图论学习笔记 3
自认为写了很多,后面会出 仙人掌、最小树形图 学习笔记。
多图警告。
众所周知王老师有一句话:
⼀篇⽂章不宜过⻓,不然之后再修改使⽤的时候,在其中找想找的东⻄就有点麻烦了。当然⽂章也不宜过多,不然想要的⽂章也不容易找。
于是我写了《图论学习笔记 1》之后写了《图论学习笔记 2》,现在又来了《图论学习笔记 3》.
基环树
英文名 Unicyclic Pseudotree,但是我不要求记下来,因为直接叫中文名甚至更简单一些。
上次我们讲到了圆方树,现在就来讲基环树了!
基环树属于知识简单,但是应用难的那种。
基环树的定义很简单,就是在一棵树(无环连通图)上多连一条边得到的图,显然这样就会多出一个环。
所以基环树相比树的最大差别就是那个显眼的环,也是这样比就树复杂了一些。
首先我们先会说怎么找到这个基环树里面的环(有些友善的题可能会直接给你,有些题就需要你自己去找)。以后就会考虑对基环树和仙人掌图进行缩点以将其转换为一个树上动态规划的问题。
前置定义
首先需要了解一些定义。
基环树:直白来讲就是一棵树,然后把其中某两个没有边的点连边,得到了基环树。
而基环树又分有向和无向。
**无向基环树:**就是 n n n 点 n n n 边的连通图。至于为什么 n n n 点 n n n 边的连通图就一定有一个环,而且去掉一条边之后会变成一棵树,可以感性理解。
有向基环树:有好几个条件:
-
首先这个有向图是弱连通的,而且恰好有一个有向环。
-
而且有:
- 如果其他点都可以到环,则称为内向基环树。
- 如果其他点都可以被环到,则称为外向基环树。
- 否则就不是有向基环树。
我们可以充分发挥人类智慧简化这些条件:
内向基环树:每一个点出度恰好为 1 1 1,且图弱连通。(这个也很容易想到,图论题做多了就很好理解了)
外向基环树:每一个点入度恰好为 1 1 1,且图弱连通。
而如果图不是弱连通的话,就会形成基环树森林。
基环树找环
既然是基环树,那么找环一定是绝对不可以缺少的(不然基环树就失去了它的精髓)。
显然可以通过 tarjan 找边双连通分量或强连通分量的方法来解决,这样并不难写,而且很现成。
对于内向的基环树,有另一种方法,甚至比 tarjan 还好写!!
考虑搞一个栈,记录每一个点是否在栈的里面,以及每一个点是否已经被访问到。
当发现对于一点 x x x,此时 a x a_x ax 在栈里面,说明 x → a x x \to a_x x→ax 在环的上面!!!这是显然的(当自己要到的点已经到达了自己到时候就一定有一个环)。
所以考虑从 a x a_x ax 再搜一遍,一直走走走,直到走到 x x x 的位置,这时候就得出了环上面所有的点。
P8269 [USACO22OPEN] Visits S
利用前面讲到的东西就可以做这道题目了。
显然可以考虑对于每一个 i i i,连有向边 i → a i i \to a_i i→ai。这样的每一个点的出度都为 1 1 1,最终一定会形成一个内向基环树森林。(题目并没有保证图是弱连通的)
而根据题目可以发现两个基环树之间是完全独立的,所以就可以单独考虑每一个基环树。
考虑单独的一个基环树。
由于这是一个内向基环树,所以一定是以环上点为根的树 + 中间的环得到的结果。
考虑这些到环上点的树,显然这些树除了终点的位置互不相交,所以是相互独立的。
考虑这些树能对答案造成什么影响,显然如果每一次选择走叶结点,就可以得到这些树里面所有的值。
考虑对于环上的点,显然一定会有恰好一个点无法对答案产生贡献,直接把这个走不到的点设成 v v v 值最小的即可。
不妨来观察一下这个基环树:
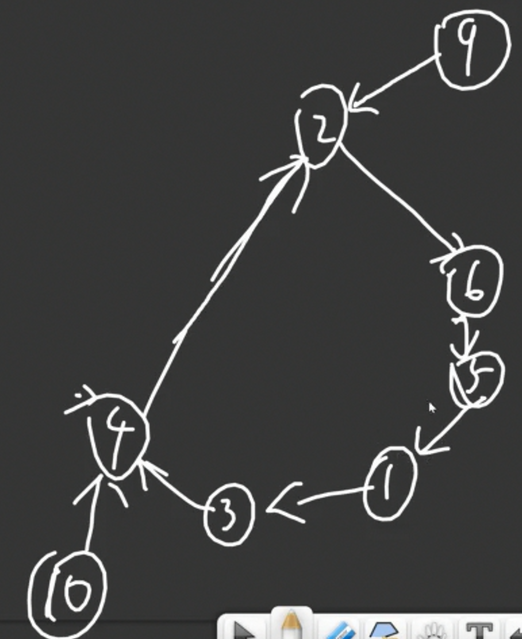
由于我的语文实在不行,所以大家可以借着图理解一下。
对于多棵基环树,可以算出答案之后加起来即可。
这里采用前面介绍过的内向基环树比较好写的方法。因为这里并不需要记录每一个环上面具体由什么点,我们关心的是环上面最小的权值。
在极限卡常之下成功把 317ms 卡到了 92ms,成功跻身最优解第一页。
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 100010;
int n;
int a[N], v[N], sum = 0;
bool vis[N], nw[N];inline int read() {char c = getchar();int x = 0, s = 1;while (c < '0' || c > '9') {if (c == '-')s = -1;c = getchar();}while (c >= '0' && c <= '9') {x = x * 10 + c - '0';c = getchar();}return x * s;
}inline void write(int x) {if (x > 9)write(x / 10);putchar(x % 10 | 48);
}inline void dfs(int u) {vis[u] = 1, nw[u] = 1;if (nw[a[u]]) {int m = v[u];for (register int i = a[u]; i != u; i = a[i])m = min(m, v[i]);sum -= m;} else if (!vis[a[u]])dfs(a[u]);nw[u] = 0;
}signed main() {n = read();for (register int i = 1; i <= n; i++)a[i] = read(), v[i] = read(), sum += v[i];for (register int i = 1; i <= n; i++)if (!vis[i])dfs(i);write(sum);return 0;
}
另外 P9869 [NOIP2023] 三值逻辑 这道题也是不错的。
接下来我们的有向基环树就告一段落。因为有向基环树要么是大部分点入度恰为 1 1 1 要么就是大部分点出度恰为 1 1 1(这样很好做),而无向基环树就不一样了。
比较需要的东西
接下来的题目就没有那么友善了,所以我们需要做好充足的准备。
一般来说,基环树的题目需要存储:
-
一个点是不是在环上。
-
环在深搜树上面的最上方和最下方的编号。
-
对于环上点 x x x,还要存储环上 x x x 的下一个结点。
-
最好也写上每一个点的深度,有些题要用。
这三个东西都并不是很难求,直接在 dfs 的时候记录一下就可以了。
#include <bits/stdc++.h>
