MLM之MiniCPM-o:MiniCPM-o的简介(涉及MiniCPM-o 2.6和MiniCPM-V 2.6)、安装和使用方法、案例应用之详细攻略
MLM之MiniCPM-o:MiniCPM-o的简介(涉及MiniCPM-o 2.6和MiniCPM-V 2.6)、安装和使用方法、案例应用之详细攻略
目录
MiniCPM-o的简介
0、更新日志
1、MiniCPM-o系列模型特点
MiniCPM-o 2.6 的主要特点
MiniCPM-V 2.6的主要特点
2、MiniCPM-o系列模型架构
MiniCPM-o 2.6
MiniCPM-V 2.6
3、MiniCPM-o系列模型评估
MiniCPM-o 2.6
MiniCPM-V 2.6
MiniCPM-o的安装和使用方法
1、安装
2、使用方法
T1、Online Demo
T2、本地 WebUI Demo
实时流式视频/语音通话demo:
启动model server:
启动web server:
浏览器打开https://localhost:8088/
Chatbot图文对话demo:
3、推理
模型库
多轮对话
多卡推理
Mac 推理
基于 llama.cpp、ollama、vLLM 的高效推理
4、微调
简易微调
使用 Align-Anything
使用 LLaMA-Factory
使用 SWIFT 框架
MiniCPM-o的案例应用
MiniCPM-o 2.6的典型示例
MiniCPM-V 2.6的典型示例
MiniCPM-o的简介
MiniCPM-o是基于MiniCPM-V升级的多模态大型语言模型(MLLM)系列。该系列模型能够以端到端的方式接收图像、视频、文本和音频作为输入,并提供高质量的文本和语音输出。自2024年2月以来,已经发布了6个版本的模型,目标是实现强大的性能和高效的部署。
MiniCPM-o 2.6:MiniCPM-o系列最新也是功能最强大的模型。它拥有80亿参数,在视觉、语音和多模态实时流媒体方面达到了与GPT-4o-202405相当的性能,使其成为开源社区中最通用和高性能的模型之一。新的语音模式支持双语实时语音对话,并可配置语音;还支持情绪/速度/风格控制、端到端语音克隆、角色扮演等有趣的功能。它还改进了MiniCPM-V 2.6的视觉能力,例如强大的OCR能力、可靠的行为、多语言支持和视频理解。由于其优越的token密度,MiniCPM-o 2.6首次支持在iPad等终端设备上的多模态实时流媒体。但是,MiniCPM-o 2.6存在一些局限性,例如语音输出不稳定、重复响应以及Web演示的高延迟。
MiniCPM-V 2.6:MiniCPM-V系列功能最强大的模型。它拥有80亿参数,在单图像、多图像和视频理解方面超越了GPT-4V。在单图像理解方面,它的性能优于GPT-4o mini、Gemini 1.5 Pro和Claude 3.5 Sonnet,并且首次支持在iPad上的实时视频理解。
总而言之,MiniCPM-o系列模型,特别是MiniCPM-o 2.6和MiniCPM-V 2.6,在多模态能力方面展现了强大的性能和效率,并在开源社区中具有重要的影响力。
GitHub地址:https://github.com/OpenBMB/MiniCPM-o
0、更新日志
[2025.01.24] ������ MiniCPM-o 2.6 技术报告已发布! 欢迎点击这里查看.
[2025.01.23] ������ MiniCPM-o 2.6 现在已被北大团队开发的 Align-Anything,一个用于对齐全模态大模型的框架集成,支持 DPO 和 SFT 在视觉和音频模态上的微调。欢迎试用!
[2025.01.19] �� 注意! 我们正在努力将 MiniCPM-o 2.6 的支持合并到 llama.cpp、ollama、vLLM 的官方仓库,但还未完成。请大家暂时先使用我们提供的 fork 来进行部署:llama.cpp、ollama、vllm。 合并完成前,使用官方仓库可能会导致不可预期的问题。
[2025.01.19] ⭐️⭐️⭐️ MiniCPM-o 在 GitHub Trending 上登顶, Hugging Face Trending 上也达到了第二!
[2025.01.17] 我们更新了 MiniCPM-o 2.6 int4 量化版本的使用方式,解决了模型初始化的问题,欢迎点击这里试用!
[2025.01.13] ������ 我们开源了 MiniCPM-o 2.6,该模型视觉、语音和多模态流式能力达到了 GPT-4o-202405 级别,进一步优化了 MiniCPM-V 2.6 的众多亮点能力,还支持了很多有趣的新功能。欢迎试用!
[2024.08.17] ������ llama.cpp 官方仓库正式支持 MiniCPM-V 2.6 啦!点击这里查看各种大小的 GGUF 版本。
[2024.08.06] ������ 我们开源了 MiniCPM-V 2.6,该模型在单图、多图和视频理解方面取得了优于 GPT-4V 的表现。我们还进一步提升了 MiniCPM-Llama3-V 2.5 的多项亮点能力,并首次支持了 iPad 上的实时视频理解。欢迎试用!
