有时候一些网站进行了加密,显示的内容还用JS搞活字乱刷术,但是可以通过抓包抓到XHR中的JSON数据,而drissionpage(下文简称DP)相较于selenium可以更方便地抓这种数据;
本文内容仅用于学习交流,不得用于商用,侵权告删;
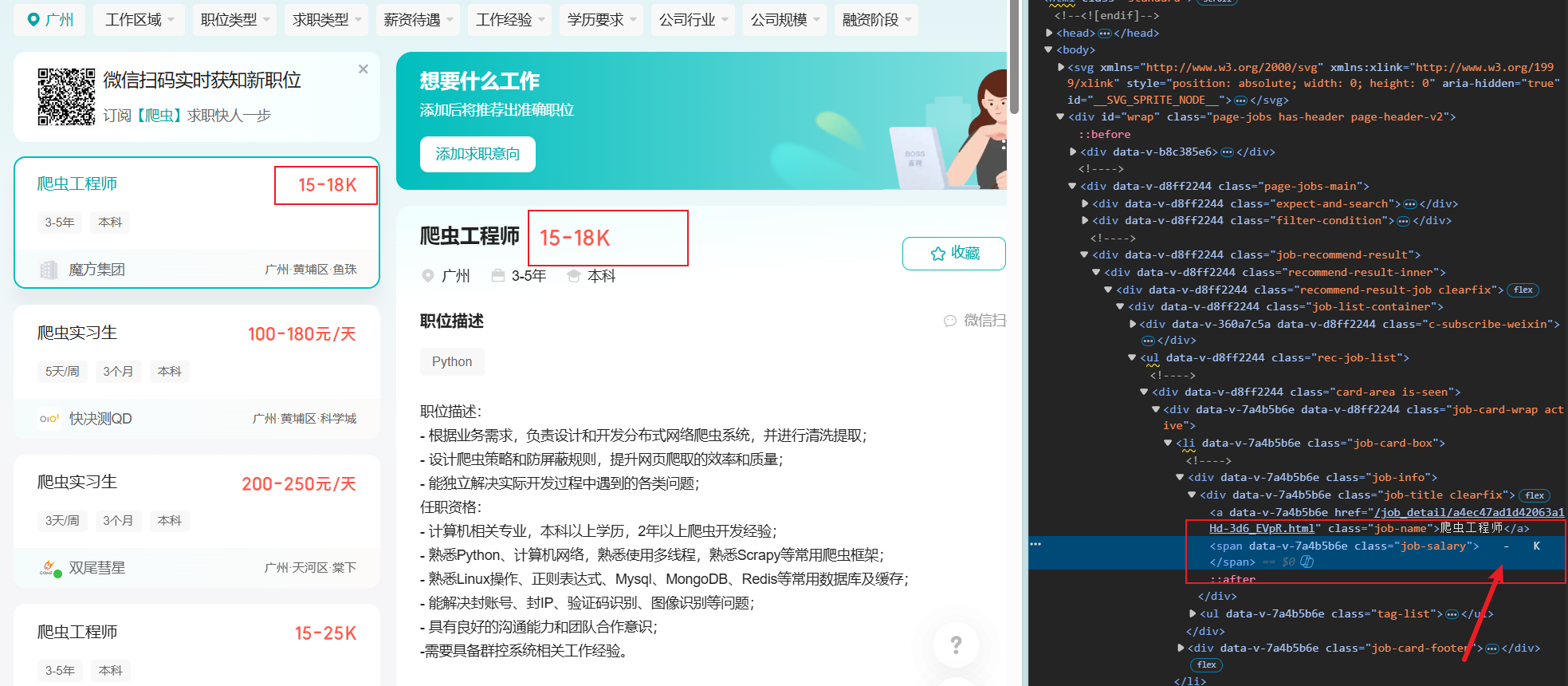
可以看到唯独工资这块,被JS动了,由于参数很多,逆向难度比较大,我们直接找这个数据,可知每次返回15条数据
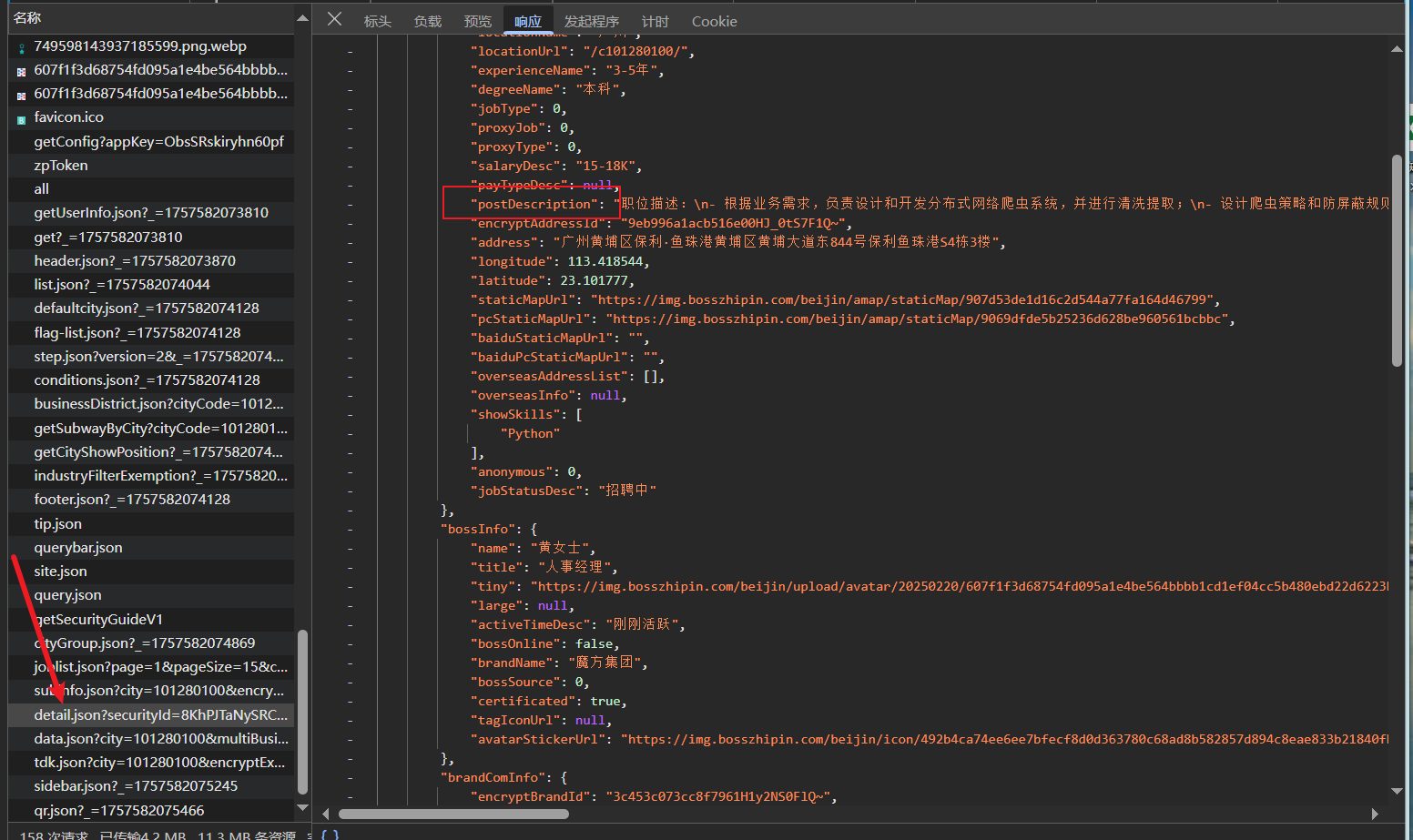
joblist.json是左边的简略信息,而需要点击具体岗位,才会返回右边的detail.json具体信息,其实详细信息对我们而言,主要是多了①岗位内容介绍,一般是较长的一段文本;②HR的状态,是在线还是几个月不在线;③公司简介其实也有返回,但不会显示出来;
再具体内容的步骤不做详细解释,随手写的没有做过多封装,主要功能已实现,由于DP可以为每个端口存储不同的登录信息,所以只要扫过一次码,之后就不需要再登录,并且调试的时候已打开的网页不会重复打开,可以继续下一步,灰常方便,代码中不明白的需看自行学习爬虫知识和DP官网教程和说明:
每次的15条简略信息:
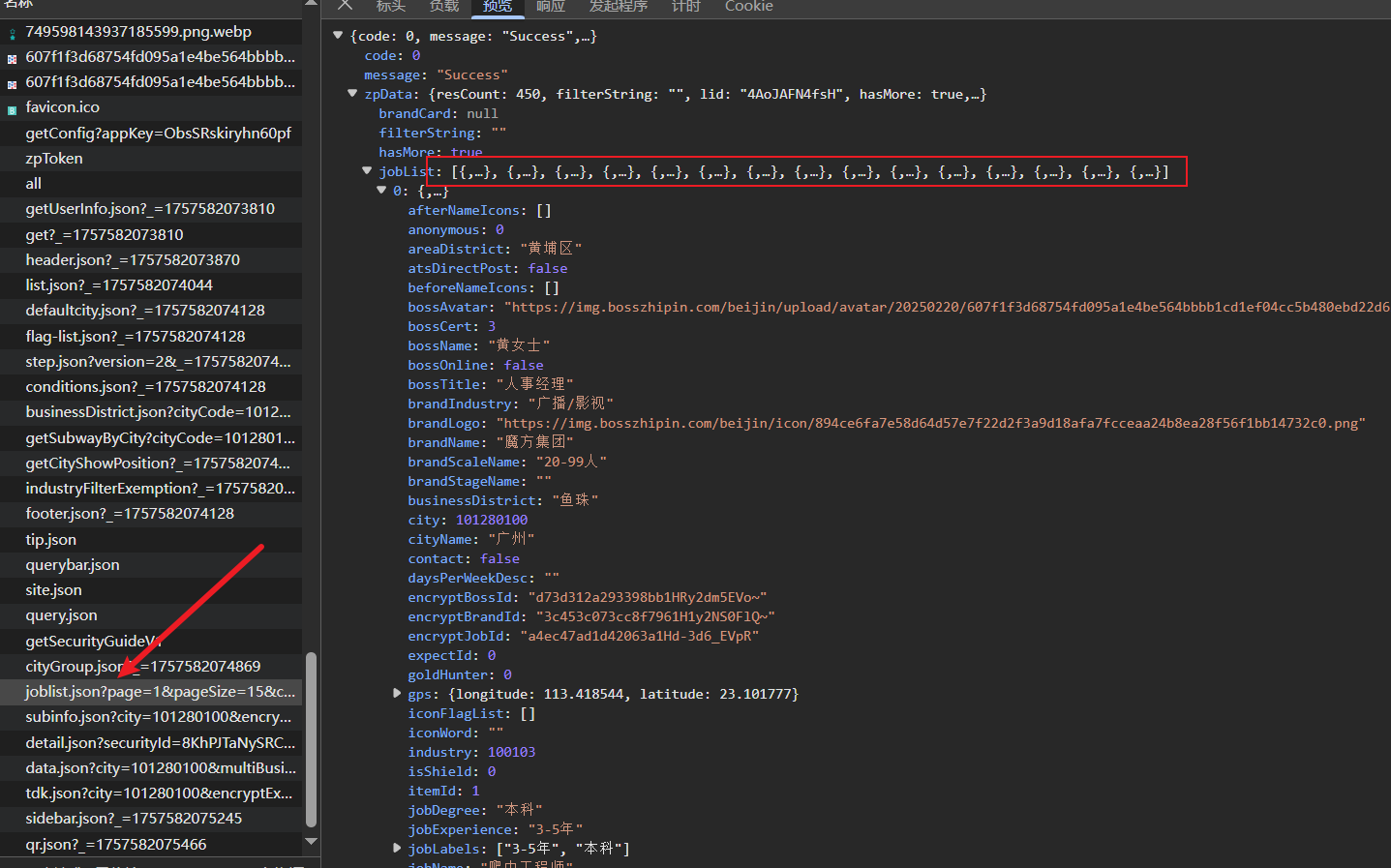
岗位具体信息:
1.1准备工作
from DrissionPage import Chromium,ChromiumOptions
from DrissionPage.common import Keys
import json
import pandas as pd
web_path = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
test_url = 'https://www.zhipin.com/'
co = ChromiumOptions().set_browser_path(web_path) #临时使用
browser = Chromium(co)
# --------------------
tab = browser.latest_tab
tab.get(test_url)
1.2定位岗位和城市
def get_start(tab,key_word='爬虫',city_short='FGHJ',city='佛山'):"""ABCDE,FGHJ,KLMN,PQRST,WXYZ"""# 输入搜索的职位search_input = tab.ele('xpath:.//input[@placeholder="搜索职位、公司"]')tab.actions.click(search_input)search_input.clear()tab.actions.click(search_input).type(key_word)# 按下搜索按钮
