专业视角深度解析:DeepSeek的核心优势何在?
杭州深度求索(DeepSeek)人工智能基础技术研究有限公司,是一家成立于2023年7月的中国人工智能初创企业,总部位于浙江省杭州市。该公司由量化对冲基金幻方量化(High-Flyer)的联合创始人梁文锋创立,致力于开发开源大型语言模型(LLM)及相关技术。
此前,DeepSeek 并不为大众所熟知,但最近其发布的新人工智能模型 DeepSeek-R1 在全球科技界引起了巨大反响。该模型的能力被认为可与谷歌和 OpenAI 的先进技术相媲美。根据上周(即2025年1月22日)发布的研究论文,DeepSeek 团队在训练该模型时仅花费了不到 600 万美元的计算成本,这一数字远低于 OpenAI 和谷歌(ChatGPT 和 Gemini 的开发者)数十亿美元的人工智能预算。因此,硅谷知名风险投资家马克·安德森(Marc Andreessen)将这一突破称为“人工智能的斯普特尼克时刻”。“斯普特尼克”一词源自1957年苏联发射的世界首颗人造卫星“斯普特尼克1号”(Sputnik 1),它曾震惊美国并推动了美国航天和科技的快速发展,最终促成了阿波罗登月计划(Apollo Program)的创立。
DeepSeek 作为一家中国小型初创公司,能够与硅谷顶尖企业竞争,挑战了美国在人工智能领域的主导地位,并引发了对英伟达、Meta 等公司高估值的质疑。本周周一,英伟达股价暴跌 17%,市值蒸发近 6000 亿美元,该公司在生成人工智能所需的半导体领域几乎处于垄断地位。摩根士丹利认为,DeepSeek的成功可能会激发一波AI创新浪潮。美国“元”公司首席AI科学家杨立昆在社交媒体上发文说,Deep-Seek-R1的面世,意味着开源模型正在超越闭源模型。美国总统唐纳德·特朗普上周宣布启动一项价值 5000 亿美元的人工智能计划,由 OpenAI、甲骨文(总部位于德克萨斯州)和日本软银集团牵头。特朗普表示,DeepSeek 应该成为“警钟”,提醒美国工业界需要“全神贯注于竞争以赢得胜利”。

图1,美国总统特朗普宣布斥资 5000 亿美元建立 AI 基础设施的“星际之门”项目
本文旨在避开政治和社会层面的喧哗,专注于从技术角度剖析 DeepSeek 的核心创新,以及它为何能够在短期内,在生成人工智能领域取得如此显著的成功。
自 2024 年以来,DeepSeek 共发表了 8 篇DeekSeek相关的科技论文,其中三篇尤为关键,揭示了其技术核心以及在人工智能技术创新和实际应用中的重大突破:
-
DeepSeek-LLM:以长期主义推动开源语言模型扩展
该论文于 2024 年 1 月发布,从长期主义的角度提出了开源语言模型的发展策略,旨在推动技术民主化。论文提出了社区驱动的开源治理框架和多任务优化方法,为开源生态的可持续发展提供了理论支持。 -
DeepSeek-V3:高效的混合专家模型
2024 年 12 月发布的这篇论文,提出了一种高效的混合专家模型。该模型通过仅激活少量参数,在性能和计算成本之间实现了优化平衡,成为大规模模型优化领域的重要突破。 -
DeepSeek-R1:通过强化学习提升大型语言模型的推理能力
2025 年 1 月发布的这篇论文,提出了一种基于强化学习而非传统监督学习的方法,显著提升了语言模型在数学和逻辑推理任务中的表现。这一成果为大型语言模型的研究开辟了新的方向。
这三篇论文集中体现了 DeepSeek 在技术创新和实际应用中的核心贡献,展示了其如何通过开源策略、模型优化和新学习方法推动人工智能领域的发展。
1. DeepSeek-LLM:以长期主义扩展开源语言模型
2024年1月,DeepSeek大语言模型团队在《以长期主义扩展开源语言模型》 (LLM Scaling Open-Source Language Models with Longtermism)论文中提出从长期主义角度推动开源语言模型的发展,重点研究了大语言模型的规模效应。他们基于研究成果开发了DeepSeek Chat,并在此基础上不断升级迭代。

