大数据Hadoop集群搭建
文章目录
- 大数据Hadoop集群搭建
- 一、VMware准备Linux虚拟机
- 二、VMware虚拟机系统设置
- 1、主机名、IP、SSH免密登录
- 2、JDK环境部署
- 3、防火墙、SELinux、时间同步
- 三、VMware虚拟机集群上部署HDFS集群
- 1、集群规划
- 2、上传&解压
- 3、Hadoop安装包目录结构
- 4、修改配置文件,应用自定义设置
- 5、准备数据目录
- 6、分发Hadoop文件夹
- 7、配置环境变量
- 8、授权为hadoop用户
- 9、格式化整个文件系统
- 10、查看HDFS WEBUI
- 四、HDFS的Shell操作
- 1、HDFS相关进程的启停管理命令
- 一键启停脚本
- 单进程启停
- 2、HDFS的文件系统操作命令
- HDFS文件系统基本信息
- 介绍
- 1、创建文件夹
- 2、查看指定目录下内容
- 3、上传文件到HDFS指定目录下
- 4、查看HDFS文件内容
- 5、下载HDFS文件
- 6、拷贝HDFS文件
- 7、追加数据到HDFS文件中
- 8、HDFS数据移动操作
- 9、HDFS数据删除操作
- 10、HDFS shell其它命令
- 11、HDFS WEB浏览
- 3、HDFS客户端 - Jetbrians产品插件
- 4、HDFS客户端 - NFS
- 五、MapReduce和YARN的部署
- 一、部署说明
- 二、集群规划
- 三、MapReduce配置文件
- 四、YARN配置文件
- 五、分发配置文件
- 六、集群启动命令介绍
- 七、查看YARN的WEB UI页面
- 提交MapReduce程序至YARN运行
- 六、Hive部署
- WordCount单词计数程序
- JobMain类
- WordCountMapper类
- WordCountReducer类
大数据Hadoop集群搭建
一、VMware准备Linux虚拟机
1、首先准备VMware软件,用于后续创建虚拟机:
这里我使用的是VMware WorkStation Pro 17的版本,如下图:

2、设置VMware网段
在VMware的虚拟网络编辑器中,将VMnet8虚拟网卡的网段设置为192.168.88.0,网关设置为192.168.88.2,如下图:

点击右下角的“更改设置”,进入到下图所示的页面进行网段修改:
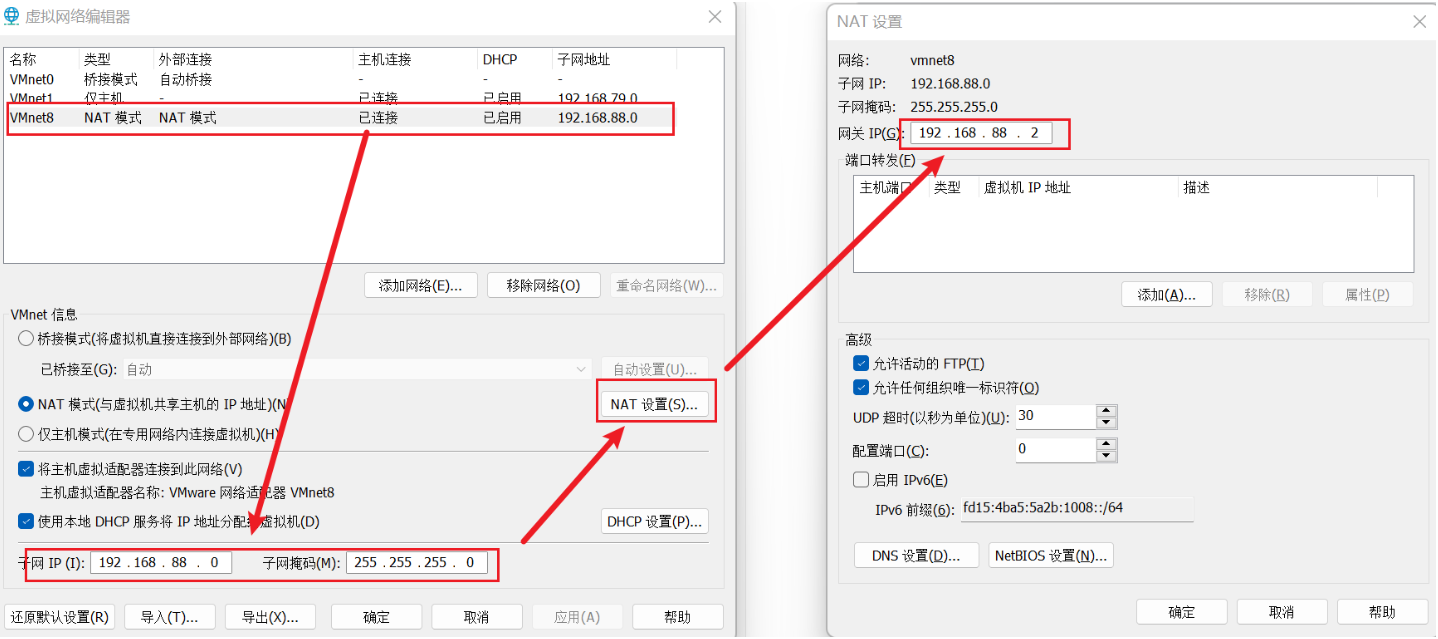
修改好之后点击“确定”即可。
3、下载CentOS的操作系统镜像文件
这里我放在了D:\Hadoop大数据虚拟机路径下

4、创建虚拟机
选择创建虚拟机

选择“典型”

选择刚刚下载好的虚拟机镜像文件

然后设置账号和密码(用于学习的话密码建议直接设置为123456):

