基于深度学习的电力负荷预测研究
一、深度学习模型框架
在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,即准确预估未来特定时间段内的电力需求,这关系到电力资源的合理分配与调度。数据收集是模型构建的基石,涵盖历史负荷数据、气象数据、节假日信息、经济指标等诸多变量。历史负荷数据能反映电力需求的周期性、趋势性变化规律;气象数据如温度、湿度、风速等,与人类生活用电行为紧密相关,温度的细微变化可能引发空调等大功率电器使用频率的波动,进而影响负荷;节假日信息可区分工作日与休息日不同的用电模式;经济指标则关联工商业活动强度与居民生活水平,影响整体电力消耗。
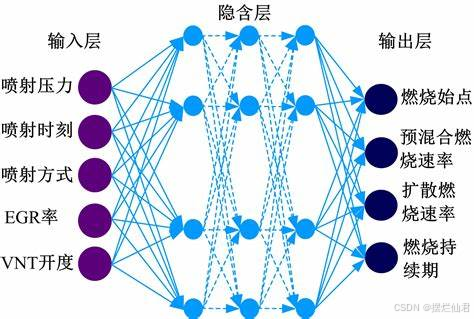
在数据预处理阶段,需对收集到的原始数据进行清洗,去除噪声、异常值与缺失值,确保数据质量。例如,对于缺失的负荷数据,可采用插值法或基于时间序列的预测算法进行填补;异常值可通过统计分析方法或聚类分析识别并修正,以避免其对模型训练过程的干扰,使模型能基于准确、可靠的数据进行学习。
深度学习模型的选择至关重要,常见的有循环神经网络(RNN)及其变体长短期记忆网络(LSTM)、门控循环单元(GRU)。RNN 能处理序列数据,但存在梯度消失问题,难以捕捉长周期的依赖关系。LSTM 通过引入遗忘门、输入门与输出门结构,有效缓解了梯度消失,能记忆长时间序列中的关键信息,对电力负荷这类具有明显时间先后关联的数据有良好适应性;GRU 在 LSTM 基础上进行简化,将遗忘门与输入门整合为更新门,减少参数数量,提高训练效率,在处理部分电力负荷数据时可取得与 LSTM 相当甚至更优的效果。
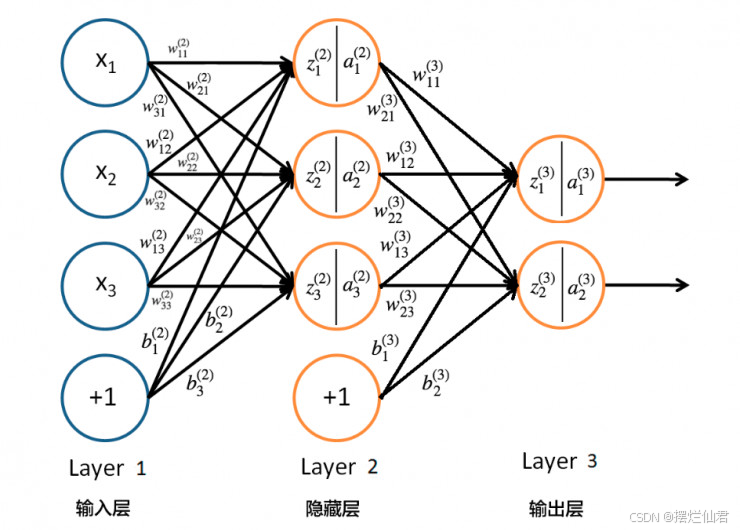
以 LSTM 为例,其模型构建细节如下。输入层接收预处理后的多维数据,包括历史负荷值、对应时刻的气象参数等,数据维度需根据实际数据特征与模型输入要求合理设置。隐藏层由多个 LSTM 单元构成,这些单元相互连接,形成时间序列处理链路。每个 LSTM 单元内部,遗忘门决定了先前时刻记忆信息中有多少被保留或舍弃;输入门控制当前输入数据进入单元状态的程度;输出门则依据单元状态输出有价值的信息用于后续预测。隐藏层的层数与每层神经元数量需通过反复试验确定,过多可能导致过拟合,过少则预测精度不足。输出层通常采用线性激活函数,输出未来特定时间点或时间段的电力负荷预测值。
在模型训练过程中,定义合适的损失函数是关键。对于电力负荷预测这类回归问题,均方误差(MSE)、平均绝对误差(MAE)是常用损失函数,它们衡量预测值与真实值之间的偏差大小,模型训练旨在最小化该误差。采用优化算法如随机梯度下降(SGD)、Adam 等调整模型参数,根据损失函数梯度更新 LSTM 单元的权重与偏置,不断优化模型预测能力。训练过程中需划分训练集、验证集与测试集,利用训练集对模型进行初步训练,通过验证集监控模型在未见数据上的表现,防止过拟合,当验证集误差不再显著下降时停止训练,最后在测试集上评估模型最终性能,确保其在实际应用中具备良好的泛化能力。
二、网络模型优化
在深度学习模型构建过程中,以下三种优化技术被广泛用于提高模型的性能和泛化能力:(1)超参数调优:超参数的选择对模型性能影响巨大,包括学习率、隐藏层数量、神经元数量等。利用网格搜索或随机搜索等方法,通过在验证集上评估不同超参数组合的表现,选择最优的超参数组合。(2)正则化:防止模型过拟合,主要通过L1和L2正则化实现。L2正则化在损失函数中加入权重的平方和,而L1正则化加入权重的绝对值之和,限制模型复杂度,提高泛化能力。(3)数据增强:通过生成新的训练样本来扩充数据集,如对历史负荷数据进行平移、添加噪声扰动,增强模型对数据变化的适应能力,提高泛化性能。
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras import regularizers
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from tensorflow.keras.callbacks import EarlyStopping# 读取数据
data = pd.read_csv('electric_load_data.csv')
features = data[['temperature', 'humidity', 'historical_load', 'holiday_flag']]
labels = data['target_load']# 数据预处理
scaler_features = MinMaxScaler()
scaler_labels = MinMaxScaler()
features_scaled = scaler_features.fit_transform(features)
