Elasticsearch 深入分析三种分页查询【Elasticsearch 深度分页】
前言:
在前面的 Elasticsearch 系列文章中,分享了 Elasticsearch 的各种查询,分页查询也分享过,本篇将再次对 Elasticsearch 分页查询进行专题分析,“深度分页” 这个名词对于我们来说是一个非常常见的业务场景,本篇再次进行 Elasticsearch 分页查询进行分析,也是围绕深度分页这个业务场景来展开的。
Elasticsearch 系列文章传送门
Elasticsearch 基础篇【ES】
Elasticsearch Windows 环境安装
Elasticsearch 之 ElasticsearchRestTemplate 普通查询
Elasticsearch 之 ElasticsearchRestTemplate 聚合查询
Elasticsearch 之 ElasticsearchRestTemplate 嵌套聚合查询【嵌套文档聚合查询】
分页查询前景回顾
我们来回忆下在之前的分页查询,代码如下:
public List<CarDO> pageList(int currentPage, int pageSize) {NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();queryBuilder.withPageable(PageRequest.of(currentPage - 1, pageSize)).build();queryBuilder.withQuery(QueryBuilders.matchQuery("color", "雅灰"));SearchHits<CarDO> search = elasticsearchRestTemplate.search(queryBuilder.build(), CarDO.class);return search.getSearchHits().stream().map(SearchHit::getContent).collect(Collectors.toList());
}
以上代码我们使用了 【queryBuilder.withPageable】来实现的分页查查询,通过 PageRequest 传入了当前页和分页大小构建了一个分页对象,以上分页会有什么问题?
Elasticsearch 分页原理探讨
Elasticsearch 分页官方文档
官方文档描述如下:
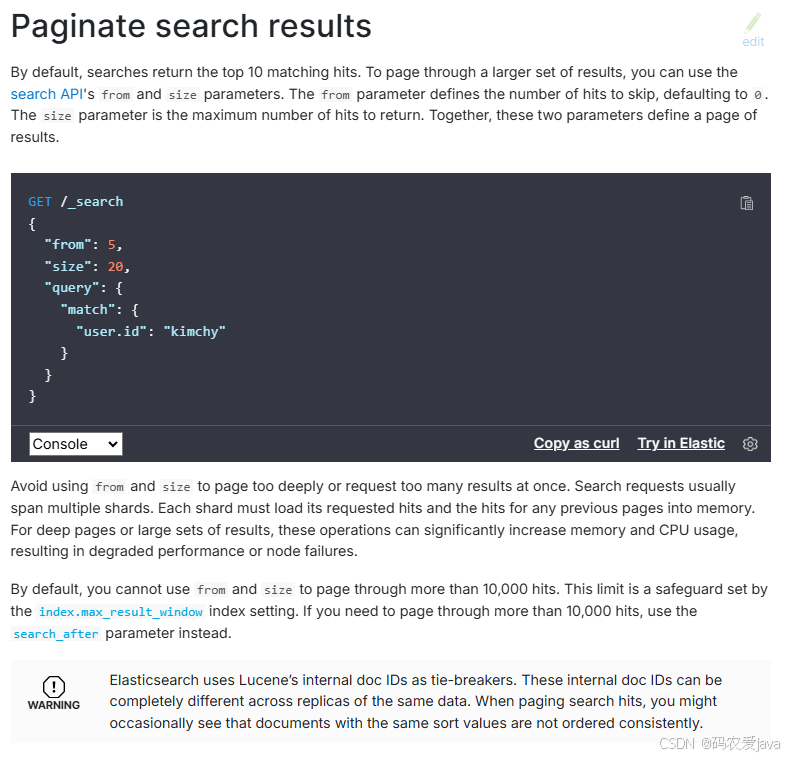
官方文档说的大概意思如下:
默认情况下,搜索会返回前 10 个匹配结果,如果要翻阅更多结果,可以使用搜索 API 的 from 和 size 参数来实现。from 参数定义要跳过的匹配数,默认为 0。size 参数是返回的最大匹配数,这两个参数一起定义了一页结果。
但是要避免使用 from 和 size 分页太深或一次请求太多结果的情况。搜索请求通常跨越多个分片。每个分片必须将其请求的命中和任何先前页面的命中加载到内存中。对于深层页面或大量结果,这些操作可能会显著增加内存和 CPU 使用率,从而导致性能下降或节点故障。