# search_confirm = tab.ele('xpath:.//*[@class="search-btn"]') # 登录页切换搜索定位search_confirm = tab.ele('xpath:.//button[@class="btn btn-search"]') #跳转页定位search_confirm.click()tab.wait(2)# 切换城市city_switch = tab.ele('xpath:.//div[@class="city-label active"]')city_switch.click()tab.wait(1)# 选择缩写,使用DP方法定位元素city_list = tab.ele(city_short) # tab.ele('xpath:.//ul[@class="city-char-list"]//li[text()="FGHJ"]') city_list.click()tab.wait(1)# 选择指定的城市city_target = tab.ele(f'xpath:.//ul[@class="city-list-select"]//*[text()="{city}"]')city_target.click()tab.wait(1)
# 调用
get_start(tab,key_word='爬虫',city_short='FGHJ',city='广州')
此时你要做出选择,是抓简略信息,抓15个就下滑一次,继续抓,有个参数hasmore,代表着还有没有继续的内容;
或者是挨个点击,获取详细信息,由于第一个岗位的详细信息是默认要给的,所以我们必须刷新一次网页,不然会漏一个;
这里都有,需注意第2次返回的岗位简略信息,即第30个岗位,跟着一个调查反馈,所以定位元素要定深一层,不然分分钟陷入死循环给你看
1.3选择抓详细信息
def parse_detail(data):"""根据detail.json抓详细信息的方法"""data_body = data['zpData']['jobInfo']href_part = data_body['encryptId']# 拼出完整链接,不含其他加密参数full_href = "https://www.zhipin.com/job_detail/" + href_part + ".html"jobname = data_body['jobName']location = data_body['locationName']experience = data_body['experienceName']degree = data_body['degreeName']salary = data_body['salaryDesc']desc = data_body['postDescription']address = data_body['address']skills = data_body['showSkills']hr_name = data['zpData']['bossInfo']['name']hr_title = data['zpData']['bossInfo']['title']hr_active = data['zpData']['bossInfo']['activeTimeDesc']company = data['zpData']['bossInfo']['brandName']comp_scale = data['zpData']['brandComInfo']['scaleName']industry = data['zpData']['brandComInfo']['industryName']comp_intro = data['zpData']['brandComInfo']['introduce']welfare = data['zpData']['brandComInfo']['labels']result_dict = {'jobname': jobname,'company': company,'comp_scale': comp_scale,'salary': salary,'hr_active': hr_active,'industry': industry,'skills': skills,'experience': experience,'hr_name': hr_name,'hr_title': hr_title,'degree': degree,'location': location,'address': address,'desc': desc,'comp_intro': comp_intro,'welfare': welfare,}return result_dict
接上这个循环就行,网站也有频率检测,干太多太猛出问题,概不负责;
tab.listen.start('zpgeek/job/detail.json') #开始监听
tab.refresh() # 刷新页面
my_columns = ['jobname', 'company', 'comp_scale', 'salary', 'hr_active', 'industry', 'skills', 'experience', 'hr_name', 'hr_title', 'degree', 'location', 'address', 'desc', 'comp_intro', 'welfare']
old_df = pd.DataFrame(columns=my_columns)
# 首先创建一个空的EXCEL,含表头,用于追加
custom_path= "d:/new_detail2.csv"
old_df.to_csv(custom_path,index=False,header=True,encoding='utf_8_sig')finished = 0
