【深度学习】Transformer 的应用
目录
一、自然语言处理领域
1、自然语言处理领域的应用
2、BART模型
3、BERTSum模型与自动文本摘要
4、SG-Net与机器阅读理解
5、SG-Net的应用
6、总结
二、计算机视觉领域
1、图像分类
(1)背景与挑战
(2)Transformer的优势
(3)Vision Transformer(ViT)模型
(4)数学表达与公式
(5)ViT模型的优势与挑战
(6)总结
2、目标检测
(1)传统目标检测方法的局限性
(2)Transformer在目标检测中的应用
2.1 DETR模型概述
2.2 Transformer架构
2.3 匹配与损失函数
2.4 目标查询与注意力机制
(3)DETR与传统方法的区别
(4)模型性能与应用
(5)挑战与未来方向
(6)结论
3、图像分割
(1)背景与动机
(2)DETR 在实例分割中的扩展:Mask‐DETR
2.1 架构概览
2.2 关键组件
(3)DETR 在全景分割中的演进:Panoptic-DETR & MaskFormer
3.1 Panoptic-DETR
3.2 MaskFormer / Mask2Former
(4)典型完整架构示例
(5)小结
三、多模态领域
1、CNN-Transformer类方法
(1)X-Transformer,M2Transformer,RSTNet和DLCT等方法
(2)M2Transformer
(3)跨模态注意力
(4)自注意力与门控机制
2、M2Transformer(Meshed-Memory Transformer)
(1)背景与动机
(2)整体架构概述
(3)内存增强编码器(Memory-Augmented Encoder)详解
3.1 概念与动机
3.2 具体结构
3.3 内存增强的优势
(4)网格化连接(Meshed Connectivity)详解
4.1 动机
4.2 实现细节
(5)解码器(Meshed-Memory Decoder)设计
5.1 结构概览
5.2 详细步骤(以第 t 时刻、第 l 层为例)
(6)损失函数与训练策略
(7)实验结果
(8)优缺点与应用场景
8.1 优点
8.2 缺点
8.3 应用场景
(9)关键公式与要点梳理
(10)总结
3、Transformer-Transformer 类方法
4、PureT模型
(1)背景与动机
(2)模型架构概览
(3)核心模块与机制
3.1 Backbone Encoder (骨干编码器)
3.2 Refining Encoder(增强编码器)
3.3 Decoder(解码器)
(4)训练与优化策略
(5)实验与性能分析
(6)优缺点与改进方向
一、自然语言处理领域
1、自然语言处理领域的应用
-
机器翻译:通过引入Transformer模型,2019年Mike Lewis等人提出的BART模型,改进了机器翻译任务。BART结合了双向编码器(如BERT)和自回归解码器(如GPT)的优势,既能够处理序列到序列的任务,也能够解决不同翻译领域的挑战。
-
自动文本摘要:BERTSum模型用于自动生成文本摘要。该模型基于BERT架构,通过加入句子间的依赖关系来生成摘要。
-
机器阅读理解:SG-Net(语法引导的自注意力网络)则引入了自注意力机制,并结合语法引导的机制,改善了传统Transformer模型在处理复杂问题时的性能。
2、BART模型
-
BART模型的结构:BART结合了双向编码器(BERT)和自回归解码器(GPT)的结构,适用于非常广泛的序列到序列任务。它通过破坏原始文档并进行重建训练,允许使用任何类型的文档破碎方式。
-
BART的激活函数:与GPT不同,BART的激活函数使用了GeLU(Gaussian Error Linear Unit),这一点与传统的ReLU(Rectified Linear Unit)有所不同。
3、BERTSum模型与自动文本摘要
-
BERTSum:该模型通过BERT作为编码器,并在此基础上扩展,采用了BERT的生成式模型,在多个句子对话中进行处理。它通过句子级别的编码来完成文本的摘要生成。BERTSum的特点在于,它使用了预训练的BERT模型,能够更好地利用语言模型在上下文中的表现。
-
句子编码方式:BERTSum将输入的文本进行拆分并生成表示,借助段向量和位置向量等技术,使得模型能够理解文本的上下文关系。
4、SG-Net与机器阅读理解
-
SG-Net(语法引导的自注意力网络):这个网络通过将语法信息引入Transformer的自注意力机制,增强了模型对语法结构的感知。SG-Net能够通过语法引导,优化模型对词汇之间关系的处理,从而提升阅读理解的性能。
-
SG-Net在任务中的应用:SG-Net专注于两种类型的机器阅读理解任务,分别是基于片段选择的任务和基于多项选择的任务,后者通常用于答题系统的场景(如SQuAD和RACE数据集)。
5、SG-Net的应用
-
SQuAD任务:在SQuAD 2.0数据集上,SG-Net能够有效地预测文本中的起始和结束位置。通过这种方式,SG-Net不仅能够增强模型对文本的理解能力,还能提高其在实际任务中的表现。
-
RACE任务:在RACE数据集上,SG-Net模型训练后,能够准确选择正确答案。通过SG-Net,模型能够对问题进行更精确的理解,最终提升答题的正确率。
6、总结
-
这些模型(如BERT、BERTSum、BART和SG-Net)通过深度学习和自注意力机制,极大地提升了自然语言处理任务的性能,特别是在文本生成、翻译、摘要和阅读理解等任务中。
-
BERT通过预训练技术,使得模型在面对各种自然语言任务时具有较强的适应性。BART结合了双向编码器和自回归解码器,能够在各种任务中发挥优势。SG-Net引入了语法引导的自注意力机制,进一步提升了模型的表现。
二、计算机视觉领域
1、图像分类
(1)背景与挑战
在图像分类任务中,传统的卷积神经网络(CNN)长期以来作为主流方法,尤其在处理二维图像时,CNN的卷积层能有效提取局部特征。然而,随着图像数据复杂度的增加,CNN在处理长序列或长距离依赖时,面临着一些限制,尤其是当图像变得更大或需要更高的分辨率时,CNN容易遇到梯度消失和长序列依赖关系建模困难的问题。
(2)Transformer的优势
与CNN相比,Transformer通过**自注意力机制(Self-Attention)**能够更好地捕捉图像中长距离像素之间的依赖关系。在传统的卷积操作中,信息传播仅限于局部邻域,而Transformer可以通过全局的信息交互来建立图像中远距离像素之间的关联。这使得Transformer在处理长序列数据时更具优势,尤其在长文本或长图像序列中,能有效克服CNN的不足。
(3)Vision Transformer(ViT)模型
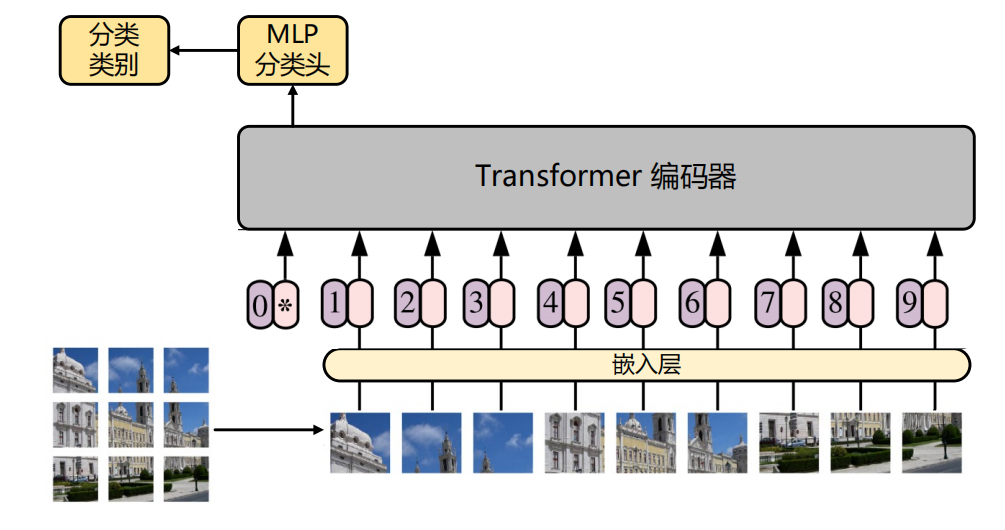
Vision Transformer(ViT)是一种基于Transformer的图像分类模型,它将图像作为序列输入,并通过Transformer进行处理。ViT的核心创新在于将图像切分为多个小的图块(patches),然后将这些图块作为一个序列输入到Transformer中。这种方法借鉴了NLP中的序列建模思想,通过自注意力机制捕捉图像块之间的关系。用VIT如果只实现图像分类,只用编码器即可,解码器不用,而且输入编码器的token会多一个这个token从编码器的输出即为类别(如上图)。以下是ViT的主要步骤:
图像处理与分块
在ViT模型中,图像被首先划分为固定大小的图块(patches),每个图块的维度为 P×P×C,其中 P 是每个图块的大小,C 是图像的通道数。这样,原始图像就被转化为一个2D图块序列,每个图块的维度为 ,且图块的数量为
,其中 H 和 W 是图像的高和宽。
位置编码(Positional Encoding)
为了使得Transformer能够感知图像块之间的空间关系,ViT通过**位置编码(Positional Encoding)**来为每个图块加上位置的表示,使得模型能够知道每个图块在图像中的相对位置。这是ViT与传统Transformer模型的不同之处,后者在NLP中使用固定的、预定义的位置信息。
Transformer编码器(Encoder)
这些图块被输入到Transformer的编码器中进行处理。每个图块会通过**多头自注意力机制(Multi-head Self-Attention)进行信息交互,捕捉图块之间的关联。同时,图块的信息也会经过前馈神经网络(Feed Forward Network)的处理。每一层的输出会通过残差连接(Residual Connection)和层归一化(Layer Normalization)**进行优化,以保持训练的稳定性。
分类头(Classification Head)
经过Transformer的多层处理后,最终的输出会通过一个MLP(多层感知机)分类头进行处理,输出图像的类别。这一过程与传统的图像分类方法(例如CNN)类似,只不过在ViT中,整个图像的分类是基于Transformer模型提取到的全局信息,而不仅仅是局部特征。
(4)数学表达与公式
在ViT模型中,图像处理的核心步骤可以用以下几个公式来描述:
-
图块编码与位置编码:通过公式 (1),ViT首先将图像划分为图块,并为每个图块加上位置编码,得到每个图块的表示。公式中的
是类别标记,
是每个图块的嵌入表示,
是位置编码。
-
Transformer的自注意力与前馈神经网络:在每一层,输入数据通过**多头自注意力机制(MSA)和前馈神经网络(MLP)**进行处理,最终通过残差连接和归一化步骤进行优化。公式 (2) 和 (3) 分别表示这两步操作。
-
其中 L 是Transformer的层数,MSA 表示多头自注意力操作,LN 表示层归一化,MLP 表示前馈神经网络。
-
最终分类输出:通过公式 (4),模型最终生成类别预测,经过归一化和softmax处理后得到最终的分类结果。
(5)ViT模型的优势与挑战
优势:
-
全局信息建模:Transformer能够通过自注意力机制有效捕捉图像中远距离像素之间的依赖关系,避免了CNN中卷积核固定大小的限制。
-
灵活的输入结构:ViT不依赖于固定的卷积操作,而是通过图块输入和序列化的方式,可以处理更高分辨率的图像,具有更大的灵活性。
-
良好的迁移学习效果:ViT在大规模数据集(如ImageNet)上表现出色,尤其是在训练时间足够长时,Transformer模型的性能能够超越传统的CNN模型。
挑战:
-
数据需求:ViT相比CNN模型,需要更多的训练数据才能表现出优势,因为Transformer模型需要较大的数据量来充分训练自注意力机制。
-
计算复杂度:Transformer的计算复杂度较高,尤其是在处理大尺寸图像时,可能需要大量的计算资源和时间。