图2,DeepSeek 2024年发布的大语言模型(DeepSeek-LLM)论文
1.1 背景与目标
近年来,大型语言模型(LLM)通过自监督预训练和指令微调,逐步成为实现通用人工智能(AGI)的核心工具。然而,LLM 的规模化训练存在挑战,尤其是在计算资源和数据分配策略上的权衡问题。DeepSeek LLM 的研究旨在通过深入分析模型规模化规律,推动开源大模型的长期发展。该项目探索了模型规模和数据分配的最优策略,并开发了性能超越 LLaMA-2 70B 的开源模型,尤其在代码、数学和推理领域表现卓越。
1.2 数据与预训练
1.2.1 数据处理
文章处理了包含 2 万亿个 token 的双语数据集(中文和英文)。采取了去重、过滤和重新混合三阶段策略,以提高数据多样性和信息密度。使用 Byte-level Byte-Pair Encoding(BBPE)分词算法,词表大小设置为 102,400。
1.2.2 模型架构
微观设计:借鉴 LLaMA 的架构,采用 RMSNorm 和 SwiGLU 激活函数,以及旋转位置编码。
宏观设计:DeepSeek LLM 7B 具有 30 层,而 67B 增加至 95 层,并通过深度扩展优化性能。
1.2.3 超参数优化
作者引入多阶段学习率调度器,优化训练过程并支持持续训练。使用 AdamW 优化器,并对学习率、批次大小等关键超参数进行了规模化规律研究。
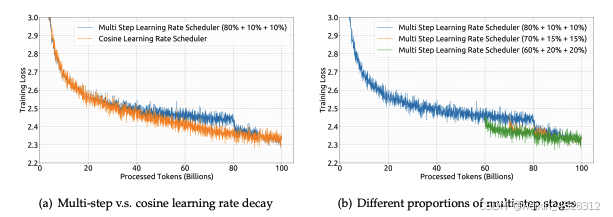
图3. DeepSeek使用不同的学习率调度器或不同的调度器参数的训练损失曲线。模型规模为 16 亿参数,在包含 1000 亿个标记的数据集上进行训练。
1.2.4 基础设施
作者开发了高效轻量化的训练框架 HAI-LLM,集成了数据并行、张量并行等技术,显著提升硬件利用率。
1.3 模型规模化规律
1.3.1 超参数规模化规律
作者通过实验发现,随着计算预算增加,最佳批次大小随之增大,而学习率则逐渐降低。他们提出了经验公式,以更准确地预测不同规模模型的超参数。
表1,DeepSeek LLM 系列模型的详细规格
1.3.2 模型与数据规模分配策略
作者引入了非嵌入 FLOPs/token(MMM)作为模型规模的度量方式,替代传统的参数数量表示,显著提高了计算预算分配的精确性。实验表明,高质量数据允许更多的预算分配到模型规模扩展上,从而提升性能。
1.4 对齐与微调
1.4.1 监督微调(supervised fine-tuning,SFT)
作者收集了 150 万条指令数据,包括通用语言任务、数学问题和代码练习。在微调中,通过两阶段策略,降低了模型的重复生成率,同时保持了基准性能。
1.4.2 直接偏好优化(direct preference optimization,DPO)
作者使用多语言提示生成偏好数据,通过优化模型,使其对开放式问题的生成能力显著增强。
1.5 性能评估
1.5.1 公共基准测试
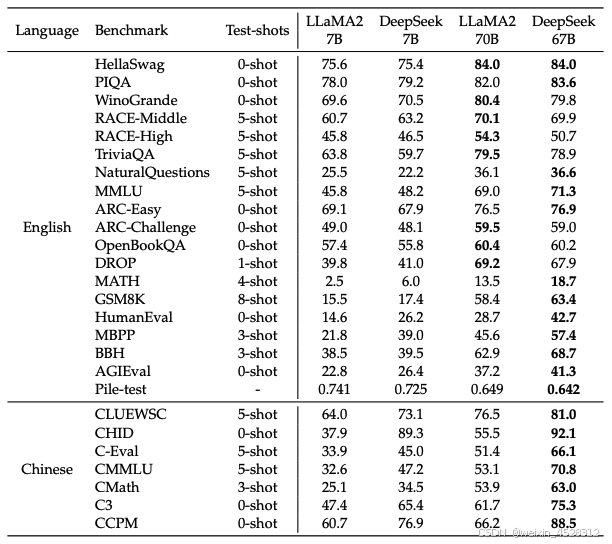
首先,对于数学和代码,DeepSeek LLM 67B 在 HumanEval 和 GSM8K 上显著优于 GPT-3.5 和 LLaMA-2 70B。
其次,对于中文任务,在 C-Eval、CMath 等基准上,DeepSeek 表现出色,尤其在中文成语填空(CHID)等文化任务中远超 LLaMA-2。在英文测试中,DeepSeek 67B Chat 在多轮对话生成能力上超越大多数开源模型。
最后,对于开放式生成能力,在 AlignBench 中文测试中,DeepSeek 67B Chat 在逻辑推理和文本生成等任务上表现接近 GPT-4。
表2. DeepSeek LLM 基准测试的主要结果。加粗数字表示 4 个模型中最优的结果。对于 Pile-test,作者报告比特每字节(BPB);对于 DROP,作者报告 F1 分数;对于其他任务,作者报告 准确率。请注意,测试时的 shots 取最大值,但在某些情况下,由于上下文长度限制或同一段落中可用的 few-shot 示例数量有限(如 RACE 等阅读理解任务),可能会使用更少的 shots。
1.5.2 安全评估
专业团队设计了覆盖多种安全问题的测试集,而DeepSeek 在歧视偏见、合法权益和违法行为等多方面均展现出高安全性。
1.6. 结论与未来方向
论文总结了 DeepSeek LLM 在开源大模型规模化领域的突破,包括:(1) 提出了更精确的模型规模与数据分配策略。(2) 在多个领域的任务中实现性能领先,尤其在数学、代码和中文任务上表现出色。 未来将继续优化高质量数据的利用,并探索更广泛的安全性和对齐技术。
2. DeepSeek-V3:高效的混合专家模型
DeepSeek于2024年12月27日发布了他们第二篇重要论文,《DeepSeek-V3: A Strong Mixture-of-Experts Language Model》。这是一项关于混合专家(Mixture-of-Experts,MoE)模型的研究,旨在通过激活少量专家网络实现高效计算,平衡模型性能和算力成本。该模型在多个复杂任务中表现出卓越的能力,同时显著降低了运行成本,为大模型的实际应用提供了新的思路。

