论文阅读:MGMAE : Motion Guided Masking for Video Masked Autoencoding
MGMAE:Motion Guided Masking for Video Masked Autoencoding
Abstract
掩蔽自编码(Masked Autoencoding)在自监督视频表示学习中展现了出色的表现。时间冗余导致了VideoMAE中高掩蔽比率和定制的掩蔽策略。本文旨在通过引入运动引导掩蔽策略,进一步提升视频掩蔽自编码的性能。我们的关键见解是,运动是视频中的一种普遍且独特的先验信息,应在掩蔽预训练过程中加以考虑。我们提出的运动引导掩蔽明确地结合了运动信息,构建了时间一致的掩蔽体积。基于这个掩蔽体积,我们能够追踪时间上的未掩蔽标记,并从视频中采样一组时间一致的立方体。这些时间对齐的未掩蔽标记将进一步缓解信息泄漏问题,并鼓励MGMAE学习更多有用的结构信息。我们使用在线高效光流估计器和反向掩蔽图扭曲策略实现了MGMAE,并在Something-Something V2和Kinetics-400数据集上进行了实验,展示了MGMAE相较于原始VideoMAE的优越性能。此外,我们还提供了可视化分析,说明MGMAE能够以运动自适应的方式采样时间一致的立方体,从而更有效地进行视频预训练。
1. Introduction
基于注意力机制的Transformer(如Vision Transformer,ViT)自从引入以来,在计算机视觉领域取得了巨大成功。ViT被广泛应用于各种视觉任务,并取得了最先进的性能,如图像分类[36, 59, 52]、目标检测[23, 46]、语义分割[49]和目标跟踪[8]。得益于其优异的性能,ViT模型也已被应用于视频领域,如动作识别[5, 1]和检测[33, 54]。然而,Transformer通常具有较高的模型容量,这常常需要在大规模数据集上进行预训练,以降低后续微调时过拟合的风险。因此,ViT的有效预训练策略对于在视频领域获得优异的性能尤为重要,因为视频数据集相对较小。
早期的video Transformer[1, 5]通常依赖于基于图像的大规模数据集进行预训练,这些vision Transformer衍生于大规模的图像数据集[10]。这种预训练方案使得学习到的视频模型往往受到基于图像的ViT的影响。近年来,掩蔽自编码(MAE)[35, 14, 41]由于其简洁性以及在图像领域的良好表现[17],已被探索用于video Transformer的预训练。然而,与图像不同,视频数据具有额外的时间维度,并展现出时间冗余性和相关性的独特特性。这一特性要求视频掩蔽自编码器相比图像MAE需要一些定制化的设计。例如,VideoMAE和MAE-ST都提出在视频掩蔽自编码器的预训练中使用极高的掩蔽比率以提高其性能。此外,VideoMAE设计了一种管道掩蔽策略,在所有帧中相同位置丢弃标记,以进一步减少时间上的信息泄漏。尽管这种管道掩蔽方法较为简单,但其假设相邻帧之间几乎没有或只有微小的运动,这种假设对于某些高速运动场景可能并不成立。
基于上述分析,本文提出了一种新的掩蔽策略,旨在通过显式利用运动信息来减少时间上的信息泄漏,从而改善视频掩蔽自编码器的预训练。具体而言,我们在视频掩蔽编码器处理中设计了运动引导掩蔽(Motion Guided Masking),并将所得到的掩蔽自编码器命名为MGMAE。运动是视频中普遍存在的先验信息。光流表示法明确地编码了每个像素从当前帧到下一帧的运动信息。我们提出利用这种光流信息来对相邻帧之间的掩蔽图进行对齐,从而在时间上构建一致的掩蔽体积。通过构建一致的掩蔽体积,可以通过仅让编码器看到一个小的立方体轨迹集合,构建更具挑战性的重建任务。希望这种运动引导掩蔽能够进一步减轻时间上的信息泄漏风险,并促使学习到更有意义的视觉表示。
更具体地,我们使用了一种在线且轻量的光流估计器(RAFT [34])来捕捉运动信息,该估计器可以无缝集成到现有的VideoMAE框架中。为了构建时间一致的掩蔽体积,我们首先在基准帧上随机生成一个初始掩蔽图。然后,我们使用估算的光流将初始掩蔽图扭曲到相邻帧。通过多次扭曲操作,我们为视频中的所有帧构建了时间一致的掩蔽体积。最后,基于该掩蔽体积,我们使用基于帧的top-k选择方法从中采样一组可见标记供MAE编码器处理。对这些采样标记应用与原始VideoMAE相同的自编码过程进行视频预训练。通过这种简单的运动引导掩蔽,我们能够进一步增加视频预训练任务的难度,从而得到一个更好的预训练模型,供后续微调使用。
我们主要通过在Something-Something V2 [16]和Kinetics-400 [20]数据集上与原始VideoMAE中的管道掩蔽进行对比,验证了所提出的MGMAE的有效性。结果表明,MGMAE的预训练能够生成更强大的视频基础模型,并在下游任务中取得更高的微调准确率。特别是在以动作为中心的Something-Something基准上,MGMAE的改进更加明显,表明我们的运动引导掩蔽能够适应运动变化,并能更好地捕捉时间结构信息,从而为预训练提供支持。我们希望我们的研究结果能够启发在视频掩蔽自编码领域进行一些特定且独特的设计,尤其是在与图像对比时。