(6)总结
ViT模型通过引入Transformer架构在图像分类任务中取得了显著的进展,尤其是在处理复杂图像和高分辨率图像时,比传统CNN方法表现得更为有效。通过将图像划分为图块,并将这些图块作为序列输入到Transformer中,ViT克服了CNN的局部特征提取限制,实现了全局信息建模。然而,ViT在训练数据和计算资源方面的要求较高,因此在实践中需要适当的计算支持和数据准备。
2、目标检测
在目标检测领域,Transformer模型,特别是DETR(Detection Transformer),通过引入自注意力机制,突破了传统卷积神经网络(CNN)在处理长序列和捕捉长程依赖方面的限制。下面是对Transformer在目标检测中的应用进行的综合分析:
(1)传统目标检测方法的局限性
传统的目标检测模型,如Fast R-CNN和YOLO,通常基于卷积神经网络(CNN)架构。这些模型使用CNN来从图像中提取特征,然后使用后续的层进行目标检测。CNN的结构通常会有以下问题:
-
长序列处理的困难:当处理非常长的图像序列时,CNN在进行特征提取时可能会导致网络变得非常深,从而引发梯度消失的问题。
-
区域提议问题:传统的检测方法(如Faster R-CNN)依赖于区域提议网络(RPN),这意味着需要额外的步骤来生成候选区域,再进行目标检测,这增加了计算复杂度。
(2)Transformer在目标检测中的应用
Transformer通过自注意力机制解决了CNN在长序列处理中的不足,特别是在捕捉长程依赖关系和全局信息方面。以下是Transformer应用于目标检测的几个关键点:
2.1 DETR模型概述
DETR(Detection Transformer)模型的核心创新是完全摆脱了传统的区域提议网络(RPN)和先验框(Anchor Boxes)的依赖,直接使用Transformer来处理图像中的所有对象:
-
图像处理与自注意力机制:DETR通过将整个图像输入到Transformer中,利用**自注意力机制(Self-Attention)**来捕捉图像中各个部分之间的依赖关系。这允许模型通过全局上下文来理解图像中的对象。
-
Object Queries:与传统的目标检测方法不同,DETR使用一组**可学习的查询(Object Queries)**来直接预测图像中的所有目标,而不是通过RPN来提议区域。这些查询能够与Transformer解码器结合,通过自注意力机制获得对象信息。
-
End-to-End学习:DETR是一个端到端的模型,所有组件(包括特征提取、目标预测、边界框回归等)都在一个统一的框架下进行优化,而不需要分阶段训练。
2.2 Transformer架构
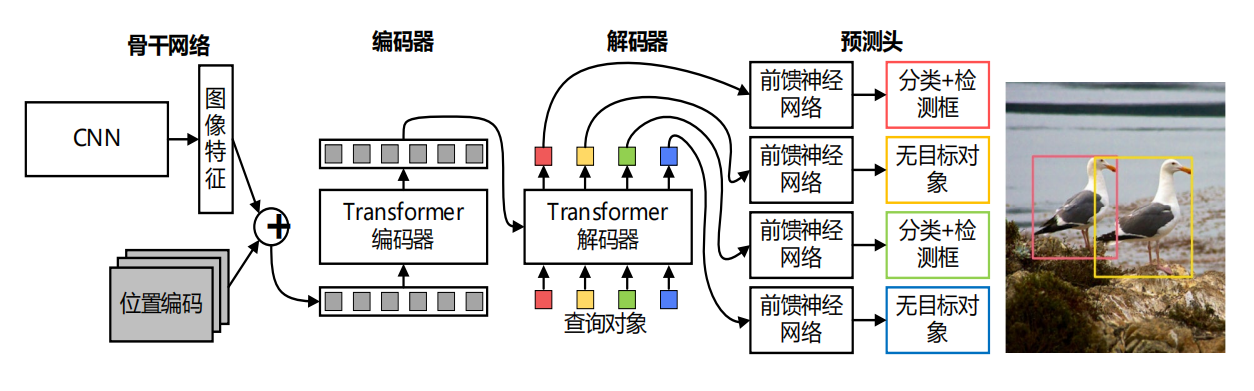
DETR的Transformer架构可以分为以下几个部分:
-
CNN Backbone:用来提取图像特征。
-
Transformer编码器:对提取到的特征图进行自注意力处理,捕捉全局依赖关系。
-
Transformer解码器:生成目标类别和边界框预测。
-
Position Encoding:通过2D位置编码(考虑到图像的二维特性)来提供空间位置信息。
-
Object Queries:这些查询用于生成最终的预测结果,通过与Transformer解码器的交互来确定图像中的每个对象。
2.3 匹配与损失函数
DETR通过匈牙利算法进行预测与真实目标(Ground Truth)的匹配。通过最小化匹配损失,DETR优化了目标检测任务中的精度和召回率:
-
匹配损失(L_match):用于计算预测和真实目标之间的匹配度。具体来说,这包括类别匹配损失和边界框回归损失。
-
匈牙利算法:DETR通过匈牙利算法对预测和实际目标进行一对一的匹配,从而实现最佳匹配。
2.4 目标查询与注意力机制
DETR模型的解码器主要有两个输入:
-
Transformer编码器的输出:通过自注意力机制捕捉图像特征。
-
Object Queries:这些查询作为额外的信息传递给解码器,帮助模型预测图像中的目标。
这些查询是可学习的,并且在模型训练过程中不断调整,以学习图像中不同对象的表示。
(3)DETR与传统方法的区别
DETR与传统的目标检测方法(如Faster R-CNN、YOLO等)在以下方面存在显著差异:
-
无区域提议网络:DETR不再依赖于手工设计的区域提议网络(RPN),而是直接从图像中提取全局信息,通过自注意力机制进行目标检测。
-
端到端训练:DETR的所有处理步骤都在端到端的训练框架中进行,简化了训练流程并减少了对复杂的训练阶段的需求。
(4)模型性能与应用
-
效果与效率:DETR在COCO数据集上展现了非常好的性能,尽管其计算复杂度较高,但它在准确率和执行效率方面与Faster R-CNN等传统方法相当。
-
应用场景:DETR适用于多种目标检测任务,尤其是在那些需要全局理解和复杂关系建模的场景中,如密集目标场景和多目标检测。
(5)挑战与未来方向
尽管DETR在多个任务中表现出色,但它仍然面临一些挑战:
-
计算复杂度:由于Transformer的自注意力机制需要对所有像素对进行计算,因此在处理大尺寸图像时,计算复杂度较高。
-
训练数据的需求:DETR的性能在大规模数据集上表现更佳,这意味着它需要大量的标注数据来发挥其优势。
未来,DETR可以通过以下方式进一步提升:
-
优化计算效率:通过改进自注意力机制的计算方式,减少计算负担。
-
改进目标查询的生成:通过更加高效的目标查询生成方式,提升模型对复杂场景的适应能力。
(6)结论
Transformer模型,特别是DETR,凭借其全局信息建模和端到端训练的优势,极大地推动了目标检测领域的发展。通过自注意力机制,DETR能够有效捕捉图像中长距离的依赖关系,并简化了传统方法中的复杂步骤,使得目标检测任务变得更加高效和灵活。随着计算技术的进步和优化,Transformer在目标检测中的应用将越来越广泛,未来将能应对更加复杂的检测任务。
3、图像分割
(1)背景与动机
-
实例分割 vs. 目标检测
-
目标检测(object detection)只关心物体的框选和分类;
-
实例分割(instance segmentation)不仅要定位并分类每个物体,还要输出精确的像素级掩码。
-
-
传统方法的局限
-
多阶段流水线(如 Mask R-CNN):先生成候选框,再在每个框内预测掩码,训练繁琐且推理延迟较大;
-
RPN + ROI Align 等模块较多,整体架构复杂。
-
-
DETR 的优势
-
端到端:无需设计 RPN、Anchor、NMS 等多余模块;
-
自注意力:能全局建模物体之间及物体与背景之间的长程依赖;
-
统一 Query:采用一组可学习的查询(object queries)同时预测所有实例。
-
(2)DETR 在实例分割中的扩展:Mask‐DETR
Mask-DETR 是将传统 DETR 扩展到实例分割的直观版本,其核心思想是在 DETR 预测类别和边框的基础上,额外添加掩码(mask)预测分支。
2.1 架构概览
输入图像│▼
CNN Backbone ──▶ 特征图 F ∈ ℝ^{C×H×W}│▼
Transformer Encoder ──▶ 全局特征 Z_e│▼
Transformer Decoder ──▶ N 个 query 特征 {q_i}_{i=1..N}│ ├─> class logits│ ├─> bbox coords│ └─> mask embedding e_i│▼
掩码预测 Head:• 将每个 e_i 与 F 进行点乘或动态卷积,生成对应的二值掩码• 掩码分辨率可按需上采样至原图大小
2.2 关键组件
-
Mask Embedding
-
在 decoder 中,为每个 query 除了输出分类和边框外,还预测一个 mask embedding 向量
。
-
-
像素解码器(Pixel Decoder)
-
直接在 backbone 特征图 F 上,基于卷积或轻量级 Transformer,构建高分辨率的像素特征图
;
-
-
动态掩码生成(Dynamic Mask Head)
-
使用
与
-
其中
表示从
为 sigmoid 函数。
-
-
损失函数
-
分类 Loss:与 DETR 相同,使用交叉熵;
-
边框 Loss:与 DETR 相同,使用 L1 + GIoU;
-
掩码 Loss:对每个正匹配 query,使用 Dice Loss 或 binary cross‐entropy 监督像素级预测;
-
(3)DETR 在全景分割中的演进:Panoptic-DETR & MaskFormer
3.1 Panoptic-DETR
在实例分割之外,全景分割(panoptic segmentation)需要同时输出“事物”(things)和“背景”(stuff)的像素级标注。Panoptic-DETR 将 DETR 框架扩展如下:
-
Unified Queries:将 “things” 类用 object queries 预测,将 “stuff” 类(例如天空、道路)也编码为一组特殊的 queries;
-
双分支 Mask Head:为 things 和 stuff 分别生成掩码;
-
融合策略:通过类别置信度和层次优先,合并 instance masks 与 semantic masks,得到最终 panoptic map。
3.2 MaskFormer / Mask2Former
MaskFormer 提出了“掩码分类”(mask classification)新范式,将分割视为 N 个掩码 类别化 的任务,与 DETR 思路极其契合:
-
Query 统一:仅用一组可学习的 queries,分别输出类别、掩码向量;
-
Pixel Decoder + Transformer Decoder:解耦语义分割与实例分割,通过同一组 queries 即可完成两者;
-
损失与匹配:同样采用匈牙利算法进行 query-to-ground-truth 匹配,mask IoU + CE 联合匹配和监督。
Mask2Former 则进一步在多尺度上融合特征,增强小目标的捕捉能力。
(4)典型完整架构示例
flowchart LRA[输入图像] --> B[Backbone(CNN)]B --> C[Pixel Decoder<br/>高分辨率特征 F_pix]B --> D[Transformer Encoder]D --> E[Transformer Decoder]E -->|每个 query| F{class, bbox, mask emb}subgraph "Mask Head"F --> G[动态卷积头<br/>w(m_i) from mask emb]G --> H[与 F_pix 卷积]H --> I[掩码 M_i]endF --> J[分类分支]F --> K[框回归分支]