[2024.08.03] MiniCPM-Llama3-V 2.5 技术报告已发布!欢迎点击这里查看。
[2024.05.23] ������ MiniCPM-V 在 GitHub Trending 和 Hugging Face Trending 上登顶!MiniCPM-Llama3-V 2.5 Demo 被 Hugging Face 的 Gradio 官方账户推荐,欢迎点击这里体验!
1、MiniCPM-o系列模型特点
MiniCPM-o 2.6 的主要特点
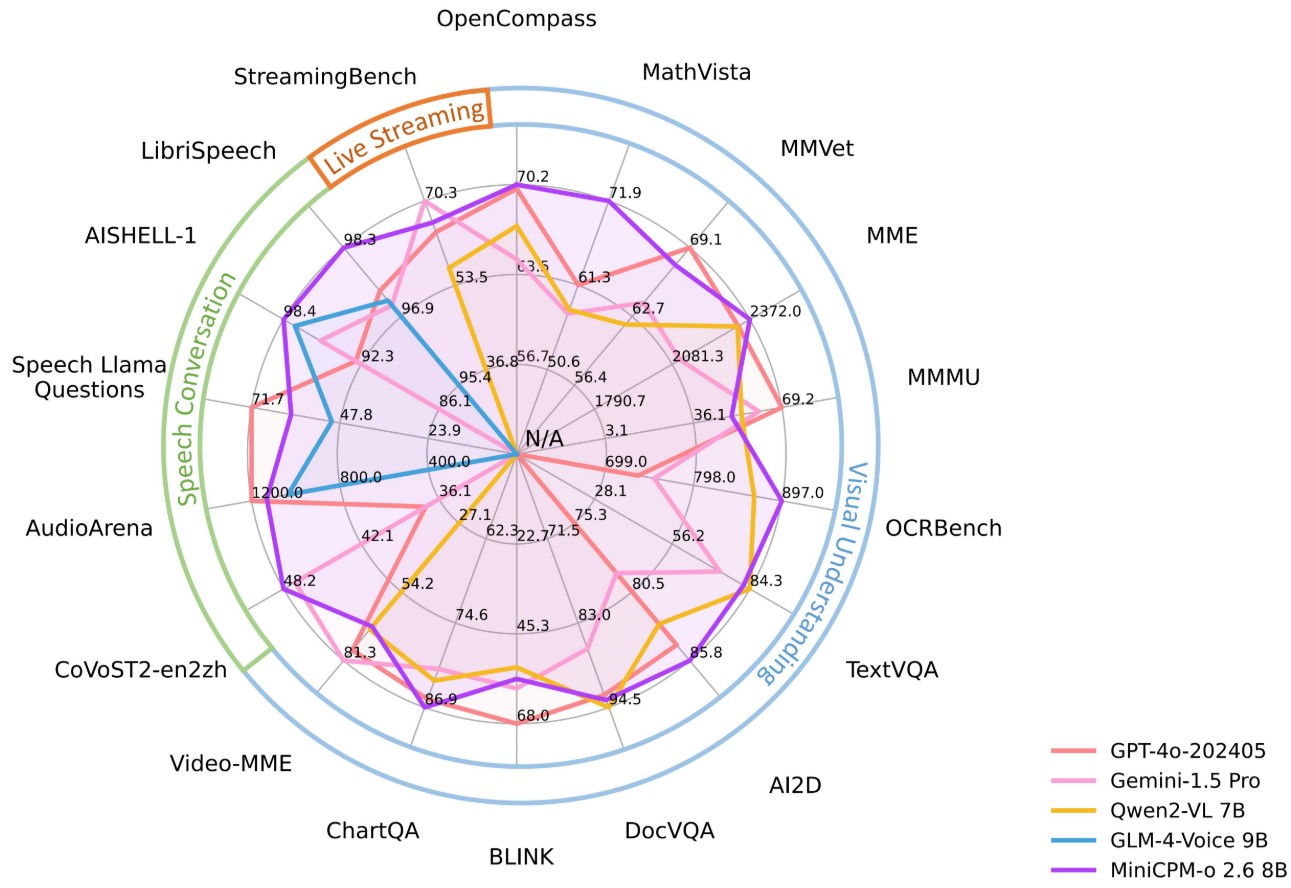
>> 领先的视觉能力:在OpenCompass(8个流行基准的综合评估)上平均得分达到70.2。仅用80亿参数就超过了GPT-4o-202405、Gemini 1.5 Pro和Claude 3.5 Sonnet等广泛使用的专有模型的单图像理解能力;在多图像和视频理解方面也优于GPT-4V和Claude 3.5 Sonnet,并展现出良好的上下文学习能力。
>> 最先进的语音能力:支持英语和中文的双语实时语音对话,并可配置语音。在ASR和STT翻译等音频理解任务上优于GPT-4o-realtime,并在开源社区的语义和声学评估中展现出最先进的语音对话性能。还支持情绪/速度/风格控制、端到端语音克隆、角色扮演等有趣的功能。
>> 强大的多模态实时流媒体能力:MiniCPM-o 2.6可以接收独立于用户查询的连续视频和音频流,并支持实时语音交互。在StreamingBench(实时视频理解、全源(视频和音频)理解和多模态上下文理解的综合基准)上,其性能优于GPT-4o-202408和Claude 3.5 Sonnet,并在开源社区中展现出最先进的性能。
>> 强大的OCR能力和其他能力:继承了MiniCPM-V系列流行的视觉能力,MiniCPM-o 2.6可以处理任意纵横比和最多180万像素的图像。在OCRBench(250亿参数以下的模型)上取得了最先进的性能,超过了GPT-4o-202405等专有模型。基于最新的RLAIF-V和VisCPM技术,它具有可靠的行为,在MMHal-Bench上优于GPT-4o和Claude 3.5 Sonnet,并支持30多种语言的多语言能力。
>> 优越的效率:MiniCPM-o 2.6具有出色的token密度(即编码到每个视觉token中的像素数量)。处理180万像素图像时仅产生640个token,比大多数模型少75%。这直接提高了推理速度、首个token延迟、内存使用率和功耗。因此,MiniCPM-o 2.6能够高效地支持iPad等终端设备上的多模态实时流媒体。
>> 易于使用:支持llama.cpp(在本地设备上进行高效的CPU推理)、int4和GGUF格式量化模型、vLLM(高吞吐量和内存高效的推理)、LLaMA-Factory(在新的领域和任务上进行微调)、本地WebUI演示和在线Web演示。
MiniCPM-V 2.6的主要特点
>> 领先的性能:在最新的OpenCompass版本(8个流行基准的综合评估)上平均得分达到65.2。仅用80亿参数就超过了GPT-4o mini、GPT-4V、Gemini 1.5 Pro和Claude 3.5 Sonnet等广泛使用的专有模型的单图像理解能力。
>> 多图像理解和上下文学习:可以对多张图像进行对话和推理,在Mantis-Eval、BLINK、Mathverse mv和Sciverse mv等流行的多图像基准测试中取得了最先进的性能,并展现出良好的上下文学习能力。
>> 视频理解:可以接收视频输入,进行对话并为时空信息提供密集的字幕。在Video-MME(有/无字幕)上优于GPT-4V、Claude 3.5 Sonnet和LLaVA-NeXT-Video-34B。
>> 强大的OCR能力和其他能力:可以处理任意纵横比和最多180万像素的图像。在OCRBench上取得了最先进的性能,超过了GPT-4o、GPT-4V和Gemini 1.5 Pro等专有模型。基于最新的RLAIF-V和VisCPM技术,它具有可靠的行为,在Object HalBench上的幻觉率明显低于GPT-4o和GPT-4V,并支持英语、中文、德语、法语、意大利语、韩语等多种语言。
>> 优越的效率:具有出色的token密度。处理180万像素图像时仅产生640个token,比大多数模型少75%。这直接提高了推理速度、首个token延迟、内存使用率和功耗。因此,MiniCPM-V 2.6能够高效地支持iPad等终端设备上的实时视频理解。
>> 易于使用:支持llama.cpp和ollama(在本地设备上进行高效的CPU推理)、int4和GGUF格式量化模型、vLLM(高吞吐量和内存高效的推理)、Gradio(快速搭建本地WebUI演示)和在线Web演示。
2、MiniCPM-o系列模型架构
MiniCPM-o 2.6

