javaEE-8.JVM(八股文系列)
目录
一.简介
二.JVM中的内存划分
JVM的内存划分图:
堆区:编辑
栈区:编辑
程序计数器:编辑
元数据区:编辑
经典笔试题:
三,JVM的类加载机制
1.加载:
2.验证:
3.准备:
4.解析:
5.初始化:
双亲委派模型
概念:
JVM的类加载器 默认有三种:
双亲委派模型的工作流程:
四.JVM的垃圾回收机制(GC)
垃圾回收步骤:
1.识别出垃圾
1)引用计数
2)可达性分析
2.把标记为垃圾的对象的内存空间进行释放
1)标记-清除:
2)复制算法
3)标记整理
分带回收
一.简介
JVM : java Virtual Machine 的简称,意为Java虚拟机。

java的执行流程是:先通过javac 将.java文件转为.class(字节码文件)文件,之后在某个平台执行;然后 通过JVM 将.class文件转换为CPU能识别的机器指令。
因此,编写一个java程序,只需要发布.class文件就行了。JVM拿到.class文件,就知道该如何转换了.
二.JVM中的内存划分
JVM也相当于一个进程,在启动一个java程序后,需要个JVM分配资源空间.
JVM从系统中申请的内存,会根据java程序中不同的使用途径,为其分配空间.这就是内存划分.
JVM会将申请到的空间划分成几个区域,每个区域有不同的功能,
JVM的内存划分图:

堆区:
存放的是代码中new出来的对象,对象中的非静态成员也在堆区.
栈区:
包含了一些方法调用关系和局部变量.
由本地方法栈和虚拟机栈组成,本地方法栈是JVM内部,是由C++写的;虚拟机栈保存了一些java的方法调用和局部变量。
平时所说的栈区,指的是虚拟机栈,
程序计数器:
这个区域比较小,专门用来保存下一条要执行的java指令的地址。
元数据区:
包含了一些辅助性质的,描述性质的属性。元数据区也叫做方法区。
元数据是计算机中的一个常见术语(Meta data)。
对于硬盘来说,不仅要存储文件的数据本体,还要存储一些辅助信息,像文件的大小,文件的位置,文件的使用权限,文件的拥有者....这些都称为“元数据”。
一个程序中,有哪些类,有哪些方法,每个方法中有哪些指令,....这些信息都会保存在JVM的元数据区.

对于堆区和元数据区,整个进程中只有一份;而对于栈区和程序计数区,在内存中是有很多份的.
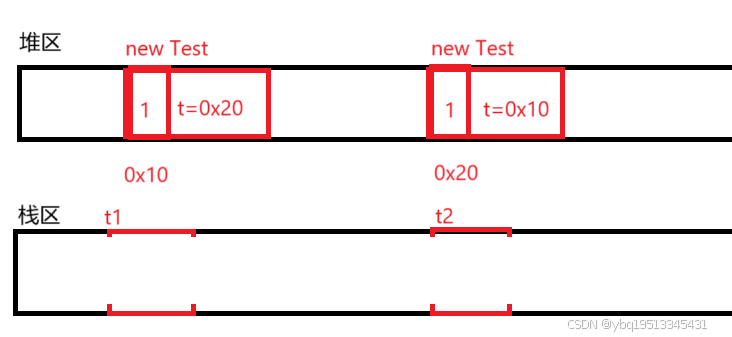
经典笔试题:
class Test {private int n;private static int m;
}
public static void main(String args[]){Test t = new Test();
}问: n,m,t 都在哪块JVM的哪个内存区域中?
n属于局部变量,在作用域中生效,出作用域就销毁了,存在栈区.
m:属于静态变量,存在元数据区。
t:是new出来了一个Test对象,t中保存的是Test的地址,属于局部变量,保存在栈区;而Test对象则保存在堆区.

