flink sink kafka的事务提交现象猜想
现象
查看flink源码时 sink kafka有事务提交机制,查看源码发现是使用两阶段提交策略,而事务提交是checkpoint完成后才执行,那么如果checkpoint设置间隔时间比较长时,事务未提交之前,后端应该消费不到数据,而观察实际现象为写入kafka的消费数据可以立马消费。
测试用例
测试流程
- 编写任务1,设置较长的checkpoint时间,并且指定 CheckpointingMode.EXACTLY_ONCE,输出输出到kafka。
- 编写任务2消费任务的结果topic,打印控制台,验证结果。
- 根据现象查看源码,分析原因。
测试用例
测试任务1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(1000*60l, CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setCheckpointStorage("file:///flink/checkpoint");// 超时时间,checkpoint没在时间内完成则丢弃env.getCheckpointConfig().setCheckpointTimeout(50000L); //10秒env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);env.getCheckpointConfig().setTolerableCheckpointFailureNumber(1);//最小间隔时间(前一次结束时间,与下一次开始时间间隔)env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
// 当 Flink 任务取消时,保留外部保存的 checkpoint 信息KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("127.0.0.1:9092").setTopics("test001").setGroupId("my-group")
// .setStartingOffsets(OffsetsInitializer()).setStartingOffsets(OffsetsInitializer.committedOffsets()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");// 从文件读取数据
// DataStream<SensorReading> dataStream = env.addSource( new SourceTest4.MySensorSource() );DataStream<String> map = kafkaSource.map(new MapFunction<String, String>() {@Overridepublic String map(String s) throws Exception {return s;}});Properties properties = new Properties();
// 根据上面的介绍自己计算这边的超时时间,满足条件即可properties.setProperty("transaction.timeout.ms","900000");
// properties.setProperty("bootstrap.servers", "127.0.0.1:9092");KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers("192.168.65.128:9092").setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("test002").setValueSerializationSchema(new SimpleStringSchema()).build()).setKafkaProducerConfig(properties).setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("flink-xhaodream-").build();map.sinkTo(sink);// 打印输出env.execute();测试任务2
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(1000*150l, CheckpointingMode.EXACTLY_ONCE);env.getCheckpointConfig().setCheckpointStorage("file:///flink/checkpoint");
// 当 Flink 任务取消时,保留外部保存的 checkpoint 信息Properties properties1 = new Properties();
// properties1.put("isolation.level","read_committed");KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("127.0.0.1:9092").setTopics("test002").setGroupId("my-group2").setProperties(properties1).setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST)).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");kafkaSource.print(" test2接受数据");// 打印输出env.execute();测试结果分析
测试结果:
任务1开启后,无论是否执行checkpoint,任务checkpoint都可以正常消费数据,与预期不符合。
原因排查
查看kafkaSink 的源码,找到跟与两阶段提交相关的代码,1.18源码中TwoPhaseCommittingSink有重构。kafkasink实现TwoPhaseCommittingSink接口实现,创建Commiter和Writer。
@PublicEvolving
public interface TwoPhaseCommittingSink<InputT, CommT> extends Sink<InputT> {PrecommittingSinkWriter<InputT, CommT> createWriter(Sink.InitContext var1) throws IOException;Committer<CommT> createCommitter() throws IOException;SimpleVersionedSerializer<CommT> getCommittableSerializer();@PublicEvolvingpublic interface PrecommittingSinkWriter<InputT, CommT> extends SinkWriter<InputT> {Collection<CommT> prepareCommit() throws IOException, InterruptedException;}
}--------------------------------------
public class KafkaSink<IN>implements StatefulSink<IN, KafkaWriterState>,TwoPhaseCommittingSink<IN, KafkaCommittable> {private final DeliveryGuarantee deliveryGuarantee;private final KafkaRecordSerializationSchema<IN> recordSerializer;private final Properties kafkaProducerConfig;private final String transactionalIdPrefix;KafkaSink(DeliveryGuarantee deliveryGuarantee,Properties kafkaProducerConfig,String transactionalIdPrefix,KafkaRecordSerializationSchema<IN> recordSerializer) {this.deliveryGuarantee = deliveryGuarantee;this.kafkaProducerConfig = kafkaProducerConfig;this.transactionalIdPrefix = transactionalIdPrefix;this.recordSerializer = recordSerializer;}/*** Create a {@link KafkaSinkBuilder} to construct a new {@link KafkaSink}.** @param <IN> type of incoming records* @return {@link KafkaSinkBuilder}*/public static <IN> KafkaSinkBuilder<IN> builder() {return new KafkaSinkBuilder<>();}
-- 创建Committer@Internal@Overridepublic Committer<KafkaCommittable> createCommitter() throws IOException {return new KafkaCommitter(kafkaProducerConfig);}@Internal@Overridepublic SimpleVersionedSerializer<KafkaCommittable> getCommittableSerializer() {return new KafkaCommittableSerializer();}
-- 创建writer@Internal@Overridepublic KafkaWriter<IN> createWriter(InitContext context) throws IOException {return new KafkaWriter<IN>(deliveryGuarantee,kafkaProducerConfig,transactionalIdPrefix,context,recordSerializer,context.asSerializationSchemaInitializationContext(),Collections.emptyList());}@Internal@Overridepublic KafkaWriter<IN> restoreWriter(InitContext context, Collection<KafkaWriterState> recoveredState) throws IOException {return new KafkaWriter<>(deliveryGuarantee,kafkaProducerConfig,transactionalIdPrefix,context,recordSerializer,context.asSerializationSchemaInitializationContext(),recoveredState);}@Internal@Overridepublic SimpleVersionedSerializer<KafkaWriterState> getWriterStateSerializer() {return new KafkaWriterStateSerializer();}@VisibleForTestingprotected Properties getKafkaProducerConfig() {return kafkaProducerConfig;}
}KafkaWriter和KafkaCommitter源码,
在KafkaWriter中snapshotState方法中发现如果deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE的开启事务的判断逻辑。