MiniCPM-o 2.6采用端到端的全模态架构。不同的模态编码器/解码器以端到端的方式连接和训练,以充分利用丰富的多模态知识。模型以端到端的方式进行训练,只使用交叉熵损失。它还设计了一种多模态系统提示,包括传统的文本系统提示和新的音频系统提示来确定助手的语音,从而实现推理时的灵活语音配置,并促进端到端语音克隆和基于描述的语音创建。
>> 端到端全模态架构:通过端到端的方式连接和训练不同模态的编/解码模块以充分利用丰富的多模态知识。模型完全使用 CE 损失端到端训练。
>> 全模态流式机制: (1) 我们将不同模态的离线编/解码器改造为适用于流式输入/输出的在线模块。 (2) 我们针对大语言模型基座设计了时分复用的全模态流式信息处理机制,将平行的不同模态的信息流拆分重组为周期性时间片序列。
>> 可配置的声音方案:我们设计了新的多模态系统提示,包含传统文本系统提示词,和用于指定模型声音的语音系统提示词。模型可在推理时灵活地通过文字或语音样例控制声音风格,并支持端到端声音克隆和音色创建等高级能力。
MiniCPM-V 2.6
MiniCPM-V 2.6的架构细节未在提供的文本中详细说明,但它基于SigLip-400M和Qwen2-7B构建,总参数为80亿。
3、MiniCPM-o系列模型评估
MiniCPM-o 2.6和MiniCPM-V 2.6在多个基准测试中都取得了领先的性能,涵盖了图像理解、多图像理解、视频理解、音频理解、语音生成、端到端语音克隆和多模态实时流媒体等方面。 这些评估结果与GPT-4o、GPT-4V、Gemini 1.5 Pro和Claude 3.5 Sonnet等专有模型进行了比较。
MiniCPM-o 2.6
MiniCPM-V 2.6

