MySQL中的重要常见知识点(入门到入土!)
基础篇
基础语法
添加数据
-- 完整语法
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);-- 示例
insert into employee(id,workno,name,gender,age,idcard,entrydate)
values(1,'1','Itcast','男',10,'123456789012345678','2000-01-01')修改数据
-- 完整语法
UPDATE 表名 SET 字段名1 = 值1 , 字段名2 = 值2 , .... [ WHERE 条件 ] ;-- 示例
update employee set name = '小昭' , gender = '女' where id = 1;删除数据
-- 完整语法
DELETE FROM 表名 [ WHERE 条件 ] ;--示例
delete from employee where gender = '女';查询语句
SELECT字段列表
FROM表名列表
WHERE条件列表
GROUP BY分组字段列表
HAVING分组后条件列表
ORDER BY排序字段列表
LIMIT分页参数聚合函数查询
-- 完整语法
SELECT 聚合函数(字段列表) FROM 表名 ;-- 示例
select count(*) from emp; -- 统计的是总记录数
select count(idcard) from emp; -- 统计的是idcard字段不为null的记录数
select sum(age) from emp where workaddress = '西安'; -- 统计西安地区员工的年龄之和聚合函数是对表中一列数据的操作
分组查询
-- 完整语法
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组
后过滤条件 ];--示例
select gender, count(*) from emp group by gender ; -- 根据性别分组 , 统计男性员工 和 女性员工的数量select workaddress, count(*) address_count from emp where age < 45 group by workaddress having address_count >= 3; -- 查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址排序查询
-- 完整语法
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;-- 示例-- 根据年龄对公司的员工进行升序排序
select * from emp order by age asc;
select * from emp order by age;-- 根据入职时间进行降序排序
select * from emp order by entrydate desc;分页查询
-- 完整语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数 ;-- 示例
select * from emp limit 0,10; -- 查询第1页员工数据, 每页展示10条记录
select * from emp limit 10,10; --查询第2页员工数据, 每页展示10条记录DCL常用语法
创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';修改用户密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码' ;删除用户
DROP USER '用户名'@'主机名' ;查询权限
SHOW GRANTS FOR '用户名'@'主机名' ;赋予权限
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';函数
常用字符串函数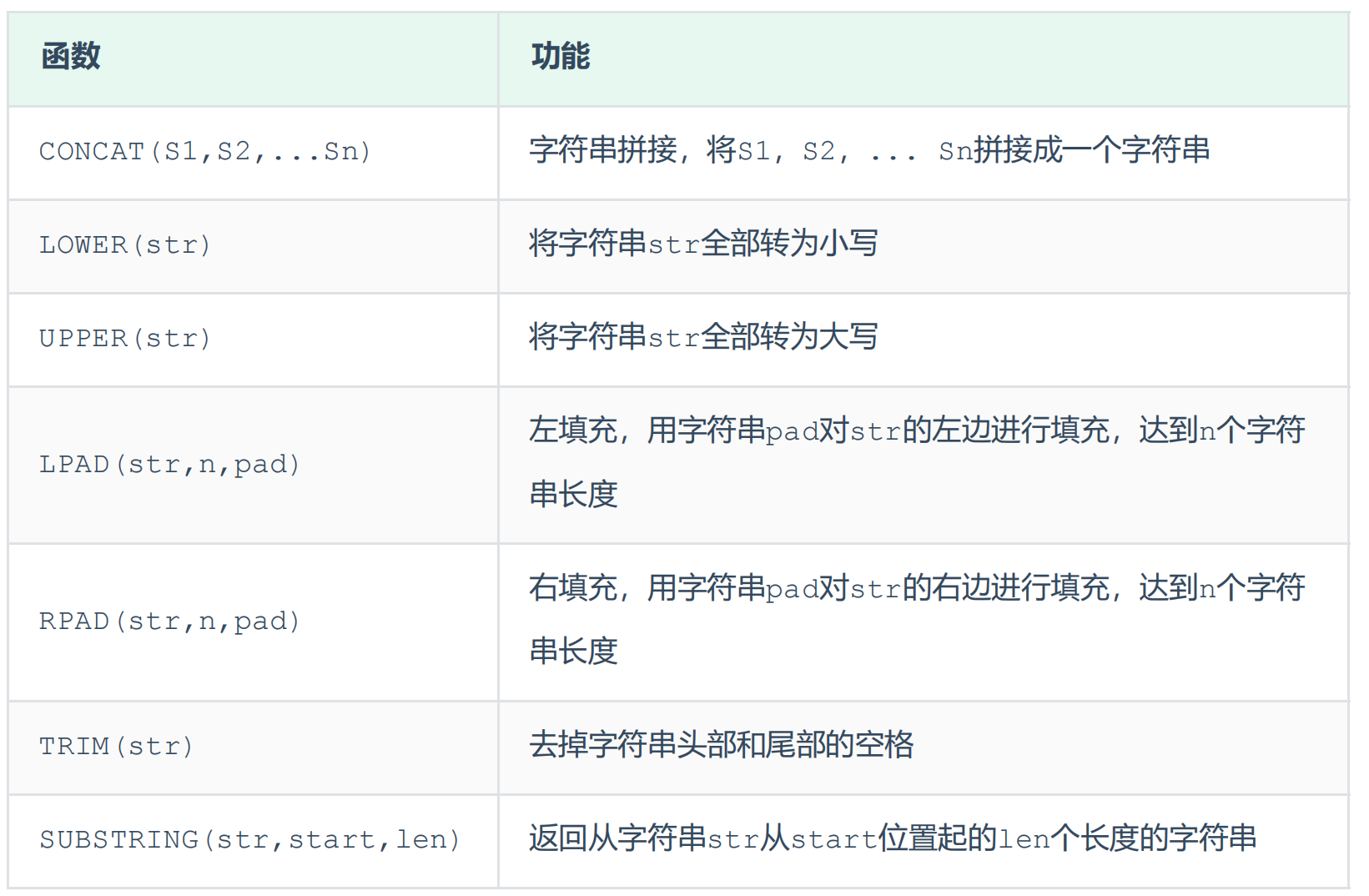
常用数值函数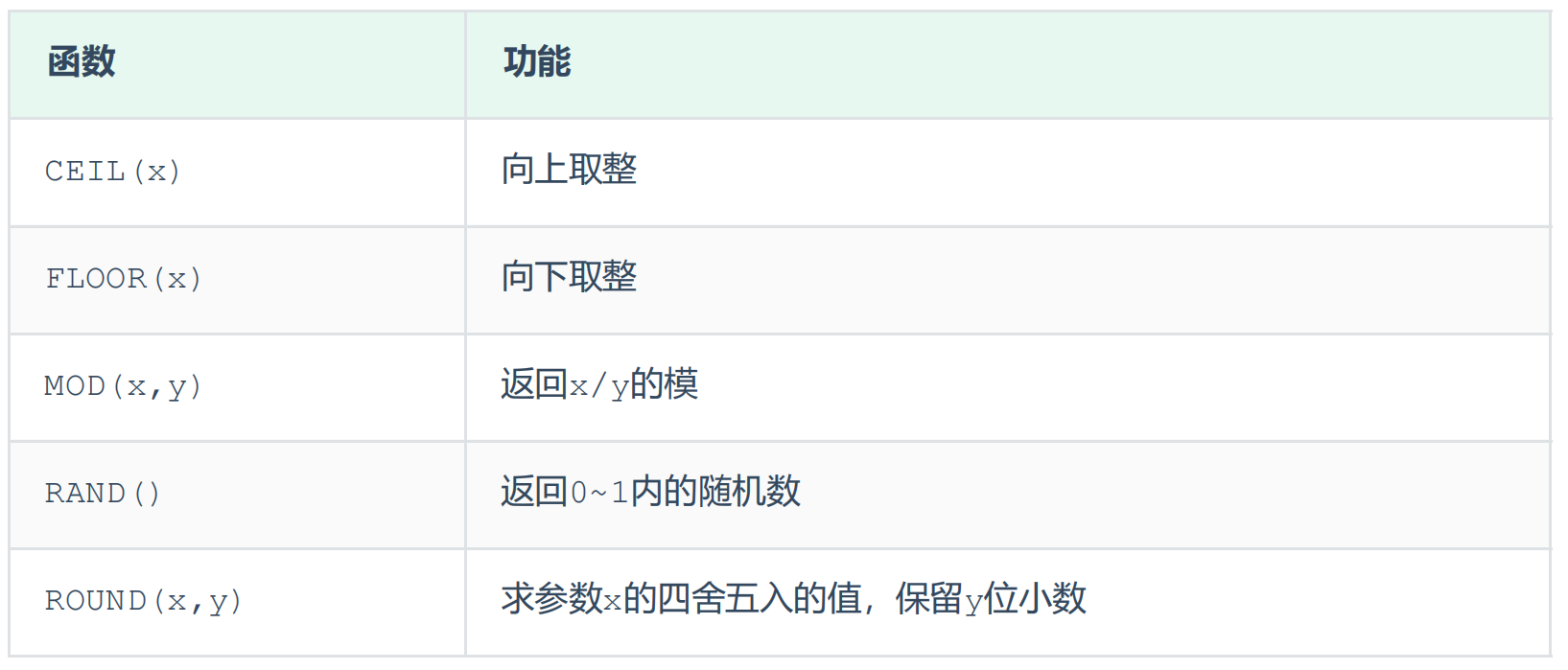 常用日期函数
常用日期函数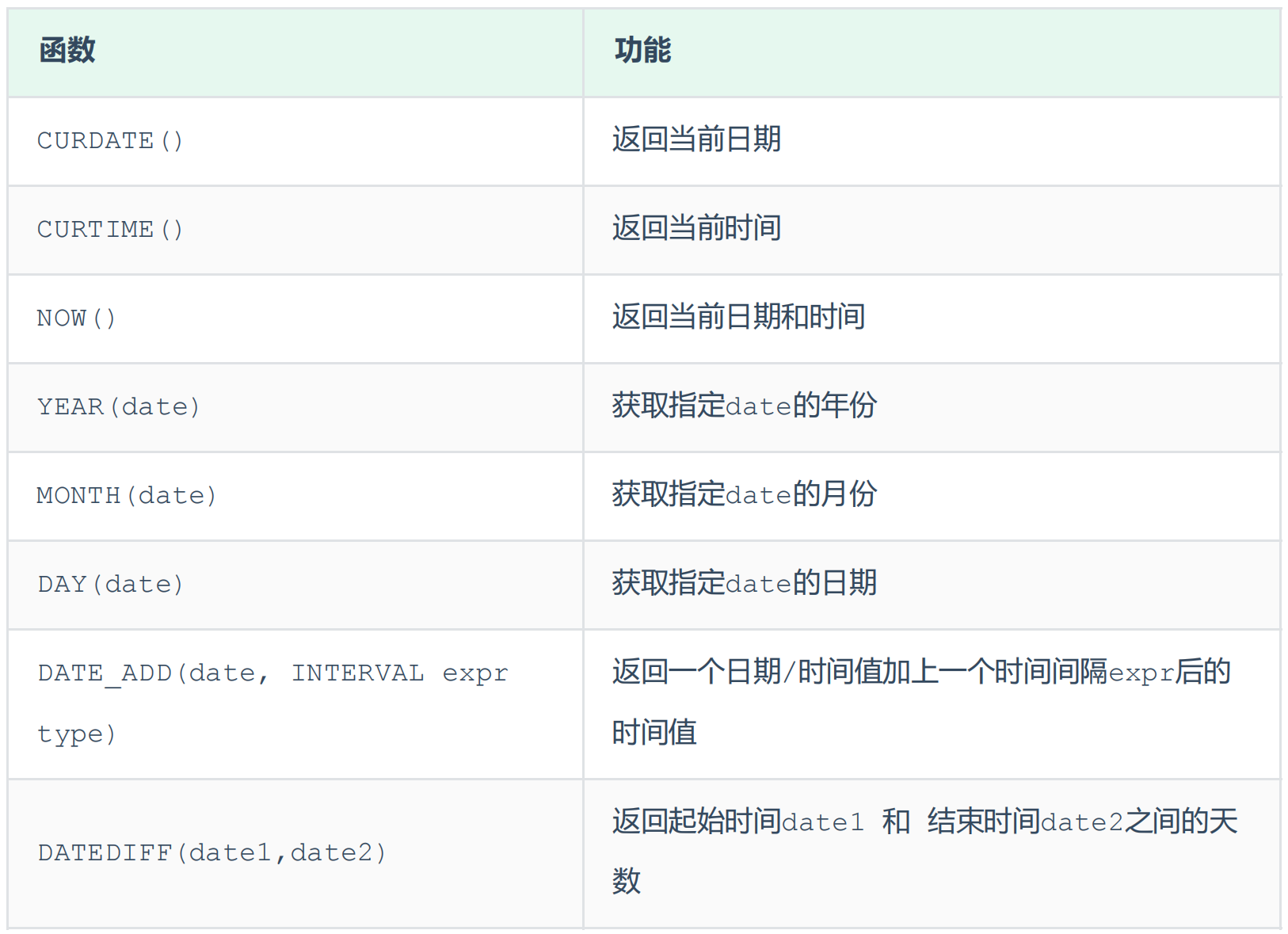
流程函数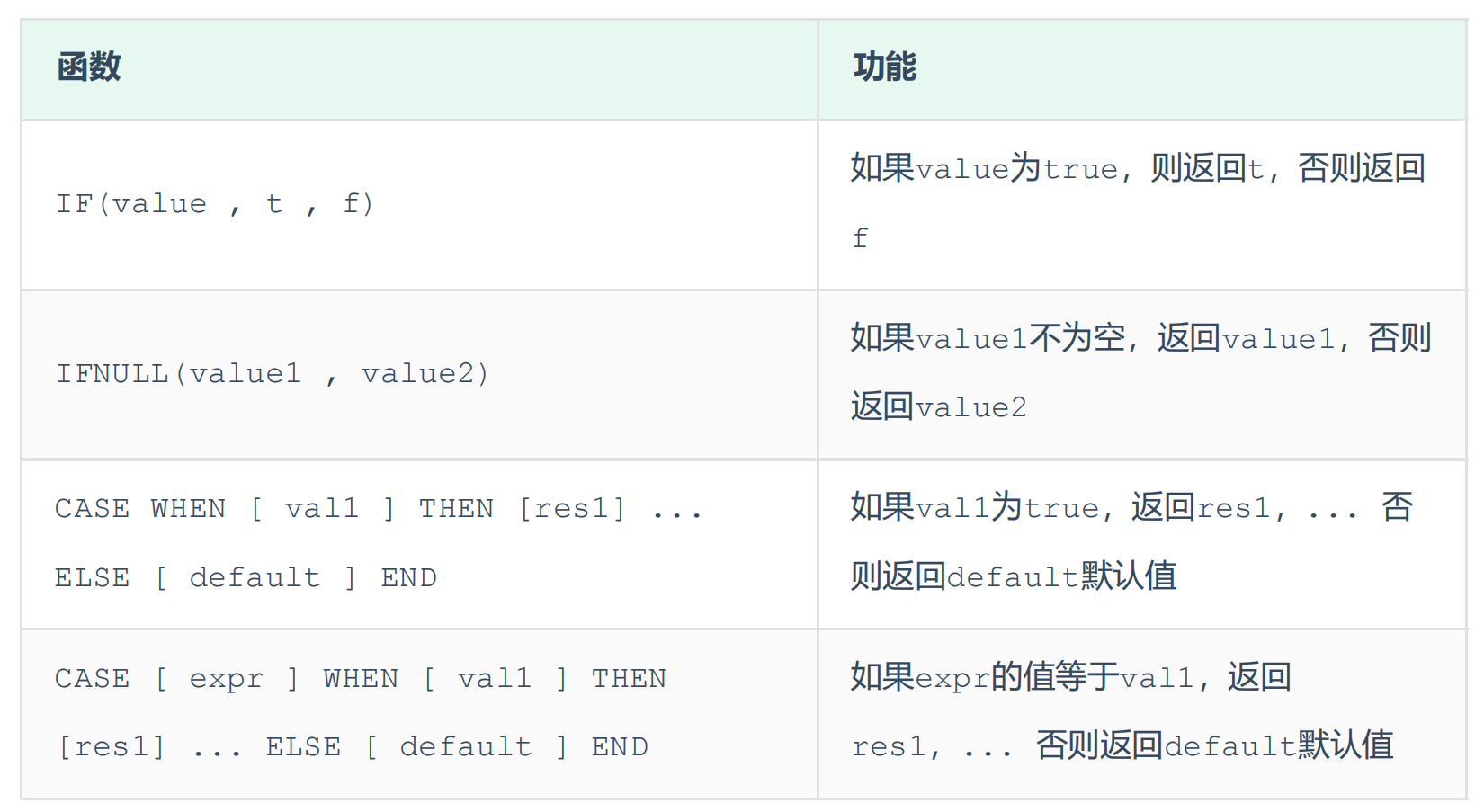
约束
常见的约束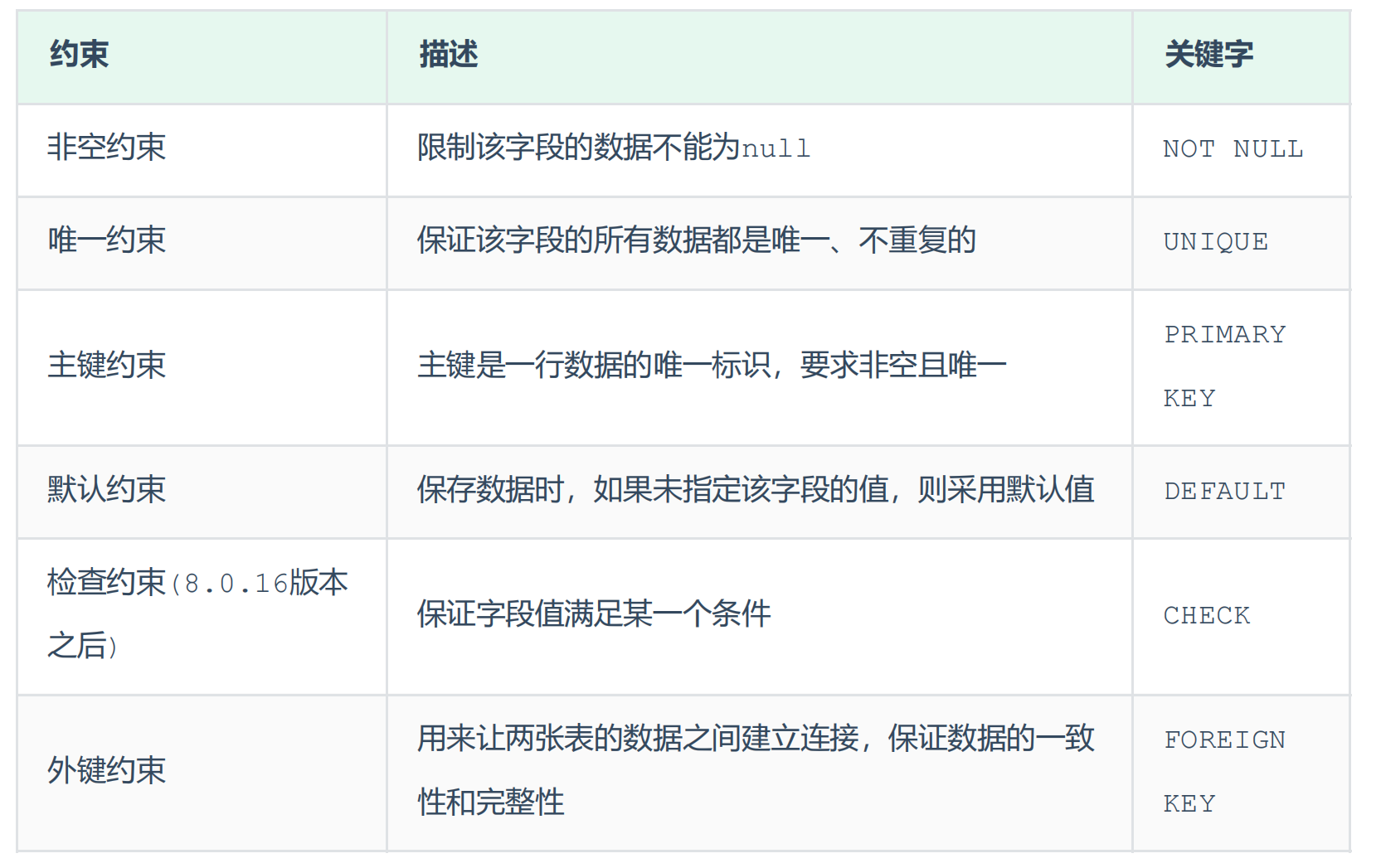
可以在创建或者修改表时添加约束
-- 具体示例
CREATE TABLE tb_user(id int AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识',name varchar(10) NOT NULL UNIQUE COMMENT '姓名' ,age int check (age > 0 && age <= 120) COMMENT '年龄' ,status char(1) default '1' COMMENT '状态',gender char(1) COMMENT '性别'
);添加外键约束
-- 创建时指定
CREATE TABLE 表名(
字段名 数据类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名)
);-- 修改时指定
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名)
REFERENCES 主表 (主表列名) ;-- 示例 为emp表的dept_id字段添加外键约束,关联dept表的主键id
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;删除/更新行为
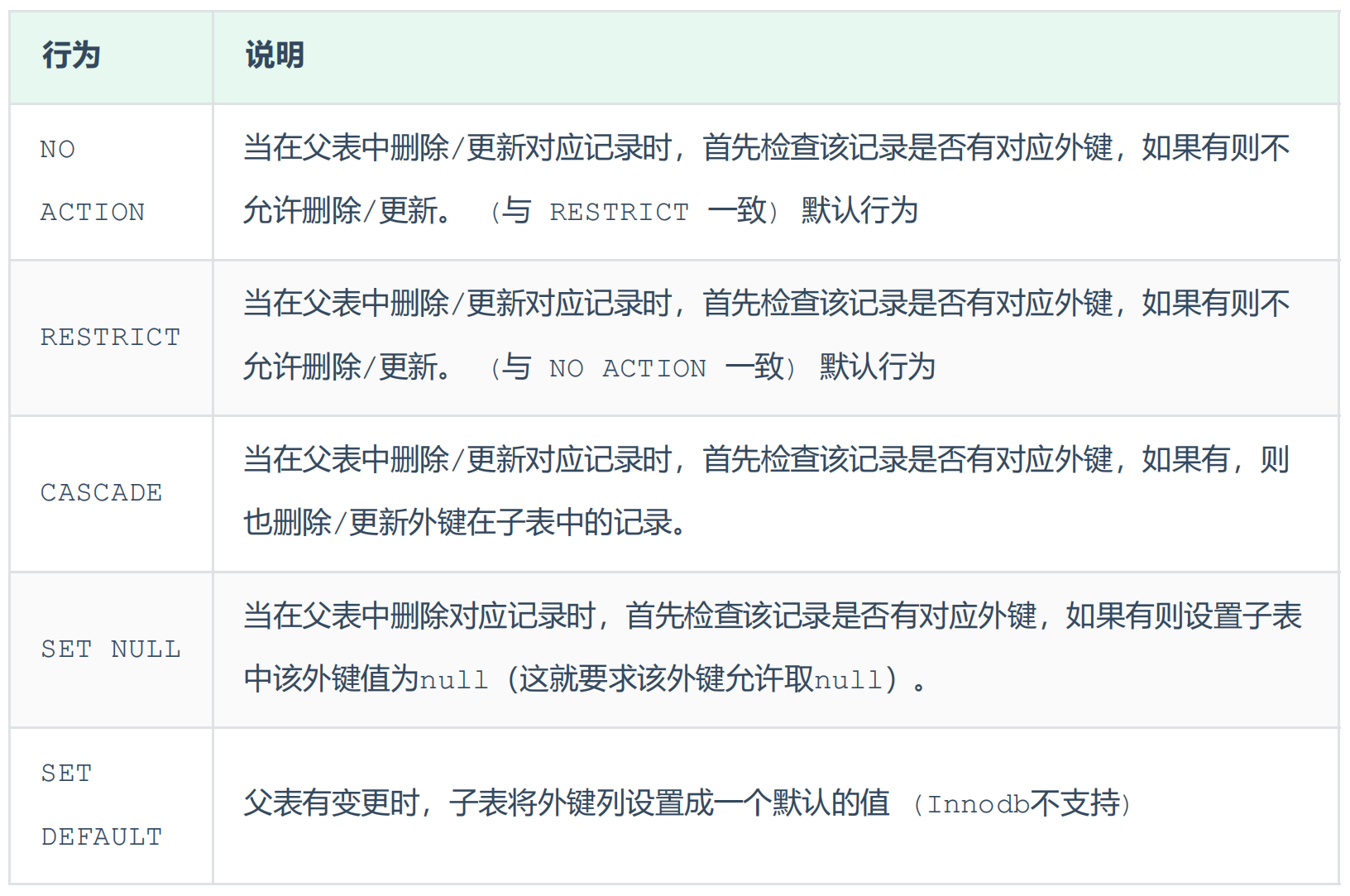
具体语法:
-- 完整语法
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;-- 示例
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;当对id为1的记录进行修改时:

多表查询
数据库的多表关系:
- 一对一
- 一对多
- 多对多
连接查询的分类:
- 内连接:相当于查询A、B交集部分数据
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集部分数据
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
内连接
-- 隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;-- 显式内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;-- 示例
select e.name,d.name from emp e , dept d where e.dept_id = d.id; -- 查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)select e.name, d.name from emp e join dept d on e.dept_id = d.id; -- 查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现)外连接
-- 左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;-- 右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;-- 示例
select e.*, d.name from emp e left join dept d on e.dept_id = d.id; -- 查询emp表的所有数据, 和对应的部门信息select d.*, e.* from emp e right join dept d on e.dept_id = d.id; -- 查询dept表的所有数据, 和对应的员工信息(右外连接)自连接查询
-- 全部语法
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;-- 示例
select a.name , b.name from emp a , emp b where a.managerid = b.id; -- 查询员工 及其 所属领导的名字select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid = b.id; -- 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底 是哪一张表的字段。
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
-- 语法
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );-- 示例
select * from emp where dept_id = (select id from dept where name = '销售部'); -- 查询 "销售部" 的所有员工信息select * from emp where entrydate > (select entrydate from emp where name = '方东白'); -- 查询在 "方东白" 入职之后的员工信息列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
-- 示例
select * from emp where salary > all ( select salary from emp where dept_id = (select id from dept where name = '财务部') ); -- 查询比 财务部 所有人工资都高的员工信息select * from emp where salary > any ( select salary from emp where dept_id = (select id from dept where name = '研发部') ); -- 查询比研发部其中任意一人工资高的员工信息行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
-- 示例
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌'); -- 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
-- 示例
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ; -- 查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息事务
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
-- 开启事务
start transaction
-- 1. 查询张三余额
select * from account where name = '张三';-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';-- 如果正常执行完毕, 则提交事务
commit;
-- 如果执行过程中报错, 则回滚事务
-- rollback;事务的四大特性(ACID)
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
并发事务问题
赃读:一个事务读到另外一个事务还没有提交的数据。
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了 "幻影"。
事务隔离级别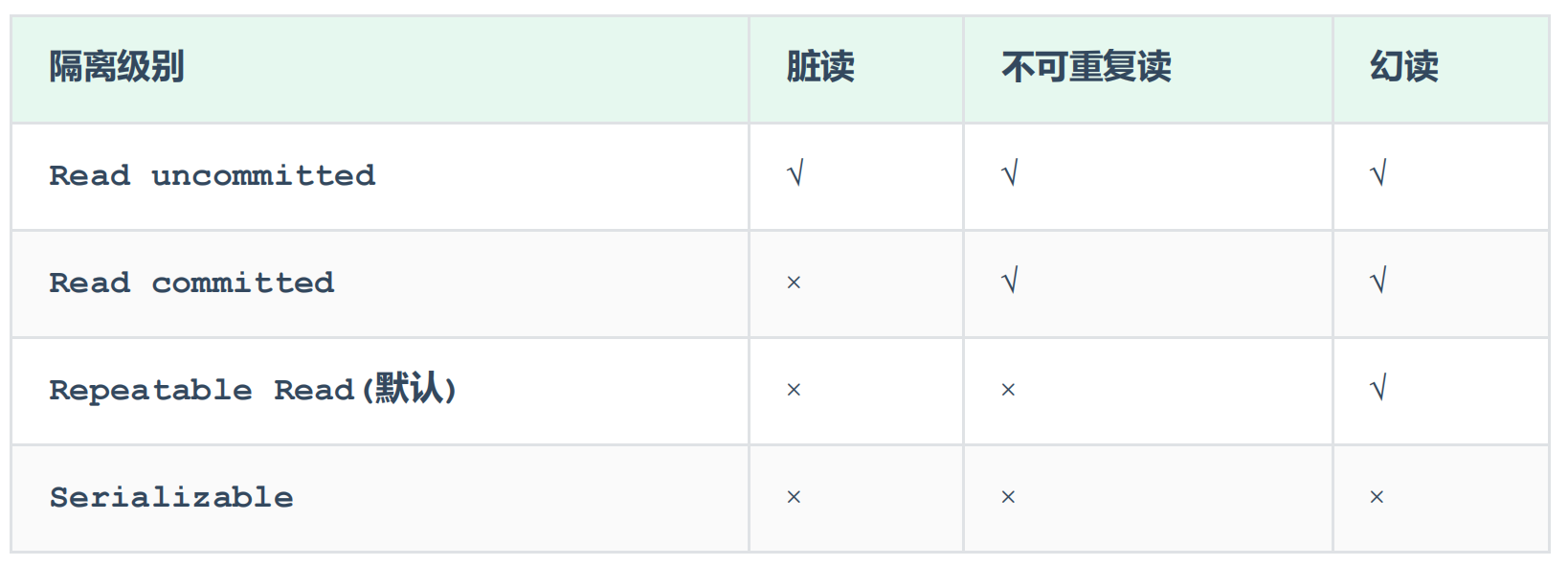
进阶篇
主要是MySQL索引、通过索引对SQL语句进行优化,事务底层原理和MVCC,之前都有专门的博客
MySQL索引:https://blog.csdn.net/Satoru000/article/details/147897956?spm=1001.2014.3001.5501![]() https://blog.csdn.net/Satoru000/article/details/147897956?spm=1001.2014.3001.5501 SQL优化:
https://blog.csdn.net/Satoru000/article/details/147897956?spm=1001.2014.3001.5501 SQL优化:
https://blog.csdn.net/Satoru000/article/details/147927247?spm=1001.2014.3001.5501![]() https://blog.csdn.net/Satoru000/article/details/147927247?spm=1001.2014.3001.5501 事务和MVCC详解: https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501
https://blog.csdn.net/Satoru000/article/details/147927247?spm=1001.2014.3001.5501 事务和MVCC详解: https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501![]() https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501
https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501
运维篇
二进制日志
binlog记录的是数据库所有的能影响数据库的语句(不包括select和show),可以用于主从复制时给从库做数据的拷贝
具体的数据格式:
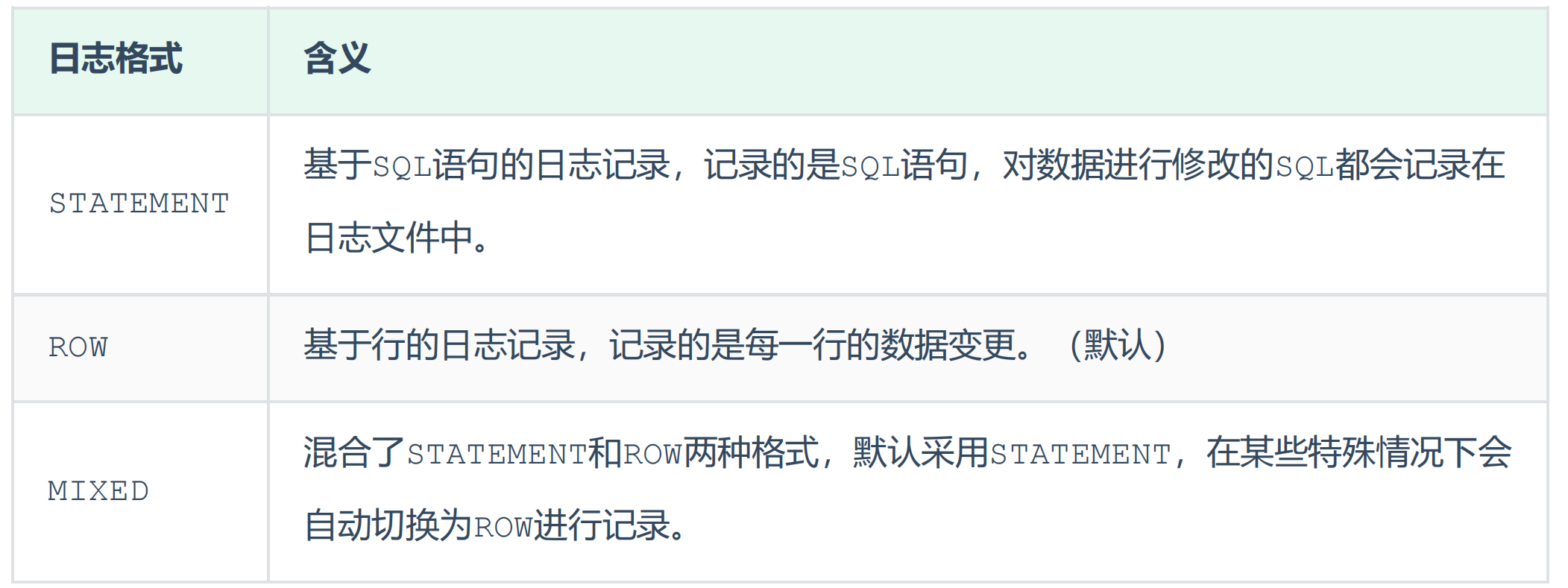
binlog如果数据量太大可以定期进行删除或者手动进行删除
慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志,默认未开启。long_query_time 默认为10秒,最小为 0, 精度可以到微秒。
开启慢查询日志需要再配置文件中进行配置
#慢查询日志
slow_query_log=1
#执行时间参数
long_query_time=2注意:这样配置的慢查询日志只会记录使用了索引并且超出范围的语句,也不会记录管理语句,所以要追加配置
#记录执行较慢的管理语句
log_slow_admin_statements =1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes = 1主从复制原理
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
主从复制的优点:
- 高可用,主库出现问题可以切换到从库
- 可以实现读写分离,减少数据库的访问压力
- 从库可以进行备份操作,提高效率
主从复制的原理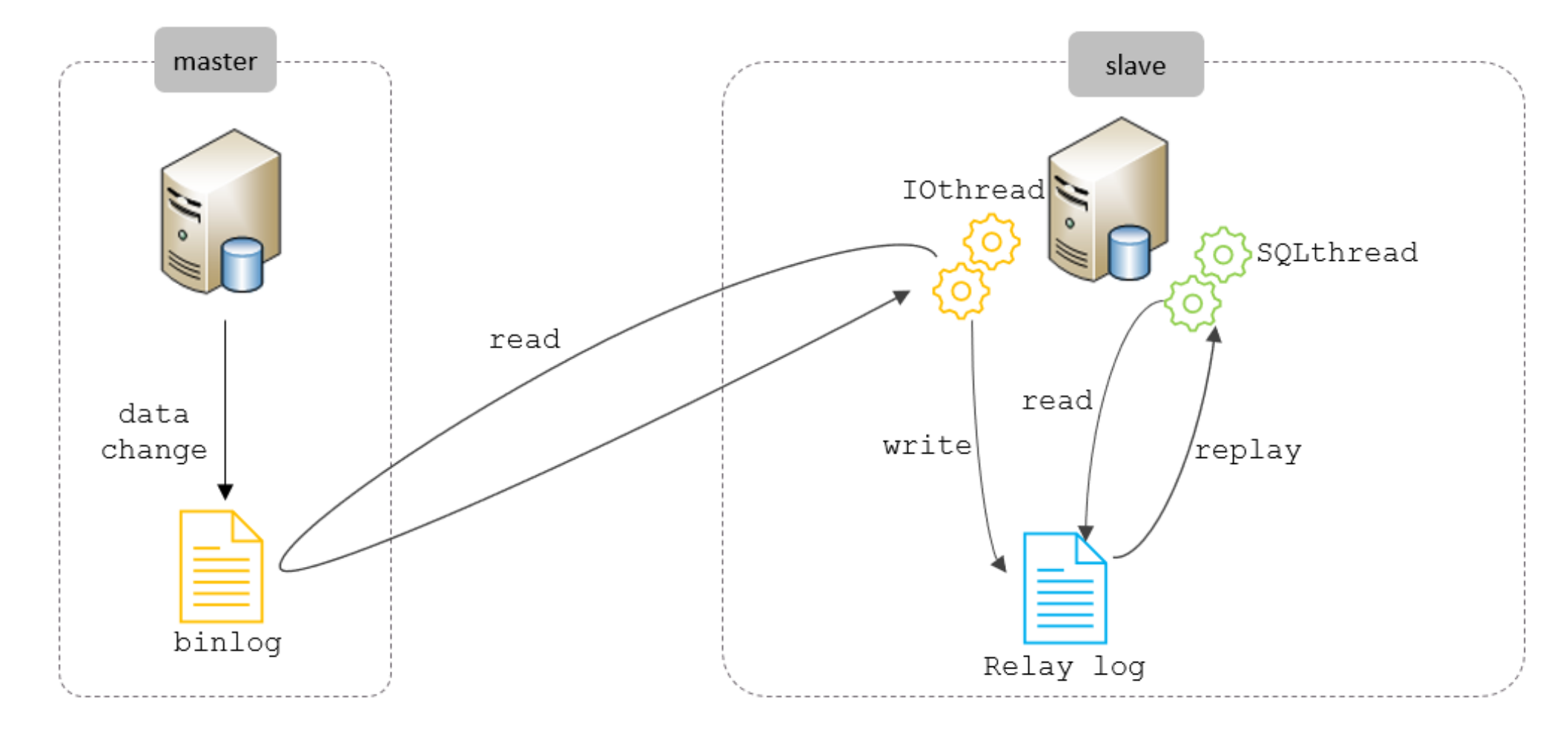
master将DDL和DML语句保存到binlog文件中,从库通过IO线程读取binlog文件到Relay log,再通过一个后台的SQL线程进行复制
主从复制搭建
主库的配置:
- 在配置文件中追加配置
- 重启MySQL服务
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
server-id=1
#是否只读,1 代表只读, 0 代表读写
read-only=0
#忽略的数据, 指不需要同步的数据库
#binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01从库的配置:
- 在配置文件中追加配置
- 重启MySQL服务
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=1建立主库和从库的链接
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.200.200', SOURCE_USER='itcast',
SOURCE_PASSWORD='Root@123456', SOURCE_LOG_FILE='binlog.000004',
SOURCE_LOG_POS=663;source_host:主库的ip地址
source_user:连接主库的用户名
source_password:连接主库的密码
source_log_file:主库同步到从库的binlog文件
source_log_pos:从binlog进行同步的位置
分库分表
垂直拆分
垂直分库: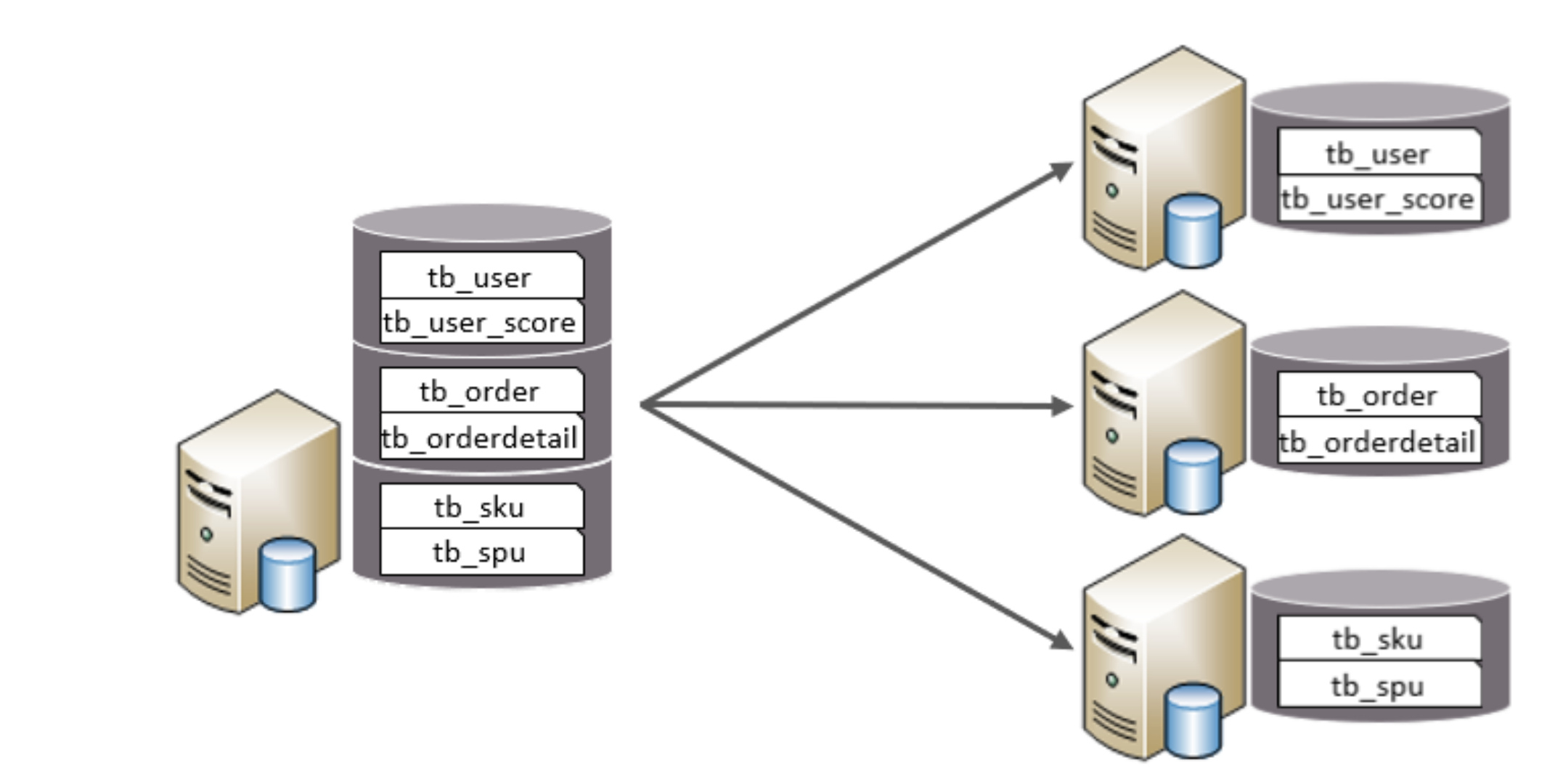
将一个数据库中的所有表都拆分到多个数据库中,若干个表分配到一个数据库中,这样每个数据库中的表就能代表不同的业务
所以垂直分库中:
- 每个数据库的表结构都不同
- 每个数据库中的数据都不同
- 所有数据库全部加在一起就是全部的数据
垂直分表:
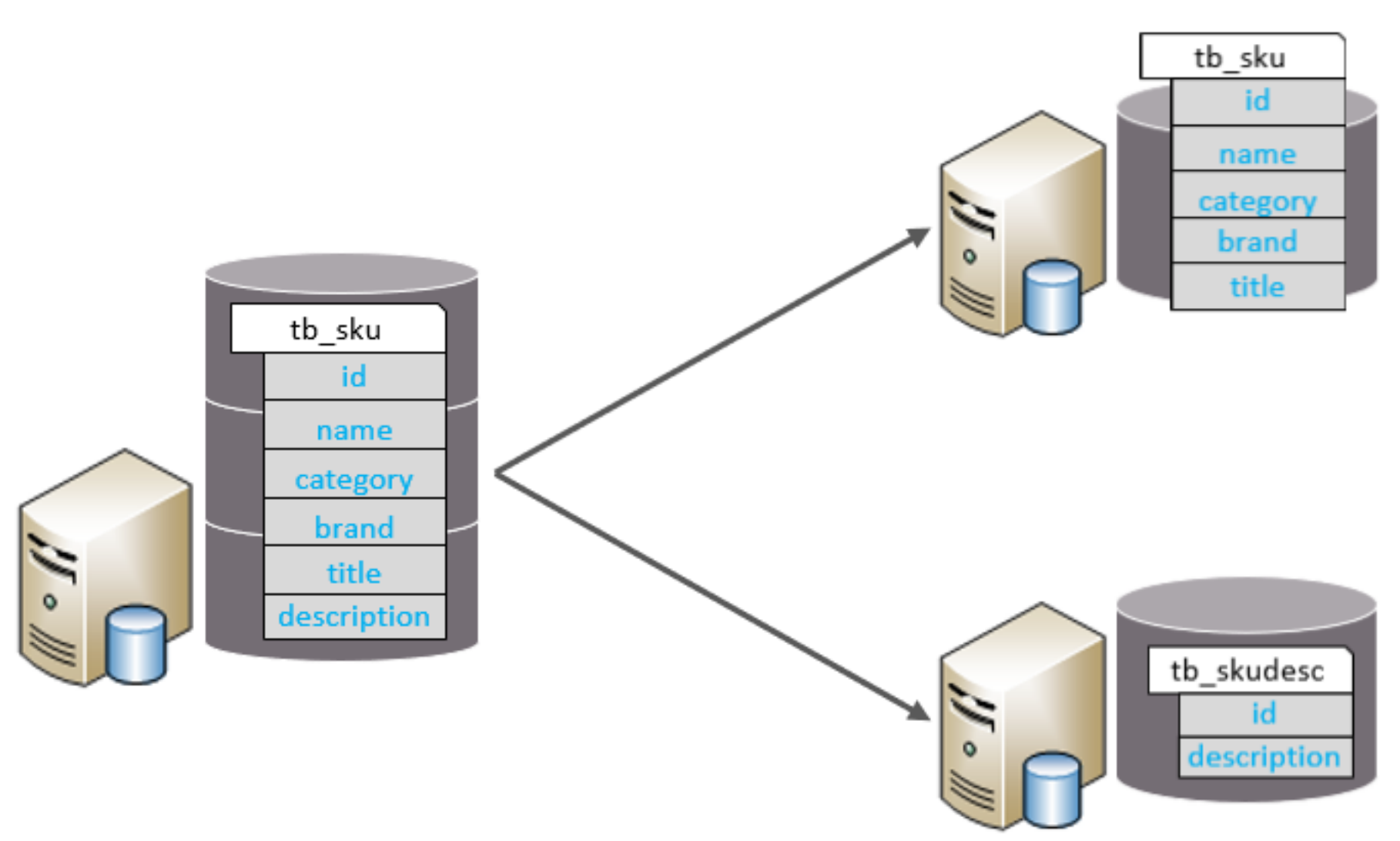
既然知道了垂直分库,那么垂直分表也差不多,只不过比数据库低了一级,就是将数据库中的字段拆分到不同的表中,然后再将这些表分配到不同的数据库中。
所以垂直分表的特点:
- 每个表的结构都不一样。
- 每个表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有表的并集是全量数据。
水平拆分
水平分库: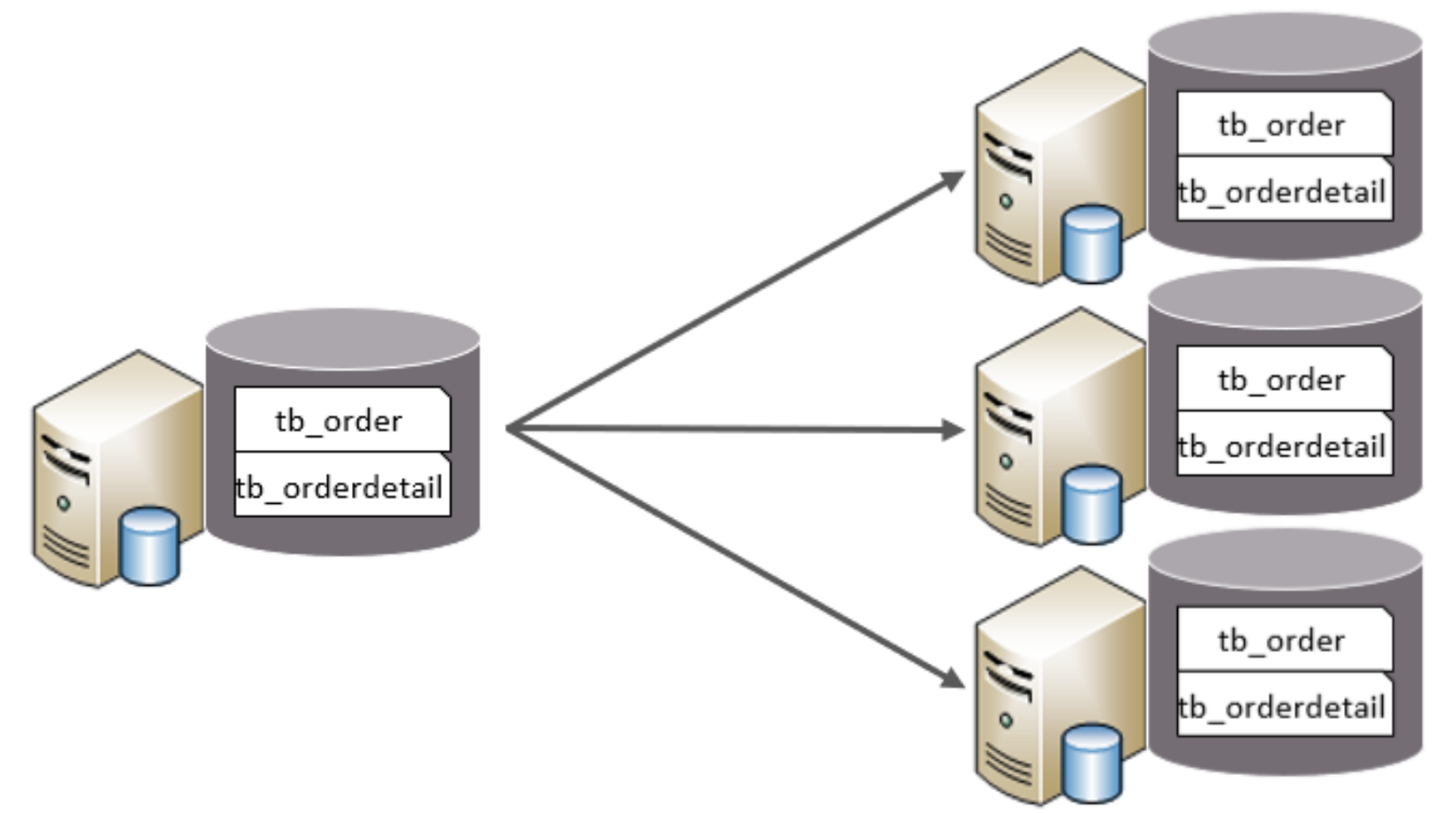
就是将数据库中表的数据分配到不同的数据库中,但是每个数据库中表的数据都只占原有表数据的一部分
所以水平分库的特点:
- 所有数据库表的结构都一样
- 每个数据库表中的数据都不一样
- 每个数据库表中的数据之和就是原来数据库表中的全部数据
水平分表: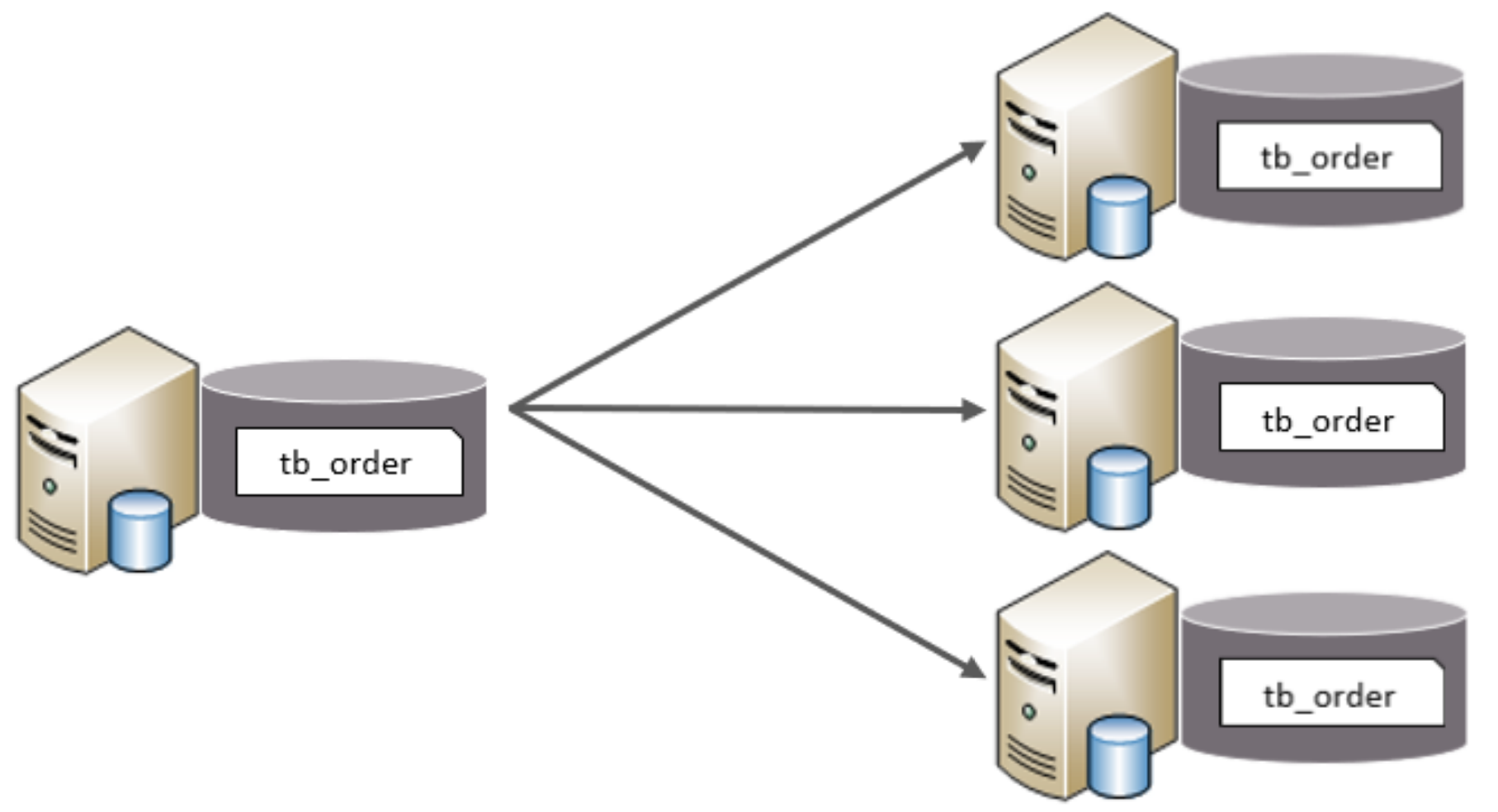
和水平分库同理,水平分库是将数据库中所有的表进行拆分,那么水平分表就是只将这张表的数据进行拆分,分配到各个数据库中
水平分表的特点:
- 每个表的表结构都一样。
- 每个表的数据都不一样。
- 所有表的并集是全量数据。
MyCat入门
MyCat概述
MyCat是一个数据库中间件,用户之前是直接访问MySQL,加入了MyCat后就是访问MyCat,再由MyCat路由到对应的MySQL服务。Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。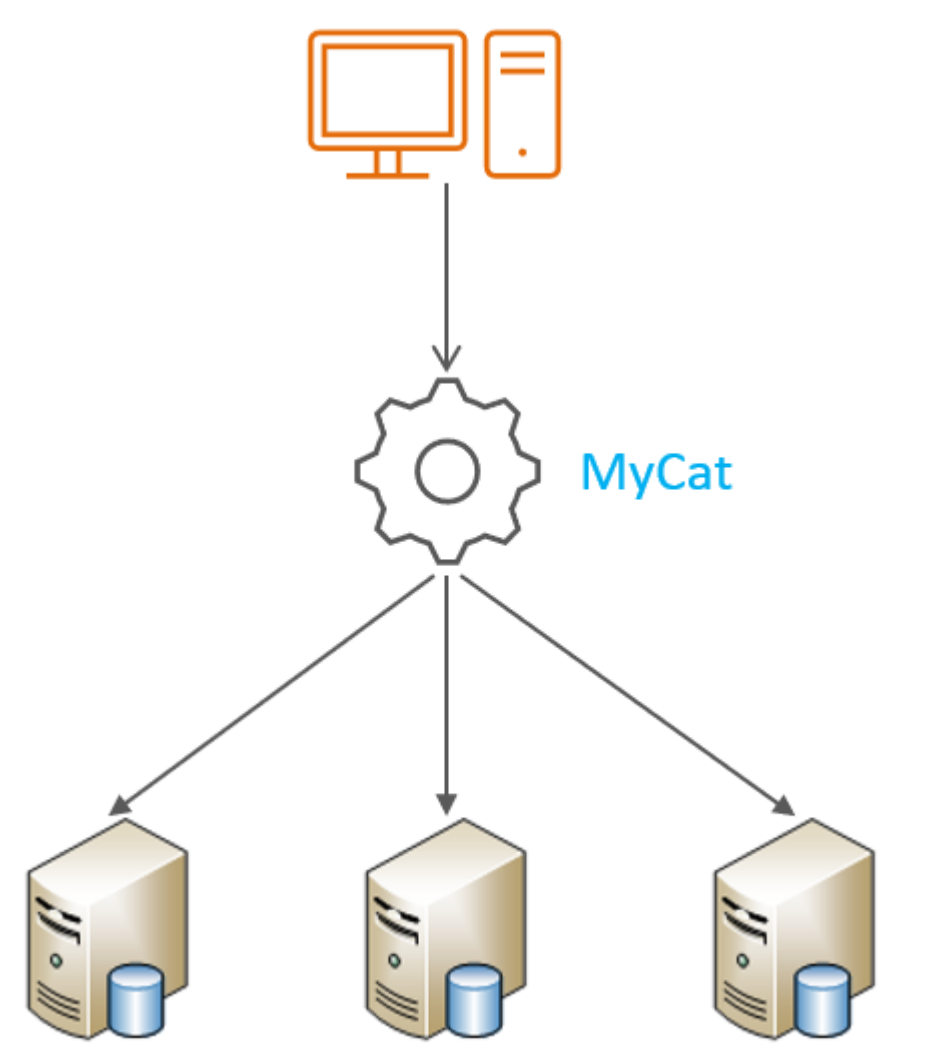
mycat的结构大致如下