接下来给虚拟机起一个名称,选择虚拟机的存放位置,这里我选择放在路径D:\Hadoop大数据虚拟机\vm\bigdata下面,后续创建的三个虚拟机结点也是存放在这个文件夹下面:


磁盘大小选择20~40GB都可以,我这里选择默认的20GB:

最后点击完成,等待虚拟机的安装完成:

接下来我通过已经创建好的名为“CentOS-7.6 Base”的这一个虚拟机去克隆出来三个结点的虚拟机:

虚拟机创建好后如下所示:

然后还要修改一下每个结点的硬件配置,如下:(硬件配置集群规划)
因为后续在node1的节点上运行的软件会多一些,所以这里我们给node1的内存调大一些。
| 节点 | CPU | 内存 |
|---|---|---|
| node1 | 1核心 | 4GB |
| node2 | 1核心 | 2GB |
| node3 | 1核心 | 2GB |
二、VMware虚拟机系统设置
1、主机名、IP、SSH免密登录
配置固定IP地址
开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131
在终端的root用户下执行下面的命令:
# 修改主机名
hostnamectl set-hostname node1# 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.88.131"# 重启网卡
systemctl stop network
systemctl start network
# 或者直接
ststemctl restart network
同样的操作启动node2和node3,修改node2主机名为node2,设置ip为192.168.88.132;修改node3主机名为node3,设置ip为192.168.88.133。
配置主机名映射
在Windows系统中修改hosts文件,填入如下内容:
192.168.88.131 node1
192.168.88.132 node2
192.168.88.133 node3
在3台Linux的/etc/hosts的文件中,填入如下内容(3台都要添加)
192.168.88.131 node1
192.168.88.132 node2
192.168.88.133 node3
配置SSH免密登录
后续安装的集群化软件,多数需要远程登录以及远程执行命令,我们可以简单起见,配置三台Linux服务器之间的免密码互相SSH登录
1、在每一台机器都执行:ssh-keygen -t rsa -b 4096,一路回车到底即可。
2、在每一台机器都执行:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
3、执行完毕后,node1、node2、node3之间将完成root用户之间的免密互通。
创建hadoop用户并配置免密登录
后续大数据的软件,将不会以root用户启动(确保安全,养成良好的习惯)。
我们为大数据的软件创建一个单独的用户hadoop,并为三台服务器同样配置hadoop用户的免密互通。
1、在每一台机器都执行:useradd hadoop,创建hadoop用户
2、在每一台机器都执行:passwd hadoop,设置hadoop用户密码为123456
3、在每一台机器均切换到hadoop用户:su -hadoop,并执行ssh-keygen -t rsa -b 4096,创建ssh秘钥
4、在每一台机器均执行
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
2、JDK环境部署
下载JDK1.8,这里我存放到了D:\Hadoop大数据虚拟机路径下:

1、创建文件夹,用来部署JDK,将JDK和Tomcat都安装部署到:/export/server内
mkdir -p /export/server
2、解压缩JDK安装文件
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/server
3、配置JDK的软连接
ln -s /export/server/jdk1.8.0_361 /export/server/jdk
4、配置JAVA_HOME环境变量
# 编辑/etc/profile文件
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
3、防火墙、SELinux、时间同步
关闭防火墙和SELinux:
集群化软件之间需要通过端口互相通讯,为了避免出现网络不通的问题,我们可以简单的在集群内部关闭防火墙。
在每一台机器都执行:
systemctl stop firewalld
systemctl disable firewalld
Linux有一个安全模块:SELinux,用以限制用户和程序的相关权限,来确保系统的安全稳定。
在当前,我们只需要关闭SELinux功能,避免导致后面的软件出现问题即可。
在每一台机器都执行:
vim /etc/sysconfig/selinux# 将第七行,SELINUX=enforcing改为
SELINUX=disabled
# 退出保存后,重启虚拟机即可,千万要注意disabled单词不要写错,不然无法启动系统
修改时区并配置自动时间同步:
一下操作在三台Linux均执行
1、安装ntp软件
yum install -y ntp
2、更新时区
rm -f /etc/localtime;sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3、同步时间
ntpdate -u ntp.aliyun.com
4、开启ntp服务并设置开机自启
systemctl start ntpd
systemctl enable ntpd
至此,配置Hadoop大数据集群环境的前置准备就已经全部完成了,下面开始正式进入Hadoop集群环境的配置:
三、VMware虚拟机集群上部署HDFS集群
Hadoop安装包下载:(这里我使用hadoop3.3.4的版本)