labels_scaled = scaler_labels.fit_transform(labels.values.reshape(-1, 1))# 数据增强
def data_augmentation(features, labels):augmented_features = []augmented_labels = []for feature, label in zip(features, labels):# 添加噪声扰动noise = np.random.normal(0, 0.01, feature.shape)augmented_features.append(feature + noise)augmented_labels.append(label)return np.array(augmented_features), np.array(augmented_labels)augmented_features, augmented_labels = data_augmentation(features_scaled, labels_scaled)# 数据集划分
X_train, X_val, y_train, y_val = train_test_split(augmented_features, augmented_labels, test_size=0.2, random_state=42)# 构建LSTM模型
def build_lstm_model(input_shape):model = Sequential()model.add(LSTM(64, input_shape=input_shape, return_sequences=True, kernel_regularizer=regularizers.l2(0.01)))model.add(Dropout(0.2))model.add(LSTM(32, kernel_regularizer=regularizers.l1(0.01)))model.add(Dropout(0.2))model.add(Dense(1, activation='linear'))model.compile(optimizer='adam', loss='mse')return modelmodel = build_lstm_model((X_train.shape[1], X_train.shape[2]))# 学习率调度器
def learning_rate_scheduler(epoch, lr):if epoch < 10:return lrelse:return lr * 0.95callbacks = [EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True),tf.keras.callbacks.LearningRateScheduler(learning_rate_scheduler)
]# 模型训练
history = model.fit(X_train, y_train, epochs=50, batch_size=32,validation_data=(X_val, y_val), callbacks=callbacks)# 模型评估
loss = model.evaluate(X_val, y_val)
print(f"Validation Loss: {loss}")# 预测结果反归一化
predicted = model.predict(X_val)
predicted_load = scaler_labels.inverse_transform(predicted)
true_load = scaler_labels.inverse_transform(y_val)# 计算预测误差
mse = mean_squared_error(true_load, predicted_load)
print(f"Mean Squared Error: {mse}")三、测试结果分析
在电力负荷预测中,准确评估模型的预测性能至关重要。我们主要关注以下几个方面:(1)预测误差分析:计算预测值与真实值之间的误差,包括平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R²)等指标,以定量评估模型的预测精度。(2)结果可视化:通过绘制预测值与真实值的对比图,直观展示模型的预测效果,并分析预测曲线与实际曲线的吻合程度。(3)模型性能评估:综合考虑模型在不同时间段的表现,评估其在处理不同负荷模式时的适应性和稳定性,其定性分析的结果如下图所示。
通过对模型预测结果的详细分析,我们可以全面评估模型的性能和可靠性。低预测误差和高R²值表明模型能够较好地捕捉电力负荷的变化趋势,为电力系统调度和资源分配提供有力支持。可视化结果进一步验证了模型的预测效果,使其在实际应用中具有较高的参考价值。
相关文章:

基于深度学习的电力负荷预测研究
一、深度学习模型框架 在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,…...

没有 Mac,我如何用 Appuploader 完成 iOS App 上架
没有 Mac,我如何用 Appuploader 完成 iOS App 上架|一个跨平台开发者的实战笔记 在做移动开发这些年里,唯一让我频繁想砸电脑的时刻,大概就是每次要把 iOS App 上传到 App Store。 作为一个主要在 Windows 和 Linux 开发的程序员…...

卓力达手撕垫片:精密制造的创新解决方案与多领域应用
目录 引言 一、手撕垫片的技术特性与核心功能 二、手撕垫片的多领域应用 三、南通卓力达手撕垫片的核心优势 四、未来技术展望 结语 引言 手撕垫片作为一种创新型精密金属部件,凭借其“可分层剥离、快速安装”的特性,在工业制造、电子通信、航空航天等…...

[[春秋云境] Privilege仿真场景
文章目录 靶标介绍:知识点卷影拷贝(VSS) 外网任意文件读取Jenkins管理员后台rdp远程登录Gitlab apiToken 内网搭建代理 Oracle RCESeRestorePrivilege提权mimikatzspn卷影拷贝提取SAM 参考文章 靶标介绍: 在这个靶场中,您将扮演一名资深黑客…...

【工具推荐】--Git详解
本文讲诉,git命令环境的安装和git命令的介绍 Git 是一个非常流行的分布式版本控制系统,它帮助开发者管理和跟踪项目中的代码变化。通俗地说,可以认为 Git 就像是一个代码的时间机器,它记录了项目从开始到结束的每一次代码变动。 …...

在linux里上传本地项目到github中
首先先安装git,安装完git后,输入如下操作指令: 输入自己的用户名和邮箱(为注册GITHUB账号时的用户名和邮箱): git config --global user.name "111"git config --global user.email "121…...
操作入门)
【基础】Windows开发设置入门8:Windows 子系统 (WSL)操作入门
前言 大家熟悉的docker、Python,但对于Windows上有一套开配合开发的相对底层的环境设置,包括powershell、winget、WSL、还有开发驱动器什么的,我准备系统学一下,不然地基不牢,也盖不起冲天高楼~ 本节,介绍…...

服务器上的Nano 编辑器进行git合并
使用git pull拉取后,出现如下部分: GNU nano 2.9.3 /data/zhouy24Files/embody/DSLab-embodied-intelligence/.git/MERGE_MSG Merge branch …...

【idea 报错:java: 非法字符: ‘\ufeff‘】
执行main方法报错:: ‘\ufeff’?package cn.com 截图如下:任何一个mian都不能执行,都报这个 写出来希望大家都能快速解决这种少见的问题,还不好弄。 我是参考这篇文章就好了:idea 报错:java: 非法字符: …...
介绍与使用)
BM25(Best Matching 25)介绍与使用
BM25(Best Matching 25)是一种基于概率检索框架的改进算法,主要用于信息检索中的相关性评分。它通过引入词频饱和函数、文档长度归一化等机制,克服了传统TF-IDF算法的局限性。 一、BM25的核心原理 1. 改进TF-IDF的三大维度 词频…...

.NET 函数:检测 SQL 注入风险
以下是一个用 C# 编写的 .NET 函数,用于检测用户输入是否存在潜在的 SQL 注入风险: using System; using System.Text.RegularExpressions;public class SqlInjectionChecker {// 常见 SQL 注入关键词和模式private static readonly string[] SqlKeywor…...

远程数据采集智能网关支持下的雨洪资源分布式监测网络搭建实践
一、项目背景 随着城市化进程的加快以及气候变化的影响,雨洪水管理成为了城市基础设施建设中的重要课题。传统的雨洪水监测手段主要依赖人工巡查和固定站点监测,存在数据获取不及时、不全面,以及在恶劣天气条件下人员安全隐患等诸多问题。为…...

LinuxYUM下载笔记
在基于RPM的Linux发行版(如CentOS、RHEL、Fedora等)中,YUM(Yellowdog Updater Modified)是默认的包管理工具,用于简化软件的安装、更新和依赖管理。以下是YUM的使用指南: 一、检查YUM是否安装 …...
)
研读论文《Attention Is All You Need》(7)
原文 14 3.2 Attention An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight…...

