微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
摘要
本文深入探讨GPU微架构的核心概念,重点分析多线程架构、存储体冲突、流水线设计以及全局内存合并等关键技术。内容涵盖GPU与CPU在上下文切换方面的根本差异,多线程架构的资源需求分析,以及如何通过存储体分区和内存访问优化来提升性能。文章通过详细的架构示意图和实例说明,为读者提供全面而深入的GPU微架构知识。
目录
-
• GPU架构回顾
-
• 多线程架构原理
-
• 存储体冲突分析与解决方案
-
• GPU流水线工作机制
-
• 全局内存合并技术
-
• 存储体与端口区别
-
• 静态与动态分析比较
GPU架构目标
-
• 描述GPU微架构
-
• 能够解释基本GPU架构术语
阅读材料
-
• 通用图形处理器架构(计算机架构综合讲座)第3章[1]
模块4课程1:多线程架构
课程学习目标:
-
• 解释多线程和上下文切换之间的区别
-
• 描述GPU多线程的资源需求
在本模块中,我们将更深入地研究GPU架构。在整个视频中,我们将探讨GPU中多线程和上下文切换之间的区别。我们还将讨论GPU多线程的资源需求。
回顾:GPU

GPU架构
首先回顾GPU架构的基础知识。
-
• GPU配备众多核心
-
• 每个核心具有多线程功能
-
• 便于在核心内执行线程束或波前
-
• 每个核心还具有共享内存和硬件缓存
多线程
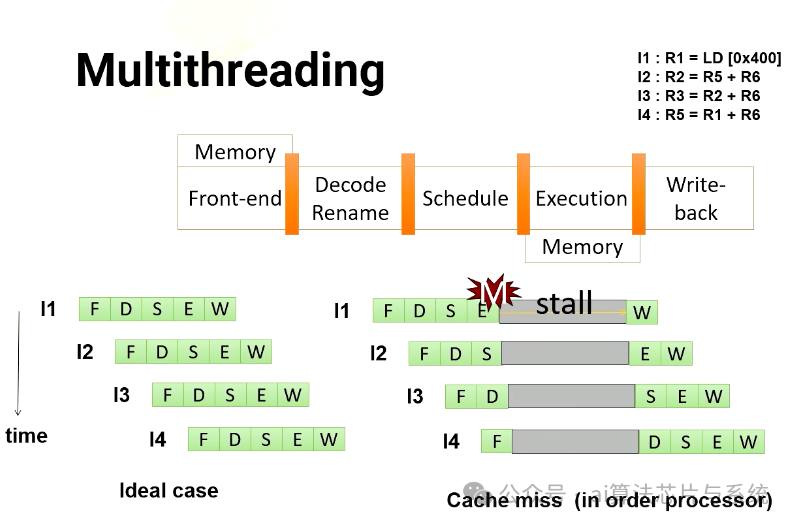
顺序处理器流水线
深入了解多线程。想象一个具有五级流水线和四条指令的GPU。在理想情况下,每条指令将一次一个阶段地通过流水线。然而,在顺序处理器中,如果指令发生缓存未命中,后续指令必须等待第一条指令完成。如果仔细观察,指令2实际上并不依赖于指令1。因此,在乱序处理器中,指令2不必等待。
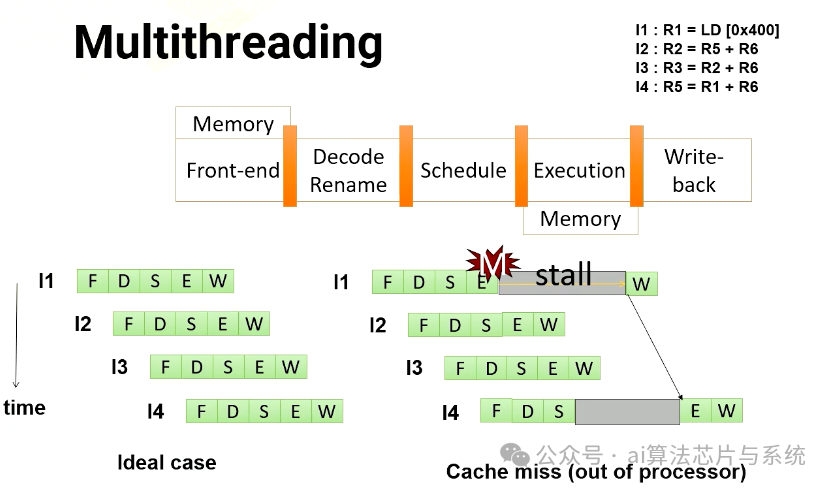
乱序处理器流水线
在乱序处理器中,它开始在指令1完成之前执行指令2和3。一旦指令1收到内存请求,就可以执行指令4。

