OpenCV-图像分割
实验1
实验内容
上述代码通过使用OpenCV和Matplotlib库来执行以下操作:
- 读取名为’kt.jpg’的图像文件,并存储在变量img中。
- 将图像img转换为灰度图像,将其存储在变量gray中。
- 使用cv2.threshold函数对灰度图gray进行阈值化处理,生成不同类型的二值图像。
a. 使用cv2.THRESH_BINARY类型,将灰度值小于175的像素点设置为0,灰度值大于等于175的像素点设置为255,结果存储在变量thresh1中。
b. 使用cv2.THRESH_BINARY_INV类型,将灰度值小于175的像素点设置为255,灰度值大于等于175的像素点设置为0,结果存储在变量thresh2中。
c. 使用cv2.THRESH_TRUNC类型,将灰度值小于175的像素点保持不变,大于175的像素点设置为175,结果存储在变量thresh3中。
d. 使用cv2.THRESH_TOZERO类型,将灰度值小于175的像素点设置为0,大于等于175的像素点保持不变,结果存储在变量thresh4中。
e. 使用cv2.THRESH_TOZERO_INV类型,将灰度值小于175的像素点保持不变,大于等于175的像素点设置为0,结果存储在变量thresh5中。 - 创建一个包含标题的列表titles,用于在绘图时显示每个图像的名称。
- 创建一个包含所有图像的列表images,以便在循环中访问图像数据。
- 使用循环遍历每个图像,并使用plt.subplot将其显示在一个2行3列的子图中。
- 设置子图的标题为对应的titles中的名称。
- 禁用x轴和y轴的刻度。
- 使用plt.show()显示所有图像。
代码注释
import cv2
import matplotlib.pyplot as pltimg = cv2.imread('kt.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 将灰度图gray中灰度值小于175的点置0,灰度值大于175的点置255
ret, thresh1 = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 将灰度图gray中灰度值小于175的点置255,灰度值大于175的点置0
ret, thresh2 = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
ret, thresh3 = cv2.threshold(gray, 127, 255, cv2.THRESH_TRUNC)
ret, thresh4 = cv2.threshold(gray, 127, 255, cv2.THRESH_TOZERO)
ret, thresh5 = cv2.threshold(gray, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['img', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')plt.title(titles[i])plt.xticks([]), plt.yticks([])
plt.show()
功能说明
该代码会将原始图像转换为灰度图像,并通过不同类型的阈值化操作生成多幅图像。每幅图像的标题和显示方式都会在绘图中显示。
效果展示
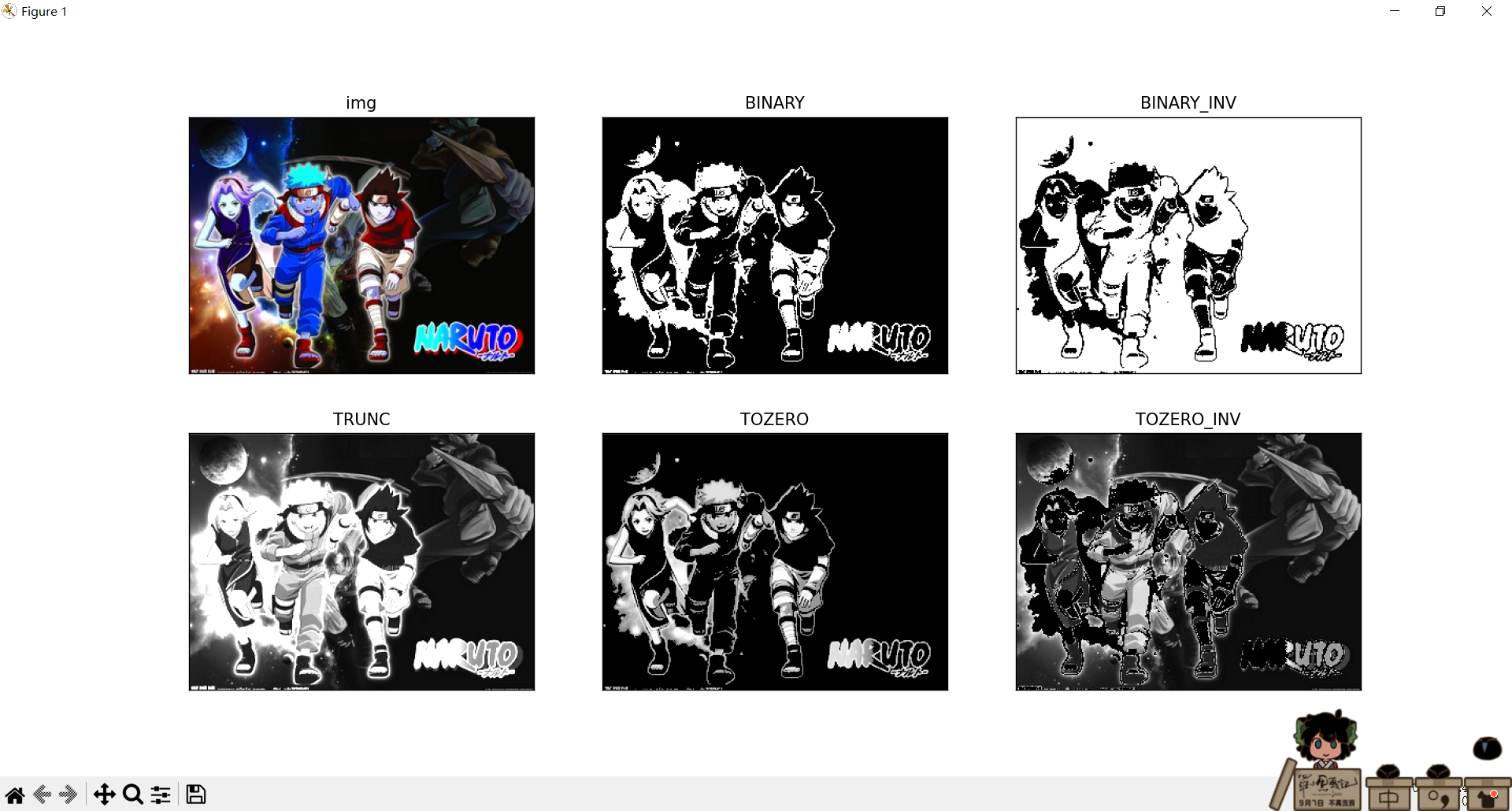
效果分析比较
