计算机视觉(为天地立心,为生民立命)
4. 逻辑回归中,对数损失函数怎么来表示的?


5. relu激活函数它的一些特点?
ReLU的数学表达式为:f(x)=max(0,x)
特点:
1.简单高效:ReLU 的计算非常简单,直接将输入小于 0 的部分置为 0,大于 0 的部分保持不变。相比于 Sigmoid 或 Tanh 激活函数,它的计算代价更低。
2.非线性:尽管 ReLU 的定义看起来很简单,但它是非线性的,可以帮助神经网络学习复杂的非线性关系。
3.稀疏激活:当输入为负时,ReLU 的输出为 0,这意味着神经元在该区域不激活。这种特性能够使模型更高效,减少无用信息的传播,增强稀疏性。
4.避免梯度消失问题:对于 Sigmoid 和 Tanh 激活函数,随着网络层数增加,梯度容易消失,从而导致深层网络难以训练。而 ReLU 在正值区域的梯度恒为 1,可以缓解梯度消失问题。
5.快速收敛:使用 ReLU 激活函数的网络通常收敛速度更快,因为它在正值区域的梯度是恒定的 1,不会像 Sigmoid 那样饱和。
局限性:
1.“神经元死亡”问题:如果一个神经元的输入始终小于 0,它的输出就会永远是 0,导致该神经元失效,无法再参与学习。这种现象被称为“神经元死亡”问题,尤其在学习率过高时更容易发生。
2.梯度爆炸:虽然 ReLU 减少了梯度消失问题,但如果输入值过大,可能会导致梯度爆炸,尤其是在初始化不当或学习率较大时。
6.目标检测中,(NMS)非极大值抑制怎么来理解?
在目标检测中,非极大值抑制 (NMS, Non-Maximum Suppression) 是一种后处理方法,用于去除多余的、重叠的边界框(bounding boxes),从而保留更准确的检测结果。它是解决检测框重复问题的关键算法。
NMS的核心思想:
1.输入:
一组边界框 B={b1,b2,…,bn},每个边界框具有一个置信度分数(通常是目标分类的概率)和位置信息。
一个阈值(通常称为 IoU 阈值),用来决定哪些框过于重叠而需要被抑制。
2.算法流程:
- 按照边界框的置信度分数降序排列。
- 选择置信度最高的框 bmaxb_{max}bmax 作为最终检测结果。
- 计算 bmaxb_{max}bmax 与剩余所有框的 IoU(Intersection over Union,交并比)。
- 如果某个框的 IoU 高于预设阈值(表示重叠过多),则将其移除。
- 重复步骤 2 到 4,直到所有框都处理完。
3.输出:一组抑制后、无多余重叠的边界框。
关键概念:IOU(交并比)


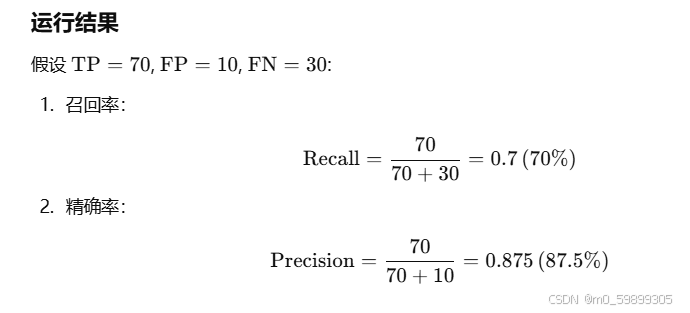
7.如何计算召回率?
召回率(Recall) 和 精确率(Precision) 是分类模型的重要性能指标,分别衡量模型的检出能力和预测准确性。以下是它们的计算方法和例子。




8.关于模型过拟合和欠拟合怎么来理解?
过拟合和欠拟合是机器学习模型在训练过程中常见的问题,反映了模型对数据的拟合程度是否合理。
1.过拟合
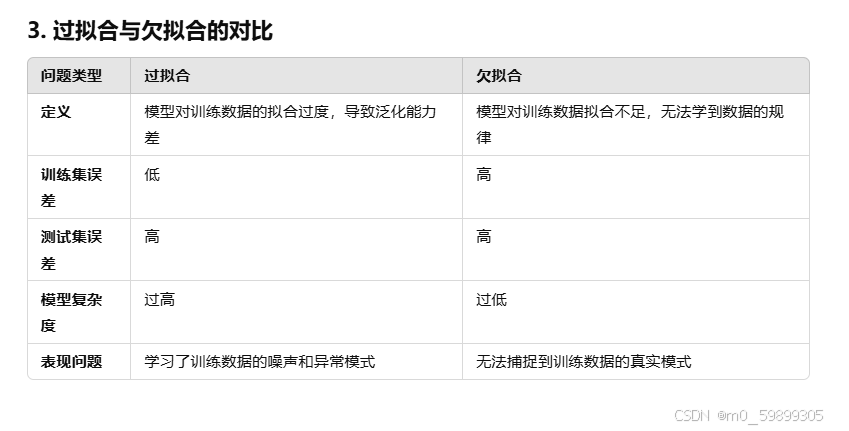
定义:过拟合是指模型在训练数据上表现很好(即低误差),但在测试数据或新数据上表现较差(即高误差)。这种情况表明模型学习到了训练数据中的噪声或细节模式,而非数据的普遍规律。
特点:(1)训练集误差低,测试集误差高。(2)模型复杂度过高(如过多的参数或层数)。
(3)学习到了数据中的随机噪声或异常模式。
原因:(1)数据不足:训练数据量太少,导致模型记住了训练数据而不是学会泛化。(2)模型过于复杂:例如,使用了高阶多项式、过多的神经元或层数。(3)训练时间过长:模型在训练过程中逐渐记住了训练数据的细节。
示例:
假设拟合一个二维数据点的关系:
- 数据分布: 近似线性分布。
- 过拟合模型: 用 10 次多项式拟合数据。虽然训练数据点的误差接近 0,但模型在测试数据上表现极差。
解决方法:
- 正则化:引入 L_1 或 L_2正则化项(如 Ridge 或 Lasso)限制模型参数过大。
- 减少模型复杂度:降低模型的自由度(如减少网络层数或神经元)。
- 增加训练数据:通过数据增强或收集更多数据来增强模型泛化能力。
- 早停法(Early Stopping):在验证集性能停止提升时提前停止训练。
2.欠拟合
定义:欠拟合是指模型在训练数据上表现不佳,无法很好地学习数据的特征。欠拟合通常表明模型的复杂度不足,无法捕捉到数据的规律。
特点:(1)训练集误差和测试集误差都较高。(2)模型简单,无法表达数据的真实分布。(3)学习不足,未捕捉到数据的模式。
原因:(1)模型复杂度过低:例如,尝试用线性模型拟合非线性数据。(2)训练时间不足:模型尚未充分学习数据特征。(3)特征不足:未提供足够的输入特征或特征表达能力差。(4)数据质量问题:数据可能存在噪声或缺乏有效信息。
示例:
- 数据分布: 数据呈非线性关系。
- 欠拟合模型: 用线性模型拟合,导致模型无法捕捉到数据的非线性特征。
解决方法:
- 增加模型复杂度:使用更复杂的模型(如从线性回归切换到多项式回归或神经网络)。
- 增加训练时间:延长训练时间,让模型有更多机会学习数据特征。
- 特征工程:加入更多相关特征,或对现有特征进行非线性变换。
- 减少正则化强度:如果正则化过强,可能限制了模型的表达能力。
3.过拟合与欠拟合对比

