Kafka Stream实战教程
Kafka Stream实战教程
1. Kafka Streams 基础入门
1.1 什么是 Kafka Streams
Kafka Streams 是 Kafka 生态中用于 处理实时流数据 的一款轻量级流处理库。它利用 Kafka 作为数据来源和数据输出,可以让开发者轻松地对实时数据进行处理,比如计数、聚合、过滤等操作。Kafka Streams 的一个显著特点是其设计简洁,帮助我们快速构建和部署实时流处理应用,而不需要复杂的集群管理。
对比传统流处理框架(如 Spark Streaming):传统流处理框架通常需要独立的集群支持,并有较重的计算资源需求。而 Kafka Streams 内置在 Kafka 中,既不需要单独的集群支持,性能上也更轻量,适合需要实时响应的场景,比如在线日志监控、实时订单处理等。
Kafka Streams 的应用场景
- 实时数据分析:如热门商品实时排名、网站的热点数据追踪
- 实时监控和告警:如系统指标监控,异常行为检测
- 数据清洗与格式转换:如从原始数据中抽取特定字段、转换格式用于下游系统
- 复杂事件处理:如订单状态跟踪、用户行为关联分析
1.2 Kafka Streams 核心概念
要理解 Kafka Streams,先了解几个核心概念:
-
Stream(数据流):一个数据流是源源不断的数据记录流(类似于消息流)。在 Kafka 中,每个数据流对应 Kafka 的一个主题(topic)。
-
Table(表):类似于数据库中的表,是数据的快照,通常包含每个键的最新状态。Kafka Streams 通过将流(Stream)聚合为表(Table),提供了在实时数据上进行去重和合并的能力。
-
KStream 和 KTable
- KStream:一个记录的无状态流,适合用于过滤、转换等操作,适合处理简单的逐条消息处理。
- KTable:类似于数据库的表,有键值对的结构,适合做聚合、去重、统计等操作。
- 两者可以互相转换,比如可以将一个 KStream 聚合成 KTable,也可以从 KTable 中生成 KStream。
-
时间语义:Kafka Streams 提供了事件时间(Event Time)、处理时间(Processing Time)、摄取时间(Ingestion Time)三种时间语义,帮助用户更灵活地处理时序数据。
-
状态存储和窗口(Windows):Kafka Streams 提供内置的状态存储来保存流的中间状态,如用户登录状态等。窗口操作(windowing)允许我们在一定的时间间隔内对流数据进行聚合和分组操作,比如每 5 分钟统计一次某产品的点击量。
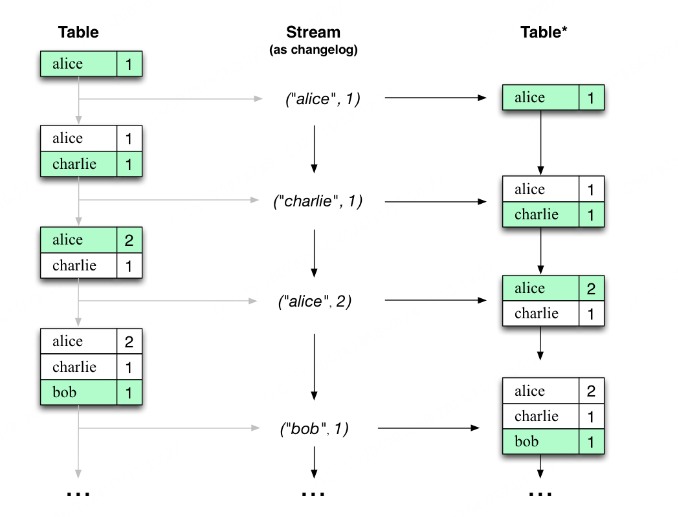
流表二元性描述了流和表之间的紧密关系。
- 流作为表:流可以被视为表的变更日志,其中流中的每个数据记录都捕获表的状态变化。因此,流是伪装的表,可以通过从头到尾重放变更日志来重建表,从而轻松地将其转换为“真实”表。同样,在更一般的类比中,聚合流中的数据记录(例如从页面浏览事件流中计算用户的总页面浏览量)将返回一个表(此处的键和值分别是用户及其对应的页面浏览量)。
- 表作为流:表可以被视为某个时间点的快照,是流中每个键的最新值(流的数据记录是键值对)。因此,表是伪装的流,通过迭代表中的每个键值条目,可以轻松地将其转换为“真实”流。
kafka文档
1.3 开发环境搭建
搭建 Kafka Streams 开发环境的步骤如下:
-
安装 Kafka:
- 下载安装 Kafka,然后启动 Kafka 服务和 Zookeeper 服务。
- 常用命令:启动 Kafka 服务器,
bin/kafka-server-start.sh config/server.properties
-
创建 Kafka Streams 项目:
-
新建一个 Maven 或 Gradle 项目,并添加 Kafka Streams 的依赖:
<!-- Maven 依赖 --> <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>3.0.0</version> </dependency>
-
-
开发Hello Kafka Streams 应用:
- 创建一个简单的 Kafka Streams 应用,读取输入流,进行简单的数据处理,然后输出结果。
import org.apache.kafka.streams.KafkaStreams; import org.apache.kafka.streams.StreamsBuilder; import org.apache.kafka.streams.StreamsConfig; import org.apache.kafka.streams.kstream.KStream;import java.util.Properties;public class HelloKafkaStreams {public static void main(String[] args) {// 配置 Kafka StreamsProperties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "hello-streams-app");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, "org.apache.kafka.common.serialization.Serdes$StringSerde");props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, "org.apache.kafka.common.serialization.Serdes$StringSerde");// 构建流处理拓扑StreamsBuilder builder = new StreamsBuilder();KStream<String, String> inputStream = builder.stream("input-topic");// 进行简单的处理,比如将消息转换为大写KStream<String, String> processedStream = inputStream.mapValues(value -> value.toUpperCase());// 将处理后的流写入输出主题processedStream.to("output-topic");// 创建并启动 Kafka StreamsKafkaStreams streams = new KafkaStreams(builder.build(), props);streams.start();// 添加关闭钩子Runtime.getRuntime().addShutdownHook(new Thread(streams::close));} } -
运行 Kafka Streams 应用:
- 确保 Kafka 服务已启动,运行该应用,将消息发到“input-topic”主题,观察“output-topic”主题中的转换结果。
完成以上步骤后,你已经实现了第一个简单的 Kafka Streams 应用。这个应用读取“input-topic”中的消息,将其内容转换为大写后写入“output-topic”中。
2. Kafka Streams 实现原理
在理解和使用 Kafka Streams 进行流处理之前,深入了解其实现原理可以帮助我们更好地优化应用性能和处理策略。Kafka Streams 作为一个轻量级、分布式的数据处理库,提供了流处理的易用性和强大的实时性。这一节将介绍 Kafka Streams 的实现原理,包括其架构设计和核心组件。
1. Kafka Streams 架构概述
Kafka Streams 是构建在 Kafka 消息系统之上的一个流处理库,它提供了一些特性,使得其容易集成到现有的 Kafka 基础设施中进行实时数据流的处理。Kafka Streams 的主要组成部分包括:
- 流处理拓扑(Topology):描述了应用中各个流处理过程的图结构,包括数据的源、处理逻辑和输出。
- 任务(Tasks):一个 Kafka Streams 应用程序被分配为多个任务,每个任务负责处理特定的分区数据。
- 线程模型:每个 Kafka Streams 实例可以通过配置线程数来实现并行处理。
2. 核心组件
1. 流处理拓扑(Topology)
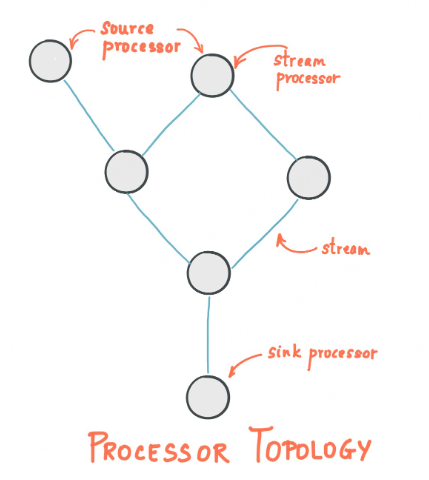
流处理的核心是通过定义流处理拓扑来实现的。拓扑由多个处理节点(Processor)、source 和 sink 组成。每个节点负责执行特定的数据转换逻辑。
- **Source Processor **:从 Kafka 主题读取数据。
- Processor Node:应用具体的数据处理逻辑,如过滤、转换、聚合等。
- **Sink Processor **:将处理结果输出到 Kafka 主题。
kafka stream core-concepts
Stream Processing Topology
- A stream is the most important abstraction provided by Kafka Streams: it represents an unbounded, continuously updating data set. A stream is an ordered, replayable, and fault-tolerant sequence of immutable data records, where a data record is defined as a key-value pair.
- A stream processing application is any program that makes use of the Kafka Streams library. It defines its computational logic through one or more processor topologies, where a processor topology is a graph of stream processors (nodes) that are connected by streams (edges).
- A stream processor is a node in the processor topology; it represents a processing step to transform data in streams by receiving one input record at a time from its upstream processors in the topology, applying its operation to it, and may subsequently produce one or more output records to its downstream processors.
There are two special processors in the topology:
- Source Processor: A source processor is a special type of stream processor that does not have any upstream processors. It produces an input stream to its topology from one or multiple Kafka topics by consuming records from these topics and forwarding them to its down-stream processors.
- Sink Processor: A sink processor is a special type of stream processor that does not have down-stream processors. It sends any received records from its up-stream processors to a specified Kafka topic.
Note that in normal processor nodes other remote systems can also be accessed while processing the current record. Therefore the processed results can either be streamed back into Kafka or written to an external system.
Example:
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input-topic");// Data processing logic
KStream<String, String> processed = source.filter((key, value) -> value.contains("important"));
processed.to("output-topic");
2. 状态存储(State Store)
Kafka Streams 支持有状态流处理,使用状态存储(如 RocksDB)来保存中间结果。每个处理节点都可以维护自己的状态,以便实现如计数、聚合等操作。
- Persistent State Store:通过内存和磁盘存储队列实现持久化。
- Changelog Topics:每次对状态的更新都会被记录到 Kafka 中的 changelog 主题,确保数据的恢复能力。
3. 时间语义
Kafka Streams 提供了三种时间语义,用于进行窗口化的流分析:
- Event Time:事件或数据记录发生的时间点,即最初在“源头”创建的时间点。**例如:**如果事件是汽车中的 GPS 传感器报告的地理位置变化,则相关事件时间将是 GPS 传感器捕获位置变化的时间。
- Processing Time: 事件或数据记录恰好被流处理应用程序处理的时间点,即记录被使用的时间点。处理时间可能比原始事件时间晚几毫秒、几小时或几天等。
- Ingestion Time:事件被记录进入 Kafka 的时间。
4. 错误处理
通过自定义的异常处理机制(如 DeserializationExceptionHandler),Kafka Streams 能够继续处理其余数据而不影响整体流程。
3. 任务执行
Kafka Streams 将应用程序拓扑根据 Kafka 主题的分区自动划分为多个任务(Task),这些任务可以在多个线程中并行执行。每个 Task 负责处理特定的分区数据,因此从根本上提高了水平扩展能力。
- 独立性:每个 Task 具有独立的状态和处理逻辑,与其他 Task 相互隔离。
- 自动负载均衡:当 Kafka Streams 实例的数量改变时,任务会自动重新分配,以实现负载均衡。
4. 线程与实例
-
线程配置:通过配置线程数,应用程序可以在单个实例中并行处理多个任务。
Properties props = new Properties(); props.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 2); // 设置应用程序使用两个线程 -
实例扩缩:多个实例共同构成 Stream 应用,可以水平扩展应用性能,实例之间通过协调协议共享状态。
总结
理解 Kafka Streams 的实现原理能够帮助我们更高效地开发和部署实时流应用。通过合理设计流处理拓扑、利用状态存储、制定抗故障策略,以及搭配适当的时间语义,Kafka Streams 能够有效地应对复杂的数据流处理场景。最终,这种深刻的理解可以在系统性能优化和调优中发挥关键作用。
3. Kafka Streams 的基础操作
在完成第一个 Kafka Streams 应用后,我们将进一步了解 Kafka Streams 的基础操作,重点关注一些常用的流数据处理方法,包括数据过滤、映射、聚合、分组、和窗口操作等。这些操作让我们可以针对不同业务需求进行丰富的流数据转换和处理。
3.1 基础操作方法概览
在 Kafka Streams 中,我们通常会用 KStream 和 KTable 来表示数据流。以下是一些常见的操作方法:
- 过滤(filter):筛选符合条件的记录
- 映射(map, mapValues):转换每条记录的键和值
- 分组(groupByKey, groupBy):将记录按指定键分组,为聚合操作做准备
- 聚合(count, reduce, aggregate):对记录进行汇总,如计数、求和等
- 窗口操作(windowedBy):按时间窗口进行分组聚合
3.2 数据过滤(Filter)
过滤操作允许我们筛选出符合条件的数据。例如,如果只想要某个主题中记录的特定字段,我们可以使用 filter 方法进行筛选。