class KafkaWriter<IN>implements StatefulSink.StatefulSinkWriter<IN, KafkaWriterState>,TwoPhaseCommittingSink.PrecommittingSinkWriter<IN, KafkaCommittable> {
.... 省略代码 @Overridepublic Collection<KafkaCommittable> prepareCommit() {if (deliveryGuarantee != DeliveryGuarantee.EXACTLY_ONCE) {return Collections.emptyList();}// only return a KafkaCommittable if the current transaction has been written some dataif (currentProducer.hasRecordsInTransaction()) {final List<KafkaCommittable> committables =Collections.singletonList(KafkaCommittable.of(currentProducer, producerPool::add));LOG.debug("Committing {} committables.", committables);return committables;}// otherwise, we commit the empty transaction as is (no-op) and just recycle the producercurrentProducer.commitTransaction();producerPool.add(currentProducer);return Collections.emptyList();}@Overridepublic List<KafkaWriterState> snapshotState(long checkpointId) throws IOException {
-- 开启事务判断
if (deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE) {currentProducer = getTransactionalProducer(checkpointId + 1);currentProducer.beginTransaction();}return Collections.singletonList(kafkaWriterState);}
。。。。。
}查看 KafkaCommitter的commit()方法发现producer.commitTransaction();操作
/*** Committer implementation for {@link KafkaSink}** <p>The committer is responsible to finalize the Kafka transactions by committing them.*/
class KafkaCommitter implements Committer<KafkaCommittable>, Closeable {private static final Logger LOG = LoggerFactory.getLogger(KafkaCommitter.class);public static final String UNKNOWN_PRODUCER_ID_ERROR_MESSAGE ="because of a bug in the Kafka broker (KAFKA-9310). Please upgrade to Kafka 2.5+. If you are running with concurrent checkpoints, you also may want to try without them.\n"+ "To avoid data loss, the application will restart.";private final Properties kafkaProducerConfig;@Nullable private FlinkKafkaInternalProducer<?, ?> recoveryProducer;KafkaCommitter(Properties kafkaProducerConfig) {this.kafkaProducerConfig = kafkaProducerConfig;}@Overridepublic void commit(Collection<CommitRequest<KafkaCommittable>> requests)throws IOException, InterruptedException {for (CommitRequest<KafkaCommittable> request : requests) {final KafkaCommittable committable = request.getCommittable();final String transactionalId = committable.getTransactionalId();LOG.debug("Committing Kafka transaction {}", transactionalId);Optional<Recyclable<? extends FlinkKafkaInternalProducer<?, ?>>> recyclable =committable.getProducer();FlinkKafkaInternalProducer<?, ?> producer;try {producer =recyclable.<FlinkKafkaInternalProducer<?, ?>>map(Recyclable::getObject).orElseGet(() -> getRecoveryProducer(committable));--- 事务提交producer.commitTransaction();producer.flush();recyclable.ifPresent(Recyclable::close);} catch (RetriableException e) {LOG.warn("Encountered retriable exception while committing {}.", transactionalId, e);request.retryLater();} catch (ProducerFencedException e) {......}}}
。。。。
}分析结果
发现除了设置checkpoint还需要kafkasink单独设置.才会实现输出端的开启事务,因此在任务1中添加设置setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
KafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers("192.168.65.128:9092").setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("test002").setValueSerializationSchema(new SimpleStringSchema()).build()).setKafkaProducerConfig(properties).setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("flink-xhaodream-").build();再次验证任务任务2依然可以正常消费。这是有一点头大,不明白为什么?想到既然开启事务肯定有事务的隔离级别,查询了kafka的事务隔离级别,有两种,分别是读已提交和读未提交,默认消费事务是读未提交。
kafka的事务隔离级别:
读已提交(Read committed):此隔离级别保证消费者只能读取已经提交的消息。这意味着事务中的消息在提交之前对消费者是不可见的。使用此隔离级别可以避免消费者读取到未提交的事务消息,确保消费者只读取到已经持久化的消息。读未提交(Read Uncommitted):此隔离级别允许消费者读取未提交的消息。这意味着事务中的消息在提交之前就对消费者可见。使用此隔离级别可以实现更低的延迟,但可能会导致消费者读取到未提交的事务消息。在任务2中添加isolation.level="read_committed",设定读取消费事务级别为读已提交,再次测试,发现任务1执行完checkpoint前任务2消费不到数据。而命令行可以及时消费任务1的输出topic可可以消费到数据。结果与预期相同。
Properties properties1 = new Properties();properties1.put("isolation.level","read_committed");KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("127.0.0.1:9092").setTopics("test002").setGroupId("my-group2").setProperties(properties1)注意事项
Kafka | Apache Flink
FlinkKafkaProducer 已被弃用并将在 Flink 1.15 中移除,请改用 KafkaSink。
官网文档信息
Kafka | Apache Flink
Kafka Consumer 提交 Offset 的行为配置 #
Flink Kafka Consumer 允许有配置如何将 offset 提交回 Kafka broker 的行为。请注意:Flink Kafka Consumer 不依赖于提交的 offset 来实现容错保证。提交的 offset 只是一种方法,用于公开 consumer 的进度以便进行监控。
配置 offset 提交行为的方法是否相同,取决于是否为 job 启用了 checkpointing。
-
禁用 Checkpointing: 如果禁用了 checkpointing,则 Flink Kafka Consumer 依赖于内部使用的 Kafka client 自动定期 offset 提交功能。 因此,要禁用或启用 offset 的提交,只需将
enable.auto.commit或者auto.commit.interval.ms的Key 值设置为提供的Properties配置中的适当值。 -
启用 Checkpointing: 如果启用了 checkpointing,那么当 checkpointing 完成时,Flink Kafka Consumer 将提交的 offset 存储在 checkpoint 状态中。 这确保 Kafka broker 中提交的 offset 与 checkpoint 状态中的 offset 一致。 用户可以通过调用 consumer 上的
setCommitOffsetsOnCheckpoints(boolean)方法来禁用或启用 offset 的提交(默认情况下,这个值是 true )。 注意,在这个场景中,Properties中的自动定期 offset 提交设置会被完全忽略。
kafkasink支持语义保证
kafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)。对于 DeliveryGuarantee.AT_LEAST_ONCE 和 DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint 必须启用。默认情况下 KafkaSink 使用 DeliveryGuarantee.NONE。 以下是对不同语义保证的解释:
DeliveryGuarantee.NONE不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。
推荐查看1.14版本和1.18版本结合起来看,在一些细节处理上有差异。
Kafka | Apache Flink
其他源码简介
如果查看1.18版本源码不太好理解两阶段提交,可以查看1.14.5的源码,发现FlinkKafkaProducer被标记废除请改用 KafkaSink,并将在 Flink 1.15 中移除, 在1.14.5中TwoPhaseCommitSinkFunction为抽象类,有明确定开启事务、预提交和提交的抽象方法,比较好理解。