图4,DeepSeek的《DeepSeek-V3》论文截图
2.1 背景与目标
随着大语言模型(LLM)的发展,DeepSeek-AI 团队提出了 DeepSeek-V3,一个拥有 6710 亿参数的混合专家(MoE)模型,每个子词单元(token)激活 370 亿参数。DeepSeek-V3 通过高效推理和经济成本的训练方法,旨在推动开源模型能力的极限,同时在性能上与闭源模型(如 GPT-4o 和 Claude-3.5)竞争。
2.2 核心技术与架构创新
2.2.1 多头潜在注意力(Multi-head Latent Attention, MLA)
作者使用低秩联合压缩方法减少注意力计算的缓存需求,同时保持多头注意力的性能。同时,他们引入旋转位置嵌入(Rotary Positional Embedding,RoPE)提高推理精度。
2.2.2 混合专家架构(DeepSeekMoE)
作者采用辅助损失优化的专家负载平衡策略,避免因负载不均导致的计算效率降低。同时,他们引入“无辅助损失”的负载平衡新方法,通过动态调整路由偏差值,确保训练过程中的负载均衡。
2.2.3 多 Token 预测目标(Multi-Token Prediction,MTP)
作者扩展了模型在每个位置预测多个未来 token 的能力,提高训练数据效率。特别是,在推理阶段,MTP 模块可被重新用于推测解码,从而加速生成。
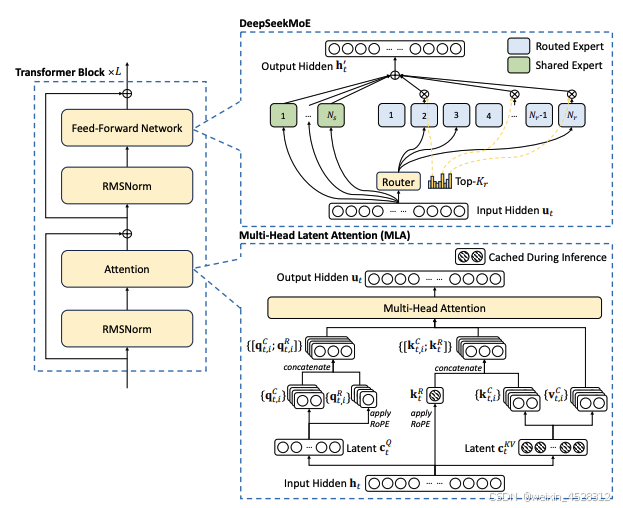
图 5,DeepSeek-V3 基本架构示意图。在继承 DeepSeek-V2 的基础上,作者采用 MLA 和 DeepSeekMoE 以实现高效推理和经济型训练。
2.3 数据与训练效率
2.3.1 数据与预训练:
作者使用了14.8 万亿高质量多样化 token 数据进行训练。他们发现,预训练过程非常稳定,未发生任何不可恢复的损失激增。
2.3.2 优化训练框架:
作者设计了 DualPipe 算法,通过前向和反向计算的重叠,显著减少通信开销。模型支持 FP8 混合精度训练,结合细粒度量化策略,显著降低内存使用和通信开销。
另外,他们发现,训练效率极高,每训练万亿 token 仅需 18 万 H800 GPU 小时,总成本约 557.6 万美元。
2.3.3 长上下文扩展:
DeepSeek 支持最大上下文长度从 32K 扩展至 128K,使模型更适用于长文档处理。
2.4 后期优化与推理部署
2.4.1 监督微调(Supervised Fine-Tuning,SFT)与强化学习(Reinforcement Learning,RL):
DeepSeek 通过 SFT 对齐模型输出与人类偏好。同时,他们引入自适应奖励模型和 相对策略优化(GRPO),提升模型的推理能力。
2.4.2 推理与部署:
DeepSeek 在 NVIDIA H800 GPU 集群上部署,结合高效的专家路由和负载均衡策略,实现低延迟的实时服务。同时,作者使用冗余专家策略进一步优化推理阶段的负载平衡。
2.5 DeepSeek V3 的性能表现
2.5.1 知识任务:
在 MMLU 和 GPQA 等教育基准上,DeepSeek-V3 超越所有开源模型,并接近 GPT-4o 的性能。特别是,DeepSeek V3 在中文事实性任务中表现尤为突出,领先大部分闭源模型。
2.5.2 代码与数学任务:
DeepSeek V3在数学基准(如 MATH-500)上实现开源模型的最佳表现。同时,它在编程任务(如 LiveCodeBench)中排名第一,展示了卓越的代码生成能力。
2.5.3 开放式生成任务:
在开放式生成任务中,DeepSeek-V3 的胜率显著高于其他开源模型,并接近闭源模型的水平。
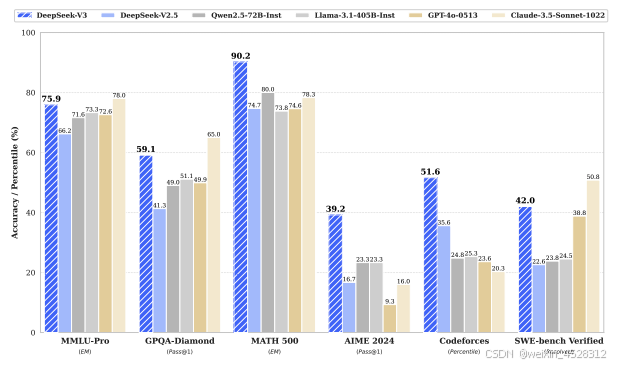
图 6. DeepSeek-V3 及其对比模型的基准测试性能。
2.6 结论与未来方向
DeepSeek-V3 是目前最强的开源基础模型之一,特别是在代码、数学和长上下文任务上表现突出。未来计划包括:(1)优化模型在多语言和多领域的泛化能力。(2) 探索更高效的硬件支持和训练方法。
3. DeepSeek-R1:通过强化学习提升大型语言模型的推理能力
2025年01月20日,deepseek 正式发布 DeepSeek-R1,并同步开源模型权重。这篇题为《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》是一篇开创性的论文。它专注于通过纯强化学习方法(而非传统的监督学习)来提升大型语言模型的推理能力。研究展示了模型在训练过程中通过强化学习表现出的“顿悟”现象,并显著提升了模型在数学和逻辑推理任务中的性能。这也是DeepSeek在近期产生全球范围引发轰动效应的主要论文,它的第一作者是中山大学毕业的郭达雅博士。

