面向B站商业化场景的广告标题智能推荐
01.背景
大模型的发展也在不断改变广告主/代理商广告创编的过程,为了提高广告主的创作效率,提升广告主投放标题的质量,我们利用大语言模型技术以及B站商业数据,能够让广告主仅需要输入特定的关键词,即可以生成理论上无穷多的创意标题,并且这些标题能够贴合b站的画风,既提升效率也提升效果。本文将展开介绍我们在B站商业化场景下智能广告标题推荐的技术实践及产品化方案。
02.技术实践
2.1. 评估指标的确定
2.1.1. 出发点
为了量化模型迭代的方向和达成质量,我们需要一套完整的评估体系来评判模型产出的标题质量,从而帮助我们判断模型是否可行以及模型和数据后续的迭代方向。起初想用一个端到端的模型仅对标题是否好坏进行评判,但是好坏本身的指标制定会有偏差且较难定义,但是如果把这个目标进行解构,通过多且精细的指标来评估结果是较为合理的方式。
我们认为,适合在b站进行投放广告标题应该语义通顺、符合b站风格,同时满足具有普适意义的好标题的条件(包含精准表达关键词内容,可以吸引用户点击等),因此我们将评估指标分为流畅度、风格分和质量分(此处指是否符合好标题的定义)三个角度。
2.1.2. 评估指标的含义和训练细节
评估方法上我们用群体二分类分数代替了奖励评分,因为奖励模型的构建比较困难,我们没有足够的标注数据,而用二分类就会简化很多,评测多条标题做群体估计也是比较合理的。具体实施是每个指标各训练了一个二分类模型来进行打分。
流畅度
-
出发点:作为用户体验最基础的属性,我们希望模型产出的结果不要出现不流畅的语句,所以该部分作为我们后续更新模型的准入条件,也是重要的评估指标之一。
-
含义:评估生成标题的流畅程度,分数越高流畅度越高。
-
训练方案:
-
参考bert训练的思想,对通顺语句进行破坏操作构造负样本,同时收集模型产出的不流畅样本作为负样本。
-
二分类模型训练数据:使用b站真实标题数据。正负样本对共5w,比例1:1。
-
正样本采用b站真实标题数据;
-
负样本生成逻辑:选取标题中任意两个非首尾的汉字,50%替换成常用汉字表中的其他汉字,25%丢弃,25%交换二者的位置。
-
训练结果:随机抽取2000个样本作为测试集,准确率 auc均在0.98以上。
风格分
-
出发点:我们在数据集整理时发现qwen zero-shot生成的标题和真实b站广告标题之间存在明显但是无法通过词频统计等显式说明的风格化差异。为验证以上观点,我们对b站原生标题与对应关键词使用qwen zero-shot生成的标题组合进行了kappa一致性检验(两人在不互通信息的情况下共同标注同一份数据,最后汇总标注结果),结果表明,原生标题能够很好的和qwen生成的标题进行区分,结论符合我们的假设,所以我们把是否与b站标题画风相近作为了标题评估指标之一。
-
含义:评估生成的标题是否符合b站标题的画风,分数越高风格越像。
-
训练方案:
-
二分类模型训练数据:
-
正样本采用b站真实投放的标题数据25k条;
-
负样本采用qwen-72b生成的标题数据25k条;
-
训练结果:随机抽取2000个样本作为测试集,准确率 auc均在0.95以上。
质量分
-
出发点:最开始的设定是使用一个打分模型能够区分出好的标题和坏的标题,但面临的问题和其他主观分类问题类似,我们需要假设一个先验分布来符合我们对于好标题的后验分布,但是这个后验好坏(ctr高低or其他指标)其实都没有办法定义。参考nlp中关于qa任务中问题难度的定义方式,我们决定采用两个大模型联合标注的方式来进行对应的数据标注。为了明确标注标准,我们采用了如下方法进行质量分正负样本的构造:
-
逆向工程:将人工筛选后的若干条高点击率标题(我们假定满足高点击率的标题是较好的标题)输入进GPT4,询问这则标题为什么能够收获高点击率。将GPT4的回答收集并进行主题分析并统计出现次数最高的特征,得到四个主要的特征:激发好奇心、情感共鸣、简洁有力、直击需求,以及若干个次要特征:紧迫感、挑战性、承诺。
-
使用这些特征构造出大模型打标的prompt:

-
对于同一个标题,使用两个大模型进行评估(GPT4和qwen-72b),当两个大模型对这个标题的打标都是优秀,则任务这个标题是优秀的,反之两者都觉得不优秀则标为负例,两者意见不一致时暂时不考虑这部分标题。
-
含义:是否符合一个高质量标题的标准
-
训练:
-
二分类模型训练数据:上述方法构造的正负样本(均约1w对)。
-
训练结果:随机抽取2000个样本作为测试集,准确率 auc均在0.88以上。
2.2. 数据集的构建与清洗
2.2.1. 数据构成
对于专有任务的SFT,为了防止灾难遗忘和模型坍塌,训练数据的配比通常为「专有任务数据: 商业领域数据: 开放域数据 = 1:1:N(5<=N<=10)」
-
开放域数据集:开放域数据维持模型在各种非商业场景下的zero-shot能力,提供了基础的任务泛化能力。我们参考业界实践经验选择较高质量的中文开放域数据(若无中文版本则使用gpt4翻译成中文)。
样例:

-
B站商业域数据集:商业化域的数据可以加强模型在商业化相关任务上的泛化能力。我们基于稿件标题、视频ASR文本、搜索query及对应广告标题等构建B站商业域相关指令任务数据集。
样例:

-
标题生成专有任务数据集:专有任务数据集,进一步加强对于某个专有任务的遵从能力,不必再使In-Context Learning (ICL) 来引导。我们拉取高消耗创意的高点击率标题,通过LLM提取关键词并清洗,构造了『关键词 vs 生成标题 』与『关键词 vs 原标题 』 两种专有任务数据,在关键词提取时为了模仿用户行为,限制产出至多2个关键词、至多3个关键词和不限量关键词的数据。
样例:

2.2.2. 数据清洗
业界反复强调在进行专有任务SFT时,最重要的就是高质量的训练数据,在精不在多。我们针对不同域的数据也分别进行了精细化的清洗。
对开放域 + 商业域数据利用下图所示的MoDS框架进行清洗,目前保留了开源预训练打分模型的高分样本:MoDS主要分为质量筛选(通过打分模型huggingface.co对QA对进行质量打分,挑选高分)、多样性筛选(贪心选择语义差距最大的QA对)、必要性筛选三部分(贪心选择能对大模型造成最大loss的QA对)。
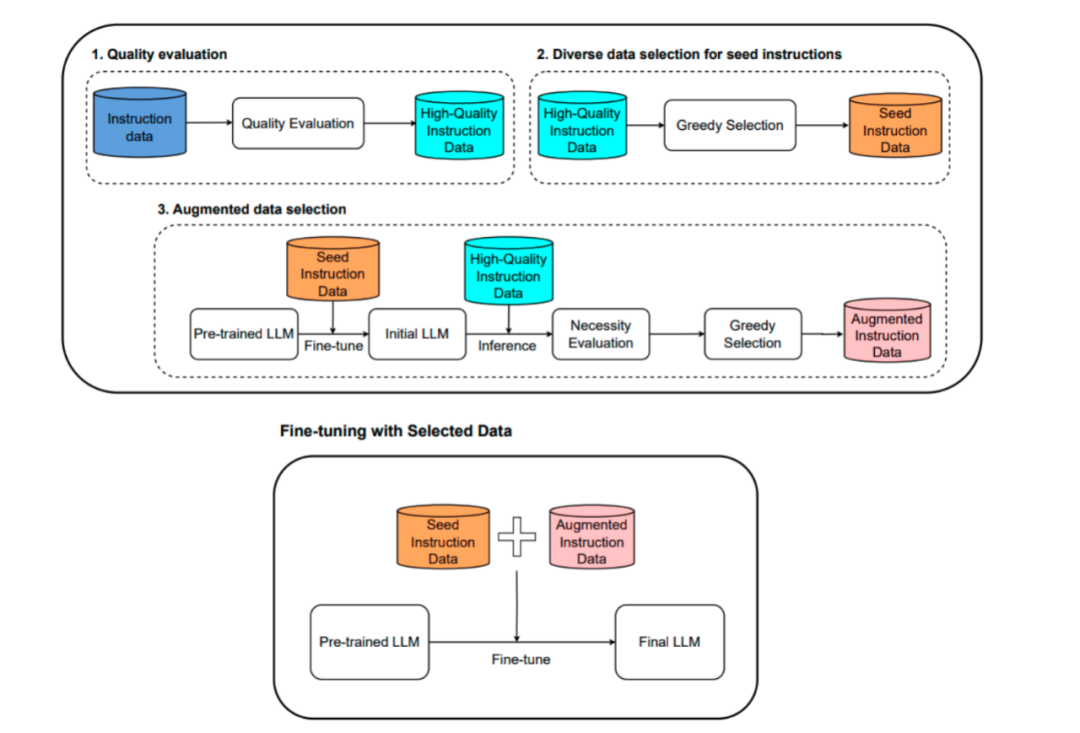
-
由于专有数据集的数据较为珍贵和稀有,且我们挑选了高消耗的标题,构建数据的流程本质上规避了上述框架所要过滤的低质量问题,但为了更好地让模型学到更加泛化的任务,我们还是对专有数据进行了如下的清洗:
-
量化数字替换:因需替换数字包含语义信息,无法使用正则处理。使用 Qwen-72B 进行量化数字替换,替换为数字通用符号X。
-
后处理:由于上一步大模型输出有几率产生badcase,但是该部分数据需要极为细致的清洗,所以我们手工校验了存在数字替换的所有数据并保证数据的流畅性和通顺度,对输出数据进行规范后处理,避免模型训练数据出现较为严重的错误导致模型训练效果降低。
-
2.3. 对齐算法的探索及优化
2.3.1. SFT
我们首先通过SFT来完成模型对于业务逻辑和相关指令的学习,在最开始的训练阶段,我们通过不停的迭代训练数据取得了较大的效果提升,主要是由于前期的数据噪声较大,干扰较多,通过对整个数据清洗流程的完善,模型效果也反应了对应的迭代效果。当数据问题解决后,我们又通过增加sft阶段prompt指令的丰富程度和多样性(多组prompt表达同一任务),让模型学到更加泛化的任务表达来提升模型生成的能力,我们通过调整sft阶段的prompt组合提升了模型整体的鲁棒性和泛化性。
表1 SFT迭代结果

SFT结束之后,我们发现虽然在流畅度和风格化上都取得了较为好的效果,但是在质量分上,模型依旧有提升空间,且这部分刚好时与人类的偏好相关,这部分的业务和技术角度都把解决问题的办法指向了RLHF。但是由于常规基于强化学习的对齐工作周期较长成本较高且效果未必稳定,所以我们将研究中心放在了直接偏好对齐DPO及其相关方法。
2.3.2. DPO算法
直接偏好优化算法DPO (Direct Preference Optimization) 出自2023年5月的斯坦福大学研究院的论文《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》,大概是2023-2024年最广为人知的RLHF的替代对齐方法了,通过一种巧妙的设计思路将强化学习的最大化奖励和转化为损失函数,使得可以直接基于监督学习进行训练。
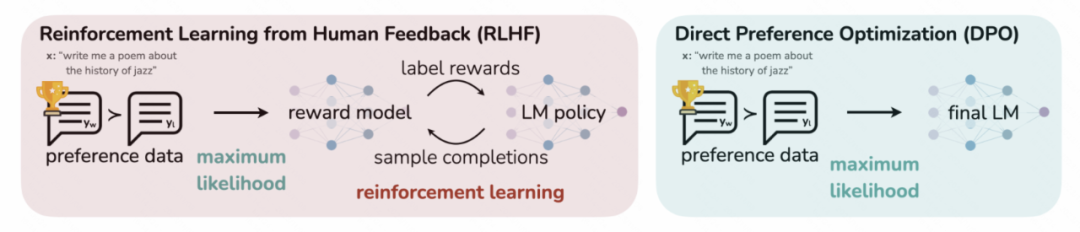
DPO将偏好分数表示为LLM的概率分布,从而在训练阶段省略掉了用于估计偏好分数的reward model,直接通过最大似然估计对LLM本身进行优化,是当前实现最为简单的对齐方法之一。它将问题表述为使用人类偏好对数据集的分类任务,其中每一对都包含一个提示和两个可能的完成 (一个首选,一个不首选),DPO 最大化生成首选完成的概率并最小化生成非首选完成的概率。它不涉及多轮训练,也不需要训练Reward模型,将奖励函数表示为LLM的概率表达形式,在一个模型中完成梯度回传。
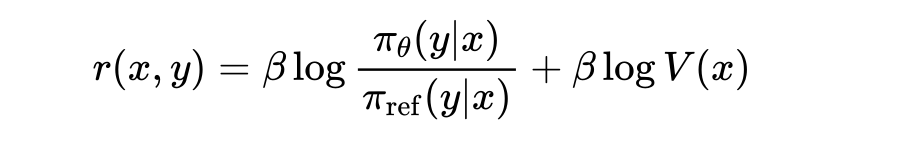
直接用人工标注的偏好数据对LLM进行pair-wise的偏好学习:
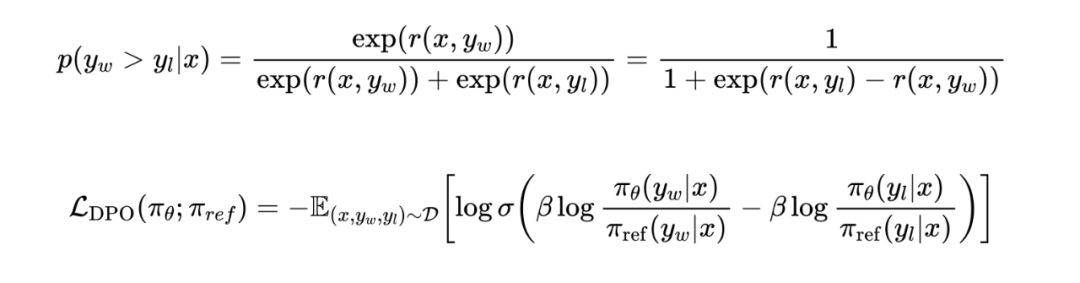
相关符号的解释:

2.3.3. 我们在DPO及其变种算法的探索及优化
DPO的变种算法近两年发展也非常迅速,我们一方面尝试了这些变种算法,另一方面也结合我们实际的业务情况进行了算法的改进。我们整个尝试路径如下,对齐算法迭代结果如表2所示。
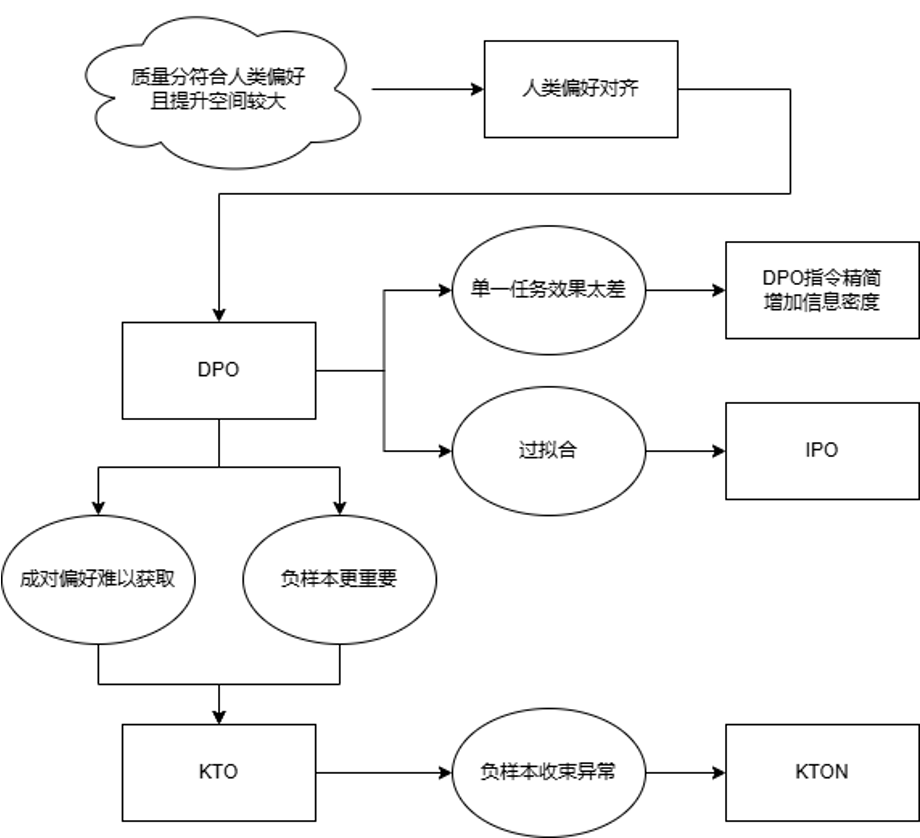
表2 对齐算法迭代结果

-
提升prompt信息密度优化DPO:在DPO对齐尝试的初期,我们遇到了所有业界学界使用DPO来完成单一任务学习所遇到的标准问题即模型收敛过快,且在短暂的学习过程中模型生成的内容面目全非,其中大部分人选择跳过DPO阶段,或者使用其它方式来绕过此类的问题。但是在我们的不断尝试中发现,该类问题仅出现在单一任务的场景中,在多指令场景下DPO则表现出正向的性能,所以我们通过解构分析多任务场景下的DPO指令与观察我们的DPO指令得到了非常重要的结论:由于我们SFT阶段与DPO阶段的prompt相对较长,且不同指令之间变化的仅有用户输入的行业信息与关键词,导致我们的指令构成虽然看起来很复杂但是在分布上却极其相近,所以DPO过程中极小的变动都会为结果带来极大的震荡,所以我们精简了我们DPO的输入,增加了prompt的信息密度,虽然收敛速度依旧较快,但是可以在有限的收敛中得到非常直观的指标提升,证明了我们方法的有效性,也为我们后续的对齐工作做了很重要的基础。
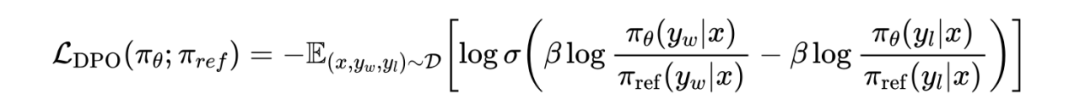
-
引入IPO加入正则化进行优化:尽管DPO通过RTL-free的方法超越了RLHF,但它面临着过度拟合和需要大量正则化等约束,这可能会阻碍策略模型的有效性。为了解决这些限制,研究学者引入了IPO算法,该算法定义了一个MSE形式的loss,将偏好概率拟合成一个定值,本质上等效在DPO基础上增加了一个L2正则。表2中IPO的指标结果相比DPO有所提升。
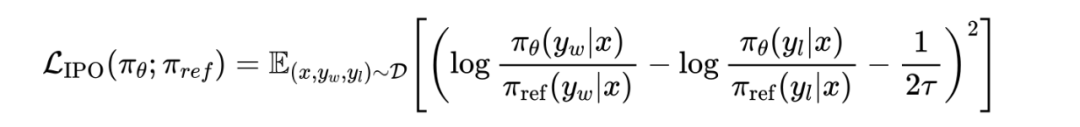
-
引入KTO进行正负样本解耦:DPO在数据集构成上有一个非常大的弊端,导致无法进一步提升。就是它需要成对的正负样本,过于依赖人工标注。而且产品只是明确标出了badcase,将非负样本当作正样本不一定正确,模型一直正向学习自己产出的标题可能也会陷入质量和多样性的局限。所以我们使用了KTO这种进阶方法,虽然KTO和DPO最终形式有非常多相似的地方,但基于两种偏好的对齐方法有不同的复杂性。KTO是直接从KT前景理论更换参考点和价值函数得出的公式。KTO只需要单一偏好策略就能提高DPO方法的有效性,无需pair对数据,而且可以参照经验值调大负样本权重,保证模型下限。表2中的结果显示,KTO的质量分相比IPO进一步提升。
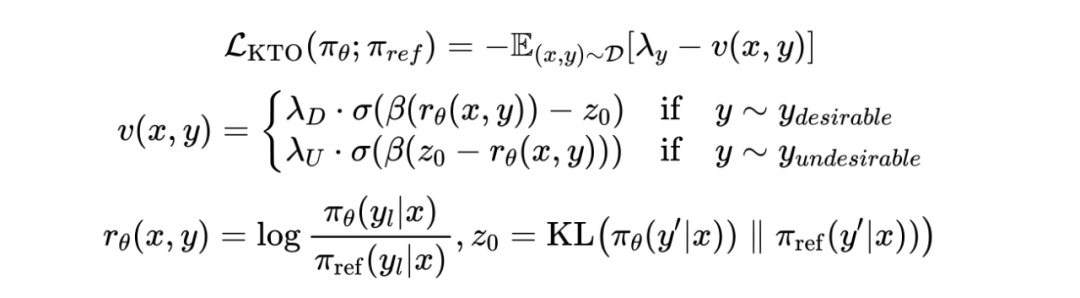
-
创新地提出KTON,对KTO进行改进,严格优化负样本约束:虽然对齐阶段取得了很好的成绩,但我们在各阶段仍然发现了负样本收束异常的现象,最直观的结果就是导致模型在流畅度上虽然还是达到了准入标准但是有所下降(如表2所示,KTO的流畅度下降比较明显)。
这里用DPO Loss公式进行说明。
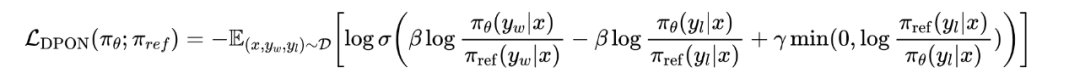
将加粗的第三项去掉就是DPO公式,第一项是模型出好答案的概率,第二项是模型出坏答案的概率,中间是个减号。理想情况下我们希望出好答案概率上升,出坏答案概率下降,loss稳步减小。但实际上还有一种情况就是模型出好答案和坏答案的概率都上升了,只不过第一项上升的幅度更大,导致loss仍然在正常减小,但在我们这个场景下负样本是最置信的准入标准,我们不希望负样本出任何问题。所以我们在Loss里面加了第三项作为惩罚项,坏答案的log ratio和第二项是颠倒过来的,正常优化时不会起作用,但是如果负样本异常收束了就会进行惩罚。最终模型也是在更严格的约束下取得了效果。如表2所示,质量分进一步提高,流畅度也提升到了准入门限0.96以上。
03. 产品入口
3.1. 基于关键词输入的标题生成
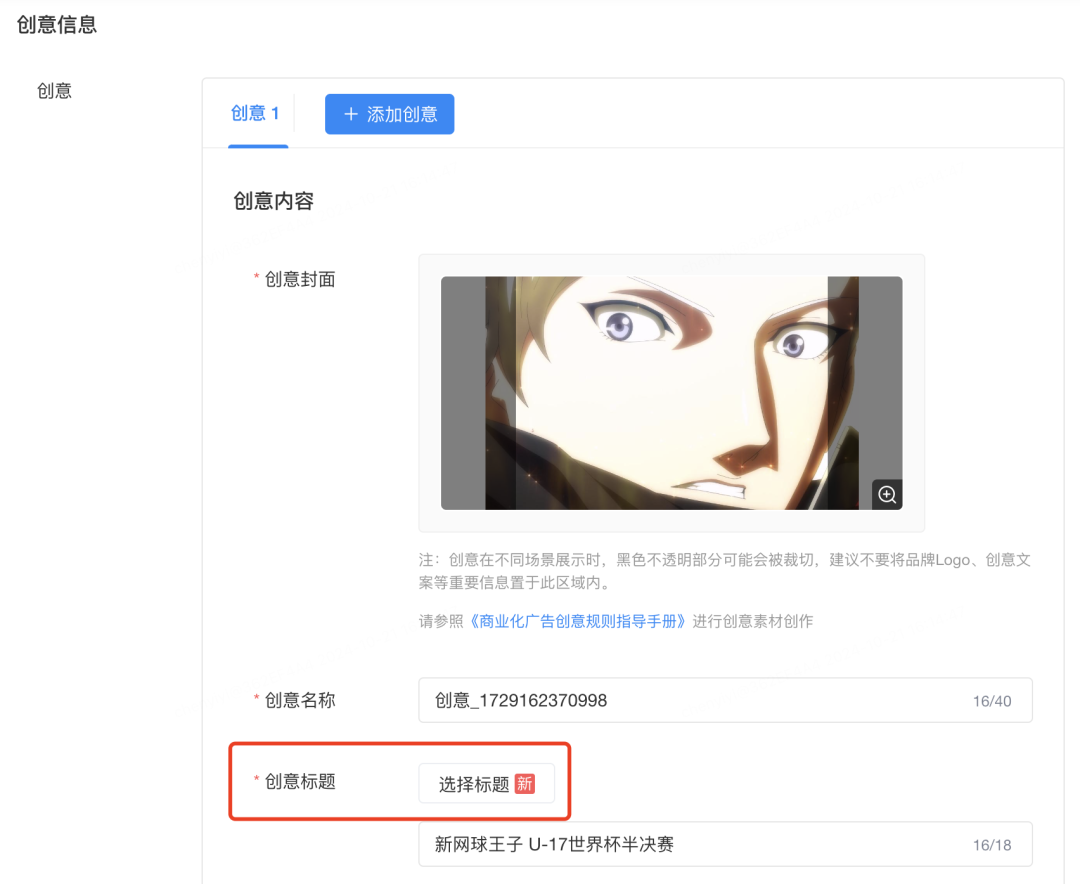
在创意创编流程中,用户为创意编写标题时会跳出如下弹窗,可以通过输入多个关键词生成标题,不满意时可以重复生成多次。

