CLIP:论文阅读 -- 视觉模型
更多内容:XiaoJ的知识星球
目录
- 1.CLIP概述
- 2.CLIP的方法
- 2.1. 自然语言监督
- 2.2. 创建足够大的数据集
- 2.3. 选择有效的预训练方法
- 2.4. 选择和缩放模型
- 1)CLIP模型选择:
- 2)模型缩放
- 2.5 训练
- 3.CLIP 核心伪代码
- 3.1. CLIP伪代码
- 3.2. CLIP伪代码介绍
- 3.3. 概念理解
- 3.4. 伪代码示例
CLIP:《Learning Transferable Visual Models From Natural Language Supervision》论文阅读
.
1.CLIP概述
CLIP(Contrastive Language–Image Pre-training)是一种创新的计算机视觉模型,旨在解决传统目标检测模型依赖固定分类体系和大量标注数据的局限性。该模型通过在4亿对互联网收集的图文数据上进行预训练,采用“预测图文匹配”的简单任务,成功从零开始学习到强大的图像表征能力。其核心优势在于:
-
突破固定分类限制 :利用自然语言作为通用接口,既能引用已学视觉概念,也可描述新类别,实现零样本迁移(zero-shot transfer),无需针对特定任务微调
-
跨任务泛化性能 :在超过30个计算机视觉任务(如OCR、视频动作识别、细粒度分类等)中达到或接近全监督模型水平。例如,在ImageNet上零样本迁移即可复现ResNet-50的精度,且不使用其原始训练数据
-
高效可扩展性 :预训练任务设计简洁,支持大规模数据训练,为后续多模态研究提供了开源代码和模型权重。
这一方法标志着从封闭域监督学习向开放域知识迁移的范式转变。
图1:CLIP
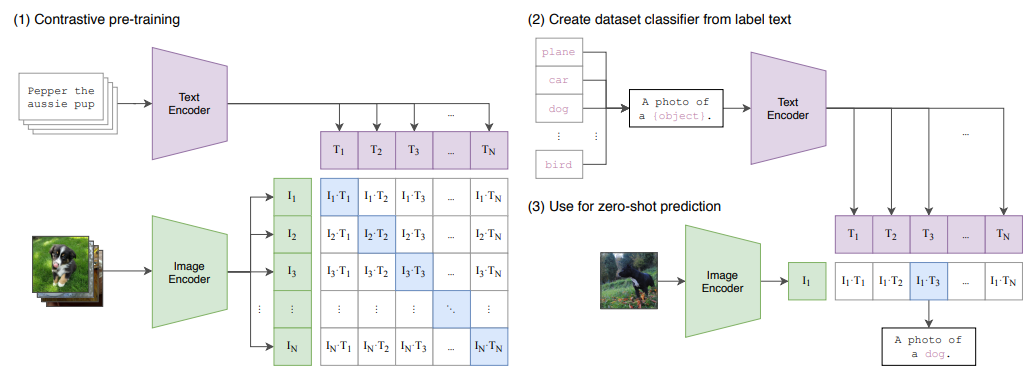
标准图像模型:联合训练图像特征提取器和线性分类器来预测某些标签;
CLIP:
-
联合训练图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对。
-
在测试时,学习的文本编码器通过嵌入目标数据集类的名称或描述来合成零样本线性分类器。
2.CLIP的方法
2.1. 自然语言监督
CLIP的核心思想:
- 通过自然语言中的监督信号学习视觉表征(Natural Language Supervision)。
相比传统方法,自然语言监督具有显著优势:
-
可扩展性强:无需人工标注“机器学习兼容格式”(如ImageNet的1-of-N标签),可直接从互联网海量文本中被动学习;
-
零样本迁移能力:不仅学习视觉表征,还建立语言与视觉的关联,实现灵活的任务迁移(如动态识别未见过的类别)。
.
2.2. 创建足够大的数据集
CLIP团队指出,现有主流数据集(MS-COCO、Visual Genome、YFCC100M)存在规模或质量限制:
-
MS-COCO 和 Visual Genome:高质量人工标注,但仅约10万图像,远低于现代视觉模型常用的大规模数据(如Instagram的35亿图片);
-
YFCC100M:包含1亿图像,但元数据稀疏且质量参差,过滤后仅剩1500万条有效英文图文对,规模与ImageNet相当。
为此,CLIP构建了包含4亿图像-文本对的新数据集 WIT(WebImageText),以充分挖掘自然语言监督的潜力。
.
2.3. 选择有效的预训练方法
经典计算机视觉系统依赖海量算力,传统方法因依赖预测固定类别难以扩展至开放视觉概念。CLIP创新设计如下:
对比学习框架
-
将图文匹配转化为相似度对比任务,替代逐词预测;
-
最大化正图文对的余弦相似度,最小化负对相似度;
-
采用对称交叉熵损失。
架构优化
-
双编码器结构:独立图像编码器(ResNet/ViT)和文本编码器(Transformer);
-
简化设计:移除非线性投影层,仅保留线性映射;
-
动态温度参数:将温度系数τ设为可训练参数,避免超参调优;
训练优化
-
数据增强:仅使用随机方形裁剪;
-
文本处理:直接使用单句描述(无需复杂采样);
-
初始化策略:完全从零训练,不依赖ImageNet预训练权重;
.
2.4. 选择和缩放模型
1)CLIP模型选择:
图像编码器: ResNet-50或ViT
-
改进版ResNet-50 :基于ResNet-50,引入ResNetD改进(如抗锯齿模糊池化)和注意力池化机制(以全局平均池化特征为查询的多头注意力),替代原全局平均池化层;
-
Vision Transformer (ViT) :严格遵循Dosovitskiy等人的实现,仅增加卷积块与位置嵌入的层归一化,并调整初始化策略;
文本编码器 :
- 基于Transformer架构,采用Radford等人的改进设计,包含12层、512维宽、8头注意力的63M参数模型。输入文本经小写BPE编码(词汇量49,152),序列上限76词,通过[SOS]/[EOS]标记界定,最终以[EOS]位置的归一化特征线性投影至多模态嵌入空间 。
2)模型缩放
扩展ResNet图像编码器:采用复合缩放策略
-