图 7. DeepSeek的DeepSeek-R1论文截图。该论文近期引发全球范围的广泛影响。
3.1 背景与目标
近年来,大型语言模型(large language model, LLM)的推理能力成为人工智能研究的重要方向。然而,当前的许多方法依赖监督微调(supervised fine-tuning,SFT),这需要大量标注数据。论文提出了 DeepSeek-R1-Zero 和 DeepSeek-R1 两种新型模型,通过大规模强化学习(reinforcement learning, RL)方法提升推理能力,旨在减少对监督数据的依赖,探索纯强化学习对推理能力的优化潜力。
3.2 方法
3.2.1 DeepSeek-R1-Zero:基于纯强化学习的推理能力提升
DeepSeek-R1-Zero有两方面的特性:
- (1)强化学习算法: 使用 Group Relative Policy Optimization (GRPO),通过群体奖励优化策略模型。奖励设计包括准确性奖励(评估答案正确性)和格式奖励(引导模型按照指定格式输出推理过程)。
- (2)自我演化与“灵光一现”现象: 模型通过 RL 自动学习复杂的推理行为,如自我验证和反思。随着训练过程的深入,模型逐步提升了复杂任务的解答能力,并在推理任务上显现突破性的性能提升。
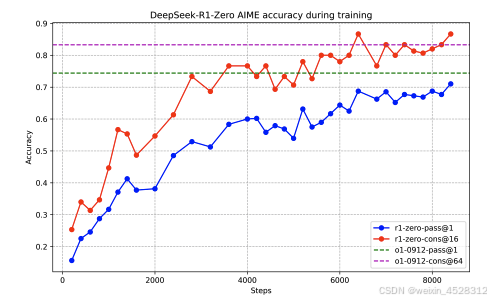
图8. DeepSeek-R1-Zero 在训练过程中的 AIME 准确率。对于每个问题,作者采样 16 个回答并计算整体平均准确率,以确保评估的稳定性。
3.2.2 DeepSeek-R1:结合冷启动数据的多阶段训练
DeepSeek-R1算法的主要特性:
- (1)冷启动数据的引入: 从零开始的 RL 容易导致初期性能不稳定,为此设计了包含高质量推理链的冷启动数据集。该数据提高了模型的可读性和训练初期的稳定性。
- (2)推理导向的强化学习: 通过多轮 RL,进一步优化模型在数学、编程等推理密集型任务中的表现。
- (3)监督微调与拒绝采样: 使用 RL 检查点生成额外的推理和非推理任务数据,进一步微调模型。
- (4)全场景强化学习: 在最终阶段结合多种奖励信号,提升模型的有用性和安全性。
- (5)蒸馏:将推理能力传递至小模型。将 DeepSeek-R1 的推理能力通过蒸馏技术传递至 Qwen 和 Llama 系列小型模型。蒸馏后的模型在多个基准任务中超越了部分开源大模型。
3.3 性能评估
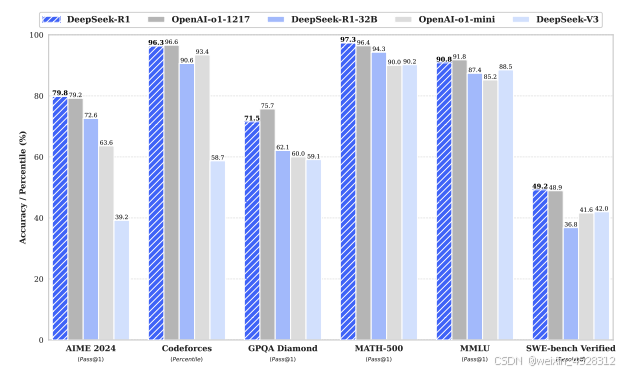
图9. DeepSeek-R1 的基准测试性能以及和OpenAI程序的比较。
3.3.1 推理任务
在 AIME 2024、MATH-500 等数学任务中,DeepSeek-R1 达到 OpenAI-o1-1217 的性能水平。另外,在编程任务(如 Codeforces 和 LiveCodeBench)上,表现优于大多数对比模型。
3.3.2 知识任务
在 MMLU 和 GPQA Diamond 等多学科基准测试中,DeepSeek-R1 展现了卓越的知识推理能力。特别是,其中文任务表现(如 C-Eval)显著优于其他开源模型。
3.3.3 生成任务
在 AlpacaEval 和 ArenaHard 等开放式生成任务中,DeepSeek-R1 的胜率分别达到 87.6% 和 92.3%,展现了强大的文本生成能力。
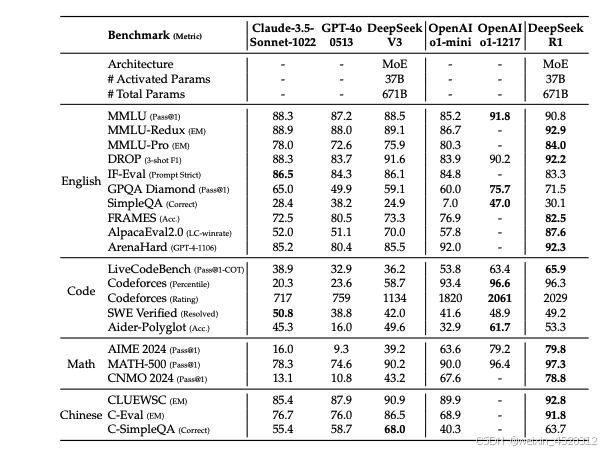
表3. DeepSeek-R1 与其他代表性模型的定量对比结果。
3.4 结论与未来展望
3.4.1 关键发现
通过强化学习,DeepSeek的语言推理能力可显著提升。即使对于无需监督数据,也依然成立。其次,将推理能力蒸馏到小型模型中可以有效地提高计算效率,同时保持较高的性能。
3.4.2 局限性
尽管这些成功,DeepSeek存在语言混合问题,即模型在处理多语言任务时可能输出混合语言。第二,DeepSeek存在提示敏感性问题,即模型对 few-shot 提示不够鲁棒(robust)。
3.4.3 未来方向
作者希望,在未来的研究中,增强多语言支持,优化对中文以外语言的推理能力。其次,加强研究大规模 强化学习在软件工程任务中的应用。
附录:梁文锋简介
梁文锋,中国人工智能公司DeepSeek的创始人兼首席执行官。他于1985年出生于广东省湛江市,父母均为小学教师。梁文锋于2007年获得浙江大学电子信息工程学士学位,2010年取得信息与通信工程硕士学位,师从项志宇教授,主要研究机器视觉领域。
在攻读硕士期间,梁文锋与同学组建团队,收集金融市场数据,探索将机器学习应用于全自动量化交易。2013年,他与浙江大学校友徐进共同创立了杭州雅克比投资管理有限公司,将人工智能与量化交易相结合。2015年,他们进一步创立了杭州幻方科技有限公司(现为浙江九章资产管理有限公司),并于2016年成立了宁波幻方量化投资管理合伙企业,专注于利用数学和人工智能进行量化投资。
在量化投资领域取得成功后,梁文锋将目光投向人工智能的更广阔应用。2023年,他宣布进军通用人工智能(AGI)领域,创立了DeepSeek,专注于大型语言模型的研究与开发。DeepSeek迅速崛起,其发布的DeepSeek-V2和DeepSeek-R1模型在性能和成本方面表现出色,引起全球关注。
梁文锋以其务实且创新的领导风格著称。他强调创新应通过速度和适应能力来实现,而非依赖保密。他主张中国应从模仿转向原创,积极参与全球技术创新浪潮。在人才招聘方面,DeepSeek注重吸纳具有能力和热情的年轻人才,团队主要由毕业不久的本土人才组成。
2025年1月,梁文锋受邀参加由中国国务院总理李强主持的专家、企业家座谈会,体现了他在中国人工智能领域的重要地位。DeepSeek的成功不仅展示了中国在人工智能领域的创新能力,也对全球科技产业格局产生了深远影响。