示例:假设我们有一个主题 orders,每条记录包含订单的信息。我们想要过滤出金额大于100的订单:
KStream<String, Order> ordersStream = builder.stream("orders");// 过滤金额大于100的订单
KStream<String, Order> filteredOrders = ordersStream.filter((key, order) -> order.getAmount() > 100
);
filteredOrders.to("filtered-orders");
在此示例中,符合条件的订单将被写入 filtered-orders 主题。
3.3 数据映射(Map 和 MapValues)
映射操作用于修改流中的每条记录。Kafka Streams 提供了 map 和 mapValues 两种方法:
map可以对记录的键和值进行转换;mapValues只会对值进行转换,保留键不变。
示例:将每个订单的金额增加10%并保留其他信息:
KStream<String, Order> updatedOrders = ordersStream.mapValues(order -> {order.setAmount(order.getAmount() * 1.1);return order;}
);
updatedOrders.to("updated-orders");
这里我们用 mapValues 调整了每个订单的金额,更新后的订单数据会被写入 updated-orders 主题。
3.4 数据分组(GroupBy 和 GroupByKey)
分组操作将数据按指定键重新分组,通常用于聚合操作的前一步。分组后的数据会被存储在 KGroupedStream 中,便于后续的聚合操作。
groupByKey:按现有键分组groupBy:可指定新的分组键
示例:按用户 ID 对订单数据进行分组:
KGroupedStream<String, Order> ordersByUser = ordersStream.groupBy((key, order) -> order.getUserId()
);
在这里,我们按用户 ID 重新分组,以便于在接下来的步骤中对每个用户的订单进行聚合。
3.5 数据聚合(Count、Reduce 和 Aggregate)
聚合操作用于计算分组数据的汇总信息,如计数、求和等。
- count:统计每组记录的数量
- reduce:可以实现自定义的聚合逻辑,例如最大值、最小值等
- aggregate:实现更灵活的聚合操作,可创建复杂的聚合结果
示例:计算每个用户的订单总金额
KTable<String, Double> totalAmountPerUser = ordersByUser.aggregate(() -> 0.0, // 初始化值(userId, order, total) -> total + order.getAmount(),Materialized.with(Serdes.String(), Serdes.Double())
);totalAmountPerUser.toStream().to("total-amount-per-user");
这里我们使用 aggregate 方法,按用户 ID 统计每个用户的订单总金额,结果会被写入 total-amount-per-user 主题。
3.6 窗口操作(WindowedBy)
窗口操作用于在时间窗口内对流数据进行分组和聚合,非常适合处理时序数据,例如每小时统计一次销售数据。常用的窗口类型有:
- Tumbling Window:固定长度的窗口,不重叠
- Hopping Window:固定长度,允许窗口之间重叠
- Session Window:根据活动时间自动调整的窗口
示例:每隔5分钟统计一次订单数量
KTable<Windowed<String>, Long> orderCountByWindow = ordersByUser.windowedBy(TimeWindows.of(Duration.ofMinutes(5))).count();orderCountByWindow.toStream().to("order-count-by-window");
在这个示例中,我们按5分钟窗口统计每个用户的订单数量,结果会被写入 order-count-by-window 主题。
@Override
public <T> KTable<Windowed<K>, T> aggregate(final Initializer<T> initializer,
final Aggregator<? super K, ? super V, T> aggregator,
final Merger<? super K, T> sessionMerger) {
return aggregate(initializer, aggregator, sessionMerger, NamedInternal.empty());
}@Override
public <VR> KTable<Windowed<K>, VR> aggregate(final Initializer<VR> initializer,
final Aggregator<? super K, ? super V, VR> aggregator,
final Materialized<K, VR, WindowStore<Bytes, byte[]>> materialized) {
return aggregate(initializer, aggregator, NamedInternal.empty(), materialized);
}
3.7 实战案例
案例1:订单流数据处理示例
我们将多个操作组合起来,创建一个实际的订单数据处理流程。
需求:对 orders 主题中的订单数据进行以下处理:
- 过滤出金额大于100的订单
- 按用户 ID 重新分组
- 计算每个用户过去1小时的订单数量(使用滚动窗口)
- 将结果写入
high-value-orders和order-count-by-hour主题
代码实现:
KStream<String, Order> ordersStream = builder.stream("orders");// 1. 过滤金额大于100的订单
KStream<String, Order> highValueOrders = ordersStream.filter((key, order) -> order.getAmount() > 100
);
highValueOrders.to("high-value-orders");// 2. 按用户 ID 分组
KGroupedStream<String, Order> ordersByUser = highValueOrders.groupBy((key, order) -> order.getUserId()
);// 3. 每小时统计一次订单数量
KTable<Windowed<String>, Long> hourlyOrderCount = ordersByUser.windowedBy(TimeWindows.of(Duration.ofHours(1))).count();// 4. 将统计结果写入主题
hourlyOrderCount.toStream().to("order-count-by-hour");
通过以上步骤,我们利用 Kafka Streams 的基础操作完成了一个流数据的实时处理任务。
案例 2:销售额实时统计
本案例将带大家了解如何利用 Kafka Streams 实现销售额的实时统计。假设我们有一个主题 sales,每条记录包含一个订单的销售信息,我们将计算每个商品的实时总销售额和每小时的销售额。
需求分析
我们需要从 sales 主题中读取订单记录,并进行以下处理:
- 过滤出金额大于0的有效订单;
- 按商品 ID 分组计算每个商品的总销售额;
- 对每个商品进行时间窗口统计,计算每小时的销售额;
- 将实时总销售额和每小时的销售额写入不同的 Kafka 主题。
步骤详解
以下是每个步骤的详细实现和代码示例。
步骤 1:过滤有效订单
我们首先从 sales 主题中读取订单流,并过滤掉销售金额小于或等于0的无效订单记录。
KStream<String, SaleOrder> salesStream = builder.stream("sales");// 过滤出有效的销售记录
KStream<String, SaleOrder> validSalesStream = salesStream.filter((key, saleOrder) -> saleOrder.getAmount() > 0
);
在这个代码片段中,我们读取 sales 主题中的数据,使用 filter 方法筛选出 amount 大于0的有效销售记录。
步骤 2:按商品 ID 计算总销售额
接下来,我们将按商品 ID 对订单流重新分组,并计算每个商品的总销售额。
KGroupedStream<String, SaleOrder> salesByProduct = validSalesStream.groupBy((key, saleOrder) -> saleOrder.getProductId()
);KTable<String, Double> totalSalesByProduct = salesByProduct.aggregate(() -> 0.0, // 初始化值(productId, saleOrder, total) -> total + saleOrder.getAmount(),Materialized.with(Serdes.String(), Serdes.Double())
);totalSalesByProduct.toStream().to("total-sales-by-product");
在这段代码中:
- 我们按商品 ID 分组;
- 使用
aggregate方法为每个商品累计销售额; - 将计算出的每个商品的总销售额结果写入
total-sales-by-product主题。
步骤 3:按小时计算每个商品的销售额
我们为每个商品创建一个滚动窗口,每小时计算一次销售额。这有助于我们按时间区间了解每个商品的销售趋势。
KTable<Windowed<String>, Double> hourlySalesByProduct = salesByProduct.windowedBy(TimeWindows.of(Duration.ofHours(1))).aggregate(() -> 0.0,(productId, saleOrder, total) -> total + saleOrder.getAmount(),Materialized.with(Serdes.String(), Serdes.Double()));hourlySalesByProduct.toStream().to("hourly-sales-by-product");
在这段代码中:
windowedBy方法定义了一个每小时的时间窗口;aggregate计算每小时的销售额;- 结果数据会写入
hourly-sales-by-product主题,其中窗口包含商品 ID 和每小时的销售额。
步骤 4:综合输出
将上述两种统计结果分别输出到 total-sales-by-product 和 hourly-sales-by-product 主题中,消费者可以订阅这两个主题,获取商品的实时销售额及每小时的销售额动态变化。
完整代码示例
将上述步骤组合成完整的 Kafka Streams 程序代码如下:
StreamsBuilder builder = new StreamsBuilder();// 1. 从 'sales' 主题读取数据
KStream<String, SaleOrder> salesStream = builder.stream("sales");// 2. 过滤有效的销售记录
KStream<String, SaleOrder> validSalesStream = salesStream.filter((key, saleOrder) -> saleOrder.getAmount() > 0
);// 3. 按商品 ID 计算总销售额
KGroupedStream<String, SaleOrder> salesByProduct = validSalesStream.groupBy((key, saleOrder) -> saleOrder.getProductId()
);KTable<String, Double> totalSalesByProduct = salesByProduct.aggregate(() -> 0.0,(productId, saleOrder, total) -> total + saleOrder.getAmount(),Materialized.with(Serdes.String(), Serdes.Double())
);
totalSalesByProduct.toStream().to("total-sales-by-product");// 4. 按小时计算每个商品的销售额
KTable<Windowed<String>, Double> hourlySalesByProduct = salesByProduct.windowedBy(TimeWindows.of(Duration.ofHours(1))).aggregate(() -> 0.0,(productId, saleOrder, total) -> total + saleOrder.getAmount(),Materialized.with(Serdes.String(), Serdes.Double()));
hourlySalesByProduct.toStream().to("hourly-sales-by-product");// 启动流处理应用程序
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
总结
通过该案例,我们完成了:
- 使用
filter进行数据筛选; - 使用
aggregate计算总销售额和窗口销售额; - 定义每小时窗口,帮助我们跟踪产品的实时销售趋势。
这套流程可广泛用于实时数据分析,帮助业务监控产品销量、把握销售动态等。
4.Kafka Streams 状态管理与持久化
在数据流处理过程中,有时需要维护一些中间状态或记录,以便进行更复杂的操作。这一章将介绍 Kafka Streams 的状态管理功能,包括如何使用内置的状态存储,以及如何实现自定义的状态存储。
4.1 状态存储(State Store)
概述
Kafka Streams 提供了本地状态存储的能力,允许我们在进行流处理时记录和查询中间状态。这是进行高级流计算操作的基础,比如保持当前计数、生成聚合结果等。
内部状态存储的类型
- 内存存储:适用于轻量级、快速的状态存储场景,但受到内存限制。
- RocksDB:默认情况下,Kafka Streams 使用 RocksDB 作为嵌入式数据库来存储状态。它支持磁盘存储,适合大量数据的情况。
状态存储与拓扑的关系
状态存储紧密集成在 Kafka Streams 的流处理拓扑中,可以在流处理逻辑中随时读取或更新状态。
实践:创建一个状态存储
在 Kafka Streams 程序中使用 store 方法,将状态存储与流处理连接起来:
KStream<String, Long> views = builder.stream("user-views");KTable<String, Long> viewCounts = views.groupByKey().count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("view-counts-store"));// “view-counts-store” 是用于保存当前视图计数的状态存储
4.2 定制状态存储
有时,内置的状态存储不能完全满足需求。Kafka Streams 提供了扩展 API,可以实现自定义状态存储。
自定义 State Store
通过实现 StateStore 接口以及创建自定义的 Processor,可以将流处理的状态保存到外部数据库或自定义存储中。
使用 Processor API 进行状态管理
Processor API 提供了低级别的流处理控制能力,允许我们直接操作状态存储,提供了更多灵活性。
实战:实时账户余额监控
设计一个实时账户余额监控系统,每当用户进行消费或充值时,系统更新用户的账户余额并将其存于状态存储中。
步骤:
- 定义处理逻辑:实现一个自定义
Processor以更新账户余额。 - 设置拓扑:利用
Topology类来定义流处理的拓扑结构,包括数据的来源、处理器、状态更新以及输出。 - 部署与测试:将流处理任务部署到 Kafka Streams,进行实时数据处理和验证。
代码示例
