机器学习头歌(第三部分-强化学习)
一、强化学习及其关键元素


二、强化学习的分类



三、任务与奖赏


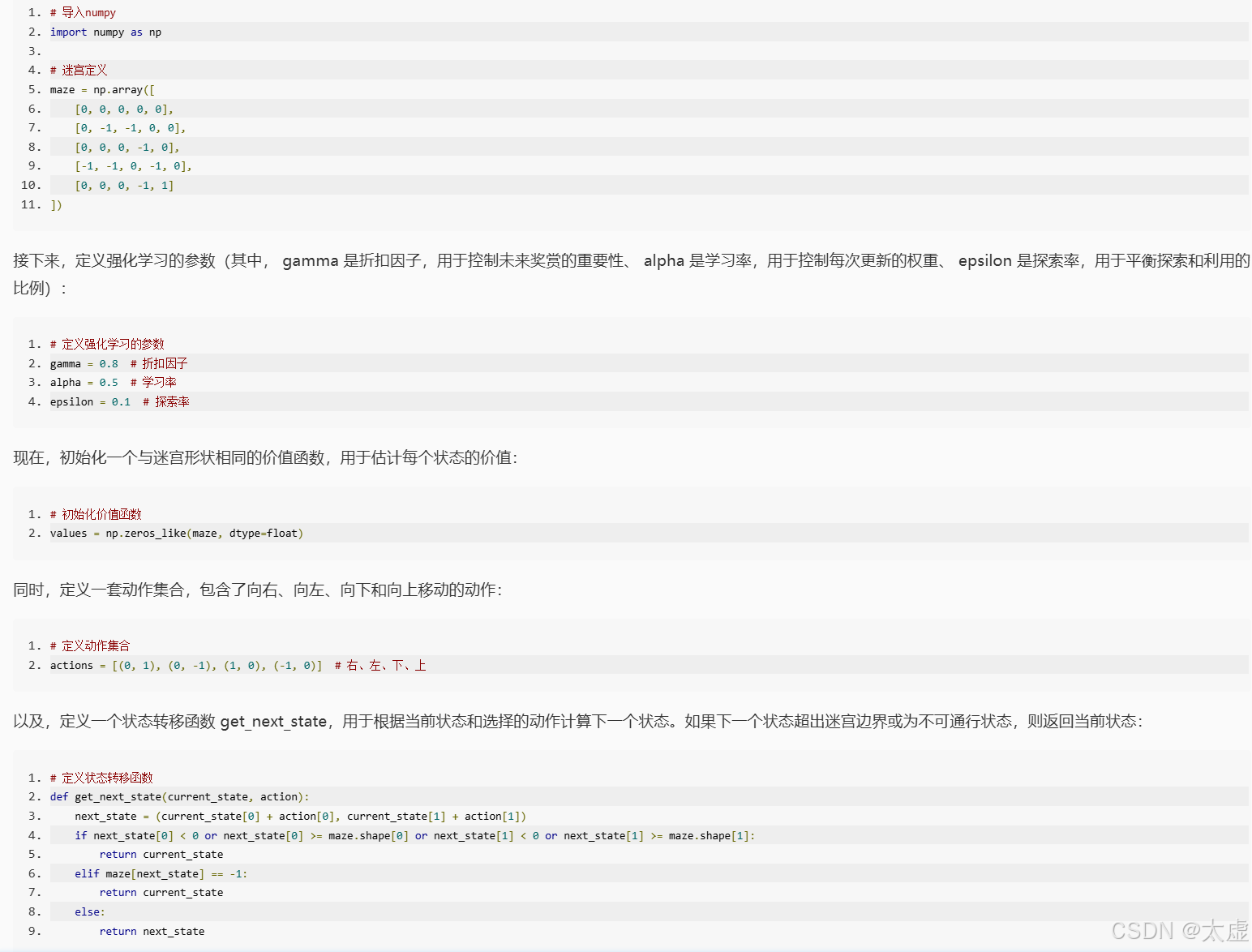


import numpy as np# 迷宫定义
maze = np.array([[0, 0, 0, 0, 0],[0, -1, -1, 0, 0],[0, 0, 0, -1, 0],[-1, -1, 0, -1, 0],[0, 0, 0, -1, 1]
])# 定义强化学习的参数
gamma = 0.8 # 折扣因子
alpha = 0.5 # 学习率
epsilon = 0.1 # 探索率# 初始化价值函数
values = np.zeros_like(maze, dtype=float)# 定义动作集合
actions = [(0, 1), (0, -1), (1, 0), (-1, 0)] # 右、左、下、上# 定义状态转移函数
def get_next_state(current_state, action):next_state = (current_state[0] + action[0], current_state[1] + action[1])if next_state[0] < 0 or next_state[0] >= maze.shape[0] or next_state[1] < 0 or next_state[1] >= maze.shape[1]:return current_stateelif maze[next_state] == -1:return current_stateelse:return next_state# 进行强化学习训练
num = 0
for _ in range(10):# 请在下面的 Begin-End 之间按照注释中给出的提示编写正确的代码########## Begin ##########state = (0, 0) # 初始状态while state != (4, 4): # 未到达目标状态时if np.random.rand() < epsilon: # 探索action = actions[np.random.randint(len(actions))]else: # 利用action_values = []for a in actions:next_state = get_next_state(state, a)action_values.append(values[next_state])max_value = np.max(action_values)max_indices = [i for i, v in enumerate(action_values) if v == max_value]action_index = np.random.choice(max_indices)action = actions[action_index]next_state = get_next_state(state, action)reward = maze[next_state]values[state] += alpha * (reward + gamma * values[next_state] - values[state])state = next_state########## End ##########next_state = get_next_state(state, action)reward = maze[next_state]values[state] += alpha * (reward + gamma * values[next_state] - values[state])state = next_statenum = num + 1四、K-摇臂赌博机
1.探索与利用




import numpy as np# 请在下面的 Begin-End 之间按照注释中给出的提示编写正确的代码
########## Begin ########### 定义k-摇臂赌博机类
# 定义k-摇臂赌博机类
class Bandit:def __init__(self, k):self.k = kself.q_star = np.random.normal(0, 1, k) # 真实回报分布# 选择拉杆并获得奖励def pull(self, action):reward = np.random.normal(self.q_star[action], 1)return reward# 选择摇臂
actions=6# 第六步:创建一个 10-摇臂赌博机实例
bandit = Bandit(k=10)# 第七步:完成一次摇臂选择和奖励获取
reward = bandit.pull(actions)# 选择摇臂
actions=6########## End ##########2.ϵ -贪心


