Java并发08 - 并发安全容器详解
并发容器详解
文章目录
- 并发容器详解
- 一:不使用并发容器如何保证安全
- 二:阻塞队列容器
- 2:ArrayBlockingQueue
- 2.1:内部成员
- 2.2:put方法的实现
- 2.3:take方法的实现
- 3:LinkedBlockingQueue
- 3.1:内部成员
- 3.2:put方法的实现
- 3.3:take方法的实现
- 三:写时复制容器
- 1:CopyOnWriteArrayList
- 1.1:内部成员
- 1.2:get方法的实现
- 1.3:修改方法的实现
- 2:CopyOnWriteArraySet
- 3:总结
- 四:锁分段容器(面)
- 1:HashMap原理回顾
- 2:ConcurrentHashMap(1.7-)
- 2.1:概述
- 2.2:put()原理
- 2.3:get() 原理
- 2.4:size原理
- 3:ConcurrentHashMap(1.8+)
- 3.1:成员属性
- 3.2:put原理
- 3.3:get原理
一:不使用并发容器如何保证安全
一般Java中的容器可分为四类:Map、List、Queue以及Set容器
在使用过程中,对于ArrayList、HashMap等这类容器都是经常使用的,但问题在于这些容器在并发环境下都会存在线程安全问题
所以当我们在多线程环境下使用容器时,一般会使用Vector、HashTable来代替之前的ArrayList、HashMap
或者通过如下几个Collections提供的方法来将容器转换线程安全的:
// 将一个List转换为线程安全的List
Collections.synchronizedList(new ArrayList<E>());
// 将一个Set转换为线程安全的Set
Collections.synchronizedSet(new HashSet<E>());
// 将一个map转换为线程安全的map
Collections.synchronizedMap(new HashMap<K,V>());
然而这些方法虽然能保证线程安全,但是底层的工作原理都是对方法加上sync关键字实现的
因此,在JDK1.5之后,JUC并发包中,则推出了三个系列的并发容器:
- 阻塞队列容器
- 写时复制容器
- 分段容器
二:阻塞队列容器
明白了ReentrantLock的多条件等待Condition原理即可理解队列的阻塞原理的实现过程
阻塞队列容器一般可以在创建线程池的时候使用到
阻塞队列与普通队列最大的不同点在于:支持队列内元素的阻塞添加与阻塞弹出,也就是代表着:
-
当在往队列中添加元素时,如果队列已经满了,那么当前添加元素的线程则会阻塞,直至队列弹出一个元素后才会唤醒,并将元素添加至队列中
-
阻塞弹出同理,如若队列为空,那么会阻塞至队列中有元素为止。
在JUC中主要提供了两类阻塞队列:单向阻塞队列以及双向阻塞队列,在JUC包分别对应着BlockingQueue、BlockingDeque两个接口
- BlockingQueue单向FIFO先进先出阻塞队列:
- ArrayBlockingQueue:由数组结构支持的有界队列
- LinkedBlockingQueue:由链表结构支持的可选有界队列
- PriorityBlockingQueue:由最小二叉堆(优先级堆)结构支持的无界优先级队列
- DelayQueue:由最小二叉堆(优先级堆)结构支持且基于时间的调度队列
- SynchronousQueue:实现简单聚集(rendezvous)机制的同步阻塞交换队列(只存一个元素)
- LinkedTransferQueue:由链表结构支持的无界队列(1-②、1-⑤与3-①优点组成的超集)
- DelayWorkQueue:由最小二叉堆(优先级堆)结构支持的定时线程池定制版无界优先级队列
- BlockingDeque双向阻塞队列:
- LinkedBlockingDeque:由链表结构支持的可选双向有界队列
- 其他队列(非阻塞队列):
- ConcurrentLinkedQueue:由链表结构支持的并发无界队列
- PriorityQueue:由最小二叉堆(优先级堆)结构支持无界队列
- ConcurrentLinkedDeque:由链表结构支持的并发双向无界队列
- ArrayDeque:由数组结构支持的双向有界队列
单向,双向,有界,无界
- 有界:代表队列可以设置固定长度,队列中元素数量达到队列最大长度时则不能入列
- 无界:代表队列不需要设长度,在内存允许的情况下可以一直添加元素直至溢出。
- 单向:遵循先进先出FIFO原则的队列
- 双向:两端都可以插入/弹出元素的队列,可以使用双向队列实现栈结构
Java中的阻塞队列都实现自BlockingQueue接口,也包括BlockingDeque接口也继承自BlockingQueue接口
public interface BlockingQueue<E> extends Queue<E> {// 如果队列未满则将元素e插入队列尾部,插入成功返回true,// 如果队列已满,则抛IllegalStateException异常boolean add(E e); // 如果队列未满则将元素e插入队列尾部,插入成功返回trueboolean offer(E e);// 如果队列未满则将元素e插入队列尾部,插入成功返回true,// 如果该队列已满,则在指定的等待时间之内阻塞至可用空间出现// 如果超出指定时间还未将元素插入队列则返回(可响应线程中断)boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException; // 将元素插入队列的尾部,如果该队列已满,则一直阻塞等待void put(E e) throws InterruptedException; // 获取并移除队列的头部元素,如果没有元素则阻塞等待, // 直到有线程添加元素后再唤醒等待线程执行该操作 E take() throws InterruptedException; // 获取并移除队列的头部元素,在指定的等待时间之内阻塞等待获取元素,// 如果超出指定时间还未获取到元素则返回(可响应线程中断)E poll(long timeout, TimeUnit unit) throws InterruptedException; // 从队列中移除某个指定元素,移除成功返回true,没有该元素则返回falseboolean remove(Object o); // 获取队列剩余的可用空位// 假设队列长度为10,已有3个元素,调用该方法则返回7int remainingCapacity();// 检查队列中是否存在指定元素,存在返回true,反之falsepublic boolean contains(Object o);// 一次性从队列中获取所有可用元素int drainTo(Collection<? super E> c);// 一次性从队列中获取指定个数的可用元素int drainTo(Collection<? super E> c, int maxElements);
}
总的来说,阻塞队列中的方法可分为三类:增删查(有时也称为生产/消费、新增/弹出、添加/获取)
在使用阻塞队列时一般都是通过这三类方法操作队列容器
package com.example.bootrocketmq.mythread;import java.util.UUID;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;/*** @author cui haida* 2025/1/17*/
public class BlockingQueueDemo {// 阻塞队列, 线程安全, 容量固定 = 5private static ArrayBlockingQueue<String> arrayBlockingQueue = new ArrayBlockingQueue<>(5);/*** 生产者*/static class Producer implements Runnable {// 阻塞队列声明private BlockingQueue<String> blockingQueue;private Producer(BlockingQueue<String> b) {this.blockingQueue = b;}@Overridepublic void run() {// 死循环模拟无限生产for (; ; )producer();}private void producer() {String task = "hello-" + UUID.randomUUID();try {// 尝试将任务加入到阻塞队列中blockingQueue.put(task);System.out.println(Thread.currentThread().getName() + "生产任务:" + task);Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}/*** 消费者*/static class Consumer implements Runnable {// 阻塞队列声明private BlockingQueue<String> blockingQueue;private Consumer(BlockingQueue<String> b) {this.blockingQueue = b;}@Overridepublic void run() {// 死循环模拟无限消费for (; ; )consumer();}private void consumer() {try {Thread.sleep(200);String task = blockingQueue.take(); // 尝试消费任务System.out.println(Thread.currentThread().getName() + "消费任务:" + task);} catch (InterruptedException e) {e.printStackTrace();}}}public static void main(String[] args) {// create producer and consumerProducer producerTask = new Producer(arrayBlockingQueue);Consumer consumerTask = new Consumer(arrayBlockingQueue);// thread group of producerThread p1 = new Thread(producerTask, "p1");Thread p2 = new Thread(producerTask, "p2");// thread group of consumerThread c1 = new Thread(consumerTask, "c1");Thread c2 = new Thread(consumerTask, "c2");p1.start();p2.start();c1.start();c2.start();}
}
2:ArrayBlockingQueue
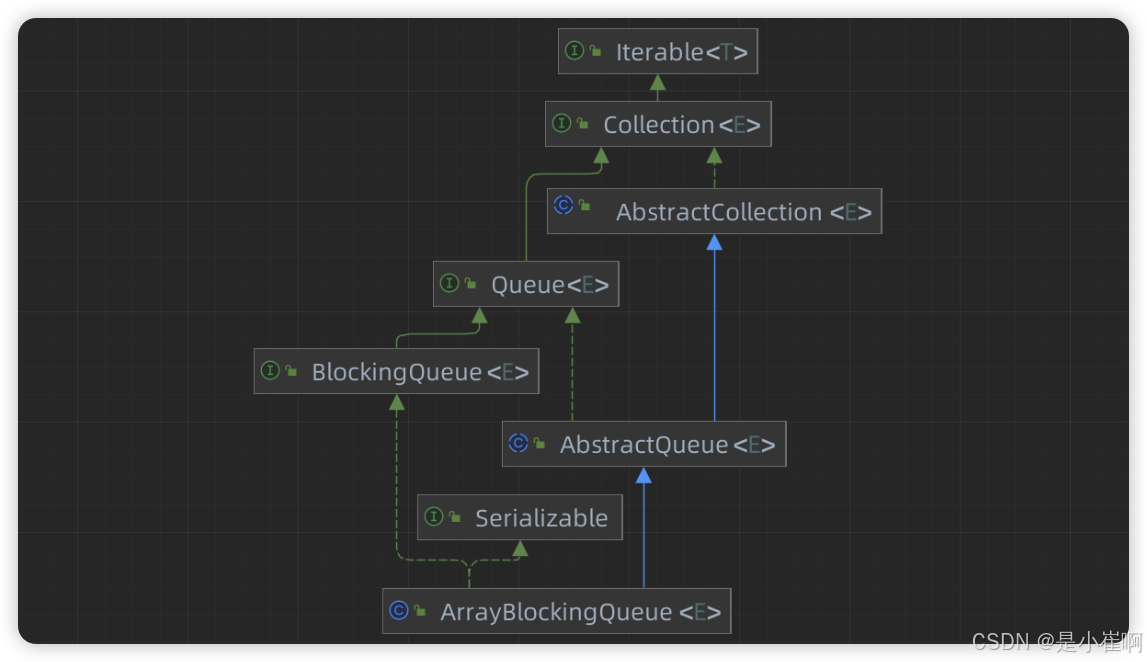
2.1:内部成员
构造器
属性
// 内部存储元素的数组结构
final Object[] items;// 记录获取元素的下标(take、poll、peek、remove方法都会用到)
int takeIndex;// 记录添加元素的下标(put、offer、add方法都会用到)
int putIndex;// 当前队列中元素的数量
int count;// 控制并发的ReentrantLock锁对象
final ReentrantLock lock;// 用于控制获取元素线程的condition对象[不空添加满足的时候才能取数据]
private final Condition notEmpty;// 用于控制添加元素线程的condition对象[不满条件满足的时候才能加数据]
private final Condition notFull;// 迭代器对象,注意此处声明为transient,说明序列化的时候忽略这个
transient Itrs itrs = null;
ArrayBlockingQueue内部使用一个数组成员items存储所有的队列元素
分别使用三个数值:takeIndex、putIndex以及count记录添加与获取元素的数组位置与队列中的元素个数