MyCat配置
在schema.xml中配置逻辑库、逻辑表、数据节点、节点主机等相关信息。具体的配置如下:
table标签:逻辑表
dataNode标签:数据节点
rule:分片规则
dataHost:连接的MySQL主机的信息
writeHost:读写分离的标签,这里是标记主节是读主机,用于读写分离,这里只用于标记没有实现读写分离
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="DB01" checkSQLschema="true" sqlMaxLimit="100"><table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"/></schema><dataNode name="dn1" dataHost="dhost1" database="db01"/><dataNode name="dn2" dataHost="dhost2" database="db01"/><dataNode name="dn3" dataHost="dhost3" database="db01"/><dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/></dataHost><dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/></dataHost><dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/></dataHost>
</mycat:schema>需要在server.xml中配置用户名、密码,以及用户的访问权限信息,具体的配置如下:
<user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">DB01</property><!-- 表级 DML 权限设置 --><!--<privileges check="true"><schema name="DB01" dml="0110"><table name="TB_ORDER" dml="1110"></table></schema></privileges>-->
</user><user name="user"><property name="password">123456</property><property name="schemas">DB01</property><property name="readOnly">true</property>
</user>MyCat实现垂直拆分
在业务系统中, 涉及以下表结构 ,但是由于用户与订单每天都会产生大量的数据, 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分, 原有的数据库表如下
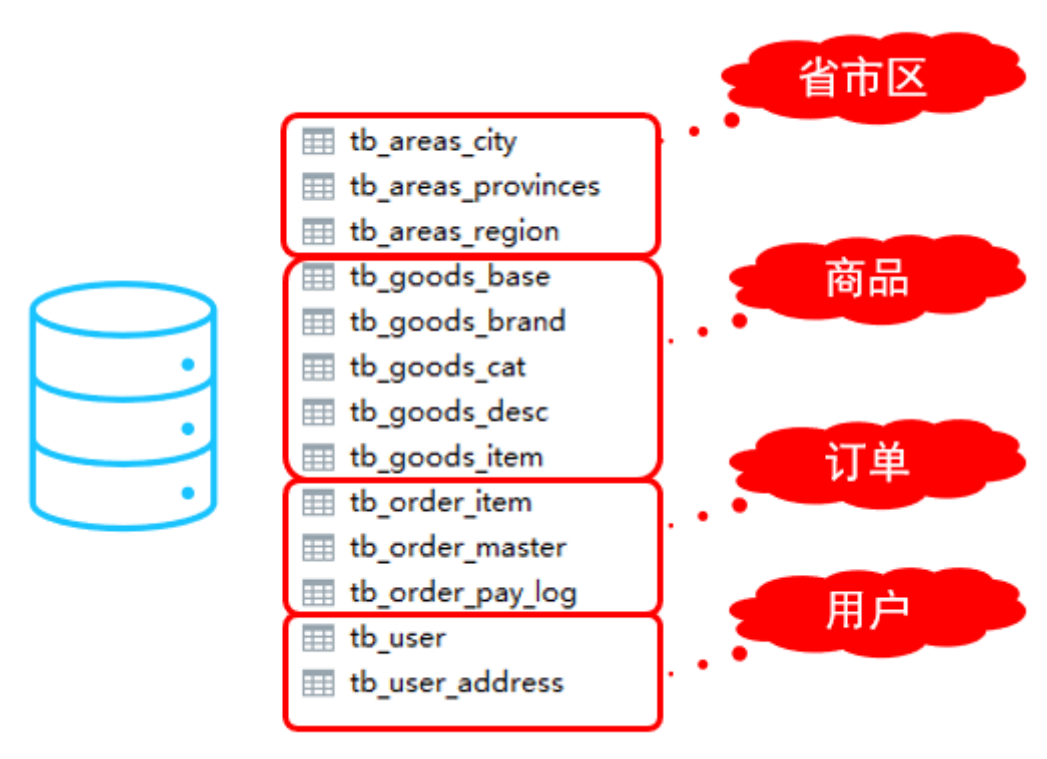
然后对数据库中的表进行垂直拆分得到以下的结构
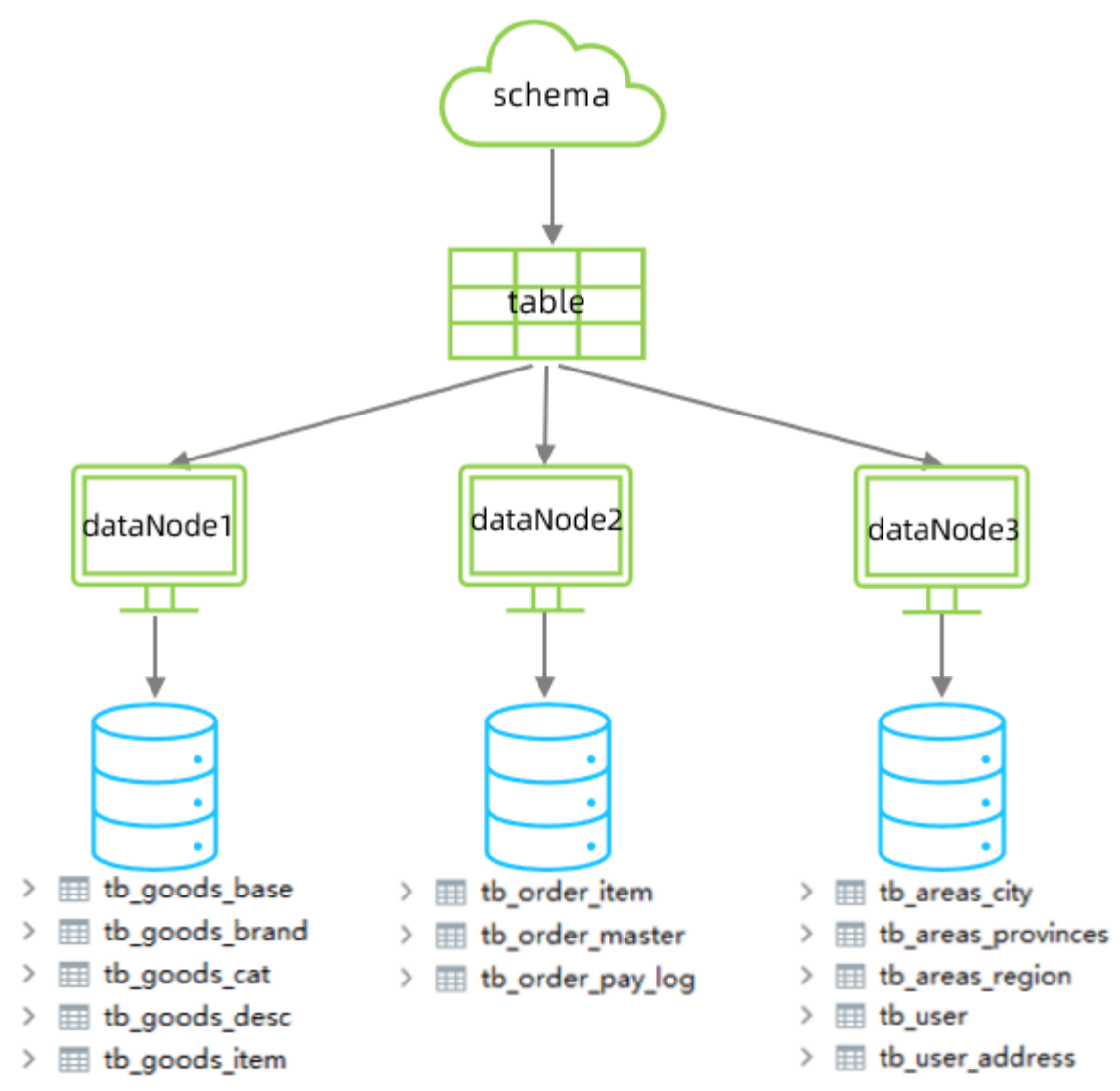
schema.xml的配置如下
1、在虚拟库中配置虚拟表
2、配置数据节点dn1、dn2、dn3
3、配置数据节点跟数据库的链接
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100"><table name="tb_goods_base" dataNode="dn1" primaryKey="id"/><table name="tb_goods_brand" dataNode="dn1" primaryKey="id"/><table name="tb_goods_cat" dataNode="dn1" primaryKey="id"/><table name="tb_goods_desc" dataNode="dn1" primaryKey="goods_id"/><table name="tb_goods_item" dataNode="dn1" primaryKey="id"/><table name="tb_order_item" dataNode="dn2" primaryKey="id"/><table name="tb_order_master" dataNode="dn2" primaryKey="order_id"/><table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no"/><table name="tb_user" dataNode="dn3" primaryKey="id"/><table name="tb_user_address" dataNode="dn3" primaryKey="id"/><table name="tb_areas_provinces" dataNode="dn3" primaryKey="id"/><table name="tb_areas_city" dataNode="dn3" primaryKey="id"/><table name="tb_areas_region" dataNode="dn3" primaryKey="id"/>
</schema><dataNode name="dn1" dataHost="dhost1" database="shopping"/>
<dataNode name="dn2" dataHost="dhost2" database="shopping"/>