while True:# 新的用来存放一次搞到的15个数据new_df = pd.DataFrame(columns=my_columns)jobs = tab.eles('xpath:.//div[contains(@class,"card-area")]/div[contains(@class,"job-card-wrap")]')length_jobs = len(jobs)for i in jobs[finished:]:i.click() data = tab.listen.wait().response.bodyres = parse_detail(data)new_df.loc[len(new_df)] = restab.wait(3,scope=5)new_df.to_csv(custom_path,mode='a', encoding='utf_8_sig', index=False,header=False)finished =length_jobs# 重新获取最新数量new_jobs = tab.eles('xpath:.//div[contains(@class,"card-area")]')new_length = len(new_jobs)if new_length>length_jobs:print('继续干')if new_length==length_jobs:print('无新数据,退出')break if finished >=30:print('干太猛,休息会')break
1.4获取简略信息
def parse_json(data,custom_path = 'd:/zhipin.csv'):"""这方法会重复写入表头,照着上面的自己改一下啦"""data_body = data['zpData']['jobList']df = pd.DataFrame(columns=['jobname','company','salary','industry','scale','jobdegree','fullurl','joblabels','skills','bossname','bosstitle','cityname','area','district','welfare'])df.loc[0] = ['jobname','company','salary','industry','scale','jobdegree','fullurl','joblabels','skills','bossname','bosstitle','cityname','area','district','welfare']for i in data_body:joburl = i['encryptJobId']fullurl = 