同时内部使用ReentrantLock解决线程安全问题,用两个Condition对象:notEmpty、notFull控制“写”线程与“读”线程的阻塞。
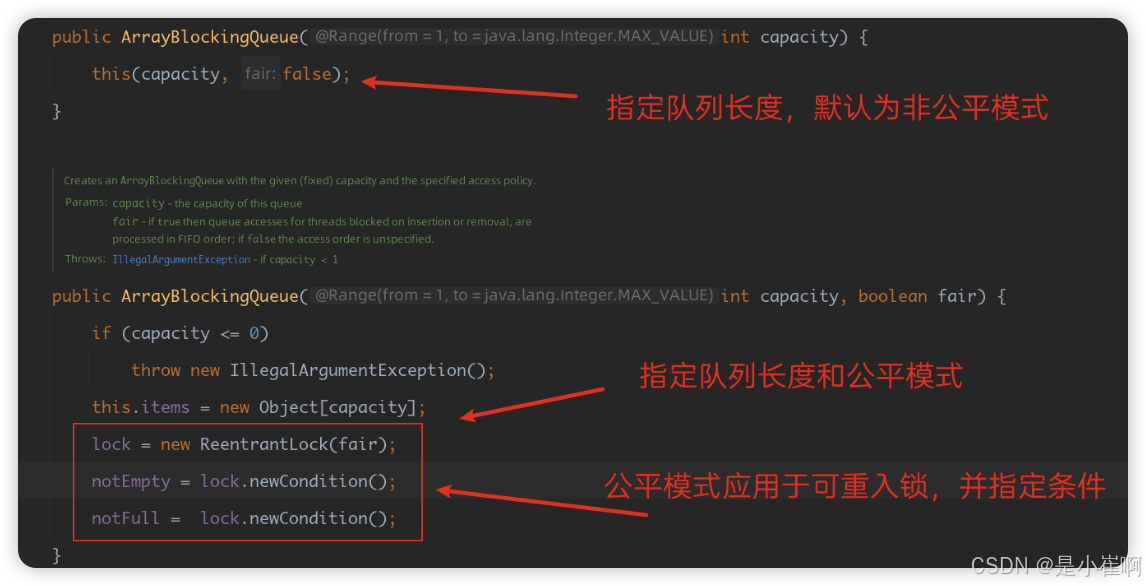
🎉 ArrayBlockingQueue的阻塞操作是基于ReentrantLock与Condition实现的,所以在创建ArrayBlockingQueue队列对象时也可以指定为公平/非公平模式,所以公平模式则是指:先阻塞的线程一定先操作队列。
2.2:put方法的实现
// ArrayBlockingQueue类 → put()方法
public void put(E e) throws InterruptedException {// 检查元素是否为空,为空则抛出空指针异常checkNotNull(e);// 获取ReentrantLock成员锁对象final ReentrantLock lock = this.lock;// 可响应中断式获取锁lock.lockInterruptibly();try {// 如果队列元素已满while (count == items.length)// 阻塞当前添加元素的线程notFull.await();// 如果队列元素未满则执行添加操作enqueue(e);} finally {// 释放锁lock.unlock();}
}// 添加元素的逻辑
// ArrayBlockingQueue类 → enqueue()方法
private void enqueue(E x) {// 获取存储元素的items数组成员final Object[] items = this.items;// 将元素放在数组的putIndex下标位置items[putIndex] = x;// 对putIndex+1,+1后如果=数组长度了则重置为0if (++putIndex == items.length)putIndex = 0;// 记录队列元素的数值count+1count++;// 唤醒等待获取队列元素的线程【声明不是空的条件满足了】notEmpty.signal();
}
非常简单,一共就四步:
- 判断元素是否为空,为空抛出空指针异常
- 获取锁资源(保证多线程情况下容器操作的安全问题)
- 判断队列是否已满,如果满了则阻塞当前执行线程
- 如果未满则调用
enqueue(e);方法进行添加操作
2.3:take方法的实现
// ArrayBlockingQueue类 → take()方法
public E take() throws InterruptedException {// 获取成员ReentrantLock锁对象final ReentrantLock lock = this.lock;// 可响应中断式获取锁lock.lockInterruptibly();try {// 如果队列为空while (count == 0)// 通过condition对象阻塞当前获取元素的线程notEmpty.await();// 如果队列不为空则获取元素return dequeue();} finally {// 释放锁lock.unlock();}
}// 获取元素的逻辑
// ArrayBlockingQueue类 → dequeue()方法
private E dequeue() {// 获取存储队列元素的成员数组itemsfinal Object[] items = this.items;@SuppressWarnings("unchecked")// 获取数组中下标为taseIndex位置上的元素E x = (E) items[takeIndex];// 获取后清除该位置的元素items[takeIndex] = null;// 对takeIndex进行+1if (++takeIndex == items.length)// 如果takeIndex=数组长度时则将takeIndex置为0takeIndex = 0;// 记录队列元素数量的数值count-1count--;// 同时更新迭代器中的元素if (itrs != null)itrs.elementDequeued();// 当取出一个元素后唤醒添加操作的线程【拿出元素之后不是满的条件将会满足】notFull.signal();// 返回return x;
}
也是非常简单,一共就四步:
- 判断元素是否为空,为空抛出空指针异常
- 获取锁资源(保证多线程情况下容器操作的安全问题)
- 判断队列是否为空,如果满了则阻塞当前执行线程
- 如果未满则调用
dequeue(e);方法进行获取操作
3:LinkedBlockingQueue
其中采用了读写分离的思想提升了容器整体的吞吐量
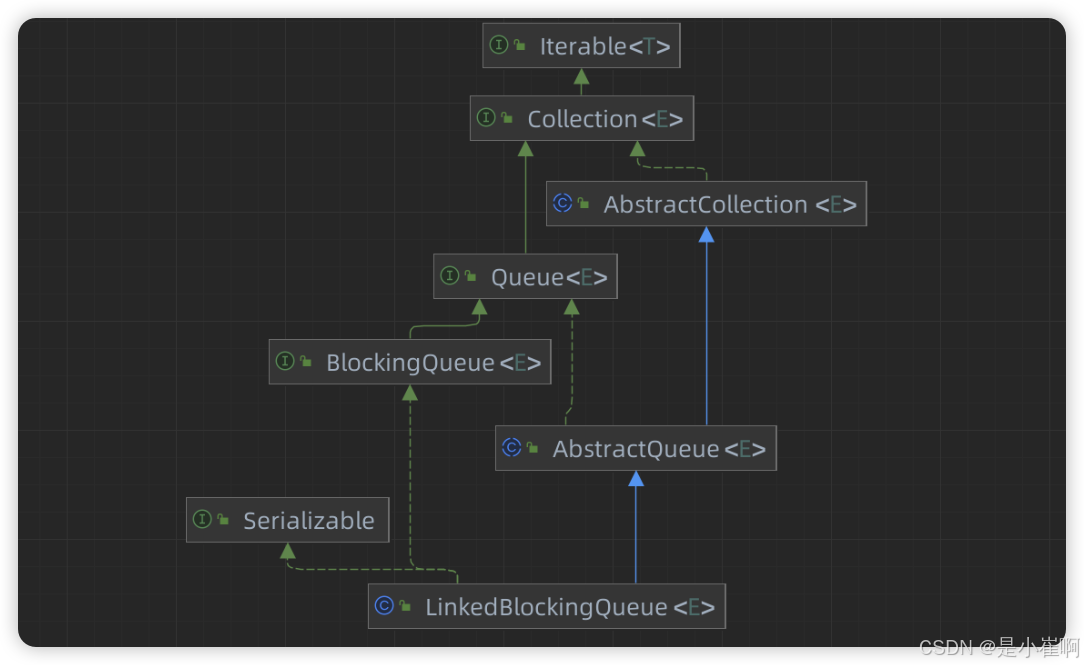
3.1:内部成员
构造器
// 构造器:可指定队列长度
public LinkedBlockingQueue(int capacity) {// 如果指定的队列长度为0或小于0则抛出异常if (capacity <= 0) throw new IllegalArgumentException();// 将传入的指定长度赋值给capacity成员this.capacity = capacity;// 初始化空的节点作为队列头节点last = head = new Node<E>(null);
}
// 构造器:不指定长度默认则为Integer.MAX_VALUE
public LinkedBlockingQueue() {this(Integer.MAX_VALUE);
}
内部类
// LinkedBlockingQueue类 → Node内部类
static class Node<E> {// 当前节点存储的元素本身E item;// 当前节点的后继节点Node<E> next;// 构造器Node(E x) { item = x; }
}
内部属性
// 队列的长度(可以指定长度,默认为Integer.MAX_VALUE)
private final int capacity;// 原子计数器:记录队列中元素的个数
private final AtomicInteger count = new AtomicInteger();// 队列(内部链表)的头节点
transient Node<E> head;// 队列(内部链表)的尾节点
private transient Node<E> last;// 读锁:线程从队列中获取元素时,使用这把锁
private final ReentrantLock takeLock = new ReentrantLock();// 获取元素时,队列为空,线程加入该condition队列等待
private final Condition notEmpty = takeLock.newCondition();// 写锁:线程向队列中添加元素时,使用这把锁
private final ReentrantLock putLock = new ReentrantLock();// 添加元素时,队列已满,线程加入该condition队列等待
private final Condition notFull = putLock.newCondition();
LinkedBlockingQueue因为是基于链表结构实现的队列容器,所以通过Node内部类构建了一个单向链表
同时使用AtomicInteger原子类记录队列中元素数量,head、last分别指向队列的头部以及尾部
同时使用takeLock、putLock两个ReentrantLock控制队列容器的读写并发访问。
3.2:put方法的实现
// LinkedBlockingQueue类 → put()方法
public void put(E e) throws InterruptedException {// 如果元素为空则抛出空指针异常if (e == null) throw new NullPointerException();int c = -1;// 将要添加的元素封装成node节点Node<E> node = new Node<E>(e);// 拿到写锁final ReentrantLock putLock = this.putLock;// 获取当前队列的元素数量final AtomicInteger count = this.count;// 可响应中断式加锁putLock.lockInterruptibly();try {// 如果队列已满while (count.get() == capacity) {// 挂起当前线程notFull.await();}// 如果队列未满,将封装的node节点加入队列enqueue(node);// 更新count计数器并获取更新前的count值c = count.getAndIncrement();// 如果队列还未满if (c + 1 < capacity)// 唤醒下一个添加线程,执行元素添加操作notFull.signal();} finally {// 释放锁putLock.unlock();}// 如果更新前队列为空,现在添加了一个元素// 代表着目前队列中肯定有数据了// 那么则唤醒等待获取元素的线程if (c == 0)// 如果存在元素则唤醒take线程signalNotEmpty();
}// LinkedBlockingQueue类 → enqueue()方法
private void enqueue(Node<E> node) {// 将新来的节点添加到链表的尾部last = last.next = node;
}
整体原理看上去好像和ArrayBlockingQueue差不多,但是有一点不同的是:LinkedBlockingQueue在添加元素完成后会唤醒等待队列中的其他线程执行添加操作,而之前的ArrayBlockingQueue却不会
这是因为LinkedBlockingQueue添加和获取元素使用的是两把不同的锁,而之前的ArrayBlockingQueue添加和获取元素是公用同一把锁
在ArrayBlockingQueue中同时只允许添加/获取中一个操作执行。在添加完成后会唤醒take线程,获取完成后会唤醒put线程。
在LinkedBlockingQueue中则不同,使用的是两把完全不同的锁,也就是说LinkedBlockingQueue的读/写完全是分离的,各自使用自己的锁进行并发控制,添加元素与获取元素的线程并不会产生互斥,所以这也是为什么一条线程添加元素后会继续唤醒等待列队中的其他线程的原因。
同时这种做法也可以在很大程度上提升容器的吞吐量。
3.3:take方法的实现
// LinkedBlockingQueue类 → take()方法
public E take() throws InterruptedException {E x;int c = -1;// 获取队列中元素数量以及读锁final AtomicInteger count = this.count;final ReentrantLock takeLock = this.takeLock;// 可响应中断式加锁takeLock.lockInterruptibly();try {// 如果队列为空则挂起当前线程while (count.get() == 0) {notEmpty.await();}// 如果队列不为空则获取元素x = dequeue();// 更新count成员并获取更新前的count值c = count.getAndDecrement();// 如果队列中还有元素if (c > 1)// 唤醒等待队列的其他线程,继续执行获取操作notEmpty.signal();} finally {// 释放锁takeLock.unlock();}// 如果之前队列是满的,那么现在弹出了一个元素// 则代表着当前队列出现了空位,那么唤醒添加线程if (c == capacity)signalNotFull();return x;
}
// LinkedBlockingQueue类 → dequeue()方法
private E dequeue() {// 获取队列头节点// 因为头节点是空节点// 所以队列中的第一个带数据的节点为:// 头结点的后继节点Node<E> h = head;// 获取head节点的后继节点Node<E> first = h.next;h.next = h; // 方便GC,置空引用信息// 将头节点的后继节点变为头节点head = first; // 获取后继节点上存储的元素数据E x = first.item;// 置空头节点的后继节点数据,将后继节点变为头节点first.item = null;// 返回获取到的数据return x;