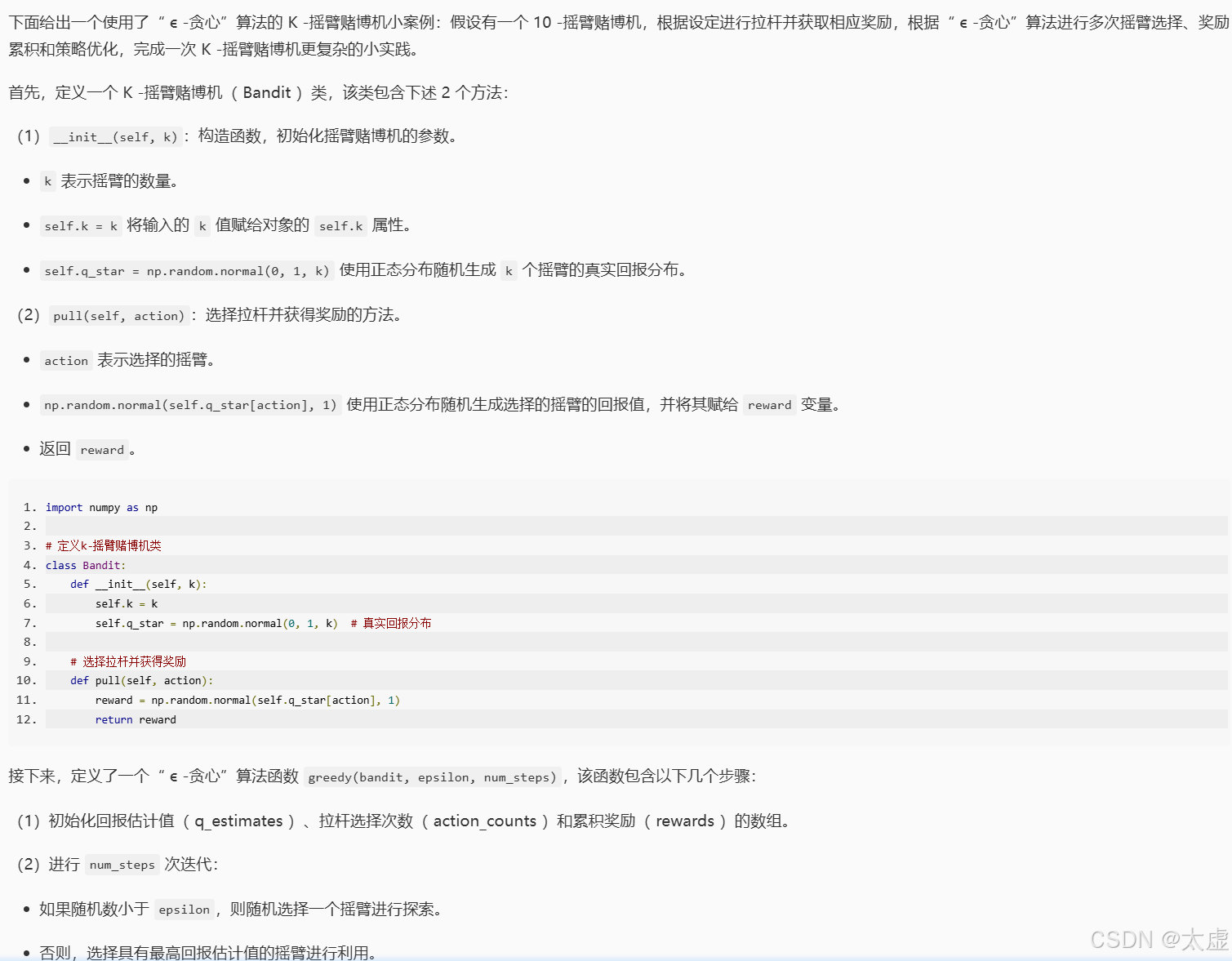


import numpy as np# 定义k-摇臂赌博机类
class Bandit:def __init__(self, k):self.k = kself.q_star = np.random.normal(0, 1, k) # 真实回报分布# 选择拉杆并获得奖励def pull(self, action):reward = np.random.normal(self.q_star[action], 1)return reward# 请在下面的 Begin-End 之间按照注释中给出的提示编写正确的代码
########## Begin ########### 贪心算法
def greedy(bandit, epsilon, num_steps):q_estimates = np.zeros(bandit.k) # 回报估计值action_counts = np.zeros(bandit.k) # 拉杆选择次数rewards = np.zeros(num_steps) # 累积奖励for step in range(num_steps):if np.random.random() < epsilon:# 随机选择拉杆进行探索action = np.random.randint(0, bandit.k)else:# 选择具有最高回报估计值的拉杆进行利用action = np.argmax(q_estimates)reward = bandit.pull(action)action_counts[action] += 1q_estimates[action] += (reward - q_estimates[action]) / action_counts[action]rewards[step] = rewardreturn rewards
########## End ########### 创建一个k-摇臂赌博机实例
bandit = Bandit(k=10)# 使用贪心算法进行探索与利用
epsilon = 0.1
num_steps = 10
rewards_greedy = greedy(bandit, epsilon, num_steps)3.Softmax




import numpy as np# 定义k-摇臂赌博机类
class Bandit:def __init__(self, k):self.k = kself.q_star = np.random.normal(0, 1, k) # 真实回报分布# 选择拉杆并获得奖励def pull(self, action):reward = np.random.normal(self.q_star[action], 1)return reward# 请在下面的 Begin-End 之间按照注释中给出的提示编写正确的代码
########## Begin ########### Softmax算法
def softmax(bandit, temperature, num_steps):action_preferences = np.zeros(bandit.k) # 拉杆的偏好值rewards = np.zeros(num_steps) # 累积奖励for step in range(num_steps):action_probs = np.exp(action_preferences / temperature) / np.sum(np.exp(action_preferences / temperature))action = np.random.choice(range(bandit.k), p=action_probs)reward = bandit.pull(action)action_preferences[action] += rewardrewards[step] = rewardreturn rewards########## End ########### 创建一个k-摇臂赌博机实例
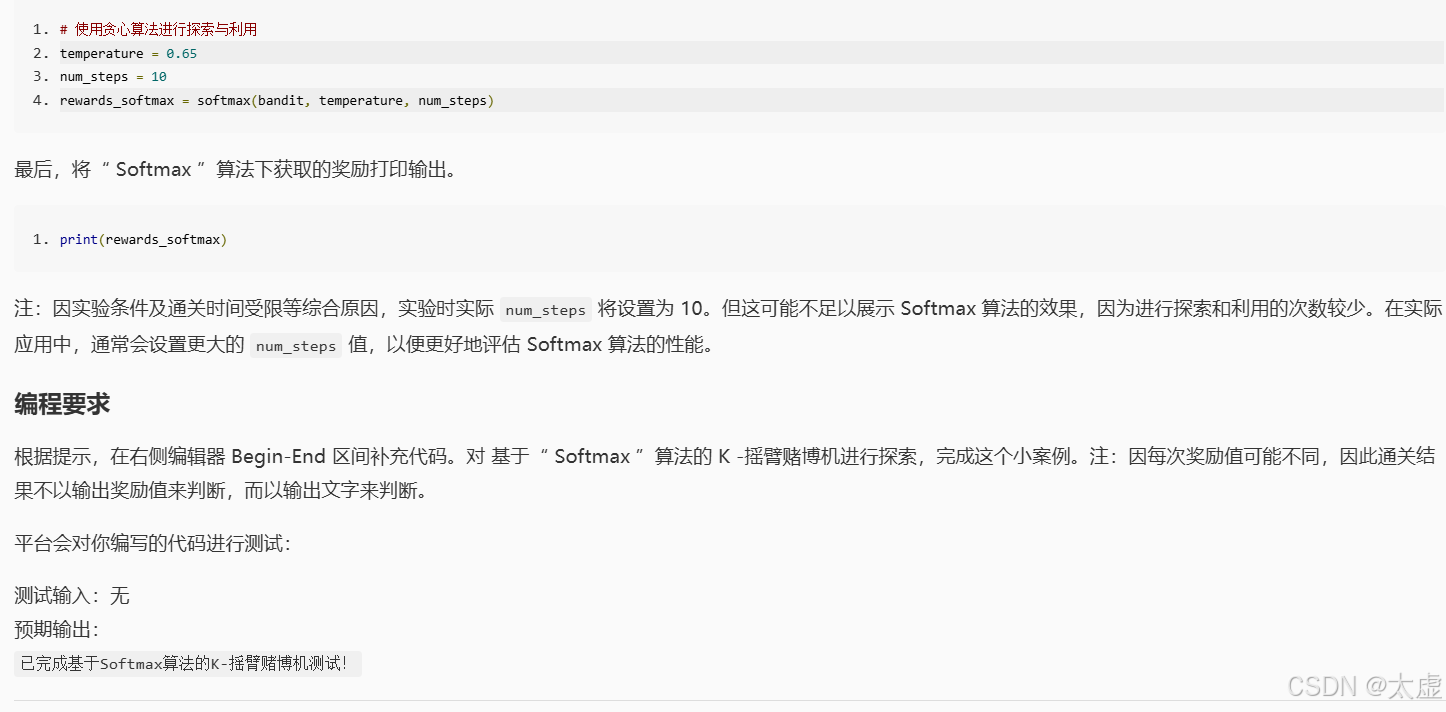
bandit = Bandit(k=10)# 使用Softmax算法进行探索与利用
temperature = 0.65
num_steps = 10
rewards_softmax = softmax(bandit, temperature, num_steps)
五、有模型学习
1.策略评估