不同于传统单独增加模型宽度或深度的方法,参考Tan & Le 的研究结论;
-
将新增计算资源平均分配至宽度、深度和分辨率三个维度,以提升整体效率 。
扩展文本编码器:
- 仅按ResNet宽度扩展比例线性增加其宽度,未调整深度,因实验表明CLIP性能对文本编码器容量变化不敏感 。
.
2.5 训练
CLIP团队训练了以下模型:
-
5个ResNets(ResNet-50、ResNet-101及3个基于EfficientNet风格扩展的RN50x4/RN50x16/RN50x64);
-
3个Vision Transformer(ViT-B/32、ViT-B/16、ViT-L/14),所有模型均训练32个epoch 。
训练采用Adam优化器(含解耦权重衰减正则化)和余弦学习率衰减策略,超参数通过网格搜索、随机搜索和手动调优在ResNet-50单epoch实验中确定,更大模型的参数根据经验调整 。
关键技术细节:
-
内存与速度优化:使用32,768的大批量、混合精度训练、梯度检查点、半精度Adam统计量及权重随机舍入;
-
分布式计算:将嵌入相似度计算分片至各GPU,仅计算本地批次所需子集;
-
温度参数:初始化为0.07,限制logits缩放不超过100以防止训练不稳定 。
最大规模模型耗时:
-
ResNet-RN50x64(592张V100 GPU)18天;
-
ViT-L/14(256张V100 GPU)12天;
-
对ViT-L/14额外进行1轮336像素预训练以提升性能(记作ViT-L/14@336px),该模型为论文主结果 。
3.CLIP 核心伪代码
3.1. CLIP伪代码
- 它将图像和文本特征映射到一个共享嵌入空间,通过对比学习来学习这些特征的关系。
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter# extract feature representations of each modality
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2
.
3.2. CLIP伪代码介绍
# image_encoder: 图像编码器,可以是 ResNet 或 Vision Transformer(ViT)。
# text_encoder: 文本编码器,可以是 CBOW(连续词袋模型)或基于 Transformer 的文本编码器(如 BERT、GPT)。
# I: 图像数据批次,形状为 [n, h, w, c],其中 n 是批量大小,h 和 w 是图像的高度和宽度,c 是通道数(通常是 3 对于 RGB 图像)。
# T: 文本数据批次,形状为 [n, l],其中 n 是批量大小,l 是每个文本的最大长度(通常通过填充或截断处理)。#################################################################
# 提取每个模态的特征表示
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
#I_f: 图像特征向量,形状为 [n, d_i],其中 d_i 是图像特征的维度。
#T_f: 文本特征向量,形状为 [n, d_t],其中 d_t 是文本特征的维度。#################################################################
# 联合多模态嵌入空间 [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# W_i 和 W_t: 投影矩阵,分别用于将图像特征和文本特征映射到一个共享的嵌入空间。
# W_i 的形状为 [d_i, d_e];W_t 的形状为 [d_t, d_e];
# 其中 d_e 是嵌入空间的维度。
# I_e 和 T_e: 映射后的联合嵌入表示,形状均为 [n, d_e]。# 线性变换(Linear Projection):
# np.dot(I_f, W_i):将图像特征 I_f 投影到嵌入空间,得到 I_proj,形状为 [n, d_e]。
# np.dot(T_f, W_t):将文本特征 T_f 投影到嵌入空间,得到 T_proj,形状为 [n, d_e]。
# L2 归一化(Normalization):
# l2_normalize(I_proj, axis=1):对每个样本的嵌入向量进行 L2 归一化,使其长度为 1。归一化后的向量 I_e 的形状为 [n, d_e]。
# l2_normalize(T_proj, axis=1):对每个样本的嵌入向量进行 L2 归一化,使其长度为 1。归一化后的向量 T_e 的形状为 [n, d_e]。#################################################################
# 计算相似度矩阵 [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# t: 温度参数(temperature parameter),用于控制相似度矩阵的尺度。
# logits: 相似度矩阵,形状为 [n, n]。
# I_e 的形状为 [n, d_e];
# T_e.T 是 T_e 的转置,形状为 [d_e, n];
# np.dot(I_e, T_e.T) 计算 I_e 和 T_e 之间的余弦相似度矩阵,因为 I_e 和 T_e 已经归一化。
# * np.exp(t) 对相似度矩阵进行缩放。#################################################################
# 计算损失函数
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2