}
也是非常简单,一共是四个大步骤:
- 获取take锁并判断队列是否为空,为空则挂起当前线程
- 如果不为空则移除并获取队列头部节点中存储的元素信息
- 更新count并获取更新之前的count值,判断队列是否还有元素,有则唤醒其他线程继续执行
- 判断之前的队列是否是满的,如果是满的现在弹出了一个元素,代表队列有空位,那么唤醒添加线程
⚠️ 这里所谓的“读锁”并非真正意义上的读,因为如果只是读操作的话是不需要加锁的,而队列的take方法在读取了元素之后还需移除该元素,所以里面也涉及到了写的操作,自然也需要加锁保证线程安全。准确来说,我所谓的“读/写锁”实际上是指“take/put”锁。
三:写时复制容器
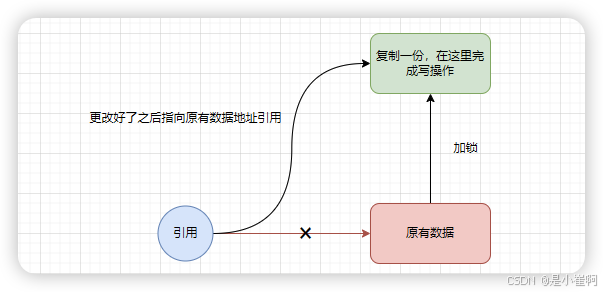
写时复制容器是计算机程序设计领域惯用的一种优化思想
在很多系统设计中,比如Linux中的Fork父子进程数据同步等机制都采用了这种思想
子进程在创建时并不会拷贝父进程的数据,对于需要用到的数据仅仅只是存在一个引用指向父进程中存储的数据地址,每次读取时都是通过引用地址从父进程中读取数据,而当子进程中要修改数据时才发生真正的拷贝动作,将父进程中的数据拷贝一份,修改完成后再将指向父进程数据的指针改成指向拷贝数据。
当然,写时复制实则也是懒加载、惰性加载思想的产物。
在JUC包中,写时复制容器主要提供了两种:CopyOnWriteArrayList与CopyOnWriteArraySet
在使用这两个容器时,读操作不会加锁,写操作时则会先获取锁,然后再复制一份原有数据进行修改,修改完成后再修改原有引用指向。【数据不一致问题】
1:CopyOnWriteArrayList
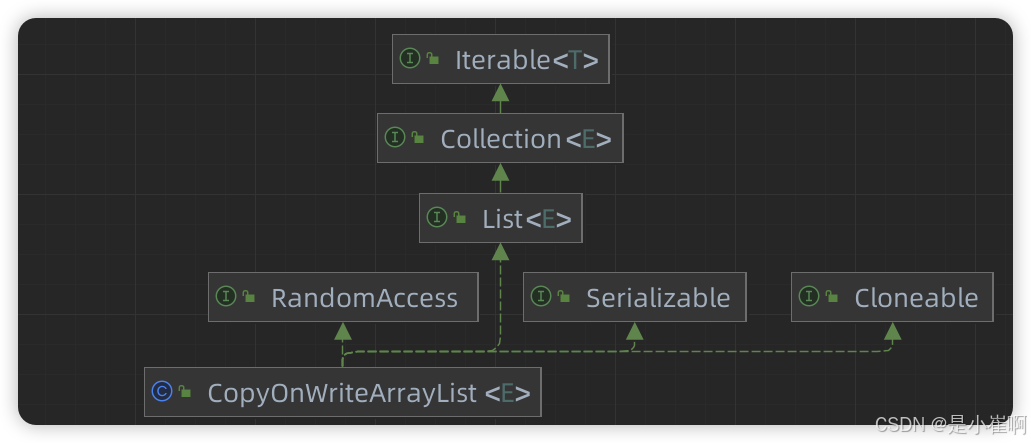
1.1:内部成员
构造器
// 构造器1:初始化长度为0的数组
public CopyOnWriteArrayList() {setArray(new Object[0]);
}//构造器2:入参为一个Collection集合对象
public CopyOnWriteArrayList(Collection<? extends E> c) {Object[] elements;// 如果传入的Collection对象就是COWL对象则直接拷贝数据if (c.getClass() == CopyOnWriteArrayList.class)elements = ((CopyOnWriteArrayList<?>)c).getArray();// 如果不是else {// 将Collection集合对象转换为Object数组elements = c.toArray();// 如果调用toArray()后没返回数组if (elements.getClass() != Object[].class)// 再次自己copy集合的数据转化为数组elements = Arrays.copyOf(elements, elements.length, Object[].class);}// 赋值给array成员setArray(elements);
}// 构造器3:入参为一个数组对象
public CopyOnWriteArrayList(E[] toCopyIn) {setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
内部类
// COWIterator内部类:迭代器。该迭代器不是fail-fast的
static final class COWIterator<E> implements ListIterator<E> {private final Object[] snapshot;// 省略其他代码.......
}// COWSubList内部类:子列表。与ArrayList的子列表同样的作用
private static class COWSubList<E> extends AbstractList<E> implements RandomAccess{}// COWSubListIterator内部类:子列表的迭代器。
private static class COWSubListIterator<E> implements ListIterator<E> {}
属性
private static final long serialVersionUID = 8673264195747942595L;// ReentrantLock独占锁:用于保证线程安全
final transient ReentrantLock lock = new ReentrantLock();// volatile修饰的数组:用于存储数据,volatile保证读取可见性
private transient volatile Object[] array;// array的封装方法
final void setArray(Object[] a) {array = a;
}
CopyOnWriteArrayList使用ReentrantLock独占锁保证容器整体写操作的安全问题
其内部使用一个volatile关键字修饰的Object类型数组存储数据
同时CopyOnWriteArrayList存在三个内部类,分别为自身的迭代器、子列表以及子列表的迭代器类。
值得注意的是:CopyOnWriteArrayList的迭代器并不是fail-fast的,即代表着当有一条线程在通过迭代器遍历一个CopyOnWriteArrayList对象时,另外一条线程对该容器进行了写操作,不会对使用迭代器遍历容器的线程产生影响。
而ArrayList容器,迭代器则是fail-fast的,当一条线程使用迭代器遍历数据,另外一条执行修改操作时,迭代器线程会抛出异常。
1.2:get方法的实现
// CopyOnWriteArrayList类 → get()方法
public E get(int index) {return get(getArray(), index);
}// CopyOnWriteArrayList类 → get()重载方法
private E get(Object[] a, int index) {return (E) a[index];
}
get()方法的实现一目了然,无非就是将数组指定下标的元素数据返回了而已
1.3:修改方法的实现
set方法
// CopyOnWriteArrayList类 → set()方法
public E set(int index, E element) {// 获取锁对象并加锁final ReentrantLock lock = this.lock;lock.lock();try {// 获取内部存储数据的数组成员:arrayObject[] elements = getArray();// 获取数组中指定下标原有的数据E oldValue = get(elements, index);// 如果指定下标位置原本存储的数据与新的数据不同if (oldValue != element) {// 获取数组的长度int len = elements.length;// 拷贝一个新的数组对象Object[] newElements = Arrays.copyOf(elements, len);// 将指定下标位置的元素修改为指定的数据newElements[index] = element;// 将成员array的引用从原本的数组改为新的数组setArray(newElements);} else {// 如果指定下标位置原本存储的数据与新的数据相同// 不做任何更改setArray(elements);}// 返回原本下标位置的值return oldValue;} finally {// 释放锁/解锁lock.unlock();}
}
set()方法是直接替换的方法,比如指定的下标位置已经有数据的情况下会覆盖之前的数据
该方法需要传递两个参数,第一个参数为下标位置,第二个参数为要设置的数据本身,下面是set方法的执行流程:
- 加锁后获取原本的数组,同时获取指定下标原有的值
- 判断原有值与新值是否相同,相同则不做任何修改
- 老值与新值不同时,先拷贝原有数组内的元素数据,然后将指定下标位置的数据修改为新值,最后将array成员的引用指向新数组并释放锁
- 返回指定下标被替换掉的老值
add方法
// CopyOnWriteArrayList类 → add()方法
public void add(int index, E element) {// 获取锁/加锁final ReentrantLock lock = this.lock;lock.lock();try {// 获取内部存储数据的数组成员:arrayObject[] elements = getArray();int len = elements.length;// 如果指定下标位置超出数组长度或小于0则抛出异常if (index > len || index < 0)throw new IndexOutOfBoundsException("Index: "+index+", Size: "+len);// 创建一个新的数组对象Object[] newElements;// 计算插入的下标位置是在数组中间还在数组最后int numMoved = len - index;// 如果在数组最后,那么拷贝原本的数组并长度+1,留个空位if (numMoved == 0)newElements = Arrays.copyOf(elements, len + 1);// 如果要在数组中间插入数据else {// 先创建一个长度为len+1的新数组newElements = new Object[len + 1];// 然后将拷贝老数组中的所有数据拷贝过来// 但是将下标为index的位置空出来System.arraycopy(elements, 0, newElements, 0, index);System.arraycopy(elements, index, newElements, index + 1, numMoved);}// 将要添加的数据设置到数组的index下标位置newElements[index] = element;// 将成员array的引用从原本的数组改为新的数组setArray(newElements);} finally {// 释放锁/解锁lock.unlock();}
}
add()方法与set()方法参数是相同的,但区别在于:add方法不会替换指定下标位置之前的老值,而是将新值插入到数组中,执行流程如下:
- 加锁后获取数组数据、数组长度
- 判断要插入数据的下标位置是否超出数组长度+1或小于0,如果是则抛出异常
- 判断要插入数据的下标位置在数组中间还是在数组最后
- 如果是在最后位置插入,那么先创建一个长度+1的新数组,同时拷贝原有数组的所有数据,将要插入的数据添加到数组的最后位置,最后将array成员的引用指向新数组并释放锁
- 如果要插入的下标位置在数组中间,也会先创建一个长度+1的新数组,同时拷贝原有数组的所有数据,但是在拷贝时会将指定下标位置空出来,然后将要插入的数据添加到该位置,最后将array成员的引用指向新数组并释放锁
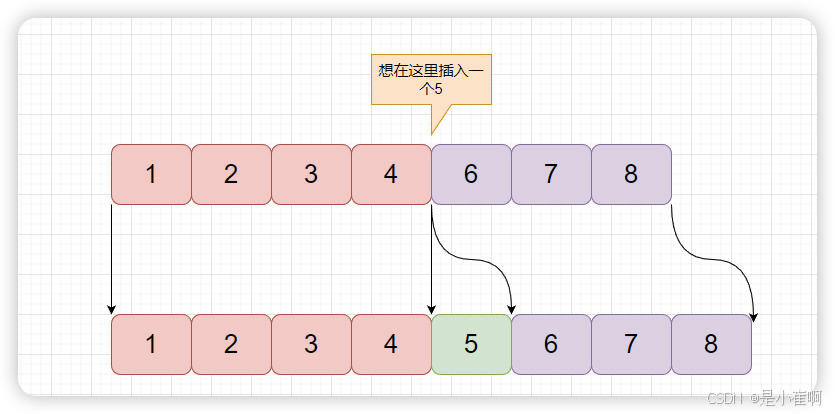
remove方法
// CopyOnWriteArrayList类 → remove()方法
public E remove(int index) {// 获取锁/加锁final ReentrantLock lock = this.lock;lock.lock();try {// 拷贝原本的数组Object[] elements = getArray();// 获取数组长度与数组中要移除的值int len = elements.length;E oldValue = get(elements, index);// 计算要移除的位置是在数组的最后还是在数组的中间int numMoved = len - index - 1;// 如果在数组最后if (numMoved == 0)// 拷贝数组时,将最后一个元素不拷贝即可// 拷贝完成后重新更改引用指向setArray(Arrays.copyOf(elements, len - 1));// 如果要移除的位置是在数组中间else {// 创建一个长度为原本长度-1的新数组Object[] newElements = new Object[len - 1];// 在拷贝数据时,将指定位置的元素不拷贝即可System.arraycopy(elements, 0, newElements, 0, index);System.arraycopy(elements, index + 1, newElements, index,numMoved);// 更改成员array的引用指向setArray(newElements);}// 返回被移除的值return oldValue;} finally {// 释放锁/解锁lock.unlock();}