2.策略改进




import numpy as np# 定义一个简单的环境类
class Environment:def __init__(self):self.num_states = 3self.num_actions = 2self.transition_matrix = np.array([[[0.6, 0.2, 0.2], [0.2, 0.6, 0.2], [0.4, 0.4, 0.2]], # 状态0对应的两个动作的转移概率[[0.3, 0.3, 0.4], [0.4, 0.3, 0.3], [0.9, 0.05, 0.05]], # 状态1对应的两个动作的转移概率[[0.1, 0.3, 0.6], [0.5, 0.2, 0.3], [0.1, 0.4, 0.5]] # 状态2对应的两个动作的转移概率])self.reward_matrix = np.array([[1, -1, 0], # 状态0对应的两个动作的奖励[-1, 1, 0], # 状态1对应的两个动作的奖励[0, 0, 1] # 状态2对应的两个动作的奖励])def step(self, state, action):next_state = np.random.choice(range(self.num_states), p=self.transition_matrix[state][action])reward = self.reward_matrix[state][action]return next_state, reward# 策略评估算法
def policy_evaluation(env, policy, gamma, theta, num_iterations):V = np.zeros(env.num_states) # 初始化状态价值函数for i in range(num_iterations):delta = 0for s in range(env.num_states):v = V[s]q_values = np.zeros(env.num_actions)for a in range(env.num_actions):for s_next in range(env.num_states):p = env.transition_matrix[s][a][s_next]r = env.reward_matrix[s][a]q_values[a] += p * (r + gamma * V[s_next])V[s] = np.sum(policy[s] * q_values)delta = max(delta, abs(v - V[s]))if delta < theta:breakreturn V# 请在下面的 Begin-End 之间按照注释中给出的提示编写正确的代码
########## Begin ########### 策略改进算法
# 策略改进算法
def policy_improvement(env, policy, gamma, theta, num_iterations):while True:V = policy_evaluation(env, policy, gamma, theta, num_iterations)policy_stable = Truefor s in range(env.num_states):old_action = np.argmax(policy[s]) # 记录旧的行动q_values = np.zeros(env.num_actions)for a in range(env.num_actions):for s_next in range(env.num_states):p = env.transition_matrix[s][a][s_next]r = env.reward_matrix[s][a]q_values[a] += p * (r + gamma * V[s_next])best_action = np.argmax(q_values) # 寻找最优行动policy[s] = np.eye(env.num_actions)[best_action]if old_action != best_action:policy_stable = Falseif policy_stable:breakreturn V########## End ########### 创建一个环境实例
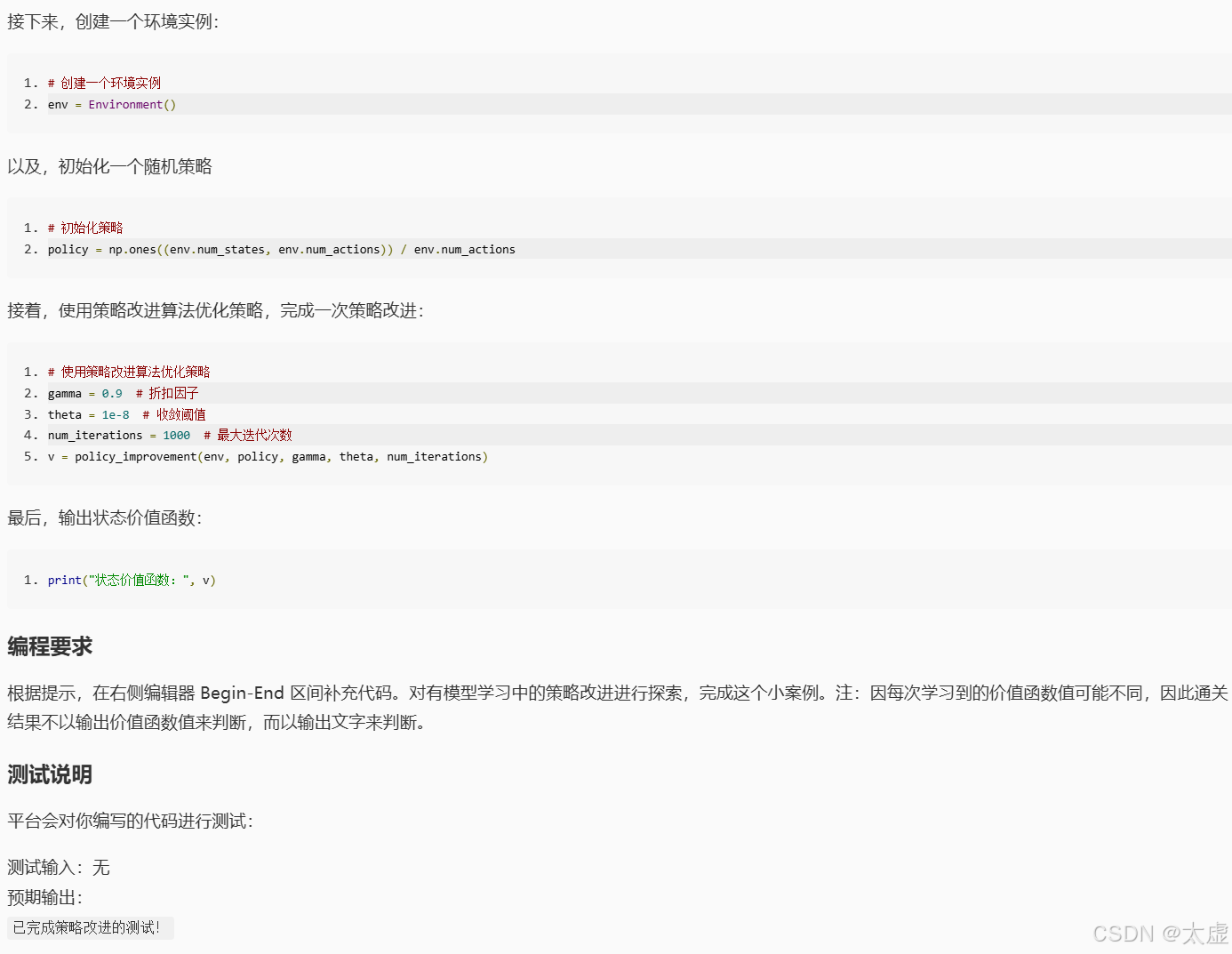
env = Environment()# 初始化一个随机策略
policy = np.ones((env.num_states, env.num_actions)) / env.num_actions# 使用策略改进算法优化策略
gamma = 0.9 # 折扣因子
theta = 1e-8 # 收敛阈值
num_iterations = 1000 # 最大迭代次数
v = policy_improvement(env, policy, gamma, theta, num_iterations)3.策略迭代与值迭代









import gym
import numpy as npdef policy_evaluation(env, policy, gamma=0.9, threshold=1e-6):num_states = env.observation_space.nnum_actions = env.action_space.n# 初始化值函数values = np.zeros(num_states)while True:delta = 0for state in range(num_states):v = values[state]# 根据贝尔曼方程更新值函数q_values = np.zeros(num_actions)for action in range(num_actions):for prob, next_state, reward, _ in env.P[state][action]:q_values[action] += prob * (reward + gamma * values[next_state])# 更新值函数values[state] = np.sum(policy[state] * q_values)delta = max(delta, np.abs(v - values[state]))if delta < threshold:breakreturn values# 请在下面的 Begin-End 之间按照注释中给出的提示编写正确的代码
########## Begin ##########def policy_iteration(env, gamma=0.9, max_iterations=10000):num_states = env.observation_space.nnum_actions = env.action_space.n# 初始化策略函数policy = np.ones((num_states, num_actions)) / num_actionsfor _ in range(max_iterations):# 策略评估values = policy_evaluation(env, policy, gamma)policy_stable = Truefor state in range(num_states):old_action = np.argmax(policy[state])# 策略改进q_values = np.zeros(num_actions)for action in range(num_actions):for prob, next_state, reward, _ in env.P[state][action]:q_values[action] += prob * (reward + gamma * values[next_state])new_action = np.argmax(q_values)if old_action != new_action:policy_stable = Falsepolicy[state] = np.eye(num_actions)[new_action]if policy_stable:breakreturn policydef value_iteration(env, gamma=0.9, max_iterations=10000):num_states = env.observation_space.nnum_actions = env.action_space.n# 初始化值函数values = np.zeros(num_states)for _ in range(max_iterations):delta = 0for state in range(num_states):# 第六步:记录当前状态的旧值# 更新值函数q_values = np.zeros(num_actions)for action in range(num_actions):for prob, next_state, reward, _ in env.P[state][action]:q_values[action] += prob * (reward + gamma * values[next_state])# 第七步:使用Q值的最大值更新值函数# 第八步:计算值函数的变化量if delta < 1e-6:break# 根据最终的值函数,生成最优策略policy = np.zeros((num_states, num_actions))for state in range(num_states):q_values = np.zeros(num_actions)for action in range(num_actions):for prob, next_state, reward, _ in env.P[state][action]:q_values[action] += prob * (reward + gamma * values[next_state])best_action = np.argmax(q_values)policy[state][best_action] = 1.0return values########## End ##########env = gym.make('FrozenLake-v0')# 使用策略迭代
v1 = policy_iteration(env)# 使用值迭代
v2 = value_iteration(env)六、未标记样本