3.2. 引入标题联想提升消耗覆盖
在我们产品的迭代过程中,发现可能在标题生成的前置入口加入更为便捷的联想标题功能,会对用户的输入效率提升更为明显,并且在扩充标题库的时候也可以快速融入更新的内容以及更有讨论度的话题内容或者标题,这相比于迭代模型更加可控效果更加明显。产品设计形态如下。
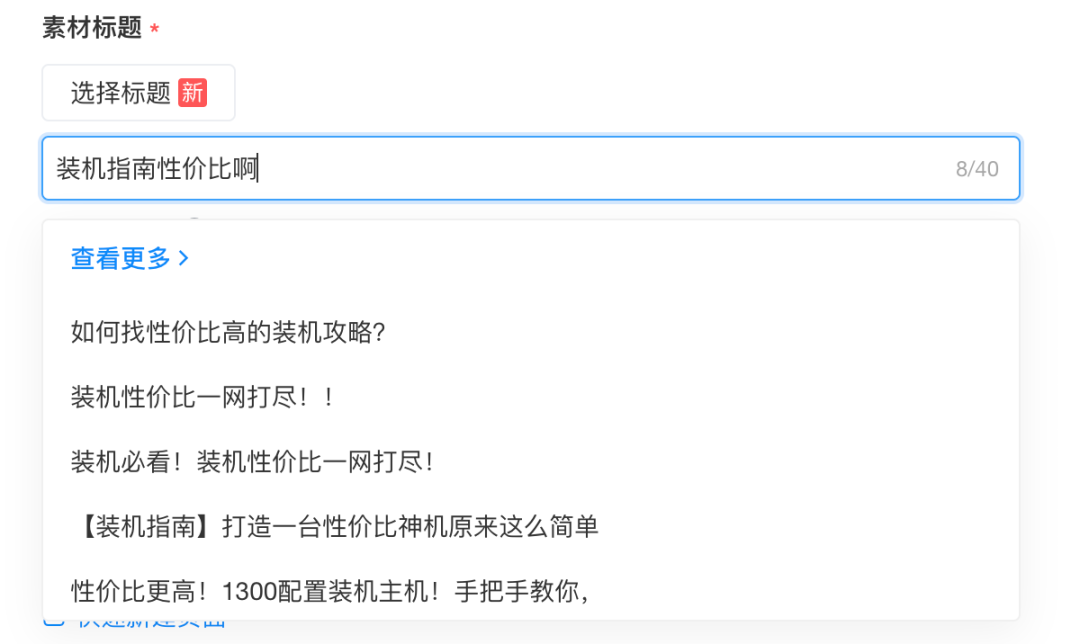
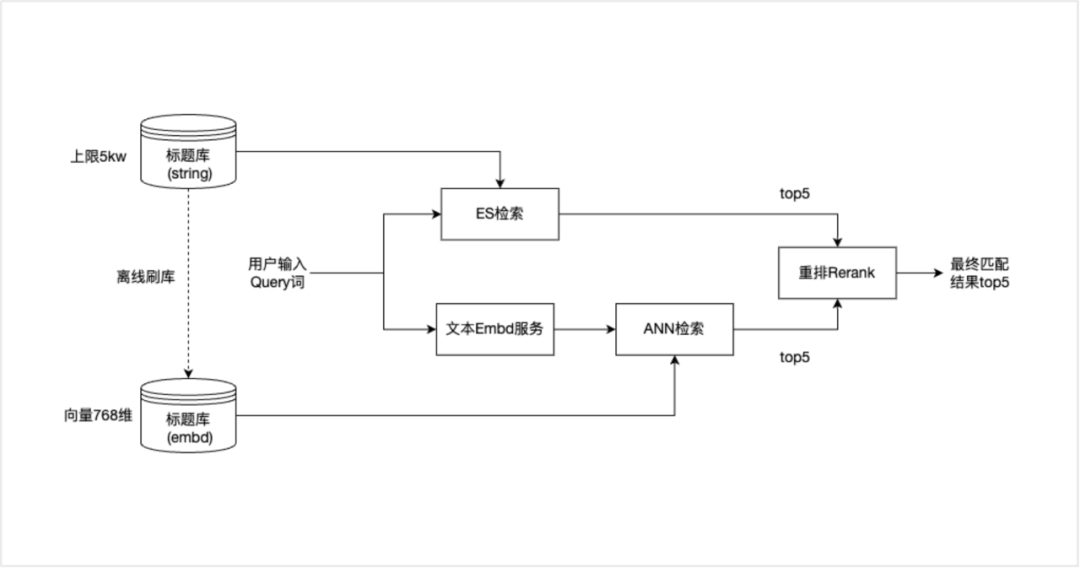
我们通过已经有的模型以及b站历史标题信息衍生出千万级别的标题,并且根据用户的输入来进行智能的推荐,同时我们在联想标题的功能搭建上采用了ANN + ES双重召回逻辑的思路,在短词query输入时联想用户更想补全的信息,在长文本query输入时召回与输入内容语义更相近的内容,系统结构如下。
04.业务场景迭代
产品上线后,我们也与广告主/代理商持续交流他们的使用体验,根据他们的反馈和需求我们也进行了一些有效的产品逻辑以及生成效果的优化。
4.1. 无关键词输入的首屏效果优化
在最初的产品设计中,进入到标题推荐的弹窗界面时,默认是没有任何关键词输入的,如下图所示,此时首屏的生成内容由于没有任何信息输入导致生成效果欠佳,首屏采纳率仅为20.4%左右。