默认情况下,不能使用 from 和 size 来翻阅超过 10000 个匹配结果。此限制是 index.max_result_window 索引设置设定的一项保障措施。如果您需要翻阅超过 10,000 个匹配项,请使用 search_after 来实现。
简单概括就是 Elasticsearch 使用的 from 和 size 来实现分页,但是不建议使用 from 和 size 这种方式来实现深度分页,当分页深度超过 10000 的时候就不建议使用 from 和 size 来实现了,否则会大量占用内存和 CPU,也就是说我们上面的分页在深度分页的时候会有性能问题。
Elasticsearch 分页的内部执行过程分析
在 Elasticsearch 搜索是一个两阶段的过程,分别为查询阶段和取回阶段。
查询阶段
- 广播查询请求:客户端发送查询请求到某个节点,该节点会将查询请求广播到索引的所有分片上。
- 分片处理:每个分片在本地执行独立查询,根据查询条件得到符合条件的文档,并会为每个文档计算得分,每个分片中会按照得分来对文档进行排序,然后保留得分靠前的文档 ID。
- 合并结果:各分片将本地的部分结果返回给协调节点,协调节点会对这些结果进行合并排序,得到需要返回的额文档 ID。
取回阶段
- 获取文档详情:根据文档 ID,向包含这些文档的分片发送查询请求,获取文档的详细内容。
- 返回结果到客户端:协调节点在收到所有的文档内容后,再进行整理得到最终的文档,返回给客户端。
Elasticsearch 分页过程的问题
假设在一个有 3 个主分片的索引中进行分页搜索,每 10 个文档为一页数据,当请求结果的第一页(结果从 1 到 10 ),每一个分片产生前 10 的结果,返回给协调节点 ,协调节点对 30 个结果排序得到全部结果的前 10 个,这个并没有什么问题。
当我们请求第 1000 页的时候,就需要每个分片返回 10001 到 10010 的文档,然后返回给协调节点,最后协调节点对全部 30030 个结果排序,最后丢弃掉这些结果中的 30020 个结果,很明显这里有一个非常大的内存占用的浪费,这就是 from 和 size 方式分页的问题,也就是我们常说的深度分页问题。
Elasticsearch 分页之 Search After
Elasticsearch 官方文档关于 Search After 的介绍比较多,这里简单截图如下,想了解更多点击以下超链接跳转。
Elasticsearch 分页官方文档
Elasticsearch 分页之 Search after
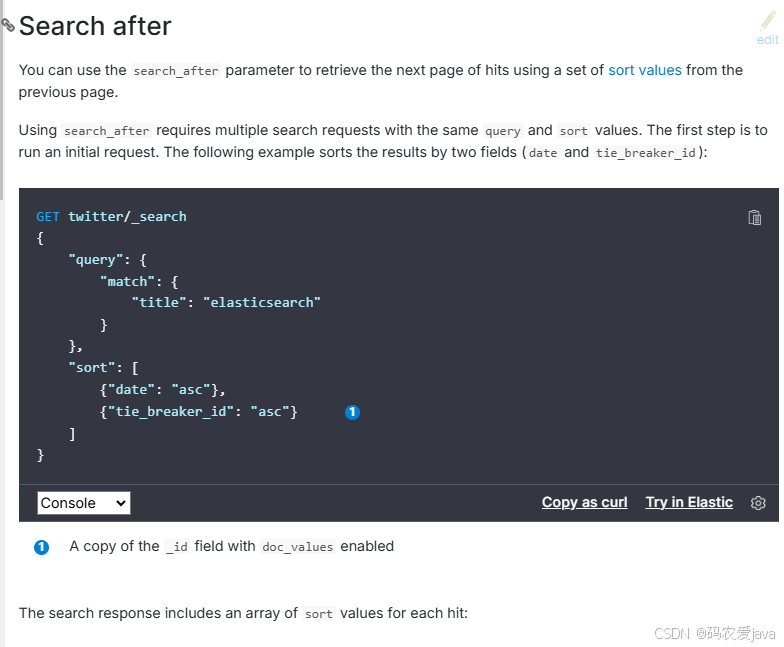
Elasticsearch 的 Search after 的分页是基于上一次查询结果的最后一条数据的指定字段值来进行下一页数据的查询,它通过在查询请求中指定 search_after 参数来实现。与传统的分页方式(from 和 size 参数)不同,Search after 不需要记录页码,也不会受到 from + size 的深度限制,能更高效地处理深层分页问题,因为每一页的数据依赖于上一页最后一条数据,所以无法进行跳页。
Java API 使用 Elasticsearch 的 search_after 实现分页
我们上面了解了 Elasticsearch 的 search_after 分页原理,现在我们使用 Java API 实现分页。代码如下:
@Autowired