通过不同类型的阈值化操作,可以实现对图像的不同程度的二值化处理。具体效果如下:
- BINARY:将灰度值小于175的像素点设置为0,大于等于175的像素点设置为255,产生黑白二值图像。
- BINARY_INV:将灰度值小于175的像素点设置为255,大于等于175的像素点设置为0,产生反相的黑白二值图像。
- TRUNC:将灰度值小于175的像素点保持不变,大于175的像素点设置为175。
- TOZERO:将灰度值小于175的像素点设置为0,大于等于175的像素点保持不变。
- TOZERO_INV:将灰度值小于175的像素点保持不变,大于等于175的像素点设置为0。
结论
通过不同类型的阈值化操作,可以根据具体需求将图像进行二值化处理,以突出或过滤特定灰度范围的图像特征。这些操作可以在图像处理和分析中起到重要的作用,例如图像分割、轮廓提取等应用场景。
实验2
实验内容
代码使用OpenCV库对图像进行自适应阈值处理。
代码注释
import cv2 as cvsrcImage = cv.imread('kt.jpg')
srcGray = cv.cvtColor(srcImage, cv.COLOR_BGR2GRAY) # 【2】灰度转换cv.imshow("Src Image", srcImage)
cv.imshow("Gray Image", srcGray)
# 【3】初始化相关变量
# 初始化自适应阈值参数
maxVal = 255
blockSize = 3 # 取值3、5、7....等
constValue = 10
# 自适应阈值算法
adaptiveMethod = 0 # 0:ADAPTIVE_THRESH_MEAN_C,1:ADAPTIVE_THRESH_GAUSSIAN_C
thresholdType = 1 # 阈值类型,0:THRESH_BINARY,1:THRESH_BINARY_INV
# ---------------【4】图像自适应阈值操作-------------------------
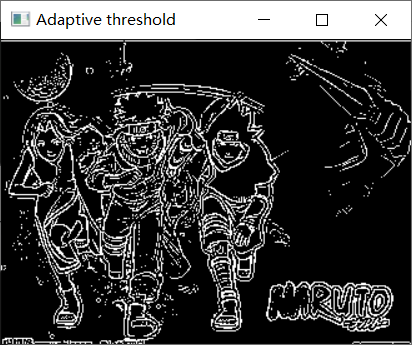
dstImage = cv.adaptiveThreshold(srcGray, maxVal, adaptiveMethod, thresholdType, blockSize, constValue);
cv.imshow("Adaptive threshold", dstImage)
cv.waitKey(0)
功能说明
- 通过
cv.imread读取名为’kt.jpg’的图像,将其存储在srcImage中。 - 使用
cv.cvtColor将原始图像转换为灰度图像,存储在srcGray中。 - 初始化自适应阈值处理的相关参数,包括最大阈值(
maxVal)、块大小(blockSize)、常数值(constValue)、自适应方法(adaptiveMethod)和阈值类型(thresholdType)。 - 使用
cv.adaptiveThreshold函数对灰度图像进行自适应阈值处理,将结果存储在dstImage中。
效果展示
Src Image
Gray Image
Adaptive threshold
效果分析比较
- 自适应阈值处理是根据图像局部区域的灰度情况来确定阈值的一种方法,相比全局阈值,更适应图像局部的变化。