<dataNode name="dn3" dataHost="dhost3" database="shopping"/><dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost><dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost><dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost>server.xml的配置,赋予root用户操作虚拟库的能力
<user name="root" defaultAccount="true"><property name="password">123456</property><property name="schemas">SHOPPING</property><!-- 表级 DML 权限设置 --><!--<privileges check="true"><schema name="DB01" dml="0110"><table name="TB_ORDER" dml="1110"></table></schema></privileges>-->
</user><user name="user"><property name="password">123456</property><property name="schemas">SHOPPING</property><property name="readOnly">true</property>
</user>最终的效果
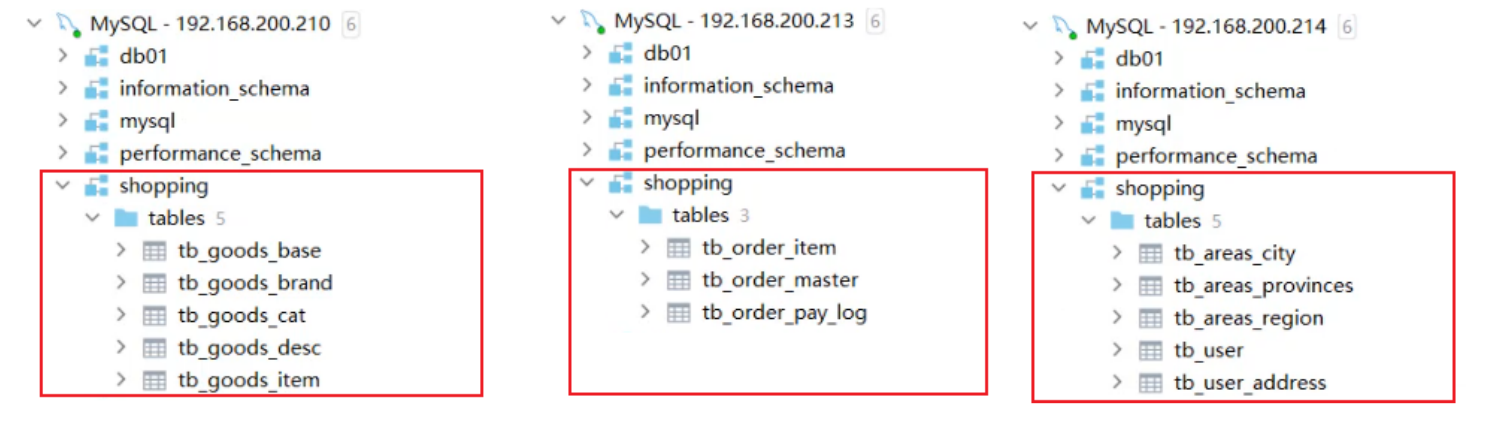
每个数据库进行多表联查是没问题的,但是如果涉及不同库之间的多表联查就不行了,所以可以将一些公共的表抽取成为全局表,改schema.xml中的逻辑表的配置增加 type 属性,配置为global,就代表该表是全局表,就会在所涉及到的dataNode中创建给表。
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/> 最终效果如下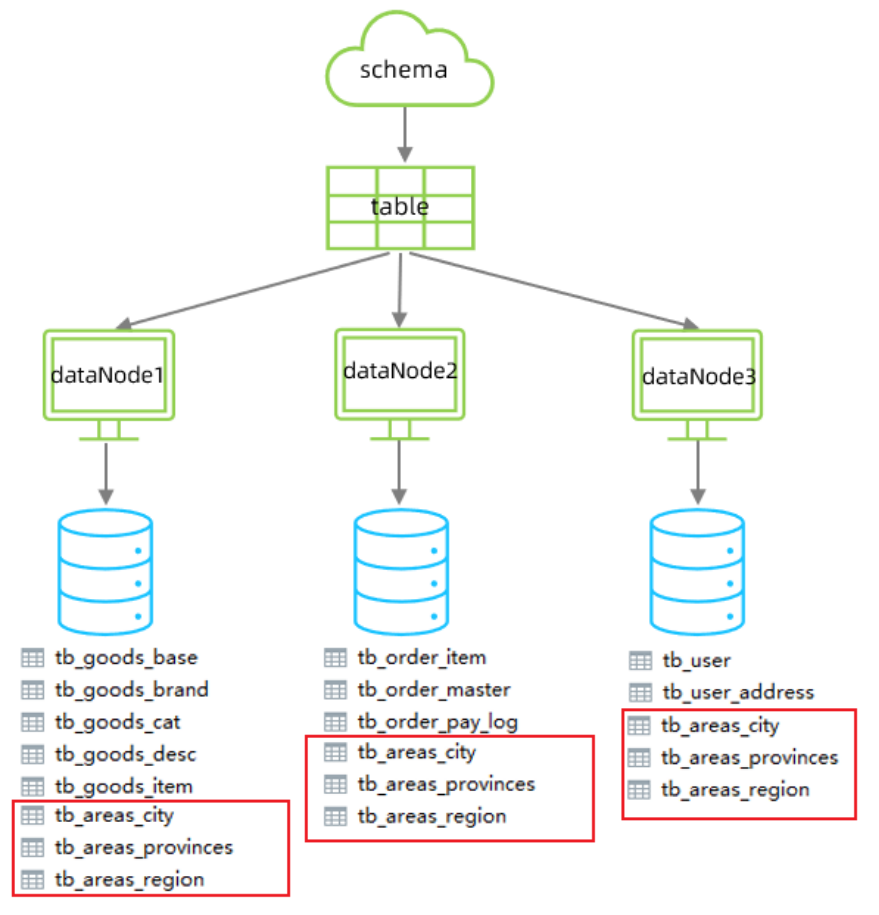
MyCat实现水平拆分
在业务系统中, 有一张表(日志表), 业务系统每天都会产生大量的日志数据 , 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分
结构如图所示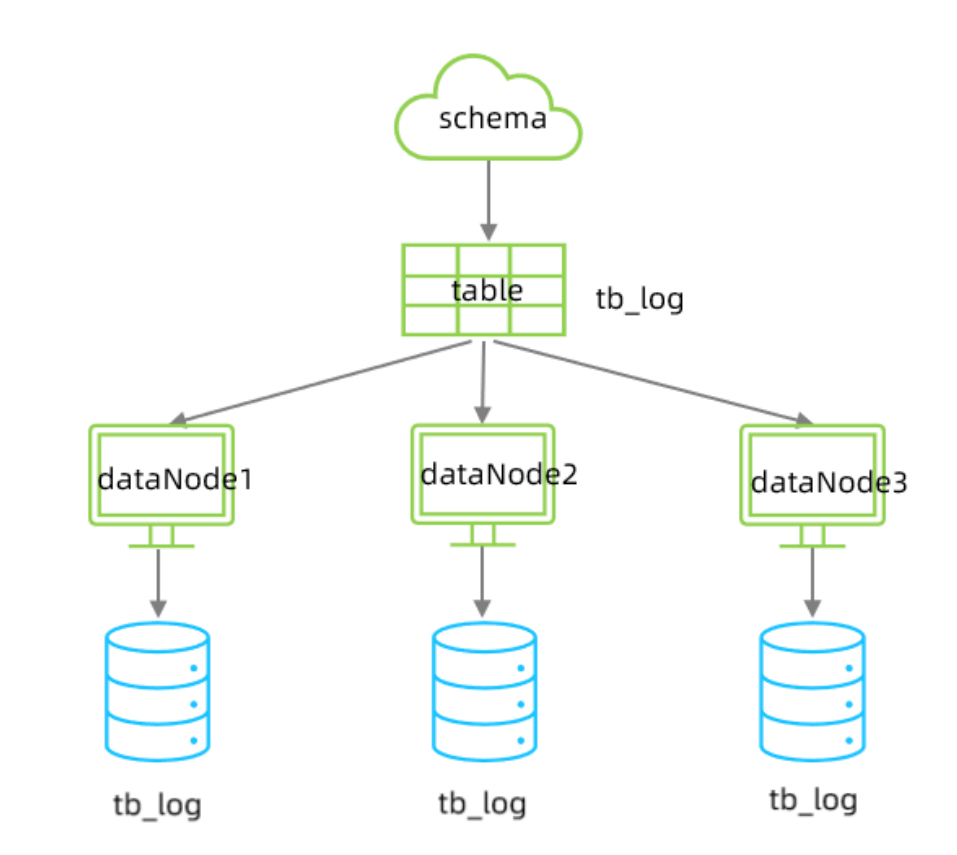
对应的schema.xml文件
<schema name="ITCAST" checkSQLschema="true" sqlMaxLimit="100"><table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long"/>
</schema><dataNode name="dn4" dataHost="dhost1" database="itcast"/>
<dataNode name="dn5" dataHost="dhost2" database="itcast"/>
<dataNode name="dn6" dataHost="dhost3" database="itcast"/>在将这张表的权限赋予给root用户在server.xml中配置
分片规则
分片规则就是决定你要操作哪个数据库的规则,可以在虚拟表中通过rule来指定,对应的规则可以在rule.xml中进行配置
范围分片
根据指定的字段及其配置的范围与数据节点的对应情况, 来决定该数据属于哪一个分片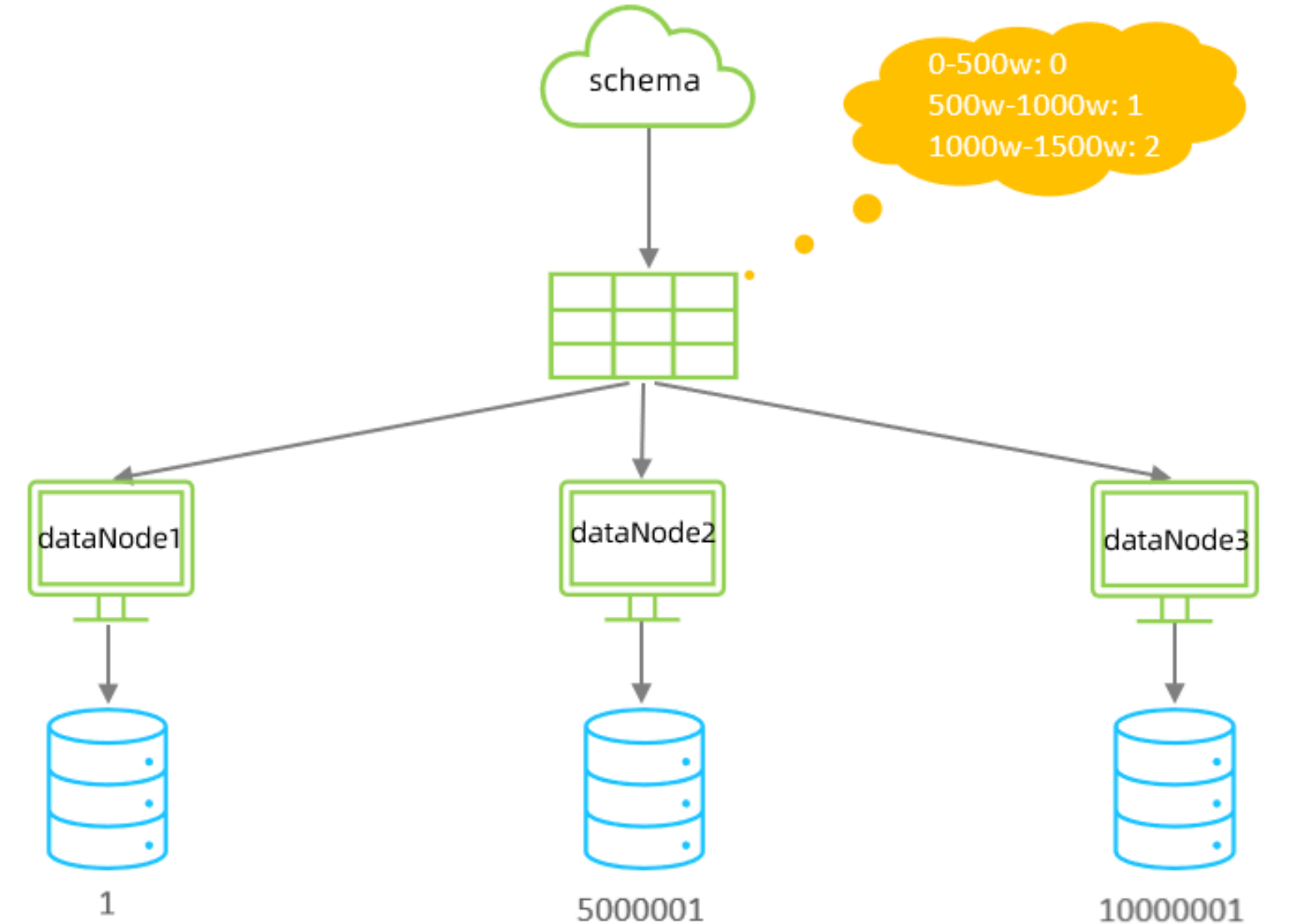
取模分片
根据指定的字段值与节点数量进行求模运算,根据运算结果, 来决定该数据属于哪一个分片。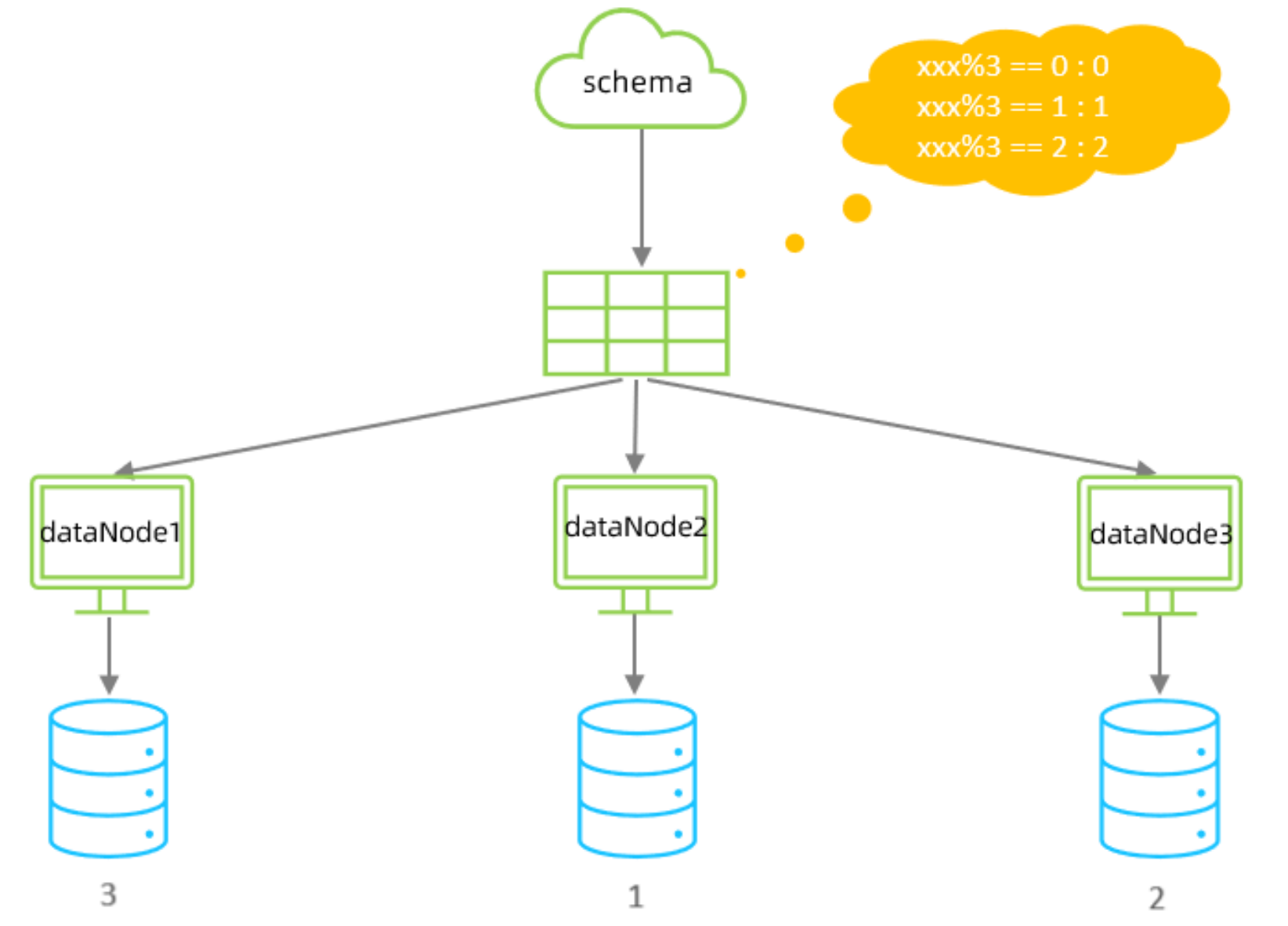
一致性hash分片
相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置,有效的解决了分布式数据的拓容问题。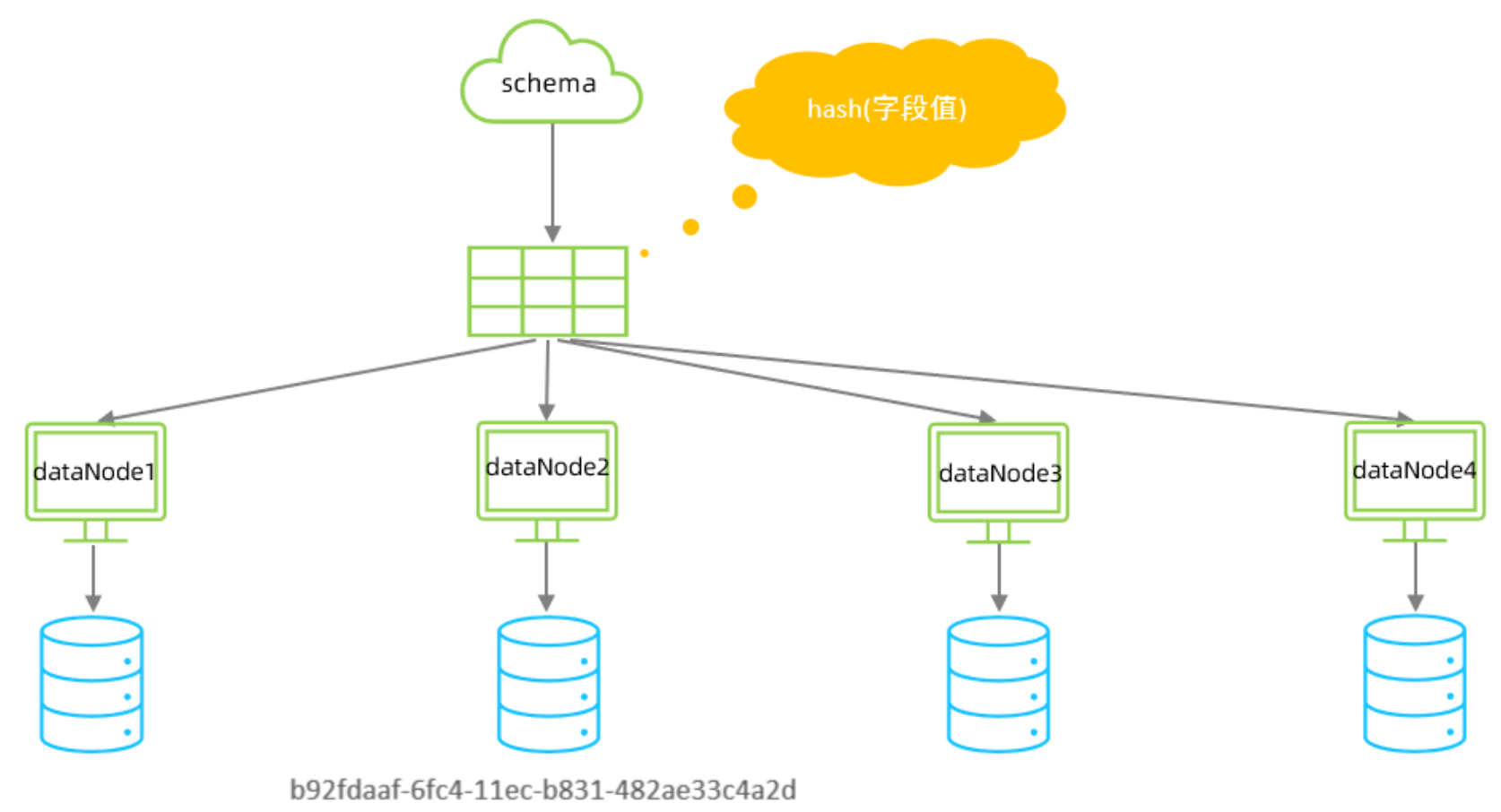
枚举分片
通过在配置文件中配置可能的枚举值, 指定数据分布到不同数据节点上, 主要适用于按照省份、性别、状态拆分数据等业务 。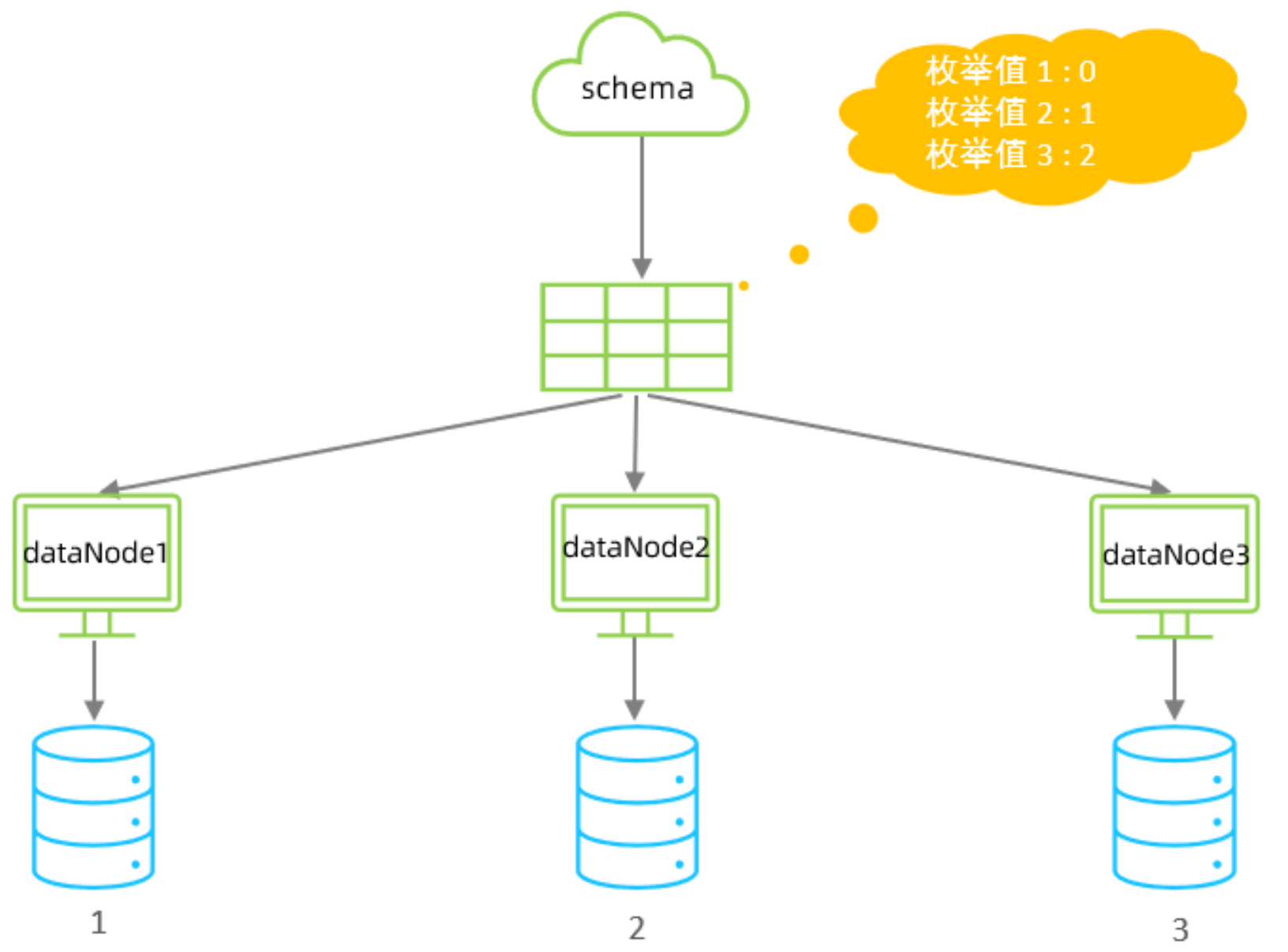
应用指定算法
运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号。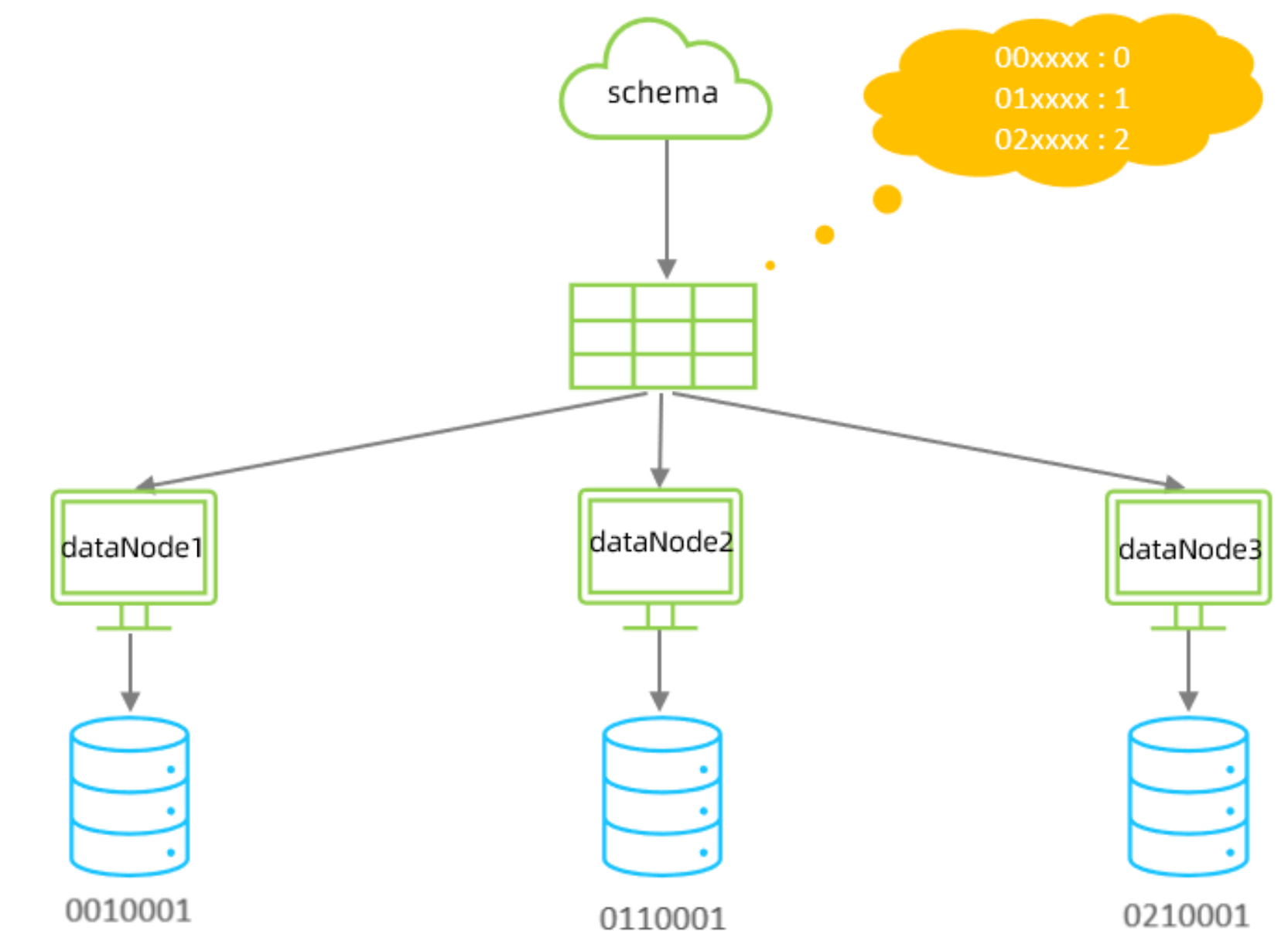
固定分片hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十进制,也就是位于0-1023之间。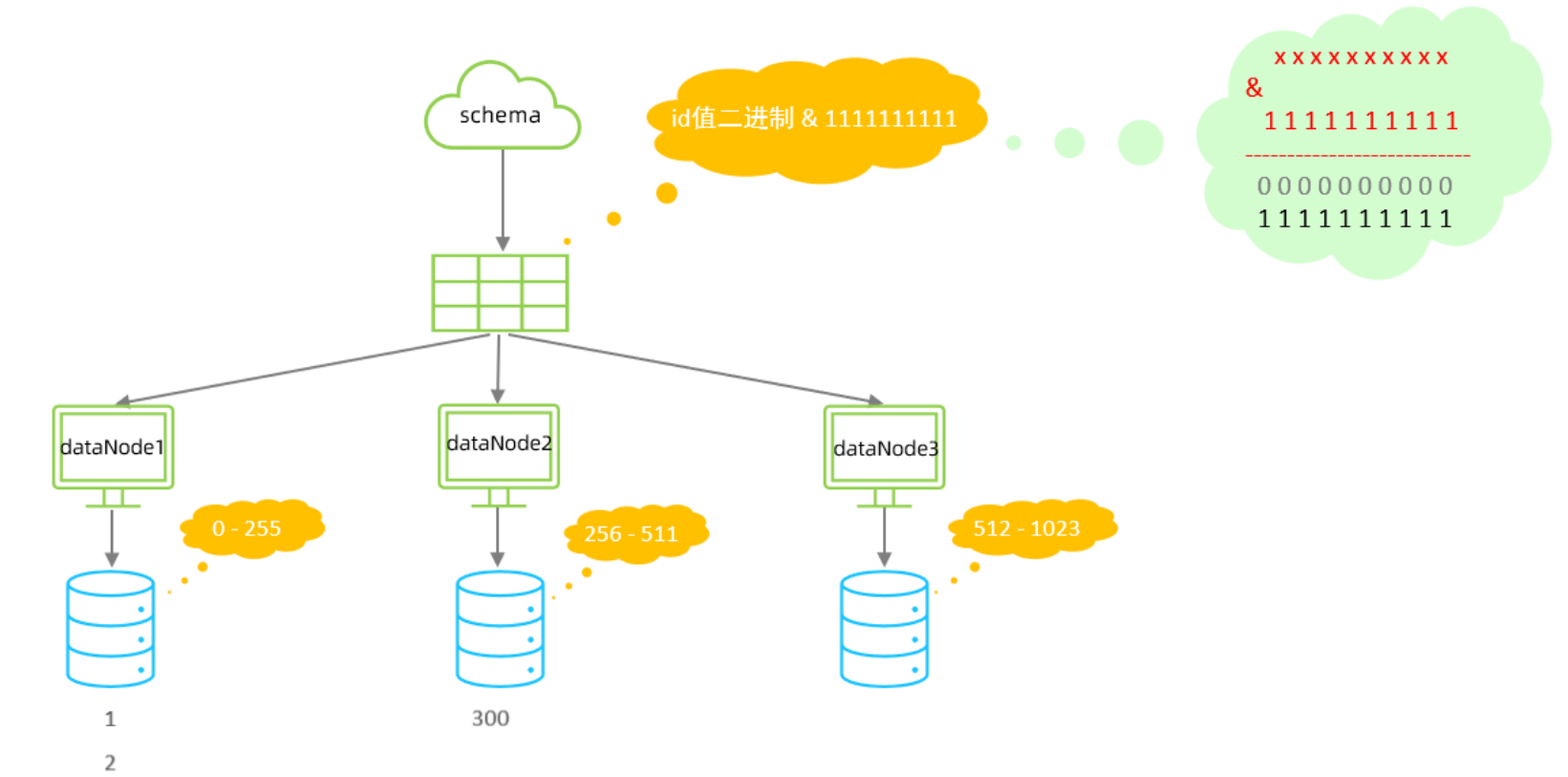
字符串hash解析算法
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片。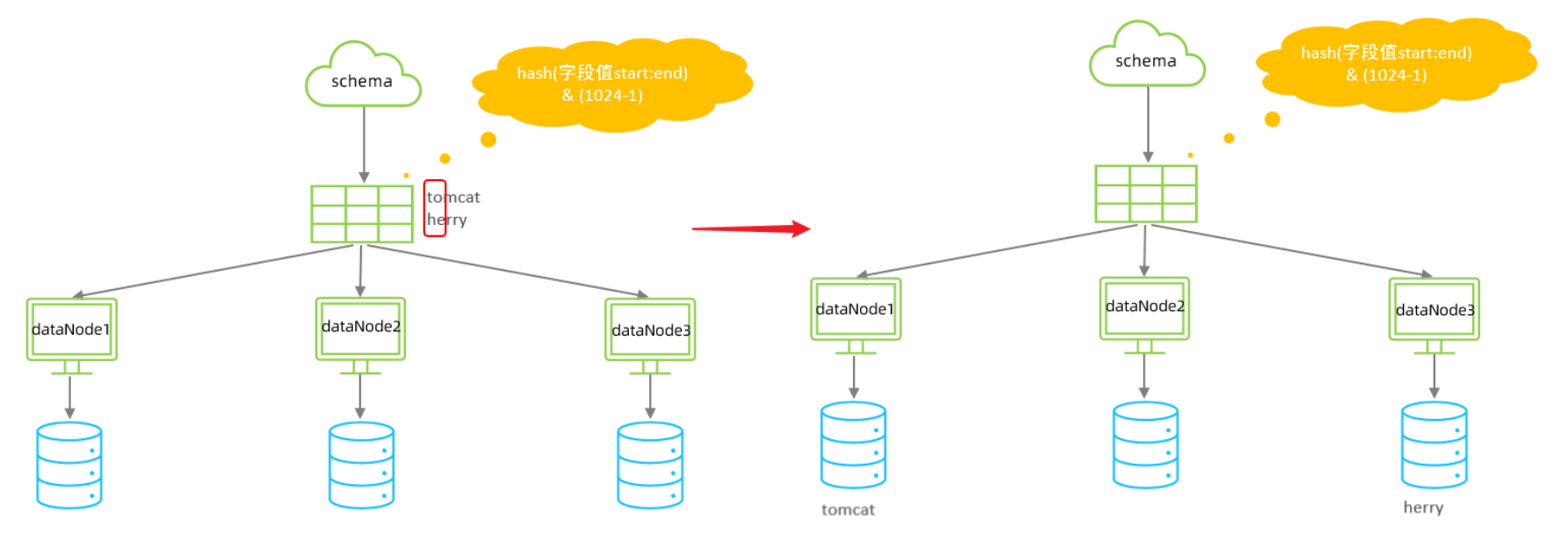
按天分片算法
按照日期及对应的时间周期来分片,如果超出了结束时间则重新计算并分配,例如2022-2-1就会被分配到dataNode1然后以此类推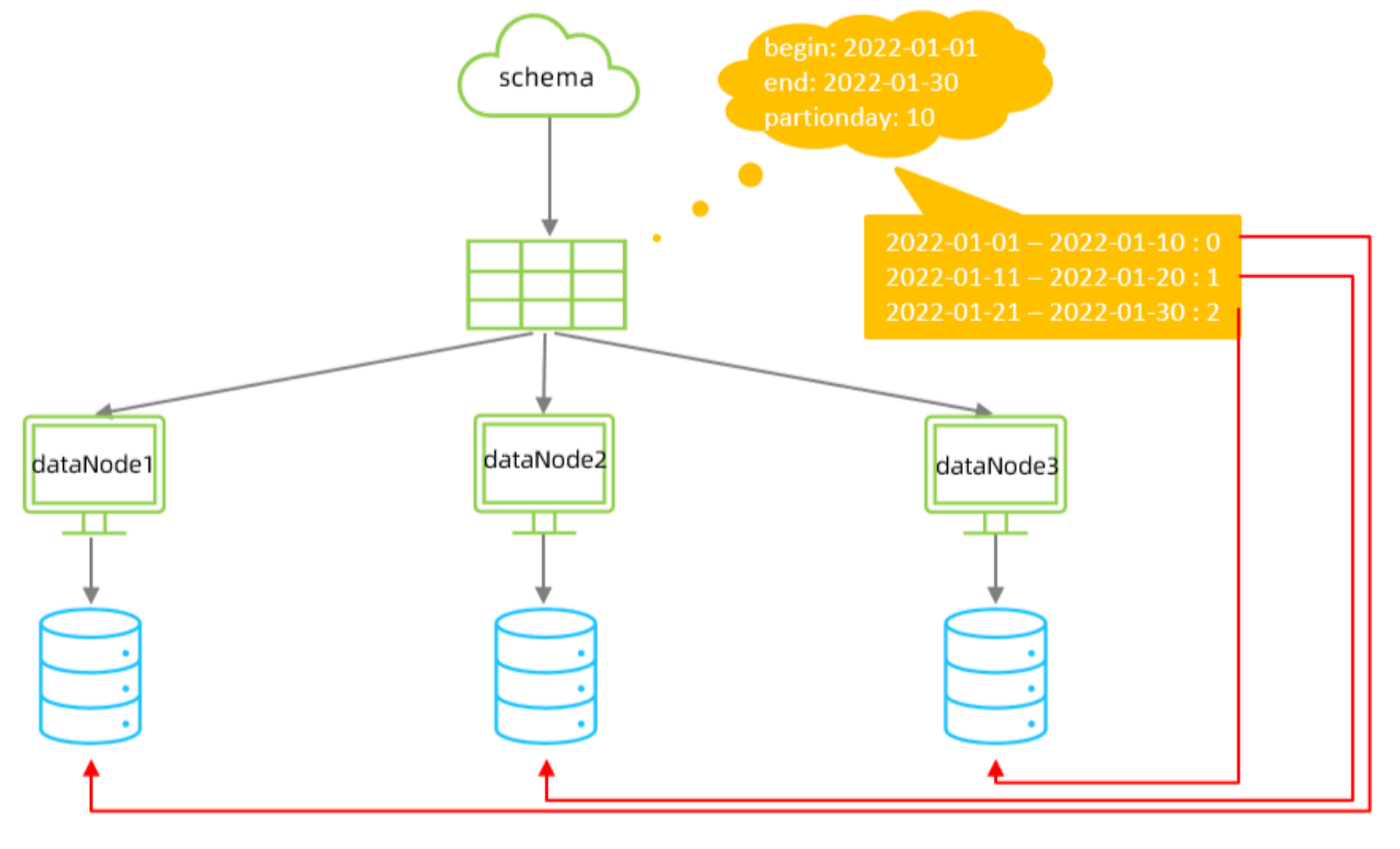
自然月分片