-
Backbone:ResNet、Swin-Transformer 等;
-
Pixel Decoder:上采样 + 多尺度融合;
-
Transformer Encoder:6 层/多头自注意力;
-
Transformer Decoder:6 层 + N=100–300 个 queries;
-
Mask Head:动态卷积或内积方式,实现高效的像素级预测。
(5)小结
-
Mask-DETR:最直接的 DETR 实例分割扩展,加入 mask embedding + 动态卷积;
-
Panoptic-DETR:统一 things 与 stuff query,完成全景分割;
-
MaskFormer / Mask2Former:将分割视为掩码分类问题,和 DETR 的 query 匹配框架高度契合,并在多尺度上进一步优化。
-
优势:端到端、全局建模、统一 query 分割;
-
挑战:计算复杂度高、对高分辨率分割需更多像素解码策略。
三、多模态领域
在多模态领域,Transformer的应用非常广泛,尤其是在图像描述任务中。根据你的图片内容,Transformer被广泛应用于以下几项任务:
-
图像描述(Image Captioning):该任务通过自然语言生成图像的描述,结合了计算机视觉和自然语言处理的能力。Transformer在此任务中通过其自注意力机制,能够有效地理解图像中的复杂特征,并生成相应的自然语言描述。
-
视觉问答(Visual Question Answering,VQA):此任务通过对图像内容和问题进行联合处理来生成答案。Transformer能够根据图像和问题的语义信息,通过自注意力机制来推断正确的答案。
-
文本生成图像(Text-to-Image Generation):这种任务的目标是根据输入的文本描述生成与之相关的图像,Transformer在此任务中也得到了广泛的应用。它可以有效地将文本信息映射到图像空间。
这些任务表明Transformer能够在处理多模态数据时发挥重要作用,尤其是其自注意力机制可以在输入的不同模态之间建立联系和依赖关系。Transformer模型的成功也促使了研究人员探索其在图像描述任务上的应用, 进而出现了CNN-Transformer类方法与Transformer-Transformer类方法。
1、CNN-Transformer类方法
CNN-Transformer类方法结合了卷积神经网络(CNN)和Transformer模型的优势,针对图像任务中的一些特定挑战进行了创新。以下是几个关键方法的详细分析:
(1)X-Transformer,M2Transformer,RSTNet和DLCT等方法
这些方法通过将CNN和Transformer结合,创新性地处理了图像特征的提取和学习。Transformer最初是作为自然语言处理的模型,但在图像任务中,采用了类似的结构,如将CNN用于图像特征提取,Transformer用于捕捉长距离的依赖关系。这种融合方法为图像分类、检测等任务带来了新的突破。
(2)M2Transformer
M2Transformer是一个经典的CNN-Transformer方法,特别之处在于其采用了记忆增强编码器(Memory-Augmented Encoder)。这个方法结合了Faster R-CNN的特征提取方式,将其与Transformer的结构结合,形成了一个非常高效的图像处理架构。
-
骨干编码器(Backbone Encoder):使用Faster R-CNN提取图像的区域特征,这是一个常用的目标检测方法。它通过区域提取来优化特征。
-
记忆增强编码器:这个编码器使用了Memory Slots来存储图像的高级特征,能够在处理时更好地捕捉和整合图像中重要的信息。
-
网格解码器:用来处理图像生成任务,能够有效地解码来自Transformer编码器的信息,生成相应的图像描述或其他任务的输出。
(3)跨模态注意力
在CNN-Transformer方法中,跨模态注意力机制(Cross Attention)被引入,用于在不同模态(如图像和文本)之间建立关联。例如,在图像描述任务中,模型不仅需要理解图像的视觉信息,还需要理解文本描述的内容。这种机制让模型能够在不同模态之间进行信息的交换和融合,从而提高了多模态任务的表现。
(4)自注意力与门控机制
CNN-Transformer模型中使用了自注意力机制(Self-Attention)和门控机制(Gating Mechanism)来增强信息的传递和控制。门控机制通过控制信息流,帮助模型决定哪些信息需要被强化或忽略。这种机制在处理多模态数据时尤其重要,因为不同模态之间的信息量和相关性不尽相同,门控机制可以帮助模型更好地进行决策。
2、M2Transformer(Meshed-Memory Transformer)
Meshed-Memory Transformer:网状记忆Transformer。
链接:aimagelab/meshed-memory-transformer: Meshed-Memory Transformer for Image Captioning. CVPR 2020![]() https://github.com/aimagelab/meshed-memory-transformer
https://github.com/aimagelab/meshed-memory-transformer
(1)背景与动机
-
图像描述(Image Captioning)任务挑战
图像描述需要模型既能理解视觉内容,又能以自然语言生成流畅、准确的句子。传统方法一般先利用卷积神经网络(如 CNN 或 Faster R-CNN)提取图像特征,再通过循环神经网络(RNN)或普通 Transformer 解码器生成文本。然而,单纯的特征提取往往忽略了区域间长程依赖与全局上下文信息,使生成的描述在细节与多样性方面存在瓶颈。 -
Transformer 在图像领域的先行尝试
Transformer 模型在 NLP 领域已证明了其强大的序列建模能力。将其引入图像描述中,需要解决两大问题:-
如何将视觉特征(尤其是多区域检测特征)与文本信息高效结合?
-
如何让多层编码器之间的信息流更加丰富,避免仅依赖最后一层特征?
-
-
Meshed-Memory Transformer(M² Transformer)的核心目标
M² Transformer 由 Cornia 等人于 CVPR 2020 提出,全称为 “Meshed-Memory Transformer for Image Captioning”。它的两个核心创新点是:-
内存增强编码器(Memory-Augmented Encoder):在每一层编码器中保留并传递一组可学习的“内存向量”(Memory Slots),帮助捕捉全局上下文与跨区域交互。
-
网格化连接(Meshed Connectivity):在解码阶段,生成每个词时同时关注所有编码器层的输出,而非仅仅关注最后一层,形成类似“网格”状的层间信息流动,增强多层次特征的利用。
-
(2)整体架构概述
M² Transformer 可以看作是一个典型的 Encoder-Decoder 架构,但在编码器侧加入了“内存增强”结构,在解码器侧实现了“网格化连接”。整体流程如下:
-
视觉特征提取(Backbone)
-
首先使用 Faster R-CNN(通常使用在 COCO 数据集上预训练的检测模型)对图像进行区域级别的检测与特征提取。Faster R-CNN 生成若干候选区域(region proposals)及其对应的特征向量,通常会选取 top K(如 100 或 36)个评分最高的区域特征。记这些区域特征为 {
},其中每个
。
-
-
内存增强编码器(Memory-Augmented Encoder)
-
将上述 K 个区域特征作为编码器的输入序列,同时引入一组可学习的“记忆向量”(Memory Slots),记为 {
},其中 M 通常远小于 K,例如 40。
-
编码器由 L 层 Transformer 编码单元堆叠而成,每一层都能同时作用于区域特征和记忆向量。经过每层计算后,区域特征与记忆向量都会更新,并传给下一层,形成跨层“记忆”传递。
-
-
网格化连接(Meshed Connectivity)
-
在解码器生成文本时,标准 Transformer 会让解码器的每一层仅关注编码器最后一层输出;而 M² Transformer 提出“网格化连接”,即在解码器的每个注意力模块(Attention)中,都要跨层级地访问编码器所有 L 层的输出。
-
因此,解码器某一层在计算时,会对每一层编码器输出分别做一次多头注意力,并将各层结果进行加权汇总,从而得到更为丰富多尺度的视觉表示。
-
-
解码器(Meshed-Memory Decoder)
-
解码器仍然由 L 层 Transformer 解码单元组成。每一层都包含自注意力模块(Self-Attention)、跨注意力模块(Cross-Attention)以及全连接前馈网络(Feed-Forward)。其中“跨注意力”模块采用上述“网格化连接”策略。
-
最终,解码器在每个时间步输出一个词汇分布,用于生成描述。
-
下面将分别对上述关键模块展开详解。
(3)内存增强编码器(Memory-Augmented Encoder)详解
3.1 概念与动机
-
传统 Transformer 编码器:每层仅有一套 Query-Key-Value(Q-K-V)机制,输入一般是区域特征
。层与层之间虽然有残差连接和归一化操作,但无法直接保留(或强化)一组“全局记忆”或“先验知识”向量。如果模型只依赖区域特征,可能会忽略整体上下文或难以捕捉多层次的全局模式。
-
内存增强的想法:给每一层编码器都引入一组“可学习的记忆向量”(Memory Slots),这些向量在整个编码过程中不断更新,将不同区域间的交互信息以更集中的方式存储下来。这样不仅有助于提炼图像的全局信息,也能够加强区域特征之间的交互与“记忆”能力。
3.2 具体结构
假设我们提取到 K 个区域特征 ,每个特征维度为 d。同时初始化 M 个可学习记忆向量
,同样维度为 d。编码器共有 L 层。
输入拼接
-
在第 0 层(输入层),将区域特征与记忆向量拼接成一个总序列:
这里可以将它们按序拼成长度为 K+M 的序列,或分别维护各自的表示,但在计算自注意力时,它们会被当作整体序列参与。
单层编码单元
每一层编码单元由以下几个子模块构成(以第 l 层为例):
-
多头自注意力(Multi-Head Self-Attention)
-
输入为上一层输出(长度为 K+M),包括区域特征与上一层的记忆向量:
-
通过多头自注意力计算得到新的特征表示:
-
