InternLM 论文分类微调实践(XTuner 版)
1.环境安装
我创建开发机选择镜像为Cuda12.2-conda,选择GPU为100%A100的资源配置
Conda 管理环境
conda create -n xtuner_101 python=3.10 -y
conda activate xtuner_101
pip install torch==2.4.0+cu121 torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
pip install xtuner timm flash_attn datasets==2.21.0 deepspeed==0.16.1
conda install mpi4py -y
#为了兼容模型,降级transformers版本
pip uninstall transformers -y
pip install transformers==4.48.0 --no-cache-dir -i https://pypi.tuna.tsinghua.edu.cn/simple检验环境安装
xtuner list-cfg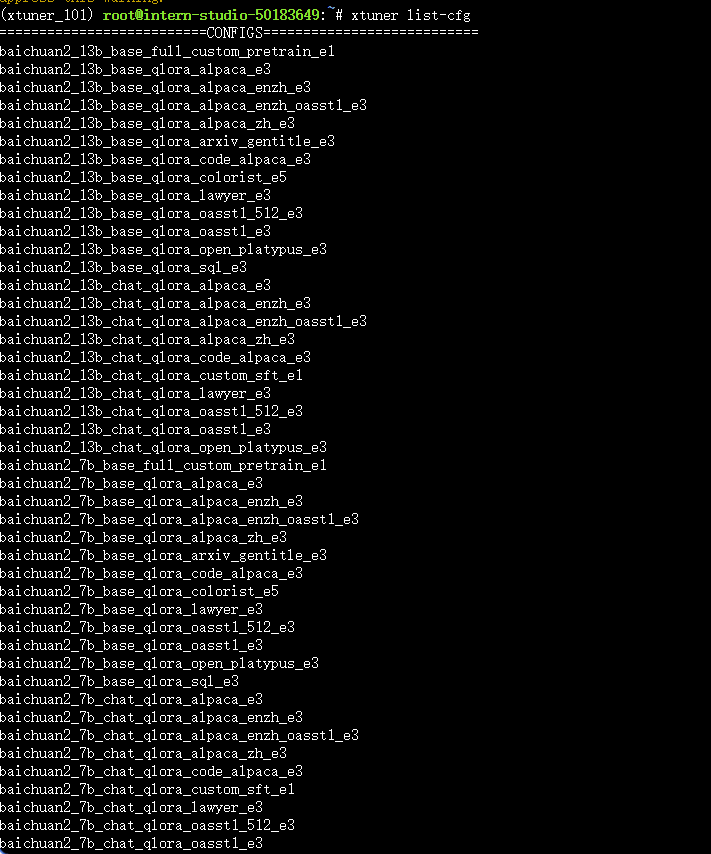
2.数据获取
数据为sftdata.jsonl,已上传。
3.训练
链接模型位置命令
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2_5-7b-chat ./3.1 微调脚本
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook,DistSamplerSeedHook,IterTimerHook,LoggerHook,ParamSchedulerHook,
)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfigfrom xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook,EvaluateChatHook,VarlenAttnArgsToMessageHubHook,
)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = "./internlm2_5-7b-chat"
use_varlen_attn = False# Data
alpaca_en_path = "/root/xtuner/datasets/train/sftdata.jsonl"#换成自己的数据路径
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 2048
pack_to_max_length = True# parallel
sequence_parallel_size = 1# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 1
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 3
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03# Save
save_steps = 500
save_total_limit = 2 # Maximum checkpoints to keep (-1 means unlimited)# Evaluate the generation performance during the training
evaluation_freq = 500
SYSTEM = SYSTEM_TEMPLATE.alpaca
evaluation_inputs = ["请给我介绍五个上海的景点", "Please tell me five scenic spots in Shanghai"]#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side="right",
)model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=dict(type=BitsAndBytesConfig,load_in_4bit=True,load_in_8bit=False,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",),),lora=dict(type=LoraConfig,r=64,lora_alpha=16,lora_dropout=0.1,bias="none",task_type="CAUSAL_LM",),
)#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path='json', data_files=alpaca_en_path),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=alpaca_map_fn,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn,
)sampler = SequenceParallelSampler if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=alpaca_en,sampler=dict(type=sampler, shuffle=True),collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn),
)#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale="dynamic",dtype="float16",
)# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [dict(type=LinearLR,start_factor=1e-5,by_epoch=True,begin=0,end=warmup_ratio * max_epochs,convert_to_iter_based=True,),dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,begin=warmup_ratio * max_epochs,end=max_epochs,convert_to_iter_based=True,),
]# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),dict(type=EvaluateChatHook,tokenizer=tokenizer,every_n_iters=evaluation_freq,evaluation_inputs=evaluation_inputs,system=SYSTEM,prompt_template=prompt_template,),
]if use_varlen_attn:custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 10 iterations.logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per `save_steps`.checkpoint=dict(type=CheckpointHook,by_epoch=False,interval=save_steps,max_keep_ckpts=save_total_limit,),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method="fork", opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend="nccl"),
)# set visualizer
visualizer = None# set log level
log_level = "INFO"# load from which checkpoint
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)# set log processor
log_processor = dict(by_epoch=False)
将模型和地址改为自己的路径
3.2 启动微调
cd /root/101
conda activate xtuner_101
xtuner train internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero1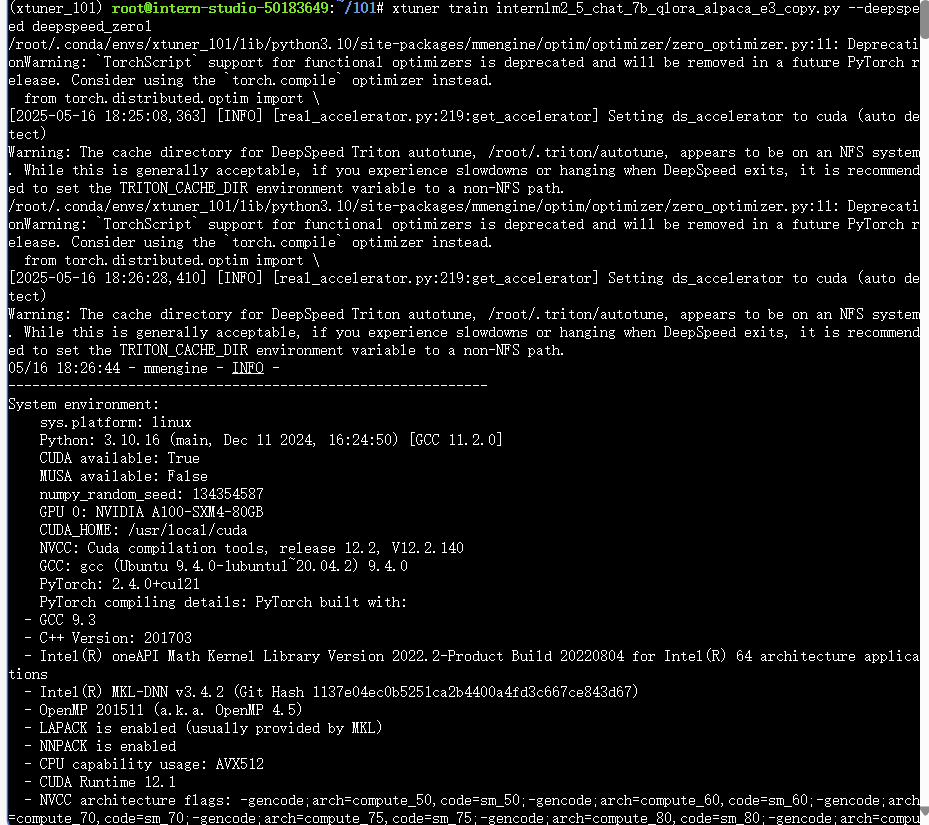
3.3 合并
3.3.1 将PTH格式转换为HuggingFace格式
xtuner convert pth_to_hf internlm2_5_chat_7b_qlora_alpaca_e3_copy.py ./work_dirs/internlm2_5_chat_7b_qlora_alpaca_e3_copy/iter_195.pth ./work_dirs/hf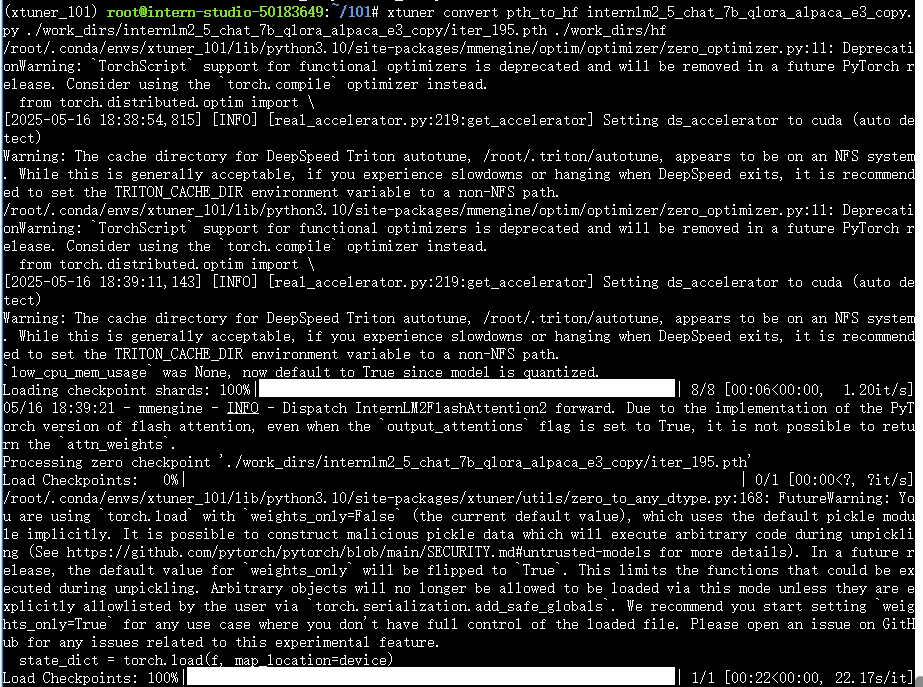
3.3.2 合并adapter和基础模型
xtuner convert merge \
/root/internlm2_5-7b-chat \
./work_dirs/hf \
./work_dirs/merged \
--max-shard-size 2GB \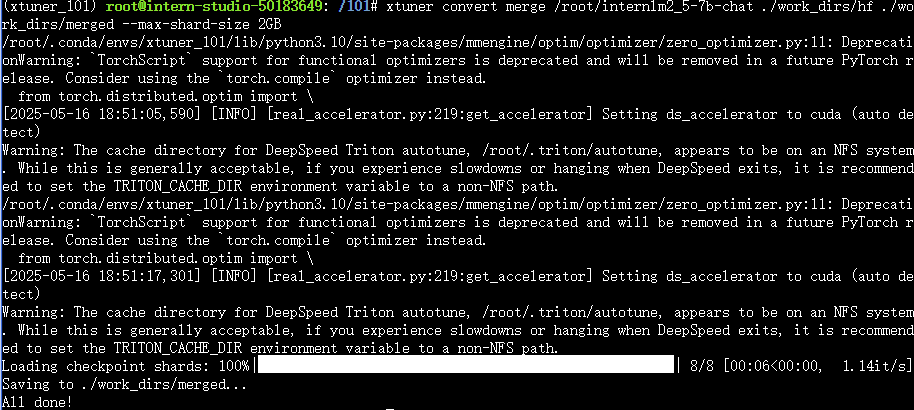
完成这两个步骤后,合并好的模型将保存在./work_dirs/merged目录下,你可以直接使用这个模型进行推理了。
3.4 推理
from transformers import AutoModelForCausalLM, AutoTokenizer
import time# 加载模型和分词器
# model_path = "./lora_output/merged"
model_path = "./internlm2_5-7b-chat"
print(f"加载模型:{model_path}")start_time = time.time()tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True, torch_dtype="auto", device_map="auto"
)def classify_paper(title, authors, abstract, additional_info=""):# 构建输入,包含多选选项prompt = f"Based on the title '{title}', authors '{authors}', and abstract '{abstract}', please determine the scientific category of this paper. {additional_info}\n\nA. astro-ph\nB. cond-mat.mes-hall\nC. cond-mat.mtrl-sci\nD. cs.CL\nE. cs.CV\nF. cs.LG\nG. gr-qc\nH. hep-ph\nI. hep-th\nJ. quant-ph"# 设置系统信息messages = [{"role": "system", "content": "你是个优秀的论文分类师"},{"role": "user", "content": prompt},]# 应用聊天模板input_text = tokenizer.apply_chat_template(messages, tokenize=False)# 生成回答inputs = tokenizer(input_text, return_tensors="pt").to(model.device)outputs = model.generate(**inputs,max_new_tokens=10, # 减少生成长度,只需要简短答案temperature=0.1, # 降低温度提高确定性top_p=0.95,repetition_penalty=1.0,)# 解码输出response = tokenizer.decode(outputs[0][inputs.input_ids.shape[1] :], skip_special_tokens=True).strip()# 如果回答中包含选项标识符,只返回该标识符for option in ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J"]:if option in response:return option# 如果回答不包含选项,返回完整回答return response# 示例使用