使用excel 工具做数据清洗
数据分析中有个很重要的预处理步骤,叫做「数据清洗」。 简单来说就是把数据中「脏脏的 」部分 —— 缺失的、重复的、错误的等等,给它清除掉,剩下「干净的」数据。 1、缺失数据 如果某处缺了一两个数据,最简单的方法就是 —— …...

LeetCode 217.存在重复元素
目录 题目: 题目描述: 题目链接: 思路: 思路一详解(排序): 思路二详解(Set): 思路三详解(Map): 代码: …...

Flask 与 Django 服务器部署
一、引言 在 Web 开发领域,Flask 和 Django 是 Python 生态中最受欢迎的两个 Web 框架。Flask 以其轻量级和灵活性著称,适合快速开发小型应用和 API;而 Django 则提供了全面的功能套件,包括 ORM、管理界面和认证系统,…...

Python:操作Excel按行写入
Python按行写入Excel数据,5种实用方法大揭秘! 在日常的数据处理和分析工作中,我们经常需要将数据写入到Excel文件中。Python作为一门强大的编程语言,提供了多种库和方法来实现将数据按行写入Excel文件的功能。本文将详细介绍5种常见的Python按行写入Excel数据的方法,并附上…...

架构演变 -单体到云原生
软件架构的演变是随着技术发展、业务需求和硬件条件的变化而不断迭代的过程。以下是从单体架构到现代云原生架构的典型演变路径及关键阶段特点: 一、单体架构(Monolithic Architecture) 时间阶段:2000 年代前 特点: …...

VSCode 安装教程
访问官网 Visual Studio Code 官网 打开下载的exe文件 选一个安装位置 创建桌面快捷方式 (D) 在桌面生成 VSCode 的快捷图标,方便快速启动程序。 将 “通过 Code 打开” 操作添加到 Windows 资源管理器文件上下文菜单 右键点击文件时,菜单中会新增 “通…...

开源表单设计器FcDesigner配置多语言教程
开源低代码表单设计器FcDesigner中提供了强大的多语言支持功能,允许开发者在表单中实现一键式语言切换。在现代业务应用中,多语言支持是一项基本需求,尤其在国际化产品中。 源码地址: Github | Gitee | 文档 | 在线演示 设计器中配置多语言…...

ONIE安装NOS操作说明
ONIE 安装 NOS 操作说明 1. ONIE 简介 ONIE(Open Network Install Environment)是开放网络设备的出厂预装环境,类似于服务器的PXE/BIOS,主要用于自动或手动安装网络操作系统(NOS,如SONiC、Cumulus、FBOSS等…...

fastadmin 数据导出,设置excel行高和限制图片大小
fastadmin默认导出图片全部都再一块,而且不在单元格里 话不多说,上代码 修改文件的路径: /public/assets/js/require-table.js exportOptions: {fileName: export_ Moment().format("YYYY-MM-DD"),preventInjection: false,mso…...

仿腾讯会议——音频服务器部分
1、中介者定义处理音频帧函数 2、 中介者实现处理音频帧函数 3、绑定函数映射 4、服务器定义音频处理函数 5、 服务器实现音频处理函数...

国产化替代对金融行业有哪些影响?如何应对?
在全球产业链重构与科技自主创新的时代背景下,国产化替代已从技术领域的局部探索,升级为金融行业应对复杂外部环境、夯实发展根基的战略选择。作为国家核心竞争力的重要组成部分,金融行业长期依赖国外技术设备的传统模式正面临安全性、可控性…...
)
包装类(1)
1.包装类的分类 1.针对八种基本数据类型相应的引用类型--包装类 2.有了类的特点,就可以调用类中的方法. 基本数据类型. 包装类 例: 手动装箱 int->Integer 手动执箱 Integer->int 注:jdk5后就可以自动装箱和拆箱 2.包装类和基本数据的转换 (1)jdk5前的…...

java中如何优雅处理多租户系统的查询?
多租户系统通常是指一个应用服务多个客户(租户),每个租户的数据需要隔离,确保数据安全和隐私。处理这样的系统需要考虑数据隔离、查询效率、代码的可维护性等方面。 首先,我应该明确多租户的实现方式。常见的多租户数据…...
方式实践)
Ubuntu服务器部署多语言项目(Node.js/Python)方式实践
Ubuntu服务器部署多语言项目(Node.js/Python)方式实践 服务器脚本运行方式命令行直接执行nohup后台执行进程 Screen概述安装基本操作命令启动 Screen退出当前会话(不终止进程)查看所有会话重连会话关闭会话 常用快捷键典型使用场景…...

