【Linux系统】线程:线程控制

一、POSIX线程库
- 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的。
- 使用这些函数库,要通过引入头文件
<pthread.h>。 - 链接这些线程函数库时要使用编译器命令的
-lpthread选项。
二、轻量级进程创建:vfork
因为 Linux 系统是使用 LWP 模拟实现的,因此 Linux 系统只会提供轻量级进程的创建方法,而没有所谓线程的创建方法
轻量级进程的创建方法即为:vfork
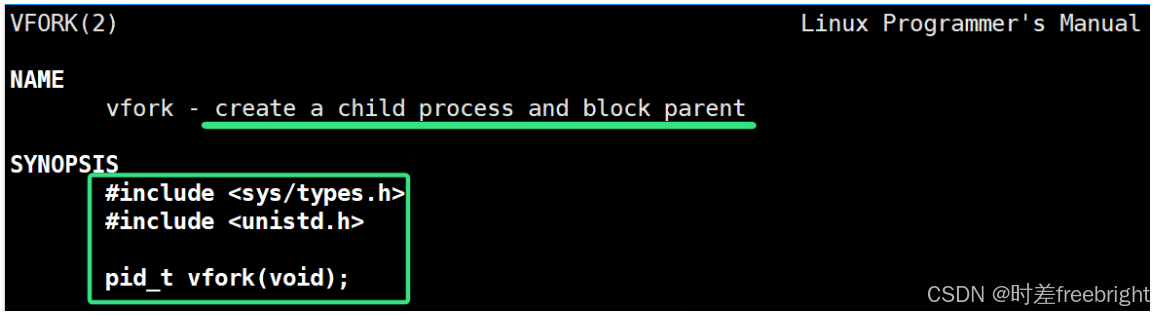
vfork 和 fork 底层调用的都是系统调用:clone
系统调用clone 可以根据传递的标志位 flags ,决定创建一般进程 or 轻量级进程
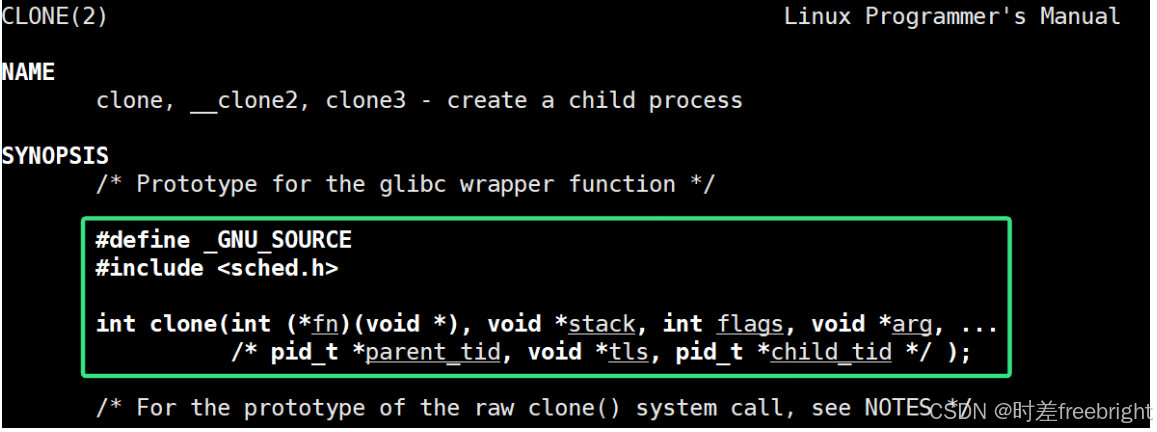
看着系统调用clone 的这些参数,可以知道系统调用clone 的使用对用户来说还是比较复杂的,Linux 底层使用进程模拟线程,但是这是底层原理,用户不一定知道,用户只知道线程概念,若让用户使用系统调用clone,一定程度上拉低用户使用体验
因此 Linux 设计者在底层和用户之间封装一层软件层,将 clone封装成可调用的库函数,用这个库函数创建线程,而封装底层关于线程操作的相关库,就是所谓的用户级线程库,如 POSIX线程库(pthreads)
使得线程的概念留在用户层面,而无需关注Linux底层是用进程模拟线程的“假象”
而 windows 系统中是真的有进程PCB和线程TCB等进程和线程独立的概念,线程是需要独立创建TCB的,并不是使用进程PCB模拟的,因此 windows 系统能够给用户提供线程相关的系统调用
具体可以看这篇文章:
【Linux系统】Linux中的用户级线程与内核级线程 / Windows中的线程实现TCB / 两系统的对比-CSDN博客
从这里可以看出,操作系统理论其实是一种方法论,而并非具体实现,不同操作系统共同使用这套方法论,而有各自不同具体的实现形式,所以我们才应该从一款具体的操作系统学起,在其中学习操作系统理论会更好!
三、线程创建
1、函数介绍
库函数 pthread_create :创建线程
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
参数说明
简单来说:
pthread_t *thread: 新线程的 IDconst pthread_attr_t *attr: 一般设置为 NULLvoid *(*start_routine) (void *): 就是线程执行函数 func 这种void *arg: 传给线程执行函数的参数,不用可以设置为 NULL
具体来说:
pthread_t *thread: 指向pthread_t类型的指针,用来存储新创建线程的标识符。const pthread_attr_t *attr: 一个指向线程属性对象的指针,用于设置线程的属性(如栈大小等)。若不需要特殊属性,则可以传递NULL使用默认属性。void *(*start_routine) (void *): 新线程开始执行的函数的名称,该函数返回void*并接受一个void*类型的参数。这是新线程启动时将要执行的函数。void *arg: 传递给start_routine函数的参数。如果不需要传递参数,可以传入NULL。
返回值
- 成功时,返回
0。- 失败时,返回错误编号
2、函数使用
使用线程库中的函数,创建多线程代码:
#include<iostream>
#include<string>
#include<cstring>
#include<pthread.h>
#include<unistd.h>void* func(void* argc)
{std::string name = static_cast<char*>(argc);while(true){std::cout << "I am 新线程, name: " << name << '\n';sleep(1);}
}int main()
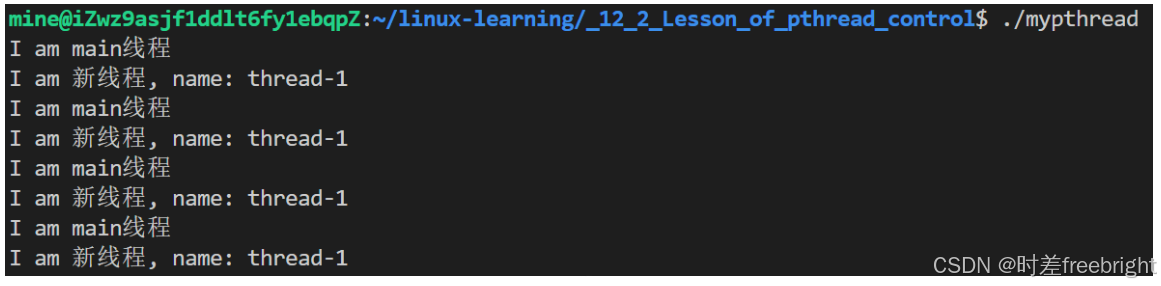
{pthread_t tid;int ret = pthread_create(&tid, nullptr, func, (void*)"thread-1");// 返回值为0表示创建成功, 非0表示创建失败(1,2,3...表示错误码)if(ret != 0){std::cout << "pthread_create error: " << strerror(ret) << '\n';}while(true){std::cout << "I am main线程" << '\n';sleep(1);}return 0;
}
运行结果如下:
3、C++11中的创建线程函数
其实C++11开始就支持多线程,并且使用起来非常容易:
C++的头文件:<thread> 包含线程相关操作函数
代码如下:
#include <iostream>
#include <string>
#include <cstring>
#include <unistd.h>
#include <thread>int main()
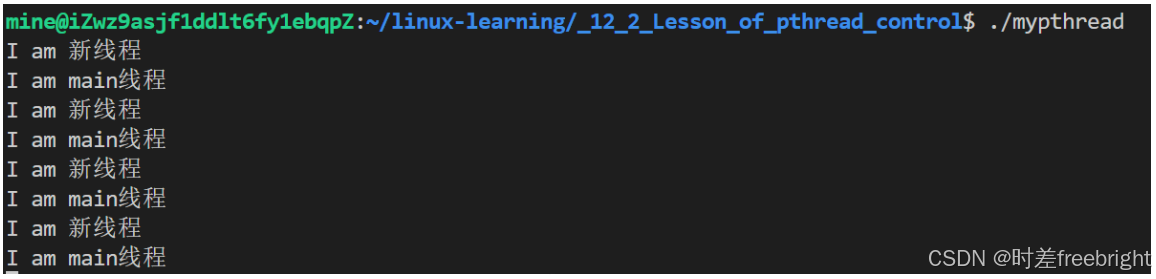
{// C++创建多线程:std::thread t([](){while(true){std::cout << "I am 新线程" << '\n';sleep(1);} });while (true){std::cout << "I am main线程" << '\n';sleep(1);}return 0;
}
运行结果如下:
编译本代码需要加上链接线程库的选项 -lpthread
如果我们将编译命令中的应用线程库的选项 -lpthread 去掉,就会发现编译不通过,原因是找不到函数 pthread_create ??