}
remove()方法是移除容器中数据的方法,该方法需要传入要移除的下标位置,执行流程如下:
- 加锁后获取原本的数组数据及其长度,同时获取指定下标原有的值
- 判断要删除数据的下标位置在数组中间还是在数组最后
- 如果是在数组最后一个位置,则在拷贝数组数据时,不拷贝最后一个元素,完成后将array成员的引用指向新数组并释放锁
- 如果要删除的下标在数组中间位置,那么则先创建一个长度-1的新数组,同时在拷贝数据时,不拷贝指定下标位置的元素数据即可,完成后将array成员的引用指向新数组并释放锁
2:CopyOnWriteArraySet
CopyOnWriteArraySet的底层是CopyOnWriteArrayList,所以不再赘述
public class CopyOnWriteArraySet<E> extends AbstractSet<E>implements java.io.Serializable {// 内部存储数据的结构private final CopyOnWriteArrayList<E> al;// 构造器public CopyOnWriteArraySet() {al = new CopyOnWriteArrayList<E>();}
}
3:总结
关于写时复制的容器,优势比较明显,其内部充分运用了读写分离的思想提升了容器的整体并发吞吐量,以及避免了并发修改抛出异常。
但是也存在两个致命的缺陷:
- 内存占用问题。因为CopyOnWrite容器每次在发生修改时都会复制一个新的数组,所以当数组数据过大时对内存消耗比较高。
- 数据不一致性问题。CopyOnWrite容器保证的是最终一致性,一条线程在执行修改操作,另一条线程在执行读取操作,读取的线程并不能看到最新的数据,就算修改操作执行了
setArray()方法将指向改成了新数组,原本读取的线程也不能看到最新的数据。因为读取线程在执行读操作时并不是直接访问成员array完成的,而是通过getArray()方法的形式获取到的数组数据,在getArray()方法执行完成之后,读取数据的线程拿到的引用已经是旧数组的地址了,之后就算修改成员array的指向也不会影响get的访问。
⚠️ CopyOnWrite写时复制容器提升的只是读操作的吞吐量,而整个容器的写操作还是基于同一把独占锁保证的线程安全,所以如果需要频繁执行写操作的场景,并不适合用CopyOnWrite容器,同时还会因为复制带来的内存、时间开销导致性能下降。
四:锁分段容器(面)
1:HashMap原理回顾
HashMap是基于哈希表结构实现的一个容器,底层是基于数组+单向链表结构实现的,数组长度默认为16,每个数组下标的位置用于存储每个链表的头节点。
而链表的每个节点在JDK1.7中是Entity对象,Entity对象则由key、value以及next向下指针三个元素组成。
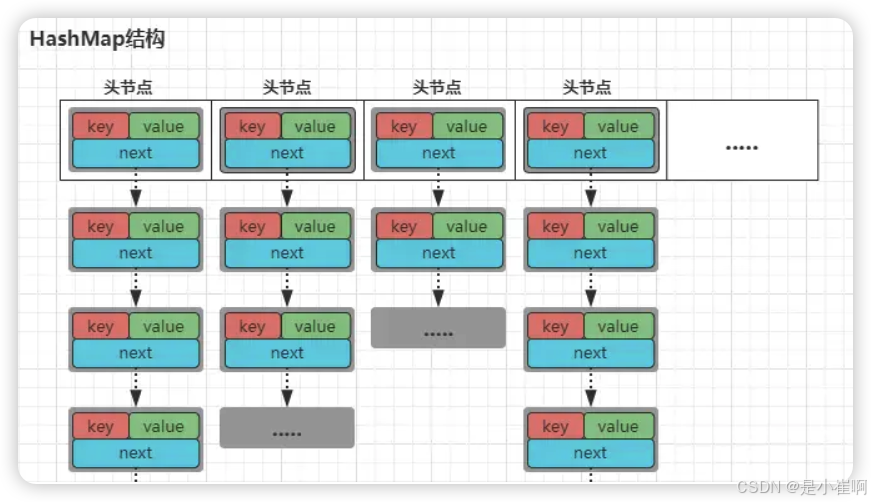
在HashMap中,结构采用的是数组+单向链表的形式存储数据(数组的每个位置也被称作为“桶”)
使用数组结构存储每个链表的头节点,如果某个数据经过计算后得到下标位置上已经有了数据,那么则追加在链表的尾部。
put原理
- 首先将
key-value封装成节点对象 - 调用
hashcode()方法计算出key的哈希值 - 通过哈希算法将哈希值转换为具体的下标值
- 根据计算出的下标位置将key-value数据进行存储。但在存储前会先判断该下标是否有数据:
- 如果没有:将该数据存储在数组的该下标位置,作为链表头节点
- 如果有:会用key值与链表每个节点的key值比较,如果相同则覆盖,如果全部不同则将数据使用头插法添加到链表的头部(jdk1.8之后是尾插法,追加到链表尾部)
get原理
- 调用
hashcode()方法计算出key的哈希值并计算出具体的下标值 - 通过下标值快速定位到数组的某个位置,首先会判断该位置上是否有数据:
- 如果没有:代表该位置还不存在链表,直接返回null
- 如果有:会用key值与链表每个节点的key值进行比较,相同则获取该节点的数据返回,如果遍历完整个链表后如果还是不存在返回null
⚠️ HashMap重写了equals()方法,因为equals()默认是比较内存地址,而重写后,在HashMap中是比较key值
resize原理
- 前置条件:默认容量=16,负载因子=0.75,阈值 = 容量*负载因子
- 扩容条件:当数组容器中的元素数量达到阈值时,会发生扩容动作
- 扩容实现过程:
- 当容量达到阈值时,创建一个2倍长度的新数组,调用
transfer()方法迁移数据 - 遍历原本老数组的所有元素(头节点),根据每个头节点循环每个链表,使用头插法将数据转移到新的数组中
- 当容量达到阈值时,创建一个2倍长度的新数组,调用
⚠️ 1.7中因为使用的是头插法,所以在多线程环境下容易导致死循环、数据丢失的问题。
Jdk1.8的改进
JDK1.8中,当链表长度大于8时,链表结构会转换为红黑树结构。
但前提是:当数组长度小于64时,如果有链表的长度大于8了,那么代表着当前数组中的数据哈希冲突比较严重,在这种情况下是不会直接发生红黑树转换的,而是会先对于数组进行扩容,扩容之后对数据重新进行哈希计算,重新散列分布。
所以其实真正的链表转红黑树的条件是:当数组长度已经超过64并且链表中的元素数量超过默认设定(8个)时,才会将链表转化为红黑树结构。
| 对比项 | JDK1.7 | JDK1.8 |
|---|---|---|
| 节点类型 | Entry | Node/TreeNode |
| 存储结构 | 数组+单向链表 | 数组+单向链表/红黑树 |
| 插入方式 | 头插法 | 尾插法 |
| 扩容时机 | 先扩容再插入 | 先插入再扩容 |
| 哈希算法 | 4次位运算+五次异或 | 1次位运算+1次异或 |
| 插入方式 | 数组+单向链表 | 数组+单向链表/红黑树 |
2:ConcurrentHashMap(1.7-)
2.1:概述
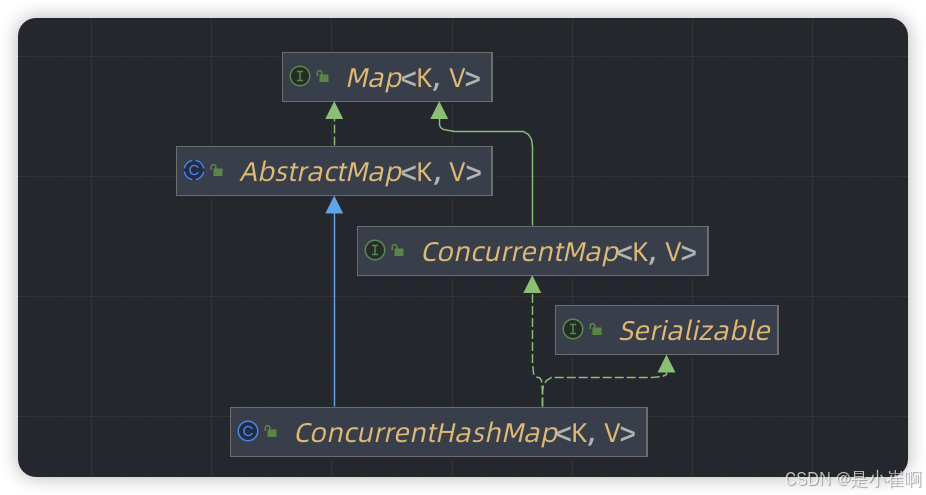
在多线程环境下使用HashMap是线程不安全的,而使用线程安全的HashTable效率又非常低下[全局锁],所以便诞生了ConcurrentHashMap
ConcurrentHashMap中采用了锁分段的技术实现了更细粒度的并发控制,从而提升了容器吞吐
在JDK1.7中,ConcurrentHashMap使用Segment数组+HashEntry数组+单向链表的方式实现。
而Segment继承了ReentrantLock,所以Segment对象也可以作为ConcurrentHashMap中的锁资源使用。结构如下:
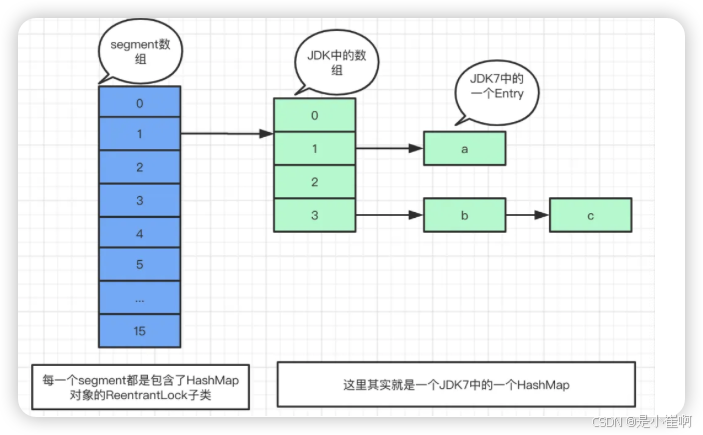
如上,ConcurrentHashMap的每个Segment(段)相当于一个HashTable容器【所有的方法都是synchronized的,所以是全局锁】
而Segment数组长度默认为16,但在创建时可以指定段数,必须为2的次幂,如果不为2的次幂则会自优化。
在写入数据时都会分段上锁,每个段之间互不影响。而当有线程读取数据时则不会加锁,但是在一个数据在读的时候发生了修改则会重新加锁读取一次。
🎉 在ConcurrentHashMap的每个段(Segment对象)中都存在一个计数器:volatile修饰的count变量,count表示每个段中的所有HashEntry数组中所有链表的数据总和数量。同时在每个段中还有一个modCount计数器,记录着当前这个段的写入操作次数,主要用于跨段操作时判断段中是否发生了更改操作。
2.2:put()原理
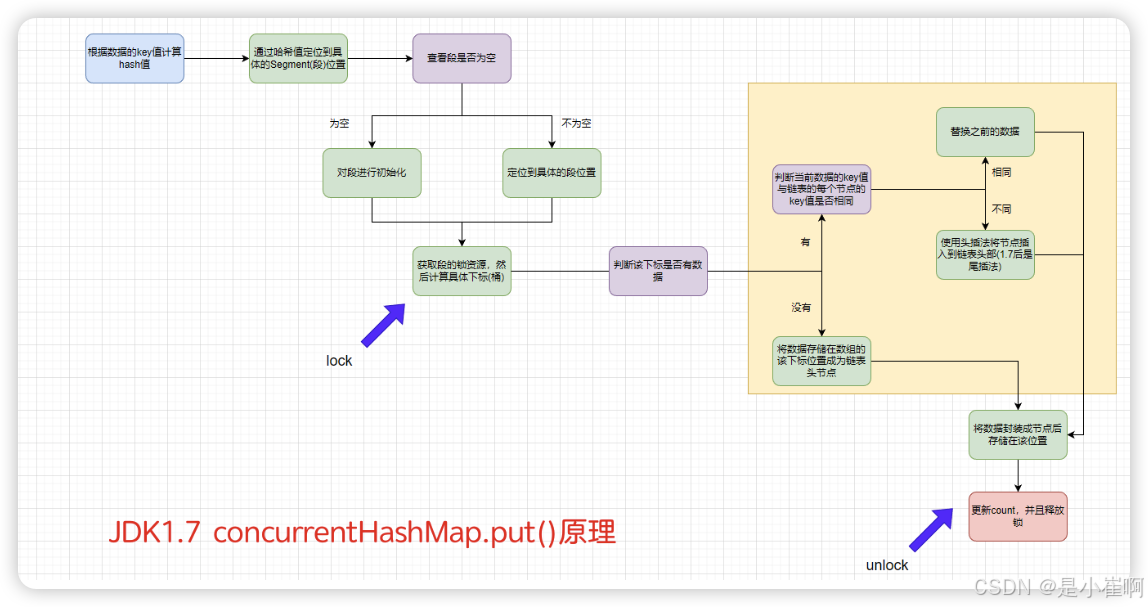
⚠️ ConcurrentHashMap中不允许key=null,也不允许value=null。 因为如果允许放入null,会产生二义性
2.3:get() 原理
- 根据数据的key值计算hash值,通过哈希值定位到具体的Segment(段)位置【定位段的位置,知道要上那条道去找】
- 再次根据哈希值在段中定位具体的数组位置,获取数组位置上存储的头节点【定位数组的位置,知道具体的位置】
- 根据头节点遍历整个链表,用传入的key值和每个节点的key值进行判断是否相同:【遍历具体位置的冲突链表,判断有没有相等的】
- 相同:返回该节点中存储的value值
- 全部不同:返回null
- 如果key值相同,但读到的value依旧为null时会加锁重读一次【因为ConcurrentHashMap中不允许value=null,所以当存在key,但value为null时可能是出现了指令重排导致数据暂时为null,所以需要加锁重读一次】
2.4:size原理
- 先记录所有段的modCount值且统计总和
- 统计所有段中记录元素个数的count成员总和
- 统计完成后再将之前记录的modCount与现在每个段中的modCount进行判断是否相同:
- 相同:代表统计前后没有发生写操作,直接返回求和所有段count的总数
- 不同:代表统计前后发生了写操作,重新再执行①②③步骤重新统计一次(最多执行三次)
- 如果统计三次后,每次统计总和前后都发生了写入操作,则对容器所有段上锁进行统计并返回
3:ConcurrentHashMap(1.8+)
在JDK1.8中,采用了更轻量级的Node数组+链表+红黑树+CAS+Synchronized关键字实现。
3.1:成员属性
// Node节点数组,该数组中每个位置要存储的元素为每个链表的头节点
transient volatile Node<K,V>[] table;
// 在扩容时过渡用的table表,扩容时节点会暂时转迁到这个数组
private transient volatile Node<K,V>[] nextTable;
// 计数器值=baseCount+每个CounterCell[i].value。所以baseCount只是计数器的一部分
private transient volatile long baseCount;
// 这个值在不同情况时存放值都不同,主要有如下几种情况:
// 1. 数组没新建时,暂时存储数组容量大小的数值
// 2. 数组正在新建时,该成员为-1
// 3. 数组正常情况时,存放阈值
// 4. 数组扩容时,高16bit存放旧容量唯一对应的一个标签值,低16bit存放进行扩容的线程数量
private transient volatile int sizeCtl;
//扩容时使用,正常情况时=0,扩容刚开始时为容量,代表下一次领取的扩容任务的索引上界
private transient volatile int transferIndex;
//CounterCell相配套一个独占锁
private transient volatile int cellsBusy;
//counterCells也是计数器的一部分
private transient volatile CounterCell[] counterCells;// 三种特殊的节点哈希值,一个节点正常的哈希值都为>=0的正数
// 此节点是扩容期间的转发节点,这个节点持有新table的引用
static final int MOVED = -1;
// 代表此节点是红黑树的节点
static final int TREEBIN = -2;
// 代表此节点是一个占位节点,不包含任何实际数据
static final int RESERVED = -3;
节点类型
ConcurrentHashMap的节点稍微有些复杂,如下:
- Node:如果数组某个下标位置(桶)的结构为单向链表,那所有数据会被封装成Node节点加入链表中。Node类的value与next指针都为volatile修饰的,保证了写操作的可见性