MiniCPM-o的安装和使用方法
1、安装
使用pip install -r requirements_o2.6.txt安装MiniCPM-o 2.6所需的依赖项。
MiniCPM-V 2.6的依赖项类似,可能需要安装不同的requirements文件。
2、使用方法
大量的Python代码示例,涵盖了多轮对话、多图像对话、少样本学习、视频对话、语音对话(包括模仿、可配置语音的通用语音对话、作为AI助手的语音对话、指令到语音、语音克隆)、各种音频理解任务和多模态实时流媒体等场景。 这些示例代码展示了如何使用transformers库加载模型,并使用模型的chat方法进行推理。 对于实时语音/视频通话演示和聊天机器人演示,需要启动模型服务器和Web服务器。 此外,还提供了在多个GPU和Mac上进行推理的示例。 项目还支持使用llama.cpp、ollama和vLLM进行高效推理,以及使用Hugging Face、Align-Anything、LLaMA-Factory和SWIFT框架进行微调。
我们提供由 Hugging Face Gradio 支持的在线和本地 Demo。Gradio 是目前最流行的模型部署框架,支持流式输出、进度条、process bars 和其他常用功能。
T1、Online Demo
欢迎试用 Online Demo: MiniCPM-V 2.6 | MiniCPM-Llama3-V 2.5 | MiniCPM-V 2.0 。
T2、本地 WebUI Demo
您可以使用以下命令轻松构建自己的本地 WebUI Demo。更详细的部署教程请参考文档。
实时流式视频/语音通话demo:
启动model server:
pip install -r requirements_o2.6.txtpython web_demos/minicpm-o_2.6/model_server.py请确保 transformers==4.44.2,其他版本目前可能会有兼容性问题,我们正在解决。 如果你使用的低版本的 Pytorch,你可能会遇到这个错误"weight_norm_fwd_first_dim_kernel" not implemented for 'BFloat16', 请在模型初始化的时候添加 self.minicpmo_model.tts.float()
启动web server:
# Make sure Node and PNPM is installed.
sudo apt-get update
sudo apt-get install nodejs npm
npm install -g pnpmcd web_demos/minicpm-o_2.6/web_server# 为https创建自签名证书, 要申请浏览器摄像头和麦克风权限须启动https.
bash ./make_ssl_cert.sh # output key.pem and cert.pempnpm install # install requirements
pnpm run dev # start server浏览器打开https://localhost:8088/
开始体验实时流式视频/语音通话.
Chatbot图文对话demo:
pip install -r requirements_o2.6.txt
python web_demos/minicpm-o_2.6/chatbot_web_demo_o2.6.py浏览器打开http://localhost:8000/,开始体验图文对话Chatbot.
3、推理
模型库
| 模型 | 设备 | 资源 | 简介 | 下载链接 |
|---|---|---|---|---|
| MiniCPM-o 2.6 | GPU | 18 GB | 最新版本,提供端侧 GPT-4o 级的视觉、语音、多模态流式交互能力。 | 🤗 |
| MiniCPM-o 2.6 gguf | CPU | 8 GB | gguf 版本,更低的内存占用和更高的推理效率。 | 🤗 |
| MiniCPM-o 2.6 int4 | GPU | 9 GB | int4量化版,更低显存占用。 | 🤗 |
| MiniCPM-V 2.6 | GPU | 17 GB | 提供出色的端侧单图、多图、视频理解能力。 | 🤗 |
| MiniCPM-V 2.6 gguf | CPU | 6 GB | gguf 版本,更低的内存占用和更高的推理效率。 | 🤗 |
| MiniCPM-V 2.6 int4 | GPU | 7 GB | int4量化版,更低显存占用。 | 🤗 |
更多历史版本模型
多轮对话
请确保 transformers==4.44.2,其他版本目前可能会有兼容性问题
pip install -r requirements_o2.6.txtimport torch
from PIL import Image
from transformers import AutoModel, AutoTokenizertorch.manual_seed(100)model = AutoModel.from_pretrained('openbmb/MiniCPM-o-2_6', trust_remote_code=True,attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-o-2_6', trust_remote_code=True)image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]answer = model.chat(msgs=msgs,tokenizer=tokenizer
)
print(answer)# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})answer = model.chat(msgs=msgs,tokenizer=tokenizer
)
print(answer)多卡推理
您可以通过将模型的层分布在多个低显存显卡(12 GB 或 16 GB)上,运行 MiniCPM-Llama3-V 2.5。请查看该教程,详细了解如何使用多张低显存显卡载入模型并进行推理。
Mac 推理
点击查看 MiniCPM-Llama3-V 2.5 / MiniCPM-V 2.0 基于Mac MPS运行 (Apple silicon 或 AMD GPUs)的示例。
# test.py Need more than 16GB memory to run.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizermodel = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, low_cpu_mem_usage=True)
model = model.to(device='mps')tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
model.eval()image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
question = 'Where is this photo taken?'
msgs = [{'role': 'user', 'content': question}]answer, context, _ = model.chat(image=image,msgs=msgs,context=None,tokenizer=tokenizer,sampling=True
)
print(answer)基于 llama.cpp、ollama、vLLM 的高效推理
llama.cpp 用法请参考我们的fork llama.cpp, 在iPad上可以支持 16~18 token/s 的流畅推理(测试环境:iPad Pro + M4)。
ollama 用法请参考我们的fork ollama, 在iPad上可以支持 16~18 token/s 的流畅推理(测试环境:iPad Pro + M4)。
点击查看, vLLM 现已官方支持MiniCPM-V 2.6、MiniCPM-Llama3-V 2.5 和 MiniCPM-V 2.0,MiniCPM-o 2.6 模型也可以临时用我们的 fork 仓库运行。
4、微调
简易微调
我们支持使用 Huggingface Transformers 库简易地微调 MiniCPM-o 2.6、MiniCPM-V 2.6、MiniCPM-Llama3-V 2.5 和 MiniCPM-V 2.0 模型。
使用 Align-Anything
我们支持使用北大团队开发的 Align-Anything 框架微调 MiniCPM-o 系列模型,同时支持 DPO 和 SFT 在视觉和音频模态上的微调。Align-Anything 是一个用于对齐全模态大模型的高度可扩展框架,开源了数据集、模型和评测。它支持了 30+ 开源基准,40+ 模型,以及包含SFT、SimPO、RLHF在内的多种算法,并提供了 30+ 直接可运行的脚本,适合初学者快速上手。
最佳实践: MiniCPM-o 2.6.
使用 LLaMA-Factory
我们支持使用 LLaMA-Factory 微调 MiniCPM-o 2.6 和 MiniCPM-V 2.6。LLaMA-Factory 提供了一种灵活定制 200 多个大型语言模型(LLM)微调(Lora/Full/Qlora)解决方案,无需编写代码,通过内置的 Web 用户界面 LLaMABoard 即可实现训练/推理/评估。它支持多种训练方法,如 sft/ppo/dpo/kto,并且还支持如 Galore/BAdam/LLaMA-Pro/Pissa/LongLoRA 等高级算法。
最佳实践: MiniCPM-o 2.6 | MiniCPM-V 2.6.
使用 SWIFT 框架
我们支持使用 SWIFT 框架微调 MiniCPM-V 系列模型。SWIFT 支持近 200 种大语言模型和多模态大模型的训练、推理、评测和部署。支持 PEFT 提供的轻量训练方案和完整的 Adapters 库支持的最新训练技术如 NEFTune、LoRA+、LLaMA-PRO 等。
参考文档:MiniCPM-V 1.0,MiniCPM-V 2.0 MiniCPM-V 2.6.
MiniCPM-o的案例应用
MiniCPM-o 2.6和MiniCPM-V 2.6在iPad等终端设备上的演示视频,展示了其在多模态实时流媒体和视频理解方面的能力。 代码示例中也包含了各种应用场景,例如图像问答、视频描述、语音转录、语音合成和多模态交互等。
MiniCPM-o 2.6的典型示例