图 1:不同掩蔽策略的比较。掩蔽自动编码 [11, 17] 已在视频领域进行了探索,用于自我监督预训练,采用不同的掩蔽策略:随机掩蔽 [14] 和管掩蔽 [35]。我们建议在运动信息的指导下跟踪掩蔽图(称为运动引导掩蔽)。我们得到的 MGMAE 可以为视频预训练构建更具挑战性和意义的任务。
2. Related Work
掩蔽视觉建模。掩蔽自编码器是一种长期存在的无监督学习框架,广泛应用于计算机视觉领域。早期的研究提出了去噪自编码器的通用形式[40, 39],通过从噪声输入中重建干净信号来学习表示。另一项工作[27]也将掩蔽建模视为通过卷积从周围上下文中填充缺失区域的图像修复任务。受掩蔽语言建模(Masked Language Modeling, MLM)[11]成功的启发,一些研究尝试将这一预训练范式应用于视觉领域的自监督预训练。例如,iGPT[7]借鉴了自然语言处理(NLP)中的GPT工作[30],通过处理一系列像素进行下一像素的自回归预测。原始的ViT[12]使用掩蔽标记预测作为自监督训练步骤,在大规模图像数据集上进行预训练,但未能取得令人印象深刻的结果。近年来,一些有趣的工作通过使用掩蔽图像建模在自监督图像预训练中取得了突破性进展,如BEiT[3]、SimMIM[50]和MAE[17]。BEiT[3]直接借鉴了BERT框架,提出通过预测掩蔽块的离散标记来进行训练,要求使用显式的分词器来构建标记词典。SimMIM[50]和MAE[17]共享相同的设计,直接预测掩蔽块的像素,而不需要任何分词器设计。此外,MAE[17]设计了一个非对称的编码器-解码器架构,以加速掩蔽图像预训练。
自掩蔽图像建模取得巨大成功以来,一些研究尝试将这一新的预训练范式扩展到视频领域进行自监督视频预训练。BEVT[45]和VIMPAC[32]提出通过类似于BEiT的方法,预测离散视觉标记来学习视频表示。然而,它们在视频动作识别中的性能提升有限。MaskFeat[48]将HOG特征[9]作为掩蔽块的重建目标,并在视频识别中取得了优秀的性能,采用了多尺度视觉Transformer。VideoMAE[35]和MAE-ST[14]将图像MAE扩展到视频领域,使用普通的vision Transformer进行表示学习。它们都提出使用极高的掩蔽比率来处理视频数据冗余问题。同时,VideoMAE[35]使用管道掩蔽策略进一步增加了重建任务的难度。基于VideoMAE的多项工作应运而生。例如,MAR[29]通过引入运行单元掩蔽减少了训练和推理成本。与此同时,VideoMAE V2[41]提出了双重掩蔽策略,以降低预训练开销,并通过扩展模型规模和数据集进一步探索了VideoMAE的可扩展性。我们提出的运动引导掩蔽旨在通过构建更具挑战性的掩蔽和重建任务来提高VideoMAE的性能。与原始VideoMAE不同,我们的MGMAE显式地使用光流对跨帧的掩蔽图进行对齐,并生成时间一致的掩蔽体积来采样一组可见标记。
运动引导建模。运动信息,如光流,是视频中的一种通用先验信息,代表了与图像不同的独特特性。光流已广泛应用于为视频中的低层次和高层次视觉任务提供强大的先验信息。对于低层次的视频任务,运动通常用于对齐辅助帧的信息与目标帧的对应区域。例如,在视频超分辨率任务中,BasicVSR++[6]利用光流通过从邻近帧传递特征来增强低分辨率帧的外观。对于视频修复,Zhang等[56]利用光流提取的运动差异来指导Transformer中的注意力检索,以实现高保真度的视频修复。至于视频帧插值,主流方法直接利用光流在图像上合成中间帧,如DAIN[4]和RIFE[18],而Zhang等[55]则提出了一个统一的操作,利用帧间注意力同时提取运动和外观信息,并融合了混合CNN和Transformer设计,以提高效率和精细细节的保留。对于高层次视频任务,光流直接作为数据模态输入到网络中进行动作识别[44, 31]。TDD[42]利用运动轨迹池化深度卷积特征进行动作识别。Trajectory Convolution[57]将运动信息融入时间卷积核设计中。MSNet[21]提出了一个可插拔的MotionSqueeze模块,用于生成跨帧的运动信息。VideoMS[19]通过计算补丁嵌入后的特征差异来生成掩蔽图,并尝试动态调整掩蔽位置。AdaMAE[2]引入了一种端到端可训练的自适应掩蔽策略,利用辅助采样网络优先选择来自高时空信息区域的标记。Yang等[51]利用分层运动信息改进提取的视频特征。MotionFormer[28]在视频Transformer中采用轨迹进行注意力计算。TEA[22]和TDN[43]使用RGB差异近似运动信息,并将其融入视频CNN骨干网设计中。MGSampler[58]探索了运动信息,用于选择一组代表性帧以提高视频动作识别的效率。我们的MGMAE与这些运动引导建模的工作具有相同的精神。我们专注于利用运动信息作为提示,生成掩蔽图进行视频预训练。