# labels: 标签数组,形状为 [n],表示每个图像和文本对的正确匹配关系。
# cross_entropy_loss: 交叉熵损失函数,用于计算预测概率分布与真实标签之间的差异。
# loss_i: 沿着行方向计算交叉熵损失,即每个图像与所有文本的匹配情况。
# loss_t: 沿着列方向计算交叉熵损失,即每个文本与所有图像的匹配情况。
# loss: 对称损失函数,取 loss_i 和 loss_t 的平均值,确保损失函数对称且均衡。
.
3.3. 概念理解
对比学习(Contrastive Learning):最大化匹配样本对间的相似度,同时最小化不匹配样本对间的相似度。
余弦相似度(Cosine Similarity): 衡量两向量间夹角余弦值,取值为 [-1, 1],值越大表示越相似。
-
归一化向量:通过 L2 归一化,将向量长度缩放到 1,使得余弦相似度仅取决于方向。
-
相似度矩阵:
logits矩阵中的每个元素表示一对样本的相似度。
温度参数(Temperature Parameter): 温度参数 t 控制相似度矩阵的尺度
-
t > 1: 增大相似度差距,使正样本对之间的相似度更高,负样本对之间的相似度更低。 -
t < 1: 减小相似度差距,使模型对相似度变化不那么敏感。 -
t = 1: 默认值,通常在实践中效果较好。
交叉熵损失(Cross-Entropy Loss): 衡量预测的概率分布与真实标签之间的差异。
.
3.4. 伪代码示例
假设我们有一个批量大小为 4 的数据集,图像和文本特征如下:
import numpy as npdef l2_normalize(x, axis=1):norm = np.linalg.norm(x, axis=axis, keepdims=True)return x / normdef cross_entropy_loss(logits, labels, axis=0):log_probs = np.log_softmax(logits, axis=axis)n_samples = logits.shape[axis]loss = -np.sum(log_probs[labels, np.arange(n_samples)]) / n_samplesreturn loss# 假设我们有 4 个样本,图像特征维度是 2048,文本是 300,统一投影到 512 维
n = 4
I_f = np.random.randn(n, 2048)
T_f = np.random.randn(n, 300)# 定义两个投影矩阵
W_i = np.random.randn(2048, 512)
W_t = np.random.randn(300, 512)# 定义温度参数
t = 0.07# 映射 + 归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)# 计算相似度矩阵
logits = np.dot(I_e, T_e.T) * np.exp(t)# 计算损失函数
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2print("Image Embedding Shape:", I_e.shape) # (4, 512)
print("Text Embedding Shape:", T_e.shape) # (4, 512)
print("Logits Shape:", logits.shape) # (4, 4)
print("Labels:", labels) # [0, 1, 2, 3]
print("Loss_i:", loss_i)
print("Loss_t:", loss_t)
print("Total Loss:", loss)
输出示例:
Image Embedding Shape: (4, 512)
Text Embedding Shape: (4, 512)
Logits Shape: (4, 4)
Labels: [0 1 2 3]
Loss_i: 1.0986122886681096
Loss_t: 1.0986122886681096
Total Loss: 1.0986122886681096
.
声明:资源可能存在第三方来源,若有侵权请联系删除!
相关文章:

CLIP:论文阅读 -- 视觉模型
更多内容:XiaoJ的知识星球 目录 1.CLIP概述2.CLIP的方法2.1. 自然语言监督2.2. 创建足够大的数据集2.3. 选择有效的预训练方法2.4. 选择和缩放模型1)CLIP模型选择:2)模型缩放 2.5 训练 3.CLIP 核心伪代码3.1. CLIP伪代码3.2. CLIP…...
)
26、DAPO论文笔记(解耦剪辑与动态采样策略优化,GRPO的改进)
DAPO论文笔记 1、项目背景与目标2、DAPO算法与关键技术3、过长响应奖励塑形(Overlong Reward Shaping)**一、问题背景:截断惩罚的缺陷****二、解决方案:分层惩罚与软截断策略**1. **过长过滤:屏蔽无效惩罚**2. **软过长…...

【框架安装】win10 配置安装GPU加速的tensorflow和keras教程
本机配置 win10 4090,需要安装最后支持windows GPU加速的最后版本tensorflow2.10 重点安装命令 pip install tensorflow-gpu2.10.0 protobuf3.19.6 numpy1.23.5 pip install keras2.10.0 pip install keras-cv0.3.5 pip install tensorflow-addons0.17.1conda li…...

整合安全能力:观测云进一步强化数据价值
在 2025 年 5 月 13 日的观测云年度发布会上,观测云发布了 GuanceDB 3.0 全新数据引擎。这次更新标志着观测云进一步整合了云端安全能力,帮助用户进一步挖掘数据的价值。 全新底座:GuanceDB 3.0,数据驱动的安全基石 GuanceDB 3.…...

质检LIMS系统检测数据可视化大屏 全流程提效 + 合规安全双保障方案
在质检实验室的数字化转型浪潮中,「数据看得见、问题找得准、决策下得快」成为衡量管理水平的核心标准。然而传统模式下,检测数据分散在设备日志、纸质记录和 Excel 表格中,管理者如同在迷雾中摸索,决策失误率高达 30% 以上。 一、…...

