deepseek 本地化部署和小模型微调
安装ollama
因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报

所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama
启动命令
docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama查看ollama 是否启动成功,Ollama 没有用户界面,在后台运行。
打开浏览器,输入 “http://xx:11434/”,显示 “Ollama is running”。

docker exec -it ollama ollama list
deepseek-r1 目前有7b, 32b, 70b, 671b 多个版本, 考虑到下载时间目前只下载最大70b的模型

应该说Deepseek 底层应该是很牛,两张40卡都能跑70B参数的模型

安装openwebui
Open-webui 则提供直观的 Web 用户界面来与 Ollama 平台进行交互。直接使用docker进行部署
docker run -d --privileged -p 3000:8080 \--add-host=host.docker.internal:host-gateway \-v /data/openwebui:/app/backend/data \-e TRANSFORMERS_CACHE=/app/backend/data/huggingface/cache \-e HF_DATASETS_CACHE=/app/backend/data/huggingface/datasets \-e HF_ENDPOINT=https://hf-mirror.com \--name open-webui --restart always \ghcr.io/open-webui/open-webui:main打开3000端口选择70b的模型

使用下deepseek的深度思考模式

下面演示下如何对DeepSeek-V1:7b模型进行微调,让模型成为一位算命大师
微调代码参考self-llm/models/DeepSeek at master · datawhalechina/self-llm · GitHub
R1 和 V1 的区别集中在 优化方向(速度、领域、资源)或 迭代阶段(V1 为初版,R1 为改进版)模型微调通过 peft 库来实现模型的 LoRA 微调。peft 库是 huggingface 开发的第三方库,其中封装了包括 LoRA、Adapt Tuning、P-tuning 等多种高效微调方法,可以基于此便捷地实现模型的 LoRA 微调。
微调数据格式化
准备一份微调数据

instruction:用户指令,告知模型其需要完成的任务;
input:用户输入,是完成用户指令所必须的输入内容;
output:模型应该给出的输出。
如果你的 JSON 文件包含多个 JSON 对象而不是一个有效的 JSON 数组,Pandas 将无法处理。例如,以下格式是不正确的:
{"key1": "value1"}
{"key2": "value2"}转化下该格式到正确json格式
import jsoninput_file = 'data.json'
output_file = 'corrected_data.json'json_objects = []with open(input_file, 'r', encoding='utf-8') as f:for line in f:line = line.strip() # 去除前后空白if line: # 确保行不为空try:json_objects.append(json.loads(line))except json.JSONDecodeError as e:print(f"Error decoding JSON: {e} - Line: {line}")if json_objects:with open(output_file, 'w', encoding='utf-8') as f:json.dump(json_objects, f, ensure_ascii=False, indent=4)print(f"Corrected JSON format has been saved to {output_file}.")后面训练的时候会使用,是从一个 JSON 文件中读取数据,将其转换为 Pandas DataFrame,然后进一步转换为 Hugging Face 的 Dataset 对象。接着,它对这个数据集应用一个名为 process_func 的处理函数,最终返回一个经过处理的 tokenized 数据集,返回处理后的数据集 tokenized_id,通常是一个包含 token ID 或其他处理结果的新数据集。
def get_tokenized_id(json_file):df = pd.read_json(json_file)ds = Dataset.from_pandas(df)# 处理数据集tokenized_id = ds.map(process_func, remove_columns=ds.column_names)# print(tokenized_id)return tokenized_id安装了huggingface_cli库,可以使用进行安装。
pip install huggingface-cli修改下载源:
export HF_ENDPOINT="https://hf-mirror.com"
下载deepseek-vl-7b-chat 到models文件夹
huggingface-cli download deepseek-ai/deepseek-vl-7b-chat --local-dir ./models
通过加载DeepSeek-7B-chat 模型完成微调数据的初始化,以保证微调时数据的一致性。
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('./deepseek-ai/deepseek-llm-7b-chat/', use_fast=False, trust_remote_code=True)
tokenizer.padding_side = 'right' # padding在右边'''
Lora训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉Pytorch模型训练流程的同学会知道,
我们一般需要将输入文本编码为input_ids,将输出文本编码为labels,编码之后的结果都是多维的向量。
'''设置lora相关的参数
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 模型类型# 需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式。target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # False:训练模式 True:推理模式r=8, # Lora 秩lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理lora_dropout=0.01
)
各模块含义
这些名称对应 Transformer 模型中的关键投影层(Projection Layers):
-
q_proj,k_proj,v_proj:
自注意力机制中的 查询(Query)、键(Key)、值(Value) 的投影矩阵,用于生成注意力权重。 -
o_proj:
自注意力机制的 输出投影矩阵,将注意力计算结果映射回原始维度。 -
gate_proj,up_proj,down_proj:
Transformer 中 MLP 层(多层感知机)的投影矩阵:-
gate_proj: 门控投影(用于激活函数前的门控控制,如 SwiGLU)。 -
up_proj和down_proj: 上下投影矩阵(用于特征维度的升维和降维)。
-
2. 为什么选择这些层?
这些层是模型的核心计算单元,对模型行为影响显著:
-
注意力层:控制信息交互(如关注哪些词);
-
MLP 层:负责非线性特征变换。
对它们进行微调,能以较少参数高效调整模型行为。
3. 底层原理