5.如何在实践中避免?
检测方法:
- 观察误差曲线:
- 如果训练误差很低,但验证误差很高,说明过拟合。
- 如果训练误差和验证误差都很高,说明欠拟合。
- 交叉验证:
- 使用交叉验证方法(如 K 折交叉验证)来评估模型的泛化能力。
- 学习曲线:
- 观察模型性能随训练数据量的变化趋势。
- 如果增加数据能显著改善性能,可能是过拟合。
- 如果增加数据无明显效果,可能是欠拟合。
- 观察模型性能随训练数据量的变化趋势。
预防策略:
- 对过拟合:
- 正则化(L1/L2)
- Dropout
- 增加数据量
- 早停法
- 对欠拟合:
- 增加模型复杂度
- 提供更多或更好的特征
- 训练更长时间
9.关于如何设计网络结构的?
一 明确任务目标
设计网络的第一步是明确任务类型和目标:
- 分类问题: 图片分类、文本分类、语音分类等。
- 回归问题: 连续值预测,如房价预测。
- 生成问题: 图像生成、文本生成。
- 目标检测/分割: 检测图像中的物体或分割像素区域。
任务类型决定了网络的输出形式(如分类的 Softmax 层、回归的线性输出层)。
二 数据的规模和特性
设计网络时,要根据数据量和特性调整模型的复杂度:
- 大数据集: 可以使用更深的网络,如 ResNet、Transformer。
- 小数据集: 适当减少参数(如浅层网络、使用正则化),或者利用预训练模型(Transfer Learning)。
- 数据特性:
- 如果数据是时序型,考虑 RNN 或 Transformer。
- 如果数据是二维图像型,使用 CNN。
- 如果数据是非结构化文本型,使用 NLP 特定模型(如 BERT)。
三 选择网络架构
根据任务特点选择基础架构:
- 全连接网络 (MLP): 适用于结构化数据。
- 卷积神经网络 (CNN): 擅长处理图像数据(如 ResNet、VGG、EfficientNet)。
- 循环神经网络 (RNN): 用于时序数据(如 LSTM、GRU)。
- Transformer 架构: 适用于图像、文本、音频等任务(如 ViT、GPT、BERT)。
四 网络深度和宽度
- 深度 (Depth):
- 深度决定了模型的抽象能力。
- 太浅的网络无法学到复杂模式,太深的网络可能引发梯度消失/爆炸。
- 常用方法:使用残差网络(ResNet)避免梯度问题。
- 宽度 (Width):
- 宽网络可以捕获更多局部特征。
- 需要注意宽网络会增加计算量和内存需求。
五 网络的基本组件设计
以下是设计每一层的关键点:
输入层
- 输入的形状应与数据维度匹配:
- 图像数据:(C,H,W)(C, H, W)(C,H,W),如 RGB 图片为 (3,224,224)(3, 224, 224)(3,224,224)。
- 文本数据:序列长度 + 词嵌入维度。
- 数据需进行归一化或标准化处理。
卷积层 (Convolutional Layer)
- 用于提取空间特征。
- 设计要点:
- 滤波器大小 (Kernel Size): 通常选择 3×33 \times 33×3 或 5×55 \times 55×5。
- 步长 (Stride): 控制特征图的缩小程度(通常为 1 或 2)。
- 通道数 (Channels): 决定提取的特征数量。
- 激活函数: 常用 ReLU 或 Leaky ReLU。
池化层 (Pooling Layer)
- 用于降维,减少计算量。
- 设计要点:
- 最大池化 (Max Pooling): 提取显著特征。
- 平均池化 (Average Pooling): 平滑特征。
- 通常采用 2×22 \times 22×2 或 3×33 \times 33×3 的池化核。
全连接层 (Fully Connected Layer)
- 用于组合提取的特征,输出最终的结果。
- 常用于分类或回归任务的最后几层。
激活函数 (Activation Function)
- ReLU:常用默认选择。
- Sigmoid:适合输出概率值。
- Softmax:用于多分类问题。
正则化
- Dropout:随机丢弃部分神经元,防止过拟合。
- Batch Normalization:加速训练,稳定梯度。
输出层
- 分类任务:用 Softmax 输出类别概率。
- 回归任务:输出一个连续值,通常不使用激活函数。
六 网络结构优化
优化网络结构时可以考虑以下方法:
网络模块化
- 利用现有的模块化设计,如 ResNet 的残差模块、Inception 模块,减少设计复杂性。
自动搜索 (NAS)
- 使用 Neural Architecture Search (NAS) 自动化设计网络结构。
迁移学习
- 利用预训练模型(如 ResNet、BERT)进行微调,特别适用于小数据集任务。
模型压缩
- 在资源有限的情况下,使用剪枝(Pruning)、量化(Quantization)等技术优化网络性能。
七 性能调优和测试
评估模型
- 训练集、验证集和测试集的性能差异可以判断过拟合或欠拟合。
- 使用交叉验证(如 K 折验证)进一步稳定评估结果。
超参数调节
- 学习率:过高会导致训练不稳定,过低会收敛缓慢。
- Batch Size:需要平衡内存占用和模型性能。
- 网络层数和神经元数:实验调整,避免过拟合或欠拟合。
损失函数
- 分类任务:交叉熵损失。
- 回归任务:均方误差 (MSE) 或绝对误差 (MAE)。
- 特定任务:设计自定义损失函数(如目标检测中的 Focal Loss)。
八 实践建议
- 从简单模型开始: 先从浅层网络或经典架构开始,确保训练流程正确。
- 多实验验证: 调整网络结构和超参数,记录结果。
- 借鉴经典网络: 如 ResNet、VGG、Transformer 的模块和结构。
- 可视化: 使用工具(如 TensorBoard)监控模型训练过程。
10.如何计算反卷积的输出尺寸?(反卷积在图像分割中经常用)
反卷积(Transposed Convolution) 是一种常用的操作,尤其是在图像分割任务中(如 U-Net 等网络架构)。它的主要目的是将特征图上采样到更高的分辨率。计算反卷积的输出尺寸是理解其工作的关键。
反卷积输出尺寸公式:
Output Size = (Input Size−1) ⋅ Stride + Kernel Size−2 ⋅ Padding + Output Padding
符号解释:
- Input Size:输入特征图的大小(如宽度或高度)。
- Stride:步长(通常 ≥1)。
- Kernel Size:反卷积核的大小(通常为 3×3,4×4 等)。
- Padding:输入特征图在每一边的填充量(通常为 0)。
- Output Padding:反卷积过程中用于调整输出尺寸的额外填充(通常为 0 或 1)。
计算流程:
以下是逐步解析公式的方法:
- 输入尺寸和步长决定了输出尺寸的基本扩大倍数。
- 卷积核大小决定了每个输入单元如何扩展到输出空间。
- Padding 和 Output Padding用于调整边界对齐问题。
实例1:简单反卷积
假设以下参数:输入尺寸=4,卷积核大小=3,步长=2,padding=1,outpadding=0
代入公式计算:Output Size=(4−1)⋅2+3−2⋅1+0=8+3−2=7
实例2:具有output Padding的反卷积
假设以下参数:输入尺寸=5,卷积核大小=4,步长=2,padding=1,outpadding=1
代入公式计算:Output Size=(5−1)⋅2+4−2⋅1+1=8+4−2+1=11
11.计算题(三小问)
第一小问:如何计算某一层卷积层神经元的感受野?(不是第一层)
感受野(Receptive Field, RF) 是指卷积网络中某一层神经元在输入图像上的感知范围。随着网络层数加深,感受野会逐渐扩大,表征更大范围的特征。对于中间层的神经元感受野,计算需要考虑网络的核大小、步长、填充等参数,以及前几层的感受野。
感受野的计算公式
假设网络有 L 层,每一层的参数为:
- 核大小 (Kernel Size): k_i(第 i 层卷积核的大小)
- 步长 (Stride): s_i (第 i层的步长)
- 填充 (Padding): p_i (第 i层的填充)
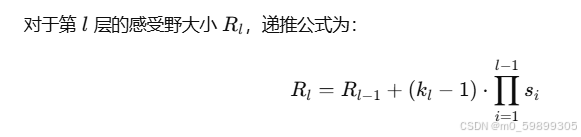
递推过程说明
- 基础感受野: 第一层感受野大小直接等于卷积核大小 k_1,即 R_1 = k_1。
- 步长放大: 每次下采样(即步长s_i > 1)会放大感受野的步幅。
- 卷积核扩展: 每层的卷积核大小会直接增加感受野范围。
计算示例
假设有如下三层卷积网络:
- 第一层:卷积核k_1 = 3,步长 s_1 = 1,填充 p_1 = 0。
- 第二层:卷积核k_2 = 3,步长 s_2 = 2,填充 p_2 = 0。
- 第三层:卷积核k_3 = 3,步长 s_3 = 2,填充 p_3 = 0。
计算步骤
1.第一层感受野:R1=k1=3
2.第二层感受野:R2=R1+(k2−1)⋅s1=3+(3−1)⋅1=5
3.第三层感受野:R3=R2+(k3−1)⋅(s1⋅s2)=5+(3−1)⋅(1⋅2)=9
最终,第三层的感受野大小为 9。
更复杂的情况
如果网络层有填充,填充会对感受野的计算产生影响,因为它在每一层额外扩展了特征图的感知范围。
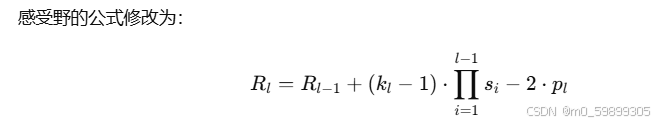
示例
假设和上述例子相同,但加入以下填充:第一层 p_1 = 1,第二层 p_2 = 1,第三层 p_3 = 1。
1.第一层感受野:R1=k1−2⋅p1=3−2⋅1=1
2.第二层感受野:R2=R1+(k2−1)⋅s1−2⋅p2=1+(3−1)⋅1−2⋅1=1
3.第三层感受野:R3=R2+(k3−1)⋅(s1⋅s2)−2⋅p3=1+(3−1)⋅(1⋅2)−2⋅1=3
最终,第三层的感受野大小为 3。

