Vision Transformer模型详解(附pytorch实现)
写在前面
最近,我在学习Transformer模型在图像领域的应用。图像处理任务一直以来都是深度学习领域的重要研究方向,而传统的卷积神经网络已在许多任务中取得了显著的成绩。然而,近年来,Transformer模型由于其在自然语言处理中的成功,逐渐被引入到计算机视觉领域。Vision Transformer(ViT)是应用Transformer架构于图像分类任务的一个重要突破,它证明了Transformer在视觉任务中的潜力。ViT通过将图像分割成若干固定大小的图块,并将每个图块视为一个序列输入到Transformer中进行处理。与传统的卷积神经网络不同,ViT摆脱了卷积操作,完全依赖自注意力机制来捕捉图像中的长距离依赖关系。
本篇文章将深入探讨Vision Transformer的原理、架构以及其在图像分类任务中的表现,并通过代码实现来帮助大家更好地理解其工作方式。
论文地址:https://arxiv.org/pdf/2010.11929
官方代码实现:vision_transformer/vit_jax/models_vit.py
VIT网络结构
Vision Transformer(ViT)是将Transformer架构应用于图像分类任务的一个创新模型。传统上,卷积神经网络(CNN)是图像处理任务的主流方法,而ViT提出了一种完全不同的视角:将图像分割成固定大小的图块,并将这些图块视为一维的序列来输入Transformer模型。ViT模型摒弃了卷积操作,完全依赖于Transformer的自注意力机制来捕捉图像中的长距离依赖。
下面的动态图是从网上找到的,展示也比较形象。