private RestHighLevelClient restHighLevelClient;@Override
public List<CarDO> searchAfter(int lastId, int pageSize) {//使用 searchAfter 分页SearchRequest searchRequest = new SearchRequest("car_7");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//查询所有的数据searchSourceBuilder.query(QueryBuilders.matchAllQuery());//使用 search after 分页需要设置 from 为 0searchSourceBuilder.from(0);searchSourceBuilder.size(pageSize);searchSourceBuilder.searchAfter(new Object[]{lastId});//设置超时时间 超过 60秒还没有返回则返回一个超时错误searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));//定义排序规则SortBuilder<FieldSortBuilder> id4Sort = SortBuilders.fieldSort("id").order(SortOrder.ASC);searchSourceBuilder.sort(id4Sort);searchRequest.source(searchSourceBuilder);List<CarDO> carList = new ArrayList<>();try {SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);org.elasticsearch.search.SearchHit[] hits = search.getHits().getHits();if (Objects.nonNull(hits) && hits.length > 0) {//下一次分页的起始点lastId = Integer.parseInt(hits[hits.length - 1].getSortValues()[0].toString());}for (org.elasticsearch.search.SearchHit hit : hits) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();CarDO carDO = JSON.parseObject(JSON.toJSONString(sourceAsMap), CarDO.class);carDO.setLastId(lastId);carList.add(carDO);}} catch (IOException e) {e.printStackTrace();}return carList;
}
我们来分析一下上面这段代码:
- lastId:上一次查询的最后一个 id,我们需要使用这个 id 来查询下一页的数据。
- pageSize:每页显示的条数。
- from:从第几条开始查询,使用 search_after 的时候需要设置为 0。