查看1.14.5版本的KafkaSink 的依赖,发现没有直接使用TwoPhaseCommitSinkFunction,但是查看源码可以看到使用了commiter和kafkawriter对象

public class KafkaSink<IN> implements Sink<IN, KafkaCommittable, KafkaWriterState, Void> { public static <IN> KafkaSinkBuilder<IN> builder() {return new KafkaSinkBuilder<>();}
-- KafkaWriter 中会判断是否需要开启事务@Overridepublic SinkWriter<IN, KafkaCommittable, KafkaWriterState> createWriter(InitContext context, List<KafkaWriterState> states) throws IOException {final Supplier<MetricGroup> metricGroupSupplier =() -> context.metricGroup().addGroup("user");return new KafkaWriter<>(deliveryGuarantee,kafkaProducerConfig,transactionalIdPrefix,context,recordSerializer,new InitContextInitializationContextAdapter(context.getUserCodeClassLoader(), metricGroupSupplier),states);}-- 事务提交在kafkaCommitter@Overridepublic Optional<Committer<KafkaCommittable>> createCommitter() throws IOException {return Optional.of(new KafkaCommitter(kafkaProducerConfig));}@Overridepublic Optional<GlobalCommitter<KafkaCommittable, Void>> createGlobalCommitter()throws IOException {return Optional.empty();}...
}KafkaWriter源码
@Overridepublic List<KafkaCommittable> prepareCommit(boolean flush) {if (deliveryGuarantee != DeliveryGuarantee.NONE || flush) {currentProducer.flush();}if (deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE) {final List<KafkaCommittable> committables =Collections.singletonList(KafkaCommittable.of(currentProducer, producerPool::add));LOG.debug("Committing {} committables, final commit={}.", committables, flush);return committables;}return Collections.emptyList();}
-- 快照状态开启事务@Overridepublic List<KafkaWriterState> snapshotState(long checkpointId) throws IOException {if (deliveryGuarantee == DeliveryGuarantee.EXACTLY_ONCE) {currentProducer = getTransactionalProducer(checkpointId + 1);currentProducer.beginTransaction();}return ImmutableList.of(kafkaWriterState);}
1.14.5 版本TwoPhaseCommitSinkFunction是一个抽象类 在1.18 中是接口
/*** Flink Sink to produce data into a Kafka topic. By default producer will use {@link* FlinkKafkaProducer.Semantic#AT_LEAST_ONCE} semantic. Before using {@link* FlinkKafkaProducer.Semantic#EXACTLY_ONCE} please refer to Flink's Kafka connector documentation.** @deprecated Please use {@link org.apache.flink.connector.kafka.sink.KafkaSink}.*/
@Deprecated
@PublicEvolving