using namespace std;
const int N = 500010;
int n;
vector<int> v[N];
//vis 表示是否访问过,stk 表示是否在搜索栈里面,cir 表示在不在环上
bool vis[N], stk[N], cir[N];
//up 和 dn 表示深搜树的最上方 和 最下方的结点编号。
int up, dn;
//nxt[x] 表示对于环上面的点 x,在环上面的下一个点。
//lvl 表示结点的深度
int nxt[N], lvl[N];void dfs(int u, int pre, int lv) {vis[u] = stk[u] = 1, lvl[u] = lv;//记录深度和标记for (auto i : v[u])if (!vis[i]) {//目前走到了树边dfs(i, u, lv + 1);//往下走if (cir[i] && i != up)//如果一个点 u 的儿子 i 在环上面的话,而且点 u 并不是再走一步就到达了环,而是就在环上nxt[u] = i, cir[u] = 1;//那么就记录后继,也要标记在环的上面} else if (i != pre && stk[i])//目前走的是子孙回到祖先的边(祖先关系不是父子关系),也就是找到了环dn = u, up = i, cir[u] = 1, nxt[u] = i;//显然祖先就是最高的点,自己就是最低的点。记录 + 标记stk[u] = 0;
}int main() {cin >> n;for (int i = 1; i <= n; i++) {int x, y;cin >> x >> y;v[x].push_back(y);v[y].push_back(x);//连边}dfs(1, 0, 1);//从任意一个点开始搜均可,就是 nxt 和 lvl 可能不太一样return 0;
}
另外还要注意一个结论:基环树上面任意删除一条环边,得到的一定是一棵树。
P5049 [NOIP 2018 提高组] 旅行 加强版
难度飙升。运用前面所学的内容,做一下这道题。
发现要么 m = n − 1 m=n-1 m=n−1 要么 m = n m=n m=n,显然分别对应树和基环树的情况。
至于树,直接对于邻接表排序即可,然后直接 dfs。可以得到 60pts 的好成绩。
#include <bits/stdc++.h>
using namespace std;
int n, m;
const int N = 5010;
vector<int> v[N], ans;void dfs(int u, int pre) {ans.push_back(u);for (auto i : v[u])if (i != pre)dfs(i, u);
}int main() {
// freopen("travel.in", "r", stdin);
// freopen("travel.out", "w", stdout);scanf("%d%d", &n, &m);for (int i = 1; i <= m; i++) {int x, y;scanf("%d%d", &x, &y);v[x].push_back(y);v[y].push_back(x);}for (int i = 1; i <= n; i++)sort(v[i].begin(), v[i].end());dfs(1, 0);for (auto i : ans)printf("%d ", i);return 0;
}
但是剩下的 40pts 不是 MLE 就是 TLE,这证明我们这种方法在基环树的时候时行不通的。
考虑图是基环树的情况。
因为所有的边都走的话是不可以的(会产生 MLE 或 TLE 的问题),所以考虑抛弃一条边。这条边显然就是环边。
为什么呢?只需要回想一下前面提过的结论:
另外还要注意一个结论:基环树上面任意删除一条环边,得到的一定是一棵树。
所以我们可以找出来环之后枚举那一条环边被抛弃了,然后对剩下的树跑深搜即可。这样就可以得到 O ( n 2 ) O(n^2) O(n2) 的做法,足以通过简单版。
考虑 100pts 的正解。
发现我们并不需要枚举哪一条边被抛弃了,只需要使用回溯来处理即可。那么就需要考虑什么时候需要回溯。
显然对于某一条环上的边 x → y x \to y x→y,如果 x x x 选择在遍历完其他的子结点子树的时候回溯,则我们需要考虑回溯之后遍历的点 z z z(只需要考虑第一个,因为这是字典序)和 y y y 的关系。
考虑不能回溯或者是回溯更优的情况。
首先 y y y 肯定是没有被访问到的,访问它没有意义,要不然就会疯狂递归直到爆炸。
显然,**当前的这条边 x → y x \to y x→y 一定要在环的上面,也就是两端都是环上面的点。**否则不能回溯。(我们放弃的是一条环边。)
PS:如果 x → y x \to y x→y 不是环边的话,直接走就是了。因为这个时候完全不需要讨论下面的东西,所以把 z z z 设为 + ∞ +\infty +∞ 即可。
也很显然,如果我们已经放弃过了一条环边,则也不可以回溯。(不能放弃多条环边。)
考虑 y y y 在 x x x 的邻点列表中的位置。显然, y y y 必须是 x x x 的最后一个邻点,要不然回溯之后就访问不了其他的邻点了。(如果 y y y 是 x x x 最后一个邻点的话还可以通过环的另一边回来)
但是,即使是最后一个邻点,也要担心字典序的问题。所以还要判断 y y y 和 z z z 的关系是否是 y > z y>z y>z,如果满足这个关系,就可以放弃这条环边,回溯了。否则不能回溯。
上面已经把怎么判断讲得很清楚了。如果不懂的话也可以看代码注释。
#include <bits/stdc++.h>
using namespace std;
int n, m;
const int N = 500010;
vector<int> v[N];
bool vis[N], nw[N], cir[N];
int up;//去除了一些不需要的东西void dfs(int u, int pre) {//就是模板,原封不动的,就是删了一些没用的东西vis[u] = nw[u] = 1;for (auto i : v[u])if (!vis[i]) {dfs(i, u);if (cir[i] && i != up)cir[u] = 1;} else if (i != pre && nw[i])up = i, cir[u] = 1;nw[u] = 0;
}