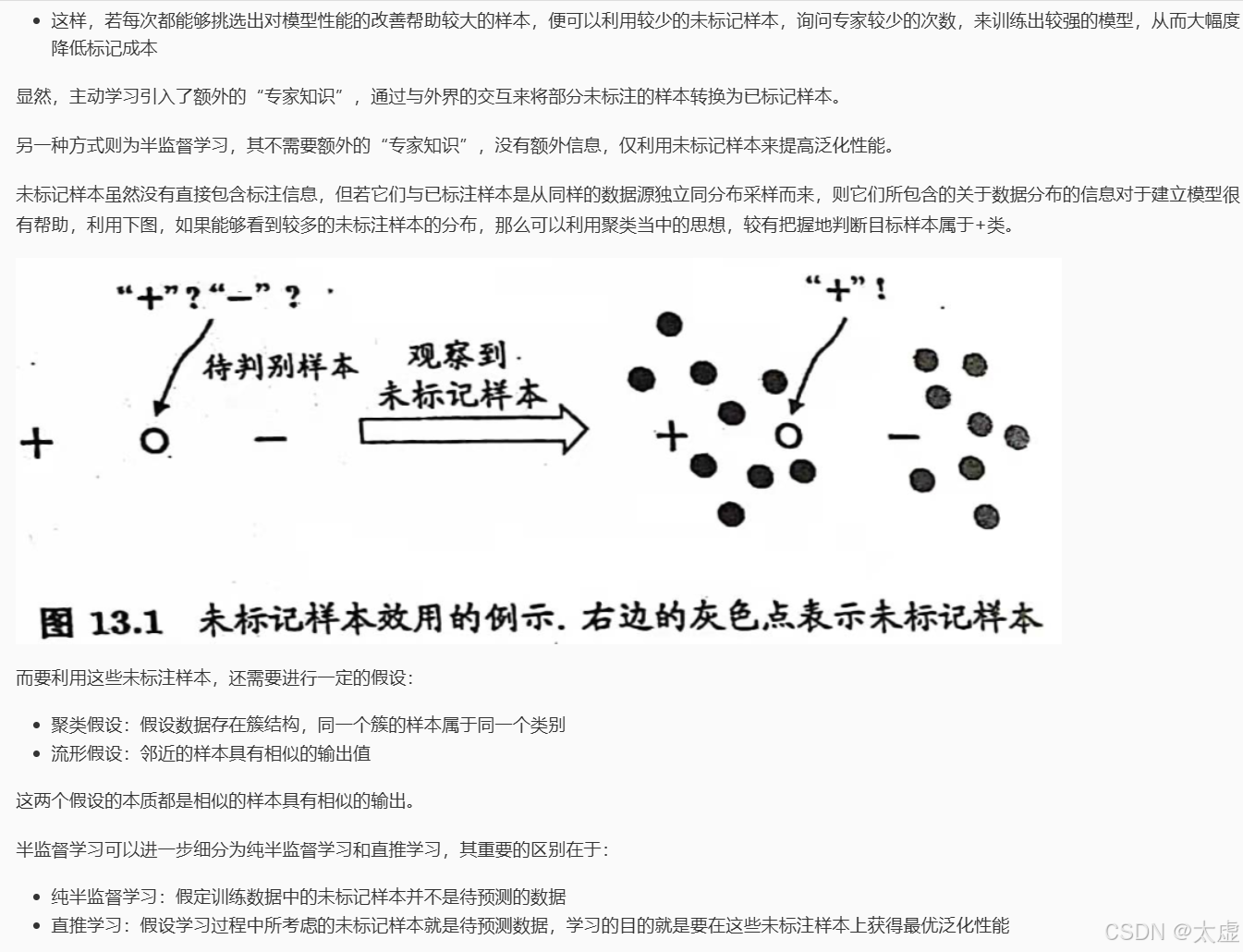
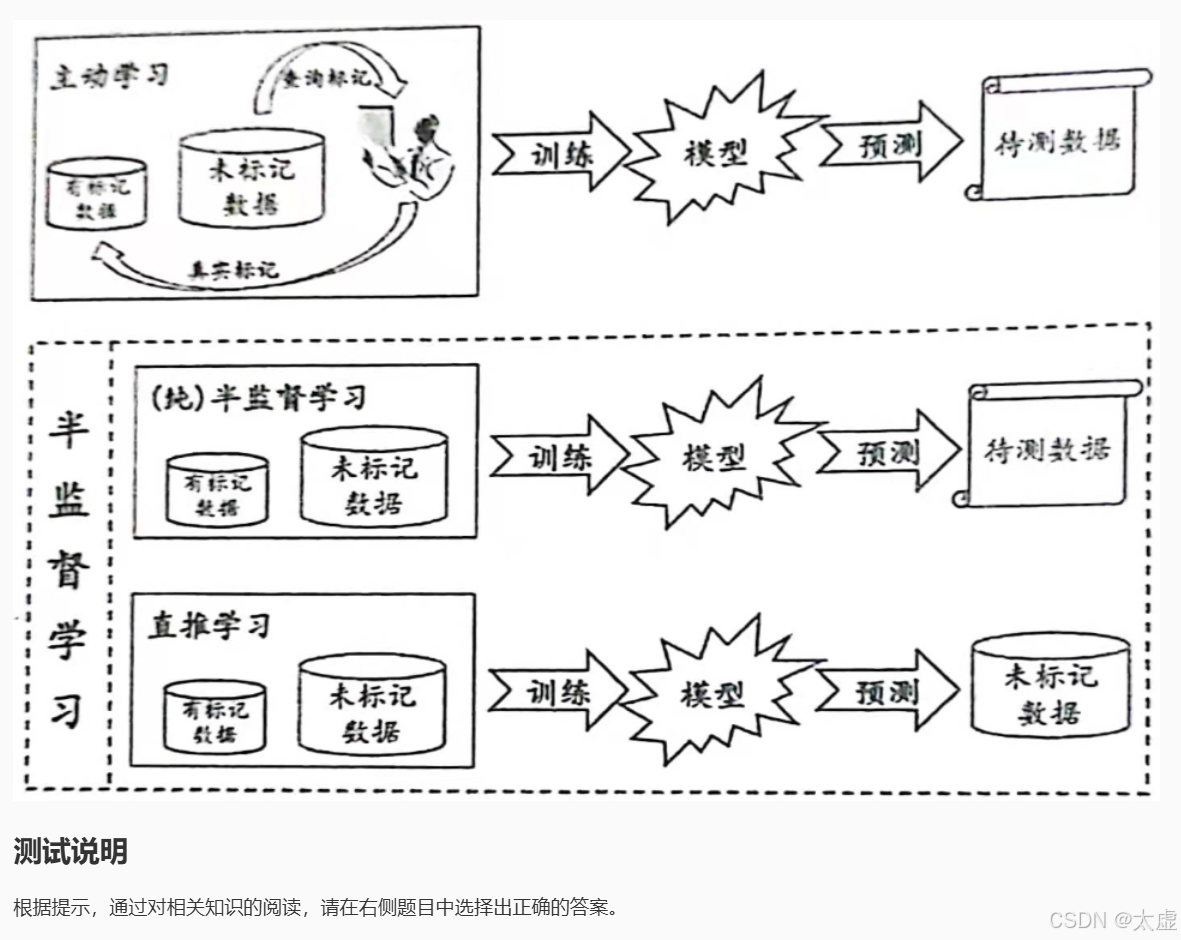

七、 生成式方法


import numpy as np
from sklearn.datasets import make_classification
from sklearn.semi_supervised import LabelSpreading
from sklearn.model_selection import train_test_split # ********** Begin **********#
# 生成模拟数据集,生成了一个包含2000个样本和20个特征的数据集,其中只有2个特征是有信息的,10个特征是冗余的,随机种子是42。
X, y = make_classification(n_samples=2000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
# ********** End **********## 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化模型
lp_model = LabelSpreading(kernel="knn", alpha=0.8) # 使用有标签数据进行训练
lp_model.fit(X_train, y_train) # 预测未标记数据的标签
y_pred = lp_model.predict(X_test) # 输出准确率
print("Accuracy:", np.mean(y_pred == y_test))八、半监督SVM



