【强化学习】#6 n步自举法
主要参考学习资料:《强化学习(第2版)》[加]Richard S.Suttion [美]Andrew G.Barto 著
文章源文件:https://github.com/INKEM/Knowledge_Base
概述
- n步时序差分方法是蒙特卡洛方法和时序差分方法更一般的推广。
- 将单步Sarsa推广到n步Sarsa我们得到n步方法的同轨策略控制。
- n步方法最基本的离轨策略控制是基于重要度采样的。
- n步树回溯法是一种不需要重要度采样的离轨策略控制。
目录
- n步时序差分预测
- n步Sarsa
- n步离轨策略学习
- n步树回溯法
- 总结
回顾动态规划和时序差分学习,它们都根据对后继状态价值的估计来更新对当前状态价值的估计,这种基于其他估计来更新自己的估计的思想被称为自举法。通过将单步时序差分推广到 n n n步,我们可以得到一系列 n n n步自举法,甚至在极限状态下得到蒙特卡洛方法。
n步时序差分预测
对于固定策略 π \pi π下的给定的多幕采样序列,从某一状态开始,蒙特卡洛方法利用直至终止状态的收益序列对该状态的价值进行更新,而时序差分方法只根据下一步的即时收益,在后继状态的价值估计值的基础上进行自举更新。
我们很容易想到一种介于二者之间的方法是利用该状态之后的多个中间时刻的收益来进行更新,但又不到达终止状态。对于 n n n步更新,我们利用当前状态之后的 n n n步收益和 n n n步之后的价值估计来更新当前状态价值估计。 n n n步更新仍然属于时序差分方法,因为前面状态的估计值仍根据它与后继状态估计值的差异进行更新,只不过后继状态可以是 n n n步之后的状态。时序差分量被扩展成 n n n的方法被称为n步时序差分方法。
利用回溯图可以直观地对算法进行图示总结。不同步数下的时序差分方法更新的回溯图如下,空心圈代表采样的状态,实心点代表采样的动作:
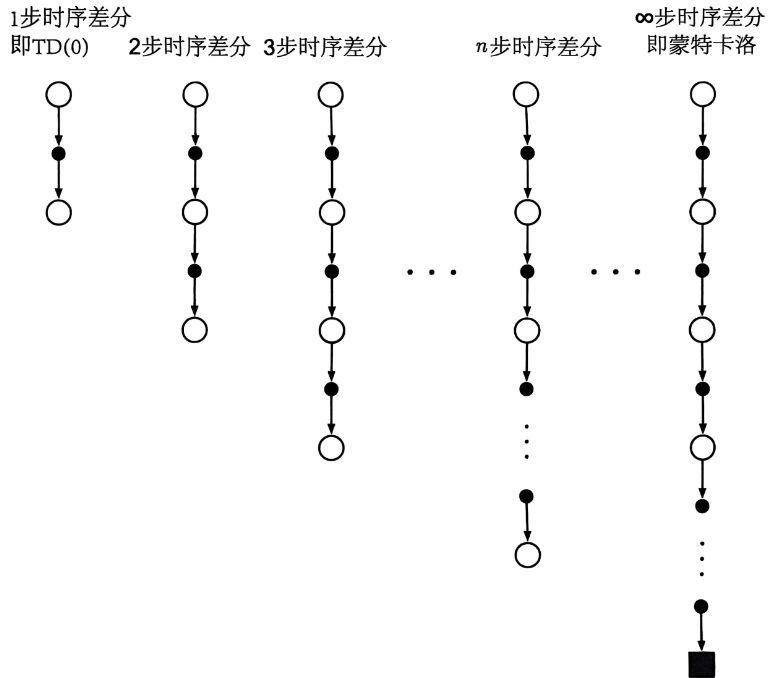
接下来我们考虑该方法的数学表示。我们知道,在蒙特卡洛方法中,更新目标 G t G_t Gt沿着完整回报的方向计算
G t = ˙ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ + γ T − t − 1 R T G_t\dot=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots+\gamma^{T-t-1}R_T Gt=˙Rt+1+γRt+2+γ2Rt+3+⋯+γT−t−1RT
其中 T T T是终止状态的时刻。
而在单步时序差分中,更新的目标是即时收益加上后继状态的价值函数估计值乘以折扣系数,我们称其为单步回报
G t : t + 1 = ˙ R t + 1 + γ V t ( S t + 1 ) G_{t:t+1}\dot=R_{t+1}+\gamma V_t(S_{t+1}) Gt:t+1=˙Rt+1+γVt(St+1)
其中 V t V_t Vt是在 t t t时刻 v π v_\pi vπ的估计值,后继状态的折后价值函数估计 γ V t ( S t + 1 ) \gamma V_t(S_{t+1}) γVt(St+1)可以视为对后续完整回报 γ R t + 2 + ⋯ + γ T − t − 1 R T \gamma R_{t+2}+\cdots+\gamma^{T-t-1}R_T γRt+2+⋯+γT−t−1RT的估计。类似地,将这种想法扩展到两步的情况,我们有两步更新的目标两步回报
G t : t + 2 = ˙ R t + 1 + γ R t + 2 + γ 2 V t + 1 ( S t + 2 ) G_{t:t+2}\dot=R_{t+1}+\gamma R_{t+2}+\gamma^2V_{t+1}(S_{t+2}) Gt:t+2=˙Rt+1+γRt+2+γ2Vt+1(St+2)
而任意 n n n步更新的目标是n步回报
G t : t + n = ˙ R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n V t + n − 1 ( S t + n ) G_{t:t+n}\dot=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^nV_{t+n-1}(S_{t+n}) Gt:t+n=˙Rt+1+γRt+2+⋯+γn−1Rt+n+γnVt+n−1(St+n)
其中 n ⩾ 1 n\geqslant1 n⩾1, 0 ⩽ t ⩽ T − n 0\leqslant t\leqslant T-n 0⩽t⩽T−n。 n n n步回报即在 n n n步后截断完整回报,并用 V t + n − 1 ( S t + n ) V_{t+n-1}(S_{t+n}) Vt+n−1(St+n)作为对剩余部分的估计。如果 t + n ⩾ T t+n\geqslant T t+n⩾T,则超出终止状态的部分均为零, n n n步回报等于完整回报。
计算时刻 t t t的 n n n步回报需要在时刻 t + n t+n t+n时得到 R t + n R_{t+n} Rt+n和 V t + n − 1 V_{t+n-1} Vt+n−1后才能计算。最基础的基于 n n n步回报的状态价值函数更新算法即n步时序差分( n n n步TD)算法
V t + n ( S t ) = ˙ V t + n − 1 ( S t ) + α [ G t : t + n − V t + n − 1 ( S t ) ] , 0 ⩽ t < T V_{t+n}(S_t)\dot=V_{t+n-1}(S_t)+\alpha[G_{t:t+n}-V_{t+n-1}(S_t)],0\leqslant t<T Vt+n(St)=˙Vt+n−1(St)+α[Gt:t+n−Vt+n−1(St)],0⩽t<T
在更新当前状态的过程中,其他状态 s ≠ S t s\neq S_t s=St的价值估计保持不变
V t + n ( S ) = V t + n − 1 ( S ) V_{t+n}(S)=V_{t+n-1}(S) Vt+n(S)=Vt+n−1(S)
用 n n n步回报在 V t + n − 1 V_{t+n-1} Vt+n−1的基础上更新 V t + n V_{t+n} Vt+n的一个重要依据是, n n n步回报的期望和真实状态价值函数 v π ( s ) v_\pi(s) vπ(s)之间的最大误差能保证不大于 V t + n − 1 V_{t+n-1} Vt+n−1和 v π ( s ) v_\pi(s) vπ(s)之间的最大误差的 γ n \gamma^n γn倍
max s ∣ E π [ G t : t + n ∣ S t = s ] − v π ( s ) ∣ ⩽ γ n max s ∣ V t + n − 1 ( s ) − v π ( s ) ∣ \underset s\max|\mathbb E_\pi[G_{t:t+n}|S_t=s]-v_\pi(s)|\leqslant\gamma^n\underset s\max|V_{t+n-1}(s)-v_\pi(s)| smax∣Eπ[Gt:t+n∣St=s]−vπ(s)∣⩽γnsmax∣Vt+n−1(s)−vπ(s)∣
这被称为 n n n步回报的误差减少性质,其可以证明所有的 n n n步时序差分方法在合适的条件下都能收敛到正确的预测,且 n n n越大,收敛性越好。
n n n步TD的伪代码如下:

该伪代码的逻辑较为晦涩,其进一步解释如下:在每一幕,我们从 S 0 S_0 S0根据策略 π \pi π选择动作直至终止状态 S T S_T ST,其中 T T T在一开始并不知道,直到遇到终止状态才能确定。 S 0 S_0 S0的更新需要等到时刻 t = n + 1 t=n+1 t=n+1时才能执行,相应地,往后 S τ ( τ ⩾ 0 ) S_\tau(\tau\geqslant0) Sτ(τ⩾0)的更新则在时刻 t = n + 1 + τ t=n+1+\tau t=n+1+τ执行,在代码中则表示为在时刻 t t t执行对 S t − n + 1 ( τ = t − n + 1 ⩾ 0 ) S_{t-n+1}(\tau=t-n+1\geqslant0) St−n+1(τ=t−n+1⩾0)的更新。在更新中,如果 S τ S_\tau Sτ距离终止状态 S T S_T ST不足 n n n步,则 min ( τ + n , T ) = T \min(\tau+n,T)=T min(τ+n,T)=T,回报只能在终止状态截断,即直接使用完整回报作为更新目标,此时也无需再加上后继状态的折后价值估计,因为终止状态的价值 v ( S T ) = 0 v(S_T)=0 v(ST)=0。
事实证明,对于大小为 ∣ S ∣ |\mathcal S| ∣S∣的状态集合, n n n取其中间大小的值时通常效果最好,这也证明了将单步时序差分方法和蒙特卡洛方法推广到 n n n步时序差分方法可能会得到更好的效果。
n步Sarsa
将 n n n步方法与Sarsa结合,我们可以得到同轨策略下的 n n n步时序差分学习控制方法。 n n n步版本的Sarsa被称为n步Sarsa,相应地,上一章介绍的初始版本的Sarsa被称为单步Sarsa或Sarsa(0)。不同步数下的Sarsa方法更新的回溯图如下:
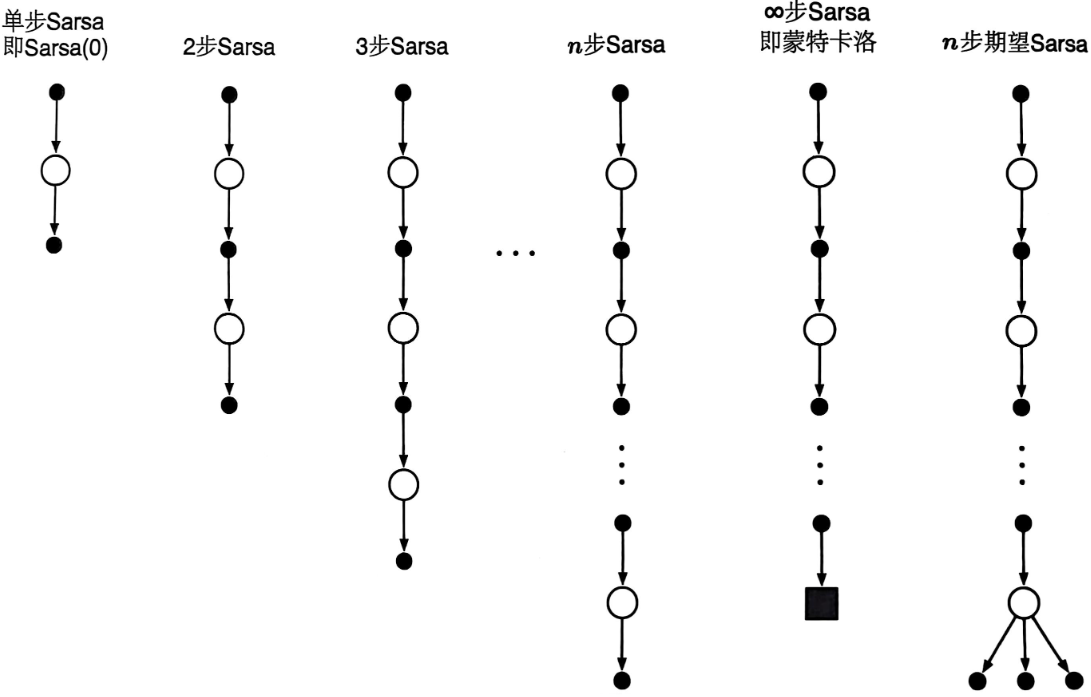
和单步TD到单步Sarsa的转换一样, n n n步TD到 n n n步Sarsa的核心思想也是将状态替换为“状态-动作”二元组,并使用 ϵ \epsilon ϵ-贪心策略。我们根据动作价值估计重新定义 n n n步Sarsa方法下的 n n n步回报
G t : t + n = ˙ R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n Q t + n − 1 ( S t + n , A t + n ) , n ⩾ 1 , 0 ⩽ t < T − n G_{t:t+n}\dot=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^nQ_{t+n-1}(S_{t+n},A_{t+n}),n\geqslant1,0\leqslant t<T-n Gt:t+n=˙Rt+1+γRt+2+⋯+γn−1Rt+n+γnQt+n−1(St+n,At+n),n⩾1,0⩽t<T−n
当 t + n ⩾ T t+n\geqslant T t+n⩾T时, G t : t + n = G t G_{t:t+n}=G_t Gt:t+n=Gt。
则 n n n步Sarsa的更新公式为
Q t + n ( S t , A t ) = ˙ Q t + n − 1 ( S t , A t ) + α [ G t : t + n − Q t + n − 1 ( S t , A t ) ] , 0 ⩽ t < T Q_{t+n}(S_t,A_t)\dot=Q_{t+n-1}(S_t,A_t)+\alpha[G_{t:t+n}-Q_{t+n-1}(S_t,A_t)],0\leqslant t<T Qt+n(St,At)=˙Qt+n−1(St,At)+α[Gt:t+n−Qt+n−1(St,At)],0⩽t<T
在处理对应“动作-状态”二元组的更新时,所有其他二元组保持不变,即对于所有 s ≠ S t s\neq S_t s=St, a ≠ A t a\neq A_t a=At,有
Q t + n ( s , a ) = Q t + n − 1 ( s , a ) Q_{t+n}(s,a)=Q_{t+n-1}(s,a) Qt+n(s,a)=Qt+n−1(s,a)
n n n步Sarsa算法的伪代码如下:

n n n步Sarsa相比单步Sarsa能够加速策略学习。假设在一个网格世界中,除了终点具有高收益,其余格子的收益均为零,则完成一幕序列的采样后,单步Sarsa的终点收益只能影响到达终点的前一个格子相应的动作价值,而 n n n步Sarsa却能更新路径上到达终点的前 n n n个格子相应的动作价值,学到了更多的知识。
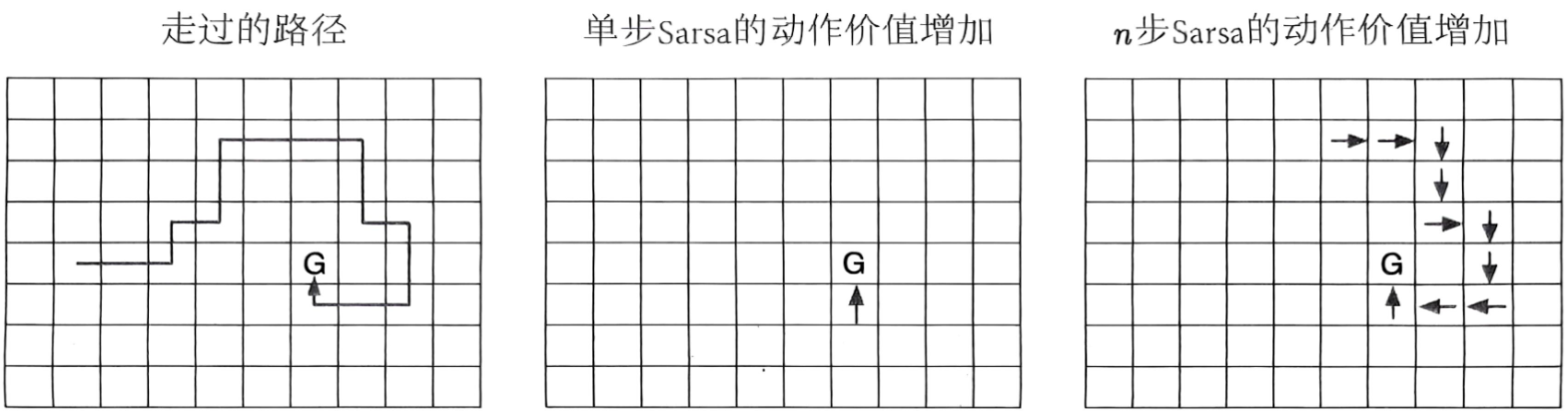
n n n步期望Sarsa则在Sarsa的基础上重新定义了 n n n步回报
G t : t + n = ˙ R t + 1 + γ R t + 2 + ⋯ + γ n − 1 R t + n + γ n V ˉ t + n − 1 ( S t + n ) , n ⩾ 1 , 0 ⩽ t < T − n G_{t:t+n}\dot=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{n-1}R_{t+n}+\gamma^n\bar V_{t+n-1}(S_{t+n}),n\geqslant1,0\leqslant t<T-n Gt:t+n=˙Rt+1+γRt+2+⋯+γn−1Rt+n+γnVˉt+n−1(St+n),n⩾1,0⩽t<T−n
其中 V ˉ ( s ) \bar V(s) Vˉ(s)表示状态 s s s的期望近似价值,它通过在目标策略下 t t t时刻的动作价值估计的期望来计算
V ˉ t ( s ) = ˙ ∑ a π ( a ∣ s ) Q t ( s , a ) \bar V_t(s)\dot=\sum_a\pi(a|s)Q_t(s,a) Vˉt(s)=˙a∑π(a∣s)Qt(s,a)
终止状态的期望近似价值为零。
n步离轨策略学习
n n n步时序差分方法的离轨策略学习与蒙特卡洛方法中介绍的离轨策略控制相似,因为我们需要行动策略和目标策略在 n n n步上采取相同行动的相对概率(重要度采样比),进而由行动策略 b b b的 n n n步回报来预测目标策略 π \pi π的 n n n步回报。
对于由策略 b b b从 t t t时刻采样的 n n n步回报 G t : t + n G_{t:t+n} Gt:t+n,在对 n n n步之后 t + n t+n t+n时刻策略 π \pi π的状态价值估计 V t + n ( S t ) V_{t+n}(S_t) Vt+n(St)进行更新时,可以简单地用重要度采样比 ρ t : t + n − 1 \rho_{t:t+n-1} ρt:t+n−1(两种策略采取 A t ∼ A t + n A_t\sim A_{t+n} At∼At+n这 n n n个动作的相对概率)进行修正
V t + n ( S t ) = ˙ V t + n − 1 ( S t ) + α ρ t : t + n − 1 [ G t : t + n − V t + n − 1 ( S t ) ] , 0 ⩽ t < T V_{t+n}(S_t)\dot=V_{t+n-1}(S_t)+\alpha\rho_{t:t+n-1}[G_{t:t+n}-V_{t+n-1}(S_t)],0\leqslant t<T Vt+n(St)=˙Vt+n−1(St)+αρt:t+n−1[Gt:t+n−Vt+n−1(St)],0⩽t<T
这里,重要度采样比的计算为
ρ t : h = ˙ ∏ k = t min ( h , T − 1 ) π ( A k ∣ S k ) b ( A k ∣ S k ) \rho_{t:h}\dot=\prod^{\min(h,T-1)}_{k=t}\frac{\pi(A_k|S_k)}{b(A_k|S_k)} ρt:h=˙k=t∏min(h,T−1)b(Ak∣Sk)π(Ak∣Sk)
其中 min ( h , T − 1 ) \min(h,T-1) min(h,T−1)在终止状态截断截断计算。
在蒙特卡洛方法的离轨策略控制中,我们使用贪心策略作为目标策略。但是尽管我们选择了具有试探性的行为策略,在重要度采样中,价值估计的更新仍然取决于目标策略是否有概率选择,因此在学习中使用绝对的贪心策略并不是一个好的选择。我们仍可以采取 ϵ \epsilon ϵ-贪心策略使得所有价值估计都有被更新的可能,在合适的条件下,基于 ϵ \epsilon ϵ-贪心策略收敛后的价值估计生成一个贪心策略也能得到最优策略。
离轨策略下的 n n n步Sarsa算法伪代码如下:

n步树回溯法
n n n步树回溯法是一种不需要重要度采样的 n n n步离轨策略学习方法。普通的 n n n步离轨策略方法只依赖行动策略采样的具体动作,因此需要对行动策略的动作采取概率进行修正。而在 n n n步树回溯法中,行动策略的作用仅仅是产生状态转移,决定采样的动作-状态路径,在计算 n n n步回报时,行动策略选择的动作和未选择的动作都会以在目标策略下的选择概率被加权。一个三步树回溯更新的回溯图如下:
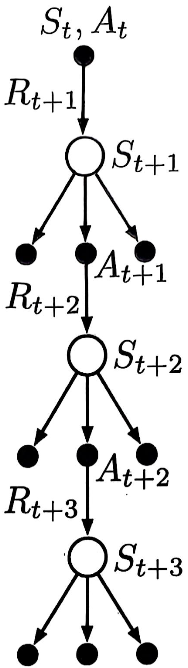
树回溯算法的单步回报与期望Sarsa相同,即对于 t < T − 1 t<T-1 t<T−1,有
G t : t + 1 = ˙ R t + 1 + γ ∑ a π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) G_{t:t+1}\dot=R_{t+1}+\gamma\sum_a\pi(a|S_{t+1})Q_t(S_{t+1},a) Gt:t+1=˙Rt+1+γa∑π(a∣St+1)Qt(St+1,a)
对于 t < T − 2 t<T-2 t<T−2,两步树回溯的回报将 Q ( S t + 1 , A t + 1 ) Q(S_{t+1},A_{t+1}) Q(St+1,At+1)展开为在 S t + 1 S_{t+1} St+1选择 A t + 1 A_{t+1} At+1转移到 S t + 2 S_{t+2} St+2的单步回报
G t : t + 2 = ˙ R t + 1 + γ ∑ a ≠ A t + 1 π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) + γ π ( A t + 1 ∣ S t + 1 ) ( R t + 2 + γ ∑ a π ( a ∣ S t + 2 ) Q t + 1 ( S t + 2 , a ) ) = R t + 1 + γ ∑ a ≠ A t + 1 π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) + γ π ( A t + 1 ∣ S t + 1 ) G t + 1 : t + 2 \begin{split} G_{t:t+2}&\dot=R_{t+1}+\gamma\sum_{a\neq A_{t+1}}\pi(a|S_{t+1})Q_t(S_{t+1},a)+\gamma\pi(A_{t+1}|S_{t+1})(R_{t+2}+\gamma\sum_a\pi(a|S_{t+2})Q_{t+1}(S_{t+2},a))\\ &=R_{t+1}+\gamma\sum_{a\neq A_{t+1}}\pi(a|S_{t+1})Q_t(S_{t+1},a)+\gamma\pi(A_{t+1}|S_{t+1})G_{t+1:t+2} \end{split} Gt:t+2=˙Rt+1+γa=At+1∑π(a∣St+1)Qt(St+1,a)+γπ(At+1∣St+1)(Rt+2+γa∑π(a∣St+2)Qt+1(St+2,a))=Rt+1+γa=At+1∑π(a∣St+1)Qt(St+1,a)+γπ(At+1∣St+1)Gt+1:t+2
从这个公式中我们可以看出树回溯的 n n n步回报的递归形式,即对于 t < T − 1 , n ⩾ 2 t<T-1,n\geqslant2 t<T−1,n⩾2,有
G t : t + n = ˙ R t + 1 + γ ∑ a ≠ A t + 1 π ( a ∣ S t + 1 ) Q t ( S t + 1 , a ) + γ π ( A t + 1 ∣ S t + 1 ) G t + 1 : t + n G_{t:t+n}\dot=R_{t+1}+\gamma\sum_{a\neq A_{t+1}}\pi(a|S_{t+1})Q_t(S_{t+1},a)+\gamma\pi(A_{t+1}|S_{t+1})G_{t+1:t+n} Gt:t+n=˙Rt+1+γa=At+1∑π(a∣St+1)Qt(St+1,a)+γπ(At+1∣St+1)Gt+1:t+n
上式是我们在代码中更新 n n n步回报的基础。对于 t + n t+n t+n超出 T − 1 T-1 T−1的部分,我们仍使用终止状态的收益 R T R_T RT截断,即 G T − 1 : t + n = R T G_{T-1:t+n}=R_T GT−1:t+n=RT。价值估计的更新公式与 n n n步Sarsa一样
Q t + n ( S t , A t ) = ˙ Q t + n − 1 ( S t , A t ) + α [ G t : t + n − Q t + n − 1 ( S t , A t ) ] , 0 ⩽ t < T Q_{t+n}(S_t,A_t)\dot=Q_{t+n-1}(S_t,A_t)+\alpha[G_{t:t+n}-Q_{t+n-1}(S_t,A_t)],0\leqslant t<T Qt+n(St,At)=˙Qt+n−1(St,At)+α[Gt:t+n−Qt+n−1(St,At)],0⩽t<T
n n n步树回溯算法的伪代码如下:

总结
n n n步方法向前看若干步的收益、状态和动作,使得价值估计的更新更加准确、稳定,但代价是延迟更新和更大的内存与计算量。在更靠后的章节,我们将学习如何借助资格迹用最少的内存和计算复杂度来实现 n n n步TD方法。
相关文章:

【强化学习】#6 n步自举法
主要参考学习资料:《强化学习(第2版)》[加]Richard S.Suttion [美]Andrew G.Barto 著 文章源文件:https://github.com/INKEM/Knowledge_Base 概述 n步时序差分方法是蒙特卡洛方法和时序差分方法更一般的推广。将单步Sarsa推广到n…...

双指针算法:原理与应用详解
文章目录 一、什么是双指针算法二、双指针算法的适用场景三、双指针的三种常见形式1. 同向移动指针2. 相向移动指针3. 分离指针 四、总结 一、什么是双指针算法 双指针算法(Two Pointers Technique)是一种在数组或链表等线性数据结构中常用的高效算法技…...
卷积操作)
小土堆pytorch--神经网路的基本骨架(nn.Module的使用)卷积操作
小土堆pytorch–神经网路的基本骨架(nn.Module的使用) 对于官网nn.Module操作的解释 在pytorch官网可以看到 对于上述forward函数的解释: 示例代码 import torch from torch import nnclass Test(nn.Module): # 继承神经网路的基本骨架…...