多线程
在多线程中,处理器只是简单地切换到另一个线程,而不管前一条指令是否产生缓存未命中。由于它们来自不同的线程,它们都是独立的。在此示例中,处理器执行来自四个不同线程的四条指令。此外,处理器还同时生成四个内存请求。
多线程的优势
为了利用生成多个内存请求的优势,GPU采用了多线程技术。当遇到阻塞指令时,GPU会切换到另一个线程执行指令,从而实现并行处理并提高内存请求效率。
-
• 多线程的优势在于其能够隐藏处理器停滞时间,这通常由以下因素造成:
-
• 缓存未命中
-
• 分支指令
-
• 长延迟指令,如ALU指令
-
• GPU利用多线程来缓解此类长延迟问题
-
• 而CPU采用乱序执行、缓存系统和指令级并行(ILP)来应对延迟
-
• 更长的内存延迟需要更多数量的线程来隐藏延迟
多线程的前端扩展
前端具有多个程序计数器(PC)值,每个线程束需要一个PC寄存器,因此支持四个线程束需要四个寄存器。它还有四组寄存器。因此,GPU中的上下文切换意味着简单地在多个PC寄存器和寄存器文件之间切换指针。
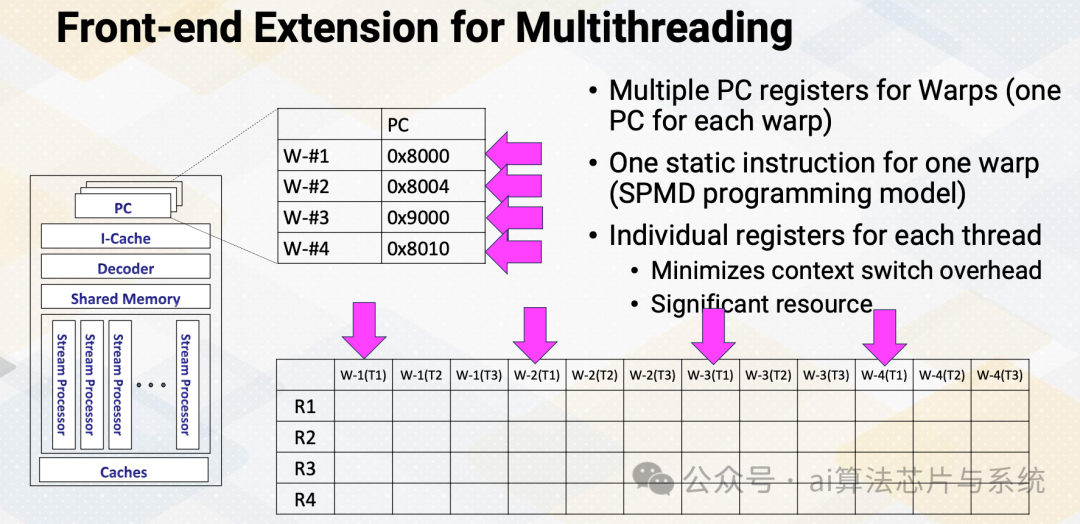
前端扩展
CPU上下文切换
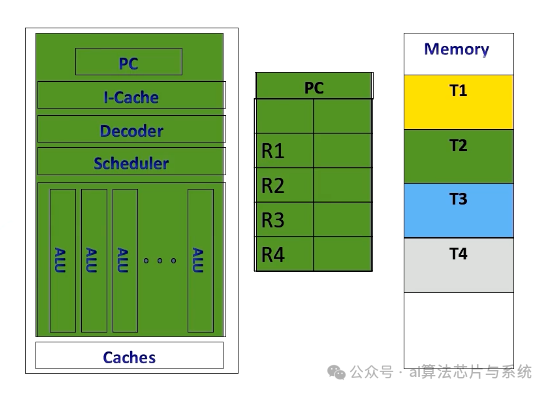
CPU上下文
相比之下,CPU以不同的方式实现上下文切换。当执行线程时,指令流水线、PC和寄存器专用于特定线程。
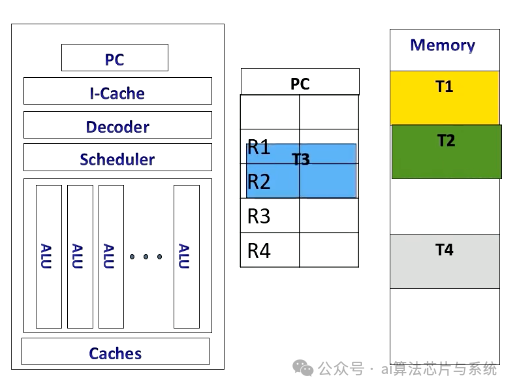
CPU上下文切换
如果CPU切换到另一个线程,例如从T2切换到T3,它将T2的内容存储在内存中并从内存加载T3内容。

CPU上下文切换
完成后,它执行原始线程上下文。CPU中的上下文切换由于需要从内存存储和检索寄存器内容而产生显著的性能开销。
多线程的硬件支持
现在更详细地讨论多线程的资源需求。
-
• 前端需要多个PC
-
• 每个线程束一个PC,因为线程束中的所有线程共享相同的PC
-
• 后来的GPU具有其他高级功能,我们将保持简单并假设每个线程束一个PC
-
• 此外,需要大型寄存器文件
-
• 每个线程需要"K"个架构寄存器
-
• 总寄存器文件大小需求 = K × 线程数
-
• "K"因应用程序而异
-
• 记住占用率计算?
-
• 每个SM(共享内存)可以执行Y个线程,Z个寄存器等
-
• 这里,Y与PC寄存器的数量相关。因此,如果硬件有五个PC寄存器,它最多可以支持5乘以32,即160个线程
-
• Z与K相关
重新审视之前的占用率计算示例
重新审视之前的示例以计算占用率。如果我们可以执行256个线程,拥有64×1024个寄存器和32 KB的共享内存,这里假设每个线程束32个线程。那么问题是需要多少个PC?
-
• 答案是256除以32,即8个PC
如果一个程序有10条指令,一个SM需要获取指令多少次?
-
• 答案很简单,10乘以8,即80次
模块4课程2:存储体冲突
课程学习目标:
-
• 解释寄存器文件访问和共享内存访问的SIMT行为
-
• 描述增强寄存器和共享内存访问带宽的技术
CUDA块/线程/线程束
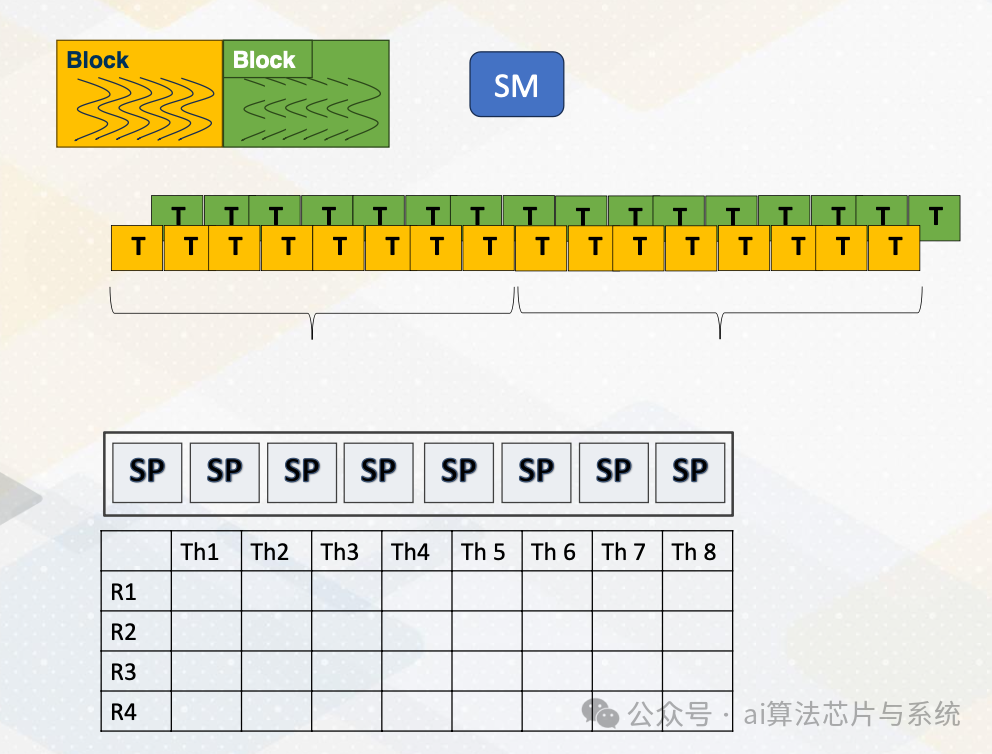
线程束
重新审视GPU架构基础。在GPU中,多个CUDA块在一个多处理器上运行,每个块有多个线程。一组线程作为线程束执行。如本动画所示,一个线程束将执行,然后另一个线程束将执行。线程束中的每个线程都需要访问寄存器,因为寄存器是每个线程的。假设每条指令需要读取两个源操作数并写入一个操作数,执行宽度为八。在这种情况下,我们需要一次提供八乘以三,两个读取和一个写入,即24个值。
端口与存储体
让我们提供一些关于端口和存储体的背景。端口是用于数据访问的硬件接口。例如,每个线程需要两个读取和一个写入端口。如果执行宽度为四,那么总共有八个读取端口和四个写入端口。