public class BalanceProcessorSupplier implements ProcessorSupplier<String, Long> {@Overridepublic Processor<String, Long> get() {return new BalanceProcessor();}
}public class BalanceProcessor extends AbstractProcessor<String, Long> {private KeyValueStore<String, Long> balanceStore;@Overridepublic void init(ProcessorContext context) {super.init(context);balanceStore = (KeyValueStore) context.getStateStore("balance-store");}@Overridepublic void process(String accountId, Long amount) {Long currentBalance = balanceStore.get(accountId);Long updatedBalance = (currentBalance == null ? 0L : currentBalance) + amount;balanceStore.put(accountId, updatedBalance);}
}// 示例拓扑结构
Topology topology = new Topology();
topology.addSource("Source", "transactions").addProcessor("Process", new BalanceProcessorSupplier(), "Source").addStateStore(Stores.keyValueStoreBuilder(Stores.persistentKeyValueStore("balance-store"),Serdes.String(),Serdes.Long()), "Process");KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
总结
通过学习这一章,你应掌握 Kafka Streams 中的状态存储功能,包括如何使用内置存储以及如何进行自定义存储。通过状态存储,流处理程序可以保持中间状态,为更复杂的计算提供支持。在实践中,可以使用状态存储来实现许多实时计算系统的关键功能。
5.Kafka Streams 的高级数据流操作
在进行基本的数据流操作之后,你会发现需要处理更加复杂的数据流场景,比如流的连接、复杂的拓扑定义以及更高级的数据转换。这一章将深入探讨 Kafka Streams 中的高级数据流操作。
5.1 数据连接(Join)操作
概述
连接(Join)操作是数据流处理中非常有用的能力,能够把多个数据流合并在一起,以便从不同来源的信息中获取更丰富的数据关系。Kafka Streams 支持多种类型的 Join,包括 KStream 和 KTable 之间的不同组合。
不同类型的 Join 操作
-
KStream-KStream Join:用于两个流之间的连接。每当一个流中收到新数据时,查找另一流中满足时间窗口条件的数据进行合并。
用例:订单流和支付流的合并,产生包含订单支付状态的新记录。
-
KStream-KTable Join:流和表之间的连接。适合需要查找静态或相对稳定的数据进行关联的场景。
用例:用户购买行为流与用户信息表的连接,获取更详细的用户信息。
-
KTable-KTable Join:表和表之间的连接,适合静态信息的合并。
用例:用户信息表和地址信息表的合并。
时间窗口及其注意事项
Join 操作中的数据通常需要定义一个时间窗口,允许合并操作在流中不同步到达的数据间执行。重要的是选择合适的时间窗口以及处理时间的边界情况。
代码示例:KStream-KStream Join
以下代码示例展示了如何在 Kafka Streams 中进行 KStream-KStream Join 操作:
KStream<String, Order> orders = builder.stream("orders");
KStream<String, Payment> payments = builder.stream("payments");KStream<String, EnrichedOrder> enrichedOrders = orders.join(payments,(order, payment) -> new EnrichedOrder(order, payment),JoinWindows.of(Duration.ofMinutes(5))
);// orders 和 payments 流中的数据依据订单id进行连接,JoinWindows 指定了5分钟的时间窗口
5.2 数据拓扑(Topology)与 Processor API
流处理拓扑的概念与结构
在 Kafka Streams 中,拓扑(Topology)是一系列有序的处理节点,定义了信息从输入到输出的流经路径。每个拓扑都包含一个或多个处理器节点,节点之间可以通过多个流进行连接。
Processor API 基本操作
Kafka Streams 提供的 Processor API 是一个更底层的 API,允许对流处理任务进行细粒度的可控操作。主要组件包括:
- Processor:流处理逻辑单元,可以处理输入、更新状态,以及生成输出。
- Transformer:用于转换现有数据并可能保留处理状态。
- Punctuator:可以在特定时间触发操作,适用于定时任务。
创建自定义流处理拓扑
通过 Processor API,你可以创建自定义的流处理拓扑,以更灵活地处理流数据。
Topology topology = new Topology();topology.addSource("Source", "source-topic").addProcessor("Process", MyProcessor::new, "Source").addSink("Sink", "output-topic", "Process");KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
5.3实战:订单实时分析系统
在现代电子商务平台上,实时订单分析对于理解用户行为和优化业务运作至关重要。本实战项目将带你实现一个通过 Kafka Streams 进行的订单实时分析系统,结合订单流与用户信息,从而实现用户行为的实时洞察。
项目目标
- 实现订单流与用户信息数据的实时关联查询。
- 使用 Kafka Streams 的 Join 操作,结合不同类型的数据流。
- 构建自定义的数据处理拓扑,实现特定的业务逻辑。
步骤详解
1. 数据流准备
在本项目中,假设我们有以下两种数据来源:
- 订单流(orders):包含订单的基本信息,如订单 ID、用户 ID、产品详情、价格等。
- 用户信息表(user-info):包含用户的静态信息,如用户 ID、姓名、城市等。
2. 定义数据连接
首先,我们需要从 Kafka Topic 中读取订单流和用户信息表。然后,使用 Kafka Streams 的 Join 操作,将两个数据流联系在一起。
KStream<String, Order> orders = builder.stream("orders");
KTable<String, UserInfo> userInfo = builder.table("user-info");// 使用用户 ID 作为连接键,将订单流与用户信息表结合
KStream<String, EnrichedOrder> enrichedOrders = orders.join(userInfo,(order, user) -> new EnrichedOrder(order, user)
);// enrichedOrders 流现在包含了结合用户信息的完整订单记录
3. 配置处理拓扑
在 Kafka Streams 中,我们需要定义数据从输入到输出经过的路径,即所谓的“拓扑结构”。
Topology topology = new Topology();topology.addSource("OrderSource", "orders").addSource("UserSource", "user-info").addProcessor("JoinProcessor", () -> new JoinProcessor(), "OrderSource", "UserSource").addSink("EnrichedOrderSink", "enriched-orders", "JoinProcessor");KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
4. 开发自定义处理器
你可能需要更多定制的逻辑以增强流处理。在此项目中,可以编写一个自定义处理器(Processor)来复杂化分析,比如过滤订单、打标签、或变换格式。
public class JoinProcessor extends AbstractProcessor<String, Order> {private KeyValueStore<String, UserInfo> userStore;@Overridepublic void init(ProcessorContext context) {super.init(context);userStore = (KeyValueStore<String, UserInfo>) context.getStateStore("user-info-store");}@Overridepublic void process(String key, Order order) {UserInfo userInfo = userStore.get(order.getUserId());if (userInfo != null) {EnrichedOrder enrichedOrder = new EnrichedOrder(order, userInfo);context().forward(key, enrichedOrder);}}
}// 注:此处理器假定 "user-info-store" 是一个存储用户信息的状态存储。
5. 部署与监控
完成逻辑开发后,部署 Kafka Streams 应用并配置监控以保障实时数据处理的可靠性。
- 部署:应用可以通过本地、容器(Docker)、或者 Kubernetes 等环境进行部署。
- 监控:使用监控工具(如 Prometheus、Grafana)实时分析吞吐量、延迟等关键指标,确保流处理的性能和稳定性。
总结与扩展
经过本实战项目的学习,你已经掌握了如何通过 Kafka Streams 实现订单数据流和用户信息表的实时数据加工作业。选择合适的 Join 操作、合理设计拓扑结构,以及灵活运用自定义处理器,可以提高实时分析系统的准确性和效率。
扩展:
- 增加进一步的分析功能,比如趋势分析、异常检测等。
- 探索分布式系统设计优化,提升数据流处理的拓展性。
- 实现更多异构数据源的整合,拓展数据处理链条。
总结
通过学习这一章,你将掌握如何使用 Kafka Streams 进行高级数据流操作。这些技能使你有能力构建复杂的数据流网络,满足现实世界应用场景中对数据处理的高级需求。正确理解和使用 Join 操作和 Processor API,是实现高效流处理系统的关键。
6.错误处理、容错与调试
在构建实时数据处理系统时,错误处理、容错和调试是确保系统稳定性和可靠性的关键。这一章将介绍 Kafka Streams 如何处理错误,如何保障系统的容错能力,并提供调试技巧来帮助开发和维护。
6.1 错误处理
概述
在流处理过程中,可能会遇到各种错误,包括数据格式错误、网络问题或系统异常。Kafka Streams 提供了多种机制来帮助处理这些错误,以保证流处理程序的健壮性。
错误处理策略
-
全局异常处理器:可以通过 Kafka Streams 配置全局异常处理策略,以便在出现无法处理的异常时做出适当响应。
Properties props = new Properties(); props.put(StreamsConfig.DEFAULT_DESERIALIZATION_EXCEPTION_HANDLER_CLASS_CONFIG, LogAndContinueExceptionHandler.class.getName());- LogAndContinueExceptionHandler:日志记录之后继续处理。
- LogAndFailExceptionHandler:日志记录后终止处理。
-
局部异常处理:在特定的操作中捕获和处理异常。例如,在 Java 代码中使用 try-catch 块来处理特定操作中的异常。
-
自定义错误处理:可以实现自己的
DeserializationExceptionHandler以处理反序列化过程中发生的错误。
实践中的错误处理
在实现过程中,使用 try-catch 块保护可能出现问题的处理逻辑,如先进的解析或网络操作。
KStream<String, String> stream = builder.stream("input-topic");stream.foreach((key, value) -> {try {// 业务逻辑} catch (Exception e) {// 错误处理逻辑System.err.println("Error processing record: " + e.getMessage());}
});
6.2 容错机制
基本原理
Kafka Streams 自带强大的容错能力,包括自我修复和状态恢复,以确保处理任务的持续运行及数据处理的一致性。
容错策略
-
State Store 的备份与恢复:使用 Kafka 的 changelog topic,确保数据在处理节点故障时可以恢复。RocksDB 提供了本地持久化存储,结合 changelog 作数据恢复。
-
端点冗余节点:Kafka Streams 集群可以自动分配任务到多个实例上。当某一部分的实例失败,任务会在其他实例上重新分配和执行。
-
自动检查与重新启动:Kafka Streams 的心跳机制会定期检查实例的状态,并在发现故障时自动重新启动处理任务。
示例配置
Properties props = new Properties();
props.put(StreamsConfig.NUM_STANDBY_REPLICAS_CONFIG, 1); // 设置备用副本数
props.put(StreamsConfig.REPLICATION_FACTOR_CONFIG, 3); // 状态主题的副本因子
6.3 性能优化
优化策略
在流数据处理过程中,性能调优是实现高效处理的关键。Kafka Streams 提供的多种配置可以帮助我们实现性能优化。
-
优化缓存和批处理:
-
适当加大缓存配置,以减少请求负荷。
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10485760L); // 10 MB 缓存大小 -
配置批处理大小,适应网络和处理能力。
props.put(StreamsConfig.BUFFERED_RECORDS_PER_PARTITION_CONFIG, 100); // 每分区的缓存记录数
-
-
线程配置与资源管理:
-
适当配置线程数,确保充分利用 CPU 而不导致线程竞争。
props.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 4); // 设定流处理线程数
-
-
负载均衡和扩展:
- 增加更多的 Kafka 实例,负载均衡处理任务。
6.4 实战:构建高可用的实时订单处理系统
在实际业务环境中,实时订单处理系统需要处理大量的订单数据,并进行高效可靠的处理。在这部分,我们将结合错误处理、容错机制和性能优化知识,构建一个高可用的实时订单处理系统。
系统设计目标
- 高可用性:通过冗余和真实状态的恢复能力,保证系统在故障后能够迅速恢复。
- 高性能:确保系统可以在高并发情况下维持低延迟和高吞吐量。
- 稳定性:有效处理和避免运行时错误,保障流处理正常运行。
步骤详解
1. 定义数据流处理逻辑
我们假定我们的订单流包含订单 ID、用户 ID、订单金额、产品信息等。我们将从订单数据中分析出每个用户的实时消费情况。
// 创建 Kafka Streams Builder
StreamsBuilder builder = new StreamsBuilder();// 从 "orders" 主题读取订单流
KStream<String, Order> orders = builder.stream("orders");// 示例处理:计算每个用户的总消费
