【CUDA】内存模型
目录
一、Programmable
1.1 寄存器(Registers)
1.2 本地内存(Local Memory)
1.4 常量内存(Constant Memory)
1.5 全局内存(Global Memory)
1.6 纹理内存(Textrue Memory)
1.7 总结
二、Cache(Non-programmable)
三、固定内存
四、零拷贝内存
五、统一内存
对于程序员而言,memory可以分为下面两类:
- Programmable:可以灵活操作的部分。
- Non-programmable:不能操作,由一套自动机制来达到很好的性能
一、Programmable
在CUDA中可编程内存的类型有:
-
寄存器(Registers)
-
本地内存(Local Memory)
-
共享内存(Shared Memory)
-
常量内存(Constant Memory)
-
纹理内存(Texture Memory)
-
全局内存(Global Memory)
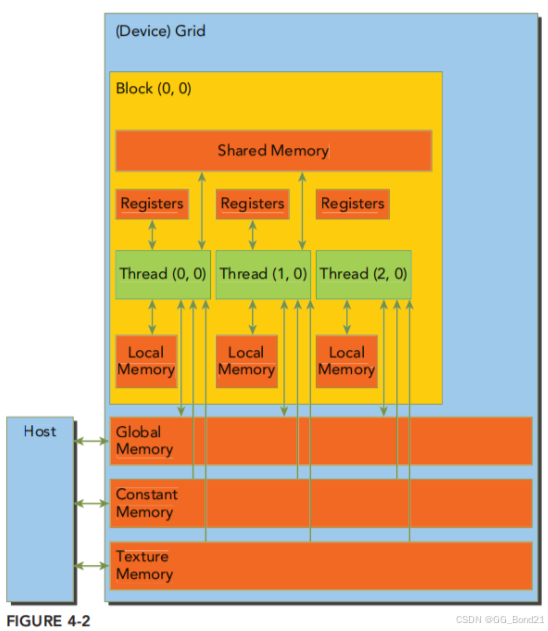
- 一个线程拥有自己私有的寄存器和局部内存(local memory)
- 一个block内的所有线程可以读写该block专有的共享内存(shared memory)
- 所有线程可以读写全局内存(Global memory),只读常量内存(constant memory)和纹理内存(texture memory)
1.1 寄存器(Registers)
在内核函数中声明且没有其他修饰符修饰的变量通常存放在GPU的寄存器中。如:下面代码中的线程索引变量i。寄存器通常用于存放内核函数中需要频繁访问的线程私有变量,这些变量与内核函数的生命周期相同,内核函数执行完毕后,就不能再进行访问了
__global__ void VectorAddGPU(const float *const a, const float *const b, float *const c, const int n)
{int i = blockDim.x * blockIdx.x + threadIdx.x; if (i < n)c[i] = a[i] + b[i];
}寄存器是稀有资源。在Fermi上,每个thread限制最多拥有63个register,Kepler则是255个。让kernel使用较少的register就能够允许更多block驻留在SM中,就增加了Occupancy,提升了性能
可以通过如下编译选项查看线程的寄存器,共享内存的使用情况
-Xptxas -v,-abi=no若使用的寄存器超出了硬件限制,那么多出来的部分就会存放在Local memory里
CUDA编译器提供了关键字__launch_bound__启发式地限制寄存器的使用,从而提高SM内active block数量
__global__ void
__launch_bounds__(maxThreadsPerBlock, minBlocksPerMultiprocessor)
kernel(...) {// your kernel body
}heuristics(启发式)一词,说通俗一点,就是在代码中显示告知编译器,该Kernel函数每个Block分配的最大线程数以及SM最小支持的active block数,这样编译器就可以调整每个线程拥有的寄存器数,优化SM中active block的数量了
maxThreadPerblock:参数指定了一个Block内最大线程数
minBlockkPerMultiprocessor:一个SM最少支持的active block数。这个参数不是必需的,编译器会根据不同的GPU架构赋值
另一种方法限制线程使用的寄存器的数量,采用如下编译参数,
-maxrregcount=32所有CUDA线程的寄存器都被限制在32个,除非某个Kernel函数显示的使用__launch_bounds__
1.2 本地内存(Local Memory)
线程私有
在内核函数中符合存储在寄存器中但不能进入分配的寄存器空间中的变量将被溢出到本地内存中,可能存放到本地内存中的变量有:
- 编译时使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地结构体或者数组
- 任何不满足内核函数寄存器限定条件的变量
物理上并不存在单独的Local memory。编译器会将其放入片外的DRAM中(与Global Memory相同),访存延迟大,带宽小
1.3 共享内存(shared Memory)
共享内存是SM的私有资源,属于on-chip内存,带宽相对较高,延迟也较低
在内核函数中被__shared__修饰符修饰的变量被存储到共享内存中。每个SM都有一定数量供线程块分配的共享内存,在内核函数内进行声明,生命周期伴随整个线程块,一个线程块执行结束后,为其分配的共享内存也被释放以便重新分配给其他线程块进行使用。线程块中的线程通过使用共享内存中的数据可以实现互相之间的协作,不过使用共享内存可通过如下函数进行同步:
void __sybcthreads()该函数为线程块中的所有线程设置了一个执行障碍点,使得同一线程块中的所有线程必须都执行到该障碍点才能往下执行,这样就可以避免一些潜在的数据冲突
1.4 常量内存(Constant Memory)
offchip内存,只读,拥有SM私有的constant cache,因此在cache hit的情况下速度快。常量内存是全局的,对所有Kernel函数可见。因此声明要在Kernel函数外
__constant__ float variable;常量变量存储在常量内存中,内核函数只能从常量内存中读取数据,常量内存必须在host端代码中进行初始化
cudaError_t cudaMemcpyToSymbol(const void* symbol, const void* src,size_t count);下面的例子展示了如何声明常量内存并与之进行数据交换:
__constant__ float const_data[256];
float data[256];
cudaMemcpyToSymbol(const_data, data, sizeof(data));
cudaMemcpyFromSymbol(data, const_data, sizeof(data));常量内存适合用于线程束中的所有线程都需要从相同的内存地址中读取数据的情况,如:所有线程都需要的常量参数,每个GPU只可以声明不超过64KB的常量内存
1.5 全局内存(Global Memory)
offchip内存,所有线程可见
一个全局内存变量可以在host代码中使用cudaMalloc函数进行动态声明,或者使用__device__修饰符在device代码中静态声明。全局内存变量可以在任何SM设备中被访问到,其生命周期贯穿应用程序的整个生命周期
静态声明并使用全局变量
#include <cuda_runtime.h>
#include <stdio.h>__device__ float dev_data;__global__ void AddGlobalVariable(void) {printf("device, global variable before add: %.2f\n", dev_data);dev_data += 2.0f;printf("device, global variable after add: %.2f\n", dev_data);
}int main(void) {float host_data = 4.0f;cudaMemcpyToSymbol(dev_data, &host_data, sizeof(float));printf("host, copy %.2f to global variable\n", host_data);AddGlobalVariable<<<1, 1>>>();cudaMemcpyFromSymbol(&host_data, dev_data, sizeof(float));printf("host, get %.2f from global variable\n", host_data);cudaDeviceReset();return 0;
}注意:变量 dev_data 只是作为一个标识符存在,并不是 device 端的全局内存变量地址,所以不能直接使用 cudaMemcpy 函数将 host 上的数据拷贝到 device 端。不能直接在 host 端的代码中使用运算符&对 device 端的变量进行取地址操作,因为其只是一个表示 device 端物理位置的符号
不过可以使用如下函数来获取其地址:
cudaError_t cudaGetSymbolAddress(void** devPtr, const void* symbol);获取地址后,就可以使用 cudaMemcpy 函数进行操作
int main(void)
{float host_data = 4.0f;float *dev_ptr = NULL;cudaGetSymbolAddress((void **)&dev_ptr, dev_data);cudaMemcpy(dev_ptr, &host_data, sizeof(float), cudaMemcpyHostToDevice);printf("host, copy %.2f to global variable\n", host_data);AddGlobalVariable<<<1, 1>>>();cudaMemcpy(&host_data, dev_ptr, sizeof(float), cudaMemcpyDeviceToHost);printf("host, get %.2f from global variable\n", host_data);cudaDeviceReset();return 0;
}在CUDA编程中,一般情况下 device 端的内核函数不能访问 host 端声明的变量,host 端的函数也不能直接访问 device 端的变量,即使是在同一个文件内声明的
1.6 纹理内存(Textrue Memory)
offchip内存,拥有SM私有的cache,在cache hit的情况下访存速度快,对所有线程可见。纹理内存是一种通过指定的只读缓存访问的全局内存,是对二维空间局部性的优化,所以使用纹理内存访问二维数据的线程可以达到最优性能
texture<type,
dim>
tex_var; //Initialize
cudaChannelFormatDesc(); //Options
cudaBindTexture2D(...); //Bind
tex2D(tex_var,
x_index,
y_index); //Fetch1.7 总结
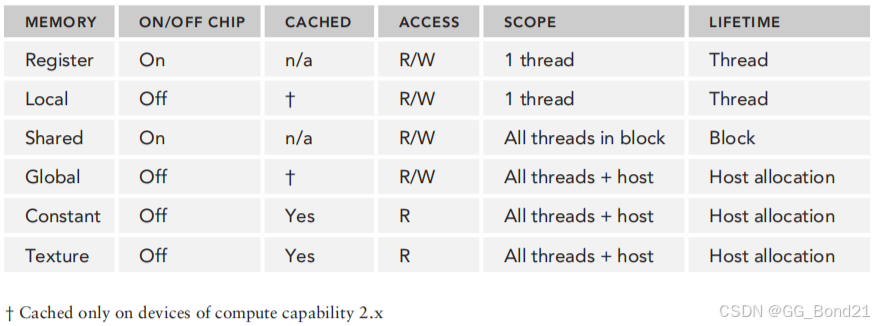
- Local,Global,Contant,Texture为片外DRAM,其中Global,Constant,Texture内存在Host端代码声明,所有线程可见
- SM拥有私有的Registers和Shared Memory(其实还有SM私有的L1 cache以及共有的L2 cache),Constant和Texture内存有专有的Caches(片上)
二、Cache(Non-programmable)
GPU上有4种缓存:
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
每个SM都有一个一级缓存,所有SM共享一个二级缓存,每个SM只有一个只读常量缓存和只读纹理缓存。一级和二级缓存用来存储本地内存和全局内存中的数据,包括寄存器溢出的部分