其中:
-
BA是低秩适配器,仅训练 A和 B;
-
原始权重 W 冻结不更新,避免破坏预训练知识。
常见配置策略
1. 选择哪些层?
-
通用场景:覆盖所有注意力层 (
q_proj,k_proj,v_proj,o_proj) 和 MLP 层 (gate_proj,up_proj,down_proj)。 -
轻量化微调:仅选择注意力层(减少参数量)。
-
任务相关:根据任务特性调整(如代码生成任务可能更关注 MLP 层)。
2. 不同模型的层名差异
-
Llama、Mistral: 使用
q_proj,k_proj,v_proj,o_proj等命名。 -
GPT-2: 可能命名为
c_attn(合并 Q/K/V 投影)或c_proj(输出投影)。 -
BERT: 通常为
query,key,value,dense。
自定义 TrainingArguments 参数这里就简单说几个常用的。
output_dir:模型的输出路径
per_device_train_batch_size:顾名思义 batch_size
gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
logging_steps:多少步,输出一次log
num_train_epochs:顾名思义 epoch
fp16=True, # 开启半精度浮点数训练,减少显存使用
save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间
gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()
配置如下
args = TrainingArguments(output_dir="./output/DeepSeek_full",per_device_train_batch_size=8, # 每个设备上的 batch sizegradient_accumulation_steps=2, # 梯度累积步数,减少显存占用logging_steps=10, # 记录日志的步数num_train_epochs=3, # 训练轮数save_steps=100, # 保存检查点的步数learning_rate=1e-4, # 学习率fp16=True, # 开启半精度浮点数训练,减少显存使用save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间save_on_each_node=True,gradient_checkpointing=True#logging_dir="./logs" # 设置日志文件夹
)deepseek 微调训练代码
# -*- coding: utf-8 -*-from deepseek_vl.models import MultiModalityCausalLM
from peft import LoraConfig, TaskType, get_peft_model
from tokenizers import Tokenizer
from transformers import Trainer, TrainingArguments, AutoModelForCausalLM, GenerationConfig, \DataCollatorForSeq2Seqfrom tokenizer_text import get_tokenized_idtokenizer = Tokenizer.from_file("./models/tokenizer.json")
# tokenizer = AutoTokenizer.from_pretrained('./models/', use_fast=False, trust_remote_code=True)
# tokenizer.padding_side = 'right' # padding在右边model: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True)
print('model', model)
# model = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True, torch_dtype=torch.half, device_map="auto")
#model.generation_config = GenerationConfig.from_pretrained('./models/')
#model.generation_config.pad_token_id = model.generation_config.eos_token_id# 开启梯度
#model.enable_input_require_grads()
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 任务类型,常用于因果语言模型target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # 训练模式r=8, # LoRA 矩阵的秩,控制训练参数量,常用值为 4 或 8lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理:控制更新幅度的超参数lora_dropout=0.1 # Dropout 比例,防止过拟合
)model = get_peft_model(model, config)# 确保所有需要的参数启用梯度
for name, param in model.named_parameters():if param.requires_grad:print(f"Parameter {name} is trainable.")else:print(f"Parameter {name} is not trainable will set.")param.requires_grad = True'''
自定义 TrainingArguments 参数
TrainingArguments这个类的源码也介绍了每个参数的具体作用,当然大家可以来自行探索,这里就简单说几个常用的。
output_dir:模型的输出路径
per_device_train_batch_size:顾名思义 batch_size
gradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把 batch_size 设置小一点,梯度累加增大一些。
logging_steps:多少步,输出一次log
num_train_epochs:顾名思义 epoch
fp16=True, # 开启半精度浮点数训练,减少显存使用
save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间
gradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads()
'''args = TrainingArguments(output_dir="./output/DeepSeek_full",per_device_train_batch_size=8, # 每个设备上的 batch sizegradient_accumulation_steps=2, # 梯度累积步数,减少显存占用logging_steps=10, # 记录日志的步数num_train_epochs=3, # 训练轮数save_steps=100, # 保存检查点的步数learning_rate=1e-4, # 学习率fp16=True, # 开启半精度浮点数训练,减少显存使用save_total_limit=1, # 限制保存的检查点数量,节省磁盘空间save_on_each_node=True,gradient_checkpointing=True# logging_dir="./logs" # 设置日志文件夹
)trainer = Trainer(model=model,args=args,train_dataset=get_tokenized_id('./data.json'),data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)trainer.train()# 直接合并模型开始。。。。。
# 将 adapter 合并进模型(去除 adapter 依赖)
model = model.merge_and_unload()
model.save_pretrained("./output/DeepSeek_full")
