9.机器学习--SVM支持向量机
支持向量机(Support Vector Machine,SVM)是一种二分类监督学习模型。支持向量机最早在 1964 年被提出,1995年前后理论成熟并开始被大量应用与人像识别、文本分类等问题中。它的基本模型是定义在特征空间上的间隔最大的线性分类器,这有区别与感知机。SVM 通过核技巧变成了实质上的非线性分类器。在 SVM 中学习的目的可以理解为求解凸二次规划的最优化算法。
目录
1.支持向量
2.最优化问题
3.对偶性
4.SVM优化
5.软间隔
6.核函数
7.优缺点
8.示例代码
1.支持向量
首先我们来看一下在二维空间中线性可分数据是什么样的。在二维空间中,两类可以被一条直线(实际上也可以被称之为一维“平面”)完全分开的点被称之为线性可分。

在三维空间中,分割的方法变成了用一个面(也就是二维平面)进行分割。
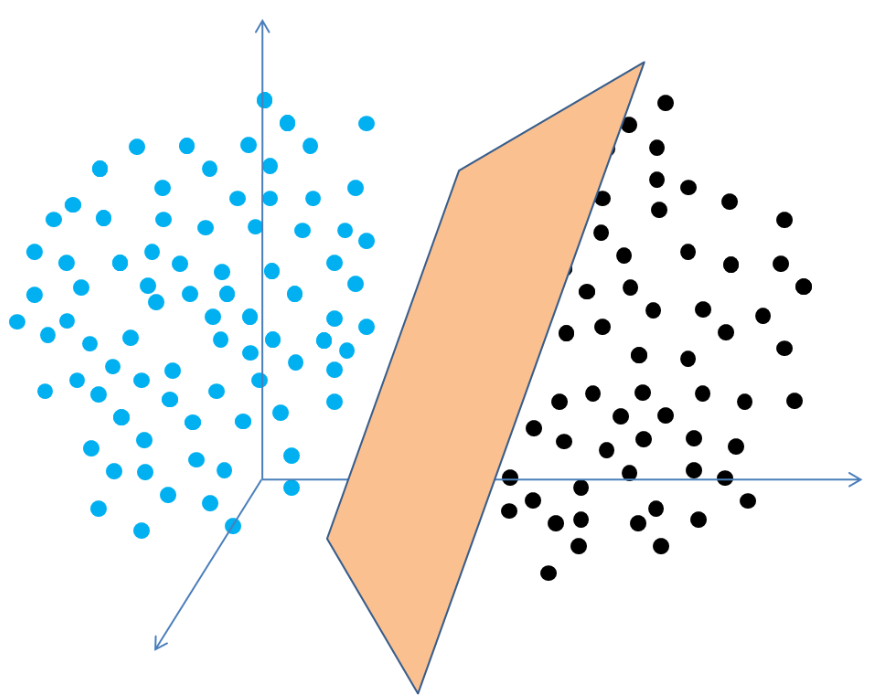
分割的过程在数学上可以被这样定义:
D0 和 D1 是 n 维欧式空间中的两个点击。如果存在 n 维向量 w 和实数 b,使得所有属于 D0 的点 xi 都有 wxi+b>0,而对于所有属于 D1 的点 xj 则有 wxj+b<0,则我们称 D0 和 D1 线性可分。
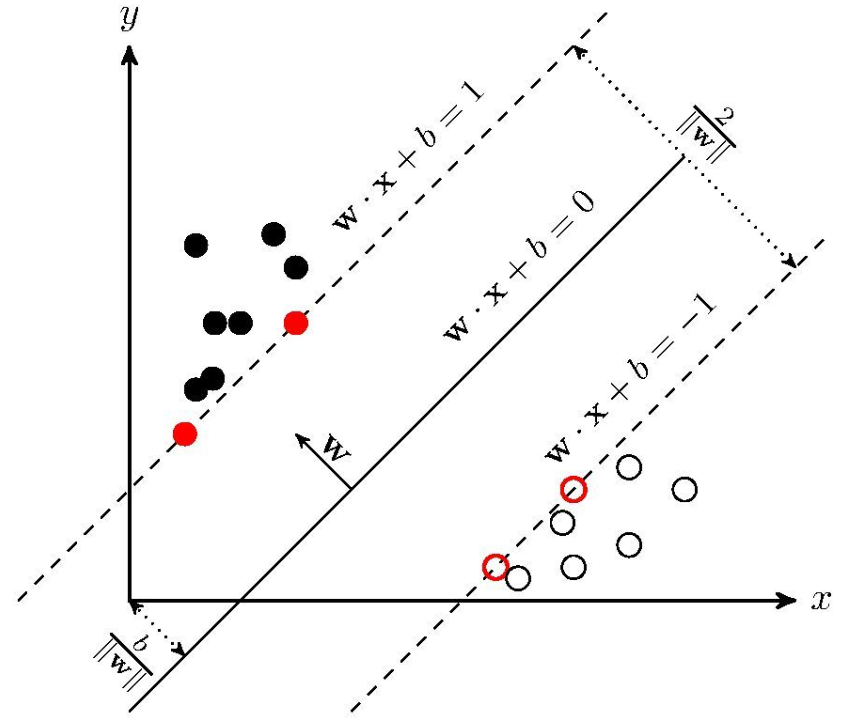
通俗的来说,我们在 n 维空间中可以使用一个 n−1 维的超平面进行分割。为了使这个超平面具有最佳鲁棒性,我们通常会寻找一个可以以最大间隔将两类样本分开的超平面(最大间隔也意味着具有更高的容错率),两侧距离超平面最近的点到超平面的距离被最大化了。
在上面一段定义中,我们提到了两侧距离超平面最近的点这样一个概念,这些点实际上就是我们提到过的支持向量。用图像来表示的话可以参考下面的图,图中标红的样本点就是支持向量。
2.最优化问题