为什么?我们自己明明没有调用该函数,我们使用的是C++库的 thread 函数
答:这是因为C++的头文件 <thread> 其实底层就是封装了原生库 POSIX线程库 !!
C++使用 std::thread t 的构造函数中就含有创建线程的pthread_create !!!
而这类高级语言,如C++、java、python…之所以能够支持多线程,本质上都是封装了 POSIX线程库
4、POSIX线程库的标准化与跨平台性
POSIX线程库像一种标准,一种模板,所有支持POSIX线程库的系统(如Linux / macos / BSD)可以以 POSIX线程库 为标准,为自己本系统使用一套适合本系统使用的线程操作。对于跨平台性,所有支持POSIX线程库的系统都可以运行使用了POSIX线程库中的方法的程序,这就是一种跨平台性。对于高级语言,像C++ / Java / python 等,它们都会封装一套语言层面的线程操作,底层都是基于POSIX线程库,如C++的thread库就是封装了POSIX线程库,这使得这些高级语言的使用了线程的相关代码可以在不同系统下运行,前提是这些系统都是支持POSIX线程库的,这样不同的高级语言的代码可以在不同系统下运行,也体现了跨平台性。
进一步阐述:
标准化与系统实现
- 作为标准:
POSIX线程库提供了一套统一的API,如创建线程(pthread_create)、等待线程结束(pthread_join)等,定义了多线程编程的基本操作规范。- 系统特定实现:不同的操作系统,如Linux、macOS和BSD,基于这套标准实现自己的线程管理机制,以适应各自的系统架构和特性。
跨平台性
- 直接支持:所有支持
POSIX线程库的操作系统可以直接运行使用这些API编写的程序,实现了跨平台的目标。- 兼容层:对于不直接支持
POSIX线程库的系统(如Windows),可以通过第三方库(例如pthreads-w32)提供的兼容层来支持这些API,从而扩展跨平台能力。
高级语言中的应用
- 封装实现:许多高级编程语言,如C++、Java和Python,提供了各自的语言级别的线程操作接口(如C++的
std::thread,Java的JVM线程模型,Python的threading模块)。这些接口通常在底层封装了POSIX线程库或其他系统的本地线程API。- 跨平台开发:通过在语言级别上进行抽象和封装,开发者可以编写出能够跨平台运行的代码。只要目标系统支持相应的底层线程模型(比如
POSIX线程库),那么这些高级语言编写的多线程程序就可以在不同平台上顺利运行。因此,无论是直接使用
POSIX线程库还是通过高级语言提供的线程操作接口,都可以借助这一标准促进代码的可移植性和跨平台性,使得同一份代码能够在多种操作系统上运行,极大地提升了开发效率和灵活性。
四、线程相关概念补充
1、获取线程标识符
该函数可以获取该线程的标识符
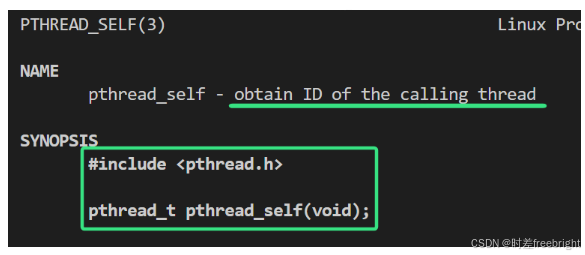
代码如下:
我将线程的标识符转换成 16进制的格式,方便观看
#include<iostream>
#include<string>
#include<cstring>
#include<pthread.h>
#include<unistd.h>std::string toHex(pthread_t tid)
{char buff[64];snprintf(buff, sizeof(buff), "0x%lx", tid);return std::string(buff);
}void* func(void* argc)
{std::string name = static_cast<char*>(argc);while(true){std::cout << "I am 新线程, tid: " << toHex(pthread_self()) << '\n';sleep(1);}
}int main()
{pthread_t tid;int ret = pthread_create(&tid, nullptr, func, (void*)"thread-1");// 返回值为0表示创建成功, 非0表示创建失败(1,2,3...表示错误码)if(ret != 0){std::cout << "pthread_create error: " << strerror(ret) << '\n';}while(true){std::cout << "I am main线程" << '\n';sleep(1);}return 0;
}
运行结果如下:

如何理解线程表示符 和 LWD 号
可以发现,这个线程的标识符明显不是线程的 LWP 号,怎么理解这个“ID”呢?
这个“ID”是
pthread库给每个线程定义的进程内唯一标识,是pthread库维持的。由于每个进程有自己独立的内存空间,故此
“ID”的作用域是进程级而非系统级(内核不认识)。其实
pthread库也是通过内核提供的系统调用(例如clone)来创建线程的,而内核会为每个线程创建系统全局唯一的“ID”来唯一标识这个线程。
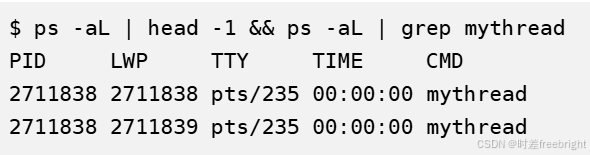
使用PS命令查看线程信息:
ps -aL | head -1 && ps -aL | grep mythread运行代码后执行:
LWP是什么呢? LWP 得到的是真正的线程ID。之前使用pthread_self得到的这个数实际上是一个地址,在虚拟地址空间上的一个地址,通过这个地址,可以找到关于这个线程的基本信息,包括线程ID,线程栈,寄存器等属性。
在
ps -aL得到的线程ID,有一个线程ID和进程ID相同,这个线程就是主线程,主线程的栈在虚拟地址空间的栈上,而其他线程的栈是在共享区(堆栈之间),因为pthread系列函数都是pthread库提供给我们的。而pthread库是在共享区的。所以除了主线程之外的其他线程的栈都在共享区。
2、线程之间运行没有先后
主线程创建一个新线程
并不是主线程一定先运行,线程和进程一样,线程和进程的运行,都是需要看CPU调度器调度选择,没有绝对主次先后之分
3、线程的时间片
线程的时间片是瓜分进程的,并不是单独被系统分配的
1、时间片是占用CPU资源的时间,这个也属于进程的资源,会被线程瓜分
2、如果线程会被单独分配时间片,则一个进程的时间片就会增加,这对其他进程不公平,同时系统也不好调度进程
4、非线程安全造成共享资源数据不一致
认识一下非线程安全造成使用共享资源数据不一致问题:显示器文件为共享资源,多线程共享使用同一个显示器文件,不加保护下,多线程就会不按顺序的使用该共享资源,导致数据不一致!
举个例子:先创建多个线程,共同调用同一个函数 func !
代码如下:
#include<iostream>
#include<string>
#include<cstring>
#include<pthread.h>
#include<unistd.h>std::string toHex(pthread_t tid)
{char buff[64];snprintf(buff, sizeof(buff), "0x%lx", tid);return std::string(buff);
}void* func(void* argc)
{std::string name = static_cast<char*>(argc);while(true){std::cout << "I am 新线程, tid: " << toHex(pthread_self()) << '\n';sleep(1);}
}int main()
{pthread_t tid1;pthread_create(&tid1, nullptr, func, (void*)"thread-1");pthread_t tid2;pthread_create(&tid2, nullptr, func, (void*)"thread-2");pthread_t tid3;pthread_create(&tid3, nullptr, func, (void*)"thread-3");pthread_t tid4;pthread_create(&tid4, nullptr, func, (void*)"thread-4");pthread_t tid5;pthread_create(&tid5, nullptr, func, (void*)"thread-5");while(true){std::cout << "I am main线程" << '\n';sleep(1);}return 0;
}
运行结果如下:

多个线程创建出来都调用同一个函数,该函数就是一种共享资源,即多个执行流可以同时使用同一个函数,该函数就是可重入函数!
同时,你可以看到显示器上打印的信息有错乱的地方(下图),这说明了多线程在显示器上打印有问题,显示器本身是当前多线程打印数据的唯一目标文件,本质上显示器也是多线程共享的资源,在没有同步互斥等保护机制的前提下,多线程不会按照顺序使用共享资源(显示器、共享函数)
如下:显示器打印信息时就出现了错乱,这就是数据不一致了
程序中转 16 进制的函数 toHex 也被多线程重入了,但他们返回的转换结果是各自独立的
这是因为每个线程都有独立栈,因此结果不同
5、全局变量被线程共享:线程不安全问题
全局变量在线程中也是共享的,可以被多线程同时修改(因此有线程安全问题)
代码如下:创建两个线程,各自有自己的回调函数,一个为全局变量++, 另一个不修改
#include<iostream>
#include<string>
#include<cstring>
#include<pthread.h>
#include<unistd.h>int gval = 100;std::string toHex(pthread_t tid)
{char buff[64];snprintf(buff, sizeof(buff), "0x%lx", tid);return std::string(buff);
}void* func1(void* argc)
{std::string name = static_cast<char*>(argc);while(true){std::cout << "I am 新线程, tid: " << toHex(pthread_self()) << ", 全局变量(修改): " << gval << '\n';gval++;sleep(1);}
}void* func2(void* argc)
{std::string name = static_cast<char*>(argc);while(true){std::cout << "I am 新线程, tid: " << toHex(pthread_self()) << ", 全局变量(不修改): " << gval << '\n';sleep(1);}
}int main()
{pthread_t tid1;pthread_create(&tid1, nullptr, func1, (void*)"thread-1");pthread_t tid2;pthread_create(&tid2, nullptr, func2, (void*)"thread-2");while(true){std::cout << "I am main线程" << '\n';sleep(1);}return 0;
}
运行结果如下:可以看到两个线程看到的全局变量 gval 是同一个
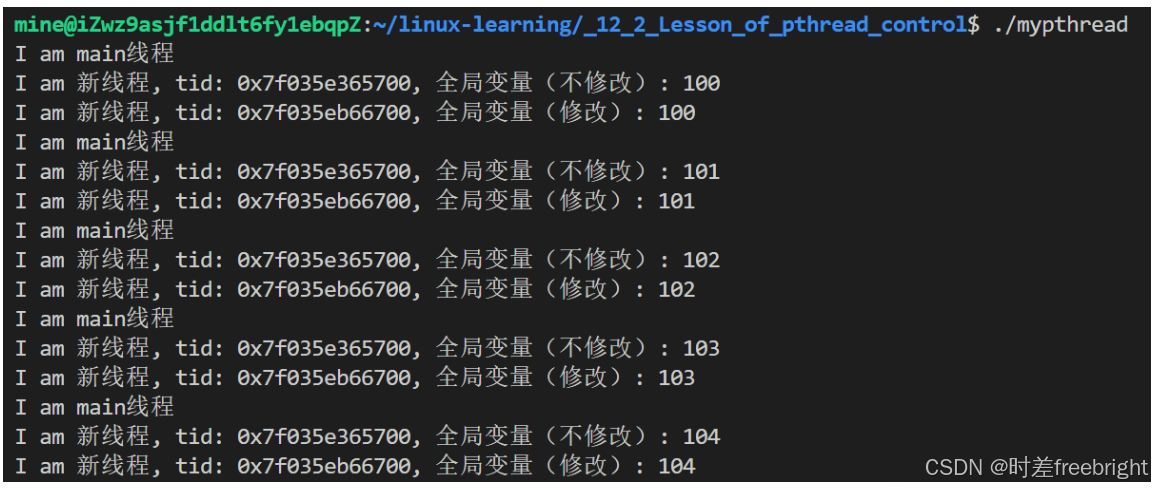
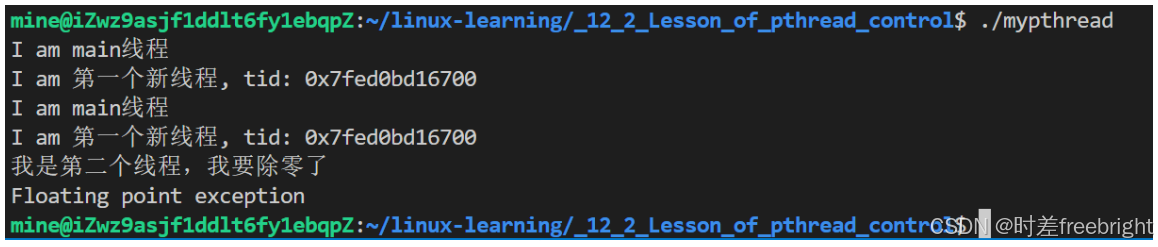
6、线程除零异常导致所有线程被杀
下面演示除零异常杀掉本进程,即杀掉所有线程
第二个线程除零异常,可以看到一个线程已经在运行打印,当本线程除零后,整个进程直接崩溃,所有线程被杀掉
系统给进程发信号,杀掉进程,因为进程资源是线程赖以生存的资源,因此线程也挂了
代码如下:
#include<iostream>
#include<string>
#include<cstring>
#include<pthread.h>
#include<unistd.h>std::string toHex(pthread_t tid)
{char buff[64];snprintf(buff, sizeof(buff), "0x%lx", tid);return std::string(buff);
}void* func1(void* argc)
{std::string name = static_cast<char*>(argc);while(true){std::cout << "I am 第一个新线程, tid: " << toHex(pthread_self()) << '\n';sleep(1);}
}void* func2(void* argc)
{std::string name = static_cast<char*>(argc);// 阻塞该线程,然后才除零异常sleep(2);std::cout << "我是第二个线程,我要除零了\n";// 设置除零int a = 10;a /= 0;while(true){std::cout << "I am 第二个新线程, tid: " << toHex(pthread_self()) << '\n';sleep(1);}
}int main()
{pthread_t tid1;pthread_create(&tid1, nullptr, func1, (void*)"thread-1");pthread_t tid2;pthread_create(&tid2, nullptr, func2, (void*)"thread-2");while(true){std::cout << "I am main线程" << '\n';sleep(1);}return 0;
}
运行结果如下:
7、系统如何知道哪些 线程 LWP 是一伙的呢?
进程被杀,进程下所有线程也会被杀,系统如何知道哪些线程 LWP 是一伙的呢?
其实在进程PCB内部会有一种双链表结构,将一伙的线程 LWP 连接起来,这一些线程属于同一个进程,进程下存在一种线程组的概念,同一个进程下所有的线程属于同一个线程组
在多线程环境中,属于同一进程的所有线程共同组成一个线程组(thread group)。
线程组内的所有线程共享一些资源,如地址空间、文件描述符等,但每个线程有自己的执行路径和栈。
- 双链表结构:
- 如您所述,在进程的 PCB 中,会有一个双链表(或其他形式的数据结构,如循环列表)用来链接所有的 TCB。这种结构允许操作系统快速遍历和访问属于同一个进程的所有线程。
- 信号传递:
- 当一个信号被发送到进程时,操作系统会根据进程的 PCB 找到对应的线程组,并将信号传递给线程组中的所有线程。
- 线程组ID (TGID):
- 在Linux系统中,每个线程都有一个线程组ID(TGID),它实际上与进程ID(PID)相同。所有属于同一个线程组的线程都共享相同的 TGID。这使得内核能够轻松地确定哪些线程应该作为一个整体来响应信号。
线程创建之后,新建线程也是要被等待和回收的!同时要保证主线程最后退出,因为新建线程都是由主线程创建的,也要由主线程等待回收(就和进程那套一样!)
为什么要等待线程退出:
a.线程也会出现类似僵尸进程的问题;
b.为了知道新线程的执行结果
这就需要认识线程是如何等待和回收的,如下:
五、线程等待
函数 pthread_join
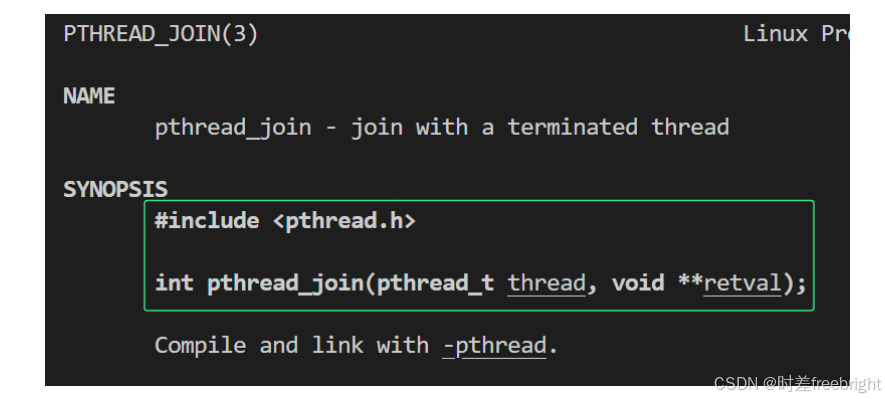
int pthread_join(pthread_t thread, void **retval);// pthread_t thread : 被等待的那个线程的标识符
// void **retval : 一个输出型参数,这是线程处理函数的返回值(那个自定义函数的返回值)
如果线程不退出,则主线程需要阻塞等待!(和进程一样!)
代码如下:
#include <iostream>
#include <string>
#include <cstring>
#include <pthread.h>
#include <unistd.h>std::string toHex(pthread_t tid)
{char buff[64];snprintf(buff, sizeof(buff), "0x%lx", tid);return std::string(buff);
}void *func(void *argc)
{std::string name = static_cast<char *>(argc);std::cout << "I am 新线程, tid: " << toHex(pthread_self()) << '\n';sleep(3);return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, func, (void *)"thread-1");while (true){std::cout << "I am main线程, 等待新线程退出中..." << '\n';int join_ret = pthread_join(tid, nullptr);// On success, pthread_join() returns 0;if(join_ret == 0){std::cout << "新线程已经退出, tid: " << toHex(tid) << '\n';break;}sleep(1);}return 0;
}

