GPT-4.1特点?如何使用GPT-4.1模型,GPT-4.1编码和图像理解能力实例展示
几天前,OpenAI在 API 中推出了三个新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。这些模型的性能全面超越 GPT-4o 和 GPT-4o mini(感觉这个GPT-4.1就是GPT-4o的升级迭代版本),主要在编码和指令跟踪方面均有显著提升。还拥有更大的上下文窗口——支持多达 100 万个上下文标记——并且能够通过改进的长上下文理解更好地利用这些上下文。
知识截止日期已更新至 2024 年 6 月,而对于plus、Pro、Team用户可以在模型的更多选择器中使用GPT-4.1,如下图所示
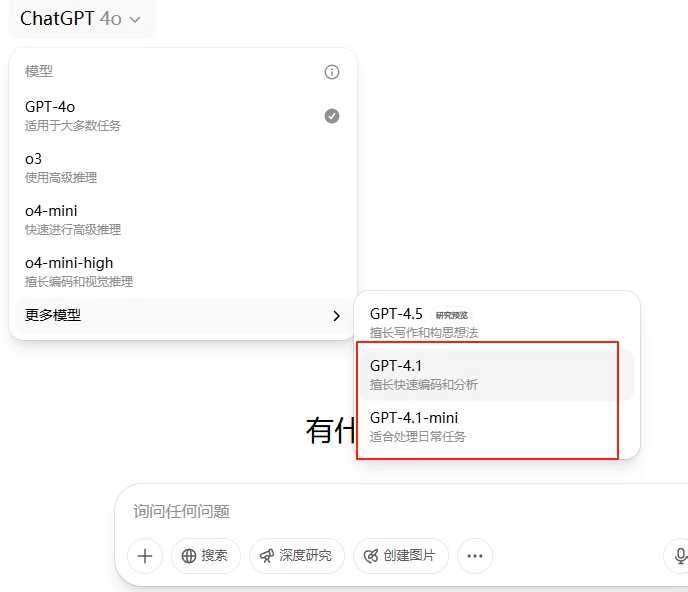
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano更新了哪些特点
接下来我们一起来看看GPT-4.1的编码、绘画、上下文能力到底如何,值不值得试试呢? 先看看官方的基准测试数据,然后再来实现一个小应用吧,最后告诉大家如何才能使用升级到CahtGPTplus/Pro会员去试试GPT-4.1
-
编码:GPT-4.1 在SWE-bench Verified上的得分为 54.6%,比 GPT-4o 提高了 21.4%,比 GPT-4.5 提高了 26.6% ,使其成为领先的编码模型。
-
说明如下: 在Scale 的MultiChallenge基准,即衡量指令遵循能力的标准,GPT-4.1 得分为 38.3%,比 GPT-4o 提高了10.5 % 。
-
详细背景:关于视频MME作为多模态长上下文理解的基准,GPT-4.1 创造了新的最先进成果——在长篇无字幕类别中得分为 72.0%,比 GPT-4o 提高了6.7 % 。
GPT-4.1 VS GPT-4o模型系列以更低的成本提供了更好的性能。这些模型在延迟曲线的每个点上都实现了性能的提升。
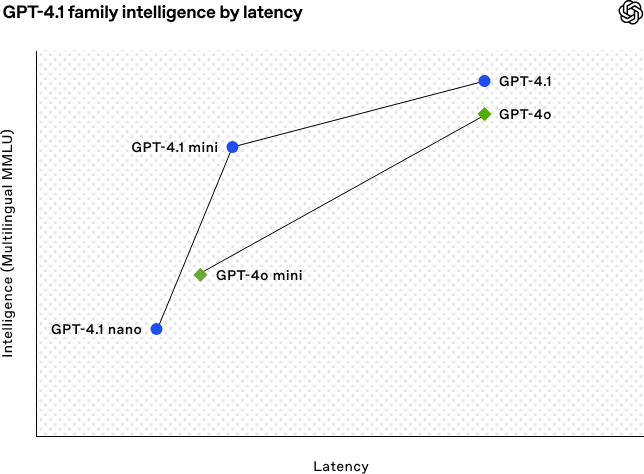
GPT-4.1 mini 在小模型性能上实现了显著飞跃,甚至在多项基准测试中超越了 GPT-4o。它在智能评估方面达到甚至超越了 GPT-4o,同时将延迟降低了近一半,成本降低了 83%。
而对于需要低延迟的任务,GPT-4.1 nano 是目前速度最快、成本最低的模型。它拥有 100 万个 token 上下文窗口,在小规模下实现了卓越的性能,在 MMLU 测试中得分高达 80.1%,在 GPQA 测试中得分高达 50.3%,在 Aider 多语言编码测试中得分高达 9.8%,甚至高于 GPT-4o mini。它是分类或自动完成等任务的理想选择。 这些在指令遵循可靠性和长上下文理解方面的改进,也使得 GPT-4.1 模型在驱动代理(即能够代表用户独立完成任务的系统)方面更加有效。当与 Responses API 等原语结合使用时,开发人员现在可以构建在实际软件工程中更有用、更可靠的代理,从大型文档中提取见解,以最少的手动操作解决客户请求以及其他复杂任务。 在此之前GPT-4.1 仅通过 API 提供。在 ChatGPT 中,指令遵循、编码和智能方面的许多改进已逐步融入最新版的GPT-4o,OpenAI将在未来的版本中继续融入更多内容。
下面,将分析 GPT-4.1 在多个基准测试中的表现,并结合 Windsurf、Qodo、Hex、Blue J、Thomson Reuters 和 Carlyle 等 alpha 测试人员的示例,展示其在特定领域任务的生产中的表现。
特点一:编码能力提升
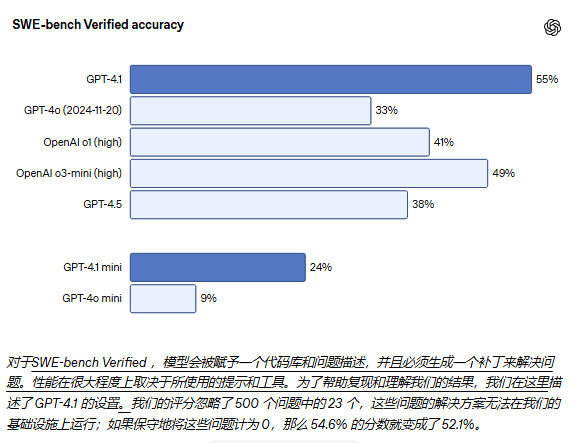
GPT-4.1 在各种编码任务上都比 GPT-4o 表现得更好,包括代理解决编码任务、前端编码、减少无关编辑、可靠地遵循差异格式、确保一致的工具使用等等。 在衡量真实世界软件工程技能的 SWE-bench Verified 测试中,GPT-4.1 完成了 54.6% 的任务,而 GPT-4o(2024-11-20)的完成率为 33.2%。这反映了模型在探索代码库、完成任务以及生成可运行并通过测试的代码方面的能力有所提升。
在SWE‑bench Verified accuracy正确性对比
对比模型有GPT-4.1、GPT-4o (2024-11-20)、OpenAI o1 (high)、OpenAI o3-mini (high)、GPT-4.5、GPT-4.1 mini、GPT-4o mini
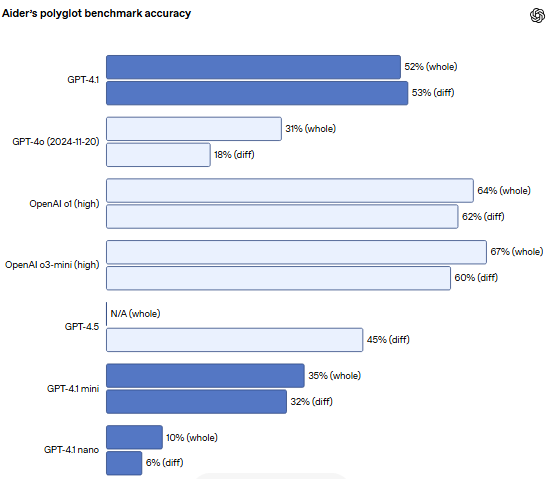
特点二:多编程语言支持
对于需要编辑大型文件的 API 开发者来说,GPT-4.1 在跨多种格式的代码差异分析方面更加可靠。在Aider 的多语言差异基准测试中,GPT-4.1 的得分是 GPT-4o 的两倍多。甚至比 GPT-4.5 还高出 8% 。这项评估既衡量了跨各种编程语言的编码能力,也衡量了模型在整体和差异格式下生成更改的能力。OpenAI还专门训练了 GPT-4.1,使其能够更可靠地遵循差异格式,这使得开发人员只需让模型输出更改的行,而无需重写整个文件,从而节省成本和延迟。为了获得最佳的代码差异性能,请参阅 prompting-gpt-4-1-models
提示指南,对于喜欢重写整个文件的开发者,OpenAI将 GPT-4.1 的输出令牌限制增加到 32,768 个令牌(GPT-4o 为 16,384 个令牌)。并建议使用预测输出减少完整文件重写的延迟。 在 Aider 的多语言基准测试中,模型解决了来自Exercism的编码练习通过编辑源文件,允许重试一次。“whole”格式要求模型重写整个文件,这可能很慢且成本高昂。“diff”格式要求模型编写一系列搜索/替换块。
GPT-4.1 在前端编码方面也比 GPT-4o 有了显著提升,能够创建功能更强大、更美观的 Web 应用。在我们的面对面对比中,付费人工评分员 80% 的评分结果显示,GPT-4.1 的网站比 GPT-4o 的网站更受欢迎。
特点三:长上下文(最多可以处理100W个上下文标记)
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 最多可以处理 100 万个上下文标记,而之前的 GPT-4o 型号最多可以处理 128,000 个。100 万个标记相当于整个 React 代码库的 8 个以上副本,因此长上下文非常适合处理大型代码库或大量长文档。 OpenAI训练了 GPT-4.1,使其能够可靠地处理长达 100 万个上下文中的信息。此外,我们还训练它比 GPT-4o 更加可靠地识别相关文本,并忽略长短上下文中的干扰项。长上下文理解是法律、编码、客户支持以及许多其他领域应用的关键能力。
特点四:图像视觉
GPT-4.1 系列在图像理解方面非常强大,尤其是 GPT-4.1 mini 实现了重大的飞跃,在图像基准测试中经常击败 GPT-4o。
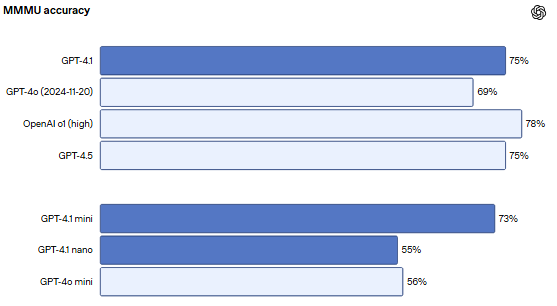
在 MMMU中,模型回答包含图表、图解、地图等的问题。(注意:即使不包含图像,许多答案仍然可以从上下文中推断或猜测。)
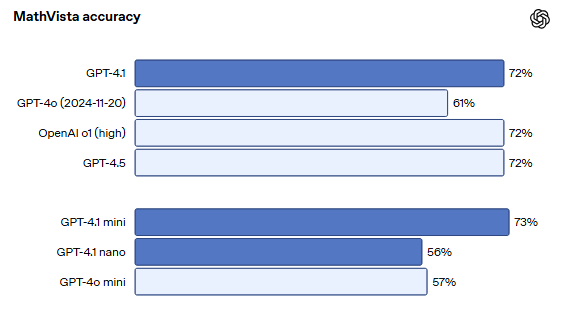
在MathVista中,一个模型解决了视觉数学任务。
看长视频内容然后回答问题正确性对比