adaptiveMethod为0表示使用均值自适应阈值算法(ADAPTIVE_THRESH_MEAN_C),为1表示使用高斯自适应阈值算法(ADAPTIVE_THRESH_GAUSSIAN_C)。thresholdType为0表示二值化类型为THRESH_BINARY,为1表示二值化类型为THRESH_BINARY_INV。blockSize表示每个块的大小,较小的块大小适用于较小的图像细节,但也可能受到噪声的影响;较大的块大小适用于平滑的图像区域。constValue是用于调整阈值的常数值。
结论
自适应阈值处理能够有效地处理图像中局部灰度变化较大的情况,通过动态调整阈值,使得不同区域的阈值适应局部特征。在图像处理中,选择合适的自适应阈值方法和参数对于获取清晰的二值图像是很重要的。在这个例子中,通过改变blockSize、constValue、adaptiveMethod和thresholdType等参数,可以观察到不同的效果。
实验3
实验内容
使用OpenCV库对图像进行分割和阈值处理的示例
代码注释
import cv2 as cvsrcImage = cv.imread('kt.jpg')
img = cv.cvtColor(srcImage, cv.COLOR_BGR2GRAY) # 【2】灰度转换
cv.imshow("Src Image", srcImage);
img = cv.medianBlur(img, 5); # 中值滤波
ret, dst1 = cv.threshold(img, 127, 255, cv.THRESH_BINARY); # 固定阈值分割
# 自适应阈值分割,邻域均值
dst2 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 11, 2);
# 自适应阈值分割,高斯邻域
dst3 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, 11, 2);cv.imshow("dst1", dst1);
cv.imshow("dst2", dst2);
cv.imshow("dst3", dst3);
cv.imshow("img", img);
cv.waitKey(0);
功能说明
- 使用
cv.imread读取名为’kt.jpg’的图像,将其存储在srcImage中。 - 使用
cv.cvtColor将原始图像转换为灰度图像,将结果存储在img中。 - 使用
cv.medianBlur对灰度图像进行中值滤波,该步骤用于去除图像中的噪声。 - 使用
cv.threshold对滤波后的图像进行固定阈值分割,将结果存储在dst1中。阈值设定为127,大于阈值的像素值设为255,小于等于阈值的像素值设为0。 - 使用
cv.adaptiveThreshold对滤波后的图像进行自适应阈值分割,方法是邻域均值法。将结果存储在dst2中。阈值根据图像的局部区域进行计算,具体阈值计算方式是取邻域中的像素平均值加上一个常数(这里是2)。 - 使用
cv.adaptiveThreshold对滤波后的图像进行自适应阈值分割,方法是高斯邻域法。将结果存储在dst3中。阈值根据图像的局部区域进行计算,具体阈值计算方式是取邻域中的像素加权平均值加上一个常数(这里是2)。
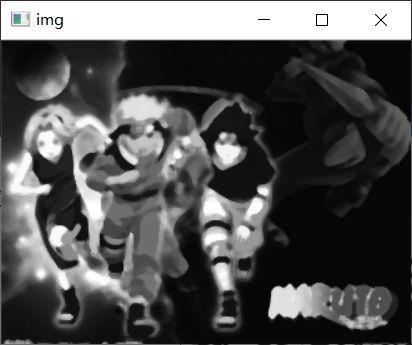
效果展示
Src Image
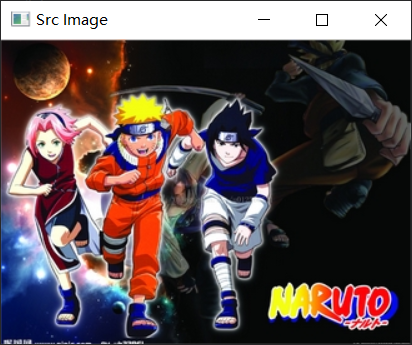
dst1
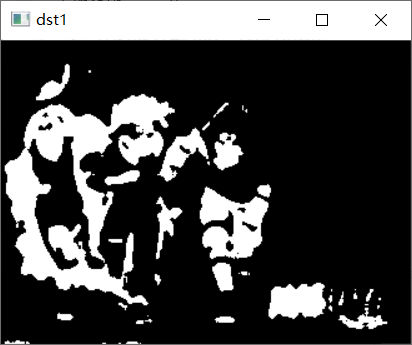
dst2

dst3

img
效果分析比较
- 固定阈值分割使用的是固定的全局阈值。根据设定的阈值进行二值分割,可以直接将图像中较亮或较暗的部分分割出来。
