ES 调优帖:关于索引合并参数 index.merge.policy.deletePctAllowed 的取值优化
最近发现了 lucene 9.5 版本把 merge 策略的默认参数改了。
* GITHUB#11761: TieredMergePolicy now allowed a maximum allowable deletes percentage of down to 5%, and the defaultmaximum allowable deletes percentage is changed from 33% to 20%. (Marc D'Mello)
也就是 index.merge.policy.deletePctAllowed 最小值可以取 5%(原来是 20%),而默认值为 20%(原来是 33%)。
这是一个控制索引中已删除文档的占比的参数,简单来说,调低这个参数能够降低存储大小,同时也需要更多的 cpu 和内存资源来完成这个调优。
通过这个帖子的讨论,大家可以发现,“实践出真知”,这次的参数调整是 lucene 社区对于用户积极反馈的采纳。因此,对于老版本的用户,也可以在 deletepct 比较高的场景下,调优这个参数,当然一切生产调整都需要经过测试。
对于 ES 的新用户来说,这时候可能冒出了下面这些问题
- 这个参数反馈的已删除文档占比 deletepct 是什么?
- 它怎么计算的呢?较高的 deletepct 会有什么影响?
- 较低的 deletepct 为什么会有更多的资源消耗?
- 除了调优这个参数还有什么优化办法么?
伴随这些问题,来探讨一下这个参数的来源和作用。
deletePctAllowed:软删除的遗留
在 Lucene 中,软删除是一种标记文档以便后续逻辑删除的机制,而不是立即从索引中物理删除文档。
但是这些软删除文档又不是永久存在的,deletePctAllowed 表示索引中允许存在的软删除文档占总文档数的最大百分比。
当软删除文档的比例达到或超过 deletePctAllowed 所设定的阈值时,Lucene 会触发索引合并操作。这是因为在合并过程中,那些被软删除的文档会被物理地从索引中移除,从而减少索引的存储空间占用。
当 deletePctAllowed 设置过低时,会频繁触发索引合并,因合并操作需大量磁盘 I/O、CPU 和内存资源,会使写入性能显著下降,磁盘 I/O 压力增大。假设 deletePctAllowed 为 0,则每次写入都需要消耗额外的资源来做 segment 的合并。
deletePctAllowed 过高,索引会容纳大量软删除文档,占用过多磁盘空间,增加存储成本且可能导致磁盘空间不足。查询时要过滤大量软删除文档,使查询响应时间变长、性能下降。同时也观察到,在使用 soft-deleted 特性后,文档更新和 refresh 也会受到影响,deletePctAllowed 过高,文档更新/refresh 操作耗时也会明显上升。
deletePctAllowed 的实际效果
从上面的解释看,index.merge.policy.deletePctAllowed 这个参数仿佛并不难理解,但实际上这个参数是应用到各个 segment 级别的,并且 segment 对这个参数的触发条件也是有限制(过小的 segment 并不会因为这个参数触发合并操作)。在多分片多 segment 的条件下,索引对 deletePctAllowed 参数实际的应用效果并不完全一致。因此,可以做个实际测试来看 deletePctAllowed 对索引产生的效果。