- TreeNode:如果数组某个下标位置(桶)的结构为红黑树结构,那么其桶内存储的节点则为TreeNode类型,而TreeBin是TreeNode的封装体,用作放在数组下标上作为根节点使用,但TreeBin并不是真正的根节点,根节点为其内部封装的root成员。这样包装的好处在于:因为红黑树随着平衡旋转操作,根节点随时可能发生变化,所以如果直接使用TreeNode作为根节点,数组上的成员会经常变化,而用TreeBin进行封装,可以让数组成员不会发生变化
- ForwardingNode:扩容期间的转发节点,这个节点持有新table的引用
- ReservationNode:占位节点,不包含任何实际数据
🎉 1.8的ConcurrentHashMap和1.8的HashMap链表转红黑树的时机是相同的,都为:当数组容量>=64且单个链表长度>=8
3.2:put原理
put()方法为整个ConcurrentHashMap的核心
// ConcurrentHashMap类 → put()方法
public V put(K key, V value) {// 调用其内部的putVal()方法return putVal(key, value, false);
}// ConcurrentHashMap类 → putVal()方法
final V putVal(K key, V value, boolean onlyIfAbsent) {// ================== 1:初始工作 ==================if (key == null || value == null) {throw new NullPointerException(); // // 检查key,value是否为空,如果有为空的,直接抛出空指针}// 根据key的原始哈希值计算新的哈希值,目的是为了找到桶int hash = spread(key.hashCode());// 代表一个位置下(桶)的节点数量int binCount = 0;// 开始遍历整个table数组(Node数组)for (Node<K,V>[] tab = table; ; ) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0) { // 情况1:如果数组还未初始化// 对数组进行初始化操作tab = initTable();} else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 情况2:如果通过哈希值计算出的下标位置为null// 使用CAS机制将现有数据封装成Node节点插入该位置成为头节点if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) {// 插入到空桶(空箱)时不需要上锁,也无法上锁break; } } else if ((fh = f.hash) == MOVED) {// 情况3:如果计算出的下标位置不为空,但节点的哈希值为MOVED -代表当前位置的桶正在执行扩容操作// 当前线程执行帮忙扩容操作tab = helpTransfer(tab, f);} else { // 情况4:如果计算出的下标位置不为空,且哈希值不为MOVEDV oldVal = null;// 以数组下标位置的元素(头节点)作为锁资源上锁synchronized (f) {// 加锁成功后要再次检查f是否为头节点if (tabAt(tab, i) == f) {// 如果哈希值>=0代表是正常节点if (fh >= 0) {// 把binCount=1binCount = 1;// 根据头节点遍历整个链表,每遍历一次对binCount+1for (Node<K,V> e = f;; ++binCount) {K ek;// 如果节点的key与传入的key相同if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {// 用新值替换旧值oldVal = e.val;if (!onlyIfAbsent)e.val = value;// 停止遍历操作break;}// 如果在整个链表中没有找到key值相同的节点Node<K,V> pred = e;// 找到链表尾部if ((e = e.next) == null) {// 将传入的数据封装成Node节点插入到链表尾部pred.next = new Node<K,V>(hash, key,value, null);// 插入完成后停止链表遍历操作break;}}}// 如果头节点是一个TreeBin类型// 代表当前位置的结构已经变为了红黑树结构else if (f instanceof TreeBin) {Node<K,V> p;// 把binCount=2,红黑树结构时binCount固定为2binCount = 2;// 将传入的k,v,hash值作为参数,调用putTreeVal方法// putTreeVal方法可能返回两种结果:// ①在整棵树中没有找到key相同的节点,新建Node插入返回null// ②找到key相同的节点并返回原本的value值// 如果找到了key值相同的节点if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {// 用新值替换旧值oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}// 如果binCount!=0,代表着当前线程肯定执行了写入操作if (binCount != 0) {// 如果链表节点数量达到了8if (binCount >= TREEIFY_THRESHOLD)// 执行扩容操作或链表转红黑树的操作treeifyBin(tab, i);// 如果这次put操作仅是新值换旧值,那么返回旧值if (oldVal != null)return oldVal;break;}}}// 如果本次put是插入操作,那么size增加1addCount(1L, binCount);// 并且返回nullreturn null;
}/*** 初始化table*/
private final Node<K,V>[] initTable() {// 声明标识Node<K,V>[] tab; int sc;// 再次判断数组有没有初始化,并且复制tabwhile ((tab = table) == null || tab.length == 0) {// 将sizeCtl赋值给sc变量,并且判断是否小于0if ((sc = sizeCtl) < 0)Thread.yield(); // 尝试让出线程占用,可能失败// 可以尝试初始化数组,线程会以CAS的方式,将sizeCtl修改成为-1, 代表当前的线程可以初始化数组else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {// 再次判断当前的数组是不是已经初始化完毕if ((tab = table) == null || tab.length == 0) {// 开始进行初始化// 如果sizeCtl > 0, 就初始化sizeCtl长度的数组// 如果sizeCtl == 0, 就初始化默认长度16的数组int n = (sc > 0) ? sc : DEFAULT_CAPACITY;// 初始化数组@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];// 将初始化的数组nt,复制给table & tabtable = tab = nt;// sc赋值为数组长度 - 数组长度右移2位 n - n / 4// 作为下次的阈值sc = n - (n >>> 2);}} finally {// 将复制好的sc,赋值给sizeCtlsizeCtl = sc;}break;}}return tab;
}
可见,复杂的部分都在情况四[put的正常情况],这里给出具体过程:
- 以头节点作为锁资源进行加锁操作,加锁成功后再次判断头节点是否被移除,没有则执行put操作
- 判断头节点的哈希值是否>=0,如果大于等于0说明是普通的链表的头结点,否则是红黑树
如果当前节点是普通的链表头节点
- 将binCount=1
- 根据头节点指针开始遍历整个链表,判断传入的key值是否与链表中节点的key值相同:
- 相同:代表是同一个key值,用新值替换旧值,返回旧值
- 不同:将数据封装成节点对象,使用尾插法插入到链表尾部,返回null
- ⚠️ :在遍历链表时,每遍历一个节点,binCount += 1
- 判断binCount是否>=8,如果是则代表当前链表过长,调用treeifBin方法扩容或树化
- 判断本次put操作是否为新值换旧值:
- 是:返回旧值
- 不是:代表是插入操作,那么对size+1,然后返回null
如果头节点的类型为TreeBin类型,代表当前位置(桶)的结构已经变为了红黑树
- 将binCount=2
- 调用putTreeVal()方法查找整棵树,查看是否有key值相同的节点:
- 有:返回旧值,在外部执行新值换旧值的操作,返回旧值
- 没有:将数据封装成树节点插入到红黑树中,返回null
- 判断本次put操作是否为新值换旧值:
- 是:返回旧值
- 不是:代表是插入操作,那么对size+1,然后返回null
两个疑问?
为什么当计算出的下标位置(桶)元素为空时,不加锁反而使用CAS机制添加元素?
因为1.8之后的ConcurrentHashMap是基于synchronized关键字实现锁机制的,而synchronized是基于对象上锁的,如果下标位置元素为空则代表没有头节点,那么无法基于头节点进行上锁,所以只能通过CAS机制进行添加,将第一个数据添加到下标位置变为头节点。
binCount这个值,在链表结构的情况下,遍历链表时,每遍历一个节点则binCount自增1,而在红黑树结构时,binCount保持为2,这是为什么?
因为binCount最终的作用是:判断当前位置是否发生扩容或者树化的,而只有链表结构的情况下需要扩容或树化。
3.3:get原理
public V get(Object key) {// 定义相关局部变量Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;// 通过key的hashcode计算新的哈希值int h = spread(key.hashCode());// 如果数组不为空,并且数组已经初始化,并且计算出的具体下标位置不为空if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 判断头节点的key是否与传入的key相同if ((eh = e.hash) == h) {// 相同则直接返回头节点中存储的value值if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}// 如果头节点的哈希值小于0,代表当前位置(桶)处于特殊状态,有如下三种:// ①为ForwardingNode节点:当前在扩容中,需转发到nextTable上查找// ②为TreeBin节点:代表当前位置是红黑树结构,需要二叉查找// ③为ReservationNode节点:代表当前槽位之前是null,是占位节点,所以直接返回nullelse if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;// 如果头节点为正常节点,那么根据next指针遍历整个链表while ((e = e.next) != null) {// 比较每个节点中的key值是否相同,相同则返回节点中的value值if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}// 在链表中没有找到key值相同的节点则返回nullreturn null;
}
- 通过传入的key值计算出新的哈希值
- 判断map内部的数组是否为空,是否已经初始化,key所在的位置(桶)是否为空
- 判断计算后的桶位置,头节点是否为要查找的数据,如果是则直接返回头节点的value
- 判断头节点的哈希值是否小于0,如果小于0代表当前位置(桶)处于特殊状态,有三种情况:
- 为ForwardingNode节点:当前在扩容中,需转发到nextTable上查找
- 为TreeBin节点:代表当前位置是红黑树结构,需要二叉查找
- 为ReservationNode节点:代表当前槽位之前是null,是占位节点,所以直接返回null
- 如果头节点为普通的链表节点,那么根据头节点遍历整个链表,判断每个节点中的key是否相同:
- 相同:返回对应节点中的value值
- 遍历完整个链表还找到key值相同的节点,代表没有这个数据,返回null

