R9打卡——RNN实现阿尔茨海默病诊断(优化特征选择版)
🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
1.检查GPU
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
import seaborn as sns#设置GPU训练,也可以使用CPU
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
2.查看数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDatasetplt.rcParams["font.sans-serif"] = ["Microsoft YaHei"] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号data_df = pd.read_csv("data/alzheimers_disease_data.csv")data_df.head()# 标签中文化
data_df.rename(columns={ "Age": "年龄", "Gender": "性别", "Ethnicity": "种族", "EducationLevel": "教育水平", "BMI": "身体质量指数(BMI)", "Smoking": "吸烟状况", "AlcoholConsumption": "酒精摄入量", "PhysicalActivity": "体育活动时间", "DietQuality": "饮食质量评分", "SleepQuality": "睡眠质量评分", "FamilyHistoryAlzheimers": "家族阿尔茨海默病史", "CardiovascularDisease": "心血管疾病", "Diabetes": "糖尿病", "Depression": "抑郁症史", "HeadInjury": "头部受伤", "Hypertension": "高血压", "SystolicBP": "收缩压", "DiastolicBP": "舒张压", "CholesterolTotal": "胆固醇总量", "CholesterolLDL": "低密度脂蛋白胆固醇(LDL)", "CholesterolHDL": "高密度脂蛋白胆固醇(HDL)", "CholesterolTriglycerides": "甘油三酯", "MMSE": "简易精神状态检查(MMSE)得分", "FunctionalAssessment": "功能评估得分", "MemoryComplaints": "记忆抱怨", "BehavioralProblems": "行为问题", "ADL": "日常生活活动(ADL)得分", "Confusion": "混乱与定向障碍", "Disorientation": "迷失方向", "PersonalityChanges": "人格变化", "DifficultyCompletingTasks": "完成任务困难", "Forgetfulness": "健忘", "Diagnosis": "诊断状态", "DoctorInCharge": "主诊医生" },inplace=True)data_df.columnsdata_df.isnull().sum()from sklearn.preprocessing import LabelEncoder# 创建 LabelEncoder 实例
