MySQL索引详解
MySQL索引详解
- 什么是索引
- 索引的原理
- 索引的分类
- 索引的数据结构
- 二叉树
- 平衡二叉树
- B树
- B+树
- 聚集索引与非聚集索引
- 概念
- 利用聚集索引查找数据
- 利用非聚集索引查找数据
- 覆盖索引与回表操作
- 如何正确使用索引
什么是索引
索引是存储引擎中一种数据结构,或者说数据的组织方式,又称之为键key,是存储引擎用于快速找到记录的一种数据结构。
为数据建立索引就好比是为书建目录,或者说是为字典创建音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引的原理
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等
本质都是通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围査询(>、<、between、in)、模糊査询(like)、并集査询(and、or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段.……这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是 lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万信左右,所以简单的搜索树难以满足复杂的应用场景。
索引的分类
B+树索引(等值查询与范围查询都快)(主要研究这个)
二叉树 -> 平衡二叉树 -> B树 -> B+树
HASH索弓(等值查询快,范围查询慢)
将数据打散再去查询
FULLTEXT:全文索引 (只可以用在MyISAM引擎)
- 通过关键字的匹配来进行查询,类似于like的模糊匹配
- like + % 在文本比较少时是合适的,但是对于大量的文本数据检索会非常的慢
- 全文索引在大量的数据面前能比like快得多,但是准确度很低
mysql默认的存储引擎就是 innodb,而 innodb 存储引擎的索引结构就是B+树。
索引的数据结构
B+树是由二叉树 -----> 平衡二叉树 -----> B树 -----> B+树演变而来
| 数据结构 | 问题 |
|---|---|
| 二叉树 | 不平衡会导致查询效率低 |
| 平衡二叉树 | 一个节点中只存放一组键值对 |
| B树 | 只擅长做等值查询 |
| B+树 |
工作原理
- 提取每行记录中该字段的值,亦该值当作key,至于key对的value是什么?每种索引结构各不相同
- 然后以key值为基础构建索引结构
- 以后查询条件中使用了该字段,则会命中索引结构
二叉树
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。
顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
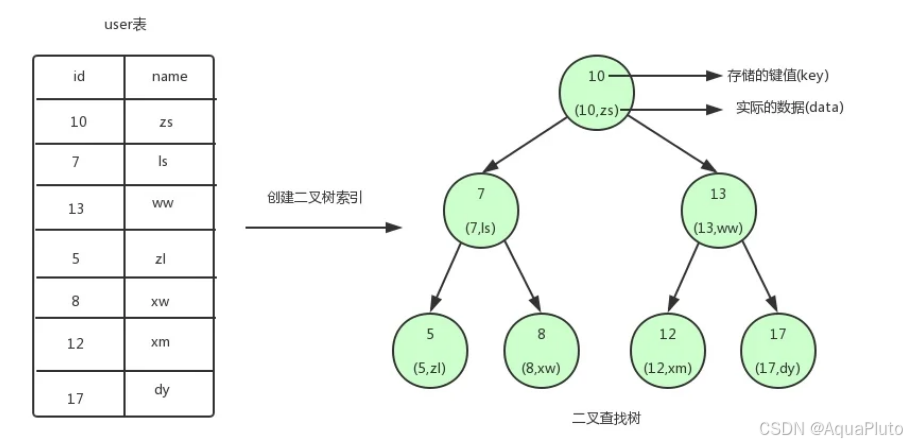
查找流程:如果要查找 id=12 这个用户的数据
- 将根节点作为当前节点,把12与当前节点的键值10比较,12大于10,接下来我们把当前节点的右子节点作为当前节点。
- 继续把12和当前节点的键值13比较,发现12小于13,把当前节点的左子节点作为当前节点。
- 把12和当前节点的键值12对比,12等于12,满足条件,我们从当前节点中取出data。
二叉树也可以是以下所示