在此过程中,区域特征之间、区域与记忆之间、记忆与记忆之间都会发生交互。这样一来,一组记忆向量不仅能够在一层内部与所有区域特征进行信息交换,还会在下一层继续更新。
-
-
Add & Norm(残差连接 + LayerNorm)
-
将自注意力输出与输入做残差相加,并进行层归一化:
-
-
前馈网络(Feed-Forward Network)
-
对
应用两层全连接网络(注意每个位置独立计算):
其中
(或
)等。
-
-
Add & Norm(残差连接 + LayerNorm)
经过上述步骤后, 中前 K 个位置对应更新后的区域特征
,后 M 个位置对应更新后的记忆向量
。
跨层传递
-
上述过程在每一层都会执行一次,并将更新后的记忆向量
传递到下一层,当作第 l 层的 “输入记忆”。这样,记忆向量会在整个编码器中不断累积与更新,既保留了来自先前层的全局信息,也能在后续层中与区域特征进行更深层的交互。
-
最终在第 L 层结束后,我们得到所有区域特征
以及最终的记忆向量
。在解码器阶段,通常只将编码器中所有层的区域特征输出(记忆向量也可以视作某种补充全局信息)作为“键/值(K/V)”用于跨注意力。
3.3 内存增强的优势
-
全局上下文聚合
-
记忆向量在每层都与区域特征交互,形成对图像各局部区域的全局信息摘要,使得模型更容易理解图像的整体语义。
-
-
跨层信息融合
-
将记忆视作“跨层缓存”,可以将底层较为局部的特征信息与更高层的抽象信息相互融合。相比只利用最后一层特征,内存增强可以保留多层次的信息。
-
-
提高特征表达力
-
记忆向量以可学习的形式存在,可以在训练中逐渐演化为一组有用的图像“原型”或“概念”,帮助解码器更精准地生成描述。
-
(4)网格化连接(Meshed Connectivity)详解
4.1 动机
-
传统跨注意力(Cross-Attention):在标准 Transformer 中,解码器每层仅会访问编码器的最后一层输出
。这种设计忽略了前面各层可能保留的中间信息;在图像描述中,底层编码器更关注细节、纹理等局部信息,而高层编码器更多关注全局语义,解码器若只依赖最高层输出,可能会丢失某些细节或层次特征。
-
网格化连接思路:让解码器在每层通过多头注意力同时查询所有 L 层的编码器输出,并对它们进行加权融合。如此一来,解码器就像在“网格”中穿行,能够同时利用不同层级的视觉特征,使生成依据更加多样化、信息更丰富。
4.2 实现细节
假设编码器共有 L 层。对于第 t 时刻要生成第 t 个词时,解码器第 l 层需要完成如下操作:
-
自注意力(Self-Attention)
-
解码器本层先基于前面所有已生成词的嵌入,计算自注意力,得出一个上下文表示
。
-
-
网格化跨注意力(Meshed Cross-Attention)
-
对于每一层编码器 i (
),取其输出区域特征
。
-
解码器第 l 层将
这里可以只用区域特征
作为 K/V,也可同时包含记忆向量
。原论文通常将所有位置(区域 + 记忆)都作为 K/V。
-
对于不同层 i ,可以额外引入可学习的标量或向量
作为权重,对各层的注意力输出进行加权融合:
其中
,可通过 Softmax 得到;或直接让解码器学习一组固定的融合方式。
-
-
Add & Norm(残差 + 归一化)
-
前馈网络(FFN)及最后的 Add & Norm
其中
就是解码器第 l 层在时刻 t 对下一个子模块(或输出)的输入。
通过上述“网格化跨注意力”机制,解码器能够灵活选择来自不同编码层的特征信息。可以认为编码层每一层都代表了不同语义粒度:
-
底层编码输出 关注局部纹理、边缘、简要形状;
-
中层编码输出 关注局部物体、部件间关系;
-
高层编码输出 关注整体场景、全局语义。
解码器通过网格化融合后,就能综合利用多尺度、多层次的视觉信息,使生成的每个词既有细节支撑,又有整体语义保证。
(5)解码器(Meshed-Memory Decoder)设计
5.1 结构概览
-
解码器同样由 L 层组成。每一层包括三部分:
-
自注意力模块(Masked Multi-Head Self-Attention):仅对已生成词进行掩码,保证自回归生成。
-
网格化跨注意力模块(Meshed Multi-Head Cross-Attention):如上所述,从编码器所有层获取视觉信息。
-
前馈网络(Feed-Forward Network):对跨注意力结果进行非线性映射与整合。
-
-
在最顶层(第 L 层)计算完成后,解码器会得到一个表示当前生成环境的向量
。最后通过一个线性+Softmax 层,将其映射到词汇表空间,生成前一时刻的预测分布:
其中
,V 为词汇量大小。
5.2 详细步骤(以第 t 时刻、第 l 层为例)
-
自注意力(Masked Self-Attention)
-
输入为上一层的隐藏状态
(即时刻 t 前已经生成的所有词的向量表示)。
-
通过掩码多头自注意力得到
-
残差连接 + 归一化之后,
-
-
网格化跨注意力
-
对每一层编码器输出的区域特征和记忆向量序列分别进行多头注意力,得到
。
-
按照可学习权重
或直接拼接融合,得到整体跨注意力结果
。
-
残差连接 + 归一化产生
。
-
-
前馈网络(FFN)
-
对
-
该向量继续传给下一层,直到最顶层生成最终结果。
-
通过上述多层 Meshed-Cross-Attention 的交互,解码器能够在每一步生成时充分考虑不同层次的视觉线索。
(6)损失函数与训练策略
-
最大似然估计(MLE)损失
-
最基础的方法,就是在训练阶段用以训练模型预测下一个词的概率分布。设语料中一张图对应的真实描述为
,MLE 损失为:
-
-
强化学习(CIDEr 优化)
-
在 M² Transformer 及后续工作中,常常采用自举(Self-Critical Sequence Training,SCST)策略对模型进行微调,通过直接优化评价指标(如 CIDEr)来提升最终表现。具体来说:
-
采样:从当前模型中采样若干描述序列;
-
计算奖励:用 CIDEr 等指标分别计算样本序列及贪心解序列的奖励;
-
策略梯度更新:最大化奖励差,减少与基线之间的差距。
-
-
-
训练细节
-
预训练权重:通常先用 COCO 数据集上的 Faster R-CNN 提取区域特征,再将编码器、解码器参数随机初始化或从开源预训练模型加载,如从 ImageNet 预训练的 Transformer 参数。
-
学习率与调度:采用 Adam 优化器,初始学习率较小(如
),训练若干 epoch 后使用衰减策略,或采用线性预热+指数衰减。
-
正则化:使用 Dropout(如 0.1)、标签平滑(Label Smoothing)等手段防止过拟合。
-
(7)实验结果
下表列出了 M² Transformer 在 MSCOCO 数据集上与其他主流模型的对比(均在 Karpathy 划分上评测)。
| 模型 | BLEU-4 | METEOR | ROUGE-L | CIDEr | SPICE |
|---|---|---|---|---|---|
| Up-Down (LSTM+Stacked LSTM) | 36.3 | 27.0 | 56.5 | 120.1 | 20.3 |
| AoANet (Attention on Attention) | 37.2 | 27.5 | 57.0 | 125.6 | 20.9 |
| M² Transformer (MLE) | 37.5 | 27.8 | 57.3 | 130.4 | 21.5 |
| M² Transformer (CIDEr RL) | 39.8 | 28.9 | 58.7 | 145.2 | 22.7 |
| OSCAR | 38.7 | 28.5 | 58.1 | 138.3 | 22.0 |
说明:
上表中的 M² Transformer 在直接使用 MLE 训练时,即可取得比传统 LSTM+Attention 方法更好的结果;应用 CIDEr 优化后,CIDEr 分数能达到 145.2,超过 AOANet、Up-Down 等多种方法。
SPICE 指标也在 21.5→22.7 上获得提升,说明生成文本在语义质量上更优。
(8)优缺点与应用场景
8.1 优点
-
多层次信息融合更充分
-
通过内存增强及网格化连接,模型同时利用了不同层的局部与全局特征,使生成内容既包含细节描述,也兼顾整体语义。
-
-
内存向量作为跨层“中心”
-
记忆向量在每层更新并与所有区域特征交互,类似于一种跨层信息集散中心,有助于全局上下文的汇聚与利用。
-
-
无需过多手工设计特征融合策略
-
直接让模型在多头注意力中自动学习如何在不同层次间分配权重,比传统方法在多尺度融合上更为灵活。
-
-
在多种任务中可迁移
-
虽然 M² Transformer 最初针对图像描述,但其内存增强与网格化跨注意力思路,也可应用于视觉问答(VQA)、视觉对话、文本生成图像(Text-to-Image)、多模态检索等任务。
-
8.2 缺点
-
计算与显存开销较大
-
由于每层编码器都需要维护额外的 M 个记忆向量,且解码器每层需要对 L 层编码输出做 Attention,其计算复杂度约为
量级,显存和计算都比传统 Transformer 要大。
-
-
参数量更多,训练难度增大
-
内存向量、跨层权重
-
-
潜在过拟合风险
-
如果数据集规模有限,过多的跨层连接和内存向量可能使模型过度拟合训练集,需要更多正则化或提前停止。
-
8.3 应用场景
-
图像描述(Image Captioning)
-
M² Transformer 在 COCO、Flickr30k 等数据集上都有卓越表现,尤其适合对细节要求高,且需要兼顾全局场景理解的场景。
-
-
视觉问答(Visual Question Answering, VQA)
-
可以将内存向量视作“视觉上下文记忆”,解码器在回答问题时能够多层次检索图像信息。
-
-
视觉对话(Visual Dialog)
-
对话过程中,模型需不断更新历史交互状态,内存增强编码器可将视觉上下文与对话历史共同存储并迭代,提升回答质量。
-
-
文本生成图像(Text-to-Image Generation)
-
虽然原生 M² 是从图像到文本,但思路可逆:先将文本编码为“概念记忆向量”,再通过网格化交互为条件信息生成图像。
-
(9)关键公式与要点梳理
-
内存增强自注意力(第 l 层)
-
最终
分为前 K 个区域特征
和后 M 个记忆向量
。
-
-
网格化跨注意力(解码器第 l 层第 t 时刻)
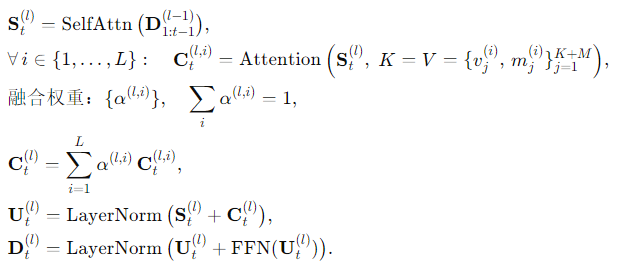
-
-
-
生成概率与损失
-
在 SCST 阶段,用 CIDEr 作为奖励进行强化学习优化。
-
(10)总结
-
M² Transformer 的两大核心创新:
-