区分变量在内存的哪个区域上,最重要的就是确定该变量的"形态",是 局部变量/成员变量/静态变量....
三,JVM的类加载机制
类加载指的是JVM把.class文件从硬盘读取到内存,进行一系列的校验解析的过程.转换成类对象的过程.
类加载过程大致分为五步:
1.加载:
把.class文件找到并打开,读取到文件中的内容.
2.验证:
需要确定当前读到的文件是合法的.class文件(字节码文件).否则若读到错误的文件,后面的工作就白费了.
具体的验证依据是在java的虚拟机规范中,有明确的格式说明:

左面这一列是类型,右面这一列是名字.
![]() :
:
也叫做:magic number 魔幻数字,用来标识二进制文件中的格式的类型.
![]() :
:
这两个都是版本号,u4 是主版本,u2 是次版本.属于JVM内部的版本,JVM会验证.class文件的版本号是否符合要求.
一般来说 高版本的JVM可以运行低版本的.class文件,反之不行.
3.准备:
为类对象申请内存空间.此时申请到的内存空间都为默认值 为全0的.
4.解析:
主要是针对类中的字符串常量进行处理.
将常量池中的 符号引用 替换为 直接引用 的过程,也就是初始化常量的过程.
我们知道,在.class文件中,是不存在地址的,而对于创建的字符串常量,变量中保存的是常量的地址,这又是怎样记录的呢?
class Test{private String s="hello";
}这个hello在.class文件中,是否会保存呢?
当然是要保存的,只不过s中保存的是一个字符串常亮的"偏移量".

在文件中,不存在地址这样的概念,地址是内存的地址,而文件是在硬盘中的.
为了保存字符串常来那个,可以存储一个"偏移量"的概念, 这里的偏移量就认为是符号引用.
之后,把.class文件加载到内存中,就有地址了,s中的值就能根据偏移量来转换为真正地址了,也就是直接引用.
5.初始化:
针对类对象,完成后续的初始化操作.
执行静态代码块,构造方法,还可能触发父类加载.....
双亲委派模型
在类加载过程的第一步:加载环节中使用 双亲委派模型 描述如何查找.class文件的策略.
JVM在进行类加载的时候,有一个专门的模块,称为"类加载器".(ClassLoader)
概念:
双亲委派模型: 如果一个类加载器收到一个类加载的请求,他首先不会自己加载该类,而是将这个类委派给父类加载器,让父类加载器去完成对类的加载.每层次的类加载器都是这样委派,最终所有的加载请求都会到达 最顶层的类加载器,直到当父类加载器反馈自己无法完成这个类加载请求时,子类加载器就会尝试自己完成加载.
JVM的类加载器 默认有三种:
BootstrapClassLoader: 负责查找标准库目录.
ExtensionClassLoader: 负责查找扩展库目录.
ApplicationClassLoader: 负责查找当前项目的代码目录,以及第三方库.
这三个类加载器存在父子类(二叉树关系)关系.
ApplicationClassLoader的父类是ExtensionClassLoader;
ExtensionClassLoader的父类是BootstrapClassLoader,BootstrapClassLoader属于顶层父类。
双亲委派模型的工作流程:
1.类加载任务先从ApplicationClassLoader为入口,开始工作;
2.ApplicationClassLoader自己不会立即搜索自己负责的目录,会将搜索的任务向上传递给父类;
3.代码进入ExtensionClassLoader的范畴,同样,ExtensionClassLoader 也不是立即搜索自己负责的目录,继续将搜索的任务向父类传递;
4.代码进入BootstrapClassLoader的范畴,由于BootstrapClassLoader是顶级父类了,就会真正进行负责搜索目录(标准库目录),尝试在标准库目录中找到符合要求的.Class文件;
5.若是找到了,就会进入打开文件,读文件流程了,此时类加载步骤就结束了;若是没有找到,就会返回到子类的类加载器中,继续尝试加载。
6.若是在ExtensionClassLoader类加载器中找到符合要求的.Class文件,此时类加载步骤就结束了;若还未找到,就会返回给子类加载器ApplicationClassLoader继续尝试加载.
7.若在ApplicationClassLoader类加载器中搜索到了,此时类加载就结束了,就会进入后续流程;若是没有找到,就会继续向子类寻找,由于ApplicationClassLoader是底层了,就表示类加载失败了.

