LLM大语言模型系列1-token
一,什么是token
1,什么是token:
参考:https://en.wikipedia.org/wiki/Token
https://en.wikipedia.org/wiki/Lexical_analysis#Token
我们有很多描述token的解释,建议是汇总在一起进行综合理解:
1️⃣Token 是大语言模型(LLM, Large Language Model)中最基本的输入单元,它是语言被模型“理解”的方式;
2️⃣token:是一个原子解析级别(即不可再分,从语言内容角度上通俗来讲)的word,这个概念是联系英语语言学(一般是词法分析部分的),简单理解就是自然语言处理的词元(词的单元)

从语言的角度,我们可以找到很多和token有类似概念或者说是神韵的词,比如说词素、词的基本单元
参考:https://learn.microsoft.com/en-us/dotnet/ai/conceptual/understanding-tokens
3️⃣token是大型语言模型(LLMs)在分解文本时生成的单词、字符集或单词和标点符号的组合。
(words, character sets, or combinations of words and punctuation that are generated by large language models (LLMs) )
Tokenization分词化是训练的第一步。
LLM 分析token之间的语义关系,例如它们一起使用的频率或是否在相似的场景中使用。
训练后,LLM 利用这些模式和关系,根据输入序列生成输出标记序列。

LLM 在训练中使用的唯一token集称为其词汇表(vocabulary)。
The set of unique tokens that an LLM is trained on is known as its vocabulary.

2,Tokenization
参考:https://en.wikipedia.org/wiki/Lexical_analysis#Tokenization
从词法分析(也就是语言学的角度)来讲所谓的tokenization,其实就是一种转换,即分词(化)、(到/去)分词、(转换为)分词、,本意是指将文本text转换为(语义或句法)上有意义的词汇标记的过程;
什么是有意义的词汇标记,对于纯语言学来讲,我们有名词、动词、形容词等概念;
对于计算机来讲,我们有标识符、运算符、数据类型、关键字等概念(不同的编程语言中共同的概念)。
语言学中的分词化与LLM即大语言模型中的分词化的区别在于:
语言学中的词汇分词化通常基于词汇语法,而 LLM 中的分词化通常基于概率。
其次,LLM 分词化执行第二步,将这些分词,也就是token转换为数值。


https://platform.openai.com/tokenizer

3,tokenizer
tokenization是一个过程,那么执行这个过程需要相应的tokenizer(分词器);
简单举例来说,加法是一个运算过程,我们需要执行这个过程的一个函数、一个抽象的映射,也就是1个操作符,即加法的运算操作符。
再用语言举一个例子,比如说"hello world",我怎么将这个输入的文本text,进行分词化,
我可以认为这个文本中最基本的2个词元是hello、world,
我也可以认为是he、llo、world这3个,以及等等,有各种不同的划分/映射规则/操作逻辑,就表明有不同的分词器。


可以参考:https://en.wikipedia.org/wiki/Word_(computer_architecture)看看,但不是相同的概念
我们区分的话,可以从语言学角度的lexical token和大语言模型角度的probabilistic token去区分,但是理解的化,可以类比在一起进行理解:



我们随便举一个编程语言的例子来看看:

我们再回到自然语言处理(也就是大语言模型背景下)的token中:
这里有一篇非常有趣的科普文章:
参考https://mp.weixin.qq.com/s/NiQXAdr6EzAHCLelAWWZGQ

