传输层协议 UDP 与 TCP

🌈 个人主页:Zfox_
🔥 系列专栏:Linux

目录
- 一:🔥 前置复盘
- 🦋 传输层
- 🦋 再谈端口号
- 🦋 端口号范围划分
- 🦋 认识知名端口号 (Well-Know Port Number)
- 二:🔥 UDP 协议
- 🦋 UDP 协议段格式
- 🦋 UDP 的特点
- 🦋 面向数据报
- 🦋 UDP 的缓冲区
- 🦋 UDP 使用注意事项
- 🦋 基于 UDP 的应用层协议
- 三:🔥 传输层协议 TCP (重点)
- 🦋 TCP 协议
- 🦋 TCP 协议段格式
- 🦋 确认应答 (ACK) 机制
- 🦋 超时重传机制
- 🦋 连接管理机制
- 🦋 MSL(Maximum Segment Lifetime)
- 🦋 理解 TIME_WAIT 状态
- 🦋 解决 TIME_WAIT 状态引起的 bind 失败的方法 (作业)
- 🦋 理解 CLOSE_WAIT 状态
- 🦋 滑动窗口
- 滑动窗口如何滑动?
- 滑动窗口丢包问题
- 滑动窗口的特点
- 🦋 流量控制
- 🦋 拥塞控制
- 🦋 发送窗口的最终上限由谁决定?
- 🦋 延迟应答
- 🦋 捎带应答
- 🦋 面向字节流
- 🦋 粘包问题
- 五:🔥 TCP 异常情况
- 七:🔥 TCP 小结
- 🦋 基于 TCP 应用层协议
- 🦋 TCP/UDP 对比
- 🦋 用 UDP 实现可靠传输(经典面试题)
- 八:🔥 共勉
一:🔥 前置复盘
🦋 传输层
🧑💻 负责数据能够从发送端传输到接收端.
🦋 再谈端口号
💻 端口号 (Port) 标识了一个主机上进行通信的不同的应用程序;

🛜 在 TCP/IP 协议中, 用 “源 IP”, “源端口号”, “目的 IP”, “目的端口号”, “协议号” 这样一个五元组来标识一个通信 (可以通过 netstat -n 查看);

🦋 端口号范围划分
- 🌾 🦁 0 - 1023: 知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议, 他们的端口号都是固定的.
- 🌾 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的.
🦋 认识知名端口号 (Well-Know Port Number)
✈️ 有些服务器是非常常用的, 为了使用方便, 人们约定一些常用的服务器, 都是用以下这些固定的端口号:
ssh服务器, 使用 22 端口ftp服务器, 使用 21 端口telnet服务器, 使用 23 端口http服务器, 使用 80 端口https服务器, 使用 443
🖱️ 执行下面的命令, 可以看到知名端口号
cat /etc/services
🎯 我们自己写一个程序使用端口号时, 要避开这些知名端口号.
二:🔥 UDP 协议
🦋 UDP 协议段格式

- 16 位 UDP 长度: 表示整个数据报 (UDP 首部+UDP 数据) 的最大长度;
- 16 位 UDP 校验和: 用于检测报文在传输过程中是否出错。如果校验和出错, 就会直接丢弃;
- 如果校验和为 0,表示未启用校验(不推荐)
🦋 UDP 的特点
🧑💻 UDP 传输的过程类似于寄信
- 🌰 无连接: 知道对端的 IP 和端口号就直接进行传输, 不需要建立连接;
- 🌰 不可靠: 没有确认机制, 没有重传机制; 如果因为网络故障该段无法发到对方, UDP 协议层也不会给应用层返回任何错误信息;
- 🌰 面向数据报: 不能够灵活的控制读写数据的次数和数量;
🦋 面向数据报
🛜 应用层交给 UDP 多长的报文, UDP 原样发送, 既不会拆分, 也不会合并; 用 UDP 传输 100 个字节的数据.
- 如果发送端调用一次 sendto, 发送 100 个字节, 那么接收端也必须调用对应的一次 recvfrom, 接收 100 个字节; 而不能循环调用 10 次 recvfrom, 每次接收 10 个字节。
🦋 UDP 的缓冲区
- UDP 没有真正意义上的 发送缓冲区. 调用 sendto 会直接交给内核, 由内核将数据传给网络层协议进行后续的传输动作;
- UDP 具有接收缓冲区. 但是这个接收缓冲区不能保证收到的 UDP 报的顺序和发送 UDP 报的顺序一致; 如果缓冲区满了, 再到达的 UDP 数据就会被丢弃;
🦁 UDP 的 socket 既能读, 也能写, 这个概念叫做 全双工
🦋 UDP 使用注意事项
⚠️ 我们注意到, UDP 协议首部中有一个 16 位的最大长度. 也就是说一个 UDP 能传输的数据最大长度是 64K(包含 UDP 首部).
📊 然而 64K 在当今的互联网环境下, 是一个非常小的数字.
📊 如果我们需要传输的数据超过 64K, 就需要在应用层手动的分包, 多次发送, 并在接收端手动拼装;
🦋 基于 UDP 的应用层协议
- NFS: 网络文件系统
- TFTP: 简单文件传输协议
- DHCP: 动态主机配置协议
- BOOTP: 启动协议(用于无盘设备启动)
- DNS: 域名解析协议
💤 当然, 也包括你自己写 UDP 程序时自定义的应用层协议;
三:🔥 传输层协议 TCP (重点)
🦋 TCP 协议
🧑💻 TCP 全称为 "传输控制协议(Transmission Control Protocol"). 人如其名, 要对数据的传输进行一个详细的控制;
🦋 TCP 协议段格式