图 2: MGMAE 的流程
我们的 MGMAE 遵循简单的掩码和重建流程进行视频自监督预训练。我们的核心设计是提出一种运动引导的掩码策略,用于生成时间一致性的掩码体积。通过这个掩码体积,我们追踪可见的块并确保掩码图的时间一致性。最终,这使得我们能够构建一个更具挑战性的重建任务,并在掩码自监督预训练过程中鼓励提取更有效的表示。
3. Method
在本节中,我们首先回顾了 VideoMAE 的预训练范式,以在 3.1 节中清楚地介绍我们的 MGMAE。然后在 3.2 节中详细说明了运动引导的遮罩映射生成的细节。最后,在 3.3 节中描述了在时间一致的遮罩映射下的 MGMAE 预训练方法。
3.1. VideoMAE 回顾
VideoMAE 是一种简单的遮罩视频自动编码器,具有一个非对称的编码器-解码器架构,并通过立方体嵌入来处理输入的采样帧。接下来,我们简要回顾其实现细节。
立方体嵌入
VideoMAE 将输入视频片段 III(大小为 T×3×H×W)划分为不重叠的立方体 C={Ci∣Ci∈R2×16×16×3}i=1N,其中 N=2×H/16×W/16是立方体的数量。然后,对这些立方体进行嵌入生成视频标记 T={Ti∣Ti∈RD}i=1N,其中 Ti表示带有位置编码的立方体嵌入,D 是通道数。
遮罩策略
VideoMAE 使用管状遮罩策略,并设置极高的遮罩比率 ρ(即 90%),在输入视频片段的所有帧中采样相同的空间位置。具体而言,VideoMAE 首先生成一个二值遮罩映射 M′(大小为 H/16×W/16,0 表示未遮罩,1 表示遮罩),然后在时间维度上复制它,并展平成令输入视频片段的标记级遮罩映射 M 的大小为 N。
编码器
编码器是一个采用联合时空注意力机制的标准 ViT 模型。为了提高计算效率,仅将未遮罩的可见标记 Tv={Ti∣i∉M}(加上固定的位置编码)输入编码器,从而获得大小为 Nv×D的潜在特征Z,其中 Nv=⌊(1−ρ)N⌋ 是未遮罩的可见标记总数。
解码器
解码器比编码器更窄、更浅。它将由潜在特征 Z 与带有固定位置编码的可学习 [MASK] 标记连接形成的标记序列作为输入,以重建归一化的视频立方体 C^={C^i∣C^i∈R2×16×16×3}i=1N。
损失
预训练目标是在遮罩位置上最小化归一化 C 和 C^之间的均方误差损失:
 完成预训练后,编码器将作为主干网络用于下游任务的微调以获得专门模型。
完成预训练后,编码器将作为主干网络用于下游任务的微调以获得专门模型。
3.2. 运动引导遮罩图 (Motion Guided Masking Map)
时间是视频的一个独特特性,与空间维度有着不同的属性。在设计掩蔽视频自编码器时,我们需要仔细考虑这一额外的时间维度,并提出定制化的设计。时间信息泄漏是掩蔽视频预训练中的一个重要问题。当信息泄漏发生时,模型可以轻易地基于相邻帧的可见标记重建掩蔽的块,这将大大降低重建任务的难度,从而导致预训练模型在后续微调中的性能较差。一个简单的解决方案是增加掩蔽比率。VideoMAE[35]和MAE-ST[14]通过将掩蔽比率增加到90%,大大增加了重建任务的难度。此外,VideoMAE做出了小运动假设,并采用了管道掩蔽策略,该策略在所有帧中掩蔽相同的空间位置。然而,这种小运动先验并不总是适用于以运动为主的视频。一个更合理的方法是确保视频片段中的每个物体在所有帧中始终可见或不可见。为实现这一目标,我们提出了运动引导掩蔽策略,用以替代VideoMAE中的管道掩蔽策略。该策略包含两个过程:首先,我们使用光流作为指导,生成输入视频片段的时间一致的掩蔽体积;然后,基于时间一致的掩蔽体积采样未掩蔽的可见标记。我们将在第3.2节和第3.3节中详细介绍这两个过程。
一般而言,生成时间一致掩蔽体积的过程分为以下四个步骤:
- 步骤1:确定基准帧 Ib,其中 b 是基准帧的索引。
- 步骤2:随机生成一个像素级的初始掩蔽图 Mb ,大小为 H×W,作为基准帧 Ib的掩蔽图。
- 步骤3:从基准帧 Ib 中双向提取密集光流 F。
- 步骤4:在密集光流 F 的指导下,扭曲初始掩蔽图 Mb ,并逐步构建时间一致的掩蔽体积 M,大小为 T×H×W。
确定基准帧
默认情况下,我们选择中间帧作为基准帧。在运动引导掩蔽中,我们需要确保基准帧中的所有物体在输入片段的所有帧中始终保持一致的可见性或不可见性。需要注意的是,物体可能由于物体或相机的运动而在时间上(不)出现,通过光流来扭曲掩蔽图可能会导致一些“孔洞”,因为某些像素可能会被映射到边界外。因此,基准帧的选择可能会影响信息泄漏的抑制效果。我们将在第4.2节中探讨基准帧选择的影响,结果表明,中间帧是最优选择。
生成初始掩蔽图
我们为基准帧初始化一个像素级的掩蔽图,使用高斯混合模型(GMM)来分布这些掩蔽区域。掩蔽图用来指示基准帧中块的可见或不可见状态。以往的掩蔽策略通常使用基于标记级的二进制初始化,即每个大小为 2×16×16 的标记要么全为0,要么全为1,这种做法实际上打破了物体表面纹理的连续性。
具体而言,我们首先随机选择 N^v=⌊(1−ρ)×H/16×W/16⌋ 个标记,其中心坐标为 c={c⃗i:(ci1,ci2)}iN^v。然后,我们在每个标记的中点生成二维高斯分布 Ni(ci,σ2),其中 σ是标准差,取为块大小(16,16)。由此,我们会得到与基准帧对应的混合高斯分布  ,并使用混合高斯分布的概率密度函数来指示基准帧中块(标记)的可见性。
,并使用混合高斯分布的概率密度函数来指示基准帧中块(标记)的可见性。
提取光流
我们使用在线和离线两种方法提取光流。在线方法使用RAFT[34](小版本)来估计输入视频片段的光流;离线方法则应用传统的TVL1[53]算法提前提取所有相邻帧之间的密集光流。在读取光流时,我们执行一致的裁剪、缩放操作。在线和离线方法的结果相似,更多细节请参见第4.2节。
在实践中,我们仅从基准帧 Ib 提取前向和后向光流 F,即:
 其中,光流 νi→j表示从帧 Ii到帧 Ij的光流。
其中,光流 νi→j表示从帧 Ii到帧 Ij的光流。
使用光流扭曲掩蔽图
我们使用反向扭曲方法逐步生成视频片段的时间一致掩蔽图。前向扭曲 ϕF 和反向扭曲 ϕB 是两种相对的扭曲模式,都可以有效地用于从初始掩蔽图构建掩蔽体积。遗憾的是,前向扭曲会遇到“孔洞”或遮挡问题,即某些像素可能无法接收到光流,或者可能有多个光流指向同一像素。相比之下,反向扭曲将给定图像的像素逐一映射到各自的目标位置。值得注意的是,尽管反向扭曲并不能避免因光流映射超出边界而产生的孔洞,但这些孔洞通常比前向扭曲少,并且大多发生在图像的边界,因此对信息分布的影响较小。对于反向扭曲造成的孔洞,我们用基准帧中相应位置的值填充这些孔洞,从而模拟管道掩蔽策略。
形式化地,给定光流 F 和基准帧掩蔽体积 Mb ,可以通过反向扭曲构建视频帧 Ii的掩蔽图 Mi:
 随后,整个掩蔽体积 M={Mi}i=1T可以通过双向反向扭曲光流 FFF,从基准帧掩蔽图 Mb开始逐步构建。
随后,整个掩蔽体积 M={Mi}i=1T可以通过双向反向扭曲光流 FFF,从基准帧掩蔽图 Mb开始逐步构建。
3.3 运动引导的掩蔽自编码器 (MGMAE)
我们基于上述的运动引导掩蔽图构建了MGMAE。时间一致的掩蔽体积表示在光流追踪下,邻近帧中对应位置的可见性概率。为了尽可能抑制信息泄漏,我们沿时间维度采样具有最高可见概率的视频标记。具体来说,我们首先对掩蔽体积 M 执行大小为 2×16×16的平均池化操作,以获得大小为 T/2×H/16×W/16 的标记级掩蔽体积 M′。然后,我们在时间维度上选择前 N^v 个掩蔽图位置,并从中采样相应的视频标记作为未掩蔽的可见标记。
根据我们得到的时间一致掩蔽体积,这些采样的标记被输入到非对称的编码器-解码器中进行自编码器式的预训练。通过我们MGMAE预训练得到的模型与原始的VideoMAE模型在微调下游任务时采用相同的方法。
讨论
此前的研究 [35, 14] 将MAE扩展到了视频领域,它们分别采用了随机(无关)掩蔽和管道(仅空间)掩蔽策略。随机掩蔽不会对视频的空间和时间维度引入明确的归纳偏差,其目的是提供一个最小领域知识的统一特征表示学习框架。我们认为,尽管这个思想很简单,但时间本质上是与空间不同的维度。认识到这一点后,我们可以更好地利用这一先验信息来增强视频的掩蔽自编码。
管道掩蔽假设帧的大面积区域没有运动或只有很小的运动,因此跨帧掩蔽相同的位置可以大大减少信息泄漏的风险。然而,对于以运动为主的视频数据集,如Something-Something,这一假设将不再成立,正如表1b所示,反向扭曲的贡献证明了这一点。我们提出的运动引导掩蔽提供了一个更通用且概念上简单的解决方案,可以考虑时间关联性。它可以视为一种自适应的视频掩蔽策略,并在视频预训练中创造出更具挑战性但意义重大的任务。
4. Experiments
4. 实验
4.1 数据集
与原始的VideoMAE相同,我们在Kinetics-400 (K400) [20] 和 Something-Something V2 (SSV2) [16] 数据集上评估我们的MGMAE。K400包含约24万条训练视频和2万条验证视频,视频中的动作通常与特定的物体或场景相关,如刷牙和弹钢琴。而SSV2包含约16.9万条训练视频和2.5万条验证视频,SSV2中的类别主要关注特定的运动模式(例如推、拉)。我们首先在相应的数据集上使用MGMAE对视频Transformer进行自监督表示学习的预训练。然后,我们报告预训练模型在目标数据集上进行动作识别的微调表现。在我们的MGMAE预训练中,我们通常遵循原始VideoMAE的设置和实现。由于RAFT [34] 在MGMAE预训练中的效率和准确性,我们采用它来提取光流。有关MGMAE实现的详细信息,可以在附录中找到。
4.2 消融实验
在本小节中,我们对运动引导掩蔽策略中每个步骤的选择进行了深入的消融实验。我们使用16台80G-A100 GPU在SSV2数据集上训练ViT-base模型800个epoch,然后在SSV2数据集上微调编码器进行动作识别。所有模型共享相同的训练计划,并报告2个剪辑×3个裁剪的准确性。
基帧选择
在本研究中,我们探讨了基帧选择对初始掩蔽生成过程的影响。我们将中间帧作为基帧与第一帧或随机帧进行比较,结果如表1a所示。结果表明,中间帧是最佳选择。
使用光流的扭曲方法
我们比较了两种用于对齐帧间掩蔽图的扭曲方法,如第3.2节所述。正如之前提到的,前向扭曲往往会导致掩蔽扭曲过程中更严重的遮挡和孔洞问题。相反,反向扭曲可以有效缓解这一问题,并确保更加平滑的掩蔽扭曲。表1b的结果表明,反向扭曲有助于更好的性能。
顶部k个可见标记的采样策略
我们检查并比较了两种采样策略,基于我们的时间一致掩蔽体积选择可见标记。帧级策略为每帧独立采样前k个位置,而剪辑级策略为整个视频联合采样前k个位置。正如表1c所示,帧级前k采样策略的性能略优。
基帧的掩蔽初始化
我们消融了在基帧生成初始掩蔽图的选择,如表1d所示。标记级初始化方法将掩蔽图划分为大小为 H16×W16\frac{H}{16} \times \frac{W}{16}16H×16W 的16×16标记,并随机将90%的标记设置为0(表示被掩蔽)和10%的标记设置为1(表示未掩蔽)。像素级初始化方法随机将90%的像素设置为0,10%的像素设置为1。混合高斯方法的初始化过程在第3.2节中有详细描述。结果表明,混合高斯初始化方法效果最好。
孔洞填充方法
我们研究了在反向扭曲中通过映射出界产生的孔洞问题的不同处理方法,如表1e所示。为了确定反向扭曲所造成的真实孔洞,我们将初始掩蔽图中的0值设置为1e−8,然后将新掩蔽图中等于0的位置视为孔洞。我们试验了五种填充孔洞的方法:
- 不可见方法:将所有孔洞填充为0;
- 可见方法:将所有孔洞填充为1;
- 随机方法:根据掩蔽率ρ以随机概率将孔洞填充为0或1;
- 先前图方法:使用与上一个生成的掩蔽图相同位置的值填充孔洞;
- 管道方法:根据初始掩蔽图中对应位置的值填充孔洞,符合管道掩蔽的原则。
我们发现,管道方法在所有方法中表现最好。
光流估计方法
我们评估了不同光流估计方法的效果,如表1f所示。对于离线方法,我们使用TVL1算法提前提取光流,其准确性与在线的RAFT光流相当。尽管VideoMAE在使用RAFT-small(设为6次测试迭代)估计光流时训练速度比MGMAE快1.3倍,但MGMAE在性能和减少过拟合风险方面有明显优势。我们发现,离线方法的训练速度并不比在线方法快,因为读取光流(IO操作)会成为训练速度的瓶颈。值得注意的是,我们的默认设置并不是最优的,但其他消融实验中得出的结论应该不受影响。
掩蔽率
MGMAE的表现突出了即使在高掩蔽率下(例如90%),改进掩蔽策略的重要性。然而,在应用MGMAE之后,仍然有一个问题是是否仍然需要这么高的掩蔽率。正如[35, 14]所指出的,盲目提高掩蔽率可能会降低模型的性能。我们的消融实验如图3所示,表明即使在MGMAE的情况下,维持80%以上的高掩蔽率也是至关重要的。我们认为,视频背景和大物体主要驱动了高掩蔽率的需求。视频背景通常宽广且简单。如果掩蔽率不够高,模型仍然可以从其他背景部分重建像素,即使邻近帧掩蔽了相似的区域。对于大物体,较低的掩蔽率可能会让模型使用不同部分的纹理来重建被掩蔽的部分。从实验中也可以观察到,MGMAE在85%的掩蔽率下表现最佳,但90%仍然是一个不错的选择,考虑到训练效率和性能之间的折衷。
掩蔽对象的暴露
另一个值得考虑的建议是,偶尔暴露被掩蔽的对象是否有助于掩蔽视频建模的预训练。我们进行了一个补充实验。具体而言,在构建掩蔽体积之后,我们向一个随机选择的帧的掩蔽图上添加了高斯噪声。这种修改可能会提供一个机会,让被掩蔽的对象暴露出来。结果显示,准确率为71.2%,略高于默认设置的71.0%。