第二小问:如何计算特征图的尺寸?第一层卷积的输出尺寸什么样,第二层什么样,第三层什么样,推导计算
在卷积神经网络中,计算特征图的尺寸(即输出的宽度和高度)需要根据输入尺寸、卷积核大小、步幅(stride)、填充(padding)等参数来推导。以下是逐层推导特征图尺寸的公式和步骤:
1.计算特征图尺寸公式:

2.逐层推导:
假设输入图片尺寸为 H_in * W_in,你需要明确以下信息:
- 每一层的卷积核大小 K;
- 步幅 S;
- 填充 P;
- 输入特征图的尺寸。


3.实例计算:

第三小问:计算卷积层最后一层输出的尺寸?



12.计算题(三小问)
第一小问:输出的尺寸(同上)
第二小问:卷积层的感受野(同上)
第三小问:求卷积核的参数,一个模型的未知参数,(在做模型的时候,参数量也是一个衡量指标)

2.实际例子


13.问答题:卷积神经网络中有一个平移不变性怎么理解?
卷积神经网络(Convolutional Neural Network, CNN)中的平移不变性是指网络能够对输入的平移(如物体在图像中位置的改变)具有一定的鲁棒性,即使输入发生了平移,CNN 依然可以提取出类似的特征并作出相似的输出预测。
理解平移不变性的几个关键点包括:
-
局部感受野和共享权重:卷积层通过滑动窗口操作对输入数据进行卷积运算,每个神经元只与其局部区域内的输入相连,即局部感受野。此外,在同一层的各个位置上的滤波器(或称为核、卷积核)是相同的,意味着权重是共享的。这样的结构有助于网络学习到对位置不敏感的特征。
-
池化层的作用:通常在卷积层之后会跟随一个池化层,最常用的是最大池化。池化层可以降低数据的空间尺寸,同时保持最重要的信息。例如,最大池化会选取局部区域的最大值,这样即便目标有轻微的位移,只要它还在池化窗口内,输出就不会受到影响。因此,池化操作有助于增强平移不变性。
-
多层堆叠:随着网络深度增加,多个卷积层和池化层的组合使得网络的感受野逐渐增大,从而可以在更大的空间范围内实现平移不变性。
-
非线性激活函数:如ReLU等非线性激活函数,它们虽然不会直接导致平移不变性,但可以帮助网络学习更复杂的模式,间接支持这一性质。
4. 总结
卷积神经网络的平移不变性来源于共享权重的卷积操作和池化层的降采样特性,使得 CNN 在处理位置变化时具有一定的鲁棒性。然而,其不变性是有限的,需要结合数据增强或其他模型改进方法来提升处理大范围平移的能力。
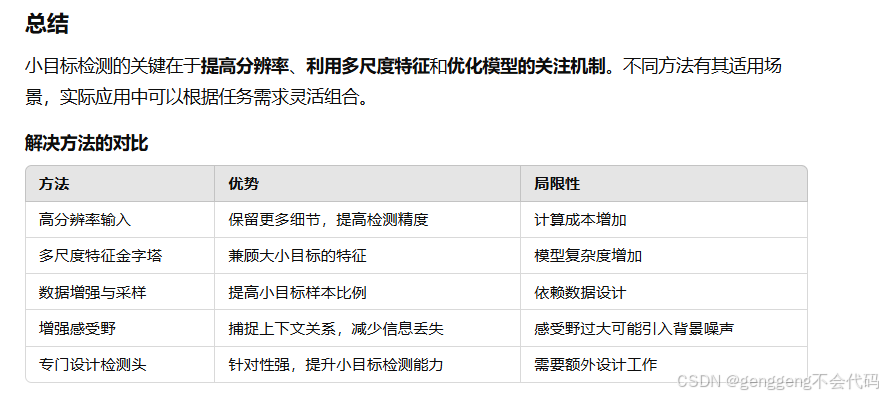
14.问答题:目标检测的时候一个小目标怎么办?
目标检测中的小目标检测问题是一个经典挑战。小目标(如图像中非常小的物体)往往会因为分辨率低、特征弱、容易被背景信息淹没而难以检测。以下是针对小目标的解决方法:
1. 提高输入图像分辨率
- 问题来源: 小目标本身像素少,分辨率不足。
- 解决方式:
- 使用高分辨率输入图像(例如,将原始图像放大)。
- 使用超分辨率技术对小目标区域进行增强。
- 效果: 提高了小目标的细节分辨率,使得特征提取更加准确。
- 注意: 高分辨率会增加计算成本,需平衡效率和精度。
2. 使用多尺度特征金字塔 (Feature Pyramid Network, FPN)
- 问题来源: 小目标信息在深层特征图中容易被丢失。
- 解决方式:
- 构建多尺度特征金字塔(如 FPN)模型,将浅层的高分辨率特征与深层的语义特征结合。
- 在检测过程中,模型同时关注小目标的浅层特征和大目标的深层特征。
- 效果: 改善了小目标的检测能力,增强了特征表达。
3. 增强感受野
- 问题来源: 感受野不足,无法充分捕获小目标周围的上下文信息。
- 解决方式:
- 使用较大的卷积核或引入空洞卷积(Dilated Convolution)以扩大感受野。
- 将小目标的上下文区域纳入考虑,帮助模型更好地区分小目标与背景。
- 效果: 更好地捕捉小目标的上下文关系,提高检测精度。
4. 数据增强与采样策略
- 问题来源: 数据集中小目标数量不足,模型倾向于优先检测大目标。
- 解决方式:
- 使用数据增强技术(如随机裁剪、放大小目标区域等)来增强小目标样本的比例。
- 在数据采样时,对小目标赋予更高的权重(如在训练过程中增加小目标样本的频率)。
- 效果: 改善模型对小目标的关注度,减少对大目标的偏向。
5. 增加检测头与特征分支
- 问题来源: 单一检测头可能无法适应小目标的特征分布。
- 解决方式:
- 在多任务检测框架中,为小目标专门设计检测头或特征分支。
- 例如在 YOLO 等模型中,增加小尺度特征图的检测分支。
- 效果: 提高对小目标的检测能力,同时兼顾多尺度目标。
6. 聚焦局部区域(Region Proposal/Attention)
- 问题来源: 图像中小目标较多时,全局检测效率低。
- 解决方式:
- 使用 Region Proposal Network (RPN) 提前定位可能的小目标区域,并进行局部检测。
- 使用注意力机制(Attention)增强小目标所在区域的特征。
- 效果: 提升模型对小目标的聚焦能力,减少对背景区域的干扰。
7. 专门设计损失函数
- 问题来源: 小目标误差在损失函数中占比较小,优化过程中被忽略。
- 解决方式:
- 修改损失函数,例如使用 Focal Loss,让模型更加关注小目标和难以检测的样本。
- 对小目标的预测框给予更高的权重。
- 效果: 平衡了小目标和大目标的检测精度。
8. 结合实例分割
- 问题来源: 小目标边界模糊,容易与背景混淆。
- 解决方式:
- 在目标检测任务中结合实例分割(Instance Segmentation),通过像素级信息辅助小目标检测。
- 效果: 提高了小目标的检测精度,尤其适用于背景复杂的场景。
15.问答题:图像分类应该用什么样的模型,为什么?
在图像分类任务中,选择合适的模型取决于数据规模、任务复杂度、计算资源等因素。以下是一些常用的模型类型和适用场景,以及选择的原因:
1. 小规模数据集(几千到几万张图像)
推荐模型:
- VGG: 如 VGG16、VGG19
- ResNet: 如 ResNet18、ResNet34
选择原因:
- 结构简单,易于理解和实现:
- VGG 使用堆叠的卷积层和池化层,容易上手。
- ResNet 引入了残差连接(skip connections),解决了深度网络训练困难的问题。
