[python] 轻量级定时任务调度库schedule使用指北
schedule是一款专为简化定时任务调度而设计的Python库,它通过直观的语法降低了周期性任务的实现门槛。作为进程内调度器,它无需额外守护进程,轻量且无外部依赖,适合快速搭建自动化任务。不过,该库在功能完整性上有所取舍,目前暂不支持断点续传、亚秒级精度控制以及多任务并行执行等复杂场景。
schedule库的官方仓库地址见:schedule,schedule库的官方文档见:schedule-doc。

schedule库支持在Python 3.7及以上版本的环境中运行,schedule库的安装命令如下:
pip install schedule
文章目录
- 1 使用入门
- 1.1 基础使用
- 1.1.1 相对调用
- 1.1.2 绝对调用
- 1.2 进阶使用
- 1.2.1 调用程序管理
- 1.2.2 调用时间管理
- 1.2.3 调用运行方式管理
- 2 参考
1 使用入门
1.1 基础使用
1.1.1 相对调用
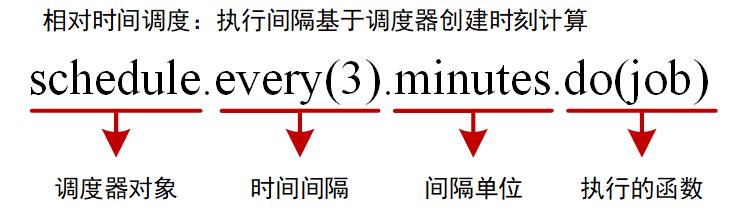
schedule库通过创建调度器,设置时间单位,注册待调用函数,返回任务对象实现任务周期调用。例如:
# 每3秒执行一次任务
schedule.every(3).seconds.do(job)
这种调用方式是相对调用方式,任务执行间隔是相对于当前时间点计算的。例如17:59:01创建调度器,下一次执行时间为17:59:04。
示例代码如下:
import schedule
import time
from datetime import datetimedef get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return nowdef job():"""定时执行的任务函数"""print(f"{get_now_time()} I'm working...") print(f"调度器创建时间:{get_now_time()}")
# 调度器返回job对象
schedule_job = schedule.every(3).seconds.do(job)print(f"调度器下一次运行时间:{schedule_job.next_run}")# 任务调度主循环
# 持续检查是否有待执行的任务
while True:schedule.run_pending() # 检查并执行待执行的任务time.sleep(1) # 休眠1秒避免CPU占用过高# 为None就是没运行print(f"调度器上一次运行时间:{schedule_job.last_run}")print(f"调度器下一次运行时间:{schedule_job.next_run}")
其他相对时间间隔调用代码如下:
# 每3分钟执行一次任务
schedule.every(3).minutes.do(job)
# 每小时执行一次任务
schedule.every().hours.do(job)
# 每3天执行一次任务
schedule.every(3).days.do(job)
# 每3周执行一次任务
schedule.every(3).weeks.do(job)
# 每周一执行任务
schedule.every().monday.do(job)
1.1.2 绝对调用
schedule可以在相对调用的基础上结合at函数实现绝对时间的调度。例如:
schedule.every(3).hours.at("11:16").do(job)
上述代码可拆解为:
job1 = schedule.every(3).hours
job2 = job1.at("11:16").do(job)
此处的job1基于当前调用器创建时间(例如18:34:54),以小时为间隔粒度进行设定,即每间隔3小时执行一次任务,因此下一次任务执行时间为21:34:54。而at()函数的作用是在job1设定的时间粒度和间隔范围内,具体指定分钟和秒。以job2中的at("11:16")为例,这里的11:16代表分钟和秒。它会在18:34:54至21:34:54的时间区间内,定位离21:34:54最近的11分16秒时刻,即21:11:16。
若按每分钟调用一次任务,可通过at指定固定执行秒数。例如,当创建时间为18:34:54时,下一次执行时间为18:35:16,对应代码如下:
schedule_job = schedule.every().minutes.at(":16").do(job)