这个时候可以看到我们的二又查找树变成了一个链表。如果我们需要查找id=17的用户信息,我们需要查找7次,也就相当于全表扫描了。导致这个现象的原因其实是二叉查找树变得不平衡了,也就是高度太高了,从而导致查找效率的不稳定。为了解决这个问题,我们需要保证二又查找树一直保持平衡,就需要用到平衛二叉树了。
平衡二叉树
平衡二叉树又称AVL树,在满足二又查找树特性的基础上,要求每个节点的左右子树的高度不能超过1。下面是平衡二又树和非平衡二叉树的对比
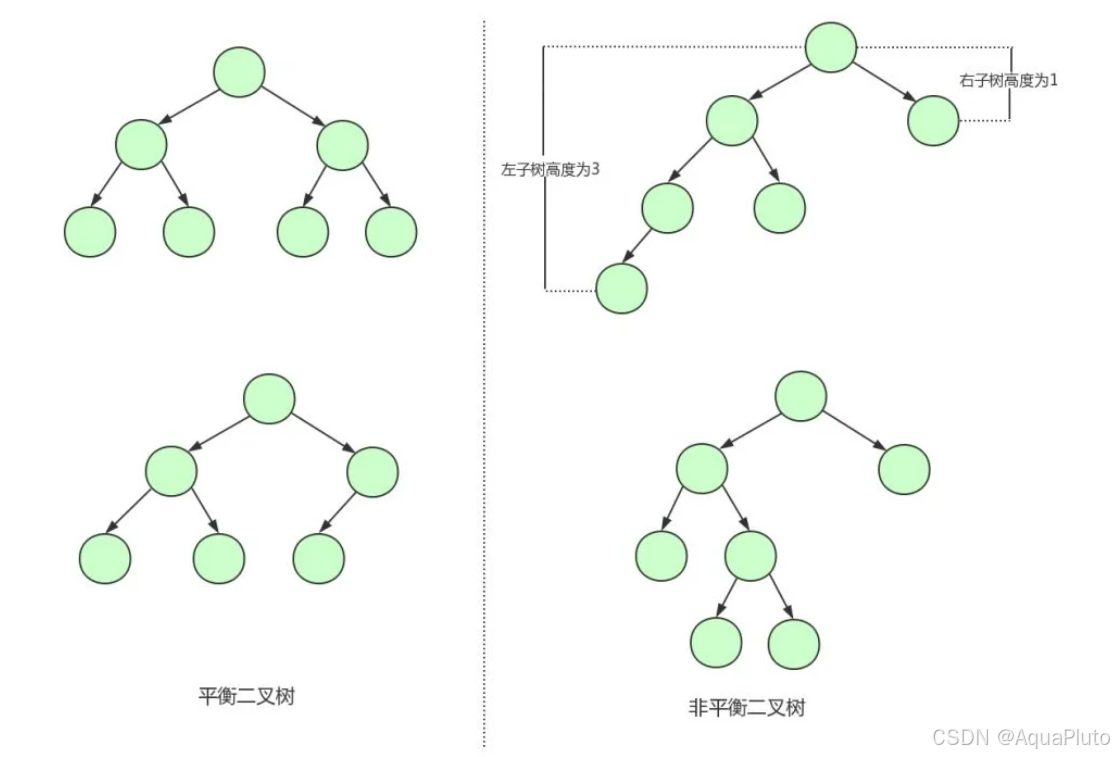
由平衡二叉树的构造我们可以发现第一张图中的二叉树其实就是一棵平衡二叉树。平衡二又树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二又树会进行调整树上的节点来保持平衡。平衡二又树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。
总结:因此可以得出实际树结构越高,查询次数越多,查询速度就会越慢。
那么是不是说基于平衡二又树构建索引的结构就可以了呢?答案是否!直接用平衡二叉树这种数据结构来构建索引有什么问题?
- 首先,因为内存的易失性。一般情况下,我们都会选择将user表中的数据和索引存储在磁盘这种外围设备中。但是和内存相比,从磁盘中读取数据的速度会慢上百倍千倍甚至万倍,所以,我们应当尽量减少从磁盘中读取数据的次数。
- 另外,从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。如果我们能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多数据,那我们查找数据的时间也会大幅度降低。
- 所以,如果我们单纯用平衡二又树这种数据结构作为索引的数据结构,即每个磁盘块只放一个节点,每个节点中只存放一组键值对,此时如果数据量过大,二叉树的节点则会非常多,树的高度也随即变高,我们查找数据的也会进行很多次磁盘IO,查找数据的效率也会变得极低。
- 综上,如果我们能够在平衡二叉的树的基础上,在一个节点中存放多组键值对,那么平衡二又树的弊端也就解决了。即构建一个单节点可以存储多个键值对的平衡树,这就是B树。
B树
B树(Balance Tree)是平衡树的意思
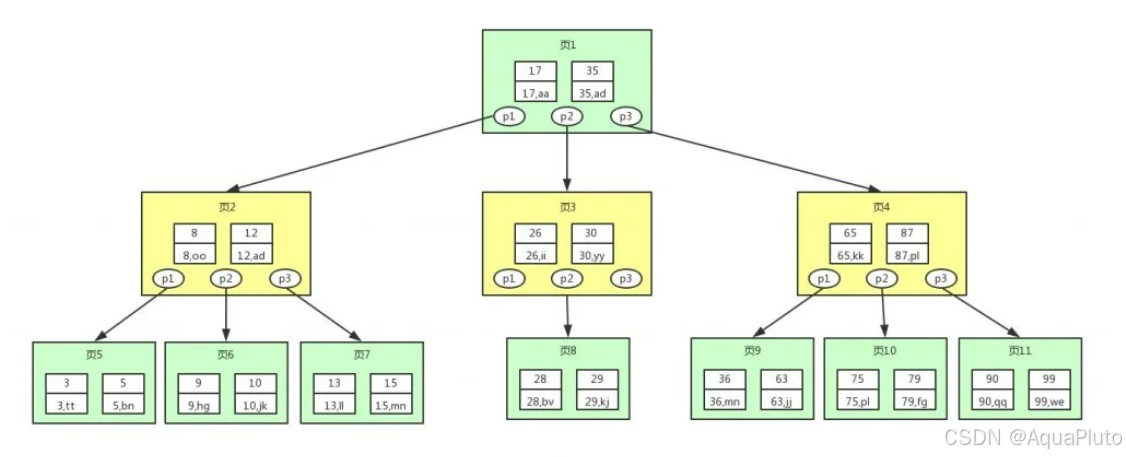
注意:
- 图中的 p 节点为指向子节点的指针,二又查找树和平衡二叉树其实也有,因为图的美观性,被省略了。
- 图中的每个节点里面放入了多组键值对,一个节点也称为页,一页即一个磁盘块,在mysql中数据读取的基本单位都是页,即一次IO读取一个页的数据,所以我们这里叫做页更符合mysql中索引的底层数据结构。
从上图可以看出,B树相对于平衡二叉树,每个节点存储了更多的键值(Key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衛二叉树高很多,假如我们要查找 id=28 的用户信息,那么我们在上图B树中查找的流程如下:
- 先找到根节点也就是页1,判断28是否在键值17和35之间,在的话那么我们根据页1中的指针p2找到页3
- 将28和页3中的键值相比较,28在26和30之间,我们根据页3中的指针p2找到页8
- 将28和页8中的键值相比较,发现有匹配的键值28,键值28对应的用户信息为(28,bv)
注意:
- B树的构造是有一些规定的,但这不是本文的关注点,有兴趣的同学可以另行了解
- B树也是平衡的,当增加或删除数据而导致B树不平衡时,也是需要进行节点调整的
但是B树只擅长做等值查询,对于范围查询(范围查询的本质就是n次等值查询),或者说排序操作,B树帮不了我们
B+树
B+树是对B树的进一步优化,如下图
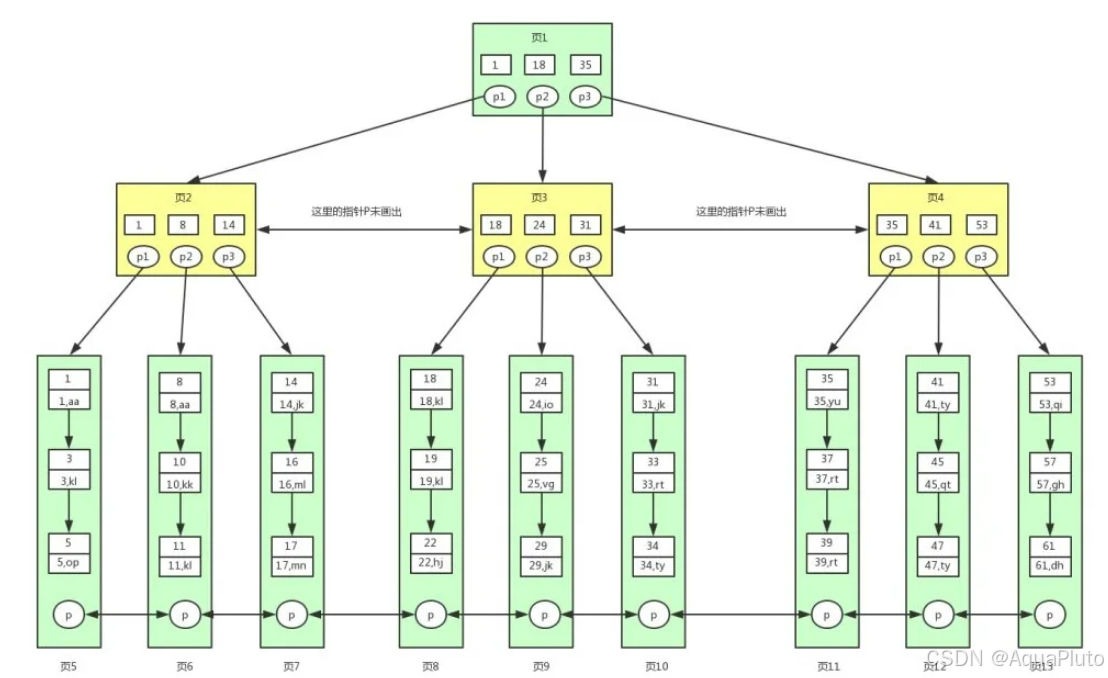
根据上图B+树和B树的不同
- B+树非叶子节点 non-leaf node 上是不存储数据的,仅存储键,而B树的非叶子节点中不仅存储键,也会存储数据。B+树之所以这么做的意义在于:单个节点就是一个页,而数据库中页的大小是固定的,innodb存储引擎默认一页为16KB,所以在页大小固定的前提下,能往一个页中放入更多的节点,相应的树的阶数(节点的子节点树)就会更大,那么树的高度必然更矮更胖,如此来我们查找数据进行磁盘的IO次数就会再次减少,数据查询的效率也会更快。
- B+树的阶数是等于键的数量的,例如上图,我们的B+树中每个节点可以存储3个键,3层B+树可以存储 333=27个数据。所以如果我们的B+树一个节点可以存储1000个键值,那么3层B+树可以存储 1000x1000x1000=10亿个数据。而一般根节点是常驻内存的,所以一般我们査找10亿数据,只需要2次磁盘IO。