1、集群规划
在前面的操作中,我们准备了基于VMware的三台虚拟机,其硬件配置如下:
| 节点 | CPU | 内存 |
|---|---|---|
| node1 | 1核心 | 4GB |
| node2 | 1核心 | 2GB |
| node3 | 1核心 | 2GB |
Hadoop HDFS的角色包含:
- NameNode,主节点管理者
- DataNode,从节点工作者
- SecondaryNameNode,主节点辅助
服务规划:
| 节点 | 服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNameNode |
| node2 | DataNode |
| node3 | DataNode |
2、上传&解压
注意:请确认已经完成前置准备中的服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等操作。
(下面的操作均在node1节点执行,以root身份登录)
1、上传Hadoop安装包到node1节点中
2、解压缩安装包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
3、构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
4、进入hadoop安装包内
cd hadoop
3、Hadoop安装包目录结构
cd进入Hadoop安装包内,通过ls -l命令查看文件夹内部结构
4、修改配置文件,应用自定义设置
配置HDFS集群,我们主要涉及到如下文件的修改:
- workers:配置从节点(DataNode)有哪些
- hadoop-env.sh:配置Hadoop的相关环境变量
- core-site.xml:Hadoop核心配置文件
- hdfs-site.xml:HDFS核心配置文件
这些文件均存在与 H A D O O P H O M E / e t c / h a d o o p 文件夹中。( HADOOP_HOME/etc/hadoop文件夹中。( HADOOPHOME/etc/hadoop文件夹中。(HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即/export/server/hadoop)
- 配置workers文件
# 进入配置文件目录
cd etc/hadoop
# 编辑workers文件
vim workers
# 填入如下内容
node1
node2
node3
上面填入的node1、node2、node3表明集群记录了三个从节点(DataNode)
- 配置hadoop-env.sh文件
# 填入如下内容
export JAVA_HOME=/export/server/jdk #JAVA_HOME,指明JDK环境的位置在哪
export HADOOP_HOME=/export/server/hadoop #HADOOP_HOME,指明Hadoop安装位置
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop #HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
export HADOOP_LOG_DIR=$HADOOP_HOME/logs #HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
通过记录这些环境变量,来指明上述运行时的重要信息。
- 配置core-site.xml文件
# 在文件内部填入如下内容
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
-
hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
-
表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
-
此配置固定了node1必须启动NameNode进程
-
配置hdfs-site.xml文件
<configuration><property> # key:dfs.datanode.data.dir.perm<name>dfs.datanode.data.dir.perm</name> # 含义:hdfs文件系统,默认创建的文件权限位置<value>700</value> # 值:700,即:rwx------</property><property> # key:dfs.namenode.name.dir<name>dfs.namenode.name.dir</name> # 含义:NameNode元数据的存储位置<value>/data/nn</value> # 值:/data/nn,在node1节点的/data/nn目录下</property><property> # key:dfs.namenode.hosts<name>dfs.namenode.hosts</name> # 含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)<value>node1,node2,node3</value> # 值:node1、node2、node3,这三台服务器被授权</property><property> # key:dfs.blocksize<name>dfs.blocksize</name> # 含义:hdfs默认块大小<value>268435456</value> # 值:268435456(256MB)</property><property> # key:dfs.namenode.handler.count<name>dfs.namenode.handler.count</name> # 含义:nameode处理的并发线程数<value>100</value> # 值:100,以100个并行度处理文件系统的管理任务</property><property> # key:dfs.datanode.data.dir<name>dfs.datanode.data.dir</name> # 含义:从节点DataNode的数据存储目录<value>/data/dn</value> # 值:/data/dn,即数据存放在node1、node2、node3,三台机器的</property> # /data/dn内
</configuration>
<configuration><property> <name>dfs.datanode.data.dir.perm</name> <value>700</value> </property><property> <name>dfs.namenode.name.dir</name> <value>/data/nn</value> </property><property> <name>dfs.namenode.hosts</name> <value>node1,node2,node3</value> </property><property> <name>dfs.blocksize</name> <value>268435456</value> </property><property> <name>dfs.namenode.handler.count</name> <value>100</value> </property><property> <name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>
5、准备数据目录

6、分发Hadoop文件夹
目前,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3。
- 分发
# 在node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/
- 在node2执行,为hadoop配置软链接
# 在node2执行如下命令
ln -s /export/server/hadoop-3.3.4/export/server/hadoop
- 在node3执行,为hadoop配置软链接
# 在node3执行如下命令
ln -s /export/server/hadoop-3.3.4/export/server/hadoop

7、配置环境变量
为了方便我们操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中,方便后续使用。
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置一下环境变量。
1、vim /etc/profile
# 在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

2、在node2和node3配置同样的环境变量
8、授权为hadoop用户
hadoop部署准备的工作基本完成。
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务。
所以,现在需要对文件权限进行授权。
(请确保已经提前创建好了hadoop用户,并配置好了hadoop用户之间的免密登录)
- 以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
9、格式化整个文件系统
前期准备全部完成,现在对整个文件系统执行初始化。
- 格式化namenode
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
- 启动
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
启动后,可以通过jps命令来查看当前系统重正在运行的Java进行进程有哪些。
10、查看HDFS WEBUI
启动完成后,可以在浏览器打开:http://node1:9870,即可查看到hdfs文件系统的管理网页。
四、HDFS的Shell操作
1、HDFS相关进程的启停管理命令
一键启停脚本
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
-
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行原理:
- 在执行此脚本的机器上,启动SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,启动NameNode
- 读取workers内容,确认DataNode所在机器,启动全部DataNode
-
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行原理:
- 在执行此脚本的机器上,关闭SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,关闭NameNode
- 读取workers内容,确认DataNode所在机器,关闭全部DataNode
单进程启停
除了一键启停外,也可以单独控制进程的启停。
1、$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)
2、$HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
2、HDFS的文件系统操作命令
HDFS文件系统基本信息
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式。