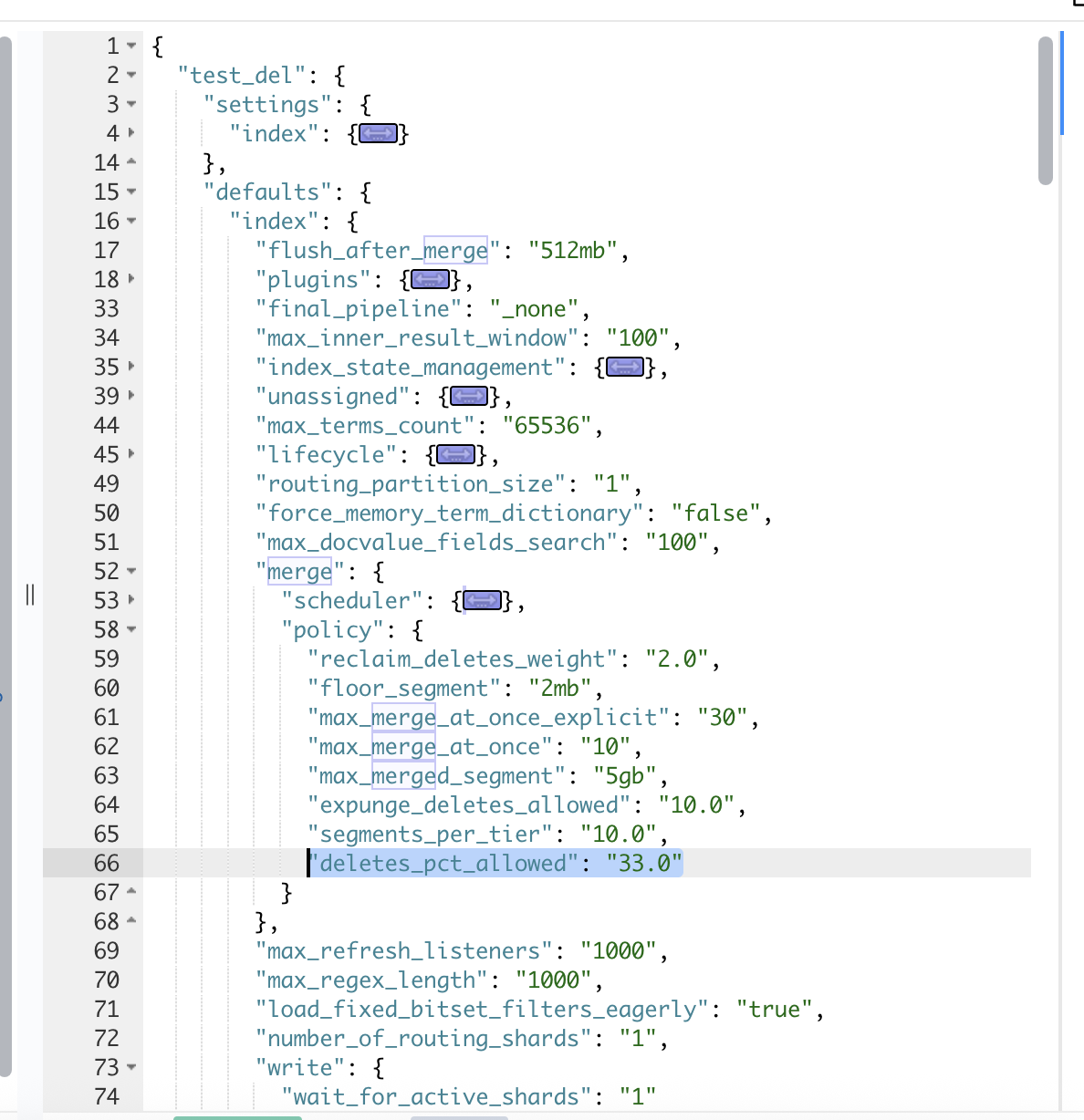
这里创建一个一千万文档的索引,然后全量更新一遍,看最后 deletePctAllowed 会保留多少的被删除文档。
GET test_del/_count
{"count": 10000000,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}
}# 查看 delete 文档数量GET test_del/_stats
···"primaries": {"docs": {"count": 10000000,"deleted": 0},
···这里的 deletePctAllowed 还是使用的 33%。
更新任务命令:
POST test_del/_update_by_query?wait_for_completion=false
{"query": {"match_all": {}},"script": {"source": "ctx._source.field_name = 'new_value'","lang": "painless"}
}
完成后,
# 任务状态
···"task": {"node": "28HymM3xTESGMPRD3LvtCg","id": 10385666,"type": "transport","action": "indices:data/write/update/byquery","status": {"total": 10000000,"updated": 10000000,# 这里可以看到全量更新"created": 0,"deleted": 0,"batches": 10000,"version_conflicts": 0,"noops": 0,"retries": {"bulk": 0,"search": 0},"throttled_millis": 0,"requests_per_second": -1,"throttled_until_millis": 0}
···# 索引的状态
GET test_del/_stats
···"_all": {"primaries": {"docs": {"count": 10000000,"deleted": 809782},
···
实际删除文档与非删除文档的比例为 8.09%。
现在尝试调低 index.merge.policy.deletes_pct_allowed到 20%。
PUT test_del/_settings
{"index.merge.policy.deletes_pct_allowed":20}由于之前删除文档占比过低,调整参数并不会触发新的 merge,因此需要重新全量更新数据查看一下是否有改变。
最终得到的索引状态如下:
GET test_del/_stats
···"primaries": {"docs": {"count": 10000000,"deleted": 190458}
···
这次得到的实际删除文档与非删除文档的比例为 1.9%
deletes_pct_allowed 默认值的调整
上面提到 deletePctAllowed 设置过低时,会频繁触发索引合并,而合并任务的线程使用线程类型是 SCALING 的,是一种动态扩展使用 cpu 的策略。