3.对偶性
对于上述不等式约束的凸二次规划问题,我们可以使用拉格朗日乘子法获得其对偶问题。上面的式子可以被重写为如下形式:

拉格朗日乘数法可以将有约束优化转化为无约束优化。假设有一个有约束优化问题:

我们令![]() 则函数 L(x,λ) 被称之为拉格朗日函数,参数 λ 被称为拉格朗日乘子,且λk≥0。接下来可以通过等式约束的极值必要条件找到可能的极值点:
则函数 L(x,λ) 被称之为拉格朗日函数,参数 λ 被称为拉格朗日乘子,且λk≥0。接下来可以通过等式约束的极值必要条件找到可能的极值点:

在等式约束下引入了 l 个拉格朗日乘子,考虑到xi 和 λk 均为优化变量,此时我们共有 (n+l) 个优化变量。
现在我们将之前获得的不等式写为拉格朗日函数:



4.SVM优化
现在让我们回到 SVM 的优化上。已知我们的优化目标如下所示:

现在我们带回到原函数中可得:
对于这种二次规划问题,我们常用 SMO(Sequential Minimal Optimization,序列最小优化)算法求解。该算法的思想就是每次固定其余参数,仅求当前参数的极值。有关于使用 SMO 算法求解在这里我们就不进行推导了,有兴趣的同学可以查阅相关资料。
通过 SMO 算法我们可以算出拉格朗日乘子的最优解 λ∗。接下来我们可以对 L(w,b,λ) 求取偏导数,则 w 的偏导数为:

5.软间隔
在真实的生活中,完全线性可分的数据集或者样本是非常少的,而 SVM 的计算过程又严格要求数据集完全线性可分。为了解决这个问题,我们可以加入软间隔来进行缓冲。所谓软间隔就是指允许部分样本点出现在间隔带中。软间隔的情况如下图所示:

可以看到相比于最开始的图,这张图中的间隔带中存在三个样本点,将原本无法完全线性分割的数据集分割开来,这就是软间隔的作用。
为了衡量这个间隔究竟软到何种程度,我们为每个样本引入一个松弛变量 ξi。令 ξi=0,且 1-![]()

在添加软间隔后我们的优化目标就变成了如下形式:
其中 C 是一个大于 0 的常数,通常被称之为惩罚参数,越大越不能容忍错误样本。当 C 趋向无穷大时,ξi 必然趋向无穷小,如此我们的优化目标又退化为完全线性可分的情况。等 C 为有限值的时候,才会允许部分样本不遵循约束条件。
现在我们针对新的优化目标求解最优化。首先构造拉格朗日函数:
此时我们可以发现在公式中并不存在松弛变量 ξi 的拉格朗日乘子 μi,因此我们仍然只需要最大化 λ 即可:

6.核函数
在上述过程中,实际上我们只考虑了样本线性可分或者大多数样本线性可分的情况,但是实际上还有很多数据集完全无法被线性分割,例如下图这种情况:

对这种情况我们可以将线性不可分样本映射到高维空间中,这样我们就可以在高维空间中完成线性分割。以上图为例,我们可以将这个数据集做如下映射:

这样这个数据集就可以在三维空间中被线性分割。像这样在优先维度向量空间中线性不可分的样本,我们将其映射到更高维度的向量空间中,再通过间隔最大化的方式学习获得支持向量机,这就是非线性 SVM。
然而直接将低维空间映射到高维空间时(尤其是非常高的维度)计算量会非常大,因此我们会通过核函数(kernel function)来进行这种变换。由于在线性 SVM 的对偶问题中,目标函数和分类决策函数都只涉及实例与实例之间的内积,因此我们不需要显式地指定非线性变换,而是用核函数替换其中的内积。核函数的一般形式可以表现为:

由此可见核函数的引入同时降低了计算量和内存使用量。
当我们使用核函数进行非线性分类时,步骤如下:
首先选择适当的核函数和惩罚系数,构造拉格朗日函数并进行求解:

7.优缺点
SVM 的优点包括:
- 严格的数学理论支持,具有很强的可解释性
- 支持向量通常可以理解为关键样本,在某种程度上可以用于数据预处理
- 添加核函数后,可以用于处理非线性分类及回归任务
- 最终决策函数仅由支持向量确定,计算复杂度取决于支持向量的数目而非样本空间维数,在面对高维问题时具有较好的性能
除了优点,SVM 同样具有一些固有问题:
- 训练时间较长。采用 SMO 算法求取拉格朗日乘子时,时间复杂度为O(N2)
- 使用核函数时,如果需要储存核矩阵则空间复杂度将变为O(N2)
- 同样由于决策函数由支持向量决定,当支持向量数量较大时计算复杂度也会迅速上升。因此 SVM 常用于处理小批量样本数据,大规模样本通常不会使用 SVM 进行计算。
8.示例代码
在鸢尾花数据集中,目标变量(y)有三种类型,分别用0、1、2表示,具体对应的鸢尾花种类如下:
- 0: 山鸢尾(Iris setosa)
- 1: 变色鸢尾(Iris versicolor)
- 2: 维吉尼亚鸢尾(Iris virginica)
这三种鸢尾花的特征在数据集中有四个属性,包括花瓣长度、花瓣宽度、萼片长度和萼片宽度。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target# 选取前两个特征用于可视化
X = X[:, :2]# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 数据标准化# StandardScaler(): 创建一个标准化对象。
# fit_transform(): 在训练集上计算平均值和标准差,并应用标准化。
# transform(): 使用在训练集上计算得到的平均值和标准差来标准化测试集。
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 创建SVM分类器
svm = SVC(kernel='linear') # 线性核
svm.fit(X_train, y_train)# 预测和评估
predictions = svm.predict(X_test)
print(classification_report(y_test, predictions))# 绘制分类直线及数据点
# 绘制散点图展示测试集数据的分类情况
plt.scatter(X_test[:, 0], X_test[:, 1], c=predictions, cmap=plt.cm.Set1)# 绘制决策边界线(分类直线)
xx, yy = np.meshgrid(np.arange(X_test[:, 0].min() - 1, X_test[:, 0].max() + 1, 0.02),np.arange(X_test[:, 1].min() - 1, X_test[:, 1].max() + 1, 0.02))
Z = svm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, colors='k', levels=[-1, 0, 1], linewidths=1)plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('SVM Classification Result')
plt.show()
好的,下面高级玩法。。。
**Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
1.数据准备
# 导入相关库
# 导入相关包
import numpy as np#numpy:python第三方库,用于科学计算
import pandas as pd#pandas:提供高性能,易于使用的数据结构和数据分析工具
from pandas import plotting#plotting包是一个Python包,用于绘制各种图形和图表。它提供了一组功能强大的绘图函数和工具,可以快速生成高质量的图形。
from sklearn import datasets#datasets包:文本数据集的处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt#plt:plt包是Python中的一个数据可视化库,它的主要功能是绘制各种类型的图表和图形
plt.style.use('seaborn')
import seaborn as sns#sns:提供了一系列高级绘图函数和样式设置,用于创建漂亮的、高效的、统计学模型中必要的图表。
sns.set_style("whitegrid")
from sklearn.linear_model import LogisticRegression #LogisticRegression包是一个Python机器学习库,用于实现逻辑回归算法
from sklearn.model_selection import train_test_split#train_test_split包是用于将数据集分为训练集和测试集的Python库
from sklearn.preprocessing import LabelEncoder#将字符串类型的类别特征转换成数字,以便进行机器学习算法的训练和预测。
from sklearn.neighbors import KNeighborsClassifier#一种基于K近邻算法的分类器,它能够根据给定的训练集中的样本,通过计算测试样本与训练集中每个样本的距离,找到K个离测试样本最近的邻居
from sklearn import svm#支持向量机(SVM)是一种经典的监督机器学习算法,主要用于二分类和多分类问题的分类和回归任务。
from sklearn import metrics #metrics包是Python中用于度量算法性能的包
from sklearn.tree import DecisionTreeClassifier#DecisionTreeClassifier包是一个决策树分类器,用于分类任务#1.数据准备
#*************将字符串转为整型,便于数据加载***********************
def iris_type(s):it = {b'Iris-setosa':0, b'Iris-versicolor':1, b'Iris-virginica':2}return it[s]
#加载数据
data_path=r'C:\pythonProject\机器学习\SVM\iris.data' #数据文件的路径
data = np.loadtxt(data_path, #数据文件路径dtype=float, #数据类型delimiter=',', #数据分隔符converters={4:iris_type}) #将第5列使用函数iris_type进行转换
print(len(data))
print()
# 加载数据
data_path = 'C:\pythonProject\机器学习\SVM\iris.data' # 数据文件的路径
iris = pd.read_csv(data_path, header=None) # 读数据
iris.columns = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm', 'Species'] # 确定列名,参考下面的信息
print(iris.info())
print(iris.describe())
# 设置颜色主题
antV = ['#1890FF', '#2FC25B', '#FACC14', '#223273', '#8543E0', '#13C2C2', '#3436c7', '#F04864']# 绘制 Violinplot
f, axes = plt.subplots(2, 2, figsize=(8, 8), sharex=True)
sns.despine(left=True)
#下面需要连续四句,分别画出横坐标为种类,纵坐标为四个特征的小提琴图sns.violinplot(x='Species', y='SepalLengthCm', data=iris, palette=antV, ax=axes[0, 0])
sns.violinplot(x='Species', y='SepalWidthCm', data=iris, palette=antV, ax=axes[0, 1])
sns.violinplot(x='Species', y='PetalLengthCm', data=iris, palette=antV, ax=axes[1, 0])
sns.violinplot(x='Species', y='PetalWidthCm', data=iris, palette=antV, ax=axes[1, 1])# 设置标题
axes[0, 0].set_title('SepalLengthCm')
axes[0, 1].set_title('SepalWidthCm')
axes[1, 0].set_title('PetalLengthCm')
axes[1, 1].set_title('PetalWidthCm')
plt.show()# 绘制 pointplot
f, axes = plt.subplots(2, 2, figsize=(8, 8), sharex=True)
sns.despine(left=True)
#下面需要连续四句,分别画出横坐标为种类,纵坐标为四个特征的点线图
sns.pointplot(x='Species', y='SepalLengthCm', data=iris, color=antV[0], ax=axes[0, 0])
sns.pointplot(x='Species', y='SepalWidthCm', data=iris, color=antV[1], ax=axes[0, 1])