没有存储体版本
此图说明了每个寄存器元素的八个读取端口和四个写入端口。读取和写入端口字面上需要连接电线。因此它实际上占用了相当多的空间。
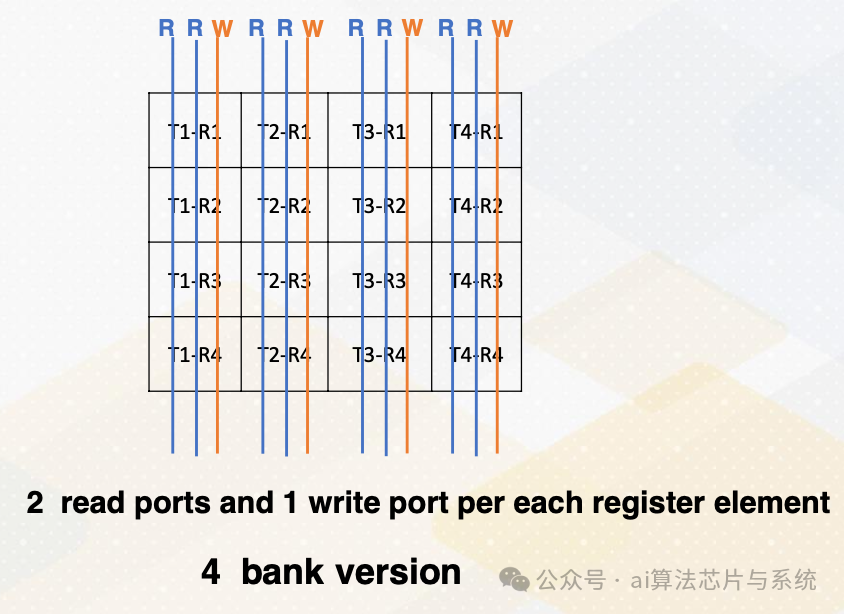
四存储体版本
另一方面,我们可以不同地放置寄存器文件,并为每个寄存器元素仅放置两个读取端口和一个写入端口。这称为四存储体版本,需要更少的端口数。
什么是存储体?存储体是寄存器文件的分区或组。存储体的好处是可以同时访问多个存储体,这意味着我们不需要拥有所有读取和写入端口。我们可以简单地拥有多个存储体,具有更少的读取和写入端口,如图所示。这很重要,因为更多端口意味着更多硬件布线,和更多资源使用。
存储体冲突
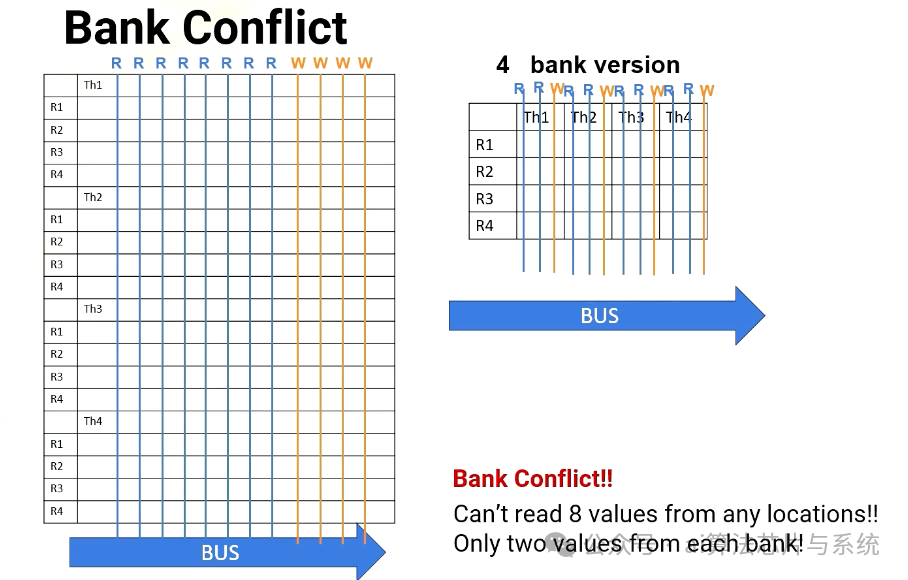
场景1:从T1、T2、T3、T4读取R1(每个线程在不同的存储体上
然而,当线程束中的多个线程需要同时访问同一存储体时,会出现挑战,这会导致存储体冲突。例如,在场景1中,处理器需要从线程1、2、3、4读取R1。每个线程寄存器文件位于不同的存储体上。
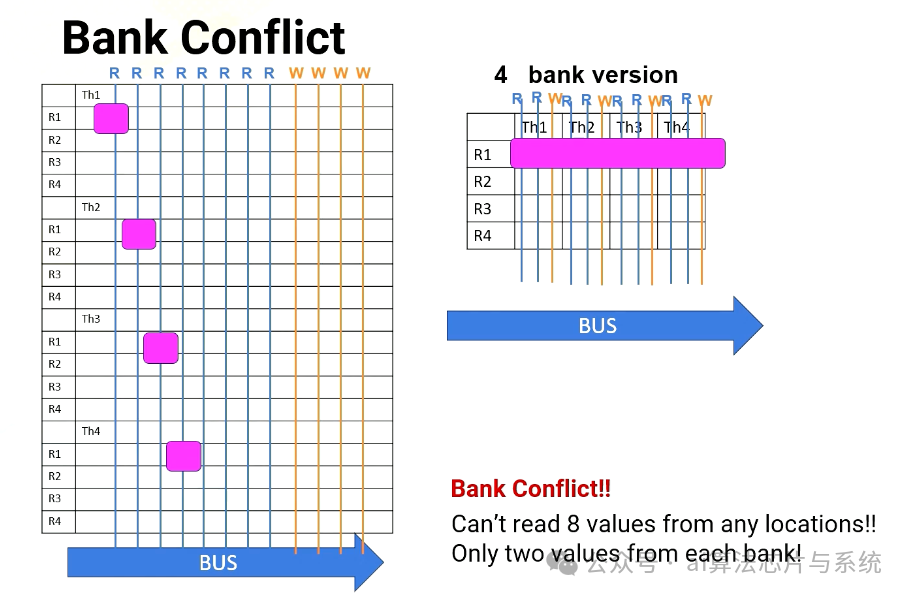
场景1:从T1、T2、T3、T4读取R1(每个线程在不同的存储体上
场景#1:从T1、T2、T3、T4读取R1(每个线程在不同的存储体上)
在无存储体版本中,它有八个读取端口。因此它可以轻松提供四个读取值,四存储体版本也可以,因为所有寄存器文件访问都在不同的存储体中。
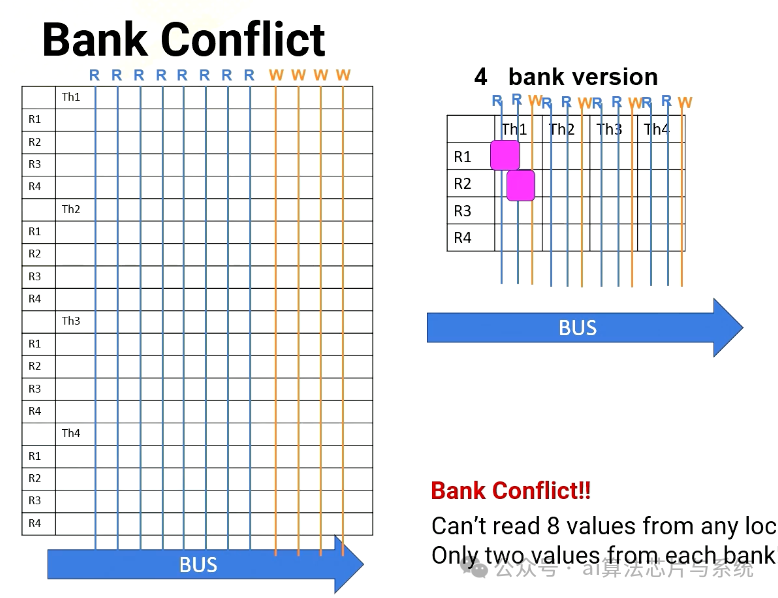
场景2:从T1读取R1、R2、R3、R4