at函数的输入范围由设定的时间粒度决定,且仅支持日级、时级、分级三类时间粒度,具体子粒度支持规则如下:
- 每日任务:支持HH:MM:SS(时分秒)和HH:MM两种格式(HH:MM默认补全为HH:MM:00);
- 每小时任务:支持MM:SS(分秒)和:MM两种格式(:MM默认补全为MM:00);
- 每分钟任务:仅支持:SS(秒)格式。
其他绝对时间间隔调用代码如下:
# 基于当前时间,每分钟的16秒执行任务
schedule.every().minutes.at(":16").do(job)
# 基于当前时间,每小时的第23分钟00秒执行任务
schedule.every().hours.at(":23").do(job)
# 基于当前时间,每5小时的第20分30秒执行任务
schedule.every(5).hours.at("20:30").do(job)
# 基于当前时间,每天上午10:30:00执行任务
schedule.every().days.at("10:30").do(job)
# 基于当前时间,每天上午10:30:42执行任务
schedule.every().days.at("10:30:42").do(job)
# 基于当前时间,每天上午12:42(阿姆斯特丹时区)执行任务
schedule.every().days.at("12:42", "Europe/Amsterdam").do(job)
# 基于当前时间,每周三下午1点15分执行任务
schedule.every().wednesday.at("13:15").do(job)
以下示例代码演示了多任务调度场景。作为轻量级任务调度库,schedule会维护任务列表,调用schedule.run_pending()时检查所有任务触发条件,满足条件的任务将按顺序执行。若任务时间冲突,schedule不会主动处理,而是按任务添加顺序依次执行。
import schedule
import time
from datetime import datetimedef get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return nowdef job():"""定时执行的任务函数"""print(f"{get_now_time()} I'm working...") # 基于当前时间,设置各种定时任务
# 基于当前时间,每分钟的16秒执行任务
schedule.every().minutes.at(":16").do(job)
# 基于当前时间,每小时的第23分钟00秒执行任务
schedule.every().hours.at(":23").do(job)
# 基于当前时间,每5小时的第20分30秒执行任务
schedule.every(5).hours.at("20:30").do(job)
# 基于当前时间,每天上午10:30:00执行任务
schedule.every().days.at("10:30").do(job)
# 基于当前时间,每天上午10:30:42执行任务
schedule.every().days.at("10:30:42").do(job)
# 基于当前时间,每天上午12:42(阿姆斯特丹时区)执行任务
# 需要安装pip install pytz
schedule.every().days.at("12:42", "Europe/Amsterdam").do(job)
# 基于当前时间,每周三下午1点15分执行任务
schedule.every().wednesday.at("13:15").do(job)# 任务调度主循环
# 持续检查是否有待执行的任务
while True:schedule.run_pending() time.sleep(1)
1.2 进阶使用
1.2.1 调用程序管理
装饰器调用
可以通过使用@repeat装饰器来调度函数。传递给它一个时间间隔,但省略do函数:
from schedule import every, repeat, run_pending
import time
from datetime import datetimedef get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return now@repeat(every(2).seconds)
def job():print(f"{get_now_time()} I'm working...") while True:run_pending()time.sleep(1)
参数传递
在调用时,可以通过do函数传递额外的参数给任务函数:
import schedule
import time
from schedule import every, repeat, run_pending
from datetime import datetimedef get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return nowdef job(name, message):print(f"{get_now_time()} {message} {name}")
# 传递name和message参数
schedule.every(2).seconds.do(job, name='world!', message='hello')@repeat(every().seconds, "code", "good")
def hello(name, message):print(message, name)while True:run_pending()time.sleep(1)
任务取消
若要从调度器中移除任务,可使用schedule.cancel_job(job)方法。
import scheduledef some_task():print('Hello world')job = schedule.every().days.at('12:30').do(some_task)
schedule.cancel_job(job)
任务移除
从任务调用的函数中返回schedule.CancelJob可以将其从调度器中移除,注意以下代码由于有while函数,移除后代码并不会退出:
import schedule
import timedef job_that_executes_once(name):print(f"hello {name}")return schedule.CancelJobschedule.every().minutes.at(':30').do(job_that_executes_once,name="job1")while True:schedule.run_pending()time.sleep(1)
任务批管理
以下代码展示了获取所有运行的任务,同时一次性清除所有任务:
# 导入 schedule 库用于创建和管理定时任务
import schedule# 定义任务函数,接收一个名字参数并打印问候语
def greet(name):print('Hello {}'.format(name))job1 = schedule.every().second.do(greet, name='job1')
schedule.every().second.do(greet, name='job2')# 获取当前所有已注册的定时任务
all_jobs = schedule.get_jobs()
# 打印任务列表(包含任务类型、执行周期、函数名和参数等信息)
print(all_jobs)schedule.every().second.do(greet, name='job3')# 取消job1任务(通过之前保存的任务对象引用)
# 取消后该任务将不再执行
schedule.cancel_job(job1)# 重新获取当前所有已注册的定时任务
all_jobs = schedule.get_jobs()
print(all_jobs)# 清除所有已注册的定时任务
schedule.clear()
标签管理
以下代码展示了如何为任务设置标签,并基于标签挑选和管理任务:
import schedule
import timedef greet(name):print(f"Hello {name}")# 创建带标签的定时任务
schedule.every().days.do(greet, 'Andrea').tag('daily-tasks', 'friend')
schedule.every().hours.do(greet, 'John').tag('hourly-tasks', 'friend')
schedule.every().hours.do(greet, 'Monica').tag('hourly-tasks', 'customer')