表1:在Something-Something V2数据集上的部分消融实验结果。
我们的MGMAE预训练采用16帧的基础ViT-B骨干网络实现。所有模型均在掩码比例ρ=90%的条件下进行800个周期的预训练。推理协议采用2片段×3裁剪的方式报告微调动作识别的准确率。
默认设置在表中以灰色标出。尽管在光流估计方法上默认设置可能不是最优的,但我们认为这并不影响消融实验的结论。

图3:掩蔽比例对SSV2的影响。
4.3 主要结果与可视化分析
在对 MGMAE 设计进行详细的消融研究后,我们进一步通过与原始 VideoMAE 的比较进行更深入的分析,同时提供了一些中间可视化结果以说明运动引导采样过程。

表2:MGMAE和VideoMAE的预训练损失比较。
预训练损失表明任务更具挑战性
MGMAE 的核心设计是借助光流动态采样被遮掩 token 的位置,从而增加重建任务的难度。如表 2 所示,MGMAE 的预训练损失始终比 VideoMAE 高出 0.05 以上。此损失差距表明运动引导遮掩进一步抑制了信息泄露,并构建了更具挑战性的遮掩-重建预训练任务。这一更困难的任务有助于学习更有效的表示。

图 4:MGMAE 和 Video MAEbyClass 的准确率比较。
MGMAE 和 VideoMAE 的详细比较
为了理解 MGMAE 和 VideoMAE 遮掩策略对视频模型预训练的不同影响,我们深入分析了两者在每个类别上的准确率变化。图 4 展示了分类准确率差异最显著的 29 个类别,直观反映了两种方法的区别。

表3:MG MAE与VideoMAE的准确度比较。
MGMAE:更有效的视频表示学习器
MGMAE 因运动引导遮掩策略构建的更困难任务而受益匪浅。一方面,模型必须更加努力地编码可见 token 与不可见 token 之间的关系,从而更好地指导模型训练。另一方面,信息泄露的抑制可能有效降低预训练的过拟合风险,使得模型可以进行更长时间的预训练。如表 3 所示,在以动作为中心的 SSV2 数据集上,MGMAE 的微调性能相较 VideoMAE 一直保持明显优势(800 轮时提升 1.4%,2400 轮时提升 1.5%)。在以场景为中心的 Kinetics-400 数据集上也有一定提升(800 轮时提升 1.2%,1600 轮时提升 0.3%)。

图5:SSV2验证集视频的可视化。
我们展示了运动引导掩码图以及重建图像。从上到下依次为:原始图像、x方向的光流、y方向的光流、运动引导掩码图、掩码后的图像以及重建的图像。
可视化分析
我们随机选取了 SSV2 验证集中的一个视频片段,并在图 5 中展示了其重建示例。可以看到,遮掩图随着物体运动而变化,使得模型更难以重建原始视频。

表 4:Something-Something V2 数据集上的比较。我们仅列出使用类似主干获得的结果。
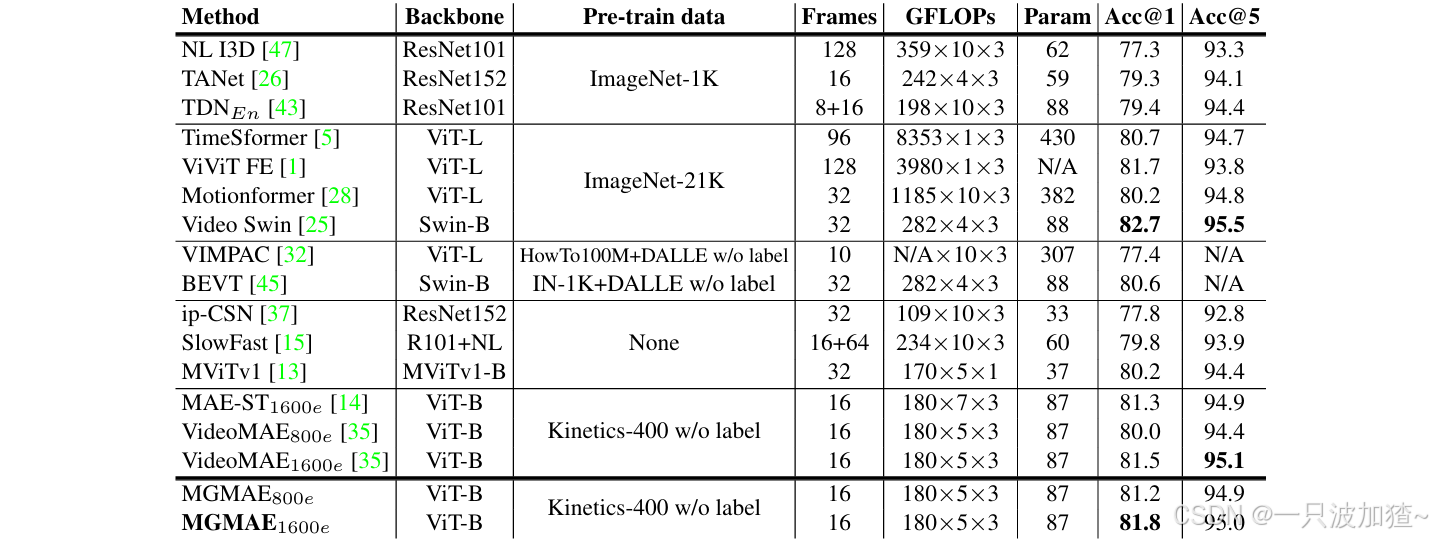
表 5:Kinetics-400 数据集上的比较。我们仅列出使用相似主链获得的结果。
4.4 与最新方法的比较
我们将 MGMAE 与之前的最新方法在 Kinetics-400 和 Something-Something V2 数据集上进行了比较,结果分别展示在表 5 和表 4 中。为保证公平比较,我们主要列出计算成本相近的结果。在 Something-Something V2 数据集上,MGMAE 使用 ViT-B 骨干网络在 2400 轮训练中取得了 72.3% 的性能,相较原始 VideoMAE 提升了 1.5%。在 Kinetics-400 数据集上,MGMAE 的性能略优于原始 VideoMAE。这种较小的性能提升可能归因于 Kinetics-400 是一个以场景为中心的动作识别基准,相较于 Something-Something 数据集,运动信息的重要性较低。
5. Conclusion
总结
本文提出了运动引导的掩码自动编码器 (MGMAE),它通过运动引导的掩码策略,在光流的指导下动态采样未掩码的可见 Token,从而抑制信息泄露,为掩码视频预训练构建了一个更具挑战性的任务。实验结果表明,MGMAE 性能良好,并在公平比较的条件下始终保持对现有方法的显著性能优势。此外,该策略还降低了预训练过程中过拟合的风险,使得模型能够从更长时间的预训练中受益。
相关文章:

论文阅读:MGMAE : Motion Guided Masking for Video Masked Autoencoding
MGMAE:Motion Guided Masking for Video Masked Autoencoding Abstract 掩蔽自编码(Masked Autoencoding)在自监督视频表示学习中展现了出色的表现。时间冗余导致了VideoMAE中高掩蔽比率和定制的掩蔽策略。本文旨在通过引入运动引导掩蔽策略࿰…...

【NodeJS】解决NodeJS前端项目在开发环境访问指定的地址失败或超时,测试和设置环境变量的方式
本文目录 代码测试网络 两种解决方式设置环境变量代码中设置 在日常开发中,代码中偶尔需要访问特定的服务例如github,而NodeJS在访问网络时默认是不受其他工具影响的,需要通过环境变量或代码配置的方式实现Proxy,本文简单描述了调…...

深度学习中的梯度相关问题
1.求偏导的意义、作用?为什么要求偏导? 偏导数帮助我们理解函数在某一个变量变化时,函数值如何变化,同时保持其他变量不变。在机器学习中,尤其是训练神经网络时,我们通过求偏导数来确定如何调整模型参数以…...

Spider 数据集上实现nlp2sql训练任务
NLP2SQL(自然语言处理到 SQL 查询的转换)是一个重要的自然语言处理(NLP)任务,其目标是将用户的自然语言问题转换为相应的 SQL 查询。这一任务在许多场景下具有广泛的应用,尤其是在与数据库交互的场景中&…...

Ubuntu 下 nginx-1.24.0 源码分析 - ngx_show_version_info函数
声明 在 nginx.c 开头 static void ngx_show_version_info(void); 实现 static void ngx_show_version_info(void) {ngx_write_stderr("nginx version: " NGINX_VER_BUILD NGX_LINEFEED);if (ngx_show_help) {ngx_write_stderr("Usage: nginx [-?hvVtTq] [-s s…...

LM Studio本地调用模型的方法
首先需要下载LM Studio,(LM Studio - Discover, download, and run local LLMs)安装好后,需要对index.js文件进行修改,主要是对相关源hugging face的地址修改。 以macOS为例: cd /Applications/LM\ Studi…...

Open3d Qt的环境配置
Open3d Qt的环境配置 一、概述二、操作流程2.1 下载文件2.2 新建文件夹2.3 环境变量设置2.4 qt6 引用3、qt中调用4、资源下载一、概述 目前统一使用qt6配置,open3d中可视化功能目前使用vtk代替,语言为c++。 二、操作流程 2.1 下载文件 访问open3d github链接,进入releas…...

数据结构——链表
引言 链表(Linked List)是计算机科学中最基础且灵活的数据结构之一。与数组的连续内存分配不同,链表通过指针将零散的内存块串联起来,允许动态调整数据规模,避免内存浪费。链表广泛应用于操作系统内核、数据库索引、动…...

数据结构 图
目录 前言 一,图的基本知识 二,图的表示法:边列表 三,图的表示方法:邻接矩阵 四,图的表示方法:邻接表 五,功能 总结 前言 图是一个非常有意思东西,可以运用到生活中…...

2025.2.8总结
题目描述 如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出 orz。 输入格式 第一行包含两个整数 N,MN,M,表示该图共有 NN 个结点和 MM 条无向边。 接下来 MM 行每行包含三个整数 Xi,Yi,ZiXi,Yi,Zi&#…...
)
软件模拟I2C案例(寄存器实现)
引言 在经过前面对I2C基础知识的理解,对支持I2C通讯的EEPROM芯片M24C02的简单介绍以及涉及到的时序操作做了整理。接下来,我们就正式进入该案例的实现环节了。本次案例是基于寄存器开发方式通过软件模拟I2C通讯协议,然后去实现相关的需求。 阅…...

开源CodeGPT + DeepSeek-R1 是否可以替代商业付费代码辅助工具
开源CodeGPT + DeepSeek-R1 是否可以替代商业付费代码辅助工具 背景与研究目的 在快速发展的软件开发领域,代码辅助工具已成为提高开发效率和质量的关键。然而,商业付费工具如通义灵码和腾讯AI代码助手,尽管功能强大,但其高昂的成本和许可证限制,使得许多企业寻求更具吸…...

c++:list
1.list的使用 1.1构造 1.2迭代器遍历 (1)迭代器是算法和容器链接起来的桥梁 容器就是链表,顺序表等数据结构,他们有各自的特点,所以底层结构是不同的。在不用迭代器的前提下,如果我们的算法要作用在容器上…...

Websocket从原理到实战
引言 WebSocket 是一种在单个 TCP 连接上进行全双工通信的网络协议,它使得客户端和服务器之间能够进行实时、双向的通信,既然是通信协议一定要从发展历史到协议内容到应用场景最后到实战全方位了解 发展历史 WebSocket 最初是为了解决 HTTP 协议在实时…...