源/目的端口号: 表示数据是从哪个进程来, 到哪个进程去;32 位序号: 当前报文段数据的第一个字节的序列号;
用于保证数据的有序性和可靠性;后面详细讲。32 位确认序号: 期望收到的下一个报文段的序列号;仅在 ACK 标志位为 1 时有效;后面详细讲。4 位 TCP 报头长度: 表示该 TCP 头部有多少个 32 位 bit (有多少个 4 字节); 所以TCP 头部最大长度是 15 * 4 = 606 位标志位:URG (Urgent): 紧急指针是否有效ACK(Acknowledgment): 确认序号是否有效PSH(Push): 提示接收端应用程序立刻从 TCP 缓冲区把数据读走RST(Reset): 对方要求重新建立连接; 我们把携带 RST 标识的称为复位报文段SYN(Synchronize): 请求建立连接; 我们把携带 SYN 标识的称为同步报文段FIN(Finish): 通知对方, 本端要关闭了, 我们称携带 FIN 标识的为结束报文段
16 位窗口大小: 接收方当前可接收的数据量(以字节为单位)16 位校验和: 发送端填充, CRC 校验. 接收端校验不通过, 则认为数据有问题. 此处的检验和不光包含 TCP 首部, 也包含 TCP 数据部分.16 位紧急指针: 标识哪部分数据是紧急数据;40 字节头部选项: 可选部分(Options,最多 40 字节)。接收方需要通过 “4 位 TCP 报头长度” 字段动态确定:
1️⃣ 头部结束位置
2️⃣ 载荷数据(Payload)的起始位置;
🦋 确认应答 (ACK) 机制

🌲 TCP 将每个字节的数据都进行了编号. 即为序列号(这里我们可以想像成字节数组。

⚡️ 每一个 ACK 都带有对应的确认序列号, 意思是告诉发送者, 确认序列号之前的报文我已经全部收到了; 下一次你从哪一个序号开始发.
🦋 超时重传机制

- 🫧 主机 A 发送数据给 B 之后, 可能因为网络拥堵等原因, 数据无法到达主机 B;
- 🫧 如果主机 A 在一个特定时间间隔内没有收到 B 发来的确认应答, 就会进行重发;
🎯 但是, 主机 A 未收到 B 发来的确认应答, 也可能是因为 ACK 丢失了;
- 对于主机 A 来说,无论是数据丢了还是应答丢了,都是一样的

🌊 因此主机 B 会收到很多重复数据. 那么 TCP 协议需要能够识别出那些包是重复的包, 并且把重复的丢弃掉.
这时候我们可以利用前面提到的序列号, 就可以很容易做到去重的效果.
那么, 如果超时的时间如何确定?
最理想的情况下, 找到一个最小的时间, 保证 “确认应答一定能在这个时间内返回”.
- 但是这个时间的长短, 随着网络环境的不同, 是有差异的.
- 如果超时时间设的太长, 会影响整体的重传效率;
- 如果超时时间设的太短, 有可能会频繁发送重复的包;
- TCP 为了保证无论在任何环境下都能比较高性能的通信, 因此会动态计算这个最大超时时间.
- Linux 中 (BSD Unix 和 Windows 也是如此), 超时以 500ms 为一个单位进行控制, 每次判定超时重发的超时时间都是 500ms 的整数倍.
- 如果重发一次之后, 仍然得不到应答, 等待 2*500ms 后再进行重传.
- 如果仍然得不到应答, 等待 4*500ms 进行重传. 依次类推, 以指数形式递增.
- 累计到一定的重传次数, TCP 认为网络或者对端主机出现异常, 强制关闭连接。
🦋 连接管理机制
☕️ 在正常情况下, TCP 要经过三次握手建立连接, 四次挥手断开连接

💻 服务端状态转化:
[CLOSED -> LISTEN]服务器端调用 listen 后进入 LISTEN 状态, 等待客户端连接;[LISTEN -> SYN_RCVD]一旦监听到连接请求(同步报文段), 就将该连接放入内核等待队列中, 并向客户端发送 SYN 确认报文.[SYN_RCVD -> ESTABLISHED]服务端一旦收到客户端的确认报文, 就进入 ESTABLISHED 状态, 可以进行读写数据了.[ESTABLISHED -> CLOSE_WAIT]当客户端主动关闭连接 (调用 close), 服务器会收到结束报文段, 服务器返回确认报文段并进入 CLOSE_WAIT;[CLOSE_WAIT -> LAST_ACK]进入 CLOSE_WAIT 后说明服务器准备关闭连接(需要处理完之前的数据); 当服务器真正调用 close 关闭连接时, 会向客户端发送 FIN, 此时服务器进入 LAST_ACK 状态, 等待最后一个 ACK 到来(这个 ACK 是客户端确认收到了 FIN)[LAST_ACK -> CLOSED]服务器收到了对 FIN 的 ACK, 彻底关闭连接.
💻 客户端状态转化:
[CLOSED -> SYN_SENT]客户端调用 connect, 发送同步报文段;[SYN_SENT -> ESTABLISHED]connect 调用成功, 则进入 ESTABLISHED 状态, 开始读写数据;[ESTABLISHED -> FIN_WAIT_1]客户端主动调用 close 时, 向服务器发送结束报文段, 同时进入 FIN_WAIT_1;[FIN_WAIT_1 -> FIN_WAIT_2]客户端收到服务器对结束报文段的确认, 则进入 FIN_WAIT_2, 开始等待服务器的结束报文段;[FIN_WAIT_2 -> TIME_WAIT]客户端收到服务器发来的结束报文段, 进入TIME_WAIT, 并发出 LAST_ACK;[TIME_WAIT -> CLOSED]客户端要等待一个 2MSL (Max Segment Life, 报文最大生存时间) 的时间, 才会进入 CLOSED 状态.
🦋 MSL(Maximum Segment Lifetime)
- 定义:
- MSL 是 TCP 报文段在网络中能够存活的最长时间。超过这个时间后,报文段会被丢弃。
- 作用:
- 确保网络中旧的、重复的 TCP 报文段不会干扰新的连接。
- 在 TCP 连接关闭时,MSL 用于确定 TIME_WAIT 状态的持续时间。
- 典型值:
- MSL 的默认值通常是 30 秒 到 2 分钟,具体取决于操作系统实现。
- 因此,TIME_WAIT 状态通常持续 1 分钟 到 4 分钟。
- TIME_WAIT 状态:
🦋 理解 TIME_WAIT 状态
📚 防止旧连接的报文干扰新连接(游离报文):
- 如果客户端在关闭连接后立即建立新连接,网络中可能还有旧连接的延迟报文,这会导致数据混乱。
📚 确保服务器收到最后一个 ACK:
- 如果服务器没有收到最后一个 ACK,会重传 FIN 报文,TIME_WAIT 状态允许客户端重新发送 ACK。
现在做一个测试,首先启动 server,然后启动 client,然后用 Ctrl-C 使 server 终止,这时马上再运行 server, 结果是:

🐮 这是因为,虽然 server 的应用程序终止了,但 TCP 协议层的连接并没有完全断开,因此不能再次监听同样的 server 端口. 我们用 netstat 命令查看一下:
root# netstat -apn | grep 8080
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:8080 127.0.0.1:17256 TIME_WAIT -
- TCP 协议规定,主动关闭连接的一方要处于 TIME_ WAIT 状态,等待两个 MSL (maximum segment lifetime) 的时间后才能回到 CLOSED 状态.
我们使用 Ctrl-C 终止了 server, 所以 server 是主动关闭连接的一方, 在 TIME_WAIT 期间仍然不能再次监听同样的 server 端口;- MSL 在 RFC1122 中规定为两分钟,但是各操作系统的实现不同, 在 Centos7 上默认配置的值是 60s;
- 可以通过
cat /proc/sys/net/ipv4/tcp_fin_timeout查看MSL的值;
root# cat /proc/sys/net/ipv4/tcp_fin_timeout
60
🤔 想一想, 为什么是 TIME_WAIT 的时间是 2MSL?
- MSL 是 TCP 报文的最大生存时间, 因此 TIME_WAIT 持续存在 2MSL 的话。
- 就能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失 (
否则服务器立刻重启, 可能会收到来自上一个进程的迟到的数据, 但是这种数据很可能是错误的);- 同时也是在理论上保证最后一个报文可靠到达 (
假设最后一个 ACK 丢失, 那么服务器会再重发一个 FIN. 这时虽然客户端的进程不在了, 但是 TCP 连接还在, 仍然可以重发 LAST_ACK);
🦋 解决 TIME_WAIT 状态引起的 bind 失败的方法 (作业)
🧑💻 在 server 的 TCP 连接没有完全断开之前不允许重新监听, 某些情况下可能是不合理的:
- 服务器需要处理非常大量的客户端的连接 (每个连接的生存时间可能很短, 但是每秒都有很大数量的客户端来请求).
- 这个时候如果由服务器端主动关闭连接 (比如某些客户端不活跃, 就需要被服务器端主动清理掉), 就会产生大量 TIME_WAIT 连接.
- 由于我们的请求量很大, 就可能导致 TIME_WAIT 的连接数很多, 每个连接都会占用一个通信五元组 (源 ip, 源端口, 目的 ip, 目的端口, 协议). 其中服务器的 ip 和端口和协议是固定的. 如果新来的客户端连接的 ip 和端口号和 TIME_WAIT 占用的链接重复了, 就会出现问题.
📚 使用 setsockopt()设置 socket 描述符的 选项 SO_REUSEADDR 为 1, 表示允许创建端口号相同但 IP 地址不同的多个 socket 描述符:
// 保证服务器,异常断开之后,可以立即重启,不会有bind问题
int opt = 1;
int n = ::setsockopt(_sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
(void)n;
🦋 理解 CLOSE_WAIT 状态
以之前写过的 TCP 服务器为例, 我们稍加修改将 套接字的文件描述符关闭的 close(); 这个代码去掉.
我们编译运行服务器. 启动客户端链接, 查看 TCP 状态, 客户端服务器都为 ESTABLELISHED 状态, 没有问题.
然后我们关闭客户端程序, 观察 TCP 状态
tcp 0 0 0.0.0.0:9090 0.0.0.0:* LISTEN 5038/./server
tcp 0 0 127.0.0.1:49958 127.0.0.1:9090 FIN_WAIT2 -
tcp 0 0 127.0.0.1:9090 127.0.0.1:49958 CLOSE_WAIT 5038/./server
🧑💻 小结: 对于服务器上出现大量的 CLOSE_WAIT 状态, 原因就是服务器没有正确的关闭 socket, 导致四次挥手没有正确完成. 这是一个 BUG. 只需要加上对应的 close 即可解决问题.
🦋 滑动窗口
💻 刚才我们讨论了确认应答策略, 对每一个发送的数据段, 都要给一个 ACK 确认应答. 收到 ACK 后再发送下一个数据段. 这样做有一个比较大的缺点, 就是性能较差. 尤其是数据往返的时间较长的时候.

‼️ 既然这样一发一收的方式性能较低, 那么我们一次发送多条数据, 就可以大大的提高性能(其实是将多个段的等待时间重叠在一起了).

- 窗口大小指的是无需等待确认应答而可以继续发送数据的最大值(由接收方的缓冲区剩余空间决定). 上图的窗口大小就是 4000 个字节(四个段).
- 发送前四个段的时候,
不需要等待任何 ACK, 直接发送;- 收到第一个 ACK 后, 滑动窗口向后移动, 继续发送第五个段的数据; 依次类推;
- 操作系统内核为了维护这个滑动窗口, 需要开辟 发送缓冲区 来记录当前还有哪些数据没有应答; 只有确认应答过的数据, 才能从缓冲区删掉;
- 窗口越大, 则网络的吞吐率就越高
- 滑动窗口的大小实际上就是对方接收缓冲区剩余空间的大小,左侧是已经发送完且 ACK 完毕的

滑动窗口如何滑动?
- 窗口的边界:
- Start:窗口的起始位置,通常是接收方已确认的最后一个字节的序号(ACK 序号)。
- End:窗口的结束位置,计算公式为:
- End = Start + 接收方缓冲区剩余空间的大小
- 窗口的滑动:
- 窗口会根据接收方的确认信息(ACK)和缓冲区剩余空间动态调整。
- 窗口只会向右滑动(即序号递增),但窗口的大小可以不变、变大、变小,甚至变为 0。
- 环形缓冲区:
- 在逻辑上,TCP 的序号空间是环形的(32 位序号,范围为0 到 )。
- 当序号达到最大值时,会回绕到 0。
滑动窗口丢包问题
🎯 那么如果出现了丢包, 如何进行重传? 这里分两种情况讨论.
-
情况一: 数据包已经抵达, ACK 被丢了.
这种情况下, 部分 ACK 丢了并不要紧, 因为可以通过后续的 ACK 进行确认; -
情况二: 数据包就直接丢了