【MySQL】基础操作
MySQL(二)基础操作 一、数据库操作 1.创建库 2.查看库 3.选中库 4.删除库 二、表操作 1.创建表 1.1[comment 注释]: 1.2,...: 2.查看表 2.1查看所有表 2.2查看表结构 3.删除表 三、记录操作 1.插入记录 1.1全列插入 1.2指定列插入 1.3…...

在 Java MyBatis 中遇到 “操作数类型冲突: varbinary 与 float 不兼容” 的解决方法
在 MyBatis 中遇到 “操作数类型冲突: varbinary 与 float 不兼容” 错误,通常是因为当字段值为 null 时,MyBatis 无法正确推断其 JDBC 类型,导致向数据库传递 null 值时类型不匹配。以下是原因分析和解决方案: 问题原因 未指定 j…...
估计pmsm的位置误差)
课题推荐——扩展卡尔曼滤波(EKF)估计pmsm的位置误差
扩展卡尔曼滤波(EKF)是一种常用于非线性系统状态估计的方法,特别适用于永磁同步电机(PMSM)的位置和速度估计。EKF可以实时估计电机的转子位置误差(与实际转子位置的偏差),从而提高控…...

elasticsearch之记录es7.17升级8.17 springboot2.7.0 程序改造坑
es7.17升级8.x问题目录 一、硬件安装1-1. centos7 服务器上,删除elasticsearch7.17,安装es8.17 二、 程序改造2-1. Java API Client 8.17.52-2. 依赖引入2-3. 配置文件2-4. Java 配置类 三、根据 Elasticsearch 集群信息(版本 8.17.2…...

SpringBoot+ELK 搭建日志监控平台
ELK 简介 ELK(Elasticsearch, Logstash, Kibana)是一个目前主流的开源日志监控平台。由三个主要组件组成的: Elasticsearch: 是一个开源的分布式搜索和分析引擎,可以用于全文检索、结构化检索和分析,它构建…...

家庭数字生态构建实战:基于飞牛fnOS的智能家居数据中台搭建全流程解析
文章目录 前言1. VMware安装飞牛云(fnOS)1.1 打开VMware创建虚拟机1.3 初始化系统 2. 安装Cpolar工具3. 配置远程访问地址4. 远程访问飞牛云NAS5. 固定远程访问地址 前言 在数字生活时代,数据管理正成为每个家庭的刚需。今天要向大家重点推荐…...

博客系统功能测试
博客系统网址:http://8.137.19.140:9090/blog_list.html 主要测试内容 功能测试、界面测试、性能测试、易用性测试、安全测试、兼容性测试、弱网测试、安装卸载测试、压力测试… 测试方法及目的 利用selenium和python编写测试脚本,对博客系统进行的相关…...

抽奖相关功能测试思路
1. 抽奖系统功能测试用例设计(登录 每日3次 中奖40% 道具兑换码) ✅ 功能点分析 必须登录后才能抽奖每天最多抽奖3次抽奖有 40% 概率中奖中奖返回兑换码 ✅ 测试用例设计 编号 用例描述 前置条件 操作 预期结果 TC01 未登录时抽奖 未登录 …...

paddle ocr本地化部署进行文字识别
一、Paddle 简介 1. 基本概念 Paddle(全称 PaddlePaddle,飞桨)是百度开发的 开源深度学习平台,也是中国首个自主研发、功能丰富、技术领先的工业级深度学习平台。它覆盖了深度学习从数据准备、模型训练、模型部署到预测的全流程…...

在CentOS系统上部署GitLabRunner并配置CICD自动项目集成!
在CentOS系统上部署GitLabRunner并配置CICD自动项目集成 在CentOS系统上部署GitLab Runner并配置CI/CD自动项目集成GitLab CI/CD是一个强大的持续集成和持续部署工具,能够显著提高开发团队的效率。 本文将详细介绍如何在CentOS系统上部署GitLab Runner,…...
)
python学习day2(未写完,明天继续补充)
今天主要学习了变量的数据类型,以及如何使用格式化符号进行输出。 一、认识数据类型 在python里为了应对不同的业务需求,也把数据分为不同的类型。 代码如下: """ 1、按类型将不同的变量存储在不同的类型数据 2、验证这些…...