然而,在场景2中,处理器必须从R1、R2、R3和R4读取。全部在同一线程或同一存储体中。对于8端口版本,没问题。它可以同时读取所有四个值,但在四存储体版本中,它一次只能读取两个值。因此需要多个周期。
每个线程的可变寄存器数
-
• 寄存器文件会有存储体冲突吗?
-
• 为什么我们担心寄存器的存储体冲突?我们不是总是需要从不同线程访问两个寄存器吗?
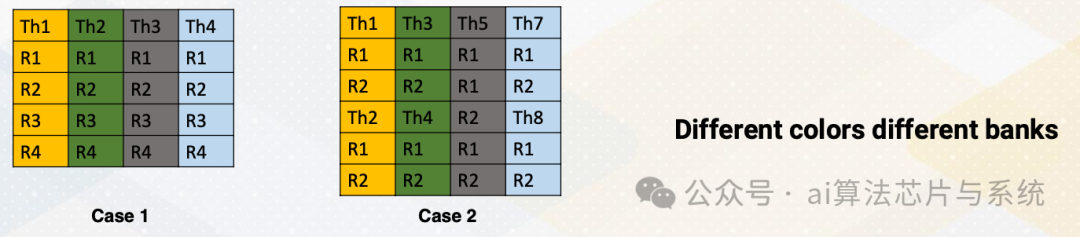
添加图片注释,不超过 140 字(可选)
挑战的出现是因为CUDA编程将从每个线程的不同寄存器计数中获得好处。假设我们想操作指令R3 = R1+R2。这里有两种情况。
-
• 在第一种情况下,每个线程四个寄存器
-
• 在第二种情况下,每个线程两个寄存器。不同的颜色表示不同的存储体
-
• 在情况1中,读取寄存器不会导致存储体冲突,因为每个线程寄存器文件位于不同的存储体中
-
• 然而,在情况2中,从多个线程读取R1、R2会导致存储体冲突,因为线程1和线程2在同一存储体中。线程3和线程4也是如此
-
• 记住,GPU执行一组线程(线程束),因此多个线程正在读取相同的寄存器。那么如何克服这个问题?第一个解决方案是使用编译时优化
克服寄存器存储体冲突的解决方案
那么如何克服这个问题?第一个解决方案是使用编译时优化。编译器可以优化代码布局,因为寄存器ID在静态时已知。
侧边栏:静态与动态
让我简要提供一些关于静态与动态的背景。在本课程中,静态通常意味着在运行代码之前。属性不依赖于程序的输入。动态意味着属性依赖于程序的输入。
这是一个例子。有一个代码ADD和BREQ。
LOOP: ADD R1 R1 #1 BREQ R1, 10, LOOP