1、线程处理函数的返回值
线程创建函数 pthread_create 的第三个参数,线程处理函数 start_routine 的返回值为 void* 类型的:void *(*start_routine) (void *)
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
线程等待函数 pthread_join 的第二个参数是个输入型参数,就是用于获取线程处理函数的返回值或退出值,这个参数是二级指针类型(即需要传递一个一级指针的地址,会得到一个一级指针的数据)
int pthread_join(pthread_t thread, void **retval);
问题:为什么这里使用二级指针参数 void **retval:
因为线程处理函数的返回值是 void* 类型的,这里参数 retval 是 void** 类型的,就是为了接收 函数返回值的 指针
获取线程退出结果示例代码:
#include <iostream>
#include <string>
#include <cstring>
#include <pthread.h>
#include <unistd.h>std::string toHex(pthread_t tid)
{char buff[64];snprintf(buff, sizeof(buff), "0x%lx", tid);return std::string(buff);
}void *func(void *argc)
{std::string name = static_cast<char *>(argc);std::cout << "I am 新线程, tid: " << toHex(pthread_self()) << '\n';sleep(3);return (void *)10;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, func, (void *)"thread-1");std::cout << "I am main线程, 等待新线程退出中..." << '\n';void *retval = nullptr;int join_ret = pthread_join(tid, &retval);std::cout << "retval: " << (int)retval << '\n';sleep(1);return 0;
}
核心代码:
定义一个输入型参数:retval,用于接收线程退出结果
void *func(void *argc)
{// ....return (void*)10; // 强转成 (void*)
}void* retval = nullptr;
int join_ret = pthread_join(tid, &retval);
std::cout << "retval: " << (int)retval << '\n';
问题:为什么可以直接对 void* 指针强转成 int 类型:(int)retval?
因为,在本质上, void* 指针类型也只不过是一个 8 字节的数据,而类型决定的是访问的数据大小范围
强转成 int 类型就是对这块空间的访问修改为 4 字节的数据大小范围
函数返回 (void*10) 就是现在内存中开辟一块 8字节空间,然后将整型 10 写入该空间中
其实强转成 int 类型有点不正确:会精度损失则报错
我使用的系统为 64位系统,地址类型大小为 8 字节,因此 int 的 4 字节会造成精度损失(如果是 32位系统,地址类型大小为 4 字节,直接使用 int 即可)
修改成 long long 类型:刚好是 8 字节
std::cout << "retval: " << (long long)retval << '\n';
最后运行结果为:

问题:为什么将返回值设置成 void* 类型呢?
好像很多函数和系统调用的参数,都会设置成 void* 类型
这是因为 void* 类型可以被强转为任何类型:基本数据类型、结构体、类……使得返回值变得通用!!
但是 void 类型是不完整数据类型,本身不能携带任何信息(在一般的系统下 void 的大小都为 0,使得它不能携带信息,也就不能强转成其他类型获取数据了)
返回一个指针类型:证明线程共享堆区
示例代码如下:
#include <iostream>
#include <string>
#include <cstring>
#include <pthread.h>
#include <unistd.h>std::string toHex(pthread_t tid)
{char buff[64];snprintf(buff, sizeof(buff), "0x%lx", tid);return std::string(buff);
}void *func(void *argc)
{std::string name = static_cast<char *>(argc);std::cout << "I am 新线程, tid: " << toHex(pthread_self()) << '\n';int* p = new int(10);return (void *)p; // 一律强转成 void* 类型
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, func, (void *)"thread-1");std::cout << "I am main线程, 等待新线程退出中..." << '\n';void *retval = nullptr;int join_ret = pthread_join(tid, &retval);std::cout << "retval: " << *(int*)retval << '\n';// 先将该指针强转成 int* 类型指针,然后再解引用,得到该指针指向的 int 类型的值return 0;
}
得到返回值 void* 类型,先将该指针强转成 int* 类型指针,然后再解引用,得到该指针指向的 int 类型的值
运行结果如下:

这里得出的结论:
该线程执行函数返回一个该线程在堆上开辟的空间指针,回到主线程处,主线程也能通过解引用得到该堆空间中的值
int* p = new int(10);
return (void *)p; // 一律强转成 void* 类型
这说明,其实堆区也是被多线程共享的!
我们认为线程的堆空间是独立的,但为什么主线程可以通过另一个线程开辟的堆空间的地址来访问对应堆空间,其实多线程共享同一个虚拟地址空间,堆区当然共享,但是一个线程可以访问另一个线程的开辟的堆空间的前提是获得该堆空间的地址!
简单来说,只要给你堆空间的地址,就能通过该地址访问对应堆空间,如果拿不到地址,则当然不能直接访问,因此我们说线程之间的堆空间是独立的
其实,因为同一个进程下的所有线程共享瓜分同一个虚拟地址空间,因此地址空间中的 堆区、栈区、代码区、全局数据区….都是共享的!!!
线程瓜分空间的手段就是获取某块空间的地址,即访问权,有了地址就能访问对应的地址空间
而其他线程想要访问其他线程占领的空间,就需要获得这些空间的地址,即如果其他线程给你地址,你就能用!
理论上来讲,任何线程都能通过地址随便访问到其他线程占领的空间(前提是该地址不是野指针而是指向有效数据空间的指针)
2、线程处理任务:主进程不用理会
数据处理任务:传递数据类
定义数据类,线程的相关数据都放到一个类中:运行函数、线程入口函数返回值….
#include <iostream> // 标准输入输出流库
#include <string> // 字符串处理库
#include <cstring> // C风格字符串处理函数
#include <pthread.h> // POSIX线程库
#include <unistd.h> // UNIX标准库,包含一些系统调用如fork, pipe等// 定义一个类用于在线程间传递数据
class threadData
{
public:// 构造函数,初始化两个整数成员变量_a和_bthreadData(int a, int b): _a(a), _b(b){}// 执行任务的方法:将_a和_b相加,结果保存在_result中void Execute() { _result = _a + _b; }// 获取_a的值int getA() const { return _a; }// 获取_b的值int getB() const { return _b; }// 设置线程名void setName(std::string name) { _name = name; }// 获取线程名std::string getName() const { return _name; }// 获取计算结果int getResult() const { return _result; }// 默认析构函数~threadData()=default;private:int _a, _b; // 存储要相加的两个整数std::string _name; // 线程的名字int _result; // 存储计算的结果
};// 将pthread_t类型的线程ID转换为十六进制字符串表示
std::string toHex(pthread_t tid)
{char buff[64]; // 创建一个足够大的字符数组来存储转换后的字符串// 使用snprintf格式化线程ID为16进制并存储到buff中snprintf(buff, sizeof(buff), "0x%lx", tid);// 返回转换后的字符串return std::string(buff);
}// 线程执行的函数
void *func(void *argc)
{// 输出新线程的信息,包括线程IDstd::cout << "I am 新线程, tid: " << toHex(pthread_self()) << '\n';// 将传入的参数(void指针)转换为threadData指针threadData *td = static_cast<threadData *>(argc);// 执行任务: 计算a+b,在该线程执行函数中执行任务,计算结果保存在td中td->Execute();// 返回指向threadData对象的指针,以便主线程可以访问计算结果return (void *)td;
}int main()
{pthread_t tid; // 定义一个pthread_t类型变量,用于存储创建的新线程ID// 创建一个threadData对象,并分配内存,初始化为10和20threadData *td = new threadData(10, 20);// 创建新线程,线程开始执行func函数,传递td作为参数pthread_create(&tid, nullptr, func, (void *)td);// 主线程输出等待信息std::cout << "I am main线程, 等待新线程退出中..." << '\n';// 定义一个空指针用于接收子线程返回的值threadData *retval = nullptr;// 调用pthread_join等待新线程结束,并获取其返回值int join_ret = pthread_join(tid, (void**)&retval);// 输出新线程的计算结果std::cout << "新线程退出, 结果为: " << retval->getResult() << '\n';// 注意:这里应当释放动态分配的threadData对象以避免内存泄漏delete retval;return 0; // 程序正常结束
}
这样做对主线程有什么好处:我们可以保证,新线程执行完毕,任务一定处理完了,结果变量一定已经被写入了 threadData !!
主线程只需传入一个 threadData 对象,然后坐等新线程执行完成即可,就可以拿到结果了!
这样主线程就无需关心新线程执行结果如何,主线程只需通过 join 函数获取到返回的 threadData 对象,就能直接得到最终运行结果!
多线程处理多数据
根据这个思想,我们可以创建多个线程帮我们处理一批数据,最后主线程只需要访问每个线程对应的 threadData 对象 就能获得处理后的结果!
代码如下:
#include <iostream> // 标准输入输出流库
#include <string> // 字符串处理库
#include <cstring> // C风格字符串处理函数
#include <pthread.h> // POSIX线程库
#include <unistd.h> // UNIX标准库,包含一些系统调用如fork, pipe等// 定义一个类用于在线程间传递数据
class threadData
{
public:// 默认构造函数threadData() {}// 构造函数,初始化两个整数成员变量_a和_bthreadData(int a, int b): _a(a), _b(b){}// 执行任务的方法:将_a和_b相加,结果保存在_result中void Execute() { _result = _a + _b; }// 获取_a的值int getA() const { return _a; }// 获取_b的值int getB() const { return _b; }// 获取线程IDpthread_t getTid() const { return _tid; }// 设置_a的值void setA(int a) { _a = a; }// 设置_b的值void setB(int b) { _b = b; }// 设置线程IDvoid setTid(pthread_t tid) { _tid = tid; }// 设置线程名void setName(std::string name) { _name = name; }// 获取线程名std::string getName() const { return _name; }// 获取计算结果int getResult() const { return _result; }// 默认析构函数~threadData() = default;private:int _a, _b; // 存储要相加的两个整数std::string _name; // 线程的名字int _result; // 存储计算的结果pthread_t _tid; // 存储线程ID
};// 将pthread_t类型的线程ID转换为十六进制字符串表示
std::string toHex(pthread_t tid)
{char buff[64]; // 创建一个足够大的字符数组来存储转换后的字符串// 使用snprintf格式化线程ID为16进制并存储到buff中snprintf(buff, sizeof(buff), "0x%lx", (long)tid); // 强制转换为 long 类型以确保正确格式化// 返回转换后的字符串return std::string(buff);
}// 线程执行的函数
void *func(void *argc)
{// 输出新线程的信息,包括线程IDstd::cout << "I am 新线程, tid: " << toHex(pthread_self()) << '\n';// 将传入的参数(void指针)转换为threadData指针threadData *td = static_cast<threadData *>(argc);// 设置当前线程的 TIDtd->setTid(pthread_self());// 执行任务: 计算a+b,在该线程执行函数中执行任务,计算结果保存在td中td->Execute();// 返回指向threadData对象的指针,以便主线程可以访问计算结果return (void *)td;
}int main()
{threadData td_arr[10];for (int i = 0; i < 10; i++){td_arr[i].setName("thread-" + std::to_string(i));td_arr[i].setA(i * 10);td_arr[i].setB(i * 20);}// 创建多线程, 并将线程tid记录到 threadData 对象中for (int i = 0; i < 10; ++i){// 创建新线程pthread_t tid = 0;pthread_create(&tid, nullptr, func, (void *)&td_arr[i]);// 等待线程退出threadData *retval = nullptr;int join_ret = pthread_join(tid, (void **)&retval);std::cout << "I am main线程, 新线程[" << retval->getTid() << "]退出, 结果为: " << retval->getResult() << std::endl;}return 0;
}
运行结果如下:
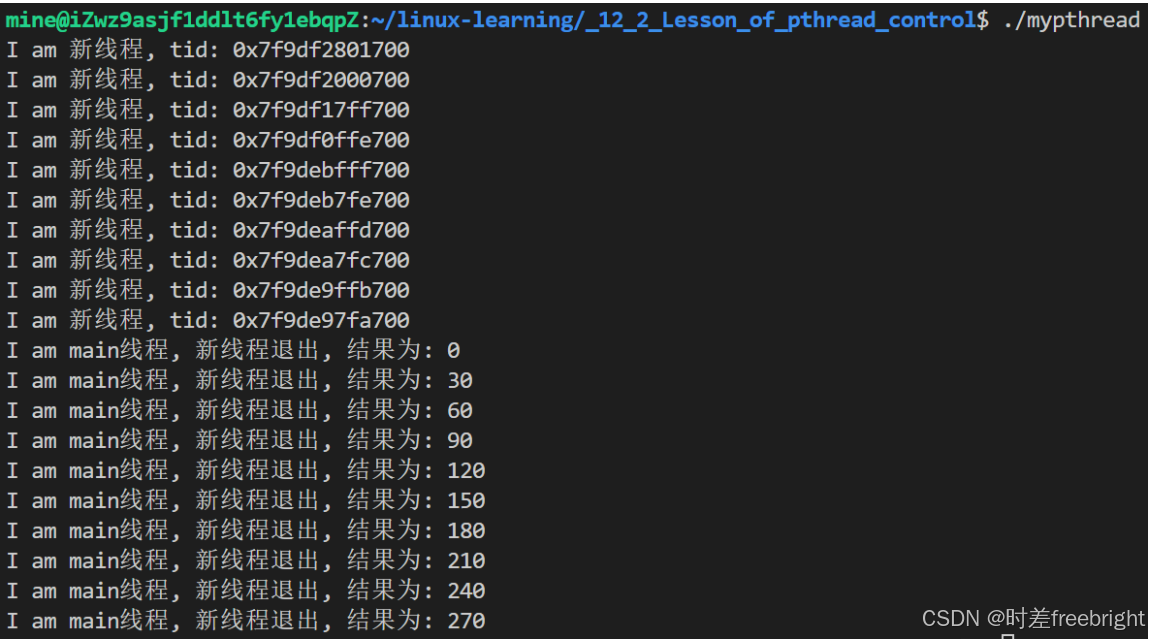
这里想要表达的意思是:我们可以将任务拆分成多个模块,分别交给不同的线程执行,最后多线程执行完成,主线程就可以拿着结果,进一步汇总处理,这就是多线程的作用
例如:我们需要排序一个大文件的数据,如有10G,我们可以创建10个线程,每个线程排序一个G的数据
最后进行汇总再次归并排序等操作,提高效率
又例如:我们需要对一个大文件进行加密处理,我们可以设计类中的处理函数为加密逻辑,然后每个线程分别加密某一小部分,主线程对结果进行汇总处理,最后完成对整个大文件的加密工作
3、证明栈可以被共享
#include <iostream>
#include <string>
#include <cstring>
#include <pthread.h>
#include <unistd.h>int* addr = nullptr;
void* run1(void* argv)
{std::string name = static_cast<char*>(argv);int a = 100;addr = &a;while(true){std::cout << "I am [" << name << "], tid: " << a << std::endl;a++;sleep(1);}
}
void* run2(void* argv)
{std::string name = static_cast<char*>(argv);while(true){std::cout << "I am [" << name << "], tid: " << *addr << std::endl;sleep(1);}
}int main()
{pthread_t tid1, tid2;pthread_create(&tid1, nullptr, run1, (void*)"thread-1");pthread_create(&tid2, nullptr, run2, (void*)"thread-2");pthread_join(tid1, nullptr);pthread_join(tid2, nullptr);return 0;
}
运行结果如下:
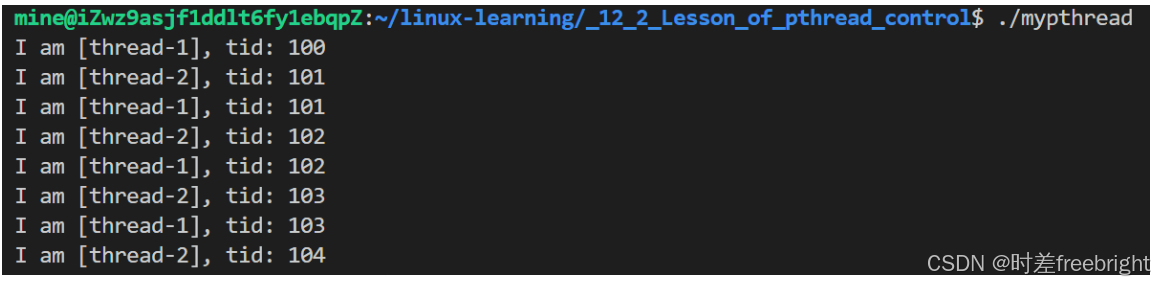
在多线程中,一个线程的栈为什么说具有独立性,因为在每个线程执行函数中定义的基本都是属于本代码块的局部变量,如果不向外界传出局部变量的地址,则外界就不可能访问获取我这个线程的栈内资源!
其实栈区也是共享的,只不过线程是通过不让你看到我栈区资源的方式达到独立隔离的目的!
六、线程退出
return 0 语句
1、主线程return,表示进程结束!
2、新线程return,表示该线程退出
exit():不管是新线程还是主线程,只要调用 exit(),整个进程都会退出,因为 exit()是向进程发信号,而不是单独一个线程
函数 pthread_exit
函数 pthread_exit(void* retval) :哪个线程调这个函数,哪个线程就退出
同时可以传递一个参数作为返回值
#include <iostream>
#include <string>
#include <cstring>
#include <pthread.h>
#include <unistd.h>void* run(void* argv)
{std::string name = static_cast<char*>(argv);std::cout << "I am [" << name << "]" << std::endl;sleep(1);pthread_exit((void*)10);
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, run, (void*)"thread-1");void* ret = 0;pthread_join(tid, &ret);std::cout << (long long int)ret << '\n';return 0;
}