- Linux:file:/// => file:///usr/local/hello.txt
- HDFS:hdfs://namenode:port**/** => hdfs://node1:8020/usr/local/hello.txt
协议头file:///或hdfs://node1:8020/可以省略
- 需要提供Linux路径的参数,会自动识别为file://
- 需要提供HDFS路径的参数,会自动识别为hdfs://
除非是明确需要写或者是不写会有BUG,否则一般不用写协议头。
介绍
关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系。
- hadoop命令(老版本用法),用法:hadoop fs [generic options]
- hdfs命令(新版本用法),用法:hdfs dfs [generic options]
两者在文件系统操作上,用法完全一致,用哪个都可以(只有某些个别的特殊操作需要选择hadoop命令或hdfs命令)
1、创建文件夹
- hadoop fs -mkdir [-p]
… - hdfs dfs -mkdir [-p]
…
path为待创建的目录,-p选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录。
2、查看指定目录下内容
- hadoop fs -ls [-h] [-R] [
…] - hdfs dfs -ls [-h] [-R] [
…]
path指定目录路径,-h人性化显示文件size,-R递归查看指定目录及其子目录。
3、上传文件到HDFS指定目录下
- hadoop fs -put [-f] [-p] …
- hdfs dfs -put [-f] [-p] …
4、查看HDFS文件内容
- hadoop fs -cat …
- hdfs dfs -cat …
读取大文件可以使用管道符配合more(more命令是Linux中对内容进行翻页的命令)
- hadoop fs -cat | more
- hdfs dfs -cat | more
5、下载HDFS文件
- hadoop fs -get [-f] [-p] …
- hdfs dfs -get [-f] [-p] …
下载文件到本地文件系统指定目录,localhost必须是目录。
-f 覆盖目标文件(已存在下);-p 保留访问和修改时间,所有权和权限。
6、拷贝HDFS文件
- hadoop fs -cp [-f] …
- hdfs dfs -cp [-f] …
-f 覆盖目标文件(已存在下)
7、追加数据到HDFS文件中
整个HDFS文件系统,它的文件的修改只支持两种,第一种是直接删掉,第二种是追加内容。(整个HDFS文件系统只能够进行删除和追加,不能修改里面某一行某一个字符)。
- hadoop fs -appendToFile …
- hdfs dfs -appendToFile …
将所有给定本地文件的内容追加到给定dst文件。dst如果文件不存在,将创建该文件 。如果为-,则输入为从标准输入中读取。
8、HDFS数据移动操作
- hadoop fs -mv …
- hdfs dfs -mv …
移动文件到指定文件夹下,可以使用该命令移动数据以及重命名文件的名称。
9、HDFS数据删除操作
- hadoop fs -rm -r [-skipTrash] URI [URI…]
- hdfs dfs -rm -r [-skipTrash] URI [URI…]
删除指定路径的文件或文件夹,-skipTrash 跳过回收站,直接删除。
# 回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
<property><name>fs.trash.interval</name><value>1440</value>
</property><property><name>fs.trash.checkpoint.interval</name><value>120</value>
</property>#无需重启集群,在哪个机器配的,在哪个机器执行命令就生效。回收站默认位置在:/usr/用户名(hadoop)/.Trash
10、HDFS shell其它命令
命令官方指导文档:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
11、HDFS WEB浏览
除了使用命令操作HDFS文件系统之外,在HDFS的WEB UI上也可以查看HDFS文件系统的内容。

但使用WEB浏览操作文件系统,一般会遇到权限问题:

这是因为WEB浏览器中是以匿名用户(dr.who)登录的,其只有只读权限,多数操作是做不了的。
如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群。
<property><name>hadoop.http.staticuser.user</name><value>hadoop</value>
</property>
但是,不推荐这样做:HDFS WEBUI只读权限挺好的,简单浏览即可。而且如果给与高权限,会有很大的安全问题,造成数据泄露或丢失。
3、HDFS客户端 - Jetbrians产品插件
4、HDFS客户端 - NFS
注意:要求Windows电脑为专业版,家庭版没有NFS服务。

五、MapReduce和YARN的部署
一、部署说明
Hadoop HDFS分布式文件系统,我们会启动:
- NameNode进程作为管理节点
- DataNode进程作为工作节点
- SecondaryNameNode作为辅助
同理,Hadoop YARN分布式资源调度,会启动:
- ResourceManager进程作为管理节点
- NodeManager进程作为工作节点
- ProxyServer、JobHistoryServer这两个辅助节点