Patch Embedding结构
ViT的输入是一个大小为 H×W×C 的图像,其中 H 和 W 是图像的高和宽,C 是图像的通道数。ViT将图像分割成大小为 P×P 的小块,称为“patches”(图像块)。假设输入图像的大小是 H × W,通过将其切割成 P×P 的小块后,每个小块的大小为,并且总共有
个图块。每个图块的大小就是一个向量。每个图块被展平(flatten)并通过一个线性变换(即一个全连接层)映射到一个固定的维度 D,形成每个图块的嵌入(embedding)。该嵌入向量的维度就是Transformer的输入维度。
from functools import partialimport torch
import torch.nn as nn
from pyzjr.utils.FormatConver import to_2tupleLayerNorm = partial(nn.LayerNorm, eps=1e-6)class PatchEmbedding(nn.Module):def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768, norm_layer=None):super().__init__()self.img_size = to_2tuple(img_size)self.patch_size = to_2tuple(patch_size)self.embed_dim = embed_dim# self.num_patches = (self.img_size[0] // self.patch_size[0]) * (self.img_size[1] // self.patch_size[1])self.norm = norm_layer(self.embed_dim) if norm_layer else nn.Identity()self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size, padding=0)def forward(self, x):x = self.proj(x) # 结果形状为 (batch_size, embed_dim, num_patches_H, num_patches_W)x = x.flatten(2) # 将输出展平成 (batch_size, embed_dim, num_patches)x = x.transpose(1, 2) # 转置为 (batch_size, num_patches, embed_dim)x = self.norm(x)return xif __name__ == "__main__":img_size = 224 # 图像大小patch_size = 16 # 每个patch的大小in_channels = 3 # 图像通道数embed_dim = 768 # Patch嵌入维度patch_embedding = PatchEmbedding(img_size=img_size, patch_size=patch_size, in_channels=in_channels,embed_dim=embed_dim)batch_size = 2x = torch.randn(batch_size, in_channels, img_size, img_size)output = patch_embedding(x)print("Final output shape:", output.shape)上面的实现其实就可以用一个卷积核就能实现patch的分割和嵌入,卷积核公式为:
代入计算刚好就是14。
在ViT中,输入到 Transformer Encoder 之前,需要添加两种类型的编码信息:类别编码 (Class Token) 和 位置编码 (Position Encoding)。这两种编码信息能够帮助 Transformer 更好地理解输入图像的全局信息和局部结构。下面分别介绍这两种编码。
类别编码
类别编码是一个用于表示图像整体的特殊标记符号,它的作用是让 Transformer 在整个图像的上下文中获取全局信息。Transformer 本身是基于序列模型的,它不像卷积神经网络 (CNN) 那样有局部感受野的结构,因此 Transformer 在处理图像时需要有一个机制来了解图像的全局信息。
类别编码就是一个类似于“占位符”的向量,表示图像的全局信息。它会与其他 patch 一同输入到 Transformer Encoder 中,最终模型会学习到类别编码的输出代表了整个图像的特征,最终用于分类或其他任务。
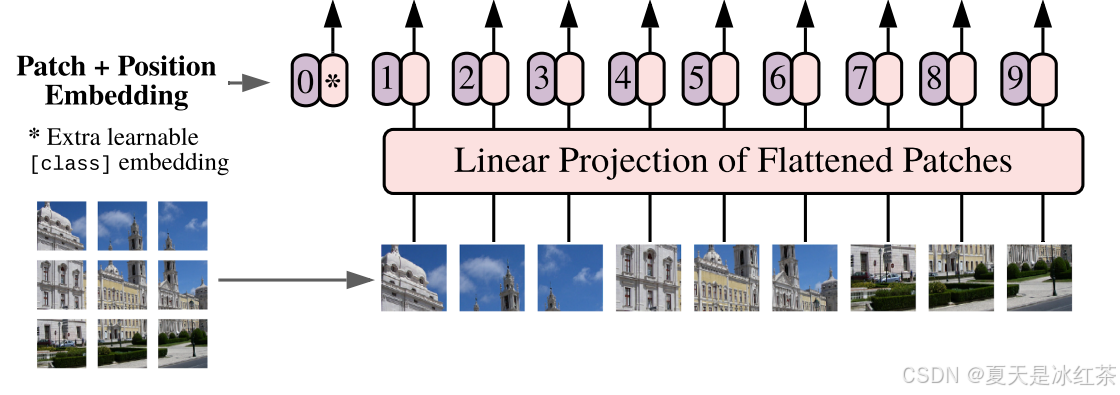
在上面的结构图中就是左侧的0,1,2,3...等等,它是一个与其他图像 patch 同样维度的向量,通常初始化为随机的可训练向量,会与 patch 嵌入向量进行拼接,从而形成一个包含图像所有局部特征和全局特征的输入序列。
位置编码
位置编码用于提供每个 patch 在图像中的相对位置信息。因为 Transformer 的注意力机制本身并不考虑输入的顺序,所以我们需要显式地为每个 patch 添加位置信息,来表示它们在原图中的空间布局。在 Transformer 中,输入的序列是无序的,模型并没有自动的空间位置信息。所以必须通过显式的方式引入每个 patch 的位置信息,才能让模型理解各个 patch 之间的空间关系。
对于图像任务,位置编码能够帮助模型保持空间结构信息,从而提高对图像内容的理解。
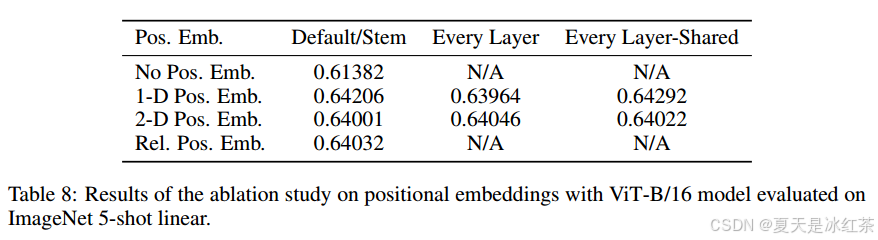
作者通过实验对比,发现加了位置编码的效果更好,而加几维的差别不大,关键是有没有。
位置编码通常是一个与图像的 patch 数量相匹配的向量,每个 patch 对应一个位置编码。通常有两种方式生成位置编码:一种是使用 固定的位置编码,另一种是使用 可学习的位置编码。ViT 中通常使用可学习的位置编码,允许模型根据数据学习每个位置的语义表示。
Transformer Encoder结构
LayerNorm
我想大家都知道常用的比较多的是 BatchNorm,它依赖于批量数据(即通过计算整个 mini-batch 的均值和方差),而 LayerNorm 是针对每一个样本进行标准化的,它不依赖于 batch 的大小。
Transformer 是基于序列的模型,序列的长度可能变化很大。使用 LayerNorm 可以避免依赖 batch 的统计量,从而使模型能够在不同批次之间保持一致性,且更加稳定,特别是在处理变长序列时。
原理可以看看文档LayerNorm。
Multi-Head Attention
详细可以看我之前写的一篇博文Transformer中Self-Attention以及Multi-Head Attention模块详解。
这里参考的是其他博主(参考文章第一个)的写法,我觉得这里可以直接使用官方实现的torch.nn.MultiheadAttention。
class MultiheadAttention(nn.Module):def __init__(self,embed_dim,num_heads=8,qkv_bias=False,attn_drop=0.,proj_drop=0.,):super(MultiheadAttention, self).__init__()self.num_heads = num_headsself.head_dim = embed_dim // num_headsself.scale = self.head_dim ** -0.5self.qkv = nn.Linear(embed_dim, embed_dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.out_linear = nn.Linear(embed_dim, embed_dim)self.out_linear_drop = nn.Dropout(proj_drop)def forward(self, x):B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[:3]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = F.softmax(attn, dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.out_linear(x)x = self.out_linear_drop(x)return xif __name__ == "__main__":embed_dim = 64num_heads = 8batch_size = 2seq_len = 10# 随机生成输入数据 (batch_size, seq_len, embed_dim)x = torch.rand(batch_size, seq_len, embed_dim)attention_layer = MultiheadAttention(embed_dim, num_heads)output = attention_layer(x)print("输入形状:", x.shape)print("输出形状:", output.shape)MLP Head
在 ViT 中,MLP 被用来处理 Transformer Encoder 的每一层输出,结构上就是全连接+GELU激活函数+Dropout层。
class MLP(nn.Module):def __init__(self, embed_dim, hidden_dim, drop_rate=0.1, act_layer=nn.GELU):super(MLP, self).__init__()self.fc1 = nn.Linear(embed_dim, hidden_dim)self.act = act_layer()self.fc2 = nn.Linear(hidden_dim, embed_dim)self.dropout = nn.Dropout(drop_rate)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.dropout(x)x = self.fc2(x)x = self.dropout(x)return xTransformer Encoder Block