相关文章:

Java并发08 - 并发安全容器详解
并发容器详解 文章目录 并发容器详解一:不使用并发容器如何保证安全二:阻塞队列容器2:ArrayBlockingQueue2.1:内部成员2.2:put方法的实现2.3:take方法的实现 3:LinkedBlockingQueue3.1ÿ…...
)
抽奖系统(3——奖品模块)
1. 图片上传 application.properties 配置上传文件路径 ## 文件上传 ## # 目标路径 pic.local-pathD:/PIC # spring boot3 升级配置名 spring.web.resources.static-locationsclasspath:/static/,file:${pic.local-path} tip: 1. 如果访问的是本地路径,…...

36.centos7上安装python3.6.5、安装卸载依赖包
查看openssl的版本号,默认python3.6.5需要OpenSSL 1.0.2以上的版本支持。 监测安装好的python,是否可以正确导入ssl和_ssl包 pip3安装依赖包 通过Pycharm工具导出requirements.txt文件 查看/usr/bin/目录下的软连接 pip3, python...

微透镜阵列精准全检,白光干涉3D自动量测方案提效70%
广泛应用的微透镜阵列 微透镜是一种常见的微光学元件,通过设计微透镜,可对入射光进行扩散、光束整形、光线均分、光学聚焦、集成成像等调制,进而实现许多传统光学元器件难以实现的特殊功能。 微透镜阵列(Microlens Array&#x…...