label_encoder = LabelEncoder()# 对非数值型列进行标签编码
data_df['主诊医生'] = label_encoder.fit_transform(data_df['主诊医生'])data_df.head()# 计算是否患病, 人数
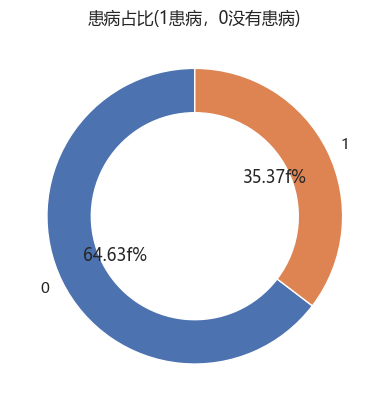
counts = data_df["诊断状态"].value_counts()# 计算百分比
sizes = counts / counts.sum() * 100# 绘制环形图
fig, ax = plt.subplots()
wedges, texts, autotexts = ax.pie(sizes, labels=sizes.index, autopct='%1.2ff%%', startangle=90, wedgeprops=dict(width=0.3))plt.title("患病占比(1患病,0没有患病)")plt.show()plt.figure(figsize=(40, 35))
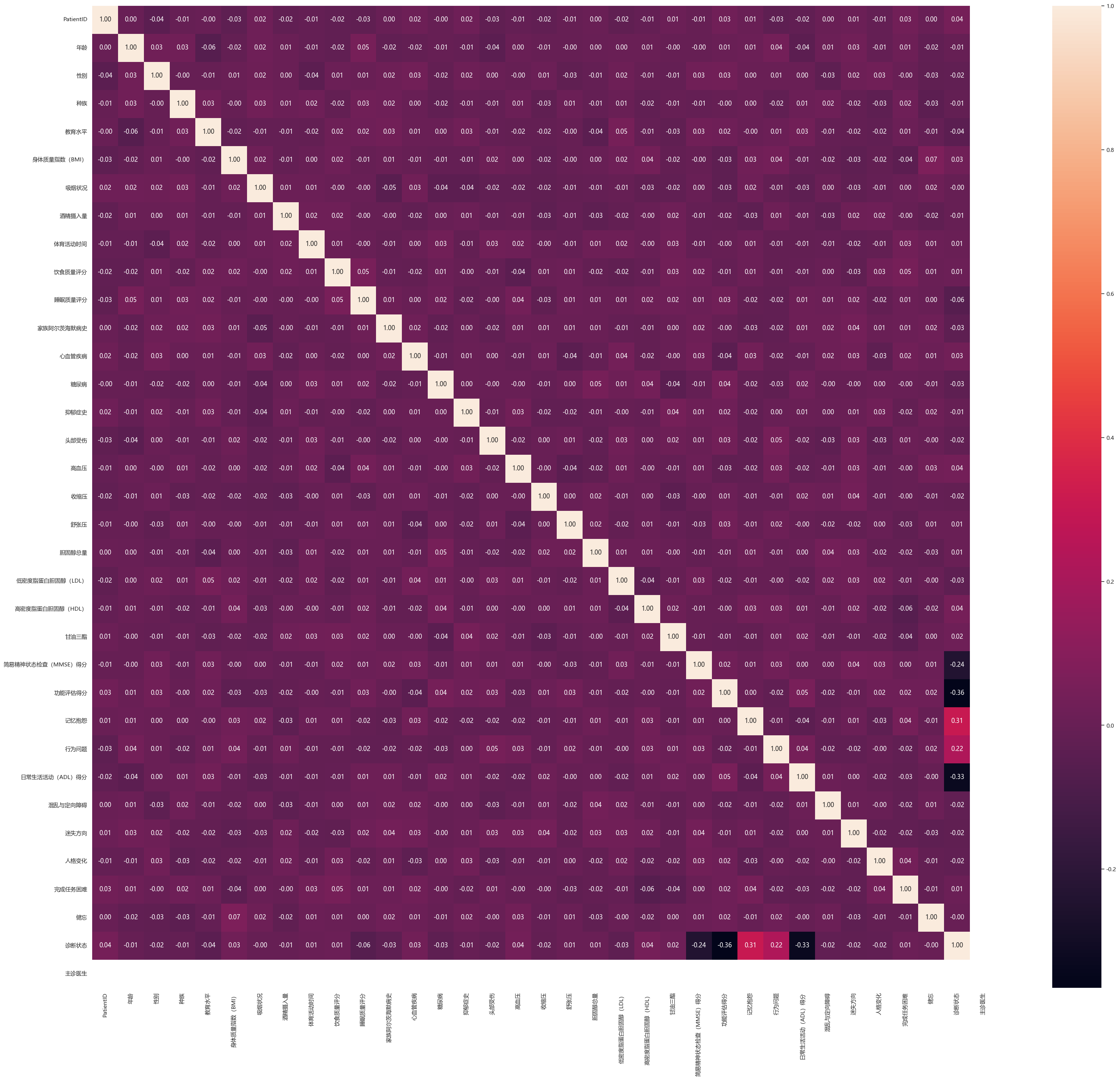
sns.heatmap(data_df.corr(), annot=True, fmt=".2f")
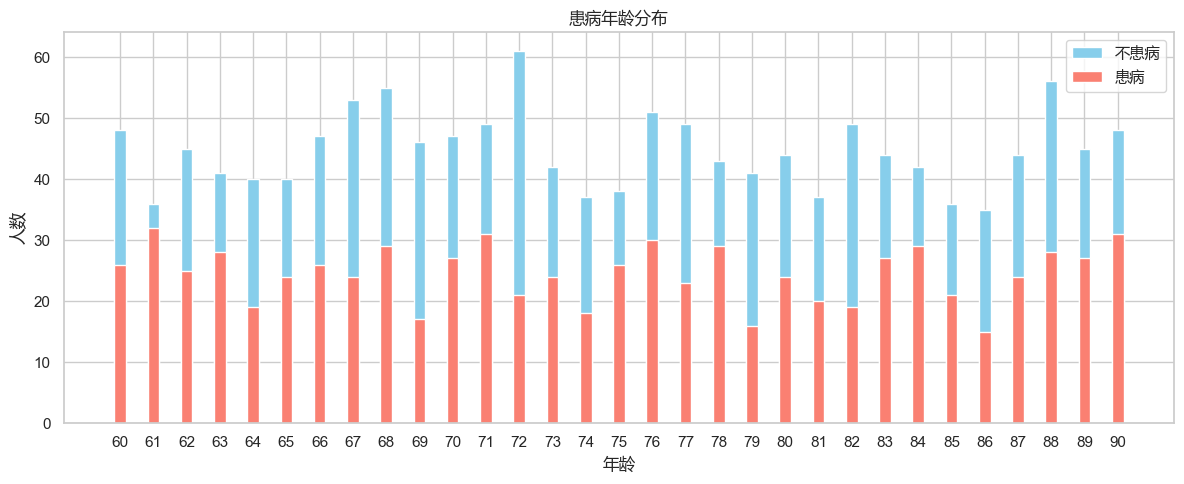
plt.show()data_df['年龄'].min(), data_df['年龄'].max()# 计算每一个年龄段患病人数
age_bins = range(60, 91)
grouped = data_df.groupby('年龄').agg({'诊断状态': ['sum', 'size']}) # 分组、聚合函数: sum求和,size总大小
grouped.columns = ['患病', '总人数']
grouped['不患病'] = grouped['总人数'] - grouped['患病'] # 计算不患病的人数# 设置绘图风格
sns.set(style="whitegrid")plt.figure(figsize=(12, 5))# 获取x轴标签(即年龄)
x = grouped.index.astype(str) # 将年龄转换为字符串格式便于显示# 画图
plt.bar(x, grouped["不患病"], 0.35, label="不患病", color='skyblue')
plt.bar(x, grouped["患病"], 0.35, label="患病", color='salmon')# 设置标题
plt.title("患病年龄分布", fontproperties='Microsoft YaHei')
plt.xlabel("年龄", fontproperties='Microsoft YaHei')
plt.ylabel("人数", fontproperties='Microsoft YaHei')# 如果需要对图例也应用相同的字体
plt.legend(prop={'family': 'Microsoft YaHei'})# 展示
plt.tight_layout()
plt.show()