MapReduce运行在YARN容器内,无需启动独立进程。
所以关于MapReduce和YARN的部署,其实就是2件事情:
- 关于MapReduce:修改相关配置文件,但是没有进程可以启动。
- 关于YARN:修改相关配置文件,并启动ResourceManager、NodeManager进程以及辅助进程(代理服务器、历史服务器)。
通过表格汇总如下:
| 组件 | 配置文件 | 启动进程 | 备注 |
|---|---|---|---|
| Hadoop HDFS | 需修改 | 需启动NameNode作为主节点、DataNode作为从节点、SecondaryNameNode主节点辅助 | 分布式文件系统 |
| Hadoop YARN | 需修改 | 需启动ResourceManager作为集群资源管理者、NodeManager作为单机资源管理者、ProxyServer代理服务器提供安全性、JobHistoryServer记录历史信息和日志 | 分布式资源调度 |
| Hadoop MapReduce | 需修改 | 无需启动任何进程,MapReduce程序运行在YARN容器内 | 分布式数据计算 |
二、集群规划
有3台服务器,其中node1配置较高。
集群规划如下:
| 主机 | 角色 |
|---|---|
| node1 | ResourceManager、NodeManager、ProxyServer、JobHistoryServer |
| node2 | NodeManager |
| node3 | NodeManager |
三、MapReduce配置文件
在$HADOOP_HOME/etc/hadoop文件夹内,修改:
- mapred-env.sh文件,添加如下环境变量
# 设置JDK路径
export JAVA_HOME=/export/server/jdk
# 设置JobHistoryServer进程的内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
- mapred-site.xml文件,添加如下配置信息
<property><name>mapreduce.framework.name</name><value>yarn</value><description>MapReduce的运行框架设置为YARN</description>
</property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value><description>历史服务器通讯端口为node1:10020</description>
</property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value><description>历史服务器web端口为node1的19888</description>
</property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description>历史信息在HDFS的记录临时路径</description>
</property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description>历史信息在HDFS的记录路径</description>
</property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description>
</property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description>
</property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description>
</property>
四、YARN配置文件
在$HADOOP_HOME/etc/hadoop文件夹内,修改:
- yarn-env.sh文件,添加如下4行环境变量内容:
# 设置JDK路径的环境变量
export JAVA_HOME=/export/server/jdk
# 设置HADOOP_HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
# 设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- yarn-site.xml文件
<property><name>yarn.resourcemanager.hostname</name><value>node1</value><description>ResourceManager设置在node1节点</description>
</property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>NodeManager中间数据本地存储路径</description>
</property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>NodeManager数据日志本地存储路径</description>
</property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>为MapReduce程序开启Shuffle服务</description>
</property><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value><description>历史服务器URL</description>
</property><property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>代理服务器主机和端口</description>
</property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>开启日志聚合</description>
</property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>程序日志HDFS的存储路径</description>
</property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>选择公平调度器</description>
</property>
五、分发配置文件
MapReduce和YARN的配置文件修改好后,需要分发到其它的服务器节点中。
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/
分发完配置文件,就可以启动YARN的相关进程了。
六、集群启动命令介绍
常见的进程启动命令如下:
- 一键启动YARN集群:$HADOOP_HOME/sbin/start-yarn.sh
- 会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
- 会基于workers文件配置的主机启动NodeManager
- 一键停止YARN集群:$HADOOP_HOME/sbin/stop-yarn.sh
七、查看YARN的WEB UI页面
打开http://node:8080即可看到YARN集群的监控页面(ResourceManager的WEB UI)
提交MapReduce程序至YARN运行
六、Hive部署
Hive是分布式运行的框架还是单击运行的?
Hive是单机工具,只需要部署在一台服务器即可。
Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
WordCount单词计数程序
下面单词计数程序的运行命令:
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain
hdfs dfs -rm -r hdfs://node1:8020/wordcount_out
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain 1
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain 2
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain 3
JobMain类
package cn.itcast.mapreduce;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;public class JobMain extends Configured implements Tool {@Overridepublic int run(String[] strings) throws Exception {//创建一个任务对象Job job = Job.getInstance(super.getConf(), "mapreduce-wordcount");//打包放在集群运行时,需要做一个配置job.setJarByClass(JobMain.class);//第一步:设置读取文件的类:K1和V1job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/wordcount"));//第二步:设置Mapper类job.setMapperClass(WordCountMapper.class);//设置Map阶段的输出类型:K2和V2的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);//第三、四、五、六步采用默认方式(分区、排序、规约、分组)//第七步:设置我们的Reducer类job.setReducerClass(WordCountReducer.class);//设置Reduce阶段的输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//第八步:设置输出类job.setOutputFormatClass(TextOutputFormat.class);//设置输出路径TextOutputFormat.setOutputPath(job,new Path("hdfs://node1:8020/wordcount_out"));boolean b = job.waitForCompletion(true);return b?0:1;}public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();//启动一个任务int run = ToolRunner.run(configuration, new JobMain(), args);System.exit(run);}
}
WordCountMapper类
package cn.itcast.mapreduce;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** Mapper的泛型:* KEYIN:K1的类型 行偏移量 LongWritable* VALUEIN:v1的类型 一行的文本数据 Text* KEYOUT:k2的类型 每个单词 Text* VALUEOUT:v2的类型 固定值1 LongWritable*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {/*map方法是将k1和v1转为k2和v2key:k1value:v1context:表示MapReduce上下文对象K1 V10 hello,world11 hello,hadoop-----------------------K2 V2hello 1world 1hadoop 1
*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1、对每一行的数据进行字符串拆分String line = value.toString();String[] split = line.split(",");//2、遍历数组,获取每一个单词for(String word : split){context.write(new Text(word),new LongWritable(1));}}
}
WordCountReducer类
package cn.itcast.mapreduce;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** KEYIN:K2的类型 Text 每个单词* VALUEIN:v2的类型 LongWritable 集合中泛型的类型* KEYOUT:k3的类型 Text 每个单词* VALUEOUT:v3的类型 LongWritable 每个单词出现的次数*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {/*reduce的方法的作用是将K2和V2转化为K3和V3key:K2values:集合context:MapReduce的上下文对象*//*新 K2 V2hello <1,1>world <1,1>hadoop <1,1,1>--------------------K3 V3hello 2world 2hadoop 3*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {long count = 0;//1、遍历values集合for(LongWritable value : values){//2、将集合中的值相加count+=value.get();}//3、将k3和v3写入上下文中context.write(key,new LongWritable(count));}
}
package cn.itcast.mapreduce;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** KEYIN:K2的类型 Text 每个单词* VALUEIN:v2的类型 LongWritable 集合中泛型的类型* KEYOUT:k3的类型 Text 每个单词* VALUEOUT:v3的类型 LongWritable 每个单词出现的次数*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {/*reduce的方法的作用是将K2和V2转化为K3和V3key:K2values:集合context:MapReduce的上下文对象*//*新 K2 V2hello <1,1>world <1,1>hadoop <1,1,1>--------------------K3 V3hello 2world 2hadoop 3*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {long count = 0;//1、遍历values集合for(LongWritable value : values){//2、将集合中的值相加count+=value.get();}//3、将k3和v3写入上下文中context.write(key,new LongWritable(count));}
}
相关文章:

大数据Hadoop集群搭建
文章目录 大数据Hadoop集群搭建一、VMware准备Linux虚拟机二、VMware虚拟机系统设置1、主机名、IP、SSH免密登录2、JDK环境部署3、防火墙、SELinux、时间同步 三、VMware虚拟机集群上部署HDFS集群1、集群规划2、上传&解压3、Hadoop安装包目录结构4、修改配置文件࿰…...