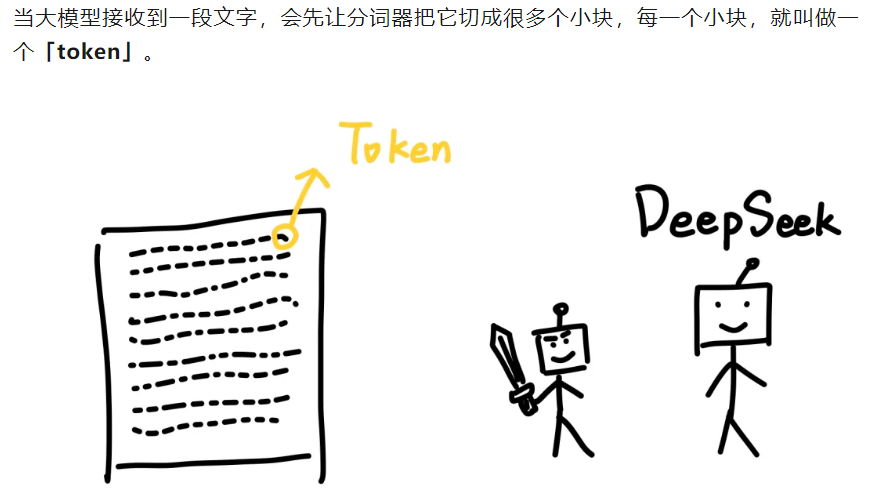
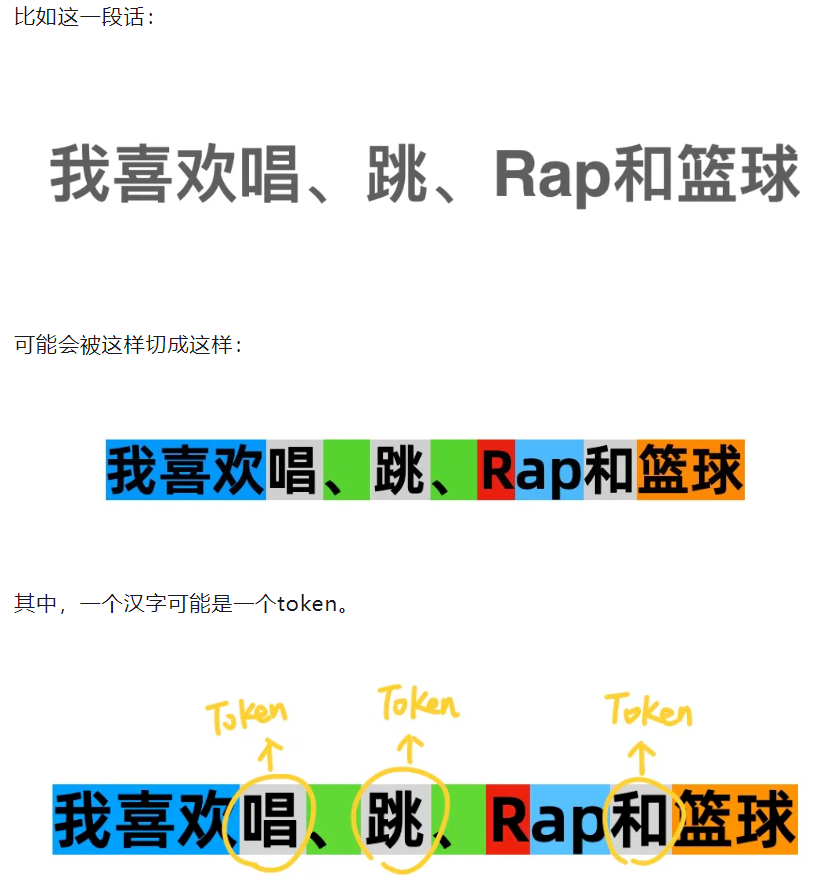
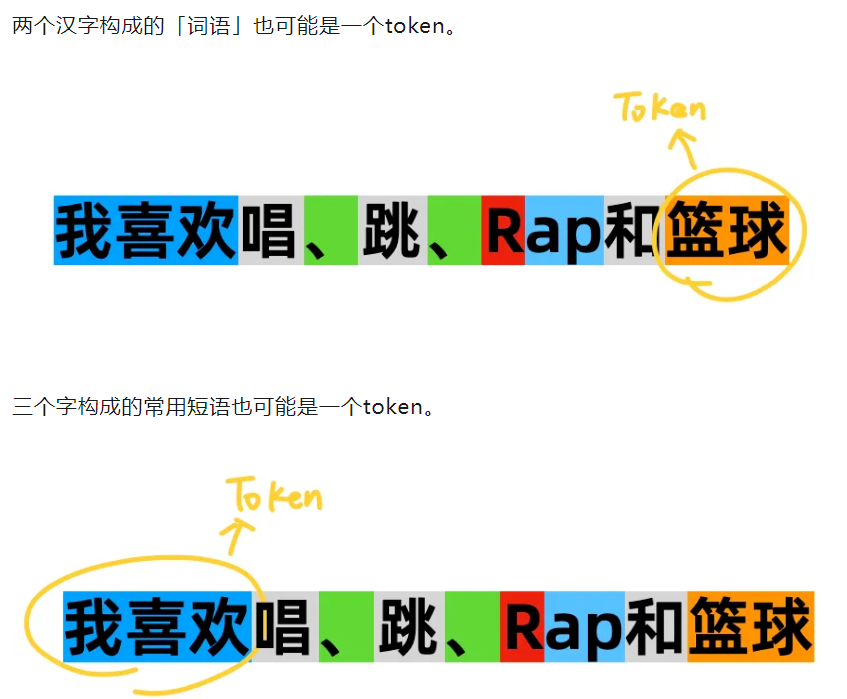
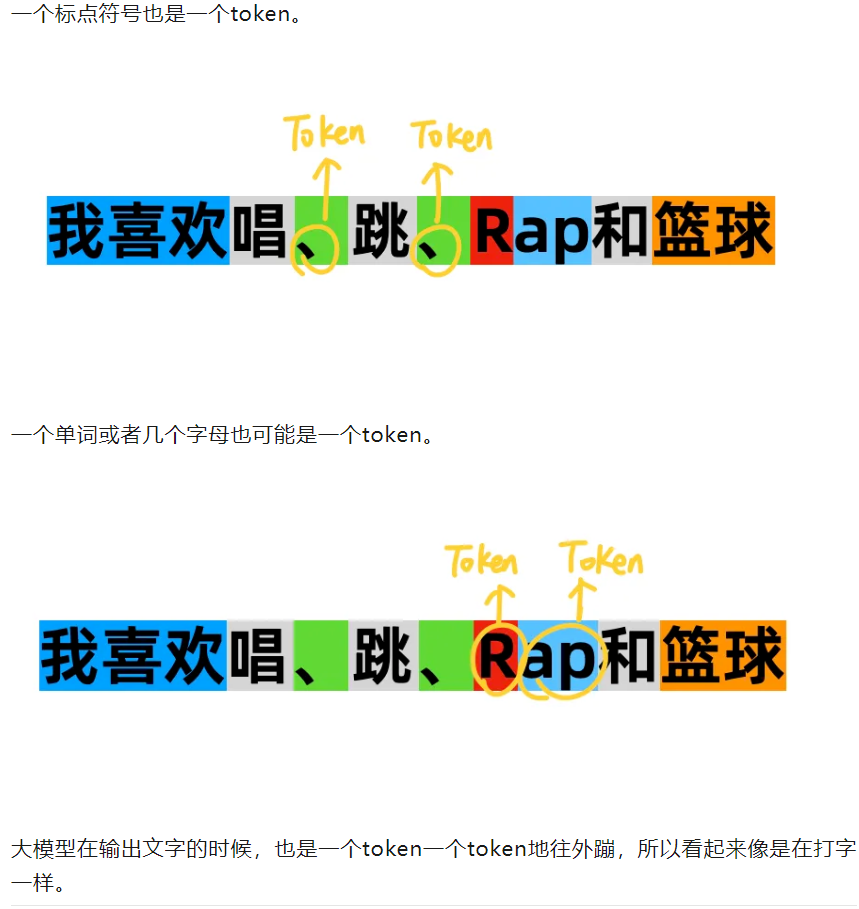
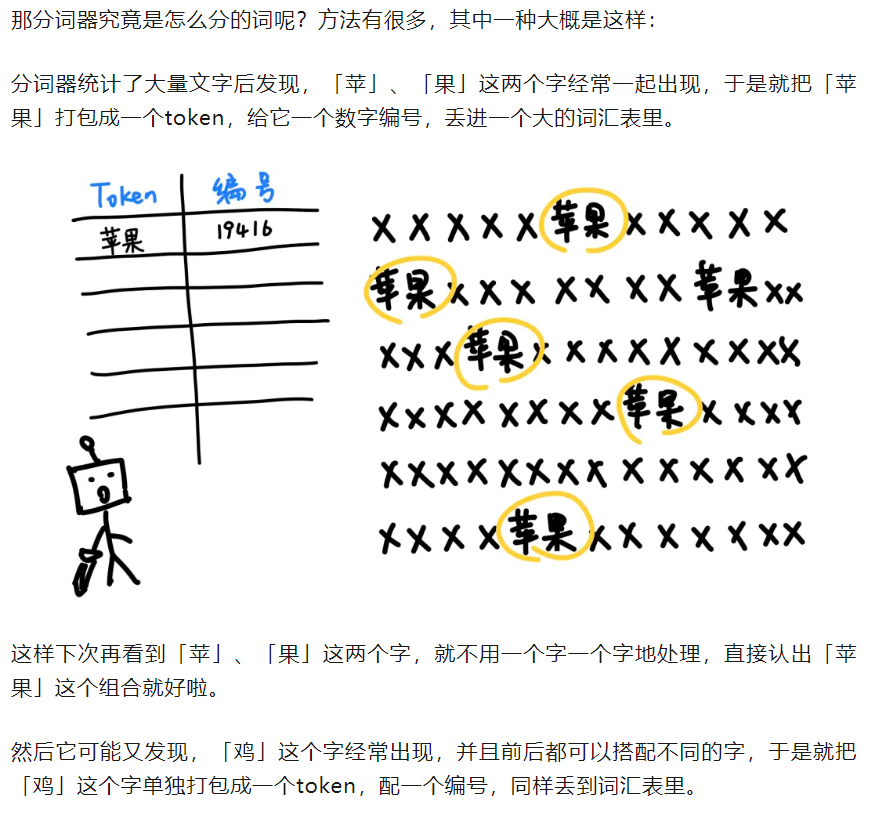
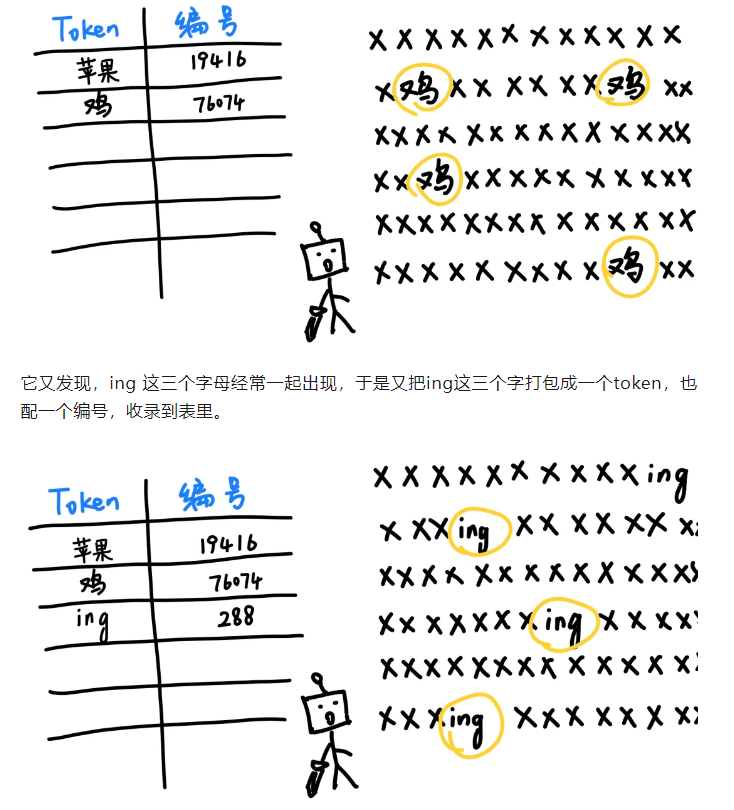
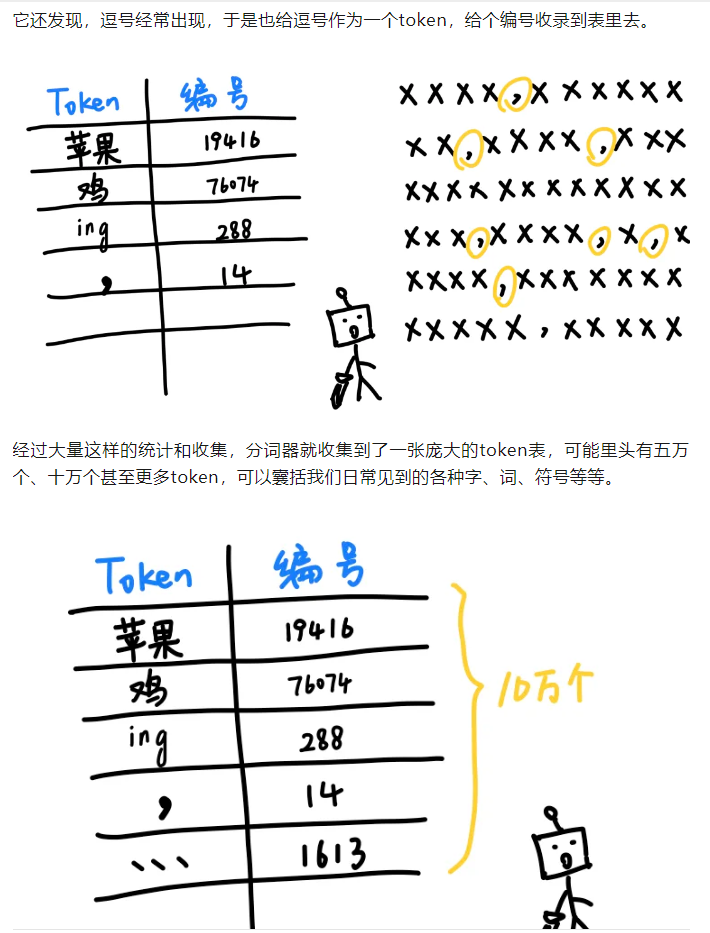
有一个网站,可以用来演示分词器的作用:
https://tiktokenizer.vercel.app/?model=deepseek-ai%2FDeepSeek-R1
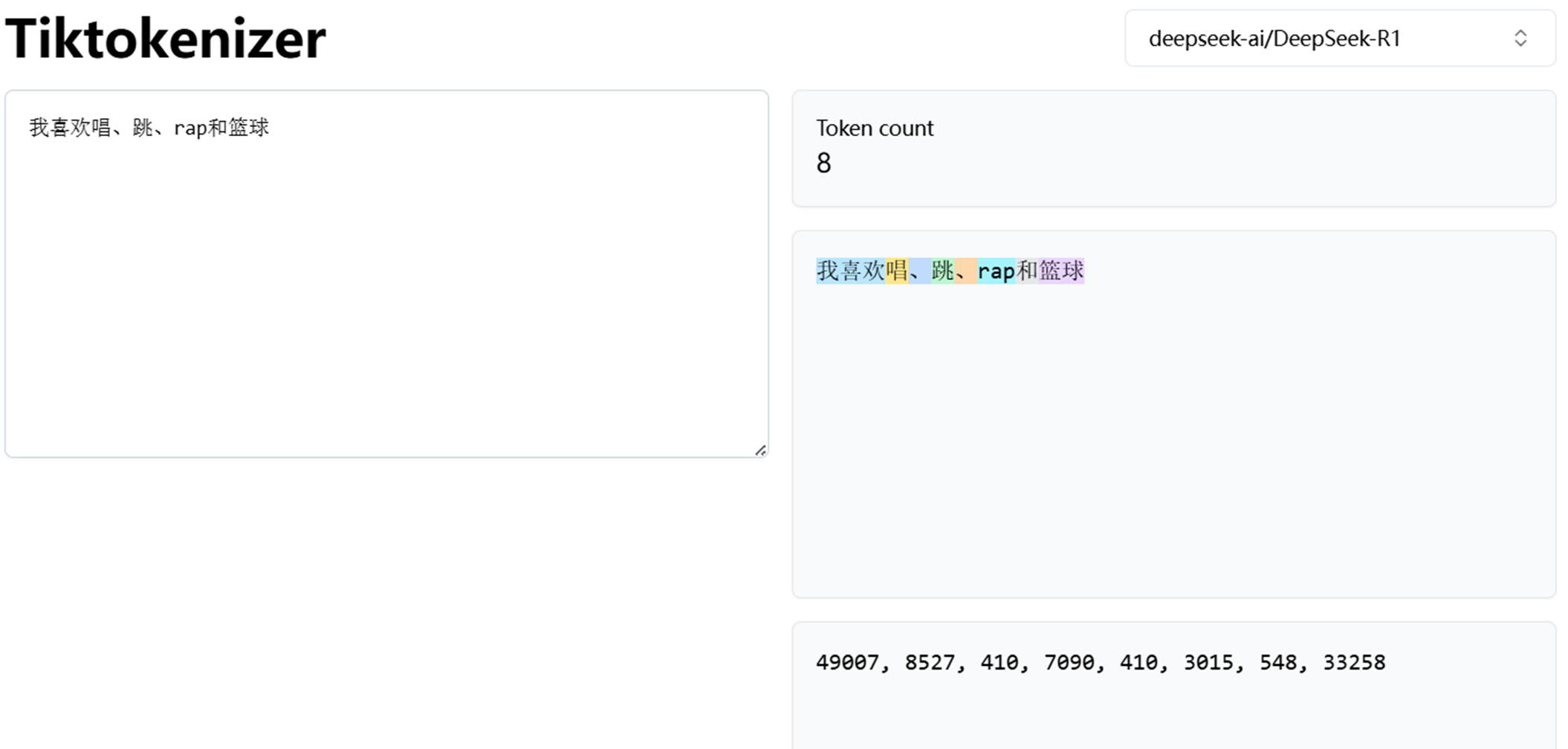
就比如说有一个问题,我们的输入是"what do i like eating?",假设说这里按照概率拆分成了5个token,
即what、do、i、like、eating,然后对于这5个token,分词器建立了1个hash表的索引分别为10、15、20、25、30,
相当于你给大模型输入了这么一串数字,也就是1个向量,[10,15,20,25,30],
然后如果这个大模型学到的另外一个单词,比如说KFC也是1个token,假设是666,
那么对于大模型而言,这个回答,或者说这整个的操作过程,其实就是输入[10,15,20,25,30],输出666的过程;
相当于我们实际理解中的"what do i like eating?—— KFC"。
这么一个数值向量的映射过程,我们可以简单理解为大模型学会了饮食知识,成功地依据饮食知识解答了这个问题。
参考:https://learn.microsoft.com/en-us/dotnet/ai/conceptual/understanding-tokens