-
优化一:我们进一步尝试从用户账号关联的商品信息中抽取商品实体词来优化模型,首屏采纳率提升到21.9%
-
优化二:引入标题联想后,我们进一步去思考用户的使用习惯,更多的使用方式是在输入一些信息后在联想框中没有找到合适的标题,那么进入到标题生成的弹窗时,我们将用户输入的query信息带过来,基于这个query信息生成标题展示在首屏上。如下图所示,用户输入「新网球王子」但是在标题联想环节没有找到喜欢的标题,进入到推荐标题的弹窗后系统会默认先基于「新网球王子」这个关键词进行标题的生成,目前的首屏采纳率已经提升到45%
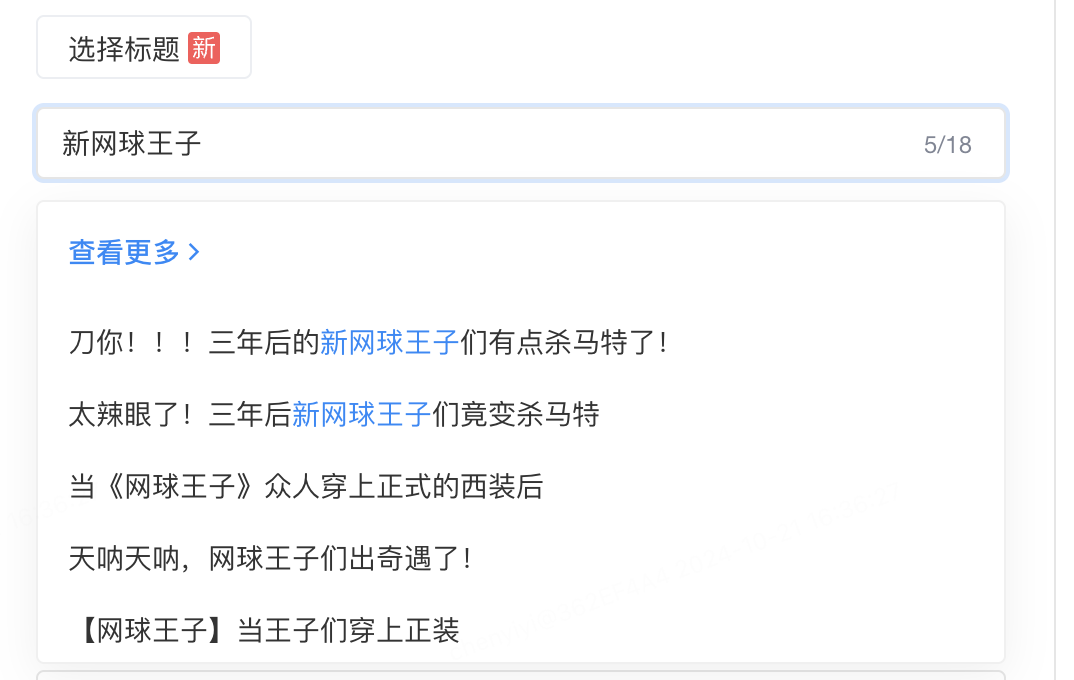