sns.pointplot(x='Species', y='PetalLengthCm', data=iris, color=antV[2], ax=axes[1, 0])
sns.pointplot(x='Species', y='PetalWidthCm', data=iris, color=antV[3], ax=axes[1, 1])plt.show()#画出四个特征的与类别交汇图,参考约会数据预测中的交汇图
sns.pairplot(iris, hue='Species', palette=antV)
plt.show()#下面分别基于花萼和花瓣做线性回归的可视化:
g = sns.lmplot(data=iris, x='SepalWidthCm', y='SepalLengthCm', palette=antV, hue='Species')
g = sns.lmplot(data=iris, x='PetalWidthCm', y='PetalLengthCm', palette=antV, hue='Species')
plt.show()#最后,通过热图找出数据集中不同特征之间的相关性,高正值或负值表明特征具有高度相关性:
fig=plt.gcf()
fig.set_size_inches(12, 8)
fig=sns.heatmap(iris.corr(), annot=True, cmap='GnBu', linewidths=1, linecolor='k', square=True, mask=False, vmin=-1, vmax=1, cbar_kws={"orientation": "vertical"}, cbar=True)
plt.show()# #接下来,通过机器学习,以花萼和花瓣的尺寸为根据,预测其品种。
#
# 在进行机器学习之前,将数据集拆分为训练和测试数据集。首先,使用标签编码将 3 种鸢尾花的品种名称转换为分类值(0, 1, 2)。# 载入特征和标签集
X = iris[['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']]
y = iris['Species']# 标签编码
le = LabelEncoder()
y = le.fit_transform(y)
print(y)# 拆分数据集
train_X, test_X, train_y, test_y = train_test_split(X, y,test_size=0.3 , random_state = 101) #使用train_test_split对训练集和测试集划分
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)# # 2.SVM分类器
# Support Vector Machine
model = svm.SVC()
model.fit(train_X,train_y)
prediction=model.predict(test_X) #model训练
#model预测
print('The accuracy of the SVM is: {0}'.format(metrics.accuracy_score(prediction,test_y)))# # 3.KNN分类器
# K-Nearest Neighboursmodel=KNeighborsClassifier(n_neighbors=3)model.fit(train_X, train_y)
prediction = model.predict(test_X)#model定义#model训练#model预测print('The accuracy of the KNN is: {0}'.format(metrics.accuracy_score(prediction,test_y)))# # 4.决策树分类器
# Decision Tree
model= DecisionTreeClassifier()
model.fit(train_X,train_y)
prediction=model.predict(test_X) #model训练#model预测print('The accuracy of the Decision Tree is: {0}'.format(metrics.accuracy_score(prediction,test_y)))# # 5.逻辑回归分类器
# Logistic Regression
model = LogisticRegression()
model.fit(train_X,train_y)
prediction=model.predict(test_X) #model定义#model训练#model预测
print('The accuracy of the Logistic Regression is: {0}'.format(metrics.accuracy_score(prediction,test_y)))
# # 6.模型比较
# 我们可以比较不同模型的准确率,并选择最好的模型。
#只使用花瓣
petal = iris[['PetalLengthCm', 'PetalWidthCm', 'Species']]
train_p,test_p=train_test_split(petal,test_size=0.3,random_state=0)
train_x_p=train_p[['PetalWidthCm','PetalLengthCm']]
train_y_p=train_p.Species
test_x_p=test_p[['PetalWidthCm','PetalLengthCm']]
test_y_p=test_p.Species#只使用花萼sepal = iris[['SepalLengthCm', 'SepalWidthCm', 'Species']]
train_s,test_s=train_test_split(sepal,test_size=0.3,random_state=0)
train_x_s=train_s[['SepalWidthCm','SepalLengthCm']]
train_y_s=train_s.Species
test_x_s=test_s[['SepalWidthCm','SepalLengthCm']]
test_y_s=test_s.Species#SVM分类器
model=svm.SVC()
model.fit(train_x_p,train_y_p)
prediction=model.predict(test_x_p)
print('The accuracy of the SVM using Petals is: {0}'.format(metrics.accuracy_score(prediction,test_y_p)))
model.fit(train_x_s,train_y_s)
prediction=model.predict(test_x_s)
print('The accuracy of the SVM using Sepal is: {0}'.format(metrics.accuracy_score(prediction,test_y_s)))#KNN分类器
model = LogisticRegression()
model.fit(train_x_p, train_y_p)
prediction = model.predict(test_x_p)
print('The accuracy of the Logistic Regression using Petals is: {0}'.format(metrics.accuracy_score(prediction,test_y_p)))
print('The accuracy of the Logistic Regression using Sepals is: {0}'.format(metrics.accuracy_score(prediction,test_y_s)))#决策树分类器
model=DecisionTreeClassifier()
model.fit(train_x_p, train_y_p)
prediction = model.predict(test_x_p)
print('The accuracy of the Decision Tree using Petals is: {0}'.format(metrics.accuracy_score(prediction,test_y_p)))
model.fit(train_x_s, train_y_s)
prediction = model.predict(test_x_s)
print('The accuracy of the Decision Tree using Sepals is: {0}'.format(metrics.accuracy_score(prediction,test_y_s)))#逻辑回归分类器
model=KNeighborsClassifier(n_neighbors=3)
model.fit(train_x_p, train_y_p)
prediction = model.predict(test_x_p)
print('The accuracy of the KNN using Petals is: {0}'.format(metrics.accuracy_score(prediction,test_y_p)))
model.fit(train_x_s, train_y_s)
prediction = model.predict(test_x_s)
print('The accuracy of the KNN using Sepals is: {0}'.format(metrics.accuracy_score(prediction,test_y_s)))相关文章:

9.机器学习--SVM支持向量机
支持向量机(Support Vector Machine,SVM)是一种二分类监督学习模型。支持向量机最早在 1964 年被提出,1995年前后理论成熟并开始被大量应用与人像识别、文本分类等问题中。它的基本模型是定义在特征空间上的间隔最大的线性分类器&…...

探索Python的HTTP之旅:揭秘Requests库的神秘面纱
文章目录 **探索Python的HTTP之旅:揭秘Requests库的神秘面纱**第一部分:背景介绍第二部分:Requests库是什么?第三部分:如何安装Requests库?第四部分:Requests库的五个简单函数使用方法第五部分&…...

vue3项目使用动态表单formcreate
使用两个插件: 支持可视化设计的低代码表单组件 | FormCreate 好用的低代码可视化表单设计器 | FcDesigner 一、安装 1.使用 Node.js 引入 npm install form-create/element-ui npm install form-create/designer^3 npm install element-plus 2. main.js引入…...

指针的奥秘:深入探索内存的秘密
前言 在计算机编程的广阔天地中,指针作为一种独特的数据类型,它不仅是C语言的核心,也是理解计算机内存管理的基石。指针的概念虽然强大,但对于初学者来说,它常常是学习过程中的一个难点。本文旨在揭开指针的神秘面纱&a…...

车载摄像camera基础知识和评估
一、车载摄像头应用 以下是根据图片内容重新制作的表格: | 序号 | 产品用途 |------|---------------- | 1 | AVM/环视360摄像头 | 2 | DMS摄像头 | 3 | IMS/OMS摄像头 | 4 | RVC摄像头 | 5 | 红外夜视摄像头 | 6 | 底盘透明摄像头 | 7 …...

OpenCV 图像轮廓查找与绘制全攻略:从函数使用到实战应用详解
摘要:本文详细介绍了 OpenCV 中用于查找图像轮廓的 cv2.findContours() 函数以及绘制轮廓的 cv2.drawContours() 函数的使用方法。涵盖 cv2.findContours() 各参数(如 mode 不同取值对应不同轮廓检索模式)及返回值的详细解析,搭配…...

微信小程序WXSS全局样式与局部样式的使用教程
微信小程序WXSS全局样式与局部样式的使用教程 引言 在微信小程序的开发中,样式的设计与实现是提升用户体验的关键部分。WXSS(WeiXin Style Sheets)作为微信小程序的样式表语言,不仅支持丰富的样式功能,还能通过全局样式与局部样式的灵活运用,帮助开发者构建美观且易于维…...
)
Leetcode142. 环形链表 II(HOT100)
链接 我的错误代码: class Solution { public:ListNode *detectCycle(ListNode *head) {if(!head||!head->next)return nullptr;ListNode* f head->next,*s head;while(f){f f->next,s s->next;if(!f)return nullptr;f f->next;if(fs){ListNo…...