bool f;void get(int u, int pre, int z) {vis[u] = 1;//记录cout << u << " ";for (int i = 0; i < (int)v[u].size(); i++) {int to = v[u][i];if (vis[to])//显然访问过的点不能走continue;if (cir[u] && cir[to] && !f) {//如果这条边在环的上面,而且没有抛弃其他的环边if (i < (int)v[u].size() - 1 - (pre > to))//如果这个点不是 u 最后一个邻点get(to, u, v[u][i + 1] == pre ? v[u][i + 2] : v[u][i + 1]);//只能乖乖地继续走else if (z > to)//虽然是最后一个邻点,但是抛弃了这条边并不优get(to, u, z);//继续走,注意这里和上面的差别else//可以走f = 1;//直接抛弃环边} elseget(to, u, 1e9);}
}int main() {cin >> n >> m;for (int i = 1; i <= m; i++) {int x, y;cin >> x >> y;v[x].push_back(y), v[y].push_back(x);//建边}for (int i = 1; i <= n; i++)sort(v[i].begin(), v[i].end());//为了最小化字典序,需要对它排序dfs(1, 0);//找环memset(vis, 0, sizeof vis);//清空重新利用get(1, 0, 1e9);//获取答案return 0;
}显然这个代码也可以通过简单版,这样就白嫖了一个双倍经验!
基环树上尝试递推
递推也可以说是动态规划,实际上动态规划是包含递推的。
目前我们学过两个不是线性结构上面的 dp:一个是在无向无环图上面的 dp,一个是在有向无环图上面的 dp。
而我们知道 dp 是不支持环形结构的:这样就会无法转移。
但是这并不意味着基环树上面就无法 dp。为了处理这个特殊的环,还是延伸出了若干个科技的。
观察基环树的形态,容易发现它一定是一个环,周围带上很多棵很小的树。
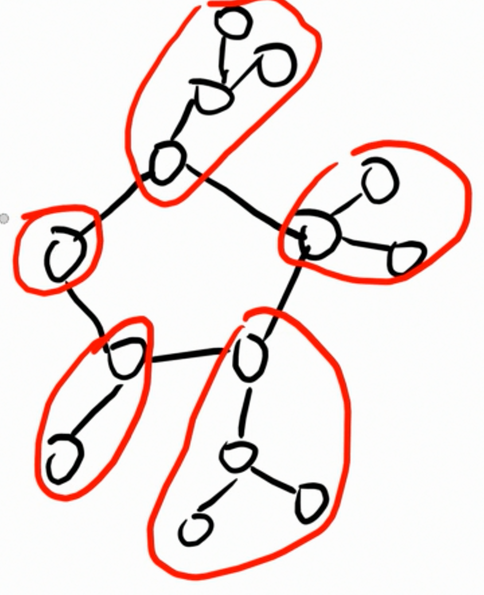
于是我们可以把环上的点视作根。 而且,对于这些小的树,有一种特殊的叫法叫做环点树。
于是我们可以对这几棵环点树进行树形 dp,存储在环点上面。于是基环树就变成了简单的一个环。
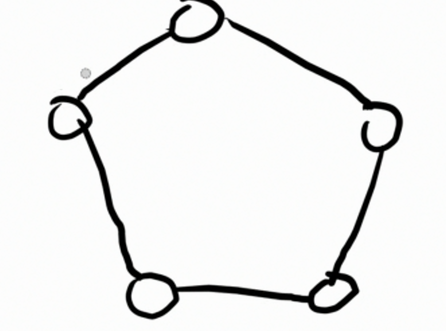
但是这样的 dp 还是无法进行。虽然结构简单了许多,但是那个环仍然存在。
于是我们考虑断环为链。
试图将某一条边切开,那么就变成了一条线性的链。我们可以在上面跑某些东西以得到答案。
但是切开的那条边仍然不可以忽略。所以可以对这条边特别考虑,分类讨论以得出答案。
这种方法完全可行。但是还有其他的方法,来看看另一种方法。
另一种方法
那么还有什么处理基环树的环的方法呢?因为基环树和深搜树有诸多相同点,所以考虑在深搜树上面处理这个问题。
这种方法里面,我们不会尝试断环为链破坏深搜树的结构,而是会尝试在深搜树上面就地解决问题。
这种方法更多的是为了铺垫后面的仙人掌图,如果只是基环树的话也可以使用上面提到的做法。
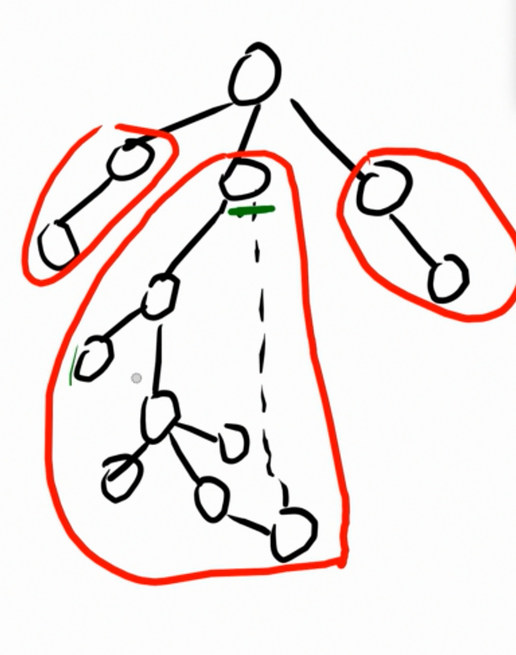
首先,尝试在深搜树上面找到所有的环点树。
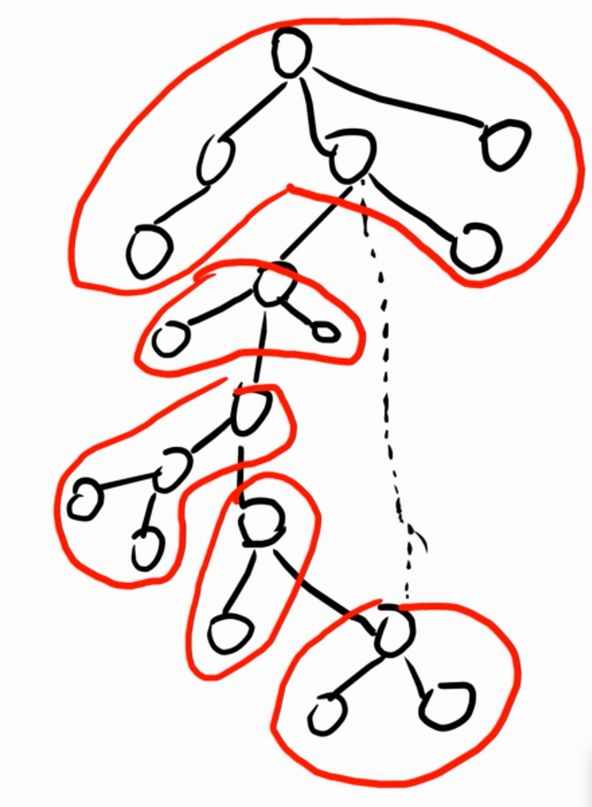
被圈出来的就是环点树。
在深搜树上面找环点树其实并不难,唯一的特殊点就是环上最高点的环点树。
因为最高点的环点树不止需要其不在环上面的子树,还需要其父亲的子树,这需要做一个类似换根的操作。当然,这有些困难。
所以我们有一种转换方式:将环和最高结点看成一个子树,然后交给父结点来处理。类似这样:
P4381 [IOI 2008] Island
很容易发现给出的图是一个基环树森林。而基环树之间可以任意从一个点到另外一个点,所以我们的目标就是求出所有基环树的直径,再相加即可。
很容易联想到求出树的直径(加权),可以两次 dfs,也可以使用树形 dp 来求(枚举 lca)。
那么如果这棵树变成了一棵基环树,区别又在那里呢?
考虑一颗基环树。
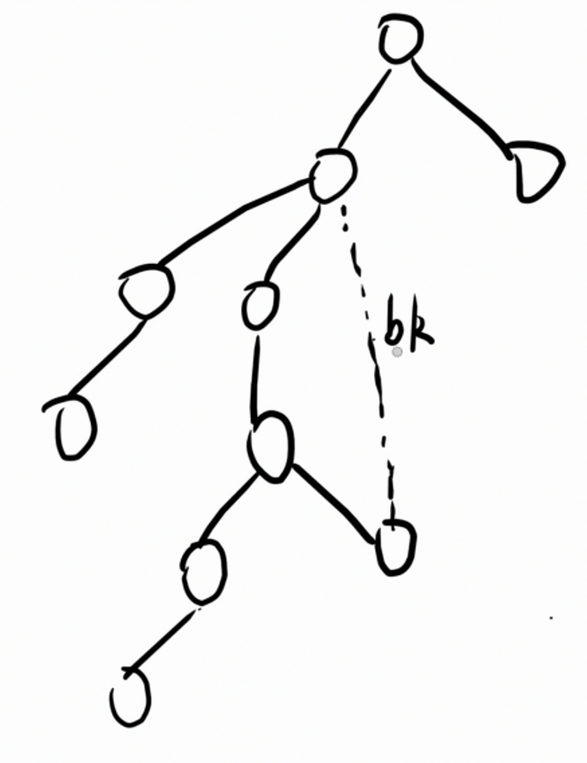
将其中的一条构成环的回边称作 b k bk bk。显然 b k bk bk 是环上最高点 u p up up 和最低点 d n dn dn 连的一条边。
此时考虑分类讨论:考虑基环树直径经过/不经过 b k bk bk 得到的答案。
直径不过 b k bk bk 这条边。
显然这个时候就相当于求去除 b k bk bk 这条边之后的树的直径。所以直接按照上面交代的树上求直径的方法做就即可。
直径过 b k bk bk 这条边。
很容易发现,当直径走到了环的外面,在以后也不会回到环上。(要不然就和走到环的外面矛盾了)
所以, u p up up 和 d n dn dn 周围的结点也同样比较重要。因为 u p up up 和 d n dn dn 要使用它们走出环。
例如这两个结点:
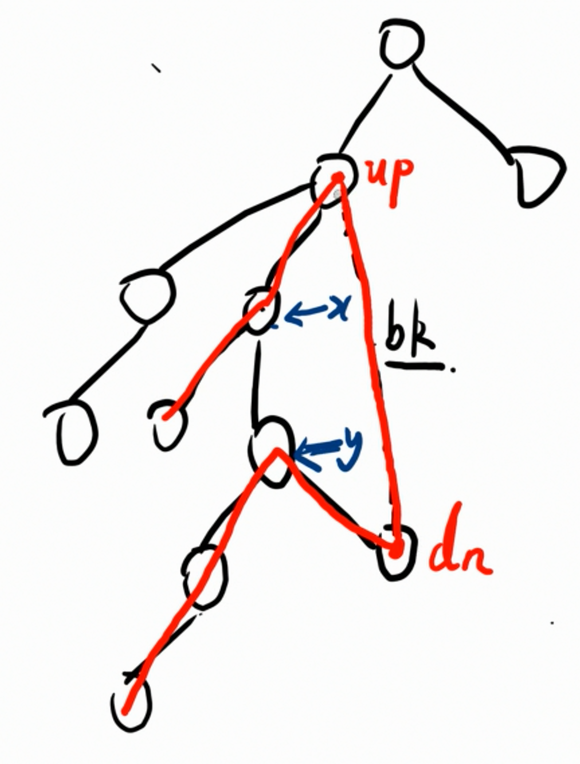
最终的答案显然就是 x x x 的环点树的根到结点的最大距离 + y y y 的环点树的根到结点的最大距离 + x → u p x \to up x→up 的路径的边权 + y → d n y \to dn y→dn 的路径的边权 + b k bk bk 的边权。
如果使用 l v l lvl lvl 来表示结点到根结点的距离,那么就可以说答案为 b k + l v l x − l v l u p + l v l d n − l v l y bk + lvl_x - lvl_{up}+lvl_{dn}-lvl_{y} bk+lvlx−lvlup+lvldn−lvly。发现 l v l x − l v l u p lvl_x - lvl_{up} lvlx−lvlup 和 l v l d n − l v l y lvl_{dn} - lvl_y lvldn−lvly 可以简化一下,不妨设 l v l x − l v l u p = d p 1 x lvl_x - lvl_{up}=dp1_x lvlx−lvlup=dp1x, l v l d n − l v l y = d p 2 x lvl_{dn}-lvl_y = dp2_x lvldn−lvly=dp2x。