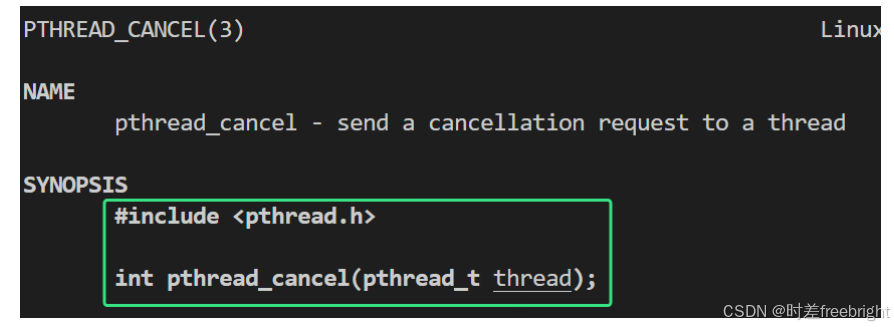
函数 pthread_cancel
线程可以被取消
#include <iostream>
#include <string>
#include <cstring>
#include <pthread.h>
#include <unistd.h>void *run(void *argv)
{std::string name = static_cast<char *>(argv);while (true){std::cout << "I am [" << name << "]" << std::endl;sleep(1);}pthread_exit((void *)10);
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, run, (void *)"thread-1");sleep(3);// 取消该线程pthread_cancel(tid);void* ret = nullptr;pthread_join(tid, &ret);std::cout << "new thread exit code: " << (long)ret << std::endl;return 0;
}

其实不建议主线程用该函数直接取消该线程,除非是你有准备的…
因为主线程并不知道该线程的工作进度与工作状态,如果线程一定不要了,也可以直接kill
取消的线程,执行函数的返回值为 -1
一个取消的线程也是需要 join 的,否则会产生类似僵尸进程的问题
取消掉的线程退出码为 PTHREAD_CANCELED

七、线程分离
1、引入
主线程的 pthread_join 是阻塞等待线程,而线程库并不提供非阻塞等待的方法,如果主线程阻塞等待某线程退出,岂不是优点浪费,有没有不用阻塞等待线程的方法,让我主线程可以腾出手做其他事?有的,就是线程分离
在进程章节,最后我们学习到的信号 SIGCHIL 是子进程退出系统向父进程发送的信号,父进程可以通过忽略该信号来不等待子进程
而对于线程,线程可以被分离:线程有两种状态
1、joined:线程需要被join(默认)
2、detach:线程分离(主线程不需要等待新线程)
线程分离 detach 就类似于一家人分家了,儿子脱离家庭,自己生活
而线程分离,也不会分出进程,因为还要共享该进程的相关资源
2、主线程最后退
另外,在多执行流多线程的情况下,一般会让主线程一定是最后退出的
因为主线程一旦退出,表示整个进程退出,所有的线程也会被终止退出
线程不像进程,进程间具有独立性,父进程退出,子进程不影响(还是会被托孤到 Init 进程)
3、线程分离正式介绍
在多线程编程中,线程分离(detaching a thread)指的是让一个线程独立于创建它的线程运行。分离后的线程不再需要被显式地加入(joined),即不需要等待其完成。操作系统会自动回收分离线程的资源,当该线程结束时。
当主线程退出时,整个进程将会结束,分离的线程也会随之被强制终止,则线程任务就被强制终止,没办法完成最终任务了
因此,我们一般会保证主线程最后退出(如何保证:我们后面的程序基本上都不会让主线程提前退出的)
#include <iostream>
#include <string>
#include <cstring>
#include <pthread.h>
#include <unistd.h>void *run(void *argv)
{// 分离该线程pthread_detach(pthread_self());std::string name = static_cast<char *>(argv);while (true){std::cout << "I am [" << name << "]" << std::endl;sleep(1);}
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, run, (void *)"thread-1");sleep(3);void *ret = nullptr;int n = pthread_join(tid, &ret);std::cout << "new thread exit code: " << (long)ret << std::endl;std::cout << "n: " << n << std::endl;return 0;
}
运行结果如下:
本程序新线程自己分离,当 3 秒后,主线程 join 等待该线程

我们可以发现 pthread_join 函数的 返回值为 22
而返回值大于 0 就表示 join 失败,这也表示主线程等待线程退出失败
问题:为什么线程分离后就不允许主线程 join 它
- 资源回收:当一个线程被分离后,操作系统或运行时环境会在该线程结束时自动回收其占用的资源,如栈空间、线程本地存储等。如果允许对分离后的线程进行
join操作,那么在调用join之前,系统将无法确定是否应该回收这些资源,这可能导致资源泄露或者资源过早释放。 - 线程状态不确定性:一旦线程被分离,它的生命周期就变得不确定了。它可能在任何时候完成并终止。如果你尝试对一个已经完成并且资源已被回收的分离线程调用
join,这会导致未定义行为,因为此时没有有效的线程对象可以等待。 - 避免竞态条件:允许对分离线程进行
join可能会引入竞态条件(race condition)。例如,如果一个线程在你决定调用join之前就已经结束了,那么这个join调用可能会失败或者产生其他意外的行为。相反,如果线程还没有结束,那么join将会阻塞主线程直到分离线程结束,这违背了分离线程的目的,即让它们独立运行而不必等待。
简单来说: 线程分离了,线程的结束工作就有操作系统管理了,只要该线程执行完毕,操作系统会自动处理该线程,如果主线程主动 join,则该线程结束时,该线程的退出处理工作不知道是由主线程还是操作系统执行,造成冲突,导致可能资源泄露或者资源过早释放
应该是:简单来说,一个线程会负责某些任务,主线程若想要知道该线程何时处理完成这些任务,就需要 pthread_join 阻塞等待该线程退出,这样比较耗时费劲。因此可以将该线程分离,主线程不再关心该线程任务是否完成,该线程任务完成,系统会帮主线程把该线程处理掉(回收资源,回收线程)
八、问题:线程是否可以程序替换
线程不能直接使用exec进行程序替换,因为exec系列函数是用于进程的程序替换,并非单独一个线程,如果线程使用exec,则可能会将本进程全部进行程序替换,造成其他线程的代码被更换或失效
在多线程环境中使用 exec 会导致以下问题:
- 其他线程失效:所有其他正在运行的线程将被终止,因为它们的代码和数据段被新的程序所取代。这可能导致未完成的任务突然中断,资源没有得到适当的释放或清理。
- 共享资源丢失:如果线程之间共享了某些资源(如文件描述符、内存区域等),这些资源可能会在
exec调用后变得无效或丢失,导致程序行为异常。 - 信号处理问题:进程的信号处理机制也会被新的程序所覆盖,这可能会影响原本设置好的信号处理器,造成不可预见的行为。
解决办法:
可以在线程中 fork 创建子进程,来进行进程程序替换
相关文章:

【Linux系统】线程:线程控制
一、POSIX线程库 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的。使用这些函数库,要通过引入头文件 <pthread.h>。链接这些线程函数库时要使用编译器命令的 -lpthread 选项。 二、轻量级进程创建:…...