数据库连接池技术与 Druid 连接工具类实现
目录 1. 数据库连接池简介 1.1. 什么是数据库连接池 1.2. 不使用数据库连接池可能存在的问题 1.3. JDBC数据库连接池的必要性 1.4. 数据库连接池的优点 1.5. 常用的数据库连接池 2. Druid连接池 2.1. Druid简介 2.2. Druid使用步骤 2.2.1. 第一步的步骤详解ÿ…...

chrome源码中WeakPtr 跨线程使用详解:原理、风险与最佳实践
base::WeakPtr 在 Chromium 中 不能安全地跨线程使用。这是一个很关键的点,下面详细解释原因及正确用法。 🔍原理与使用 ✅ 先说答案: base::WeakPtr 本质上是**线程绑定(thread-affine)**的。不能在多个线程之间创建…...

vue2使用three.js实现一个旋转球体
vue页面中 <div ref"container"></div>data声明 scene: null, camera: null, renderer: null, controls: null, rotationType: sphere, rotationTimer: null,backgroundImageUrl: https://mini-app-img-1251768088.cos.…...

社交平台推出IP关联机制:增强用户体验与网络安全的新举措
社交平台为我们提供与亲朋好友保持联系、分享生活点滴的便捷渠道,还成为了信息传播、观点交流的重要平台。然而,随着社交平台的普及,网络空间中的虚假信息、恶意行为等问题也日益凸显。为了应对这些挑战,许多社交平台相继推出IP关…...

sherpa-ncnn:音频处理跟不上采集速度 -- 语音转文本大模型
目录 1. 问题报错2. 解决方法 1. 问题报错 报错: An overrun occurred, which means the RTF of the current model on your board is larger than 1. You can use ./bin/sherpa-ncnn to verify that. Please select a smaller model whose RTF is less than 1 fo…...

【android bluetooth 协议分析 01】【HCI 层介绍 8】【ReadLocalVersionInformation命令介绍】
1. HCI_Read_Local_Version_Information 命令介绍 1. 功能(Description) HCI_Read_Local_Version_Information 命令用于读取本地 Bluetooth Controller 的版本信息,包括 HCI 和 LMP 层的版本,以及厂商 ID 和子版本号。 这类信息用…...

android13以太网静态ip不断断开连上问题
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.log记录3.问题分析4.代码修改5.彩蛋1.前言 android13以太网静态ip不断断开连上,具体情况为保存静态以太网成功后,可以看到以太网链接成功的图标,但是几秒后会消失,出现断网,几秒后又出现,反复出现和消失。 2.log记录…...
)
UA 编译和建模入门教程(zhanzhi学习笔记)
一、使用SIOME免费工具建模 从西门子官网下载软件SIOS,需要注册登录,下载安装版就行。下载后直接安装就可以用了,如图: 安装完成后打开,开始建模,如图左上角有新建模型的按钮。 新建了新工程后,…...

系统架构设计-案例分析总结
系统架构设计-案例分析总结 2024年下半年系统架构设计师案例第1题 2022年下半年系统架构设计师案例第1题第2题 2021年下半年系统架构设计师案例第1题第2题 2024年下半年系统架构设计师案例 题:效用树可用性中ping/echo策略和心跳策略比较 第1题 阅读以下关于面向质…...
)
【QT】一个界面中嵌入其它界面(三)
在 Qt 中,通过 UI 设计 或 代码布局 实现界面 A 中同时显示界面 B 和 C,并精确指定它们的位置,可以通过以下两种方式实现。以下是详细步骤和完整代码: 方法 0:使用 Qt Designer 可视化布局 通过 Qt Designer 拖拽控件…...

实战教程:影刀RPA采集闲鱼商品并分享钉钉
1.实战目标 采集字段: 采集时间商品ID商品标题标价商品链接 采集的第一个品 可通过钉钉分享给好友 也可以通过钉钉群通知指令,发送到指定群 2.实战代码 2.1 主体代码 2.2 采集初始化 先初始化环境 这一步骤主要是连接手机,能使用影刀RPA操…...
)
多模态大语言模型arxiv论文略读(八十二)
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning ➡️ 论文标题:Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning ➡️ 论文作者:Zebang Cheng, Zhi-Qi Cheng, Jun-Yan H…...
)
常见排序算法整理(Java实现)
1.冒泡排序(Bubble Sort) 原理 重复遍历数组,比较相邻元素,若顺序错误则交换。每趟将最大元素"冒泡"到末尾。 每次遍历保证了最大元素被放在最后,所以内层循环不需要遍历到最后的位置。 代码实现 public …...
)
c++字符串常用语法特性查询示例文档(二)
在 C中,除了std::string和std::string_view,还有其他一些与字符串相关的类型,它们各自针对不同的场景进行了优化。以下是一些常见的字符串类型及其使用方式和适用场景的汇总。 紧接上篇 c字符串常用语法特性查询示例文档(一&#…...

10.14 Function Calling与Tool Calling终极解析:大模型工具调用的5大核心差异与实战优化
Function Calling vs Tool Calling:大模型工具调用机制深度解析 关键词:Function Calling 原理, Tool Calling 实现, @tool 装饰器, ToolMessage 机制, 工具调用优化 1. 核心概念对比分析 #mermaid-svg-uDxSPB1CoQrHDxrT {font-family:"trebuchet ms",verdana,ari…...

opencascade如何保存选中的面到本地
环境:occ 7.6 需求场景:用户点击了一个TopoDS_Shape,还选中了其中一个面,这时候他点了保存。用户下次打开模型文件时,我们的viewer窗口要恢复上次的选中状态。 核心问题:如何把用户选中的面保存,…...