KGroupedStream<String, Order> groupedByUser = orders.groupBy((key, order) -> order.getUserId());KTable<String, Double> totalSpentByUser = groupedByUser.aggregate(() -> 0.0,(key, order, total) -> total + order.getAmount(),Materialized.with(Serdes.String(), Serdes.Double()));
2. 实施错误处理
根据不同的场景设置错误处理逻辑,特别是反序列化错误。在本例中,采用 LogAndContinueExceptionHandler,确保即便遇到数据问题,也不会影响整体流处理。
Properties props = new Properties();
props.put(StreamsConfig.DEFAULT_DESERIALIZATION_EXCEPTION_HANDLER_CLASS_CONFIG, LogAndContinueExceptionHandler.class.getName());
3. 配置容错策略
确保在节点故障时系统能够迅速恢复。设置应用的容错机制,包括配置 Replica 和 Standby 副本,避免单点故障。
props.put(StreamsConfig.NUM_STANDBY_REPLICAS_CONFIG, 1);
props.put(StreamsConfig.REPLICATION_FACTOR_CONFIG, 3);
4. 性能调优
确保系统能够以高效能运行,即便在订单高峰期。
-
缓存与批处理:使用适当的缓存和批处理,将数据延迟降到最低。
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10485760L); // 设定10 MB的缓存 -
线程配置:配置适当的流处理线程数,以充分利用系统资源。
props.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 4);
5. 部署与监控
部署流处理系统时,考虑到实际的生产环境,推荐使用 Docker 或 Kubernetes 等工具来管理应用的生命周期。
-
监控关键指标:使用监控工具如 Prometheus 和 Grafana 实时监控系统的延迟、吞吐量和错误率,尽早发现并解决潜在问题。
使用 Kafka Streams 内置的 JMX 指标导出器,配合 Prometheus 的 JMX Exporter 收集数据,Grafana 用于可视化展示。
总结
本章介绍了处理实时流处理中常见问题的方法,包括错误处理、提供容灾措施以及性能调优。通过合理化的策略和设置,可以大大提高 Kafka Streams 应用程序的稳定性和效率。最后的实战案例展示了如何将这些概念应用于构建高可用的数据处理系统。
7.Kafka Streams 部署与监控
在完成 Kafka Streams 应用的开发后,部署和监控是确保其在生产环境中高效稳定运行的关键步骤。本章将介绍如何在不同环境下部署 Kafka Streams 应用,以及如何对其进行监控,以及时发现并解决潜在问题。
7.1 Kafka Streams 部署
概述
Kafka Streams 应用的部署需要考虑运行环境的条件和特点,也需要做好相应的配置以满足性能和稳定性要求。常见的部署方式包括本地部署、容器化部署(如 Docker)和 Kubernetes 部署。
1. 本地部署
在本地环境下,Kafka Streams 可以通过直接运行 Java 应用程序来部署。这种方式便于开发和调试,但不适用于生产环境。
- 步骤:
- 将 Kafka Streams 应用打包为 JAR 文件。
- 在运行时附带配置文件,使用 java 命令运行 JAR。
java -jar your-kafka-streams-app.jar --server.port=8080
- 注意事项:确保本地安装的 Kafka 及其相关服务正常运行,并配置好网络和端口。
2. 容器化部署(Docker)
使用 Docker 可以创建 Kafka Streams 应用的轻量级容器,使其具有跨平台的兼容性。
-
步骤:
-
编写 Dockerfile 描述如何构建应用的 Docker 镜像。
FROM openjdk:11-jre COPY target/your-kafka-streams-app.jar /usr/app/ WORKDIR /usr/app CMD ["java", "-jar", "your-kafka-streams-app.jar"] -
使用 Docker 命令构建镜像并运行容器。
docker build -t kafka-streams-app . docker run -d -p 8080:8080 kafka-streams-app
-
-
注意事项:确保 Kafka 服务的网络配置能被 Docker 容器访问。
3. Kubernetes 部署
Kubernetes 提供了更强大的编排功能,适合在生产环境中管理和扩展 Kafka Streams 应用。
-
步骤:
-
编写 Kubernetes 部署配置文件(YAML)描述应用部署方式。
apiVersion: apps/v1 kind: Deployment metadata:name: kafka-streams-app spec:replicas: 3selector:matchLabels:app: kafka-streamstemplate:metadata:labels:app: kafka-streamsspec:containers:- name: kafka-streams-appimage: kafka-streams-app:latestports:- containerPort: 8080 -
使用 kubectl 命令进行部署。
kubectl apply -f kafka-streams-deployment.yaml
-
-
注意事项:配置 Kubernetes 集群以确保服务发现和负载均衡。
7.2 Kafka Streams 监控
概述
在生产中监控 Kafka Streams 应用的状态和性能是确保其正常运行的基础。监控涉及到延迟、吞吐量、状态存储等多个指标。
1. 使用内置 JMX 指标
Kafka Streams 支持通过 JMX 输出应用的运行指标。这些指标可以被其他监控系统(如 Prometheus)收集和分析。
-
配置 Kafka Streams 以启用 JMX:
在应用启动参数中指定 JMX 端口。
java -Dcom.sun.management.jmxremote \-Dcom.sun.management.jmxremote.port=9010 \-Dcom.sun.management.jmxremote.local.only=false \-Dcom.sun.management.jmxremote.authenticate=false \-Dcom.sun.management.jmxremote.ssl=false \-jar your-kafka-streams-app.jar -
常见指标:
- 处理延迟:从接收到消息到处理完成所需的时间。
- 吞吐量:单位时间内处理的消息数量。
- 错误率:处理数据时发生的错误数量。
2. 使用 Prometheus 和 Grafana
Prometheus 可以从 Kafka Streams 收集 JMX 指标,Grafana 则用于将这些指标进行可视化,以便于监控和分析。
-
集成步骤:
- 安装和配置 Prometheus 以抓取 Kafka Streams 应用的 JMX 指标。
- 在 Grafana 上配置仪表板,通过 Prometheus 数据源展示实时指标。
-
监控内容:
- 实时监控吞吐量和延迟:及时检测性能瓶颈。
- 异常告警:设置告警规则,及时通知潜在问题。
总结
本章中,我们详细介绍了 Kafka Streams 应用的部署和监控方法,覆盖了从本地简单部署到生产级的容器化及 Kubernetes 部署。监控部分强调了通过 JMX 以及 Prometheus 和 Grafana 进行系统运行状态的检测,这些技能是维持 Kafka Streams 应用稳定性的核心。本章所学将帮助你在不同环境下以最佳实践方式管理和监控你的 Kafka Streams 项目。
8.springboot集成kafka 与kafkaStream
1.引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions>
</dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId>
</dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions>
</dependency>
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
2.application配置文件
server:port: 8088spring:application:name: spring-kafkakafka:bootstrap-servers: kafka:9092producer:retries: 5key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.springframework.kafka.support.serializer.JsonSerializerconsumer:group-id: ${spring.application.name}-testkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer properties:# 序列化的时候,解决不信任kafka If you believe this class is safe to deserializespring.json.trusted.packages: "*"kafka:hosts: kafka:9092group: ${spring.application.name}3.kafka stream的配置需要单独配一下
package com.example.springkafka.config;import com.example.springkafka.serializer.OrderDeserializer;
import lombok.Getter;
import lombok.Setter;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.WallclockTimestampExtractor;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafkaStreams;
import org.springframework.kafka.annotation.KafkaStreamsDefaultConfiguration;
import org.springframework.kafka.config.KafkaStreamsConfiguration;
import org.springframework.kafka.support.serializer.JsonSerde;import java.util.HashMap;
import java.util.Map;@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {private static final int MAX_MESSAGE_SIZE = 16 * 1024 * 1024;private String hosts;private String group;@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {Map<String, Object> props = new HashMap<>();props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_id");props.put(StreamsConfig.RETRIES_CONFIG, 5);// 序列化方式props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());// 反序列化方式props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, JsonSerde.class.getName());props.put(StreamsConfig.DEFAULT_TIMESTAMP_EXTRACTOR_CLASS_CONFIG, WallclockTimestampExtractor.class.getName());// 自定义实体时,防止报路径不信任错误props.put("spring.json.trusted.packages", "*");return new KafkaStreamsConfiguration(props);}
}
4.消息实体
@NoArgsConstructor
@AllArgsConstructor
@Accessors(chain = true)
@Data
public class Order implements Serializable{private String orderId;private String userId;private String userName;private String productId;private String productName;private Integer amount;}
5.自定义消息监听者stream listener,获取topic消息,进行流处理
import com.example.springkafka.entity.Order;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Produced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.support.serializer.JsonSerde;@Configuration
public class StreamCountListener {@Beanpublic KStream<String, Order> upperCaseStream(StreamsBuilder streamsBuilder){// 获取topic的消息KStream<String, Order> inputStream = streamsBuilder.stream("order-topic");// 进行简单的处理// 1.查询获取订单金额大于100的订单数据KStream<String, Order> processedStream = inputStream.filter((key, order) -> order.getAmount() > 100);//processedStream.foreach((key, value) -> System.out.println("------result Received message: "+ key +" : "+ value));// 将处理后的流写入输出主题processedStream.to("data-topic", Produced.with(Serdes.String(), new JsonSerde<>()));return inputStream;}}
6.kafka消费者接受消息并打印
import com.example.springkafka.entity.Order;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;@Service
public class KafkaConsumer {@KafkaListener(topics = "data-topic", groupId = "spring-kafka-test")public void listen(Order msg) {System.out.printf("普通A message: %s%n", msg.toString());}
}
7.发送消息
@Autowired
private KafkaTemplate<String, Order> kafkaTemplate;@Test
public void testSend2() {System.out.println("----------开始发送数据-----------");Order order = new Order("1", "1", "张三", "1", "商品1", 200);kafkaTemplate.send("order-topic", order);
}
8.执行结果