tokenizer.save_pretrained("./output/DeepSeek_full")# 直接合并模型结束。。。。。text = "现在你要扮演我碰到一位神秘的算命大师, 你是谁?今天我的事业运道如何?"inputs = tokenizer(f"User: {text}\n\n", return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
上面用到的tokenizer 相关代码
import tokenizer
import pandas as pd
from datasets import Datasetfrom transformers import AutoTokenizer# 加载分词器
tokenizer = AutoTokenizer.from_pretrained('./deepseek-llm-7b/', use_fast=False, trust_remote_code=True)
tokenizer.padding_side = 'right' # padding在右边'''
Lora训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉Pytorch模型训练流程的同学会知道,
我们一般需要将输入文本编码为input_ids,将输出文本编码为labels,编码之后的结果都是多维的向量。
'''def process_func(example):MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性input_ids, attention_mask, labels = [], [], []instruction = tokenizer(f"User: {example['instruction'] + example['input']}\n\n",add_special_tokens=False) # add_special_tokens 不在开头加 special_tokensresponse = tokenizer(f"Assistant: {example['output']}<|end▁of▁sentence|>", add_special_tokens=False)input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]if len(input_ids) > MAX_LENGTH: # 做一个截断input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}def get_tokenized_id(json_file):df = pd.read_json(json_file)ds = Dataset.from_pandas(df)# 处理数据集tokenized_id = ds.map(process_func, remove_columns=ds.column_names)# print(tokenized_id)return tokenized_id由于deepseek-v1是多模态模型,需要安装deepseek_vl 模块
git clone https://github.com/deepseek-ai/DeepSeek-VL
cd DeepSeek-VLpip install -e .加载模型时转为model: MultiModalityCausalLM,打印下模型结构
MultiModalityCausalLM(
(vision_model): HybridVisionTower(
(vision_tower_high): CLIPVisionTower(
(vision_tower): ImageEncoderViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
)
(blocks): ModuleList(
(0-11): 12 x Block(
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, bias=True)
(proj): Linear(in_features=768, out_features=768, bias=True)
)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(mlp): MLPBlock(
(lin1): Linear(in_features=768, out_features=3072, bias=True)
(lin2): Linear(in_features=3072, out_features=768, bias=True)
(act): GELU(approximate='none')
)
)
)
(neck): Sequential(
(0): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
(downsamples): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
)
(neck_hd): Sequential(
(0): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): LayerNorm2d()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(3): LayerNorm2d()
)
)
(image_norm): Normalize(mean=[0.48145466, 0.4578275, 0.40821073], std=[0.26862954, 0.26130258, 0.27577711])
)
(vision_tower_low): CLIPVisionTower(
(vision_tower): VisionTransformer(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 1024, kernel_size=(16, 16), stride=(16, 16))
(norm): Identity()
)
(pos_drop): Dropout(p=0.0, inplace=False)
(patch_drop): Identity()
(norm_pre): Identity()
(blocks): Sequential(
(0): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(1): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(2): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(3): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(4): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(5): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(6): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(7): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(8): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(9): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(10): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(11): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(12): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(13): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(14): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(15): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(16): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(17): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(18): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(19): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(20): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(21): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(22): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