- 因为B+树索引的所有数据均存储在叶子节点 leaf node,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点是很不容易的,而且B+树中各个页之间也是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。其实上面的B树我们也可以对各个节点加上链表。其实这些不是它们之前的区别,是因为在mysql的innodb存储引擎中,索引就是这样存储的。也就是说上图中的B+树索引就是innodb中B+树索引真正的实现方式,准确的说应该是聚集索引。
通过上图可以看到,在innodb中,我们数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。
MyISAM中的B+树索引实现与innodb中的略有不同。在MyISAM中,B+树索引的叶子节点并不存储数据,而是存储数据的文件地址。
聚集索引与非聚集索引
概念
聚集索引(又称聚族索引、主键索引,一张表必须有且只有一个):以 innodb 作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。这是因为 innodb 是把数据存放在B+树中的,而B+树的键用的就是主键,在B+树的叶子节点中,存储了表中所有的数据。这种以主键作为B+树索引的键值而构建的B+树索引,我们称之为聚集索引。
非聚集索引(又称非聚族索引、辅助索引,一张表可以创建多个辅助索引):以主键以外的列值作为键值构建的B+树索引,我们称之为非聚集索引。非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据而是存储该列对应的主键(聚簇索引),想要查找数据我们还需要根据主键再去聚集索引中进行查找。这个再根据聚集索引查找数据的过程,我们称为回表。明白了聚集索引和非聚集索引的定义,我们应该明白这样一句话:数据即索引,索引即数据。
利用聚集索引查找数据
根据上面B+树索引图,这就是聚集索引,表中的数据存储其中。
现在假设要查找 id>=18 并且 id<40 的用户数据。对应的 sql 语句为:select * from user where id>=18 and id <40,其中id为主键。具体的查找过程如下:
- 一般根节点都是常驻内存的,也就是说页1己经在内存中了,此时不需要到磁盘中读取数据,直接从内存中读取即可。从内存中读取到页1,要查找这个 id>=18 and id<40 的范围值,我们首先需要找到 id=18 的键值。从页1中我们可以找到键值18,此时我们需要根据指针p2,定位到页3。
- 要从页3中查找数据,我们就需要拿着p2指针去磁盘中进行读取页3。从磁盘中读取页3后将页3放入内存中,然后进行查找,我们可以找到键值18,然后再拿到页3中的指针p1,定位到页8。
- 同样的页8页不在内存中,我们需要再去磁盘中将页8读取到内存中。将页8读取到内存中后。因为页中的数据是链表进行连接的,而目键值是按照顺序存放的,此时可以根据二分查找法定位到键值18。此时因为已经到数据页了,我们就已经找到一条满足条件的数据了,就是键值18对应的数据。因为是范围查找,而且此时所有的数据又都存在叶子节点,并且是有序排列的,那么我们就可以对页8中的键值依次进行遍历查找并匹配满足条件的数据。我们可以一直找到键值为22的数据,然后页8中就没有数据了,此时我们需要拿着页8中的p指针去读取页9中的数据。
- 因为页9不在内存中,就又会加载页9到内存中,并通过和页8中一样的方式进行数据的查找,直到将页12加载到内存中,发现41大于40,此时不满足条件。那么查找到此终止。最终我们找到满足条件的所有数据为:(18,Kl),(19,kl),(22,hj),(24,io),(25,vg),(29,jk),(31,jk),(33,rt),(34,ty).(35,yu),(37,rt).(39,rt)。共12条记录。
利用非聚集索引查找数据
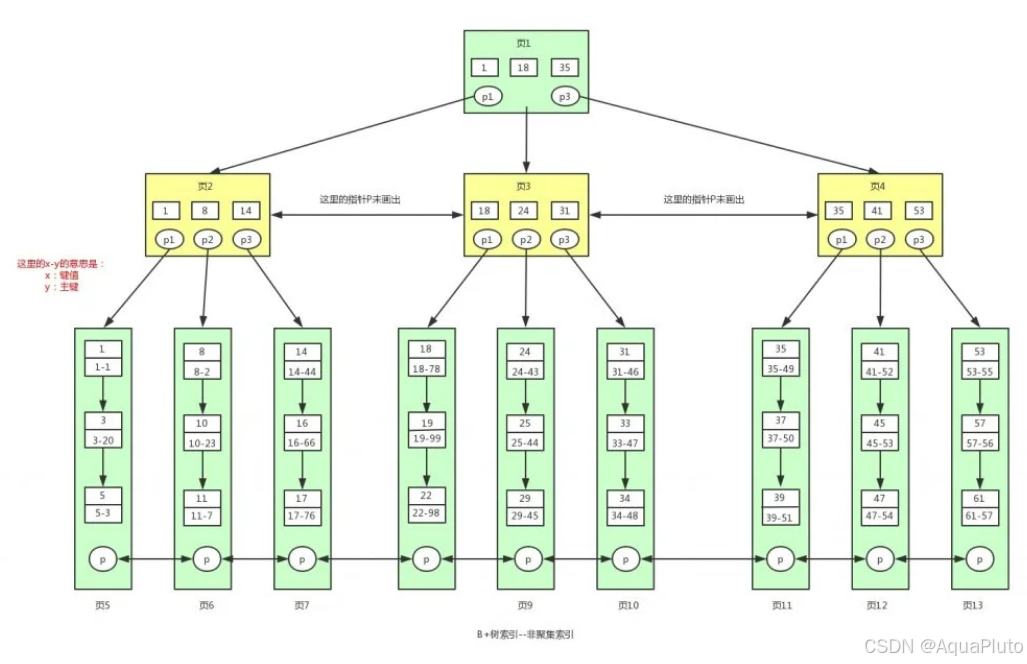
在叶子节点中,不再存储所有的数据了,存储的是键和主键,对于叶子节点中的 x-y,比如10-23,左边的10表示的是索引的键值,右边的23表示的其对应的主键值,如果我们要找到幸运数字为33的用户信息,对应的sql语句为:selete * from user where LuckNum=33;,查找的流程跟聚焦索引一样,最终会找到主键值。
覆盖索引与回表操作
命中了辅助索引,然后要找的字段值不存在与辅助索引的叶子节点上,则需要根据拿到的主键值再去聚焦索引中查询一遍,然后在聚焦索引的叶子节点找到你想要的内容,这就叫做回表操作,例如只对name字段创建了索引:
create index xxx on user(name);
下述语句,名中了辅助索引,但是select需要查询出的除了辅助索引叶子节点有的name字段值外还想要age字段的值,那么需要进行回表操作
select name,age from user where name="Alan";
