hi168大数据离线项目环境搭建
hi168大数据离线项目环境搭建
## **1. 服务器准备**##### 1.1 创建集群应用节点 集群服务器使用“我的应用“中的Ubuntu22.04集群模版创建三个节点应用,并且进入“我的应用”中去修改一下节点名称(node1对应master,node2对应hadoop1,node3对应hadoop3)。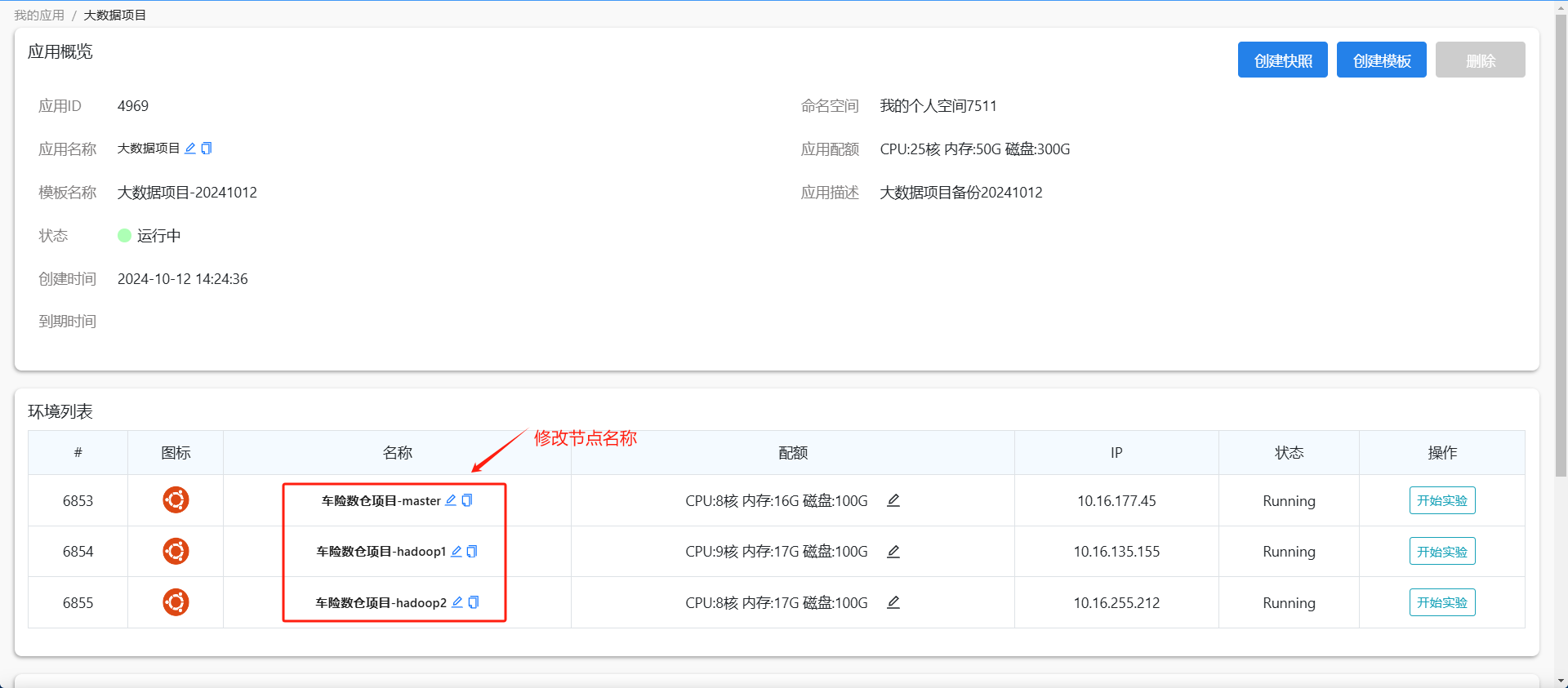 刷新一下页面,在桌面上的三个节点名称会自动会更新,然后分别打开三个节点进入终端,进行后续的操作。##### 1.2 更新软件源 三个节点分别编辑一下软件源的配置文件/etc/apt/sources.list,将软件源更新为阿里云。打开配置文件
vim /etc/apt/sources.list
按shift+:进入底行模式,将默认软件源替换成阿里云,保存退出
:%s/archive.ubuntu.com/mirrors.aliyun.com/g
更新软件源
apt update
##### 1.3 修改host主机名三个节点分别执行如下命令去设置主机名。hostnamectl hostname master
hostnamectl hostname hadoop1
hostnamectl hostname hadoop2
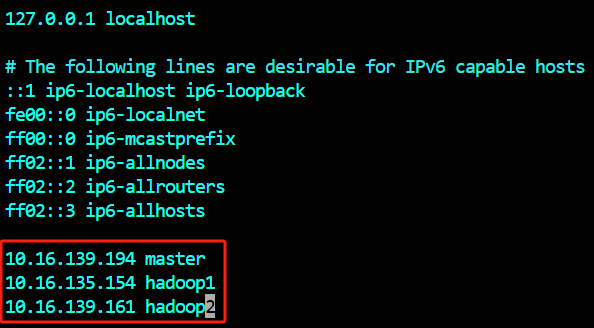
设置完毕后执行exit命令再重新连接一下,主机名就自动更新过来了。##### 1.4 配置/etc/hosts主机和ip映射 三个节点分别根据ifconfig获得的实际ip,在配置文件/etc/hosts中添加主机和ip映射。 三个节点都要修改添加映射
root@master:~# vim /etc/hosts
root@hadoop1:~# vim /etc/hosts
root@hadoop2:~# vim /etc/hosts
 ##### 1.5 安装中文包(1)三个节点均安装中文简体包apt install language-pack-zh-hans
(2)配置.bashrc中的环境变量编辑.bashrc文件
vim ~/.bashrc
添加中文环境变量
export LANG=“zh_CN.UTF-8”
export LANGUAGE=“zh_CN:zh:en_US:en”
添加cd命令,每次打开节点终端可以切换到root家目录
cd;
保存退出后,使配置文件生效
source ~/.bashrc
## **2. SSH免密登录配置**三个节点master、hadoop1、hadoop2之间配置SSH免密登录。##### 2.1 生成公钥和私钥(1)master上生成公钥和私钥root@master:~# ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。(2)hadoop1上生成公钥和私钥root@hadoop1:~# ssh-keygen -t rsa
(3)hadoop2上生成公钥和私钥root@hadoop2:~# ssh-keygen -t rsa
##### 2.2 公钥拷贝到要免密登录的目标节点(1)将master公钥拷贝到要免密登录的目标节点上root@master:~# ssh-copy-id master
root@master:~# ssh-copy-id hadoop1
root@master:~# ssh-copy-id hadoop2
(2)将hadoop1公钥拷贝到要免密登录的目标节点上root@hadoop1:~# ssh-copy-id master
root@hadoop1:~# ssh-copy-id hadoop1
root@hadoop1:~# ssh-copy-id hadoop2
(3)将hadoop2公钥拷贝到要免密登录的目标节点上root@hadoop2:~# ssh-copy-id master
root@hadoop2:~# ssh-copy-id hadoop1
root@hadoop2:~# ssh-copy-id hadoop2
##### 2.3 master上测试一下免密登录root@master:~# ssh master
root@master:~# ssh hadoop1
root@master:~# ssh hadoop2
## **3. JDK准备**##### 3.1 jdk安装包上传到master ##### 3.2 在三个节点的/opt目录下均创建module目录,用于放在安装的项目组件root@master:~# mkdir -p /opt/module/
root@hadoop1:~# mkdir -p /opt/module/
root@hadoop2:~# mkdir -p /opt/module/
##### 3.3 jdk安装包解压到/opt/module/目录下并改名解压至/opt/module目录
root@master:~# tar -zxvf amazon-corretto-11.0.24.8.1-linux-x64.tar.gz -C /opt/module/
改名为jdk
root@master:~# mv /opt/module/amazon-corretto-11.0.24.8.1-linux-x64 /opt/module/jdk
##### 3.4 在.bashrc中添加JAVA_HOME环境变量root@master:~# vim ~/.bashrc
添加JAVA_HOME环境变量
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
保存退出后source一下.bashrc
root@master:~# source ~/.bashrc
##### 3.5 测试Java是否配置成功root@master:~# java -version
 ##### 3.6 分发JDK和配置文件.bashrc分发jdk
root@master:~# scp -r /opt/module/jdk hadoop1:/opt/module
root@master:~# scp -r /opt/module/jdk hadoop2:/opt/module
分发.bashrc
root@master:~# scp ~/.bashrc hadoop1:/root
root@master:~# scp ~/.bashrc hadoop2:/root
hadoop1和hadoop2生效配置文件
root@hadoop1:~# source ~/.bashrc
root@hadoop2:~# source ~/.bashrc
# **2. 集群组件安装**##### 2.1 Hadoop安装(1)hadoop安装包上传到master (2)hadoop安装包解压到/opt/module/目录下并改名解压至/opt/module目录
root@master:~# tar -zxvf hadoop-3.3.6.tar.gz -C /opt/module/
改名为hadoop
root@master:~# mv /opt/module/hadoop-3.3.6 /opt/module/hadoop
(3)在.bashrc中添加HADOOP_HOME环境变量root@master:~# vim ~/.bashrc
添加HADOOP_HOME环境变量
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin
export PATH= P A T H : PATH: PATH:HADOOP_HOME/sbin
保存退出后source一下.bashrc
root@master:~# source ~/.bashrc
(4)查看Hadoop版本root@master:~# hadoop version
 (5)修改核心配置文件core-site.xmlroot@master:~# cd /opt/module/hadoop/etc/hadoop/