if __name__ == "__main__":title = "Outilex, plate-forme logicielle de traitement de textes 'ecrits"authors = "Olivier Blanc (IGM-LabInfo), Matthieu Constant (IGM-LabInfo), Eric Laporte (IGM-LabInfo)"abstract = "The Outilex software platform, which will be made available to research, development and industry, comprises software components implementing all the fundamental operations of written text processing: processing without lexicons, exploitation of lexicons and grammars, language resource management. All data are structured in XML formats, and also in more compact formats, either readable or binary, whenever necessary; the required format converters are included in the platform; the grammar formats allow for combining statistical approaches with resource-based approaches. Manually constructed lexicons for French and English, originating from the LADL, and of substantial coverage, will be distributed with the platform under LGPL-LR license."result = classify_paper(title, authors, abstract)print(result)# 计算并打印总耗时end_time = time.time()total_time = end_time - start_timeprint(f"程序总耗时:{total_time:.2f}秒")
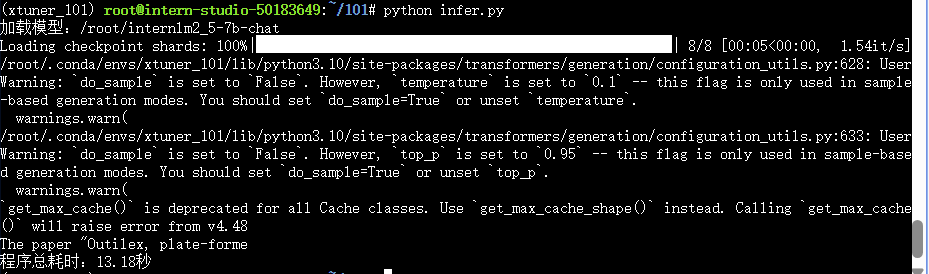
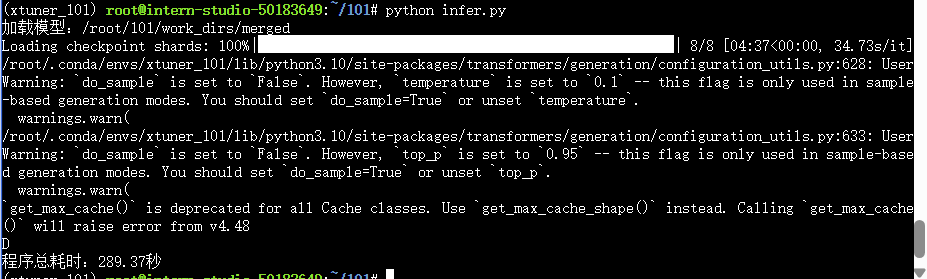
推理结果如下:
微调前模型推理
微调后模型推理
3.5 部署
pip install lmdeploy
python -m lmdeploy.pytorch.chat ./work_dirs/merged \
--max_new_tokens 256 \
--temperture 0.8 \
--top_p 0.95 \
--seed 0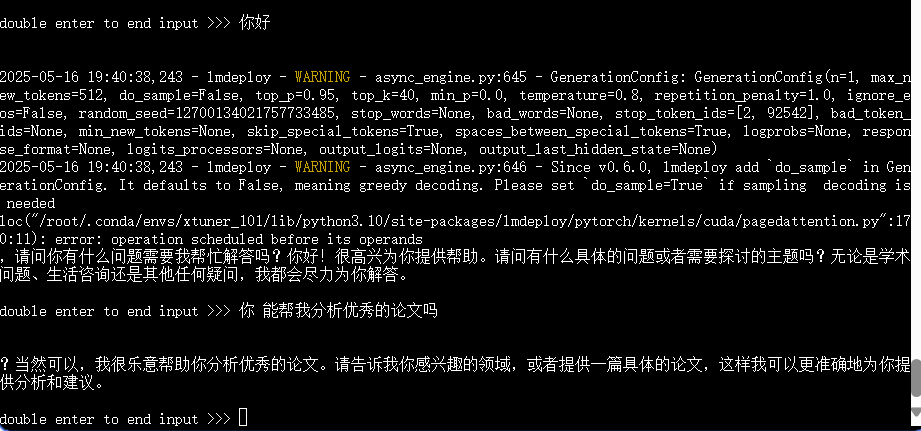
4.评测(跳过)
5.上传模型到魔搭
pip install modelscope
使用脚本
from modelscope.hub.api import HubApi
YOUR_ACCESS_TOKEN='自己的令牌'
api=HubApi()
api.login(YOUR_ACCESS_TOKEN)from modelscope.hub.constants import Licenses, ModelVisibility
owner_name='Raven10086'
model_name='InternLM-gmz-camp5'
model_id=f"{owner_name}/{model_name}"
api.create_model(model_id,visibility=ModelVisibility.PUBLIC,license=Licenses.APACHE_V2,chinese_name="gmz文本分类微调端侧小模型"
)
api.upload_folder(repo_id=f"{owner_name}/{model_name}",folder_path='/root/swift_output/InternLM3-8B-SFT-Lora/v5-20250517-164316/checkpoint-62-merged',commit_message='fast commit',)上传成功截图
相关文章:
)
InternLM 论文分类微调实践(XTuner 版)
1.环境安装 我创建开发机选择镜像为Cuda12.2-conda,选择GPU为100%A100的资源配置 Conda 管理环境 conda create -n xtuner_101 python3.10 -y conda activate xtuner_101 pip install torch2.4.0cu121 torchvision torchaudio --extra-index-url https://downloa…...