Transformer Encoder其实就是重复堆叠Encoder Block L次,下面是原论文当中给出的图形结构,在实际的代码实现当中,Encoder Block其实是由LayerNorm+Multi-Head Attention+Dropout和LayerNorm+MLP++Dropout实现,我看也有实现的时候使用的是DropPath。
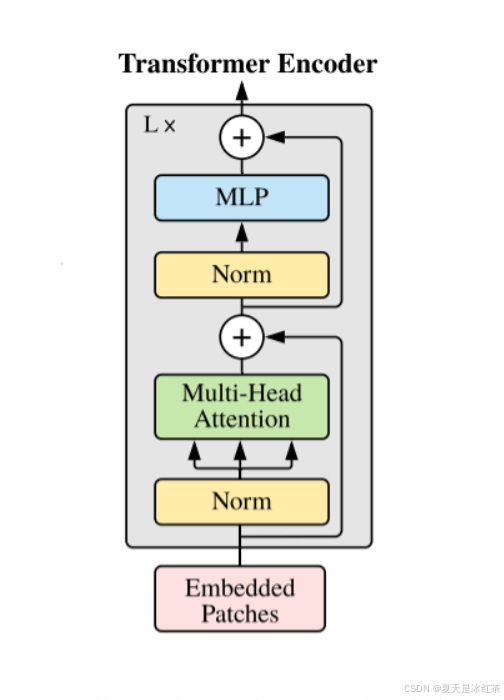
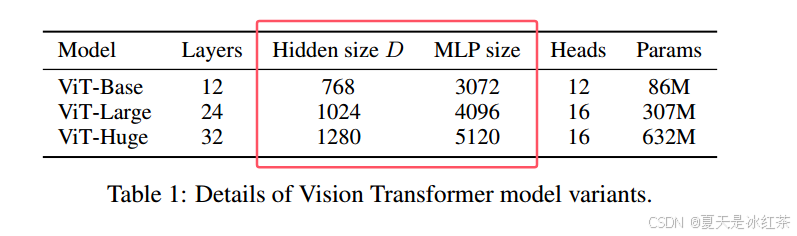
class EncoderBlock(nn.Module):"""Transformer encoder block.在 mlp block中, MLP 层的隐藏维度是输入的维度的4倍, 详见 Table 1: Details of Vision Transformer model variants"""mlp_ratio = 4 def __init__(self,dim,num_heads,drop_ratio=0.,attention_dropout_ratio=0.,drop_path_ratio=0.,norm_layer=LayerNorm,act_layer=nn.GELU):super(EncoderBlock, self).__init__()self.num_heads = num_heads# Attention blockself.norm1 = norm_layer(dim)self.attention = MultiheadAttention(dim, num_heads, attn_drop=attention_dropout_ratio, proj_drop=drop_ratio)self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()# MLP blockself.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * self.mlp_ratio)self.mlp = MLP(dim, mlp_hidden_dim, drop_ratio=drop_ratio, act_layer=act_layer)def forward(self, x):x = x + self.drop_path(self.attention(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return x在mlp block中, MLP 层的隐藏维度是输入的维度的4倍,可以查看论文当中的Table 1。
VIT模型实现
from functools import partialimport torch
import torch.nn as nn
import torch.nn.functional as F
from pyzjr.utils.FormatConver import to_2tuple
from pyzjr.nn.models.bricks.drop import DropPathLayerNorm = partial(nn.LayerNorm, eps=1e-6)class PatchEmbedding(nn.Module):def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768, norm_layer=None):super().__init__()self.img_size = to_2tuple(img_size)self.patch_size = to_2tuple(patch_size)self.embed_dim = embed_dimself.norm = norm_layer(self.embed_dim) if norm_layer else nn.Identity()self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size, padding=0)def forward(self, x):x = self.proj(x) # 结果形状为 (batch_size, embed_dim, num_patches_H, num_patches_W)x = x.flatten(2) # 将输出展平成 (batch_size, embed_dim, num_patches)x = x.transpose(1, 2) # 转置为 (batch_size, num_patches, embed_dim)x = self.norm(x)return xclass MultiheadAttention(nn.Module):def __init__(self,embed_dim,num_heads=8,qkv_bias=False,attention_dropout_ratio=0.,proj_drop=0.,):super(MultiheadAttention, self).__init__()self.num_heads = num_headsself.head_dim = embed_dim // num_headsself.scale = self.head_dim ** -0.5self.qkv = nn.Linear(embed_dim, embed_dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attention_dropout_ratio)self.out_linear = nn.Linear(embed_dim, embed_dim)self.out_linear_drop = nn.Dropout(proj_drop)def forward(self, x):B, N, C = x.shapeqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[:3]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = F.softmax(attn, dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.out_linear(x)x = self.out_linear_drop(x)return xclass MLP(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop_ratio=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop_ratio)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass EncoderBlock(nn.Module):"""Transformer encoder block.在 mlp block中, MLP 层的隐藏维度是输入的维度的4倍,详见 Table 1: Details of Vision Transformer model variants"""mlp_ratio = 4def __init__(self,dim,num_heads,qkv_bias=False,drop_ratio=0.,attention_dropout_ratio=0.,drop_path_ratio=0.,norm_layer=LayerNorm,act_layer=nn.GELU):super(EncoderBlock, self).__init__()self.num_heads = num_heads# Attention blockself.norm1 = norm_layer(dim)self.attention = MultiheadAttention(dim, num_heads, qkv_bias=qkv_bias, attention_dropout_ratio=attention_dropout_ratio, proj_drop=drop_ratio)self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()# MLP blockself.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * self.mlp_ratio)self.mlp = MLP(dim, mlp_hidden_dim, drop_ratio=drop_ratio, act_layer=act_layer)def forward(self, x):x = x + self.drop_path(self.attention(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass TransformerEncoder(nn.Module):"""堆叠 L 次 Transformer encoder block"""def __init__(self,num_layers,dim,num_heads,qkv_bias=False,drop_ratio=0.,attention_dropout_ratio=0.,drop_path_ratio=0.,norm_layer=LayerNorm,act_layer=nn.GELU):super(TransformerEncoder, self).