顺序表和链表
线性表
线性表(linear list)是n 个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构。常见的线性表:顺序表、链表、栈、队列、字符串…
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
顺序表
概念与结构
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。顺序表和数组的区别?
顺序表的底层结构是数组,对数组的封装,实现了常用的增、删、查、改等接口。
分类
静态顺序表
使用定长数组存储元素。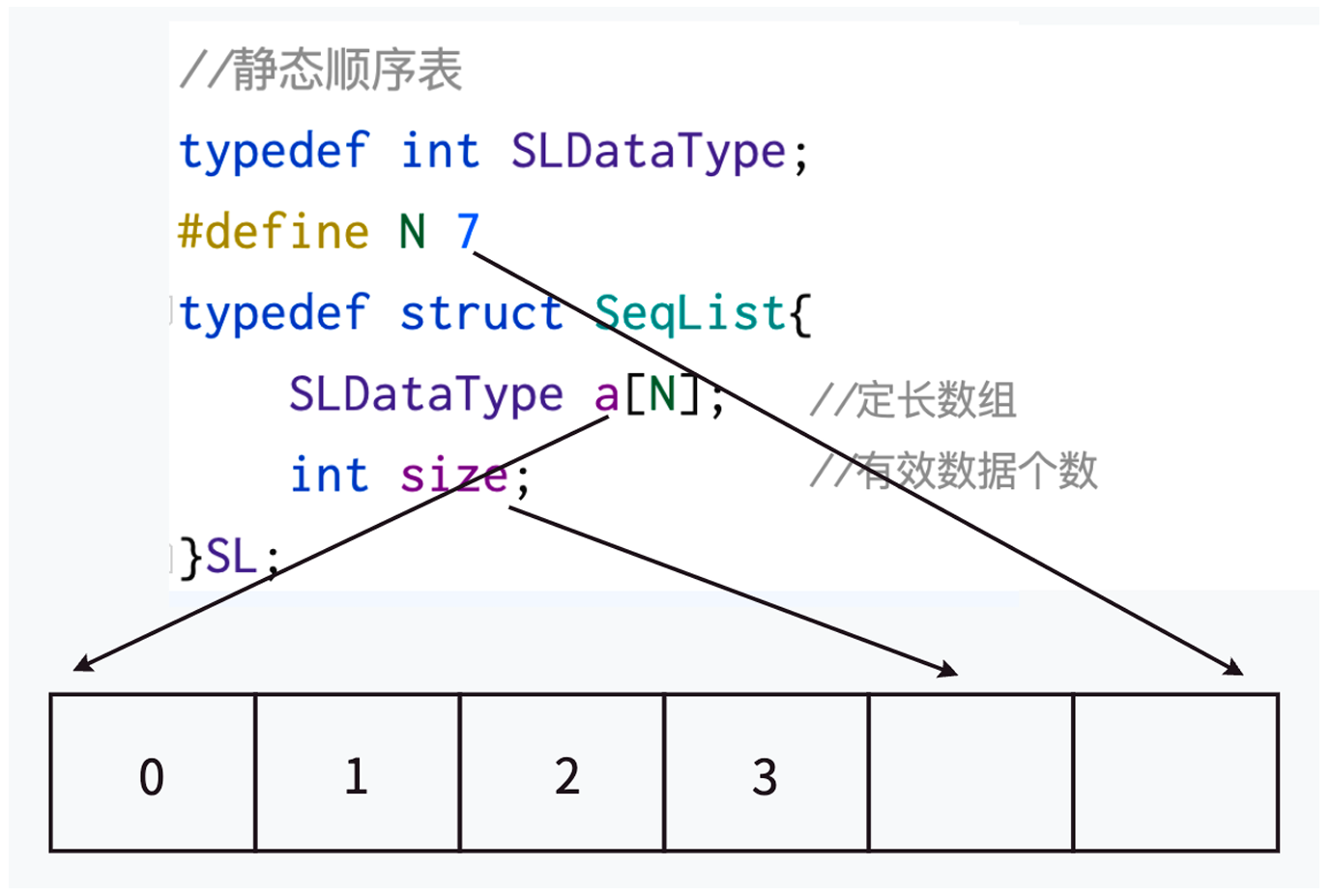
typedef int SLDatatype;#define N 7typedef struct SeqList
{SLDatatype a[N]; //定长数组int size; //有效数据个数
}SL;
缺陷:
- 空间给少了不够用
- 空间给多了造成空间浪费
动态顺序表
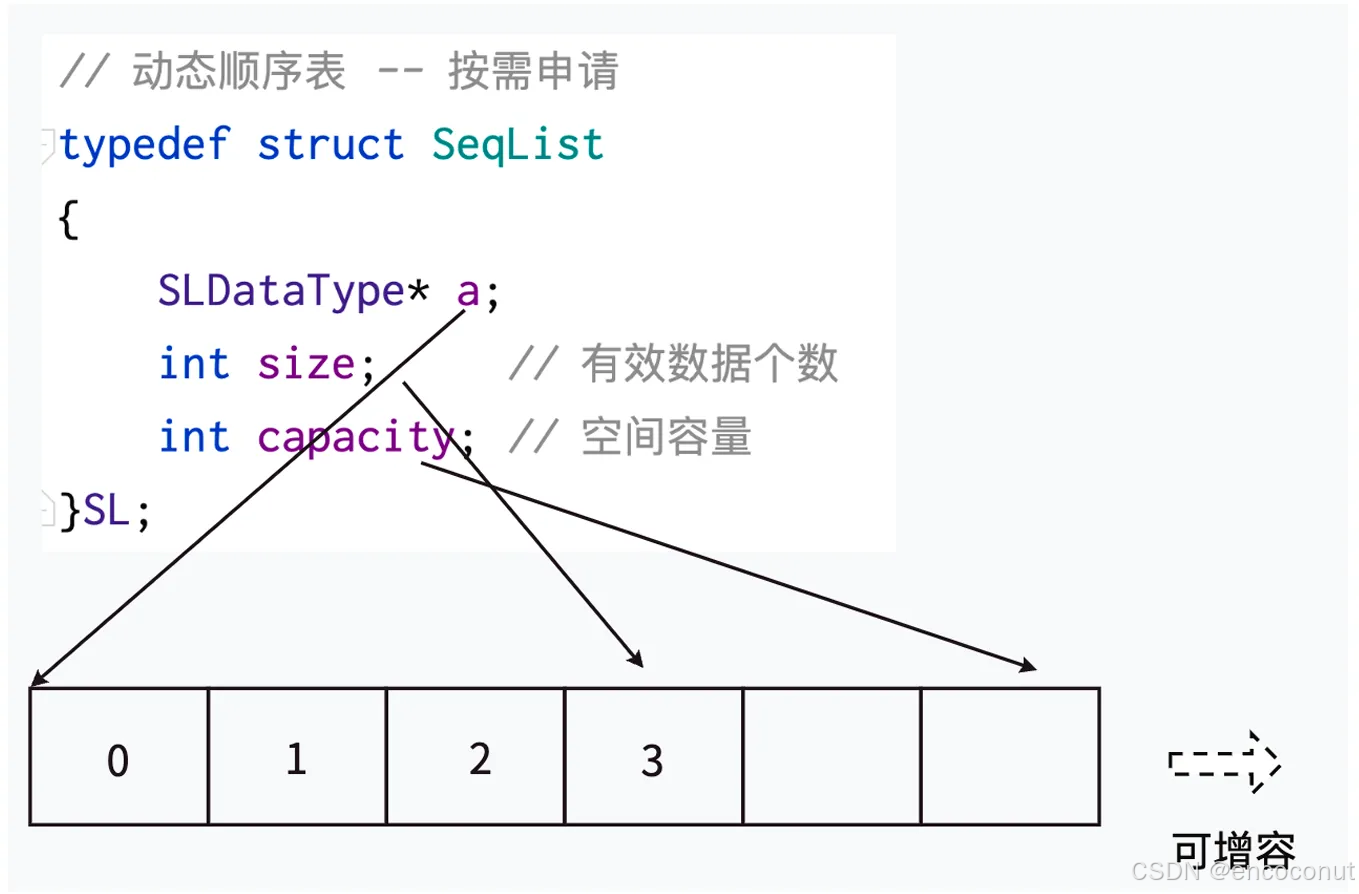
typedef int SLDatatype;typedef struct SeqList
{SLDatatype* a;int size; //有效数据个数int capacity; //空间容量
}SL;
动态顺序表的实现
SeqList.c
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>//定义顺序表结构
typedef int SLDataType;typedef struct SeqList
{SLDataType* arr;int size;int capacity;
}SL;//初始化
void SLInit(SL* s);//销毁
void SLDesTory(SL* ps);//查找
int SLFind(SL* ps, SLDataType x);//打印
void SLPrint(SL s);//扩容
void SLCheckCapacity(SL* ps);//尾插
void SLPushBack(SL* ps, SLDataType x);//头插
void SLPushFront(SL* ps, SLDataType x);//在指定位置之前插入数据
void SLInsert(SL* ps, int pos, SLDataType x);//尾删
void SLPopBack(SL* ps);//头删
void SLPopFront(SL* ps);//删除指定位置的数据
void SLErase(SL* ps, int pos);
SeqList.c
#include"SeqList.h"//初始化
void SLInit(SL* ps)
{/*传址调用,能够直接对顺序表的值进行修改*/ps->arr = NULL;ps->size = ps->capacity = 0;
}//销毁
void SLDesTory(SL* ps)
{if (ps->arr)free(ps->arr);ps->arr = NULL;ps->size = ps->capacity = 0;
}//查找
int SLFind(SL* ps, SLDataType x)
{/*找到了,返回下标没找到,返回-1*/assert(ps);for (int i = 0; i < ps->size; i++){if (ps->arr[i] == x)return i;}return -1;
}//打印
void SLPrint(SL s)
{for (int i = 0; i < s.size; i++){printf("%d ", s.arr[i]);}
}//扩容
void SLCheckCapacity(SL* ps)
{/*可能存在的问题:1. capacity为02. 若每次增加的空间较小,可能导致频繁扩容,效率低下若每次开辟的空间较大,可能存在空间浪费-->扩容一般成倍数增加内存*/if (ps->size == ps->capacity)//空间满了{int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity;SLDataType* tmp = (SLDataType*)realloc((void*)ps->arr, newcapacity * sizeof(SLDataType));if (tmp == NULL){perror("realloc");exit(1);}ps->arr = tmp;ps->capacity = newcapacity;}
}//尾插
void SLPushBack(SL* ps, SLDataType x)
{assert(ps);SLCheckCapacity(ps);ps->arr[ps->size++] = x;
}//头插
void SLPushFront(SL* ps, SLDataType x)
{assert(ps);SLCheckCapacity(ps);for (int i = ps->size; i > 0; i--){ps->arr[i] = ps->arr[i - 1];}ps->arr[0] = x;ps->size++;
}//在指定位置之前插入数据
void SLInsert(SL* ps, int pos, SLDataType x)
{/*pos可以直接输入值,也可以为SLFind的返回值0 <= pos < size*/assert(ps);assert(pos >= 0 && pos < ps->size);SLCheckCapacity(ps);for (int i = ps->size; i > pos; i--){ps->arr[i] = ps->arr[i - 1];}ps->arr[pos] = x;ps->size++;
}//尾删
void SLPopBack(SL* ps)
{/*顺序表不能为空*/assert(ps && ps->size);ps->size--;/*不需要给ps->arr[size - 1]修改值ps->size--后,ps->arr[size - 1]的值并不会影响其他操作*/
}//头删
void SLPopFront(SL* ps)
{assert(ps && ps->size);for (int i = 0; i < ps->size - 1; i++){ps->arr[i] = ps->arr[i + 1];}ps->size--;
}//删除指定位置的数据
void SLErase(SL* ps, int pos)
{assert(ps && ps->size);assert(pos >= 0 && pos < ps->size);for (int i = pos; i < ps->size - 1; i++){ps->arr[i] = ps->arr[i + 1];}ps->size--;
}
顺序表算法题
[移除元素](https://leetcode.cn/problems/remove-element/description/)
思路 1:另建临时数组(空间的复杂度为
O(N),且需要对numsSize = 0的请况另外做讨论,方法不好)。
思路 2:双指针法,创建两个变量指向数组。
int removeElement(int* nums, int numsSize, int val)
{int src = 0;int dst = 0;//由dst直接记录不等于 val 的元素个数,不用额外创建变量//不用额外讨论 numsSize = 0 的请况。while (src < numsSize){//找出不等于 val 的元素个数if (nums[src] != val){nums[dst++] = nums[src];}src++;}return dst;
}