- 自适应阈值分割根据图像局部的特征进行阈值的计算。对于不同的局部区域,根据邻域中的像素值进行调整,适应不同的光照条件和局部变化。
- 邻域均值法:使用邻域中像素的平均值作为阈值。
- 高斯邻域法:使用邻域中像素加权平均值作为阈值,权重由高斯核函数计算得出,离中心像素越近的像素权重越大
结论
- 不同的阈值分割方法适用于不同的图像和应用场景。固定阈值适用于图像中有明显亮暗差异的分割;而自适应阈值适用于不同光照条件下的图像分割。
- 中值滤波可以在分割前对图像进行去噪处理,有助于提升分割的准确性。
- 通过调整阈值、邻域大小和常数等参数,可以对分割结果进行调整,以满足不同的需求和图像特点。
实验4
实验内容
使用OpenCV库对图像进行颜色分离的示例
代码注释
import cv2 as cv
import numpy as npdef color_seperate(image):hsv = cv.cvtColor(image, cv.COLOR_BGR2HSV) # 对目标图像进行色彩空间转换lower_hsv = np.array([100, 43, 46]) # 设定蓝色下限upper_hsv = np.array([124, 255, 255]) # 设定蓝色上限# 依据设定的上下限对目标图像进行二值化转换mask = cv.inRange(hsv, lowerb=lower_hsv, upperb=upper_hsv)# 将二值化图像与原图进行“与”操作;实际是提取前两个frame 的“与”结果,然后输出mask 为1的部分dst = cv.bitwise_and(src, src, mask=mask) # 注意:括号中要写mask=xxxcv.imshow('result', dst) # 输出src = cv.imread('test.jpg') # 导入目标图像,获取图像信息
color_seperate(src)
cv.imshow('image', src)
cv.waitKey(0)
cv.destroyAllWindows()
功能说明
- 使用
cv.cvtColor将原始图像从BGR色彩空间转换为HSV色彩空间,将结果保存在hsv中。 - 设定颜色的下限
lower_hsv和上限upper_hsv,表示在该颜色范围内的像素会被保留,其他颜色的像素则被过滤。 - 使用
cv.inRange根据设定的上下限对图像进行二值化,将落在颜色范围内的像素设置为白色(255),其他像素设置为黑色(0),结果保存在mask中。 - 使用
cv.bitwise_and将二值化图像与原始图像进行按位与操作,提取颜色范围内的部分,结果保存在dst中。 - 使用
cv.imshow展示结果图像dst和原始图像src。 - 使用
cv.waitKey等待用户按下键盘按键。 - 使用
cv.destroyAllWindows关闭所有图像窗口。
效果展示
result

效果分析比较
根据设定的颜色下限和上限,将图像中在颜色范围内的部分保留下来,其他部分被过滤掉。这样做可以聚焦于感兴趣的颜色区域,突出图像中特定颜色的部分。
结论
颜色分离可以用于目标检测、图像分割等应用场景。通过设定不同的颜色下限和上限,可以实现对不同颜色的分离。需要根据具体的实际需求,调整颜色范围的设定,以满足对特定颜色的提取要求。
基于阈值化的分割方法
实验内容
基于阈值化的分割方法
此方法实质是利用图像的灰度直方图信息得到用于分割的阈值
Ostu 法,最频值法( Mode 法),·矩量保持法