GoFrame 微服务开发指南
基本介绍 GoFrame 框架支持微服务模式开发,提供了常用的微服务组件、开发工具、开发教程帮助团队快速微服务转型。 微服务组件简介 GoFrame 微服务组件具有低耦合及通用化设计,组件化使用支持大部分的微服务通信协议。在官方文档中,主要以…...
制作工具(进阶版))
Python-基于PyQt5,Pillow,pathilb,imageio,moviepy,sys的GIF(动图)制作工具(进阶版)
前言:在抖音,快手等社交平台上,我们常常见到各种各样的GIF动画。在各大评论区里面,GIF图片以其短小精悍、生动有趣的特点,被广泛用于分享各种有趣的场景、搞笑的瞬间、精彩的动作等,能够快速吸引我们的注意…...

PhpStorm下载、安装、配置教程
前面的文章中,都是把.php文件放在WampServer的www目录下,通过浏览器访问运行。这篇文章就简单介绍一下PhpStorm这个php集成开发工具的使用。 目录 下载PhpStorm 安装PhpStorm 配置PhpStorm 修改个性化设置 修改字符编码 配置php的安装路径 使用Ph…...

春节假期旅游热潮下,景区医疗安全如何全面升级?
春节假期旅游热潮下,景区医疗安全如何全面升级? 随着旅游业的不断繁荣,春节假期期间,各大景区再次迎来了游客的高峰期。面对如此庞大的客流量,景区不仅要在服务接待上下功夫,更要将医疗安全保障工作提升到…...

惠普HP工作站如何关闭关闭RAID?
惠普HP工作站如何关闭关闭RAID? 前言进入BIOS进入“先进”选项卡,点击“系统选项”。取消勾选“sSATA控制器RAID模式”,按下F10保存重启。 前言 惠普工作站默认启用了RAID模式,导致许多PE工具无法识别RAID模式下的硬盘。可以通过…...

ESP-Skainet智能语音助手,ESP32-S3物联网方案,设备高效语音交互
在科技飞速发展的今天,智能语音助手正逐渐渗透到我们生活的方方面面,而智能语音助手凭借其卓越的技术优势,成为了智能生活领域的一颗璀璨明星。 ESP-Skainet智能语音助手的强大之处在于其支持唤醒词引擎(WakeNet)、离…...

mac下生成.icns图标
笔记原因: 今日需要在mac下开发涉及图标文件的使用及icons文件的生成,所以记录一下。 网络上都是一堆命令行需要打印太麻烦了,写一个一键脚本。 步骤一 将需要生成的png格式文件重命名为“pic.png” mv xxxx.png pic.png 步骤二 下载我…...

【MySQL】centos 7 忘记数据库密码
vim /etc/my.cnf文件; 在[mysqld]后添加skip-grant-tables(登录时跳过权限检查) 重启MySQL服务:sudo systemctl restart mysqld 登录mysql,输入mysql –uroot –p;直接回车(Enter) 输…...

【kafka的零拷贝原理】
kafka的零拷贝原理 一、零拷贝技术概述二、Kafka中的零拷贝原理三、零拷贝技术的优势四、零拷贝技术的实现细节五、注意事项一、零拷贝技术概述 零拷贝(Zero-Copy)是一种减少数据拷贝次数,提高数据传输效率的技术。 在传统的数据传输过程中,数据需要在用户态和内核态之间…...

【JavaEE】Spring Web MVC
目录 一、Spring Web MVC简介 1.1 MVC简介1.2 Spring MVC1.3 RequestMapping注解1.3.1 使用1.3.2 RequestMapping的请求设置 1.3.2.1 方法11.3.2.2 方法2 二、Postman介绍 2.1 创建请求2.2 界面如下:2.3 传参介绍 一、Spring Web MVC简介 官方文档介绍ÿ…...

《解锁GANs黑科技:打造影视游戏的逼真3D模型》
在游戏与影视制作领域,逼真的3D模型是构建沉浸式虚拟世界的关键要素。从游戏中栩栩如生的角色形象,到影视里震撼人心的宏大场景,高品质3D模型的重要性不言而喻。随着人工智能技术的飞速发展,生成对抗网络(GANs…...
)
【大数据技术】词频统计样例(hadoop+mapreduce+yarn)
词频统计(hadoop+mapreduce+yarn) 搭建完全分布式高可用大数据集群(VMware+CentOS+FinalShell) 搭建完全分布式高可用大数据集群(Hadoop+MapReduce+Yarn) 在阅读本文前,请确保已经阅读过以上两篇文章,成功搭建了Hadoop+MapReduce+Yarn的大数据集群环境。 写在前面 Wo…...

deepseek与openai关系
DeepSeek与OpenAI之间的关系主要体现在技术竞争和合作的可能性上。 首先,DeepSeek是由中国的深度求索公司开发的,成立于2023年,专注于人工智能技术研发。其大模型DeepSeek-R1在数学、代码、自然语言推理等任务上的性能能够比肩OpenAI的G…...

51页精品PPT | 数据中台与数据治理服务及案例
案例的核心内容围绕数据中台与数据治理服务展开,详细介绍了数据治理的整体方法论、数据中台的建设路径以及如何通过数据治理和数据中台提升业务效率和数据质量。本案例强调了数据治理的重要性,包括数据标准、数据质量、数据安全等方面的管理,…...
 - 随笔)
使用 cipher /w 清除磁盘删除残留数据(Windows) - 随笔
cipher命令是Windows 系统自带的一个用于管理文件加密和磁盘数据清除的工具。通过 cipher /w 命令,可以清除磁盘上已删除文件的残留数据,确保这些数据无法被恢复。以下是一个简易的批处理脚本,用于清除指定磁盘上的加密数据。 echo off :: 清…...

RuntimeWarning: invalid value encountered in sqrt
代码出处: GitHub - wangsen1312/joints2smpl: fit smpl parameters model using 3D joints RuntimeWarning: invalid value encountered in sqrt 你可以通过以下几种方式解决这个问题: 1. 检查负值或零行列式 确保协方差矩阵是正半定的,这…...

3步打造C# API安全密盾
引言:API 安全的重要性 在数字化浪潮中,应用程序编程接口(API)已成为不同软件系统之间通信和数据交互的关键桥梁。无论是企业内部的微服务架构,还是面向外部用户的在线服务,API 都承担着数据传输和业务逻辑…...

项目实操:windows批处理拉取git库和处理目录、文件
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...

接入 deepseek 实现AI智能问诊
1. 准备工作 注册 DeepSeek 账号 前往 DeepSeek 官网 注册账号并获取 API Key。 创建 UniApp 项目 使用 HBuilderX 创建一个新的 UniApp 项目(选择 Vue3 或 Vue2 模板)。 安装依赖 如果需要在 UniApp 中使用 HTTP 请求,推荐使用 uni.requ…...

ubuntu22.04源码编译mysql8.0.X详细流程【由deepseek提供】
以下是在 Ubuntu 22.04 上从源代码编译安装 MySQL 8.0.X(以 MySQL 8.0.37 为例)的详细操作流程: 一、准备工作 1. 更新系统 sudo apt update && sudo apt upgrade -y sudo apt install -y build-essential cmake pkg-config libssl…...

富唯智能复合机器人拓展工业新维度
富唯智能复合机器人是富唯智能倾力打造的一款集高度自动化、智能化和多功能性于一体的机器人。它融合了机械、电子、计算机、传感器等多个领域的前沿技术,通过精密的算法和控制系统,实现了对复杂生产环境的快速适应和高效作业。 富唯智能复合机器人的特点…...

【2】高并发导出场景下,服务器性能瓶颈优化方案-异步导出
Java 异步导出是一种在处理大量数据或复杂任务时优化性能和用户体验的重要技术。 1. 异步导出的优势 异步导出是指将导出操作从主线程中分离出来,通过后台线程或异步任务完成数据处理和文件生成。这种方式可以显著减少用户等待时间,避免系统阻塞&#x…...

verdi 查看覆盖率
点击Tools -> Coverage,会出现一个Verdi:vdCoverage:1页面点击File->Open/Add Database, 会出现一个 Open/Add Coverage Database页面, 在Design Hierarchy/Testbench Location 中输入 vdb路径点击… , 会出现当前路径下的文件…...

【React】路由处理的常见坑与解决方法,React Router 的动态路由与懒加载问题
在使用 React Router 时,动态路由和懒加载是非常常见的需求,但也可能会遇到一些坑。以下是常见问题以及对应的解决方法。 一、React Router 动态路由常见问题 1. 动态路由匹配问题 动态路由通常通过 :param 定义路径参数,但如果路径参数与静态路由有重叠,可能会导致匹配问…...