4.2. 如何提升标题新颖性
为了提升新颖性,我们主要有三方面优化:
-
优化一:引入社区稿件标题,社区的稿件相比广告更容易紧跟最新热点,且更原生化
-
优化二:每周基于当周新建的标题进行衍生生成,更新标题联想库
-
优化三:引入梗词RAG,我们基于b站社区弹幕、评论、标题等数据,利用算法挖掘其中的高频热梗及热门标题,利用向量数据库对热梗词进行相似检索,同时利用训练后大模型的few-shot能力,对召回后的标题进行prompt填充,让生成的标题能够更精确的使用与之主题贴合的社区热点内容,从而生成更新颖、更具有卖点的标题
05.上线效果
经过我们两个Q的开发和持续优化,目前标题智能推荐日均消耗可达到XX万元,整体广告平台每日新建的标题数的10%由AIGC参与创建,在业界已经处于领先水平。
06.后续规划
6.1. 离线评估指标尽可能贴近线上投放指标
尽快我们花费了大量精力确定了一套离线评估的标准,可以用来衡量我们模型的迭代程度,但是离线评估指标与线上真实的投放指标还是存在一定gap。我们也在持续探索更为合理和鲁棒的离线评估指标,例如考虑引入离线CTR预估模型也作为离线评估的一个维度,在引导模型进行离线优化时也能对线上指标的提升有正向的帮助。
6.2. 提升生成多样性,探索如何适配广告系统做”千人千面“的标题生成
多样性也是广告主/代理商所关注的一个方面,后续我们也会考虑纳入到我们的离线评估体系中。我们可以通过修改LLM模型的温度系数提升回答的多样性,也可以在推理时使用多prompt提升多样性。
此外,我们还可以结合广告推荐系统为广告主/代理商提供”千人千面“的标题生成暗投能力。生成模块可以针对不同的用户群体、不同的兴趣、不同的标题风格生成多样化的标题,再结合广告模型将其推送给最匹配的用户,实现匹配效率的最大化。
6.3. 探索基于RAG/CoT的业务效果优化,缓解LLM模型时效性差和幻觉的问题
尽管经过Alignment后,LLM能够生成符合审核原则和用户偏好的内容,但由于输入侧信息的匮乏以及可能存在的歧义,使得其输出结果容易产生幻觉,往往包含与事实不符的信息。除此之外,一些非标准化的知识,比如时效性强、营销活动、特有信息等并不适合通过模型训练来让模型掌握,我们需要通过外部知识检索增强 (Retrieval Augmented Generation) 来输出这类知识的能力。
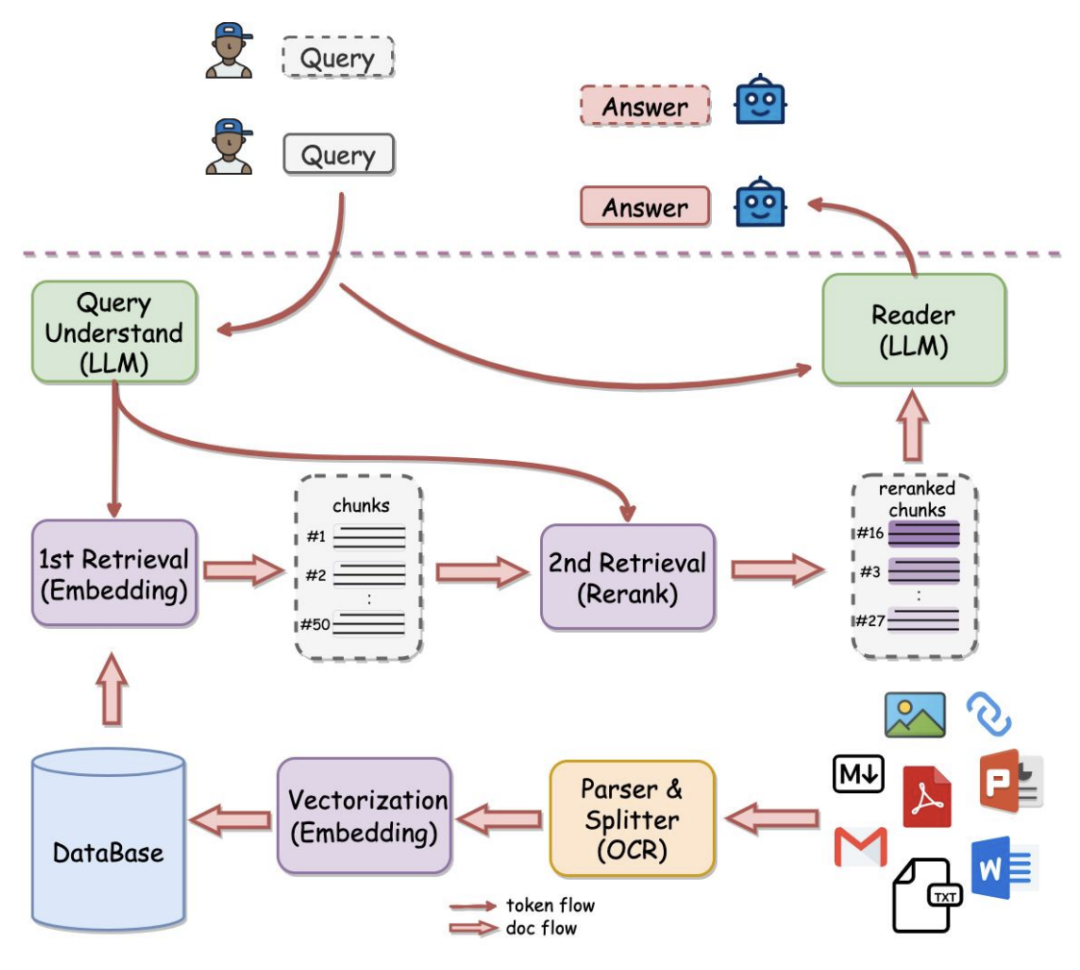
对于标题/文案生成,我们可以考虑利用商品信息等外部知识增强商品及广告的输入,还可以结合一些当下热梗爆梗生成更吸引用户的内容。
此外,针对线索类场景,我们还可以探索基于多轮对话的表单场景线索收集,结合RAG与客户进行多轮对话,解答客户问题,把客户信息结构化储存下来,促进客户填报信息。
此外,OpenAI最新发布的O1大模型体现了CoT的能力,虽然CoT本身对于我们的任务提升程度还是未知的,我们的SFT模型能否适应CoT的模式也是未知的,但是CoT本身代表了一种方式,可以在最小程度上取得一定的效果提升,如果结合RAG可能带来的收益更大,因为要处理的信息变多了,所以可能会一定程度上减少badcase出现的概率,提高模型的下限,也可以减少模型的幻觉。
6.4. 构建基于商业化数据的继续预训练能力和benchmark,建设鲁棒的商业基座模型和评价准则
继续预训练
目前开源大模型对于商业业务理解非常有限,具体表现在对于常见商品、行业基础知识的Faithfulness和Factualness两个方面表现都不尽如人意,可能的原因是目前开源大模型使用的预训练数据中对于商业化数据的覆盖非常有限,这是由于预训练数据中最主要的数据集Common Crawl需要遵从爬虫协议,电商网站通常会禁止网络爬虫的访问,同时大量的商品、产品信息是以图上文案的形式展现的,这部分数据没有被公开数据集所覆盖。具体到B站商业域,数据又具有更多自身的特点,比如吸引二次元用户、宅男用户等的特定商业话术。因此,我们有必要基于B站商业域数据 + 外站商业域数据构建商业领域的继续预训练能力和基座模型,作为后续适配各种应用场景的起点。
B站商业benchmark
考虑到现有的一些评测标准不能很好的反应模型在商业域知识程度,构建一个B站商业域专用Benchmark是有必要的,可以有效评估预训练的效果。通用领域的Benchmark通常是事实类的问答,考虑到商业化的特殊场景,我们可以构建包含商业事实类—商业内容知识、商业事实类—商业内容理解、商业事实类—推理事实文案、商业营销类—商业意图理解、商业营销类—营销语言能力,商业营销类—商业知识体系方面的评估数据集。
6.5. 探索如何基于Agent高效适配新业务场景
即使我们有了商业化的基座模型,针对不同的业务场景还是需要进行大量的适配操作,尤其是专有任务数据集的构建和清洗上。业界已有基于智能体Agent进行数据工程的实践,我们可以探索如何通过Agent高效适配新业务,尽可能将任务适配流程自动化、平台化。
参考文献
-
https://arxiv.org/pdf/2311.15653 MoDS: Model-oriented Data Selection for Instruction Tuning.
-
https://arxiv.org/pdf/2305.18290 Direct Preference Optimization: Your Language Model is Secretly a Reward Model.
-
https://argilla.io/blog/mantisnlp-rlhf-part-6/ RLHF and alternatives: IPO
-
https://arxiv.org/pdf/2402.01306 KTO: Model Alignment as Prospect Theoretic Optimization
-
https://arxiv.org/pdf/2405.19320 Value-Incentivized Preference Optimization: A Unified Approach to Online and Offline RLHF.
-
https://github.com/netease-youdao/QAnything
-End-
作者丨争气尾流;Nevis;聆风;小爱;奕辰;牧川;李民;保保;星汉;雷七刀;二师弟
相关文章:

面向B站商业化场景的广告标题智能推荐
01.背景 大模型的发展也在不断改变广告主/代理商广告创编的过程,为了提高广告主的创作效率,提升广告主投放标题的质量,我们利用大语言模型技术以及B站商业数据,能够让广告主仅需要输入特定的关键词,即可以生成理论上无…...

element plus 使用 upload 组件达到上传数量限制时隐藏上传按钮
最近在重构项目,使用了 element plus UI框架,有个功能是实现图片上传,且限制只能上传一张图片,结果,发现,可以限制只上传一张图片,但是上传按钮还在,如图: 解决办法&…...

java进行pdf文件压缩
文章目录 pdf文件压缩 pdf文件压缩 添加依赖 <dependency><groupId>com.luhuiguo</groupId><artifactId>aspose-pdf</artifactId><version>23.1</version> </dependency>public class OptimizePdf {public static void opti…...

初识算法和数据结构P1:保姆级图文详解
文章目录 前言1、算法例子1.1、查字典(二分查找算法)1.2、整理扑克(插入排序算法)1.3、货币找零(贪心算法) 2、算法与数据结构2.1、算法定义2.2、数据结构定义2.3、数据结构与算法的关系2.4、独立于编程语言…...