nature genetics | scATAC-seq预测scRNA-seq,识别影响基因表达的新染色质区域
–https://doi.org/10.1038/s41588-024-01689-8 Single-cell multi-ome regression models identify functional and disease-associated enhancers and enable chromatin potential analysis 研究团队和单位 Christina S. Leslie–Memorial Sloan Kettering Cancer Center …...

简述mysql 主从复制原理及其工作过程,配置一主两从并验证。
MySQL 主从同步是一种数据库复制技术,它通过将主服务器上的数据更改复制到一个或多个从服务器,实现数据的自动同步。 主从同步的核心原理是将主服务器上的二进制日志复制到从服务器,并在从服务器上执行这些日志中的操作。 MySQL主从同步是基…...

Java API:封装自定义响应类
本文介绍 Web 服务开发中自定义响应,涵盖标准 HTTP 响应状态码局限性、自定义响应价值、设计原则与实现、在 Spring Boot 项目应用、与其他响应格式对比总结及应用场景。 1. 标准HTTP响应与自定义响应 1.1标准HTTP响应状态码 在 Web 服务开发中,HTTP…...

【Unity3D】利用Hinge Joint 2D组件制作绳索效果
目录 一、动态绳索 (可移动根节点) 二、静态绳索 三、利用Skinning Editor(Unity2022.3.15f1正常使用) 四、注意事项 一、动态绳索 (可移动根节点) 动态绳索 DynamicRope空物体 Anchor和whitecircle是相同位置的物体ÿ…...
)
vim练级攻略(精简版)
vim推荐配置: curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh 0. 规定 Ctrl-λ 等价于 <C-λ> :command 等价于 :command <回车> n 等价于 数字 blank字符 等价于 空格,tab&am…...

嵌入式硬件篇---PID控制
文章目录 前言第一部分:连续PID1.比例(Proportional,P)控制2.积分(Integral,I)控制3.微分(Derivative,D)控制4.PID的工作原理5..实质6.分析7.各种PID控制器P控…...

技术洞察:C++在后端开发中的前沿趋势与社会影响
文章目录 引言C在后端开发中的前沿趋势1. 高性能计算的需求2. 微服务架构的兴起3. 跨平台开发的便利性 跨领域技术融合与创新实践1. C与人工智能的结合2. C与区块链技术的融合 C对社会与人文的影响1. 提升生产力与创新能力2. 促进技术教育与人才培养3. 技术与人文的深度融合 结…...

C语言程序设计之小系统
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 目录 系统说明 1.1 系统概述 1.2 功能模块总体设计详细设计 3.1 程序中使用的函数 3.2各类问…...

pyinstaller : 无法将“pyinstaller”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。
pyinstaller : 无法将“pyinstaller”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。 所在位置 行:1 字符: 1pyinstaller --onefile --windowed 过年烟花.py~~~~~~~~~~~ …...

接口传参 data格式和json格式区别是什么
接口传参 data格式和json格式区别是什么 以下是接口传参 data 格式和 JSON 格式的区别: 定义和范围 Data 格式: 是一个较为宽泛的概念,它可以指代接口传递参数时所使用的任何数据的组织形式。包括但不限于 JSON、XML、Form 数据、纯文本、二进…...

ClickHouse 入门
简介 ClickHouse 是一个列式数据库,传统的数据库一般是按行存储,而ClickHouse则是按列存储,每一列都有自己的存储空间,并且只存储该列的数值,而不是存储整行的数据。这样做主要有几个好处,压缩率高&#x…...
)
Python自动化:基于faker批量生成模拟数据(以电商行业销售数据为例)
引言:个人认为,“造数据”是一个数据分析师的一项基本技能,当然啦,“造数据”不是说胡编乱造,而是根据自己的需求去构造一些模拟数据集,用于测试等用途,而且使用虚拟数据不用担心数据隐私和安全…...

3.3 OpenAI GPT-4, GPT-3.5, GPT-3 模型调用:开发者指南
OpenAI GPT-4, GPT-3.5, GPT-3 模型调用:开发者指南 OpenAI 的 GPT 系列语言模型,包括 GPT-4、GPT-3.5 和 GPT-3,已经成为自然语言处理领域的标杆。无论是文本生成、对话系统,还是自动化任务,开发者都可以通过 API 调用这些强大的模型来增强他们的应用。本文将为您详细介…...

【Spring Boot】掌握 Spring 事务:隔离级别与传播机制解读与应用
前言 🌟🌟本期讲解关于spring 事务传播机制介绍~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么废话…...

力扣203题—— 移除链表元素
题目 递归法使用 if(headnull){return null; }//假设remove返回后面已经去掉val值的链表 我们用head.next去存放他,接着我们要判断此时head head值是否等于val,如果等于我们就返回后继元素即可 head.nextremove(head.next,val); if(head.valval){return…...

Express中间件
目录 Express中间件 中间件的概念 next函数 全局中间与局部中间件 多个中间件 中间的5个注意事项 中间的分类 应用级中间件 路由级中间件 错误级中间件 Express内置中间件 express.json express.urlencoded 第三方中间件编辑 自定义中间件 Express中间件 中间…...

【AIGC】SYNCAMMASTER:多视角多像机的视频生成
标题:SYNCAMMASTER: SYNCHRONIZING MULTI-CAMERA VIDEO GENERATION FROM DIVERSE VIEWPOINTS 主页:https://jianhongbai.github.io/SynCamMaster/ 代码:https://github.com/KwaiVGI/SynCamMaster 文章目录 摘要一、引言二、使用步骤2.1 TextT…...