schedule.every().days.do(greet, 'Derek').tag('daily-tasks', 'guest')# 获取特定标签的任务
friends = schedule.get_jobs('friend')
print("所有带有friend标签的任务:")
# 取消带有daily-tasks标签的任务
schedule.clear('daily-tasks')for job in friends:print(f"- {job}")# 运行所有待执行的任务
while True:schedule.run_pending()time.sleep(1)
1.2.2 调用时间管理
随机时间
以下代码展示了按随机间隔运行任务的功能:
import schedule
import time
from datetime import datetimedef get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return nowdef my_job():print(f"{get_now_time()} hello") # 在1秒到5秒这个闭区间内,随机选择一个间隔时间,周期性地执行指定的任务函数
schedule.every(1).to(5).seconds.do(my_job)while True:schedule.run_pending()time.sleep(1)
截至时间
以下代码展示如何调用until函数设置任务的截止时间,任务在截止时间之后将不再运行。
import schedule
from datetime import datetime, timedelta, time
from datetime import datetimedef get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return nowdef job():print(f"{get_now_time()} hello") # 在今天22:30前,每隔1小时执行一次任务
schedule.every(1).hours.until("22:30").do(job)# 在2030-01-01 22:33前,每隔1小时执行一次任务
schedule.every(1).hours.until("2030-01-01 22:33").do(job)# 在接下来的8小时内,每隔1小时执行一次任务
schedule.every(1).hours.until(timedelta(hours=8)).do(job)# 在今天22:33:42前,每隔1小时执行一次任务
schedule.every(1).hours.until(time(22, 33, 42)).do(job)# 在2027-05-17 11:36:20前,每隔5秒执行一次任务
schedule.every(5).seconds.until(datetime(2027, 5, 17, 11, 36, 20)).do(job)# 主循环:持续检查并执行待处理的任务
while True:schedule.run_pending()
获取执行时间
使用schedule.idle_seconds()来获取距离下次任务计划执行的剩余秒数。如果下次计划执行的任务本应在过去执行,返回值为负数。若没有计划任务,则返回None。示例如下:
import schedule
import timedef job():print('你好')schedule.every(2).minutes.do(job)while 1:# n为距离下次执行任务的剩余秒数n = schedule.idle_seconds()print(n)if n is None:# 没有更多任务breakelif n > 0:# 精确睡眠相应的时间time.sleep(n)schedule.run_pending()
1.2.3 调用运行方式管理
任务全部运行
以下代码展示了通过run_all()忽略任务预设的时间安排,立即执行所有已定义的任务。先定义的任务先执行。示例如下:
import schedule
from datetime import datetimedef get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return nowdef job_1():print(f"{get_now_time()} job1") def job_2():print(f"{get_now_time()} job2") schedule.every().monday.at("12:40").do(job_1)
schedule.every().tuesday.at("16:40").do(job_2)# 立即运行所有任务一次
schedule.run_all()# 立即运行所有任务,每个任务运行间隔3秒
schedule.run_all(delay_seconds=3)
后台运行
默认情况下,无法在后台运行调度程序。不过,通过创建一个线程,利用该线程在不阻塞主线程的情况下运行任务。以下是实现这一操作的示例:
import threading
import timeimport scheduledef run_continuously(interval=1):"""创建一个后台线程持续运行调度器"""# 创建事件对象用于控制线程停止# Event是事件类,线程间通信的简单机制,有"set"和"clear"两种状态# 初始状态为"clear",通过cease_continuous_run.is_set()判断是否为setcease_continuous_run = threading.Event()class ScheduleThread(threading.Thread):@classmethoddef run(cls):# 在线程启动后循环执行# 只要任务状态不是set,就运行任务while not cease_continuous_run.is_set():# 检查并执行所有待执行的定时任务schedule.run_pending()# 休眠指定间隔时间time.sleep(interval)# 创建并启动调度线程continuous_thread = ScheduleThread()continuous_thread.start()# 返回事件对象用于后续停止线程return cease_continuous_rundef background_job():"""定时执行的后台任务"""print('Hello from the background thread')# 设置定时任务:每秒执行一次background_job函数
schedule.every().second.do(background_job)# 启动后台调度线程并获取停止控制器
stop_run_continuously = run_continuously()# 主线程继续执行其他任务
print("主线程继续执行中...")
time.sleep(5)# 停止后台调度线程
# 将事件对象的内部标志设置为set
stop_run_continuously.set()
print("后台线程已停止")
多任务同时执行
默认情况下,schedule任务调度工具会按顺序逐个执行所有任务。以10秒内执行30个任务为例,从日志中可以看到,这些任务会在这10秒内以串行方式依次执行,如同排队等候处理,而非同时运行。这种设计的核心目的是避免多个任务抢占资源或产生相互干扰,从而确保任务执行的稳定性和可靠性。
若需要实现多个任务并行运行,可通过为每个任务分配独立线程的方式达成,并通过统一队列进行调用。如下所示:
import time
import threading
import schedule
import queue
from datetime import datetime# 获取当前时间并格式化为字符串
def get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return now# 定义任务函数,打印当前时间和任务名称
def job(name):print(f"{get_now_time()} {name}") # 工作线程主函数,负责从队列中获取并执行任务
def worker_main():while True:joo_func,name = jobqueue.get()joo_func(name)jobqueue.task_done()# 创建任务队列
jobqueue = queue.Queue()# 调度多个相同间隔的任务,将任务放入队列
schedule.every(5).seconds.do(jobqueue.put, [job,"job1"])
schedule.every(5).seconds.do(jobqueue.put, [job,"job2"])