用以上三种阈值分割方法的实现算法,代码实现并进行结果对比##
代码
import cv2 as cv
import numpy as np# Otsu 法 - 通过自动确定阈值进行图像分割
def otsu_threshold(image):# 转换图像为灰度gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)# 使用 Otsu 方法获取阈值和分割结果_, otsu_result = cv.threshold(gray, 0, 255, cv.THRESH_BINARY + cv.THRESH_OTSU)return otsu_result# 最频值法 (Mode 法) - 使用灰度直方图中的众数作为阈值
def mode_threshold(image):# 转换图像为灰度gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)# 计算灰度直方图hist = cv.calcHist([gray], [0], None, [256], [0, 256])# 找到直方图中的众数(Mode)mode = np.argmax(hist)# 使用众数作为阈值进行分割_, mode_result = cv.threshold(gray, mode, 255, cv.THRESH_BINARY)return mode_result# 矩量保持法 - 通过保持灰度矩量的方法确定阈值
def moment_preserving_threshold(image):# 转换图像为灰度gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)# 计算灰度直方图hist = cv.calcHist([gray], [0], None, [256], [0, 256])# 计算灰度矩量total_pixels = sum(hist)sum_moments = [(idx + 1) * hist[idx] for idx in range(len(hist))]sum_moments = np.sum(sum_moments)# 计算阈值threshold = int(sum_moments / total_pixels)# 使用阈值进行分割_, moment_preserving_result = cv.threshold(gray, threshold, 255, cv.THRESH_BINARY)return moment_preserving_result# 读取图像
src = cv.imread('test.jpg')# 调用各个阈值分割方法
otsu_result = otsu_threshold(src)
mode_result = mode_threshold(src)
moment_preserving_result = moment_preserving_threshold(src)# 显示原始图像和分割结果
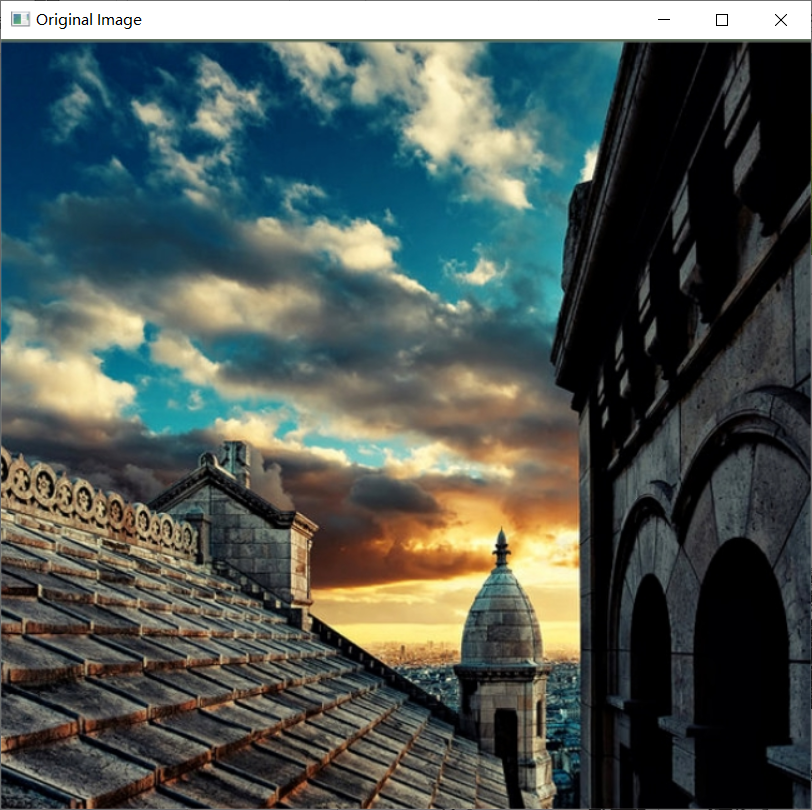
cv.imshow('Original Image', src)
cv.imshow('Otsu Result', otsu_result)
cv.imshow('Mode Result', mode_result)
cv.imshow('Moment Preserving Result', moment_preserving_result)# 等待按键
cv.waitKey(0)