使用场景为按照月份来分片, 每个自然月为一个分片,并且分片的长度必须和数据库的长度一致例如 2022-01-01 到 2022-12-31 ,一共需要12个分片。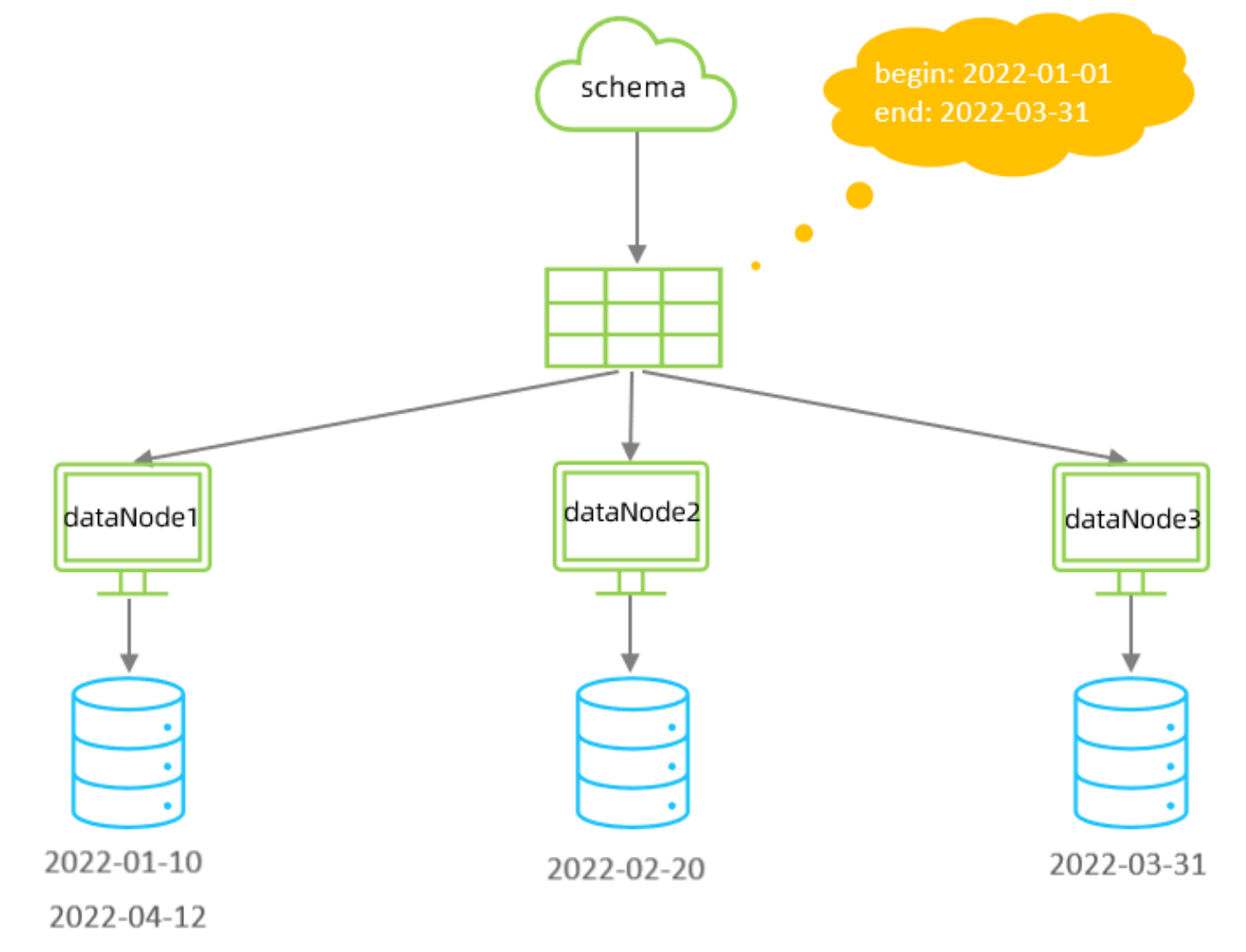
一主一从读写分离
读写分离就是在主从模式中,master节点专门负责写操作,slave节点专门负责读操作,这样能有效降低单台数据库的压力
先在schema,xml中进行配置
<!-- 配置逻辑库 -->
<schema name="ITCAST_RW" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7">
</schema><dataNode name="dn7" dataHost="dhost7" database="itcast"/><dataHost name="dhost7" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master1" url="jdbc:mysql://192.168.200.211:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"><readHost host="slave1" url="jdbc:mysql://192.168.200.212:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/></writeHost>
</dataHost> 关联情况如下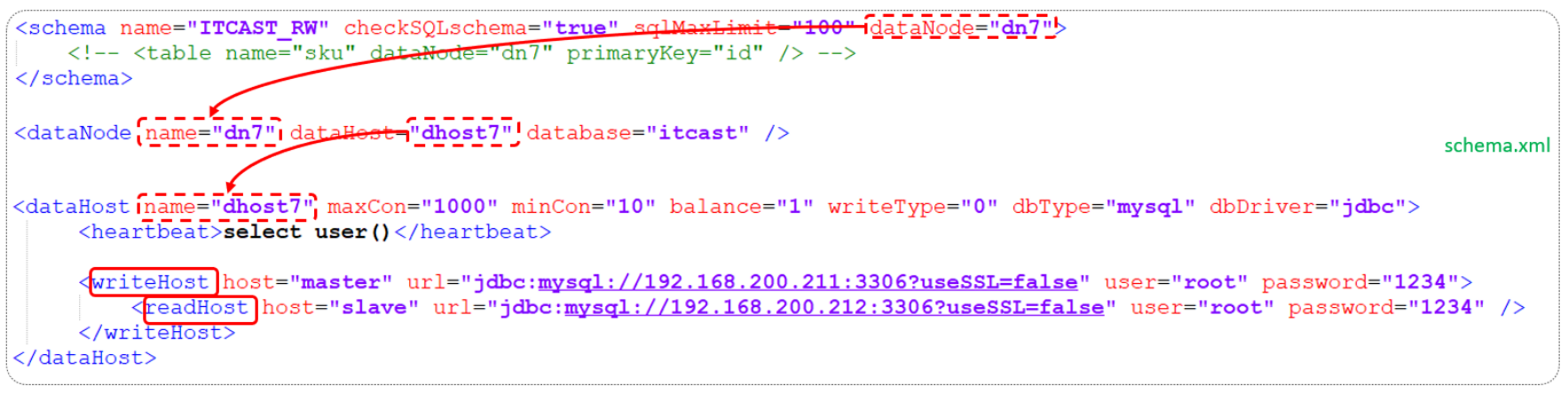
writeHost代表的是写操作对应的数据库,readHost代表的是读操作对应的数据库。 所以我们要想实现读写分离,就得配置writeHost关联的是主库,readHost关联的是从库
配置负载均衡策略balance,下面是对应参数的含义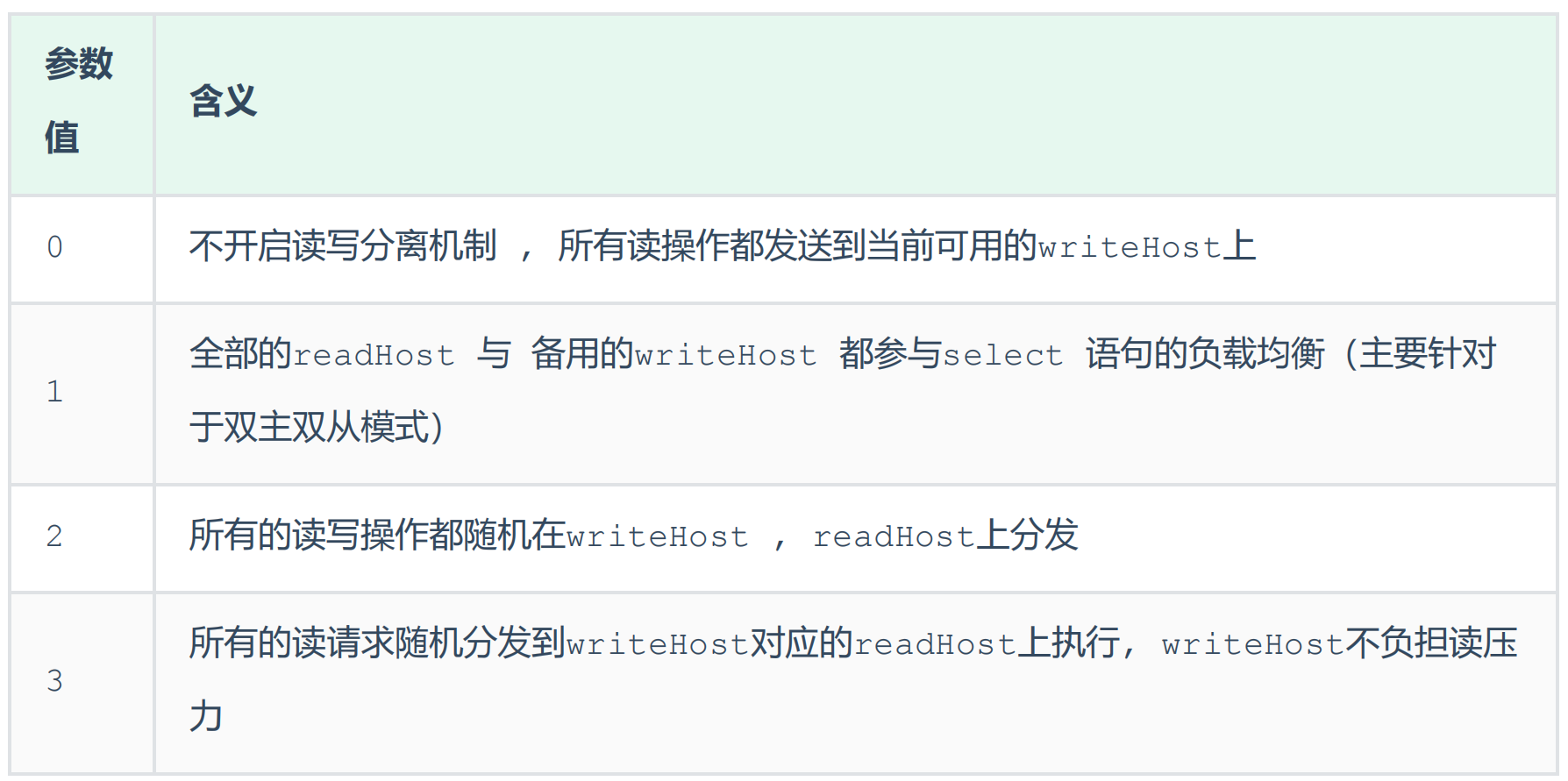
双主双从读写分离
对应的结构图就是这样的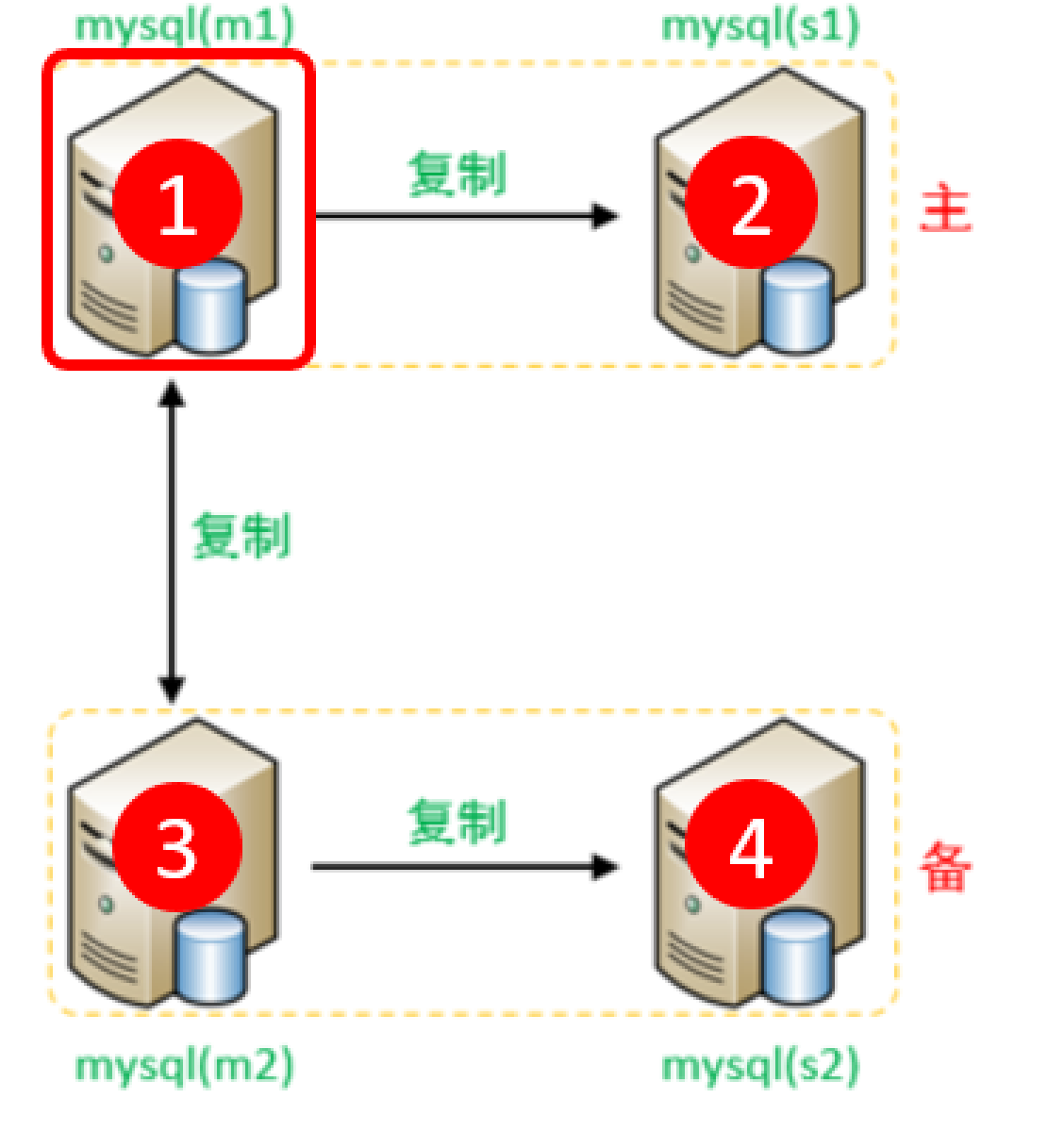
然后先要搭建两个一主一从的节点,按照上面提到的的主从复制的内容搭建
最后将两个主库互相复制,也就是互相成为对方的从库
在m1中执行
CHANGE MASTER TO MASTER_HOST='192.168.200.213', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000002',
MASTER_LOG_POS=663;在m2中执行
CHANGE MASTER TO MASTER_HOST='192.168.200.211', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000002',
MASTER_LOG_POS=663;这样就完成了主库直接的互相复制
然后就是实现读写分离对应的scema.xml
-- 配置逻辑库:
<schema name="ITCAST_RW2" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7">
</schema>-- 配置数据节点:
<dataNode name="dn7" dataHost="dhost7" database="db01" />-- 配置节点主机:<dataHost name="dhost7" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master1" url="jdbc:mysql://192.168.200.211:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"><readHost host="slave1" url="jdbc:mysql://192.168.200.212:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/></writeHost><writeHost host="master2" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"><readHost host="slave2" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/></writeHost>
</dataHost> 对应情况如下
balance="1":
代表全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡
writeType:
0 : 写操作都转发到第1台writeHost, writeHost1挂了, 会切换到writeHost2上;
1 : 所有的写操作都随机地发送到配置的writeHost上 ;
switchType
-1 : 不自动切换
1 : 自动切换
相关文章:
)
MySQL中的重要常见知识点(入门到入土!)
基础篇 基础语法 添加数据 -- 完整语法 INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);-- 示例 insert into employee(id,workno,name,gender,age,idcard,entrydate) values(1,1,Itcast,男,10,123456789012345678,2000-01-01) 修改数据 -- 完整语法 UPDA…...