schedule.every(5).seconds.do(jobqueue.put, [job,"job3"])
schedule.every(5).seconds.do(jobqueue.put, [job,"job4"])
schedule.every(5).seconds.do(jobqueue.put, [job,"job5"])# 启动工作线程,对对任务队列进行处理
worker_thread = threading.Thread(target=worker_main)
worker_thread.start()while True:schedule.run_pending()time.sleep(1)
如果不需要队列统一调用,代码如下:
import time
import threading
import schedule
import queue
from datetime import datetime# 获取当前时间并格式化为字符串
def get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return now# 定义任务函数,打印当前时间和任务名称
def job(name):print(f"{get_now_time()} {name}") def run_threaded(job_func,name):job_thread = threading.Thread(target=job_func,args=(name,))job_thread.start()schedule.every(5).seconds.do(run_threaded, job, 'job1')
schedule.every(5).seconds.do(run_threaded, job, 'job2')
schedule.every(5).seconds.do(run_threaded, job, 'job3')
schedule.every(5).seconds.do(run_threaded, job, 'job4')
schedule.every(5).seconds.do(run_threaded, job, 'job5')while True:schedule.run_pending()time.sleep(1)
异常处理
调度程序不会捕获任务执行过程中发生的异常,并将异常传递给调用函数,可能直接崩溃程序:
import schedule
import timedef bad_task():return 1 / 0schedule.every(1).minutes.do(bad_task)while True:schedule.run_pending()time.sleep(1)
如果需要防范此类异常,可以按如下方式用装饰器封装任务函数:
import schedule
import time
import functools # 导入函数工具库# 定义一个捕获异常的装饰器,用于包装定时任务
def catch_exceptions(cancel_on_failure=False):def catch_exceptions_decorator(job_func):@functools.wraps(job_func) # 保留被装饰函数的元信息def wrapper(*args, **kwargs):try:return job_func(*args, **kwargs) # 执行原函数except:import tracebackprint(traceback.format_exc()) # 打印完整的异常堆栈信息if cancel_on_failure: # 如果设置了失败后取消任务return schedule.CancelJob # 返回取消任务的标志return wrapperreturn catch_exceptions_decorator# 使用装饰器包装任务函数,设置失败后自动取消
@catch_exceptions(cancel_on_failure=True)
def bad_task():return 1 / 0 schedule.every(1).minutes.do(bad_task)# 主循环:持续检查并执行待处理的任务
while True:schedule.run_pending() time.sleep(1)
日志管理
通过logging库设置名为schedule的日志记录器并设置为DEBUG级别,使其能够捕获并处理schedule库内部产生的所有日志信息:
import schedule
import logging # 配置基本日志设置
logging.basicConfig()
# 获取名为'schedule'的日志记录器
# 由于schedule库在内部使用相同的名称('schedule')记录自己的日志
# 因此这个记录器可以捕获并处理schedule模块产生的所有日志信息
schedule_logger = logging.getLogger('schedule')
# 设置日志级别为DEBUG,以便记录详细的调试信息
schedule_logger.setLevel(level=logging.DEBUG)def job():print("Hello, Logs") # 打印信息到标准输出和logschedule.every().second.do(job)# 立即运行所有已安排的任务(仅执行一次)
schedule.run_all()# 清除所有已安排的任务
schedule.clear()
如果若想为任务添加可复用的日志记录功能,最简便的方法是实现一个处理日志的装饰器:
import functools
import time
import schedule# 这个装饰器可用于任何任务函数,用于记录每次任务的执行时间
def print_elapsed_time(func):@functools.wraps(func) # 让被装饰函数的名称、文档字符串等属性保持不变。def wrapper(*args, **kwargs):# 记录任务开始时间戳start_timestamp = time.time()print(f'LOG: 正在运行任务 "{func.__name__}"')# 执行实际任务result = func(*args, **kwargs)# 计算并打印任务执行耗时print(f'LOG: 任务 "{func.__name__}" 已完成,耗时 {time.time() - start_timestamp:.1f} 秒')return resultreturn wrapper# 应用装饰器,自动记录该任务的执行时间
@print_elapsed_time
def job():print('Hello, Logs')# 模拟耗时操作time.sleep(2)schedule.every().second.do(job)# 立即运行所有已注册的任务一次
schedule.run_all()
多调度程序运行
从一个调度程序里运行多少个任务都可以。不过要是调度程序规模比较大,可能需要用多个调度程序来管理。如下所示:
import time
import schedule
from datetime import datetime# 获取当前时间并格式化为字符串
def get_now_time():now = datetime.now()now = now.strftime("%Y-%m-%d %H:%M:%S")return nowdef fooJob(caller):print(f"{get_now_time()} Foo called by {caller}")def barJob(caller):print(f"{get_now_time()} Bar called by {caller}")scheduler1 = schedule.Scheduler()
scheduler1.every().hour.do(fooJob, caller="scheduler1")
scheduler1.every().hour.do(barJob, caller="scheduler1")scheduler2 = schedule.Scheduler()
scheduler2.every().second.do(fooJob, caller="scheduler2")
scheduler2.every().second.do(barJob, caller="scheduler2")# 主循环,使程序持续运行,不断检查并执行待处理的任务
while True:# 检查scheduler1中是否有待执行的任务,若有则执行scheduler1.run_pending()# 检查scheduler2中是否有待执行的任务,若有则执行scheduler2.run_pending()time.sleep(1)
2 参考
- schedule
- schedule-doc
相关文章:

[python] 轻量级定时任务调度库schedule使用指北
schedule是一款专为简化定时任务调度而设计的Python库,它通过直观的语法降低了周期性任务的实现门槛。作为进程内调度器,它无需额外守护进程,轻量且无外部依赖,适合快速搭建自动化任务。不过,该库在功能完整性上有所取…...

MySQL:to many connections连接数过多
当你遇到 MySQL: Too many connections 错误时,意味着当前连接数已达到 MySQL 配置的最大限制。这通常是由于并发连接过多或连接未正确关闭导致的。 一、查看当前连接数 查看 MySQL 当前允许的最大连接数 SHOW VARIABLES LIKE max_connections;查看当前使用的最大…...

uthash是一个非常轻量级的库
如大家所知,uthash是一个非常轻量级的库。该库的使用非常简单,无需格外的静态库或动态库,仅需导入目标的头文件即可。 这种配置方式虽然简单,但是使用操作却需要用到大量的宏函数。在使用宏函数时不像使用普通函数一样自由和遍历…...
:基于LlaMAFactory的LoRA微调(上))
大模型的开发应用(三):基于LlaMAFactory的LoRA微调(上)
基于LlaMAFactory的LoRA微调(上) 0 前言1 LoRA微调1 LoRA微调的原理1.2 通过peft库为指定模块添加旁支1.3 lora前后结构输出结果对比1.4 使用PyTorch复现 LoRA.Linear1.5 使用peft进行LoRA微调案例 2 LLaMA-Factory2.1 LLaMA-Factory简介2.2 LLaMA-Facto…...

跨域_Cross-origin resource sharing
同源是指"协议域名端口"三者相同,即便两个不同的域名指向同一个ip,也非同源 1.什么是CORS? CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。它允许浏览器向跨源服务器ÿ…...

奥威BI:打破AI数据分析伪场景,赋能企业真实决策价值
在当今企业数字化转型的浪潮中,AI数据分析产品如雨后春笋般涌现,但许多看似创新的功能设计实则难以落地,沦为“伪需求场景”。这些伪场景不仅浪费企业资源,还可能误导决策,阻碍企业数字化转型进程。在此背景下…...

LLaMA-Factory全解析:大模型微调的开源利器与实战指
技术演进背景与核心价值架构设计与关键技术解析环境搭建与工具链配置全流程微调实战指南企业级应用与高级功能性能优化与安全部署未来发展趋势展望1. 技术演进背景与核心价值 1.1 大模型微调的技术痛点 当前开源大模型(如LLaMA、Qwen、Baichuan等)在通用领域表现优异,但垂…...
)
python-数据可视化(大数据、数据分析、可视化图像、HTML页面)
通过 Python 读取 XLS 、CSV文件中的数据,对数据进行处理,然后生成包含柱状图、扇形图和折线图的 HTML 报告。这个方案使用了 pandas 处理数据,matplotlib 生成图表,并将图表嵌入到 HTML 页面中。 1.XSL文件生成可视化图像、生成h…...
 - 环境搭建)
Jmeter(一) - 环境搭建
1.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序)。它可以用来测试静态和动态资源的性能,例如:静态文件,Java Servlet,CGI Scripts,Java Object,数据库和FTP服务器…...

