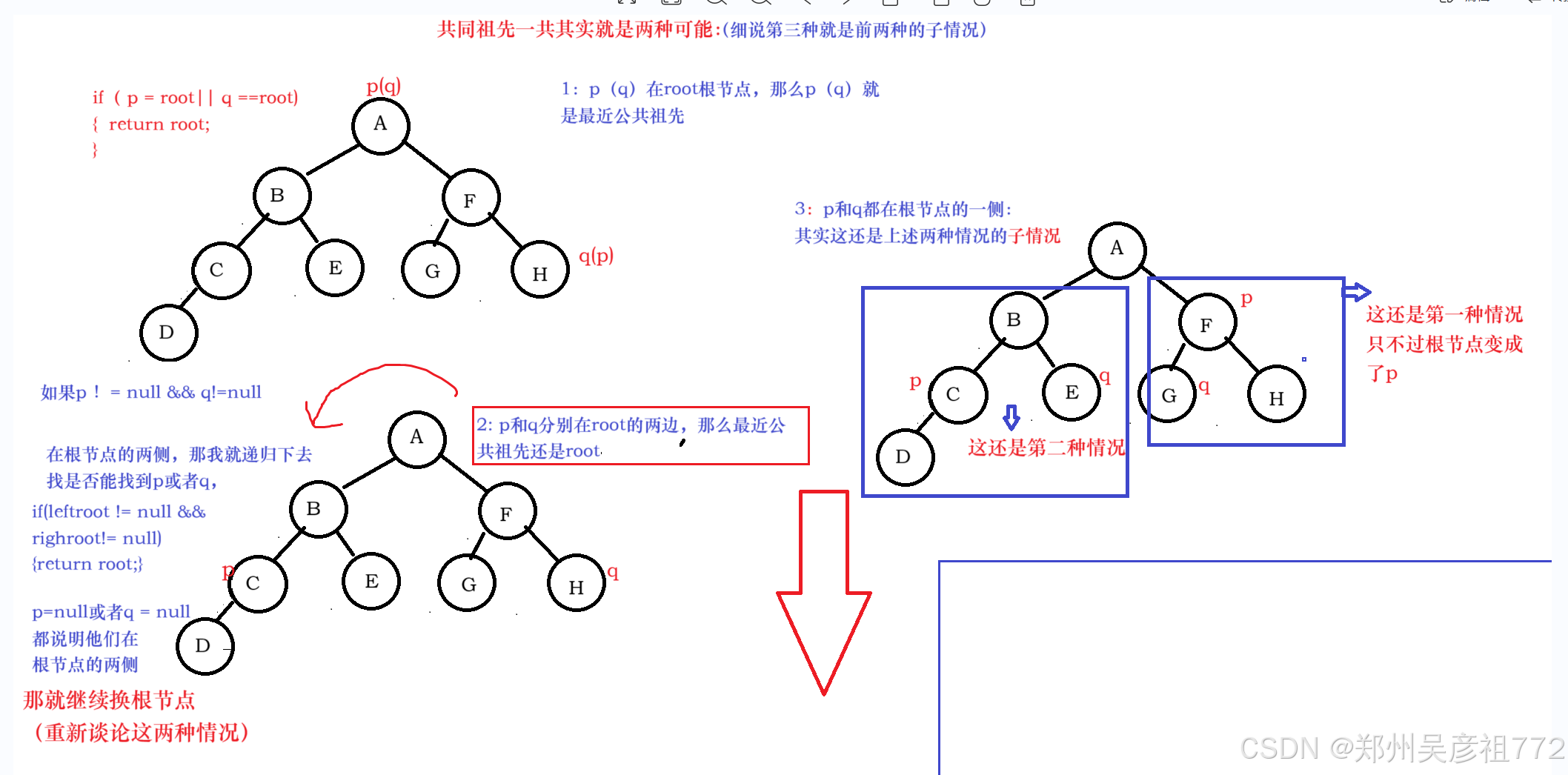
解法二:看成两个链表相交,找相交点
private boolean getPath(TreeNode root,TreeNode node,Stack<TreeNode>stack){// 判断这个节点是不是这个路径上的节点(如果不是,看看它的左子树和右子树是不是这个路径上的节点如果都不是)//就返回false,把这个节点pop出来if(root == null || node == null){return false;}stack.push(root);//一定要压进去,不然root == node 导致这个栈里面没有了元素if(root == node){return true;}boolean flg1 = getPath(root.left,node,stack);//看看左节点有没有if(flg1){return true;}boolean flg2 = getPath(root.right,node,stack);//看看右节点有没有if(flg2){return true;}//都没有就return falsestack.pop();return false;}public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {Stack<TreeNode>stack1 = new Stack<>();Stack<TreeNode>stack2 = new Stack<>();//利用getPath初始化这两个栈getPath(root,p,stack1);getPath(root,q,stack2);//初始化之后,进行比较,让长栈先走size步int size = stack1.size() -stack2.size();if(size > 0){while(size != 0){stack1.pop();size--;}}else{while(size != 0){stack2.pop();size++;}}while(!stack1.isEmpty() && ! stack2.isEmpty()){ //&&后面的写不写都行if(stack1.peek().equals(stack2.peek())){return stack1.peek();}stack1.pop();stack2.pop();}return null;}1.9. 从前序与中序遍历序列构造二叉树