kotlin Flow的技术范畴
Flow 是 Kotlin 中的技术,准确地说,它是 Kotlin 协程(Kotlin Coroutines)库的一部分,属于 Kotlin 的 异步编程范畴。 ✅ Flow 的归属与背景: 所属技术:Kotlin(由 JetBrains 开发&am…...
)
PyTorch图像建模(图像识别、分割和分类案例)
文章目录 图像分类技术:改变生活的智能之眼图形识别技术图像识别过程图像预处理图像特征提取 图像分割技术练习案例:图像分类项目源码地址实现代码(简化版)训练结果(简化版)实现代码(优化版&…...

系统安全应用
文章目录 一.账号安全控制1.基本安全措施①系统账号清理②密码安全控制 2.用户切换与提权①su命令用法②PAM认证 3.sudo命令-提升执行权限①在配置文件/etc/sudoers中添加授权 二.系统引导和登录控制1.开关机安全控制①调整bios引导设置②限制更改grub引导参数 三.弱口令检测.端…...
)
day53—二分法—搜索旋转排序数组(LeetCode-81)
题目描述 已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k1], ..., nu…...

力扣面试150题--从前序与中序遍历序列构造二叉树
Day 43 题目描述 思路(这题第一次没做出来,看了题解后理解) 做法:哈希表递归 首先复习一下前序遍历和中序遍历, 前序遍历:中左右,这个不仅是遍历树的路线,同时对一个对于一个前序遍…...