饼图:数据可视化的“切蛋糕”艺术
饼图,作为数据可视化家族中最经典、最易识别的成员之一,其核心功能如同其名——像切分蛋糕一样,直观展示一个整体(100%)被划分为若干组成部分的比例关系。 往期文章推荐: 20.用Mermaid代码画ER图:AI时代的…...

mysql server层做了什么
服务器处理客户端请求 服务器程序在处理来自客户端的查询请求时,大致需要分为3部分:连接管理、解析与优化、存储引擎。 连接管理 每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程专门处理与这个客户端的交互ÿ…...
)
3.5.1_1 信道划分介质访问控制(上)
在这个视频中我们要介绍信道划分、介质访问控制,这是两个词,我们先介绍一下什么叫做介质访问控制。 通过之前的学习,我们知道在计算机网络当中,有的信道它在逻辑上属于总线型,我们也可以把这种信道称为广播信道&#x…...

RPC常见问题回答
项目流程和架构设计 1.服务端的功能: 1.提供rpc调用对应的函数 2.完成服务注册 服务发现 上线/下线通知 3.提供主题的操作 (创建/删除/订阅/取消订阅) 消息的发布 2.服务的模块划分 1.网络通信模块 net 底层套用的moude库 2.应用层通信协议模块 1.序列化 反序列化数…...

数据分析和可视化:Py爬虫-XPath解析章节要点总结
重要知识点 XPath 概述:XPath 是一门可以在 XML 文件中查找信息的语言,也可用于 HTML 文件。它功能强大,提供简洁明了的路径表达式和多个函数,用于字符串、数值、时间比较等。1999 年成为 W3C 标准,常用于爬虫中抓取网…...

WIFI原因造成ESP8266不断重启的解决办法
一、报错 报错信息如下: 21:37:21.799 -> ets Jan 8 2013,rst cause:2, boot mode:(3,7) 21:37:21.799 -> 21:37:21.799 -> load 0x4010f000, len 3424, room 16 21:37:21.799 -> tail 0 21:37:21.799 -> chksum 0x2e 21:37:21.799 -> loa…...

OSI网络通信模型详解
OSI 模型就是把这整个过程拆解成了 7 个明确分工的步骤,每一层只负责自己那一摊事儿,这样整个系统才能顺畅运转,出了问题也容易找到“锅”在谁那。 核心比喻:寄快递 📦 想象你要把一份重要的礼物(你的数据…...

第五章 中央处理器
5.1 CPU的功能和基本构造 5.1.1 CPU的基本功能 5.1.2 CPU的基本结构 1.运算器 算术逻辑单元ALU 累加寄存器ACC 程序字状态寄存器PSW 计数器CT 暂存寄存器 通用寄存器组 移位器 通用寄存器供用户自由编程,可以存放数据和地址。而指令寄存器是专门用于存放指令的专用寄存器,…...

大模型学习入门——Day3:注意力机制
本系列笔记的教材:快乐学习大模型-DataWhale团队 注意力机制 注意力机制最先源于计算机视觉领域,其核心思想为当我们关注一张图片,我们往往无需看清楚全部内容而仅将注意力集中在重点部分即可。而在自然语言处理领域,我们往往也…...
)
C++ 学习笔记精要(二)
第一节 特殊类的设计 1. 一个类: 只能在堆上创建对象 关键点:自己控制析构 1.1 方法一: 使用delete禁掉默认析构函数 #include <iostream> using namespace std;class HeapOnly { public:HeapOnly(){_str new char[10];}~HeapOnly() delete;void Destroy(){delete[…...

博士,超28岁,出局!
近日,长沙市望城区《2025年事业引才博士公开引进公告》引发轩然大波——博士岗位年龄要求28周岁及以下,特别优秀者也仅放宽至30周岁。 图源:网络 这份规定让众多"高龄"博士生直呼不合理,并在社交平台掀起激烈讨论。 图源…...

macOS - 根据序列号查看机型、保障信息
文章目录 最近在看 MacBook 二手机,有个咸鱼卖家放个截图 说不清参数,于是想根据 序列号 查看机型。苹果提供了这样的网页: https://checkcoverage.apple.com/ (无需登录) 结果 2025-06-20(五)…...
)
C/C++ 高频八股文面试题1000题(一)
原作者:Linux教程,原文地址:C/C 高频八股文面试题1000题(一) 在准备技术岗位的求职过程中,C/C始终是绕不开的核心考察点。无论是互联网大厂的笔试面试,还是嵌入式、后台开发、系统编程等方向的岗位,C/C 都…...

C++ map 和 unordered_map 的区别和联系
C map 和 unordered_map 的区别和联系 map 和 unordered_map 都是 C 标准库中关联容器,用于存储键值对。它们的主要区别在于底层实现和性能特性,联系在于它们都提供了键值对的存储和访问功能。 区别: 特性mapunordered_map底层实现红黑树 …...

Sentinel实现原理
Sentinel 是阿里巴巴开源的分布式系统流量控制组件,主要用于服务保护,涵盖流量控制、熔断降级、系统负载保护等功能。 以下是 Sentinel 的实现原理,使用中文简要说明: 1. 总体架构 Sentinel 采用 轻量级 设计,分为 核…...

python打卡day37
疏锦行 知识点回顾: 1. 过拟合的判断:测试集和训练集同步打印指标 2. 模型的保存和加载 a. 仅保存权重 b. 保存权重和模型 c. 保存全部信息checkpoint,还包含训练状态 3. 早停策略 作业:对信贷数据集训练后保存权重…...