这一系列的列加载机制,目的是为了保证这几个类加载器的优先级顺序.
这个类加载器是系统默认的类加载机制,也可以自己实现类加载机制,可以与默认机制不同.
四.JVM的垃圾回收机制(GC)
垃圾回收指的是让程序自动回收内存,JVM中的内存分为好几种,要回收的是堆区的内存;
元数据区和程序计数区的内存不需要回收,栈区中存放的都是局部变量申请的内存,在代码结束后,会自动销毁(属于栈区自己的特点,和垃圾回收没有关系)。

回收内存其实就是回收对象,垃圾回收时,将堆区上的若干个对象释放掉。
堆区内存根据垃圾回收,又分为三类区间:

垃圾回收步骤:
1.识别出垃圾
要判定哪些对象是垃圾,哪些对象不是垃圾。就是判断该对象是否还需要使用。
在java中,使用对象,一定是通过引用指向使用对象的方式使用,若该对象没有引用指向,则表示该对象不再被使用,就可以进行垃圾回收了。
class Test{
....
}
void func(){
Test t = new Test(); }这个代码中,执行结束后,t属于局部变量,存在于栈区,会被直接释放掉,Test对象在执行完后,由于没有对象指向了,也就属于垃圾了,就会被垃圾回收。
对于一些更复杂的代码,判定过程也就更加复杂。
Test t1 = new Test();
Test t2 = t1;
Test t3 = t2;
Test t4=t3;
....很多引用都指向了同一个对象Test,只有当所用的引用都结束了,才能释放Test对象,但每个引用的生命周期又不一样,就很难判断了。
于是又设计一些方法来记录对象的引用:
1)引用计数
给每个对象再分配一个额外的空间,保存当前对象引用个数,当有一个引用指向了该对象,引用计数就+1,一个引用结束后,引用计数就-1.
此时的垃圾回收机制就是:有一个专门的扫描线程,取获取每个对象的引用计数的情况,当引用计数为0时,就表示该对象没有引用指向了,不再使用了,也就可以释放了。
class Test {....
}
void func() {
Test t1 = new Test();
Test t2 = t1;
}这个代码的内存分配:

引用计数 存在的问题:
1)耗费额外的空间:
引用计数需要耗费一个额外的空间,若对象本身占用的内存就比较小,总的对象数目有很多,那么总的消耗空间就会非常多。
2)可能出现“循环引用问题”:
class Test{Test t;
}
Test t1 = new Test();
Test t2 = new Test();
t1.t = t2;
t2.t = t1;
t1 = null;
t2 = null;当t1和t2还未被置为null的时候,此时的内存是这样的情况:

当t1和t2都被置为null后,t1,t2内存被释放,但Test对象中的t还未被释放:
此时,Test的引用计数还都不是0,不能被GC回收,但又无法使用,就产生了循环引用问题,这种情况下的引用计数就无法被正常使用了。
引用计数 这种思想 并未在java中使用,在别的语言的垃圾回收机制中有使用到。
2)可达性分析
(JVM的垃圾回收机制 识别垃圾 采用的是这种思想)
可达性分析本质上是采用“时间”换“空间”的方法。
相较于 引用计数,可达性分析要消耗更多的时间去“遍历”,不会存在上面 引用计数 中的问题。
可达性分析:一个java代码中,会定义很多变量,从这些变量为起点,向下“遍历”:从这些变量中持有的引用类型的成员,再向下遍历,所有能被访问到的对象,一定不是垃圾了,而未被访问到的对象,就是垃圾了,要被就行回收。
JVM自身有扫描线程,会不停地扫描代码,看是否有对象无法被遍历到;JVM本身是知道一共有多少个对象的。
class Node{char root;Node left;Node right;
}
Node BuildNode{
Node a = new Node();
Node b = new Node();
Node c = new Node();
Node d = new Node();
Node e = new Node();
Node f = new Node();
Node g = new Node();
a.left = b;
a.right = c;
b.left = d;
b.right = e;
c.right = f;
e.left = g;
}
public static void main(String args[]){
Node root = BuildNode();
}代码中的树是这个样子,