root@master:/opt/module/hadoop/etc/hadoop# vim core-site.xml
内容如下: <!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop/data</value></property><!-- 配置HDFS网页登录使用的静态用户为root --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- 配置该root(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 配置该root(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><!-- 配置该root(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.root.users</name><value>*</value></property>
(6)修改HDFS配置文件hdfs-site.xml
root@master:/opt/module/hadoop/etc/hadoop# vim hdfs-site.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>master:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop2:9868</value></property><!-- HDFS副本的数量3 --><property><name>dfs.replication</name><value>3</value></property></configuration>
(7)修改YARN配置文件yarn-site.xml
root@master:/opt/module/hadoop/etc/hadoop# vim yarn-site.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop1</value></property><!--yarn单个容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>true</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property><!-- 开启日志聚集功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置日志聚集服务器地址 --><property><name>yarn.log.server.url</name><value>http://master:19888/jobhistory/logs</value></property><!-- 设置日志保留时间为7天 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>
(8)修改MapReduce配置文件mapred-site.xml
root@master:/opt/module/hadoop/etc/hadoop# vim mapred-site.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><!-- 历史服务器web端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property></configuration>
(9)修改配置文件workers
root@master:/opt/module/hadoop/etc/hadoop# vim workers
内容如下:
master
hadoop1
hadoop2
(10)在相关env配置文件中添加环境变量
hadoop-env.sh中添加配置:
root@master:/opt/module/hadoop/etc/hadoop# vim hadoop-env.sh
# Many of the options here are built from the perspective that users
# may want to provide OVERWRITING values on the command line.
# For example:
#
export JAVA_HOME=/opt/module/jdkexport HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
yarn-env.sh中添加配置:
root@master:/opt/module/hadoop/etc/hadoop# vim yarn-env.sh
###
# YARN Services parameters
###
# Directory containing service examples
# export YARN_SERVICE_EXAMPLES_DIR = $HADOOP_YARN_HOME/share/hadoop/yarn/yarn-service-examples
# export YARN_CONTAINER_RUNTIME_DOCKER_RUN_OVERRIDE_DISABLE=trueexport JAVA_HOME=/opt/module/jdkexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
mapred-env.sh中添加配置:
root@master:/opt/module/hadoop/etc/hadoop# vim mapred-env.sh
# Specify the log4j settings for the JobHistoryServer
# Java property: hadoop.root.logger
#export HADOOP_JHS_LOGGER=INFO,RFAexport JAVA_HOME=/opt/module/jdk
(11)在.bashrc中添加HDFS和YARN的root权限环境变量
由于运行Hadoop集群默认是基于普通用户权限,当前是root用户,需要在配置文件.bashrc中设置相关的环境变量。
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_PROXYSERVER_USER=root
(12)分发hadoop和配置文件.bashrc
# 分发hadoop
root@master:~# scp -r /opt/module/hadoop hadoop1:/opt/module
root@master:~# scp -r /opt/module/hadoop hadoop2:/opt/module# 分发.bashrc
root@master:~# scp ~/.bashrc hadoop1:/root
root@master:~# scp ~/.bashrc hadoop2:/root# hadoop1和hadoop2生效配置文件
root@hadoop1:~# source ~/.bashrc
root@hadoop2:~# source ~/.bashrc
(13)启动集群
如果集群是第一次启动,需要在节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
root@master:~# hdfs namenode -format
启动HDFS:
root@master:~# start-dfs.sh
在配置了ResourceManager的节点(hadoop1)启动YARN:
root@hadoop1:~# start-yarn.sh
查看启动成功的进程:

(14)添加HTTP服务端口查看Web管理
master节点配置端口和查看:



hadoop1节点配置端口和查看:


hadoop2节点配置端口和查看:


(15)hadoop群起脚本
root@master:~# vim bin/hd.sh
内容如下:
#! /bin/bash
#hd.sh start/stop
#1、判断参数是否传入
if [ $# -lt 1 ]
thenecho "必须传入start/stop..."exit
fi
#2、根据参数启动/停止
case $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh master "/opt/module/hadoop/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop1 "/opt/module/hadoop/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh master "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh master "/opt/module/hadoop/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop1 "/opt/module/hadoop/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh master "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)echo "输入参数错误..."
;;
esac
增加脚本执行权限:
root@master:~# chmod +x bin/hd.sh
在配置文件.bashrc中添加脚本路径:
root@master:~# vim ~/.bashrc# 添加脚本路径
export PATH=$PATH:/root/bin# 保存退出后source一下.bashrc
root@master:~# source ~/.bashrc
启动hadoop集群(hdfs、yarn、historyServer):
root@master:~# hd.sh start
停止hadoop集群:
root@master:~# hd.sh stop
2.2 Zookeeper安装
(1)zookeeper安装包上传到master

(2)zookeeper安装包解压到/opt/module/目录下并改名
# 解压至/opt/module目录
root@master:~# tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/# 改名为zookeeper
root@master:~# mv /opt/module/apache-zookeeper-3.7.1-bin /opt/module/zookeeper
(3)在.bashrc中添加ZK_HOME环境变量
root@master:~# vim ~/.bashrc# 添加ZK_HOME环境变量
#ZK_HOME
export ZK_HOME=/opt/module/zookeeper
export PATH=$PATH:$ZK_HOME/bin# 保存退出后source一下.bashrc
root@master:~# source ~/.bashrc
(4)配置服务器编号
在/opt/module/zookeeper/目录下创建zkData:
root@master:~# cd /opt/module/zookeeper/
root@master:/opt/module/zookeeper# mkdir zkData
在/opt/module/zookeeper/zkData目录下创建一个myid的文件:
root@master:/opt/module/zookeeper/zkData# vim myid
添加myid文件,注意一定要在Linux里面创建,在notepad++里面很可能乱码。
在文件中添加与server对应的编号:
1
(5)配置zoo.cfg文件
重命名/opt/module/zookeeper/conf目录下的zoo_sample.cfg为zoo.cfg:
root@master:/opt/module/zookeeper/conf# mv zoo_sample.cfg zoo.cfg
打开zoo.cfg文件:
root@master:/opt/module/zookeeper/conf# vim zoo.cfg
修改数据存储路径配置:
dataDir=/opt/module/zookeeper/zkData
添加如下配置:
#######################cluster##########################
server.1=master:2888:3888
server.2=hadoop1:2888:3888
server.3=hadoop2:2888:3888
(6)分发zookeeper和配置文件.bashrc
# 分发zookeeper
root@master:~# scp -r /opt/module/zookeeper hadoop1:/opt/module
root@master:~# scp -r /opt/module/zookeeper hadoop2:/opt/module# 分发.bashrc
root@master:~# scp ~/.bashrc hadoop1:/root
root@master:~# scp ~/.bashrc hadoop2:/root# hadoop1和hadoop2生效配置文件
root@hadoop1:~# source ~/.bashrc
root@hadoop2:~# source ~/.bashrc
分别修改hadoop1、hadoop2上的myid文件中内容为2、3
(7)zoo.cfg配置参数解读
server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
B是这个服务器的地址;
C是这个服务器Follower与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
(8)启动zookeeper和查看状态
root@master:~# zkServer.sh start
root@hadoop1:~# zkServer.sh start
root@hadoop2:~# zkServer.sh start
root@master:~# zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: followerroot@hadoop1:~# zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: leaderroot@hadoop2:~# zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper/bin/../conf/zoo.cfg
Mode: follower
(9)ZK集群启动停止脚本
root@master:~# vim bin/zk.sh
内容如下:
#! /bin/bash
#zk.sh start/stop/status
#1、判断参数是否传入
if [ $# -lt 1 ]
thenecho "必须传入start/stop/status..."exit
fi
#2、根据参数匹配启动/停止/查看状态
case $1 in
"start"){for i in master hadoop1 hadoop2doecho ---------- zookeeper $i 启动 ------------ssh $i "/opt/module/zookeeper/bin/zkServer.sh start"done
};;
"stop"){for i in master hadoop1 hadoop2doecho ---------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper/bin/zkServer.sh stop"done
};;
"status"){for i in master hadoop1 hadoop2doecho ---------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper/bin/zkServer.sh status"done
};;
esac
增加脚本执行权限:
root@master:~# chmod +x bin/zk.sh
启动ZK集群:
root@master:~# zk.sh start
查看ZK集群状态:
root@master:~# zk.sh status
停止ZK集群:
root@master:~# zk.sh stop
2.3 Kafka安装
(1)kafka安装包上传到master