- 当某一段报文段丢失之后, 发送端会一直收到 1001 这样的 ACK, 就像是在提醒发送端 “我想要的是 1001” 一样;
- 如果发送端主机连续三次收到了同样一个 “1001” 这样的应答, 就会将对应的数据 1001 - 2000 重新发送;
- 这个时候接收端收到了 1001 之后, 再次返回的 ACK 就是 7001 了(因为 2001 - 7000) 接收端其实之前就已经收到了, 被放到了接收端操作系统内核的接收缓冲区中;
📚 这种机制被称为 “高速重发控制” (也叫 “快重传”).
在这种机制下,如果滑动窗口最左侧的数据丢失,接收方会触发快速重传机制,要求发送方重新发送丢失的数据包。如果滑动窗口中间的数据丢失,接收方会通过确认应答(ACK)指出丢失数据包的起始位置,此时问题会转化为滑动窗口最左侧数据丢失的情况,从而同样触发快速重传。类似地,如果滑动窗口最右侧的数据丢失,问题也会被转换为最左侧数据丢失的情况,最终通过快速重传机制解决。
🧑💻 通过这种设计,滑动窗口机制能够高效处理不同位置的数据丢失问题,确保数据传输的可靠性和连续性。
滑动窗口的特点
动态调整:
- 窗口大小根据接收方的缓冲区剩余空间动态调整。
流量控制:
- 通过调整窗口大小,防止发送方发送过多数据导致接收方缓冲区溢出。
可靠性:
- 通过确认序号和窗口滑动,确保数据按序到达且不丢失。
🦋 流量控制
接收端处理数据的速度是有限的. 如果发送端发的太快, 导致接收端的缓冲区被打满, 这个时候如果发送端继续发送, 就会造成丢包, 继而引起丢包重传等等一系列连锁反应.
因此 TCP 支持根据接收端的处理能力, 来决定发送端的发送速度. 这个机制就叫做流量控制 (Flow Control);
- 接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 “窗口大小” 字段, 通过 ACK 端通知发送端;
- 窗口大小字段越大, 说明网络的吞吐量越高;
- 接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端;
- 发送端接受到这个窗口之后, 就会减慢自己的发送速度;
- 如果接收端缓冲区满了, 就会将窗口置为 0; 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数据段, 使接收端把窗口大小告诉发送端;

接收端如何把窗口大小告诉发送端呢? 回忆我们的 TCP 首部中, 有一个 16 位窗口字段,就是存放了窗口大小信息;
那么问题来了, 16 位数字最大表示 65535, 那么 TCP 窗口最大就是 65535 字节么?
实际上, TCP 首部 40 字节选项中还包含了一个窗口扩大因子 M, 实际窗口大小是窗口字段的值左移 M 位;
🦋 拥塞控制
虽然 TCP 有了滑动窗口这个大杀器, 能够高效可靠的发送大量的数据. 但是如果在刚开始阶段就发送大量的数据, 仍然可能引发问题.
因为网络上有很多的计算机, 可能当前的网络状态就已经比较拥堵. 在不清楚当前网络状态下, 贸然发送大量的数据, 是很有可能引起雪上加霜的.
🧑💻 TCP 引入 慢启动 机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据;

- 此处引入一个概念称为拥塞窗口
- 发送开始的时候, 定义拥塞窗口大小为 1;
- 每次收到一个 ACK 应答, 拥塞窗口加 1;
每次发送数据包的时候, 将拥塞窗口和接收端主机反馈的窗口大小做比较, 取较小的值作为实际发送的窗口;
💻 像上面这样的拥塞窗口增长速度, 是指数级别的. “慢启动” 只是指初使时慢, 但是增长速度非常快.
- 为了不增长的那么快, 因此不能使拥塞窗口单纯的加倍.
- 此处引入一个叫做慢启动的阈值
当拥塞窗口超过这个阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长
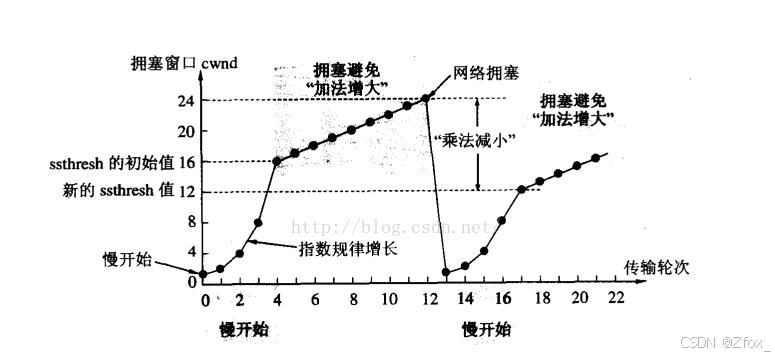
- 当 TCP 开始启动的时候, 慢启动阈值等于窗口最大值;
- 在 每次超时重发的时候, 慢启动阈值会变成原来的一半, 同时拥塞窗口置回 1; 少量的丢包, 我们仅仅是触发超时重传; 大量的丢包, 我们就认为网络拥塞; 当 TCP 通信开始后, 网络吞吐量会逐渐上升; 随着网络发生拥堵, 吞吐量会立刻下降;
- 拥塞控制, 归根结底是 TCP 协议想尽可能快的把数据传输给对方, 但是又避免给网络造成太大压力的折中方案.
🦋 发送窗口的最终上限由谁决定?
🧑💻 发送方的实际发送窗口大小 发送窗口 = min(rwnd, cwnd)。
- rwnd(接收窗口):由接收方通过 ACK 报文通告的剩余缓冲区大小。
- cwnd(拥塞窗口):由发送方根据网络拥塞状态动态调整。
-
网络拥塞时
- 若网络出现拥塞(如丢包、延迟激增),拥塞控制会减小 cwnd。
此时发送窗口由 cwnd 限制,即 发送窗口 = cwnd。
拥塞控制主导流量限制。
- 若网络出现拥塞(如丢包、延迟激增),拥塞控制会减小 cwnd。
-
网络状态良好时
- 若网络无拥塞,拥塞控制会逐步增大 cwnd(如慢启动、拥塞避免阶段)。
当 cwnd 增长到与 rwnd 相等甚至更大时,发送窗口由 rwnd 限制,即 发送窗口 = rwnd。
流量控制(滑动窗口)主导流量限制。
- 若网络无拥塞,拥塞控制会逐步增大 cwnd(如慢启动、拥塞避免阶段)。
🦋 延迟应答
💻 如果接收数据的主机立刻返回 ACK 应答, 这时候返回的窗口可能比较小.
- 假设接收端缓冲区为 1M. 一次收到了 500K 的数据; 如果立刻应答, 返回的窗口就是 500K;
- 但实际上可能处理端处理的速度很快, 10ms 之内就把 500K 数据从缓冲区消费掉了;
- 在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
- 如果接收端稍微等一会再应答, 比如等待 200ms 再应答, 那么这个时候返回的窗口大小就是 1M;
‼️ 一定要记得, 窗口越大, 网络吞吐量就越大, 传输效率就越高. 我们的目标是在保证网络不拥塞的情况下尽量提高传输效率;
那么所有的包都可以延迟应答么? 肯定也不是;
- 数量限制: 每隔 N 个包就应答一次;
- 时间限制: 超过最大延迟时间就应答一次;
🍻 具体的数量和超时时间, 依操作系统不同也有差异; 一般 N 取 2, 超时时间取 200ms;