public class FlinkKafkaProducer<IN>extends TwoPhaseCommitSinkFunction<IN,FlinkKafkaProducer.KafkaTransactionState,FlinkKafkaProducer.KafkaTransactionContext> {。。。}
-- 1.14 版本TwoPhaseCommitSinkFunction 为抽象类@PublicEvolving
public abstract class TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT> extends RichSinkFunction<IN>implements CheckpointedFunction, CheckpointListener { }-- 1.18 版本
@PublicEvolving
public interface TwoPhaseCommittingSink<InputT, CommT> extends Sink<InputT> {PrecommittingSinkWriter<InputT, CommT> createWriter(Sink.InitContext var1) throws IOException;Committer<CommT> createCommitter() throws IOException;SimpleVersionedSerializer<CommT> getCommittableSerializer();@PublicEvolvingpublic interface PrecommittingSinkWriter<InputT, CommT> extends SinkWriter<InputT> {Collection<CommT> prepareCommit() throws IOException, InterruptedException;}
}
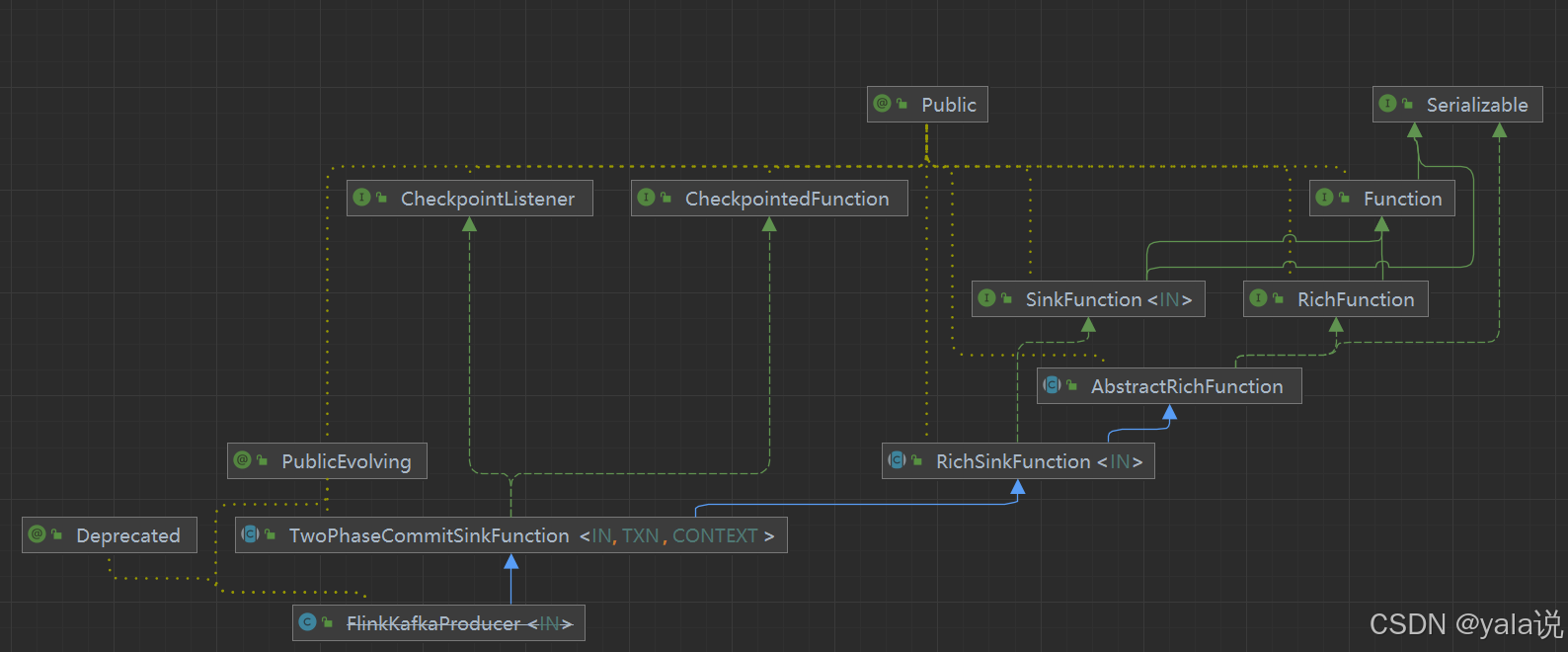
FlinkKafkaProducer继承TwoPhaseCommitSinkFunction,会重写其中的方法,查看重写开启事务的方法
-- FlinkKafkaProducer 中重写beginTransaction 方法@Overrideprotected FlinkKafkaProducer.KafkaTransactionState beginTransaction()throws FlinkKafkaException {switch (semantic) {case EXACTLY_ONCE:FlinkKafkaInternalProducer<byte[], byte[]> producer = createTransactionalProducer();
-- 开启kafka的procder的事务producer.beginTransaction();return new FlinkKafkaProducer.KafkaTransactionState(producer.getTransactionalId(), producer);case AT_LEAST_ONCE:case NONE:// Do not create new producer on each beginTransaction() if it is not necessaryfinal FlinkKafkaProducer.KafkaTransactionState currentTransaction =currentTransaction();if (currentTransaction != null && currentTransaction.producer != null) {return new FlinkKafkaProducer.KafkaTransactionState(currentTransaction.producer);}return new FlinkKafkaProducer.KafkaTransactionState(initNonTransactionalProducer(true));default:throw new UnsupportedOperationException("Not implemented semantic");}}只有当FlinkKafkaProducer.Semantic 为EXACTLY_ONCE时才会开启事务,查看其构造方法
public FlinkKafkaProducer(String topicId,SerializationSchema<IN> serializationSchema,Properties producerConfig,@Nullable FlinkKafkaPartitioner<IN> customPartitioner,FlinkKafkaProducer.Semantic semantic,int kafkaProducersPoolSize) {this(topicId,null,null,new KafkaSerializationSchemaWrapper<>(topicId, customPartitioner, false, serializationSchema),producerConfig,semantic,kafkaProducersPoolSize);}相关文章:

flink sink kafka的事务提交现象猜想
现象 查看flink源码时 sink kafka有事务提交机制,查看源码发现是使用两阶段提交策略,而事务提交是checkpoint完成后才执行,那么如果checkpoint设置间隔时间比较长时,事务未提交之前,后端应该消费不到数据,…...

Oracle 临时表空间管理与最佳实践
Oracle 临时表空间管理与最佳实践 内容摘要 本文深入探讨了Oracle数据库中临时表空间的管理和最佳实践。主要内容包括: 临时表空间的概述及其在Oracle 19c多租户架构中的特点临时表空间组的优势及其创建方法非临时表空间组的临时表空间日常维护操作命令临时表空间…...

Java转C之继承和多态
在C/C中,继承和多态是面向对象编程(OOP)的两个重要特性。以下将详细讲解C/C中如何实现继承与多态,同时结合Java的对比,帮助理解两者的异同。 继承的实现 C/C中的继承 继承允许一个类(派生类/子类…...

【密码学】ZUC祖冲之算法
一、ZUC算法简介 ZUC算法(祖冲之算法)是中国自主研发的一种流密码算法,2011年被3GPP批准成为4G国际标准,主要用于无线通信的加密和完整性保护。ZUC算法在逻辑上采用三层结构设计,包括线性反馈移位寄存器(L…...

MacOS系统 快速安装appium 步骤详解
在macOS系统上,你可以通过使用nvm(Node Version Manager)来管理Node.js的版本,并基于nvm安装的Node.js环境来快捷地安装Appium。以下是具体步骤: 一、安装nvm 下载nvm 访问nvm的GitHub仓库(nvm GitHub&…...

SEGGER | 基于STM32F405 + Keil - RTT组件07 - J-Scope数据可视化,RTT方式 + DWT定时器时间戳
导言 在上一章节SEGGER | 基于STM32F405 Keil - RTT组件06 - J-Scope数据可视化,使用RTT方式的第4.3章节提到,如果消息包不包含时间戳的话,那么J-Scope的横坐标的单位时间默认是100us,说白了时间戳是假的。会导致如下问题&#x…...
算法)
机器学习支持向量机(SVM)算法
一、引言 在当今数据驱动的时代,机器学习算法在各个领域发挥着至关重要的作用。支持向量机(Support Vector Machine,SVM)作为一种强大的监督学习算法,以其在分类和回归任务中的卓越性能而备受瞩目。SVM 具有良好的泛化…...