命中了某棵索引树,然后在其叶子节点就找到了你想要的值,即不需要回表操作,就是覆盖索引,例如:
create index xxx on user(name);
下述语句,覆盖了索引
select name from user where name="Alan";
如果id字段是主键,那么下述语句也覆盖了索引
select * from user where id=3;
如何正确使用索引
1、以什么字段的值为基础构建索引?
最好是不为空、唯一、占用空间小的字段
2、针对全表查询语句如何优化?
应用场景:用户想要浏览所有的商品信息
select count(id) from s1;
如何优化:开发层面分页查找,用户每次看先从数据中拿
3、针对等值查询
(1)以重复度低(即基数高)的字段(如主键ID)为基础创建索引加速效果明显,因为这些字段能有效地缩小查询范围,从而提高查询效率。
create index xxx on s1(id);
select count(id) from s1 where id= 33;
(2)以重复度高字段为基础创建索引加速在不同查询语句中效果不一样
create index yyy on s1(name);
select count(id) from s1 where name="Alan"; – 速度极慢,因为Alan重复度高
select count(id) from s1l where name!="Alan"; – 速度快
select count(id) from s1 where name="mm"; – 速度快
(3)以占用空间大字段为基础创建索引加速效果不明显
(4)总结:给重复低、且占用空间小的字段值为基础构建索引
4、关于范围查询
select count(id) from s1 where id=33;
select count(id) from s1 where id>33;
select count(id) from s1 where id>33 and id < 36;
select count(id) from s1 where id>33 and id < 1000000;
总结:
- innodb存储能加速范围查询,但是查询范围不能特别大
> < != between and like后的内容%应该往右放,并且左半部分的内容应该尽量精确,因为B+树索引是左前缀特性
5、关于条件字段参与运算
select count(id) from s1 where id*12 =10000;
select count(id) from s1 where id = 10000/12;
select count(id) from s1 where func(id)= 10000/12;
总结:不要让条件字段参与运算,或者说传递给函数
6、索引下堆技术
对于连续多个and的条件,mysql的优化器会分析出多条执行方案,选取最优的一种,即先找到某一个条件把范围缩小
select count(id) from s1 where name = "Alan" and email = "Alan@123" and gender = "male";
select count(id) from s1 where name = "Alan" or email = "Alan@123" or gender = "male";
总结:
- and连接的多个条件:mysql的优化器会锁定的是一个小范围,
- 例如相亲:where 年龄=18 and 身高=1.70 and 长相=好看;
- or连接的多个条件:锁定的是一个很大的范围,mysql优化没办法了,只能从左到右依次判断条件
- 例如找残次品:where 轮胎坏了 or 方向盘坏了 or 刹车坏了
7、联合索引与最左前缀匹配原则
什么时候创建联合索引:条件中需要用到多个字段,并且多次查询中的多个字段都包含某一个字段
需要注意的问题:重复都低且占用空间较少的字段应该尽量往左放,让其成为最左前缀
creat index xxx on s1(name,age,gender);
最左匹配原则,and连接的多个条件中有
- name age gender
- name age
- name gender
- name
select count(id) form s1 where name = "Alan" and email = "Alan@123" and gender ="male";
8、比较类型必须保持一致
例如 id = 10,不要 id =“10”
9、建表时尽可能把占用空间小的字段往左放
不好:creat table t1(name varchar(10),id int);
建议:creat table t1(id int,name varchar(10));
10、使用连接(JOIN)来代替子查询(Sub-Queries)
相关文章:

MySQL索引详解
MySQL索引详解 什么是索引索引的原理索引的分类索引的数据结构二叉树平衡二叉树B树B树 聚集索引与非聚集索引概念利用聚集索引查找数据利用非聚集索引查找数据覆盖索引与回表操作 如何正确使用索引 什么是索引 索引是存储引擎中一种数据结构,或者说数据的组织方式&…...
,或请求参数值是file类型时,调用在线服务接口)
【NEXT】网络编程——上传文件(不限于jpg/png/pdf/txt/doc等),或请求参数值是file类型时,调用在线服务接口
最近在使用华为AI平台ModelArts训练自己的图像识别模型,并部署了在线服务接口。供给客户端(如:鸿蒙APP/元服务)调用。 import核心能力: import { http } from kit.NetworkKit; import { fileIo } from kit.CoreFileK…...

【Qt】界面优化
界面优化 设置全局样式样式文件使⽤ Qt Designer 编辑样式选择器设置子控件样式伪类选择器样式属性盒模型设置按钮样式设置复选框样式输入框样式列表样式菜单栏样式 在 Qt 中对界面的优化和 CSS 类似。语法结构如下: 选择器 {属性名: 属性值; }例如: QP…...

机器学习算法在网络安全中的实践
机器学习算法在网络安全中的实践 本文将深入探讨机器学习算法在网络安全领域的应用实践,包括基本概念、常见算法及其应用案例,从而帮助程序员更好地理解和应用这一领域的技术。"> 序言 网络安全一直是信息技术领域的重要议题,随着互联…...