在 Video-MME
视频-MME中,一个模型根据 30-60 分钟长的无字幕视频回答多项选择题。
如何订阅升级ChatGPTplus?如何使用GPT-4.1
目前所有的chatgptPlus用户已经被推送 了GPT-4.1模型(在更多模型里面就可以使用),对于普通用户,现在也可以使用GPT-4.1
GPT-4.1使用次数限制
免费用户每24小时最多使用5次GPT-4.1,超出后自动切换其它模型;Plus用户每3小时最多使用80次
如何升级ChatGPTplus?
plus用户升级可以参考本教程:https://littlemagic8.github.io/2024/09/04/update-ChatGPT-Plus/ (笔者已经使用了一年多了,保证可行)
GPT-4.1 实例展示
我们使用镜像站(chatshare)来演示一番,目前镜像站GPT-4.1已经被推送了
PS: 想要体验共享原生镜像站的童鞋可以参考本文: https://littlemagic8.github.io/2025/04/10/how-use-share-AI-model/
实例一:AI 驱动的社交媒体分析工具
提示词:使用 Python 开发一个社交媒体分析工具,分析指定 X 用户(如 @elonmusk)最近 100 条帖子的情绪和关键词。
要求: 1. 通过 X API 获取帖子(假设 API 密钥为 'X_API_KEY')。
2. 使用 NLTK 进行情绪分析,分类为积极、消极、中性。
3. 提取前 10 个高频关键词(去除停用词)。
4. 生成柱状图(使用 Matplotlib)显示情绪分布,保存为 'sentiment_analysis.png'。
5. 输出结果为 JSON 文件 'user_analysis.json',包含情绪分布和关键词。 确保代码有错误处理、日志记录和详细注释,适合生产环境。
import os
import sys
import json
import logging
import requests
from collections import Counter
from typing import List, Dict
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
# === 初始化 NLTK 资源 ===
try:nltk.data.find('tokenizers/punkt')
except LookupError:nltk.download('punkt')
try:nltk.data.find('corpora/stopwords')
except LookupError:nltk.download('stopwords')
try:nltk.data.find('sentiment/vader_lexicon')
except LookupError:nltk.download('vader_lexicon')
# === 日志配置 ===
logging.basicConfig(level=logging.INFO,format='%(asctime)s %(levelname)s %(message)s',handlers=[logging.StreamHandler(sys.stdout), # 输出到控制台logging.FileHandler("social_media_analysis.log", encoding='utf-8')]
)
logger = logging.getLogger(__name__)
class SocialMediaAnalyzer:def __init__(self, api_key: str):self.api_key = api_keyself.base_url = "https://api.twitter.com/2" # 假设 X API 为 Twitter v2 类似结构self.headers = {"Authorization": f"Bearer {self.api_key}"}self.sia = SentimentIntensityAnalyzer()self.stop_words = set(stopwords.words('english'))
def fetch_tweets(self, username: str, max_results: int = 100) -> List[str]:"""通过 X API 获取用户近 100 条推文文本内容:param username: str, 用户名 (如 '@elonmusk' 可自动去除 '@'):param max_results: int, 最多获取的推文数量(最多 100 条):return: List[str], 文本列表"""username = username.lstrip('@')logger.info(f"开始获取用户 @{username} 的最近 {max_results} 条帖子")try:# Step1: 获取用户IDuser_resp = requests.get(f"{self.base_url}/users/by/username/{username}",headers=self.headers,timeout=10)user_resp.raise_for_status()user_id = user_resp.json()['data']['id']logger.debug(f"获取到用户ID: {user_id}")
# Step2: 获取用户推文# max_results 最大为100,分页可改进,此处单调用就够params = {"max_results": max_results,"tweet.fields": "text", # 只要文本字段"exclude": "retweets,replies" # 排除转推和回复短内容(如需)}tweets_resp = requests.get(f"{self.base_url}/users/{user_id}/tweets",headers=self.headers,params=params,timeout=15)tweets_resp.raise_for_status()
tweets_data = tweets_resp.json()texts = [tweet.get('text', '') for tweet in tweets_data.get('data', [])]logger.info(f"成功获取 {len(texts)} 条帖子")return textsexcept requests.RequestException as e:logger.error(f"获取推文失败: {e}")return []except KeyError as e:logger.error(f"解析API返回数据失败,缺少键: {e}")return []
def analyze_sentiments(self, texts: List[str]) -> Dict[str, int]:"""使用 VADER 情绪分析,对文本分类为积极、中性、消极,统计数量:param texts: List[str]:return: dict 情绪计数"""logger.info("开始进行情绪分析")sentiment_counts = {'positive': 0,'neutral': 0,'negative': 0}for text in texts:score = self.sia.polarity_scores(text)compound = score['compound']
if compound >= 0.05:sentiment_counts['positive'] += 1elif compound <= -0.05:sentiment_counts['negative'] += 1else:sentiment_counts['neutral'] += 1logger.info(f"情绪分析结果: {sentiment_counts}")
return sentiment_counts
def extract_keywords(self, texts: List[str], top_n: int = 10) -> List[str]:"""提取文本中的关键词(高频词,排除停用词和标点):param texts: 文本列表:param top_n: 前多少个:return: 关键词列表"""logger.info("开始提取关键词")all_words = []for text in texts:tokens = word_tokenize(text.lower())words = [w for w in tokens if w.isalpha() and w not in self.stop_words]all_words.extend(words)
word_counts = Counter(all_words)common_words = [word for word, count in word_counts.most_common(top_n)]logger.info(f"关键词提取结果: {common_words}")return common_words
def plot_sentiment_distribution(self, sentiment_counts: Dict[str, int], filename: str = 'sentiment_analysis.png'):"""生成情绪柱状图并保存:param sentiment_counts: dict {情绪: 数量}:param filename: 文件名"""logger.info(f"生成情绪分布图: {filename}")try:labels = list(sentiment_counts.keys())counts = [sentiment_counts[label] for label in labels]
plt.figure(figsize=(6, 4))bars = plt.bar(labels, counts, color=['green', 'gray', 'red'])plt.title("Sentiment Distribution")plt.xlabel("Sentiment")plt.ylabel("Number of Posts")plt.grid(axis='y', linestyle='--', alpha=0.7)
# 在柱上标数字for bar in bars:yval = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2, yval + 0.5, int(yval), ha='center', va='bottom')
plt.tight_layout()plt.savefig(filename)plt.close()logger.info("情绪分布图保存成功")except Exception as e:logger.error(f"绘制情绪分布图失败: {e}")
def save_analysis_json(self, username: str, sentiment_counts: Dict[str, int], keywords: List[str], filename='user_analysis.json'):"""保存分析结果为 JSON 文件"""logger.info(f"保存分析结果到 {filename}")data = {'username': username,'sentiments': sentiment_counts,'keywords': keywords}try:with open(filename, 'w', encoding='utf-8') as f:json.dump(data, f, indent=4, ensure_ascii=False)logger.info("保存 JSON 成功")except Exception as e:logger.error(f"保存 JSON 失败: {e}")
def main():API_KEY = os.getenv('X_API_KEY', 'X_API_KEY') # 你也可以在环境变量设置X_API_KEYtarget_user = '@elonmusk'
analyzer = SocialMediaAnalyzer(API_KEY)
posts = analyzer.fetch_tweets(target_user, max_results=100)if not posts:logger.error("未获取到任何帖子,程序退出")return
sentiment_counts = analyzer.analyze_sentiments(posts)keywords = analyzer.extract_keywords(posts, top_n=10)analyzer.plot_sentiment_distribution(sentiment_counts, 'sentiment_analysis.png')analyzer.save_analysis_json(target_user, sentiment_counts, keywords, 'user_analysis.json')
logger.info("分析完成,文件已生成。")
if __name__ == '__main__':main()
import os
import sys
import json
import logging
import requests
from collections import Counter
from typing import List, Dict
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
# === 初始化 NLTK 资源 ===
try:nltk.data.find('tokenizers/punkt')
except LookupError:nltk.download('punkt')
try:nltk.data.find('corpora/stopwords')
except LookupError:nltk.download('stopwords')
try:nltk.data.find('sentiment/vader_lexicon')
except LookupError:nltk.download('vader_lexicon')