CSS 单位详解:px、rem、em、vw/vh 的区别与使用场景
CSS 单位详解:px、rem、em、vw/vh 的区别与使用场景 在 CSS 中,各种单位有不同的特性和适用场景,理解它们的区别对实现响应式布局至关重要。 1. 绝对单位 px 特点: 像素(Pixel)是绝对长度单位1px 对应屏…...
的参数设置)
YOLO模型predict(预测/推理)的参数设置
上一章描述了预测初体验,基本可以使用现有的yolo模型进行预测/推理。本次我们了解一下这个过程中的参数的作用。 1.参数示例 conf=0.68 :表示模型识别这个东西是车的概率为68% 。一般默认的情况下,概率小于25%的就不显示了。 1)调整一下python的代码的参数如下,可以预测图…...

MATLAB中NLP工具箱支持聚类算法
文章目录 前言一、层次聚类(Hierarchical Clustering)二、DBSCAN(基于密度的空间聚类)三、高斯混合模型(GMM)四、谱聚类(Spectral Clustering)五、模糊 C 均值(Fuzzy C-M…...
)
甘特图工具怎么选?免费/付费项目管理工具对比测评(2025最新版)
2025年甘特图工具的全面指南 在项目管理领域,甘特图作为最直观的任务规划和进度追踪工具,已成为团队协作和项目执行的核心手段。随着数字化技术的快速发展,2025年的甘特图工具市场呈现出前所未有的多元化和智能化趋势。从开源软件到云端协作…...

Google设置app-ads.txt
问题: 应用上架后admob后台显示应用广告投放量受限,需要设置app-ads.txt才行。 如何解决: 官方教程: 看了下感觉不难,创建一个txt,将第二条的代码复制进行就得到app-ads.txt了。 然后就是要把这个txt放到哪才可以…...
)
Swift 二分查找实战:精准定位第一个“Bug版本”(LeetCode 278)
文章目录 摘要描述示例 题解答案(Swift)题解代码分析示例测试及结果输出结果: 时间复杂度分析空间复杂度分析总结 摘要 在版本迭代频繁的项目开发中,定位引入 bug 的第一个版本是一项高频任务。LeetCode 第278题“第一个错误的版…...

《AI革命重塑未来五年:医疗诊断精准度翻倍、自动驾驶事故锐减90%,全球科技版图加速变革》
1. 显著突破领域:AI 引发医疗与自动驾驶的范式变革 医疗领域的突破: AI正深刻改变医学研发和临床诊疗模式。在新药研发现代生物学中,DeepMind公司推出的 AlphaFold AI 模型在蛋白质折叠预测上取得了重大突破,被视为解决了困扰科学…...

【盈达科技】AICC™系统:重新定义生成式AI时代的内容竞争力
盈达科技AICC™系统:重新定义生成式AI时代的内容竞争力 ——全球首款AI免疫化内容中台的技术革命与商业实践 一、技术破局:AICC™系统如何重构AI内容生态 1. 技术架构:四大引擎构建闭环护城河 盈达科技AICC™(AI-Immunized Con…...

芯驰科技与安波福联合举办技术研讨会,深化智能汽车领域合作交流
5月15日,芯驰科技与全球移动出行技术解决方案供应商安波福(Aptiv)在上海联合举办以“芯智融合,共赢未来”为主题的技术研讨会。会上,双方聚焦智能座舱与智能车控的发展趋势,展开深入交流与探讨,…...

开发 前端搭建npm v11.4.0 is known not to run on Node.js v14.18.1.
错误nodejs 和npm 版本不一致 ERROR: npm v11.4.0 is known not to run on Node.js v14.18.1. This version of npm supports the following node versions: ^20.17.0 || >22.9.0. You can find the latest version at https://nodejs.org/. ERROR: D:\softTool\node-v14…...

关于systemverilog中在task中使用force语句的注意事项
先看下面的代码 module top(data);logic clk; inout data; logic temp; logic sampale_data; logic [7:0] data_rec;task send_data(input [7:0] da);begin(posedge clk);#1;force datada[7];$display(data);(posedge clk);#1;force datada[6]; $display(data); (posed…...

国产 iPaaS 与国外 iPaaS 产品相比如何?以谷云科技为例
iPaaS(Integration Platform as a Service)作为企业集成的关键技术,受到了广泛关注。国产 iPaaS 产品与国外 iPaaS 产品存在诸多差异,以下将从多个方面进行分析探讨。 一、技术架构与创新 国外 iPaaS 产品往往技术架构成熟且先进…...

低功耗:XILINX FPGA如何优化功耗?
优化Xilinx FPGA及其外围电路的功耗需要从硬件设计、软件配置和系统级优化三个层面综合考虑。以下是具体的优化策略,涵盖硬件和软件方面: 一、硬件层面的功耗优化 选择低功耗FPGA型号 选择Xilinx低功耗系列芯片,如7系列中的Artix-7ÿ…...

从纸质契约到智能契约:AI如何改写信任规则与商业效率?——从智能合约到监管科技,一场颠覆传统商业逻辑的技术革命
一、传统合同的“低效困境”:耗时、昂贵、风险失控 近年来,全球商业环境加速向数字化转型,但合同管理却成为企业效率的“阿喀琉斯之踵”。据国际商会(International Chamber of Commerce)数据显示,全球企业…...

在金融发展领域,嵌入式主板有什么优点?
在金融发展领域,嵌入式主板能够有力推动金融行业的智能化与高效化进程。主板的强大计算能力可以保障业务高效运行。例如在银行的高频交易场景下,其强大计算能力可确保系统在高负荷下依然保持流畅稳定,快速响应用户需求,大大提升金…...