那么,当 deletePctAllowed 设置过低时,merge 任务增加,cpu 线程使用增加。集群的 cpu 和磁盘的使用会随着写入增加,deletePctAllowed 降低产生了放大效果。
所以,在没有大量数据支撑的条件下,ES 的使用者们往往会选择业务低峰期使用 forcemerge 来降低文档删除比,因为 forcemerge 的线程类型是 fixed,并且为 1,对 cpu 和磁盘的压力更加可控,同时 forcemerge 的 deletePctAllowed 默认阈值是 10%,更加低。
而社区中,大家的实际反馈则更倾向使用较低的 deletePctAllowed 阈值,特别是小索引小写入的情况下。
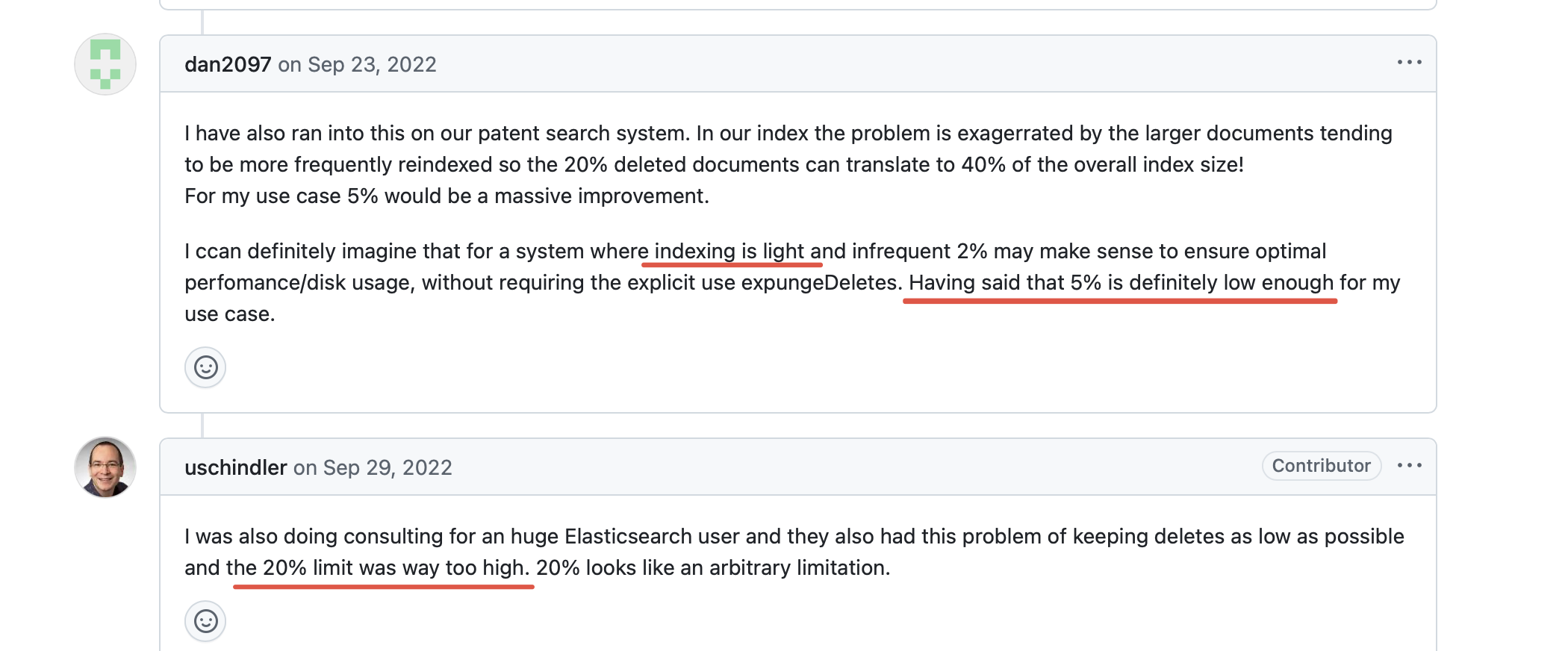
并且提供了相应的测试结果
#### RUN 1
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 50% of the total requestBaseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"| Metrics | Baseline | Target |
------------------------------------
| Store size | 39gb | 37gb |
| Deleted docs percent | 22% | 18% |
| Avg. CPU | (42 - 53)% | (43 - 55)% |
| Write throughput | 11 - 15 mbps | 11 - 17 mbps |
| Indexing latency | 0.15 - 0.36 ms | 0.15 - 0.39 ms |
| P90 search latency | 14.9 ms | 13.2 ms |
| P90 term query latency | 13.7 ms | 13.5 ms |#### RUN 2
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 75% of the total requestBaseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"| Metrics | Baseline | Target |
------------------------------------
| Store size | 19.4gb | 17.7gb |
| Deleted docs percent | 22.8% | 15% |
| Avg. CPU | (43 - 53)% | (46 - 53)% |
| Write throughput | 9 - 14.5 mbps | 10 - 15.9 mbps |
| Indexing latency | 0.14 - 0.33 ms | 0.14 - 0.28 ms |
| P90 search latency | 15.9 ms | 13.5 ms |
| P90 term query latency | 15.7 ms | 13.9 ms |#### RUN 3
Test config:
Single node domain
Instance type: EC2 m5.4xlarge