import random
import numpy as np
import sklearn.svm as svm
from sklearn.datasets import make_classification
import joblib
import warningsnp.random.seed(1477)
random.seed(1477)
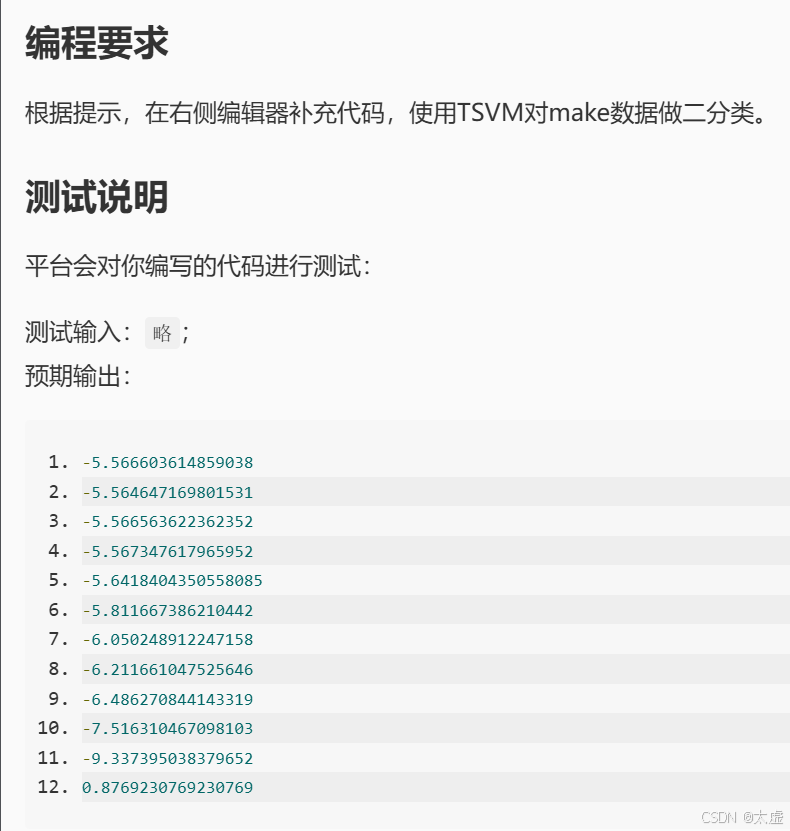
warnings.filterwarnings(action='ignore')class TSVM(object):def __init__(self, kernel='linear'):self.Cl, self.Cu = 1.5, 0.001self.kernel = kernelself.clf = svm.SVC(C=1.5, kernel=self.kernel)def train(self, X1, Y1, X2):N = len(X1) + len(X2)# 样本权值初始化sample_weight = np.ones(N)sample_weight[len(X1):] = self.Cu# 用已标注部分训练出一个初始SVMself.clf.fit(X1, Y1)# 对未标记样本进行标记#********* Begin *********#Y2 = Y2 = X = Y = #********* End *********## 未标记样本的序号Y2_id = np.arange(len(X2))while self.Cu < self.Cl:# 重新训练SVM, 之后再寻找易出错样本不断调整self.clf.fit(X, Y, sample_weight=sample_weight)while True:Y2_decision = self.clf.decision_function(X2) # 参数实例到决策超平面的距离Y2 = Y2.reshape(-1)epsilon = 1 - Y2 * Y2_decisionnegative_max_id = Y2_id[epsilon == min(epsilon)]print(epsilon[negative_max_id][0])if epsilon[negative_max_id][0] > 0:#********* Begin *********## 寻找很可能错误的未标记样本,改变它的标记成其他标记pool = Y2[negative_max_id] = Y2 = Y = self.clf.fit( )#********* End *********#else:breakself.Cu = min(2 * self.Cu, self.Cl)sample_weight[len(X1):] = self.Cudef score(self, X, Y):return self.clf.score(X, Y)def predict(self, X):return self.clf.predict(X)def save(self, path='./TSVM.model'):joblib.dump(self.clf, path)def load(self, model_path='./TSVM.model'):self.clf = joblib.load(model_path)if __name__ == '__main__':features, labels = make_classification(n_samples=200, n_features=3, n_redundant=1, n_repeated=0, n_informative=2,n_clusters_per_class=2)n_given = 70# 取前n_given个数字作为标注集X1 = np.copy(features)[:n_given]X2 = np.copy(features)[n_given:]Y1 = np.array(np.copy(labels)[:n_given]).reshape(-1, 1)Y2_labeled = np.array(np.copy(labels)[n_given:]).reshape(-1, 1)model = TSVM()model.train(X1, Y1, X2)# Y2_hat = model.predict(X2)accuracy = model.score(X2, Y2_labeled)print(accuracy)
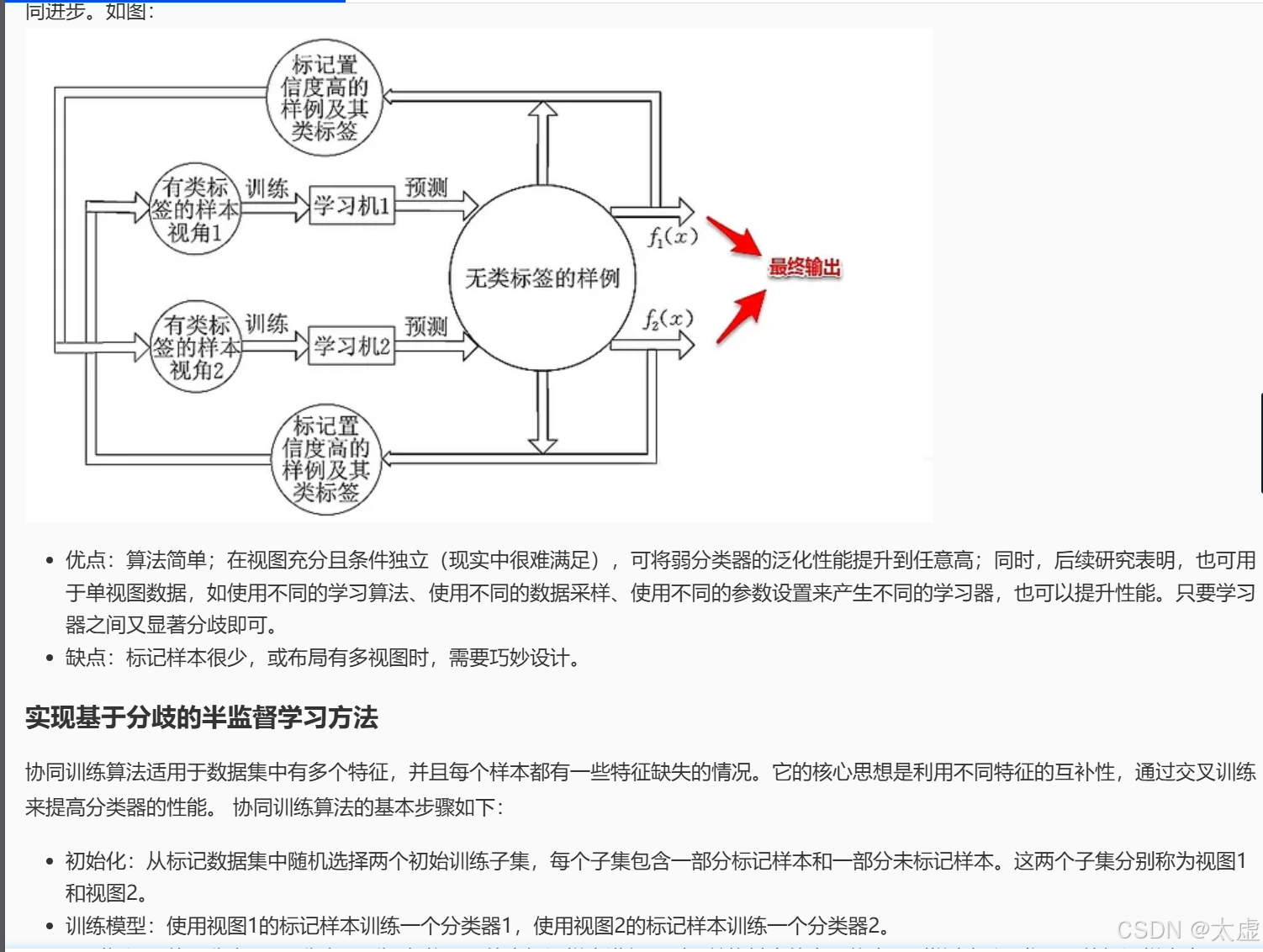
九、基于分歧的方法



from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import numpy as npdef co_training(X, y, num_iterations):# ********** Begin **********## 划分初始的视图1和视图2,测试集与训练集的比例为1:1, 随机种子为1。X_view1, X_view2, y_view1, y_view2 = train_test_split(X, y, test_size=0.5, random_state=1)# 训练两个初始分类器clf1 = SVC(probability=True) # 使用probability=True以获得类别的概率值clf2 = SVC(probability=True)clf1.fit(X_view1, y_view1)clf2.fit(X_view2, y_view2)for i in range(num_iterations):# 使用分类器1和分类器2对未标记样本进行预测y_pred_view1 = clf1.predict(X_view2)y_pred_view2 = clf2.predict(X_view1)# 使用分类器1的高置信度预测样本来扩充视图1prob_view2 = clf1.predict_proba(X_view2) # 获取预测的概率high_confidence_1 = np.max(prob_view2, axis=1) > 0.95 # 置信度阈值设定为0.95X_view1 = np.concatenate((X_view1, X_view2[high_confidence_1]))y_view1 = np.concatenate((y_view1, y_pred_view1[high_confidence_1]))# 使用分类器2的高置信度预测样本来扩充视图2prob_view1 = clf2.predict_proba(X_view1) # 获取预测的概率high_confidence_2 = np.max(prob_view1, axis=1) > 0.95 # 置信度阈值设定为0.95X_view2 = np.concatenate((X_view2, X_view1[high_confidence_2]))y_view2 = np.concatenate((y_view2, y_pred_view2[high_confidence_2]))# 重新训练分类器clf1.fit(X_view1, y_view1)clf2.fit(X_view2, y_view2)# 将视图1和视图2合并为完整的训练集X_train = np.concatenate((X_view1, X_view2))y_train = np.concatenate((y_view1, y_view2))# 在完整的训练集上训练最终的分类器clf_final = SVC()clf_final.fit(X_train, y_train)return clf_final# ********** End **********## 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 使用协同训练算法进行分类
clf = co_training(X, y, num_iterations=5)# 在测试集上进行预测
X_test = X[100:] # 使用后50个样本作为测试集
y_test = y[100:]
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
十、半监督聚类