win10 上删除文件夹失败的一个原因:sqlYog 备份/导出关联了该文件夹
在尝试删除路径为.../bak/sql的文件时,系统提示无权限操作。然而,关闭SQLyog后,删除操作成功完成。这表明SQLyog可能正在占用该文件,导致删除权限受限。关闭SQLyog后,文件被释放,删除操作得以顺利进行。建议…...

卷java、基础2
内部类 了解 1. 成员内部类(了解) 2. 静态内部类(了解) 实例化的写法 局部内部类(看看就好) 局部内部类是定义在在方法中、代码块中、构造器等执行体中。 匿名内部类(重要) 1.先…...

从 “龟速” 到流畅,英国 - 中国 SD-WAN 专线让分公司直连总部系统
对于在英国设立总部、国内开设分公司的企业而言,分公司访问总部内网系统常面临网络延迟高、连接不稳定等问题。传统网络方案难以满足跨国数据传输需求,而英国 - 中国 SD-WAN 国际组网专线凭借创新技术,为企业搭建起高效稳定的网络桥梁。 SD-W…...

C++--综合应用-演讲比赛项目
需求 分析 1、初始化,生成演讲学生数组,打乱数组以便随机分组 2、每轮比赛后需要统计每个学生的胜场,以便决定进入下一轮和最终胜利的学生 代码实现 #pragma once#include<iostream> #include<string> #include<algorithm…...