Updates: 80% of the total requestBaseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"| Metrics | Baseline | Target |
------------------------------------
| Store size | 15.9gb | 14.6gb |
| Deleted docs percent | 24% | 18% |
| Avg. CPU | (46 - 52)% | (47 - 52)% |
| Write throughput | 9 - 13 mbps | 10 - 15 mbps |
| Indexing latency | 0.14 - 0.28 ms | 0.13 - 0.26 ms |
| P90 search latency | 15.3 ms | 13.6 ms |
| P90 term query latency | 15.2 ms | 13.4 ms |#### RUN 4
Test config:
Single node domain
Instance type: EC2 m5.2xlarge
Updates: 80% of the total requestBaseline:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "33.0"
Target:
OS_2.3
"index.merge.policy.deletes_pct_allowed" : "20.0"| Metrics | Baseline | Target |
------------------------------------
| Store size | 21.6gb | 17.8gb |
| Deleted docs percent | 30% | 18% |
| Avg. CPU | (71 - 89)% | (83 - 90)% |
| Write throughput | 6 - 12 mbps | 10 - 15 mbps |
| indexing latency | 0.21 - 0.30 ms | 0.20 - 0.31 ms |
| P90 search latency | 15.4 ms | 16.3 ms |
| P90 term query latency | 15.4 ms | 14.8 ms |在测试中给出的结论是:
- CPU 和 IO 吞吐量没有明显增加。
- 由于索引中删除的文档数量较少,搜索延迟更少。
- 减少被删除文档占用的磁盘空间浪费
但是也需要注意,这里的测试索引和消耗资源并不大,有些业务量较大的索引还是需要重新做相关压力测试。
另一种调优思路
那除了降低 deletePctAllowed 和使用 forcemerge,还有其他方法么?
这里一个pr,提供一个综合性的解决方案,作者把两个 merge 策略进行了合并,在主动合并的间隙添加 forcemerge 检测方法,遇到可执行的时间段(资源使用率低),主动发起对单个 segment 的 forcemerge,这里 segment 得删选大小更加低,这样对 forcemerge 的任务耗时也更低,最终减少索引的删除文档占比。
简单的理解就是,利用了集群资源的“碎片时间”去完成主动的 forcemerge。也是一种可控且优质的调优方式。
相关文章:

ES 调优帖:关于索引合并参数 index.merge.policy.deletePctAllowed 的取值优化
最近发现了 lucene 9.5 版本把 merge 策略的默认参数改了。 * GITHUB#11761: TieredMergePolicy now allowed a maximum allowable deletes percentage of down to 5%, and the defaultmaximum allowable deletes percentage is changed from 33% to 20%. (Marc DMello)也就是…...

基于 STM32 单片机的实验室多参数安全监测系统设计与实现
一、系统总体设计 本系统以 STM32F103C8T6 单片机为核心,集成温湿度监测、烟雾检测、气体泄漏报警、人体移动监测等功能模块,通过 OLED 显示屏实时显示数据,并支持 Wi-Fi 远程传输。系统可对实验室异常环境参数(如高温、烟雾、燃气泄漏)及非法入侵实时报警,保障实验室安…...
)
Spring Boot-Swagger离线文档(插件方式)
Swagger2Markup简介 Swagger2Markup是Github上的一个开源项目。该项目主要用来将Swagger自动生成的文档转换成几种流行的格式以便于静态部署和使用,比如:AsciiDoc、Markdown、Confluence。 项目主页:https://github.com/Swagger2Markup/swagg…...

Linux下Docker使用阿里云镜像加速器
在中国大陆环境中配置 Docker 使用阿里云镜像加速器,并确保通过 Clash 代理访问 Docker Hub 我这里用的Debian12。 步骤 1:获取阿里云镜像加速器地址 登录阿里云容器镜像服务控制台:(qinyang.wang) 网址:阿里云登录 - 欢迎登录阿…...
))
每日c/c++题 备战蓝桥杯(洛谷P1440 求m区间内的最小值 详解(单调队列优化))
洛谷P1440 求m区间最小值:单调队列优化详解(从暴力到O(n)的蜕变) tags: [算法, 数据结构, 滑动窗口, 洛谷, C] 引言 在处理序列数据的区间查询问题时,暴力枚举往往难以应对大规模数据。本文以洛谷P1440为切入点,深入…...

从代码学习深度学习 - 预训练word2vec PyTorch版
文章目录 前言辅助工具1. 绘图工具 (`utils_for_huitu.py`)2. 数据处理工具 (`utils_for_data.py`)3. 训练辅助工具 (`utils_for_train.py`)预训练 Word2Vec - 主流程1. 环境设置与数据加载2. 跳元模型 (Skip-gram Model)2.1. 嵌入层 (Embedding Layer)2.2. 定义前向传播3. 训练…...

OpenCV图像边缘检测
1.概念 图像边缘检测是计算机视觉和图像处理中的基础任务,用于识别图像中像素值发生剧烈变化的区域,这些区域通常对应物体的边界、纹理变化或噪声。 1.1原理 图像中的边缘通常表现为灰度值的突变(如从亮到暗或从暗到亮的急剧变化)…...

AI能源危机:人工智能发展与环境可持续性的矛盾与解决之道
AI对能源的渴求正在演变成一个巨大的挑战。这不仅仅关乎电费支出,其环境影响也十分严重,包括消耗宝贵的水资源、产生大量电子垃圾,以及增加温室气体排放。 随着AI模型变得越来越复杂并融入我们生活的更多领域,一个巨大的问题悬而…...

基于flask+vue的电影可视化与智能推荐系统
基于flaskvue爬虫的电影数据的智能推荐与可视化系统,能展示电影评分、评论情感分析等直观的数据可视化图表,还能通过协同过滤算法为用户提供个性化电影推荐,帮助用户发现更多感兴趣的电影作品,具体界面如图所示。 本系统主要技术架…...

初步认识HarmonyOS NEXT端云一体化开发
视频课程学习报名入口:HarmonyOS NEXT端云一体化开发 1、课程设计理念 本课程采用"四维能力成长模型"设计理念,通过“能看懂→能听懂→能上手→能实战”的渐进式学习路径,帮助零基础开发者实现从理论认知到商业级应用开发的跨越。该模型将学习过程划分为四个维度…...

基于单片机的车辆防盗系统设计与实现
标题:基于单片机的车辆防盗系统设计与实现 内容:1.摘要 随着汽车保有量的不断增加,车辆被盗问题日益严峻,车辆防盗成为人们关注的焦点。本研究的目的是设计并实现一种基于单片机的车辆防盗系统。采用单片机作为核心控制单元,结合传感器技术、…...

LSM Tree算法原理
LSM Tree(Log-Structured Merge Tree)是一种针对写密集型场景优化的数据结构,广泛应用于LevelDB、RocksDB等数据库引擎中。其核心原理如下: 1. 写入优化:顺序写代替随机写 内存缓冲(MemTable):写入操作首先被写入内存中的数据结构(如跳表或平衡树),…...

通过 API 获取 1688 平台店铺所有商品信息的完整流程
在电商运营和数据分析中,获取 1688 平台店铺的商品信息是一项重要的任务。1688 作为国内领先的 B2B 电商平台,提供了丰富的开放平台 API 接口,方便开发者获取店铺商品的详细信息。本文将详细介绍如何通过 Python 调用 1688 的 API 接口&#…...

Python代码加密与发布方案详解
更多内容请见: python3案例和总结-专栏介绍和目录 文章目录 一、基础加密方案二、商业级加密方案三、高级混淆方案四、商业化发布方案五、反逆向技术六、最佳实践建议七、常见问题解决Python作为解释型语言,其源代码容易被查看和修改。本文将详细介绍多种Python代码保护方案,…...