三、固定内存
页锁定内存(Pinned Memory)或固定内存(Fixed Memory),属于主机内存中的一种特殊内存
默认的 host 端的内存是可分页的,其按照操作系统的要求将主机虚拟内存上的数据移动到不同的物理位置。GPU不能在可分页的 host 端内存上安全地访问数据,因为当 host 端操作系统在物理位置上移动该数据时它无法控制。当从可分页的 host 端内存传输数据到 device 端内存时,CUDA 驱动程序会先临时分配页面锁定的或固定的 host 端内存,再将 host 端的数据复制到该内存中,最后从该内存中把数据拷贝到 device 端的内存中
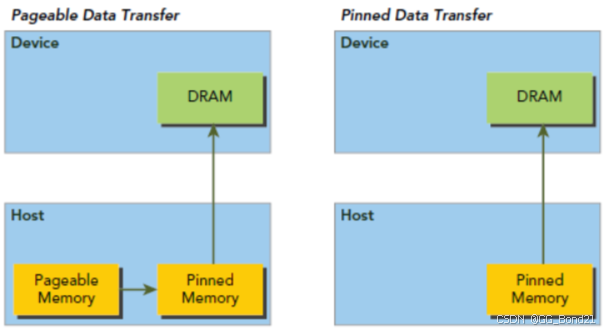
CUDA提供下面的函数,可以直接分配固定的主机内存:
cudaError_t cudaMallocHost(void **devPtr, size_t count);device 端可以用很高的带宽进行读写操作。不过,过多地分配固定内存会降低 host 系统的性能,因为能用于虚拟内存的可分页内存数量减少了。固定内存通过下面的函数进行释放:
cudaError_t cudaFreeHost(void *ptr);cudaHostRegister
cudaHostRegister可将现有的主机内存区域注册为可被GPU访问的页锁定内存
允许将已经分配的内存(如malloc等)注册为锁页内存。适用于需要将现有内存区域用作GPU访问的场景。注册的内存同样受到锁页内存资源限制的影响。在使用完毕后,需要使用cudaUnregisterHostMemory() 来注销内存
四、零拷贝内存
一般情况下 host 不能直接访问 device 端的变量,device 也不能直接访问 host 端的变量。有一种例外的情况,那就是零拷贝内存,host 和 device 都可以访问零拷贝内存。在内核函数中使用零拷贝内存有以下几个优势:
- 当 device 内存不足时使用 host 内存
- 避免 device 和 host 之间显示的数据传输
- 提高 PCIe 传输率
零拷贝内存是固定内存,CUDA 提供下面的函数创建一个固定内存到 device 地址空间的映射:
cudaError_t cudaHostAlloc(void **pHost, size_t count, unsigned int flags);flags 参数可以选择以下几种
-
cudaHostAllocDefault:使 cudaHostAlloc 函数的行为与 cudaMallocHost 一致
-
cudaHostAllocPortable:返回能被所有 CUDA 上下文使用的固定内存
-
cudaHostAllocWriteCombined:返回写结合内存,该内存可以在某些系统配置上通过PCIe总线更快地传输
-
cudaHostAllocMapped:返回被映射到 device 地址空间的 host 端内存
使用下面的函数可以获取映射到固定内存的 device 端指针:
cudaError_t cudaHostGetDevicePointer(void **pDevice, void *pHost, unsigned int flags);若需要在 host 和 device 之间共享少量的数据,那么零拷贝内存会是一个不错的选择。不过对于需频繁读写的操作,使用零拷贝内存会显著地降低程序的性能,因为每一次映射到内存的传输都需要通过 PCIe 总线进行。另外,使用零拷贝内存必须同步 host 和 device 的内存访问操作以避免潜在的数据冲突
五、统一内存
cudaMallocManaged 可分配统一内存(UM),这种内存可以在主机和设备之间自动迁移
基于 按需页面迁移 的机制。当GPU需访问统一内存时,若数据不在GPU内存中,会触发页面迁移。简化了内存管理,因为无需手动管理主机和设备之间的数据传输
统一内存的性能可能受到页面迁移开销的影响。若主机和设备频繁地对同一块内存进行访问,可能会导致"抖动"现象,降低性能
异步内存存取
分配统一内存 (UM) 时,内存尚未驻留在主机或设备上。主机或设备尝试访问内存时会发生页错误,此时主机或设备会批量迁移所需的数据。能够执行页错误并按需迁移内存对于加速应用程序简化开发流程大有助益。在处理展示稀疏访问模式的数据时(如:在应用程序实际运行之前无法得知需要处理的数据时),以及数据可能由多个 GPU 设备访问时,按需迁移内存将会带来显著优势
有些情况下(如:在运行时之前需要得知数据,以及需要大量连续的内存块时),可以有效规避页错误和按需数据迁移所产生的开销
通过异步内存存取,可以在应用程序代码使用统一内存 (UM) 前,在后台将其异步迁移至系统中的任何 CPU 或 GPU 设备。减少页错误和按需数据迁移所带来的成本,并进而提高 GPU 核函数和 CPU 函数的性能。预取往往会以更大的数据块来迁移数据,因此其迁移次数要低于按需迁移。此技术非常适用于以下情况:在运行时之前已知数据访问需求且数据访问并未采用稀疏模式
使用cudaMemPrefetchAsync函数将数据预取到当前处于活动状态的 GPU 设备,再预取到 CPU
int deviceId;
cudaGetDevice(&deviceId); // The ID of the currently active GPU devicecudaMemPrefetchAsync(pointerToSomeUMData, size, deviceId); // Prefetch to GPU device
cudaMemPrefetchAsync(pointerToSomeUMData, size, cudaCpuDeviceId); // Prefetch to host相关文章:

【CUDA】内存模型
目录 一、Programmable 1.1 寄存器(Registers) 1.2 本地内存(Local Memory) 1.3 共享内存(shared Memory) 1.4 常量内存(Constant Memory) 1.5 全局内存(Global Memory) 1.6 纹理内存(Textrue Memory) 1.7 总结 二、Cache(Non-programmable) 三、固定内存 四、零拷贝…...

使用Pygame制作“吃豆人”游戏
本篇博客展示如何使用 Python Pygame 编写一个简易版的“吃豆人(Pac-Man)” 风格游戏。这里我们暂且命名为 Py-Man。玩家需要控制主角在一个网格地图里移动、吃掉散布在各处的豆子,并躲避在地图中巡逻的幽灵。此示例可帮助你理解网格地图、角…...
)
Pyecharts系列课程04——折线图/面积图(Line)
本章我们学习在Pyecharts中折线图(Line)的使用。折线图通用应用于数据的趋势分析。 折线图 我们现在有两组数据,x_data是2024年的月份,y_data为对应张三甲每个月的用电量。 # 家庭每月用电量趋势 x_data ["1月", &q…...

mysql 学习10 多表查询 -多表关系,多表查询
多表关系 一对多 多对多 创建学生表 #多对多表 学生选课系统create table student(id int primary key auto_increment comment 主键ID,name varchar(64) comment 姓名,studentnumber varchar(10) comment 学号 )comment 学生表;insert into student(id,name,studentnumber)va…...