这是一个例子。有一个代码ADD和BREQ。假设此循环迭代10次。静态指令数是多少?静态指令数是2,因为这是我们在代码中看到的,动态指令数是2乘以10变为20。还要注意,静态时间分析意味着编译时分析。
克服寄存器存储体冲突的解决方案(续)
解决方案
回到克服寄存器存储体冲突的解决方案,我们尝试使用编译时分析来更改指令顺序或消除存储体冲突。但并非所有存储体冲突都可以避免。
因此,在真实GPU中,GPU流水线更复杂(超越5级流水线)。首先,寄存器文件访问可能需要多个周期,也许存在存储体冲突,或者因为寄存器文件可能只有一个读取端口,所以流水线实际上扩展了。
读取值后,值存储在缓冲区中。之后,使用记分牌选择指令。
记分牌
记分牌在CPU中广泛用于实现乱序执行。它用于动态指令调度。
然而,在GPU中,它用于检查线程束中的所有源操作数是否就绪,再从多个线程束中选择一个发送到执行单元。可能的调度策略包括先来先服务,也可能有其他许多用于选择线程束的策略。
读取寄存器值
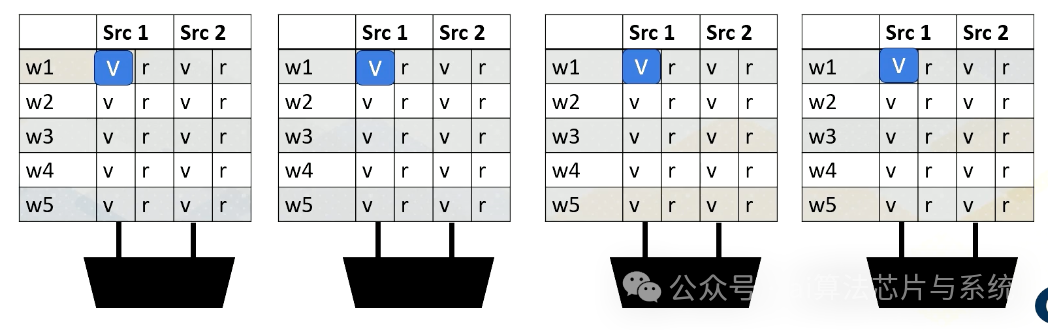
添加图片注释,不超过 140 字(可选)
这是一个例子。读取寄存器文件可能需要几个周期。就绪的寄存器值存储在缓冲区中。此图显示了缓冲区和记分牌。
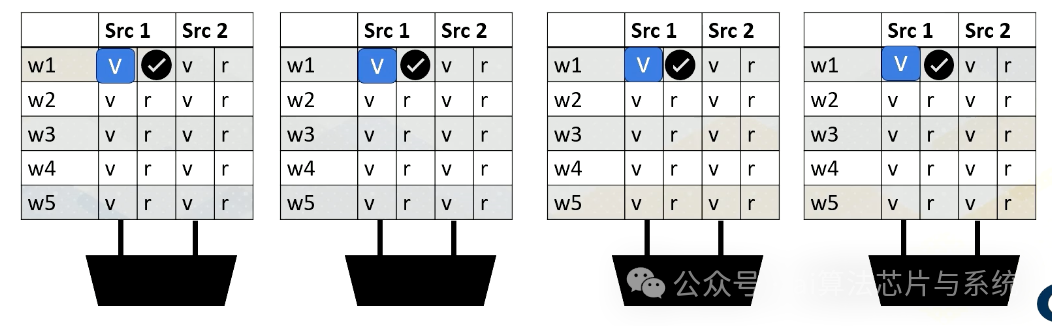
添加图片注释,不超过 140 字(可选)
每当存储值时,它设置就绪位。这里,线程束1,源1就绪。
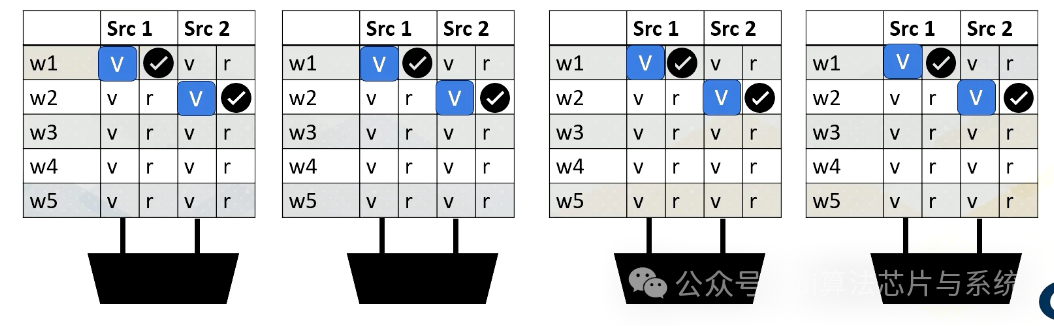
添加图片注释,不超过 140 字(可选)
然后线程束2,源2就绪,