Tractor S--二维转一维,然后最小生成树
P3073 [USACO13FEB] Tractor S - 洛谷 转成一维点图,然后最小生成树,最后的最大值就是最后一个点,记得记录维护连通块 同样的二维转一维---Cow Ski Area G---二维图转一维tarjan缩点-CSDN博客 #include<bits/stdc.h> using namespac…...

5月20日day31打卡
文件的规范拆分和写法 知识点回顾 规范的文件命名规范的文件夹管理机器学习项目的拆分编码格式和类型注解 作业:尝试针对之前的心脏病项目,准备拆分的项目文件,思考下哪些部分可以未来复用。 补充介绍: pyc文件的介绍 知识点回顾 …...

基于Spring Boot + Vue的教师工作量管理系统设计与实现
一、项目简介 随着高校信息化管理的发展,教师工作量管理成为教务系统中不可或缺的一部分。为此,我们设计并开发了一个基于 Spring Boot Vue 的教师工作量管理系统,系统结构清晰,功能完备,支持管理员和教师两个角色。…...

海康工业相机白平衡比选择器对应的值被重置后,如何恢复原成像
做项目的时候,有时候手抖,一不小心把一个成熟稳定的项目的相机配置,重置了,如何进行恢复呢,在不知道之前配置数据的情况下。 我在做项目的时候,为了让这个相机成像稳定一点,尤其是做颜色检测时…...

VMWare清理后,残留服务删除方案详解
VMWare清理后,残留服务删除方案详解 在虚拟化技术日益普及的今天,VMWare作为行业领先的虚拟化软件,广泛应用于企业和服务器的管理中。然而,由于其复杂的架构和深层次的系统集成,VMWare的卸载过程往往并不顺利。即使通…...

STM32定时器简单采集编码器脉冲
MCU:STM32H723ZGT6 编码器:(欧姆龙)E6B2-CWZ1X;1000P/R;8根线信号线分别为 A A- B B- Z Z- 以及5V和GND; A 脉冲输出 B 脉冲输出 Z 零点信号 当编码器旋转到零点时,Z信号会发出一个脉…...

第 4 章:网络与总线——CAN / Ethernet / USB-OTG
本章目标: 深入理解三种关键通信总线(CAN、Ethernet、USB-OTG)的协议架构、硬件接口与软件驱动 掌握 STM32(或同类 MCU)中各总线的寄存器配置、中断/DMA 驱动框架 通过实战案例,实现基于 CAN 总线的节点通信、基于 Ethernet 的 TCP/IP 通信,以及基于 USB-OTG 的虚拟串口…...

【python进阶知识】Day 31 文件的规范拆分和写法
知识点 规范的文件命名规范的文件夹管理机器学习项目的拆分编码格式和类型注解 机器学习流程 - 数据加载:从文件、数据库、API 等获取原始数据。 - 命名参考:load_data.py 、data_loader.py - 数据探索与可视化:了解数据特性,初期…...

leetcode 162. Find Peak Element
题目描述 如果nums[i-1]<nums[i]并且nums[i]>nums[i1],那么nums[i]就是峰值。除此情况之外,nums[i-1]和nums[i1]至少有一个大于nums[i],因为题目已经保证相邻的元素不相等。坚持向上坡方向走一定能达到一个峰值,如果往两边走…...
)
2025系统架构师---案例题(押题)
1. 微服务相关的概念: 微服务是一种架构风格,它将单体应用划分为一组小服务,服务之间相互协作,实现业务功能每个服务运行在独立的进程中,服务间采用轻量级的通信机制协作(通常是HTTP/JSON),每个服务围绕业务能力进行构建,并且能够通过自动化机制独立的部署。 微服务有…...

t检验详解:原理、类型与应用指南
t检验详解:原理、类型与应用指南 t检验(t-test)是一种用于比较两组数据均值是否存在显著差异的统计方法,适用于数据近似正态分布且满足方差齐性的场景。以下从核心原理、检验类型、实施步骤到实际应用进行系统解析。 一、t检验的…...

使用 OpenCV 实现万花筒效果
万花筒效果(Kaleidoscope Effect)是一种图像处理效果,通过对图像进行对称旋转或镜像处理,产生具有多重反射和对称的艺术效果。它常用于视频编辑、视觉艺术、游戏设计等领域,为图像添加富有创意和视觉冲击力的效果。 在…...