打卡Day30
导入官方库的三种手段 方法一:直接导入整个模块 import math print(math.sqrt(16)) # 输出: 4.0方法二:从模块中导入特定函数或类 from datetime import datetime now datetime.now() print(now) # 输出当前日期和时间方法三:使用别名简…...

AI量化交易是什么?它是如何重塑金融世界的?
第一章:证券交易的进化之路 1.1 从喊价到代码:交易方式的革命性转变 在电子交易普及之前,证券交易依赖于交易所内的公开喊价系统。交易员通过手势、喊话甚至身体语言传递买卖信息,这种模式虽然直观,但效率低下且容易…...

AIGC与数字金融:人工智能金融创新的新纪元
AIGC与数字金融:人工智能金融创新的新纪元 引言 人工智能生成内容(AIGC)在数字金融领域发挥着关键作用,从金融内容生成到智能风控,从个性化服务到投资决策,AIGC正在重塑金融的方式和效果。本文将深入探讨A…...
:芯片制造篇——纳米尺度上的精密艺术)
芯片生态链深度解析(四):芯片制造篇——纳米尺度上的精密艺术
开篇:芯片制造——现代工业的"皇冠明珠" 在芯片生态链的版图中,芯片制造是连接设计与封测的核心枢纽,堪称现代工业的“皇冠明珠”。如果说芯片设计是人类对微观世界的构想,那么制造便是将这种构想转化为现实的终极工程…...

黄金批次在流程和离散行业的概念解析
流程行业 概念 流程行业中: “黄金批次”:通常指生产过程中质量最优、性能最稳定、符合甚至超越所有关键指标的特定批次产品。这类批次在流程行业中具有标杆意义,常用于质量控制、工艺优化和客户交付。 核心特征 在流程行业中,“黄金批次”的核心特征包括: 1、质量一…...
Transformer实战——循环神经网络详解
Transformer实战——循环神经网络详解 0. 前言1. 基本循环神经网络单元1.1 循环神经网络工作原理1.2 时间反向传播1.3 梯度消失和梯度爆炸问题 2. RNN 单元变体2.1 长短期记忆2.2 门控循环单元2.3 Peephole LSTM 3. RNN 变体3.1 双向 RNN3.2 状态 RNN 4. RNN 拓扑结构小结 0. 前…...

基于Qt的app开发第九天
写在前面 笔者的课设截止时间已经越来越近了,还有不少地方的功能没有完成,所以重构一事还是放到做完整个项目、学完设计模式再考虑。目前就是继续往屎山堆屎。 需求分析 笔者的学长要做多线程,传数据的时候涉及到互斥锁之类的内容࿰…...

Baklib内容中台驱动资源管理创新
内容中台驱动智能整合 现代企业数字化进程中,内容中台通过结构化数据治理与智能算法协同,有效解决跨系统内容孤岛问题。以Baklib为例,其核心功能通过多语言支持与API接口集成能力,实现营销素材、产品文档等异构资源的统一索引与动…...

项目记录:「五秒反应挑战」小游戏的开发全过程
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 灵感来源与目标设定 最近我突然有个小想法:想做一个简洁但富有科技感的小型游戏,最好能…...

Git本地使用小Tips
要将本地仓库 d:\test 的更新推送到另一个本地仓库 e:\test,可以使用 Git 的远程仓库功能。以下是具体步骤: 在 e:\test 中添加 d:\test 作为远程仓库 在 e:\test 目录中打开 Git Bash 或命令行,执行以下命令: git remo…...
)
【AWS入门】AWS身份验证和访问管理(IAM)
【AWS入门】AWS身份验证和访问管理(IAM) [AWS Essentials] AWS Identity and Access Management (IAM) By JacksonML 众所周知,AWS亚马逊云科技位列全球云计算服务第一位,并且持续为广大客户提供安全、稳定的各类云产品和服务。…...

【NLP】36. 从指令微调到人类偏好:构建更有用的大语言模型
从指令微调到人类偏好:构建更有用的大语言模型 大语言模型(LLMs)已经成为现代自然语言处理系统的核心,但单纯依赖传统语言建模目标,往往难以满足实际应用的“人类意图”。从 Instruction Tuning(指令微调&…...

蓝桥杯1447 砝码称重
问题描述 你有一架天平和 N 个砝码,这 N 个砝码重量依次是 W1,W2,⋅⋅⋅,WN。 请你计算一共可以称出多少种不同的重量? 注意砝码可以放在天平两边。 输入格式 输入的第一行包含一个整数 N。 第二行包含 N 个整数:W1,W2,W3,⋅⋅⋅,WN…...
)
每日c/c++题 备战蓝桥杯(洛谷P4715 【深基16.例1】淘汰赛 题解)
洛谷P4715 【深基16.例1】淘汰赛 题解 题目大意 有 (2^n) 名选手进行淘汰赛,每场比赛两人对决,能力值高者胜出;若能力值相同,则编号较小者胜出。最终决出冠军,要求输出亚军的编号。 解题思路 关键观察:…...

基于深度学习的电力负荷预测研究
一、深度学习模型框架 在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,…...

没有 Mac,我如何用 Appuploader 完成 iOS App 上架
没有 Mac,我如何用 Appuploader 完成 iOS App 上架|一个跨平台开发者的实战笔记 在做移动开发这些年里,唯一让我频繁想砸电脑的时刻,大概就是每次要把 iOS App 上传到 App Store。 作为一个主要在 Windows 和 Linux 开发的程序员…...