__init__()dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, num_layers)] # stochastic depth decay ruleself.layers = nn.ModuleList([EncoderBlock(dim=dim,num_heads=num_heads,qkv_bias=qkv_bias,drop_ratio=drop_ratio,attention_dropout_ratio=attention_dropout_ratio,drop_path_ratio=dpr[_],norm_layer=norm_layer,act_layer=act_layer)for _ in range(num_layers)])self.norm = norm_layer(dim)def forward(self, x):for layer in self.layers:x = layer(x)x = self.norm(x)return xclass VisionTransformer(nn.Module):def __init__(self,img_size=224,patch_size=16,in_channels=3,num_classes=1000,hidden_dim=768,num_heads=12,num_layers=12,qkv_bias=True,drop_ratio=0.,attention_dropout_ratio=0.,drop_path_ratio=0.,norm_layer=LayerNorm,act_layer=nn.GELU):super(VisionTransformer, self).__init__()assert img_size == 224, f"Image size must be 224, but got {img_size}"assert img_size % patch_size == 0, f"Image size {img_size} must be divisible by patch size {patch_size}"self.num_classes = num_classesself.num_tokens = 1self.patch_embed = PatchEmbedding(img_size=img_size, patch_size=patch_size, in_channels=in_channels,embed_dim=hidden_dim, norm_layer=norm_layer)num_patches = (img_size // patch_size) * (img_size // patch_size)self.cls_token = nn.Parameter(torch.zeros(1, 1, hidden_dim))self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, hidden_dim))self.pos_drop = nn.Dropout(p=drop_ratio)self.blocks = TransformerEncoder(num_layers=num_layers,dim=hidden_dim,num_heads=num_heads,qkv_bias=qkv_bias,drop_ratio=drop_ratio,attention_dropout_ratio=attention_dropout_ratio,drop_path_ratio=drop_path_ratio,norm_layer=norm_layer,act_layer=act_layer)self.norm = norm_layer(hidden_dim)self.head = nn.Linear(hidden_dim, num_classes)self._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Linear):nn.init.trunc_normal_(m.weight, std=.01)if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.LayerNorm):nn.init.zeros_(m.bias)nn.init.ones_(m.weight)def forward(self, x):x = self.patch_embed(x) # [B, 196, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1) # [B, 1, 768]x = torch.cat((cls_token, x), dim=1) # [B, 196+1, 768]x = self.pos_drop(x + self.pos_embed) # [B, 197, 768]x = self.blocks(x) # [B, 197, 768]x = x[:, 0] # [B, 768]x = self.head(x) # [B, num_classes]return xdef vit_b_16(num_classes=1000) -> VisionTransformer:return VisionTransformer(img_size=224,patch_size=16,num_classes=num_classes,hidden_dim=768,num_heads=12,num_layers=12,)def vit_b_32(num_classes=1000) -> VisionTransformer:return VisionTransformer(img_size=224,patch_size=32,num_classes=num_classes,hidden_dim=768,num_heads=12,num_layers=12,)def vit_l_16(num_classes=1000) -> VisionTransformer:return VisionTransformer(img_size=224,patch_size=16,num_classes=num_classes,hidden_dim=1024,num_heads=16,num_layers=24,)def vit_l_32(num_classes=1000) -> VisionTransformer:return VisionTransformer(img_size=224,patch_size=32,num_classes=num_classes,hidden_dim=1024,num_heads=16,num_layers=24,)def vit_h_14(num_classes=1000) -> VisionTransformer:return VisionTransformer(img_size=224,patch_size=14,num_classes=num_classes,hidden_dim=1280,num_heads=16,num_layers=32,)if __name__=="__main__":import torchsummarydevice = 'cuda' if torch.cuda.is_available() else 'cpu'input = torch.ones(2, 3, 224, 224).to(device)net = vit_h_14(num_classes=4)net = net.to(device)out = net(input)print(out)print(out.shape)torchsummary.summary(net, input_size=(3, 224, 224))# vit_b_16 Total params: 85,651,204# vit_b_32 Total params: 87,420,676# vit_l_16 Total params: 303,105,028# vit_l_32 Total params: 305,464,324# vit_h_14 Total params: 630,442,244虽然我这里实现的可以进行图像分类训练,但对于大多数实际应用,我还是推荐使用官方实现的代码模型,预训练模型进行迁移学习。这里仅作为学习参考。
参考文章
Vision Transformer详解-CSDN博客
保姆级教学 —— 手把手教你复现Vision Transformer_transformer输出特征图大小-CSDN博客
【Transformer系列】深入浅出理解ViT(Vision Transformer)模型-CSDN博客
【图像分类】Vision Transformer理论解读+实践测试-CSDN博客
推荐的视频: 11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
相关文章:
Vision Transformer模型详解(附pytorch实现)
写在前面 最近,我在学习Transformer模型在图像领域的应用。图像处理任务一直以来都是深度学习领域的重要研究方向,而传统的卷积神经网络已在许多任务中取得了显著的成绩。然而,近年来,Transformer模型由于其在自然语言处理中的成…...
1990-2020年-社科数据)
中国区域创新创业指数IRIEC数据(省级、地市级)1990-2020年-社科数据
中国区域创新创业指数IRIEC数据(省级、地市级)1990-2020年-社科数据https://download.csdn.net/download/paofuluolijiang/90028728 https://download.csdn.net/download/paofuluolijiang/90028728 中国区域创新创业指数(IRIEC)…...
)
Elasticsearch:减少 Elastic 容器镜像中的 CVE(常见的漏洞和暴露)
作者:来自 Elastic Maxime Greau 在这篇博文中,我们将讨论如何通过在 Elastic 产品中切换到最小基础镜像并优化可扩展漏洞管理程序的工作流程来显著减少 Elastic 容器镜像中的常见漏洞和暴露 (Common Vulnerabilities and Exposures - CVEs)。 基于 Chai…...