🦋 捎带应答
🧑💻 在延迟应答的基础上, 我们发现, 很多情况下, 客户端服务器在应用层也是 “一发一收” 的. 意味着客户端给服务器说了 “How are you”, 服务器也会给客户端回一个 “Fine, thank you”;
那么这个时候 ACK 就可以搭顺风车, 和服务器回应的 “Fine, thank you” 一起回给客户端

🦋 面向字节流
💦 创建一个 TCP 的 socket, 同时在内核中创建一个 发送缓冲区 和一个 接收缓冲区;
调用 write 时, 数据会先写入发送缓冲区中;- 如果发送的字节数太长, 会被拆分成多个 TCP 的数据包发出;
- 如果发送的字节数太短, 就会先在缓冲区里等待, 等到缓冲区长度差不多了, 或者其他合适的时机发送出去;
- 接收数据的时候, 数据也是从网卡驱动程序到达内核的接收缓冲区;
然后应用程序可以调用 read 从接收缓冲区拿数据;- 另一方面, TCP 的一个连接, 既有发送缓冲区, 也有接收缓冲区, 那么对于这一个连接, 既可以读数据, 也可以写数据. 这个概念叫做
全双工
💻 由于缓冲区的存在, TCP 程序的读和写不需要一一匹配, 例如:
- 写 100 个字节数据时, 可以调用一次 write 写 100 个字节, 也可以调用 100 次write, 每次写一个字节;
- 读 100 个字节数据时, 也完全不需要考虑写的时候是怎么写的, 既可以一次 read 100 个字节, 也可以一次 read 一个字节, 重复 100 次;
🦋 粘包问题
[八戒吃馒头例子]
- 首先要明确, 粘包问题中的 “包” , 是指的应用层的数据包.
- 在 TCP 的协议头中, 没有如同 UDP 一样的 “报文长度” 这样的字段, 但是有一个序号这样的字段.
- 站在传输层的角度, TCP 是一个一个报文过来的. 按照序号排好序放在缓冲区中.
- 站在应用层的角度, 看到的只是一串连续的字节数据.
- 那么应用程序看到了这么一连串的字节数据, 就不知道从哪个部分开始到哪个部分, 是一个完整的应用层数据包.
那么如何避免粘包问题呢? 归根结底就是一句话, 明确两个包之间的边界.
- 对于定长的包, 保证每次都按固定大小读取即可; 例如上面的 Request 结构, 是固定大小的, 那么就从缓冲区从头开始按 sizeof(Request)依次读取即可;
- 对于变长的包, 可以在包头的位置, 约定一个包总长度的字段, 从而就知道了包的结束位置;
- 对于变长的包, 还可以在包和包之间使用明确的分隔符(应用层协议, 是程序猿自己来定的, 只要保证分隔符不和正文冲突即可);
思考: 对于 UDP 协议来说, 是否也存在 “粘包问题” 呢?
- 对于 UDP, 如果还没有上层交付数据, UDP 的报文长度仍然在. 同时, UDP 是一个一个把数据交付给应用层. 就有很明确的数据边界。
- 站在应用层的站在应用层的角度, 使用 UDP 的时候, 要么收到完整的 UDP 报文, 要么不收. 不会出现"半个"的情况。
五:🔥 TCP 异常情况
-
进程终止: 进程终止会释放文件描述符, 仍然可以发送 FIN. 和正常关闭没有什么区别.
-
机器重启: 和进程终止的情况相同.
-
机器掉电/网线断开: 接收端认为连接还在, 一旦接收端有写入操作, 接收端发现连接已经不在了, 就会进行 reset. 即使没有写入操作, TCP 自己也内置了一个保活定时器, 会定期询问对方是否还在. 如果对方不在, 也会把连接释放.
-
另外, 应用层的某些协议, 也有一些这样的检测机制. 例如 HTTP 长连接中, 也会定期检测对方的状态. 例如 QQ, 在 QQ 断线之后, 也会定期尝试重新连接.
七:🔥 TCP 小结
为什么 TCP 这么复杂? 因为要保证可靠性, 同时又尽可能的提高性能.
可靠性:
- 校验和
- 序列号(按序到达)
- 确认应答
- 超时重发
- 连接管理
- 流量控制
- 拥塞控制
提高性能:
- 滑动窗口
- 快速重传
- 延迟应答
- 捎带应答
其他:
- 定时器(超时重传定时器, 保活定时器, TIME_WAIT 定时器等)
🦋 基于 TCP 应用层协议
- HTTP
- HTTPS
- SSH
- Telnet
- FTP
- SMTP
当然, 也包括你自己写 TCP 程序时自定义的应用层协议;
🦋 TCP/UDP 对比
🦁 我们说了 TCP 是可靠连接, 那么是不是 TCP 一定就优于 UDP 呢? TCP 和 UDP 之间的优点和缺点, 不能简单, 绝对的进行比较。
- TCP 用于可靠传输的情况, 应用于文件传输, 重要状态更新等场景;
- UDP 用于对高速传输和实时性要求较高的通信领域, 例如, 早期的 QQ, 视频传输等. 另外 UDP 可以用于广播;
🧑💻 归根结底, TCP 和 UDP 都是程序员的工具, 什么时机用, 具体怎么用, 还是要根据具体的需求场景去判定.
🦋 用 UDP 实现可靠传输(经典面试题)
📚 参考 TCP 的可靠性机制, 在应用层实现类似的逻辑;
🧑💻 例如:
- 引入序列号, 保证数据顺序和完整性;
- 引入确认应答, 确保对端收到了数据;
- 引入超时重传, 如果隔一段时间没有应答, 就重发数据;
- …
八:🔥 共勉
😋 以上就是我对 传输层协议 UDP 与 TCP 的理解, 觉得这篇博客对你有帮助的,可以点赞收藏关注支持一波~ 😉