9. 实战项目:综合应用
在前面的章节中,我们已经学习了 Kafka Streams 的基础知识、高级操作、错误处理、容错和监控方法。现在,我们来进行一个综合性实战项目——构建一个用户订单实时分析系统。在这个项目中,你将利用到 Kafka Streams 的多种功能,并体验如何将这些技术结合在一起。
8.1 用户行为实时分析系统
项目目标
- 实现一个能够实时分析用户订单数据的系统。
- 解析、过滤并聚合来自用户的订单事件。
- 输出分析结果,如用户订单的总金额。
1. 项目结构
我们将设计一个由下列环节组成的数据处理管道:
- 数据流输入:从 Kafka 主题中读取用户订单数据。
- 数据处理:通过 Kafka Streams 进行实时分析,包括数据过滤、转换和聚合。
- 结果输出:处理结果写入到另一个 Kafka 主题或存储系统,以供后续分析或展示。
2. 数据流设计
假设我们有一个 Kafka Topic "order-topic",该主题中的每条记录包含用户、订单金额 以及时间戳等字段。我们的目标是统计每个客户的在5分钟之内的订单总金额。
3. 数据处理逻辑
@Bean
public KStream<String, Order> countCustomerOrderStreamSession(StreamsBuilder streamsBuilder){// 获取消息KStream<String, Order> ordersStream = streamsBuilder.stream("order-topic");KStream<String, KeyValue<String, Double>> orderAmountStream = ordersStream.mapValues(order -> new KeyValue<>(order.getUserId(), order.getAmount()));// 2.使用固定窗口函数统计3分钟之内,每个用户的订单总金额KTable<Windowed<String>, Double> aggregate = orderAmountStream.groupByKey() // 根据用户ID(key)进行分组.windowedBy(SessionWindows.with(Duration.ofMinutes(5)).grace(Duration.ofMinutes(1))) // 设置 3 分钟窗口.aggregate(() -> 0.0, // 初始化值(key, orderAmount, aggAmount) -> orderAmount.value + aggAmount, // 聚合逻辑(key, agg1, agg2) -> agg1 + agg2, // 合并多个会话Materialized.<String, Double, SessionStore<Bytes, byte[]>>as("customer-order-session-store").withKeySerde(Serdes.String()).withValueSerde(Serdes.Double()) // 配置序列化器);// 将聚合结果转换为普通流KStream<String, OrderData> map = aggregate.toStream().filter((key, value) -> null != value) // 处理因为会话窗口合并而产生的脏数据.map((key, value) -> KeyValue.pair(key.key(), new OrderData(key.key(), value)));//map.foreach((key, value) -> System.out.println("windowedBy--------key:"+key+" value:"+value));// 发送消息到下游map.to("order-count-topic", Produced.with(Serdes.String(), new JsonSerde<>()));return ordersStream;
}
4. 接收处理后的数据
@KafkaListener(topics = "order-count-topic", groupId = "order-count-test")
public void consumeData(OrderData orderData) {// 每次接收到消息时,会自动打印出用户ID和订单总金额log.info("---Consumed Message - User ID: " + orderData.getUserId() + ", Total Amount: " + orderData.getTotalAmount());
}
- 实时更新与持久化:计算每个页面的实时访问量,并可选择持久化结果用于历史数据分析。
2024-11-20 11:23:07.811 INFO 26000 --- [ntainer#1-0-C-1] c.e.springkafka.listener.KafkaConsumer : ---Consumed Message - User ID: "1", Total Amount: 45.0
2024-11-20 11:23:07.811 INFO 26000 --- [ntainer#1-0-C-1] c.e.springkafka.listener.KafkaConsumer : ---Consumed Message - User ID: "2", Total Amount: 215.0
5. 系统部署与监控
- 部署:可以选择在本地开发环境测试后,利用 Docker 或 Kubernetes 将应用部署到生产环境。
- 监控:通过 JMX + Prometheus + Grafana 方案监控系统健康状况,例如延迟、处理错误和吞吐量。设置告警可以快速应对问题。
通过本实战项目,你已经实践了如何设计和实现一个用户订单分析系统。从数据清洗、预处理到数据的统计与展示,每一步都突出了 Kafka Streams 在实时流处理中的强大功能。完成项目后,你不仅对 Kafka Streams 的各个功能有更深入的理解,且能实际应用于解决复杂的数据处理问题。
相关文章:

Kafka Stream实战教程
Kafka Stream实战教程 1. Kafka Streams 基础入门 1.1 什么是 Kafka Streams Kafka Streams 是 Kafka 生态中用于 处理实时流数据 的一款轻量级流处理库。它利用 Kafka 作为数据来源和数据输出,可以让开发者轻松地对实时数据进行处理,比如计数、聚合、…...
)
数据仓库-基于角色的权限管理(RBAC)
什么是基于角色的用户管理? 基于角色的用户管理(Role-Based Access Control,简称RBAC)是通过为角色赋予权限,用户通过成为适当的角色而得到这些角色的权限。 角色是一组权限的抽象。 使用RBAC可以极大简化对权限的管理。 什么是RBAC模型&…...

如何使用ERC404协议
ERC404 ERC404协议的性质 ERC404不是一个开发代码工具包,而是一种智能合约标准规范。它就像是一份蓝图或者规则手册,规定了在以太坊区块链上开发特定智能合约应该遵循的接口、函数和事件等规则。如何使用ERC404协议 定义合约接口 首先,在开发智能合约时,要根据ERC404标准定…...
)
Spring Boot 工程分层实战(五个分层维度)
1、分层思想 计算机领域有一句话:计算机中任何问题都可通过增加一个虚拟层解决。这句体现了分层思想重要性,分层思想同样适用于Java工程架构。 分层优点是每层只专注本层工作,可以类比设计模式单一职责原则,或者经济学比较优势原…...