内存增强编码器:引入可学习记忆向量,让模型能够在编码阶段对跨区域、跨层信息进行更有效的存储与传递。
-
网格化连接的跨注意力:解码阶段同时关注所有编码器层输出,实现多层、多尺度视觉信息的动态融合。
-
-
关键优势:
-
在图像描述任务上取得了显著提升,尤其是在 CIDEr、BLEU-4、SPICE 等指标上均超越多种基线方法。
-
模型对多层次视觉信息的整合更为灵活,可以避免只使用最高层特征带来的信息缺失。
-
-
关键瓶颈:
-
计算与显存开销大,需要更多资源;
-
参数更多、训练相对复杂;
-
对于小规模数据集,可能存在过拟合风险。
-
-
延伸方向:
-
在 VQA、视觉对话、跨模态检索等其他任务中,可借鉴“内存增强 + 网格化连接”思路;
-
探索更轻量级的记忆机制或稀疏注意力策略,以降低计算复杂度;
-
引入视觉 Transformer(如 ViT)或自监督预训练方式,进一步提升表征能力。
-
总的来说,M² Transformer 通过巧妙地将跨层次记忆与多尺度跨注意力结合起来,为图像描述及其他多模态任务提供了一条可行的、效果显著的研究思路。
3、Transformer-Transformer 类方法
Transformer-Transformer 类方法主要通过Transformer结构进行图像处理,目标是解决传统的CNN-RNN方法和CNN-Transformer方法中存在的限制。以下是对Transformer-Transformer 类方法的详细分析:
-
背景与问题定义:
-
传统的CNN-RNN和CNN-Transformer方法在图像区域特征提取时具有局限性,尤其是Faster R-CNN方法需要在外部数据集上进行预训练,导致图像的划分过程使得模型无法执行End2End训练,从而限制了图像描述任务的深度应用。
-
这些限制促使研究人员转向基于Transformer的全新结构,以解决现有方法的局限性。Transformer-Transformer类方法就是在此背景下提出的,其中包括PureT、PTSN、ViTCAP等不同的Transformer结构。
-
-
PureT模型:
-
构成:PureT模型由三个主要部分组成:骨干编码器(Backbone Encoder)、增强编码器(Refining Encoder)和解码器(Decoder)。这些模块通过Transformer结构处理输入图像特征。
-
骨干编码器(Backbone Encoder):用于从输入图像中提取网络特征。
-
增强编码器(Refining Encoder):增强图像局部特征,提升网络对图像细节的感知能力。
-
解码器(Decoder):通过增强特征生成描述图像的输出。
-
-
-
PureT的架构设计:
-
骨干编码器通过Swin Transformer从输入图像中提取12x12的特征,并进行标准化处理。Swin Transformer的引入使得图像处理过程具有更高的效率。
-
增强编码器则通过多次优化,逐步增强图像特征的质量,从而使得图像描述更具细节。
-
解码器采用了多个模块进行图像特征的增强和图像描述生成。
-
-
W-MSA与SW-MSA:
-
PureT使用原始的多头自注意力机制(MSA)以及变体,如窗口自注意力机制(W-MSA)和移位窗口自注意力机制(SW-MSA)。这些机制用于处理图像的局部和全局特征。
-
W-MSA:通过将图像切分为多个小块,独立处理每个块的特征,增强了模型的计算效率。
-
SW-MSA:通过移位窗口机制解决了W-MSA在跨窗口信息交流时的局限性,进一步提升了模型的建模能力。
-
-
解码器的工作原理:
-
解码器通过接收从增强编码器传来的特征,并通过多个Transformer层进行处理,逐步生成最终的输出图像描述。
-
解码器中的每个模块包含四个主要部分:预融合模块、语言编码自注意力模块、视觉编码自注意力模块、和单词生成模块。
-
-
预融合模块(Pre-Fusion Module):
-
该模块负责将增强后的全局特征与每个解码器模块的输入进行融合,确保视觉信息和语言信息之间的顺畅交流。
-
总的来说,Transformer-Transformer类方法通过PureT模型实现了在视觉和语言领域的强大交互,采用了一些创新的机制(如W-MSA和SW-MSA)来提升图像描述任务的表现。这种方法通过不同模块的组合,在处理图像特征的同时,能够产生高质量的描述输出,展现了Transformer结构在计算机视觉中的潜力。
4、PureT模型
(1)背景与动机
-
端到端瓶颈
-
以往图像描述多采用 CNN 提取区域特征 + RNN/Transformer 解码,但区域检测器(如 Faster R-CNN)依赖外部预训练,难以实现端到端微调。
-
-
Transformer 潜力
-
Transformer 在自然语言处理有卓越表现,其自注意力(Self‐Attention)机制能建模长距离依赖;近年来 Vision Transformer(ViT)证明了其在纯视觉任务中的可行性。
-
-
PureT 提出
-
受 Swin Transformer 多尺度移位窗口注意力启发,PureT 完全摒弃 CNN,提出“图像 → 全 Transformer → 文本”一体化流水线,以实现从像素到描述的端到端建模。
-
(2)模型架构概览
PureT 主要由三大子网络组成:
输入图像 → Patch 分割 → Backbone Encoder → Refining Encoder → Decoder → 文字描述
| 模块 | 作用 | 输出维度 |
|---|---|---|
| Patch 分割 | 将 H×W 图像切分为 N 个大小为 P×P 的 Patch | N × (P²·C) |
| Backbone Encoder | 基于 Swin Transformer 提取多尺度视觉特征 | N' × D |
| Refining Encoder | 多层标准 Transformer 层,增强全局特征表达 | N' × D |
| Decoder | 融合视觉特征与语言特征,逐步生成文本 | L × |
-
N = HW / P²,N′ 通常等于 N(或通过合并降低);
-
D:特征维度(如 768 或 1024);
-
L:最大生成长度;
-
|V|:词表大小(如 30K)。
(3)核心模块与机制
3.1 Backbone Encoder (骨干编码器)
-
Patch Embedding
其中
为可学习的二维位置编码。
-
Swin Transformer Block
每一层交替使用 W-MSA 与 SW-MSA:-
W-MSA(窗口自注意力):对每个不重叠窗口内的 Patch 做多头自注意力。
-
SW-MSA(移位窗口自注意力):将窗口平移
个 patch,再做注意力,实现跨窗口的全局信息流。
-
-
数学表达
对任意一层输入:
其中 MSA 可替换为 W-MSA 或 SW-MSA。
3.2 Refining Encoder(增强编码器)
-
由 NeN_eNe 层标准 Transformer 编码器堆叠组成,每层包含:
-
LayerNorm
-
全局多头自注意力(MSA)
-
前馈网络(FFN)
-
-
目标:在骨干提取的多尺度特征基础上,通过全局 MSA 让不同窗口 / 不同层级的特征完成信息交互,细化视觉表示。
3.3 Decoder(解码器)
-
预融合模块(Pre-Fusion)
将上一步已生成的文字嵌入与视觉特征
做线性投影并相加,再做 LayerNorm:
-
自注意力(Self-Attn)
建模文字序列内部依赖: -
视觉–语言交叉注意力(Cross-Attn)
将 -
输出预测
最后通过前馈网络 + Softmax 在词表上做下一个词预测。
(4)训练与优化策略
-
预训练
-
在 Conceptual Captions、Visual Genome 等大规模图文对上用交叉熵损失预训练。
-
-
微调
-
在 MS-COCO Train 上微调,优化目标:
-
随后常用强化学习(SCST)以 CIDEr 分数为奖励:
-
-
数据增强与正则化
-
图像:随机裁剪、色彩扰动、翻转;
-
文本:标签平滑(Label Smoothing),Dropout。
-
(5)实验与性能分析
| 方法 | BLEU-4 ↑ | METEOR ↑ | ROUGE-L ↑ | CIDEr ↑ | SPICE ↑ |
|---|---|---|---|---|---|
| CNN+LSTM 基线 | 36.3 | 27.1 | 56.4 | 112.3 | 19.5 |
| Up-Down + SCST | 37.2 | 27.7 | 56.8 | 117.9 | 20.1 |
| PureT | 39.1 | 28.5 | 58.2 | 129.4 | 21.7 |
| PureT-Small | 38.4 | 28.1 | 57.5 | 124.2 | 21.0 |
-
消融实验
-
去掉 Refining Encoder:CIDEr 降 4.3;
-
不使用 SW-MSA:CIDEr 降 2.7;
-
不用预融合模块:CIDEr 降 3.1。
-
(6)优缺点与改进方向
优点
-
全流程端到端:无需外部检测器,减少工程复杂度;
-
统一架构:视觉与语言统一用 Transformer,便于多模态预训练;
-
优秀性能:在 COCO 等数据集上超越多种 CNN+RNN 混合模型。
缺点
-
计算与显存消耗高:Swin+Transformer 多层堆叠,对 GPU 要求高;
-
预训练成本大:需要数亿图文对数据才能充分发挥;
-
推理速度稍慢:针对长文本生成,Cross-Attn 计算开销不容小觑。
改进与未来方向
-
高效注意力:将 Linformer、Performer 等低秩近似注意力集成进 Backbone/Decoder,降低复杂度。
-
多模态预训练:结合更大规模中英双语图文、视频字幕等数据,提升跨语言和时序场景下的效果。
-
轻量化模型:为移动端或机器人部署设计剪枝/量化策略,保持性能的同时减小模型体积。
-
更丰富的多级融合:在解码器端引入多尺度视觉特征(来自 Swin 不同 Stage),增强对细节与布局的感知。
总结:PureT 通过纯 Transformer 的骨干提取、特征增强与融合解码,实现了图像描述任务的端到端优化,并在标准基准上取得了领先效果。未来可围绕高效注意力、多模态预训和轻量化落地等方向继续深化。
相关文章:
【深度学习】Transformer 的应用
目录 一、自然语言处理领域 1、自然语言处理领域的应用 2、BART模型 3、BERTSum模型与自动文本摘要 4、SG-Net与机器阅读理解 5、SG-Net的应用 6、总结 二、计算机视觉领域 1、图像分类 (1)背景与挑战 (2)Transformer的…...