浏览器端的 js 包括哪几个部分
一、核心语言部分 1. 变量与数据类型 变量用于存储数据,在 JavaScript 中有多种数据类型,如基本数据类型(字符串、数字、布尔值、undefined、null)和引用数据类型(对象、数组、函数)。 let name "…...

【含开题报告+文档+PPT+源码】基于SpringBoot的开放实验管理平台设计与实现
开题报告 设计开放实验管理平台的目的在于促进科学研究与教学的融合。传统实验室常常局限于特定地点和时间,而开放平台可以为学生、教师和研究人员提供一个便捷的交流与共享环境。通过在线平台,他们可以分享实验资源、交流经验,从而促进科学…...

国内可以访问的github地址
国内的IP直接访问github.com官网一般会出现无法访问或者卡顿问题,可以尝试访问下面的国内的代理网站: GitHub Build and ship software on a single, collaborative platform GitHub...

Spring 框架事务管理深度剖析
1.Spring框架的事务管理有哪些优点 pring框架的事务管理具有以下优点: 声明式事务管理:Spring支持声明式事务管理,这使得开发者可以通过配置而不是编程方式来定义事务边界。这种方式简化了事务管理代码,并且可以减少出错的机会。…...

6.1 初探MapReduce
MapReduce是一种分布式计算框架,用于处理大规模数据集。其核心思想是“分而治之”,通过Map阶段将任务分解为多个简单任务并行处理,然后在Reduce阶段汇总结果。MapReduce编程模型包括Map和Reduce两个阶段,数据来源和结果存储通常在…...

SpringBoot - 动态端口切换黑魔法
文章目录 关键技术点核心原理Code 关键技术点 利用 Spring Boot 内嵌 Servlet 容器 和 动态端口切换 的方式实现平滑更新的方案,关键技术点如下: Servlet 容器重新绑定端口:Spring Boot 使用 ServletWebServerFactory 动态设置新端口。零停…...

【Excel】单元格分列
目录 分列(新手友好) 1. 选中需要分列的单元格后,选择 【数据】选项卡下的【分列】功能。 2. 按照分列向导提示选择适合的分列方式。 3. 分好就是这个样子 智能分列(进阶) 高级分列 Tips: 新手推荐基…...

Scratch教学作品 | 3D圆柱体俄罗斯方块——旋转视角的全新挑战! ✨
今天为大家推荐一款创意十足的Scratch益智游戏——《3D圆柱体俄罗斯方块》!由Ceratophrys制作,这款作品将经典俄罗斯方块与立体圆柱舞台相结合,为玩家带来了前所未有的空间挑战与乐趣。更棒的是,这款游戏的源码可以在小虎鲸Scratc…...

智慧商城:登录页静态布局,axios请求数据切换图形验证
登录页静态布局 在src目录下新建 styles,主要用于 存放公共样式。在该文件夹下新建common.less文件,并将其在main.js中引入 将图片拷贝到src文件夹下的 assets文件夹下 完成静态布局 点击左箭头能返回到首页 所有组件头部返回左箭头颜色都是一样的&#…...

HTML知识点详解教程
文章目录 HTML知识点详解教程1. HTML基本语法2. HTML标签详解2.1 分区标签 <div>2.2 标题标签 <h1> ~ <h6>2.3 段落标签 <p>2.4 图片标签 <img>2.5 列表标签 <ul> 和 <ol>无序列表 <ul>有序列表 <ol> 2.6 超链接标签 &l…...

知识分享第二十八天-数学篇一
组合.二项式定理.常见导数 组合 让我们通过一个具体的例子来理解组合(Combinations)的概念 假设你有一个装有5个不同颜色球的袋子:红、蓝、绿、黄和紫。你想从中随机抽取3个球, 不考虑顺序,那么你可以有多少种不同的…...
---Servlet容器)
搭建Tomcat(四)---Servlet容器
目录 引入 Servlet容器 一、优化MyTomcat ①先将MyTomcat的main函数搬过来: ②将getClass()函数搬过来 ③创建容器 ④连接ServletConfigMapping和MyTomcat 连接: ⑤完整的ServletConfigMapping和MyTomcat方法: a.ServletConfigMappin…...

P1029 [NOIP2001 普及组] 最大公约数和最小公倍数问题
题目描述 输入两个正整数 𝑥0,𝑦0,求出满足下列条件的 𝑃,𝑄 的个数: 𝑃,𝑄是正整数。 要求 𝑃,𝑄 以 𝑥0为最大公约数,以 …...