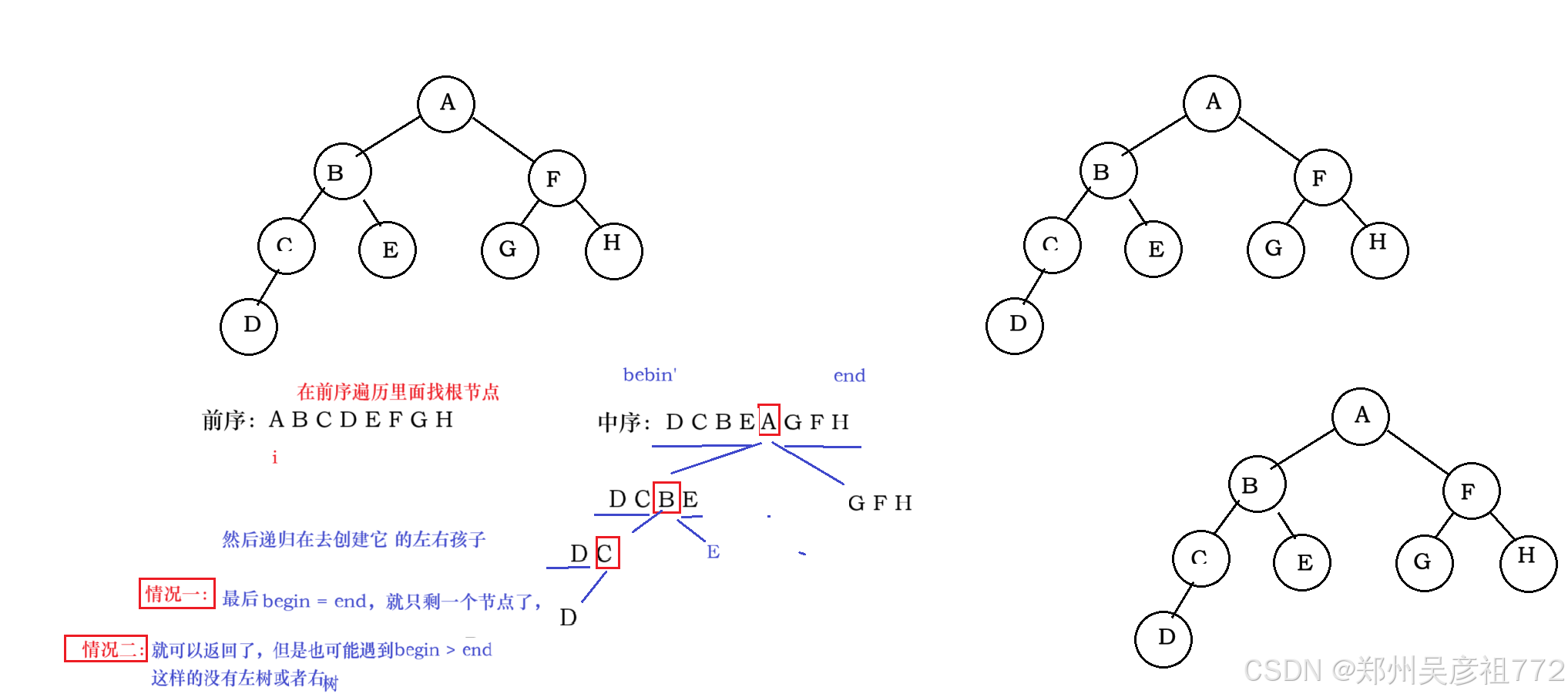
从前序与中序遍历序列构造二叉树
class Solution {public int preIndex;//一定要设置成成员变量(全局效果),局部变量的话放方法参数里,每次都是传值调用//不能保证preIndex一直往前走public TreeNode buildTree(int[] preorder, int[] inorder) {return buildTreeChild(preorder,inorder,0,inorder.length -1);}private TreeNode buildTreeChild(int[] preorder,int[] inorder,int inbegin,int inend){if(inbegin > inend ){ //其实这里的结束有两次,inbegin = inend 也应该结束(但是合并成一种情况了)return null;}if(inbegin == inend){int pre = preIndex;preIndex++;return new TreeNode(preorder[pre]);}//先看这个(前序遍历的)节点是否在中序遍历的这个范围内,在的话我再把这个根节点给创建出来int rootIndex = findIndex(inorder,inbegin,inend,preorder[preIndex]);if(rootIndex == -1){return null;}TreeNode root = new TreeNode(preorder[preIndex]);preIndex++;root.left = buildTreeChild(preorder,inorder,inbegin,rootIndex-1);root.right = buildTreeChild(preorder,inorder,rootIndex + 1,inend);return root;}private int findIndex(int[] inorder,int inbegin,int inend,int key){for(int i = inbegin; i<= inend ; i++){if(inorder[i] == key){return i;}}return -1;}
}