cv.destroyAllWindows()效果展示



效果比较分析
Otsu方法、最频值法和矩量保持法是图像分割中常用的三种方法,它们各自有不同的原理和适用场景。下面是对它们的简要比较:
-
Otsu方法:
- 原理: Otsu方法基于图像的灰度直方图,通过最大类间方差的方法自动确定一个灰度阈值,将图像分成两个类别(前景和背景)。
- 优点: 对于具有双峰直方图的图像效果好,自动选择阈值,无需人工干预。
- 缺点: 在直方图单峰的情况下可能不太准确。
-
最频值法:
- 原理: 最频值法通过寻找灰度直方图中的峰值,选择峰值对应的灰度值作为分割阈值。
- 优点: 简单直观,对于单峰直方图的图像效果较好。
- 缺点: 对于复杂场景的图像可能不够灵活,适用性有限。
-
矩量保持法:
- 原理: 矩量保持法利用图像的矩特性,通过最小化目标函数实现分割,以保持目标区域的矩特性。
- 优点: 对于复杂场景和具有多个区域的图像效果较好,能够保持目标的形状特性。
- 缺点: 计算相对较复杂,需要对图像的矩进行处理。
结论
综合来看,选择哪种方法取决于图像的特性以及具体的分割需求。如果图像具有明显的双峰直方图,Otsu方法可能更合适;如果图像简单且直方图单峰,最频值法可能更适用;而对于需要保持目标形状特性的场景,矩量保持法可能是一个更好的选择。通常,在实际应用中,需要根据具体情况进行实验和调整,选择最适合的分割方法。
指令
基于聚类的分割方法
K-Means算法
代码实现
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 计算欧拉距离
def calcDis(dataSet, centroids, k):clalist = []for data in dataSet:diff = np.tile(data, (k,1)) - centroids # 相减 (np.tile(a,(2,1))就是把a先沿x轴复制1倍,即没有复制,仍然是 [0,1,2]。 再把结果沿y方向复制2倍得到array([[0,1,2],[0,1,2]]))squaredDiff = diff ** 2 # 平方squaredDist = np.sum(squaredDiff, axis=1) # 和 (axis=1表示行)distance = squaredDist ** 0.5 # 开根号clalist.append(distance)clalist = np.array(clalist) # 返回一个每个点到质点的距离len(dateSet)*k的数组return clalist# 计算质心
def classify(dataSet, centroids, k):# 计算样本到质心的距离clalist = calcDis(dataSet, centroids, k)# 分组并计算新的质心minDistIndices = np.argmin(clalist, axis=1) # axis=1 表示求出每行的最小值的下标newCentroids = pd.DataFrame(dataSet).groupby(minDistIndices).mean() # DataFramte(dataSet)对DataSet分组,groupby(min)按照min进行统计分类,mean()对分类结果求均值newCentroids = newCentroids.values# 计算变化量changed = newCentroids - centroidsreturn changed, newCentroids# 使用k-means分类