(23): Block(
(norm1): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn): Attention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(attn_drop): Dropout(p=0.0, inplace=False)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Identity()
)
(ls1): Identity()
(drop_path1): Identity()
(norm2): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
(ls2): Identity()
(drop_path2): Identity()
)
)
(norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(attn_pool): AttentionPoolLatent(
(q): Linear(in_features=1024, out_features=1024, bias=True)
(kv): Linear(in_features=1024, out_features=2048, bias=True)
(q_norm): Identity()
(k_norm): Identity()
(proj): Linear(in_features=1024, out_features=1024, bias=True)
(proj_drop): Dropout(p=0.0, inplace=False)
(norm): LayerNorm((1024,), eps=1e-06, elementwise_affine=True)
(mlp): Mlp(
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(act): GELU(approximate='none')
(drop1): Dropout(p=0.0, inplace=False)
(norm): Identity()
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(drop2): Dropout(p=0.0, inplace=False)
)
)
(fc_norm): Identity()
(head_drop): Dropout(p=0.0, inplace=False)
(head): Identity()
)
(image_norm): Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
)
(high_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(low_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(resize): Resize(size=384, interpolation=bilinear, max_size=None, antialias=True)
)
(aligner): MlpProjector(
(high_up_proj): Linear(in_features=1024, out_features=2048, bias=True)
(low_up_proj): Linear(in_features=1024, out_features=2048, bias=True)
(layers): Sequential(
(0): GELU(approximate='none')
(1): Linear(in_features=4096, out_features=4096, bias=True)
)
)
(language_model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(102400, 4096)
(layers): ModuleList(
(0-29): 30 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
(post_attention_layernorm): LlamaRMSNorm((4096,), eps=1e-06)
)
)
(norm): LlamaRMSNorm((4096,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=4096, out_features=102400, bias=False)
)
)
开始训练,受限于资源单机单线程开启
accelerate launch --num_processes=1 --num_machines=1 train_deepseek.py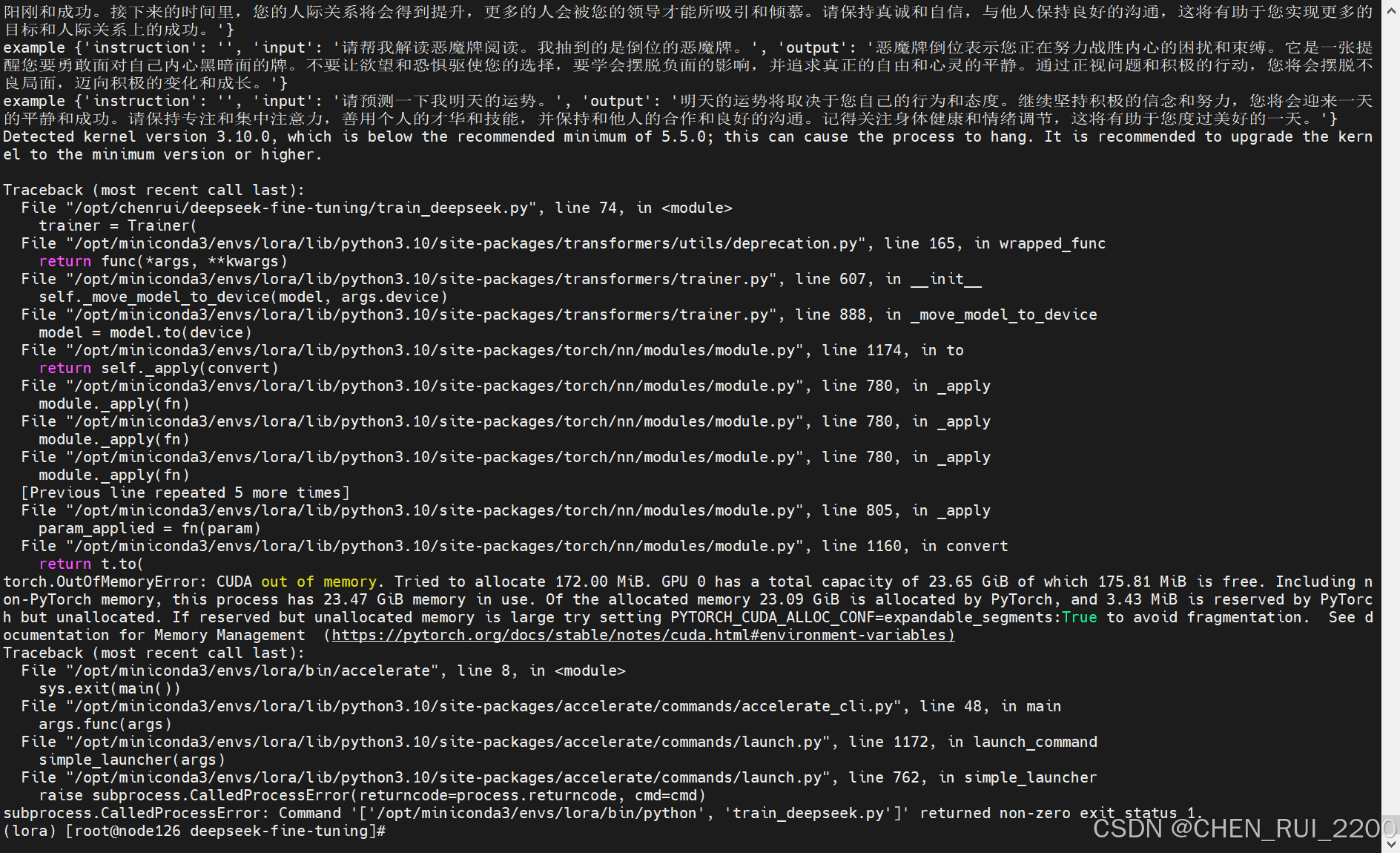
还是挺费显存的,试验受限于设备只能先进行到这里
附一段使用微调模型进行试验的代码(没有测试过)
# -*- coding: utf-8 -*-import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from deepseek_vl.models import MultiModalityCausalLM, VLChatProcessorimport warnings
warnings.filterwarnings("ignore", category=FutureWarning, module="torch.utils._pytree")# 指定合并后的模型路径
merged_model_path = "./output/DeepSeek_full"# 加载模型
# model = AutoModelForCausalLM.from_pretrained(merged_model_path, torch_dtype=torch.float16, device_map="auto")
model: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained('./models/', trust_remote_code=True)
if hasattr(model, 'tie_weights'):model.tie_weights()tokenizer = AutoTokenizer.from_pretrained(merged_model_path)# 使用模型生成文本示例
input_text = '''
###重要信息-你是一个善于洞察人心的算命大师,请直接以算命大师的角度回复,注意角色不要混乱,你是算命大师,你是算命大师,你是算命大师,你会积极对用户调侃,长度20字。User:测一下我今天的运势'''inputs = tokenizer(input_text, return_tensors="pt").to("cuda")# 生成
with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=50, # 可调整生成长度do_sample=True,top_p=0.95,temperature=0.7,num_return_sequences=1)# 解码生成的文本
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("生成的文本:", generated_text)相关文章:

deepseek 本地化部署和小模型微调
安装ollama 因为本人gpu卡的机器系统是centos 7, 直接使用ollama会报 所以ollama使用镜像方式进行部署, 拉取镜像ollama/ollama 启动命令 docker run -d --privileged -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama 查看ollama 是否启动…...

Heptagon 同步语言介绍
同步语言于20世纪80年代创立,用于建模、设计和实现实时关键反应系统。随着被控制系统的复杂性不断增加,执行速度成为一个重要标准。与此同时,处理器在核心数量上的增长超过了速度的提升。因此,我们正在寻求一种并行执行方式&#…...

Golang 并发机制-5:详解syn包同步原语
并发性是现代软件开发的一个基本方面,Go(也称为Golang)为并发编程提供了一组健壮的工具。Go语言中用于管理并发性的重要包之一是“sync”包。在本文中,我们将概述“sync”包,并深入研究其最重要的同步原语之一…...

数组排序算法
数组排序算法 用C语言实现的数组排序算法。 排序算法平均时间复杂度最坏时间复杂度最好时间复杂度空间复杂度是否稳定适用场景QuickO(n log n)O(n)O(n log n)O(log n)不稳定大规模数据,通用排序BubbleO(n)O(n)O(n)O(1)稳定小规模数据,教学用途InsertO(n)…...

利用腾讯云cloud studio云端免费部署deepseek-R1
1. cloud studio 1.1 cloud studio介绍 Cloud Studio(云端 IDE)是基于浏览器的集成式开发环境,为开发者提供了一个稳定的云端工作站。支持CPU与GPU的访问。用户在使用 Cloud Studio 时无需安装,随时随地打开浏览器即可使用。Clo…...
(A-D))
Codeforces Round 1002 (Div. 2)(A-D)
题目链接:Dashboard - Codeforces Round 1002 (Div. 2) - Codeforces A. Milya and Two Arrays 思路 数组a中不同数的数量*数组b的,就是能够组成不同数的数量 代码 void solve(){int n;cin>>n;int cnt10;int cnt20;map<int,bool> mp;ma…...

半导体器件与物理篇7 微波二极管、量子效应和热电子器件
基本微波技术 微波频率:微波频率涵盖约从0.1GHz到3000GHz,相当于波长从300cm到0.01cm。 分布效应:电子部件在微波频率,与其在较低频率的工作行为不同。 输运线:一个由电阻、电容、电感三种等效基本电路部件所组成的…...

Hot100之图论
200岛屿数量 题目 思路解析 把访问过的格子插上棋子 思想是先污染再治理,我们有一个inArea()函数,是判断是否出界了 我们先dfs()放各个方向遍历,然后我们再把这个位置标为0 我们岛屿是连着…...

CSS 样式化表格:从基础到高级技巧
CSS 样式化表格:从基础到高级技巧 1. 典型的 HTML 表格结构2. 为表格添加样式2.1 间距和布局2.2 简单的排版2.3 图形和颜色2.4 斑马条纹2.5 样式化标题 3. 完整的示例代码4. 总结 在网页设计中,表格是展示数据的常见方式。然而,默认的表格样式…...