1.10.从中序与后序遍历序列构造二叉树
如果后序:是先递归右树,再左树,再根(此刻的后序的字符串就是前序的逆转)
1从中序与后序遍历序列构造二叉树
class Solution {public int postIndex ;//一定要设置成成员变量(全局效果),局部变量的话放方法参数里,每次都是传值调用//不能保证preIndex一直往前走public TreeNode buildTree(int[] inorder, int[] postorder) {postIndex = postorder.length -1;return buildTreeChild(postorder,inorder,0,inorder.length -1);}private TreeNode buildTreeChild(int[] postorder,int[] inorder,int inbegin,int inend){if(inbegin > inend ){ //其实这里的结束有两次,inbegin = inend 也应该结束(但是合并成一种情况了)return null;}//先看这个(前序遍历的)节点是否在中序遍历的这个范围内,在的话我再把这个根节点给创建出来int rootIndex = findIndex(inorder,inbegin,inend,postorder[postIndex]);if(rootIndex == -1){return null;}TreeNode root = new TreeNode(postorder[postIndex]);postIndex--;root.right = buildTreeChild(postorder,inorder,rootIndex + 1,inend);root.left = buildTreeChild(postorder,inorder,inbegin,rootIndex-1);return root;}private int findIndex(int[] inorder,int inbegin,int inend,int key){for(int i = inbegin; i<= inend ; i++){if(inorder[i] == key){return i;}}return -1;}
}1.11.前序遍历二叉树(迭代实现)
public static void preOrder1(TreeNode root) {if (root == null) {return;}//本质上这还是递归的思想(stack还是往回走,不然你路上的节点,没办法遍历他的右边;Stack<TreeNode> stack = new Stack<>();TreeNode cur = root;while (cur != null || !stack.isEmpty()) {// 加个cur !=null,纯粹是因为,第一次stack是空的while (cur != null) {//一直往System.out.print(cur.val);stack.push(cur);cur = cur.left;//其实一开始我是这么想的/*if(cur == null){cur = stack.pop();cur = cur.right;//但是这样就废了呀,右边为空就完蛋了,循环结束,gameOver}*/}//左边为空,直接就拿回我上一个根,然后打印右边cur = stack.pop();cur = cur.right;}}1.11.中序遍历二叉树(迭代实现)
public static void inOrder1(TreeNode root) {if (root == null) {return;}//本质上这还是递归的思想(stack还是往回走,不然你路上的节点,没办法遍历他的右边;Stack<TreeNode> stack = new Stack<>();TreeNode cur = root;while (cur != null || !stack.isEmpty()) {// 加个cur !=null,纯粹是因为,第一次stack是空的while (cur != null) {//一直往stack.push(cur);cur = cur.left;}//左边为空,直接就拿回我上一个根,然后打印右边cur = stack.pop();System.out.print(cur.val);cur = cur.right;}}
1.11.后序遍历二叉树(迭代实现)
//根据字符串循环进行后序遍历public static void postOrder1(TreeNode root) {if (root == null) {return;}//本质上这还是递归的思想(stack还是往回走,不然你路上的节点,没办法遍历他的右边;Stack<TreeNode> stack = new Stack<>();TreeNode cur = root;TreeNode prev = null;TreeNode top = null;while (cur != null || !stack.isEmpty()) {// 加个cur !=null,纯粹是因为,第一次stack是空的while (cur != null) {//一直往stack.push(cur);cur = cur.left;}//左边为空,直接就拿回我上一个根,然后打印右边top = stack.peek();if(top .right == null || top.right == prev){stack.pop();System.out.print(top.val + " ");prev = top;}else {// 右边不为空不能popcur = top.right;}}}上述就是二叉树习题讲解的全部内容了,能看到这里相信您一定对小编的文章有了一定的认可,二叉树的出现让我们对于数据的组织的利用有了更加方便的使用~~
有什么问题欢迎各位大佬指出
欢迎各位大佬评论区留言修正
您的支持就是我最大的动力!!!!