- 预训练权重:
- 在小规模数据集上,可以利用在大规模数据集(如 ImageNet)上预训练的权重进行迁移学习,显著提高性能。
- 计算成本适中:
- VGG 和较浅的 ResNet 网络(如 ResNet18、ResNet34)计算量相对较低,适合资源有限的场景。
2. 中等规模数据集(几十万张图像)
推荐模型:
- ResNet: 如 ResNet50、ResNet101
- DenseNet
-
EfficientNet
选择原因:
- 深度与宽度结合:
- ResNet50 和 ResNet101 更深的结构适合挖掘更复杂的特征。
- DenseNet 通过特征复用(feature reuse)提高效率和精度。
- 计算效率高:
- EfficientNet 通过对网络宽度、深度和分辨率的自动搜索(compound scaling),在精度和计算量之间找到了良好平衡。
- 可扩展性:
- 这些模型可以根据任务需求调整大小,例如 ResNet 从18层到101层,EfficientNet 从B0到B7,可以选择适合任务规模的模型。
3. 大规模数据集(百万级别或更多)
推荐模型:
- Vision Transformer (ViT)
- Swin Transformer
-
ConvNeXt
选择原因:
- 处理全局特征:
- Vision Transformer (ViT) 使用自注意力机制,适合捕捉图像的全局特征,尤其是当数据规模足够大时表现突出。
- Swin Transformer 是改进版的 ViT,结合了卷积的局部特性和 Transformer 的全局特性,适合各种图像尺度。
- SOTA 性能:
- ConvNeXt 是一种结合卷积网络和 Transformer 思想的新型卷积架构,能在大规模数据集上获得与 Swin Transformer 类似的性能。
- 高精度需求:
- 对于要求极高精度的分类任务(如医学影像分析),这些更复杂的模型通常表现更优。
4. 资源受限的场景(如嵌入式设备或移动端)
推荐模型:
- MobileNet
- ShuffleNet
- EfficientNet-Lite
选择原因:
- 轻量化设计:
- MobileNet 和 ShuffleNet 使用深度可分离卷积,显著降低计算复杂度和模型参数量。
- EfficientNet-Lite 是对 EfficientNet 的轻量化版本,专门针对移动端优化。
- 实时性需求:
- 在嵌入式设备或移动端,模型需要快速推理,这些模型在保持高精度的同时能满足低延迟要求。
5. 为什么要选择这些模型?
(1) 性能优异
- 深度学习模型(如 ResNet、EfficientNet)在处理复杂的图像特征时表现优异,能够适应从简单到复杂的图像分类任务。
(2) 迁移学习支持
- 主流模型(如 ResNet、EfficientNet、ViT)通常有预训练权重,可以在小数据集上快速迁移并取得较好效果。
(3) 可扩展性
- 许多模型家族(如 ResNet、EfficientNet)提供了多个版本,允许用户根据数据规模和计算资源选择不同的深度和宽度。
(4) 社区支持与工具链完善
- 这些模型广泛应用,工具链(如 PyTorch、TensorFlow)支持良好,易于训练、优化和部署。
6. 总结
- 如果是 小数据集:选择 VGG、ResNet18/34,迁移学习效果好。
- 如果是 中等数据集:选择 ResNet50/101、DenseNet 或 EfficientNet,性能和计算成本平衡。
- 如果是 大规模数据集:选择 Vision Transformer、Swin Transformer 或 ConvNeXt,适合高精度需求。
- 如果是 嵌入式设备:选择 MobileNet、ShuffleNet,满足资源限制的场景。
最终的模型选择应结合数据规模、硬件资源和应用需求综合考虑。
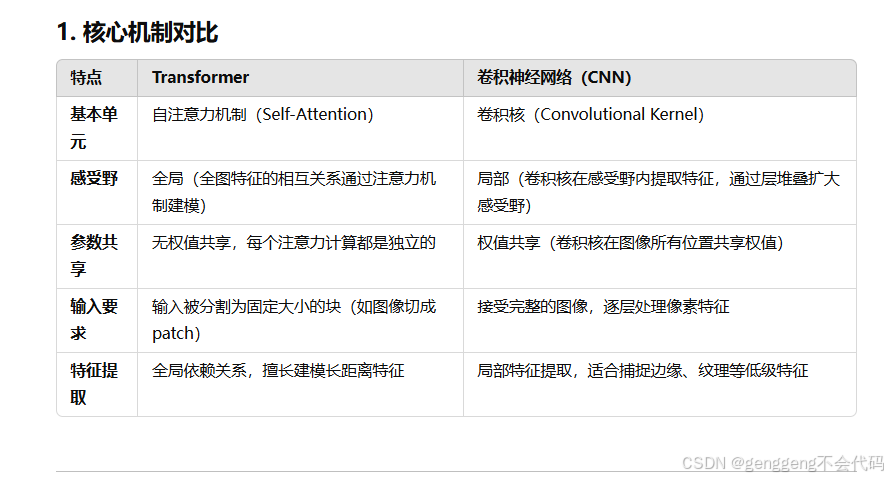
16.问答题:transformer 和卷积神经网络的区别,优劣对比?
Transformer 和 CNN 是两种重要的深度学习模型架构,虽然它们都可以处理计算机视觉任务,但设计思想、适用场景和性能表现存在显著差异。
2. 优势与劣势对比
(1) Transformer 的优劣
优势:
- 全局感受野:Transformer 通过自注意力机制,能够直接捕获全局特征关系,适合建模远距离依赖(如图像中远处物体的关联)。
- 通用性:Transformer 起源于自然语言处理(NLP),可以轻松迁移到计算机视觉任务,并适用于多模态学习。
- 可扩展性:更适合大规模数据(如百万级数据集),当数据量足够大时,性能通常优于 CNN。
- 模型容量大:Transformer 的表达能力强,能学习更复杂的特征。
劣势:
- 数据需求大:Transformer 对训练数据量敏感,在小数据集上容易过拟合。
- 计算开销高:自注意力机制的计算复杂度为 O(n^2)(对于序列长度 n),需要更多的计算资源。
- 缺乏对局部特征的敏感性:直接切分图像为 patch 可能丢失局部信息(如边缘、纹理),需要结合 CNN 或其他技术改善局部特征捕获能力。
(2) CNN 的优劣
优势:
- 高效局部特征提取:卷积核对局部特征敏感,能够有效捕捉边缘、纹理等低级特征。
- 参数共享:卷积操作具有权值共享机制,参数量少,计算复杂度低。
- 对小数据集表现优异:CNN 能够充分利用局部特征信息,在中小规模数据集上通常优于 Transformer。
- 现成工具链和预训练权重:CNN 在计算机视觉领域已经发展多年,工具链成熟且有丰富的预训练权重。
劣势:
- 有限感受野:CNN 的感受野需要通过多层堆叠扩大,可能难以捕捉全局特征。
- 特征空间有限:CNN 的特征提取偏向于固定模式(如边缘或纹理),对复杂全局关系的建模能力不足。
- 难以扩展:CNN 设计时多为任务专用模型,迁移到其他领域(如 NLP)需要较大的改造。
(3) 总结
- Transformer 和 CNN 各有优势和适用场景:
- CNN 更适合局部特征提取和小规模数据任务。
- Transformer 在大规模数据和全局特征建模上更具优势。
17.编程题(算是填空)如何实现张量的标准化规范化,写的三行代码