29.第二阶段x64游戏实战-技能冷却
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:28.第二阶段x64游戏实战-代码实现遍历技能 找技能冷却要通过一个技能cd长点的&…...
)
第19天-Python自动化生成PPT图文教程(基于python-pptx)
环境准备 pip install python-pptx Pillow 基础示例:批量插入图片 from pptx import Presentation from pptx.util import Inches import os from PIL import Image def create_image_slides(): # 初始化演示文稿 prs = Presentation() # 获取当前目录所…...

基于STM32的骑行语音播报系统
目录 一、前言 二、项目功能说明 三、主要元器件 四、原理图与PCB 五、手机APP 六、完整资料 一、前言 项目成品图片: 哔哩哔哩视频链接: 咸鱼商品链接: 基于STM32的骑行语音播报系统 二、项目功能说明 基础功能: 1&…...

springboot链接nacos测试
代码资料链接:https://download.csdn.net/download/ly1h1/90881498 场景说明:本次测试是springboot项目,可以链接上ncaos,将对应命名空间下的配置信息读取出俩,然后可以在接口进行返回显示。 0.环境配置 1.代码结构 …...

【初识】内网渗透——基础概念,基本工具使用
目录 一、域,工作组,域控制器,活动目录相关概念: 域环境: 工作组: 域控制器DC: 活动目录AD: 二、内网的基本场景: 三、内网渗透基本测试方案: #案例1一基本信…...