相关文章:

数据结构——二叉树经典习题讲解
各位看官早安午安晚安呀 如果您觉得这篇文章对您有帮助的话 欢迎您一键三连,小编尽全力做到更好 欢迎您分享给更多人哦 大家好,我们今天来学习java数据结构的二叉树 递归很重要的一些注意事项: 1:递归你能不能掌握在于࿱…...

centos 9 时间同步服务
在 CentOS 9 中,默认的时间同步服务是 chrony,而不是传统的 ntpd。 因此,建议使用 chrony 来配置和管理时间同步。 以下是使用 chrony 配置 NTP 服务的步骤: 1. 安装 chrony 首先,确保系统已安装 chrony。 在 CentOS…...
)
视觉应用工程师(面试)
视觉应用工程师(面试) 1.自我介绍、会的技能、项目 2.相机和机械手调试过程 检查硬件,看软件驱动是否链接,调节相机和镜头保证能够识别这个物料,看接口和通讯是否正常,如:波特率,数…...

macos sequoia 禁用 ctrl+enter 打开鼠标右键菜单功能
macos sequoia默认ctrlenter会打开鼠标右键菜单,使得很多软件有冲突。关闭方法: end...

【后端基础】布隆过滤器原理
文章目录 一、Bloom Filter(布隆过滤器)概述1. Bloom Filter 的特点2. Bloom Filter 的工作原理 二、示例1. 添加与查询2. 假阳性 三、Bloom Filter 的操作1、假阳性概率2、空间效率3、哈希函数的选择 四、应用 Bloom Filter 是一种非常高效的概率型数据…...

cs*n 网页内容转为html 加入 onenote
csdn上有好用的内容,我们怎么将它们加到 onenote 里吃灰呢。 一、创建 新html create_html.py import sysdef create_html_file(filename):# 检查是否提供了文件名if not filename:print("请提供HTML文件名")return# 创建HTML内容html_content f"…...