'https://www.zhipin.com/job_detail/'+joburl+'.html'bossname = i['bossName']bosstitle = i['bossTitle']jobname = i['jobName']salary = i['salaryDesc']joblabels = i['jobLabels']skills = i['skills']jobdegree = i['jobDegree']cityname = i['cityName']area = i['areaDistrict']district =i['businessDistrict']company = i['brandName']industry = i['brandIndustry']scale = i['brandScaleName']welfare = i['welfareList']print(jobname,company,salary,industry,scale,jobdegree,fullurl,joblabels,skills,bossname,bosstitle,cityname,area,district,welfare,'\n')df.loc[len(df)] = [jobname,company,salary,industry,scale,jobdegree,fullurl,joblabels,skills,bossname,bosstitle,cityname,area,district,welfare]df.to_csv(custom_path,mode='a', encoding='utf_8_sig', index=False,header=False)
# parse_json(data_json)
接上这个死循环
tab.listen.start('search/joblist.json') #开始监听
tab.refresh() # 刷新页面
num_count=0
while True:tab.scroll.to_bottom() # 向下滑tab.wait(5,scope=10) # 等待5-10秒packet = tab.listen.wait()data_listen = packet.response.bodyhasmore = data_listen['zpData']['hasMore'] # 判断是否有下一页parse_json(data_listen,custom_path='d:/zhipin_gz.csv')num_count+=1if not hasmore:breakif num_count>=3:break
经研究,网上已经有人写过DP抓这个网站的文章,本文所写内容仅用于学习交流,不得对别人网站进行过多或过快的爬取。




)















)
















)