课题介绍:基于惯性与单目视觉信息融合的室内微小型飞行器智能自主导航研究
室内微小型飞行器在国防、物流和监测等领域中应用广泛,但在复杂的非合作环境中实时避障和导航仍面临诸多挑战。由于微小型飞行器的载荷和能源限制,迫切需要开发高效的智能自主导航系统。本项目旨在研究基于惯性导航与单目视觉信息融合的技术,…...

Observability:实现 OpenTelemetry 原生可观察性的商业价值
作者:来自 Elastic David Hope 利用开放标准和简化的数据收集转变组织的可观察性策略。 现代组织面临着前所未有的可观察性挑战。随着系统变得越来越复杂和分散,传统的监控方法难以跟上步伐。由于数据量每两年翻一番,系统跨越多个云和技术&am…...

nginx 报错404
404:服务器无法正常解析页面,大多是配置问题(路径配置错误)、或访问页面不存在 如果你也是用nginx来转接服务的话,那你有可能碰到过这种情况,当你启动服务后,在本地打开页面,发现404,然后你找遍…...

2.2.1 人眼色觉与色度图
文章目录 人眼色觉色度图 人眼色觉 视网膜上的视杆细胞、视锥细胞在人眼色觉中起到重要作用。视杆细胞主要用在弱光暗环境下,其数量远远多于视锥细胞。视锥细胞负责明亮环境的视觉,有L,M,S三种类型的细胞,分别对长、中、短波长敏感࿰…...

DeepSeek 遭 DDoS 攻击背后:DDoS 攻击的 “千层套路” 与安全防御 “金钟罩”
当算力博弈升级为网络战争:拆解DDoS攻击背后的技术攻防战——从DeepSeek遇袭看全球网络安全新趋势 在数字化浪潮席卷全球的当下,网络已然成为人类社会运转的关键基础设施,深刻融入经济、生活、政务等各个领域。从金融交易的实时清算…...
)
c语言(关键字)
前言: 感谢b站鹏哥c语言 内容: 栈区(存放局部变量) 堆区 静态区(存放静态变量) rigister关键字 寄存器,cpu优先从寄存器里边读取数据 #include <stdio.h>//typedef,类型…...

眼见着折叠手机面临崩溃,三星计划增强抗摔能力挽救它
据悉折叠手机开创者三星披露了一份专利,通过在折叠手机屏幕上增加一个抗冲击和遮光层的方式来增强折叠手机的抗摔能力,希望通过这种方式进一步增强折叠手机的可靠性和耐用性,来促进折叠手机的发展。 据悉三星和研发可折叠玻璃的企业的做法是在…...

Excel to form ?一键导入微软表单
一句话痛点 “你的Excel越强大,手动复制到Forms就越痛苦。” 合并单元格崩溃成乱码、下拉菜单变纯文本、条件逻辑消失无踪——这些不是技术问题,而是低效工作模式的死刑判决书。 直击解决方案:3分钟,3步,300%效率 1…...

使用Ollama本地化部署DeepSeek
1、Ollama 简介 Ollama 是一个开源的本地化大模型部署工具,旨在简化大型语言模型(LLM)的安装、运行和管理。它支持多种模型架构,并提供与 OpenAI 兼容的 API 接口,适合开发者和企业快速搭建私有化 AI 服务。 Ollama …...
)
【xdoj-离散线上练习】T251(C++)
解题反思: 开始敲代码前想清楚整个思路比什么都重要嘤嘤嘤!看到输入m, n和矩阵,注意不能想当然地认为就是高m,宽n的矩阵,细看含义 比如本题给出了树的邻接矩阵,就是n*n的,代码实现中没有用到m这…...
)
【数据结构】_链表经典算法OJ(力扣/牛客第二弹)
目录 1. 题目1:返回倒数第k个节点 1.1 题目链接及描述 1.2 解题思路 1.3 程序 2. 题目2:链表的回文结构 2.1 题目链接及描述 2.2 解题思路 2.3 程序 1. 题目1:返回倒数第k个节点 1.1 题目链接及描述 题目链接: 面试题 …...

线性代数复习笔记
1. 课程学习 1.1 3Blue1Brown 线性代数 2. 基本术语 eigenvector(特征向量):线性变换中方向保持不变的向量 可以视作3D旋转矩阵形成的旋转的轴...

51单片机 01 LED
一、点亮一个LED 在STC-ISP中单片机型号选择 STC89C52RC/LE52RC;如果没有找到hex文件(在objects文件夹下),在keil中options for target-output- 勾选 create hex file。 如果要修改编程 :重新编译-下载/编程-单片机重…...

用一个例子详细说明python单例模式
单例模式是一种设计模式,它确保一个类只有一个实例,并提供一个全局访问点来访问该实例。这在需要控制资源(如数据库连接、文件系统等)的访问时非常有用。 下面是一个使用Python实现单例模式的例子: class Singleton:…...