3.特征选择
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_reportdata = data_df.copy()X = data_df.iloc[:, 1:-2]
y = data_df.iloc[:, -2]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 标准化
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)# 模型创建
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
pred = tree.predict(X_test)reporter = classification_report(y_test, pred)
print(reporter)# Set a font that supports CJK characters (e.g., SimHei for Chinese on Windows)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Noto Sans CJK JP'] # Choose appropriate fonts# Disable the "unicode minus" setting to avoid rendering issues
plt.rcParams['axes.unicode_minus'] = False
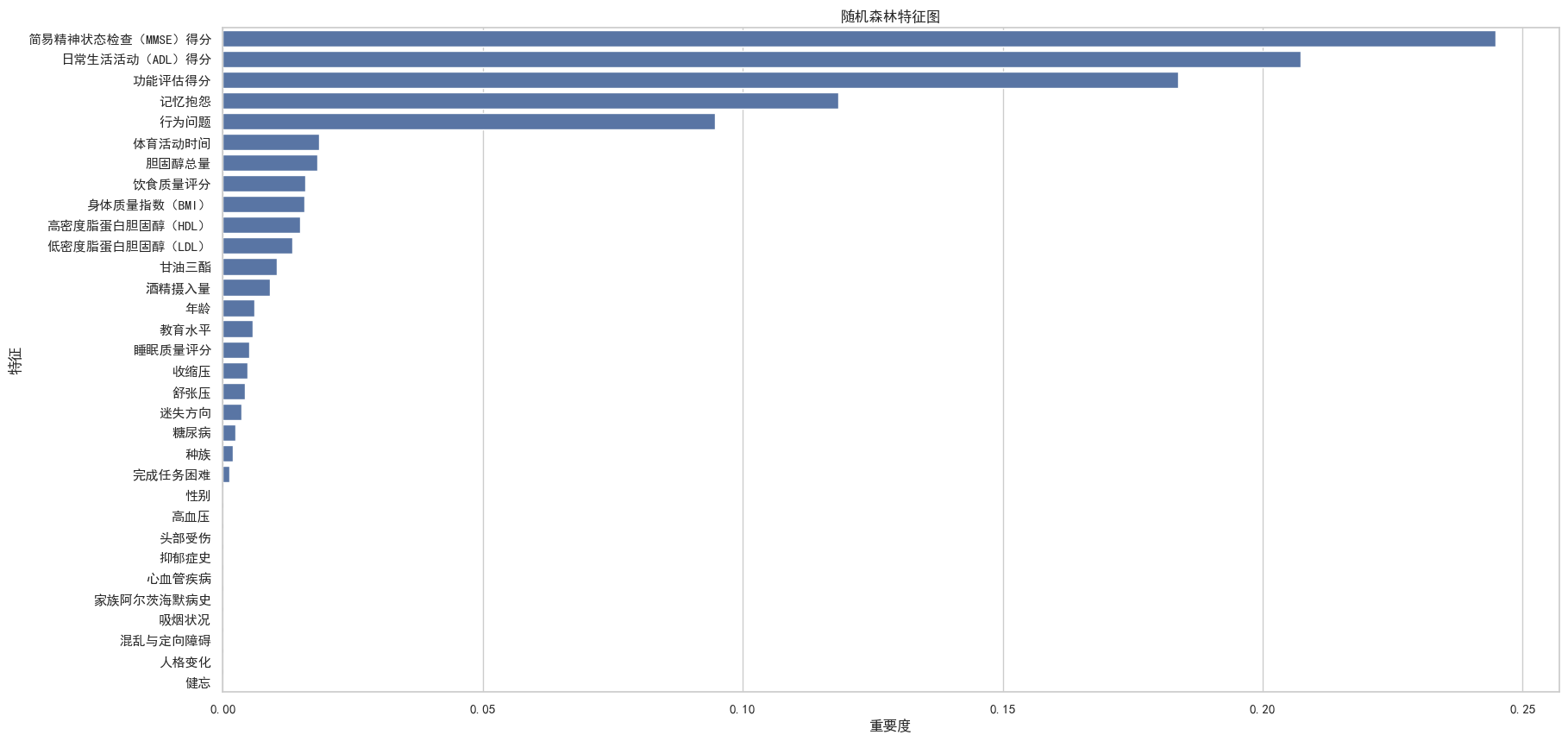
# 特征展示
feature_importances = tree.feature_importances_
features_rf = pd.DataFrame({'特征': X.columns, '重要度': feature_importances})
features_rf.sort_values(by='重要度', ascending=False, inplace=True)
plt.figure(figsize=(20, 10))
sns.barplot(x='重要度', y='特征', data=features_rf)
plt.xlabel('重要度')
plt.ylabel('特征')
plt.title('随机森林特征图')
plt.show()from sklearn.feature_selection import RFE# 使用 RFE 来选择特征
rfe_selector = RFE(estimator=tree, n_features_to_select=20) # 选择前20个特征
rfe_selector.fit(X, y)
X_new = rfe_selector.transform(X)
feature_names = np.array(X.columns)
selected_feature_names = feature_names[rfe_selector.support_]
print(selected_feature_names)feature_selection = ['年龄', '种族','教育水平','身体质量指数(BMI)', '酒精摄入量', '体育活动时间', '饮食质量评分', '睡眠质量评分', '心血管疾病','收缩压', '舒张压', '胆固醇总量', '低密度脂蛋白胆固醇(LDL)', '高密度脂蛋白胆固醇(HDL)', '甘油三酯','简易精神状态检查(MMSE)得分', '功能评估得分', '记忆抱怨', '行为问题', '日常生活活动(ADL)得分']X = data_df[feature_selection]# 标准化sc = StandardScaler()
X = sc.fit_transform(X)X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.long)# 再次进行特征选择
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)X_train.shape, y_train.shapetest_X = X_test[0].reshape(1, -1) # X_test[0]即我们的输入数据pred = model(test_X.to(device)).argmax(1).item()
print("模型预测结果为:",pred)
print("=="*20)
print("0:未患病")
print("1:已患病")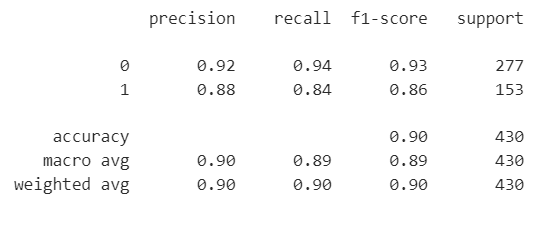