相关文章:

传输层协议 UDP 与 TCP
🌈 个人主页:Zfox_ 🔥 系列专栏:Linux 目录 一:🔥 前置复盘🦋 传输层🦋 再谈端口号🦋 端口号范围划分🦋 认识知名端口号 (Well-Know Port Number) 二…...

Vue06
目录 一、声明式导航-导航链接 1.需求 2.解决方案 3.通过router-link自带的两个样式进行高亮 二、声明式导航的两个类名 1.router-link-active 2.router-link-exact-active 三、声明式导航-自定义类名(了解) 1.问题 2.解决方案 3.代码演示 四…...

AJAX笔记进阶篇
黑马程序员视频地址: AJAX-Day04-01.同步代码和异步代码https://www.bilibili.com/video/BV1MN411y7pw?vd_source0a2d366696f87e241adc64419bf12cab&spm_id_from333.788.videopod.episodes&p47 同步代码和异步代码 回调函数地狱与解决方法 回调函数地狱…...

Linux+Docer 容器化部署之 Shell 语法入门篇 【Shell 循环类型】
文章目录 一、Shell 循环类型二、Shell while 循环三、Shell for 循环四、Shell until 循环五、Shell select 循环六、总结 一、Shell 循环类型 循环是一个强大的编程工具,使您能够重复执行一组命令。在本教程中,您将学习以下类型的循环 Shell 程序&…...

【Redis】安装配置Redis超详细教程 / Linux版
Linux安装配置Redis超详细教程 安装redis依赖安装redis启动redis停止redisredis.conf常见配置设置redis为后台启动修改redis监听地址设置工作目录修改密码监听的端口号数据库数量设置redis最大内存设置日志文件设置redis开机自动启动 学习视频:黑马程序员Redis入门到…...
)
S4 HANA明确税金汇差科目(OBYY)
本文主要介绍在S4 HANA OP中明确税金汇差科目(OBYY)相关设置。具体请参照如下内容: 1. 明确税金汇差科目(OBYY) 以上配置点定义了在外币挂账时,当凭证抬头汇率和税金行项目汇率不一致时,造成的差异金额进入哪个科目。此类情况只发生在FB60/F…...

Nginx反向代理 笔记250203
Nginx反向代理 Nginx 是一个高性能的 HTTP 服务器和反向代理服务器。反向代理是指客户端请求资源时,Nginx 作为中间层,将请求转发到后端服务器,并将后端服务器的响应返回给客户端。通过反向代理,可以实现负载均衡、缓存、SSL 终端…...

【ChatGPT:开启人工智能新纪元】
一、ChatGPT 是什么 最近,ChatGPT 可是火得一塌糊涂,不管是在科技圈、媒体界,还是咱们普通人的日常聊天里,都能听到它的大名。好多人都在讨论,这 ChatGPT 到底是个啥 “神器”,能让大家这么着迷?今天咱就好好唠唠。 ChatGPT,全称是 Chat Generative Pre-trained Trans…...

OpenAI 实战进阶教程 - 第六节: OpenAI 与爬虫集成实现任务自动化
爬虫与 OpenAI 模型结合,不仅能高效地抓取并分析海量数据,还能通过 NLP 技术生成洞察、摘要,极大提高业务效率。以下是一些实际工作中具有较高价值的应用案例: 1. 电商价格监控与智能分析 应用场景: 电商企业需要监控…...

49【服务器介绍】
服务器和你的电脑可以说是一模一样的,只不过用途不一样,叫法就不一样了 物理服务器和云服务器的区别 整台设备眼睛能够看得到的,我们一般称之为物理服务器。所以物理服务器是比较贵的,不是每一个开发者都能够消费得起的。 …...

docker pull Error response from daemon问题
里面填写 里面解决方案就是挂代理。 以虚拟机为例,将宿主机配置端口设置,https/http端口设为7899 配置虚拟机的http代理: vim /etc/systemd/system/docker.service.d/http-proxy.conf里面填写,wq保存 [Service] Environment…...

院校联合以项目驱动联合培养医工计算机AI人才路径探析
一、引言 1.1 研究背景与意义 在科技飞速发展的当下,医疗人工智能作为一个极具潜力的新兴领域,正深刻地改变着传统医疗模式。从疾病的早期诊断、个性化治疗方案的制定,到药物研发的加速,人工智能技术的应用极大地提升了医疗服务…...

C++ Primer 标准库vector
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

Mac本地部署DeekSeek-R1下载太慢怎么办?
Ubuntu 24 本地安装DeekSeek-R1 在命令行先安装ollama curl -fsSL https://ollama.com/install.sh | sh 下载太慢,使用讯雷,mac版下载链接 https://ollama.com/download/Ollama-darwin.zip 进入网站 deepseek-r1:8b,看内存大小4G就8B模型 …...

kamailio-ACC_JSON模块详解【后端语言go】
要确认 ACC_JSON 模块是否已经成功将计费信息推送到消息队列(MQueue),以及如何从队列中取值,可以按照以下步骤进行操作: 1. 确认 ACC_JSON 已推送到队列 1.1 配置 ACC_JSON 确保 ACC_JSON 模块已正确配置并启用。以下…...