DeepSeek的创始人梁文锋
参考文献:
- X Bi et al, DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. [2401.02954] DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- A Liu et al, DeepSeek-V3 Technical Report. [2412.19437] DeepSeek-V3 Technical Report.
- D Guo et al, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. [2501.12948] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
相关文章:

专业视角深度解析:DeepSeek的核心优势何在?
杭州深度求索(DeepSeek)人工智能基础技术研究有限公司,是一家成立于2023年7月的中国人工智能初创企业,总部位于浙江省杭州市。该公司由量化对冲基金幻方量化(High-Flyer)的联合创始人梁文锋创立,…...

科技巨头AI投资引领未来增长
标题:科技巨头AI投资引领未来增长 文章信息摘要: 2024年科技巨头的资本支出远超预期,达到2360亿美元,主要得益于AI基础设施和数据中心建设的加速。预计2025年这一趋势将继续保持强劲增长,资本支出可能突破3000亿美元。…...

【Unity3D】Tilemap俯视角像素游戏案例
目录 一、导入Tilemap 二、导入像素风素材 三、使用Tilemap制作地图 3.1 制作Tile Palette素材库 3.2 制作地图 四、实现A*寻路 五、待完善 一、导入Tilemap Unity 2019.4.0f1 已内置Tilemap 需导入2D Sprite、2D Tilemap Editor、以及一个我没法正常搜出的2D Tilemap…...

Java 知识速记:全面解析 final 关键字
Java 知识速记:全面解析 final 关键字 什么是 final 关键字? final 关键字是 Java 中的一个修饰符。它可以用于类、方法和变量,其作用是限制对这些元素的修改。究竟如何限制?我们来逐个分析。 final 在变量中的用法 1. 声明常…...