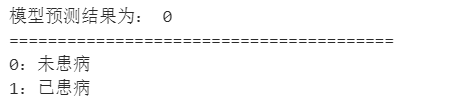

4.创建模型与编译训练
batch_size = 32train_dl = DataLoader(TensorDataset(X_train, y_train),batch_size=batch_size,shuffle=True
)test_dl = DataLoader(TensorDataset(X_test, y_test),batch_size=batch_size,shuffle=False
)class Rnn_Model(nn.Module):def __init__(self):super().__init__()# 调用rnnself.rnn = nn.RNN(input_size=20, hidden_size=200, num_layers=1, batch_first=True)self.fc1 = nn.Linear(200, 50)self.fc2 = nn.Linear(50, 2)def forward(self, x):x, hidden1 = self.rnn(x)x = self.fc1(x)x = self.fc2(x)return x# 数据不大,cpu即可
device = "cpu"model = Rnn_Model().to(device)
modelmodel(torch.randn(32, 20)).shape
5.编译及训练模型
def train(data, model, loss_fn, opt):size = len(data.dataset)batch_num = len(data)train_loss, train_acc = 0.0, 0.0for X, y in data:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)# 反向传播opt.zero_grad() # 梯度清零loss.backward() # 求导opt.step() # 设置梯度train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss /= batch_numtrain_acc /= size return train_acc, train_loss def test(data, model, loss_fn):size = len(data.dataset)batch_num = len(data)test_loss, test_acc = 0.0, 0.0 with torch.no_grad():for X, y in data: X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= batch_numtest_acc /= sizereturn test_acc, test_loss loss_fn = nn.CrossEntropyLoss() # 损失函数
learn_lr = 1e-4 # 超参数
optimizer = torch.optim.Adam(model.parameters(), lr=learn_lr) # 优化器train_acc = []
train_loss = []
test_acc = []
test_loss = []epoches = 50for i in range(epoches):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 输出template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')print(template.format(i + 1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))print("Done")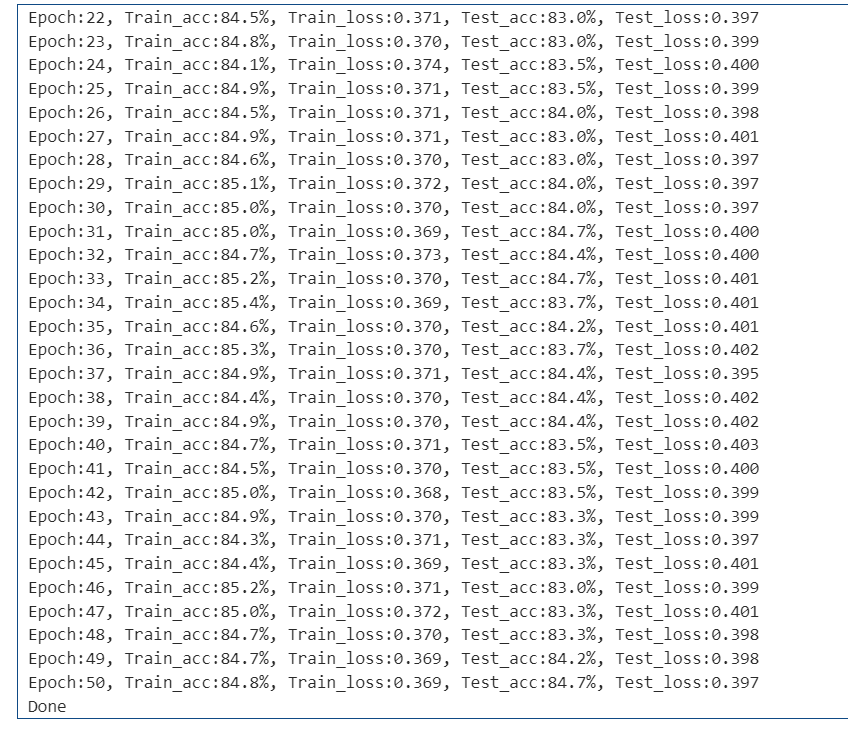
6.结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
from datetime import datetime
current_time = datetime.now() # 获取当前时间epochs_range = range(epoches)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training= Loss')
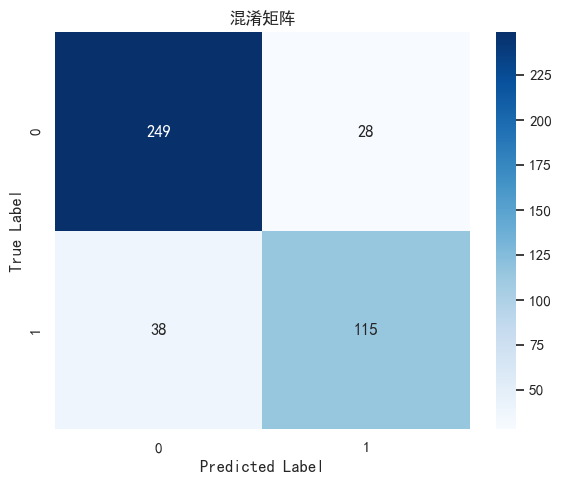
plt.show()from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay pred = model(X_test.to(device)).argmax(1).cpu().numpy()# 计算混淆矩阵
cm = confusion_matrix(y_test, pred)# 计算
plt.figure(figsize=(6, 5))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
# 标题
plt.title("混淆矩阵")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")plt.tight_layout() # 自适应
plt.show()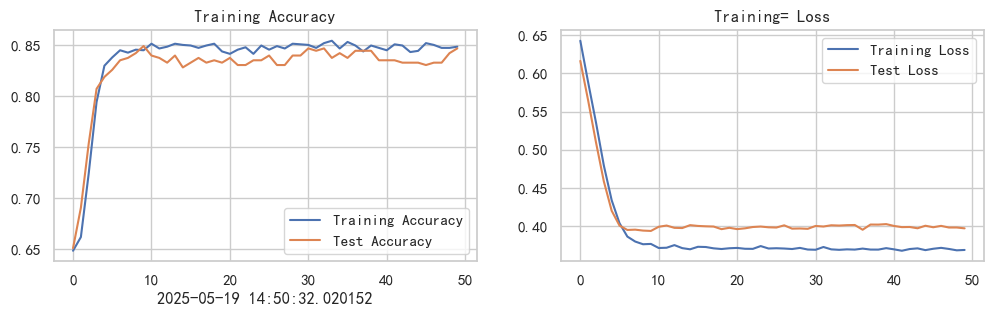