利用Python高效处理大规模词汇数据
在本篇博客中,我们将探讨如何使用Python及其强大的库来处理和分析大规模的词汇数据。我们将介绍如何从多个.pkl文件中读取数据,并应用一系列算法来筛选和扩展一个核心词汇列表。这个过程涉及到使用Pandas、Polars以及tqdm等库来实现高效的数据处理。 引…...

安装hami的笔记
k3s环境下安装hami提示如下错误: "failed to “StartContainer” for “kube-scheduler” with InvalidImageName: "Failed to apply default image tag “registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.31.2k3s1”: 没有Inva…...

2024美团春招硬件开发笔试真题及答案解析
目录 一、选择题 1、在 Linux,有一个名为 file 的文件,内容如下所示: 2、在 Linux 中,关于虚拟内存相关的说法正确的是() 3、AT89S52单片机中,在外部中断响应的期间,中断请求标志位查询占用了()。 4、下列关于8051单片机的结构与功能,说法不正确的是()? 5、…...

HTML 字符实体
HTML 字符实体 在HTML中,字符实体是一种特殊的表示方式,用于在文档中插入那些无法直接通过键盘输入的字符。字符实体在网页设计和文档编写中扮演着重要的角色,尤其是在处理特殊字符、符号和数学公式时。以下是关于HTML字符实体的详细解析。 字符实体概述 HTML字符实体是一…...

FPGA|生成jic文件固化程序到flash
1、单击file-》convert programming files 2、flie type中选中jic文件,configuration decive里根据自己的硬件选择,单击flash loader选择右边的add device选项 3、选择自己的硬件,单击ok 4、选中sof选项,单机右侧的add file 5、选…...

Java | CompletableFuture详解
关注:CodingTechWork CompletableFuture 概述 介绍 CompletableFuture是 Java 8 引入的一个非常强大的类,属于 java.util.concurrent 包。它是用于异步编程的一个工具,可以帮助我们更方便地处理并发任务。与传统的线程池或 Future 对比&…...

高阶开发基础——快速入门C++并发编程6——大作业:实现一个超级迷你的线程池
目录 实现一个无返回的线程池 完全代码实现 Reference 实现一个无返回的线程池 实现一个简单的线程池非常简单,我们首先聊一聊线程池的定义: 线程池(Thread Pool) 是一种并发编程的设计模式,用于管理和复用多个线程…...

deep generative model stanford lecture note3 --- latent variable
1 Introduction 自回归模型随着gpt的出现取得很大的成功,还是有很多工程上的问题并不是很适合使用自回归模型: 1)自回归需要的算力太大,满足不了实时性要求:例如在自动驾驶的轨迹预测任务中,如果要用纯自回…...

【PDF提取局部内容改名】批量获取PDF局部文字内容改名 基于QT和百度云api的完整实现方案
应用场景 1. 档案管理 在企业或机构的档案管理中,常常会有大量的 PDF 格式的文件,如合同、报告、发票等。这些文件的原始文件名可能没有明确的标识,不利于查找和管理。通过批量获取 PDF 局部文字内容并改名,可以根据文件中的关键信息(如合同编号、报告标题等)为文件重新…...

吴恩达深度学习——卷积神经网络基础
本文来自https://www.bilibili.com/video/BV1FT4y1E74V,仅为本人学习所用。 文章目录 矩阵和张量边缘检测计算方式检测原理 Valid卷积和Same卷积卷积步长三维卷积单层卷积网络总结符号定义输入输出维度其他参数维度 举例 池化层示例输入层第一层卷积 - 池化第二层卷…...

MySQL锁详解
MySQL锁详解 数据库的锁机制锁的分类行级锁与表级锁行级锁之共享锁与排他锁乐观锁与悲观锁悲观锁乐观锁 Innodb存储引擎的锁机制行级锁与表级锁的使用区分三种行锁的算法死锁的问题多版本并发控制MVCC 数据库的锁机制 什么是锁?锁是一种保障数据的机制 为何要用锁…...

快速提升网站收录:利用网站用户反馈机制
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/59.html 利用网站用户反馈机制是快速提升网站收录的有效策略之一。以下是一些具体的实施步骤和建议: 一、建立用户反馈机制 多样化反馈渠道: 设立在线反馈表、邮件…...

初五,很棒
20元一瓶的水见过没?配料只有水和维C,养生佳品?除非我疯了。 今晚和大姨爹等人探讨成家问题。没错,我变成最应该成家的人了。 的确,从年龄上,发展阶段上,也是应该成家啦。 难道我不知道嘛。 人…...

Vue指令v-html
目录 一、Vue中的v-html指令是什么?二、v-html指令与v-text指令的区别? 一、Vue中的v-html指令是什么? v-html指令的作用是:设置元素的innerHTML,内容中有html结构会被解析为标签。 二、v-html指令与v-text指令的区别…...

ubuntu磁盘扩容
ubuntu磁盘扩容 描述先在虚拟机设置里面扩容进入Ubuntu 配置使用命令行工具parted进行分区输出如下完成 描述 执行命令,查看 fs 类型是什么 lsblk -o NAME,FSTYPE,MOUNTPOINT将60G扩容到100G,其中有些操作我也不知道什么意思,反正就是成功了࿰…...
——搜索算法)
BFS(广度优先搜索)——搜索算法
BFS,也就是广度(宽度)优先搜索,二叉树的层序遍历就是一个BFS的过程。而前、中、后序遍历则是DFS(深度优先搜索)。从字面意思也很好理解,DFS就是一条路走到黑,BFS则是一层一层地展开。…...
之1 - 定期请求(定期开票))
SAP SD学习笔记27 - 请求计划(开票计划)之1 - 定期请求(定期开票)
上两章讲了贩卖契约(框架协议)的概要,以及贩卖契约中最为常用的 基本契约 - 数量契约和金额契约。 SAP SD学习笔记26 - 贩卖契约(框架协议)的概要,基本契约 - 数量契约_sap 框架协议-CSDN博客 SAP SD学习笔记27 - 贩卖契约(框架…...

string例题
一、字符串最后一个单词长度 题目解析:由题输入一段字符串或一句话找最后一个单词的长度,也就是找最后一个空格后的单词长度。1.既然有空格那用我们常规的cin就不行了,我们这里使用getline,2.读取空格既然是最后一个空格后的单词,…...