DeepSeek相关技术整理
相关介绍 2024年12月26日,DeepSeek V3模型发布(用更低的训练成本,训练出更好的效果)671B参数,激活37B。2025年1月20日,DeepSeek-R1模型发布(仅需少量标注数据(高质量长cotÿ…...

Spring Boot框架下的单元测试
1. 什么是单元测试 1.1 基本定义 单元测试(Unit Test) 是对软件开发中最小可测单位(例如一个方法或者一个类)进行验证的一种测试方式。在 Java 后端的 Spring Boot 项目中,单元测试通常会借助 JUnit、Mockito 等框架对代码中核心逻辑进行快…...

OpenAI 实战进阶教程 - 第四节: 结合 Web 服务:构建 Flask API 网关
目标 学习将 OpenAI 接入 Web 应用,构建交互式 API 网关理解 Flask 框架的基本用法实现 GPT 模型的 API 集成并返回结果 内容与实操 一、环境准备 安装必要依赖: 打开终端或命令行,执行以下命令安装 Flask 和 OpenAI SDK: pip i…...

xss-labs靶场
xss-labs靶场 xss攻击类型 反射型xss 即攻击者将恶意脚本嵌入到url或者表单中,当用户访问特定的url或者提交表单时(用户端请求时),恶意脚本会执行 攻击需要用户点击恶意链接或访问包含恶意参数的url触发 存储型xss 即攻击者将恶意脚本提交…...

Eigen::Tensor使用帮助
0 引言 用python实现了某些算法之后,想转成C来获取更高的性能。但是python数组的操作太灵活了,尤其是3维、4维、5维等高维数组,以及它们的广播、数组坐标、切片等机制。还有numpy的pad、where等操作更是给C转换带来了更多的麻烦。 查阅了相…...

高阶开发基础——快速入门C++并发编程4
目录 使用call_once来确保调用的唯一性 先看我们的原始的单例模式 使用call_once来确保调用的唯一性 一个相似的概念是——单例模式,笔者找到的是stack_overflow的一个问答,如果不喜欢看英文,可以考虑看一下这个CSDN回答: c - H…...

C++基础day1
前言:谢谢阿秀,指路阿秀的学习笔记 一、基础语法 1.构造和析构: 类的构造函数是一种特殊的函数,在创建一个新的对象时调用。类的析构函数也是一种特殊的函数,在删除所创建的对象时调用。 构造顺序:父类->子类 析…...

Deepseek:网页版OR本地部署版本?
使用本地部署的 DeepSeek 还是网页版的 DeepSeek,取决于具体需求和使用场景。以下是两者的对比及推荐建议: 响应速度 网页版 DeepSeek:响应速度受网络状况和服务器负载影响较大。如果网络不稳定或服务器繁忙,可能会出现延迟甚至…...

【文件上传】
目录 一. 介绍二. 本地存储三. 阿里云OSS3.1 准备工作3.2 入门程序3.3 案例集成3.4 程序优化 \quad 一. 介绍 \quad 三要素缺一不可 \quad 二. 本地存储 \quad 解决相同命名覆盖问题 \quad 三. 阿里云OSS \quad \quad 3.1 准备工作 \quad \quad 3.2 入门程序 \quad \quad 3.3…...

股票入门知识
股票入门(更适合中国宝宝体制) 股市基础知识 本文介绍了股票的基础知识,股票的分类,各板块发行上市条件,股票代码,交易时间,交易规则,炒股术语,影响股价的因素…...

Debezium Oracle Connector SCN处理优化指南
Debezium Oracle Connector SCN处理优化指南 📌 问题场景 SCN跳跃场景: 起始SCN:15,000(含数据变更)结束SCN:1,000,000(无中间数据)默认批次大小:10,000 → 需执行985次无效查询🚀 优化方案 1. 自适应批次调整 代码位置:LogMinerStreamingChangeEventSource.j…...
)
2021版小程序开发5——小程序项目开发实践(1)
2021版小程序开发5——小程序项目开发实践(1) 学习笔记 2025 使用uni-app开发一个电商项目; Hbuidler 首选uni-app官方推荐工具:https://www.dcloud.io/hbuilderx.htmlhttps://dev.dcloud.net.cn/pages/app/list 微信小程序 管理后台:htt…...

软件测试02----用例设计方法
今天目标 1.能对穷举场景设计测试点 2.能对限定边界规则设计测试点 3.能对多条件依赖关系进行设计测试点 4.能对项目业务进行设计测试点 一、解决穷举场景 重点:使用等价类划分法 1.1等价类划分法 重点:有效等价和单个无效等价各取1个即可。 步骤&#…...