OpenCV CUDA 模块特征检测与描述------在GPU上执行特征描述符匹配的类cv::cuda::DescriptorMatcher
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::DescriptorMatcher 是 OpenCV 的 CUDA 模块中用于在 GPU 上执行特征描述符匹配的类。它允许你利用 NVIDIA GPU 的并行计算能力来加速特…...

idea如何让文件夹分层显示,而不是圆点分割
网上说是点击小齿轮的都是过时了,对于新版idea不适用,直接上图 1、如图 2、如图 注意也是去掉Compact Middle Packages,只不过新版的方式UI和老版本的不一样了...

5:OpenCV—直方图均衡化
直方图均衡 直方图均衡是一种用于增强和调整图像对比度的图像处理技术。它通过重新分配图像的像素值,使得图像的灰度级在整个范围内均匀分布,从而增强图像的视觉效果。 图像的直方图是像素强度分布的图形表示。它提供了像素值集中位置以及是否存在异常偏…...

内存分页法
现在有个场景,页面需要分页处理,但是后端在查询完数据库后又会进行筛选,就会导致后端的查询数目跟请求的每页条数是不一样。 解决方案:内存分页法 在内存筛选后手动实现分页逻辑,保证返回数量与请求的 pageSize 一致…...

深入解析FramePack:高效视频帧打包技术原理与实践
摘要 本文深入探讨FramePack技术在视频处理领域的核心原理,解析其在不同场景下的应用优势,并通过OpenCV代码示例演示具体实现方法,为开发者提供可落地的技术解决方案。 目录 1. FramePack技术背景 2. 核心工作原理剖析 3. 典型应用场景 …...
)
【EI会议火热征稿中】第二届云计算与大数据国际学术会议(ICCBD 2025)
# ACM独立出版 | EI检索稳定、往届会后4个半月完成EI检索 # 热门征稿主题:大数据、5G/6G、物联网、云计算 # 早投稿早送审早录用! 重要信息 大会官网:www.iccbd.net 会议主页:【ACM独立出版|EI稳定】第二届云计算与大数据国际…...

对未来软件的看法
有了大模型之后,TypeScript这样增强型javascript语言可能更方便AI来调试。未来的应用会越来越广泛。node.js vue.js会越来越流行。因为方便AI调试,处理错误。 未来,随着 AI 编程工具对 TypeScript 的深度支持(如自动类型推导、错误…...

新兴技术与安全挑战
7.1 云原生安全(K8s安全、Serverless防护) 核心风险与攻击面 Kubernetes配置错误: 风险:默认开放Dashboard未授权访问(如kubectl proxy未鉴权)。防御:启用RBAC,限制ServiceAccount权限。Serverless函数注入: 漏洞代码(AWS Lambda):def lambda_handler(event, cont…...

Prompt Tuning:轻量级大模型微调全攻略
Prompt Tuning(提示调优)步骤金额流程 传统的 Prompt Tuning(提示调优) 是一种轻量级的大模型微调技术,核心是通过优化连续的提示向量(而非模型参数)来适配特定任务。 一、核心步骤概述 准备任务与数据 明确任务类型(如分类、问答等),准备输入文本和目标标签。加载…...

centos7安装mysql8.0
yum install -y mysql-community-server --nogpgcheckcentos7.9安装mysql8.0 在 CentOS 7.9 上安装 MySQL 8.0,你可以通过多种方式实现,但最推荐的方法是使用 MySQL 官方提供的 yum 仓库。这样可以确保安装的 MySQL 版本是最新的,并且易于管理…...

ZooKeeper 原理解析及优劣比较
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 引言 在分布式系统中,服务注册、配置管理、分布式锁、选举等场景都需要一个高可用、一致性强的协调服务。Apache ZooKeeper 凭…...

OD 算法题 B卷 【需要打开多少监视器】
文章目录 需要打开多少监视器 需要打开多少监视器 某长方形停车场,每个车位上方都有对应监控器,在当前车位和前后左右四个方向任意一个车位范围停车时,监控器才需要打开。给出某一时刻停车场的停车分布,统计最少需要打开多少个监…...

鸿蒙路由参数传递
页面test.ets 代码如下: import router from ohos.router Entry Component struct Test {State message: string Hello WorldState username: string huState password: string 1build() {Row() {Column() {Text(this.message).fontSize(50).fontWeight(FontWe…...