在模型的最大上下文窗口限制下,输入和输出的总token数量不能超过模型的最大上下文窗口大小。换句话说,模型在一次处理过程中,输入和输出的token数量加起来不能超过其最大上下文窗口的限制。
核心概念
- 最大上下文窗口(Context Window):模型在一次处理过程中能够处理的最大token数量,包括输入和输出。
- 输入token:模型接收的文本被分词后得到的token数量。
- 输出token:模型生成的文本被分词后得到的token数量。
关键点
- 输入和输出的总token数量不能超过最大上下文窗口。例如,如果模型的最大上下文窗口是100个token,那么输入和输出的token数量加起来不能超过100个。
- 分词方法会影响输入和输出的token数量。不同的分词方法会将相同的文本分割成不同数量的token,从而影响输入和输出的可用token数量。
举例说明
假设模型的最大上下文窗口是100个token:
使用基于词的分词方法
- 输入文本:“I heard a dog bark loudly at a cat”。
- 通过基于词的分词方法,这句话被分成9个token。
- 剩下的91个token可以用于输入和输出的总和,而不是单独用于输出。
如果模型需要生成一个完整的句子作为输出,假设输出句子是“ The cat ran away quickly”,通过基于词的分词方法,这句话可能被分成6个token。那么,输入和输出的总token数量为:
- 输入:9个token
- 输出:6个token
- 总计:9 + 6 = 15个token,这在100个token的限制范围内。
使用基于字符的分词方法
- 输入文本:“I heard a dog bark loudly at a cat”。
- 通过基于字符的分词方法,这句话被分成34个token(包括空格)。
- 剩下的66个token可以用于输入和输出的总和,而不是单独用于输出。
如果模型需要生成一个完整的句子作为输出,假设输出句子是“ The cat ran away quickly”,通过基于字符的分词方法,这句话可能被分成22个token(包括空格)。那么,输入和输出的总token数量为:
- 输入:34个token
- 输出:22个token
- 总计:34 + 22 = 56个token,这也符合100个token的限制。
1. token限制的本质
token限制是指模型在一次处理过程中能够处理的最大token数量,包括输入和输出的总和。这个限制是模型架构和计算资源的约束,而不是对输出内容的具体词汇的限制。
2. 输出内容的多样性
- token限制只限制数量,不限制内容:模型的输出内容可以是任何符合上下文逻辑和语法的文本,只要这些文本的总token数不超过限制。
- 输出内容的多样性取决于模型的训练和上下文:即使token数量有限,模型仍然可以生成多种不同的内容。例如,模型可以用有限的token生成一个长句子、多个短句子,或者一个详细的描述,只要这些内容的总token数不超过限制。
3. 举例说明
假设一个模型的最大上下文窗口为100个token,输入占用了30个token,那么输出最多可以有70个token。这70个token可以是以下任何一种情况:
- 一个长句子:由70个单词组成的长句子。
- 多个短句子:例如3个句子,每个句子约20-30个单词。
- 详细描述:用70个单词详细描述一个场景或概念。
4. 分词方法的影响
不同的分词方法会导致不同的token数量:
- 基于单词的分词:每个单词是一个token。例如,“I love AI”会被分成3个token。
- 基于字符的分词:每个字符是一个token。例如,“I love AI”会被分成9个token。
- 基于子词的分词(如 BERT 的 WordPiece 或 GPT 的 Byte Pair Encoding):单词会被拆分成更小的子词单元。例如,“loving”可能会被拆分成“lov”和“ing”两个子词。

参考:https://en.wikipedia.org/wiki/Large_language_model#Tokenization

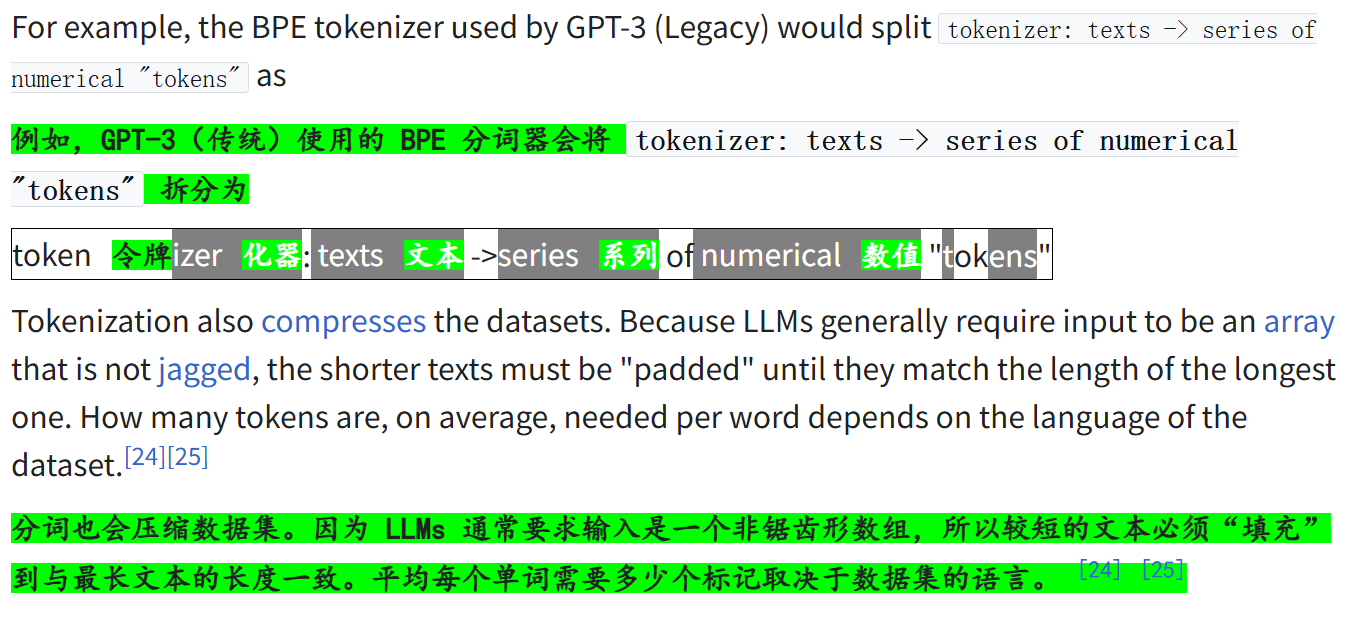
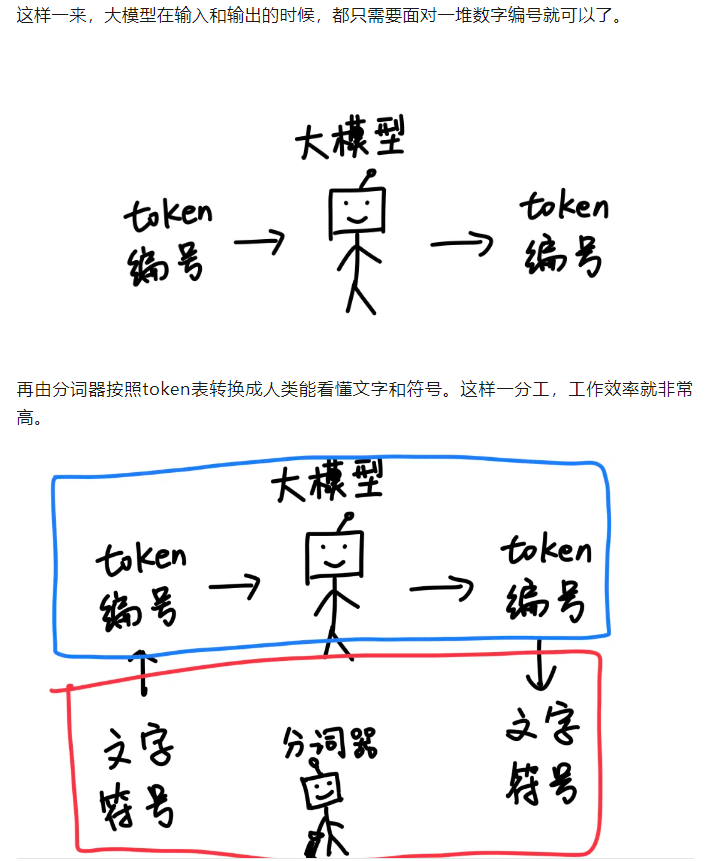
我想说的是:计算机/大模型能够理解的是数字,一切都得以数值形式的内容去呈现,分词器干的就是给大模型建立1张token(词元)到数值索引(数字)的一张hash表(可以这么理解),
然后大模型要做的就是从一堆输入的数字中,输出一堆数字;
分词器要做的就是输入端以及输出端的解码,首先输入端是给机器也就是大模型做翻译,也就是给机器解码,把我们的sequence序列数据(比如说text文本)解码为token——》数字;
在输出端的话相当于是给我们做翻译,也就是给我们解码,把机器输出的数字再转换为我们输入时候的sequence一样的语言(一样的text文本语言形式)。
本质就是模型能够理解的是数字,我们人类大脑能够理解的是自然语言,都可以看作是不同的语言,都有各自的语言基本单位,核心是不同语言基本单位之间的映射(hash)罢了。
(1)以字节对编码为基础的分词器:


参考:https://en.wikipedia.org/wiki/Byte_pair_encoding


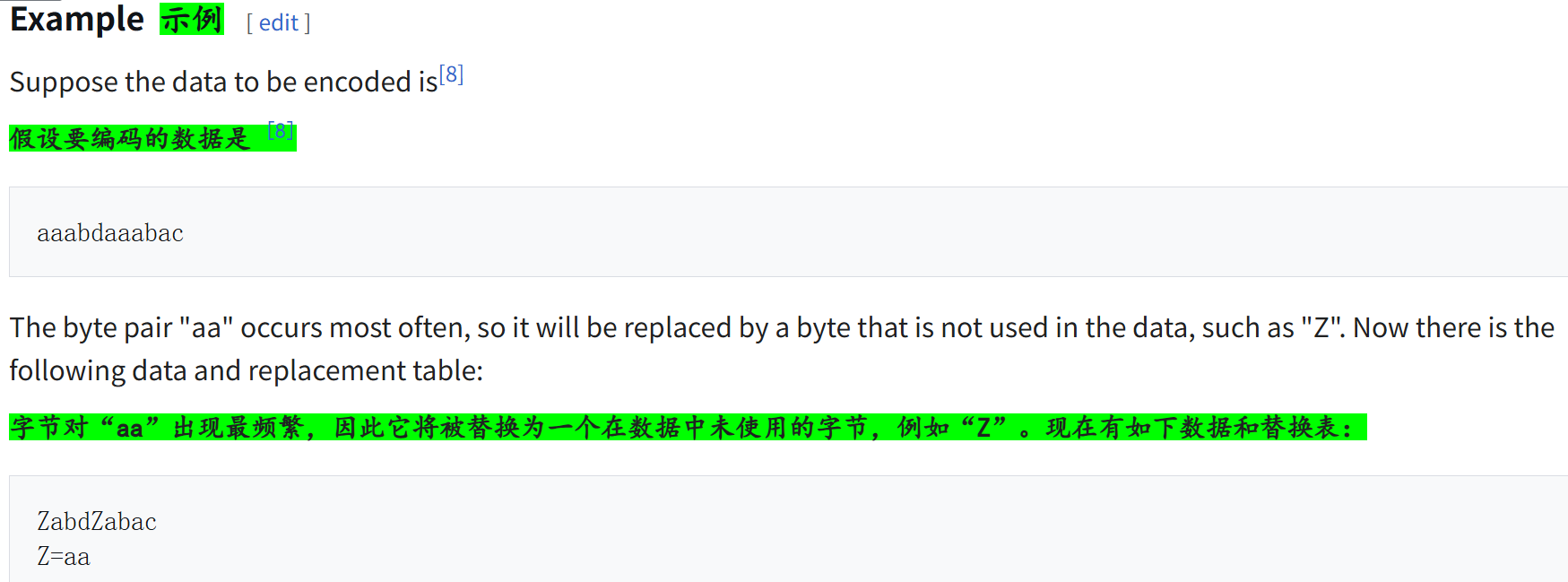
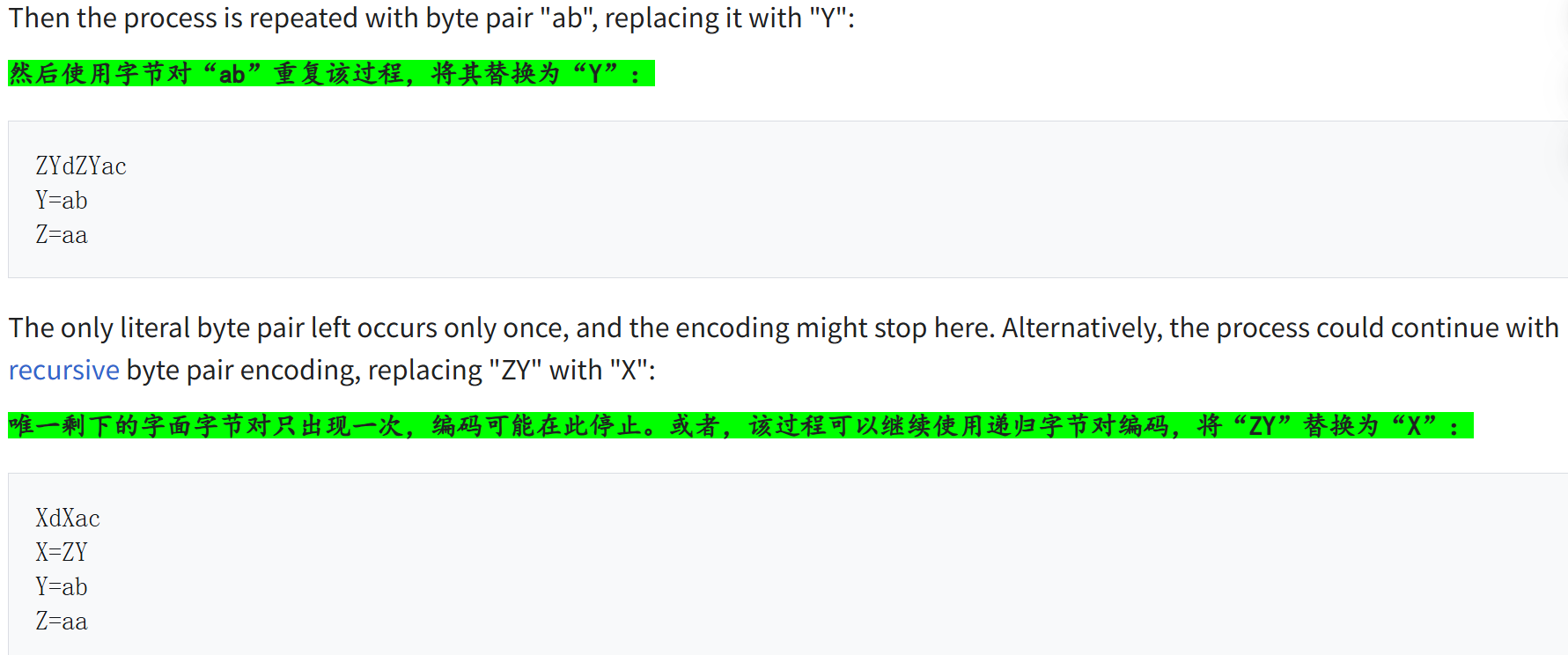