总结:
1. 数据准备与预处理
- 导入库:主要使用了
pandas、numpy、matplotlib、seaborn、sklearn和torch进行数据处理和建模。 - 读取数据:从
data/alzheimers_disease_data.csv加载数据集,并对列名进行了中文化重命名以便于理解。 - 缺失值检查:通过
isnull().sum()检查是否存在缺失值。 - 标签编码:对“主诊医生”字段使用
LabelEncoder进行编码,将其转换为数值型数据。 - 数据可视化:
- 绘制饼图展示患病比例(1为患病,0为未患病)。
- 使用热力图分析各特征之间的相关性。
- 绘制柱状图展示不同年龄段的患病情况。
2. 特征选择与处理
- 划分训练集和测试集:使用
train_test_split将数据划分为训练集和测试集(8:2)。 - 标准化处理:使用
StandardScaler对数据进行标准化,以提高模型性能。 - 特征重要性评估:
- 使用决策树(
DecisionTreeClassifier)计算特征重要性,并绘制条形图展示最重要的特征。 - 使用递归特征消除(RFE)方法选择前20个关键特征。
- 使用决策树(
- 最终特征选择:选择了20个最具代表性的特征用于后续建模。
3. 构建RNN模型
-
定义RNN模型:
class Rnn_Model(nn.Module):def __init__(self):super().__init__()self.rnn = nn.RNN(input_size=20, hidden_size=200, num_layers=1, batch_first=True)self.fc1 = nn.Linear(200, 50)self.fc2 = nn.Linear(50, 2)def forward(self, x):x, hidden1 = self.rnn(x)x = self.fc1(x)x = self.fc2(x)return x模型结构:
- 输入层:20维特征
- 隐藏层:200个隐藏单元
- 全连接层:输出2类(0:未患病,1:已患病)
-
数据加载器:使用
DataLoader将数据封装成批次,便于训练时使用。
4. 训练与评估模型
- 损失函数:使用交叉熵损失函数
CrossEntropyLoss。 - 优化器:使用
Adam优化器,学习率为1e-4。 - 训练过程:
- 定义了
train()和test()函数,分别用于训练和验证模型。 - 在每一轮训练后,记录训练和测试的准确率与损失。
- 总共训练50个epoch。
- 定义了
- 结果输出:
- 输出每个epoch的训练和测试准确率、损失值。
5. 可视化与评估
- 准确率和损失曲线:
- 使用
matplotlib绘制了训练和测试的准确率和损失变化趋势。
- 使用
- 混淆矩阵:
- 使用
confusion_matrix计算模型在测试集上的预测结果与真实标签的对比。 - 绘制热力图展示混淆矩阵,直观评估模型表现。
- 使用
6. 结果分析
- 模型预测示例:
展示了单个样本的预测结果。pred = model(test_X.to(device)).argmax(1).item() print("模型预测结果为:",pred) print("=="*20) print("0:未患病") print("1:已患病")
相关文章:
)
R9打卡——RNN实现阿尔茨海默病诊断(优化特征选择版)
🍨 本文为🔗365天深度学习训练营中的学习记录博客 🍖 原作者:K同学啊 1.检查GPU import numpy as np import pandas as pd import torch from torch import nn import torch.nn.functional as F import seaborn as sns#设置GPU训…...

Label Studio:开源标注神器
目录 一、Label Studio 是什么? 二、核心功能大揭秘 2.1 多类型数据全兼容 2.2 个性化定制随心配 2.3 团队协作超给力 2.4 机器学习巧集成 三、上手实操超简单 3.1 安装部署不头疼 3.1.1 Docker安装 3.1.2 pip安装 3.1.3 Anaconda安装 3.2 快速开启标注…...

flow-两种SharingStarted策略的区别示例
一 代码示例 viewModel.kt:// 上游数据源 - 模拟温度传感器 private val temperatureSource flow {var temp 20while(true) {emit(temp)delay(1000)println("上游发射温度: $temp") // 日志观察发射} }// WhileSubscribed - 有订阅者才收集 val temperature1 tem…...