探索robots.txt:网站管理者的搜索引擎指南
在数字时代,网站如同企业的在线名片,其内容和结构对搜索引擎的可见性至关重要。而在这背后,有一个默默工作的文件——robots.txt,它扮演着搜索引擎与网站之间沟通桥梁的角色。本文将深入探讨robots.txt的功能、编写方法及其在现代…...
 实测有用)
ubuntu中如何在vscode的终端目录后显示(当前的git分支名) 实测有用
效果展示 配置过程: 在 Ubuntu 中,如果你想在 VS Code 的终端提示符后显示当前的 Git 分支名,可以通过修改 Shell 配置文件(如 ~/.bashrc 或 ~/.zshrc)来实现。以下是具体步骤: 1. 确定使用的 Shell 首…...

0012—数组
存取一组数据,使用数组。 数组是一组相同类型元素的集合。 要存储1-10的数字,怎么存储? C语言中给了数组的定义:一组相同类型元素的集合。 创建一个空间创建一组数: 一、数组的定义 int arr[10] {1,2,3,4,5,6,7,8,…...

决策树算法相关文献
决策树是一种基于树状结构的机器学习算法,广泛应用于分类和回归任务。尽管决策树算法已经非常成熟,但研究者们仍在不断探索新的方法和技术,以进一步提升其性能、适应性和可解释性。 以下是当前研究者对决策树算法的最新研究方向和内容&#x…...

DeepSeek在FPGA/IC开发中的创新应用与未来潜力
随着人工智能技术的飞速发展,以DeepSeek为代表的大语言模型(LLM)正在逐步渗透到传统硬件开发领域。在FPGA(现场可编程门阵列)和IC(集成电路)开发这一技术密集型行业中,DeepSeek凭借其…...

学习threejs,使用Lensflare模拟镜头眩光
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️THREE.Lensflare 二、&…...

RuoYi-Vue-Oracle的oracle driver驱动配置问题ojdbc8-12.2.0.1.jar的解决
RuoYi-Vue-Oracle的oracle driver驱动配置问题ojdbc8-12.2.0.1.jar的解决 1、报错情况 下载:https://gitcode.com/yangzongzhuan/RuoYi-Vue-Oracle 用idea打开,启动: 日志有报错: 点右侧m图标,maven有以下报误 &…...

kafka服务端之日志磁盘存储
文章目录 页缓存顺序写零拷贝 Kafka依赖于文件系统(更底层地来说就是磁盘)来存储和缓存消息 。 那么kafka是如何让自身在使用磁盘存储的情况下达到高性能的?接下来主要从3各方面详细解说。 页缓存 页缓存是操作系统实现的一种主要的磁盘缓存…...

deepseek来讲lua
Lua 是一种轻量级、高效、可嵌入的脚本语言,广泛应用于游戏开发、嵌入式系统、Web 服务器等领域。以下是 Lua 的主要特点和一些基本概念: 1. 特点 轻量级:Lua 的核心非常小,适合嵌入到其他应用程序中。高效:Lua 的执…...
常见面试题)
C++开发(软件开发)常见面试题
目录 1、C里指针和数组的区别 2、C中空指针请使用nullptr不要使用NULL 3、http/https区别和头部结构? 4、有了mac地址为什么还要ip地址?ip地址的作用 5、有了路由器为什么还要交换机? 6、面向对象三大特性 7、友元函数 8、大端小端 …...
)
AtCoder Beginner Contest 391(A~E题题解)
A - Lucky Direction 思路:纯模拟的一个水题 #include <bits/stdc.h> using namespace std; #define int long long string s; signed main() { cin>>s;for(int i0;i<s.size();i){char cs[i];if(cN){cout<<"S";}else if(c…...

使用线性回归模型逼近目标模型 | PyTorch 深度学习实战
前一篇文章,计算图 Compute Graph 和自动求导 Autograd | PyTorch 深度学习实战 本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started 使用线性回归模型逼近目标模型 什么是回归什么是线性回归使用 PyTorch 实现线性回归模型代码执行结…...

解决com.kingbase8.util.KSQLException: This _connection has been closed.
问题描述 一个消息管理系统,系统采用kingbase8数据库,数据库采用单体模式,后台应用也采用springboot单体模式。系统正式上线后,出现几个JDBC响应的异常信息: com.kingbase8.util.KSQLException: An I/O error occurred while sending to the backend.java.net.SocketTime…...

Pyqt 的QTableWidget组件
QTableWidget 是 PyQt6 中的一个表格控件,用于显示和编辑二维表格数据。它继承自 QTableView,提供了更简单的方式来处理表格数据,适合用于需要展示结构化数据的场景。 1. 常用方法 1.1 构造函数 QTableWidget(parent: QWidget None)&#x…...
API使用详解)
DeepSeek R1 Distill Llama 70B(免费版)API使用详解
DeepSeek R1 Distill Llama 70B(免费版)API使用详解 在人工智能领域,随着技术的不断进步,各种新的模型和应用如雨后春笋般涌现。今天,我们要为大家介绍的是OpenRouter平台上提供的DeepSeek R1 Distill Llama 70B&…...

24.ppt:小李-图书策划方案【1】
目录 NO1234 NO5678 NO1234 新建PPT两种方式👇docx中视图→导航窗格→标题1/2/3ppt新建幻灯片→从大纲→重置开始→版式设计→主题插入→表格 NO5678 SmartArt演示方案:幻灯片放映→自定义幻灯片放映→新建→选中添加...

百科词条创建审核不通过的原因有哪些?
我们知道的国内有名的百科网站有百度百科、快懂百科、搜狗百科、360百科,这些有名的百科网站。一般来说,百科的词条排名都是在第一页的,无论是名人、明星、软件、影视名称,还是其他名称,大多排名都在首页,这就拥有了更多的曝光量和流量,而且由于百科是人们获取信息、查找资料的…...

amis组件crud使用踩坑
crud注意 过滤条件参数同步地址栏 默认 CRUD 会将过滤条件参数同步至浏览器地址栏中,比如搜索条件、当前页数,这也做的目的是刷新页面的时候还能进入之前的分页。 但也会导致地址栏中的参数数据合并到顶层的数据链中,例如:自动…...