webpack02
webpack中常用loader postcss-loader 在css-loader之前,对css进行一些操作,,,比如统一加前缀,,或者是重置样式,,, 这个postcss-loader会自己去找 postcss工具࿰…...

腾讯云更改用户为root
最近买了台99元一年的2核的云服务器,方便学习一些java开发中间件,以及部署一些项目。 1.设置root用户密码 sudo passwd root 2.修改配置文件 ll /etc | grep ssh cd /etc/ssh/ ls vim sshd_config 输入/PasswordAuthentication 寻找 输入:set nu 再按下…...

Excel导入导出-若依版本
最终效果 1、导出 1、在实体类上加注解 Excel(name “客户类型名称”) ToString AllArgsConstructor NoArgsConstructor public class UserType extends BaseEntity2 implements Serializable {Excel(name "客户类型ID", cellType Excel.ColumnType.NUMERIC…...

【Qt】快速添加对应类所需的头文件包含
快速添加对应类所需的头文件包含 一,简介二,操作步骤 一,简介 本文介绍一下,如何快速添加对应类所需要包含的头文件,可以提高开发效率,供参考。 二,操作步骤 以QTime类为例: 选中…...

基于服务器部署的综合视频安防系统的智慧快消开源了。
智慧快消视频监控平台是一款功能强大且简单易用的实时算法视频监控系统。它的愿景是最底层打通各大芯片厂商相互间的壁垒,省去繁琐重复的适配流程,实现芯片、算法、应用的全流程组合,从而大大减少企业级应用约95%的开发成本。国产化人工智能“…...