其实算法的核心就在:
将唯一字符集视为 1 个字符长的 n-gram(初始标记)。然后,逐步地将最频繁的相邻标记对合并成一个新的、更长的 n-gram,并将该对的所有实例替换为这个新标记。重复此过程,直到获得规定大小的词汇表。
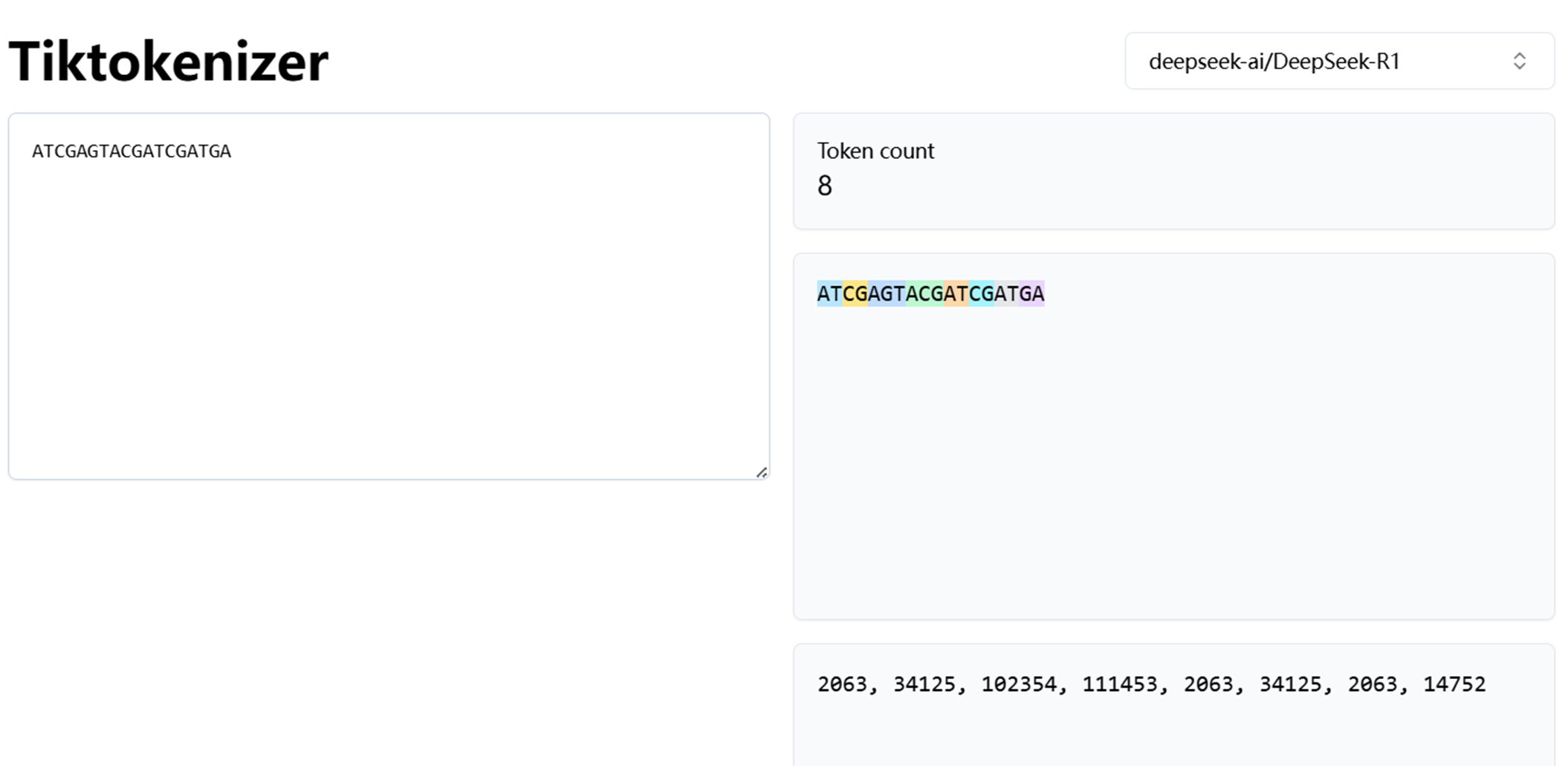
我们可以以1个DNA序列为例进行说明(下面例子中部分token的统计频率仅作为演示参考,纯粹数字,重点在于理解这个操作的原理以及流程,数据例子不是重点)
假设我们有一个DNA序列:
ATGCGTACGTTAGC
1. 初始阶段:将唯一字符集视为1个字符长的n-gram
- DNA序列中只有四种字符:A、T、C、G。
- 初始的token词汇表可以定义为:
A = 0
T = 1
C = 2
G = 3
- 将DNA序列编码为token序列:
ATGCGTACGTTAGC
↓
0 1 3 2 3 1 0 3 1 1 0 2
2. 合并最频繁的相邻token对
- 第一次合并:统计相邻token对的频率:
(0, 1): 2次 # 仅作参考,假设序列中出现过2次
(1, 3): 2次 # 同上
(3, 2): 2次 # 同上
(2, 3): 1次
(3, 1): 1次
(1, 1): 1次
(0, 2): 1次
- 最频繁的相邻token对是
(0, 1)和(1, 3)和(3, 2),都出现了2次。假设我们选择(0, 1)进行合并。 - 创建一个新的token:
(0, 1) = 4
- 更新token词汇表:
A = 0
T = 1
C = 2
G = 3
AT = 4
- 替换序列中的
(0, 1):
0 1 3 2 3 1 0 3 1 1 0 2
↓
4 3 2 3 1 4 3 1 1 2
- 第二次合并:统计新的相邻token对的频率:
(4, 3): 2次
(3, 2): 2次
(2, 3): 1次
(1, 4): 1次
(3, 1): 1次
(1, 1): 1次
- 最频繁的相邻token对是
(4, 3)和(3, 2),都出现了2次。假设我们选择(4, 3)进行合并。 - 创建一个新的token:
(4, 3) = 5
- 更新token词汇表:
A = 0
T = 1
C = 2
G = 3
AT = 4
ATG = 5
- 替换序列中的
(4, 3):
4 3 2 3 1 4 3 1 1 2
↓
5 2 3 1 5 1 1 2
3. 重复合并过程,直到达到预设的词汇表大小
假设我们希望词汇表大小为10,继续合并:
- 第三次合并:统计新的相邻token对的频率:
(5, 2): 2次
(2, 3): 1次
(3, 1): 1次
(1, 5): 1次
(1, 1): 1次
- 最频繁的相邻token对是
(5, 2),出现了2次。 - 创建一个新的token:
(5, 2) = 6
- 更新token词汇表:
A = 0
T = 1
C = 2
G = 3
AT = 4
ATG = 5
ATGC = 6
- 替换序列中的
(5, 2):
5 2 3 1 5 1 1 2
↓
6 3 1 6 1 1
- 假设继续合并,直到词汇表达到预设的大小(这里简化为10)。
最终结果
假设经过多次合并后,词汇表大小达到10,最终的token词汇表可能如下:
A = 0
T = 1
C = 2
G = 3
AT = 4
ATG = 5
ATGC = 6
...
原始DNA序列 ATGCGTACGTTAGC 被编码为:
6 3 1 6 1 1
BPE的token编码方式原理
- 从最简单的单位(单字符)开始:将每个字符视为一个独立的token。
- 逐步合并:通过统计相邻token对的频率,将最频繁的相邻token对合并成一个新的token。
- 动态更新词汇表:每次合并后,更新token词汇表,并用新的token替换序列中的相应部分。
- 重复过程:直到达到预设的词汇表大小。
- 高效表示:最终的token序列比原始字符序列更短,同时保留了原始序列的信息。
以上仅作为示例展示,总得来说,n-gram合并的时候,我们可以合并相邻的2个:
每次合并两个符号,可以逐步构建出更复杂的token,同时保持token的粒度适中,便于模型学习;
另外一方面,语言的结构通常是层次化的,从字符到单词,再到句子,逐步合并两个符号可以更好地捕捉这种层次结构。如果一次性合并三个或更多符号,可能会错过一些重要的中间层次信息。
而且从实操上讲,这种逐步的合并方式可以很容易地通过迭代实现,而不需要复杂的多符号组合逻辑