(2)kafka安装包解压到/opt/module/目录下并改名
# 解压至/opt/module目录
root@master:~# tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/module/# 改名为kafka
root@master:~# mv /opt/module/kafka_2.12-3.3.1 /opt/module/kafka
(3)在.bashrc中添加KAFKA_HOME环境变量
root@master:~# vim ~/.bashrc# 添加KAFKA_HOME环境变量
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin# 保存退出后source一下.bashrc
root@master:~# source ~/.bashrc
(4)进入到/opt/module/kafka目录,修改配置文件
root@master:~# cd /opt/module/kafka/config/
root@master:/opt/module/kafka/config# vim server.properties
输入内容如下:
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=0#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://master:9092
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=master:2181,hadoop1:2181,hadoop2:2181/kafka
(5)分发kafka和配置文件.bashrc
# 分发kafka
root@master:~# scp -r /opt/module/kafka hadoop1:/opt/module
root@master:~# scp -r /opt/module/kafka hadoop2:/opt/module# 分发.bashrc
root@master:~# scp ~/.bashrc hadoop1:/root
root@master:~# scp ~/.bashrc hadoop2:/root# hadoop1和hadoop2生效配置文件
root@hadoop1:~# source ~/.bashrc
root@hadoop2:~# source ~/.bashrc
(6)分别在hadoop1和hadoop2上修改配置文件/opt/module/kafka/config/server.properties中的broker.id及advertised.listeners
hadoop1:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop1:9092
hadoop2:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
#broker对外暴露的IP和端口 (每个节点单独配置)
advertised.listeners=PLAINTEXT://hadoop2:9092
注:broker.id不得重复,整个集群中唯一。
(7)启动集群
先启动ZK集群:
root@master:~# zk.sh start
依次在master、hadoop1、hadoop2节点上启动Kafka:
root@master:~# kafka-server-start.sh -daemon config/server.properties
root@hadoop1:~# kafka-server-start.sh -daemon config/server.properties
root@hadoop2:~# kafka-server-start.sh -daemon config/server.properties
节点上依次查看进程:
root@master:~# jps
root@hadoop1:~# jps
root@hadoop2:~# jps
--------- master ----------
3768 QuorumPeerMain
4251 Kafka
4349 Jps
--------- hadoop1 ----------
4769 Kafka
4292 QuorumPeerMain
4878 Jps
--------- hadoop2 ----------
3298 Jps
3206 Kafka
2719 QuorumPeerMain
(8)关闭集群
root@master:~# kafka-server-stop.sh
root@hadoop1:~# kafka-server-stop.sh
root@hadoop2:~# kafka-server-stop.sh
(9)集群启停脚本
root@master:~# vim bin/kf.sh
内容如下:
#! /bin/bash
#kf.sh start/stop
#1、判断参数是否传入
if [ $# -lt 1 ]
thenecho "必须传入start/stop..."exit
fi
#2、根据参数匹配启动/停止
case $1 in
"start"){for i in master hadoop1 hadoop2doecho " --------启动 $i Kafka--------"ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done
};;
"stop"){for i in master hadoop1 hadoop2doecho " --------停止 $i Kafka--------"ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "done
};;
esac
增加脚本执行权限:
root@master:~# chmod +x bin/kf.sh
启动kafka集群:
root@master:~# kf.sh start
停止kafka集群:
root@master:~# kf.sh stop
2.4 Flume安装
(1)flume安装包上传到master