- searchSourceBuilder.searchAfter(new Object[]{lastId}):从 lastId 开始查询,用于指定分页的起始位置,它接收上一页最后一条数据的排序值数组。
- searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)):设置超时时间,超过 60 秒还没有返回则返回一个超时错误。
- searchSourceBuilder.sort(id4Sort):指定排序的字段和顺序,用于确定 search_after 分页的顺序,这里我们按照 id 排序,使用 search_after 进行分页查询,必须定义一个排序字段。也可以指定按照某个日期字段升序或降序排序,或者按照多个字段的组合排序,排序字段的选择要确保在整个查询过程中能够唯一标识每一条数据。
以上就是使用 search_after 实现 Elasticsearch 分页的核心代码的解释。
scroll-search 分页
Elasticsearch 还提供了 scroll-search 的方式来实现分页,官方文档如下:
scroll-search 分页官方文档
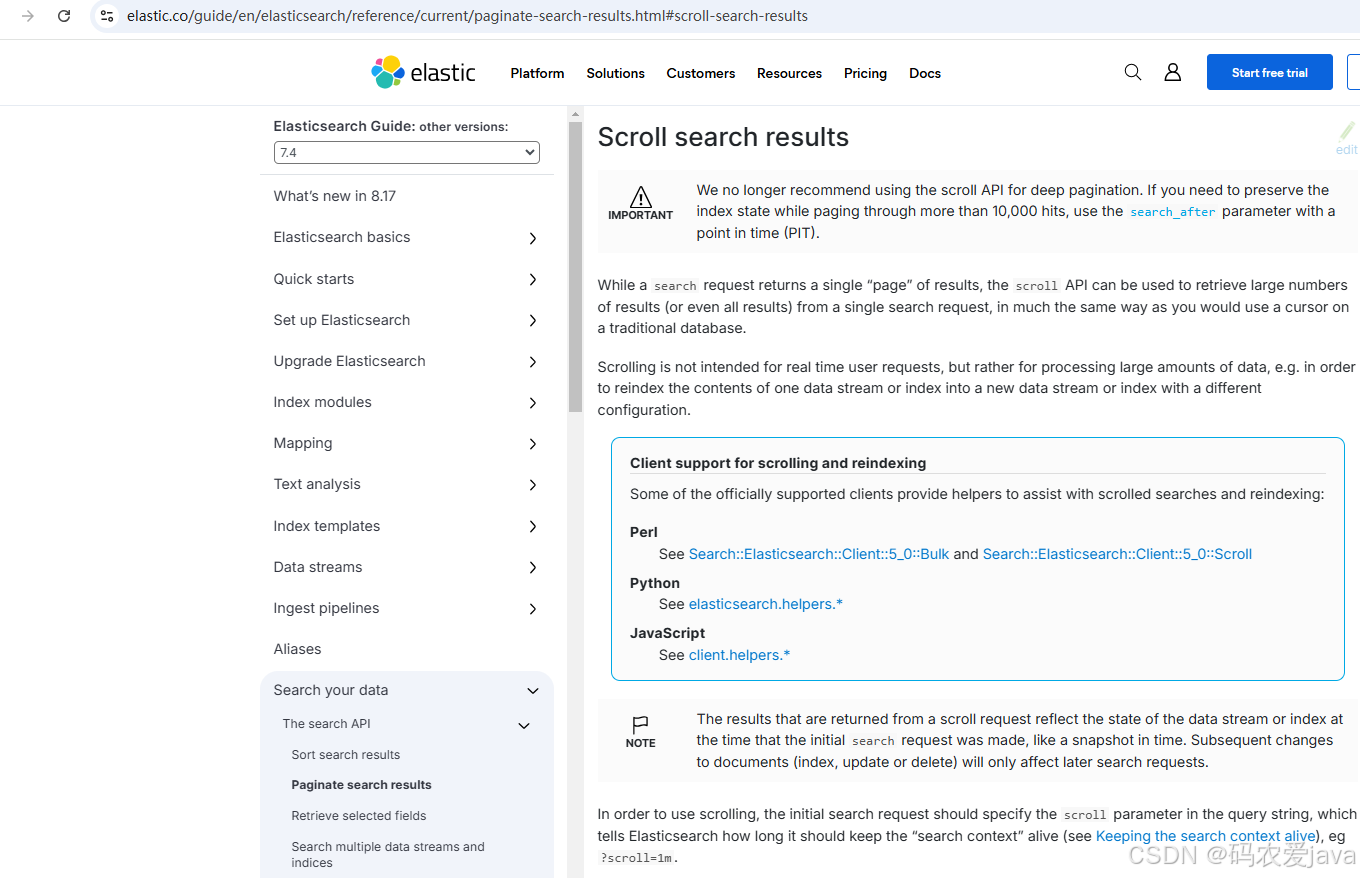
官方文档不建议使用 scroll-search 实现 Elasticsearch 深度分页,推荐使用 search_after 实现深度分页,因为官方文档已经不在推荐使用,这里就不在对 scroll-search 分页进行代码演示了,这里只简单对 scroll-search 进行简单优缺点分析如下:
优点:
- 深度分页性能较好:可以满足大量数据的深度分页场景,在处理深度分页时性能稳定,不会像 from/size 分页那样,随着分页深度的增加,ES 需要遍历和丢弃的文档增多而导致性能显著下降(但已不推荐使用,推荐使用 search_after 来实现)。
- 打破结果窗口限制:不受 index.max_result_window 限制,能方便地进行全量数据的遍历处理,可用于导出大量数据操作。
- 查询结果稳定性好:因为 scroll-search 基于快照查询,在整个 scroll 查询过程中,只要快照有效,查询结果是稳定的,不会出现遗漏或重复数据的情况,对于需要准确获取大量数据但对数据实时性要求不敏感的场景非常实用。
缺点:
- 数据实时性差:因为 scroll-search 是基于快照查询,Scroll 上下文维护的搜索结果是在快照创建时的数据状态,因此有可能查询到的不是最新的数据,不适合数据实时性要求高的业务场景。
- 内存占用问题:因为 scroll-search 是基于快照查询,需要维护快照,会占用额外的内存资源,如果处理的数据量非常大,可能会对服务器内存造成较大压力,需要合理设置相关参数并关注服务器资源使用情况。
- 数据过期问题:scroll-search 查询结果是快照查询,如果快照过期,过期后需要重新初始化查询,会导致整个过程变的更为复杂。
- 不支持跳页。
总结:本篇分享了 Elasticsearch 三种分页方式的实现,并对两种常用的分页方式进行了代码演示,深度分页推荐使用 search_after 的方式实现,希望可以帮助到对 Elasticsearch 分查询不太熟悉的朋友。
如有不正确的地方欢迎各位指出纠正。
相关文章:

Elasticsearch 深入分析三种分页查询【Elasticsearch 深度分页】
前言: 在前面的 Elasticsearch 系列文章中,分享了 Elasticsearch 的各种查询,分页查询也分享过,本篇将再次对 Elasticsearch 分页查询进行专题分析,“深度分页” 这个名词对于我们来说是一个非常常见的业务场景&#…...

避开封禁陷阱:动态IP在爬虫、跨境电商中的落地实践
1. 为什么需要动态IP? 在日常网络操作中,你是否遇到过: 爬虫被封:频繁请求目标网站,IP被限制访问。跨境业务受限:某些平台对特定地区的账号有限制。数据采集失败&#x…...

公网ip是固定的吗?动态ip如何做端口映射?内网ip怎么让外网远程访问?
网络IP地址有内网与公网区分,公网IP同时有固定IP和动态IP之分。很多企业所用的办公网络都是公网ip,下载文件的速度更快,而且平台存储的问题可以让他人看得到,体验度比较好。对于无公网IP环境想要申请公网ip的用户来说,…...

MyBatis入门指南
查询user表中所有数据 创建user表,添加数据导入依赖,创建模块编写MyBatis核心配置文件编写SQL映射文件编写代码 定义P0J0类加载核心配置文件,获取SqlSessionFactory对象获取SqlSession对象,执行SQL语句释放资源 一、创建user表…...

GitHub排名第一的开源ERP项目:Odoo生产计划与执行的功能概述
Odoo生产计划与执行隶属于Odoo MRP与MES的运营管理解决方案。Odoo中生产计划有多种形式,从销售预测到销售运作计划(SOP)开始,到随后的主生产计划、物料需求计划(MRP)、分销需求计划(DRP)、长期生产计划,以及粗能力计划(RCCP)和详细能力计划。…...

使用 OpenCV 实现 ArUco 码识别与坐标轴绘制
🎯 使用 OpenCV 实现 ArUco 码识别与坐标轴绘制(含Python源码) Aruco 是一种广泛用于机器人、增强现实(AR)和相机标定的方形标记系统。本文将带你一步一步使用 Python OpenCV 实现图像中多个 ArUco 码的检测与坐标轴…...

RAC共享存储扩容
存储工程师扩完共享存储后,DBA做如下操作: 1.主机端识别磁盘 在两个节点扫描磁盘命令 # for i in find /sys/class/scsi_host/host*; do echo - - - > $i/scan; done lsblk 2.比对确定新加的盘的uuid,确保uuid是一致的,别…...
)
高德地图 MCP,可用 Java SolonMCP 接入(支持 java8, java11, java17, java21)
1、MCP技术概述 1.1 什么是 MCP MCP (Model Control Protocol) 是一种允许大模型与外部工具交互的协议,高德地图基于此协议提供了地图服务能力,使 AI 大模型能够直接调用高德的 LBS。 1.2 两种接入架构对比 高德地图 MCP 提供了两种不同的接入方式&a…...

rosbag使用记录
1. 查看某个话题频率 rqt—topic 2. 查看对齐 rqt_bag...

7. 数据库技术
在数据库技术实战中,我们通过MySQL数据库的安装与操作,掌握了从创建数据库、数据表到插入、查询、更新和删除记录的全过程。借助Navicat工具,我们能够更直观地进行数据库管理与开发,提升效率。同时,通过JDBC技术&#…...
和浮点数(float))
Python中的整型(int)和浮点数(float)
在很多初学者眼中,int和float不过是Python中代表整数和小数的基本类型,似乎只是编程语言中最“平凡”的组成部分。但在真正深入软件开发、测试乃至AI数值计算的世界后,你会发现,这两个基础类型背后隐藏着诸多重要的设计哲学、性能…...

Python元组全面解析:从入门到精通
文章目录 Python元组全面解析:从入门到精通一、元组的基本概念1. 什么是元组?2. 元组与列表的对比3. 为什么需要元组? 二、元组的创建方式1. 基本创建方法2. 其他创建方式 三、元组的访问与操作1. 访问元素2. 切片操作3. 元组解包 四、元组的…...