# === 日志配置 ===
logging.basicConfig(level=logging.INFO,format='%(asctime)s %(levelname)s %(message)s',handlers=[logging.StreamHandler(sys.stdout), # 输出到控制台logging.FileHandler("social_media_analysis.log", encoding='utf-8')]
)
logger = logging.getLogger(__name__)
class SocialMediaAnalyzer:def __init__(self, api_key: str):self.api_key = api_keyself.base_url = "https://api.twitter.com/2" # 假设 X API 为 Twitter v2 类似结构self.headers = {"Authorization": f"Bearer {self.api_key}"}self.sia = SentimentIntensityAnalyzer()self.stop_words = set(stopwords.words('english'))
def fetch_tweets(self, username: str, max_results: int = 100) -> List[str]:"""通过 X API 获取用户近 100 条推文文本内容:param username: str, 用户名 (如 '@elonmusk' 可自动去除 '@'):param max_results: int, 最多获取的推文数量(最多 100 条):return: List[str], 文本列表"""username = username.lstrip('@')logger.info(f"开始获取用户 @{username} 的最近 {max_results} 条帖子")try:# Step1: 获取用户IDuser_resp = requests.get(f"{self.base_url}/users/by/username/{username}",headers=self.headers,timeout=10)user_resp.raise_for_status()user_id = user_resp.json()['data']['id']logger.debug(f"获取到用户ID: {user_id}")
# Step2: 获取用户推文# max_results 最大为100,分页可改进,此处单调用就够params = {"max_results": max_results,"tweet.fields": "text", # 只要文本字段"exclude": "retweets,replies" # 排除转推和回复短内容(如需)}tweets_resp = requests.get(f"{self.base_url}/users/{user_id}/tweets",headers=self.headers,params=params,timeout=15)tweets_resp.raise_for_status()
tweets_data = tweets_resp.json()texts = [tweet.get('text', '') for tweet in tweets_data.get('data', [])]logger.info(f"成功获取 {len(texts)} 条帖子")return textsexcept requests.RequestException as e:logger.error(f"获取推文失败: {e}")return []except KeyError as e:logger.error(f"解析API返回数据失败,缺少键: {e}")return []
def analyze_sentiments(self, texts: List[str]) -> Dict[str, int]:"""使用 VADER 情绪分析,对文本分类为积极、中性、消极,统计数量:param texts: List[str]:return: dict 情绪计数"""logger.info("开始进行情绪分析")sentiment_counts = {'positive': 0,'neutral': 0,'negative': 0}for text in texts:score = self.sia.polarity_scores(text)compound = score['compound']
if compound >= 0.05:sentiment_counts['positive'] += 1elif compound <= -0.05:sentiment_counts['negative'] += 1else:sentiment_counts['neutral'] += 1logger.info(f"情绪分析结果: {sentiment_counts}")
return sentiment_counts
def extract_keywords(self, texts: List[str], top_n: int = 10) -> List[str]:"""提取文本中的关键词(高频词,排除停用词和标点):param texts: 文本列表:param top_n: 前多少个:return: 关键词列表"""logger.info("开始提取关键词")all_words = []for text in texts:tokens = word_tokenize(text.lower())words = [w for w in tokens if w.isalpha() and w not in self.stop_words]all_words.extend(words)
word_counts = Counter(all_words)common_words = [word for word, count in word_counts.most_common(top_n)]logger.info(f"关键词提取结果: {common_words}")return common_words
def plot_sentiment_distribution(self, sentiment_counts: Dict[str, int], filename: str = 'sentiment_analysis.png'):"""生成情绪柱状图并保存:param sentiment_counts: dict {情绪: 数量}:param filename: 文件名"""logger.info(f"生成情绪分布图: {filename}")try:labels = list(sentiment_counts.keys())counts = [sentiment_counts[label] for label in labels]
plt.figure(figsize=(6, 4))bars = plt.bar(labels, counts, color=['green', 'gray', 'red'])plt.title("Sentiment Distribution")plt.xlabel("Sentiment")plt.ylabel("Number of Posts")plt.grid(axis='y', linestyle='--', alpha=0.7)
# 在柱上标数字for bar in bars:yval = bar.get_height()plt.text(bar.get_x() + bar.get_width()/2, yval + 0.5, int(yval), ha='center', va='bottom')
plt.tight_layout()plt.savefig(filename)plt.close()logger.info("情绪分布图保存成功")except Exception as e:logger.error(f"绘制情绪分布图失败: {e}")
def save_analysis_json(self, username: str, sentiment_counts: Dict[str, int], keywords: List[str], filename='user_analysis.json'):"""保存分析结果为 JSON 文件"""logger.info(f"保存分析结果到 {filename}")data = {'username': username,'sentiments': sentiment_counts,'keywords': keywords}try:with open(filename, 'w', encoding='utf-8') as f:json.dump(data, f, indent=4, ensure_ascii=False)logger.info("保存 JSON 成功")except Exception as e:logger.error(f"保存 JSON 失败: {e}")
def main():API_KEY = os.getenv('X_API_KEY', 'X_API_KEY') # 你也可以在环境变量设置X_API_KEYtarget_user = '@elonmusk'
analyzer = SocialMediaAnalyzer(API_KEY)
posts = analyzer.fetch_tweets(target_user, max_results=100)if not posts:logger.error("未获取到任何帖子,程序退出")return
sentiment_counts = analyzer.analyze_sentiments(posts)keywords = analyzer.extract_keywords(posts, top_n=10)analyzer.plot_sentiment_distribution(sentiment_counts, 'sentiment_analysis.png')analyzer.save_analysis_json(target_user, sentiment_counts, keywords, 'user_analysis.json')
logger.info("分析完成,文件已生成。")
if __name__ == '__main__':main()说明
-
获取推文: 通过假设的 Twitter API v2(X API类似)接口,先获取用户ID再拉取最近帖子。
-
情绪分析: 使用 NLTK 的 VADER 对帖子打分并分类正面、中性、负面。
-
关键词提取: 分词后去除停用词和非字母字符,统计出现频率取前10。
-
可视化: Matplotlib 绘制并保存情绪分布柱状图。
-
输出: JSON 文件包含用户名、情绪结果和关键词列表。
-
日志记录: 全过程详细日志,保存到 social_media_analysis.log,并打印到控制台。
-
错误处理: 关键请求和文件操作有异常捕获,确保稳定运行。
请替换 API_KEY 为你真实的 X API Key,并确保网络通畅,可以访问 X API。 如果你需要帮助接入真实 API 或扩展功能,也欢迎随时告诉我。
实列二:对离线或者在线视频人物进行打码处理代码实现
提示词:设计实现可以对离线/在线直播视频中的指定的人物们进行打马赛克的插件 使用python实现,使用方法:输入相关人物的图片(支持多个人物,并且每个人物有多个图片),如果是离线视频就可以直接导入一个目标视频,输出指定人物被打码的视频;对于直播视频则直接打码处理
好的,下面给出一个更详细的版本,包含完整代码实现、详细代码注释说明、操作示例,并且讲解演示效果如何。此方案基于 Python,核心使用 face_recognition 实现人脸识别,opencv-python 用于视频读取与处理。此版本支持:
-
输入多个人物,每个人物多张图片做特征库
-
离线视频文件处理,输出带指定人物打码的视频
-
实时摄像头直播流处理,实时对指定人物打码显示
详细设计与代码示例
一、准备环境
建议先执行:
pip install face_recognition opencv-python numpy
备注:face_recognition依赖 dlib,安装时如果遇到问题,建议搜索对应系统dlib安装方案。
二、人脸特征编码模块
该模块负责从输入的多个人物多张图片,提取每个人脸的特征编码,特征由128维向量表示。
import face_recognition
from typing import List
def build_known_faces(image_paths_list: List[List[str]]) -> List[List]:"""作用:根据多个人物的图片列表,计算对应的人脸编码列表输入:image_paths_list - List[List[str]],每个人对应多张图片路径的列表例如:[['person1_img1.jpg', 'person1_img2.jpg'],['person2_img1.jpg', 'person2_img2.jpg', ...],...]返回:known_faces_encodings - List[List],每个人对应多张人脸编码的列表"""known_faces_encodings = []for person_images in image_paths_list:encodings = []for img_path in person_images:image = face_recognition.load_image_file(img_path)face_encs = face_recognition.face_encodings(image)if len(face_encs) > 0:encodings.append(face_encs[0])else:print(f"[WARNING] No face found in {img_path}")if len(encodings) == 0:print("[ERROR] No valid face encodings for one person, skipped")continueknown_faces_encodings.append(encodings)return known_faces_encodings-