课程与考核
6.1 课程讲解与实战考核 6.1.1 SQL注入篇考核 考核目标:通过手动注入与工具结合,获取目标数据库敏感信息。 题目示例: 目标URL:http://vuln-site.com/product?id1 要求: 判断注入类型(联合查询/报错注…...
CNN、RNN、Transformer对于长距离依赖的捕捉能力分析
卷积网络CNN主要依靠深度来捕捉长距离依赖。但这个过程太间接了,因为信息在网络中实际传播了太多层。究竟哪些信息被保留,哪些被丢弃了,弄不清楚。从实践经验来看,卷积网络捕捉长依赖的能力非常弱。这也是为什么在大多数需要长依赖…...

封装POD与PinMap文件总结学习-20250516
基本概念 芯片封装外形图(POD,Package Outline Drawing),详细描述了芯片的物理尺寸、引脚布局和封装类型等信息; Pin Map是芯片封装的一个重要概念。它是一张详细描述芯片封装外形上各个引脚(Pinÿ…...

Qt项目开发中所遇
讲述下面代码所表示的含义: QWidget widget_19 new QWidget(); QVBoxLayout *touchAreaLayout new QVBoxLayout(widget_19);QWidget *buttonArea new QWidget(widget_19); 1、新建一个名为widget_19的QWidget,将给其应用垂直管路布局。 2、新建一个…...

ubuntu chrome无法使用搜狗拼音输入法,无法输入中文
安装好搜狗输入法后用了很久,突然有一天点击chrome自动升级后就没法用了,在别的软件都能用,还以为是配置问题,就在网上搜了好一阵子才找到解决方案,各种找问题,最后发现是需要安装fcitx5-frontend-gtk4&…...

数据结构与算法分析实验14 实现基本排序算法
实现基本排序算法 1. 常用的排序算法简介2. 上机要求3. 上机环境4.程序清单(写明运行结果及结果分析)4.1 程序清单4.1.1 头文件 sort.h 内容如下:4.1.2 实现文件 sort.cpp 内容如下:4.1.3 源文件 main.cpp 内容如下: 4.2 实现展效果示 5.上机…...

uni-app 中使用 mumu模拟器 进行调试和运行详细教程
一、下载mumu模拟器 二、复制安装路径暴保留 在文件夹中打开 三、配置全局adb命令 adb为Android Debug Bridge,就是起到调试桥的作用 打开shell文件夹、里面有一个adb.exe 将当前文件夹地址复制一下,即‘D:\Program Files\Netease\MuMu Player 12\sh…...
)
Visual Studio Code 改成中文模式(汉化)
1、打开工具软件(双击打开) 2、软件左边图标点开 3、在搜索框,搜索 chinese 出现的第一个 就是简体中文 4、点击第一个简体中文,右边会出来基本信息 点击 install 就可以安装了(记得联网)。 5、安装完右…...

破解 PCB 制造四大痛点:MOM 系统构建智能工厂新范式
在全球电子信息产业加速向智能化、高端化转型的背景下,PCB(印制电路板)作为 "电子产品之母",既是支撑 5G 通信、新能源汽车、人工智能等战略新兴产业发展的核心基础部件,也面临着 "多品种小批量快速切换…...

【基于深度学习的非线性光纤单像素超高速成像】
基于深度学习的非线性光纤单像素超高速成像是一种结合深度学习技术和单像素成像方法的前沿技术,旨在实现高速、高分辨率的成像。以下是一些关键点和方法: 深度学习在单像素成像中的应用 深度学习技术可以通过训练神经网络来优化单像素成像的重建过程。…...

Backend - Oracle SQL
目录 一、CRUD 增删改查(基础) (一)查询 (二)插入 (三)更新 (四)清空 二、常用 SQL 1. exists 搭配 select 1 2. FROM DUAL 3. INSTR()函数 4. 提取…...

WebSocket心跳机制
通常,心跳机制包括: 定期发送消息(如ping)到服务器以保持连接活跃检测服务器的相应(pong)如果一段时间没有收到相应,可能需要重新连接 ::: warning 在连接关闭或者发生错误时,清除心跳定时器,避免内存泄漏 ::: 在实现…...
)
计算机视觉与深度学习 | PSO-MVMD粒子群算法优化多元变分模态分解(Matlab完整代码和数据)
以下是一个基于PSO优化多元变分模态分解(MVMD)的Matlab示例代码框架,包含模拟数据生成和分解结果可视化。用户可根据实际需求调整参数。 %% 主程序:PSO优化MVMD参数 clc; clear; close all;% 生成模拟多变量信号 fs = 1000; % 采样频率 t = 0:1/fs:...