【docker】Failed to allocate manager object, freezing:兼容兼容 cgroup v1 和 v2
参考大神让系统同时兼容 cgroup v1 和 v2 要解决你系统中只挂载了 cgroup v2 但需要兼容 cgroup v1 的问题,可以通过以下几步来使系统同时兼容 cgroup v1 和 cgroup v2。这样 Docker 和其他服务就可以正常工作了。步骤 1:更新 Grub 配置,启用兼容模式 编辑 GRUB 配置来启用同…...

LeetCode:503.下一个更大元素II
跟着carl学算法,本系列博客仅做个人记录,建议大家都去看carl本人的博客,写的真的很好的! 代码随想录 LeetCode:503.下一个更大元素II 给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[…...

【AI日记】25.02.08
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】【读书与思考】【AI应用】 探索 AI 应用探索周二有个面试,明后天打算好好准备一下,我打算主要研究下 AI 如何在该行业赋能和应用,以及该行业未来的发展前景和公司痛点&#…...
)
32. C 语言 安全函数( _s 尾缀)
本章目录 前言什么是安全函数?安全函数的特点主要的安全函数1. 字符串操作安全函数2. 格式化输出安全函数3. 内存操作安全函数4. 其他常用安全函数 安全函数实例示例 1:strcpy_s 和 strcat_s示例 2:memcpy_s示例 3:strtok_s 总结 …...

常用数据结构之String字符串
字符串 在Java编程语言中,字符可以使用基本数据类型char来保存,在 Java 中字符串属于对象,Java 提供了 String 类来创建和操作字符串。 操作字符串常用的有三种类:String、StringBuilder、StringBuffer 接下来看看这三类常见用…...

Android开发获取缓存,删除缓存
Android开发获取缓存,删除缓存 app设置中往往有清理缓存的功能。会显示当前缓存时多少,然后可以点击清理缓存 直接上代码: object CacheHelper {/*** 获取缓存大小* param context* return* throws Exception*/JvmStaticfun getTotalCache…...

网络安全 | 保护智能家居和企业IoT设备的安全策略
网络安全 | 保护智能家居和企业IoT设备的安全策略 一、前言二、智能家居和企业 IoT 设备面临的安全威胁2.1 设备自身安全缺陷2.2 网络通信安全隐患2.3 数据隐私风险2.4 恶意软件和攻击手段 三、保护智能家居和企业 IoT 设备的安全策略3.1 设备安全设计与制造环节的考量3.2 网络…...
_38 JNI从C调用Java函数 01)
掌握API和控制点(从Java到JNI接口)_38 JNI从C调用Java函数 01
1. Why? 将控制点下移到下C/C层 对古典视角的反思 App接近User,所以App在整体架构里,是主导者,拥有控制权。所以, App是架构的控制点所在。Java函数调用C/C层函数,是合理的。 但是EIT造形告诉我们: App…...
)
vue组件间的数据传递:自定义输入组件(v-model/defineModel)
文章目录 引言I Vue 3.4 开始,推荐使用 defineModel() 宏子组件使用defineModel父组件用 v-model 绑定值底层机制II Vue 3.4之前:自定义输入组件(组件中实现 v-model )前置知识父组件监听自定义事件进行 v-model 的数据绑定子组件通过监听input事件触发自定义的 `update:mo…...

记录一下 在Mac下用pyinstallter 打包 Django项目
安装: pip install pyinstaller 在urls.py from SheepMasterOneToOne import settings from django.conf.urls.static import staticurlpatterns [path("admin/", admin.site.urls),path(generate_report/export/, ReportAdmin(models.Report, admin.site).generat…...

大模型相关概念
文章目录 部署相关数据并行模型并行张量并行管道并行(流水线并行) 混合并行(数据并行模型并行)显存优化技术InfiniBand去中心化的All-Reduce操作软件 大模型命名**1. 模型架构相关****2. 模型用途相关****3. 训练方法相关****4. 多…...

【实用教程】在 Android Studio 中连接 MuMu 模拟器
MuMu 模拟器是一个非常流行的安卓模拟器,特别适合开发人员进行应用测试,我使用它的根本原因在于Android Studio自带的AVM实现是太难用了,但是Mumu模拟器启动以后不会自动被Android Studio识别到,但是其他模拟器都是能够正常被Andr…...

Linux 安装 Ollama
1、下载地址 Download Ollama on Linux 2、有网络直接执行 curl -fsSL https://ollama.com/install.sh | sh 命令 3、下载慢的解决方法 1、curl -fsSL https://ollama.com/install.sh -o ollama_install.sh 2、sed -i s|https://ollama.com/download/ollama-linux|https://…...
)
双亲委派(JVM)
1.双亲委派 在 Java 中,双薪委派通常是指双亲委派模型,它是 Java 类加载器的一种工作模式,用于确保类加载的安全性和一致性。以下是其相关介绍: 定义与作用 定义:双亲委派模型要求除了顶层的启动类加载器外…...

青少年编程与数学 02-009 Django 5 Web 编程 01课题、概要
青少年编程与数学 02-009 Django 5 Web 编程 01课题、概要 一、Django 5Django 5 的主要特性包括: 二、MVT模式三、官方网站四、内置功能数据库 ORM(对象关系映射)用户认证和授权表单处理模板引擎URL 路由缓存框架国际化和本地化安全性功能管…...

为AI聊天工具添加一个知识系统 之90 详细设计之31 Derivation 之5-- 神经元变元用它衍生神经网络
本文要点 要点 Derivation 神经元变元衍生模型( 衍生 神经网络) 整体上说,它( Derivation)自己充当 整体无意识原型anestor的代言--作为所有神经网络的 共生环境。Derivation 初始断言了 基于最古老的 自然和逻辑树…...

Centos挂载镜像制作本地yum源,并补装图形界面
内网环境centos7.9安装图形页面内网环境制作本地yum源 上传镜像到服务器目录 创建目录并挂载镜像 #创建目录 cd /mnt/ mkdir iso#挂载 mount -o loop ./CentOS-7-x86_64-DVD-2009.iso ./iso #前面镜像所在目录,后面所挂载得目录#检查 [rootlocalhost mnt]# df -h…...

【Python实战练习】Python类中的方法:形式与作用详解
文章目录 Python类中的方法:形式与作用详解1. 实例方法 (Instance Method)定义与使用作用2. 类方法 (Class Method)定义与使用作用3. 静态方法 (Static Method)定义与使用作用4. 特殊方法 (Magic/Dunder Methods)常见的特殊方法定义与使用作用5. 抽象方法 (Abstract Method)定…...