注意如果 x = y x=y x=y 那么环点树的根到结点的最大距离只能计算一次。
所以我们可以 O ( n 2 ) O(n^2) O(n2) 枚举 x x x 和 y y y。如果嫌慢的话,也可以预处理达到 O ( n ) O(n) O(n) 的。
那么 O ( n ) O(n) O(n) 怎么做到呢?考虑枚举 x x x,根据 d p 1 x dp1_x dp1x 的取值来取 y y y(显然要取可以取的数中最大的)。
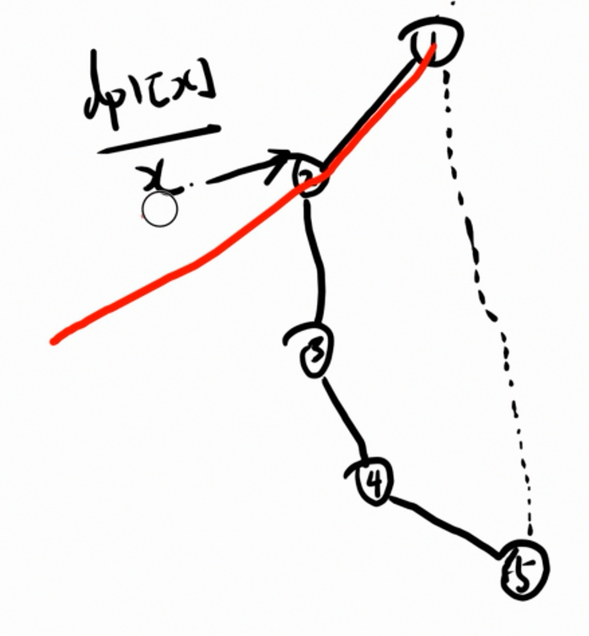
这里,如果 x = 2 x=2 x=2,我们的答案就是 d p 1 2 + max { d p 2 3 , d p 2 4 , d p 2 5 } dp1_2 + \max\{dp2_3,dp2_4,dp2_5\} dp12+max{dp23,dp24,dp25}。这样仍然需要 O ( n ) O(n) O(n) 才能确定,所以考虑优化。
思考,如果这个时候我们预处理出来 m x 3 = max { d p 2 3 , d p 2 4 , d p 2 5 } mx_3 = \max\{dp2_3,dp2_4,dp2_5\} mx3=max{dp23,dp24,dp25},那么就可以直接取值 d p 1 2 + m x 3 dp1_2 + mx_3 dp12+mx3,就可以 O ( 1 ) O(1) O(1) 计算答案了。
考虑一般的情况。这个时候就设 m x i mx_i mxi 为在环上从 i i i 到 d n dn dn 的 d p 2 dp2 dp2 最大值( i i i 必须是环上面的点),则对于一般的环上点 x x x,答案为 d p 1 x + m x n x t x dp1_x + mx_{nxt_x} dp1x+mxnxtx。
那么问题就转换为了如何计算 d p 1 dp1 dp1 和 d p 2 dp2 dp2 和 m x mx mx。前两者很容易计算,后面的只需要在深搜树回溯的时候记录一下就可以了。
然后你开心的一交,发现并不能得到满分。
为什么?
注意,我们前面说的 x , y x,y x,y 一直都是环上面的点。但是还忽略了一种情况:还可以从 u p up up 向上面走 u p up up 的祖先,也就是 u p up up 是向上走出环的。
Q:为什么向上走出环是不正确的?
A:因为 u p up up 只记录了其非环子树的最大向下距离,而没有记录向上的距离。 例如这样:
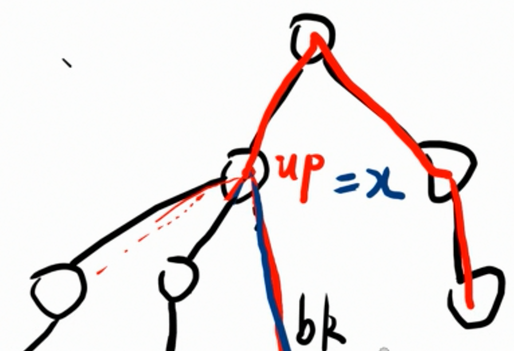
ps:你可能会想到 y = d n y = dn y=dn 的方法也不可以。但是仔细考虑一下, d n dn dn 还是从它的子树里面找一条最长路径,再不济也是 d p 2 y = 0 dp2_y = 0 dp2y=0,而这样并不会使求出来的直径变小。
考虑如何避免这种情况。显然可以换根,但是这里不采用这种方法。这里我们采用上面讲过的另一种方法,把 u p up up 下面的环也当作 u p up up 子树的一部分。
考虑将每一个路径的处理放在路径中所达到的最高的点。
然后我们就可以发现,从 u p up up 向上面走祖先的路径实际上可以不归 u p up up 管,而可以归 u p up up 的祖先管。而 u p up up 的祖先就和环没有任何关系了,可以直接取子树内的点到自己的路径长度的最大和次大值,这是一个完全 normal 的树上动态规划。
而 u p up up 要回溯的时候,也直接汇报一个到自己路径长度最大值即可。而这个路径长度最大值可以由 m x mx mx 数组的值和环点树的最大长度联合得出。
P4381 代码实现
观察样例,发现有一点点细节:有时候这个环是重边环。这个时候可以直接取较大权的边即可。具体地,对每一个点的边的权值从大到小排序。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int n;
const int N = 1000010;
vector<pair<int, int> > v[N];bool cmp(pair<int, int> x, pair<int, int> y) {return x.second > y.second;
}
int d, up, dn;
int bk, mx;
bool vis[N], stk[N], cir[N];
int lv[N], dep[N];void dfs(int u, int pre, int l) {vis[u] = stk[u] = 1, lv[u] = l;int mx1 = 0, mx2 = 0, siz = 0;for (auto [x, y] : v[u])if (!vis[x]) {dfs(x, u, l + y);if (dep[x] + y > mx1)mx2 = mx1, mx1 = dep[x] + y;else if (dep[x] + y > mx2)mx2 = dep[x] + y;if (cir[x] && x != up)cir[u] = 1;elsesiz = max(siz, dep[x] + y);} else if (stk[x] && x != pre)up = x, dn = u, bk = y, cir[u] = 1;dep[u] = mx1, d = max(d, mx1 + mx2);if (cir[u]) {d = max(d, bk + mx + lv[u] - lv[up] + siz);if (u == up)dep[u] = max(dep[u], mx + bk);elsemx = max(mx, lv[dn] - lv[u] + siz);}stk[u] = 0;
}signed main() {cin >> n;for (int i = 1; i <= n; i++) {int x, w;cin >> x >> w;v[i].push_back({x, w});v[x].push_back({i, w});}for (int i = 1; i <= n; i++)sort(v[i].begin(), v[i].end(), cmp);int ans = 0;for (int i = 1; i <= n; i++)if (!vis[i])d = 0, up = -1, bk = 0, mx = -9e18, dfs(i, 0, 0), ans += d;//这里的初始化一定要写全(差点被误导了)cout << ans << endl;return 0;
}相关文章:

图论学习笔记 3
自认为写了很多,后面会出 仙人掌、最小树形图 学习笔记。 多图警告。 众所周知王老师有一句话: ⼀篇⽂章不宜过⻓,不然之后再修改使⽤的时候,在其中找想找的东⻄就有点麻烦了。当然⽂章也不宜过多,不然想要的⽂章也不…...

进阶知识:自动化测试框架开发之无参的函数装饰器
进阶知识:自动化测试框架开发之无参的函数装饰器 from functools import wrapsdef func_2(func):"""无参的函数装饰器:param func::return:"""wraps(func)def wrap_func(*args, **kwargs):print(开始执行: func.__name__…...

【实验增效】5 μL/Test 高浓度液体试剂!Elabscience PE Anti-Mouse Ly6G抗体 简化流式细胞术流程
产品概述 Elabscience 推出的 PE Anti-Mouse Ly6G Antibody (1A8, 货号: E-AB-F1108D) 是一款高特异性、高灵敏度的流式抗体,专为小鼠中性粒细胞(Ly6G⁺细胞)的精准检测而设计。该抗体采用PE(藻红蛋白)标记࿰…...

多模态光学成像革命:OCT、荧光与共聚焦的跨尺度融合新范式
一、技术融合的必然性 在生物医学成像领域,单一模态往往存在视野-分辨率悖论。光学相干断层扫描(OCT)虽能实现毫米级深度扫描(1010mm视野),但其微米级分辨率难以解析亚细胞结构;荧光显微成像(FMI)虽具有分子特异性标记优势(88mm中观视野),却受限于光毒性及穿透深度…...