[删除有序数组中的重复项](https://leetcode.cn/problems/remove-duplicates-from-sorted-array/description/)
思路:双指针法,创建两个变量分别指向起始位置和下一个位置(便于判断是否为唯一元素)
上述代码可以进一步简化,省略对
numsSize的分类讨论。
int removeDuplicates(int* nums, int numsSize)
{int dst = 0;int src = dst + 1;while (src < numsSize){if (nums[src] != nums[dst] && ++dst != src)//避免重复赋值{nums[dst] = nums[src];}src++;}return dst + 1;
}
[合并两个有序数组](https://leetcode.cn/problems/merge-sorted-array/description/)
思路 1:先合并,再进行冒泡排序(时间复杂度
O(N^2),方法不好)
思路 2:由于
nums1的后n个元素为0,可以从后往前遍历数组。
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
{int l1 = m - 1;int l2 = n - 1;int l3 = m + n - 1;while (l1 >= 0 && l2 >= 0){nums1[l3--] = nums1[l1] > nums2[l2] ? nums1[l1--] : nums2[l2--];}while (l2 >= 0){nums1[l3--] = nums2[l2--];}//l1 >= 0的情况不需要操作
}
链表
概念与结构
链表是一种**物理结构上非连续、非顺序**的存储结构,数据元素的**逻辑顺序是通过链表中的指针链接次序实现**的。
结点
与顺序表不同,链表里的每一块区域都是独立申请下来的空间,我们称之为“结点/节点”。结点的组成主要有两个部分:当前结点要保存的数据和下一个结点的地址(指针变量)。
链表中每个结点都是独立申请的(即需要插入数据时才去申请一块结点的空间),我们需要通过指针变量来保存下一个结点位置才能从当前结点找到下一个结点。
//定义结点结构
typedef int SLTDataType;typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;
链表的性质
-
链式机构在逻辑上是连续的,在物理结构上不一定连续
-
结点一般是从堆上申请的
-
从堆上申请来的空间,是按照一定策略分配出来的,每次申请的空间可能连续,可能不连续
链表的分类
链表的结构非常多样,下列情况组合起来共有8种(2x2x2)链表结构: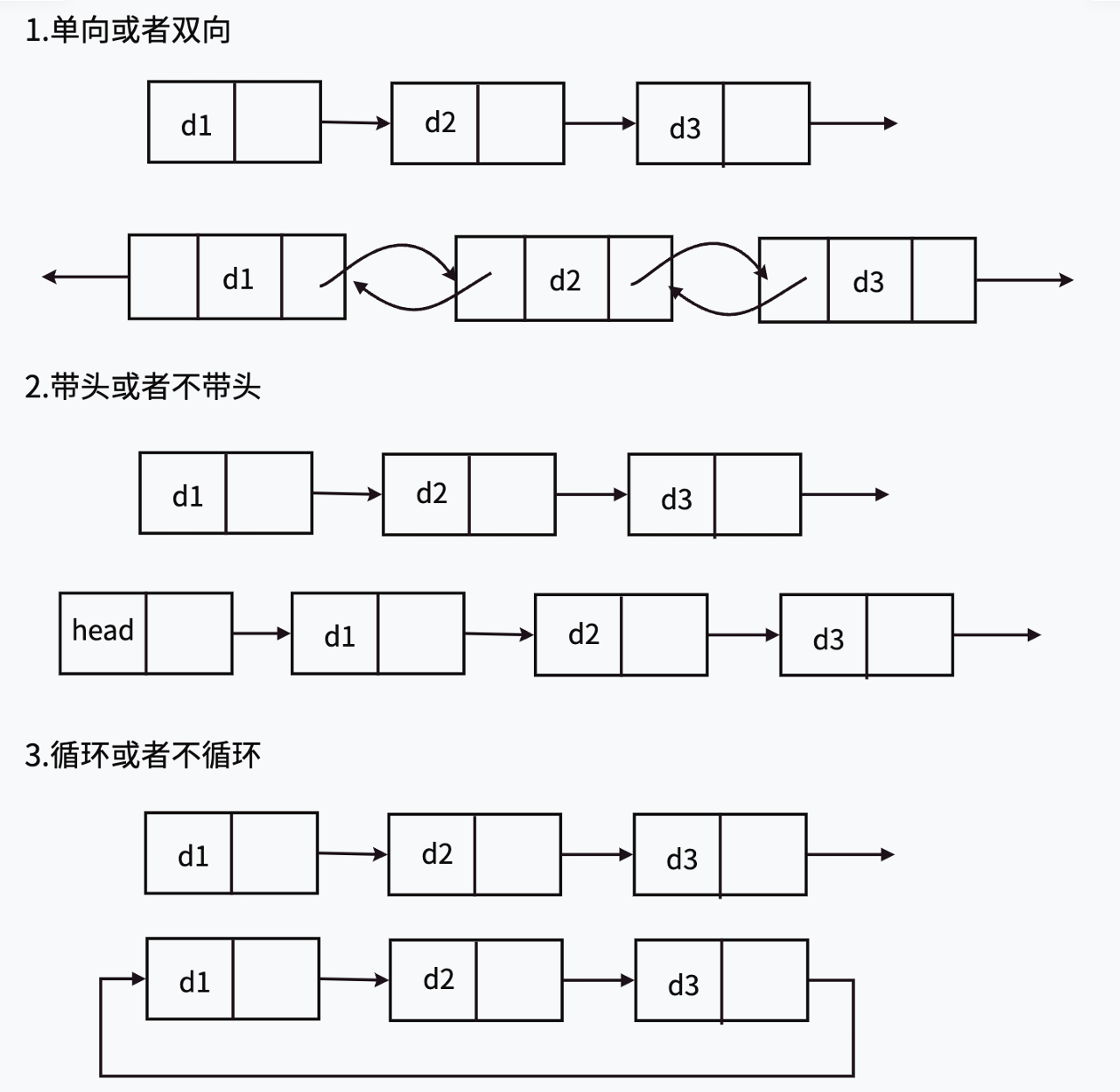
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:无头单向非循环链表(单链表)和带头双向循环链表(双向链表)。
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子
结构,如哈希桶、图的邻接表等等。- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头
双向循环链表。
单链表(singly-linked list)
注意:
在单链表中提到的头结点并不是“哨兵位”结点,而是指链表的第一个结点,这种表述是不规范的。
链表的打印
void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;while (pcur){printf("%d -> ", pcur->data);pcur = pcur->next;}printf("\n");
}
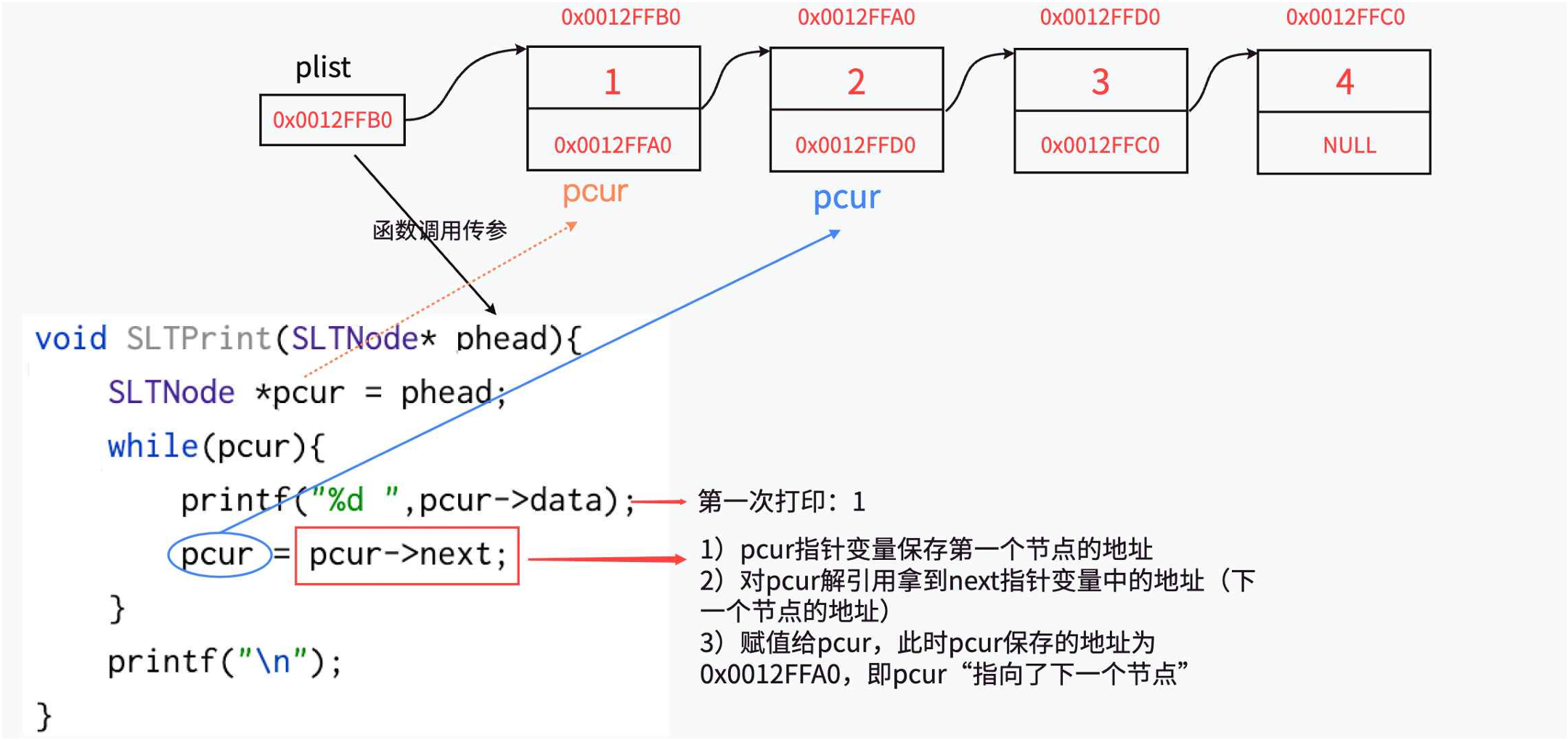
单链表的实现
SList.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>//定义结点结构
typedef int SLTDataType;typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;//向操作系统申请一个新结点
SLTNode* SLTBuyNode(SLTDataType x);//销毁链表
void SLTDesTroy(SLTNode** pphead);//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);//打印
void SLTPrint(SLTNode* phead);//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x); //在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);//在指定位置之后插入数据
void SLTInsertAfter(SLTNode** pphead, SLTNode* pos, SLTDataType x);//尾删
void SLTPopBack(SLTNode** pphead);//头删
void SLTPopFront(SLTNode** pphead);//删除指定位置的结点
void SLTErase(SLTNode** pphead, SLTNode* pos);
SList.c
#include"SList.h"//向操作系统申请一个新结点
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}//销毁链表
void SLTDesTroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{assert(phead);SLTNode* pcur = phead;while (pcur){if (pcur->data == x)return pcur;pcur = pcur->next;}return NULL;
}//打印链表
void SLTPrint(SLTNode* phead)
{/*定义pcur,避免后续需要使用首结点而找不到的情况*/SLTNode* pcur = phead;while (pcur){printf("%d -> ", pcur->data);pcur = pcur->next;}printf("NULL\n");
}//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{/*需要对plist做出修改,采用传址调用*/assert(pphead);SLTNode* newnode = SLTBuyNode(x);//链表为空,phead直接指向newnodeif (*pphead == NULL)*pphead = newnode;//链表不为空,寻找尾结点else{SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}ptail->next = newnode;}
}//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;
}//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead && pos);//pos就是头结点if (*pphead == pos){//头插SLTPushFront(pphead, x);}else{SLTNode* newnode = SLTBuyNode(x);//pos在头结点之后-->找pos的前驱结点SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = newnode;newnode->next = pos;}
}//在指定位置之后插入数据