18.编程题
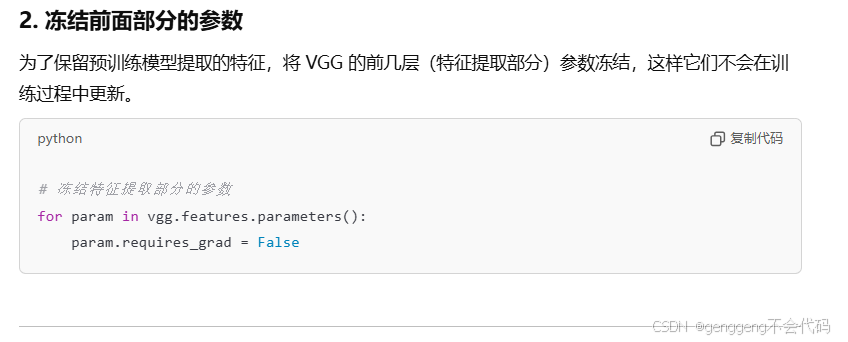
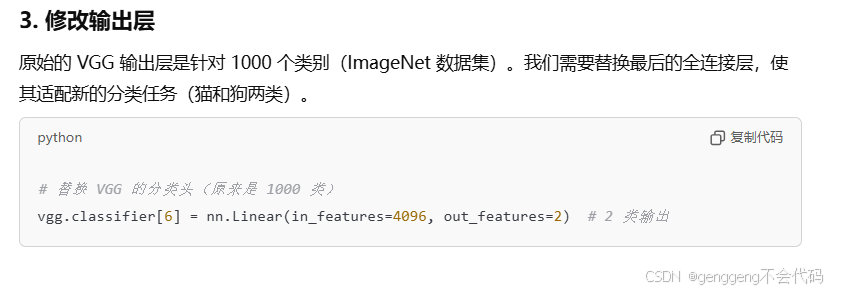
第一问:比如说我们现在要做一个猫狗的分类,但是我们现在图片数量比较少,比如说猫和狗各只有50张,你在做一个分类的时候,图片尺寸可能比较大,你输入到模型里面你要建立一个比较深的卷积神经网络,参数比较多,容易出现过拟合,所以我们可以使用别人已经训练好的模型来提取特征,这叫做预训练模型,但是别人已经训练好的模型 比如说VGG是在imagenet数据集训练的网络结构,所以输出层有1000类,但是我们现在输出只有2类,所以现在我们要用它,改变他的网络结构,你调用它的网络结构相当于我们调用前面一部分,后面一部分需要我们自己来设计,这个时候我们该怎么操作,相当于有很多层,把部分层替换成适配你任务的。