简单实现网页加载进度条
一、监听静态资源加载情况 可以通过window.performance 对象来监听⻚⾯资源加载进度。该对象提供了各种⽅法来获取资源加载的详细信息。 可以使⽤performance.getEntries() ⽅法获取⻚⾯上所有的资源加载信息。可以使⽤该⽅法来监测每个资源的加载状态,计算加载时间…...
)
C语言——深入理解指针(一)
C语言——指针(一) 进入指针后,C语言就有了一定的难度,我们需要认真理解 指针(一) 1 .内存和地址 内存:程序运行起来后,要加载到内存中,数据的存储也是在内存中。 我…...

计算机组织原理第一章
1、 2、 3、 4、 5、 从源程序到可执行文件: 6、 7、 8、 8、...

upload-labs通关笔记-第12关 文件上传之白名单GET法
目录 一、白名单过滤 二、%00截断 1、%00截断原理 2、空字符 3、截断条件 (1)PHP版本 < 5.3.4 (2)magic_quotes_gpc配置为Off (3)代码逻辑存在缺陷 三、源码分析 1、代码审计 (1&…...
)
网络学习-epoll(四)
一、为什么使用epoll? 1、poll实质是对select的优化,解决了其参数限制的问题,但是其本质还是一个轮询机制。 2、poll是系统调用,当客户端连接数量较多时,会将大量的pollfd从用户态拷贝到内核态,开销较大。…...

uWSGI、IIS、Tomcat有啥区别?
uWSGI、IIS 和 Tomcat对比 以下是 uWSGI、IIS 和 Tomcat 的对比分析,包括它们的核心特性、适用场景和典型用例: 1. uWSGI 核心特性 • 定位:专为 Python 应用设计的应用服务器(支持 WSGI/ASGI 协议)。 • 协议支持&a…...

AI本地化服务的战略机遇与发展路径
一、市场机遇:线下商业的AI赋能真空 1. 需求侧痛点明确 实体商家面临线上平台25%-30%的高额抽成挤压利润,传统地推转化率不足5%,而AI驱动的精准营销可将获客成本降低60%以上。区域性服务商凭借对本地消费习惯的深度理解,能构建更精…...

游戏盾的功有哪些?
游戏盾的功能主要包括以下几方面: 一、网络攻击防护 DDoS攻击防护: T级防御能力:游戏盾提供分布式云节点防御集群,可跨地区、跨机房动态扩展防御能力和负载容量,轻松达到T级别防御,有效抵御SYN Flood、UD…...

C++开源库argh使用教程
概述 argh 是一个轻量级的 C 命令行参数解析库,只需要包含一个头文件即可使用。 github页面: https://github.com/adishavit/argh 基本用法 #include "argh.h" 创建argh::parser对象 使用parse方法解析命令行 argh::parser重载了括号运…...

万用表如何区分零线、火线、地线
普通验电笔只能区分火线,零线和地线是区分不出来的,那么,我们就需要使用万用表来进行区分!轻松搞定! 万用表操作步骤: 1、黑表笔插Com,红表笔接电压和电阻档,万用表打到交流电压750V档。 2、黑表…...

java配置webSocket、前端使用uniapp连接
一、这个管理系统是基于若依框架,配置webSocKet的maven依赖 <!--websocket--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId></dependency> 二、配…...

01、java方法
前面与c都很相似,于是我决定从这一章开始复盘java的学习 一、方法 方法的好处主要体现在使用方便,可以在多处调用,不必反复造轮子 1、方法的使用 这就是一个简单的方法创建: public class java0517 {public static int ret(int …...

springboot实现幂等性
一 增加注解 import java.lang.annotation.*;Retention(RetentionPolicy.RUNTIME) Target({ElementType.METHOD}) Documented public interface ApiIdempotent { } 二 aop实现切面 import cn.hutool.extra.spring.SpringUtil; import com.alibaba.fastjson.JSONObject; import…...

Flink 快速入门
本文涉及到大量的底层原理知识,包括运行机制图解都非常详细,还有一些实战案例,所以导致本篇文章会比较长,内容比较多,由于内容太多,很多目录可能展示不出来,需要去细心的查看,非常适…...
)
MySQL 8.0 OCP 英文题库解析(五)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题31~40 试题31:…...

lovart design 设计类agent的系统提示词解读
文章目录 lovart 设计agent介绍角色定义工作规范工具调用任务复杂度指南任务移交指南其他ref lovart 设计agent介绍 lovart作为设计agent,产品功能包括: 全链路设计能力:可以快速生成完整的品牌视觉方案,包括标志、配色、品牌规范…...