def kmeans(dataSet, k):# 随机取质心centroids = random.sample(dataSet, k)# 更新质心 直到变化量全为0changed, newCentroids = classify(dataSet, centroids, k)while np.any(changed != 0):changed, newCentroids = classify(dataSet, newCentroids, k)centroids = sorted(newCentroids.tolist()) # tolist()将矩阵转换成列表 sorted()排序# 根据质心计算每个集群cluster = []clalist = calcDis(dataSet, centroids, k) # 调用欧拉距离minDistIndices = np.argmin(clalist, axis=1)for i in range(k):cluster.append([])for i, j in enumerate(minDistIndices): # enymerate()可同时遍历索引和遍历元素cluster[j].append(dataSet[i])return centroids, cluster# 创建数据集
def createDataSet():return [[1, 1], [1, 2], [2, 1], [2, 3], [6, 4], [6, 3], [5, 4], [5, 2]]if __name__ == '__main__':dataset = createDataSet()centroids, cluster = kmeans(dataset, 2)print('质心为:%s' % centroids)print('集群为:%s' % cluster)for i in range(len(dataset)):plt.scatter(dataset[i][0], dataset[i][1], marker='o', color='green', s=40, label='原始点')# 记号形状 颜色 点的大小 设置标签for j in range(len(centroids)):plt.scatter(centroids[j][0], centroids[j][1], marker='x', color='red', s=50, label='质心')plt.show()
功能说明
功能说明:
calcDis函数计算样本点到质心的欧拉距离;classify函数根据欧拉距离进行分类,并计算新的质心;kmeans函数使用K-means算法对数据集进行聚类,随机选择质心并迭代更新质心,直到变化量全为0;createDataSet函数创建一个样本数据集。
效果展示
数据集为[[1, 1], [1, 2], [2, 1], [2, 3], [6, 4], [6, 3], [5, 4], [5, 2]]时
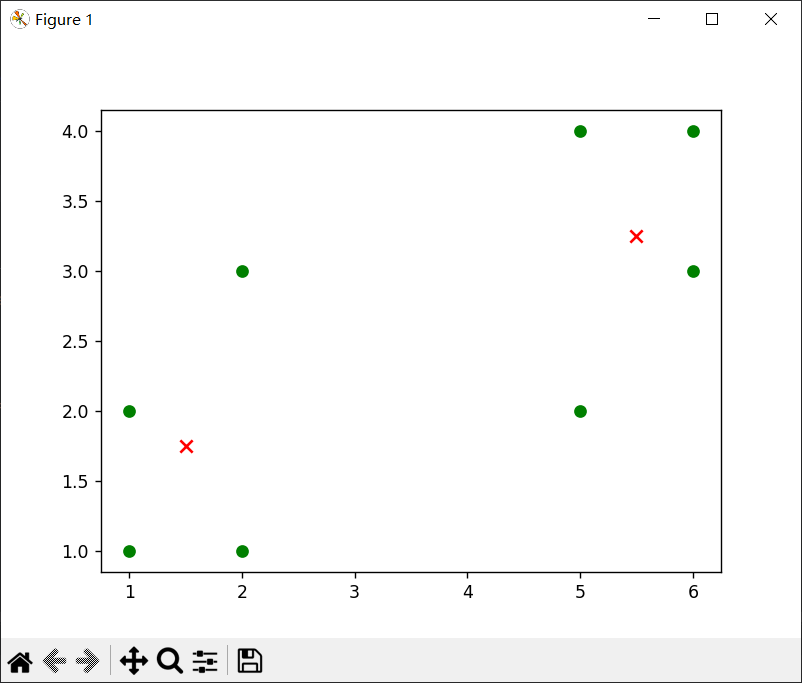
数据集为[[1, 1], [1, 2], [2, 1], [2, 2], [6, 4], [6, 3], [5, 4], [5, 3]]时
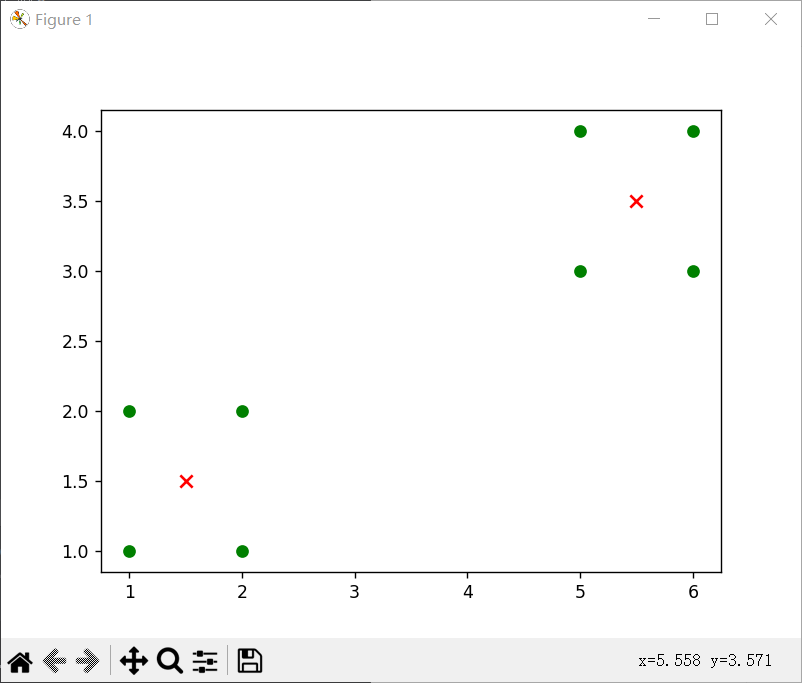
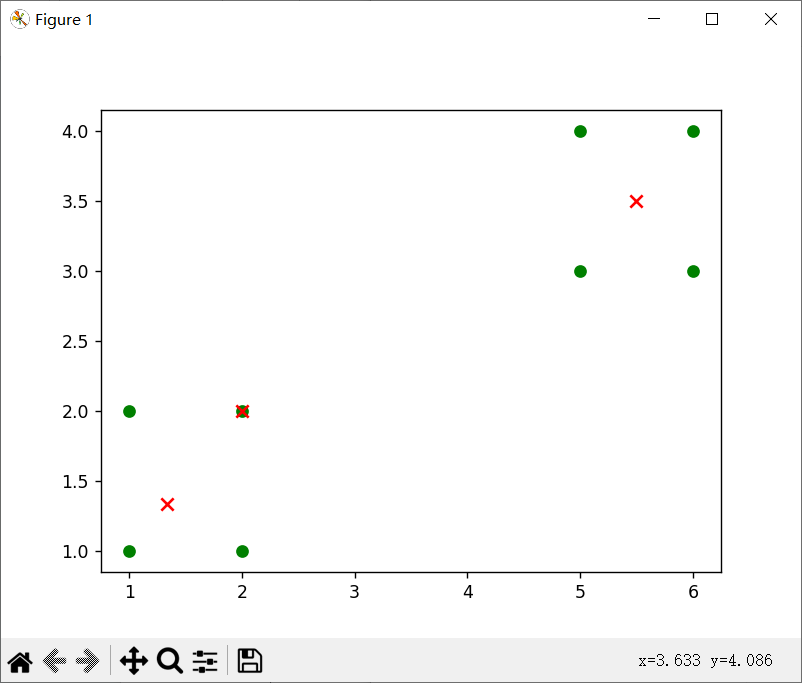
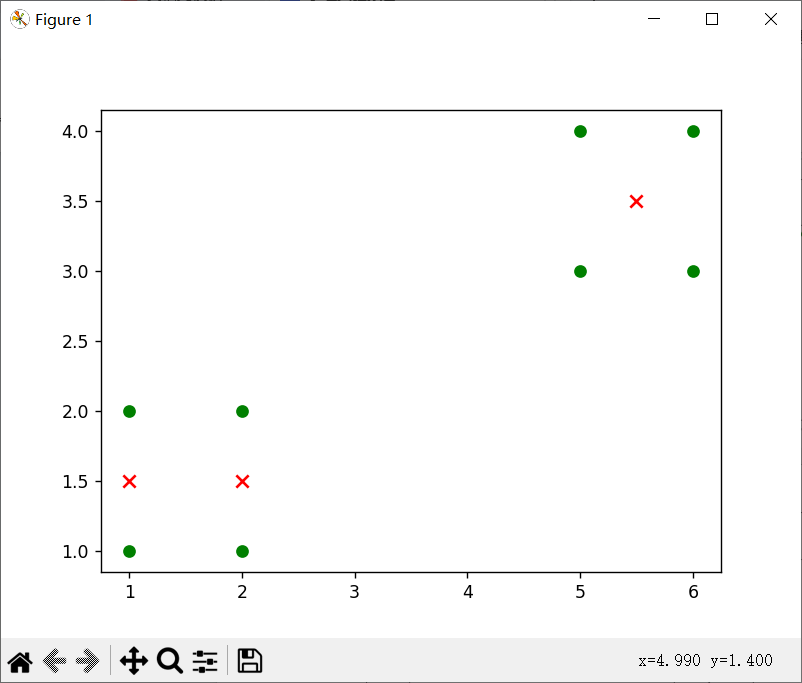