Java程序基础⑤Java数组的定义和使用+引用的概念
目录 1. Java数组的基本概念 1.1 数组的定义 1.2 数组存在的意义 1.3 数组的使用 1.4 二维数组 2. 引用类型JVM的内存分布 2.1 JVM的内存分布 2.2 基本数据类型和引用型数据类型的区别 2.3 引用注意事项 2.4 传值传递 3. 数组总结和应用场景 3.1 一维数组和二维数组…...

丁真杯理塘大赛题解
前言:部分代码思路可能与题解思路不同,请勿强行带入 真蛰虫 原题链接 1.一道非常基础的数学题。 2.主要就是在考察分解质因数。首先看真蛰虫的质因数是不是包含了容器的所有质因数,如果没有,那么就不能放入容器中。如果全部包…...

FPGA经验谈系列文章——8、复位的设计
前言 剑法往往有着固定的招式套路,而写代码似乎也存在类似的情况。不知从何时起,众多 FPGA 工程师们在编写代码时开启了一种关于 always 语句块的流行写法,那就是: always @(posedge i_clk or negedge i_rstn) 就笔者所经历的诸多项目以及所接触到的不少工程师而言,大家在…...

Android studio与JS交互
文章目录 前言一、html二、使用步骤1.2.AS 总结 前言 最近在使用Android Studio的WebView,有些功能要AS与JS交互。 一、html html文件 <!DOCTYPE html> <html> <!--javascript--> <head><meta charset"utf-8"><title>Carson…...

健身房小程序服务渠道开展
健身不单单是锻炼身体、保持身材,也是一种社交方式,城市里门店不少,每家都有一定流量和老客,但仅靠传统线下拉客/自然流量前往和线上朋友圈、短视频发硬广等方式还不够。 商家需要找到更多潜在目标客户,而消费者也对门…...

大宗商品行业区块链应用
应用场景 区块链技术具有透明性、去中心化、不可篡改等特点,因此可以在大宗商品定价方面得到应用。通过区块链技术,相关交易的各方可以在无需依赖中心化第三方的情况下,实时、准确地获取定价信息。这种技术的应用能够提高效率、降低成本、提…...

软考教材重点内容 信息安全工程师 第 5 章 物理与环境安全技术
5.1.1 物理安全概念 传统上的物理安全也称为实体安全,是指包括环境、设备和记录介质在内的所有支持网络信息系统运行的硬件的总体安全,是网络信息系统安全、可靠、不间断运行的基本保证,并且确保在信息进行加工处理、服务、决策支持的过程中&…...

蓝桥杯每日真题 - 第21天
题目:(空间) 题目描述(12届 C&C B组A题) 解题思路: 转换单位: 内存总大小为 256MB,换算为字节: 25610241024268,435,456字节 计算每个整数占用空间: 每个 32 位整数占用…...

【C++】C++11新特性详解:可变参数模板与emplace系列的应用
C语法相关知识点可以通过点击以下链接进行学习一起加油!命名空间缺省参数与函数重载C相关特性类和对象-上篇类和对象-中篇类和对象-下篇日期类C/C内存管理模板初阶String使用String模拟实现Vector使用及其模拟实现List使用及其模拟实现容器适配器Stack与QueuePriori…...

下载并安装Visual Studio 2017过程
一、下载 1、下载链接 下载链接:官方网址 先登录 往下滑找到较早的下载 2、进行搜索下载 或者直接点击🔗网站跳转 3、确认系统信息进行下载 二、安装 下载完成后右键使用管理员身份运行 1、点击同意后安装 2、若报错—设置失败 打开控制面板-&g…...
:深入探讨缓冲区管理与流量控制机制)
【消息序列】详解(6):深入探讨缓冲区管理与流量控制机制
目录 一、概述 1.1. 缓冲区管理的重要性 1.2. 实现方式 1.2.1. HCI_Read_Buffer_Size 命令 1.2.2. HCI_Number_Of_Completed_Packets 事件 1.2.3. HCI_Set_Controller_To_Host_Flow_Control 命令 1.2.4. HCI_Host_Buffer_Size 命令 1.2.5. HCI_Host_Number_Of_Complete…...

Java开发经验——Spring Test 常见错误
摘要 本文详细介绍了Java开发中Spring Test的常见错误和解决方案。文章首先概述了Spring中进行单元测试的多种方法,包括使用JUnit和Spring Boot Test进行集成测试,以及Mockito进行单元测试。接着,文章分析了Spring资源文件扫描不到的问题&am…...

麦肯锡报告 | 科技落地的真谛:超越技术本身的价值创造
科技创新正在以惊人的速度改变企业运作和客户体验,但实现其潜力的关键在于正确的策略、流程、文化和人才。麦肯锡强调了一个理念:Never just tech(不仅仅是技术)。这表明,成功的数字化转型不仅依赖于技术,还…...