(2)flume安装包解压到/opt/module/目录下并改名
# 解压至/opt/module目录
root@master:~# tar -zxvf apache-flume-1.10.1-bin.tar.gz -C /opt/module/# 改名为flume
root@master:~# mv /opt/module/apache-flume-1.10.1-bin /opt/module/flume
(3)在.bashrc中添加FLUME_HOME环境变量
root@master:~# vim ~/.bashrc# 添加FLUME_HOME环境变量
#FLUME_HOME
export FLUME_HOME=/opt/module/flume
export PATH=$PATH:$FLUME_HOME/bin# 保存退出后source一下.bashrc
root@master:~# source ~/.bashrc
(4)修改conf目录下的log4j2.xml配置文件,配置日志文件路径
root@master:~# cd /opt/module/flume/conf/
root@master:/opt/module/flume/conf# vim log4j2.xml
内容如下:
<?xml version="1.0" encoding="UTF-8"?><Configuration status="ERROR"><Properties># 指定日志路径<Property name="LOG_DIR">/opt/module/flume/log</Property></Properties><Appenders><Console name="Console" target="SYSTEM_ERR"><PatternLayout pattern="%d (%t) [%p - %l] %m%n" /></Console><RollingFile name="LogFile" fileName="${LOG_DIR}/flume.log" filePattern="${LOG_DIR}/archive/flume.log.%d{yyyyMMdd}-%i"><PatternLayout pattern="%d{dd MMM yyyy HH:mm:ss,SSS} %-5p [%t] (%C.%M:%L) %equals{%x}{[]}{} - %m%n" /><Policies><!-- Roll every night at midnight or when the file reaches 100MB --><SizeBasedTriggeringPolicy size="100 MB"/><CronTriggeringPolicy schedule="0 0 0 * * ?"/></Policies><DefaultRolloverStrategy min="1" max="20"><Delete basePath="${LOG_DIR}/archive"><!-- Nested conditions: the inner condition is only evaluated on files for which the outer conditions are true. --><IfFileName glob="flume.log.*"><!-- Only allow 1 GB of files to accumulate --><IfAccumulatedFileSize exceeds="1 GB"/></IfFileName></Delete></DefaultRolloverStrategy></RollingFile></Appenders><Loggers><Logger name="org.apache.flume.lifecycle" level="info"/><Logger name="org.jboss" level="WARN"/><Logger name="org.apache.avro.ipc.netty.NettyTransceiver" level="WARN"/><Logger name="org.apache.hadoop" level="INFO"/>
<Logger name="org.apache.hadoop.hive" level="ERROR"/># 引入控制台输出,方便学习查看日志<Root level="INFO"><AppenderRef ref="LogFile" /><AppenderRef ref="Console" /></Root></Loggers></Configuration>
(5)分发flume和配置文件.bashrc
# 分发flume
root@master:~# scp -r /opt/module/flume hadoop1:/opt/module
root@master:~# scp -r /opt/module/flume hadoop2:/opt/module# 分发.bashrc
root@master:~# scp ~/.bashrc hadoop1:/root
root@master:~# scp ~/.bashrc hadoop2:/root# hadoop1和hadoop2生效配置文件
root@hadoop1:~# source ~/.bashrc
root@hadoop2:~# source ~/.bashrc
2.5 MySQL安装
(1)mysql安装包上传到master

(2)mysql安装包解压并安装
# 新建mysql目录
root@master:~# mkdir mysql# 解压mysql安装包至mysql目录
root@master:~# tar -xvf mysql-server_8.0.31-1ubuntu22.04_amd64.deb-bundle.tar -C ./mysql# 进入到mysql目录执行安装命令
root@master:~/mysql# dpkg -i ./*# 如果执行这个命令出现有依赖在当前系统中不存在,可以使用如下指令进行修复
root@master:~/mysql# apt install -f
安装过程中会弹出三个界面,前两个是设置mysql数据库的root账号的密码与确认root的密码,可以自己设置你需要的密码(一定要记住这个密码,不然一会登不上了)。最后一个界面直接默认选择第一个选项就可以。
(3)安装完毕后检查mysql的包是否已经全部安装
root@master:~# dpkg -l | grep mysql

(4)启动服务
# 先试用命令检查mysql是否已经启动(一般在安装完成后会默认启动)
root@master:~# systemctl status mysql# 如果mysql未启动,使用下面命令启动
root@master:~# systemctl start mysql# 如下表示启动成功

(5)设置root密码和连接权限
# 连接mysql
root@master:~# mysql -uroot -p# 设置root用户的密码为123456
mysql> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password by '123456';
mysql> FLUSH privileges;# 设置客户端连接mysql的权限
mysql> use mysql;
mysql> update user set host = '%' where user ='root';
mysql> flush privileges;
:~# scp ~/.bashrc hadoop2:/root
hadoop1和hadoop2生效配置文件
root@hadoop1:~# source ~/.bashrc
root@hadoop2:~# source ~/.bashrc
##### 2.5 MySQL安装(1)mysql安装包上传到master[外链图片转存中...(img-4RWwEnBt-1734949068606)] (2)mysql安装包解压并安装新建mysql目录
root@master:~# mkdir mysql
解压mysql安装包至mysql目录
root@master:~# tar -xvf mysql-server_8.0.31-1ubuntu22.04_amd64.deb-bundle.tar -C ./mysql
进入到mysql目录执行安装命令
root@master:~/mysql# dpkg -i ./*
如果执行这个命令出现有依赖在当前系统中不存在,可以使用如下指令进行修复
root@master:~/mysql# apt install -f
安装过程中会弹出三个界面,前两个是设置mysql数据库的root账号的密码与确认root的密码,可以自己设置你需要的密码(一定要记住这个密码,不然一会登不上了)。最后一个界面直接默认选择第一个选项就可以。(3)安装完毕后检查mysql的包是否已经全部安装root@master:~# dpkg -l | grep mysql
[外链图片转存中...(img-HGOPQVRt-1734949068607)] (4)启动服务先试用命令检查mysql是否已经启动(一般在安装完成后会默认启动)
root@master:~# systemctl status mysql
如果mysql未启动,使用下面命令启动
root@master:~# systemctl start mysql
如下表示启动成功
[外链图片转存中...(img-LWAJhDc9-1734949068607)] (5)设置root密码和连接权限连接mysql
root@master:~# mysql -uroot -p
设置root用户的密码为123456
mysql> ALTER USER ‘root’@‘localhost’ IDENTIFIED WITH mysql_native_password by ‘123456’;
mysql> FLUSH privileges;
设置客户端连接mysql的权限
mysql> use mysql;
mysql> update user set host = ‘%’ where user =‘root’;
mysql> flush privileges;
相关文章:

hi168大数据离线项目环境搭建
hi168大数据离线项目环境搭建 ## **1. 服务器准备**##### 1.1 创建集群应用节点 集群服务器使用“我的应用“中的Ubuntu22.04集群模版创建三个节点应用,并且进入“我的应用”中去修改一下节点名称(node1对应master,node2对应hadoop1…...