企业销售管理痛点解析与数字化解决方案
在数字化转型浪潮中,传统销售模式正面临多重挑战: ▫️ 数据决策滞后:缺乏实时市场洞察,热销趋势依赖经验预判,战略响应慢半拍 ▫️ 客户管理碎片化:信息散存于纸质记录 / 聊天窗口,跟进细节遗漏…...

关于海光22DC4_2主板获取usb3.0端口信息重复问题的解决方案
需求 使用qt程序实现以下功能:检查主机所有usb端口是否可用,检查方法为:使用同一个3.0u盘,依次插入usb所有的端口,读取以下代码中所写的端口信息 #include <libusb-1.0/libusb.h>//只保留键鼠和u盘的设备 if (…...
常⽤插件)
GStreamer (三)常⽤插件
常⽤插件 1、Source1.1、filesrc1.2. videotestsrc1.3. v4l2src1.4. rtspsrc和rtspclientsink 2、 Sink2.1. filesink2.2. fakesink2.3. xvimagesink2.4. kmssink2.5. waylandsink2.6. rkximagesink2.7. fpsdisplaysink 3 、视频推流/拉流3.1. 本地推流/拉流3.1.1 USB摄像头3.1…...

Jenkins 使用技巧
1. 通过配置文件更改Jenkins默认端口(8080)? 这里以macos 为例来说明 Jenkins在macOS上通常通过Homebrew或类似的包管理器运行,这与Linux或Windows相比,使用了不同的配置文件布局。默认Jenkins端口8080在启动配置中是…...
)
Pichome 任意文件读取漏洞复现(CVE-2025-1743)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 前…...

Elasticsearch 深入分析三种分页查询【Elasticsearch 深度分页】
前言: 在前面的 Elasticsearch 系列文章中,分享了 Elasticsearch 的各种查询,分页查询也分享过,本篇将再次对 Elasticsearch 分页查询进行专题分析,“深度分页” 这个名词对于我们来说是一个非常常见的业务场景&#…...

避开封禁陷阱:动态IP在爬虫、跨境电商中的落地实践
1. 为什么需要动态IP? 在日常网络操作中,你是否遇到过: 爬虫被封:频繁请求目标网站,IP被限制访问。跨境业务受限:某些平台对特定地区的账号有限制。数据采集失败&#x…...

公网ip是固定的吗?动态ip如何做端口映射?内网ip怎么让外网远程访问?
网络IP地址有内网与公网区分,公网IP同时有固定IP和动态IP之分。很多企业所用的办公网络都是公网ip,下载文件的速度更快,而且平台存储的问题可以让他人看得到,体验度比较好。对于无公网IP环境想要申请公网ip的用户来说,…...

MyBatis入门指南
查询user表中所有数据 创建user表,添加数据导入依赖,创建模块编写MyBatis核心配置文件编写SQL映射文件编写代码 定义P0J0类加载核心配置文件,获取SqlSessionFactory对象获取SqlSession对象,执行SQL语句释放资源 一、创建user表…...

GitHub排名第一的开源ERP项目:Odoo生产计划与执行的功能概述
Odoo生产计划与执行隶属于Odoo MRP与MES的运营管理解决方案。Odoo中生产计划有多种形式,从销售预测到销售运作计划(SOP)开始,到随后的主生产计划、物料需求计划(MRP)、分销需求计划(DRP)、长期生产计划,以及粗能力计划(RCCP)和详细能力计划。…...

使用 OpenCV 实现 ArUco 码识别与坐标轴绘制
🎯 使用 OpenCV 实现 ArUco 码识别与坐标轴绘制(含Python源码) Aruco 是一种广泛用于机器人、增强现实(AR)和相机标定的方形标记系统。本文将带你一步一步使用 Python OpenCV 实现图像中多个 ArUco 码的检测与坐标轴…...