void SLTInsertAfter(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead && pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}//尾删
void SLTPopBack(SLTNode** pphead)
{/*链表不为空*/assert(pphead && *pphead);//只有一个结点的情况,直接释放,避免后续在prev为NULL时对其解引用if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{//双指针,使得尾结点前驱结点next指针置为NULL,并释放尾结点SLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;free(ptail);ptail = NULL;}
}//头删
void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* next = (*pphead)->next;free(*pphead);*pphead = next;
}//删除指定位置的结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead && pos);//pos就是头结点if (*pphead == pos){//头删SLTPopFront(pphead);}else{SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}
}//删除指定位置后的结点
void SLTEraseAfter(SLTNode* pos)
{assert(pos && pos->next);SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}
单链表算法题
[移除链表元素](https://leetcode.cn/problems/remove-linked-list-elements/description/)
思路一:查找值为
val的结点并返回结点位置,删除指定位置的结点(时间复杂度:O(N<sup>2</sup>))
思路二:创建新链表,将值不为
val的结点尾插到新链表中
typedef struct ListNode ListNode;ListNode* removeElements(ListNode* head, int val)
{//创建新链表的头结点与尾结点ListNode* newhead = NULL;ListNode* newtail = NULL;ListNode* pcur = head;while (pcur){if (pcur->val != val){//新链表为空if (newhead == NULL)newhead = newtail = pcur;//新链表不为空else{//尾插newtail->next = pcur;newtail = pcur;}}pcur = pcur->next;}//使尾结点的next为空if (newtail)newtail->next = NULL;return newhead;
}
[反转链表](https://leetcode.cn/problems/reverse-linked-list/description/)
思路 1:创建新链表,将原链表的每个结点依次头插到新链表。
typedef struct ListNode ListNode;
ListNode* reverseList(ListNode* head)
{ListNode* newhead = NULL;ListNode* newtail = NULL;ListNode* pcur = head;//头插while (pcur){//新链表为空if (newhead == NULL){newhead = newtail = pcur;pcur = pcur->next;}//新链表不为空else{ListNode* next = pcur->next;pcur->next = newhead;newhead = pcur;pcur = next;} }//使尾结点的next为空if (newtail)newtail->next = NULL;return newhead;
}
思路二:创建三个指针,在原链表上修改指针的指向
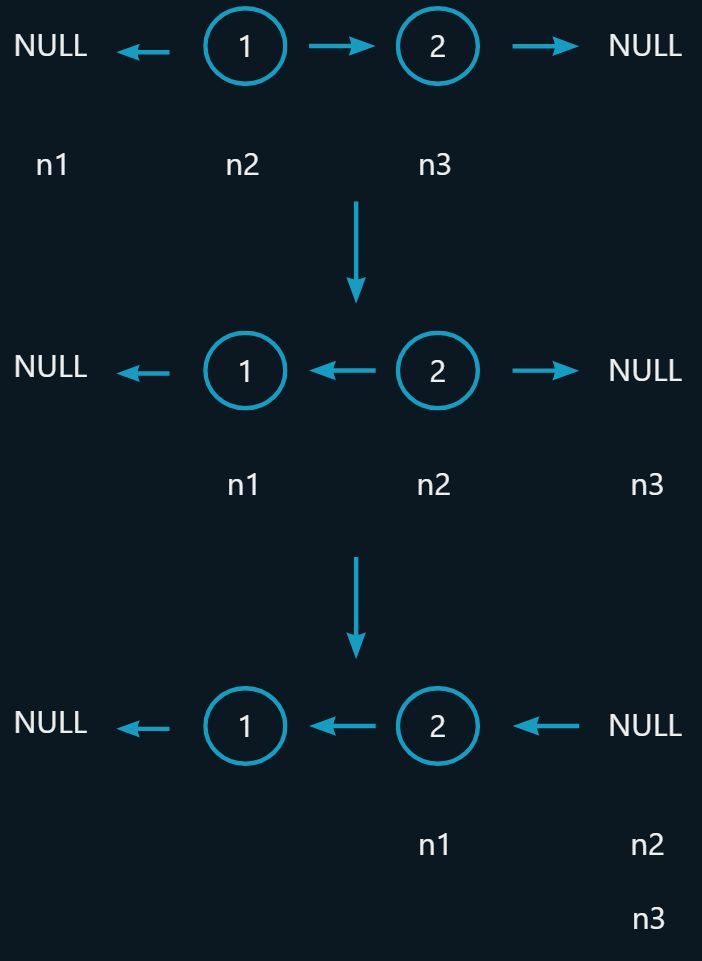
typedef struct ListNode ListNode;ListNode* reverseList(ListNode* head)
{//空链表if (head == NULL)return head;//非空链表ListNode* n1, *n2, *n3;n1 = NULL, n2 = head, n3 = head->next;while (n2){n2->next = n1;n1 = n2;n2 = n3;if (n3)n3 = n3->next;}//此时n1为反转后链表的结点return n1;
}
[链表的中间结点](https://leetcode.cn/problems/middle-of-the-linked-list/description/)
思路 1:第一次循环:遍历链表,求链表总长度,计算中间结点的位置
第二次循环:根据中间结点的位置走到中间结点
思路 2:快慢指针:慢指针每次走一步,快指针每次走两步。快指针的路程是慢指针的两倍。
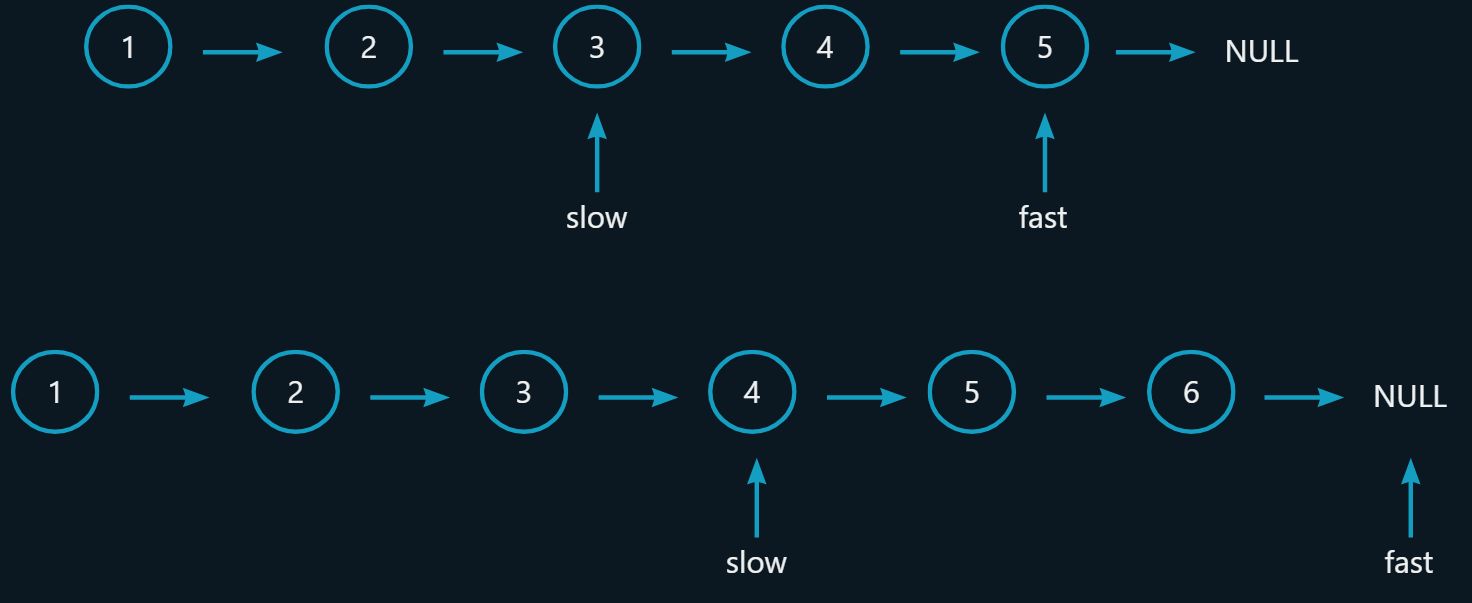
typedef struct ListNode ListNode;ListNode* middleNode(ListNode* head)
{ListNode* fast = head;ListNode* slow = head;/*注意:不能修改为fast->next && fast逻辑运算符的短路*/while (fast && fast->next){fast = fast->next->next;slow = slow->next;}return slow;
}
[合并两个有序链表](https://leetcode.cn/problems/merge-two-sorted-lists/description/)
思路 :创建新链表,遍历原链表,比较大小,将小的结点尾插到新链表。
typedef struct ListNode ListNode;ListNode* mergeTwoLists(ListNode* list1, ListNode* list2)
{//处理链表为空的情况if (list1 == NULL)return list2;if (list2 == NULL)return list1;ListNode* newhead = NULL, *newtail = NULL;ListNode* l1 = list1;ListNode* l2 = list2;while (l1 && l2){if ((l1->val) < (l2->val)){//尾插l1if (newhead == NULL){newhead = newtail = l1;}else{newtail->next = l1;newtail = newtail->next;}l1 = l1->next;}else{//尾插l2if (newhead == NULL){newhead = newtail = l2;}else{newtail->next = l2;newtail = newtail->next;}l2 = l2->next;}}if (l1)newtail->next = l1;if (l2)newtail->next = l2;return newhead;
}
注意:上述代码的尾插部分由于对新链表分空与非空的情况而非常冗余,因此可以在创建的新链表的头结点添加一个“哨兵位”来简化代码。