IIS部署程序https是访问出现403或ERR_HTTP2_PROTOCOL_ERROR
一、说明 在windows server 2016中的IIS程序池里部署一套系统,通过https访问站点,同时考虑到安全问题以及防攻击等行为,就用上了WAF云盾功能,能有效的抵挡部分攻击,加强网站的安全性和健壮性。 应用系统一直能够正常…...

【深度学习入门】深度学习介绍
1.1 深度学习介绍 学习目标 目标 知道深度学习与机器学习的区别了解神经网络的结构组成知道深度学习效果特点 应用 无 区别 特征提取方面 机器学习的特征工程步骤是要靠手动完成的,而且需要大量领域专业知识深度学习通常由多个层组成,它们通常将更简…...

node_modules文件夹删除失败解决办法
在前端开发过程中,node_modules 文件夹是一个必不可少的组成部分,里面存放着项目所需的各种依赖包。然而,随着项目的发展,node_modules 文件夹可能会变得异常庞大,甚至有时需要删除它来解决一些依赖冲突或清理空间。但…...

360智脑张向征:共建可信可控AI生态 应对大模型安全挑战
发布 | 大力财经 人工智能的加速发展,有力推动了社会的数智化转型;与此同时,带来的相关安全风险也日益凸显。近日,在北京市举办的通明湖人工智能开发与应用大会上,360智脑总裁张向征以“大模型安全研究与实践”为主题&…...

adb 常用命令笔记
adb connect <ip> #连接指定ip adb disconnect <ip> #断开连接指定ip adb devices #查看连接中的设备 adb install <flie> #安装apk adb uninstall <packageName> #卸载app adb -s install <flie> #指定设备安装 adb shell pm list package…...

uniapp中打包应用后,组件在微信小程序和其他平台实现不同的样式
今天,我们来介绍一下,uniapp中如何实现打包应用后,组件在微信小程序和其他平台不同的样式,在这里,我们使用背景颜色进行演示,使用 UniApp 提供的 uni.getSystemInfoSync() 方法来获取系统信息,包…...

代码随想录算法训练营第三天 | 链表理论基础 | 206.反转链表
从老链表第一个元素开始,逐个取出 第一个取出的元素,让其next指向nullptr。由于改变其指向,会导致后续链表没有指向消失,所以要在这步之前将其后续元素的指向放在一个新变量中再将后续结点的指向当前结点,不断反复运行…...
)
《数据结构》(非408代码题)
链表 设单链表的表头指针为L,结点结构由data和next两个域构成,其中data域为字符型。试设计算法判断该链表的全部n个字符是否中心对称。例如xyx、xyyx都是中心对称。 分析: 这题完全可以参考19年那题,我们直接找到中间结点然后将后…...
_kaic)
springboot427民航网上订票系统设计和实现(论文+源码)_kaic
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装民航网上订票系统软件来发挥其高效地信息处理的作用&#x…...

UE4_控件蓝图_制作3D生命血条
一:效果图如下: 二、实现步骤: 1、新建敌人 右键蓝图类 选择角色, 重命名为BP_Enemytest。 双击打开,配置敌人网格体 修改位置及朝向 效果如下: 选择合适的动画蓝图类: 人物就有了动作&#x…...

欧拉计划 Project Euler 21题解
欧拉计划21 Project Euler Problem21题干亲和数约数和的计算定义对于任何素数 \( p \):考虑 p a p^a pa:示例可乘性回到示例 Project Euler Problem21 题干 亲和数 记 d ( n ) d(n) d(n) 为 n 的所有真约数(小于 n 且整除 n 的正整数)之和。 如果 d(a) b , d(b) a &…...

python中的Counter函数
在 Python 中,Counter 是 collections 模块中的一个类,用于统计可迭代对象中元素的出现次数,并以字典的形式返回,键为元素,值为对应的计数。它非常适合处理频率统计问题。 用之前必须先导入 from collections import…...
- 实现带有水印和圆角的自定义 TextBox 控件)
WPF+MVVM案例实战与特效(三十七)- 实现带有水印和圆角的自定义 TextBox 控件
文章目录 1、概述2、案例实现1、基本功能2、代码实现3、控件应用4、案例效果5、源代码下载4、总结1、概述 在开发用户界面时,TextBox 是最常见的输入控件之一。为了提升用户体验,我们经常需要为 TextBox 添加一些额外的功能,例如显示提示文本(水印)和设置圆角边框。本文将…...

SQLServer到MySQL的数据高效迁移方案分享
SQL Server数据集成到MySQL的技术案例分享 在企业级数据管理中,跨平台的数据集成是一个常见且关键的任务。本次我们将探讨如何通过轻易云数据集成平台,将巨益OMS系统中的退款单明细表从SQL Server高效、安全地迁移到MySQL数据库中。具体方案名称为“7--…...

docker快速实现ELK的安装和使用
目录 一、ELK功能原理 二、项目功能展示 三、日志查询展示 四、ELK安装步骤 1、创建elasticsearch、kibana、filebeat相关data、log、conf目录 2、进入/usr/local/elk目录,并创建一个docker网络 3、启动 elasticsearch容器 4、运行kibana容器 5、启动f…...

hbase读写操作后hdfs内存占用太大的问题
hbase读写操作后hdfs内存占用太大的问题 查看内存信息hbase读写操作 查看内存信息 查看本地磁盘的内存信息 df -h查看hdfs上根目录下各个文件的内存大小 hdfs dfs -du -h /查看hdfs上/hbase目录下各个文件的内存大小 hdfs dfs -du -h /hbase查看hdfs上/hbase/oldWALs目录下…...

解决vue2中更新列表数据,页面dom没有重新渲染的问题
在 Vue 2 中,直接修改数组的某个项可能不会触发视图的更新。这是因为 Vue 不能检测到数组的索引变化或对象属性的直接赋值。为了确保 Vue 能够正确地响应数据变化,你可以使用以下几种方法: 1. 使用 Vue.set() 使用 Vue.set() 方法可以确保 …...

Go语言错误分类
错误的分类 在 Go 语言中,错误是通过实现 error 接口的类型表示的,但不同场景下的错误可以按性质和用途进行分类。以下是 Go 语言错误的常见分类,以及每类错误的解释和示例: 标准错误类型 标准库中定义了许多常见的错误类型&…...