内网服务器添加共享文件夹功能并设置端口映射
参考网址 https://blog.csdn.net/Think88666/article/details/118438465 1.服务器安装smb服务,由于网路安全不允许使用默认端口(445,446),于是修改端口为62445、62446。 2.每台需要共享的电脑都要修改端口映射&#x…...

ruoyi-cloud docker启动微服务无法连接nacos,Client not connected, current status:STARTING
ruoyi-cloud docker启动微服务无法连接nacos,Client not connected, current status:STARTING 场景 当使用sh deploy.sh base来安装mysql、redis、nacos环境后,紧接着使用sh deploy.sh modules安装微服务模块,会发现微服务无法连接nacos的情…...
函数,LEGB规则))
Python----Python高级(函数基础,形参和实参,参数传递,全局变量和局部变量,匿名函数,递归函数,eval()函数,LEGB规则)
一、函数基础 1.1、函数的用法和底层分析 函数是可重用的程序代码块。 函数的作用,不仅可以实现代码的复用,更能实现代码的一致性。一致性指的是,只要修改函数的代码,则所有调用该函数的地方都能得到体现。 在编写函数时…...

excel 整理表格,分割一列变成多列数据
数据准备 对于很多系统页面的数据是没有办法下载的。 这里用表格数据来举例。随便做数据的准备。想要看excel部分的可以把这里跳过,从数据准备完成开始看。 需要一点前端基础知识,但不多(不会也行)。 把鼠标放在你想要拿到本地的…...

Oracle 分区索引简介
目录 一. 什么是分区索引二. 分区索引的种类2.1 局部分区索引(Local Partitioned Index)2.2 全局分区索引(Global Partitioned Index) 三. 分区索引的创建四. 分区索引查看4.1 USER_IND_COLUMNS 表4.2 USER_INDEXES 表 五. 分区索…...
)
C++实现设计模式--- 观察者模式 (Observer)
观察者模式 (Observer) 观察者模式 是一种行为型设计模式,它定义了一种一对多的依赖关系,使得当一个对象的状态发生改变时,其依赖者(观察者)会收到通知并自动更新。 意图 定义对象之间的一对多依赖关系。当一个对象状…...

CentOS 6.8 安装 Nginx
个人博客地址:CentOS 6.8 安装 Nginx | 一张假钞的真实世界 提前安装: # sudo yum install yum-utils 一般情况下这个工具系统已经安装。 创建文件/etc/yum.repos.d/nginx.repo,输入内容如下: [nginx-stable] namenginx stab…...

px、em 和 rem 的区别:深入理解 CSS 中的单位
文章目录 前言一、px - 像素 (Pixel)二、em - 相对父元素字体大小 (Ems)三、rem - 相对于根元素字体大小 (Root Ems)四、综合比较结语 前言 在CSS中,px、em和rem是三种用于定义尺寸(如宽度、高度、边距、填充等)的长度单位。它们各自有不同的…...

vue 表格内点编辑,单元格不切换成输入框问题分析
vue 表格渲染时,我点击编辑时,想直接在单元格上面进行编辑。 效果如下,正常是文本效果,点击编辑时,出现输入框 其实实现起来,逻辑很简单,但是中间我却出现了一个问题,效果始终出不…...

MATLAB学习笔记-table
1.在table中叠加table table 的每一列具有固定的数据类型。如果要让表的所有单元格都可以任意填充,就得让每一列都是 cell 类型,这样表中每个单元格都是“一个元胞”。创建时可以先构造一个 空 cell 数组(大小为行数列数)&#x…...

使用 selenium-webdriver 开发 Web 自动 UI 测试程序
优缺点 优点 有时候有可能一个改动导致其他的地方的功能失去效果,这样使用 Web 自动 UI 测试程序可以快速的检查并定位问题,节省大量的人工验证时间 缺点 增加了维护成本,如果功能更新过快或者技术更新过快,维护成本也会随之提高…...

ffmpeg硬件编码
使用FFmpeg进行硬件编码可以显著提高视频编码的性能,尤其是在处理高分辨率视频时。硬件编码利用GPU或其他专用硬件(如Intel QSV、NVIDIA NVENC、AMD AMF等)来加速编码过程。以下是使用FFmpeg进行硬件编码的详细说明和示例代码。 1. 硬件编码支…...
)
脚本化挂在物理盘、nfs、yum、pg数据库、nginx(已上传脚本)
文章目录 前言一、什么是脚本化安装二、使用步骤1.物理磁盘脚本挂载(离线)2.yum脚本化安装(离线)3.nfs脚本化安装(离线)4.pg数据库脚本化安装(离线)5.nginx脚本化安装(离…...

// Error: line 1: XGen: Candidate guides have not been associated!
Maya xgen 报错// Error: line 1: XGen: Candidate guides have not been associated! 复制下面粘贴到Maya脚本管理器python运行: import maya.cmds as cmds def connect_xgen_guides():guide_nodes cmds.ls(typexgmMakeGuide)for node in guide_nodes:downstream…...

投机解码论文阅读:Falcon
题目:Falcon: Faster and Parallel Inference of Large Language Models through Enhanced Semi-Autoregressive Drafting and Custom-Designed Decoding Tree 地址:https://arxiv.org/pdf/2412.12639 一看它的架构图,可以发现它是基于EAGLE…...

OpenCV实现基于交叉双边滤波的红外可见光融合算法
1 算法原理 CBF是*Cross Bilateral Filter(交叉双边滤波)*的缩写,论文《IMAGE FUSION BASED ON PIXEL SIGNIFICANCE USING CROSS BILATERAL FILTER》。 论文中,作者使用交叉双边滤波算法对原始图像 A A A, B B B 进行处理得到细节࿰…...

Springboot整合WebService
1.1 概述 webservice 即 web 服务,因互联网而产生,通过 webservice 这种 web 服务,我们可以实现互联网应 用之间的资源共享,比如我们想知道 手机号码归属地,列车时刻表,天气预报,省市区邮…...

504 Gateway Timeout:网关超时解决方法
一、什么是 504Gateway Timeout? 1. 错误定义 504 Gateway Timeout 是 HTTP 状态码的一种,表示网关或代理服务器在等待上游服务器响应时超时。通俗来说,这是服务器之间“对话失败”导致的。 2. 常见触发场景 Nginx 超时:反向代…...

C++ 的 pair 和 tuple
1 std::pair 1.1 C 98 的 std::pair 1.1.1 std::pair 的构造 C 的二元组 std::pair<> 在 C 98 标准中就存在了,其定义如下: template<class T1, class T2> struct pair;std::pair<> 是个类模板,它有两个成员&#x…...

抢十八游戏
前言 我国民国一直流传着一个名叫“抢十八”的抢数游戏:参与游戏的两人从1开始轮流报数,每次至少报1个数,最多报2个数,每人报的每个数不得与自已报过的或对方报过的重复,也不得跳过任何一个数。谁先报到18,…...

从玩具到工业控制--51单片机的跨界传奇【2】
咱们在上一篇博客里面讲解了什么是单片机《单片机入门》,让大家对单片机有了初步的了解。我们今天继续讲解一些有关单片机的知识,顺便也讲解一下我们单片机用到的C语言知识。如果你对C语言还不太了解的话,可以看看博主的C语言专栏哟ÿ…...

LLM实现视频切片合成 前沿知识调研
1.相关产品 产品链接腾讯智影https://zenvideo.qq.com/可灵https://klingai.kuaishou.com/即梦https://jimeng.jianying.com/ai-tool/home/Runwayhttps://aitools.dedao.cn/ai/runwayml-com/Descripthttps://www.descript.com/?utm_sourceai-bot.cn/Opus Cliphttps://www.opu…...