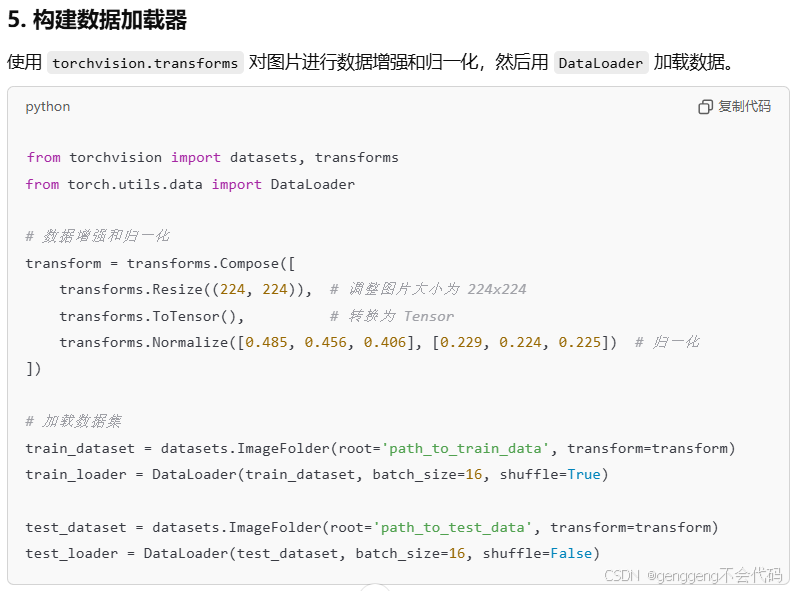
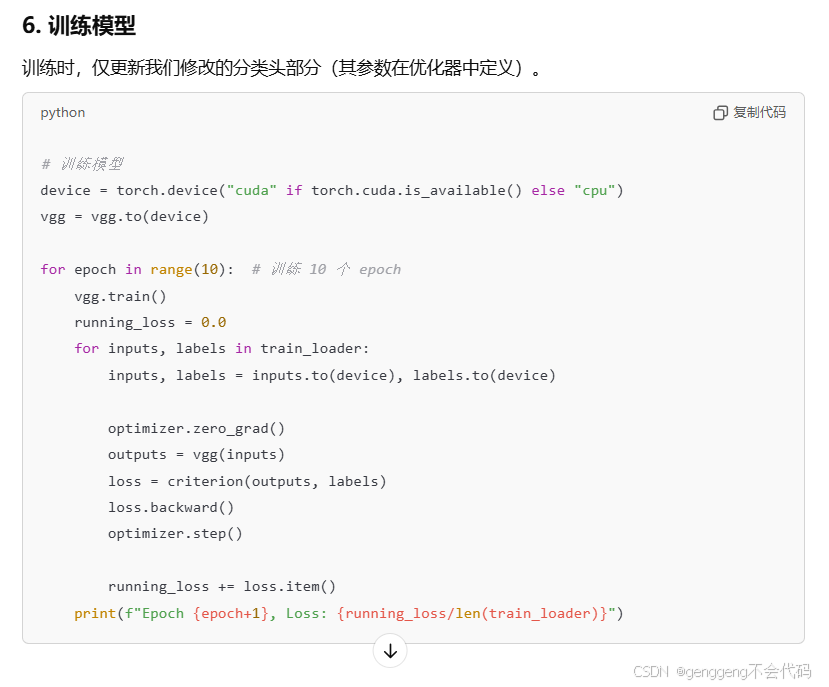
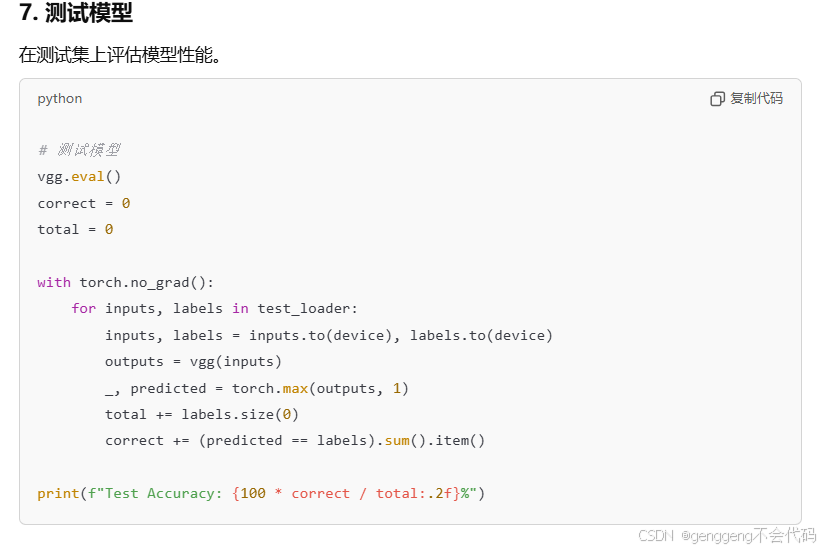

第二问.我们怎么来训练一个网络,包含遍历,设计损失函数,然后计算损失,反传,梯度更新这样一些基本步骤?
相关文章:
)
计算机视觉(为天地立心,为生民立命)
4. 逻辑回归中,对数损失函数怎么来表示的? 5. relu激活函数它的一些特点? ReLU的数学表达式为:f(x)max(0,x) 特点: 1.简单高效:ReLU 的计算非常简单,直接将输入小于 0 的部分置为 0ÿ…...

三格电子——新品IE103转ModbusTCP网关
型号:SG-TCP-IEC103 产品概述 IE103转ModbusTCP网关型号SG-TCP-IEC103,是三格电子推出的工业级网关(以下简称网关),主要用于IEC103数据采集、DLT645-1997/2007数据采集,IEC103支持遥测和遥信,可…...

金碟中间件-AAS-V10.0安装
金蝶中间件AAS-V10.0 AAS-V10.0安装 1.解压AAS-v10.0安装包 unzip AAS-V10.zip2.更新license.xml cd /root/ApusicAS/aas# 这里要将license复制到该路径 [rootvdb1 aas]# ls bin docs jmods lib modules templates config domains …...
)
最新D音滑块JS纯算法还原(含完整源码)
文章目录 1. 写在前面2. 接口分析2. 源码实现【🏠作者主页】:吴秋霖 【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究与开发工作! 【🌟作者推荐】:对爬…...

接口绑定有几种实现方式
在 MyBatis 中,接口绑定是指通过 Java 接口与 SQL 映射文件(XML)进行绑定,允许你以面向对象的方式操作数据库。MyBatis 提供了几种不同的实现方式来实现接口绑定。 MyBatis 接口绑定的几种实现方式 基于 XML 映射的实现方式 这是…...

Oracle JDK需登录下载解决
JDK下载地址 地址:https://www.oracle.com/java/technologies/downloads/archive/ 登录账号获取 访问:https://bugmenot.com/view/oracle.com 直接复制账号密码登录下载...

LabVIEW与PLC点位控制及OPC通讯
在工业自动化中,PLC通过标准协议(如Modbus、Ethernet/IP等)与OPC Server进行数据交换,LabVIEW作为上位机通过OPC客户端读取PLC的数据并进行监控、控制与处理。通过这种方式,LabVIEW能够实现与PLC的实时通信,…...
)
VM16+解压版CentOS7安装和环境配置教程(2024年12月20日)
VM16解压版CentOS7安装和环境配置教程-2024年12月20日 一、下载安装包二、vm安装三、解压版CentOS7安装四、CentOS设置静态IP 因为很多同学觉得配置CentOS7好麻烦,我特地提供了一个已经配置好的现成镜像,来简化操作本篇来记录过程。 如果你在看到这篇文章…...

SQL中的约束
约束(CONSTRAINT) 对表中字段的限制 非空约束:NOT NULL 只能声明在每个字段的后面 CREATE TABLE test( id INT NOT NULL, last_name VARCHAR(15), phone VARCHAR(20) NOT NULL );唯一性约束:UNIQUE 说明: ① 可以声明…...