C#学习10——泛型
一、什么是泛型? 官方理解:允许开发者在定义类、接口、方法或委托时使用类型参数 个人理解: 类型模具(类似Object变色龙) 二、泛型有什么用? 通过参数化类型实现代码复用,提升类型安全性并…...

Spring Validation校验
使用 JSR 303 (Bean Validation) 校验接口参数 JSR 303,也称为Bean Validation规范,提供了一种在Java应用程序中执行验证的标准化方式。它允许你通过注解直接在领域或者DTO(数据传输对象)类上定义校验规则。 1. 添加依赖 首先需…...
:MVP的核心法则——消除阻碍与聚焦关键指标)
精益数据分析(72/126):MVP的核心法则——消除阻碍与聚焦关键指标
精益数据分析(72/126):MVP的核心法则——消除阻碍与聚焦关键指标 在创业领域,许多失败案例源于对产品开发的认知偏差——过度追求功能完善或盲目跟风增长,却忽略了用户核心需求的最直接满足。今天,我们结合…...

从头实现react native expo本地生成APK
根据github上老外的经验制作了一个react native expo项目起始模版,准备放到资源下载里(已经免积分放置好),这个起始模版带有个人非常喜欢的tailwindcss,由于raact native使用sheetstyle这种风格的样式,不太喜欢.当然,我们使用react native paper组件库时,就要对组件库里的组件使…...