C++11特性
一.C的发展历史 C11是C的第二个主要版本,从C98起的重要更新,引入了大量更改,从C11起C规律的进行每3年更新一次。 二.列表初始化 2.1 C98和C11中的 { } 传统的C98中使用 { } 来进行列表初始化,结构体函数体都使用此类方法&…...

鸿蒙PC操作系统:从Linux到自研微内核的蜕变
鸿蒙PC操作系统是否基于Linux内核,需要结合其技术架构、发展阶段和官方声明综合分析。以下从多个角度展开论述: 一、鸿蒙操作系统的多内核架构设计 多内核混合架构 根据资料,鸿蒙操作系统(HarmonyOS)采用分层多内核架构,内核层包含Linux内核、LiteOS-m内核、LiteOS-a内核…...

用 RefCounted + WeakPtr 构建线程安全的异步模块
在 Chromium 的多线程异步编程中,合理管理对象生命周期非常关键。本文深入介绍 base::RefCountedThreadSafe 和 base::WeakPtr 的组合使用方法,并通过示例分析其使用要点及易踩的坑。 🌱 基础概念回顾 1. RefCountedThreadSafe<T> 是 …...

ElasticSearch 8.x 快速上手并了解核心概念
目录 核心概念概念总结 常见操作索引的常见操作常见的数据类型指定索引库字段类型mapping查看索引库的字段类型最高频使用的数据类型 核心概念 在新版Elasticsearch中,文档document就是一行记录(json),而这些记录存在于索引库(index)中, 索引名称必须是…...

2025.5.19总结
工作:今天回归了3个问题单,测需求提交两个问题。然后再工作中慢慢有了自己的一些成就感,觉得工作越来越有干劲,因为感觉自己在工作上能做得越来越好,无论是在沟通方面,还是与同事的关系上,感觉都…...
: 标准库 <deque>)
C++(25): 标准库 <deque>
目录 1、 核心概念 2. 基本语法 3. 特点 4. 特有成员函数 5. 内存与性能 6. 示例代码 7. 成员函数列表 8. 使用场景 9. 注意事项 1、 核心概念 双端队列(Double-Ended Queue,deque) 是一种允许在队列头部和尾部高效插入和删除元素的线性数据结构,同时支持随机访问。…...

[ 计算机网络 ] | 宏观谈谈计算机网络
(目录占位) 网络间通信,本质是不同的两个用户通信;本质是两个不同主机上的两个进程间通信。 因为物理距离的提升,就衍生出了很多问题。TCP/IP协议栈 / OSI七层模型,将协议分层,每一层都是为了…...

会议动态|第十五届亚太燃烧学术年会精彩探析
ASPACC 2025第十五届亚太燃烧学术年会5月19日在新加坡隆重召开,本届盛会,以“构建零碳和可持续未来”为主题,汇聚了来自亚太的2000余位专家学者进行学术交流。会议聚焦燃烧反应动力学、火焰传播、燃烧效率等方向。 千眼狼在会议上展示了高速摄…...

Dify-3:系统架构
系统架构 概述了 Dify 的系统架构,解释主要组件如何协同工作以提供大语言模型(LLM)应用开发平台。内容涵盖高层架构、部署选项、核心子系统和外部集成。 1. 整体架构 Dify 采用基于微服务的架构,将前端 Web 应用与后端 API 服务…...

使用 docker-volume-backup 备份 Docker 卷
docker-volume-backup 是一个用于备份 Docker 卷的工具,在 Windows 10 上使用它,你可以按照以下步骤操作: 1. 确保 Docker 环境已安装并正常运行 在 Windows 10 上,你需要安装 Docker Desktop for Windows。可以从 Docker 官方网…...

分布式与集群:概念、区别与协同
分布式与集群:概念、区别与协同 在分布式系统与云计算领域,分布式(Distributed)和集群(Cluster)是两个高频出现的核心概念。它们常被混淆,但本质上属于不同维度的设计思想。本文将从定义、分类、实际应用及协同关系四个层面,结合 Dubbo、Git、Hadoop 等典型案例,系统…...