RAC共享存储扩容
存储工程师扩完共享存储后,DBA做如下操作: 1.主机端识别磁盘 在两个节点扫描磁盘命令 # for i in find /sys/class/scsi_host/host*; do echo - - - > $i/scan; done lsblk 2.比对确定新加的盘的uuid,确保uuid是一致的,别…...
)
高德地图 MCP,可用 Java SolonMCP 接入(支持 java8, java11, java17, java21)
1、MCP技术概述 1.1 什么是 MCP MCP (Model Control Protocol) 是一种允许大模型与外部工具交互的协议,高德地图基于此协议提供了地图服务能力,使 AI 大模型能够直接调用高德的 LBS。 1.2 两种接入架构对比 高德地图 MCP 提供了两种不同的接入方式&a…...

rosbag使用记录
1. 查看某个话题频率 rqt—topic 2. 查看对齐 rqt_bag...

7. 数据库技术
在数据库技术实战中,我们通过MySQL数据库的安装与操作,掌握了从创建数据库、数据表到插入、查询、更新和删除记录的全过程。借助Navicat工具,我们能够更直观地进行数据库管理与开发,提升效率。同时,通过JDBC技术&#…...
和浮点数(float))
Python中的整型(int)和浮点数(float)
在很多初学者眼中,int和float不过是Python中代表整数和小数的基本类型,似乎只是编程语言中最“平凡”的组成部分。但在真正深入软件开发、测试乃至AI数值计算的世界后,你会发现,这两个基础类型背后隐藏着诸多重要的设计哲学、性能…...

Python元组全面解析:从入门到精通
文章目录 Python元组全面解析:从入门到精通一、元组的基本概念1. 什么是元组?2. 元组与列表的对比3. 为什么需要元组? 二、元组的创建方式1. 基本创建方法2. 其他创建方式 三、元组的访问与操作1. 访问元素2. 切片操作3. 元组解包 四、元组的…...

1 asyncio模块
1.1核心概念 1.1.1协程 协程是一种特殊的函数,可以在执行过程中暂停,也可以稍后恢复执行。协程通过async关键字来指定。 await关键字:如果想要立即执行,那调用协程的时候,前面加上await关键字。只想创建协程对象稍后…...
)
交通拥堵预测器(python)
这是一个基于机器学习的交通拥堵预测应用,使用随机森林算法。 功能特点: - 使用随机森林算法进行交通拥堵预测 - 直观的图形用户界面 - 支持模型训练、评估和保存/加载 - 实时预测特定时间段的拥堵程度 - 数据可视化功能(按星期分布、按时间段分布、热力图) - 支持自…...

解决服务器重装之后vscode Remote-SSH无法连接的问题
在你的windows命令窗口输入: ssh-keygen -R 服务器IPssh-keygen 不是内部或外部命令 .找到Git(安装目录)/usr/bin目录下的ssh-keygen.exe(如果找不到,可以在计算机全局搜索) 2.属性–>高级系统设置–>环境变量–>系统变量,找到Path变量&#…...

STM32实战指南:DHT11温湿度传感器驱动开发与避坑指南
知识点1【DHT11的概述】 1、概述 DHT是一款温湿度一体化的数字传感器(无需AD转换)。 2、驱动方式 通过单片机等微处理器简单的电路连接就能实时采集本地湿度和温度。DHT11与单片机之间采用单总线进行通信,仅需要一个IO口。 相对于单片机…...

使用 Terraform 创建 Azure Databricks
使用 Terraform 创建 Azure Databricks Terraform 是一种基础设施即代码(IaC)工具,允许用户通过声明式配置文件来管理和部署云资源。Azure Databricks 是一个基于 Apache Spark 的分析平台,专为数据工程和数据科学设计。通过 Terraform,可以自动化 Azure Databricks 的创…...

对话即编程:如何用 Trae 的 @智能体 5 分钟修复一个复杂 Bug?
引子:当新手遇到 "天书" 般的报错 作为刚加入团队的开发者,我在接手一个遗留的 Python 数据处理项目时,遇到了一个诡异报错: python 复制 下载 ValueError: shape mismatch: value array of shape (500,) could no…...