在这个代码中,虽然只有一个root这样的引用,但实际上有7个对象都是可达的,
若代码中出现: c.right=null;此时f就是不可达的,f就属于垃圾了.要进行回收.
若a=null;那么整个二叉树都是不可达的了.都要进行垃圾回收.
2.把标记为垃圾的对象的内存空间进行释放
具体的释放方法有三种.
1)标记-清除:
把标记为垃圾的对象,直接进行释放。(最直接的方法)
这种做法可能会产生大量的“内存碎片”,会存在很多小的,离散的可用空间。
可能导致后续申请内存空间失败,申请内存空间都是一次申请一个连续的内存空间,此时可能内存中总得空间是够当前要申请的内存空间的,但内有连续的内存空间够分配,就可能申请失败。
2)复制算法
先把申请的内存分成两部分,申请内存时都在一半的内存中创建;进行释放时,把不是垃圾的对象的内存复制到另一半内存中,然后把带有垃圾的半个内存全部释放掉。

将不是垃圾的对象都复制到另半个内存中:

再把左半部分的内存中的对象都释放掉

这个方法也存在一些问题:
1、每次释放内存,要释放一半的内存,总的可用内存减少了很多。
2、若引用的对象很多,对对象的复制也要消费很大的开销。
3)标记整理
类似于顺序表中,删除元素的方法。
遍历整个内存,若有遍历到的对象标记为垃圾,不用管,后面遍历到不是垃圾的对象内存就覆盖垃圾的内存空间,这样既不会存在“内存碎片”,又不会一次释放很多的内存。

这个方法的缺点是搬运内存会有很大的开销。
上面的方法都有一定的缺点和问题,因此,JVM并没有直接使用上面的方法,而是对上面的方法思想,采用了一个·“综合性”方案:“分带回收”。
分带回收
依据不同种类的对象,采用不同的回收方式。
JVM引入了一个概念:年龄。
JVM的扫描线程会不断的扫描内存,若该对象是可达的,年龄就+1;
JVM根据对象年龄的不同,将内存分为两个区域:新生代 和 老年代。
新生代中又划分了三个大小不等的区域:其中一个大的区域叫伊甸区 和 两个小的等大的生存区(幸存区)。

回收过程:
1.当创建出一个对象后,该对象会先被创建到伊甸区,(伊甸区的对象大多都被第一轮GC扫描到了,就会被回收掉)
2.第一轮GC后,少数存活的对象通过复制算法被送到其中一个生存区,扫描还在继续,生存区中被标记的对象就会被清除掉,极少数的生存区的对象会再次通过复制算法,从一个生存区复制到另一个生存区,这样循环扫描复制,每经过一轮GC的扫描,年龄就会+1.
3.当这个对象在生存区经过了若干轮扫描,年龄已经很大了,说明这个对象的生命周期可能很长,就将这个对象拷贝到老年代,老年代中的对象经过GC扫描的频率要比新生代低很多。

4.当扫描老年代中的对象,也被标记为垃圾了,也会进行释放。
这个分带回收就类似于找工作一样:

相关文章:
)
javaEE-8.JVM(八股文系列)
目录 一.简介 二.JVM中的内存划分 JVM的内存划分图: 堆区:编辑 栈区:编辑 程序计数器:编辑 元数据区:编辑 经典笔试题: 三,JVM的类加载机制 1.加载: 2.验证: 3.准备: 4.解析: 5.初始化: 双亲委派模型 概念: JVM的类加…...

模型/O功能之提示词模板
文章目录 模型/O功能之提示词模板什么是提示词模板提示词模板的输入和输出 使用提示词模板构造提示词 模型/O功能之提示词模板 在LangChain框架中,提示词不是简单的字符串,而是一个更复杂的结构,是一个“提示词工程”。这个结构中包含一个或多…...

[Proteus仿真]基于51单片机的智能温控系统
[Proteus仿真]基于51单片机的智能温控系统 基于51单片机的智能温控系统:DS18B20精准测温LCD1602双屏显示三键设置上下限声光报警,支持温度校准、抗干扰设计、阈值记忆。 一.仿真原理图 二.模块介绍 温度采集模块(DS18B20࿰…...