Matlab简单优化模型应用
一、目的 掌握优化模型的建立方法,能够借助Matlab工具对建立的优化模型进行求解。 二、内容与设计思想 1、分析:某石油设备制造厂每月需要100套压缩机用于维护和运营石油开采设备。这些零件由工厂内部生产,每月生产500套,每批压缩机的生产…...
)
板凳-------Mysql cookbook学习 (四)
综合对比与选择建议 维度 PHP Java Python Ruby Perl 学习门槛 低(适合新手) 高(语法复杂) 低(语法简洁) 中(需理解 Rails 理念) 中(特殊语法…...

C语言学习笔记之条件编译
编译器根据条件的真假决定是否编译相关的代码 常见的条件编译有两种方法: 一、根据宏是否定义,其语法如下: #ifdef <macro> …… #else …… #endif例子: #include <stdio.h>//def _DEBUG_ //定义_DEBUG_ int main(…...
 2-7 GB/T 25058—2019 《信息安全技术 网络安全等级保护实施指南》-2019-08-30发布【现行】)
网络安全-等级保护(等保) 2-7 GB/T 25058—2019 《信息安全技术 网络安全等级保护实施指南》-2019-08-30发布【现行】
################################################################################ GB/T 22239-2019 《信息安全技术 网络安全等级保护基础要求》包含安全物理环境、安全通信网络、安全区域边界、安全计算环境、安全管理中心、安全管理制度、安全管理机构、安全管理人员、安…...

Android设备 显示充电速度流程
整体逻辑:设备充电速度的判断 系统通过读取充电器的最大电流(Current)与最大电压(Voltage),计算最大充电功率(Wattage),以此判断当前是慢充、普通充还是快充:…...

megatron——EP并行
1、专家并行(Expert Parallelism, EP)适用场景 定义: 专家并行是指在混合专家模型(Mixture of Experts, MoE)中,将不同的专家(即子模型)分配到不同的设备上,每个设备只负…...
)
如何轻松删除电脑上的文件(无法恢复文件)
如果您想清理电脑上的存储空间,您可能需要轻松删除电脑上的文件以释放空间。此外,如果您打算出售或捐赠您的旧电脑,永久删除您的文件至关重要,这可以保护您的隐私。无论如何,您需要一种有效且可靠的方法来从计算机中删…...

搭建一个永久免费的博客
搭建永久免费的博客(1)基本介绍 HugoStackGitHub GitHub GitHub GitHub Build and ship software on a single, collaborative platform GitHub 下载安装git Git - Downloads Edge插件authenticator 2fa client Settings->Password and auth…...

计算机底层的多级缓存以及缓存带来的数据覆盖问题
没有多级缓存的情况 有多级缓存的情况 缓存带来的操作覆盖问题 锁总线带来的消耗太大了。...

ICRA 2024 PROGrasp——实用的人机交互物体抓取系统
在机器人抓取任务中,自然语言理解能够显著改善人机交互体验,尤其是在需要机器人根据人类指令进行环境交互的场景中。然而,现有的抓取系统往往要求用户明确指定目标对象的类别,限制了交互的自然性和灵活性。为了解决这一问题&#…...

【Vue篇】潮汐中的生命周期观测站
目录 引言 一、Vue生命周期 二、Vue生命周期钩子 三、、生命周期钩子实战 1.在created中发送数据 2.在mounted中获取焦点 四、综合案例-小黑记账清单 1.需求图示: 2.需求分析 3.思路分析 4.代码 5. 总结 引言 💬 欢迎讨论:如果…...

【OpenCV基础2】图像运算、水印、加密、摄像头
目录 一、图像运算 1、利用“” 2、cv2.add() 3、掩膜异或 二、摄像头 1、读取、视频流保存 2、人脸识别 三、数字水印 1、水印嵌入 2、水印提取 四、图像加密 一、图像运算 1、利用“” import cv2 利用""方法将两幅图像相加img1 cv2.imread(project…...

第 25 届中国全电展即将启幕,构建闭环能源生态系统推动全球能源转型
由 AI 算力爆发引发的能源消耗剧增,与碳中和目标、能源安全需求及电网转型压力形成叠加效应,使全球能源体系面临前所未有的挑战。在此背景下,第 25 届中国全电展(EPOWER EXPO)将于 2025 年 6 月 11 日至 13 日在上海新…...