typedef struct ListNode ListNode;ListNode* mergeTwoLists(ListNode* list1, ListNode* list2)
{if (list1 == NULL)return list2;if (list2 == NULL)return list1;ListNode* newhead, *newtail;//创建“哨兵位”newhead = newtail = (ListNode*)malloc(sizeof(ListNode));ListNode* l1 = list1;ListNode* l2 = list2;while (l1 && l2){if ((l1->val) < (l2->val)){newtail->next = l1;newtail = newtail->next;l1 = l1->next;}else{newtail->next = l2;newtail = newtail->next;l2 = l2->next;}}if (l1)newtail->next = l1;if (l2)newtail->next = l2;return newhead->next;
}
[链表分割](https://www.nowcoder.com/practice/0e27e0b064de4eacac178676ef9c9d70)
思路:创建大小两个链表,小链表存放
<x的值,大链表存放>=x的值。再将两个链表相连。
typedef struct ListNode ListNode;ListNode* partition(ListNode* pHead, int x)
{//创建两个非空链表ListNode* lesshead, *lesstail;ListNode* greaterhead, *greatertail;lesshead = lesstail = (ListNode*)malloc(sizeof(ListNode));greaterhead = greatertail = (ListNode*)malloc(sizeof(ListNode));//遍历链表ListNode* pcur = pHead;while (pcur){//尾插到小链表if (pcur->val < x){lesstail->next = pcur;lesstail = lesstail->next;}//尾插到大链表else{greatertail->next = pcur;greatertail = greatertail->next;}pcur = pcur->next;}//大小链表首尾相连lesstail->next = greaterhead->next;//将大链表的尾结点的next指针置为NULLgreatertail->next = NULL;//释放空间ListNode* ret = lesshead->next;free(lesshead);free(greaterhead);lesshead = greaterhead = NULL;return ret;
}
[链表的回文结构](https://www.nowcoder.com/practice/d281619e4b3e4a60a2cc66ea32855bfa)
思路 1:创建新链表保存原链表节点,翻转新链表,遍历两个链表比较结点是否相同(不符合额外空间复杂度为
O(1)。
思路 2(投机取巧法):由于保证链表长度小于等于 900,创建大小为 900 的数组,遍历原链表将结点的值依次存储在数组中
typedef struct ListNode ListNode;bool chkPalindrome(ListNode* A)
{int i = 0;int arr[900] = { 0 };ListNode* pcur = A;//遍历原链表,将结点的值存储在数组中while (pcur){arr[i++] = pcur->val;pcur = pcur->next;}//判断数组是否为回文结构int left = 0, right = i - 1;while (left < right){if (arr[left] != arr[right])return false;right--;left++;}return true;
}
思路 3:找链表的中间结点,以链表的中间结点为新链表的头结点反转链表,将新链表与原链表比较。
typedef struct ListNode ListNode;//找中间节点
ListNode* middleNode(ListNode* head)
{ListNode* slow = head;ListNode* fast = head;while (fast && fast->next){fast = fast->next->next;slow = slow->next;}return slow;
}//反转链表
ListNode* reverseList(ListNode* head)
{if (head == NULL)return head;ListNode* n1 = NULL, *n2 = head, *n3 = head->next;while (n2){n2->next = n1;n1 = n2;n2 = n3;if (n3)n3 = n3->next;}return n1;
}//判断回文结构
bool chkPalindrome(ListNode* A)
{ListNode* mid = middleNode(A);ListNode* right = reverseList(mid);ListNode* left = A;while (right){if (left->val != right->val)return false;left = left->next;right = right->next;}return true;
}
[相交链表](https://leetcode.cn/problems/intersection-of-two-linked-lists/description/)
思路:求两个链表长度,长链表先走长度差步,长短链表开始遍历比较结点的地址是否相同
typedef struct ListNode ListNode;ListNode *getIntersectionNode(ListNode *headA, ListNode *headB)
{ListNode* pa = headA;ListNode* pb = headB;int sizeA = 0;int sizeB = 0;while (pa){sizeA++;pa = pa->next;}while (pb){sizeB++;pb = pb->next;}int gap = abs(sizeA - sizeB);ListNode* shortlist = headA;ListNode* longlist = headB;if (sizeA > sizeB){shortlist = headB;longlist = headA;}while (gap--){longlist = longlist->next;}while (longlist){if (longlist == shortlist)return longlist;longlist = longlist->next;shortlist = shortlist->next;}return NULL;
}
[环形链表 I](https://leetcode.cn/problems/linked-list-cycle/description/)
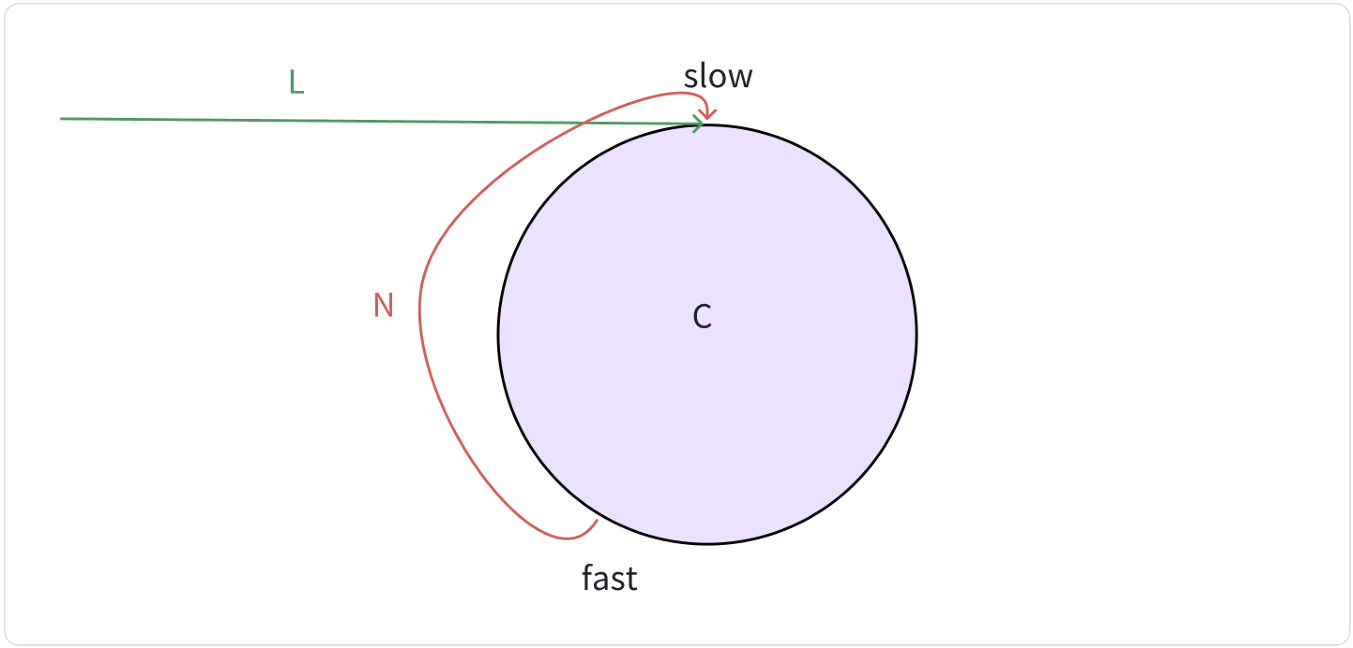
思路:快慢指针在链表中追逐,若链表有环,则快慢指针会再次相遇。
证明:快慢指针一定会相遇。
若
slow入环时fast与slow间的距离为N:
- 快指针每次走两步,慢指针每次走一步,快慢指针最终会相遇:
在追逐过程中,
fast与slow的距离变化:

typedef struct ListNode ListNode;bool hasCycle(ListNode *head)
{//快慢指针ListNode* slow = head;ListNode* fast = head;while (fast && fast->next){fast = fast->next->next;slow = slow->next;//相遇if (fast == slow)return true;}return false;
}
- 快指针每次走三步,慢指针每次走一步,快慢指针最终会相遇:
- 距离的变化
在追逐过程中,
fast与slow的距离变化:
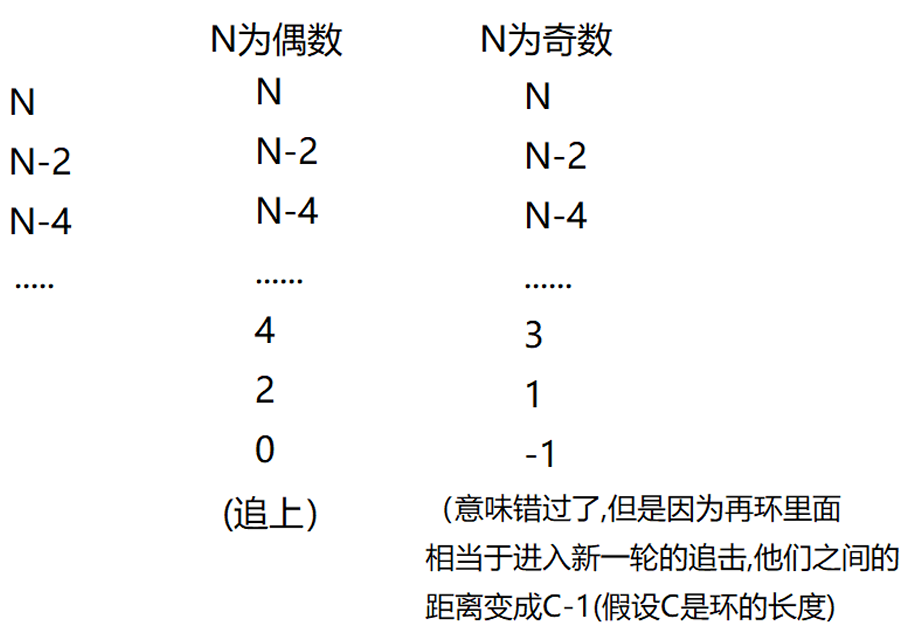
结论:
1. 如果N是偶数,第一轮就追上了2. 如果 N是奇数 ,第一轮追不上,快追上,错过了,距离变成`-1`,即`C-1`,进入新的一轮追击 1. `C-1`如果是偶数,那么下一轮就追上了2. `C-1`如果是奇数, 那么就永远都追不上总结⼀下追不上的前提条件:N是奇数,C是偶数
2. 路程
由于慢指针走一步,快指针要走三步,因此得出:3 * 慢指针路程 = 快指针路程
$ 3L=L +xC+C-N $
即:$ 2L=(x+1)C+N $
对上述公式继续分析:由于偶数乘以任何数都为偶数,因此
2L一定为偶数,则可推导出可能得情况:* 情况 1:偶数 = 偶数 + 偶数* 情况 2:偶数 = 奇数 + 奇数由 a 中的 i 得出的结论,如果
N是偶数,则第一圈快慢指针就相遇了。由 a 中的 ii 得出的结论, 如果
N是奇数,则fast指针和slow指针在第一轮的时候套圈了,开始进 行下一轮的追逐;当N是奇数,要满足以上的公式,则(x+1)C必须也要为奇数,即C为奇数,满足 中的结论,则快慢指针会相遇结论:
a 中的N是奇数,C是偶数的情况不成立,即快指针每次走三步,慢指针每次走一步的情况下,快慢指针最终也会相遇。
typedef struct ListNode ListNode;bool hasCycle(struct ListNode *head)
{ListNode* slow = head;ListNode* fast = head;while (fast && fast->next){slow = slow->next;//快指针每次走3步int n = 3;while (n--){if (fast->next)fast = fast->next;elsereturn false;}if (fast == slow)return true;}return false;
}
综上:快指针不论走多少步都可以满足在带环链表中相遇 。
[环形链表 II](https://leetcode.cn/problems/linked-list-cycle-ii/description/)
思路 1:建立数组存储地址,当地址与之前已经存储的地址相同时,结束循环。
思路 2:快慢指针在环中一定会相遇。相遇点到入环的起始结点的距离等于头结点到入环的起始结点的距离(注意顺序)
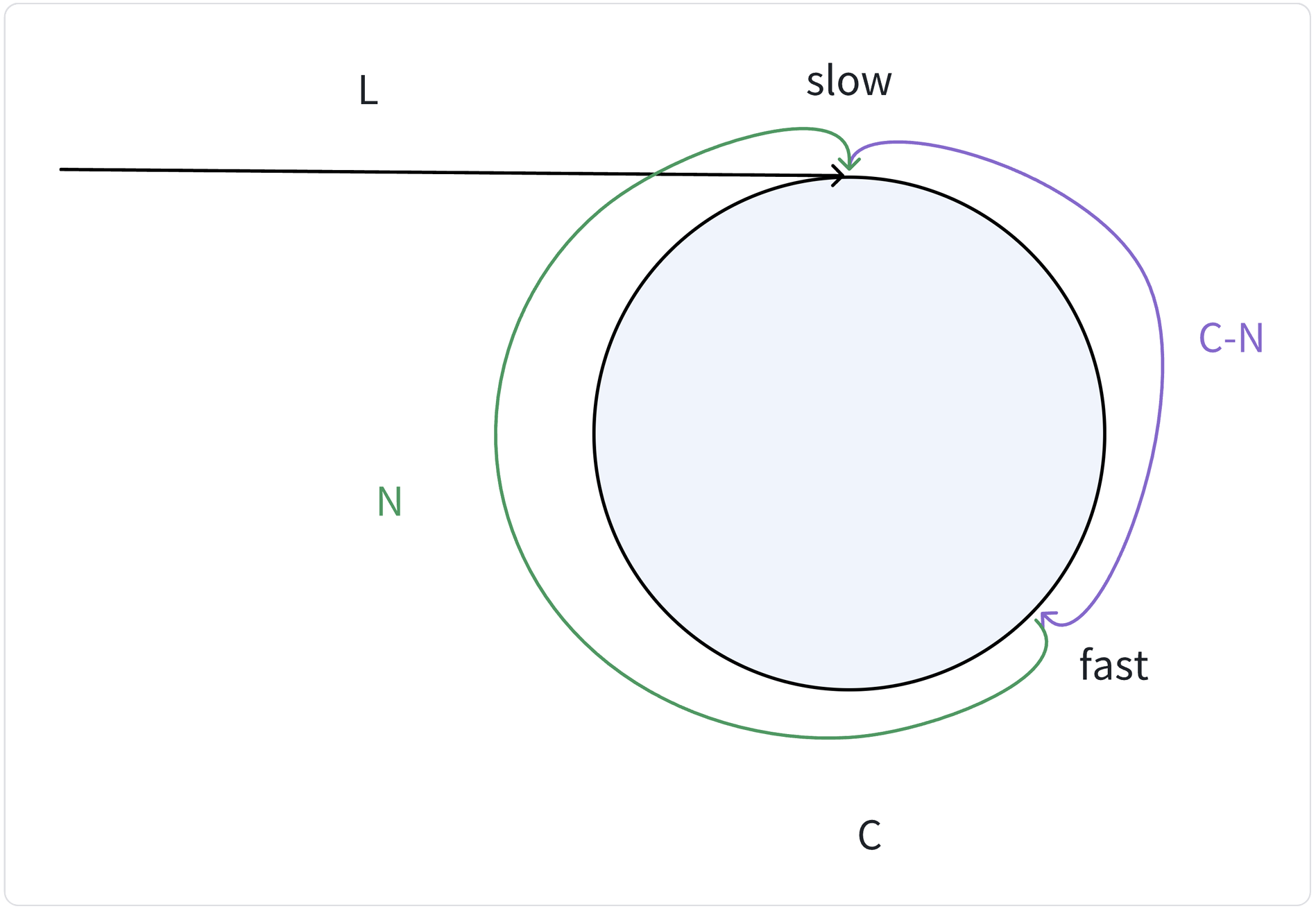
证明:快慢指针的相遇点和头结点到入环的起始结点的距离相同。
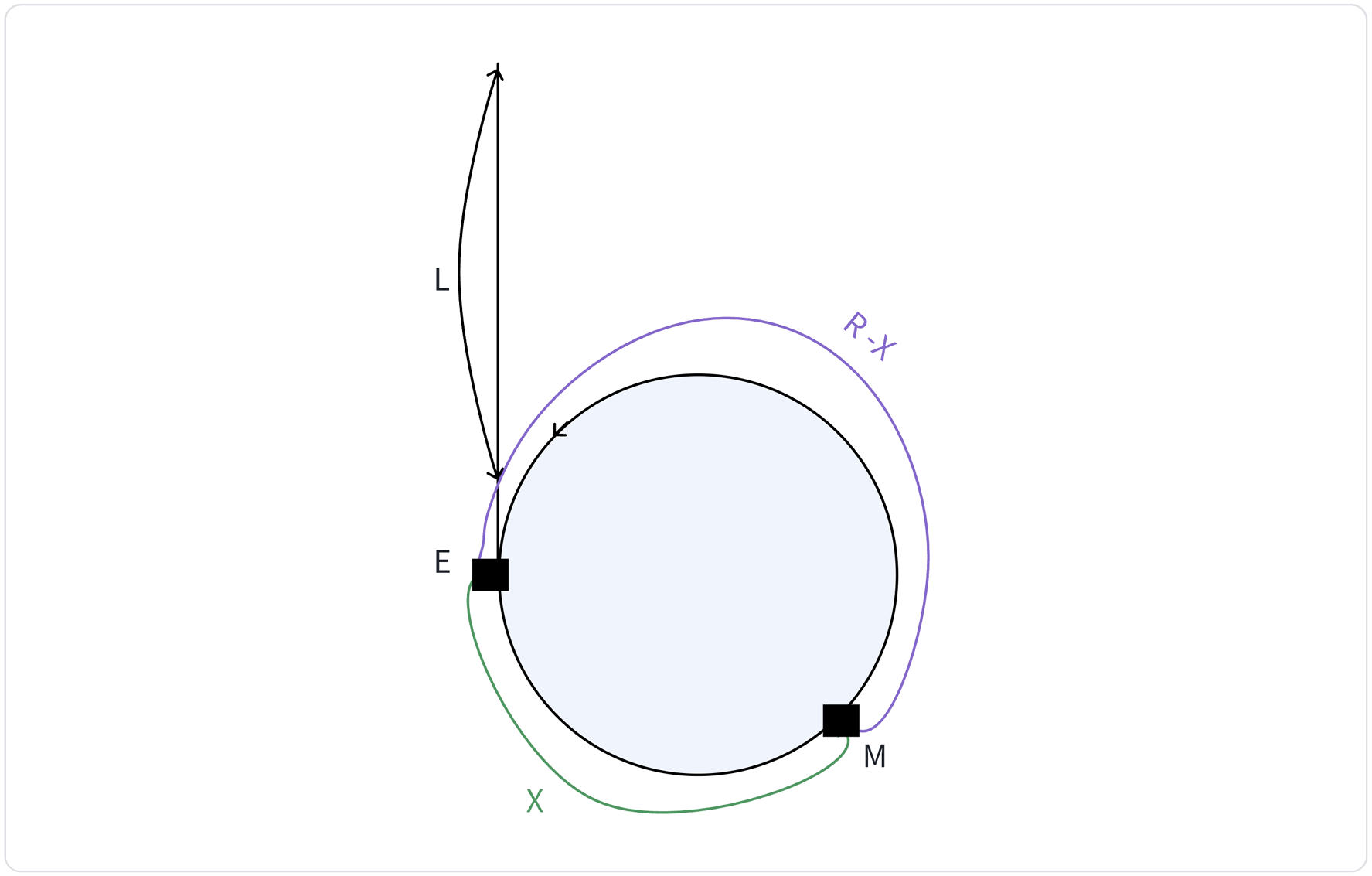
说明:
H为链表的起始点
E为环入口点
M 为快慢指针相遇点
假设:
环的长度为 R
H到E的距离为 L
E到M的距离为 X
M到E的距离为 R - X
路程:
slow = L + X
fast = L + X + nR
$fast = 2 * slow
即: L + X = nR
即: L = (n-1)R + R-X
因此一个指针从链表起始位置运行,一个指针从相遇点位置绕环,每次都走一步,两个指针最终会在环的入口点的位置相遇 。
typedef struct ListNode ListNode;ListNode *detectCycle(ListNode *head)
{ListNode* slow = head;ListNode* fast = head;while (fast && fast->next){//找相遇点fast = fast->next->next;slow = slow->next;if (slow == fast){ListNode* pcur = head;//从相遇点和头结点开始向后遍历链表,结点相同就是入环起始结点while (pcur != slow){pcur = pcur->next;slow = slow->next;}return pcur;}}return NULL;
}
双向链表
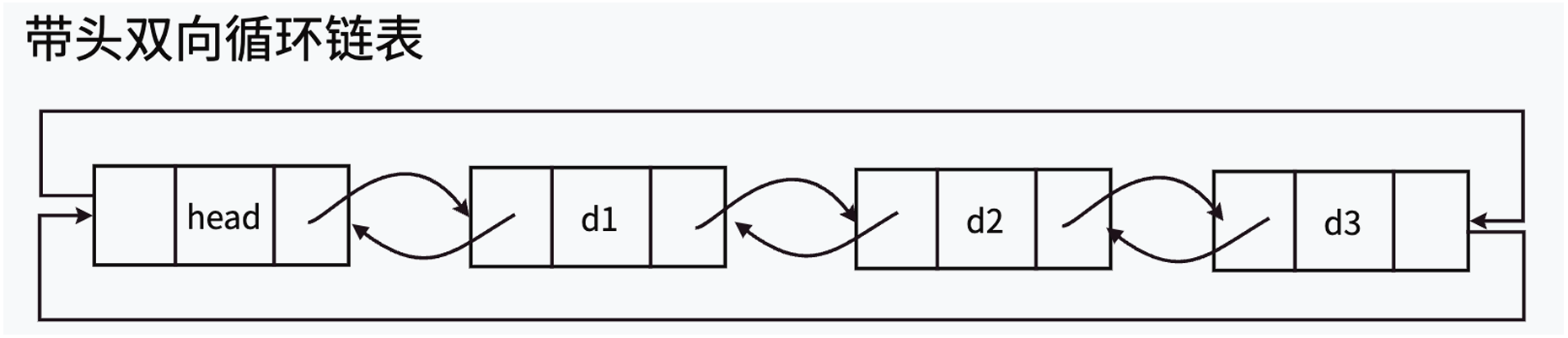
实现双向链表
List.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>//定义结点结构
typedef int LTDataType;typedef struct ListNode
{LTDataType data;struct ListNode* next;struct ListNode* prev;
}LTNode;//向操作系统申请一个新结点
LTNode* LTBuyNode(LTDataType x);//链表的初始化
LTNode* LTInit();//链表的销毁
void LTDestory(LTNode* phead);//链表的打印
void LTPrint(LTNode* phead);//判断链表为空
bool LTEmpty(LTNode* phead);//查找
LTNode* LTFind(LTNode* phead, LTDataType x);//尾插
void LTPushBack(LTNode* phead, LTDataType x);//头插
void LTPushFront(LTNode* phead, LTDataType x);//尾删
void LTPopBack(LTNode* phead);//头删
void LTPopFront(LTNode* phead);//在指定位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x);//删除指定位置的结点
void LTErase(LTNode* pos);
List.c
#include"List.h"//向操作系统申请一个新结点
LTNode* LTBuyNode(LTDataType x)
{LTNode* node = (LTNode*)malloc(sizeof(LTNode));if (node == NULL){perror("malloc");exit(1);}node->data = x;node->next = node->prev = node;return node;
}//链表的初始化
LTNode* LTInit()
{LTNode* phead = LTBuyNode(-1);return phead;
}
/*
写法二:
void LTInit(LTNode** pphead)
{*pphead = LTBuyNode(-1);
}
*///链表的销毁
/*
写法一
*/
void LTDestory(LTNode* phead)
{assert(phead);LTNode* pcur = phead->next;LTNode* next = NULL;while (pcur != phead){next = pcur->next;free(pcur);pcur = next;}free(phead);phead = NULL;
}/*
写法二:
void LTDestory(LTNode** pphead)
{assert(pphead && *pphead);LTNode* pcur = (*pphead)->next;LTNode* next = NULL;while (pcur != *pphead){next = pcur->next;free(pcur);pcur = next;}free(*pphead);*pphead = NULL;
}
此处为了保持链表接口一致性,建议都传递一级指针,后续手动将实参置为NULL
*///链表的打印
void LTPrint(LTNode* phead)
{/*双向指针为空的情况下是只有一个哨兵位*/LTNode* pcur = phead->next;while (pcur != phead){printf("%d -> ", pcur->data);pcur = pcur->next;}printf("\n");
}//判断链表为空
bool LTEmpty(LTNode* phead)
{assert(phead);return phead->next == phead;
}//查找
LTNode* LTFind(LTNode* phead, LTDataType x)
{LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x)return pcur;pcur = pcur->next;}return NULL;
}//尾插
void LTPushBack(LTNode* phead, LTDataType x)
{/*由于指向哨兵位的指针不会发生变化,不需要传址调用*/assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead;newnode->prev = phead->prev;phead->prev->next = newnode;phead->prev = newnode;
}//头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead->next;newnode->prev = phead;/*此处修改的先后顺序不能换*/phead->next->prev = newnode;phead->next = newnode;
}//尾删
void LTPopBack(LTNode* phead)
{assert(!LTEmpty(phead));LTNode* del = phead->prev;del->prev->next = phead;phead->prev = del->prev;free(del);del = NULL;
}//头删
void LTPopFront(LTNode* phead)
{assert(!LTEmpty(phead));LTNode* del = phead->next;del->next->prev = phead;phead->next = del->next;free(del);del = NULL;
}//在指定位置之后插入数据
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = LTBuyNode(x);newnode->prev = pos;newnode->next = pos->next;pos->next->prev = newnode;pos->next = newnode;
}//删除指定位置的结点
void LTErase(LTNode* pos)
{assert(pos);pos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);pos = NULL;
}
顺序表与链表的分析
| 不同点: | 顺序表 | 链表(单链表) |
|---|---|---|
| 存储空间 | 物理上一定连续 | 逻辑上连续,物理上不一定连续 |
| 随机访问 | O(1) | O(N) |
| 任意位置插入或删除数据 | 尾部:O(1)头部/中间位置: O(N) | 在指定位置之后:O(1)在指定位置之前: O(N) |
| 增加数据 | 空间不够时需要扩容,可能造成空间浪费 | 没有容量的概念,按需申请释放,不存在空间浪费 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置高效插入和删除 |
相关文章:

顺序表和链表
线性表 线性表(linear list)是n 个具有相同特性的数据元素的有限序列。线性表是一种在实际中广泛使用的数据结构。 常见的线性表:顺序表、链表、栈、队列、字符串… 线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物…...
)
若依框架使用(低级)
克隆源码 浏览器搜索若依,选择 RuoYi-Vue RuoYi-Vue RuoYi-Vue 重要的事情说三遍,进入gitee 下面这个页面(注意红色框起来的部分) 进入Gitee进行下载 我下载的是最新的springboot3 下载好后我们可以选择一个文件夹࿰…...

Spring JDBC模块解析 -深入SqlParameterSource
在前面的博客中,我们探讨了Spring Data Access Module中的主要组件: JdbcTemplate和SimpleJdbcInsert。在这两部分的基础上,我们将继续探讨更详细 的用法,包括如何使用RowMapper和SqlParameterSource等高级主题。 JdbcTemplate …...

SQL中Limit的用法详解
SQL中的LIMIT关键字是一个非常有用的工具,它可以用来限制查询结果返回的记录数量。文章将详细解析LIMIT关键字的使用方法,包括它的基本用法,以及在查询数据时如何配合使用LIMIT与OFFSET。我会通过示例代码演示LIMIT在单行结果集和多行结果集情…...