《智能家居“孤岛危机”:设备孤立如何拖垮系统优化后腿》
在科技飞速发展的今天,智能家居不再是遥不可及的概念,它正逐渐走进千家万户,为我们描绘出舒适便捷的未来生活蓝图。想象一下,下班回家前,你可以通过手机远程开启空调,让室内温度恰到好处;到家时…...

大数据学习之Kafka消息队列、Spark分布式计算框架一
Kafka消息队列 章节一.kafka入门 4.kafka入门_消息队列两种模式 5.kafka入门_架构相关名词 Kafka 入门 _ 架构相关名词 事件 记录了世界或您的业务中 “ 发生了某事 ” 的事实。在文档中 也称为记录或消息。当您向 Kafka 读取或写入数据时,您以事件的 形式执行…...

Linux《基础指令》
在之前的Linux《Linux简介与环境的搭建》当中我们已经初步了解了Linux的由来和如何搭建Linux环境,那么接下来在本篇当中我们就要来学习Linux的基础指令。在此我们的学习是包括两个部分,即指令和关于Linux的基础知识;因此本篇指令和基础知识的…...

Avalonia+ReactiveUI跨平台路由:打造丝滑UI交互的奇幻冒险
一、引言 在当今数字化时代,跨平台应用开发已成为大势所趋。开发者们迫切需要一种高效、灵活的方式,能够让应用程序在不同操作系统上无缝运行,为用户提供一致的体验。Avalonia 和 ReactiveUI 的组合,宛如一对天作之合的舞者&…...
)
Ansible自动化运维实战--通过role远程部署nginx并配置(8/8)
文章目录 1、准备工作2、创建角色结构3、编写任务4、准备配置文件(金甲模板)5、编写变量6、编写处理程序7、编写剧本8、执行剧本Playbook9、验证-游览器访问每台主机的nginx页面 在 Ansible 中,使用角色(Role)来远程部…...

H264原始码流格式分析
1.H264码流结构组成 H.264裸码流(Raw Bitstream)数据主要由一系列的NALU(网络抽象层单元)组成。每个NALU包含一个NAL头和一个RBSP(原始字节序列载荷)。 1.1 H.264码流层次 H.264码流的结构可以分为两个层…...

批量解密,再也没有任何限制了
有的时候我们在网上下载了PDF文档。发现没有办法进行任何的操作,就连打印权限都没有。今天给大家介绍的这个软件可以一键帮你进行PDF解密,非常方便,完全免费。 PDF智能助手 批量解密PDF文件 这个软件不是很大,只有10MBÿ…...

认识小程序的基本组成结构
1.基本组成结构 2.页面的组成部分 3.json配置文件 4.app.json文件(全局配置文件) 5.project.config.json文件 6.sitemap.json文件 7.页面的.json配置文件 通过window节点可以控制小程序的外观...

模型I/O
文章目录 什么是模型I/O模型I/O功能之输出解析器输出解析器的功能输出解析器的使用Pydantic JSON输出解析器结构化输出解析器 什么是模型I/O 模型I/O在所有LLM应用中,核心元素无疑都是模型本身。与模型进行有效的交互是实现高效、灵活和可扩展应用的关键。LangChain…...

DeepSeek模型:开启人工智能的新篇章
DeepSeek模型:开启人工智能的新篇章 在当今快速发展的技术浪潮中,人工智能(AI)已经成为了推动社会进步和创新的核心力量之一。而DeepSeek模型,作为AI领域的一颗璀璨明珠,正以其强大的功能和灵活的用法&…...

git push到远程仓库时无法推送大文件
一、错误 remote: Error: Deny by project hooks setting ‘default’: size of the file ‘scientific_calculator’, is 164 MiB, which has exceeded the limited size (100 MiB) in commit ‘4c91b7e3a04b8034892414d649860bf12416b614’. 二、原因 本地提交过大文件&am…...

初识ExecutorService
设计目的 ExecutorService是Java并发包(java.util.concurrent)的一部分,旨在提供一种更高层次的抽象来管理线程和任务执行。它解决了手动创建和管理线程带来的复杂性和资源浪费问题,通过复用固定数量的线程池来处理大量短生命周期的任务,从而…...

初二回娘家
昨天下午在相亲相爱一家人群里聊天,今天来娘家拜年。 聊天结束后,开始准备今天的菜肴,梳理了一下,凉菜,热菜,碗菜。 上次做菜,粉丝感觉泡的不透,有的硬,这次使用开水浸泡…...
)
js基础(黑马程序员)
Web APIs(day6) 一、正则表达式 1.介绍 正则表达式(Regular Expression):是用于匹配字符串中字符组合的模式。在 JavaScript中,正则表达式也是对象 通常用来查找、替换那些符合正则表达式的文本&#x…...

Java---猜数字游戏
本篇文章所实现的是Java经典的猜数字游戏 , 运用简单代码来实现基本功能 目录 一.题目要求 二.游戏准备 三.代码实现 一.题目要求 随机生成一个1-100之间的整数(可以自己设置区间),提示用户猜测,猜大提示"猜大了",…...

Oracle Primavera P6 最新版 v24.12 更新 2/2
目录 一. 引言 二. P6 EPPM 更新内容 1. 用户管理改进 2. 更轻松地标准化用户设置 3. 摘要栏标签汇总数据字段 4. 将里程碑和剩余最早开始日期拖到甘特图上 5. 轻松访问审计数据 6. 粘贴数据时排除安全代码 7. 改进了状态更新卡片视图中的筛选功能 8. 直接从活动电子…...