其实生物大分子序列进行token化,最常用的是BPE,也就是上面的字节对编码方式(通过统计频繁出现的字节对,逐步替换,并合并成较大的单元),以及k-mer k串方式。
对tokenizerg感兴趣的,可以huggingface上试一下,https://github.com/huggingface/tokenizers
二,为什么是token?
正如前面所述:Token 是大语言模型(LLM, Large Language Model)中最基本的输入单元,它是语言被模型“理解”的方式。
不同于人类可以直接看懂一段自然语言文本,LLM 只能处理数字,而这些数字就是由 token 转换而来的。
我们在一中已经简单讨论过了以下问题:
- 什么是 token,它和文字的关系是什么?
- 为什么 LLM 不直接处理文字,而是需要 token?
- tokenizer 是做什么的,它的原理是什么?
- 常见的 tokenizer 类型和编码方式有哪些?
大模型如何接收输入
我们平常使用大模型,比如 ChatGPT、Deepseek等,都是通过输入一段文字(也就是“提示词”,Prompt)与模型进行交互,看似模型直接把这段文字作为输入,并处理了这段文本。但真实的处理流程情况并非如此。
模型内部并不会直接接收自然语言文本,而是接收经过token转换器编码后的 token 序列。
为什么需要这个转换过程?
- 神经网络只能处理数字。
- 文本需要映射成固定的向量才能进入模型计算。
- 使用 token 可以让模型更好地压缩、理解和预测语言结构。
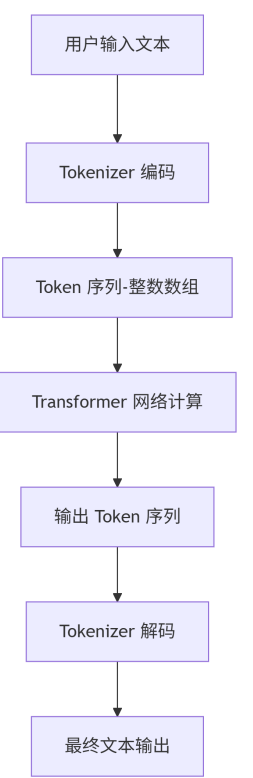
这个过程不仅用于模型输入,也用于模型输出。Transformer生成的是一个个 token,它们最终会通过一个Tokenizer解码器再被转换回自然语言。
Token 是整数序列
神经网络不理解文本,只能处理数字。因此,token 需要被编码为整数,再被嵌入成向量,供模型处理。
示例流程:
文本输入:
“你好,世界”
Tokenizer 切分:
[“你”, “好”, “,”, “世界”]
编码为整数 ID:
[9234, 8721, 13, 45012]
这些整数再被转换成向量(通过嵌入层),输入给 Transformer 模型进行计算。
为什么是整数?
因为神经网络的嵌入层(Embedding Layer)就是通过“整数索引”去查一个巨大的向量表:
embedding[token_id] → 向量
所以 token 最终表现为一串整数 ID,是大模型能够理解语言的桥梁。
Tokenizer(Token 转换器)
Tokenizer 是完成文本和 token 之间转换的关键工具。
它的作用分为两部分:
- 编码(Encode):将原始自然语言转为 token 数组。
- 解码(Decode):将 token 数组转换回文本。
一个优秀的 tokenizer 应该具备以下特点:
- 高效:转换速度快,节省内存
- 可压缩:长文本能切分成较少 token
- 泛化性强:对未知单词也能合理切分
常见的 Token 编码算法
不同的模型和任务,会使用不同的 tokenizer 和编码方式,主要包括以下几种:
1. BPE****(Byte Pair Encoding)
- 原理:通过统计频繁出现的字节对,逐步合并成较大的单元。
- 应用:GPT 系列(如 GPT-2/3/4)。
- 特点:压缩效率高,适合多语言场景。
2. WordPiece
- 原理:将词拆解成词根 + 后缀,用于解决罕见词问题。
- 应用:BERT、RoBERTa。
- 特点:词表更小,训练更稳定。
3. SentencePiece
- 原理:不依赖空格分词,基于字符级建模。
- 应用:T5、XLNet、ALBERT。
- 特点:适用于无空格语言,如中文、日文。
4. Tiktoken(OpenAI 专用)
- 特点:优化 GPT 使用场景,速度极快,token 估算准确。
- 提供工具支持编码、解码和 token 计数。
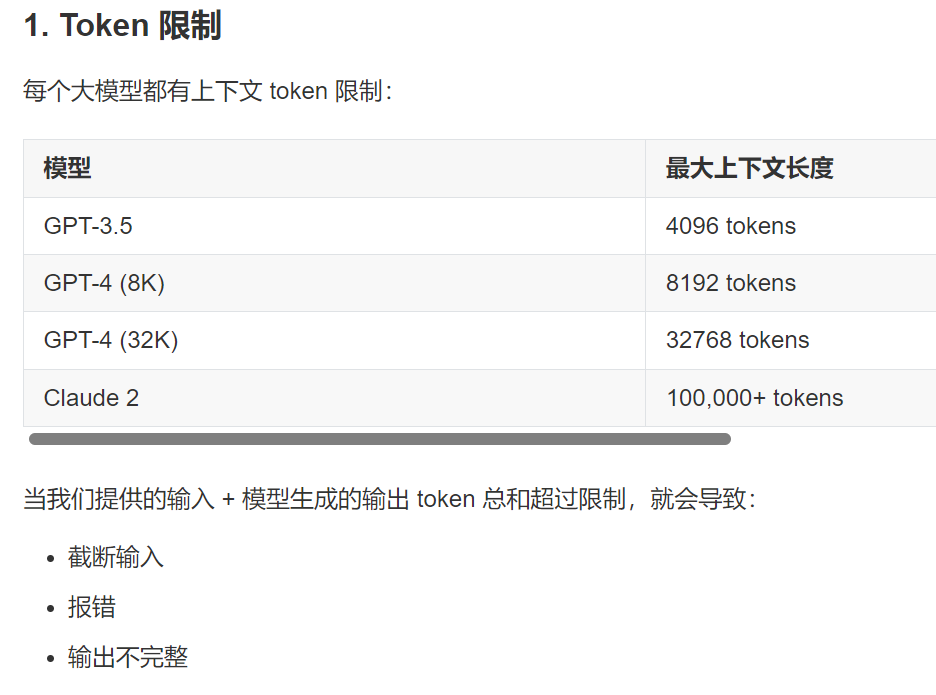
至于token限制问题,我们在熟悉理论之前,想必在使用chatbot过程中已经非常熟悉了,前面一中也有简略的讨论:
参考:https://mp.weixin.qq.com/s/8MAlBNJnRW6uBGwd9eNOAg
三,生物序列的Tokenization
此处我仅举几个例子,详细的细节可以查看原始文献:
参考:https://rpubs.com/yuchenz585/1161578
1,DNABERT: pre-trained Bidirectional Encoder Representations from Transformers model for DNA-language in genome (2021)
DNABERT,以基于上游和下游核苷酸上下文捕获基因组 DNA 序列的全局和可转移理解
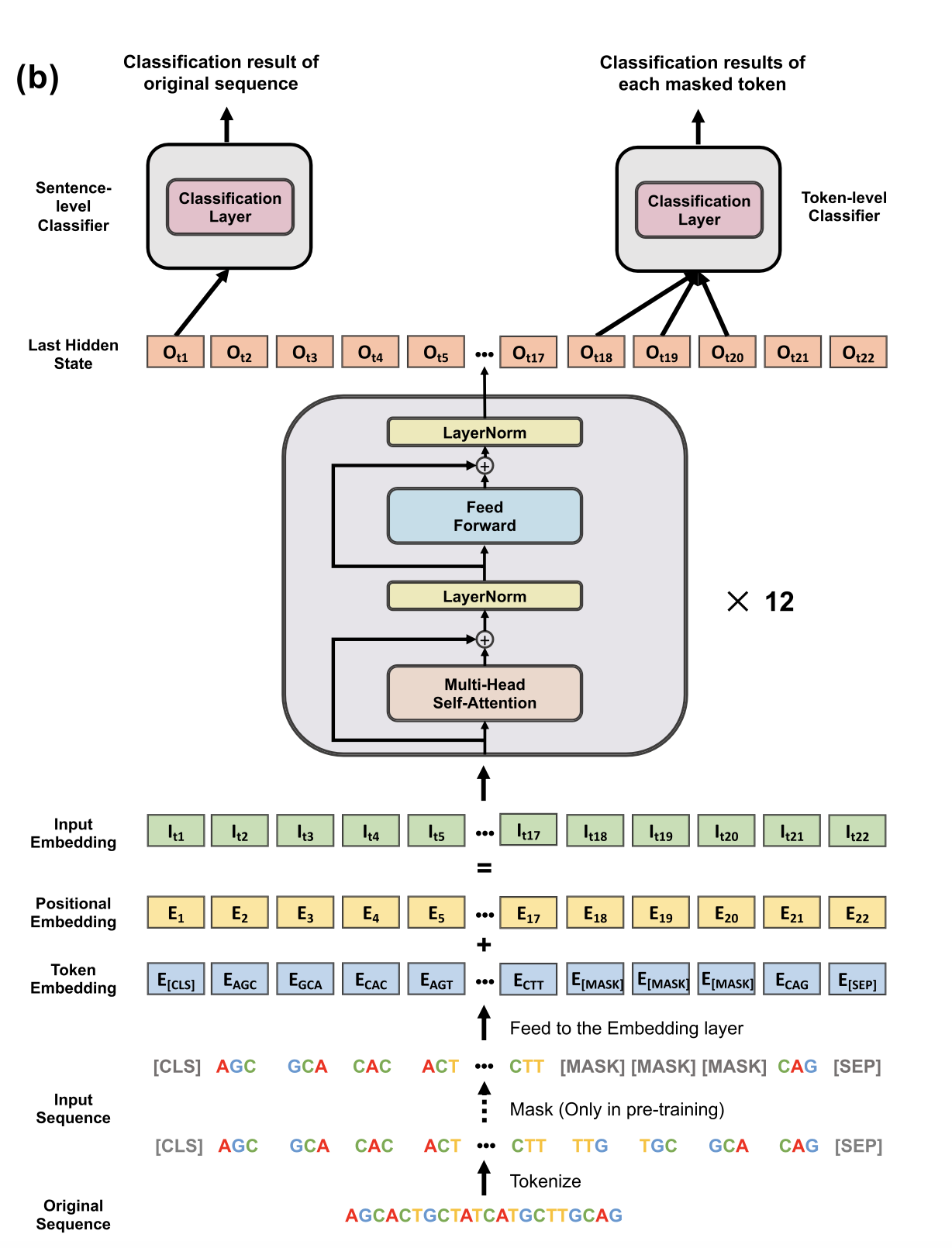
可以看到这里的tokenization就是k-mer 表示(广泛应用于分析 DNA 序列),
例如,DNA 序列“ATGGCT”可以被分词:
4个 3-mer:{ATG, TGG, GGC, GCT}
2个 5-mer:{ATGGC, TGGCT}
不同的 k 会导致 DNA 序列的不同分词,比如说DNABERT-3, DNABERT-4, DNABERT-5, DNABERT-6等等。
对于 DNABERT-k,它的词汇表由所有 k-mer 的排列以及 5 个特殊标记组成:
[CLS]代表分类标记
[PAD]代表填充标记
[UNK]代表未知标记
[Mask]表示被掩盖的 token
因此,DNABERT-k 的词汇中有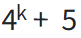 个 token。
个 token。
2,DNABERT-2: Efficient Foundation Model and Benchmark For Multi-Species Genome (2023)
DNABERT 的一项局限性:k-mer 分词导致预训练期间信息泄露和整体计算效率低下。
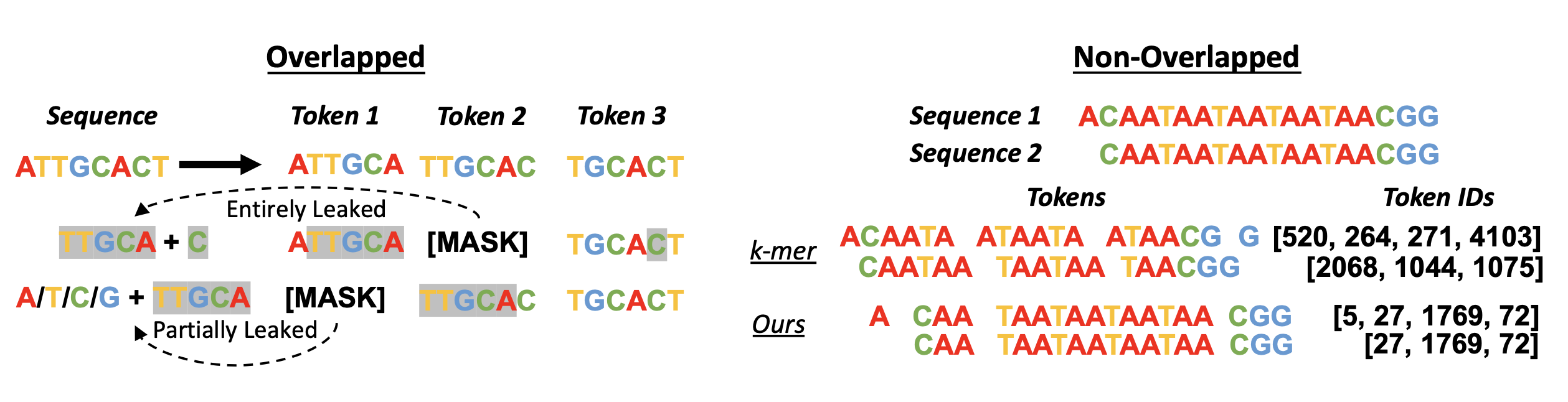
所以改进的地方在于:
用字节对编码(BPE)替换 k-mer 分词;
DNABERT-2 通过用带有线性偏差的注意力机制(ALiBi)替换学习位置嵌入,克服了 DNABERT 的限制,从而消除了输入长度的限制。
在分词过程中,采用窗口大小为 k、步长为 t 的滑动窗口将原始基因组序列转换为一系列 k-mer。
这里,步长 t 设置为 1 或 k,其中 1 代表 k-mer 分词的重叠版本,另一个代表非重叠版本。
但事实上,两个版本都不够理想。
(1)Overlapping:
对于长度为 L 的输入,其分词序列由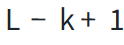 个长度为 k 的标记组成。这导致分词序列具有相当大的冗余,长度几乎等同于原始序列,从而降低了计算效率。
个长度为 k 的标记组成。这导致分词序列具有相当大的冗余,长度几乎等同于原始序列,从而降低了计算效率。
(2)Non-overlapping:
尽管其通过将序列长度减少 k 倍的优势,但存在一个显著的样本效率问题。
这种轻微的偏移导致标记化输出发生剧烈变化,这使得难以将相同或近乎相同的输入的独特表示进行对齐。
(3)Subword tokenization 框架
所以,DNABERT-2 采用了 SentencePiece [Kudo 和 Richardson, 2018] 与字节对编码(BPE)[Sennrich 等,2016] 来对 DNA 序列进行分词。
它基于字符的共现频率学习一个固定大小的、可变长度的词汇表。