lambda 表达式详解
lambda 表达式详解 lambda 表达式详解基本语法示例代码及详细解释1. 简单的lambda表达式2. 带参数的lambda表达式3. 捕获外部变量4. 使用mutable关键字修改捕获的变量5. 按引用捕获外部变量6. 自动推导返回类型 捕获列表的几种形式总结 Lambda表达式的常用的应用场景࿱…...
)
从0开始达芬奇(3.5)
媒体优化 顾名思义就是降低分辨率等来使素材的回放更加流畅。(在低配电脑上也可以流畅运行) ⭐方法一:(一般使用第二种) 播放→代理模式→二分之一或者四分之一 ⭐⭐⭐方法二:优化媒体文件(简…...

【Uniapp-Vue3】z-paging插件组件实现触底和下拉加载数据
一、下载z-paing插件 注意下载下载量最多的这个 进入Hbuilder以后点击“确定” 插件的官方文档地址: https://z-paging.zxlee.cn 二、z-paging插件的使用 在文档中向下滑动,会有使用方法。 使用z-paging标签将所有的内容包起来 配置标签中的属性 在s…...

Ubuntu20.04 本地部署 DeepSeek-R1
一、下载ollama 打开 ollama链接,直接终端运行提供的命令即可。如获取的命令如下: curl -fsSL https://ollama.com/install.sh | sh确保是否安装成功可在终端输入如下命令: ollama -v注意: 如遇到Failed to connect to github.…...
)
Linux 设备驱动分类(快速理解驱动架构)
Linux 设备驱动分类(快速理解驱动架构) 在 Linux 设备驱动开发中,最基础的概念就是 设备驱动的分类。 Linux 设备驱动主要分为 字符设备、块设备和网络设备,它们分别对应不同类型的硬件资源。 理解这些分类,不仅能帮助…...

Java语法糖详解
前言 在现代编程语言的发展历程中,语法糖(Syntactic Sugar)作为一种提升代码可读性和开发效率的重要特性,已经成为语言设计的重要组成部分。Java作为一门成熟且广泛应用的编程语言,在其长期演进过程中,语法…...

567.字符串的排列
目录 一、题目二、思路2.1 解题思路2.2 代码尝试2.3 疑难问题 三、解法四、收获4.1 心得4.2 举一反三 一、题目 二、思路 2.1 解题思路 用两个哈希表比较来判断。s1的哈希表是否与s2相同。在窗口滑动过程中,用哈希表来维护。 2.2 代码尝试 class Solution { pub…...

DB2和mysql关于表和索引是否需要reorg的研究
DB2: DB2有个reorgchk的命令,是从SYSSTAT.TABLES和syscat.indexes这两个系统表中查表和索引的信息,并给出是否需要reorg表和索引的建议。 [db2inst1t3-ucm-ucm-rdb ~]$ db2 reorgchk CURRENT STATISTICS on table DB2ADMIN.ACAGENTTREE Ta…...

【Linux系统编程】:自旋锁,读写锁
文章目录 前言1. POSIX自旋锁1.1.定义自旋锁1.2.初始化1.3. 加锁1.4. 尝试加锁操作1.5. 解锁操作1.6. 销毁操作1.7.示例1.8.优缺点优点缺点 1.9.适用场景 2. 读写锁2.1 读写锁的工作原理2.2 读写模型2.3 常用接口2.3.1 定义锁并初始化2.3.2 申请读锁2.3.3 申请写锁2.3.4 解锁2.…...

位运算及常用技巧
涉及位运算的运算符如下表所示: 位运算的运算律: 负数的位运算 首先,我们要知道,在计算机中,运算是使用的二进制补码,而正数的补码是它本身,负数的补码则是符号位不变,其余按位取反…...