CHI中ordering的抽象
上图是一个典型的读操作过程中的几个流程,其中: compdata, 这个就是CHI协议保序之Comp保序-CSDN博客中提到的,comp保序,它实现的功能是,通知这个请求的RN, 你的请求,我已经开始处理了,同时也相当…...

华为云Flexus+DeepSeek征文 | 基于ModelArts Studio 与 Cline 快速构建AI编程助手
目录 一、前言 二、ModelArts Studio(MaaS)介绍与应用场景 2.1ModelArts Studio(MaaS)介绍 2.2 ModelArts Studio(MaaS)使用场景 2.3 开通MaaS服务 2.4 开通DeepSeek-V3商用服务 三、Cline简介和安装 3.1 C…...

第二章 何谓第二大脑?笔记记录
2025/05/08 发表想法 用词太准确了,从信息过载-信息倦怠,正是我们当今社会信息工作者中正在经历的事情,同时大部分人也正在产生焦虑、不安、失眠等社会现象。 原文:然而信息的泛滥,非但难以起到赋能作用,反…...

题解:AT_abc244_e [ABC244E] King Bombee
一道图上 DP 的好题。 (题目自己看,我就不说了。) 首先一看到求方案数,首先就要反应的是 DP 或者排列组合,反正考试的时候我写半天排列组合没写出来,所以就只能是 DP 了。(好牵强的理由啊………...

C++显式声明explicit
C显示声明explicit 在 C 中,explicit 关键字用于修饰单参数构造函数或多参数构造函数(C11 起),其核心作用是禁止编译器的隐式类型转换。 一、必须加 explicit 的典型场景 1. 单参数构造函数 当构造函数只有一个参数时ÿ…...

哈希查找方法
已知哈希表长度为11,哈希函数为H(key)=key%11,随机产生待散列的小于50的8个元素,同时采用线性探测再散列的方法处理冲突。任意输入要查找的数据,无论是否找到均给出提示信息。 int f…...

AI编程辅助哪家强?深度解析主流AI编程工具的现状与未来-优雅草卓伊凡
AI编程辅助哪家强?深度解析主流AI编程工具的现状与未来-优雅草卓伊凡 引言:AI编程的崛起与开发者的新选择 在当今快速发展的科技时代,AI编程辅助工具已经成为开发者不可或缺的得力助手。作为一名资深的程序员,”优雅草卓伊凡”经…...

Python打卡训练营day27-函数-装饰器
知识点回顾: 装饰器的思想:进一步复用函数的装饰器写法注意内部函数的返回值 作业: 编写一个装饰器 logger,在函数执行前后打印日志信息(如函数名、参数、返回值) 装饰器实际上是一个增强函数,它…...

EtherCAT通信协议
EtherCAT(Ethernet for Control Automation Technology)是一种高性能的实时工业以太网通信协议,专为工业自动化和控制系统的需求设计。它结合了以太网的灵活性和工业实时通信的高效性,广泛应用于运动控制、机器人、过程自动化等领…...

多线程下如何保证事务的一致性
以下是关于Java多线程的详细介绍,适合作为知识博客的内容。我将从基础概念开始,逐步深入到分布式场景、线程池配置以及Spring Cloud集成等高级主题,并提供丰富的业务场景示例。 Java多线程核心概念 1. 线程与进程的区别 进程:程…...
——答题卡识别自动判分)
OpenCv高阶(8.0)——答题卡识别自动判分
文章目录 前言一、代码分析及流程讲解(一)初始化模块正确答案映射字典(题目序号: 正确选项索引)图像显示工具函数 (二)轮廓处理工具模块(三)几何变换核心模块 二、主处理流程图像读取…...

量子通信技术:原理、应用与未来展望
在当今数字化时代,信息安全是全球关注的焦点。随着量子计算技术的飞速发展,传统的加密方法面临着前所未有的挑战。量子通信技术作为一种新兴的通信手段,以其绝对安全的特性,为信息安全领域带来了新的希望。本文将深入探讨量子通信…...