分享半导体Fab 缺陷查看系统,平替klarity defect系统
分享半导体Fab 缺陷查看系统,平替klarity defect系统;开发了半年有余。 查看Defect Map,Defect image,分析Defect size,defect count trend. 不用再采用klarity defect系统(license 太贵) 也可以…...

C语言-----数据结构从门到精通
1.数据结构基本概念 数据结构是计算机中存储、组织数据的方式,旨在提高数据的访问和操作效率。它是实现高效算法和程序设计的基石。 目标:通过思维导图了解数据结构的知识点,并掌握。 1.1逻辑结构 逻辑结构主要四种类型: 集合:结构中的数据元素之…...

存储器知识点3
1.只读存储器中内容断电后不会丢失,通常存储固定不变的内容,不需要定时刷新。 2.虚拟存储器将主存和辅存地址空间统一编址,其大小受到辅助存储器容量的限制。使得主存空间得到了扩充,需要硬件支持,并由操作系统调度。…...

Weevely代码分析
亲测php5和php8都无效,只有php7有效 ailx10 1949 次咨询 4.9 网络安全优秀回答者 互联网行业 安全攻防员 去咨询 上一次做weevely实验可以追溯到2020年,当时还是weevely3.7,现在的是weevely4 生成php网页木马依然差不多…… php菜刀we…...
1409 - 1415 题)
leetcode解题思路分析(一百六十三)1409 - 1415 题
查询带键的排列 给定一个正整数数组 queries ,其取值范围在 1 到 m 之间。 请你根据以下规则按顺序处理所有 queries[i](从 i0 到 iqueries.length-1): 首先,你有一个排列 P[1,2,3,…,m]。 对于当前的 i ,找…...

【MATLAB例程】TOA和AOA混合的高精度定位程序,适用于三维、N锚点的情况
代码实现了一个基于到达角(AOA)和到达时间(TOA)混合定位的例程。该算法能够根据不同基站接收到的信号信息,自适应地计算目标的位置,适用于多个基站的场景 文章目录 主要功能代码结构运行结果程序代码 主要功…...

PyTorch框架——基于深度学习YOLOv8神经网络学生课堂行为检测识别系统
基于YOLOv8深度学习的学生课堂行为检测识别系统,其能识别三种学生课堂行为:names: [举手, 读书, 写字] 具体图片见如下: 第一步:YOLOv8介绍 YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本…...

智慧园区系统对比不同智能管理模式提升企业运营效率与安全性
内容概要 在当今竞争激烈的市场中,企业需要不断提高运营效率与安全性,以应对复杂的环境。这时,“智慧园区系统”应运而生,成为一种有效的解决方案。智能管理模式的多样性让企业在选择系统时有了更多的选择,而在这些模…...

读书笔记 | 《最小阻力之路》:用结构思维重塑人生愿景
一、核心理念:结构决定行为轨迹 橡皮筋模型:愿景张力的本质 书中提出:人类行为始终沿着"现状"与"愿景"之间的张力路径运动,如同橡皮筋拉伸产生的动力。 案例:音乐家每日练习的坚持,不…...

257. 二叉树的所有路径
二叉树的所有路径 已解答 简单 给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。 叶子节点 是指没有子节点的节点。 示例 1: 输入:root [1,2,3,null,5] 输出:[“1->2->5”,“…...
---- Vulkan Framebuffercommand buffer)
Vulkan 学习(13)---- Vulkan Framebuffercommand buffer
目录 Vulkan Framebuffer创建 VkFramebufferVkFrameBuffer 创建示例 Vulkan command buffercommand buffer pool分配指令缓存池释放指令缓存池录制 command buffer提交 command buffer Vulkan Framebuffer Vulkan 帧缓冲区(FrameBuffer) 是一个容器对象(资源管理类的对象)&…...
)
从零开始学习安时积分法(STM32实现程序)
在STM32微控制器上实现安时积分法(Coulomb Counting)来估算电池的SOC(State of Charge),需要完成以下几个步骤: 硬件配置: 使用STM32的ADC模块测量电池的电流。使用定时器模块进行时间积分。配置…...

基于Kamailio、MySQL、Redis、Gin、Vue.js的微服务架构
每个服务使用一台独立的服务器的可行部署方案,尤其是在高并发、高可用性要求较高的场景中。这种方案通常被称为分布式部署或微服务架构。以下是针对您的VoIP管理系统(基于Kamailio、MySQL、Redis、Gin、Vue.js)的详细分析和建议。 1. 分布式部…...

Unity 粒子特效在UI中使用裁剪效果
1.使用Sprite Mask 首先建立一个粒子特效在UI中显示 新建一个在场景下新建一个空物体,添加Sprite Mask组件,将其的Layer设置为UI相机渲染的UI层, 并将其添加到Canvas子物体中,调整好大小,并选择合适的Spriteÿ…...