Chrome 浏览器:互联网时代的浏览利器
Chrome 浏览器:互联网时代的浏览利器 引言 在互联网时代,浏览器已经成为我们日常生活中不可或缺的工具。作为全球最受欢迎的浏览器之一,Chrome 浏览器凭借其出色的性能、丰富的扩展程序和简洁的界面,赢得了广大用户的喜爱。本文…...

web-文件上传-CTFHub
前言 在众多的CTF平台当中,作者认为CTFHub对于初学者来说,是入门平台的不二之选。CTFHub通过自己独特的技能树模块,可以帮助初学者来快速入门。具体请看官方介绍:CTFHub。 作者更新了CTFHub系列,希望小伙伴们多多支持…...

【react】react面试题
react面试题 对 React 的理解、特性 react18有哪些更新 JSX是什么 解释为什么浏览器不能读取jsx ReactNative中,如何解决8081端口被占用而提示无法访问的问题? React 生命周期 react事件机制 react 组件传值 React改变state的方式 re…...

逐笔成交逐笔委托Level2高频数据下载和分析:20250206
Level2逐笔成交逐笔委托数据分享下载 通过Level2逐笔成交和逐笔委托这种每一笔的毫秒级别的数据可以分析出很多有用的点,包括主力意图,虚假动作,让任何操作无所遁形。适合交易大师来分析主力规律,也适合人工智能领域的机器学习&a…...

__cvta_generic_to_shared
一 测试代码 #include <cuda_runtime.h> #include <cstdio> #include <cstdint>__global__ void test_cp_async(int* __restrict__ A,int* __restrict__ B){int tid = threadIdx.x;A[tid] = tid;__shared__ int smem[32];size_t smemAddr = __cvta_generic_…...

C++学习——缺省参数、重载函数、引用
目录 前言 一、缺省参数 1.1概念 1.2写法 1.3半缺省 1.4使用 二、重载函数 2.1.概念 2.2类型 2.3参数 2.4顺序 2.5问题 2.6原理 三、引用 1、引用是什么? 2、引用的使用方法 3、引用特性 1、引用在定义的时候必须要初始化 2、一个变量会有多个引用…...

docker-compose 配置nginx
前言 前端打包的dist文件在宿主机,nginx运行在docker-compose 问题 nginx.conf 在本地配置可以生效,但是链接到容器就报错 基于本地的nginx运行,本地nginx.conf 如下 server {listen 8081;location / {root /usr/local/software/testweb/…...
-python-基础知识)
LQB(0)-python-基础知识
一、Python开发环境与基础知识 python解释器:用于解释python代码 方式: 1.直接安装python解释器 2.安装Anaconda管理python环境 python开发环境:用于编写python代码 1.vscode 2.pycharm # 3.安装Anaconda后可以使用网页版的jupyter n…...

【C语言】指针运算与数组关系:详细分析与实例讲解
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C语言 文章目录 💯前言💯1. 指针的基础运算1.1 指针的加减运算1.2 指针加整数与指针减整数1.3 指针与指针的运算 💯2. 指针的实际应用:模拟 strlen 函数2.1 使用指针模拟…...

C++数组
指针,是C数组工作方式的基础。 数组,基本上是元素的集合。按特定的顺序排列的一堆东西。 C数组,就是表示一堆的变量组成的集合。一般是一行相同类型的变量。 例子: #include <iostream> int main() {int example[5];exa…...
)
OSPF基础(2)
一、LSA的头部 LSA是OSPF的一个核心内容,如果没有LSA,OSPF是无法描述网络的拓扑结构及网段信息的,也无法传递路由信息,更加无法正常工作,在OSPFV2中,需要我们掌握的主要有6种。 LSA头部一共20byte,每个字段…...

DeepSeek R1 简单指南:架构、训练、本地部署和硬件要求
DeepSeek 的 LLM 推理新方法 DeepSeek 推出了一种创新方法,通过强化学习 (RL) 来提高大型语言模型 (LLM) 的推理能力,其最新论文 DeepSeek-R1 对此进行了详细介绍。这项研究代表了我们如何通过纯强化学习来增强 LLM 解决复杂问题的能力,而无…...

javaEE-6.网络原理-http
目录 什么是http? http的工作原理: 抓包工具 fiddler的使用 HTTP请求数据: 1.首行:编辑 2.请求头(header) 3.空行: 4.正文(body) HTTP响应数据 1.首行:编辑 2.响应头 3.空行: 4.响应正文…...