使用 Ansys Fluent 对气体泄漏检测进行建模
了解使用 Ansys Fluent 仿真气体泄漏和确保安全的前沿技术。 挑战 气体泄漏对人类安全和环境构成重大风险。及早检测气体泄漏可以防止潜在的灾难,包括爆炸、火灾和有毒物质暴露。有效的气体泄漏检测系统对于石油和天然气、化学加工和住宅基础设施等行业至关重要。…...
:标准化JSON报告Gherkin格式命令行报告)
Pytest-Bdd-Playwright 系列教程(16):标准化JSON报告Gherkin格式命令行报告
Pytest-Bdd-Playwright 系列教程(16):标准化JSON报告&Gherkin格式命令行报告 前言一、创建Feature文件二、创建步骤定义文件三、生成Cucumber格式的JSON报告四、使用Gherkin格式的命令行报告五、将BDD报告集成到Jenkins中总结 前言 在自动…...

lc46全排列——回溯
46. 全排列 - 力扣(LeetCode) 法1:暴力枚举 总共n!种全排列,一一列举出来放入list就行,关键是怎么去枚举呢?那就每次随机取一个,然后删去这个,再从剩下的数组中继续去随机选一个&a…...

软考:工作后再考的性价比分析
引言 在当今的就业市场中,软考(软件设计师、系统分析师等资格考试)是否值得在校学生花费时间和精力去准备?本文将从多个角度深入分析软考在不同阶段的性价比,帮助大家做出明智的选择。 一、软考的价值与局限性 1.1 …...

如何设置 Data Guard 的报警机制?
概述 设置 Data Guard 的报警机制是确保高可用性和及时响应故障的关键步骤。以下是一些常见的方法来配置 Data Guard 的报警机制,包括使用 Oracle Enterprise Manager (OEM)、Data Guard Broker 以及自定义脚本和外部监控工具。 1. 使用 Oracle Enterprise Manage…...

Elastic 8.17:Elasticsearch logsdb 索引模式、Elastic Rerank 等
作者:来自 Elastic Brian Bergholm 今天,我们很高兴地宣布 Elastic 8.17 正式发布! 紧随一个月前发布的 Elastic 8.16 之后,我们将 Elastic 8.17 的重点放在快速跟踪关键功能上,这些功能将带来存储节省和搜索性能优势…...

Please activate LaTeX Workshop sidebar item to render the thumbnail of a PDF
Latex代码中使用pdf图片,无法预览,提示: Please activate LaTeX Workshop sidebar item to render the thumbnail of a PDF 解决办法: 点击左边这个刷新下即可...
- 数据库操作)
HiveQL命令(一)- 数据库操作
文章目录 前言一、数据库操作1. 创建数据库1.1 语法及解释1.2 创建数据库示例 2. 查看数据库2.1 查看所有数据库2.2 查看数据库信息2.2.1 语法及解释2.2.2 查看数据库信息示例 3. 切换数据库3.1 语法3.2 示例 4. 修改数据库4.1 语法4.2 示例 5. 删除数据库5.1 语法及解释5.2 示…...

【esp32s3】esp-dl模型部署demo
一个单片机部署手写数字识别的demo 源码: # 别跑,给我star git clone https://gitee.com/Shine_Zhang/esp32s3_dl_helloworld.git功能: 网页绘制28x28手写数字,串口输入设备,串口打印输出10个数字的概率值࿰…...

Zemax 中的 LED 阵列模型
LED 阵列的光学特性 LED 阵列由多个发光二极管 (LED) 组成,这些二极管以特定模式或配置排列,以实现均匀照明、更高强度或特定照明特性。这些阵列广泛用于显示器、照明系统、光通信和传感等应用。 LED 阵列的光学特性对于了解它如…...

123213124
📢博客主页:https://blog.csdn.net/2301_779549673 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! 📢本文由 JohnKi 原创,首发于 CSDN🙉 📢未来很长&#…...

游戏引擎学习第42天
仓库: https://gitee.com/mrxiao_com/2d_game 简介 目前我们正在研究的内容是如何构建一个基本的游戏引擎。我们将深入了解游戏开发的每一个环节,从最基础的技术实现到高级的游戏编程。 角色移动代码 我们主要讨论的是角色的移动代码。我一直希望能够使用一些基…...

elasticsearch设置密码访问
1 用户认证介绍 默认ES是没有设置用户认证访问的,所以每次访问时,直接调相关API就能查询和写入数据。现在做一个认证,只有通过认证的用户才能访问和操作ES。 2 开启加密设置 1.生成证书文件 /usr/share/elasticsearch/bin/elasticsearch-…...

阿里云-通义灵码:测试与实例展示
目录 一.引子 二.例子 三.优点 四.其他优点 五.总结 一.引子 在软件开发的广袤天地中,阿里云通义灵码宛如一座蕴藏无尽智慧的宝库,等待着开发者们去深入挖掘和探索。当我们跨越了入门的门槛,真正开始使用通义灵码进行代码生成和开发工作…...

开发者指南--RecyclerView显示数据列表和网格
一、RecyclerView的优势 RecyclerView 的最大优势在于,它对大型列表来说非常高效: 默认情况下,RecyclerView 仅会处理或绘制当前显示在屏幕上的项。例如,如果您的列表包含一千个元素,但只有 10 个元素可见࿰…...

Ajax--实现检测用户名是否存在功能
目录 (一)什么是Ajax (二)同步交互与异步交互 (三)AJAX常见应用情景 (四)AJAX的优缺点 (五)使用jQuery实现AJAX 1.使用JQuery中的ajax方法实现步骤…...
进程)
操作系统(5)进程
一、定义与特点 定义:进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。 特点: 动态性:进程是动态创建的,有它自身的生命周期,…...

力扣9. 回文数
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。 回文数 是指正序(从左向右)和倒序(从右向左)读都是一样的整数。 例如,121 是回文,而…...

1_linux系统网络性能如何优化——几种开源网络协议栈比较
之前合集《计算机网络从入门到放弃》第一阶段算是已经完成了。都是理论,没有实操,让“程序猿”很难受,操作性不如 Modbus发送的报文何时等到应答和 tcp通信测试报告单1——connect和send。开始是想看linux内核网络协议栈的源码,然…...

C#—BitArray点阵列
C#—BitArray点阵列 在 C# 中,BitArray 类用来管理一个紧凑型的位值数组,数组中的值均为布尔类型,其中 true(1)表示此位为开启,false(0)表示此位为关闭。 当需要存储位(…...
)
特工找密码(蓝桥杯)
本来这题想用枚举暴力解的,但是运行总是超时,数值范围太大了~,所以该题不能用枚举进行暴力。 转换成二进制,我们判断一下其规律 注意:按位与是都为1时其值才为1,所以当x和y按位与的结果为2时,其…...

微信小程序--创建一个日历组件
微信小程序–创建一个日历组件 可以创建一个日历组件,来展示当前月份的日期,并支持切换月份的功能。 一、目录结构 /pages/calendarcalendar.wxmlcalendar.scsscalendar.jscalendar.json二、calendar.wxml <view class"calendar"><…...

A6919 基于java+SSM+mysql的区域物流管理系统设计与实现
的区域物流管理系统的设计与实现 1.摘要2.开发目的和意义3.系统功能设计4.系统界面截图5.源码获取 1.摘要 摘 要 随着当前我国市场经济和计算机互联网技术迅速发展,各行各业的销售和管理都在逐步转向着第三方物流服务,包括中通快递,申通&…...

Python大数据可视化:基于python的电影天堂数据可视化_django+hive
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 电影数据 看板展示 我的信息 摘要 电影天堂数据可视化是…...

美畅物联丨JS播放器录像功能:从技术到应用的全面解析
畅联云平台的JS播放器是一款功能十分强大的视频汇聚平台播放工具,它已经具备众多实用功能,像实时播放、历史录像回放、云台控制、倍速播放、录像记录、音频播放、画面放大、全屏展示、截图捕捉等等。这些功能构建起了一个高效、灵活且用户友好的播放环境…...

前端国际化实战:从需求到落地的完整实践
"我们要开拓东南亚市场了!"产品经理小王兴奋地告诉我这个消息。作为技术负责人,我立刻意识到这意味着我们需要对整个系统进行国际化改造。说实话,虽然之前也做过一些多语言的项目,但面对一个正在运行的大型系统,国际化改造的挑战还是不小。 回想起上周的…...

MySQL 内置函数
字符串函数 concat(str1, str2, ...) 描述: 这个函数用于连接两个或多个字符串,返回一个新字符串。语法: concat(str1, str2, ...)注意点: 如果任意一个参数是null,则结果为null。可以连接任意数量的字符串。示例: select concat(first name: , first_…...

【Spring】日志类Logger的使用
在Spring框架中,日志记录是一个重要的组成部分,通常使用不同的日志框架来处理应用程序的日志。Spring 本身并直接提供一个名为Logger 的类,而是通过抽象的日志 API 让开发者能够选择和使用不同的日志实现(如 Log4j、Logback、SLF4…...