打卡第二十三天
仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码。 使用Kaggle平台的注意点 Kaggle是一个数据科学竞赛平台,提供了丰富的数据…...

关于汇编语言与接口技术——单片机串行口的学习心得
学习目标: 1.了解AT89S51单片机片内串行口的基本工作原理 2.掌握与串行口有关的特殊功能寄存器以及四种工作方式 一、串行口内部结构 单片机串行口有两个独立的接收、发送缓冲器SBUF,属于特殊功能寄存器,可以同时发送、接收数据;…...

汇川PLC通过Profinet转ModbusTCP网关读取西门子PLC数据案例
Modbus TCP主站即Modbus TCP客户端,Modbus TCP主站最多支持同时与31个Modbus TCP从站 。(Modbus TCP服务器)进行通信。 第一步设置PLC IP地址; 默认PLC IP地址为192.168.1.88。根据需要判断是否需要修改。 第二步添加Modbus TCP…...

2025-05-20 模型下载--文本向量化--Faiss检索
模型下载 使用Python脚本进行下载 from huggingface_hub import snapshot_download # import os# os.environ["HF_ENDPOINT"] "https://hf-mirror.com" # 自定义下载目录(Windows 路径建议用 raw string 或 pathlib) download_di…...

idea本地debug断点小技巧
idea本地debug断点小技巧 简单的设置断点条件 断点后,右键这个断点,可以在 condition 中填写能得出布尔的表达式 a 1 你如果写如下,表示先给他赋值,然后断住 a 2; true 断点后设置某个变量的值 在 debug 区域可以设置变量…...

Mybatis面向接口编程
添加与Mapper接口的映射 <!--UserMapper.xml--> <?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> …...

谈谈对《加密算法》的理解
文章目录 一、什么是加密算法?二、常见的加密算法有哪些?2.1 对称加密2.2 非对称加密2.3 哈希算法 三、加密算法代码展示3.1 MD5加密3.2 秘钥加密3.3 AES加密解密 四、加密算法的使用场景 一、什么是加密算法? 加密算法是一种通过数学方法将…...

代码随想录算法训练营第60期第四十二天打卡
大家好,今天还是继续我们的动态规划里面的背包问题,前面我们主要接触的是0-1背包和完全背包,其实这两个背包问题主要就是看看每一件物品我们是否有多件,如果每一件物品我们只能取一次的话那这样我们就是0-1背包,如果每…...

Java并发进阶系列:深度讨论官方关于jdk1.8ConcurrentHashMap的computeIfAbsent源代码修复逻辑
在文章中《深度解析官方关于jdk1.8的resizeStamp的bug处理过程》,我们讨论关于CHM的核心设计——resizeStam需要修复的处理过程,本文再次基于openJDK的bugs讨论组提出的CHM源代码另外一个会造成死循环的bug,默认读者已经掌握CHM的核心源代码实…...

npm vs npx 终极指南:从原理到实战的深度对比 全面解析包管理器与包执行器的核心差异,助你精准选择工具
npm vs npx 终极指南:从原理到实战的深度对比 全面解析包管理器与包执行器的核心差异,助你精准选择工具 一、核心定位差异 #mermaid-svg-xM2GZt0lejj6hYk6 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}…...

RK3588 IREE+Vulkan ResNet50推理测试
RK3588 IREE+Vulkan ResNet50推理测试 背景一.性能数据【暂不考虑该框架】二.操作步骤2.1 搭建NFS服务,解决IREE编译时,空间不足的问题2.2 编译、安装`IREE`2.2.1 挂载NFS2.2.2 安装依赖2.2.3 编译`IREE`2.2.4 获取驱动及设备信息2.2.5 下载推理图片2.2.6 生成`onnx`模型转换脚…...

Blaster - Multiplayer P77-P89: 武器瞄准机制
P78_ Blaster HUD And Player Controller P78_1 创建PC和HUD P78_2 Tick Component > SetHUDCrosshairs() P79_ Drawing the Crosshairs DrawHUD() Call Every Tick. #include "HUD/BlasterHUD.h"void ABlasterHUD::DrawHUD() {Super::DrawHUD();FVector2D View…...

【每天一个MCP】【记录向】:准备工作,创建github项目
记录一下: 新建一个仓库 各种填写项目信息 点击创建 👆不错,开张了~ 尝试一下这个桌面版的github 登录 果然方便 太高级了。~...

元宇宙中的虚拟经济:机遇与挑战
随着元宇宙概念的兴起,虚拟经济逐渐成为全球科技和经济领域关注的焦点。元宇宙不仅是一个虚拟的社交和娱乐空间,更是一个充满经济活动的全新生态系统。从虚拟货币到数字资产,从虚拟商品交易到去中心化金融(DeFi)&#…...

多环境回测模拟不同市场条件下的策略表现
Backtrader库的核心组件包括数据源、策略、执行引擎和结果分析器。通过组合这些组件,可以构建一个完整的交易系统。 在进行回测之前,需要准备历史市场数据。Backtrader支持多种数据格式,如CSV文件、Pandas数据框等。 加载数据 可以使用Backtrader提供的bt.feeds.YahooFina…...
环境搭建)
nRF Connect SDK开发之(1)环境搭建
目录 一、安装 nRF Connect SDK 开发环境 1)git 2)python 3) J-Link 编辑 4)nrfutil 1.将nrfutil应用程序所在目录添加到系统路径PATH 2.在命令行中输入nrfutil检测是否可以正常运行 3.运行命令以列出可用命令:nrfutil search 4.安装 device 、toolchain-man…...

武汉火影数字|数字展厅展馆制作:沉浸式体验,全方位互动
在科技飞速发展的当下,数字技术正以前所未有的速度渗透到各个领域,展厅展馆行业也不例外。数字展厅展馆作为传统展厅展馆的创新升级,正逐渐成为展示领域的新宠,为观众带来前所未有的沉浸式体验。 与传统展厅相比,数字展…...

MinIO集群故障,其中一块driver-4异常
现象 driver-4 Offline,驱动状态为未知。 处理过程 建议每个驱动下面新建个文件,便于根据目录里面的drive-x文件区分驱动 rootpve:/mnt/drive-4# df -h Filesystem Size Used Avail Use% Mounted on /dev/sdb 3.7T 695G 3.0T 19% …...

整型数相加的溢出
当正溢出时,返回TMax,负溢出时,返回TMin。这种运算常用在执行数字信号处理的程序中。 程序代码 int saturating_add(int x,int y);void main() {static int x,y;static int i1,sum;x(i<<15)-1;y(i<<15)-1;sumsaturating_add(x,…...

科目一知识点快速回顾与总结
科目一知识点笔记 扣12分的情况 高速上倒掉逆12;普通路上倒掉1逆3 使用伪造,变造的驾驶证(行驶证)一次记12 饮酒驾驶12 代替实际机动车驾驶人接受交通违法行为处罚和记分牟取经济利益的,一次记12 驾驶校车&#x…...