把bootstrap5.3.3整合到wordpress主题中的方法
以下是将 Bootstrap 5.3.3 整合到 WordPress 主题中的方法: 下载 Bootstrap 文件:从 Bootstrap 官网下载最新的 5.3.3 版本的 CSS 和 JavaScript 文件。 上传文件到主题目录:将下载的 CSS 文件上传到 WordPress 主题文件夹中的 /css 文件夹…...

深度整理总结MySQL——Buffer Pool工作原理
Buffer Pool工作原理 前言为什么会有Buffer PoolBuffer Pool介绍Buffer Pool有多大Buffer Pool缓存什么呢Buffer Pool碎片空间查询一条记录,就只需要缓冲一条记录吗 如何管理Buffer Pool如何管理空闲页如何管理脏页如何提高缓存命中率 LRU带来的问题预读失效Buffer …...

langchain教程-9.Retriever/检索器
前言 该系列教程的代码: https://github.com/shar-pen/Langchain-MiniTutorial 我主要参考 langchain 官方教程, 有选择性的记录了一下学习内容 这是教程清单 1.初试langchain2.prompt3.OutputParser/输出解析4.model/vllm模型部署和langchain调用5.DocumentLoader/多种文档…...

凝思60重置密码
凝思系统重置密码 - 赛博狗尾草 - 博客园 问题描述 凝思系统进入单用户模式,在此模式下,用户可以访问修复错误配置的文件。也可以在此模式下安装显卡驱动,解决和已加载驱动的冲突问题。 适用范围 linx-6.0.60 linx-6.0.80 linx-6.0.100…...

指针基础知识1
1.内存和地址 1.案例 我们可以借助一个生活在的案例来熟悉电脑中内存和地址的关系: 假设有⼀栋宿舍楼,把你放在楼里,楼上有100个房间,但是房间没有编号,你的⼀个朋友来找你玩, 如果想找到你,…...

大数据学习之Spark分布式计算框架RDD、内核进阶
一.RDD 28.RDD_为什么需要RDD 29.RDD_定义 30.RDD_五大特性总述 31.RDD_五大特性1 32.RDD_五大特性2 33.RDD_五大特性3 34.RDD_五大特性4 35.RDD_五大特性5 36.RDD_五大特性总结 37.RDD_创建概述 38.RDD_并行化创建 演示代码: // 获取当前 RDD 的分区数 Since ( …...

Windows本地部署DeepSeek-R1大模型并使用web界面远程交互
文章目录 前言1. 安装Ollama2. 安装DeepSeek-r1模型3. 安装图形化界面3.1 Windows系统安装Docker3.2 Docker部署Open WebUI3.3 添加Deepseek模型 4. 安装内网穿透工具5. 配置固定公网地址 前言 最近爆火的国产AI大模型Deepseek详细大家都不陌生,不过除了在手机上安…...

【Linux系统】线程:线程控制
一、POSIX线程库 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的。使用这些函数库,要通过引入头文件 <pthread.h>。链接这些线程函数库时要使用编译器命令的 -lpthread 选项。 二、轻量级进程创建:…...

GoFrame 微服务开发指南
基本介绍 GoFrame 框架支持微服务模式开发,提供了常用的微服务组件、开发工具、开发教程帮助团队快速微服务转型。 微服务组件简介 GoFrame 微服务组件具有低耦合及通用化设计,组件化使用支持大部分的微服务通信协议。在官方文档中,主要以…...
制作工具(进阶版))
Python-基于PyQt5,Pillow,pathilb,imageio,moviepy,sys的GIF(动图)制作工具(进阶版)
前言:在抖音,快手等社交平台上,我们常常见到各种各样的GIF动画。在各大评论区里面,GIF图片以其短小精悍、生动有趣的特点,被广泛用于分享各种有趣的场景、搞笑的瞬间、精彩的动作等,能够快速吸引我们的注意…...

PhpStorm下载、安装、配置教程
前面的文章中,都是把.php文件放在WampServer的www目录下,通过浏览器访问运行。这篇文章就简单介绍一下PhpStorm这个php集成开发工具的使用。 目录 下载PhpStorm 安装PhpStorm 配置PhpStorm 修改个性化设置 修改字符编码 配置php的安装路径 使用Ph…...

春节假期旅游热潮下,景区医疗安全如何全面升级?
春节假期旅游热潮下,景区医疗安全如何全面升级? 随着旅游业的不断繁荣,春节假期期间,各大景区再次迎来了游客的高峰期。面对如此庞大的客流量,景区不仅要在服务接待上下功夫,更要将医疗安全保障工作提升到…...