这个模块会加载每个输入图片,提取第一个发现的人脸编码;如果某张图片没有检测到人脸则提示警告。
-
最终返回每个人对应的一组编码集合。
三、打码马赛克函数模块
该模块实现实际对图像中指定人脸区域进行“打马赛克”。
import cv2
import numpy as np
def mosaic_face(image: np.ndarray, face_location, mosaic_scale=0.05) -> np.ndarray:"""打马赛克功能,把指定区域马赛克处理参数解释:image: 输入BGR图像face_location: (top, right, bottom, left)人脸区域坐标mosaic_scale: 马赛克缩放比例,数值越小马赛克越粗糙返回:处理后的图像"""top, right, bottom, left = face_location# 防止坐标越界top = max(top, 0)left = max(left, 0)bottom = min(bottom, image.shape[0])right = min(right, image.shape[1])face = image[top:bottom, left:right]
# 计算缩放尺寸(宽、高)w = right - lefth = bottom - topif w == 0 or h == 0:return image
small = cv2.resize(face, (max(1,int(w*mosaic_scale)), max(1,int(h*mosaic_scale))), interpolation=cv2.INTER_LINEAR)mosaic_face = cv2.resize(small, (w, h), interpolation=cv2.INTER_NEAREST)
image[top:bottom, left:right] = mosaic_face
return image-
通过先缩小ROI区域,再放大,实现像素块放大效果,产生马赛克
-
mosaic_scale 控制颗粒大小,范围约0.03~0.1,根据清晰度与识别需求选取
四、离线视频处理模块
import cv2
import face_recognition
import numpy as np
def process_offline_video(input_path: str, output_path: str, known_faces_encodings: List[List],tolerance=0.6, mosaic_scale=0.05):"""对输入视频中与known_faces匹配的人物进行打马赛克并输出新视频参数:- input_path: 输入视频路径- output_path: 输出视频保存路径- known_faces_encodings: 已构建的多个人物的脸部编码集- tolerance:匹配门槛,越小匹配越严格- mosaic_scale: 马赛克颗粒度"""video_capture = cv2.VideoCapture(input_path)if not video_capture.isOpened():print(f"[ERROR] Cannot open video file {input_path}")return
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 保存格式可按需调整fps = video_capture.get(cv2.CAP_PROP_FPS)width = int(video_capture.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(video_capture.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
frame_num = 0total_frames = int(video_capture.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"[INFO] Video opened. Total frames: {total_frames}, FPS: {fps}")
while True:ret, frame = video_capture.read()if not ret:breakframe_num += 1rgb_frame = frame[:, :, ::-1] # BGR->RGB 用于 face_recognition
# 检测人脸坐标和编码face_locations = face_recognition.face_locations(rgb_frame)face_encodings = face_recognition.face_encodings(rgb_frame, face_locations)
for face_encoding, face_location in zip(face_encodings, face_locations):# 分别匹配所有指定人物的编码集match_found = Falsefor person_encodings in known_faces_encodings:matches = face_recognition.compare_faces(person_encodings, face_encoding, tolerance=tolerance)if True in matches:match_found = Truebreakif match_found:# 对该区域打马赛克frame = mosaic_face(frame, face_location, mosaic_scale=mosaic_scale)
out.write(frame)
if frame_num % 30 == 0:print(f"[INFO] Processed {frame_num}/{total_frames} frames...")
video_capture.release()out.release()print(f"[INFO] Process completed. Output saved to {output_path}")工作流程解释:
-
提取视频的FPS/分辨率用于写入新视频
-
循环逐帧处理
-
使用face_recognition 得到每帧的人脸定位与编码
-
比对是否属于指定人物,匹配成功就用马赛克函数替换画面人脸区域
-
写入输出文件
五、直播视频流处理(摄像头示范)
def process_live_stream(known_faces_encodings: List[List], tolerance=0.6, mosaic_scale=0.05):"""读取摄像头视频,实时识别并对指定人物打码"""cap = cv2.VideoCapture(0) # 取系统默认摄像头
if not cap.isOpened():print("[ERROR] Cannot open webcam")return
print("[INFO] Starting live stream. Press 'q' to quit.")
while True:ret, frame = cap.read()if not ret:print("[WARNING] Failed to grab frame")break
rgb_frame = frame[:, :, ::-1]
face_locations = face_recognition.face_locations(rgb_frame)face_encodings = face_recognition.face_encodings(rgb_frame, face_locations)
for face_encoding, face_location in zip(face_encodings, face_locations):match_found = Falsefor person_encodings in known_faces_encodings:matches = face_recognition.compare_faces(person_encodings, face_encoding, tolerance=tolerance)if True in matches:match_found = Truebreakif match_found:frame = mosaic_face(frame, face_location, mosaic_scale=mosaic_scale)
cv2.imshow('Live Stream (Press q to Quit)', frame)if cv2.waitKey(1) & 0xFF == ord('q'):break
cap.release()cv2.destroyAllWindows()六、插件整体封装
class MosaicPlugin:def __init__(self, known_faces_images_list: List[List[str]], tolerance: float=0.6, mosaic_scale: float=0.05):"""初始化,准备好已知人物的人脸编码"""print("[INFO] Building known faces encoding from images...")self.known_faces_encodings = build_known_faces(known_faces_images_list)self.tolerance = toleranceself.mosaic_scale = mosaic_scaleprint(f"[INFO] Plugin initialized with {len(self.known_faces_encodings)} persons.")
def process_video(self, input_video_path: str, output_video_path: str):"""离线视频文件处理"""print(f"[INFO] Processing video {input_video_path}...")process_offline_video(input_video_path, output_video_path, self.known_faces_encodings,self.tolerance, self.mosaic_scale)
def process_live(self):"""实时摄像头直播视频处理"""print("[INFO] Starting live stream processing...")process_live_stream(self.known_faces_encodings, self.tolerance, self.mosaic_scale)七、操作示例
假设有两个人物,分别保存在 data/person1 和 data/person2 文件夹,里面是多张该人物图片。
准备文件结构
project_dir/ │ ├── data/ │ ├── person1/ │ │ ├── img1.jpg │ │ └── img2.jpg │ └── person2/ │ ├── img1.jpg │ └── img2.jpg ├── input.mp4 # 目标视频 ├── mosaic_plugin.py # 本代码脚本 └── demo.py
demo.py 内容示例
from mosaic_plugin import MosaicPlugin
def get_person_image_paths():import osbase_dir = 'data'person1 = [os.path.join(base_dir, 'person1', f) for f in os.listdir(os.path.join(base_dir, 'person1')) if f.endswith('.jpg')]person2 = [os.path.join(base_dir, 'person2', f) for f in os.listdir(os.path.join(base_dir, 'person2')) if f.endswith('.jpg')]return [person1, person2]
if __name__ == "__main__":known_faces = get_person_image_paths()
plugin = MosaicPlugin(known_faces, tolerance=0.5, mosaic_scale=0.05)
# 离线视频马赛克处理演示plugin.process_video('input.mp4', 'output_masked.mp4')
# 实时摄像头直播演示(按q退出)# plugin.process_live()八、演示效果说明
-
离线视频处理效果: 输出文件 output_masked.mp4 会与原视频时长、画质基本相同。 视频中与输入库人物匹配的人物脸部区域,都会被马赛克遮挡。 一般情况下,识别算法准确率较高,但复杂角度、光线弱等情况下可能漏识别。 对于不重要的人物不会打码,保证视频内容清晰。
-
实时直播摄像头效果: 打开摄像头后,会实时捕捉图像,根据输入的人脸编码库识别,在窗口中显示带马赛克的视频窗口。 当检测到指定人物,面部会被像素化处理,保护隐私。按 q 关闭窗口并退出程序。
-
灵活调节参数: tolerance 控制识别匹配的严格程度,一般0.4~0.6间保守 mosaic_scale 调节马赛克颗粒度,颗粒数越少遮挡越明显但不影响帧率
常见问题与建议
-
视频文件或摄像头打开问题,确保路径正确且权限正常。
-
face_recognition使用的是HOG和CNN两种模型,默认是HOG快速模式,也可以改用CNN解码。
-
可考虑替换更高效/准确的模型进行人脸检测或身份识别(比如 InsightFace,MTCNN + ArcFace等)。
-
实时直播对性能要求较高,建议对视频尺寸和帧率进行适当限制。
-
若出现人脸检测失败或打码不准,可尝试用更多样本丰富人物特征编码。
如果你需要还可以帮你扩展:
-
支持指定直播流URL(RTSP等)
-
支持脱敏其他人体部位或自定义打码样式
-
支持推送处理后的直播流
实例三:图片理解能力展示
提示词:这张图片说了写啥,我需要复刻,我要按照这个进行我的sass,请给我完整详细的工作计划,涉及的工具和资料,请详细规划