添加图片注释,不超过 140 字(可选)
然后线程束3,源1,

添加图片注释,不超过 140 字(可选)
最后线程束1,源2就绪。
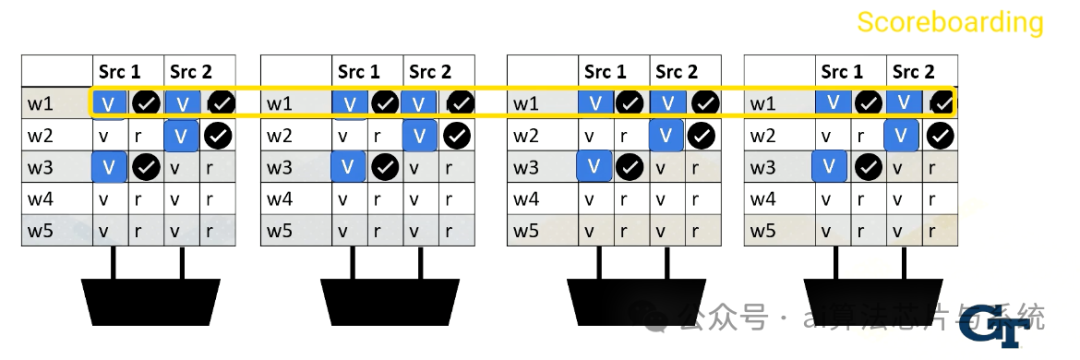
记分牌就绪
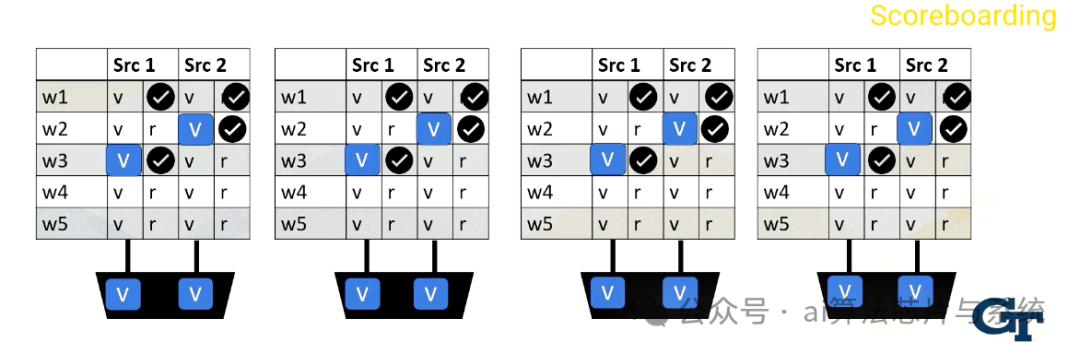
记分牌就绪执行
当所有值就绪时,记分牌选择线程束,然后值发送到执行单元。
共享内存存储体冲突
存储体冲突也可能发生在GPU上的共享内存中。共享内存是片上存储器和暂存器内存。共享内存也由存储体组成以提供高内存带宽。假设有以下共享内存。
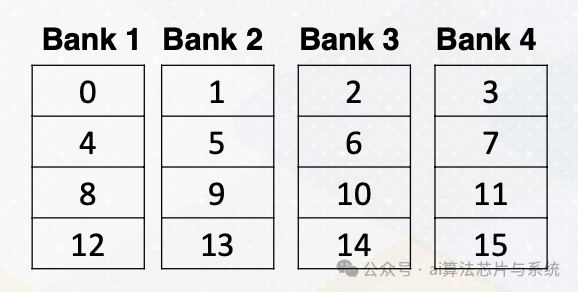
共享内存
有四个存储体,框中的数字表示内存地址。
这是一个显示共享内存的代码,共享输入。
__shared__ float sharedInput[index1]; Index1= threadIdX.x *4
共享内存的索引通过简单地将threadIdX.x乘以4来计算。这意味着线程1需要访问内存地址4,线程2需要访问内存地址8,线程3需要访问内存地址12,依此类推。不幸的是,所有这些地址都映射到同一存储体,因此所有线程将产生存储体冲突。解决方案是更改软件结构,我们将在后面的讲座中详细介绍。
总之,我们学习了存储体在寄存器和共享内存中的好处。我们还研究了寄存器文件和共享内存中存储体冲突的原因。
模块4课程3:GPU架构流水线
课程学习目标:
-
• 描述具有多线程和寄存器文件访问的GPU流水线行为
-
• 解释如何使用掩码位
GPU流水线(1)
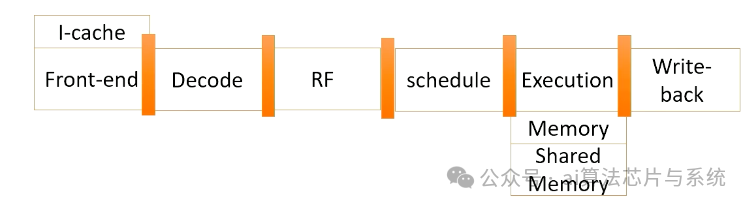
GPU流水线
这是一个GPU流水线。

PC值
这里显示了每个线程束的PC值。在此示例中,有四个线程束,第一个线程束应从PC值0x8000获取,第一个线程束来自块1和线程1-4。第二个线程束也来自块1和线程5-8。第三个线程束来自块2和线程1-4,第四个线程束来自块2线程5-8。
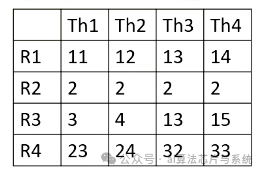
寄存器值
这里显示了块1的寄存器值。

I缓存
这里显示了一个I缓存内存地址和指令。您在8008看到tid.x。Tid.x是一个特殊寄存器,用于存储块内的线程ID。8000A的一条指令有一个ctaid,这是另一个特殊寄存器,用于存储网格内的块ID。

记分牌
这是一个记分牌。好的,前端从8000获取一条指令。整个线程束只获取一条指令。添加r1,r1,1。

添加图片注释,不超过 140 字(可选)
此指令被带到前端,然后发送到解码阶段,并将被解码。由于指令本身具有常量值或立即值1,值1将广播到记分牌。

添加图片注释,不超过 140 字(可选)
因此,线程束1的所有源2操作数就绪。在寄存器文件访问阶段,我们访问源寄存器1,即线程1、2、3、4的r1。值被读取并发送到记分牌。因此现在,处理器检查指令并看到所有源操作数就绪,因此选择此线程束。

添加图片注释,不超过 140 字(可选)
线程束发送到执行阶段并执行添加,最终结果将在正确的回写阶段写回寄存器文件。
GPU流水线(2)

添加图片注释,不超过 140 字(可选)
现在让我们看第二个线程束。它从线程束2获取指令,即块1和线程5-8。同样,指令被解码,常量值1广播到所有源操作数缓冲区。由于空间限制,我们在这里省略了一个执行单元的值。