浅谈棋牌游戏开发流程七:反外挂与安全体系——守护游戏公平与玩家体验
一、前言:为什么反外挂与安全这么重要? 对于任何一款线上棋牌游戏而言,公平性和玩家安全都是最重要的核心要素之一。如果游戏环境充斥着各式各样的外挂、作弊方式,不仅会毁坏玩家体验,更会导致游戏生态崩塌、口碑下滑…...

Laravel操作ElasticSearch
在Laravel项目中操作ElasticSearch可以通过以下步骤来实现,通常会借助相应的ElasticSearch客户端扩展包。 ### 安装ElasticSearch客户端包 在Laravel项目中,常用的是 elasticsearch/elasticsearch 这个PHP客户端库来与ElasticSearch进行交互,…...

缓存-文章目录
关于缓存系列文章: 缓存学习总结1(缓存分类) 缓存学习总结2(服务器本地缓存) 缓存学习总结3(服务器内存缓存)推荐使用 缓存学习总结4(分布式缓存) 关于redis系列文章…...
智能体客户端安装操作(Linux/windows/mac))
安装教程:慧集通集成平台(DataLinkX)智能体客户端安装操作(Linux/windows/mac)
1.下载客户端 使用提供的账号登录集成平台后台(https://www.datalinkx.cn/),点击左侧菜单栏【智能体】→【智能体】进入到智能体列表界面,在该界面我们找到功能栏中的下载按钮点击则会弹出下载界面,在该界面我们可以选择不同的系统操作系统来下载对应版…...

解决vmware虚拟机和宿主机之间不能复制粘贴
在虚拟机内执行一下命令 /usr/bin/vmware-user 更多解决方案 https://www.cnblogs.com/wutou/p/17629408.html...

由源程序到运行
由源程序到运行 第一步:编写源程序 assume cs:codesg codesg segmentmov ax,0123Hmov bx,0456Hadd ax,bxadd ax,axmov ax,4c00hint 21h codesg ends end第二步:进行编译 进入到编译目录 编译 .asm文件生成目标文件(.obj) m…...

Java-JDBC的使用
目录 一、JDBC(java数据库连接):java database connector 二、使用JDBC的步骤 三、加条件查询 四、预处理(防止SQL注入) 五、Statement和PreparedStatement的优略 六、将数据中的数据查询出来后需要保存在一个集合中,方便前端…...

如何优化亚马逊广告以提高ROI?
在竞争激烈的亚马逊市场中,优化广告以提高投资回报率(ROI)是卖家的关键任务。以下是一些实用的策略: 一、精准的关键词研究与选择 深入了解产品特性和目标受众 详细分析产品的功能、用途、优势和适用人群。例如,如果你…...

身是菩提树,心如明镜台;时时勤拂拭,莫使惹尘埃。
神秀: 身是菩提树,心如明镜台;时时勤拂拭,莫使惹尘埃。 第一个毛病1: 在神秀看来,修行就是要保持我们本来干净的心, 跟外部世界的灰尘之间的隔绝状态,始终保持这种隔绝, 尘世是什么? 尘就是烦恼,人世间无处不是烦恼&a…...

如何修复富士相机卡错误并恢复卡数据
富士相机以其卓越的图像质量而闻名,但不幸的是,其 SD 卡错误可能会意外发生,导致数据丢失和摄影会话中断。 在本指南中,我们将引导您了解常见的富士相机 SD 卡错误、如何修复这些错误,以及如何有效地从损坏的卡中恢复…...

呼叫中心中间件实现IVR进入排队,判断排队超时播放提示音
文章目录 [TOC](文章目录) 前言需求排队结束原因 联系我们实现步骤1. 调用http接口返回动作2. 启用拨号方案 前言 需求 呼叫中心需要实现调用IVR接口进入排队,如果是因为等待超时导致退出排队的,那就播放一段提示音再挂断通话;其他的情况就…...
:分析方法——RFM分析方法)
数据分析思维(八):分析方法——RFM分析方法
数据分析并非只是简单的数据分析工具三板斧——Excel、SQL、Python,更重要的是数据分析思维。没有数据分析思维和业务知识,就算拿到一堆数据,也不知道如何下手。 推荐书本《数据分析思维——分析方法和业务知识》,本文内容就是提取…...

SpringBoot3动态切换数据源
背景 随着公司业务战略的发展,相关的软件服务也逐步的向多元化转变,之前是单纯的拿项目,赚人工钱,现在开始向产品化\服务化转变。最近雷袭又接到一项新的挑战:了解SAAS模型,考虑怎么将公司的产品转换成多租…...
)
Java虚拟机面试题:内存管理(上)
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

WPF通过反射机制动态加载控件
Activator.CreateInstance 是 .NET 提供的一个静态方法,它属于 System 命名空间。此方法通过反射机制根据提供的类型信息。 写一个小demo演示一下 要求:在用户反馈界面点击建议或者评分按钮 弹出相应界面 编写MainWindow.xmal 主窗体 <Window x:C…...
)
前端学习-操作元素属性(二十三)
前言 假期快乐,大家加油 操作元素属性 操作元素常用属性 还可以通过 JS 设置/修改标签元素属性,比如通过 src更换 图片最常见的属性 比如:href、title、src等语法:对象.属性 值 const pic document.querySelector(img);pic.src ./images/b0.jpgp…...