零基础设计模式——设计模式入门
第一部分:设计模式入门 欢迎来到设计模式的世界!别担心,这听起来可能很“高大上”,但我们会用最生活化的例子来帮助你理解。 1. 什么是设计模式? 想象一下,你是个大厨,每天都要做很多菜。有些…...

通过vcpkg交叉编译grpc:构建Arm64平台的Docker化开发环境
一、引言 在现代软件开发中,交叉编译是构建跨平台应用程序的关键技术。本文将详细介绍如何使用Docker容器和vcpkg包管理器为Arm64架构交叉编译gRPC库。这种方法特别适用于需要在x86开发机上为ARM服务器或嵌入式设备构建高性能RPC服务的场景。 二、配置Docker交叉编…...

Nginx基础知识
Nginx是什么? Nginx 是一款高性能的 Web 服务器、反向代理服务器和负载均衡器,以其高并发处理能力和低内存消耗著称。以下是 Nginx 的基础知识和常见配置示例: 1. 核心概念 • 配置文件位置:通常为 /etc/nginx/nginx.conf 或 /us…...

【计算机主板架构】ITX架构
一、引言 在计算机硬件的广阔领域中,主板架构犹如大厦的基石,对整个计算机系统的性能、功能和扩展性起着至关重要的作用。其中,ITX架构以其小巧、灵活和独特的设计理念,在特定的应用场景中脱颖而出。从家庭媒体中心到小型办公电脑…...

ubuntu 20.04 运行和编译LOAM_Velodyne
摘要:创建工作空间-->src下克隆代码(https://github.com/laboshinl/loam_velodyne)-->修改四处代码(找到src/loam_velodyne路径下的CMakeLists.txt文件,注释掉35行代码和将/LOAM/src/loam_velodyne/src/lib文件夹…...

云计算简介:从“水电”到“数字引擎”的技术革命
云计算简介:从“水电”到“数字引擎”的技术革命 在当今数字化浪潮中,云计算早已从一个技术概念演变为支撑现代社会运转的核心基础设施。无论是你手机里的天气预报、电商购物的推荐系统,还是企业内部的ERP系统,背后都离不开云计算…...

femap许可与多用户共享
随着电磁仿真技术的发展,Femap作为一款领先的工具,在多个领域中发挥着不可替代的作用。然而,对于许多团队和企业来说,如何高效、经济地管理和使用Femap许可证成为了一个亟待解决的问题。本文将探讨Femap许可与多用户共享的概念、优…...

spring中yml配置上下文与tomcat等外部容器不一致问题
结论:外部优先级大于内部 在 application.yml 中配置了: server:port: 8080servlet:context-path: /demo这表示你的 Spring Boot 应用的上下文路径(context-path)是 /demo,即访问你的服务时,URL 必须以 /d…...
)
网络I/O学习-poll(三)
一、为什么要用Poll 由于select参数太多,较于复杂,调用起来较为麻烦;poll对其进行了优化 二、poll机制 poll也是一个系统调用,每次调用都会将所有客户端的fd拷贝到内核空间,然后进行轮询,判断IO是否就绪…...
)
云原生攻防2(Docker基础补充)
Docker基础入门 容器介绍 Docker是什么 Docker是基于Linux内核实现,最早是采用了 LXC技术,后来Docker自己研发了runc技术运行容器。 它基于Google Go语言实现,采用客户端/服务端架构,使用API来管理和创建容器。 虚拟机 VS Docker Namespace 内核命名空间属于容器非常核…...

【C++模板与泛型编程】实例化
目录 一、模板实例化的基本概念 1.1 什么是模板实例化? 1.2 实例化的触发条件 1.3 实例化的类型 二、隐式实例化 2.1 隐式实例化的工作原理 2.2 类模板的隐式实例化 2.3 隐式实例化的局限性 三、显式实例化 3.1 显式实例化声明(extern templat…...

CI/CD 实践:实现可灰度、可监控、可回滚的现代部署体系
CI/CD 实践:实现可灰度、可监控、可回滚的现代部署体系 一、背景 随着微服务架构、云原生技术的普及,传统的手动部署方式已难以满足现代业务快速迭代、高可用的需求。CI/CD(持续集成/持续交付)作为现代 DevOps 的核心环节&#…...

后退的风景
后退的风景 前言回退的景色 前言 坐在高铁的窗边,这是一趟回程的旅途,所有的树木、铁塔、石碑向后涌去,一如从前。 所谓风景正是如此,无非是看到了一段触动内心的感受,这段感受可能是伤心,亦或是欣喜。这…...

腾讯云安装halo博客
腾讯云安装halo博客 如果网站已经配置好可以直接使用的,可以直接跳转到《6》进行1panel的安装, 如果跳过之后安装出现问题,可以看看前面步骤 从《6》开始的安装视频 我估计是网站默认放开的端口和他返代理应用的端口冲突了,重装…...

Excel宏和VBA的详细分步指南
Excel宏和VBA的详细分步指南 一、宏录制与代码分析(超详细版)1. 启用开发工具2. 录制宏 二、VBA核心语法(深入详解)1. 变量与数据类型2. 循环结构3. 条件判断2. Worksheet对象3. Range对象的高级操作 四、实用案例扩展1. 数据清洗…...