掌握 HTML5 多媒体标签:如何在所有浏览器中顺利嵌入视频与音频
系列文章目录 01-从零开始学 HTML:构建网页的基本框架与技巧 02-HTML常见文本标签解析:从基础到进阶的全面指南 03-HTML从入门到精通:链接与图像标签全解析 04-HTML 列表标签全解析:无序与有序列表的深度应用 05-HTML表格标签全面…...

ChatGPT与GPT的区别与联系
ChatGPT 和 GPT 都是基于 Transformer 架构的语言模型,但它们有不同的侧重点和应用。下面我们来探讨一下它们的区别与联系。 1. GPT(Generative Pre-trained Transformer) GPT 是一类由 OpenAI 开发的语言模型,基于 Transformer…...

浅谈线段树
文章同步发布于洛谷,建议前往洛谷查看。 前言 蒟蒻终于学会线段树(指【模板】线段树 1 1 1)啦! 线段树思想 我们先来考虑 P3372(基础线段树模板题)给的操作: 区间修改(增加&am…...

深度解读 Docker Swarm
一、引言 随着业务规模的不断扩大和应用复杂度的增加,容器集群管理的需求应运而生。如何有效地管理和调度大量的容器,确保应用的高可用性、弹性伸缩和资源的合理分配,成为了亟待解决的问题。Docker Swarm 作为 Docker 官方推出的容器集群管理工具,正是在这样的背景下崭露头…...

在线知识库的构建策略提升组织信息管理效率与决策能力
内容概要 在线知识库作为现代企业信息管理的重要组成部分,具有显著的定义与重要性。它不仅为组织提供了一个集中存储与管理知识的平台,还能够有效提升信息检索的效率,促进知识的创新和利用。通过这样的知识库,企业可以更好地应对…...

网件r7000刷回原厂固件合集测评
《网件R7000路由器刷回原厂固件详解》 网件R7000是一款备受赞誉的高性能无线路由器,其强大的性能和可定制性吸引了许多高级用户。然而,有时候用户可能会尝试第三方固件以提升功能或优化网络性能,但这也可能导致一些问题,如系统不…...

为什么命令“echo -e “\033[9;0]“ > /dev/tty0“能控制开发板上的LCD不熄屏?
为什么命令"echo -e “\033[9;0]” > /dev/tty0"能控制开发板上的LCD不熄屏? 在回答这个问题前请先阅读我之前写的与tty和终端有关的博文 https://blog.csdn.net/wenhao_ir/article/details/145431655 然后再来看这条命令的解释就要容易些了。 这条…...

vscode软件操作界面UI布局@各个功能区域划分及其名称称呼
文章目录 abstract检查用户界面的主要区域官方文档关于UI的介绍 abstract 检查 Visual Studio Code 用户界面 - Training | Microsoft Learn 本质上,Visual Studio Code 是一个代码编辑器,其用户界面和布局与许多其他代码编辑器相似。 界面左侧是用于访…...

【Java基础-42.3】Java 基本数据类型与字符串之间的转换:深入理解数据类型的转换方法
在 Java 开发中,基本数据类型与字符串之间的转换是非常常见的操作。无论是从用户输入中读取数据,还是将数据输出到日志或界面,都需要进行数据类型与字符串之间的转换。本文将深入探讨 Java 中基本数据类型与字符串之间的转换方法,…...

【ActiveMq RocketMq RabbitMq Kafka对比】
以下是 ActiveMQ、RocketMQ、RabbitMQ 和 Kafka 的对比表格,从复杂性、功能、性能和适用场景等方面进行整理: 特性ActiveMQRocketMQRabbitMQKafka开发语言JavaJavaErlangScala/Java协议支持AMQP、STOMP、MQTT、OpenWire 等自定义协议AMQP、STOMP、MQTT …...
)
csapp笔记3.6节——控制(1)
本节解决了x86-64如何实现条件语句、循环语句和分支语句的问题 条件码 除了整数寄存器外,cpu还维护着一组单个位的条件码寄存器,用来描述最近的算数和逻辑运算的某些属性。可检测这些寄存器来执行条件分支指令。 CF(Carry Flag)…...