Android 开发:新的一年,新的征程
回顾 2023 年,Android 开发领域可谓成果斐然。这一年,Android 系统不断迭代,新技术、新工具层出不穷,为开发者们带来了前所未有的机遇与挑战。如今,我们站在新的起点,怀揣着对技术的热爱与追求,…...

手写MVVM框架-环境搭建
项目使用 webpack 进行进行构建,初始化步骤如下: 1.创建npm项目执行npm init 一直下一步就行 2.安装webpack、webpack-cli、webpack-dev-server,html-webpack-plugin npm i -D webpack webpack-cli webpack-dev-server html-webpack-plugin 3.配置webpac…...

SQL进阶实战技巧:某芯片工厂设备任务排产调度分析 | 间隙分析技术应用
目录 0 技术定义与核心原理 1 场景描述 2 数据准备 3 间隙分析法 步骤1:原始时间线可视化...

[HOT 100] 0167. 两数之和 ||
文章目录 1. 题目链接2. 题目描述3. 题目示例4. 解题思路5. 题解代码6. 复杂度分析 1. 题目链接 167. 两数之和 II - 输入有序数组 - 力扣(LeetCode) 2. 题目描述 给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 &…...

CSS整体回顾
一. 邂逅CSS和常见的CSS 1.1. CSS的编写方式 1.2. 常见的CSS font-size/color/width/height/backgroundColor 二. 文本属性 2.1. text-decoration 2.2. text-indent 2.3. text-align 三. 字体属性 3.1. font-family 3.2. font-style 3.3. font-weight 3.4. font-size 3.5. …...

使用 Grafana 和 Prometheus展现消息队列性能
引言 上篇文章通过JMX提取Kafka数据,本篇文章将通过JDBC存储Kafka性能数据存储于数据库,并通过Grafana 和 Prometheus进行展示,实现开发中常用的可视化监控 1. 环境准备 Kafka:运行中的 Kafka 集群,确保可以…...

openssl 生成证书 windows导入证书
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...

Skyeye 云 VUE 版本 v3.15.6 发布
Skyeye 云智能制造,采用 Springboot winUI 的低代码平台、移动端采用 UNI-APP。包含 30 多个应用模块、50 多种电子流程,CRM、PM、ERP、MES、ADM、EHR、笔记、知识库、项目、门店、商城、财务、多班次考勤、薪资、招聘、云售后、论坛、公告、问卷、报表…...
)
25.2.3 【洛谷】作为栈的复习不错(学习记录)
今天学习的东西不算多,放了一个星期假,感觉不少东西都没那么清楚,得复习一下才行。今天搞个栈题写,把栈复习一下,明天进入正轨,边复习边学习新东西,应该会有二叉树的学习等等... 【洛谷】P1449 …...

【C++】线程池实现
目录 一、线程池简介线程池的核心组件实现步骤 二、C11实现线程池源码 三、线程池源码解析1. 成员变量2. 构造函数2.1 线程初始化2.2 工作线程逻辑 3. 任务提交(enqueue方法)3.1 方法签名3.2 任务封装3.3 任务入队 4. 析构函数4.1 停机控制 5. 关键技术点解析5.1 完美转发实现5…...

大模型领域的Scaling Law的含义及作用
Scaling Law就像是一个“长大公式”,用来预测当一个东西(比如模型)变大(比如增加参数、数据量)时,它的性能(比如准确率)会怎么变化。 它能帮助我们提前知道,增加多少资源…...

用FormLinker实现自动调整数据格式,批量导入微软表单
每天早上打开Excel时,你是否也经历过这样的噩梦? 熬夜调整好的问卷格式,导入微软表单后全乱套 客户发来的PDF反馈表,手动录入3小时才完成10% 200道题库要转为在线测试,复制粘贴到手指抽筋 微软官方数据显示…...
实现“新建快捷方式对话框”(全网首发))
C#,shell32 + 调用控制面板项(.Cpl)实现“新建快捷方式对话框”(全网首发)
Made By 于子轩,2025.2.2 不管是使用System.IO命名空间下的File类来创建快捷方式文件,或是使用Windows Script Host对象创建快捷方式,亦或是使用Shell32对象创建快捷方式,都对用户很不友好,今天小编为大家带来一种全新…...

洛谷 P11626 题解
[Problem Discription] \color{blue}{\texttt{[Problem Discription]}} [Problem Discription] 给定长度为 n n n 的数组 A 1 ⋯ n A_{1 \cdots n} A1⋯n,求 ∑ a 1 n ∑ b a 1 n ∑ c b 1 n ∑ d c 1 n ∑ e d 1 n ∑ f e 1 n ∑ g f 1 n ( gcd …...