Rocketmq broker 是主从架构还是集群架构,可以故障自动转移吗
RocketMQ Broker的架构与故障转移机制 RocketMQ的Broker架构同时采用了主从架构和集群架构,并且支持故障自动转移。下面详细说明: 一、架构类型 1. 集群架构 RocketMQ天然支持分布式集群部署 一个RocketMQ集群包含多个Broker组(每组有主从) 不同Bro…...

MySQL中添加一个具有创建数据库权限的用户
要在MySQL中添加一个具有创建数据库权限的用户,可按以下步骤操作: 1. 登录MySQL 使用拥有足够权限(一般是root用户 )的账号登录到MySQL数据库。在命令行输入: mysql -u root -p然后输入对应的密码,即可进…...

Go语言使用通义灵码辅助开发 - AI编程助手提升效率
一、引言 Go 语言以其高效性能和简洁语法,成为构建微服务、分布式系统及高性能后端的首选。对于有其他语言编程经验的开发者和初学者,入门 Go 语言时,如何快速开发第一个程序是关键。传统方式如慢慢摸索、向老师请教或查找资料,效…...

演示:【WPF-WinCC3D】 3D工业组态监控平台源代码
一、目的:分享一个应用WPF 3D开发的3D工业组态监控平台源代码 二、功能介绍 WPF-WinCC3D是基于 WPF 3D研发的工业组态软件,提供将近200个预置工业模型(机械手臂、科幻零部件、熔炼生产线、机加生产线、管道等),支持组态…...

Oracle资源管理器
14.8资源管理器 14.8.1资源管理器的功能和控制种类 传统意义上,系统的资源分配是由 OS 来完成的,但是对于数据库资源,OS 分配资源会带来一些问题。以 Linux 为例,最为突出的一个问题是:Linux 的资源调度是基于进程的&…...

下载Ubuntu 64 位
学习目标: 下载 学习内容: 学习时间: 学习时间为学习时间 学习时间筋肉人为学习时间future 内容为笔记【有时比较抽象,有时比较过于详细,请宽恕。作者可能写的是仅个人笔记,筋肉人future】 学习产出&…...
)
ubuntu14.04/16.06 安装vscode(实测可以用)
地址:https://code.visualstudio.com/updates/v1_38 选择deb 这个版本还支持ubuntu14.04和16.06 sudo dpkg -i code_1.38.1-1568209190_amd64.deb sudo apt-get install -f安装成功,正常使用...

Linux命令大全
前言:工作中或多或少都会用到Linux服务器,我为大家分享一下常用命令 一丶文件与目录操作 命令作用示例ls列出目录内容ls -l(详细列表)cd切换目录cd /homepwd显示当前目录路径pwdmkdir创建目录mkdir -p dir1/dir2(递归…...

spark的缓存提升本质以及分区数量和task执行时间的先后
文章目录 示例代码缓存效果分析第1次 user.count第2次 user.count——这里解释了spark缓存提升的本质原因关于分区数量和task数量以及task的执行流程有多少个分区就有多少线程task并发执行不同分区数量对计算效率的提升 示例代码 import org.apache.spark.storage.StorageLeve…...

SQL次日留存率计算精讲:自连接与多字段去重的深度应用
一、问题拆解:理解次日留存率的计算逻辑 1.1 业务需求转换 题目:运营希望查看用户在某天刷题后第二天还会再来刷题的留存率。 关键分析点: 留存率 (第一天刷题且第二天再次刷题的用户数) / 第一天刷题的总用户数需…...

PostgreSQL初体验
目录 一:PostgreSQL 1.简介 3.优势 4.架构 5.应用场景 6.结论 二:安装PostgreSQL 1.编译安装 三:PostgreSQL架构 1.PG的逻辑结构 2.PG的物理结构 前言 在数据驱动的时代,掌握 PostgreSQL 这一全球顶尖的开源关系型数据…...

Vue 3.0 Transition 组件使用详解
Vue 3.0 的 Transition 组件提供了一种简单的方式来为元素或组件的进入/离开添加动画效果。下面是使用<script setup>语法糖的实现方式。 1. 基本用法 使用场景:当需要为元素的显示/隐藏添加简单的淡入淡出效果时,这是最基础的过渡实现方式。 &…...