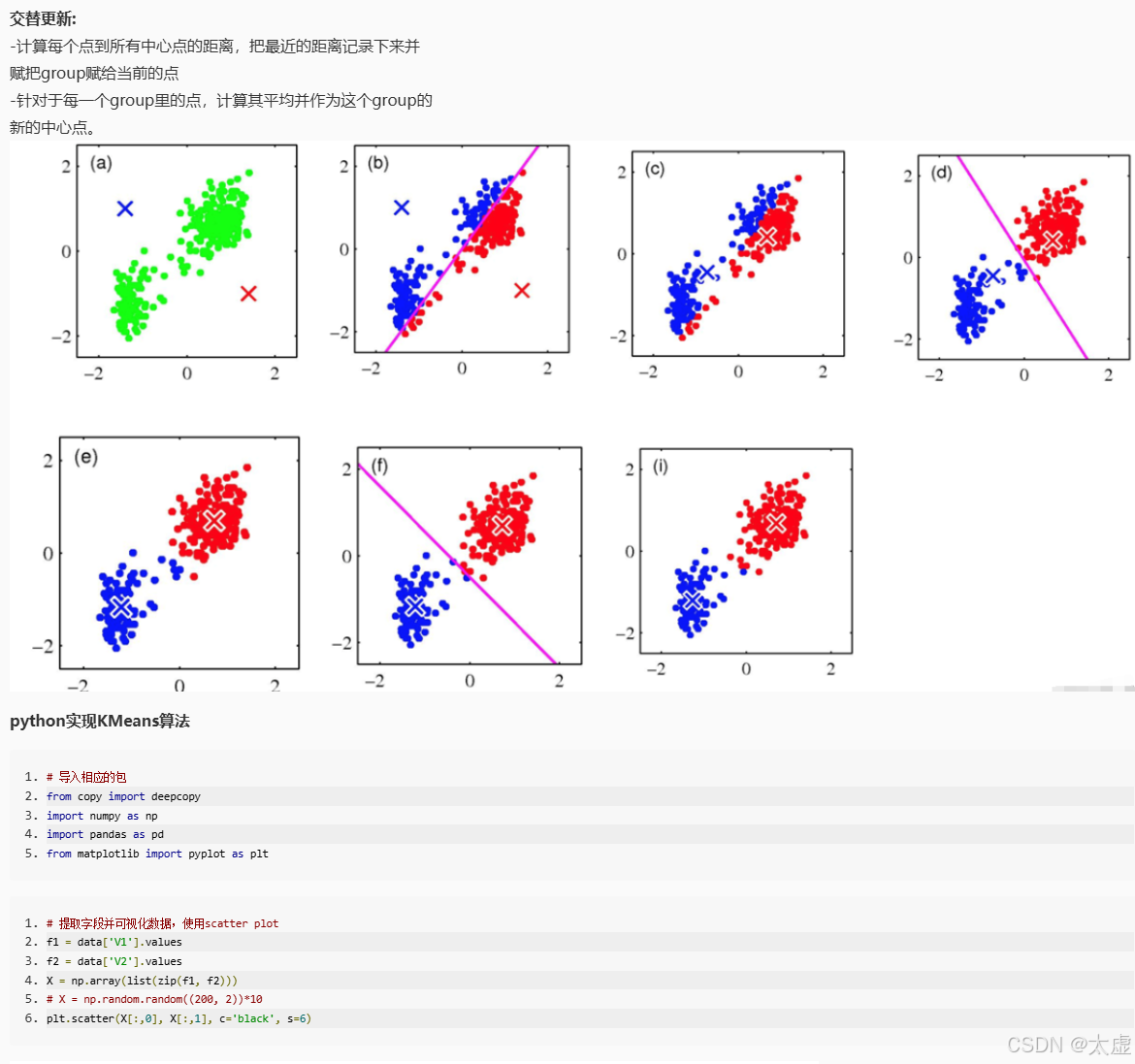
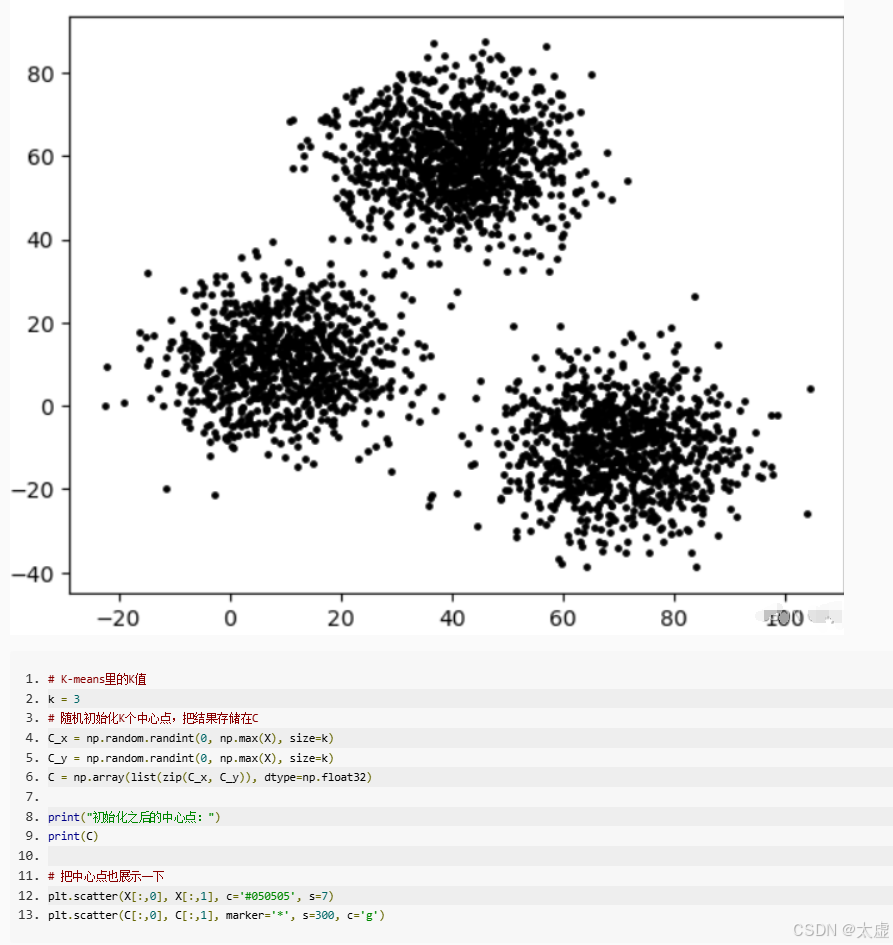
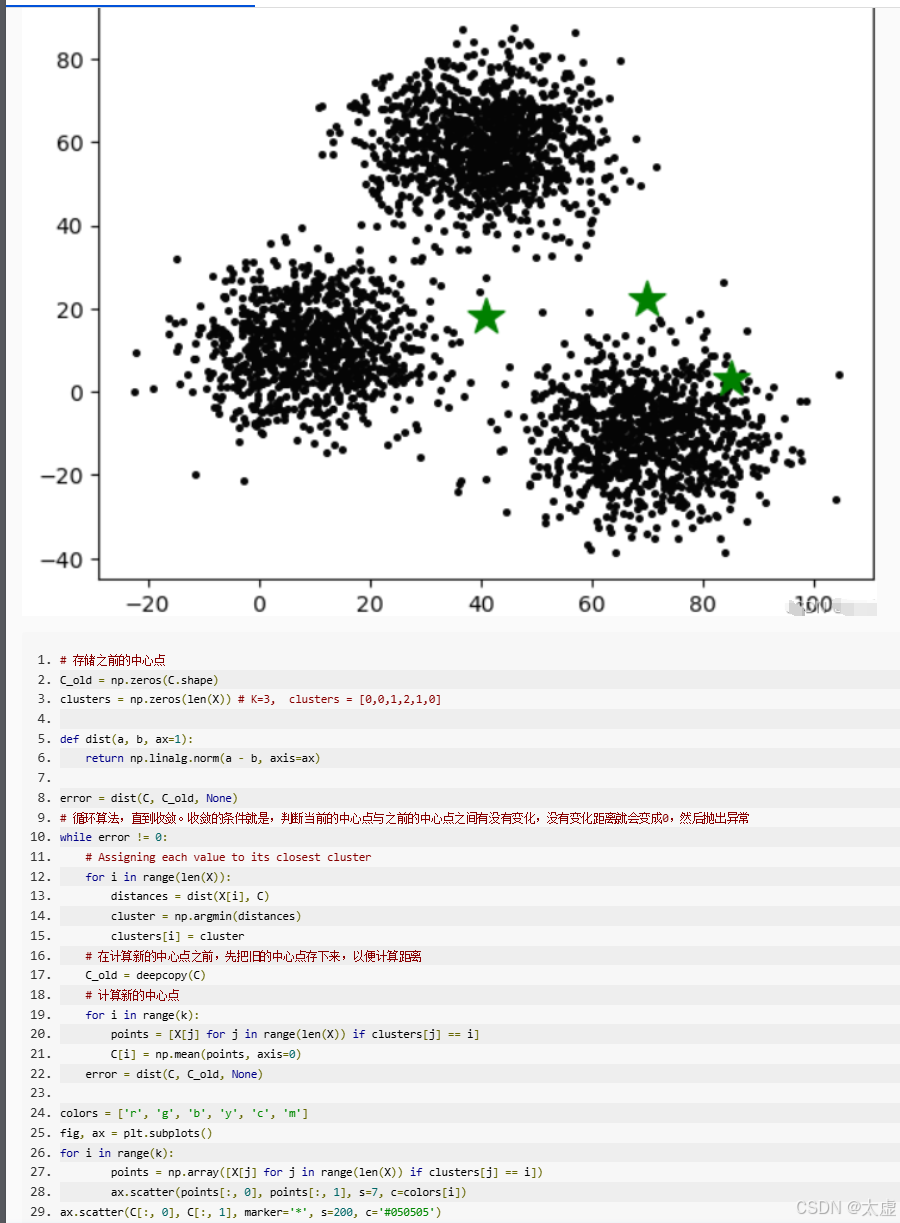