【Lua热更新】上篇
Lua 热更新 - 上篇 下篇链接:【Lua热更新】下篇 文章目录 Lua 热更新 - 上篇一、AssetBundle1.理论2. AB包资源加载 二、Lua 语法1. 简单数据类型2.字符串操作3.运算符4.条件分支语句5.循环语句6.函数7. table数组8.迭代器遍历9.复杂数据类型 - 表9.1字典9.2类9.3…...

数据压缩比 38.65%,TDengine 重塑 3H1 的存储与性能
小T导读:这篇文章是“2024,我想和 TDengine 谈谈”征文活动的三等奖作品之一。作者通过自身实践,详细分享了 TDengine 在高端装备运维服务平台中的应用,涵盖架构改造、性能测试、功能实现等多个方面。从压缩效率到查询性能&#x…...

Linux shell脚本用于常见图片png、jpg、jpeg、tiff格式批量转webp格式后,并添加文本水印
Linux Debian12基于ImageMagick图像处理工具编写shell脚本用于常见图片png、jpg、jpeg、tiff格式批量转webp并添加文本水印 在Linux系统中,使用ImageMagick可以图片格式转换,其中最常用的是通过命令行工具进行。 ImageMagick是一个非常强大的图像处理工…...
:后处理过程)
DeepFaceLab技术浅析(六):后处理过程
DeepFaceLab 是一款流行的深度学习工具,用于面部替换(DeepFake),其核心功能是将源人物的面部替换到目标视频中的目标人物身上。尽管面部替换的核心在于模型的训练,但后处理过程同样至关重要,它决定了最终生…...

怎么将pdf中的某一个提取出来?介绍几种提取PDF中页面的方法
怎么将pdf中的某一个提取出来?传统上,我们可能通过手动截取屏幕或使用PDF阅读器的复制功能来提取信息,但这种方法往往不够精确,且无法保留原文档的排版和格式。此外,很多时候我们需要提取的内容可能涉及多个页面、多个…...

imu相机EKF
ethzasl_sensor_fusion/Tutorials/Introductory Tutorial for Multi-Sensor Fusion Framework - ROS Wiki https://github.com/ethz-asl/ethzasl_msf/wiki...

CSDN数据大屏可视化【开源】
项目简介 本次基于版本3 开源 版本3开源地址:https://github.com/nangongchengfeng/CsdnBlogBoard.git 版本1开源地址:https://github.com/nangongchengfeng/CSDash.git 这是一个基于 Python 的 CSDN 博客数据可视化看板项目,通过爬虫采…...

C# 从控制台应用程序入门
总目录 前言 从创建并运行第一个控制台应用程序,快速入门C#。 一、新建一个控制台应用程序 控制台应用程序是C# 入门时,学习基础语法的最佳应用程序。 打开VS2022,选择【创建新项目】 搜索【控制台】,选择控制台应用(.NET Framew…...

什么是 DevSecOps 框架?如何提升移动应用安全性?
在如今数字化发展的时代,安全性已成为移动应用开发不可或缺的一部分。传统的开发模式通常将安全作为一个独立的部门,专门负责保护组织的整体系统,而 DevSecOps 框架则将安全融入到 DevOps 的每一个环节中,确保应用的开发、测试、发…...

数字后端项目Floorplan常见问题系列专题
今天给大家分享下数字IC后端设计实现floorplan阶段常见问题系列专题。这些问题都是来自于咱们社区IC后端训练营学员提问的问题库。目前这部分问题库已经积累了4年了,后面会陆续分享这方面的问题。希望对大家的数字后端学习和工作有所帮助。 数字IC后端设计实现floo…...

【C++读写.xlsx文件】OpenXLSX开源库在 Ubuntu 18.04 的编译、交叉编译与使用教程
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 ⏰发布时间⏰: 2024-12-17 …...

Qt设置部件的阴影效果
QT中的比如QWidget,QLabel,QPushbutton,QCheckBox都可以设置阴影效果,就像这样: 以QWidget为例,开始尝试使用样式表的形式添加阴影,但没有效果,写法如下: QWidget#widget1::shadow{color: rgb…...

【iOS安全】NSTaggedPointerString和__NSCFString
概述 简而言之 : NSTaggedPointerString和__NSCFString都是NSString类型。NSTaggedPointerString善于存短字符串,__NSCFString善于存一般或长字符串在iOS运行时,系统会根据字符串长度自动在NSTaggedPointerString和__NSCFString之间进行转换…...
命令 帮助文档)
docker(wsl)命令 帮助文档
WSL wsl使用教程 wsl -l -v 列出所有已安装的 Linux 发行版 wsl -t Ubuntu-22.04 --shutdown 关闭所有正在运行的WSL发行版。如果你只想关闭特定的发行版 wsl -d Ubuntu-22.04 登录到Ubuntu环境 wsl --list --running 查看正在wsl中运行的linux发行版 wsl --unregister (系统名…...

nginx模块ngx-fancyindex 隐藏标题中的 / 和遇到的坑
首先下载nginx源码,编译时加上 --add-module/usr/local/src/ngx-fancyindex/ 例如 : ./configure --prefix/usr/local/nginx --with-select_module --with-poll_module --with-threads --with-file-aio --with-http_ssl_module --with-http_v2_module…...

Edge Scdn防御网站怎么样?
酷盾安全Edge Scdn,即边缘式高防御内容分发网络,主要是通过分布在不同地理位置的多个节点,使用户能够更快地访问网站内容。同时,Edge Scdn通过先进的技术手段,提高了网上内容传输的安全性,防止各种网络攻击…...

音频接口:PDM TDM128 TDM256
一、 PDM接口 在麦克风(Mic)接口中,PDM(Pulse Density Modulation,脉冲密度调制)和I2S(Inter-IC Sound,集成电路内置音频总线)是两种常见的数字输出接口。 1、工作原理…...

半连接转内连接规则的原理与代码解析 |OceanBase查询优化
背景 在查询语句中,若涉及半连接(semi join)操作,由于半连接不满足交换律的规则,连接操作必须遵循语句中定义的顺序执行,从而限制了优化器根据参与连接的表的实际数据量来灵活选择优化策略的能力。为此&am…...

虚拟机VMware的安装问题ip错误,虚拟网卡
要么没有虚拟网卡、有网卡远程连不上等 一般出现在win11 家庭版 1、是否IP错误 ip addr 2、 重置虚拟网卡 3、查看是否有虚拟网卡 4、如果以上检查都解决不了问题 如果你之前有vmware 后来卸载了,又重新安装,一般都会有问题 卸载重装vmware: 第一…...

2024159读书笔记|《南山册页:齐白石果蔬册鱼虫册》节选
2024159读书笔记|《南山册页:齐白石果蔬册&鱼虫册》节选 1. 《南山册页:齐白石鱼虫册》2. 《南山册页:齐白石果蔬册》 1. 《南山册页:齐白石鱼虫册》 《南山册页:齐白石鱼虫册》南山书画,大家之作&…...