1 asyncio模块
1.1核心概念 1.1.1协程 协程是一种特殊的函数,可以在执行过程中暂停,也可以稍后恢复执行。协程通过async关键字来指定。 await关键字:如果想要立即执行,那调用协程的时候,前面加上await关键字。只想创建协程对象稍后…...
)
交通拥堵预测器(python)
这是一个基于机器学习的交通拥堵预测应用,使用随机森林算法。 功能特点: - 使用随机森林算法进行交通拥堵预测 - 直观的图形用户界面 - 支持模型训练、评估和保存/加载 - 实时预测特定时间段的拥堵程度 - 数据可视化功能(按星期分布、按时间段分布、热力图) - 支持自…...

解决服务器重装之后vscode Remote-SSH无法连接的问题
在你的windows命令窗口输入: ssh-keygen -R 服务器IPssh-keygen 不是内部或外部命令 .找到Git(安装目录)/usr/bin目录下的ssh-keygen.exe(如果找不到,可以在计算机全局搜索) 2.属性–>高级系统设置–>环境变量–>系统变量,找到Path变量&#…...

STM32实战指南:DHT11温湿度传感器驱动开发与避坑指南
知识点1【DHT11的概述】 1、概述 DHT是一款温湿度一体化的数字传感器(无需AD转换)。 2、驱动方式 通过单片机等微处理器简单的电路连接就能实时采集本地湿度和温度。DHT11与单片机之间采用单总线进行通信,仅需要一个IO口。 相对于单片机…...

使用 Terraform 创建 Azure Databricks
使用 Terraform 创建 Azure Databricks Terraform 是一种基础设施即代码(IaC)工具,允许用户通过声明式配置文件来管理和部署云资源。Azure Databricks 是一个基于 Apache Spark 的分析平台,专为数据工程和数据科学设计。通过 Terraform,可以自动化 Azure Databricks 的创…...

对话即编程:如何用 Trae 的 @智能体 5 分钟修复一个复杂 Bug?
引子:当新手遇到 "天书" 般的报错 作为刚加入团队的开发者,我在接手一个遗留的 Python 数据处理项目时,遇到了一个诡异报错: python 复制 下载 ValueError: shape mismatch: value array of shape (500,) could no…...

【工具使用】STM32CubeMX-片内Flash读写操作
一、概述 无论是新手还是大佬,基于STM32单片机的开发,使用STM32CubeMX都是可以极大提升开发效率的,并且其界面化的开发,也大大降低了新手对STM32单片机的开发门槛。 本文主要讲述STM32芯片片内Flash功能的应用及其相关知识…...
:Gorm查询)
Java转Go日记(三十九):Gorm查询
1.1.1. 查询 // 获取第一条记录,按主键排序db.First(&user)SELECT * FROM users ORDER BY id LIMIT 1;// 获取最后一条记录,按主键排序db.Last(&user)SELECT * FROM users ORDER BY id DESC LIMIT 1;// 获取所有记录db.Find(&users)SELECT *…...

终端安全与终端管理:有什么区别及其重要性?
在当今快速发展的远程和混合工作环境中,IT 团队面临双重挑战:一方面需保护终端免受日益增长的网络风险,另一方面要管理跨越日益分散网络的设备。这些需求催生了两个关键的 IT 解决方案:终端安全和终端管理。尽管二者时常被共同讨论…...

【二分 优先队列】P3611 [USACO17JAN] Cow Dance Show S|普及+
本文涉及的基础知识点 C二分查找 C堆(优先队列) [USACO17JAN] Cow Dance Show S 题面翻译 题目描述 经过几个月的排练,奶牛们基本准备好展出她们的年度舞蹈表演。今年她们要表演的是著名的奶牛芭蕾——“cowpelia”。 表演唯一有待决定的是舞台的尺寸。一个大…...

蓝桥杯分享经验
系列文章目录 提示:小白先看系列 第一章 蓝桥杯的钱白给吗 文章目录 系列文章目录前言一、自我介绍二、经验讲解:1.基础知识2.进阶知识3.个人观点 三、总结四、后续 前言 第十六届蓝桥杯已经省赛已经结束了,相信很多小伙伴也已经得到自己的成绩了。接下…...

TDengine 安全部署配置建议
背景 TDengine 的分布式、多组件特性导致 TDengine 的安全配置是生产系统中比较关注的问题。本文档旨在对 TDengine 各组件及在不同部署方式下的安全问题进行说明,并提供部署和配置建议,为用户的数据安全提供支持。 安全配置涉及组件 TDengine 包含多…...