Javascript 编写的一个红、黄、绿灯交替变亮
为了创建一个简单但功能完整的交通灯程序,我们将使用 HTML、CSS 和 JavaScript 来实现红、黄、绿三种颜色按照规定的顺序循环显示。这个例子将确保灯光按照红 -> 绿 -> 黄的顺序循环,并且可以调整每个灯光的持续时间以模拟真实的交通灯行为。 效果…...

基于64QAM的载波同步和定时同步性能仿真,包括Costas环和gardner环
目录 1.算法仿真效果 2.算法涉及理论知识概要 3.MATLAB核心程序 4.完整算法代码文件获得 1.算法仿真效果 matlab2022a仿真结果如下(完整代码运行后无水印): 仿真操作步骤可参考程序配套的操作视频。 2.算法涉及理论知识概要 载波同步是…...

小于n的最大数 - 贪心算法 - C++
字节经典面试题 给定一个整数n,并从1~9中给定若干个可以使用的数字,根据上述两个条件,得到每一位都为给定可使用数字的、最大的小于整数n的数,例如,给定可以使用的数字为 {2,3,8} 三个数:给定 n3589&#x…...
4)
leetcode(hot100)4
解题思路:双指针思想 利用两个for循环,第一个for循环把所有非0的全部移到前面,第二个for循环将指针放在非0的末尾全部加上0。 还有一种解法就是利用while循环双指针条件,当不为0就两个指针一起移动 ,为0就只移动右指针…...

【Pandas】pandas Series xs
Pandas2.2 Series Indexing, iteration 方法描述Series.get()用于根据键(索引标签)从 Series 中获取值Series.at用于快速访问标量值(单个元素)的访问器Series.iat用于快速访问标量值(单个元素)的访问器Se…...
)
【linux内核分析-存储】EXT4源码分析之“文件删除”原理【七万字超长合并版】(源码+关键细节分析)
EXT4源码分析之“文件删除”原理【七万字超长合并版】(源码关键细节分析),详细的跟踪了ext4文件删除的核心调用链,分析关键函数的细节,解答了开篇中提出的三个核心疑问。 文章目录 提示前言全文重点索引1.源码解析1.1 …...

一个在ios当中采用ObjectC和opencv来显示图片的实例
前言 在ios中采用ObjectC编程利用opencv来显示一张图片,并简单绘图。听上去似乎不难,但是实际操作下来,却不是非常的容易的。本文较为详细的描述了这个过程,供后续参考。 一、创建ios工程 1.1、选择ios工程类型 1.2、选择接口模…...

使用Python实现基于强化学习的游戏AI:打造智能化游戏体验
友友们好! 我的新专栏《Python进阶》正式启动啦!这是一个专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会找到: ● 深入解析:每一篇文章都将…...

STM32G0B1 can Error_Handler 解决方法
问题现象 MCU上电,发送0x13帧数据固定进入 Error_Handler 硬件介绍 MCU :STM32G0B1 can:NSI1042 tx 接TX RX 接RX 折腾了一下午,无解,问题依旧; 对比测试 STM32G431 手头有块G431 官方评估版CAN 模块; 同样的…...

洛谷 P2511 [HAOI2008] 木棍分割
第一问很简单,第二问 d p dp dp。 (真是哪都能混个 d p dp dp) 参考题解 #include <bits/stdc.h>using namespace std;int read() {int x 0, f 1; char c getchar();while (c < 0 || c > 9) {if (c -) f -1; c getcha…...

二极管钳位电路分享
二极管钳位(I/O的过压/浪涌保护等) 如果我们的电路环境接收外部输入信号容易受到噪声影响,那我们必须采取过压和浪涌保护措施,其中一个方式就是二极管钳位保护。 像上图,从INPUT输入的电压被钳位在-Vf与VCCVf之间&…...

guestfish/libguestfs镜像管理工具简介
文章目录 简介guestfishlibguestfs项目 例子原理代码libguestfs架构参考 简介 guestfish Guestfish 是libguestfs项目中的一个工具软件,提供修改虚机镜像内部配置的功能。它不需要把虚机镜像挂接到本地,而是为你提供一个shell接口,你可以查…...

AutoSar架构学习笔记
1.AUTOSAR(Automotive Open System Architecture,汽车开放系统架构)是一个针对汽车行业的软件架构标准,旨在提升汽车电子系统的模块化、可扩展性、可重用性和互操作性。AUTOSAR的目标是为汽车电子控制单元(ECU…...