深度强化学习框架DI-engine
深度强化学习框架DI-engine 一、DI-engine概述:决策智能的通用引擎 DI-engine是由OpenDILab开源的决策智能引擎,基于PyTorch和JAX构建,旨在为强化学习(RL)、模仿学习(IL)、离线学习等场景提供…...

gitlab迁移
需求:需要将A服务器上的 gitlab 迁移到B服务器上,均使用docker 部署 一、备份数据 进入到A服务器的 gitlab 的容器中,运行gitlab-rake gitlab:backup:create 该命令会在 /var/opt/gitlab/backups/ 目录下创建一个xxx_gitlab_backup.tar 压缩…...

UEFI Spec 学习笔记---33 - Human Interface Infrastructure Overview---33.2.6 Strings
33.2.6 Strings UEFI 环境中的 string 是使用 UCS-2 格式定义,每个字符由 16bit 数据表示。对于用户界面,strings 也是一种可以安装到 HIIdatabase 的一种数据。 为了本土化,每个 string 通过一个唯一标识符来识别,而每一个标识…...

如何确保低空经济中的数据安全?
低空经济涉及大量敏感数据,如无人机的飞行轨迹、拍摄的地理图像和视频等。为确保这些数据的安全,可从以下几方面着手: 加强数据加密 传输加密 :采用 SSL/TLS 等加密协议,对数据在传输过程中进行加密,防止…...

在linux平台下利用mingw64编译windows程序
背景 笔者平时都是基于linux平台开发C代码,已经熟悉使用CMake这一套工具上一次开发windows应用程序还要追溯到10多年前,彼时还是使用微软的visual studio这个IDE,这个IDE确实也很强大,但也确实很笨重,当时用起来也很不…...

虚幻引擎5-Unreal Engine笔记之什么时候新建GameMode,什么时候新建关卡?
虚幻引擎5-Unreal Engine笔记之什么时候新建GameMode,什么时候新建关卡? code review! 参考笔记: 1.虚幻引擎5-Unreal Engine笔记之GameMode、关卡(Level) 和 关卡蓝图(Level Blueprint)的关系 2.虚幻引擎…...

[IMX] 04.定时器 - Timer
目录 1.周期中断定时器 - EPIT 1.1.工作模式 1.2.配置寄存器 - EPIT_CR 1.3.状态寄存器 - EPIT_SR 1.4.加载寄存器 - EPIT_LR 1.5.比较寄存器 - EPIT_CMPR 1.6.计数寄存器 - EPIT_CNR 2.通用定时器 - GPT 2.1. 时钟源 2.2.模块结构 2.3.工作模式 2.4.配置寄存器 - …...

前端 vue + element-ui 框架从 0 - 1 搭建
1. 安装node 地址: Node.js — 在任何地方运行 JavaScript 2. 安装 vue 2.1 执行安装命令 npm uninstall -g vue-cli npm install -g vue/cli 安装最新的vue3版本 2.2 使用vue 脚手架 搭建项目 vue create project_name 2.2.1 注意 项目名称不能包…...

【IDEA】删除/替换文件中所有包含某个字符串的行
目录 前言 正则表达式 示例 使用方法 前言 在日常开发中,频繁地删除无用代码或清理空行是不可避免的操作。许多开发者希望找到一种高效的方式,避免手动选中代码再删除的繁琐过程。 使用正则表达式是处理字符串的一个非常有效的方法。 正则表达式 …...
2.数组、列表)
算法刷题(Java与Python)2.数组、列表
目录 Java的数组 数组介绍 注意事项 Python的列表 列表介绍 Python 的列表和 Java 的 ArrayList 一样吗? 例题1 代码分析 Java代码 Python代码 对比代码 例题2 代码分析 Java代码 Python代码 对比代码 例题三 Java代码 Python代码 代码对比 Jav…...

uniapp打包H5,输入网址空白情况
由于客户预算有限,最近写了两个uniapp打包成H5的案例,总结下面注意事项 1. 发行–网站-PCWeb或手机H5按钮,输入名称,网址 点击【发行】,生成文件 把这个给后端,就可以了 为什么空白呢 最重要一点…...