输入搜索、分组展示选项、下拉选取,全局跳转页,el-select 实现 —— 后端数据处理代码,抛砖引玉展思路
详细前端代码写于上一篇:输入搜索、分组展示选项、下拉选取,el-select 实现:即输入关键字检索,返回分组选项,选取跳转到相应内容页 —— VUE项目-全局模糊检索 【效果图】:分组展示选项 【去界面操作体验】…...
)
蓝桥杯 Java B 组之岛屿数量、二叉树路径和(区分DFS与回溯)
Day 3:岛屿数量、二叉树路径和(区分DFS与回溯) 📖 一、深度优先搜索(DFS)简介 深度优先搜索(Depth-First Search,DFS)是一种用于遍历或搜索树或图的算法。它会沿着树的分…...

【论文阅读】SAM-CP:将SAM与组合提示结合起来的多功能分割
导言 近年来,视觉基础模型的快速发展推动了多模态理解的进步,尤其是在图像分割任务中。例如,Segment Anything模型(SAM)在图像Mask分割上表现出色,但在语义及实例分割方面仍存在局限。本文提出的SAM-CP&am…...

JUC并发—9.并发安全集合四
大纲 1.并发安全的数组列表CopyOnWriteArrayList 2.并发安全的链表队列ConcurrentLinkedQueue 3.并发编程中的阻塞队列概述 4.JUC的各种阻塞队列介绍 5.LinkedBlockingQueue的具体实现原理 6.基于两个队列实现的集群同步机制 4.JUC的各种阻塞队列介绍 (1)基于数组的阻塞…...

爱普生 SG-8101CE 可编程晶振在笔记本电脑的应用
在笔记本电脑的精密架构中,每一个微小的元件都如同精密仪器中的齿轮,虽小却对整体性能起着关键作用。如今的笔记本电脑早已不再局限于简单的办公用途,其功能愈发丰富多样。从日常轻松的文字处理、网页浏览,到专业领域中对图形处理…...
)
k8s网络插件详解(flannel)
1、介绍 Flannel 是一个轻量级、易于配置的网络插件,旨在简化 Kubernetes 集群中 Pod 网络的管理。Flannel 的核心功能是提供一个虚拟的网络,允许每个 Pod 获取一个独立的 IP 地址,并实现不同节点间的 Pod 之间的通信 2、网络模式 vxlan&am…...
带论文文档1万字以上,文末可获取,系统界面在最后面。)
基于flask+vue框架的的医院预约挂号系统i1616(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,医生,科室信息,就诊信息,医院概况,挂号信息,诊断信息,取消挂号 开题报告内容 基于FlaskVue框架的医院预约挂号系统开题报告 一、研究背景与意义 随着医疗技术的不断进步和人们健康意识的日益增强,医院就诊量逐年增加。传统的现场…...

JUC并发—8.并发安全集合一
大纲 1.JDK 1.7的HashMap的死循环与数据丢失 2.ConcurrentHashMap的并发安全 3.ConcurrentHashMap的设计介绍 4.ConcurrentHashMap的put操作流程 5.ConcurrentHashMap的Node数组初始化 6.ConcurrentHashMap对Hash冲突的处理 7.ConcurrentHashMap的并发扩容机制 8.Concu…...