Grafana当前状态:SingleStat面板
Grafana的SingleStat面板是一种用于展示单个关键指标(KPI)的可视化组件,特别适合需要突出显示核心业务指标的场景(如实时销售额、在线用户数、系统错误率等)。它通过简洁的布局和丰富的样式选项,帮助用户快速聚焦核心数据。Singlem Panel侧重于展示系统的…...
)
专题五:floodfill算法(太平洋大西洋水流问题)
以leetcode417题为例 题目解析: 整张图,左边深蓝的是太平洋,右边浅蓝的是大西洋,你需要在矩阵中找到一个点,使其可以流向太平洋又可以流向大西洋,并且你每次流的时候只能由高到低,或者相等到相…...

【HTML】【面试提问】HTML面试提问总结
第一章 HTML基础相关提问 1.1 HTML基本概念 1.1.1 什么是HTML HTML 即超文本标记语言(HyperText Markup Language)😎,它是用于创建网页的标准标记语言。简单来说,HTML 就像是搭建房屋的砖块🧱࿰…...

解锁MySQL性能调优:高级SQL技巧实战指南
高级SQL技巧:解锁MySQL性能调优的终极指南 开篇 当前,随着业务系统的复杂化和数据量的爆炸式增长,数据库性能调优成为了技术人员面临的核心挑战之一。尤其是在高并发、大数据量的场景下,SQL 查询的性能直接影响到整个系统的响应…...

数据分析与应用---数据可视化基础
目录 Matplotlib基础绘图 (一)、pyplot绘图基础语法与常用参数 1、pyplot基础语法 (1) 创建画布与创建子图 (2) 添加画布内容 (3) 保存与显示图形 案例代码 2. 设置pyplot的动态…...

android双屏之副屏待机显示图片
摘要:android原生有双屏的机制,但需要芯片厂商适配框架后在底层实现。本文在基于芯发8766已实现底层适配的基础上,仅针对上层Launcher部分对系统进行改造,从而实现在开机后副屏显示一张待机图片。 副屏布局 由于仅显示一张图片&…...

oracle序列自增问题
1.先查询表名对应的序列名称 SELECT trigger_name, trigger_type, triggering_event FROM all_triggers WHERE table_name 表名;2. 查询id最大值 SELECT MAX(ID) FROM 表名;3. 查询下一次生成ID SELECT SJCJ_ENERGY_DATA_INSERTID.NEXTVAL FROM DUAL;4. 设置临时步长,越过…...

FLASHDB API分析
fdb_kvdb_init 函数详解 fdb_kvdb_init 是 FlashDB 框架中用于 初始化键值数据库(KVDB) 的核心接口,其功能涵盖底层存储配置、默认数据加载与多模式适配。以下从功能、参数、使用场景及注意事项展开分析: 一、功能与作用 …...

使用 ABP vNext 集成 MinIO 构建高可用 BLOB 存储服务
🚀 使用 ABP vNext 集成 MinIO 构建高可用 BLOB 存储服务 本文基于 ABP vNext MinIO 的对象存储集成实践,系统讲解从 MinIO 部署、桶创建、ABP 集成、上传 API、安全校验、预签名访问,到测试、扩展及多租户支持的全过程。目标是构建一套可复…...

3.安卓逆向2-安卓文件目录
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 内容参考于:图灵Python学院 上一个内容:2.安卓逆向2-adb指令 首先使用adb连接到手机,如下图使用adb命令列出手机的目录&am…...

云原生时代的系统可观测性:理念变革与实践体系
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、引言:为什么可观测性在云原生时代变得更加重要? 传统应用系统运行于固定服务器,拓扑结构稳定、依赖路径清晰,排查故障依赖日志和人工经验已足够支撑运维。但在云原生环境中,系统正快速演变为: 微…...

力扣网-复写零
1.题目要求 2.题目链接 1089. 复写零 - 力扣(LeetCode) 3.题目解答 class Solution {public void duplicateZeros(int[] arr) {int cur0,dest-1,narr.length;while(cur<n){//遇到0就dest走两步if(arr[cur]0){dest2;}//遇到非零元素dest就走一步els…...

高项-挣值管理TCPI
TCPI(完工尚需绩效指数)的英文全称及含义 TCPI 是项目管理(尤其是挣值管理EVM, Earned Value Management)中的一个关键指标,其英文全称为: To-Complete Performance Index 中文译为**“完工尚需绩效指数”…...