学习threejs,使用FlyControls相机控制器
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️THREE.FlyControls 相机控制…...

wordpress 房产网站筛选功能
自定义分类法创建 add_action( init, ashu_post_type ); function ashu_post_type() {register_taxonomy(province,post,array(label => 省,rewrite => array( slug => province ),hierarchical => true));register_taxonomy(city,post,array(label => 市,rewr…...

SQL面试题2:留存率问题
引言 场景介绍: 在互联网产品运营中,用户注册量和留存率是衡量产品吸引力和用户粘性的关键指标,直接影响产品的可持续发展和商业价值。通过分析这些数据,企业可以了解用户行为,优化产品策略,提升用户体验…...

Redis是单线程还是多线程?
大家好,我是锋哥。今天分享关于【Redis是单线程还是多线程?】面试题。希望对大家有帮助; Redis是单线程还是多线程? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Redis是 单线程 的。 尽管Redis的处理是单线程的&a…...

mysql 变量,流程控制与游标
第16章_变量,流程控制与游标 1.变量 分为系统变量和用户自定义变量 1.1系统变量 1.1.1系统变量分类 系统变量分为全局系统变量以及会话系统变量 查看所有全局变量 SHOW GLOBAL VARIABLES 查看所有会话变量 SHOW SESSION VARIABLESor SHOW VARIABLES #默认是会话变量 …...

Java配置log4j日志打印
1. 引入依赖 <dependencies><!-- Log4j 2依赖 --><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>1.2.14</version> <!-- 可以根据需要修改版本 --></…...

什么是SQL?
什么是SQL? SQL(Structured Query Language,结构化查询语言)是一种用于与关系型数据库进行交互的标准编程语言。SQL 是设计用于管理和操作关系型数据库的语言,主要用于查询、插入、更新、删除和定义数据结构。SQL 是关…...

Linux 机器学习
Linux 机器学习是指在 Linux 操作系统环境下进行机器学习相关的开发、训练和应用。 具体步骤 环境搭建: 选择合适的 Linux 发行版:如 Ubuntu、Fedora、Arch Linux 等。Ubuntu 因其易用性和丰富的软件包管理系统,适合初学者;Fed…...
实现Scroll下拉到顶刷新/上拉触底加载,Scroll滚动到顶部)
HarmonyOS 鸿蒙 ArkTs(5.0.1 13)实现Scroll下拉到顶刷新/上拉触底加载,Scroll滚动到顶部
HarmonyOS 鸿蒙 ArkTs(5.0.1 13)实现Scroll下拉到顶刷新/上拉触底加载 效果展示 使用方法 import LoadingText from "../components/LoadingText" import PageToRefresh from "../components/PageToRefresh" import FooterBar from "../components/…...

第27章 汇编语言--- 设备驱动开发基础
汇编语言是低级编程语言的一种,它与特定的计算机架构紧密相关。在设备驱动开发中,汇编语言有时用于编写性能关键的部分或直接操作硬件,因为它是接近机器语言的代码,可以提供对硬件寄存器和指令集的直接访问。 要展开源代码详细叙…...

sosadmin相关命令
sosadmin命令 以下是本人翻译的官方文档,如有不对,还请指出,引用请标明出处。 原本有个对应表可以跳转的,但是CSDN的这个[](#)跳转好像不太一样,必须得用html标签,就懒得改了。 sosadmin help 用法 sosadm…...

【git】-初始git
学习资源推荐- 标签管理 - Git教程 - 廖雪峰的官方网站 一、什么是版本控制? 二、Git的安装 三、掌握Linux常用命令 四、Git基本操作 1、提交代码 2、查看历史提交 3、版本回退 一、什么是版本控制? 版本控制是一种用于记录文件或项目内容变化的系…...

JAVA之单例模式
单例模式(Singleton Pattern)是一种设计模式,用于确保一个类只有一个实例,并提供一个全局访问点来获取该实例。在软件设计中,单例模式常用于控制对资源的访问,例如数据库连接、线程池等。以下是单例模式的详…...

无人机数据集,支持YOLO,COCO json,PASICAL VOC xml格式的标注,正确识别率可达到95.7%,10000张原始图片
无人机数据集,支持YOLO,COCO json,PASICAL VOC xml格式的标注,正确识别率可达到95.7%,10000张原始图片 下载地址: 标注好的数据集下载地址: yolo v11: https://download.csdn.net/download/p…...
)
Linux:进程概念(三.详解进程:进程状态、优先级、进程切换与调度)
目录 1. Linux中的进程状态 1.1 前台进程和后台进程 运行状态 睡眠状态 磁盘休眠状态 停止状态 kill指令—向进程发送信号 死亡状态 2. 僵尸进程 2.1 僵尸状态 2.2 僵尸进程 2.3 僵尸进程危害 3. 孤儿进程 4. 进程的优先级 概念 查看进程优先级 PRI(…...

stack和queue专题
文章目录 stack最小栈题目解析代码 栈的压入弹出序列题目解析代码 queue二叉树的层序遍历题目解析代码 stack stack和queue都是空间适配器 最小栈 最小栈的题目链接 题目解析 minst是空就进栈,或者是val < minst.top()就进栈 代码 class MinStack { public:M…...
)
一 rk3568 Android 11固件开发环境搭建 (docker)
一 目标 搭建 rk3568 android 系统内核 及固件开发编译调试环境, 支持开发环境导出分享 基于荣品 rk3568 核心板 系统环境: ubuntu22.04 /ubuntu20.04 64位桌面版 编译环境: docker + ubuntu20.04 , 独立的容器隔离环境,不受系统库版本冲突等影响,无性能损耗, 可…...

2025年华数杯国际赛B题论文首发+代码开源 数据分享+代码运行教学
176项指标数据库 任意组合 千种组合方式 14页纯图 无水印可视化 63页无附录正文 3万字 1、为了方便大家阅读,全文使用中文进行描述,最终版本需自行翻译为英文。 2、文中图形、结论文字描述均为ai写作,可自行将自己的结果发给ai,…...

三小时深度学习PyTorch
【对新手非常友好】三小时深度学习PyTorch快速入门!包教会你的! --人工智能/深度学习/pytorch_哔哩哔哩_bilibili从头开始,把概率论、统计、信息论中零散的知识统一起来_哔哩哔哩_bilibili从编解码和词嵌入开始,一步一步理解Trans…...

朴素贝叶斯分类器
一、生成模型(学习)(Generative Model) vs 判别模型(学习)(Discriminative Model) 结论:贝叶斯分类器是生成模型 1、官方说明 生成模型对联合概率 p(x, y)建模&#x…...
—术语和定义)
商用车电子电气零部件电磁兼容条件和试验(2)—术语和定义
写在前面 本系列文章主要讲解商用车电子/电气零部件或系统的传导抗干扰、传导发射和辐射抗干扰、电场辐射发射以及静电放电等试验内容及要求,高压试验项目内容及要求。 若有相关问题,欢迎评论沟通,共同进步。(*^▽^*) 目录 商用车电子电气…...

SimpleFOC01|基于STM32F103+CubeMX,移植核心的common代码
导言 如上图所示,进入SimpleFOC官网,点击Github下载源代码。 如上图所示,找到仓库。 comom代码的移植后,simpleFOC的移植算是完成一大半。simpleFOC源码分为如下5个部分,其中communication是跟simpleFOC上位机通讯&a…...

物联网之传感器技术
引言 在数字化浪潮席卷全球的今天,物联网(IoT)已成为推动各行各业变革的重要力量。而物联网传感器,作为物联网感知层的核心技术,更是扮演着不可或缺的角色。它们如同人类的五官,能够感知物理世界中的各种信…...

React:构建用户界面的JavaScript库
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...