添加图片注释,不超过 140 字(可选)
在下一阶段,处理器访问寄存器文件并从线程5-8读取值r2。在此示例中,所有源值都是二。现在所有源操作数就绪,因此调度程序选择线程束2,它们将被执行,即使它们都在操作相同的值。
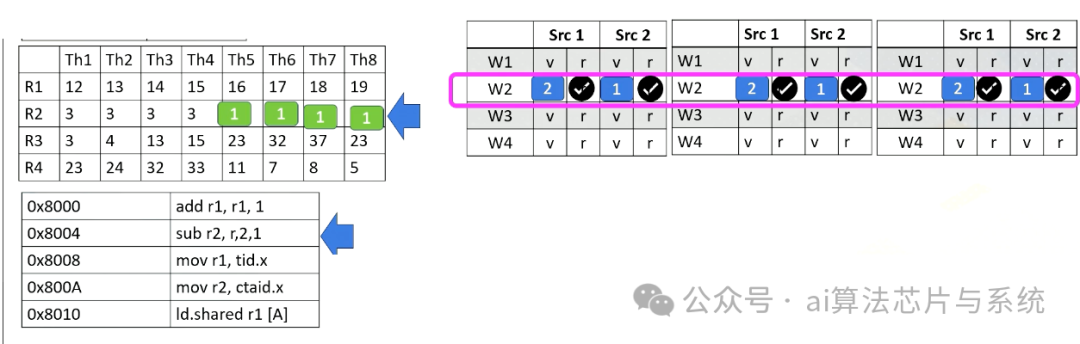
添加图片注释,不超过 140 字(可选)
硬件对线程束中的所有线程执行相同的工作,在减法中执行2减1。然后结果将在回写阶段写回,就像前面的示例一样。它们将更新线程5-8的寄存器值。
GPU流水线(3)
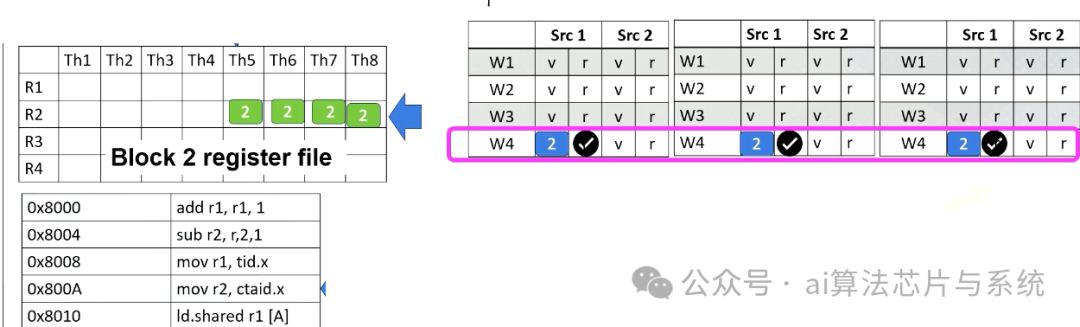
添加图片注释,不超过 140 字(可选)
现在假设处理器从线程束4获取。PC地址是8000A,它将ctid.x移动到r2,线程束4的块ID是2,因此ctid.x值也是2。Ctaid.x值被读取并存储在记分牌内部。这些值将在回写阶段存储到r2,如本动画所示。
GPU流水线(4)

添加图片注释,不超过 140 字(可选)
现在,假设处理器从8008为线程束4获取。指令有tid.x。由于这是针对线程5-8,tid.x值将是5、6、7和8。Tid.x值将被读取并存储在记分牌中,在回写阶段,所有这些值将写回r1,如本动画所示。
掩码位
如果我们不需要执行r4线程怎么办?GPU存储信息,告诉哪个线程或通道处于活动状态。一个ALU执行路径称为通道。
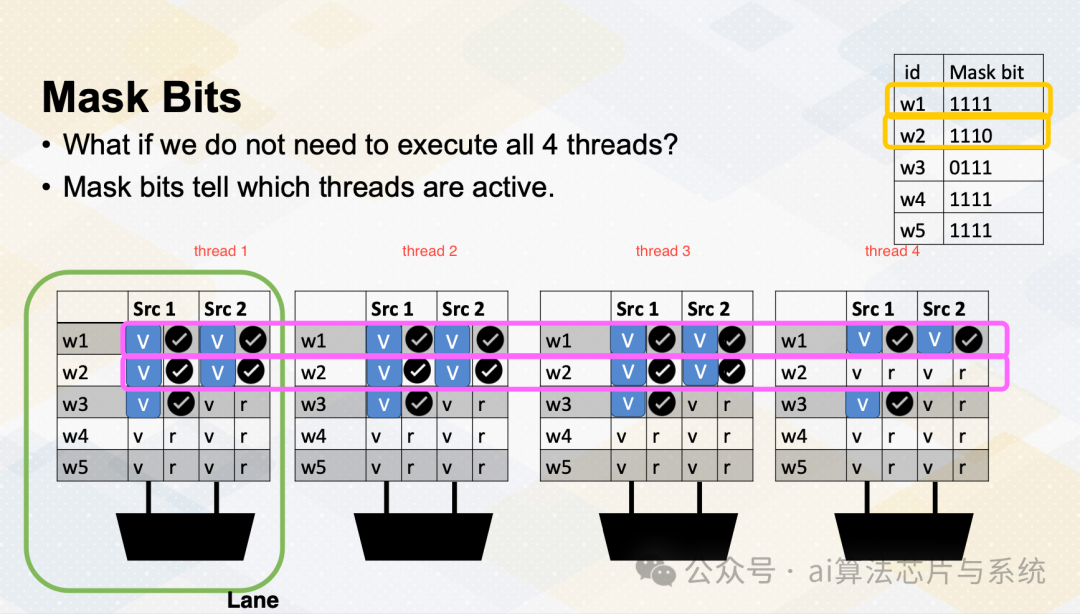
添加图片注释,不超过 140 字(可选)
活动线程执行实际计算,非活动线程不会做任何工作。掩码位告诉哪些线程处于活动状态或不活动状态。这里记分牌显示寄存器值和就绪位。线程束1在掩码位中有1111,这意味着线程束1中的所有线程将实际执行工作。选择线程束1并执行。在线程束2的情况下,掩码位是1110,因此只有前三个通道或前三个线程将执行工作。
总之,在此视频中,我们回顾了GPU流水线的指令流。我们还研究了用于线程ID和块ID的特殊寄存器的使用。此视频还介绍了用于识别活动SIMT通道的活动掩码的概念。
模块4课程4:全局内存合并
课程学习目标:
-
• 探索全局内存访问
-
• 解释内存地址合并
-
• 描述一个线程束如何生成多个内存请求
让我们更多地看着全局内存合并。在此视频中,我们将探索全局内存访问。您应该能够解释内存地址合并,并且您应该能够描述一个线程束如何生成多个内存请求。
全局内存访问