Fast Video Cutter Joiner v6.8.2 视频剪切合并器汉化版
想要快速拆解冗长视频,或是将零散片段拼接成完整作品?Fast Video Cutter Joiner 正是你需要的宝藏视频编辑软件!它以强大功能为核心,将复杂的视频处理变得简单直观。 精准的切割与合并功能,让你能随心所欲地裁剪视频…...
)
【漫话机器学习系列】269.K-Means聚类算法(K-Means Clustering)
一、K-Means 聚类算法简介 K-Means 是一种基于距离的无监督机器学习算法,属于聚类算法(Clustering Algorithm)。它的目标是将数据集划分为 K 个不重叠的子集(簇),使得每个子集中的数据点尽可能相似&#x…...
主要用到的模块库介绍)
【北邮通信系统建模与仿真simulink笔记】(1)主要用到的模块库介绍
【声明】 本博客仅用于记录博主学习内容、分享笔记经验,不得用作其他非学术、非正规用途,不得商用。本声明对本博客永久生效,若违反声明所导致的一切后果,本博客均不负责。 目录 1、信号源模块库(Sources)…...

【信息系统项目管理师】第11章:项目成本管理 - 32个经典题目及详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...
:Sql构建)
Java转Go日记(四十四):Sql构建
1.1.1. 执行原生SQL db.Exec("DROP TABLE users;")db.Exec("UPDATE orders SET shipped_at? WHERE id IN (?)", time.Now, []int64{11,22,33})// Scantype Result struct {Name stringAge int}var result Resultdb.Raw("SELECT name, age FROM use…...

数组day2
209长度最小的子数组 class Solution { public:int minSubArrayLen(int s, vector<int>& nums) {int result INT32_MAX;int sum 0; // 滑动窗口数值之和int i 0; // 滑动窗口起始位置int subLength 0; // 滑动窗口的长度for (int j 0; j < nums.size(); j) …...

《Effective Python》第三章 循环和迭代器——永远不要在迭代容器的同时修改它们
引言 本文基于《Effective Python: 125 Specific Ways to Write Better Python, 3rd Edition》第3章“循环和迭代器”中的 Item 22:“Never Modify Containers While Iterating over Them; Use Copies or Caches Instead(永远不要在迭代容器的同时修改它…...

SQLite基础及优化
SQLite 什么是SQLite SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它&#…...

数据库与存储安全
2.1 SQL注入攻防实战(手工注入、自动化工具) 攻击原理与分类 联合查询注入:通过UNION SELECT窃取数据。 UNION SELECT 1,username,password FROM users-- 布尔盲注:利用页面响应差异逐位提取数据。 AND (SELECT SUBSTRING(password,1,1) FROM users WHERE id=1)=a-- 时间…...

vue3/vue2大屏适配
vue3-scale-box 和 vue2-scale-box 可以帮助你在不同 Vue 版本中实现大屏自适应缩放。vue3-scale-box - npmvue3 scale box. Latest version: 0.1.9, last published: 2 years ago. Start using vue3-scale-box in your project by running npm i vue3-scale-box. There is 1 o…...

【数据结构 -- AVL树】用golang实现AVL树
目录 引言定义旋转方式LL型RR型LR型RL型 实现结构获取结点高度平衡因子更新高度左旋右旋插入结点中序遍历 引言 AVL树,基于二叉搜索树通过平衡得到 前面我们知道,通过🔗二叉搜索树可以便捷快速地查找到数据,但是当序列有序时&am…...

matlab慕课学习3.5
于20250520 3.5 用while 语句实现循环结构 3.5.1while语句 多用于循环次数不确定的情况,循环次数确定的时候用for更为方便。 3.5.2break语句和continue语句 break用来跳出循环体,结束整个循环。 continue用来结束本次循环,接着执行下一次…...

【jmeter】base64加密
base64加密 执行的脚本: import java.io.*; import sun.misc.BASE64Encoder; String strvars.get("param") #设置了一个user paramBASE64Encoder encodernew BASE64Encoder() log.info("--------start----------") String resultencoder.encod…...

优化Hadoop性能:如何修改Block块大小
在处理大数据时,Hadoop的性能和资源管理是至关重要的。Hadoop的分布式文件系统(HDFS)将数据切割成多个块(Block),并将这些块分布在集群中的不同节点上。在默认情况下,HDFS的块大小可能并不适合所…...

jmeter转义unicode变成中文
打开jmeter,添加后置处理器到接口请求后,在添加完成后将代码复制进入 (注意:最后执行后需要到“察看结果树”里看,需要自行添加对应的监听器) 按如下添加代码进入上图位置: //如下复制于链接&…...