OKHttp拦截器解析
OKHttp涉及到拦截器大概的执行步骤为: 1.通过newCall生成RealCall对象 具体代码如下: Override public Call newCall(Request request) {return new RealCall(this, request, false /* for web socket */);}2.调用Call的execute方法 当然这也可以是执…...

顺序表和链表
线性表 线性表(linear list)是n 个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构。 常见的线性表:顺序表、链表、栈、队列、字符串… 线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物…...
)
若依框架使用(低级)
克隆源码 浏览器搜索若依,选择 RuoYi-Vue RuoYi-Vue RuoYi-Vue 重要的事情说三遍,进入gitee 下面这个页面(注意红色框起来的部分) 进入Gitee进行下载 我下载的是最新的springboot3 下载好后我们可以选择一个文件夹࿰…...

Spring JDBC模块解析 -深入SqlParameterSource
在前面的博客中,我们探讨了Spring Data Access Module中的主要组件: JdbcTemplate和SimpleJdbcInsert。在这两部分的基础上,我们将继续探讨更详细 的用法,包括如何使用RowMapper和SqlParameterSource等高级主题。 JdbcTemplate …...

SQL中Limit的用法详解
SQL中的LIMIT关键字是一个非常有用的工具,它可以用来限制查询结果返回的记录数量。文章将详细解析LIMIT关键字的使用方法,包括它的基本用法,以及在查询数据时如何配合使用LIMIT与OFFSET。我会通过示例代码演示LIMIT在单行结果集和多行结果集情…...

mac 安装 dotnet 环境
目录 一、安装准备 二、安装方法(两种任选) 方法 1:使用官方安装包(推荐新手) 方法 2:使用 Homebrew(适合开发者) 1. 安装 Homebrew(如未安装) 2. 通过 …...

DeepSeek辅助学术写作【句子重写】效果如何?
句子重写(功能指数:★★★★★) 当我们想引用一篇文章中的一-些我们认为写得很好的句子时,如果直接将原文加人自己的文章,那么即使我们标注上了引用,也依旧会被查重软件计算在重复比例中。查重比例过高的话,会影响投稿或毕业答辩送…...

SpringUI Web高端动态交互元件库
Axure Web高端动态交互元件库是一个专为Web设计与开发领域设计的高质量资源集合,旨在加速原型设计和开发流程。以下是关于这个元件库的详细介绍: 一、概述 Axure Web高端动态交互元件库是一个集成了多种预制、高质量交互组件的工具集合。这些组件经过精…...

QT +FFMPEG4.3 拉取 RTMP/http-flv 流播放 AVFrame转Qimage
QT FFMPEG4.3 拉取 RTMP/http-flv 流播放 Cc_Video_thread.h #ifndef CC_VIDEO_THREAD_H #define CC_VIDEO_THREAD_H#include <QThread> #include <QAtomicInt> #include <QImage>#ifdef __cplusplus extern "C" { #endif #include <libavfor…...

Docker最佳实践:安装Nacos
文章目录 Docker最佳实践:安装Nacos一、引言二、安装 Nacos1、拉取 Nacos Docker 镜像2、启动 Nacos 容器 三、配置 Nacos(可选)四、使用示例1、服务注册2、服务发现 五、总结 Docker最佳实践:安装Nacos 一、引言 Nacos 是阿里巴…...

106,【6】 buuctf web [SUCTF 2019]CheckIn
进入靶场 文件上传 老规矩,桌面有啥传啥 过滤了<? 寻找不含<?的一句话木马 文件名 123(2).php.jpg 文件内容 GIF89a? <script language"php">eval($_GET[123]);</script> 123即密码,可凭借个人喜好更换 再上传一个文…...
)
【Linux】27.Linux 多线程(1)
文章目录 1. Linux线程概念1.1 线程和进程1.2 虚拟地址是如何转换到物理地址的1.3 线程的优点1.4 线程的缺点1.5 线程异常1.6 线程用途 2. Linux进程VS线程2.1 进程和线程2.2 关于进程线程的问题 3. Linux线程控制3.1 POSIX线程库3.2 创建线程3.3 线程终止3.4 线程等待3.5 分离…...

旋转变压器工作及解调原理
旋转变压器 旋转变压器是一种精密的位置、速度检测装置,广泛应用在伺服控制、机器人、机械工具、汽车、电力等领域。但是,旋转变压器在使用时并不能直接提供角度或位置信息,需要特殊的激励信号和解调、计算措施,才能将旋转变压器…...

字符串转浮点数函数atof、strtod、strtof和strtold使用场景
字符串转浮点数函数 atof、strtod、strtof 和 strtold 在 C 语言标准库中都有各自的使用场景,它们的主要功能是将字符串转换为浮点数,但在处理的浮点数类型、错误处理机制和精度方面有所不同。 一、atof 函数使用场景 atof(ASCII to Float&…...
和从模式(Slave Mode))
GD32F4xx系列微控制器中,定时器的主模式(Master Mode)和从模式(Slave Mode)
在GD32F4xx系列微控制器中,定时器的主模式(Master Mode)和从模式(Slave Mode)是两种不同的工作模式,它们的主要区别在于定时器的操作是否依赖于外部信号或另一个定时器的输出信号。以下是对这两种模式的详细…...

深度学习系列--03.激活函数
一.定义 激活函数是一种添加到人工神经网络中的函数,它为神经网络中神经元的输出添加了非线性特性 在神经网络中,神经元接收来自其他神经元的输入,并通过加权求和等方式计算出一个净输入值。激活函数则根据这个净输入值来决定神经元是否应该…...

在linux 中搭建deepseek 做微调,硬件配置要求说明
搭建 可参考 使用deepseek-CSDN博客 官方网站:DeepSeek DeepSeek 是一个基于深度学习的开源项目,旨在通过深度学习技术来提升搜索引擎的准确性和效率。如果你想在 Linux 系统上搭建 DeepSeek,你可以遵循以下步骤。这里我将提供一个基本的指…...

机器学习之数学基础:线性代数、微积分、概率论 | PyTorch 深度学习实战
前一篇文章,使用线性回归模型逼近目标模型 | PyTorch 深度学习实战 本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started 本篇文章内容来自于 强化学习必修课:引领人工智能新时代【梗直哥瞿炜】 线性代数、微积分、概率论 …...

MySQL - Navicat自动备份MySQL数据
对于从事IT开发的工程师,数据备份我想大家并不陌生,这件工程太重要了!对于比较重要的数据,我们希望能定期备份,每天备份1次或多次,或者是每周备份1次或多次。 如果大家在平时使用Navicat操作数据库&#x…...

javaEE-9.HTML入门
目录 一.什么是html 二.认识html标签 1.标签的特点: 2.html文件基本结构 3.标签的层次结构 三、html工具 四、创建第一个文件 五.html常见标签 1标题标签h1-h6 2.段落标签:p 3.换行标签:br 4.图片标签:img 图片路径有1三种表示形式: 5.超链接:a 链接的几种形式: …...

springcloud微服务使用不同端口启动同一服务
若想同时启动两个服务,则会产生端口冲突,在启动类设置界面,添加虚拟机选项,随后设置 -Dserver.portxxxx即可...
--边缘计算应用开发详解)
JavaScript系列(61)--边缘计算应用开发详解
JavaScript边缘计算应用开发详解 🌐 今天,让我们深入探讨JavaScript的边缘计算应用开发。边缘计算是一种将计算和数据存储分布到更靠近数据源的位置的架构模式,它能够提供更低的延迟和更好的实时性能。 边缘计算基础架构 🌟 &am…...

【容器技术01】使用 busybox 构建 Mini Linux FS
使用 busybox 构建 Mini Linux FS 构建目标 在 Linux 文件系统下构建一个 Mini 的文件系统,构建目标如下: minilinux ├── bin │ ├── ls │ ├── top │ ├── ps │ ├── sh │ └── … ├── dev ├── etc │ ├── g…...
:使用zip函数同时遍历两个迭代器)
Effective Python系列(1.3):使用zip函数同时遍历两个迭代器
zip函数是 Python 中的一个内置函数,用于将多个可迭代对象(如列表、元组等)的元素配对,生成一个迭代器。 使用 zip 函数的好处之一就是能够节省内存空间,因为该函数会创建惰性生成器,每次遍历时只生成一个元…...

gitlab个别服务无法启动可能原因
目录 一、gitlab的puma服务一直重启 1. 查看日志 2. 检查配置文件 3. 重新配置和重启 GitLab 4. 检查系统资源 5. 检查依赖和服务状态 6. 清理和优化 7. 升级 GitLab 8. 查看社区和文档 二、 gitlab个别服务无法启动可能原因 1.服务器内存或磁盘已满 2.puma端口冲突…...