MiniCPM-V 2.6的典型示例

相关文章:
、安装和使用方法、案例应用之详细攻略)
MLM之MiniCPM-o:MiniCPM-o的简介(涉及MiniCPM-o 2.6和MiniCPM-V 2.6)、安装和使用方法、案例应用之详细攻略
MLM之MiniCPM-o:MiniCPM-o的简介(涉及MiniCPM-o 2.6和MiniCPM-V 2.6)、安装和使用方法、案例应用之详细攻略 目录 MiniCPM-o的简介 0、更新日志 1、MiniCPM-o系列模型特点 MiniCPM-o 2.6 的主要特点 MiniCPM-V 2.6的主要特点 2、MiniCPM-o系列模型架构 MiniC…...

【Conda 和 虚拟环境详细指南】
Conda 和 虚拟环境的详细指南 什么是 Conda? Conda 是一个开源的包管理和环境管理系统,支持多种编程语言(如Python、R等),最初由Continuum Analytics开发。 主要功能: 包管理:安装、更新、删…...

Rust 控制流语法详解
Rust 控制流语法详解 控制流是编程语言中用于控制代码执行顺序的重要机制。Rust 提供了多种控制流语法,包括条件判断(if、else if)、循环(loop、while、for)等。本文将详细介绍这些语法,并通过示例展示它们…...

VLC-Qt: Qt + libVLC 的开源库
参考链接 https://blog.csdn.net/u012532263/article/details/102737874...

洛谷 P5146 最大差值 C语言
P5146 最大差值 - 洛谷 | 计算机科学教育新生态 题目描述 HKE 最近热衷于研究序列,有一次他发现了一个有趣的问题: 对于一个序列 A1,A2,…,An,找出两个数 i,j(1≤i<j≤n),使得 Aj−Ai 最大。…...
)
Zabbix 推送告警 消息模板 美化(钉钉Webhook机器人、邮件)
目前网络上已经有很多关于Zabbix如何推送告警信息到钉钉机器人、到邮件等文章。 但是在搜索下来,发现缺少了对告警信息的美化的文章。 本文不赘述如何对Zabbix对接钉钉、对接邮件,仅介绍我采用的美化消息模板的内容。 活用AI工具可以减轻很多学习、脑力负…...

MySQL数据库环境搭建
下载MySQL 官网:https://downloads.mysql.com/archives/installer/ 下载社区版就行了。 安装流程 看b站大佬的视频吧:https://www.bilibili.com/video/BV12q4y1477i/?spm_id_from333.337.search-card.all.click&vd_source37dfd298d2133f3e1f3e3c…...