好的,基于你提供的图片内容,这张图片讲的是“用AI在周末快速构建一个赚钱的SaaS产品只需要12步”的流程。你需要按照这个流程复刻SaaS产品,下面我将给你一个完整且详细的工作计划,包含每一步要做的内容、所用工具和所需资料。
用AI在周末快速构建SaaS产品完整详细工作计划
目标
利用AI的能力,通过12个明确步骤,在短时间内完成一个SaaS产品的从构思到设计的全过程,快速验证并落地产品。
第1步:确定产品方向
-
目标: 明确想要开发的SaaS产品类型和定位(例如客户管理、团队协作等)。
-
操作:
-
团队头脑风暴。
-
结合自身资源、兴趣点、市场机会选定方向。
-
工具:
-
头脑风暴工具(Miro,MindMeister)
-
记事工具(Notion/OneNote)
-
资料准备:
-
行业分析报告
-
市场趋势文章
-
竞争对手简要名单
第2步:市场调研
-
目标: 深入分析市场,确认市场需求和痛点。
-
操作:
-
利用AI工具进行竞品调研
-
收集目标用户反馈和需求数据
-
工具:
-
Gemini(Google的AI工具,用于数据检索)
-
SurveyMonkey或Google Forms设计问卷调查
-
行业数据平台(如Statista)
-
资料准备:
-
竞品市场表现数据
-
产品点评与用户评价
-
目标用户访谈整理数据
第3步:竞品分析
-
目标: 详细拆解竞品功能和卖点,确定自身产品差异化方向。
-
操作:
-
作出竞品功能横向对比表
-
分析竞品优势与缺陷
-
工具:
-
Excel或Google Sheets(做功能矩阵)
-
SWOT分析工具(MindTools, Lucidchart)
-
资料准备:
-
竞品介绍文档和官网
-
用户反馈和评价集中总结
第4步:验证想法
-
目标: 用AI工具提出20个问题验证产品创意是否可行和完善。
-
操作:
-
编写产品创意概要
-
用Claude(AI对话工具)提出验证问题
-
根据问题修改优化创意
-
工具:
-
Claude (OpenAI)
-
文字记录工具如Notion/Trello
-
资料准备:
-
竞品疑难点汇总
-
市场反馈
第5步:撰写需求文档(PRD)
-
目标: 形成详细产品需求文档,包括功能描述、用户场景。
-
操作:
-
结合前期调研和问题验证,撰写文档
-
用AI辅助生成文档,提升效率
-
工具:
-
Claude或Notion AI(撰写文档)
-
文档管理工具(Google Docs, Confluence)
-
资料准备:
-
验证阶段问题与结论
-
竞品功能结构总结
第6步:形成设计
-
目标: 设计产品的整体架构和主要流程。
-
操作:
-
画出产品框架图
-
明确用户使用流程
-
工具:
-
Lucidchart或Miro(流程图/架构图)
-
纸笔草图作为辅助
-
资料准备:
-
PRD文档
-
用户体验设计原则
第7步:拆分UI模块
-
目标: 将整个产品界面拆解成独立的UI模块,方便迭代开发。
-
操作:
-
基于设计图拆分模块
-
制作模块列表和UI要素
-
工具:
-
Figma、Sketch、Adobe XD(界面设计)
-
Notion/Trello任务拆解
-
资料准备:
-
设计图纸
-
UI规范文档
第8步(额外建议):产品原型制作
-
目标: 基于UI模块制作原型,进行内部验证与修改。
-
操作:
-
创建交互原型
-
内部测试产品流程
-
工具:
-
Figma 原型设计
-
InVision
-
资料准备:
-
UI模块设计稿
-
PRD文档
第9步(额外建议):确定技术架构和开发计划
-
目标: 定义产品的技术框架和开发路线。
-
操作:
-
技术选型(前端、后端、数据库、API等)
-
制定开发里程碑
-
工具:
-
Jira、Trello 任务管理
-
技术文档
-
资料准备:
-
产品PRD与UI设计
-
技术文档和参考资料
第10步(额外建议):开发实施
-
目标: 按计划进行开发,阶段性迭代。
-
操作:
-
代码开发
-
单元测试和集成测试
-
工具:
-
GitHub / GitLab 版本控制
-
CI/CD工具(Jenkins, GitHub Actions)
-
资料准备:
-
项目经理分配任务
-
测试用例和BUG记录
第11步(额外建议):上线前测试
-
目标: 完整的系统测试和用户体验测试。
-
操作:
-
内部测试
-
用户测试
-
工具:
-
Bugzilla、JIRA测试管理
-
UserTesting平台
-
资料准备:
-
测试报告
-
用户反馈记录
第12步(额外建议):正式上线及推广
-
目标: 产品上线并进行市场推广,实现变现。
-
操作:
-
部署上线
-
制定并执行市场营销策略
-
工具:
-
AWS、Azure、Heroku等云平台部署
-
MailChimp,Facebook Ads,Google Ads 等
-
资料准备:
-
营销计划
-
运营团队准备
总结表格
| 步骤 | 内容 | 目标 | 工具 | 资料 |
|---|---|---|---|---|
| 1 | 确定产品方向 | 锁定产品领域 | Miro,Notion | 行业报告,市场趋势 |
| 2 | 市场调研 | 确认需求,痛点 | Gemini,SurveyMonkey | 竞品数据,用户反馈 |
| 3 | 竞品分析 | 找差异点 | Excel,Lucidchart | 竞品详情,用户评价 |
| 4 | 验证想法 | 产品可行性验证 | Claude,Notion | 创意概要,调研反馈 |
| 5 | 撰写需求文档 | 确定功能 | Claude,Google Docs | 竞品以及调研数据 |
| 6 | 形成设计 | 产品架构设计 | Lucidchart,Miro | PRD文档,用户体验原则 |
| 7 | 拆分UI模块 | 界面模块拆分 | Figma,Notion | 设计稿,UI规范 |
| 8 | 制作原型 | 交互验证 | Figma,InVision | UI设计文件 |
| 9 | 技术架构 | 技术规划,开发计划 | Jira,技术文档 | PRD,设计稿 |
| 10 | 开发实施 | 产品开发 | GitHub,CI/CD | 任务分配,测试用例 |
| 11 | 测试 | 保证质量 | Bugzilla,UserTesting | 测试报告,反馈 |
| 12 | 上线及推广 | 产品发布变现 | 云平台,广告平台 | 营销方案,推广内容 |
总结
-
以上计划细化了图片中的12步,确保你依流程稳步推进。
-
重点依赖AI工具(Claude, Gemini)做创意和验证环节的加速。
-
UI设计和项目管理必须用专业工具保证效率。
-
测试和上线步骤建议合理利用团队力量实际完成。
如果你需要,我可以继续帮你针对具体步骤制定更详尽的执行计划和模板。你可以告诉我哪一步想深挖,也可以问我工具的具体用法。祝你SaaS开发成功!
相关文章:

GPT-4.1特点?如何使用GPT-4.1模型,GPT-4.1编码和图像理解能力实例展示
几天前,OpenAI在 API 中推出了三个新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。这些模型的性能全面超越 GPT-4o 和 GPT-4o mini(感觉这个GPT-4.1就是GPT-4o的升级迭代版本),主要在编码和指令跟踪方面均有显著提升。还拥有更大的上下文窗口…...

网络工程师案例分析
✅ Huawei Super VLAN 通信规则总结 🌐 基本结构 Super VLAN:逻辑 VLAN,承载三层网关(VLANIF 接口)。 Sub VLAN:实际的用户 VLAN,不配置 IP,仅做二层转发。 🔒 通信规…...

tcp/ip协议
OSI参考模型 应用层:OSI最高层。确定进程之间通信性质 协议:http:80,https:443,ftp:21,telnet:23,ssh:22,smtp:25,pop3 表示层:处理流经结点的数据编码的表示方式问题,以保证一个系统应用层发出的消息可被另一系统的应用层读出,数据压缩和加…...
)
小红书的视频怎么保存没有水印(方法分享)
你是不是也经常在小红书上刷到超赞的旅行vlog、美妆教程或美食探店视频,想保存下来慢慢看,却发现下载后总有烦人的水印?别急!今天教你一招,3秒轻松保存无水印高清视频,简单又实用! 为什么需要无…...

RK3568解码1080P视频时遇到系统崩溃内核挂掉的解决方案
接上篇rk3568。 实际使用 rock_mpp库硬解码时,会遇到解码1080P视频整个系统卡死,内核崩溃的问题。 以下是内核崩溃的日志,下面这句是典型的内核某块驱动挂掉的信息。 [ 292.469580] Unable to handle kernel NULL pointer dereference at…...

C++ —— Lambda 表达式
🎁个人主页:工藤新一 🔍系列专栏:C面向对象(类和对象篇) 🌟心中的天空之城,终会照亮我前方的路 🎉欢迎大家点赞👍评论📝收藏⭐文章 文章目录 L…...

Keepalived相关配置和高可用
目录 一. Keepalived的工作原理 二. 实现单独的心跳网卡 三. keepalive一些优化 3.1 主从之间加密验证 3.2 修改心跳线发送时间 四. 添加独立日志 五. 抢占模式,非抢占模式,延迟抢占模式 六. 单播地址和多播地址 1. 单播地址(Unicast…...

gtest 库的安装和使用
目录 介绍 安装 使用 介绍 官方文档:GoogleTest 入门 |GoogleTest 谷歌测试 gtest 库是谷歌开源的 C测试单元框架,方便我们测试程序的正确性。 安装 sudo apt-get install libgtest-dev 使用 GTest 中的断言的宏可以分为两类: • ASS…...
)
Python训练营打卡——DAY30(2025.5.19)
目录 模块和库的导入 一、导入官方库 1. 标准导入:导入整个库 2. 从库中导入特定项 3. 非标准导入:导入整个库 二、模块、包的定义 三、使用案例 场景1: main.py 和 circle.py 都在同一目录 场景2: main.py 和 circle.py 都在根目录的子目录 mo…...