第十六届蓝桥杯复盘
文章目录 1.数位倍数2.IPv63.变换数组4.最大数字5.小说6.01串7.甘蔗8.原料采购 省赛过去一段时间了,现在复盘下,省赛报完名后一直没准备所以没打算参赛,直到比赛前两天才决定参加,赛前两天匆匆忙忙下载安装了比赛要用的编译器ecli…...
)
深度学习---模型预热(Model Warm-Up)
一、基本概念与核心定义 模型预热是指在机器学习模型正式训练或推理前,通过特定技术手段使模型参数、计算图或运行环境提前进入稳定状态的过程。其本质是通过预处理操作降低初始阶段的不稳定性,从而提升后续任务的效率、精度或性能。 核心目标…...

python:pymysql概念、基本操作和注入问题讲解
python:pymysql分享目录 一、概念二、数据准备三、安装pymysql四、pymysql使用(一)使用步骤(二)查询操作(三)增(四)改(五)删 五、关于pymysql注入…...

科普:极简的AI乱战江湖
本文无图。 大模型 2022年2月,文生图应用的鼻祖Midjourney上线。 2022年8月,开源版的Midjourney,也就是Stable Diffusion上线。 2022年11月30日,OpenAI正式发布ChatGPT-3.5。 此后,不断有【大模型】面世&…...

养生指南:解锁健康生活新方式
一、饮食:精准搭配,科学滋养 饮食以 “少加工、多天然” 为核心。早餐选择希腊酸奶搭配蓝莓与一把混合坚果,富含蛋白质与抗氧化成分;午餐用藜麦饭搭配香煎龙利鱼和彩椒炒芦笋,营养全面且低脂;晚餐则是山药…...

Dolphinscheduler执行工作流失败,后台报duplicate key错误
背景 现场童鞋发来一张图如下 我很懵逼,不知道出了啥问题,在聊天工具上聊了10m还不知道啥,干脆就搞个腾讯会议(在此感谢腾讯爸爸免费会议)。哦,现场临时搭建了dolphinscheduler,然后导入工作流…...

【Vue】路由2——编程式路由导航、 两个新的生命周期钩子 以及 路由守卫、路由器的两种工作模式
目录 一、路由的push 与 replace切换 二、编程式路由导航 三、缓存路由组件 四、新增的两个生命周期钩子 五、路由守卫 5.1 前置路由守卫 5.2 后置路由守卫 5.3 独立路由守卫 5.4 组件内 路由守卫 六、路由器的两种工作模式 6.1 hash模式 6.2 history模式 6.3 V…...

VDC、SMC、MCU怎么协同工作的?
华为视频会议系统中,VDC(终端控制)、SMC(会话管理)、MCU(媒体处理) 通过分层协作实现端到端会议管理,其协同工作机制可总结为以下清晰架构: 1. 角色分工 组件核心职责类…...

ETL数据集成产品选型需要关注哪些方面?
ETL(Extract,Transform,Load)工具作为数据仓库和数据分析流程中的关键环节,其选型对于企业的数据战略实施有着深远的影响。谷云科技在 ETL 领域耕耘多年,通过自身产品的实践应用,对 ETL 产品选型…...

DriveGenVLM:基于视觉-语言模型的自动驾驶真实世界视频生成
《DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving》2024年8月发表,来自哥伦比亚大学的论文。 自动驾驶技术的进步需要越来越复杂的方法来理解和预测现实世界的场景。视觉语言模型(VLM)正在成…...

【达梦数据库】过程、函数、包头和包体详解零基础
目录 背景参考链接解释包头包体 背景 最近遇到关于包头和包体的问题,学习并记录 参考链接 参考链接: oracle的过程、函数、包头和包体详解零基础 解释 包头主要用于定义接口,包体主要用以实现包体中声明的存储过程、函数等。 包头 包体...

HarmonyOS开发样式布局
个人简介 👨💻个人主页: 魔术师 📖学习方向: 主攻前端方向,正逐渐往全栈发展 🚴个人状态: 研发工程师,现效力于政务服务网事业 🇨🇳人生格言&…...

SpringCloud——EureKa
目录 1.前言 1.微服务拆分及远程调用 3.EureKa注册中心 远程调用的问题 eureka原理 搭建EureKaServer 服务注册 服务发现 1.前言 分布式架构:根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为服务。 优点: 降…...

【力扣刷题】LeetCode763-划分字母区间
文章目录 1. LeetCode763_划分字母区间 1. LeetCode763_划分字母区间 题目链接🔗 🐧解题思路: 区间合并 题目中这句话很关键“我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。” 你这句话你可以理解为 把…...
)
使用for循环和字典功能,统计字符出现在一个英文句子中的次数(python)
本题目要求写出一段代码实现输入一个英文句子后,统计句子中各个字符(不区分大小写,包含空格和标点符号)出现的次数。 输入格式: 请例如:输入 Life is short,we need Python. 。 输出格式: 对每一个字符输出对应的出现次数&…...

带你搞懂@Valid和@Validated的区别
前言 有参数传递的地方都少不了参数校验。在实际开发过程中,参数校验是保证程序健壮性的重要环节,前端的参数校验是为了用户体验,后端的参数校验是为了安全。试想一下,如果在 Controller 层中没有经过任何校验的参数通过 Service层…...

大数据hadoop小文件处理方案
Hadoop处理小文件问题的解决方案可分为存储优化、处理优化和架构优化三个维度,以下是综合技术方案及实施要点: 一、存储层优化方案 1.文件合并技术 离线合并:使用hadoop fs -getmerge命令将多个小文件合并为大文件并重新上传; MapReduce合并:开发专用MR…...