校园社交圈子系统APP开发校园社交圈子系统校园社交圈子系统平台校园社交圈子系统论坛开发校园社交圈子系统圈子APP
关于校园社交圈子系统APP及平台的开发,以下是从需求分析、系统设计、技术选型、功能实现等多个方面进行的详细阐述: 点击可获得前后端完整演示查看 一、需求分析 校园社交圈子系统的开发需求主要来源于大学生的社交需求。通过问卷调查、用户需求收集等…...

【Leetcode 热题 100】437. 路径总和 III
问题背景 给定一个二叉树的根节点 r o o t root root,和一个整数 t a r g e t S u m targetSum targetSum,求该二叉树里节点值之和等于 t a r g e t S u m targetSum targetSum 的 路径 的数目。 路径 不需要从根节点开始,也不需要在叶子…...
的结构与用法)
Solidity中的事件(Event)的结构与用法
Solidity中的事件(Event)的结构与用法 event的简单例子被索引的参数(Indexed Parameters)没有被索引的参数(Non-indexed Parameters) event扩展event 更多举例无参数的event有什么用 event的简单例子 在So…...
)
基于STM32的房间湿度控制系统设计与实现(论文+源码)
1.系统总体设计 根据系统的实际应用需求,从硬件电路以及软件程序两个方面展开房间湿度控制系统设计。如图所示为系统的整体架构图。系统采用单片机作为控制器,在传感器检测模块中包括DHT11温湿度检测、有害气体浓度检测,在系统执行模块包括加…...

docker 使用 xz save 镜像
适用场景 如果docker save -o xxx > xxx 镜像体积过大,可以使用 xz 命令压缩。 命令 例如 save busybox:1.31.1 镜像,其中 -T 是使用多核心压缩,可以加快压缩。 docker save busybox:1.31.1 |xz -T 8 > /tmp/busybox:1.31.1安装 xz Ubuntu/Debian sudo apt upda…...

Dockerfile文件编写
目录 Dockerfile文件编写 1.什么是Dockerfile 2. Dockerfile作用 3.dockerfile 的基本结构: 4.dockerfile指令: FROM 指定基础镜像,dockerfile构建镜像的第一个指令 LABEL 指定镜像维护人信息 ADD/COPY 复制本地文件/目录到镜像中 …...

linux高性能服务器编程读书笔记目录建议
linux高性能服务器编程读书笔记目录&&建议 文章目录 linux高性能服务器编程读书笔记目录&&建议目录第一篇 TCP/IP协议详解第二篇 深入解析高性能服务器编程第三篇 高性能服务器优化与监测 自己总结的内容linux这本书上没有但是黑马上有的东西epoll反应堆模型本…...
)
java全栈day20--Web后端实战(Mybatis基础2)
一、Mybatis基础 1.1辅助配置 配置 SQL 提示。 默认在 mybatis 中编写 SQL 语句是不识别的。可以做如下配置: 现在就有sql提示了 新的问题 产生原因: Idea 和数据库没有建立连接,不识别表信息 解决方式:在 Idea 中配置 MySQL 数…...

页面加载速度优化策略:提升用户体验的关键
文章目录 前言一、为什么需要优化页面加载速度?二、前端优化技术三、后端优化策略四、构建与部署优化五、案例研究:实际效果展示结语 前言 在当今快节奏的互联网环境中,页面加载速度不仅是用户体验的重要组成部分,更是影响网站性…...

多模块程序的测试策略
例1.如图“自顶向下”: 采用广度优先:模块M1结合模块M2,M3和M4,然后再结合下一控制层中的模块M5,M6和M7,继续下去直到所有模块结合近来。 混合策略: 改进的自顶向下测试方法 基本上使用自顶向下的测试方法…...

聚水潭数据无缝集成到金蝶云星空的实现方案
聚水潭数据集成到金蝶云星空:聚水潭调拨对接金蝶直接调拨ok 在企业信息化管理中,数据的高效流动和准确对接是实现业务流程顺畅运行的关键。本文将分享一个具体的系统对接集成案例——如何通过轻易云数据集成平台,将聚水潭的数据无缝集成到金…...

electron打包linux环境
注意:新版的electron已经不支持在win上直接打包Linux的环境了,服务会卡住,会一直生成文件占用磁盘(我发现的时候占了我100G,而且文件夹很深,找了java代码while循环,好不容易删除的o(╥﹏╥)o) electron有一个专门打包的docker镜像,…...

设计模式--单例模式【创建型模式】
设计模式的分类 我们都知道有 23 种设计模式,这 23 种设计模式可分为如下三类: 创建型模式(5 种):单例模式、工厂方法模式、抽象工厂模式、建造者模式、原型模式。结构型模式(7 种)࿱…...

Mybatis分页插件的使用问题记录
项目中配置的分页插件依赖为 <dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper</artifactId><version>5.1.7</version></dependency>之前的项目代码编写分页的方式为,通过传入的条件…...

BERTective: Language Models and Contextual Information for Deception Detection
目录 概要 实验设置 数据集 实验条件 指标和基准 实验方法 神经网络基准 基于transformer的模型 基于BERT的模型 实验结果 分析 非上下文化模型 上下文化模型 欺骗语言 讨论 结论 概要 本文基于一组包含虚假陈述的意大利对话语料库,建立了一种新的…...

python 配置 oracle instant client
1.问题描述 想用python连接oracle数据库,百度得知需要cx_Oracle这个第三方库 import cx_Oracle# 设置Oracle数据源名称 dsn cx_Oracle.makedsn(host, port, service_nameservice_name)# 创建数据库连接 connection cx_Oracle.connect(userusername, passwordpas…...

【C语言】一文讲通 和*
&和*详解 前言符号 &:取地址符& 的用法& 用于函数参数传递 符号 *:解引用符* 的用法* 用于指针的初始化 结合使用 & 和 *1. * 和 & 配合使用示例 常见错误与注意事项总结 前言 在 C 语言中,* 和 & 是两个非常重…...

编译原理复习---基本概念+推导树
适用于电子科技大学编译原理期末考试复习。 本文只适合复习不适合预习,即适合上课听过一点或自己学过一点的同学。 1. 编译原理概述 编译原理是计算机科学的一个重要分支,它涉及将高级编程语言编写的源代码转换为机器能够理解和执行的低级代码的过程。…...

ThinkPHP 吸收了Java Spring框架一些特性
ThinkPHP 吸收了Java Spring框架一些特性,下面介绍如下: 1、controller 控制器层 存放控制器层的文件,用于处理请求和响应 2、model 实体类 存放实体类的文件,用于定义数据模型 3、dao DAO层 存放DAO(数据访问…...

【Java基础面试题019】什么是Java中的不可变类?
回答重点 不可变类是指在创建后无法被修改的类。一旦对象被创建,它的所有属性都不能被更改。这种类的实例在整个生命周期内保持不变。 关键特征: 声明类为final,防止子类继承类的所有字段都是private和final,确保它们在初始化后…...

JAVA开发时获取用户信息失败,分析后端日志信息
从日志信息(见文章最后)来看,JWT 认证过程似乎是成功的。具体来说,以下几点表明认证流程正常: Token 解析成功: 日志显示 Parsing token: eyJhbGciOiJIUzUxMiJ9.eyJ1c2VySWQiOjEsImV4cCI6MTczNDM2MzUwMH0.jQtaj1sTBCMh…...