网站快速收录:如何优化网站音频内容?
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/60.html 为了优化网站音频内容以实现快速收录,以下是一些关键的策略和步骤: 一、高质量音频内容创作 原创性: 确保音频内容是原创的,避免使…...
——使用Wireshark分析RTP)
音视频入门基础:RTP专题(8)——使用Wireshark分析RTP
一、引言 通过Wireshark可以抓取RTP数据包,该软件可以从Wireshark Go Deep 下载。 二、通过Wireshark抓取RTP数据包 首先通过FFmpeg将一个媒体文件转推RTP,生成RTP流: ffmpeg -re -stream_loop -1 -i input.mp4 -vcodec copy -an -f rtp …...

4-图像梯度计算
文章目录 4.图像梯度计算(1)Sobel算子(2)梯度计算方法(3)Scharr与Laplacian算子4.图像梯度计算 (1)Sobel算子 图像梯度-Sobel算子 Sobel算子是一种经典的图像边缘检测算子,广泛应用于图像处理和计算机视觉领域。以下是关于Sobel算子的详细介绍: 基本原理 Sobel算子…...

深入解析 Redis AOF 机制:持久化原理、重写优化与 COW 影响
深入解析 Redis AOF 机制:持久化原理、重写优化与 COW 影响 1. 引言2. AOF 机制详解2.1 AOF 解决了什么问题?2.2 AOF 写入机制2.2.1 AOF 的基本原理2.2.2 AOF 运行流程2.2.3 AOF 文件刷盘策略 3. AOF 重写机制3.1 AOF 文件为什么会变大?3.2 解…...

机器学习day8
自定义数据集 ,使用朴素贝叶斯对其进行分类 代码 import numpy as np import matplotlib.pyplot as pltclass1_points np.array([[2.1, 2.2], [2.4, 2.5], [2.2, 2.0], [2.0, 2.1], [2.3, 2.3], [2.6, 2.4], [2.5, 2.1]]) class2_points np.array([[4.0, 3.5], …...

【前端】ES6模块化
文章目录 1. 模块化概述1.1 什么是模块化?1.2 为什么需要模块化? 2. 有哪些模块化规范3. CommonJs3.1 导出数据3.2 导入数据3.3 扩展理解3.4 在浏览器端运行 4.ES6模块化 参考视频地址 1. 模块化概述 1.1 什么是模块化? 将程序文件依据一定规则拆分成多个文件,这种编码方式…...

【leetcode练习·二叉树拓展】快速排序详解及应用
本文参考labuladong算法笔记[拓展:快速排序详解及应用 | labuladong 的算法笔记] 1、算法思路 首先我们看一下快速排序的代码框架: def sort(nums: List[int], lo: int, hi: int):if lo > hi:return# 对 nums[lo..hi] 进行切分# 使得 nums[lo..p-1]…...

Gurobi基础语法之 addConstr, addConstrs, addQConstr, addMQConstr
在新版本的 Gurobi 中,向 addConstr 这个方法中传入一个 TempConstr 对象,在模型中就会根据这个对象生成一个约束。更重要的是:TempConstr 对象可以传给所有addConstr系列方法,所以下面先介绍 TempConstr 对象 TempConstr TempC…...

游戏引擎 Unity - Unity 设置为简体中文、Unity 创建项目
Unity Unity 首次发布于 2005 年,属于 Unity Technologies Unity 使用的开发技术有:C# Unity 的适用平台:PC、主机、移动设备、VR / AR、Web 等 Unity 的适用领域:开发中等画质中小型项目 Unity 适合初学者或需要快速上手的开…...

Kamailio、MySQL、Redis、Gin后端、Vue.js前端等基于容器化部署
基于容器化的部署方案,通常会将每个核心服务(如Kamailio、MySQL、Redis、Gin后端、Vue.js前端等)独立运行在不同的容器中,通过Docker或Kubernetes统一管理。以下是具体实现方式和关键原因: 1. 容器化部署的核心思路 每…...

从1号点到n号点最多经过k条边的最短距离
目录 解析方法思路代码解释代码逐行注释1. 头文件和常量定义:2.边的结构体:3.全局变量:4.Bellman-Ford算法实现:5.主函数: 注意事项代码含义为什么需要 backup[a]?举例说明关键点 总结 解析 要实现从1号点…...