【工具使用】STM32CubeMX-片内Flash读写操作
一、概述 无论是新手还是大佬,基于STM32单片机的开发,使用STM32CubeMX都是可以极大提升开发效率的,并且其界面化的开发,也大大降低了新手对STM32单片机的开发门槛。 本文主要讲述STM32芯片片内Flash功能的应用及其相关知识…...
:Gorm查询)
Java转Go日记(三十九):Gorm查询
1.1.1. 查询 // 获取第一条记录,按主键排序db.First(&user)SELECT * FROM users ORDER BY id LIMIT 1;// 获取最后一条记录,按主键排序db.Last(&user)SELECT * FROM users ORDER BY id DESC LIMIT 1;// 获取所有记录db.Find(&users)SELECT *…...

终端安全与终端管理:有什么区别及其重要性?
在当今快速发展的远程和混合工作环境中,IT 团队面临双重挑战:一方面需保护终端免受日益增长的网络风险,另一方面要管理跨越日益分散网络的设备。这些需求催生了两个关键的 IT 解决方案:终端安全和终端管理。尽管二者时常被共同讨论…...

【二分 优先队列】P3611 [USACO17JAN] Cow Dance Show S|普及+
本文涉及的基础知识点 C二分查找 C堆(优先队列) [USACO17JAN] Cow Dance Show S 题面翻译 题目描述 经过几个月的排练,奶牛们基本准备好展出她们的年度舞蹈表演。今年她们要表演的是著名的奶牛芭蕾——“cowpelia”。 表演唯一有待决定的是舞台的尺寸。一个大…...

蓝桥杯分享经验
系列文章目录 提示:小白先看系列 第一章 蓝桥杯的钱白给吗 文章目录 系列文章目录前言一、自我介绍二、经验讲解:1.基础知识2.进阶知识3.个人观点 三、总结四、后续 前言 第十六届蓝桥杯已经省赛已经结束了,相信很多小伙伴也已经得到自己的成绩了。接下…...

TDengine 安全部署配置建议
背景 TDengine 的分布式、多组件特性导致 TDengine 的安全配置是生产系统中比较关注的问题。本文档旨在对 TDengine 各组件及在不同部署方式下的安全问题进行说明,并提供部署和配置建议,为用户的数据安全提供支持。 安全配置涉及组件 TDengine 包含多…...

Grafana当前状态:SingleStat面板
Grafana的SingleStat面板是一种用于展示单个关键指标(KPI)的可视化组件,特别适合需要突出显示核心业务指标的场景(如实时销售额、在线用户数、系统错误率等)。它通过简洁的布局和丰富的样式选项,帮助用户快速聚焦核心数据。Singlem Panel侧重于展示系统的…...
)
专题五:floodfill算法(太平洋大西洋水流问题)
以leetcode417题为例 题目解析: 整张图,左边深蓝的是太平洋,右边浅蓝的是大西洋,你需要在矩阵中找到一个点,使其可以流向太平洋又可以流向大西洋,并且你每次流的时候只能由高到低,或者相等到相…...

【HTML】【面试提问】HTML面试提问总结
第一章 HTML基础相关提问 1.1 HTML基本概念 1.1.1 什么是HTML HTML 即超文本标记语言(HyperText Markup Language)😎,它是用于创建网页的标准标记语言。简单来说,HTML 就像是搭建房屋的砖块🧱࿰…...

解锁MySQL性能调优:高级SQL技巧实战指南
高级SQL技巧:解锁MySQL性能调优的终极指南 开篇 当前,随着业务系统的复杂化和数据量的爆炸式增长,数据库性能调优成为了技术人员面临的核心挑战之一。尤其是在高并发、大数据量的场景下,SQL 查询的性能直接影响到整个系统的响应…...