import numpy as npdef distEclud(vecA, vecB):'''输入:向量A和B输出:A和B间的欧式距离'''return np.sqrt(sum(np.power(vecA - vecB, 2)))def newCent(L):'''输入:有标签数据集L输出:根据L确定初始聚类中心'''centroids = []label_list = np.unique(L[:, -1]) # 获取所有的类别标签for i in label_list:L_i = L[(L[:, -1]) == i] # 按照标签分割数据cent_i = np.mean(L_i, 0) # 计算每个簇的均值centroids.append(cent_i[:-1]) # 忽略最后一列标签return np.array(centroids)def semi_kMeans(L, U, distMeas=distEclud, initial_centriod=newCent):'''输入:有标签数据集L(最后一列为类别标签)、无标签数据集U(无类别标签)输出:聚类结果'''# 合并有标签数据L和无标签数据UdataSet = np.vstack((L[:, :-1], U)) # L去掉标签,U本身无标签label_list = np.unique(L[:, -1]) # 获取L中所有类别标签k = len(label_list) # L中类别个数m = np.shape(dataSet)[0] # 数据集总共有多少样本# 初始化样本分配(记录每个点的聚类标签)clusterAssment = np.zeros(m)centroids = initial_centriod(L) # 确定初始聚类中心clusterChanged = Truewhile clusterChanged:clusterChanged = False# 1. 将每个样本分配到最近的聚类中心for i in range(m):minDist = np.inf # 初始化最小距离为无穷大minIndex = -1for j in range(k):dist = distMeas(dataSet[i], centroids[j]) # 计算样本i到聚类中心j的距离if dist < minDist:minDist = distminIndex = j # 找到最近的聚类中心if clusterAssment[i] != minIndex: # 如果该样本的标签发生了变化clusterChanged = TrueclusterAssment[i] = minIndex # 更新该样本的标签# 2. 更新聚类中心for j in range(k):# 获取当前簇中所有样本pointsInCluster = dataSet[clusterAssment == j]if len(pointsInCluster) > 0:newCentroid = np.mean(pointsInCluster, axis=0) # 计算该簇样本的均值centroids[j] = newCentroid # 更新聚类中心return clusterAssment# 测试数据
L = np.array([[1.0, 4.2, 1],[1.3, 4.0, 1],[1.0, 4.0, 1],[1.5, 4.3, 1],[2.0, 4.0, 0],[2.3, 3.7, 0],[4.0, 1.0, 0]]) # L的最后一列是类别标签U = np.array([[1.4, 5.0],[1.3, 5.4],[2.0, 5.0],[4.0, 2.0],[5.0, 1.0],[5.0, 2.0]])# 执行半监督K-means
clusterResult = semi_kMeans(L, U)
print(clusterResult)
相关文章:
)
机器学习头歌(第三部分-强化学习)
一、强化学习及其关键元素 二、强化学习的分类 三、任务与奖赏 import numpy as np# 迷宫定义 maze np.array([[0, 0, 0, 0, 0],[0, -1, -1, 0, 0],[0, 0, 0, -1, 0],[-1, -1, 0, -1, 0],[0, 0, 0, -1, 1] ])# 定义强化学习的参数 gamma 0.8 # 折扣因子 alpha 0.5 # 学习率…...
后,旧分区无法更新数据问题)
【Hive】新增字段(column)后,旧分区无法更新数据问题
TOC 【一】问题描述 Hive修改数据表结构的需求,比如:增加一个新字段。 如果使用如下语句新增列,可以成功添加列col1。但如果数据表tb已经有旧的分区(例如:dt20190101),则该旧分区中的col1将为…...

智能化的城市管理解决方案,智慧城管执法系统源码,微服务架构、Java编程语言、Spring Boot框架、Vue.js前端技术
智慧城管执法系统是一种高度信息化、智能化的城市管理解决方案,它利用现代信息技术,如微服务架构、Java编程语言、Spring Boot框架、Vue.js前端技术、Element UI组件库、UniApp跨平台开发工具以及MySQL数据库等,构建了一个综合性的执法管理平…...

【区间DP】【hard】力扣1312. 让字符串成为回文串的最少插入次数
加粗样式给你一个字符串 s ,每一次操作你都可以在字符串的任意位置插入任意字符。 请你返回让 s 成为回文串的 最少操作次数 。 「回文串」是正读和反读都相同的字符串。 示例 1: 输入:s “zzazz” 输出:0 解释:字…...

android刷机
android ota和img包下载地址: https://developers.google.com/android/images?hlzh-cn android启动过程 线刷 格式:ota格式 模式:recovery 优点:方便、简单,刷机方法通用,不会破坏手机底层数据࿰…...

web-前端小实验8
实现以上图片中的内容 代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"wid…...
)
C++实现设计模式---单例模式 (Singleton)
单例模式 (Singleton) 概念 单例模式 确保一个类在整个程序生命周期中只有一个实例,并提供一个全局访问点。 它是一种创建型设计模式,广泛用于需要共享资源的场景。 使用场景 配置管理器:程序中需要一个全局的配置对象。日志系统ÿ…...

【大数据】机器学习-----线性模型
一、线性模型基本形式 线性模型旨在通过线性组合输入特征来预测输出。其一般形式为: 其中: x ( x 1 , x 2 , ⋯ , x d ) \mathbf{x}(x_1,x_2,\cdots,x_d) x(x1,x2,⋯,xd) 是输入特征向量,包含 d d d 个特征。 w ( w 1 , w 2 , ⋯ ,…...

C#类型转换
C#是静态类型的语言,变量一旦声明就无法重新声明或者存储其他类型的数据,除非进行类型转换。本章的主要任务就是学习类型转换的知识。类型转换有显式的,也有隐式的。所谓显式,就是我们必须明确地告知编译器,我们要把变…...
通用解决 PnP 问题函数solvePnPGeneric()的使用)
OpenCV相机标定与3D重建(55)通用解决 PnP 问题函数solvePnPGeneric()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 根据3D-2D点对应关系找到物体的姿态。 cv::solvePnPGeneric 是 OpenCV 中一个更为通用的函数,用于解决 PnP 问题。它能够返回多个可能…...

NVIDIA CUDA Linux 官方安装指南
本文翻译自:https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#post-installation-actions NVIDIA CUDALinux安装指南 CUDA工具包的Linux安装说明。 文章目录 1.导言1.1.系统要求1.2.操作系统支持政策1.3.主机编译器支持政策1.3.1.支持的C方言…...

C++中的STL
STL(标准模板库)在广义上分为:容器,算法,迭代器 容器和算法之间通过迭代器进行无缝衔接 STL大体上分为六大组件:分别为容器,算法,迭代器,仿函数,适配器,空间…...

前端进程和线程及介绍
前端开发中经常涉及到进程和线程的概念,特别是在浏览器中。理解这两个概念对于理解浏览器的工作机制和前端性能优化非常重要。以下是详细介绍: 1. 什么是进程和线程? 进程: 是操作系统分配资源的基本单位。一个程序启动后…...

本地用docker装mysql
目录 拉取镜像查看镜像 启动容器查看运行中的容器连接到 MySQL 容器其他一些操作 装WorkBench链接mysql——————————————允许远程登录MySql 拉取镜像 docker pull mysql查看镜像 docker image lsREPOSITORY TAG IMAGE ID CREATED SIZE mysq…...
与 常见技术框架应用 解析)
设计模式 行为型 责任链模式(Chain of Responsibility Pattern)与 常见技术框架应用 解析
责任链模式(Chain of Responsibility Pattern)是一种行为型设计模式,它允许将请求沿着处理者链进行发送。每个处理者对象都有机会处理该请求,直到某个处理者决定处理该请求为止。这种模式的主要目的是避免请求的发送者和接收者之间…...

Apache Spark中与数据分区相关的配置和运行参数
Apache Spark中与数据分区相关的配置和运行参数涉及多个方面,包括动态分区设置、分区数设置、Executor与并行度配置等。合理配置这些参数可以显著提高Spark作业的执行效率和资源利用率。在实际应用中,建议根据业务需求和计算集群的特性进行相应的调整和测…...
什么是设计模式)
“深入浅出”系列之设计模式篇:(0)什么是设计模式
设计模式六大原则 1. 单一职责原则:一个类或者一个方法只负责一项职责,尽量做到类的只有一个行为原因引起变化。 核心思想:控制类的粒度大小,将对象解耦,提高其内聚性。 2. 开闭原则:对扩展开放…...

【Git版本控制器--1】Git的基本操作--本地仓库
目录 初识git 本地仓库 认识工作区、暂存区、版本库 add操作与commit操作 master文件与commit id 修改文件 版本回退 撤销修改 删除文件 初识git Git 是一个分布式版本控制系统,主要用于跟踪文件的更改,特别是在软件开发中。 为什么要版本…...

如何在Jupyter中快速切换Anaconda里不同的虚拟环境
目录 介绍 操作步骤 1. 选择环境,安装内核 2. 注册内核 3. 完工。 视频教程 介绍 很多网友在使用Jupyter的时候会遇到各种各样的问题,其中一个比较麻烦的问题就是我在Anaconda有多个Python的环境里面,如何让jupyter快速切换不同的Pyt…...
)
Python自学 - “包”的创建与使用(从头晕到了然)
<< 返回目录 1 Python自学 - “包”的创建与使用(从头晕到了然) 相对于模块,包是一个更大的概念,按照业界的开发规范,1个代码文件不要超过1000行,稍微有点规模的任务就超过这个代码限制了,必然需要多个文件来管…...

ElasticSearch 同义词匹配
synonym.txt 电脑, 计算机, 主机 复印纸, 打印纸, A4纸, 纸, A3 平板电脑, Pad DELETE /es_sku_index_20_20250109 PUT /es_sku_index_20_20250109 {"settings": {"index": {"number_of_shards": "5","number_of_replicas&quo…...

android 官网刷机和线刷
nexus、pixel可使用google官网线上刷机的方法。网址:https://flash.android.com/ 本文使用google线上刷机,将Android14 刷为Android12 以下是失败的线刷经历。 准备工作 下载升级包。https://developers.google.com/android/images?hlzh-cn 注意&…...