3,Nucleotide Transformer(Dalla-Torre et al. 2023)
使用 6-mer 标记作为序列长度(最长 6kb)和嵌入大小之间的权衡,并且与其他标记长度相比,它实现了最高的性能。
相关文章:

LLM大语言模型系列1-token
一,什么是token 1,什么是token: 参考:https://en.wikipedia.org/wiki/Token https://en.wikipedia.org/wiki/Lexical_analysis#Token 我们有很多描述token的解释,建议是汇总在一起进行综合理解: 1️⃣To…...

数据清洗-案例
四)实现代码 在之前的项目的基础之上,重写去写一个包,并创建两个类:WebLogMapper和WebLogDriver类。 (1)编写WebLogMapper类 package com.root.mapreduce.weblog; import java.io.IOException; import…...

项目的部署发布和访问的流程
首先打包项目: npm run build 打包后的文件会生成在dist文件夹中,将dist文件夹需要放到服务器里面,意味着服务有dist静态资源(index.html,css/,js/,img/) 用户在浏览器输入域名&am…...

人工智能、机器学习、深度学习定义与联系
人工智能、机器学习、深度学习定义与联系目录 一、人工智能(Artificial Intelligence, AI)1、定义2、特征:3、关键阶段的概述:1. 萌芽期(1940s–1950s):理论奠基2. 形成期(1950s–19…...
集成到应用架构》学习心得)
Gartner《如何将生成式人工智能(GenAI)集成到应用架构》学习心得
针对软件架构师、技术专业人士如何更好的把 GenAI 如何融入解决方案,提升用户体验、生产力并带来差异化成果的趋势,Gartner发布了《Integrating GenAI Into Your Application Architecture》研究报告。 报告首先介绍了 GenAI 的发展背景,指出其已成为主流趋势,大型语言模型…...

vscode中Debug c++
在vscode中Debug ros c程序 1 在Debug模式下编译 如果用命令行catkin_make,在输入catkin_make时加上一个参数: catkin_make -DCMAKE_BUILD_TYPEDebug 或者直接修改CMakelist.txt,添加以下代码: SET(CMAKE_BUILD_TYPE "D…...
--特殊工具与技术-完结篇)
c++从入门到精通(六)--特殊工具与技术-完结篇
特殊工具与技术-完结篇 控制内存分配 重载new和delete: 如果应用程序希望控制内存分配的过程,则它们需要定义自己的operator new函数和operator delete函数。当自定义了全局的operator new函数和operator delete函数后,我们就担负起了控…...

原型链的详细解释及使用场景
一、原型链的概念 原型链是JavaScript实现继承和属性共享的核心机制。每个对象都有一个内部属性[[Prototype]](可通过proto访问),指向其原型对象。当访问对象的属性时,若对象自身不存在该属性,则会沿着原型链向上查找…...

OpenCL C C++核心对象与属性对比
基础对象对应关系 OpenCL C 对象OpenCL C 对应类型创建函数示例cl::Platformcl_platform_idclGetPlatformIDs(1, &platform, NULL)cl::Devicecl_device_idclGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL)cl::Contextcl_contextclCreateContext(NULL,…...

Azure 机器学习初学者指南
Azure 机器学习初学者指南 在我们的初学者指南中探索Azure机器学习,了解如何设置、部署模型以及在Azure生态系统中使用AutoML & ML Studio。Azure 机器学习 (Azure ML) 是一项全面的云服务,专为机器学习项目生命周期而设计&am…...

一文读懂----Docker 常用命令
Docker 是一个强大的容器化平台,广泛用于开发、测试和生产环境。通过 Docker 命令行工具(CLI),我们可以轻松管理容器、镜像、网络和卷等资源。本文将详细介绍 Docker 的常用命令,带你熟练掌握 Docker 的核心操作命令。…...

React 19 中的useRef得到了进一步加强。
文章目录 前言一 useRef 的核心原理1.1 为什么需要 useRef?1.2 基本语法 二、React 19 中 useRef 的常见用法2.1 访问 DOM 元素2.2 保存跨渲染的数据 三、React 19 中的改进ref 作为一个属性案例演示(触发子组件焦点事件) 注意 总结 前言 在 React 的世界里&#x…...
”)
报错System.BadImageFormatException:“试图加载格式不正确的程序。 (异常来自 HRESULT:0x8007000B)”
this.hWindowControl_Player new HalconDotNet.HWindowControl();报错System.BadImageFormatException:“试图加载格式不正确的程序。 (异常来自 HRESULT:0x8007000B)” System.BadImageFormatException 错误通常是由于平台架构不匹配导致的。它意味着你正在尝试在一个平台上加…...

【图像处理基石】OpenCV中都有哪些图像增强的工具?
OpenCV 图像增强工具系统性介绍 OpenCV 提供了丰富的图像增强工具,主要分为以下几类: 亮度与对比度调整 线性变换(亮度/对比度调整)直方图均衡化自适应直方图均衡化(CLAHE) 滤波与平滑 高斯滤波中值滤波双…...
的介绍)
Nordic 的RTC(Real-time counter)的介绍
目录 概述 1 RTC(Real-time counter)介绍 1.1 框架结构 1.2 时钟源 1.3 分辨率与溢出和precaler 2 寄存器功能介绍 2.1 计数寄存器 2.2 事件控制功能 2.3 比较功能 2.4 读取COUNTER寄存器 概述 本文主要介绍Nordic 的RTC(Real-time…...

【数据结构】2-2-2 顺序表的插入删除查找
数据结构知识点合集 知识点 顺序表的插入 ListInsert(&L,i,e):插入操作。在表L中的第i个位置上插入指定元素e。 /*在顺序表L的第i个位置插入元素e*/ bool ListInsert(SqList &L,int i,int e) {/*判断i的范围是否有效*/if(i<0||i>L.length)return fals…...
动态API)
【免杀】C2免杀技术(五)动态API
一、什么是动态API 在C2免杀领域中,“动态API” 主要指的是绕过静态检测的一种技术手段,其本质是运行时动态解析和调用Windows API函数,而不是在程序编译阶段就明确引用这些API。这种方式可以有效躲避静态分析工具和杀软的签名识别。 为什么…...

77.数据大小端赋值的差异与联系
上述赋值a定义为大端模式 a[7] a[6] a[5] a[4] a[3] a[2] a[1] a[0] 上述赋值b定义为小端模式 a[0] a[1] a[2] a[3] a[4] a[5] a[6] a[7] 因为5的二进制数…...

GO语言语法---switch语句
文章目录 基本语法1. 特点1.1 不需要break1.2 表达式可以是任何类型1.3 省略比较表达式1.4 多值匹配1.5 类型switch1.6 case穿透1.7 switch后直接声明变量1.7.1 基本语法1.7.2 带比较表达式1.7.3 不带比较表达式1.7.4 结合类型判断 1.8 switch后的表达式必须与case语句中的表达…...

PH热榜 | 2025-05-16
1. Tolt 标语:专为SaaS初创公司打造的一体化联盟营销软件 介绍:Tolt帮助SaaS初创公司启动和发展联盟计划。它提供自动化的支付、欺诈保护、与多种平台的无缝集成(包括Stripe、Paddle和Chargebee),还有一个品牌化的联…...

Java正则表达式:从基础到高级应用全解析
Java正则表达式应用与知识点详解 一、正则表达式基础概念 正则表达式(Regular Expression)是通过特定语法规则描述字符串模式的工具,常用于: 数据格式验证文本搜索与替换字符串分割模式匹配提取 Java通过java.util.regex包提供支持,核心类…...

iOS 初识RunLoop
iOS 初识RunLoop 文章目录 iOS 初识RunLoopRunLoop的概念RunLoop的功能RunLoop和线程的关系RunLoop的结构ModeObserverTimer 和 source小结 RunLoop的核心RunLoop的流程RunLoop的应用AutoreleasePool响应触控事件刷新界面常驻线程网络请求NSTimer 和 CADisplayLinkNSTimerGCDTi…...

备忘录模式
1.意图 备忘录模式是一种行为型设计模式,允许在不破坏封装的特性前提,获取并保存一个对象的内部状态,后续需要时恢复该状态。核心是将对象的状态存储在一个独立的备忘录对象中,并在需要时恢复。 2.模式类型 行为型对象设计模式 …...