Java大厂面试三轮问答:微服务与数据库技术深度解析
Java大厂面试:谢飞机的三轮挑战 第一轮:微服务基础与电商场景设计 面试官: "谢飞机,假设我们要设计一个电商平台,需要支持用户下单、支付以及订单追踪。你会如何设计微服务架构?" 谢飞机: "呃&#…...

Linux 移植 Docker 详解
一、移植前的环境准备 在将 Docker 移植到 Linux 系统之前,需要确保系统满足一定的条件,以保证 Docker 能够稳定运行。 1. 操作系统版本要求 Docker 对 Linux 操作系统版本有一定的要求,不同的 Docker 版本适配不同的 Linux 发行版及版本。常…...

滑动验证码缺口识别与自动化处理技术解析
在如今的网络安全环境中,滑动验证码作为一种主流的人机验证方案,被广泛应用。它的核心挑战主要集中在两个方面:一是如何准确地识别出缺口位置,二是如何模拟出逼真的拖动轨迹。 一、缺口识别技术方案 (一)…...

C++字符串处理:`std::string`和`std::string_view`的区别与使用
在 C中,std::string和std::string_view都用于处理字符串,但它们的用途和性能特点有很大不同。本教程将通过代码示例和流程图,帮助你快速掌握它们的使用方法。 1.什么是std::string和std::string_view? 1.1std::string std::str…...

Uniapp中动态控制scroll-view滚动的方式
在Uniapp 4.45中,动态修改scroll-view的scroll-left属性时无法触发滚动(直接设置scroll-left属性值没问题),这通常是因为数据更新与 DOM 渲染之间的异步特性导致的。知道了原因,但是直接修改scroll-left属性值还是失败…...

手机怎么查看网络ip地址?安卓/iOS设备查询指南
在移动互联网时代,IP地址作为设备的网络身份证,无论是网络调试、远程连接还是排查故障都至关重要。本文将系统介绍安卓和iOS设备查看IP地址的多种方法,帮助您快速掌握这一实用技能。 一、安卓手机查看IP地址方法 1、通过WiFi设置查看 打开设…...

R语言+贝叶斯网络:涵盖贝叶斯网络的基础、离散与连续分布、混合网络、动态网络,Gephi可视化,助你成为数据分析高手!
🔍 在现代生态、环境及地学研究中,变量及其因果关系的推断是核心课题之一。然而,传统的因果关系研究通常依赖于昂贵的实验,而实验结果往往与天然环境中的实际因果联系存在较大偏差。例如,在生态系统中,物种…...

手机内存不够,哪些文件可以删?
1️⃣应用缓存文件 安卓:通过「文件管理器」→「Android」→「data」或「cache」文件夹(部分需权限),或直接在应用设置中清除缓存 iOS:无需手动清理,系统会自动管理,或在应用内设置中清除&…...
、字节(Byte)、字(Word)、整数(Int))
C语言之 比特(bit)、字节(Byte)、字(Word)、整数(Int)
在C语言中,经常出现上述的概念,即比特(bit)、字节(Byte)、字(Word)、整数(Int)。查看C语言标准,比特(bit)的定义如下&…...

组态王通过开疆智能profinet转ModbusTCP网关连接西门子PLC配置案例
本案例是组态王通过使用开疆智能研发的Profinet转ModbusTCP网关采集西门子1200PLC中数据的案例。 网关配置 首先来配置网关的参数,打开网关配置软件“Gateway Configuration Studio” 由于组态王那侧设定为ModbusTCP客户端所以网关作为ModbusTCP服务器。新建项目…...
)
GO语言学习(五)
GO语言学习(五) 前面我们已经学了一些关于golang的基础知识,从这一期开始,我们就来讲解一下基于golang为后端的web开发,首先这一期为一些golang为后端的web开发基础讲解,我们将会从web的工作方式、golang如…...

Supermemory:让大模型拥有“长效记忆“
目录 引言:打破大语言模型的记忆瓶颈,迎接AI交互新范式 一、Supermemory 核心技术 1.1 透明代理机制 1.2 智能分段与检索系统 1.3 自动Token管理 二、易用性 三、性能与成本 四、可靠性与兼容性 五、为何选择 Supermemory? 六、对…...

Hooks实现原理与自定义Hooks
React Hooks 是 React 16.8 引入的一种机制,允许在函数组件中使用状态(state)、副作用(effect)等功能,而无需编写 class 组件。其核心原理是通过闭包和链表结构,在 React 的 Fiber 架构中管理组…...