安装NASM
安装NASM 注意:这篇文章在librdkafka安装系列,不需要参考,仅为了记录而写,请不要参考,后续编译openssl的时候,可以使用参数no-asm,不影响整个的编译步骤。这里主要作为记录帖子。 本篇是Windows系统编译Qt使用的kafka(librdkafka)系列可以不参考的一篇,编译librdkaf…...

RabbitMQ-高级
RabbitMQ-高级 文章目录 RabbitMQ-高级前言:消息可靠性问题1.生产者可靠性1.生产者重连2.生产者确认机制3.生产者代码实现原理 2.MQ的可靠性1.数据持久化2.LazyQueue 3.消费者可靠性1.消费者确认机制1.确认机制2.确认功能 2.失败重试机制1.开启失败重试机制2.多次失…...

深入解析Spring Boot与Kafka集成:构建高效消息驱动微服务
深入解析Spring Boot与Kafka集成:构建高效消息驱动微服务 引言 在现代微服务架构中,消息队列扮演着至关重要的角色,而Apache Kafka凭借其高吞吐量、低延迟和可扩展性,成为了许多企业的首选。本文将详细介绍如何在Spring Boot应用…...

Unreal Engine: Windows 下打包 AirSim项目 为 Linux 平台项目
环境: Windows: win10, UE4.27, Visual Studio 2022 Community.Linux: 22.04 windows环境安装教程: 链接遇到的问题(问题:解决方案) 点击Linux打包按钮,跳转至网页而不是执行打包流程:用VS打开项…...

【图像大模型】FLUX.1-dev:深度解析与实战指南
FLUX.1-dev:深度解析与实战指南 一、引言二、模型架构与技术原理(一)模型架构(二)Rectified Flow 技术(三)指导蒸馏(Guidance Distillation) 三、项目运行方式与执行步骤…...
)
mariadb 升级 (通过yum)
* 注意下 服务名, 有的服务器上是mysql,有的叫mariadb,mysqld的 #停止 systemctl stop mysql #修改源 vi /etc/yum.repos.d/MariaDB.repo baseurl http://yum.mariadb.org/11.4/centos7-amd64 #卸载 yum remove mysql #安装 yum install MariaDB-server galera-4 MariaDB-…...

Flink 非确定有限自动机NFA
Flink 是一个用于状态化计算的分布式流处理框架,而非确定有限自动机(NFA, Non-deterministic Finite Automaton)是一种在计算机科学中广泛使用的抽象计算模型,常用于正则表达式匹配、模式识别等领域。 Apache Flink 提供了对 NFA…...

Profinet转Ethernet IP主站网关:点燃氢醌生产线的智慧之光!
案例分享:转角指示器和Profinet转EthernetIP网关的应用 在现代工业自动化中,设备和系统之间的高效通信至关重要。最近,我们在某大型化工企业的生产线上实施了一个项目,旨在通过先进的设备和通信技术提高生产效率和安全性。该项目…...

动态IP技术在跨境电商中的创新应用与战略价值解析
在全球化4.0时代,跨境电商正经历从"流量红利"向"技术红利"的深度转型。动态IP技术作为网络基础设施的关键组件,正在重塑跨境贸易的运营逻辑。本文将从技术架构、应用场景、创新实践三个维度,揭示动态IP如何成为跨境电商突…...

WEB安全--SQL注入--Oracle注入
一、Oracle知识点了解 1.1、系统变量与表 版本号:SELECT * FROM V$VERSION 用户名:USER、SYS_CONTEXT(USERENV,SESSION_USER) 库名:ALL_USERS、USER_USERS、DBA_USERS 表名:ALL_TABLES、DBA_TABLES、USER_TABLES 字段名&…...
、接口(Interface)、抽象类(Abstract Class)、枚举(Enumeration))
Unity预制体变体(Prefab Variants)、接口(Interface)、抽象类(Abstract Class)、枚举(Enumeration)
一、预制体变体(Prefab Variants) 预制体变体是什么? 预制体变体是指从同一个基础预制体派生出来的不同版本的预制体。这些变体可以包含不同的组件配置、属性值、子对象或者行为,但它们共享一些共同的基础结构和特性。通过创建预…...

pymol包安装和使用
PyMOL 是一款分子可视化软件,而pymol则是其对应的 Python 包,借助它能够实现对 PyMOL 的编程控制。 主要功能 分子结构可视化:支持展示蛋白质、核酸、小分子等多种分子的 3D 结构。自定义渲染:可对分子的表示方式、颜色以及光照…...
 | 第七章|神经网络(2))
【学习笔记】机器学习(Machine Learning) | 第七章|神经网络(2)
机器学习(Machine Learning) 简要声明 基于吴恩达教授(Andrew Ng)课程视频 BiliBili课程资源 文章目录 机器学习(Machine Learning)简要声明 神经网络在图像识别及手写数字识别中的应用一、神经网络在图像识别中的应用࿰…...
 模式)
【神经网络与深度学习】model.eval() 模式
引言 在深度学习模型的训练和推理过程中,不同的模式设置对模型的行为和性能有着重要影响。model.eval() 是 PyTorch 等深度学习框架中的关键操作,它用于将模型切换到评估模式(evaluation mode),确保模型在测试和推理阶…...

ASIC和FPGA,到底应该选择哪个?
ASIC和FPGA各有优缺点。 ASIC针对特定需求,具有高性能、低功耗和低成本(在大规模量产时);但设计周期长、成本高、风险大。FPGA则适合快速原型验证和中小批量应用,开发周期短,灵活性高,适合初创企…...