mac 安装 dotnet 环境
目录 一、安装准备 二、安装方法(两种任选) 方法 1:使用官方安装包(推荐新手) 方法 2:使用 Homebrew(适合开发者) 1. 安装 Homebrew(如未安装) 2. 通过 …...

DeepSeek辅助学术写作【句子重写】效果如何?
句子重写(功能指数:★★★★★) 当我们想引用一篇文章中的一-些我们认为写得很好的句子时,如果直接将原文加人自己的文章,那么即使我们标注上了引用,也依旧会被查重软件计算在重复比例中。查重比例过高的话,会影响投稿或毕业答辩送…...

SpringUI Web高端动态交互元件库
Axure Web高端动态交互元件库是一个专为Web设计与开发领域设计的高质量资源集合,旨在加速原型设计和开发流程。以下是关于这个元件库的详细介绍: 一、概述 Axure Web高端动态交互元件库是一个集成了多种预制、高质量交互组件的工具集合。这些组件经过精…...

QT +FFMPEG4.3 拉取 RTMP/http-flv 流播放 AVFrame转Qimage
QT FFMPEG4.3 拉取 RTMP/http-flv 流播放 Cc_Video_thread.h #ifndef CC_VIDEO_THREAD_H #define CC_VIDEO_THREAD_H#include <QThread> #include <QAtomicInt> #include <QImage>#ifdef __cplusplus extern "C" { #endif #include <libavfor…...

Docker最佳实践:安装Nacos
文章目录 Docker最佳实践:安装Nacos一、引言二、安装 Nacos1、拉取 Nacos Docker 镜像2、启动 Nacos 容器 三、配置 Nacos(可选)四、使用示例1、服务注册2、服务发现 五、总结 Docker最佳实践:安装Nacos 一、引言 Nacos 是阿里巴…...

106,【6】 buuctf web [SUCTF 2019]CheckIn
进入靶场 文件上传 老规矩,桌面有啥传啥 过滤了<? 寻找不含<?的一句话木马 文件名 123(2).php.jpg 文件内容 GIF89a? <script language"php">eval($_GET[123]);</script> 123即密码,可凭借个人喜好更换 再上传一个文…...
)
【Linux】27.Linux 多线程(1)
文章目录 1. Linux线程概念1.1 线程和进程1.2 虚拟地址是如何转换到物理地址的1.3 线程的优点1.4 线程的缺点1.5 线程异常1.6 线程用途 2. Linux进程VS线程2.1 进程和线程2.2 关于进程线程的问题 3. Linux线程控制3.1 POSIX线程库3.2 创建线程3.3 线程终止3.4 线程等待3.5 分离…...

旋转变压器工作及解调原理
旋转变压器 旋转变压器是一种精密的位置、速度检测装置,广泛应用在伺服控制、机器人、机械工具、汽车、电力等领域。但是,旋转变压器在使用时并不能直接提供角度或位置信息,需要特殊的激励信号和解调、计算措施,才能将旋转变压器…...

字符串转浮点数函数atof、strtod、strtof和strtold使用场景
字符串转浮点数函数 atof、strtod、strtof 和 strtold 在 C 语言标准库中都有各自的使用场景,它们的主要功能是将字符串转换为浮点数,但在处理的浮点数类型、错误处理机制和精度方面有所不同。 一、atof 函数使用场景 atof(ASCII to Float&…...
和从模式(Slave Mode))
GD32F4xx系列微控制器中,定时器的主模式(Master Mode)和从模式(Slave Mode)
在GD32F4xx系列微控制器中,定时器的主模式(Master Mode)和从模式(Slave Mode)是两种不同的工作模式,它们的主要区别在于定时器的操作是否依赖于外部信号或另一个定时器的输出信号。以下是对这两种模式的详细…...

深度学习系列--03.激活函数
一.定义 激活函数是一种添加到人工神经网络中的函数,它为神经网络中神经元的输出添加了非线性特性 在神经网络中,神经元接收来自其他神经元的输入,并通过加权求和等方式计算出一个净输入值。激活函数则根据这个净输入值来决定神经元是否应该…...

在linux 中搭建deepseek 做微调,硬件配置要求说明
搭建 可参考 使用deepseek-CSDN博客 官方网站:DeepSeek DeepSeek 是一个基于深度学习的开源项目,旨在通过深度学习技术来提升搜索引擎的准确性和效率。如果你想在 Linux 系统上搭建 DeepSeek,你可以遵循以下步骤。这里我将提供一个基本的指…...

机器学习之数学基础:线性代数、微积分、概率论 | PyTorch 深度学习实战
前一篇文章,使用线性回归模型逼近目标模型 | PyTorch 深度学习实战 本系列文章 GitHub Repo: https://github.com/hailiang-wang/pytorch-get-started 本篇文章内容来自于 强化学习必修课:引领人工智能新时代【梗直哥瞿炜】 线性代数、微积分、概率论 …...

MySQL - Navicat自动备份MySQL数据
对于从事IT开发的工程师,数据备份我想大家并不陌生,这件工程太重要了!对于比较重要的数据,我们希望能定期备份,每天备份1次或多次,或者是每周备份1次或多次。 如果大家在平时使用Navicat操作数据库&#x…...

javaEE-9.HTML入门
目录 一.什么是html 二.认识html标签 1.标签的特点: 2.html文件基本结构 3.标签的层次结构 三、html工具 四、创建第一个文件 五.html常见标签 1标题标签h1-h6 2.段落标签:p 3.换行标签:br 4.图片标签:img 图片路径有1三种表示形式: 5.超链接:a 链接的几种形式: …...

springcloud微服务使用不同端口启动同一服务
若想同时启动两个服务,则会产生端口冲突,在启动类设置界面,添加虚拟机选项,随后设置 -Dserver.portxxxx即可...
--边缘计算应用开发详解)
JavaScript系列(61)--边缘计算应用开发详解
JavaScript边缘计算应用开发详解 🌐 今天,让我们深入探讨JavaScript的边缘计算应用开发。边缘计算是一种将计算和数据存储分布到更靠近数据源的位置的架构模式,它能够提供更低的延迟和更好的实时性能。 边缘计算基础架构 🌟 &am…...