【React】 react路由
这一篇文章的重点在于将React关于路由的问题都给搞清楚。 一个路由就是一个映射关系,key:value。key是路径,value 可能是function或者component。 安装react-router-dom包使用路由服务,我这里想要用的是6版本的包,因此后面加”6&q…...

Linux的常用指令的用法
目录 Linux下基本指令 whoami ls指令: 文件: touch clear pwd cd mkdir rmdir指令 && rm 指令 man指令 cp mv cat more less head tail 管道和重定向 1. 重定向(Redirection) 2. 管道(Pipes&a…...

【Numpy核心编程攻略:Python数据处理、分析详解与科学计算】1.18 逻辑运算引擎:数组条件判断的智能法则
1.18 逻辑运算引擎:数组条件判断的智能法则 1.18.1 目录 #mermaid-svg-QAFjJvNdJ5P4IVbV {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-QAFjJvNdJ5P4IVbV .error-icon{fill:#552222;}#mermaid-svg-QAF…...

C语言实现库函数strlen
size_t是 unsigned int fgets会读入\n,用strcspn函数除去 assert判读指针是否为空指针,使用前要引头文件<assert.h> #include <stdio.h> #include <assert.h> size_t mystrlen(const char* str) {assert(str);size_t count 0;while …...

18 大量数据的异步查询方案
在分布式的应用中分库分表大家都已经熟知了。如果我们的程序中需要做一个模糊查询,那就涉及到跨库搜索的情况,这个时候需要看中间件能不能支持跨库求交集的功能。比如mycat就不支持跨库查询,当然现在mycat也渐渐被摒弃了(没有处理笛卡尔交集的…...

FastExcel使用详解
文章目录 FastExcel使用详解一、引言二、环境准备与依赖引入1、Maven 依赖引入2、实体类定义 三、核心操作:读写 Excel1、读取 Excel1.1 自定义监听器1.2 读取文件 2、写入 Excel2.1 简单写入2.2 模板写入 四、Spring Boot 集成示例1、文件上传(导入&…...
 元组、字符串、集合和字典)
深度学习python基础(第四节) 元组、字符串、集合和字典
本节主要介绍元组,字符串,集合,字典的基本语法定义,以及相关的操作. 元组的定义和操作 元组一旦定义完成就不可修改. """ # 定义元组字面量 (元素,元素,....,元素) # 元素可以不同的数据类型# 定义元组变量 变量名称 (元素,…...

QT串口通信,实现单个温湿度传感器数据的采集
1、硬件设备 RS485中继器(一进二出),usb转485模块、电源等等 => 累计115元左右。 2、核心代码 #include "MainWindow.h" #include "ui_MainWindow.h"MainWindow::...

绘制决策树尝试3
目录 代码解读AI 随机状态 种子 定义决策树回归模型 tree的decision regressor fit 还可用来预测 export 效果图 我的X只有一个特征 为何这么多分支 ??? 这是CART回归 CART回归 为什么说代码是CART回归? 不是所有的决…...

【逻辑学导论第15版】A. 推理
识别下列语段中的前提与结论。有些前提确实支持结论,有些并不支持。请注意,前提可能直接或间接地支持结论,而简单的语段也可能包含不止一个论证。 例题: 1.管理得当的民兵组织对于一个自由国家的安全是必需的,因而人民…...

qt-C++笔记之QLine、QRect、QPainterPath、和自定义QGraphicsPathItem、QGraphicsRectItem的区别
qt-C笔记之QLine、QRect、QPainterPath、和自定义QGraphicsPathItem、QGraphicsRectItem的区别 code review! 参考笔记 1.qt-C笔记之重写QGraphicsItem的paint方法(自定义QGraphicsItem) 文章目录 qt-C笔记之QLine、QRect、QPainterPath、和自定义QGraphicsPathItem、QGraphic…...
泛型方法)
[Java]泛型(二)泛型方法
1.定义 在 Java 中,泛型方法是指在方法声明中使用泛型类型参数的一种方法。它使得方法能够处理不同类型的对象,而不需要为每种类型写多个方法,从而提高代码的重用性。 泛型方法与泛型类不同,泛型方法的类型参数仅仅存在于方法的…...

ProfibusDP主机与从机交互
ProfibusDP 主机SD2索要数据下发:68 08 F7 68 01 02 03 21 05 06 07 08 1C 1668:SD2 08:LE F7:LEr 68:SD2 01:目的地址 02:源地址 03:FC_CYCLIC_DATA_EXCHANGE功能码 21:数据地址 05,06,07,08&a…...
)
jQuery小游戏(二)
jQuery小游戏(二) 今天是新年的第二天,本人在这里祝大家,新年快乐,万事胜意💕 紧接jQuery小游戏(一)的内容,我们开始继续往下咯😜 游戏中使用到的方法 key…...

【MQ】如何保证消息队列的高可用?
RocketMQ NameServer集群部署 Broker做了集群部署 主从模式 类型:同步复制、异步复制 主节点返回消息给客户端的时候是否需要同步从节点 Dledger:要求至少消息复制到半数以上的节点之后,才给客户端返回写入成功 slave定时从master同步数据…...
)
简易计算器(c++ 实现)
前言 本文将用 c 实现一个终端计算器: 能进行加减乘除、取余乘方运算读取命令行输入,输出计算结果当输入表达式存在语法错误时,报告错误,但程序应能继续运行当输出 ‘q’ 时,退出计算器 【简单演示】 【源码位置】…...