模拟实战-用CompletableFuture优化远程RPC调用
实战场景 这是广州某500-900人互联网厂的面试原题 手写并发优化解决思路 我们要调用对方的RPC接口,我们的RPC接口每调用一次对方都会阻塞50ms 但是我们的业务要批量调用RPC,例如我们要批量调用1k次,我们不可能在for循环里面写1k次远程调用…...

【pinia状态管理配置】
pinia状态管理配置 安装main.ts引入自定义user仓库使用自定义仓库 安装 pnpm add piniamain.ts引入 // createPinia() 函数调用创建了一个新的 Pinia 实例。 // 这个实例是状态管理的核心,它将管理应用中所有的 store。 import { createPinia } from pinia app.us…...

SpringBoot 引⼊MybatisGenerator
SpringBoot 引⼊MybatisGenerator 1. 引入插件2. 添加generator.xml并修改3. 生成文件 1. 引入插件 <plugin><groupId>org.mybatis.generator</groupId><artifactId>mybatis-generator-maven-plugin</artifactId><version>1.3.5</vers…...

在线销售数据集分析:基于Python的RFM数据分析方法实操训练
一、前言 个人练习,文章用于记录自己的学习练习过程,分享出来和大家一起学习。 数据集:在线销售数据集 分析方法:RFM分析方法 二、过程 1.1 库的导入与一些必要的初始设置 import pandas as pd import datetime import matplo…...

LeetCode - #197 Swift 实现找出温度更高的日期
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

分析哲学:从 语言解剖到 思想澄清的哲学探险
分析哲学:从 语言解剖 到 思想澄清 的哲学探险 第一节:分析哲学的基本概念与公式解释 【通俗讲解,打比方来讲解!】 分析哲学,就像一位 “语言侦探”,专注于 “解剖语言”,揭示我们日常使用的语…...

C++【iostream】数据库的部分函数功能介绍
在 C 编程世界中,iostream 库扮演着举足轻重的角色,它是 C 标准库的核心组成部分,为程序提供了强大的输入输出功能。无论是简单的控制台交互,还是复杂的文件操作,iostream 库都能提供便捷高效的解决方案。本文将深入剖…...

金山打字游戏2010绿色版,Win7-11可用DxWnd完美运行
金山打字游戏2010绿色版,Win7-11可用DxWnd完美运行 链接:https://pan.xunlei.com/s/VOIAYCzmkbDfdASGJa_uLjquA1?pwd67vw# 进入游戏后,如果输入不了英文字母(很可能是中文输入状态),就按一下“Shift”键…...

洛谷[USACO08DEC] Patting Heads S
题目传送门 题目难度:普及/提高一 题面翻译 今天是贝茜的生日,为了庆祝自己的生日,贝茜邀你来玩一个游戏。 贝茜让 N N N ( 1 ≤ N ≤ 1 0 5 1\leq N\leq 10^5 1≤N≤105) 头奶牛坐成一个圈。除了 1 1 1 号与 N N N 号奶牛外࿰…...

讲清逻辑回归算法,剖析其作为广义线性模型的原因
1、逻辑回归算法介绍 逻辑回归(Logistic Regression)是一种广义线性回归分析模型。虽然名字里带有“回归”两字,但其实是分类模型,常用于二分类。既然逻辑回归模型是分类模型,为什么名字里会含有“回归”二字呢?这是因为其算法原…...

基于STM32的智能安防监控系统
1. 引言 随着物联网技术的普及,智能安防系统在家庭与工业场景中的应用日益广泛。本文设计了一款基于STM32的智能安防监控系统,集成人体感应、环境异常检测、图像识别与云端联动功能,支持实时报警、远程监控与数据回溯。该系统采用边缘计算与…...
)
八. Spring Boot2 整合连接 Redis(超详细剖析)
八. Spring Boot2 整合连接 Redis(超详细剖析) 文章目录 八. Spring Boot2 整合连接 Redis(超详细剖析)2. 注意事项和细节3. 最后: 在 springboot 中 , 整合 redis 可以通过 RedisTemplate 完成对 redis 的操作, 包括设置数据/获取数据 比如添加和读取数据 具体整…...