React 常见问题解答:设置、安装、用户事件和最佳实践
在本文中,我们将回答您在开始使用 React 时可能会问的 9 个常见问题。 1、开始使用 React 需要哪些技能和知识? 在深入研究 React 之前,您应该对以下内容有深入的了解: HTML、CSS 和 JavaScript (ES6)&a…...

Mairadb 最大连接数、当前连接数 查询
目录 查询数据库 最大连接数 查询当前连接总数 环境 Mariadb 10.11.6 跳转mysql数据库: 查询数据库 最大连接数 show variables like max_connections; 注意; 这个版本不能使用 : show variables like ‘%max_connections%’; 会报错 ÿ…...

【R库包安装】R库包安装总结:conda、CRAN等
【R库包安装】R库包安装总结:conda、CRAN等 方法1:基于 R 的 CRAN 仓库安装CRAN库包查询从 CRAN 安装 方法2:使用conda安装库包确保已安装 R 和 Conda 环境使用 Conda 官网浏览是否存在相应库包Conda 安装 R 库 方法3:从 GitHub 安…...

php反序列化1_常见php序列化的CTF考题
声明: 以下多内容来自暗月师傅我是通过他的教程来学习记录的,如有侵权联系删除。 一道反序列化的CTF题分享_ctf反序列化题目_Mr.95的博客-CSDN博客 一些其他大佬的wp参考:php_反序列化_1 | dayu’s blog (killdayu.com) 序列化一个对象将…...

LabVIEW动态显示控件方案
在LabVIEW开发中,涉及到动态显示和控制界面的设计时,经常需要根据用户选择的不同参数来动态显示或隐藏相关控件。例如,某些能可能会根据“Type”控件的不同选择显示不同的参数,如“Target”、“Duration”和“EndType”等。在一个…...

游戏引擎学习第22天
移除 DllMain() 并成功重新编译 以下是对内容的详细复述与总结: 问题和解决方案: 在编译过程中遇到了一些问题,特别是如何告知编译器不要退出程序,而是继续处理。问题的根源在于编译过程中传递给链接器的参数设置不正确。原本尝试…...

GitLab|GitLab报错:PG::ConnectionBad: could not connect to server...
错误信息: PG::ConnectionBad: could not connect to server: No such file or directory Is the server running locally and accepting connections on Unix domain socket "/var/opt/gitlab/postgresql/.s.PGSQL.5432"? /opt/gitlab/embedded/service…...

Ray 和 PyTorch
Ray 和 PyTorch 的介绍 Ray 是什么? Ray 是一个用于 分布式计算和机器学习任务 的开源框架,提供了一个高效的、灵活的并行计算平台。它的核心功能是支持分布式计算,帮助开发者以简单的方式扩展 Python 应用程序。 Ray 适用于以下场景&…...

Qt之详解QLockFile 文件锁
文章目录 QLockFile 详解前言什么是 QLockFile?QLockFile 的构造函数和常用成员函数构造函数1. 指定锁文件路径的构造函数 常用成员函数1. lock2. unlock3. isLocked4. setStaleLockTime5. getLockInfo6. removeStaleLock 完整示例代码总结 QLockFile 详解 前言 在…...
)
从0开始学PHP面向对象内容之常用设计模式(组合,外观,代理)
二、结构型设计模式 4、组合模式(Composite) 组合模式(Composite Pattern)是一种结构型设计模式,它将对象组合成树形结构以表示”部分–整体“的层次结构。通过组合模式,客户端可以以一致的方式处理单个对…...

机械设计学习资料
免费送大家学习资源,已整理好,仅供学习 下载网址: https://www.zzhlszk.com/?qZ02-%E6%9C%BA%E6%A2%B0%E8%AE%BE%E8%AE%A1%E8%A7%84%E8%8C%83SOP.zip...

论文笔记3-XCube: Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies
目录 Abtract 相关工作 核心算法: 整体流程概述 具体流程解析 1. 输入(Input) 2. 稀疏结构 VAE(Sparse Structure VAE) 3.分层体素潜在扩散(Hierarchical Voxel Latent Diffusion)…...

【组件】前端ElementUi 下拉Tree树形组件 带模糊搜索自动展开高亮功能
【组件】前端ElementUi 下拉Tree树形组件 带模糊搜索自动展开高亮功能 https://live.csdn.net/v/435737 <template><div><el-popoverstyle"overflow-y: auto; "placement"bottom"trigger"click"><el-inputstyle"margi…...

诠视科技受邀出席“中国虚拟现实产学研大会”
2024年11月2-3日,由中国虚拟现实技术与产业创新平台举办的第十届“中国虚拟现实产学研大会” 在北京顺利召开,大会围绕“虚拟现实技术与产业创新融合”这一主题进行深入探讨。诠视科技作为虚拟现实产业的创新领军企业,CEO林瓊受邀参加本次活动…...

【达梦数据库】授权查询
目录 授权查询EXPIRED_DATECLUSTER_TYPE 更换原则更换方法 授权查询 select * from v$license;EXPIRED_DATE 过期日期,如果是正式版会显示NULL CLUSTER_TYPE 授权使用的集群类型CLUSTER_TYPE,格式为字符串“XXXX”, 每一位上 0 表示禁止…...