Linux 内核网络设备驱动编程:私有协议支持
一、struct net_device的通用性与私有协议的使用 struct net_device是Linux内核中用于描述网络设备的核心数据结构,它不仅限于TCP/IP协议,还可以用于支持各种类型的网络协议,包括私有协议。其原因如下: 协议无关性:struct net_device的设计是通用的,它本身并不依赖于任何…...
——概率与信息论)
机器学习的数学基础(三)——概率与信息论
目录 1. 随机变量2. 概率分布2.1 离散型变量和概率质量函数2.2 连续型变量和概率密度函数 3. 边缘概率4. 条件概率5. 条件概率的链式法则6. 独立性和条件独立性7. 期望、方差和协方差7.1 期望7.2 方差7.3 协方差 8. 常用概率分布8.1 均匀分布 U ( a , b ) U(a, b) U(a,b)8.2 Be…...

使用Docker Desktop部署GitLab
1. 环境准备 确保Windows 10/11系统支持虚拟化技术(需在BIOS中开启Intel VT-x/AMD-V)内存建议≥8GB,存储空间≥100GB 2. 安装Docker Desktop 访问Docker官网下载安装包安装时勾选"Use WSL 2 instead of Hyper-V"(推荐…...

推理模型时代:大语言模型如何从对话走向深度思考?
一、对话模型和推理模型的区别概述 对话模型是专门用于问答交互的语言模型,符合人类的聊天方式,返回的内容可能仅仅只是一个简短的答案,一般模型名称后面会带有「chat」字样。 推理模型是比较新的产物,没有明确的定义,一般是指输出过程中带有<think>和</think&…...
交流问题))
GESP2024年3月认证C++七级( 第三部分编程题(1)交流问题)
参考程序: #include <iostream> #include <vector> #include <unordered_map> using namespace std;// 深度优先搜索,给每个节点染色,交替染色以模拟两校同学的划分 void dfs(vector<vector<int>>& graph…...

DeepSeek:AI商业化的新引擎与未来蓝图
摘要 在人工智能迅猛发展的浪潮中,DeepSeek以其卓越的技术实力和高超的商业化能力崭露头角。作为一款现象级AI产品,它不仅在算法性能上位居行业前列,还通过灵活的定制解决方案渗透到金融、医疗、零售等多个领域。DeepSeek以创新的商业模式和场…...

2025年度福建省职业院校技能大赛中职组“网络建设与运维”赛项规程模块三
模块三:服务搭建与运维 任务描述: 随着信息技术的快速发展,集团计划把部分业务由原有的 X86 服 务器上迁移到ARM 架构服务器上,同时根据目前的部分业务需求进行 了部分调整和优化。 一、X86 架构计算机操作系统安装与管理 1&…...
)
Python----数据结构(队列,顺序队列,链式队列,双端队列)
一、队列 1.1、概念 队列(Queue):也是一种基本的数据结构,在队列中的插入和删除都遵循先进先出(First in First out,FIFO)的原则。元素可以在任何时刻从队尾插入,但是只有在队列最前面 的元素才能被取出或…...

【自学笔记】Spring Boot框架技术基础知识点总览-持续更新
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 Spring Boot框架技术基础知识点总览一、Spring Boot简介1.1 什么是Spring Boot?1.2 Spring Boot的主要特性 二、Spring Boot快速入门2.1 搭建Spring Boo…...

神经网络剪枝技术的重大突破:sGLP-IB与sTLP-IB
神经网络剪枝技术的重大突破:sGLP-IB与sTLP-IB 在人工智能飞速发展的今天,深度学习技术已经成为推动计算机视觉、自然语言处理等领域的核心力量。然而,随着模型规模的不断膨胀,如何在有限的计算资源和存储条件下高效部署这些复杂的神经网络模型,成为了研究者们亟待解决的…...

Django-Vue 学习-VUE
主组件中有多个Vue组件 是指在Vue.js框架中,主组件是一个父组件,它包含了多个子组件(Vue组件)。这种组件嵌套的方式可以用于构建复杂的前端应用程序,通过拆分功能和视图,使代码更加模块化、可复用和易于维…...
)
【Gin】2:快速上手Gin框架(模版、cookie、session)
本文目录 一、模版渲染二、自定义模版函数三、cookie四、Session五、cookie、session区别六、会话攻击 一、模版渲染 在 Gin 框架中,模板主要用于动态生成 HTML 页面,结合 Go 语言的模板引擎功能,实现数据与视图的分离。 模板渲染是一种动态…...