【泛微系统】自定义报表查看权限
自定义报表查询权限 前言:流程自定义报表,可查看每个报表都有哪些人有权限 --SQLserver写法 select a.id,a.workflowname,自定义报表权限 type,b.reportname,c.typename...
介绍)
NPM国内镜像源多选择与镜像快速切换工具(nrm)介绍
多镜像源选择 淘宝镜像(推荐) 镜像地址:https://registry.npmmirror.com 特性:官方推荐,镜像更新速度快,稳定性高。 使用方式: npm config set registry https://registry.npmmirror.com恢复…...

详解负载均衡
什么是负载均衡? 想象一下,你有一家餐厅,当有很多客人同时到来时,如果只有一名服务员接待,可能会导致服务变慢。为了解决这个问题,你可以增加更多的服务员来分担工作,这样每位服务员就可以更快…...

AngularJS 与 SQL 的集成应用
AngularJS 与 SQL 的集成应用 引言 在当今的Web开发领域,AngularJS 和 SQL 是两种非常重要的技术。AngularJS,作为一个强大的前端框架,能够帮助开发者构建复杂且高性能的客户端应用。而SQL(Structured Query Language),作为一种广泛使用的数据库查询语言,是管理关系型…...

ANOMALY BERT 解读
出处: ICLR workshop 2023 代码:Jhryu30/AnomalyBERT 可视化效果: 一 提出动机 动机:无监督 TSAD 领域内,“训练集” 也缺失:真值标签(GT);换句话说,一个…...

51c视觉~YOLO~合集6~
我自己的原文哦~ https://blog.51cto.com/whaosoft/12830685 一、其他yolo 1.1 Spiking-YOLO 使用常规深度神经网络到脉冲神经网络转换方法应用于脉冲神经网络域时,性能下降的很多,深入分析后提出了可能的解释:一是来自逐层归一化的效率…...

软考高级架构 —— 10.6 大型网站系统架构演化实例 + 软件架构维护
10.6 大型网站系统架构演化实例 大型网站的技术挑战主要来自于庞大的用户,高并发的访问和海量的数据,主要解决这类问题。 1. 单体架构 特点: 所有资源(应用程序、数据库、文件)集中在一台服务器上。适用场景: 小型网站&am…...
)
两数之和(Hash表)
优质博文:IT-BLOG-CN 一、题目 给定一个整数数组nums和一个整数目标值target,请你在该数组中找出"和"为目标值target的那两个整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元…...

【问题定位记录】哪些情况可能造成403
起因 403是我们平时在http请求中常见的一种错误码,如果有一天别人问你什么情况下可能造成403,我想大家都能想到的一种就是权限问题,比如鉴权失败会造成403。 但实际上不止这一种原因可能造成403,还有一种可能的原因今天就被我遇…...
)
SmartX分享:SMTX ZBS的纠删码EC与多副本介绍、对比与其他概念(分布式存储)
目录 背景多副本EC相关概念限制工作方式写入读取编辑故障移除硬盘、节点 EC存储配置EC推荐节点数EC的容错能力EC的数据块数k与m的互相限制 EC和多副本的对比其他涉及到全新存储分层的概念可以参考的原文链接: 背景 近期,SmartX的SMTX ZBS 分布式存储 推…...
)
C++并发与多线程(创建多个线程)
创建和等待多个线程 基础示例 // ConsoleApplication10.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 //#include <iostream> #include <vector> #include <map> #include <string> #include <thread> #include <…...

【开发日志】ASP.NET Core Minimal APIs开发日志
后端 实现登录注册 注册API 在数据库中存储/注册账户密码 登录API 检测接收来的账户密码,如果正确,则生成JWT Token返回给客户端 未配置密钥 报错信息,这是我在提交注册请求时,后端报的错,看起来是在生成JWT Token时出现了…...

5G学习笔记之Non-Public Network R18
只是协议的搬运工 目录 0. NPN其它笔记 1. 概述 2. R18增强 2.1 等效SNPN间的移动性管理 2.2 non-3GPP接入SNPN 2.3 Localized Service 2.4 Charging 2.5 Management 0. NPN其它笔记 1. SNPN系列ID和广播消息 1. 概述 NPN,Non-Public Network, 非公共网络…...

sheng的学习笔记-AI-WaveNet模型
Ai目录:sheng的学习笔记-AI目录-CSDN博客 需要先看一下这些文章,作为基础 sheng的学习笔记-AI-残差网络-Residual Networks (ResNets)_神经网络的衰变是什么-CSDN博客 sheng的学习笔记-AI-卷积神经网络_单层卷积神经网络-CSDN博客 sheng的学习笔记-T…...

0002.基于springboot +layui二手物品交易平台
适合初学同学练手项目,部署简单,代码简洁清晰; 注:当前项目架构使用前后端未分离哦! 一、系统架构 前端:layui| html 后端:springboot | mybatis-plus 环境:jdk1.8 | mysql | maven 二、代…...

java集合基础
Java的java.util包主要提供了以下三种类型的集合: List:一种有序列表的集合,例如,按索引排列的Student的List;Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set&…...
?)
如何在NGINX中实现基于IP的访问控制(IP黑白名单)?
大家好,我是锋哥。今天分享关于【如何在NGINX中实现基于IP的访问控制(IP黑白名单)?】面试题。希望对大家有帮助; 如何在NGINX中实现基于IP的访问控制(IP黑白名单)? 1000道 互联网大…...