Ubuntu 22.04安装Docker
陈拓 2024/10/19-2024/12/26 0. 概述 docker是容器(Container),有点像一个轻量级的虚拟机。 容器是一种轻量级、可移植、并将应用程序进行的打包的技术,使应用程序可以在几乎任何地方以相同的方式运行。Docker将镜像文件运行起…...

穿山甲等广告联盟依据哪些维度给APP、小程序结算广告变现收益
媒体在开展广告变现商业化时,最关心的是变现收益问题,所运营的不同体量的APP、小程序能产生多少广告变现收益。#广告联盟# 广告变现的价格、收益不是一成不变的,广告转化是影响广告收益的重要因素之一。广告平台针对整个变现链路上的各环节&…...
)
【ES6复习笔记】迭代器(10)
什么是迭代器? 迭代器(Iterator)是一种对象,它能够遍历并访问一个集合中的元素。在 JavaScript 中,迭代器提供了一种统一的方式来处理各种集合,如数组、字符串、Map、Set 等。通过迭代器,我们可…...

ROS1入门教程6:复杂行为处理
一、新建项目 # 创建工作空间 mkdir -p demo6/src && cd demo6# 创建功能包 catkin_create_pkg demo roscpp rosmsg actionlib_msgs message_generation tf二、创建行为 # 创建行为文件夹 mkdir action && cd action# 创建行为文件 vim Move.action# 定义行为…...

【 Copilot】云开发 Copilot 实战教程:从入门到精通,掌握云开发核心技能
我的个人主页 我的领域:人工智能篇,希望能帮助到大家!!!👍点赞 收藏❤ 引言 云开发 Copilot 作为一款革新性的开发辅助工具,利用先进的人工智能技术,为开发者在云开发的征程中点亮…...

DataCap MongoDB Driver: 全面解析MongoDB在DataCap中的使用指南
在大数据时代,MongoDB作为一款广受欢迎的NoSQL数据库,其灵活的文档存储模型和强大的查询能力使其成为许多现代应用的首选数据存储方案。今天,我们将深入探讨DataCap MongoDB Driver,这是一个强大的工具,它让在DataCap环…...

[x86 ubuntu22.04]双触摸屏的触摸事件都响应在同一个触摸屏上
1 问题描述 CPU:G6900E OS:ubuntu22.04 Kernel:6.8.0-49-generic 系统下有两个一样的 edp 触摸屏,两个触摸屏的触摸事件都响应在同一个 edp 屏幕上。 2 解决过程 使用“xinput”命令查看输入设备,可以看到只有一个 to…...

Linux:SystemV通信
目录 一、System V通信 二、共享内存 代码板块 总结 一、System V通信 System V IPC(inter-process communication),是一种进程间通信方式。其实现的方法有共享内存、消息队列、信号量这三种机制。 本文着重介绍共享内存这种方式。 二、共…...

全面Kafka监控方案:从配置到指标
文章目录 1.1.监控配置1.2.监控工具1.3.性能指标系统相关指标GC相关指标JVM相关指标Topic相关指标Broker相关指标 1.4.性能指标说明1.5.重要指标说明 1.1.监控配置 开启JMX服务端口:kafka基本分为broker、producer、consumer三个子项,每一项的启动都需要…...

Springboot项目Druid运行时动态连接多数据源的功能
项目支持多数据库连接是个很常见的需求,这不仅是要在编译前连已经知道的多个数据库,有时还要在程序运行时连后期增加的多个数据源来获得数据。 一、编译前注册数据库连接 1.引入依赖包 <!-- springboot 3.x --><dependency><groupId&g…...
)
【漏洞复现】F5 BIG-IP Next Central Manager SQL注入漏洞(CVE-2024-26026)
免责声明 请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,作者不为此承担任何责任。工具来自网络,安全性自测,如有侵权请联系删除。本次测试仅供学习使用,如若非法他用,与平台和本文作…...

中间件xxl-job安装
拉取镜像 docker pull xuxueli/xxl-job-admin:2.4.2 创建xxl-job-admin容器 docker create --name xxl-job-admin -p 9099:8080 -e PARAMS"--spring.datasource.urljdbc:mysql://192.168.96.57:3306/xxl_job2Unicodetrue&characterEncodingUTF-8 --spring.dataso…...

Pytorch | 利用SMI-FGRM针对CIFAR10上的ResNet分类器进行对抗攻击
Pytorch | 利用I-FGSSM针对CIFAR10上的ResNet分类器进行对抗攻击 CIFAR数据集SMI-FGRM介绍SMI-FGRM算法流程 SMI-FGRM代码实现SMI-FGRM算法实现攻击效果 代码汇总smifgrm.pytrain.pyadvtest.py 之前已经针对CIFAR10训练了多种分类器: Pytorch | 从零构建AlexNet对CI…...

论文解读 | EMNLP2024 一种用于大语言模型版本更新的学习率路径切换训练范式
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 点击 阅读原文 观看作者讲解回放! 作者简介 王志豪,厦门大学博士生 刘诗雨,厦门大学硕士生 内容简介 新数据的不断涌现使版本更新成为大型语言模型(LLMsÿ…...