Vue环境变量配置指南:如何在开发、生产和测试中设置环境变量
-## 前言 Vue.js是一个流行的JavaScript框架,它提供了许多工具和功能来帮助开发人员构建高效、可维护的Web应用程序。其中一个重要的工具是环境变量,它可以让你在不同的环境中配置不同的参数和选项。在这篇博客中,我们将介绍如何在Vue应用程…...
)
蓝桥杯_B组_省赛_2022(用作博主自己学习)
题目链接算法11.九进制转十进制 - 蓝桥云课 进制转换 21.顺子日期 - 蓝桥云课 时间与日期 31.刷题统计 - 蓝桥云课 时间与日期 41.修剪灌木 - 蓝桥云课 思维 51.X 进制减法 - 蓝桥云课 贪心 61.统计子矩阵 - 蓝桥云课 二维前缀和 71.积木画 - 蓝桥云课 动态规划 82.扫雷 - 蓝桥…...

【干货】交换网络环路介绍
定义 以太网交换网络中为了提高网络可靠性,通常会采用冗余设备和冗余链路,然而现网中由于组网调整、配置修改、升级割接等原因,经常会造成数据或协议报文环形转发,不可避免的形成环路。如图7-1所示,三台设备两两相连就…...

unity——Preject3——面板基类
目录 1.Canvas Group Canvas Group 的功能 Canvas Group 的常见用途 如何使用 Canvas Group 2.代码 3.代码分析 类分析:BasePanel 功能 作用 实际应用 代码解析:hideCallBack?.Invoke(); 语法知识点 作用 虚函数(virtual)和抽象类(abstract)的作用与区别 …...

BTC系列 - 启示录
推荐《区块链启示录:中本聪文集》这本书, 原来早在2010年, BTC生态还不完善的时候, 社区中就已经畅想出了未来其它链上的特色方案, 中本聪也都一一做了教父级回应: coinbase币的成熟时间, 交易池, 交易确认机制, 防51%攻击, 防双重消费, 水龙头, 轻量级客户端, 链上…...

C# 25Dpoint
C# 25Dpoint ,做一个备份 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms;namespace _25Dpoint {public partial cl…...

Kotlin构造函数
class Person {var name: String? nullvar age: Int? nullfun think() {println("Mr./Ms.$name, who is $age years old, is thinking!")} }fun main () {val p Person()p.name "Jimmy"p.age 20p.think() } 在Kotlin中任意一个非抽象类都无法被继承…...

springMVC---resultful风格
目录 一、创建项目 pom.xml 二、配置文件 1.web.xml 2.spring-mvc.xml 三、图解 四、controller 一、创建项目 pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi…...

flutter 装饰类【BoxDecoration】
装饰类 BoxDecoration BoxDecoration 是 Flutter 中用于控制 Container 等组件外观的装饰类,它提供了丰富的属性来设置背景、边框、圆角、阴影等样式。 BoxDecoration 的主要属性 1.color 背景颜色。类型:Color?示例: color: Colors.blu…...
)
自动连接校园网wifi脚本实践(自动网页认证)
目录 起因执行步骤分析校园网登录逻辑如何判断当前是否处于未登录状态? 书写代码打包设置开机自动启动 起因 我们一般通过远程控制的方式访问实验室电脑,但是最近实验室老是断电,但重启后也不会自动连接校园网账户认证,远程工具&…...

微信小程序集成Vant Weapp移动端开发的框架
什么是Vant Weapp Vant 是一个轻量、可靠的移动端组件库,于 2017 年开源。 目前 Vant 官方提供了 Vue 2 版本、Vue 3 版本和微信小程序版本,并由社区团队维护 React 版本和支付宝小程序版本。 官网地睛:介绍 - Vant Weapp (vant-ui.gith…...

MySQL从库 Last_SQL_Errno: 1197 问题处理过程
记录一个遇到过的错误,今天整理一下。 问题 MySQL error code MY-001197 (ER_TRANS_CACHE_FULL): Multi-statement transaction required morethan max_binlog_cache_size bytes of storage; increase this mysqld variable and try again报错很明显是max_binlog_…...

springboot 加载本地jar到maven
在Spring Boot项目中,如果你想要加载一个本地的jar文件到Maven本地仓库,你可以使用Maven的install-file目标来实现。以下是一个简单的例子: 打开命令行工具(例如:终端或者命令提示符)。 执行以下Maven命令…...

面向B站商业化场景的广告标题智能推荐
01.背景 大模型的发展也在不断改变广告主/代理商广告创编的过程,为了提高广告主的创作效率,提升广告主投放标题的质量,我们利用大语言模型技术以及B站商业数据,能够让广告主仅需要输入特定的关键词,即可以生成理论上无…...

element plus 使用 upload 组件达到上传数量限制时隐藏上传按钮
最近在重构项目,使用了 element plus UI框架,有个功能是实现图片上传,且限制只能上传一张图片,结果,发现,可以限制只上传一张图片,但是上传按钮还在,如图: 解决办法&…...

java进行pdf文件压缩
文章目录 pdf文件压缩 pdf文件压缩 添加依赖 <dependency><groupId>com.luhuiguo</groupId><artifactId>aspose-pdf</artifactId><version>23.1</version> </dependency>public class OptimizePdf {public static void opti…...

初识算法和数据结构P1:保姆级图文详解
文章目录 前言1、算法例子1.1、查字典(二分查找算法)1.2、整理扑克(插入排序算法)1.3、货币找零(贪心算法) 2、算法与数据结构2.1、算法定义2.2、数据结构定义2.3、数据结构与算法的关系2.4、独立于编程语言…...

内网服务器添加共享文件夹功能并设置端口映射
参考网址 https://blog.csdn.net/Think88666/article/details/118438465 1.服务器安装smb服务,由于网路安全不允许使用默认端口(445,446),于是修改端口为62445、62446。 2.每台需要共享的电脑都要修改端口映射&#x…...

ruoyi-cloud docker启动微服务无法连接nacos,Client not connected, current status:STARTING
ruoyi-cloud docker启动微服务无法连接nacos,Client not connected, current status:STARTING 场景 当使用sh deploy.sh base来安装mysql、redis、nacos环境后,紧接着使用sh deploy.sh modules安装微服务模块,会发现微服务无法连接nacos的情…...
函数,LEGB规则))
Python----Python高级(函数基础,形参和实参,参数传递,全局变量和局部变量,匿名函数,递归函数,eval()函数,LEGB规则)
一、函数基础 1.1、函数的用法和底层分析 函数是可重用的程序代码块。 函数的作用,不仅可以实现代码的复用,更能实现代码的一致性。一致性指的是,只要修改函数的代码,则所有调用该函数的地方都能得到体现。 在编写函数时…...

excel 整理表格,分割一列变成多列数据
数据准备 对于很多系统页面的数据是没有办法下载的。 这里用表格数据来举例。随便做数据的准备。想要看excel部分的可以把这里跳过,从数据准备完成开始看。 需要一点前端基础知识,但不多(不会也行)。 把鼠标放在你想要拿到本地的…...

Oracle 分区索引简介
目录 一. 什么是分区索引二. 分区索引的种类2.1 局部分区索引(Local Partitioned Index)2.2 全局分区索引(Global Partitioned Index) 三. 分区索引的创建四. 分区索引查看4.1 USER_IND_COLUMNS 表4.2 USER_INDEXES 表 五. 分区索…...
)
C++实现设计模式--- 观察者模式 (Observer)
观察者模式 (Observer) 观察者模式 是一种行为型设计模式,它定义了一种一对多的依赖关系,使得当一个对象的状态发生改变时,其依赖者(观察者)会收到通知并自动更新。 意图 定义对象之间的一对多依赖关系。当一个对象状…...

CentOS 6.8 安装 Nginx
个人博客地址:CentOS 6.8 安装 Nginx | 一张假钞的真实世界 提前安装: # sudo yum install yum-utils 一般情况下这个工具系统已经安装。 创建文件/etc/yum.repos.d/nginx.repo,输入内容如下: [nginx-stable] namenginx stab…...

px、em 和 rem 的区别:深入理解 CSS 中的单位
文章目录 前言一、px - 像素 (Pixel)二、em - 相对父元素字体大小 (Ems)三、rem - 相对于根元素字体大小 (Root Ems)四、综合比较结语 前言 在CSS中,px、em和rem是三种用于定义尺寸(如宽度、高度、边距、填充等)的长度单位。它们各自有不同的…...

vue 表格内点编辑,单元格不切换成输入框问题分析
vue 表格渲染时,我点击编辑时,想直接在单元格上面进行编辑。 效果如下,正常是文本效果,点击编辑时,出现输入框 其实实现起来,逻辑很简单,但是中间我却出现了一个问题,效果始终出不…...

MATLAB学习笔记-table
1.在table中叠加table table 的每一列具有固定的数据类型。如果要让表的所有单元格都可以任意填充,就得让每一列都是 cell 类型,这样表中每个单元格都是“一个元胞”。创建时可以先构造一个 空 cell 数组(大小为行数列数)&#x…...

使用 selenium-webdriver 开发 Web 自动 UI 测试程序
优缺点 优点 有时候有可能一个改动导致其他的地方的功能失去效果,这样使用 Web 自动 UI 测试程序可以快速的检查并定位问题,节省大量的人工验证时间 缺点 增加了维护成本,如果功能更新过快或者技术更新过快,维护成本也会随之提高…...