220.存在重复元素③
目录 一、题目二、思路三、解法四、收获 一、题目 给你一个整数数组 nums 和两个整数 indexDiff 和 valueDiff 。 找出满足下述条件的下标对 (i, j): i ! j, abs(i - j) < indexDiff abs(nums[i] - nums[j]) < valueDiff 如果存在,返回 true &a…...

【Linux】从硬件到软件了解进程
个人主页~ 从硬件到软件了解进程 一、冯诺依曼体系结构二、操作系统三、操作系统进程管理1、概念2、PCB和task_struct3、查看进程4、通过系统调用fork创建进程(1)简述(2)系统调用生成子进程的过程〇提出问题①fork函数②父子进程关…...

volatile变量需要减少读取次数吗
问题说明 本人在前期读Netty源码时看到这样一段源码和注释: private boolean invokeHandler() {// Store in local variable to reduce volatile reads.int handlerState this.handlerState;return handlerState ADD_COMPLETE || (!ordered && handlerS…...

红黑树的封装
一、封装思路 在 STL 中 map set 的底层就是封装了一棵红黑树。 其中连接红黑树和容器的是迭代器,map set 暴露出的接口都不是自己写的,而是红黑树写的,外部接口封装红黑树接口。 所以写出红黑树为 map set 写的接口,再在上层的…...

Java 泛型<? extends Object>
在 Java 泛型中,<? extends Object> 和 <?> 都表示未知类型,但它们在某些情况下有细微的差异。泛型的引入是为了消除运行时错误并增强类型安全性,使代码更具可读性和可维护性。 在 JDK 5 中引入了泛型,以消除编译时…...

TensorFlow简单的线性回归任务
如何使用 TensorFlow 和 Keras 创建、训练并进行预测 1. 数据准备与预处理 2. 构建模型 3. 编译模型 4. 训练模型 5. 评估模型 6. 模型应用与预测 7. 保存与加载模型 8.完整代码 1. 数据准备与预处理 我们将使用一个简单的线性回归问题,其中输入特征 x 和标…...

解码大数据的四个V:体积、速度、种类与真实性
解码大数据的四个V:体积、速度、种类与真实性 在大数据领域,有一个大家耳熟能详的概念——“四个V”:Volume(体积)、Velocity(速度)、Variety(种类)、Veracityÿ…...
)
【单层神经网络】基于MXNet的线性回归实现(底层实现)
写在前面 基于亚马逊的MXNet库本专栏是对李沐博士的《动手学深度学习》的笔记,仅用于分享个人学习思考以下是本专栏所需的环境(放进一个environment.yml,然后用conda虚拟环境统一配置即可)刚开始先从普通的寻优算法开始ÿ…...
:高效的进程创建方式(中英双语))
深入解析 posix_spawn():高效的进程创建方式(中英双语)
深入解析 posix_spawn():高效的进程创建方式 1. 引言 在 Unix/Linux 系统中,传统的进程创建方式主要依赖 fork() 和 exec() 组合。但 fork() 在某些情况下可能存在性能瓶颈,特别是当父进程占用大量内存时,fork() 仍然需要复制整…...

2024-我的学习成长之路
因为热爱,无畏山海...

【Java异步编程】基于任务类型创建不同的线程池
文章目录 一. 按照任务类型对线程池进行分类1. IO密集型任务的线程数2. CPU密集型任务的线程数3. 混合型任务的线程数 二. 线程数越多越好吗三. Redis 单线程的高效性 使用线程池的好处主要有以下三点: 降低资源消耗:线程是稀缺资源,如果无限…...

前缀和多种基础
前缀和加法 #include<iostream> #include<algorithm> using namespace std; typedef long long ll; int n; const int N 1e310; int arr[N]; int pre[N]; int org[N]; int main(void) {cin >> n;for(int i 1 ; i < n ; i){cin >> arr[i];pre[i] …...

关于贪心学习的文笔记录
贪心,顾名思义就是越贪越好,越多越有易,他给我的感觉是,通常是求最大或最小问题,相比于动态规划贪心让人更加琢磨不透,不易看出方法,为此在这记录我所见过的题型和思维方法,以便回头…...