Django框架的前端部分使用Ajax请求一
Ajax请求 目录 1.ajax请求使用 2.增加任务列表功能(只有查看和新增) 3.代码展示集合 这篇文章, 要开始讲关于ajax请求的内容了。这个和以前文章中写道的Vue框架里面的axios请求, 很相似。后端代码, 会有一些细节点, 跟前几节文章写的有些区别。 一、ajax请求使用 我们先…...

w~自动驾驶~合集3
我自己的原文哦~ https://blog.51cto.com/whaosoft/13269720 #FastOcc 推理更快、部署友好Occ算法来啦! 在自动驾驶系统当中,感知任务是整个自驾系统中至关重要的组成部分。感知任务的主要目标是使自动驾驶车辆能够理解和感知周围的环境元素&…...

LeetCode 39. 组合总和 LeetCode 40.组合总和II LeetCode 131.分割回文串
LeetCode 39. 组合总和 需要注意的是题目已经明确了数组内的元素不重复(重复的话需要执行去重操作),且元素都为正整数(如果存在0,则会出现死循环)。 思路1:暴力解法 对最后结果进行去重 每一…...
关键字+数据类型 +数据类型输入)
C++(2)关键字+数据类型 +数据类型输入
(1)如下关键字是 不能用于定义变量名和常量名的 !。 如int int 这样就会报错 所以注意即可 。 (2)标识符命名规则 (即变量和常量的命名规则) 最主要注意 第一个 字符必须是字母或是下划线 —…...

第二道re
题目来源:天狩CTF竞赛平台 Lihuas for 题目提示说是for循环,不管了干吧 先看加没加壳,没有,直接无脑IDAF5 代码功能概述 程序会要求用户输入一个 flag,然后将输入的每个字符与索引值进行异或运算,并将结…...

【C语言内存函数】--memcpy和memmove的使用和模拟实现,memset函数的使用,memcmp函数的使用
目录 一.memcpy的使用和模拟实现 1.1--memcpy的使用演示 1.2--memcpy的模拟实现 二.memmove的使用和模拟实现 2.1--memmove的使用演示 2.2--memmove的模拟实现 三.memset函数的使用 3.1--memset的使用演示 3.2--总结 四.memcmp函数的使用 4.1--memcmp的使用演示 4.2…...

java集合详细讲解
Java 8 集合框架详解 Java集合框架是Java中最重要、最常用的API之一,Java 8对其进行了多项增强。下面我将全面讲解Java 8中的集合框架。 一、集合框架概述 Java集合框架主要分为两大类: Collection - 单列集合 List:有序可重复Set…...

UniApp 实现的文件预览与查看功能#三方框架 #Uniapp
UniApp 实现的文件预览与查看功能 前言 在开发移动应用时,文件预览功能是一个非常常见的需求。无论是查看PDF文档、图片还是Office文件,都需要一个稳定且易用的预览解决方案。本文将详细介绍如何在UniApp中实现各类文件的预览功能,并分享一…...

用户行为日志分析的常用架构
## 1. 经典Lambda架构 Lambda架构是一种流行的大数据处理架构,特别适合用户行为日志分析场景。 ### 1.1 架构组成 Lambda架构包含三层: - **批处理层(Batch Layer)**: 存储全量数据并进行离线批处理 - **实时处理层(Speed Layer)**: 处理最新数据&…...

【VBA/word】批量替换字体大小
将5号或6号字体改为10.5号字体(循环10次) AI复制的文案问题调整 Sub Change5or6ptTo16pt_10Loops()Dim rng As RangeDim doc As DocumentDim found As BooleanDim i As IntegerDim totalChanges As LongDim targetSizes As VariantDim size As VariantSe…...

C++类与对象--3 C++对象模型和this指针
3.1 类成员分开存储 成员变量和成员函数在内存中是分开存储的只有非静态成员变量是存储在对象上的 C为空对象分配1字节的空间非空对象的大小为其内部非成员变量大小总和 静态成员不占对象空间不同对象的成员函数共享一个函数实例,不占对象空间(通过th…...

DV SSL证书管理主要有哪些功能?
在互联网信息传输高速发展的今天,用户对网站安全性的要求越来越高。SSL证书已成为网站“身份认证数据加密”的标配。其中,DV SSL证书由于其签发快速、价格低廉、使用广泛,成为大量中小型网站、个人博客、电商平台的首选。然而,选择…...
el-tree结合el-tree-transfer实现穿梭框里展示树形数据
参考文章:我把他的弹框单拉出来一个独立文件作为组件方便使用,遇到一些问题记录一下。 testComponet.vue <template><div class"per_container"><div class"per_con_left"><div class"per_con_title&q…...

浅谈GC机制-三色标记和混合写屏障
标记清除法 stw(stop the world):暂停所有goroutine,扫描出可达与不可达对象,进行回收 三色标记法 不暂停,并发扫描,从根节点出发,扫描过对象的为黑,下一个可达对象为…...

Python训练营打卡 Day30
模块和库的导入 知识点回顾: 导入官方库的三种手段 直接导入整个库:使用 import library_name 语法。 导入库中的特定模块或函数:使用 from library_name import module_name 或 from library_name import function_name。 导入库并起别名&…...

深入探讨死区生成:原理、实现与应用
在电力电子、信号处理等众多领域中,“死区生成”是一个十分关键的概念,它能有效避免器件误动作、减少干扰,保障系统稳定运行。今天就通过问答的形式,和大家深入聊聊死区生成相关知识。 什么是死区生成? 死区生成是指…...

OpenCV 环境搭建与概述
// //OpenCV-4.11.0 C VS2019 // 一、OpenCV学习路线 1、入门: OpenCV图像读写、视频读写、基本像素处理、基本卷积处理、基本C开发知识。 2、初级: OpenCV自定义卷积操作、图像梯度、边缘提取、二值分析、视频分析、形态学处理、几何变换与透视变换。 3、中级: 角点查找、BL…...

c/c++的opencv均值函数
C/C 中的均值函数:从基础到应用 📊 在 C/C 编程中,计算一组数值的**均值(平均值)**是一项非常基础且常见的操作。无论是数据分析、信号处理、图像处理还是机器学习,均值函数都扮演着重要的角色。本文将详细…...

go 数据类型转换
graph TDA[整型<br>int, int8, int16, int32, int64] -->|类型转换| B[浮点型<br>float32, float64]B -->|类型转换| AA -->|类型转换| C[布尔型<br>bool]C -->|类型转换| AB -->|类型转换| D[复数型<br>complex64, complex128]D -->…...

Go内存管理
内存管理 文章目录 内存管理何为内存?内存为什么需要管理?内存管理的方式操作系统存储模型操作系统是怎么管理内存的?虚拟内存与物理内存认识虚拟内存分页管理 Golang 内存模型TCMalloc核心概念go内存管理核心概念GO内存分配GO 内存逃逸机制一…...

解决软件连接RabbitMQ突发System.IO.IOException: 无法从传输连接中读取数据: 远程主机强迫关闭了一个现有的连接异常
一、问题描述 系统再运行时,突然出现 System.Exception: [RabbitMQ.Send Error] RabbitMQ.Client.Exceptions.AlreadyClosedException: Already closed: The AMQP operation was interrupted: AMQP close-reason, initiated by Library, code541, text“Unexpected…...