破解海外业务困局:新加坡服务器托管与跨境组网策略
在当今全球化商业蓬勃发展的浪潮之下,众多企业将目光投向海外市场,力求拓展业务版图、抢占发展先机。而新加坡,凭借其卓越的地理位置、强劲的经济发展态势以及高度国际化的营商环境,已然成为企业海外布局的热门之选。此时…...

win系统B站播放8k视频启用HEVC编码
下载HEVC插件 点击 HEVC Video Extension 2.2.20.0 latest downloads,根据教程下载安装 安装 Random User-Agent 点击 Random User-Agent 安装 配置 Random User-Agent 
Pion WebRTC 项目教程
Pion WebRTC 项目教程 webrtc Pure Go implementation of the WebRTC API [这里是图片001] 项目地址: https://gitcode.com/gh_mirrors/we/webrtc 1. 项目目录结构及介绍 Pion WebRTC 项目的目录结构如下: pion/webrtc ├── api ├── examples ├── inter…...

Opencv之对图片的处理和运算
Opencv实现对图片的处理和修改 目录 Opencv实现对图片的处理和修改灰度图读取灰度图转换灰度图 RBG图单通道图方法一方法二 单通道图显色合并单通道图 图片截取图片打码图片组合缩放格式1格式2 图像运算图像ma[m:n,x:y]b[m1:n1,x1:y1] add加权运算 灰度图 读取灰度图 imread(‘…...

基于cobra开发的k8s命令行管理工具k8s-manager
基于cobra开发的k8s命令行管理工具k8s-manager 如果觉得好用,麻烦给个Star!通用配置1 node 分析所有node的资源情况2 analysis 分析Node节点上的资源使用构成3 image 获取指定namespace的所有镜像地址4 resource 获取指定namespace的所有limit 与 Requests大小5 top…...

基于NodeMCU的物联网空调控制系统设计
最终效果 基于NodeMCU的物联网空调控制系统设计 项目介绍 该项目是“物联网实验室监测控制系统设计(仿智能家居)”项目中的“家电控制设计”中的“空调控制”子项目,最前者还包括“物联网设计”、“环境监测设计”、“门禁系统设计计”和“小…...

springboot/ssm图书大厦图书管理系统Java代码编写web图书借阅项目
springboot/ssm图书大厦图书管理系统Java代码编写web图书借阅项目 基于springboot(可改ssm)vue项目 开发语言:Java 框架:springboot/可改ssm vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库ÿ…...

【MySQL】踩坑笔记——保存带有换行符等特殊字符的数据,需要进行转义保存
问题描述 从DBeaver中导出了部分业务数据的 insert sql,明明在开发、测试环境都可以一把执行通过,却在预发环境执行前的语法检查失败了,提示有SQL语法错误。 这条SQL长这样,default_sql是要在odps上执行的sql语句,提…...

利用 Python 编写一个 VIP 音乐下载脚本
在这篇博客中,我们将介绍如何使用 Python 编写一个简单的 VIP 音乐下载脚本,利用网页爬虫技术从一个音乐网站下载歌曲。通过解析网页,获取歌曲的真实下载链接,并将音乐文件保存到本地。我们将使用 requests 和 BeautifulSoup 库来实现这个过程。 目标 本脚本的主要功能是…...

Sashulin升级啦,开箱即用!
经过多年的不断投入,升级为了Sashulin基础软件系列,本系列包含: 1、Sashulin IDE 2025全域通用开发工具 通用型Java开发工具,并可以进行业务流可视化开发。 2、发布Sashulin Webserver 2025 将Html等网页文件发布成网站…...

Java圣诞树
目录 写在前面 技术需求 程序设计 代码分析 一、代码结构与主要功能概述 二、代码功能分解与分析 1. 类与常量定义 2. 绘制树的主逻辑 3. 彩色球的绘制 4. 动态效果的实现 5. 窗口初始化 三、关键特性与优点 四、总结 写在后面 写在前面 Java语言绘制精美圣诞树…...

在Python如何用Type创建类
文章目录 一,如何创建类1:创建一个简单类2:添加属性和方法3:动态继承父类4:结合元类的使用总结 二.在什么情境下适合使用Type创建类1. **运行时动态生成类**2. **避免重复代码**3. **依赖元类或高级元编程**4. **动态扩…...

04软件测试需求分析案例-用户登录
通读文档,提取信息,提出问题,整理为需求。 从需求规格说明、设计说明、配置说明等文档获取原始需求,通读原始需求,分析有哪些功能,每种功能要完成什么业务,业务该如何实现,业务逻辑…...

替代传统FTP传输,镭速大数据传输系统实现安全高效数据流转!
信息技术的快速进步让大数据成为了企业决策的关键支撑,但同时也带来了巨大的挑战。企业在运营过程中产生的数据量急剧增加,这对数据传输的速度、安全性和效率提出了更高的要求。然而,传统的FTP传输方式在处理大规模数据时显得力不从心&#x…...
——请求与响应处理)
SpringMVC学习(一)——请求与响应处理
目录 一、SpringMVC简介 二、RequestMapping:请求路径映射 三、RestController 四、请求限定 五、请求处理 1.使用普通变量,收集请求参数 2.使用RequestParam明确指定获取参数 3.目标方法参数是一个pojo 4.RequestHeader:获取请求…...

大语言模型学习工具及资源总结和落地应用
当前,随着人工智能技术的迅猛发展,大语言模型(Large Language Models, LLMs)在各个领域的应用日益广泛。以下是国内外常见的大语言模型工具、已经落地部署的应用以及学习相关的网站和资源的详细介绍。 一、国内外常见的大语言模型…...

深度学习使用Anaconda打开Jupyter Notebook编码
新手入门深度学习使用Anaconda打开Jupyter Notebook编码 1. 安装Anaconda 第一种是Anaconda官网下载安装包,但是很慢,不太建议 第二种使用国内清华大学镜像源下载 选择适合自己电脑的版本,支持windows,linux系统 下载完之后自行…...