MySQL复杂查询优化实战:从多表关联到子查询的性能突破
文章目录 一、复杂查询性能瓶颈分析与优化框架二、多表关联查询的优化策略与实战1. JOIN顺序优化:基于成本估算的表关联策略2. 复合索引与JOIN条件优化3. 大表JOIN的分片处理 三、子查询优化:从嵌套到JOIN的转换艺术1. 标量子查询转换为JOIN2. EXISTS子查…...

LeetCode 680.验证回文串 II
目录 题目: 题目描述: 题目链接: 思路: 核心思路: 思路详解: 代码: C代码: Java代码: 题目: 题目描述: 题目链接: 680. 验证…...

window显示驱动开发—输出合并器阶段
逻辑管道中的最后一步是通过模具或深度确定可见性,以及写入或混合输出以呈现目标,这可以是多种资源类型之一。 这些操作以及输出资源 (呈现目标) 绑定在输出合并阶段定义。 1. 核心功能与管线定位 输出合并是渲染管线的最终固定功能阶段,负…...

单片机开发日志cv MDK-ARM工具链迁移到MAKE
核心经验: STM32H7 多 RAM 区域,外设相关数据段必须放在 AXI SRAM(RAM)区,不能放在 DTCMRAM,否则外设无法访问,程序表面正常但外设全失效。迁移工程时,务必检查链接脚本的内存分布&a…...

大模型与搜索引擎的技术博弈及未来智能范式演进
基于认知革命与技术替代的全景综述 一、大模型对搜索引擎的替代性分析:技术范式与市场重构 (1)技术原理的代际分野 传统搜索引擎遵循 "爬虫抓取 - 索引构建 - 关键词排序" 的三段式架构,其核心是基于 PageRank 算法的…...

Ajax-入门
Ajax: 全称Asynchronous JavaScript And XML,异步的JavaScript和XML。其作用有如下2点: 与服务器进行数据交换:通过Ajax可以给服务器发送请求,并获取服务器响应的数据。 异步交互:可以在不重新加载整个页面的情况下&a…...
和函数(function))
FPGA基础 -- Verilog 共享任务(task)和函数(function)
Verilog 中共享任务(task)和函数(function) 的详细专业培训,适合具有一定 RTL 编程经验的工程师深入掌握。 一、任务(task)与函数(function)的基本区别 特性taskfunctio…...

c++set和pair的使用
set是C中的一种关联容器,具有以下特点: 存储唯一元素(不允许重复) 元素自动排序(默认升序) 基于红黑树实现(平衡二叉搜索树) 插入、删除和查找的时间复杂度为O(log n) 前言 在C…...

数据库中间件ShardingSphere5
一、高性能架构模式 数据库集群,第一种方式“读写分离”,第二种方式“数据库分片”。 1.1 读写分离架构 读写分离原理:将数据库读写操作分散到不同的节点上。 读写分离的基本实现: 主库负责处理事务性的增删改操作,…...

window显示驱动开发—使用状态刷新回调函数
用户模式显示驱动程序可以使用 Direct3D 运行时版本 10 State-Refresh回调函数 来实现无状态驱动程序或构建命令缓冲区前导数据。 Direct3D 运行时在调用 CreateDevice (D3D10 ) 函数时,向D3D10DDIARG_CREATEDEVICE结构的 pUMCallbacks 成员指向的D3D10DDI_CORELAY…...

windows11右击恢复为windows10
文章目录 前言一、问题描述二、解决方案 前言 为了解决win11的右击更多选项的问题 一、问题描述 win11的右键更多选项过于繁琐 二、解决方案 在windows11的终端管理员中输入如下代码: reg add "HKCU\Software\Classes\CLSID\{86ca1aa0-34aa-4e8b-a509-50c…...

基于物联网的智能衣柜系统设计
标题:基于物联网的智能衣柜系统设计 内容:1.摘要 随着物联网技术的飞速发展,智能家居领域迎来了新的变革机遇。本研究的目的在于设计一种基于物联网的智能衣柜系统,以提升用户的衣物管理和使用体验。方法上,通过搭建物联网硬件平台ÿ…...

GM DC Monitor v2.0 卸载教程
以下俩种方法任选一种均可 第一种方法:一键自动卸载 进入到软件安装目录 卸载app 进入到app目录,运行一键卸载脚本:sh uninstall.sh 卸载es 进入到es目录,运行一键卸载脚本:sh uninstall.sh 卸载db 进入到db目录&a…...

C#上位机实现报警语音播报
我们在开发C#上位机时,有时候会需要将报警信息通过语音进行播报,今天跟大家分享一下具体的实现过程。 一、组件安装 首先我们创建好一个Windows窗体项目,然后添加System.Speech库引用。 点击引用,右击添加引用,在程…...

python自助棋牌室管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...

榕壹云婚恋相亲系统:ThinkPHP+UniApp打造高效婚配平台
引言 在数字化浪潮下,婚恋相亲行业正加速向线上迁移。榕壹云公司基于市场需求与技术积累,开发一款功能完备、技术开源的婚恋相亲小程序系统,为单身人士提供高效、安全的婚恋平台。本文将围绕系统背景、客户定位、核心技术、功能模块及优势场景展开详细解析,助力开发者与技…...

每日leetcode
2890. 重塑数据:融合 - 力扣(LeetCode) 题目 DataFrame report --------------------- | Column Name | Type | --------------------- | product | object | | quarter_1 | int | | quarter_2 | int | | quarter_3 | i…...
学习笔记(五))
深入理解XGBoost(何龙 著)学习笔记(五)
深入理解XGBoost(何龙 著)学习笔记(五) 本文接上一篇,内容为线性回归,介绍三部分,首先介绍了"模型评估”,然后分别提供了线性回归的模型代码:scikit-learn的Linear…...