基于局部显著位置感知的异常掩码合成方法在CT图像肺部疾病异常检测与病变定位中的应用|文献速递-深度学习医疗AI最新文献
Title 题目 Local salient location-aware anomaly mask synthesis for pulmonary disease anomaly detection and lesion localization in CT images 基于局部显著位置感知的异常掩码合成方法在CT图像肺部疾病异常检测与病变定位中的应用 01 文献速递介绍 肺部疾病是全球发…...

【cursor疑惑】cursor续杯后使用agent对话时,提示“需要pro或商业订阅的用户才能使用“
背景 cursor的pro会员体验过期了,想再次体验deepseek、Claude等agent对话提示:“免费版本不可以使用agent对话功能(英文忘记截图了,大意是这样)”。 处理方法 Step-1:再次续杯cursor的pro会员14天体验 详情,见:【c…...
)
2022年下半年信息系统项目管理师——综合知识真题及答案(3)
2022年下半年信息系统项目管理师 ——综合知识真题及答案(3) 零、时光宝盒 (https://blog.csdn.net/weixin_69553582 逆境清醒) 此文是我2025-05-19回复头条上某作者文章时的评论记录,原作者的文章是写那些被有组织…...

华为云Flexus+DeepSeek征文|基于华为云Flexus云服务的云服务器单机部署Dify-LLM应用开发平台
目录 一、前言 二、华为云Flexus云服务优势 三、华为云Flexus一键部署Dify 3.1 选择模板 3.2 参数配置 3.3 资源栈设置 3.4 配置确认 3.5 创建执行计划 3.6 部署 四、Dify-LLM应用开发平台初体验 4.1 访问Dify-LLM应用开发平台 4.2 设置管理员账户 4.3 登录Dify-LLM应用开发平台…...

NC105NC106美光固态颗粒NC108NC109
NC105NC106美光固态颗粒NC108NC109 美光固态颗粒技术矩阵深度解析:NC105/NC106/NC108/NC109的性能博弈与市场卡位 一、技术基因图谱:解密NC系列颗粒的底层架构 1. TLC与QLC的技术路线分野 美光NC系列颗粒呈现出清晰的技术分层:NC105/NC10…...

洛谷U536262 井底之“鸡” 附视频讲解
题目截图 题目背景 2024年山东财经大学新生赛的时候,xz_chicken厌倦了在鸡舍的生活,于是决定把他的主人ZQH写成QH鸡,然而除了在第一题中已经出现了ZQH所在队伍征途再起的合影,同时xz_chicken还露出其他马脚,比如说答案…...
)
特征筛选方法总结(面试准备15)
非模型方法 一.FILTER过滤法: 1.缺失值比例(80%以上缺失则删除)/方差 注意: 连续变量只删方差为0的,因为变量取值范围会影响方差大小。 离散类的看各类取值占比,如果是三分类变量可以视作连续变量。 函数:V…...

深入解析分布式数据库TiDB:原理、优化与架构实践
前言 在云计算与大数据时代,传统单机数据库面临三大挑战:海量数据存储、高并发访问和实时分析需求。MySQL 分库分表方案复杂、NoSQL 缺乏 ACID 支持、MPP 数仓难以处理 OLTP… 在这样的背景下,TiDB 应运而生。作为一款开源的分布式 NewSQL 数…...

YouTube视频字幕转成文章算重复内容吗?
很多创作者误以为「自己说的话不算抄袭」,却不知道YouTube自动生成的字幕早已被搜索引擎存档。 去年就有案例:某美食博主将教程视频字幕转为图文,结果原创度检测仅42%,导致页面权重暴跌。 本文揭秘5个实操技巧:从删除…...

codeup添加流水线docker自动化部署
在项目根目录下增加Dockerfile文件 # 使用基础镜像 FROM maven:3.8.4-openjdk-17-slim AS build # 设置工作目录 WORKDIR /app # 复制项目源代码 COPY . . # 构建项目 RUN mvn clean package -DskipTests # 验证JAR包是否生成 RUN ls -l target/your-project.jar # 使用合适的…...

面试点补充
目录 1. 搭建lnmp Linux 系统基础命令 nginx相关命令 MySQL 相关命令 PHP 相关命令 验证命令 下载并部署 Discuz! X3.4 论坛 到 Nginx 网站 2. 脑裂 2.1 脑裂的定义 2.2 脑裂产生的原因 1. 主备节点之间的心跳线中断 2. 优先级冲突 3. 系统或服务负载过高 2.3 如何…...

深入解析 Oracle session_cached_cursors 参数及性能对比实验
在 Oracle 数据库管理中,session_cached_cursors参数扮演着至关重要的角色,它直接影响着数据库的性能和资源利用效率。本文将深入剖析该参数的原理、作用,并通过性能对比实验,直观展示不同参数设置下数据库的性能表现。 一、sessi…...

MyBatis:动态SQL
文章目录 动态SQLif标签trim标签where标签set标签foreach标签include标签和sql标签 Mybatis动态SQL的官方文档: https://mybatis.net.cn/dynamic-sql.html 动态SQL 动态SQL是 MyBatis的强大特性之一,如果是使用JDBC根据不同条件拼接sql很麻烦,例如拼接…...

数据库性能调优:索引设计、缓存配置与查询计划优化
在高并发、大数据量场景下,数据库性能直接影响系统稳定性与用户体验。 本文将从索引设计、缓存配置、查询计划优化三大核心维度出发,结合实战案例与代码示例,系统解析数据库性能调优的关键策略,并深入讲解 EXPLAIN ANALYZE 与 索引覆盖策略 的应用技巧。 一、索引设计:从…...

安全强化的Linux
SElinux简介 SELinux是security-Enhanced Linux的缩写,意思是安全强化的linux SELinux主要由美国国家安全局(NSA)开发,当初开发的目的是为了避免资源的误用。传统的访问控制在我们开启权限后,系统进程可以直接访问 当我们对权限设置不严谨时,这种访问方式就是系统的安全漏洞 在…...
——应用层(上))
计算机网络(2)——应用层(上)
1.应用层概述 应用层(Application Layer)属于计算机网络体系结构中的最顶层,直接面向用户,提供各种网络服务和应用程序的接口 本文主要的学习内容如下: (1)网络应用进程通信方式 客户端-服务器方式点对点方式混合方式 (2)网络应用的需求与传输…...

day017-磁盘管理-实战
文章目录 1. 硬盘命名规则2. 添加硬盘2.1 查看硬盘名称 3. 硬盘分区3.1 分区命名规则:mbr分区表格式3.2 创建分区:fdisk3.2.1 fdisk -l:查看硬盘及分区信息3.2.2 fdisk /dev/sdc :为该硬盘分区3.2.3 创建扩展分区和逻辑分区3.2.4 保存设置并退…...
,整合IK分词器和安装Kibana)
Win10 安装单机版ES(elasticsearch),整合IK分词器和安装Kibana
一. 先查看本机windows是否安装了ES(elasticsearch),检查方法如下: 检查进程 按 Ctrl Shift Esc 组合键打开 “任务管理器”。在 “进程” 选项卡中,查看是否有 elasticsearch 相关进程。如果有,说明系统安装了 ES。 检查端口…...
:实现字符和汉字的显示)
STM32 控制 OLED 全攻略(二):实现字符和汉字的显示
目录 一 前言 二 OLED介绍 (一)SSD1306 (二)OLED屏幕 三 显示原理结合代码解释 1 指令---0x00 2 数据---0x40 3 初始化oled函数 4 codetab.h 四 显示字符串的原理 🧾 ASCII 编码范围: ✅ OLED_S…...

c#将json字符串转换为对象数组
在C#中,将JSON字符串转换为对象数组是一个常见的需求,特别是在处理来自Web API的响应或需要反序列化本地文件内容时。这可以通过使用Newtonsoft.Json(也称为Json.NET)库或.NET Core内置的System.Text.Json来完成。以下是如何使用这…...