Revit二次开发 自适应族添加放样融合
大多数博客给出的方案都是如何在有自适应族的情况下进行修改定位点或是将数据传入自适应族,如何直接在族文件中创建自适应模型并将点转换为自适应点,连接自适应点成为自适应路径这种方式没有文章介绍. 下面的代码中给出了如何在自适应族文件中创建参照点并转换为自适应点连接…...

浏览器模块化难题
CommonJS 的工作原理 当使用 require(模块路径) 导入一个模块时,node会做以下两件事情(不考虑模块缓存): 通过模块路径找到本机文件,并读取文件内容将文件中的代码放入到一个函数环境中执行,并将执行后 m…...

详细介绍:网站背景更换功能
目录 1. HTML 部分 2. JavaScript 部分 3. 完整流程 4. 总结 5. 适用场景 本文将介绍如何通过文件上传实现网站背景图片的更换。通过使用 JavaScript 和 Axios,我们可以允许用户上传图片文件并将其作为网站的背景图片。上传的图片 URL 会保存在浏览器的 localSt…...

w190工作流程管理系统设计与实现
🙊作者简介:多年一线开发工作经验,原创团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文…...

Linux——文件系统
一、从硬件出发 1)磁盘的主要构成 通常硬盘是由盘片、主轴、磁头、摇摆臂、马达、永磁铁等部件组成,其中一个硬盘中有多块盘片和多个磁头,堆叠在一起,工作时由盘片旋转和摇摆臂摇摆及逆行寻址从而运作,磁头可以对盘片…...

傅里叶分析之掐死教程
https://zhuanlan.zhihu.com/p/19763358 要让读者在不看任何数学公式的情况下理解傅里叶分析。 傅里叶分析 不仅仅是一个数学工具,更是一种可以彻底颠覆一个人以前世界观的思维模式。但不幸的是,傅里叶分析的公式看起来太复杂了,所以很多…...

使用scikit-learn中的K均值包进行聚类分析
聚类是无监督学习中的一种重要技术,用于在没有标签信息的情况下对数据进行分析和组织。K均值算法是聚类中最常用的方法之一,其目标是将数据点划分为K个簇,使得每个簇内的数据点更加相似,而不同簇之间的数据点差异较大。 准备自定…...
--LifecycleEventObserver)
Compose笔记(一)--LifecycleEventObserver
这一节了解一下LifecycleEventObserver,它在 Android Compose 中是一个接口,它允许你监听 Android 组件(如 Activity、Fragment)的生命周期事件。Lifecycle 代表 Android 组件从创建到销毁的整个生命周期,而 Lifecycle…...

算法总结-二分查找
文章目录 1.搜索插入位置1.答案2.思路 2.搜索二维矩阵1.答案2.思路 3.寻找峰值1.答案2.思路 4.搜索旋转排序数组1.答案2.思路 5.在排序数组中查找元素的第一个和最后一个位置1.答案2.思路 6.寻找旋转排序数组中的最小值1.答案2.思路 1.搜索插入位置 1.答案 package com.sunxi…...
)
MySQL(InnoDB统计信息)
后面也会持续更新,学到新东西会在其中补充。 建议按顺序食用,欢迎批评或者交流! 缺什么东西欢迎评论!我都会及时修改的! 大部分截图和文章采用该书,谢谢这位大佬的文章,在这里真的很感谢让迷茫的…...

Spring Cloud工程搭建
目录 工程搭建 搭建父子工程 创建父工程 Spring Cloud版本 创建子项目-订单服务 声明项⽬依赖 和 项⽬构建插件 创建子项目-商品服务 声明项⽬依赖 和 项⽬构建插件 工程搭建 因为拆分成了微服务,所以要拆分出多个项目,但是IDEA只能一个窗口有一…...
)
MySQL锁类型(详解)
锁的分类图,如下: 锁操作类型划分 读锁 : 也称为共享锁 、英文用S表示。针对同一份数据,多个事务的读操作可以同时进行而不会互相影响,相互不阻塞的。 写锁 : 也称为排他锁 、英文用X表示。当前写操作没有完成前,它会…...

Kafka SASL/SCRAM介绍
文章目录 Kafka SASL/SCRAM介绍1. SASL/SCRAM 认证机制2. SASL/SCRAM 认证工作原理2.1 SCRAM 认证原理2.1.1 密码存储和加盐2.1.2 SCRAM 认证流程 2.2 SCRAM 认证的关键算法2.3 SCRAM 密码存储2.4 SCRAM 密码管理 3. 配置和使用 Kafka SASL/SCRAM3.1 Kafka 服务器端配置3.2 创建…...

使用VCS进行单步调试的步骤
使用VCS对SystemVerilog进行单步调试的步骤如下: 1. 编译设计 使用-debug_all或-debug_pp选项编译设计,生成调试信息。 我的4个文件: 1.led.v module led(input clk,input rst_n,output reg led );reg [7:0] cnt;always (posedge clk) beg…...
)
计算机网络 应用层 笔记1(C/S模型,P2P模型,FTP协议)
应用层概述: 功能: 常见协议 应用层与其他层的关系 网络应用模型 C/S模型: 优点 缺点 P2P模型: 优点 缺点 DNS系统: 基本功能 系统架构 域名空间: DNS 服务器 根服务器: 顶级域…...

Node.js下载安装及环境配置
目录 一、下载 1. 查看电脑版本,下载对应的安装包 2. 下载路径下载 | Node.js 中文网 二、安装步骤 1. 双击安装包 2. 点击Next下一步 3. 选择安装路径 4. 这里我选择默认配置,继续Next下一步(大家按需选择) 5. 最后inst…...

LeetCode题练习与总结:任务调度器--621
一、题目描述 给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表,用字母 A 到 Z 表示,以及一个冷却时间 n。每个周期或时间间隔允许完成一项任务。任务可以按任何顺序完成,但有一个限制:两个 相同种类 的任务之间必须有长…...