【视觉惯性SLAM:四、相机成像模型】
相机成像模型介绍 相机成像模型是计算机视觉和图像处理中的核心内容,它描述了真实三维世界如何通过相机映射到二维图像平面。相机成像模型通常包括针孔相机的基本成像原理、数学模型,以及在实际应用中如何处理相机的各种畸变现象。 一、针孔相机成像原…...

Firewalld 防火墙详解:深入理解与实践指南
在现代网络环境中,防火墙是保护系统和网络不受未授权访问的关键工具。firewalld是Linux系统中广泛使用的动态防火墙管理工具,它提供了强大的功能和灵活的配置选项。本文将深入探讨firewalld防火墙的工作原理、配置和管理,以及如何在实际环境中…...

在linux系统中使用jdbc访问sqlite数据库时报错“java.lang.UnsatisfiedLinkError”
1. 异常描述 在linux系统中使用jdbc访问sqlite数据库时出现如下错误提示: 2. 异常分析 可能是当前使用版本的sqlite-jdbc-xxx.jar版本有bug。 3. 异常解决 我是从3.8.9.1版本换到了3.16.1版本就好了。...

华为管理变革之道:管理制度创新
目录 华为崛起两大因素:管理制度创新和组织文化。 管理是科学,150年来管理史上最伟大的创新是流程 为什么要变革? 向世界标杆学习,是变革第一方法论 体系之一:华为的DSTE战略管理体系(解决:…...

MySQL 临时表:使用技巧与最佳实践
MySQL 临时表:使用技巧与最佳实践 引言 在数据库管理系统中,临时表是一种常见的数据结构,它允许用户存储临时数据,这些数据只在当前会话或事务中有效。MySQL 作为一种广泛使用的数据库管理系统,也提供了对临时表的支…...
)
华为云语音交互SIS的使用案例(文字转语音-详细教程)
文章目录 题记一 、语音交互服务(Speech Interaction Service,简称SIS)二、功能介绍1、实时语音识别2、一句话识别3、录音文件识别4、语音合成 三、约束与限制四、使用1、API2、SDK 五、项目集成1、引入pom依赖2、初始化 Client1)…...

【Rust自学】6.3. 控制流运算符-match
喜欢的话别忘了点赞、收藏加关注哦,对接下来的教程有兴趣的可以关注专栏。谢谢喵!(・ω・) 6.3.1. 什么是match match允许一个值与一系列模式进行匹配,并执行匹配的模式对应的代码。模式可以是字面值、变量名、通配符等…...
)
AIA - IMSIC之二(附IMSIC处理流程图)
本文属于《 RISC-V指令集基础系列教程》之一,欢迎查看其它文章。 1 通过IMSIC接收外部中断的CSR 软件通过《AIA - 新增的CSR》描述的CSR来访问IMSIC。 machine level 的 CSR 与 IMSIC 的 machine level interrupt file 可相互互动;而 supervisor level 的 CSR…...

Excel中一次查询返回多列
使用Excel或wps的时候,有时候需要一次查询返回多列内容,这种情况可以选择多次vlookup或者多次xlookup,但是这种做法费时费力不说,效率还有些低下,特别是要查询的列数过多时。我放了3种查询方法,效果图&…...
)
SQLAlchemy示例(连接数据库插入表数据)
背景需求 连接数据库,插入表中一些数据。 其用户是新建用户,所以只能插入,不能更新。 再次输入数据则使用更新数据语法,这个没调试。 #! /usr/bin/env python # -*- coding: utf-8 -*-from sqlalchemy import create_engine, …...

AG32 MCU 的电机控制方案
原创 AG32 AG32MCU cpld 2024年12月24日 17:23 浙江 AG32 MCU 的电机控制方案 在工业自动化、智能家居、新能源设备等众多领域,电机控制的精准性、稳定性和高效性至关重要。 AG32 MCU 凭借其高性能处理器、丰富的外设资源以及独特的 2K CPLD 资源,在电机…...

Linux:进程概念
1.冯诺依曼体系结构 结论: --- CPU不和外设直接打交道,和内存直接打交道。 --- 所有的外设,有数据需要收入,只能载入到内存中;内存写出,也一定是写道外设中。 --- 为什么程序要运行必须加载到内存…...

使用 Webpack 优雅的构建微前端应用❕
Module Federation 通常译作“模块联邦”,是 Webpack 5 新引入的一种远程模块动态加载、运行技术。MF 允许我们将原本单个巨大应用按我们理想的方式拆分成多个体积更小、职责更内聚的小应用形式,理想情况下各个应用能够实现独立部署、独立开发(不同应用甚…...
)
【Leetcode 热题 100】208. 实现 Trie (前缀树)
问题背景 T r i e Trie Trie 或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。 请你实现 Trie 类: Trie() 初始化前缀树对象。void insert(String word…...

从0开始在linux服务器上部署SpringBoot和Vue
目录 一、申请服务器的IP (1)阿里云申请IP (2)设置服务器的密码 (3)远程终端——MobaXterm 二、Docker (1)安装Docker (2)镜像加速 (3&…...

41 stack类与queue类
目录 一、简介 (一)stack类 (二)queue类 二、使用与模拟实现 (一)stack类 1、使用 2、OJ题 (1)最小栈 (2)栈的弹出压入序列 (3…...

代码随想录-笔记-其八
让我们开始:动态规划! 70. 爬楼梯 - 力扣(LeetCode) 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? class Solution { public:int climbStairs(i…...

信号仿真高级工程师面试题
信号仿真高级工程师面试题可能涵盖多个方面,旨在全面评估应聘者的专业知识、技能水平、实践经验和问题解决能力。以下是一些可能的面试题及其简要解析: 一、专业知识与技能 描述你对信号仿真的理解 考察点:对信号仿真基本概念、原理及应用的掌握程度。参考答案:信号仿真是…...