「Mac玩转仓颉内测版51」基础篇13 - 高阶函数与闭包
本篇详细介绍高阶函数和闭包,这是仓颉语言中实现灵活逻辑的关键工具。高阶函数可将函数作为参数或返回值使用,而闭包能捕获其定义域中的变量,并在后续调用中保持状态。这些概念能让代码更加简洁、灵活,并提升复用性。 关键词 高阶…...

如何与GPT更高效的问答
与GPT进行高效沟通的关键在于提问的方式。通过合理的提问技巧,可以更清晰地表达需求,从而获得更准确的回答。以下是一些实用的建议,帮助你提升与GPT的交流效率。 1. 使用简单明了的语言: 尽量避免使用复杂的术语和行话,…...
【Android】解决 ADB 中 SELinux 设置与 `Failed transaction (2147483646)` 错误
解决 ADB 中 SELinux 设置与 Failed transaction (2147483646) 错误 在使用 ADB 进行开发和调试时,经常会遇到由于 Android 系统安全策略(SELinux)引起的权限问题,尤其是在执行某些操作时,可能会遇到类似 cmd: Failur…...

etcd常用监控
通过部署etcd-exporterPrometheus,然后配置etcd相关告警可以及时发现etcd集群风险 常见监控项目 1. etcd集群无leader Etcd cluster have no leader - alert:EtcdNoLeaderexpr: etcd_server_has_leader 0 for:0mlabels:severity: criticalannotations:summary:Et…...
)
红日靶场vulnstack 7靶机的测试报告[细节](一)
目录 一、测试环境 1、系统环境 2、注意事项 3、使用工具/软件 二、测试目的 三、操作过程 1、信息搜集 2、Redis未授权访问漏洞获取web1靶机系统权限 3、获取docker靶机系统权限 ①Laravel框架漏洞利用getshell ②Laravel主机的提权&&docker容器逃逸 提权…...
【计算机网络】Layer4-Transport layer
目录 传输层协议How demultiplexing works in transport layer(传输层如何进行分用)分用(Demultiplexing)的定义:TCP/UDP段格式: UDPUDP的特点:UDP Format端口号Trivial File Transfer Protocol…...

【conda/cuda/cudnn/tensorrt】一份简洁的深度学习环境安装清单
🚀本文主要总结一下conda、cuda、cudnn、tensorrt的快速安装。至于nvidia显卡驱动的安装,暂且不提。本文适合有一定反复安装经验的读者😂,方便其快速整理安装思路。 NVIDIA Drivers 🌔01conda ⭐️ 注意,c…...

在C语言中,访问结构体的成员时,什么时候用`.`【符号点】,什么时候用符号`->`?
在C语言中,访问结构体成员时,使用.和->的情况取决于你是否通过结构体指针来访问。 .(点运算符):当你有一个结构体变量时,使用点运算符来访问它的成员。例如: struct Person {char name[50];i…...

Java序列化
Java序列化 简单来说: 序列化是将对象的状态信息转换为可以存储或传输的形式(如字节序列)的过程。在 Java 中,通过序列化可以把一个对象保存到文件、通过网络传输到其他地方或者存储到数据库等。最直接的原因就是某些场景下需要…...

Python 方框消除小游戏
import pygame import random# 初始化pygame pygame.init()# 设置屏幕大小 screen pygame.display.set_mode((800, 600))# 设置标题 pygame.display.set_caption("打砖块")# 定义颜色 WHITE (255, 255, 255) BLACK (0, 0, 0) RED (255, 0, 0) GREEN (0, 255, 0)…...

微软 Phi-4:小型模型的推理能力大突破
在人工智能领域,语言模型的发展日新月异。微软作为行业的重要参与者,一直致力于推动语言模型技术的进步。近日,微软推出了最新的小型语言模型 Phi-4,这款模型以其卓越的复杂推理能力和在数学领域的出色表现,引起了广泛…...

OkHttp源码分析:分发器任务调配,拦截器责任链设计,连接池socket复用
目录 一,分发器和拦截器 二,分发器处理异步请求 1.分发器处理入口 2.分发器工作流程 3.分发器中的线程池设计 三,分发器处理同步请求 四,拦截器处理请求 1.责任链设计模式 2.拦截器工作原理 3.OkHttp五大拦截器 一&#…...
)
前后端跨域问题(CROS)
前端 在src中创建util文件,写request.js文件: request.js代码如下: import axios from axios import { ElMessage } from element-plus;const request axios.create({// baseURL: /api, // 注意!! 这里是全局统一加…...