QT知识点复习
1.qt核心机制 对象树、信号和槽、事件机制 2.对象树的作用 优化了内存回收机制。子对象实例化的时候,被父对象放对象树上,父对象释放内存,子对象也释放内存 3.信号和槽的作用 实现多个组件之间的通讯 4.信号和槽的几种连接方式 1.UI界面提…...

医学图像分割任务的测试代码
测试集进行测试 import os import torch import numpy as np from torch.utils.data import DataLoader from sklearn.metrics import (precision_score,recall_score,f1_score,roc_curve,auc,confusion_matrix, ) import matplotlib.pyplot as plt from utils import NiiData…...

linux下ollama更换模型路径
Linux下更换Ollama模型下载路径指南 在使用Ollama进行AI模型管理时,有时需要根据实际需求更改模型文件的存储路径。本文将详细介绍如何在Linux系统中更改Ollama模型的下载路径。 一、关闭Ollama服务 在更改模型路径之前,需要先停止Ollama服务。…...
)
手机上运行AI大模型(Deepseek等)
最近deepseek的大火,让大家掀起新一波的本地部署运行大模型的热潮,特别是deepseek有蒸馏的小参数量版本,电脑上就相当方便了,直接ollamaopen-webui这种类似的组合就可以轻松地实现,只要硬件,如显存…...

第一性原理:游戏开发成本的思考
利润 营收-成本 营收定价x销量x分成比例 销量 曝光量x 点击率x (购买率- 退款率) 分成比例 100%- 平台抽成- 税- 引擎费- 发行抽成 成本开发成本运营成本 开发成本 人工外包办公地点租金水电设备折旧 人工成本设计成本开发成本迭代修改成本后续内容…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】2.11 视图与副本:内存优化的双刃剑
2.11 视图与副本:内存优化的双刃剑 目录 #mermaid-svg-OpelXRXip4Xj1A2e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-OpelXRXip4Xj1A2e .error-icon{fill:#552222;}#mermaid-svg-OpelXRXip4Xj1A2e .…...

React 封装高阶组件 做路由权限控制
React 高阶组件是什么 官方解释∶ 高阶组件(HOC)是 React 中用于复用组件逻辑的一种高级技巧。HOC 自身不是 React API 的一部分,它是一种基于 React 的组合特性而形成的设计模式。 高阶组件(HOC)就是一个函数&…...

Python sider-ai-api库 — 访问Claude、llama、ChatGPT、gemini、o1等大模型API
目前国内少有调用ChatGPT、Claude、Gemini等国外大模型API的库。 Python库sider_ai_api 提供了一个完整的解决方案。通过调用 sider.ai 的API,开发者可以实现对这些大模型的访问。 众所周知,sider是一个Chrome,以及Edge的浏览器插件…...

深入解析 Linux 内核内存管理核心:mm/memory.c
在 Linux 内核的众多组件中,内存管理模块是系统性能和稳定性的关键。mm/memory.c 文件作为内存管理的核心实现,承载着页面故障处理、页面表管理、内存区域映射与取消映射等重要功能。本文将深入探讨 mm/memory.c 的设计思想、关键机制以及其在内核中的作用,帮助读者更好地理…...

git基础使用--3---git安装和基本使用
git基础使用–3–git-安装和基本使用 1. git工具安装 使用git如果不考虑开发工具我们一般需要关注三个点 1.1 git 本地化仓库管理的基础 打开https://git-scm.com/downloads地址下载安装 安装完成后,配置环境变量 配置完打开cmd,输入git --versio…...

Python 网络爬虫实战:从基础到高级爬取技术
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 1. 引言 网络爬虫(Web Scraping)是一种自动化技术,利用程序从网页中提取数据,广泛…...

【PyQt】学习PyQt进行GUI开发从基础到进阶逐步掌握详细路线图和关键知识点
学习PyQt的必要性 PyQt是开发跨平台GUI应用的强大工具,适合需要构建复杂、高性能界面的开发者。无论是职业发展还是项目需求,学习PyQt都具有重要意义。 1. 跨平台GUI开发 跨平台支持:PyQt基于Qt框架,支持Windows、macOS、Linux…...

Web - CSS3基础语法与盒模型
概述 这篇文章是关于 Web 前端 CSS3 的基础语法与盒模型的讲解。包括 CSS3 层叠性及处理冲突规则、伪元素和新增伪类元素、属性选择器等。还介绍了文本与字体属性,如段落和行相关属性、字体文本属性。最后阐述了盒子模型,如元素隐藏、行内与块元素转换、…...
)
【开源免费】基于Vue和SpringBoot的公寓报修管理系统(附论文)
本文项目编号 T 186 ,文末自助获取源码 \color{red}{T186,文末自助获取源码} T186,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

成绩案例demo
本案例较为简单,用到的知识有 v-model、v-if、v-else、指令修饰符.prevent .number .trim等、computed计算属性、toFixed方法、reduce数组方法。 涉及的功能需求有:渲染、添加、删除、修改、统计总分,求平均分等。 需求效果如下:…...

【tiktok 国际版抖抖♬♬ __ac_signature算法】逆向分析
一开始的参数是没有X-Bogus和 __ac_signature的 先是加密请求参数得到乱码。最终得到X-Bogus 然后请求参数添加了X-Bogus之后再去生成__ac_signature __ac_signature的生成需要用到X-Bogus...