书生大模型实战营7
文章目录 L1——基础岛提示词工程实践什么是Prompt(提示词)什么是提示工程提示设计框架CRISPECO-STAR LangGPT结构化提示词LangGPT结构编写技巧构建全局思维链保持上下文语义一致性有机结合其他 Prompt 技巧 常用的提示词模块 浦语提示词工程实践(LangGPT版)自动化生成LangGPT提…...

Spark的基本概念
个人博客地址:Spark的基本概念 | 一张假钞的真实世界 编程接口 RDD:弹性分布式数据集(Resilient Distributed Dataset )。Spark2.0之前的编程接口。Spark2.0之后以不再推荐使用,而是被Dataset替代。Datasetÿ…...
)
langchain基础(二)
一、输出解析器(Output Parser) 作用:(1)让模型按照指定的格式输出; (2)解析模型输出,提取所需的信息 1、逗号分隔列表 CommaSeparatedListOutputParser:…...

读取要素类中的几何信息
在arcpy中,每个要素都有相关的集合对象,都可以在游标中访问.本节将使用SearchCursor和Polyon对象来读取面要素类几何信息. 操作方法 1.打开IDLE,新建一个脚本 2.导入arcpy模块 3.设置输入要素类为目标面要素类 infc "<>" 4.传入输入要素类创建SearchCurs…...

洛谷 P1130 红牌 C语言
题目描述 某地临时居民想获得长期居住权就必须申请拿到红牌。获得红牌的过程是相当复杂,一共包括 N 个步骤。每一步骤都由政府的某个工作人员负责检查你所提交的材料是否符合条件。为了加快进程,每一步政府都派了 M 个工作人员来检查材料。不幸的是&…...
)
五. Redis 配置内容(详细配置说明)
五. Redis 配置内容(详细配置说明) 文章目录 五. Redis 配置内容(详细配置说明)1. Units 单位配置2. INCLUDES (包含)配置3. NETWORK (网络)配置3.1 bind(配置访问内容)3.2 protected-mode (保护模式)3.3 port(端口)配置3.4 timeout(客户端超时时间)配置3.5 tcp-keepalive()配置…...

LeetCode题练习与总结:有效三角形的个数--611
一、题目描述 给定一个包含非负整数的数组 nums ,返回其中可以组成三角形三条边的三元组个数。 示例 1: 输入: nums [2,2,3,4] 输出: 3 解释:有效的组合是: 2,3,4 (使用第一个 2) 2,3,4 (使用第二个 2) 2,2,3示例 2: 输入: nums [4,2,3,4] 输出: 4 提示: 1 &…...

【multi-agent-system】ubuntu24.04 安装uv python包管理器及安装依赖
uv包管理器是跨平台的 参考sudo apt-get update sudo apt-get install -y build-essential我的开发环境是ubuntu24.04 (base) root@k8s-master-pfsrv:/home/zhangbin/perfwork/01_ai/08_multi-agent-system# uv venv 找不到命令 “uv”,但可以通过以下软件...
【自然语言处理(NLP)】深度学习架构:Transformer 原理及代码实现
文章目录 介绍Transformer核心组件架构图编码器(Encoder)解码器(Decoder) 优点应用代码实现导包基于位置的前馈网络残差连接后进行层规范化编码器 Block编码器解码器 Block解码器训练预测 个人主页:道友老李 欢迎加入社…...
)
STM32单片机学习记录(2.2)
一、STM32 13.1 - PWR简介 1. PWR(Power Control)电源控制 (1)PWR负责管理STM32内部的电源供电部分,可以实现可编程电压监测器和低功耗模式的功能; (2)可编程电压监测器(…...

毕业设计:基于卷积神经网络的鲜花花卉种类检测算法研究
目录 前言 课题背景和意义 实现技术思路 一、算法理论基础 1.1 卷积神经网络 1.2目标检测算法 二、 数据集 2.1 数据集 2.2 数据扩充 三、实验及结果分析 3.1 实验环境搭建 3.2 模型训练 最后 前言 📅大四是整个大学期间最忙碌的时光,一边要忙着备考或…...

DeepSeek-R1模型1.5b、7b、8b、14b、32b、70b和671b有啥区别?
deepseek-r1的1.5b、7b、8b、14b、32b、70b和671b有啥区别?码笔记mabiji.com分享:1.5B、7B、8B、14B、32B、70B是蒸馏后的小模型,671B是基础大模型,它们的区别主要体现在参数规模、模型容量、性能表现、准确性、训练成本、推理成本…...
 | SQL查询操作)
云原生(五十三) | SQL查询操作
文章目录 SQL查询操作 一、数据库DDL操作 1、登陆数据库 2、创建DB数据库 二、数据表DDL操作 1、创建数据表 2、RDS中SQL查询操作 三、SQL查询操作 1、RDS中SQL查询操作 SQL查询操作 一、数据库DDL操作 1、登陆数据库 2、创建DB数据库 创建一个普通账号,…...
函数)
Ubuntu 下 nginx-1.24.0 源码分析 - ngx_strerror_init()函数
目录 ngx_strerror_init()函数声明 ngx_int_t 类型声明定义 intptr_t 类型 ngx_strerror_init()函数实现 NGX_HAVE_STRERRORDESC_NP ngx_strerror_init()函数声明 在 nginx.c 的开头引入了: #include <ngx_core.h> 在 ngx_core.h 中引入了 #include <ngx_er…...