【容器技术01】使用 busybox 构建 Mini Linux FS
使用 busybox 构建 Mini Linux FS 构建目标 在 Linux 文件系统下构建一个 Mini 的文件系统,构建目标如下: minilinux ├── bin │ ├── ls │ ├── top │ ├── ps │ ├── sh │ └── … ├── dev ├── etc │ ├── g…...
:使用zip函数同时遍历两个迭代器)
Effective Python系列(1.3):使用zip函数同时遍历两个迭代器
zip函数是 Python 中的一个内置函数,用于将多个可迭代对象(如列表、元组等)的元素配对,生成一个迭代器。 使用 zip 函数的好处之一就是能够节省内存空间,因为该函数会创建惰性生成器,每次遍历时只生成一个元…...

gitlab个别服务无法启动可能原因
目录 一、gitlab的puma服务一直重启 1. 查看日志 2. 检查配置文件 3. 重新配置和重启 GitLab 4. 检查系统资源 5. 检查依赖和服务状态 6. 清理和优化 7. 升级 GitLab 8. 查看社区和文档 二、 gitlab个别服务无法启动可能原因 1.服务器内存或磁盘已满 2.puma端口冲突…...

基于Springboot+vue的租车网站系统
基于SpringbootVue的租车网站系统是一个现代化的在线租车平台,它结合了Springboot的后端开发能力和Vue的前端交互优势,为用户和汽车租赁公司提供了一个高效、便捷、易用的租车体验和管理工具。以下是对该系统的详细介绍: 一、系统架构 后…...

Github - 记录一次对“不小心包含了密码的PR”的修复
Github - 记录一次对“不小心包含了密码的PR”的修复 前言 和好朋友一起开发一个字节跳动青训营抖音电商后端(now private)的项目,某大佬不小心把本地一密码commit上去并提了PR。 PR一旦发出则无法被删除,且其包含的commit也能被所有能看到这个仓库的…...
)
【后端开发】系统设计101——通信协议,数据库与缓存,架构模式,微服务架构,支付系统(36张图详解)
【后端开发】系统设计101——通信协议,数据库与缓存,架构模式,微服务架构,支付系统(36张图) 文章目录 1、通信协议通信协议REST API 对比 GraphQL(前端-web服务)grpc如何工作&#x…...

SpringMVC请求
一、RequestMapping注解 RequestMapping注解的作用是建立请求URL和处理方法之间的对应关系 RequestMapping注解可以作用在方法和类上 1. 作用在类上:第一级的访问目录 2. 作用在方法上:第二级的访问目录 3. 细节:路径可以不编写 / 表示应…...
)
【学术征稿-组织单位 武汉理工大学西安理工大学、西安财经大学】第三届通信网络与机器学习(CNML 2025)
重要信息 官网:www.iccnml.org 大会时间:2025年2月21日-23日 大会地点:中国 南京 通信网络 通信是人与人之间通过某种媒体进行的信息交流与传递。网络是用物理链路将各个孤立的工作站或主机相连在一起,组成的数据链路。通信网…...

代码随想录算法训练营打卡第55天:并查集相关问题;
Java并查集的模板 //并查集模板 class DisJoint{private int[] father;public DisJoint(int N) {father new int[N];for (int i 0; i < N; i){father[i] i;}}public int find(int n) {return n father[n] ? n : (father[n] find(father[n]));}public void join (int …...

设计模式学习
1.设计模式分类 1.创建型模式 用于描述“怎样创建对象”,主要特点是“将对象的创建与使用分离”。 单例,原型,工厂方法,抽象工厂,建造者 2.结构型模式 用于描述如何将类或对象按某种布局组成更大的结构 代理&…...

js-对象-JSON
JavaScript自定义对象 JSON 概念: JavaScript Object Notation,JavaScript对象标记法. JSON 是通过JavaScript 对象标记法书写的文本。 由于其语法简单,层次结构鲜明,现多用于作为数据载体,在网络中进行数据传输. json中属性名(k…...

C/C++编译器
C/C 代码是不可跨平台的,Windows 和 Unix-like 有着不同的 API,C/C 在不同平台有着不同编译器。 MSVC Windows 平台,MSVC 是 Visual Studio 中自带的 C/C 编译器。 GCC Unix-like 平台,GCC 原名 GNU C Compiler,后…...

【R语言】数据操作
一、查看和编辑数据 1、查看数据 直接打印到控制台 x <- data.frame(a1:20, b21:30) x View()函数 此函数可以将数据以电子表格的形式进行展示。 用reshape2包中的tips进行举例: library("reshape2") View(tips) head()函数 查看前几行数据&…...

Linux 安装 RabbitMQ
Linux下安装RabbitMQ 1 、获取安装包 # 地址 https://github.com/rabbitmq/erlang-rpm/releases/download/v21.3.8.9/erlang-21.3.8.9-1.el7.x86_64.rpm erlang-21.3.8.9-1.el7.x86_64.rpmsocat-1.7.3.2-1.el6.lux.x86_64.rpm# 地址 https://github.com/rabbitmq/rabbitmq-se…...

“AI智能分析综合管理系统:企业管理的智慧中枢
在如今这个快节奏的商业世界里,企业面临的挑战越来越多,数据像潮水一样涌来,管理工作变得愈发复杂。为了应对这些难题,AI智能分析综合管理系统闪亮登场,它就像是企业的智慧中枢,让管理变得轻松又高效。 过去…...

2024最新版Java面试题及答案,【来自于各大厂】
发现网上很多Java面试题都没有答案,所以花了很长时间搜集整理出来了这套Java面试题大全~ 篇幅限制就只能给大家展示小册部分内容了,需要完整版的及Java面试宝典小伙伴点赞转发,关注我后在【翻到最下方,文尾点击名片】即可免费获取…...

调用腾讯云批量文本翻译API翻译srt字幕
上一篇文章介绍了调用百度翻译API翻译日文srt字幕的方法。百度翻译API是get方式调用,参数都放在ur中,每次调用翻译文本长度除了接口限制外,还有url长度限制,而日文字符通过ur转码后会占9个字符长度,其实从这个角度来讲…...

【分块解决大文件上传的最佳实践】
前言 前几天看了一篇关于大文件上传分块实现的博客,代码实现过于复杂且冗长,而且没有进行外网上传的测试。因此,我决定自己动手实现一个大文件上传,并进行优化。 实现思路 在许多应用中,大文件上传是常见的需求&…...

机器学习中的关键概念:通过SKlearn的MNIST实验深入理解
欢迎来到我的主页:【Echo-Nie】 本篇文章收录于专栏【机器学习】 1 sklearn相关介绍 Scikit-learn 是一个广泛使用的开源机器学习库,提供了简单而高效的数据挖掘和数据分析工具。它建立在 NumPy、SciPy 和 matplotlib 等科学计算库之上,支持…...

【Elasticsearch】post_filter
post_filter是 Elasticsearch 中的一种后置过滤机制,用于在查询执行完成后对结果进行过滤。以下是关于post_filter的详细介绍: 工作原理 • 查询后过滤:post_filter在查询执行完毕后对返回的文档集进行过滤。这意味着所有与查询匹配的文档都…...

Git基础
目录 一、Git介绍二、Git下载与配置1、下载安装Git2、Git配置2.1 注册码云账号2.2 Git配置 三、Git开发流程1、相关代码2、上述代码执行截图示例 四、Git提交&撤销五、Git资料 一、Git介绍 Git是一种分布式版本控制系统,广泛用于软件开发项目的版本管理。它由L…...

深度学习系列--02.损失函数
一.定义 损失函数(Loss Function)是机器学习和深度学习中用于衡量模型预测结果与真实标签之间差异的函数,它在模型训练和评估过程中起着至关重要的作用 二.作用 1.指导模型训练 提供优化方向:在训练模型时,我们的目…...

如何在自己mac电脑上私有化部署deep seek
在 Mac 电脑上私有化部署 DeepSeek 的步骤如下: 1. 环境准备 安装 Homebrew(如果尚未安装): Homebrew 是 macOS 上的包管理工具,用于安装依赖。 /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com…...

攻防世界 fileclude
代码审计 WRONG WAY! <?php include("flag.php"); highlight_file(__FILE__);//高亮显示文件的源代码 if(isset($_GET["file1"]) && isset($_GET["file2"]))//检查file1和file2参数是否存在 {$file1 $_GET["file1"];$fi…...

Ubuntu24登录PostgreSql数据库的一般方法
命令格式如 psql -U user -d db 或者 sudo psql -U user -d db 修改配置 /etc/postgresql/16/main/postgresql.conf 改成md5,然后重新启动pgsql sudo systemctl restart postgresql...
)
3.5 Go(特殊函数)
目录 一、匿名函数 1、匿名函数的特点: 2、匿名函数代码示例 2、匿名函数的类型 二、递归函数 1. 递推公式版本 2. 循环改递归 三、嵌套函数 1、嵌套函数用途 2、代码示例 3、作用域 & 变量生存周期 四、闭包 1、闭包使用场景 2、代码示例 五、De…...
)
设计模式学习(三)
行为模式 职责链模式(Chain of Responsibility Pattern) 定义 它允许多个对象有机会处理请求,从而避免请求的发送者与接收者之间的耦合。职责链模式将这些对象连成一条链,并沿着这条链传递请求,直到有对象处理它为止…...
)
挑战项目 --- 微服务编程测评系统(在线OJ系统)
一、前言 1.为什么要做项目 面试官要问项目,考察你到底是理论派还是实战派? 1.希望从你的项目中看到你的真实能力和对知识的灵活运用。 2.展示你在面对问题和需求时的思考方式及解决问题的能力。 3.面试官会就你项目提出一些问题,或扩展需求…...
的原理与C++实现)
堆(Heap)的原理与C++实现
1. 什么是堆? 堆(Heap)是一种特殊的树形数据结构,通常用于实现优先队列。堆可以分为两种类型: 最大堆(Max Heap):每个节点的值都大于或等于其子节点的值。最小堆(Min H…...