Token的组成详解:解密数字身份凭证的构造艺术
在当今的互联网身份认证体系中,Token如同数字世界的"安全护照",承载着用户的身份信息和访问权限。据统计,现代应用中80%以上的身份验证依赖于Token机制。本文将深入解析Token的各个组成部分,通过典型实例揭示其设计原理…...

【SFT监督微调总结】大模型SFT全解析:从原理到工具链,解锁AI微调的核心密码
文章目录 一. 什么是监督微调(SFT)?二. SFT的核心原理与流程2.1 基本原理2.2 训练流程三、SFT训练的常用方法四、SFT训练用的数据格式4.1、基础单轮指令格式1. Alpaca 格式2. 单轮QA格式3. 代码-注释对4.2、多轮对话格式1. ShareGPT 格式2. 层次化对话格式3. 角色扮演对话4.…...
安装macOS Catalina所需时间)
MacBook Air A2179(Intel版)安装macOS Catalina所需时间
MacBook Air A2179(Intel版)安装macOS Catalina所需时间如下: 一、标准安装时间范围 常规安装(通过App Store) • 下载时间:约30-60分钟(取决于网络速度,安装包约8GB) •…...

Git的windows开发与linux开发配置
Git的基本配置 安装 linux可以使用包管理器安装windows可以使用 mingw的git:https://git-scm.com/downloadsTortoiseGit:https://tortoisegit.org/download/ 配置 分为系统配置–system、全局配置–global、项目配置–local 配置名称和邮箱 git co…...

使用Mathematica绘制一类矩阵的特征值图像
学习过线性代数的,都知道:矩阵的特征值非常神秘,但却携带着矩阵的重要信息。 今天,我们将展示:一类矩阵,其特征值集体有着很好的分布特征。 modifiedroots[c_List] : Block[{a DiagonalMatrix[ConstantAr…...

C++中的宏
0 资料 最值宏do{}while(0)的宏封装技巧 1 最值宏 - C最值的宏,在两个头文件中,分别为cfloat和climits。其中,float的最值宏在cfloat中,且cfloat没有负值的最小宏,而其他char、int和double是在climits中。如下// --…...

谷粒商城的三级分类实现
先查出全部的数据再分类 分类的一级分类是根据数据的Parent_id进行确定的,所以要进行筛选: 主方法: public List<CategoryEntity> listWithTree() {//1.查出所有分类List<CategoryEntity> entities baseMapper.selectList(nul…...

基于大模型预测的闭合性髌骨骨折诊疗全流程研究报告
目录 一、引言 1.1 研究背景与目的 1.2 研究意义与价值 二、大模型预测原理与方法 2.1 大模型概述 2.2 预测方法与数据输入 2.3 模型训练与优化 三、术前预测分析 3.1 骨折类型预测 3.2 损伤程度评估 3.3 潜在风险预测 四、手术方案制定 4.1 传统手术方案对比 4.…...

基于CodeBuddy的Craft完成一个数字华容道的小游戏
参考 CodeBuddy,AI 时代的智能编程伙伴 插件功能入门 总结 本文主要基于CodeBuddy的Craft 完成一个数字华容道的小游戏,如果读者还不清楚怎么安装,在本文的前面附上了CodeBuddy 编程助手的安装步骤。读者可以根据需求自行确定从那开始。 …...

一文掌握vue3基础,适合自学入门案例丰富
Vue3 本文从Vue3的基础语法出发,全面系统的介绍了Vue3的核心概念与应用,旨在帮助自学者更轻松地掌握Vue3。文章内容由浅入深,从通过CDN引入Vue3开始,逐步介绍了组合式API、模块化开发、以及常见的Vue3指令和功能并从单个html的使…...

OpenHarmony 5.0设置应用设置手势导航开关打开后重新关闭导航栏和设置界面重合
目录 1.背景 2.解决方案 1.背景 在OpenHarmony 5.0中从设置界面打开手势导航开关然后重新关闭,此时设置界面导航栏和设置列表主界面重合,导致设置界面无法点击最下面的关于设备 2.解决方案 首先参考之前的如何设置导航栏文档,我们可以自己…...

[ARM][汇编] 02.ARM 汇编常用简单指令
目录 1.数据传输指令 MRS - Move from Status Register 指令用途 指令语法 代码示例 读取 CPSR 到通用寄存器 在异常处理程序中读取 SPSR 使用场景 MSR - Move to Status Register 指令语法 使用场景 示例代码 改变处理器模式为管理模式 设置条件标志位 异常处理…...
:微服务数据一致性和高可用策略)
系统架构设计(十七):微服务数据一致性和高可用策略
数据一致性问题 问题本质 由于每个微服务拥有独立数据库,跨服务操作不能用传统的数据库事务,面临“分布式事务”一致性挑战。 数据一致性策略 策略核心思想应用场景优缺点强一致性(Strong Consistency)所有操作实时同步成功&a…...

[Harmony]获取设备参数
获取屏幕宽度/屏幕高度/状态栏高度/导航栏高度/刘海高度/设备型号/系统版本号... DevicesUtil import window from ohos.window; import { common } from kit.AbilityKit; import display from ohos.display; import deviceInfo from ohos.deviceInfo; import i18n from ohos.…...

Python60日基础学习打卡D31
如何把一个文件,拆分成多个具有着独立功能的文件,然后通过import的方式,来调用这些文件?这样具有几个好处: 可以让项目文件变得更加规范和清晰可以让项目文件更加容易维护,修改某一个功能的时候࿰…...

命名常量集合接口INamedConstantCollection<T>实现
public interface INamedConstantCollection<TObject, TName> : IEnumerable<TObject>, IEnumerable where TName : IComparable{TObject this[TName name] { get; }TObject this[int index] { get; }int Count { get; }int Capacity { get; }} 这是一个泛型接口&…...

TYUT-企业级开发教程-第6章
这一章 考点不多 什么是缓存?为什么要设计出缓存? 企业级应用为了避免读取数据时受限于数据库的访问效率而导致整体系统性能偏低,通 常会在应用程序与数据库之间建立一种临时的数据存储机制,该临时存储数据的区域称 为缓存。缓存…...