模块化架构与微服务架构,哪种更适合桌面软件开发?
前言 在现代软件开发中,架构设计扮演着至关重要的角色。两种常见的架构设计方法是模块化架构与微服务架构。它们各自有独特的优势和适用场景,尤其在C#桌面软件开发领域,模块化架构往往更加具有实践性。本文将对这两种架构进行对比࿰…...

Ubuntu 24.04 LTS 安装 tailscale 并访问 SMB共享文件夹
Ubuntu 24.04 LTS 安装 tailscale 安装 Tailscale 官方仓库 首先,确保系统包列表是最新的: sudo apt update接下来,安装 Tailscale 所需的仓库和密钥: curl -fsSL https://tailscale.com/install.sh | sh这会自动下载并安装 …...

fgets、scanf存字符串应用
题目1 夺旗(英语:Capture the flag,简称 CTF)在计算机安全中是一种活动,当中会将“旗子”秘密地埋藏于有目的的易受攻击的程序或网站。参赛者从其他参赛者或主办方偷去旗子。 非常崇拜探姬的小学妹最近迷上了 CTF&am…...

C#高级:用Csharp操作鼠标和键盘
一、winform 1.实时获取鼠标位置 public Form1() {InitializeComponent();InitialTime(); }private void InitialTime() {// 初始化 Timer 控件var timer new System.Windows.Forms.Timer();timer.Interval 100; // 设置为 100 毫秒,即每 0.1 秒更新一次timer.…...

关于AI agent的学术论文实验部分:准确率,响应时间,用户满意度
关于AI agent的学术论文实验部分 在撰写关于AI agent的学术论文时,实验设计和实施是关键部分,仅搭建完成AI agent通常是不够的,需要通过严谨的实验来验证其性能、效果和创新性。以下以一个在智能客服场景中应用AI agent的例子,说明如何完成实验: 明确实验目的:确定通过实…...

消息队列实战指南:三大MQ 与 Kafka 适用场景全解析
前言:在当今数字化时代,分布式系统和大数据处理变得愈发普遍,消息队列作为其中的关键组件,承担着系统解耦、异步通信、流量削峰等重要职责。ActiveMQ、RabbitMQ、RocketMQ 和 Kafka 作为市场上极具代表性的消息队列产品࿰…...

postgresql表分区及测试
本文主要采用list类型实现表分区,并对表分区数据进行查询对比,数据量6000万条以上,速度相差10倍以上。 一、创建表,以substationcode字段为ist类型表分区 CREATE TABLE "public"."d_population_partition" …...
1__创建VUE实例)
VUE学习笔记(入门)1__创建VUE实例
核心步骤 <div id"app"><!-- 这里存放渲染逻辑代码 --><h1>{{ msg }}</h1><a href"#">{{count}}</a> </div><!-- 引入在线的开发版本核心包 --> <!-- 引入核心包后全局可使用VUE构造函数 --> <…...

STL—stack与queue
目录 Stack stack的使用 stack的模拟实现 queue queue的使用 queue的模拟实现 priority_queue priority_queue的用法 priority_queue的模拟实现 容器适配器 种类 Stack http://www.cplusplus.com/reference/stack/stack/?kwstack stack是栈,后入先出 stack的…...

pthread_create函数
函数原型 pthread_create 是 POSIX 线程(pthread)库中的一个函数,用于在程序中创建一个新线程。 #include <pthread.h>int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *a…...

suctf2025
Suctf2025 --2标识为看的wp,没环境复现了 所有参考资料将在文本末尾标明 WEB SU_photogallery 思路👇 构造一个压缩包,解压出我们想解压的部分,然后其他部分是损坏的,这样是不是就可以让整个解压过程是出错的从而…...

二、点灯基础实验
嵌入式基础实验第一个就是点灯,地位相当于编程界的hello world。 如下为LED原理图,要让相应LED发光,需要给I/O口设置输出引脚,低电平,二极管才会导通 2.1 打开初始工程,编写代码 以下会实现BLINKY常亮&…...

ESP8266-01S、手机、STM32连接
1、ESP8266-01S的工作原理 1.1、AP和STA ESP8266-01S为WIFI的透传模块,主要模式如下图: 上节说到,我们需要用到AT固件进行局域网应用(ESP8266连接的STM32和手机进行连接)。 ESP8266为一个WiFi透传模块,和…...

微服务学习:基础理论
一、微服务和应用现代化 1、时代的浪潮,企业的机遇和挑战 在互联网化数字化智能化全球化的当今社会,IT行业也面临新的挑战: 【快】业务需求如“滔滔江水连绵不绝”,企业需要更快的交付【变】林子大了,百色用户&…...

【c++继承篇】--继承之道:在C++的世界中编织血脉与传承
目录 引言 一、定义二、继承定义格式2.1定义格式2.2继承关系和访问限定符2.3继承后子类访问权限 三、基类和派生类赋值转换四、继承的作用域4.1同名变量4.2同名函数 五、派生类的默认成员构造函数5.1**构造函数调用顺序:**5.2**析构函数调用顺序:**5.3调…...

Java操作Excel导入导出——POI、Hutool、EasyExcel
目录 一、POI导入导出 1.数据库导出为Excel文件 2.将Excel文件导入到数据库中 二、Hutool导入导出 1.数据库导出为Excel文件——属性名是列名 2.数据库导出为Excel文件——列名起别名 3.从Excel文件导入数据到数据库——属性名是列名 4.从Excel文件导入数据到数据库…...
)
基于VSCODE+GDB+GDBSERVER远程单步调试设备篇(可视化界面)
目录 说明 配置方法 1)VSCODE必备插件 2)配置launch.json文件,用于GDB调试 调试步骤 目标板运行程序 1)已启动程序,通过attach方式进入调试 2)通过gdbserver启动时加载程序(程序路径根据实际情…...
)
【设计模式】 单例模式(单例模式哪几种实现,如何保证线程安全,反射破坏单例模式)
单例模式 作用:单例模式的核心是保证一个类只有一个实例,并且提供一个访问实例的全局访问点。 实现方式优缺点饿汉式线程安全,调用效率高 ,但是不能延迟加载懒汉式线程安全,调用效率不高,能延迟加载双重检…...

lvm快照备份
前提 数据文件要在逻辑卷上; 此逻辑卷所在卷组必须有足够空间使用快照卷; 数据文件和事务日志要在同一个逻辑卷上; 前提:MySQL数据lv和将要创建的快照要在同一vg,vg要有足够的空间存储 优点 几乎是热备&…...

PHP CRM售后系统小程序
💼 CRM售后系统 📺这是一款基于PHP和uniapp深度定制的CRM售后管理系统,它犹如企业的智慧核心,精准赋能销售与售后管理的每一个环节,引领企业步入精细化、数字化的全新管理时代。系统集成了客户管理、合同管理、工单调…...

ETL 数据抽取
ETL ETL 数据抽取 ETL(Extract, Transform, Load)是数据集成和处理的重要过程,其中数据抽取(Extract)是第一步,负责从各种数据源中提取数据。以下是ETL数据抽取的详细说明和常用工具: 1. 数据…...
)
FANUC机器人系统镜像备份与恢复的具体步骤(图文)
FANUC机器人系统镜像备份与恢复的具体步骤(图文) 镜像备份: 如下图所示,进入文件—工具—切换设备,找到插入的U盘UT1, 如下图所示,进入U盘目录后,创建目录,这里目录名称为11, 如下图所示...

MindsDB - 构建企业数据源 AI 对话
一、关于 MindsDB MindsDB是世界上最有效的解决方案,用于构建与混乱的企业数据源对话的AI应用程序。把它想象成图书管理员Marie Kondo。 github : https://github.com/mindsdb/mindsdb官网:https://www.mindsdb.com/官方文档:https://docs.…...
)
正则表达式(python版最全面,最易懂)
正则表达式 正则表达式英文称regular expression 定义:正则表达式是一种文本模式匹配的工具,用于字符串的搜索,匹配和替换。在excel,word以及其他的文本编辑器都可直接适配。 一、基本匹配规则 字面值字符:例如字母、数字、空格…...

QT 使用QTableView读取数据库数据,表格分页,跳转,导出,过滤功能
文章目录 效果图概述功能点代码分析导航栏表格更新视图表格导出表格过滤 总结 效果图 概述 本案例用于对数据库中的数据进行显示等其他操作。数据库的映射,插入等功能看此博客框架:数据模型使用QSqlTableModel,视图使用QTableView࿰…...

golang标准库path/filepath使用示例
文章目录 前言一、常用方法示例1.将相对路径转换为绝对路径2.获取路径中最后一个元素3.获取路径中除去最后一个元素的部分4.路径拼接5.将路径拆分为目录和文件名两部分6.返回一个相对路径7.文件路径遍历8.根据文件扩展名过滤文件9.使用正则表达式进行路径匹配 前言 path/filep…...
 ❀ 01. 在macOS下刷新FortiAnalyzer固件 ❀ FortiAnalyzer 日志分析)
【日志篇】(7.6) ❀ 01. 在macOS下刷新FortiAnalyzer固件 ❀ FortiAnalyzer 日志分析
【简介】FortiAnalyzer 是 Fortinet Security Fabric 安全架构的基础,提供集中日志记录和分析,以及端到端可见性。因此,分析师可以更有效地管理安全状态,将安全流程自动化,并快速响应威胁。具有分析和自动化功能的集成…...

12 分布式事务
分布式事务产生的原因 我们拿mysql数据库来说,当数据库为单体数据库的时候,我们打开事务,执行sql为预执行阶段,最后commit时通过日志控制最终全部提交后存储到磁盘中,如果commit失败,可以通过日志控制回滚…...

移远通信多模卫星通信模组BG95-S5获得Skylo网络认证,进一步拓展全球卫星物联网市场
近日,全球领先的物联网整体解决方案供应商移远通信正式宣布,其支持“卫星蜂窝”多模式的高集成度NTN卫星通信模组BG95-S5已成功获得NTN网络运营商Skylo的网络认证。BG95-S5也成为了获得该认证的最新款移远卫星通信模组。 BG95-S5模组顺利获得Skylo认证&a…...