Linux修改主机名称
hostnamectl set-hostname 主机名称 exit 退出登录重新进入即可...

亲测Windows部署Ollama+WebUI可视化
一. Ollama下载 登录Ollama官网(Ollama)点击Download进行下载 如果下载很慢可用以下地址下载: https://github.com/ollama/ollama/releases/download/v0.5.7/OllamaSetup.exe 在DeepSeek官网上,你可以直接点击【model】 到达这个界面之后,…...

Java四大框架深度剖析:MyBatis、Spring、SpringMVC与SpringBoot
目录 前言: 一、MyBatis框架 1. 概述 2. 核心特性 3. 应用场景 4. 示例代码 二、Spring框架 1. 概述 2. 核心模块 3. 应用场景 4. 示例代码 三、SpringMVC框架 1. 概述 2. 核心特性 3. 应用场景 4. 示例代码 四、SpringBoot框架 1. 概述 2. 核心…...

ubuntu部署小笔记-采坑
ubuntu部署小笔记 搭建前端控制端后端前端nginx反向代理使用ubuntu部署nextjs项目问题一 如何访问端口号配置后台运行该进程pm2 问题二 包体过大生产环境下所需文件 问题三 部署在vercel时出现的问题需要魔法访问后端api时,必须使用https协议电脑端访问正常…...

23. AI-大语言模型-DeepSeek简介
文章目录 前言一、DeepSeek是什么1. 简介2. 产品版本1. 类型2. 版本3. 参数规模与模型能力 3. 特征4. 三种访问方式1. 网页端和APP2. DeepSeek API 二、DeepSeek可以做什么1. 应用场景2. 文本生成1. 文本创作2. 摘要与改写3. 结构化生成 3. 自然语言理解与分析1. 语义分析2. 文…...
)
基于SpringBoot的智慧家政服务平台系统设计与实现的设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

Java NIO与传统IO性能对比分析
Java NIO与传统IO性能对比分析 在Java中,I/O(输入输出)操作是开发中最常见的任务之一。传统的I/O方式基于阻塞模型,而Java NIO(New I/O)引入了非阻塞和基于通道(Channel)和缓冲区&a…...

基于YOLO11深度学习的果园苹果检测与计数系统设计与实现【python源码+Pyqt5界面+数据集+训练代码】
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

基于SpringBoot畅购行汽车购票系统
作者简介:✌CSDN新星计划导师、Java领域优质创作者、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流。✌ 主要内容:🌟Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能…...
)
基于 Spring Boot + 微信小程序的短文写作竞赛管理系统设计与实现(源码+文档)
大家好,今天要和大家聊的是一款基于 Spring Boot 微信小程序的“短文写作竞赛管理系统”的设计与实现。项目源码以及部署相关事宜请联系我,文末附上联系方式。 项目简介 基于 Spring Boot 微信小程序的“短文写作竞赛管理系统”设计与实现的主要使用…...

pytest运行用例的常见方式及参数
标题pytest运行用例方式及参数 用例结构目录 “”" 在最外层目录下执行所有的用例 参数说明: -s:显示用例的打印信息 -v:显示用例执行的详细信息 –alluredir:指定allure报告的路径 –clean-alluredir:清除allure报告的路径 -n:指定并发的进程数 -x:出现一条用…...

Miniconda + VSCode 的Python环境搭建
目录: 安装 VScode 安装 miniconda 在VScode 使用conda虚拟环境 运行Python程序 1.安装 vscode 编辑器 官网链接:Visual Studio Code - Code Editing. Redefined 下载得到:,双击安装。 安装成功…...

图解MySQL【日志】——Redo Log
Redo Log(重做日志) 为什么需要 Redo Log? 1. 崩溃恢复 数据库崩溃时,系统通过 Redo Log 来恢复尚未写入磁盘的数据。Redo Log 记录了所有已提交事务的操作,系统在重启后会重做这些操作,以保证数据不会丢…...