Scade pragma: separate_io
概述 在 Scade 语言中,支持对用户自定义算子使用 separate_io pragma 进行修饰。其形式如: function #pragma kcg separate_io #end N(x: int8) returns (y,z: int8) let y x;z x; tel在上例中,算子N 就被 pragma #pragma kcg separate_i…...

三天速成微服务
微服务技术栈 总结 微服务技术对比 技术栈 SpringCloud SpringCloud是目前国内使用最广泛的微服务框架。官网地址:https://spring.io/projects/spring-cloud Springboot和SpringCould兼容性 代码目录结构如下 用于远程调用Bean 代码 package cn.itcast.order.config;//import …...

【MySQL】九、表的内外连接
文章目录 前言Ⅰ. 内连接案例:显示SMITH的名字和部门名称 Ⅱ. 外连接1、左外连接案例:查询所有学生的成绩,如果这个学生没有成绩,也要将学生的个人信息显示出来 2、右外连接案例:对stu表和exam表联合查询,把…...

GitLab 创建项目、删除项目
1、创建项目 点击左上角图标,回到首页 点击 Create a project 点击 Create blank project 输入项目名称,点击Create Project 创建成功 2、删除项目 进入项目列表 点击对应项目,进入项目 进入Settings页面 拖到页面底部,展开Adva…...
使用cv2.putText()绘制文字进阶-在图像上写文字)
python学opencv|读取图像(二十六)使用cv2.putText()绘制文字进阶-在图像上写文字
【1】引言 前序已经学会了在画布上绘制文字的大部分技巧,相关文章链接为: python学opencv|读取图像(二十三)使用cv2.putText()绘制文字-CSDN博客 python学opencv|读取图像(二十四)使用cv2.putText()绘制…...

Apache HTTPD 多后缀解析漏洞
目录 漏洞简介 漏洞环境 漏洞复现 漏洞防御 漏洞简介 Apache HTTPD 支持一个文件拥有多个后缀,并为不同后缀执行不同的指令。比如,如下配置文件: AddType text/html .html AddLanguage zh-CN .cn 以上就是Apache多后缀的特性。如果运维…...
当人工智能是一个函数,函数形式怎么选择?ChatGPT的函数又是什么?)
(二)当人工智能是一个函数,函数形式怎么选择?ChatGPT的函数又是什么?
在上一篇文章中,我们通过二次函数的例子,讲解了如何训练人工智能。今天,让我们进一步探讨:面对不同的实际问题,应该如何选择合适的函数形式? 一、广告推荐系统中的函数选择 1. 业务目标 想象一下&#x…...

JavaScript学习-入门篇
JavaScript的运行环境 开发环境就是开发JavaScript代码所需的环境,一般建议新手刚刚开始使用一些记事本工具(如sublime、editPlus、VScode),锻炼代码的手感。等学习到一定阶段,就可以使用集成开发工具IDE࿰…...

今日头条ip属地根据什么显示?不准确怎么办
在今日头条这样的社交媒体平台上,用户的IP属地信息对于维护网络环境的健康与秩序至关重要。然而,不少用户发现自己的IP属地显示与实际位置不符,这引发了广泛的关注和讨论。本文将深入探讨今日头条IP属地的显示依据,并提供解决IP属…...

python之移动端测试---appium
Appium Appium介绍环境准备新版本appium的用法介绍元素定位函数被封装,统一使用By.xxx(定位方式):通过文本定位的写法 一个简单的请求示例APP操作api基础apk安装卸载发送,拉取文件uiautomatorviewer工具使用获取页面元素及属性模拟事件操作模…...

【网络安全实验室】基础关实战详情
须知少时凌云志,曾许人间第一流 1.key在哪里 url:http://rdyx0/base1_4a4d993ed7bd7d467b27af52d2aaa800/index.php 查看网页源代码的方式有4种,分别是:1、鼠标右击会看到”查看源代码“,这个网页的源代码就出现在你眼前了&…...
)
在DJI无人机上运行VINS-FUISON(PSDK 转 ROS)
安装ceres出现以下报错,将2版本的ceres换成1版本的ceres CMake did not find one.Could not find a package configuration file provided by "absl" with any ofthe following names:abslConfig.cmakeabsl-config.cmakeAdd the installation prefix of …...

MarkDown怎么转pdf;Mark Text怎么使用;
MarkDown怎么转pdf 目录 MarkDown怎么转pdf先用CSDN进行编辑,能双向看版式;标题最后直接导出pdfMark Text怎么使用一、界面介绍二、基本操作三、视图模式四、其他功能先用CSDN进行编辑,能双向看版式; 标题最后直接导出pdf Mark Text怎么使用 Mark Text是一款简洁的开源Mar…...