SelectDB 在 AWS Graviton ARM 架构下相比 x86 实现 36% 性价比提升
在海量数据分析中,追求高性价比已成为各大企业的主流趋势。ARM 架构凭借其高能效和低成本的特点,逐渐在数据中心崛起,成为理想的高性价比选择。基于 ARM 架构的 AWS Graviton 系列处理器,正是这一趋势的典型代表。Graviton 处理器…...
)
机器学习流量识别(pytorch+NSL-KDD+多分类建模)
本文主要实现以下功能,会提供完整的可运行的代码以及解释为什么这么设计。文章不会收费,若被限制查看,请私信我。 使用 NSL-KDD 数据集的CSV文件进行流量攻击检测,使用机器学习算法实现流量攻击检测,使用pytorch框架…...
,Matlab代码实现)
三种经典算法无人机三维路径规划对比(SMA、HHO、GWO三种算法),Matlab代码实现
代码功能 该MATLAB代码用于对比三种元启发式优化算法(SMA、HHO、GWO三种算法, SMA黏菌算法、HHO哈里斯鹰优化算法、GWO灰狼优化算法) 在特定优化问题上的性能,运行环境MATLABR2020b或更高 : 初始化问题模型ÿ…...

FTTR+软路由网络拓扑方案
文章目录 网络拓扑软路由配置FTTR光猫路由器TPLink路由器配置WAN设置LAN设置 参考 网络拓扑 软路由配置 配置静态IP地址:192.168.1.100设置网关指向主路由的IP 设置自定义DNS服务器 开启DHCP 这一步很关键,可以让连上wifi的所有设备自动趴强。 FTTR光猫…...

服务器获取外网IP,并发送到钉钉
服务器获取外网IP,并发送到钉钉 import time import hmac import hashlib import base64 import urllib.parse import requests# 请填入你的钉钉机器人配置 access_token XXXX secret XXXX# 获取公网 IP def get_public_ip():try:response requests.get("…...

解决uni-app发布微信小程序主包大小限制为<2M的问题
一 问题说明 我想用uniapp开发多端应用,引入了uview组件库来美化样式,可发布为微信小程序却提示我代码质量不过关,主包代码量太大了: 二 问题分析 2.1 原生微信小程序开发代码质量限制: 1.主包代码大小不得大于2M&…...

魅族“换血”出牌:手机基本盘站不稳,想靠AI和汽车“改命”
撰稿|何威 来源|贝多财经 被吉利收购后,魅族逐渐转向在AI领域躬身耕作。 自2024年2月以“All in AI”正式宣告转型、喊出不再推出传统智能手机的豪言开始,这家曾以设计见长的手机厂商,将下半场押注在AI终端、AR眼镜与智能座舱系统上&#…...

原点安全入选 Gartner®“数据安全平台”中国市场指南代表厂商
2025年1月7日,全球权威咨询与分析机构 Gartner 发布《中国数据安全平台市场指南》(China Context: ‘Market Guide for Data Security Platforms’),北京原点数安科技有限公司(简称“原点安全”,英文名称&q…...

uni-app-配合iOS App项目开发apple watch app
假设你已经用uni-app开发好了一个iOS端的app,现在想要开发一个配套的apple watch app。改怎么去开发呢?是不是一头雾水,这篇文章就会介绍一些apple watch app开发的知识以及如何在uni-app开发的iOS app基础上去开发配套的watch app。 一、ap…...

如何理解Java反射机制
反射机制原理 反射是Java在运行时动态获取类信息、操作类属性和方法的能力。核心原理是JVM在类加载时创建Class对象,该对象包含类的完整结构信息。 关键类: Class:类的元数据入口 Field:类的成员变量 Method:类的方…...
)
SM3算法C语言实现(无第三方库,带测试)
一、SM3算法介绍 SM3算法是中国国家密码管理局(OSCCA)于2010年发布的商用密码散列函数标准,属于我国自主设计的密码算法体系之一 ,标准文档下载地址为:SM3密码杂凑算法 。SM3算法输出长度为256位(32字节&a…...

King’s LIMS 系统引领汽车检测实验室数字化转型
随着汽车保有量的持续攀升和车龄的增长,消费者对汽车的需求已悄然转变,从最初对外观和性能的追求,逐渐深化为对安全性、可靠性、耐久性、性能与舒适性以及智能化功能的全方位关注。这无疑让汽车检测行业在保障车辆质量、满足市场需求方面肩负…...

CppCon 2017 学习:Mocking Frameworks Considered
当然可以,下面是对 Fowler 的 Whiskey-Store 示例。 Fowler 的 Whiskey-Store 示例(坏设计) 贴出的类图是 Martin Fowler 在《重构》书中使用的一个教学用反面案例(故意设计得不合理),用来说明如何通过重…...

通过事件过滤器拦截QRadioButton点击事件
通过事件过滤器拦截QRadioButton点击事件 一、事件过滤器完整实现 1. 核心代码扩展(含注释) bool MainWindow::eventFilter(QObject* obj, QEvent* ev) {// 拦截所有QRadioButton的鼠标事件(包括点击、释放、双击)if (ev->ty…...

领码 SPARK 融合平台赋能工程建设行业物资管理革新——数智赋能,重塑中国模式新范式
摘要 工程建设行业正加速迈向数字化与精益化转型,物资管理成为项目成败的关键瓶颈。本文深入解析中国工程企业“项目部-物资部-企业项目管理部”三级协同的独特物资管理体系,聚焦集中采购与零星采购的统筹难题。基于领码 SPARK 融合平台,提出…...