【HTML入门】Sublime Text 4与 Phpstorm
文章目录 前言一、环境基础1.Sublime Text 42.Phpstorm(1)安装(2)启动Phpstorm(3)“启动”码 二、HTML1.HTML简介(1)什么是HTML(2)HTML版本及历史(3)HTML基本结构 2.HTML简单语法(1)HTML标签语法(2)HTML常用标签(3)表格(4)特殊字符 总结 前言 在当今的软件开发领域,…...
)
亲和传播聚类算法应用(Affinity Propagation)
亲和传播聚类算法应用(Affinity Propagation) 亲和传播(Affinity Propagation,简称 AP)是一种基于“消息传递”的聚类算法,与 K-Means 等传统聚类方法不同,它不需要用户预先指定簇的数量&#…...

【VM】VirtualBox安装CentOS8虚拟机
阅读本文前,请先根据 VirtualBox软件安装教程 安装VirtualBox虚拟机软件。 1. 下载centos8系统iso镜像 可以去两个地方下载,推荐跟随本文的操作用阿里云的镜像 centos官网:https://www.centos.org/download/阿里云镜像:http://…...

pytorch实现文本摘要
人工智能例子汇总:AI常见的算法和例子-CSDN博客 import numpy as npfrom modelscope.hub.snapshot_download import snapshot_download from transformers import BertTokenizer, BertModel import torch# 下载模型到本地目录 model_dir snapshot_download(tians…...
)
大数据相关职位介绍之一(数据分析,数据开发,数据产品经理,数据运营)
大数据相关职位介绍之一 随着大数据、人工智能(AI)和机器学习的快速发展,数据分析与管理已经成为各行各业的重要组成部分。从互联网公司到传统行业的数字转型,数据相关职位在中国日益成为推动企业创新和提升竞争力的关键力量。以…...
)
Vue3.0实战:大数据平台可视化(附完整项目源码)
文章目录 创建vue3.0项目项目初始化项目分辨率响应式设置项目顶部信息条创建页面主体创建全局引入echarts和axios后台接口创建express销售总量图实现完整项目下载项目任何问题都可在评论区,或者直接私信即可。 创建vue3.0项目 创建项目: vue create vueecharts选择第三项:…...

多模态论文笔记——NaViT
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细解读多模态论文NaViT(Native Resolution ViT),将来自不同图像的多个patches打包成一个单一序列——称为Patch n’ Pack—…...

AI大模型开发原理篇-5:循环神经网络RNN
神经概率语言模型NPLM也存在一些明显的不足之处:模型结构简单,窗口大小固定,缺乏长距离依赖捕捉,训练效率低,词汇表固定等。为了解决这些问题,研究人员提出了一些更先进的神经网络语言模型,如循环神经网络、…...

无人机图传模块 wfb-ng openipc-fpv,4G
openipc 的定位是为各种模块提供底层的驱动和linux最小系统,openipc 是采用buildroot系统编译而成,因此二次开发能力有点麻烦。为啥openipc 会用于无人机图传呢?因为openipc可以将现有的网络摄像头ip-camera模块直接利用起来,从而…...

C++ Primer 自定义数据结构
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...
)
Kanass快速安装配置教程(入门级)
Kanass是一款国产开源免费的项目管理工具,工具简洁易用、开源免费,本文将介绍如何快速安装配置kanass,以快速上手。 1、快速安装 1.1 Linux 安装 点击官网 -> 演示与下载 ->下载,下载Linux安装包,…...
【自然语言处理(NLP)】基于Transformer架构的预训练语言模型:BERT 训练之数据集处理、训练代码实现
文章目录 介绍BERT 训练之数据集处理BERT 原理及模型代码实现数据集处理导包加载数据生成下一句预测任务的数据从段落中获取nsp数据生成遮蔽语言模型任务的数据从token中获取mlm数据将文本转换为预训练数据集创建Dataset加载WikiText-2数据集 BERT 训练代码实现导包加载数据构建…...

深度解析:网站快速收录与网站安全性的关系
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/58.html 网站快速收录与网站安全性之间存在着密切的关系。以下是对这一关系的深度解析: 一、网站安全性对收录的影响 搜索引擎惩罚: 如果一个网站存在安全隐患&am…...

《基于Scapy的综合性网络扫描与通信工具集解析》
在网络管理和安全评估中,网络扫描和通信是两个至关重要的环节。Python 的 Scapy 库因其强大的网络数据包处理能力,成为开发和实现这些功能的理想工具。本文将介绍一个基于 Scapy 编写的 Python 脚本,该脚本集成了 ARP 扫描、端口扫描以及 TCP…...

MySQL索引详解
MySQL索引详解 什么是索引索引的原理索引的分类索引的数据结构二叉树平衡二叉树B树B树 聚集索引与非聚集索引概念利用聚集索引查找数据利用非聚集索引查找数据覆盖索引与回表操作 如何正确使用索引 什么是索引 索引是存储引擎中一种数据结构,或者说数据的组织方式&…...
,或请求参数值是file类型时,调用在线服务接口)
【NEXT】网络编程——上传文件(不限于jpg/png/pdf/txt/doc等),或请求参数值是file类型时,调用在线服务接口
最近在使用华为AI平台ModelArts训练自己的图像识别模型,并部署了在线服务接口。供给客户端(如:鸿蒙APP/元服务)调用。 import核心能力: import { http } from kit.NetworkKit; import { fileIo } from kit.CoreFileK…...