深入浅出IIC协议 - 从总线原理到FPGA实战开发 -- 第三篇:Verilog实现I2C Master核
第三篇:Verilog实现I2C Master核 副标题 :从零构建工业级I2C控制器——代码逐行解析与仿真实战 1. 架构设计 1.1 模块分层设计 三层架构 : 层级功能描述关键信号PHY层物理信号驱动与采样sda_oe, scl_oe控制层协议状态机与数据流控制state…...

通义灵码助力JavaScript开发:快速获取API与智能编码技巧
一、引言 JavaScript 拥有丰富的 API 生态,从浏览器的 Web API 到 Node.js 的环境生态,为开发者提供了强大的工具和库。然而,面对如此庞大的生态系统,开发者常常需要花费大量时间翻阅文档来查找和学习如何使用这些 API。通义灵码…...

ubuntu kubeasz 部署高可用k8s 集群
ubuntu kubeasz 部署高可用k8s 集群 测试环境主机列表软件清单kubeasz 部署高可用 kubernetes配置源配置host文件安装 ansible 并进行 ssh 免密登录:下载 kubeasz 项⽬及组件部署集群部署各组件开始安装修改 config 配置文件增加 master 节点增加 kube_node 节点登录dashboard…...

如何看待镍钯金PCB在当代工业制造中的地位和应用?
随着电子科技的飞速发展,电路板作为电子设备的核心组成部分,其制造材料和工艺也在不断进步。镍钯金(NiPdAu)电路板因其独特的物理和化学性质,在众多领域得到了广泛应用。本文将探讨镍钯金电路板的主要应用领域…...

Datawhale PyPOTS时间序列5月第4次笔记
端到端学习:使用一个模型直接接受包含缺失值的数据。 brits_classification.py 完整代码如下: # brits_classification.pyfrom benchpots.datasets import preprocess_physionet2012 from pypots.classification import BRITS from pypots.nn.function…...
数字化转型之生产制造:从通常的离散制造到柔性化生产的全景指南)
(05)数字化转型之生产制造:从通常的离散制造到柔性化生产的全景指南
当今制造业正经历着前所未有的数字化变革,从传统的离散制造到流程制造,再到新兴的项目制造和柔性制造,各种生产模式都在加速向智能化方向演进。本文将系统性地介绍制造业生产管理的完整体系,为企业数字化转型提供全面的方法论和实…...

JMeter 教程:JSON 断言的简单介绍
目录 JMeter 教程:JSON 断言的简单介绍【快速上手】 ✅ 什么是 JSON 断言? 🛠️ 使用前提 📄 JSON 断言添加步骤 步骤一:添加 JSON Assertion 📌 示例说明 ✅ 常用 JSONPath 写法速查 ✅ 断言结果查…...

RedissonClient主要功能概述
以下是 RedissonClient 提供的主要功能和特性的详细用法说明,结合代码示例和实际应用场景: 1. 分布式集合与映射 Redisson 提供了多种线程安全的分布式集合和映射,适用于分布式环境下的数据存储和操作。 RMap(分布式 Map&#x…...

USB学习【13】STM32+USB接收数据过程详解
目录 1.官方的描述2.HAL的流程把接收到的数据从PMA拷贝到用户自己定义的空间中 3.处理接收到的数据4.最后再次开启准备接收工作 1.官方的描述 2.HAL的流程 以上的官方说法我们暂时按下不表。 如果接收到数据,会激活中断进入到USB_LP_CAN1_RX0_IRQHandler࿰…...

更新2011-2025经济类联考 396-真题+解析 PDF
目录树: ├── 2011-2025经综-真题 │ ├── 2011年396经济联考综合能力真题 .pdf │ ├── 2012年396经济联考综合能力真题 .pdf │ ├── 2013年396经济联考综合能力真题 .pdf │ ├── 2014年396经济联考综合能力真题 .pdf │ ├── 2015年396经…...
)
string在c语言中代表什么(非常详细)
在 C 语言中,string 更多让人联想到的是 <string.h> 这个标准库。 <string.h> 库为我们提供了一系列用于操作字符串的函数接口,就像是一个功能强大的工具箱,让程序员能够方便地对字符串进行各种操作。 例如,当我们想…...

JIT即时编译器全面剖析:原理、实现与优化
引言 在现代软件开发领域,性能优化一直是开发者关注的核心问题之一。随着计算能力的提升和应用场景的多元化,如何提高程序运行效率成为技术发展的关键驱动力。即时编译器(Just-In-Time Compiler,简称JIT)作为一项革命性…...