探索 ZED 双目 3D 相机发展:ZED 2i 的创新功能扩展之路
在科技迅速发展的当下,3D 视觉技术在众多领域的发展中有着重要作用。Stereolabs 公司研发的 ZED 相机受到广泛关注。Stereolabs 于 2010 年在美国旧金山成立,一直专注于立体视觉和 3D 深度相机技术的研究。2015 年推出的 ZED 相机为无人机、机器人等设备…...

基于卷积神经网络的白菜病虫害识别与防治系统,resnet50,mobilenet模型【pytorch框架+python源码】
更多目标检测和图像分类识别项目可看我主页其他文章 功能演示: 白菜病虫害识别与防治系统,卷积神经网络,resnet50,mobilenet【pytorch框架,python源码】_哔哩哔哩_bilibili (一)简介 基于卷…...

计算机网络 | 7.网络安全
1.网络安全问题概述 (1)计算机网络面临的安全性威胁 <1>计算机网络面临的完全性威胁 计算机网络面临的两大类安全威胁:被动攻击和主动攻击 被动攻击 截获:从网络上窃听他人的通信内容。主动攻击 篡改:故意篡改…...

Opencv+ROS自编相机驱动
目录 一、工具 二、原理 代码 标定 三、总结 参考: 一、工具 opencv2ros ubuntu18.04 usb摄像头 二、原理 这里模仿usb_cam功能包对Opencv_ros进行修饰,加上相机参数和相机状态,难点在于相机参数的读取。 对于相机参数话题 camera…...

js---函数参数是值传递还是引用传递
理解1:都是值(基本/地址值)传递 理解2:可能是值传递,也可能是引用传递(地址值) 在JavaScript中,函数参数的传递方式取决于参数的类型: 值传递(Pass by Val…...

如何解决DDoS导致服务器宕机?
分布式拒绝服务攻击(DDoS攻击)是一种常见的网络安全威胁,通过大量恶意流量使目标服务器无法提供正常服务。DDoS攻击可能导致服务器宕机,严重影响业务的正常运行。本文将详细介绍如何检测和防御DDoS攻击,防止服务器宕机…...

临床检验项目指标学习笔记
声明: 家有病人,记录此学习笔记仅为了更好照顾家人。本文不负责内容的准确性和版权。如果存在侵权、或不希望被转载的媒体或个人可与我们联系,我将立即进行删除处理。 血脂四项 [Q&A] 血脂四项 指导意义 测定血清中血脂含量,…...

代码管理之Gitlab
文章目录 Git基础概述场景本地修改未提交,拉取远程代码修改提交本地,远程已有新提交 GitIDEA引入Git拉取仓库代码最后位置 Git基础 概述 workspace 工作区:本地电脑上看到的目录; repository 本地仓库:就是工作区中隐…...

秒杀系统三层架构设计:缓存、消息队列与数据库
秒杀是一种极端高并发场景,短时间内数百万用户涌入,抢购有限库存的商品。为了保证系统稳定性和数据一致性,同时提升用户体验,我们可以设计一个三层架构:缓存层、消息队列层、数据库层。本文将详细设计这一架构并探讨其…...

tauri2.0版本开发苹果ios和安卓android应用,环境搭建和最后编译为apk
官网链接:What is Tauri? | Tauri 初始准备 rust版本一定要1.77.2以上的版本,查看版本和升级版本: 升级命名: rustup update 不然会报错: error: package tauri-plugin-shell v2.0.2 cannot be built because it r…...

SCI论文部分题目
SC20243213 通过氢和氨集成增强Power-to-X灵活性和可持续成本降低:绿色实验室Skive案例研究 SC20243211 分析同时发电的综合系统中的能量和能量效率、环境影响和经济可行性,淡水、热水和天然气凝液 SC20243208 双燃料生物质-天然气系统中的氢、…...

使用PyTorch在AMD GPU上进行INT8量化实现精简化的LLM推理
Leaner LLM Inference with INT8 Quantization on AMD GPUs using PyTorch — ROCm Blogs 随着大型语言模型(LLMs)规模达到数千亿参数,我们在这些庞大模型中表示数据的方式极大地影响了训练所需的资源(例如,用于推理的…...

Solon 拉取 maven 包很慢或拉不了,怎么办?
注意:如果在 IDEA 设置里指定了 settings.xml,下面两个方案可能会失效。(或者直接拿 "腾讯" 的镜像仓库地址,按自己的习惯配置) 1、可以在项目的 pom.xml 添加 "腾讯" 的镜像仓库 "阿里&qu…...

spring的事务隔离?
在Spring中,事务的隔离级别是指在多事务并发执行时,事务之间的隔离程度,隔离级别定义了一个事务可以看到另一个事务的哪些数据,Spring事务管理器允许通过Transactional注解或者xml配置来指定事务的隔离级别。 事务的隔离级别有以…...