【Linux】动静态库
一、库 静态库 .a[Linux]、.lib[windows] 动态库 .so[Linux]、.dll[windows] 二、静态库使用 如果我们要做一个静态库的话,首先我们需要把我们源文件(.c/.cpp)隐藏起来,头文件(.h)必须暴露出来, 1.我们先要把我们所有的.c文件编译成.o文件…...

《手札·开源篇》从开源到商业化:中小企业的低成本数字化转型路径 ——以Odoo为数据中台低成本实现售前售中一体化
某机电设备有限公司数字化转型案例:以Odoo为数据中台实现售前售中一体化 一、企业背景某机电设备有限公司在机电设备领域历经多年发展,业务广泛,涵盖工业自动化设备、电力设备等产品的销售与服务。随着业务版图不断拓展,企业面临…...

携程Android开发面试题及参考答案
在项目中,给别人发的动态点赞功能是如何实现的? 数据库设计:首先要在数据库中为动态表添加一个点赞字段,用于记录点赞数量,同时可能需要一个点赞关系表,记录用户与动态之间的点赞关联,包括点赞时间等信息。界面交互:在 Android 界面上,为点赞按钮设置点击事件监听器。…...

Python-列表
3.1 列表是什么 在Python中,列表是一种非常重要的数据结构,用于存储一系列有序的元素。列表中的每个元素都有一个索引,索引从0开始。列表可以包含任何类型的元素,包括其他列表。 # 创建一个列表my_list [1, 2, 3, four, 5.0]…...

【LeetCode 刷题】回溯算法-子集问题
此博客为《代码随想录》二叉树章节的学习笔记,主要内容为回溯算法子集问题相关的题目解析。 文章目录 78.子集90.子集II 78.子集 题目链接 class Solution:def subsets(self, nums: List[int]) -> List[List[int]]:res, path [], []def dfs(start: int) ->…...

31.Word:科技论文的译文审交稿【31】
目录 NO1.2.3 NO4.5.6 NO7.8样式应用和修改&多级列表 NO9奇偶页页眉 NO10自动编号&交叉引用 NO11.12 NO1.2.3 另存为/F12:考生文件夹只保留译文内容、格式设置、修订批注,删除其他:删除表格的左列→删除第一行将表格转化成…...

Java序列化详解
1 什么是序列化、反序列化 在Java编程实践中,当我们需要持久化Java对象,比如把Java对象保存到文件里,或是在网络中传输Java对象时,序列化机制就发挥着关键作用。 序列化:指的是把数据结构或对象转变为可存储、可传输的…...

尝试ai生成figma设计
当听到用ai 自动生成figma设计时,不免好奇这个是如何实现的。在查阅了不少资料后,有了一些想法。参考了:在figma上使用脚本自动生成色谱 这篇文章提供的主要思路是:可以通过脚本的方式构建figma设计。如果我们使用ai 生成figma脚本…...

每日一题——包含min函数的栈
包含min函数的栈 题目数据范围:示例C语言代码实现解释1. push(value)2. pop()3. top()4. min() 总结大小堆GPT给的原始代码 题目 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的 min 函数,输入操作时保证 pop、top 和 mi…...

【最后203篇系列】004 -Smarklink
说明 这个用来替代nginx。 最初是希望用nginx进行故障检测和负载均衡,花了很多时间,大致的结论是:nginx可以实现,但是是在商业版里。非得要找替代肯定可以搞出来,但是太麻烦了(即使是nginx本身的配置也很烦…...

二分法模板
数组具有二段性,可以分为左右两边合法区和不合法区 如果选择左端点,右边区域不合法,选择 left mid ,right mid - 1; 如果选择右端点,左边区域不合法,选择 left mid 1 ,right mid ; 1.x 的平方根 LCR 072. x 的…...
)
基于SpringBoot的智慧康老疗养院管理系统的设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

LabVIEW无人机航线控制系统
介绍了一种无人机航线控制系统,该系统利用LabVIEW软件与MPU6050九轴传感器相结合,实现无人机飞行高度、速度、俯仰角和滚动角的实时监控。系统通过虚拟仪器技术,有效实现了数据的采集、处理及回放,极大提高了无人机航线的控制精度…...

STM32CUBEIDE编译的hex使用flymcu下载后不能运行
测试后确认,不论是1.10版本还是1.16版本,编译生成的hex下载后不能运行,需要更改boot 设置才能开始运行,flymcu下载后已经告知一切正常,跳转到8000 0000处开始运行,实际没有反应,而使用mdk编译生…...

final-关键字
一、final修饰的类不能被继承 当final修饰一个类时,表明这个类不能被其他类继承。例如,在 Java 中,String类就是被final修饰的,这保证了String类的不可变性和安全性,防止其他类通过继承来改变String类的行为。 final…...

在RHEL 8.10上安装开源工业物联网解决方案Thingsboard 3.9
在RHEL/CentOS/Rocky/AlmaLinux/Oracle Linux 8单节点上安装 备注: 适用于单节点 是否支持欧拉??? 前提条件 本指南描述了如何在RHEL/CentOS 7/8上安装ThingsBoard。硬件要求取决于所选的数据库和连接到系统的设备数量。要在单…...