UCOS 嵌入式操作系统
UCOS 嵌入式操作系统是一款在嵌入式领域应用广泛且具有重要地位的实时操作系统,以下是对它的详细介绍。 发展历程 初始版本诞生:UCOS 最早由美国嵌入式系统专家 Jean J. Labrosse 于 1991 年开始开发。当时他在项目中需要一个合适的实时操作系统&#…...

redis读写一致问题
title: redis读写一致问题 date: 2025-05-18 11:11:31 tags: redis categories: redis的问题方案 Redis读写一致问题 条件: 数据库此时的数据为10,redis此时的数据也为10 业务流程: 操作数据库使得数据库的数据为20,删除redis里面的数据保证读写一致 先删缓存…...

Redis实现分布式锁的进阶版:Redisson实战指南
一、为什么选择Redisson? 在上一篇文章中,我们通过Redis原生命令实现了分布式锁。但在实际生产环境中,这样的基础方案存在三大痛点: 锁续期难题:业务操作超时导致锁提前释放不可重入限制:同一线程无法重复…...
)
标准库、HAl库和LL库(PC13初始化)
标准库 (Standard Peripheral Library) c #include "stm32f10x.h"void GPIO_Init_PC13(void) {GPIO_InitTypeDef GPIO_InitStruct;RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOC, ENABLE);GPIO_InitStruct.GPIO_Pin GPIO_Pin_13;GPIO_InitStruct.GPIO_Mode GPIO_…...

第二章:安卓端启动流程详解与疑难杂症调试手册
想让一个安卓项目跑起来,从表面看无非就是:双击打开、连接真机、点击运行。 但是到了互动娱乐组件项目里,事情就变成了:点击运行→等待→黑屏→白屏→强制退出→LogCat爆炸→你怀疑人生。 本章就来系统性解决几个问题࿱…...

备份C#的两个类
GuestIP依赖项: using System.Data.SQLite; //这是第三方依赖项,要从nuget下载 static class GuestIP {public static void ReadLastGuestIP(string constr "Data Sourceguestip_log.db;"){using (var connection new SQLiteConnection(co…...
)
通过串口设备的VID PID动态获取串口号(C# C++)
摘要 本篇文章主要介绍分别通过C#和C++使用设备VID PID如何动态获取COM口 目录 1 简述 2 VID PID查看方式 3 C#实现通过串口设备的VID PID动态获取串口号 3.1 辅助类实现 3.2 调用实例 4 C++实现通过串口设备的VID PID动态获取串口号 4.1 辅助类实现 4.2 调用实例 1 简…...
:const修饰指针、野指针、assert断言、指针的使用和传址调用)
C语言指针深入详解(二):const修饰指针、野指针、assert断言、指针的使用和传址调用
目录 一、const修饰指针 (一)const修饰变量 (二)const 修饰指针变量 二、野指针 (一)野指针成因 1、指针未初始化 2、指针越界访问 3、指针指向的空间释放 (二)如何规避野指…...

《P5283 [十二省联考 2019] 异或粽子》
题目描述 小粽是一个喜欢吃粽子的好孩子。今天她在家里自己做起了粽子。 小粽面前有 n 种互不相同的粽子馅儿,小粽将它们摆放为了一排,并从左至右编号为 1 到 n。第 i 种馅儿具有一个非负整数的属性值 ai。每种馅儿的数量都足够多,即小粽…...

C#自定义扩展方法 及 EventHandler<TEventArgs> 委托
有自定义官方示例链接: 如何实现和调用自定义扩展方法 - C# | Microsoft Learn 1.静态类 2.静态方法 3.第一参数固定为this 要修改的类型,后面才是自定的参数 AI给出的一个示例:没有自定义参数 、有自定义参数的 using System; using System.Colle…...

oracle 资源管理器的使用
14.8.2资源管理器的使用 资源管理器控制CPU资源使用说明: 第一种分配方法:EMPHASIS CPU 分配方法确定在资源计划中对不同使用者组中的会话的重视程度。CPU占用率的分配级别为从1 到8,级别1 的优先级最高。百分比指定如何将CPU 资源分配给每…...
Java集合框架源码深度解析)
(二十一)Java集合框架源码深度解析
一、集合框架概述 Java集合框架(Java Collections Framework, JCF)是Java语言中用于存储和操作数据集合的一套标准架构。它提供了一组接口、实现类和算法,使开发者能够高效地处理各种数据结构。 1.1 集合框架的历史演变 在Java 1.2之前,Java只有几种简…...

spark数据的提取和保存
Spark数据提取和保存 一、数据提取(读取数据) 1. 读取文件(文本、CSV、JSON等) scala // 读取文本文件 val textData spark.read.text("路径/文件.txt") // 读取CSV文件(带表头) val csvD…...

Graphics——基于.NET 的 CAD 图形预览技术研究与实现——CAD c#二次开发
一、Graphics 类的本质与作用 Graphics 是 .NET 框架中 System.Drawing 命名空间下的核心类,用于在二维画布(如 Bitmap 图像)上绘制图形、文本或图像。它相当于 “绘图工具”,提供了一系列方法(如 DrawLine、FillElli…...

vue3_flask实现mysql数据库对比功能
实现对mysql中两个数据库的表、表结构、表数据的对比功能, 效果如下图 基础环境请参考 vue3flasksqlite前后端项目实战 代码文件结构变化 api/ # 后端相关 ├── daos/ │ ├── __init__.py │ └── db_compare_dao.py # 新增 ├── routes/ │ ├── _…...

【数据结构】2-3-1单链表的定义
数据结构知识点合集 知识点 单链表存储结构 优点:不要求大片连续空间,改变容量方便;缺点:不可随机存取,要耗费一定空间存放指针 /*单链表节点定义*/ typedef struct LNode{ElemType data;struct LNode *next; }LNo…...

面试题总结一
第一天 1. 快速排序 public class QuickSort {public static void quickSort(int[] arr, int low, int high) {if (low < high) {// 分区操作,获取基准元素的最终位置int pivotIndex partition(arr, low, high);// 递归排序基准元素左边的部分quickSort(arr, …...

Ubuntu24.04下安装ISPConfig全过程记录
今天在网上看到ISPConfig,觉得不错,刚好手里又有一台没用的VPS,就顺手安装一个玩玩。具体安装步骤如下: 一、配置服务器hosts及hostname 【安装时候需要检查】 使用root账号登录VPS后 先安装vim编辑器,然后编辑hosts࿰…...

【NGINX】 -10 keepalived + nginx + httpd 实现的双机热备+ 负载均衡
文章目录 1、主架构图1.1 IP地址规划 2、web服务器操作3、配置nginx服务器的负载均衡4、配置keepalived4.1 master4.1 backup 5、测试双机热备5.1 两台keepalived服务器均开启5.2 模拟master节点故障 1、主架构图 1.1 IP地址规划 服务器IP地址web1192.168.107.193web2192.168.…...

NC016NC017美光固态芯片NC101NC102
NC016NC017美光固态芯片NC101NC102 在存储技术的演进历程中,美光科技的NC016、NC017、NC101与NC102系列固态芯片,凭借其技术创新与市场适应性,成为行业关注的焦点。本文将从技术内核、产品性能、行业动向、应用场景及市场价值五个维度&#…...
:fstream的一些成员函数)
C++(22):fstream的一些成员函数
目录 1 遍历读取文件 1.1 eof()方法 2 读取文件大小 2.1 seekg() 2.2 tellg() 2.3 代码实例 3 存取文字 3.1 read() 3.2 write() 3.3 代码实例 3.3.1 存取文字 3.3.2 特殊方法存储 3.3.3 特殊方法读取 4 重载的输入输出 4.1 重载的输出 << 4.2 重载的输…...

【网络】Wireshark练习3 analyse DNS||ICMP and response message
ip.addr 172.16.0.100 && ip.addr 172.16.0.5 && (dns || icmp) 包号 22–31 之所以被选中,是因为在整个抓包文件里,与执行 ping cat.inx251.edu.au 这一事件相关的所有报文,恰好连续出现在第 22 到第 31 条记录中。具体分…...

GBS 8.0服装裁剪计划软件在线试用
1、全新升级内核8.0,分床更合理,铺布床数更少; 2、支持SS AUTONESTER排料引擎切换 3、支持ASTM AAMA及国产CAD(如布衣)导出的DXF,Prj文件等 4、核心引擎优化 拖料优化 省料优化 5、经实战对比人工&…...

顺 序 表:数 据 存 储 的 “ 有 序 阵 地 ”
顺 序 表:数 据 存 储 的 “ 有 序 阵 地 ” 线 性 表顺 序 表 - - - 顺 序 存 储 结 构顺 序 表 的 操 作 实 现代 码 全 貌 与 功 能 介 绍顺 序 表 的 功 能 说 明代 码 效 果 展 示代 码 详 解SeqList.hSeqList.ctest.c 总 结 💻作 者 简 介…...
实战篇完结)
#Redis黑马点评#(七)实战篇完结
目录 一 达人探店 1 发布探店笔记 2 查看探店笔记 3 点赞功能 编辑 4 点赞排行榜(top5) 编辑 二 好友关注 1 关注与取关 2 共同关注 3 Feed流实现关注推送 4 实现滚动分页查询 三 附近商店 1 GEO数据结构 2 附近商户搜索功能 四 用户…...
)
初始C++:类和对象(中)
概述:本篇博客主要介绍类和对象的相关知识。 1. 类的默认成员函数 默认成员函数就是用户没有显示实现,编译器会自动生成的成员函数称为默认成员函数。一个类,在不写任何代码的情况下编译器会默认生成以下六个默认函数,在六个默认…...

Java开发经验——阿里巴巴编码规范实践解析3
摘要 本文深入解析了阿里巴巴编码规范中关于错误码的制定与管理原则,强调错误码应便于快速溯源和沟通标准化,避免过于复杂。介绍了错误码的命名与设计示例,推荐采用模块前缀、错误类型码和业务编号的结构。同时,探讨了项目错误信…...