Trae AI驱动开发实战:30分钟从0到1实现Django REST天气服务
目录 一、Trae 安装 1、Trae 介绍 2、Trae 安装 二、项目构建 1、项目背景与技术选型 2、开发环境准备 三、需求分析 1、功能模块设计 2、数据库设计 四、功能实现 1、用户系统开发 2、天气服务实现 3、测试用例编写 五、Trae 体验总结 随着人工智能技术的迅猛发…...

【Linux网络编程】IP协议格式,解包步骤
目录 解析步骤 1.版本字段(大小:4比特位) 2.首部长度(大小:4比特位)(单位:4字节) 🍜细节解释: 3.服务类型(大小:8比特…...

中诺CHINO-E G076大容量录音电话产品使用注意事项
•本机需插上随机配置的电源适配器才能正常工作,切勿插入其它的适配器,以免损坏话机; •当本机出现异常时,请按“Δ/上查”键3秒,屏幕弹出确定恢复,按“设置”键恢复出厂设置; 注:…...
求解23个经典函数测试集,MATLAB)
2025最新智能优化算法:改进型雪雁算法(Improved Snow Geese Algorithm, ISGA)求解23个经典函数测试集,MATLAB
一、改进型雪雁算法 雪雁算法(Snow Geese Algorithm,SGA)是2024年提出的一种新型元启发式算法,其灵感来源于雪雁的迁徙行为,特别是它们在迁徙过程中形成的独特“人字形”和“直线”飞行模式。该算法通过模拟雪雁的飞行…...

✨ 索引有哪些缺点以及具体有哪些索引类型
索引的定义与原理 索引是数据库中用于提高数据检索效率的数据结构。它就像是书籍的目录,通过目录可以快速定位到所需内容的页码,而在数据库中,索引可以帮助数据库系统快速找到符合查询条件的数据行,而不必对整个表进行扫描。 其…...

Promptic:Python 中的 LLM 应用开发利器
Promptic 是一个基于 Python 的轻量级库,旨在简化与大型语言模型(LLMs)的交互。它通过提供简洁的装饰器 API 和强大的功能,帮助开发者高效地构建 LLM 应用程序。Promptic 的设计理念是提供 90% 的 LLM 应用开发所需功能,同时保持代码的简洁和易用性。 1. Promptic 的核心…...

本地部署DeepSeek R1大模型
一、安装软件 1.1 安装Ollama 你可以访问Ollama的官方网站https://ollama.com/download,选择适合你操作系统的安装包进行下载。老周这里是Mac系统,所以选择下载macOS系统。 1.2 安装cherry studio 前往官网https://cherry-ai.com/download下载对应操…...

搅局外卖,京东连出三张牌
明牌暗牌,都不如民牌。 作者|古廿 编辑|杨舟 “京东来整顿外卖了”,这一网络热梗正在成为外界对京东近期一系列动作的高度概括。 0佣金、五险一金、品质外卖,京东连出三张牌打破外卖市场的旧秩序。此前这三项分别对应着长期被社会所诟病的…...

【ELK】【Elasticsearch】数据查询方式
1. 简单查询(URI Search) 通过 URL 参数直接进行查询,适合简单的搜索场景。 示例: bash 复制 GET /index_name/_search?qfield_name:search_value 说明: index_name:索引名称。 field_name…...
)
基于 JavaWeb 的 Spring Boot 网上商城系统设计和实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论…...

C++17中的std::scoped_lock:简化多锁管理的利器
文章目录 1. 为什么需要std::scoped_lock1.1 死锁问题1.2 异常安全性1.3 锁的管理复杂性 2. std::scoped_lock的使用方法2.1 基本语法2.2 支持多种互斥锁类型2.3 自动处理异常 3. std::scoped_lock的优势3.1 避免死锁3.2 简化代码3.3 提供异常安全保证 4. 实际应用场景4.1 数据…...