数据分析与应用---数据可视化基础
目录 Matplotlib基础绘图 (一)、pyplot绘图基础语法与常用参数 1、pyplot基础语法 (1) 创建画布与创建子图 (2) 添加画布内容 (3) 保存与显示图形 案例代码 2. 设置pyplot的动态…...

android双屏之副屏待机显示图片
摘要:android原生有双屏的机制,但需要芯片厂商适配框架后在底层实现。本文在基于芯发8766已实现底层适配的基础上,仅针对上层Launcher部分对系统进行改造,从而实现在开机后副屏显示一张待机图片。 副屏布局 由于仅显示一张图片&…...

oracle序列自增问题
1.先查询表名对应的序列名称 SELECT trigger_name, trigger_type, triggering_event FROM all_triggers WHERE table_name 表名;2. 查询id最大值 SELECT MAX(ID) FROM 表名;3. 查询下一次生成ID SELECT SJCJ_ENERGY_DATA_INSERTID.NEXTVAL FROM DUAL;4. 设置临时步长,越过…...

FLASHDB API分析
fdb_kvdb_init 函数详解 fdb_kvdb_init 是 FlashDB 框架中用于 初始化键值数据库(KVDB) 的核心接口,其功能涵盖底层存储配置、默认数据加载与多模式适配。以下从功能、参数、使用场景及注意事项展开分析: 一、功能与作用 …...

使用 ABP vNext 集成 MinIO 构建高可用 BLOB 存储服务
🚀 使用 ABP vNext 集成 MinIO 构建高可用 BLOB 存储服务 本文基于 ABP vNext MinIO 的对象存储集成实践,系统讲解从 MinIO 部署、桶创建、ABP 集成、上传 API、安全校验、预签名访问,到测试、扩展及多租户支持的全过程。目标是构建一套可复…...

3.安卓逆向2-安卓文件目录
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于:图灵Python学院 上一个内容:2.安卓逆向2-adb指令 首先使用adb连接到手机,如下图使用adb命令列出手机的目录&am…...

云原生时代的系统可观测性:理念变革与实践体系
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:为什么可观测性在云原生时代变得更加重要? 传统应用系统运行于固定服务器,拓扑结构稳定、依赖路径清晰,排查故障依赖日志和人工经验已足够支撑运维。但在云原生环境中,系统正快速演变为: 微…...

力扣网-复写零
1.题目要求 2.题目链接 1089. 复写零 - 力扣(LeetCode) 3.题目解答 class Solution {public void duplicateZeros(int[] arr) {int cur0,dest-1,narr.length;while(cur<n){//遇到0就dest走两步if(arr[cur]0){dest2;}//遇到非零元素dest就走一步els…...

高项-挣值管理TCPI
TCPI(完工尚需绩效指数)的英文全称及含义 TCPI 是项目管理(尤其是挣值管理EVM, Earned Value Management)中的一个关键指标,其英文全称为: To-Complete Performance Index 中文译为**“完工尚需绩效指数”…...

Java大厂面试三轮问答:微服务与数据库技术深度解析
Java大厂面试:谢飞机的三轮挑战 第一轮:微服务基础与电商场景设计 面试官: "谢飞机,假设我们要设计一个电商平台,需要支持用户下单、支付以及订单追踪。你会如何设计微服务架构?" 谢飞机: "呃&#…...

Linux 移植 Docker 详解
一、移植前的环境准备 在将 Docker 移植到 Linux 系统之前,需要确保系统满足一定的条件,以保证 Docker 能够稳定运行。 1. 操作系统版本要求 Docker 对 Linux 操作系统版本有一定的要求,不同的 Docker 版本适配不同的 Linux 发行版及版本。常…...

滑动验证码缺口识别与自动化处理技术解析
在如今的网络安全环境中,滑动验证码作为一种主流的人机验证方案,被广泛应用。它的核心挑战主要集中在两个方面:一是如何准确地识别出缺口位置,二是如何模拟出逼真的拖动轨迹。 一、缺口识别技术方案 (一)…...