反射在spring boot自动配置的应用
目录 一,背景 二,知识回顾 2.1 理解使用反射技术,读取配置文件创建目标对象(成员变量,方法,构造方法等) 三,springboot自动配置 3.1 反射在自动配置中的工作流程 3.2 浏览源码…...

项目进度延误,如何按时交付?
项目进度延误可以通过加强计划管理、优化资源分配、强化团队沟通、设置关键里程碑和风险管理机制等方式来实现按时交付。加强计划管理、优化资源分配、强化团队沟通、设置关键里程碑、风险管理机制。其中,加强计划管理尤为关键,因为明确而详细的计划能提…...

内网穿透:轻松实现外网访问本地服务
异步通知的是需要通过外网的域名地址请求到的,由于我们还没有真正上线,那支付平台如何请求到我们本地服务的呢? 这里可以使用【内网穿透】技术来实现,通过【内网穿透软件】将内网与外网通过隧道打通,外网可以读取内网…...

缺乏进度跟踪机制,如何掌握项目状态?
要有效掌握项目状态,必须建立明确的进度跟踪机制、使用专业的项目管理工具、定期召开沟通会议、设立清晰的关键里程碑和实施风险监控。其中,建立明确的进度跟踪机制是关键,通过系统地追踪项目各个阶段的完成情况,及时发现问题并采…...

ES 调优帖:关于索引合并参数 index.merge.policy.deletePctAllowed 的取值优化
最近发现了 lucene 9.5 版本把 merge 策略的默认参数改了。 * GITHUB#11761: TieredMergePolicy now allowed a maximum allowable deletes percentage of down to 5%, and the defaultmaximum allowable deletes percentage is changed from 33% to 20%. (Marc DMello)也就是…...

基于 STM32 单片机的实验室多参数安全监测系统设计与实现
一、系统总体设计 本系统以 STM32F103C8T6 单片机为核心,集成温湿度监测、烟雾检测、气体泄漏报警、人体移动监测等功能模块,通过 OLED 显示屏实时显示数据,并支持 Wi-Fi 远程传输。系统可对实验室异常环境参数(如高温、烟雾、燃气泄漏)及非法入侵实时报警,保障实验室安…...
)
Spring Boot-Swagger离线文档(插件方式)
Swagger2Markup简介 Swagger2Markup是Github上的一个开源项目。该项目主要用来将Swagger自动生成的文档转换成几种流行的格式以便于静态部署和使用,比如:AsciiDoc、Markdown、Confluence。 项目主页:https://github.com/Swagger2Markup/swagg…...

Linux下Docker使用阿里云镜像加速器
在中国大陆环境中配置 Docker 使用阿里云镜像加速器,并确保通过 Clash 代理访问 Docker Hub 我这里用的Debian12。 步骤 1:获取阿里云镜像加速器地址 登录阿里云容器镜像服务控制台:(qinyang.wang) 网址:阿里云登录 - 欢迎登录阿…...
))
每日c/c++题 备战蓝桥杯(洛谷P1440 求m区间内的最小值 详解(单调队列优化))
洛谷P1440 求m区间最小值:单调队列优化详解(从暴力到O(n)的蜕变) tags: [算法, 数据结构, 滑动窗口, 洛谷, C] 引言 在处理序列数据的区间查询问题时,暴力枚举往往难以应对大规模数据。本文以洛谷P1440为切入点,深入…...

从代码学习深度学习 - 预训练word2vec PyTorch版
文章目录 前言辅助工具1. 绘图工具 (`utils_for_huitu.py`)2. 数据处理工具 (`utils_for_data.py`)3. 训练辅助工具 (`utils_for_train.py`)预训练 Word2Vec - 主流程1. 环境设置与数据加载2. 跳元模型 (Skip-gram Model)2.1. 嵌入层 (Embedding Layer)2.2. 定义前向传播3. 训练…...

OpenCV图像边缘检测
1.概念 图像边缘检测是计算机视觉和图像处理中的基础任务,用于识别图像中像素值发生剧烈变化的区域,这些区域通常对应物体的边界、纹理变化或噪声。 1.1原理 图像中的边缘通常表现为灰度值的突变(如从亮到暗或从暗到亮的急剧变化)…...

AI能源危机:人工智能发展与环境可持续性的矛盾与解决之道
AI对能源的渴求正在演变成一个巨大的挑战。这不仅仅关乎电费支出,其环境影响也十分严重,包括消耗宝贵的水资源、产生大量电子垃圾,以及增加温室气体排放。 随着AI模型变得越来越复杂并融入我们生活的更多领域,一个巨大的问题悬而…...

基于flask+vue的电影可视化与智能推荐系统
基于flaskvue爬虫的电影数据的智能推荐与可视化系统,能展示电影评分、评论情感分析等直观的数据可视化图表,还能通过协同过滤算法为用户提供个性化电影推荐,帮助用户发现更多感兴趣的电影作品,具体界面如图所示。 本系统主要技术架…...

初步认识HarmonyOS NEXT端云一体化开发
视频课程学习报名入口:HarmonyOS NEXT端云一体化开发 1、课程设计理念 本课程采用"四维能力成长模型"设计理念,通过“能看懂→能听懂→能上手→能实战”的渐进式学习路径,帮助零基础开发者实现从理论认知到商业级应用开发的跨越。该模型将学习过程划分为四个维度…...

基于单片机的车辆防盗系统设计与实现
标题:基于单片机的车辆防盗系统设计与实现 内容:1.摘要 随着汽车保有量的不断增加,车辆被盗问题日益严峻,车辆防盗成为人们关注的焦点。本研究的目的是设计并实现一种基于单片机的车辆防盗系统。采用单片机作为核心控制单元,结合传感器技术、…...

LSM Tree算法原理
LSM Tree(Log-Structured Merge Tree)是一种针对写密集型场景优化的数据结构,广泛应用于LevelDB、RocksDB等数据库引擎中。其核心原理如下: 1. 写入优化:顺序写代替随机写 内存缓冲(MemTable):写入操作首先被写入内存中的数据结构(如跳表或平衡树),…...

通过 API 获取 1688 平台店铺所有商品信息的完整流程
在电商运营和数据分析中,获取 1688 平台店铺的商品信息是一项重要的任务。1688 作为国内领先的 B2B 电商平台,提供了丰富的开放平台 API 接口,方便开发者获取店铺商品的详细信息。本文将详细介绍如何通过 Python 调用 1688 的 API 接口&#…...