AI练习:混合圆
方法一:在圆内 1.画圆 选择椭圆工具,按住Shift键绘制正圆; CtrlC复制,CtrlF原地粘贴,按住Shift键缩小圆,移动位置; 再CtrlC,CtrlF,再按住Shift键缩小圆,移…...

心知天气 API 获取天气预报 2025/5/21
心知天气 API 获取天气预报 2025/5/21 URL格式: https://api.seniverse.com/v3/weather/now.json?key填你的秘钥&locationbeijing(这里填城市 可以用拼音)&languagezh-Hans&unitc 返回格式如下:...

PCB设计教程【入门篇】——电路分析基础-元件数据手册
前言 本教程基于B站Expert电子实验室的PCB设计教学的整理,为个人学习记录,旨在帮助PCB设计新手入门。所有内容仅作学习交流使用,无任何商业目的。若涉及侵权,请随时联系,将会立即处理 目录 前言 一、数据手册的重要…...
)
java上机测试错题回顾(1)
平时不能摸鱼太多,这样导致到最后不能摸鱼...... 看了看日历原来是6.12就结课了,啊哈哈,真没几天准备了,期末月你要来了吗? 1 参数传递,值传递~! 题目 以下代码的输出结果为( &a…...

HTTP相关内容
应用层 自定义应用层协议,协议:约定 1.约定好通信传输的信息 2.约定好数据的组织格式(xml, json(重点), protobuf) 也可以基于现成的应用层协议,来进行开发 协议的种类非常多(HTTP 协议属于翘楚,1.手机,2 网站) 跟正确的说,咱们现在使用的是 HTTPS 这个协议,HTTP和HTTPS …...
)
【笔记】排查并解决Error in LLM call after 3 attempts: (status code: 502)
#工作记录 一、问题描述 在部署运行部署对冲基金分析工具 ai-hedge-fund 时,不断出现以下报错,导致项目运行异常: Error in LLM call after 3 attempts: (status code: 502) Error in LLM call after 3 attempts: [WinError 10054] 远程主…...
—— 数据特征选择)
基于python的机器学习(七)—— 数据特征选择
目录 一、特征选择概念 二、特征选择的方法 2.1 过滤式特征选择 2.1.1 方差分析 2.1.2 相关系数 2.1.3 卡方检验 2.2 包裹式特征选择 2.2.1 递归特征消除 2.3 嵌入式特征选择 2.3.1 决策树特征重要性 一、特征选择概念 特征选择是机器学习非常重要的一个步骤&#x…...

从电商角度设计大模型的 Prompt
从电商角度设计大模型的 Prompt,有一个关键核心思路:围绕具体业务场景明确任务目标输出格式,帮助模型为运营、客服、营销、数据分析等工作提效。以下是电商场景下 Prompt 设计的完整指南,包含通用思路、模块范例、实战案例等内容。…...
:《状态管理》)
从零基础到最佳实践:Vue.js 系列(5/10):《状态管理》
引言 你是不是正在用 Vue.js 开发一个很酷的应用,然后发现组件之间的数据传递变得越来越混乱?比如,一个按钮的状态要传到好几层组件,或者多个页面需要共享同一个用户信息。这时候,状态管理就登场了!在 Vue…...

git checkout HEAD
git checkout HEAD 主要用于将工作目录和暂存区的内容重置为当前 HEAD 指向的提交状态,常用于撤销未提交的修改15。具体行为如下: 一、核心作用 恢复工作区文件 将指定文件或全部文件恢复到 HEAD 指向的提交状态,丢弃工作区中未暂存的修改…...

git工具使用
安装Git 在开始使用Git之前,需要在本地计算机上安装Git工具。Git支持Windows、macOS和Linux系统。可以从Git官方网站下载适合操作系统的安装包,并按照安装向导进行安装。 bash复制插入 # 在Linux上安装Git sudo apt-get install git# 在macOS上安装Git…...

极大似然估计与机器学习
复习概统的时候突然发现好像极大似然估计MLE与机器学习的数据驱动非常相似,都是采样样本然后估计模型参数。貌似,后知后觉的才意识到极大似然估计就是机器学习有效的数学保证 下面以拟合线性分布的最小二乘与分类问题为例推到以下如何从似然函数推导出M…...

基于 Guns v5.1 框架的分页教程
基于 Guns v5.1 框架的分页教程 第一步:Controller 层处理前端请求 在 Controller 中,需要接收 Bootstrap Table 传来的分页参数(limit, offset, sort, order)。Guns 提供了封装好的 PageFactory 类来简化 Page 对象的创建。 R…...

从零搭建SpringBoot Web 单体项目【基础篇】2、SpringBoot 整合数据库
系列文章 从零搭建SpringBoot Web单体项目【基础篇】1、IDEA搭建SpringBoot项目 从零搭建 SpringBoot Web 单体项目【基础篇】2、SpringBoot 整合数据库 目录 一、项目基础环境说明 二、数据库整合流程 1. 添加 MyBatis-Plus 相关依赖(pom.xml) 2…...

Supplemental Table 5FAM49B H-SCORE与其他临床特征的关系
以下是针对 Supplemental Table 5 中不同变量类型所需检验方法的 SPSS纯界面操作步骤(严格匹配原文统计方法): Supplemental Table 5 SPSS操作步骤 目标:分析FAM49B H-SCORE与其他临床特征的关系,按变量类型选择检验方法。 变量与检验方法对应表 变量变量类型检验方法SP…...

信息系统项目管理师考前练习4
项目范围基准变更 当客户提出新增功能需求时,项目经理首先应该: A. 立即更新范围说明书 B. 提交变更请求并评估影响 C. 要求团队加班实现 D. 拒绝变更以保持进度 答案:B 解析:所有范围变更必须走正式变更流程(第5版强调变更控制),评估影响是第一步。 混合项目管理模式…...
)
C语言判断素数(附带源码和解析)
素数,也称为质数,是一个大于 1 的自然数,除了 1 和它本身外,不能被其他自然数整除。换句话说,素数只有两个因子:1 和它自身。例如,2、3、5、7、11 和 13 都是素数。 素数在数学和计算机科学中扮…...

汽车电子电气架构诊断功能开发全流程解析
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

Xilinx XCAU10P-2FFVB676I 赛灵思 Artix UltraScale+ FPGA
XCAU10P-2FFVB676I 是 AMD Xilinx 推出的 Artix UltraScale™ FPGA 器件,内部集成了约 96,250 逻辑单元,满足中等规模高性能应用的需求。该芯片采用 16 nm FinFET 制程工艺,核心电压典型值约 0.85 V,能够在较低功耗下提供高达 775…...

DS18B20 温度传感器实验探索与实践分享
DS18B20 温度传感器实验探索与实践分享 在嵌入式系统开发领域,温度监测是常见的应用场景。本次实验聚焦于 DS18B20 温度传感器,旨在掌握其工作原理、单总线通信方式,以及实现温度采集与数码管显示,同时开启温度报警功能。接下来&…...

RT_Thread——内存管理
文章目录 一、为什么要自己实现内存管理二、RT-Thread 的内存管理方法2.1 小内存管理算法2.2 slab 管理算法2.3 memheap 管理算法 三、Heap 相关的函数3.1 rt_system_heap_init3.2 rt_malloc/rt_realloc/rt_calloc2.3 rt_free2.4 rt_malloc_sethook/rt_free_sethook 一、为什么…...

Temporary failure in name resolution
这个错误 ping: baidu.com: Temporary failure in name resolution 通常表示 DNS 解析的问题,也就是说你的系统无法通过域名服务器解析 baidu.com 的 IP 地址。 解决方案: 检查 DNS 配置( 有效 ): 确保系统的 DNS 配置是正确的。你可以检查 …...

【动手学深度学习】1.4~1.8 深度学习的发展及其特征
目录 1.4. 起源1.5. 深度学习的发展1.6. 深度学习的成功案例1.7. 特点1.8. 小结 1.4. 起源 深度学习的起源可追溯至多个领域的长期发展: 统计学基础:早期统计学方法(如伯努利分布、高斯分布、最小均方算法)和估计思想(…...

深度学习之序列建模的核心技术:LSTM架构深度解析与优化策略
LSTM深度解析 一、引言 在深度学习领域,循环神经网络(RNN)在处理序列数据方面具有独特的优势,例如语音识别、自然语言处理等任务。然而,传统的 RNN 在处理长序列数据时面临着严重的梯度消失问题,这使得网…...

Gartner研究报告《Generative AI 赋能Digital Commerce的三种路径》学习心得
一、研究背景 随着生成式 AI(GenAI)技术的迅速发展,其在数字商务领域的应用受到了广泛关注。这篇研究报告深入探讨了 GenAI 在数字商务中的角色以及它如何与现有的数字商务技术相结合来发挥优势,为应用领导者提供了关于如何利用 GenAI 优化技术投资策略的见解。 二、GenA…...

解锁 YOLOv8 新潜能:EfficientViT 主干网络的优化实践与实验数据解读
文章目录 一、YOLO 系列主干网络的发展历程二、EfficientViT:YOLOv8 主干网络的新宠(一)EfficientViT 的核心优势(二)EfficientViT 在 YOLOv8 中的集成与实现 三、实验对比:EfficientViT vs. MobileNet 系列…...
【注:只有最基础的说明。】)
【前端基础】12、CSS的overflow(visible、hidden、scroll、auto)【注:只有最基础的说明。】
一、overflow的作用 用于控制内容溢出时的行为。 二、overflow的使用 visible:超出的部分正常显示(默认设定) hidden:超出的部分隐藏显示(直接裁剪掉) scroll:超出的部分滚动显示 滚动条…...

创建一个element plus项目
当然可以!下面是一个 Vue 3 Element Plus 的最简单完整示例,它包括: 使用 <el-button> 按钮组件点击按钮后用 ElMessage 弹出提示 ✅ 1. 安装并初始化项目(如果还没创建项目) 你可以用官方推荐的方式快速创建…...

openCV1.1 Mat对象
imread(“D:\souse\duoxile.jpg”, IMREAD_COLOR); 功能: 从指定路径读取图像文件并解码为OpenCV的Mat对象 第一个参数: 文件路径 类型: const string&描述: 要读取的图像文件的绝对或相对路径示例: “D:\souse\duoxile.jpg” 或 “./images/test.png”第二个参数: 读取模…...

C++:array容器
array容器是序列容器,它的特点是:静态,固定数目。可以看作更安全的数组。 它还有一些成员函数,如begin():返回指向容器中第一个元素的随机访问迭代器。 #include<iostream>//数组容器 #…...
 - /安全与维护组件/ai-predictive-maintenance-turbine)
26、AI 预测性维护 (燃气轮机轴承) - /安全与维护组件/ai-predictive-maintenance-turbine
76个工业组件库示例汇总 AI 预测性维护模拟组件 (燃气轮机轴承) 概述 这是一个交互式的 Web 组件,旨在模拟基于 AI 的预测性维护 (Predictive Maintenance, PdM) 概念,应用于工业燃气轮机的关键部件(例如轴承)。它通过模拟传感器数据、动态预测剩余使用寿命 (RUL),并根…...

特种兵参会
出发(5.15) 有了去年去5月去深圳参加OpenTenBase工委会成立的经验,今年这个时候去广州就一定要在下午16点前起飞。恰好到了候机口有蔚来的牛屋,进去躺了一会。飞机顺利到达广州。晚上小聚 总监约了祁总,我们相识多年&…...

手搓四人麻将程序
一、麻将牌的表示 在麻将游戏中,总共有一百四十四张牌,这些牌被分为多个类别,每个类别又包含了不同的牌型。具体来说,麻将牌主要包括序数牌、字牌和花牌三大类。序数牌中,包含有万子、条子和筒子,每种花色…...

一命通关单调栈
前言 我们只是卑微的后端开发。按理说,我们是不需要学这些比较进阶的算法的,可是,这个世界就是不讲道理。最开始,想法是给leetcode中等题全通关,我又不打ACM我去天天钻研hard干嘛,于是碰见单调栈树状数组的…...

NV009NV010美光闪存颗粒NV011NV012
NV009NV010美光闪存颗粒NV011NV012 美光NV009-NV012闪存颗粒技术解析与行业应用全景 一、核心技术架构与制程突破 美光NV009至NV012系列闪存颗粒基于第九代3D TLC架构,通过垂直堆叠技术突破传统2D平面存储的物理限制。该架构将存储单元分层排列,如同将…...

线程、线程池、异步
目录 什么是线程 什么是线程池 什么是异步 异步与线程关系 JS中的异步 什么是线程 线程 Thread 是计算机执行的最小单位,是 进程 内的一个实体,可以被操作系统独立调用和执行 线程可以理解为进程内的“程序执行流”,一个进程可以包含多…...
)
docker面试题(4)
Docker与Vagrant有何不同 两者的定位完全不同 Vagrant类似于Boot2Docker(一款运行Docker的最小内核),是一套虚拟机的管理环境,Vagrant可 以在多种系统上和虚拟机软件中运行,可以在Windows、Mac等非Linux平台上为Docker…...
单例模式)
双检锁(Double-Checked Locking)单例模式
在项目中使用双检锁(Double-Checked Locking)单例模式来管理 JSON 格式化处理对象(如 ObjectMapper 在 Jackson 库中,或 JsonParser 在 Gson 库中)是一种常见的做法。这种模式确保了对象只被创建一次,同时在…...

建立java项目
java端: 在idea里面新建一个java,maven项目(springboot): 注意:JDK与java都得是一样的 添加基本的依赖项: 也可以在pom.xml中点击这个,从而跳转到添加依赖 建立三层架构: 在相应的java类中添加代码: <1.UserController package com.example.demo.controller;import com…...

Go语言内存共享与扩容机制 -《Go语言实战指南》
切片作为 Go 中的高频数据结构,其内存共享机制和自动扩容策略直接影响程序性能与行为,深入理解这两者,是高效使用切片的关键。 一、切片的内存结构回顾 切片是对底层数组的一个抽象,其本质是一个结构体: type slice …...

如果教材这样讲--单片机IO口Additional Functions和 Alternate Functions的区别
不管是硬件工程师还是嵌入式软件工程师,都应该能够熟练的看懂数据手册,尤其是英文。在设计单片机外围电路时,工程师需要了解单片机的GPIO口的各项功能来满足自己的设计需求,单片机小白们在查看单片机数据手册时,看到Ad…...
》笔记)
《Effective Java(第三版)》笔记
思维导图 1-4章 5-8章 9-12 章 资料 源码:https://github.com/jbloch/effective-java-3e-source-code...
)
实践大模型提示工程(Prompt Engineering)
任务目标 本文将结合实战营中的具体案例,分享在提示词设计、模型调用及复杂任务拆解中的实践心得,希望能为读者打开一扇通往 AI 开发实战的窗口。 书生浦语官方链接 实践一——写一段话介绍书生浦语实战营 在提示工程中,第一点给出清晰的…...

东莞一锂离子电池公司IPO终止,客户与供应商重叠,社保缴纳情况引疑
作者:小熊 来源:IPO魔女 5月17日,深交所发布公告称,东莞市朗泰通科技股份有限公司(简称朗泰通科技)已主动撤回其IPO申请。该公司本次IPO原拟募集资金7.0208亿元,保荐机构为国金证券股份有限公…...