大模型高效微调技术全面解析:从PEFT原理到实战应用
目录 1. 大语言模型与微调概述 1.1 大语言模型(LLM)简介 1.2 微调的必要性与挑战 2. 参数高效微调(PEFT)技术原理 2.1 PEFT概述 2.2 主要PEFT方法 2.2.1 适配器(Adapters) 2.2.2 LoRA(低秩自适应) 2.2.3 QLoRA(量化LoRA) 2.2.4 IA3(通过抑制和放大内部激活注入适配器)…...

51单片机编程学习笔记——无源蜂鸣器演奏《祝你生日快乐》
大纲 蜂鸣器分类有源蜂鸣器无源蜂鸣器 电路图发声演奏《祝你生日快乐》模拟88键钢琴发声音符时值(Note Value)演奏完整代码 蜂鸣器是一种常用的电子发声器件,有源蜂鸣器和无源蜂鸣器在工作原理和特性上有明显区别。 蜂鸣器分类 有源蜂鸣器 …...

大语言模型的评估指标
介绍 语言模型的 BLEU、ROUGE 和 困惑度(Perplexity) 三种常用的语言模型评估指标,帮助你快速理解它们的含义、计算方法及优缺点。 概览 这些指标都是为了解决:「我们自动生成的句子到底有多好?」这个问题࿱…...

绿色免安装 批量重命名软件 标签管理,文件整理提升效率
各位文件整理小能手们,今天给大家介绍一款超牛的工具——拖把更名器!它是专门搞批量文件重命名的实用家伙,能对文件名、扩展名还有音乐文件标签进行高效管理。 咱先说说它的核心功能。首先是基础重命名操作,它能添加、删除、替换…...

python-leetcode 68.有效的括号
题目: 给定一个只包括“(”),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足:左括号必须用相同类型的右括号闭合;左括号必须以正确的顺序闭合,…...
 基本概念(一))
ES(Elasticsearch) 基本概念(一)
Elasticsearch作为当前最流行的开源搜索和分析引擎,广泛应用于日志分析、全文搜索、业务智能等领域。Elasticsearch是一个基于 Apache Lucene 构建的分布式搜索和分析引擎、可扩展数据存储和矢量数据库。它针对生产级工作负载的速度和相关性进行了优化。使用 Elasti…...

软考软件评测师—— 操作系统综合知识
目录 嵌入式操作系统 三态模型 操作系统概念 其他操作系统 绝对路径与相对路径 段页式管理 嵌入式操作系统 嵌入式操作系统(EOS)具有以下特点: 可裁剪性:支持开发性和可伸缩性的体系结构,能够根据需求进行功能…...
)
简单的re(零基础AI做题)
签到题一般简单,上来就是IDA(不管了,IDA!!!) 找主函数,这个题类似的做过好几个了 int __fastcall main(int argc, const char **argv, const char **envp) {__int64 v3; // rdx__i…...

一文掌握 LoRA 常见变体
上文主要是对于 LoRA 的原理和一些常见问题进行了讲解,该篇主要是讲解一些常见的 LoRA 变体。本笔记供个人学习总结使用。 QLoRA QLoRA 是在 LoRA 的基础上进行的改进,旨在进一步减少微调大语言模型时的内存占用,同时保持或仅轻微牺牲性能。主…...

QT高DPI支持
核心函数: qputenv("QT_SCREEN_SCALE_FACTORS", envVar); 如: qputenv("QT_SCREEN_SCALE_FACTORS", "1.2"); 这是我个人目前用的效果最好的,可惜数值不能小于1,小于1的时候,会出问题。 需要程序…...

数据仓库是什么?常见问题解答
在当今数字化时代,企业每天都会产生和收集大量数据。如何有效地存储、管理和分析这些数据,从而为企业决策提供支持,成为了一个关键问题。数据仓库作为一种专门设计的数据存储和管理系统,正是为解决这一问题而生。 数据仓库的定义…...

Java 02入门,封装继承多态
static关键字 1.介绍 静态的意思,可以修饰变量以及函数2.特点 1.被类的所有对象所共享 2.多了一种调用方式,可以通过类名进行调用 3.随着类的加载而加载,优先于对象存在*****3.作用 1.在一个对象里面的一个变量改为static,那么…...

企业级 Hosts 自动化管理实战:基于 HTTP 检测的高可用域名解析方案
摘要 本文针对企业级域名解析稳定性需求,提供一套从IP 检测到Hosts 更新的完整自动化解决方案。通过 HTTP 状态码检测、权威 DNS 解析、原子化文件操作等核心技术,结合多行业真实案例,详细阐述方案设计、脚本实现与生产部署,帮助…...

HTTP/HTTPS与SOCKS5协议在隧道代理中的兼容性设计解析
目录 引言 一、协议特性深度对比 1.1 协议工作模型差异 1.2 隧道代理适配难点 二、兼容性架构设计 2.1 双协议接入层设计 2.2 统一隧道内核 三、关键技术实现 3.1 协议转换引擎 3.1.1 HTTP→SOCKS5转换 3.1.2 SOCKS5→HTTP转换 3.2 连接管理策略 3.2.1 智能连接池 …...
:LangChain Model模型)
AGI大模型(29):LangChain Model模型
1 LangChain支持的模型有三大类 大语言模型(LLM) ,也叫Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。聊天模型(Chat Model),主要代表Open AI的ChatGPT系列模型。这些模型通常由语言模型支持,但它们的API更加结构化。具体来说,这些模型将聊天消…...

鸿蒙开发进阶:深入解析ArkTS语言特性与开发范式
一、前言 在鸿蒙生态开发体系中,DevEco Studio作为核心开发工具为开发者提供了高效的集成环境。而在掌握工具使用之后,深入理解鸿蒙开发语言成为构建高质量应用的关键。本文将聚焦于鸿蒙系统的核心开发语言——ArkTS,全面解析其起源演进、声…...

数据库 1.0.1
表 数据库是一个非常大的仓库,里面的东西就是表,数据都在表里面 use yyy_company就意思是指定使用哪个仓库 show tables;就是show一下有几张表 因为主包的库是刚创建的,所以只有empty set(没有表) 创建表 创建的时候…...

Leetcode 01 java
两数之和 /* 给定一个整数数组 nums 和一个整数目标值 target, 请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。 你可以按任意顺序返回…...
(GDT和IDT)(c语言结构体)(汇编-c)(ai辅助整理))
30天自制操作系统day5(vram和显存)(GDT和IDT)(c语言结构体)(汇编-c)(ai辅助整理)
day5 harib02d c语言结构体的一些解释 struct BOOTINFO { char cyls, leds, vmode, reserve; short scrnx, scrny; char *vram; }; //最开始的struct命令只是把一串变量声明集中起来,统一叫做“struct BOOTINFO”。 //最初是1字节的变量cyls,接着是1字…...

Linux僵死进程以及文件操作
僵死进程 僵死进程产生的原因: 当子进程先于父进程结束,父进程没有获取子进程的退出码,此时子进程变成僵死进程。 如何处理僵死进程: (1)父进程先结束(子进程会变成孤儿进程,孤儿…...

19 C 语言位运算、赋值、条件、逗号运算符详解:涵盖运算符优先级与复杂表达式计算过程分析
1 位运算符 位运算符是对整数的二进制表示(补码形式)进行逐位操作的运算符。以下是主要的位运算符及其功能描述: 运算符描述操作数个数副作用&按位与2无|按位或2无^按位异或2无~按位取反1无<<按位左移2无>>按位右移2无 1.1…...

ubuntu下实时检测机械硬盘和固态硬盘温度
sudo apt update sudo apt install smartmontools然后,使用smartctl命令查看硬盘的详细信息,包括温度: sudo smartctl -a /dev/sda实时监控硬盘温度 虽然smartctl不能直接实时显示温度,你可以使用watch命令结合smartctl来定期查…...
:Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】)
游戏开发实战(三):Python复刻「崩坏星穹铁道」嗷呜嗷呜事务所---源码级解析该小游戏背后的算法与设计模式【纯原创】
文章目录 奇美拉类摸鱼仔,负能量,真老实,小坏蛋,压力怪治愈师小团体画饼王平凡王坏脾气抗压包请假狂请假王内卷王受气包跑路侠看乐子背锅侠抢功劳急先锋说怪话帮倒忙小夸夸工作狂职业经理严酷恶魔职场清流 开始工作吧小奇美拉没想…...

DeepSpeed简介及加速模型训练
DeepSpeed是由微软开发的开源深度学习优化框架,专注于大规模模型的高效训练与推理。其核心目标是通过系统级优化技术降低显存占用、提升计算效率,并支持千亿级参数的模型训练。 官网链接:deepspeed 训练代码下载:git代码 一、De…...

AIGC降重工具
使用 PyQt5 和 Python-docx 实现AIGC降重工具 在日常工作中,文档处理是一个常见的任务,尤其是对于需要批量处理文档内容的场景。今天,我将分享一个使用 PyQt5 和 Python-docx 库实现的简单文档处理工具。这个工具可以帮助用户选择文档文件&a…...