惠普HP工作站如何关闭关闭RAID?
惠普HP工作站如何关闭关闭RAID? 前言进入BIOS进入“先进”选项卡,点击“系统选项”。取消勾选“sSATA控制器RAID模式”,按下F10保存重启。 前言 惠普工作站默认启用了RAID模式,导致许多PE工具无法识别RAID模式下的硬盘。可以通过…...

ESP-Skainet智能语音助手,ESP32-S3物联网方案,设备高效语音交互
在科技飞速发展的今天,智能语音助手正逐渐渗透到我们生活的方方面面,而智能语音助手凭借其卓越的技术优势,成为了智能生活领域的一颗璀璨明星。 ESP-Skainet智能语音助手的强大之处在于其支持唤醒词引擎(WakeNet)、离…...

mac下生成.icns图标
笔记原因: 今日需要在mac下开发涉及图标文件的使用及icons文件的生成,所以记录一下。 网络上都是一堆命令行需要打印太麻烦了,写一个一键脚本。 步骤一 将需要生成的png格式文件重命名为“pic.png” mv xxxx.png pic.png 步骤二 下载我…...

【MySQL】centos 7 忘记数据库密码
vim /etc/my.cnf文件; 在[mysqld]后添加skip-grant-tables(登录时跳过权限检查) 重启MySQL服务:sudo systemctl restart mysqld 登录mysql,输入mysql –uroot –p;直接回车(Enter) 输…...

【kafka的零拷贝原理】
kafka的零拷贝原理 一、零拷贝技术概述二、Kafka中的零拷贝原理三、零拷贝技术的优势四、零拷贝技术的实现细节五、注意事项一、零拷贝技术概述 零拷贝(Zero-Copy)是一种减少数据拷贝次数,提高数据传输效率的技术。 在传统的数据传输过程中,数据需要在用户态和内核态之间…...

【JavaEE】Spring Web MVC
目录 一、Spring Web MVC简介 1.1 MVC简介1.2 Spring MVC1.3 RequestMapping注解1.3.1 使用1.3.2 RequestMapping的请求设置 1.3.2.1 方法11.3.2.2 方法2 二、Postman介绍 2.1 创建请求2.2 界面如下:2.3 传参介绍 一、Spring Web MVC简介 官方文档介绍ÿ…...

《解锁GANs黑科技:打造影视游戏的逼真3D模型》
在游戏与影视制作领域,逼真的3D模型是构建沉浸式虚拟世界的关键要素。从游戏中栩栩如生的角色形象,到影视里震撼人心的宏大场景,高品质3D模型的重要性不言而喻。随着人工智能技术的飞速发展,生成对抗网络(GANs…...
)
【大数据技术】词频统计样例(hadoop+mapreduce+yarn)
词频统计(hadoop+mapreduce+yarn) 搭建完全分布式高可用大数据集群(VMware+CentOS+FinalShell) 搭建完全分布式高可用大数据集群(Hadoop+MapReduce+Yarn) 在阅读本文前,请确保已经阅读过以上两篇文章,成功搭建了Hadoop+MapReduce+Yarn的大数据集群环境。 写在前面 Wo…...

deepseek与openai关系
DeepSeek与OpenAI之间的关系主要体现在技术竞争和合作的可能性上。 首先,DeepSeek是由中国的深度求索公司开发的,成立于2023年,专注于人工智能技术研发。其大模型DeepSeek-R1在数学、代码、自然语言推理等任务上的性能能够比肩OpenAI的G…...

51页精品PPT | 数据中台与数据治理服务及案例
案例的核心内容围绕数据中台与数据治理服务展开,详细介绍了数据治理的整体方法论、数据中台的建设路径以及如何通过数据治理和数据中台提升业务效率和数据质量。本案例强调了数据治理的重要性,包括数据标准、数据质量、数据安全等方面的管理,…...
 - 随笔)
使用 cipher /w 清除磁盘删除残留数据(Windows) - 随笔
cipher命令是Windows 系统自带的一个用于管理文件加密和磁盘数据清除的工具。通过 cipher /w 命令,可以清除磁盘上已删除文件的残留数据,确保这些数据无法被恢复。以下是一个简易的批处理脚本,用于清除指定磁盘上的加密数据。 echo off :: 清…...