【Qt】界面优化
界面优化 设置全局样式样式文件使⽤ Qt Designer 编辑样式选择器设置子控件样式伪类选择器样式属性盒模型设置按钮样式设置复选框样式输入框样式列表样式菜单栏样式 在 Qt 中对界面的优化和 CSS 类似。语法结构如下: 选择器 {属性名: 属性值; }例如: QP…...

机器学习算法在网络安全中的实践
机器学习算法在网络安全中的实践 本文将深入探讨机器学习算法在网络安全领域的应用实践,包括基本概念、常见算法及其应用案例,从而帮助程序员更好地理解和应用这一领域的技术。"> 序言 网络安全一直是信息技术领域的重要议题,随着互联…...

课题介绍:基于惯性与单目视觉信息融合的室内微小型飞行器智能自主导航研究
室内微小型飞行器在国防、物流和监测等领域中应用广泛,但在复杂的非合作环境中实时避障和导航仍面临诸多挑战。由于微小型飞行器的载荷和能源限制,迫切需要开发高效的智能自主导航系统。本项目旨在研究基于惯性导航与单目视觉信息融合的技术,…...

Observability:实现 OpenTelemetry 原生可观察性的商业价值
作者:来自 Elastic David Hope 利用开放标准和简化的数据收集转变组织的可观察性策略。 现代组织面临着前所未有的可观察性挑战。随着系统变得越来越复杂和分散,传统的监控方法难以跟上步伐。由于数据量每两年翻一番,系统跨越多个云和技术&am…...

nginx 报错404
404:服务器无法正常解析页面,大多是配置问题(路径配置错误)、或访问页面不存在 如果你也是用nginx来转接服务的话,那你有可能碰到过这种情况,当你启动服务后,在本地打开页面,发现404,然后你找遍…...

2.2.1 人眼色觉与色度图
文章目录 人眼色觉色度图 人眼色觉 视网膜上的视杆细胞、视锥细胞在人眼色觉中起到重要作用。视杆细胞主要用在弱光暗环境下,其数量远远多于视锥细胞。视锥细胞负责明亮环境的视觉,有L,M,S三种类型的细胞,分别对长、中、短波长敏感࿰…...

DeepSeek 遭 DDoS 攻击背后:DDoS 攻击的 “千层套路” 与安全防御 “金钟罩”
当算力博弈升级为网络战争:拆解DDoS攻击背后的技术攻防战——从DeepSeek遇袭看全球网络安全新趋势 在数字化浪潮席卷全球的当下,网络已然成为人类社会运转的关键基础设施,深刻融入经济、生活、政务等各个领域。从金融交易的实时清算…...
)
c语言(关键字)
前言: 感谢b站鹏哥c语言 内容: 栈区(存放局部变量) 堆区 静态区(存放静态变量) rigister关键字 寄存器,cpu优先从寄存器里边读取数据 #include <stdio.h>//typedef,类型…...

眼见着折叠手机面临崩溃,三星计划增强抗摔能力挽救它
据悉折叠手机开创者三星披露了一份专利,通过在折叠手机屏幕上增加一个抗冲击和遮光层的方式来增强折叠手机的抗摔能力,希望通过这种方式进一步增强折叠手机的可靠性和耐用性,来促进折叠手机的发展。 据悉三星和研发可折叠玻璃的企业的做法是在…...

Excel to form ?一键导入微软表单
一句话痛点 “你的Excel越强大,手动复制到Forms就越痛苦。” 合并单元格崩溃成乱码、下拉菜单变纯文本、条件逻辑消失无踪——这些不是技术问题,而是低效工作模式的死刑判决书。 直击解决方案:3分钟,3步,300%效率 1…...

使用Ollama本地化部署DeepSeek
1、Ollama 简介 Ollama 是一个开源的本地化大模型部署工具,旨在简化大型语言模型(LLM)的安装、运行和管理。它支持多种模型架构,并提供与 OpenAI 兼容的 API 接口,适合开发者和企业快速搭建私有化 AI 服务。 Ollama …...
)
【xdoj-离散线上练习】T251(C++)
解题反思: 开始敲代码前想清楚整个思路比什么都重要嘤嘤嘤!看到输入m, n和矩阵,注意不能想当然地认为就是高m,宽n的矩阵,细看含义 比如本题给出了树的邻接矩阵,就是n*n的,代码实现中没有用到m这…...
)
【数据结构】_链表经典算法OJ(力扣/牛客第二弹)
目录 1. 题目1:返回倒数第k个节点 1.1 题目链接及描述 1.2 解题思路 1.3 程序 2. 题目2:链表的回文结构 2.1 题目链接及描述 2.2 解题思路 2.3 程序 1. 题目1:返回倒数第k个节点 1.1 题目链接及描述 题目链接: 面试题 …...