DRAM
这里说明了GPU和DRAM。在GPU架构中,一条内存指令可能生成许多对DRAM的内存请求,因为一个线程束可以生成最多32个内存请求,如果我们假设线程束大小为32。因此内存请求的总数很容易是一个更大的数字。例如,如果我们有32个SM,每个SM有一个线程束要执行,32乘以32。换句话说,一个周期中可以生成1024个请求。每个内存请求是64字节,因此每周期64 KB,如果我们假设一个GHz GPU,需要64 TB/s的内存带宽。
侧边栏:DRAM与SRAM

DRAM与SRAM
让我简要提供一些关于DRAM和SRAM的背景。SRAM由六个晶体管组成,组合多个一位SRAM单元构成SRAM,SRAM通常用于缓存。另一方面,DRAM由一位晶体管组成,DRAM芯片有许多一位DRAM单元。由于每位只需要一位DRAM,DRAM可以提供大容量,但DRAM芯片中的所有通信都需要引脚进行通信,这可能是一个限制因素。
HBM克服了这个问题。首先,通过堆叠DRAM,它提供了更高的DRAM密度。然后,通过使用硅中介层连接内存与GPU,它避免了片外通信。因此,GPU和DRAM之间的所有通信都在同一封装内。因此,HBM提供了显著的内存带宽。
内存合并
即使内存可以提供高内存带宽,减少内存请求对于性能仍然至关重要。因为GPU缓存非常小。很容易饱和内存带宽。这里是两个全局内存访问的示例。
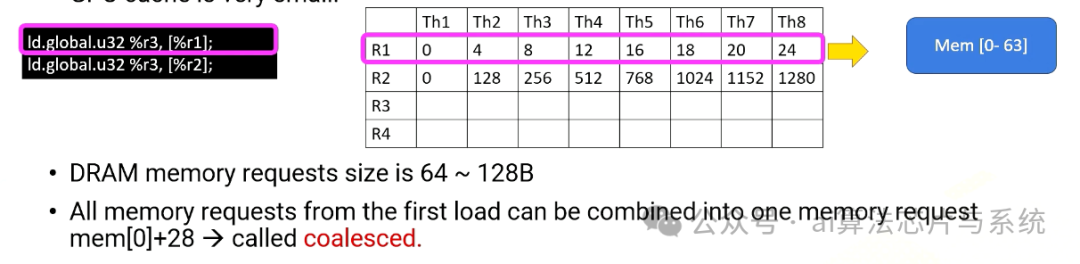
添加图片注释,不超过 140 字(可选)
第一条指令,Ld.global,它使用寄存器值R1生成内存地址。线程束内R1的内容都是顺序的,因此内存地址也都是顺序的。因此,来自第一次加载的所有内存请求可以合并为一个内存请求,内存0-28或0-63。这称为合并。
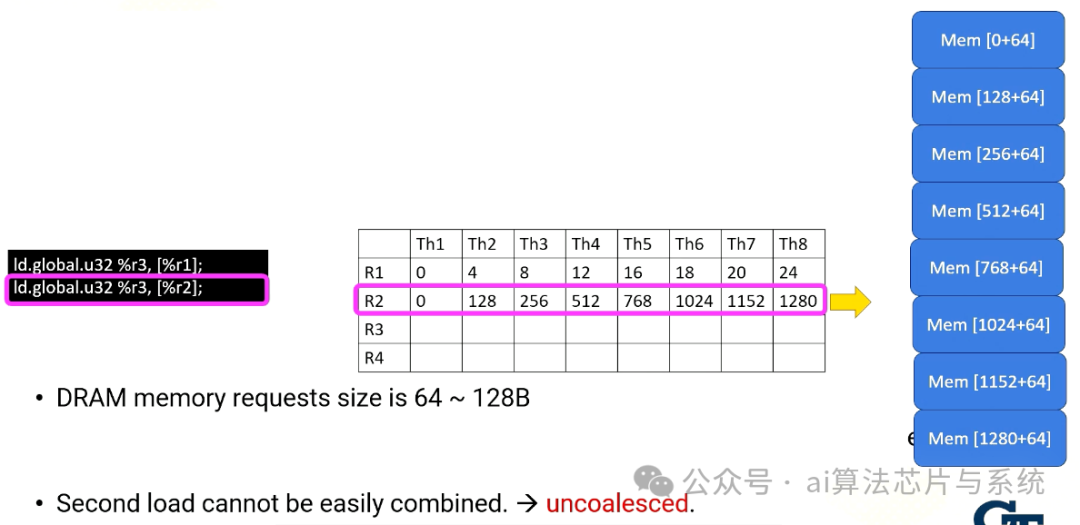
添加图片注释,不超过 140 字(可选)
另一方面,第二次加载看起来与第一条指令相同,但R2的内容 quite different,R2值全部跨步128。因此每个内存请求需要单独发送。第二次加载不能轻易合并,这称为未合并。
合并内存
合并内存将多个内存请求合并为单个或更高效的内存请求。连续的内存请求可以合并。合并内存减少了内存请求的总数。这是关键的软件优化技术之一。
总之,未合并的全局内存需要显著的性能,因此它们可以显著降低性能。GPU有潜力饱和内存带宽,因为大量并发运行的线程。合并内存请求对于高效内存访问和更好的GPU性能至关重要。
本文翻译自Gt Gpu M4[2]
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
引用链接
[1] 通用图形处理器架构(计算机架构综合讲座)第3章: https://galileo-gatech.primo.exlibrisgroup.com/discovery/fulldisplay?context=L&context=L&vid=01GALI_GIT:GT&vid=01GALI_GIT&docid=alma9916162981502950&tab=default_tab&lang=en [2] Gt Gpu M4: https://lowyx.com/posts/gt-gpu-M4/
GPU微架构与多线程架构深入解析

”超级计算机)



















)










:Lucene —— 打开现代搜索世界的第一扇门)








office2024专业增强版下载安装教程)

)