AI大模型开发原理篇-4:神经概率语言模型NPLM
神经概率语言模型(NPLM)概述 神经概率语言模型(Neural Probabilistic Language Model, NPLM) 是一种基于神经网络的语言建模方法,它将传统的语言模型和神经网络结合在一起,能够更好地捕捉语言中的复杂规律…...

SpringBoot 基础特性
SpringBoot 基础特性 SpringApplication 相关特性 自定义 banner 在主配置文件写 banner.txt 的地址 #也可以不写默认路径就是 banner.txt #从类路径下找 banner #类路径就是 编译的target 目录 还有导入的第三方类路径。 spring.banner.locationclasspath:banner.txt#控制…...

网站快速收录:提高页面加载速度的重要性
本文转自:百万收录网 原文链接:https://www.baiwanshoulu.com/32.html 网站快速收录中,提高页面加载速度具有极其重要的意义。以下从多个方面详细阐述其重要性: 一、提升用户体验 减少用户等待时间:页面加载速度直接…...

如何使用formlinker,重构微软表单创建的数字生产力法则?
仅需三步:上传文件-下载文件-导入文件到微软表单 凌晨两点的格式炼狱:被浪费的300万小时人类创造力 剑桥大学的实验室曾捕捉到一组震撼数据:全球教育工作者每年花在调整试题格式上的时间,足够建造3座迪拜哈利法塔。当北京某高校的…...

从零搭建一个Vue3 + Typescript的脚手架——day3
3.项目拓展配置 (1).配置Pinia Pinia简介 Pinia 是 Vue.js 3 的状态管理库,它是一个轻量级、灵活、易于使用的状态管理库。Pinia 是 Vue.js 3 的官方状态管理库,它可以帮助开发者更好地管理应用的状态。Pinia 是一个开源项目,它有丰富的文档…...

Three.js实战项目02:vue3+three.js实现汽车展厅项目
文章目录 实战项目02项目预览项目创建初始化项目模型加载与展厅灯光加载汽车模型设置灯光材质设置完整项目下载实战项目02 项目预览 完整项目效果: 项目创建 创建项目: pnpm create vue安装包: pnpm add three@0.153.0 pnpm add gsap初始化项目 修改App.js代码&#x…...
)
Linux——网络(tcp)
文章目录 目录 文章目录 前言 一、TCP逻辑 1. 面向连接 三次握手(建立连接) 四次挥手(关闭连接) 2. 可靠性 3. 流量控制 4. 拥塞控制 5. 基于字节流 6. 全双工通信 7. 状态机 8. TCP头部结构 9. TCP的应用场景 二、编写tcp代码函数…...

Ubuntu Server 安装 XFCE4桌面
Ubuntu Server没有桌面环境,一些软件有桌面环境使用起来才更加方便,所以我尝试安装桌面环境。常用的桌面环境有:GNOME、KDE Plasma、XFCE4等。这里我选择安装XFCE4桌面环境,主要因为它是一个极轻量级的桌面环境,适合内…...

分享|通过Self-Instruct框架将语言模型与自生成指令对齐
结论 在大型 “指令调整” 语言模型依赖的人类编写指令数据存在数量、多样性和创造性局限, 从而阻碍模型通用性的背景下, Self - Instruct 框架, 通过 自动生成 并 筛选指令数据 微调预训练语言模型, 有效提升了其指令遵循能…...
——提升指针安全性的利器)
指针空值——nullptr(C++11)——提升指针安全性的利器
C11引入的nullptr是对指针空值的正式支持,它提供了比传统NULL指针更加安全和明确的指针空值表示方式。在C语言中,指针操作是非常基础且常见的,而如何安全地处理指针空值,一直是开发者关注的重要问题。本文将详细讲解nullptr的引入…...

C++游戏开发
C 是游戏开发中广泛使用的编程语言,因其高性能、灵活性和对硬件的直接控制能力而备受青睐。以下是 C 游戏开发的一些关键点: 1. 游戏引擎 Unreal Engine:使用 C 作为主要编程语言,适合开发高质量 3D 游戏。Unity:虽然…...

【Docker】ubuntu中 Docker的使用
之前记录了 docker的安装 【环境配置】ubuntu中 Docker的安装; 本篇博客记录Dockerfile的示例,docker 的使用,包括镜像的构建、容器的启动、docker compose的使用等。 当安装好后,可查看docker的基本信息 docker info ## 查…...

Linux C openssl aes-128-cbc demo
openssl 各版本下载 https://openssl-library.org/source/old/index.html#include <stdio.h> #include <string.h> #include <openssl/aes.h> #include <openssl/rand.h> #include <openssl/evp.h>#define AES_KEY_BITS 128 #define GCM_IV_SIZ…...

【卫星通信】链路预算方法
本文介绍卫星通信中的链路预算方法,应该也适用于地面通信场景。 更多内容请关注gzh【通信Online】 文章目录 下行链路预算卫星侧参数信道参数用户侧参数 上行链路预算链路预算计算示例 下行链路预算 卫星侧参数 令卫星侧天线数为 M t M_t Mt,每根天线…...