k=3时,数据集为[[1, 1], [1, 2], [2, 1], [2, 2], [6, 4], [6, 3], [5, 4], [5, 3]]时
(1)
(2)
效果对比分析
可以发现,k相同时,数据集决定对应质点的位置,从中我们可以看出当数据不一样时,质点会出现在不同的位置,但是总是会在对应某几个数据集(或者1个)的点的中心。
当k=3时候,出现三个质点,但是由于随机的关系,两次效果不同,(1)是单独一个点,四个点,和三个点这样分,而(2)就是2、2、4这样分的对应质点。
结论
根据代码的输出和可视化结果,可以得出以下结论:
- 经过K-means聚类算法处理后,数据集被划分为2个簇,每个簇由多个样本组成;
- 质心坐标表示了每个簇的中心位置;
- 可视化结果展示了原始点和质心的分布情况。
需要注意的是,对于不同的数据集和初始质心以及k值的选择的选择,K-means算法的结果可能会有所不同。因此,在实际应用中,可能需要多次运行算法并选择最优结果。
Mean-Shift算法
代码
import numpy as np # 导入NumPy库用于数学计算
from sklearn.datasets import make_blobs # 导入make_blobs函数用于生成数据集
import matplotlib.pyplot as plt # 导入Matplotlib库用于可视化# 定义欧氏距离计算函数
def euclidean_distance(x1, x2):return np.sqrt(np.sum((x1 - x2) ** 2))# 定义高斯核函数
def gaussian_kernel(distance, bandwidth):return (1 / (bandwidth * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((distance / bandwidth) ** 2))# 定义Mean Shift算法函数
def mean_shift(data, bandwidth=2):centroids = data.copy() # 初始化聚类中心为数据点本身for i in range(len(data)): # 遍历每个数据点x = centroids[i] # 当前数据点while True:distances = [euclidean_distance(x, xi) for xi in centroids] # 计算当前点与所有点的距离weights = [gaussian_kernel(d, bandwidth) for d in distances] # 计算每个点的权重prev_x = x # 保存上一次的点x = np.dot(weights, centroids) / np.sum(weights) # 更新当前点的位置为加权平均# 检查是否收敛,如果当前点与上一次点的距离小于阈值,则认为收敛if euclidean_distance(x, prev_x) < 1e-5:breakcentroids[i] = x # 将当前点设为收敛后的点# 合并重复的聚类中心,如果两个聚类中心距离小于阈值,则认为是同一个中心unique_centroids = [centroids[0]]for i in range(1, len(centroids)):is_unique = Truefor j in range(len(unique_centroids)):if euclidean_distance(centroids[i], unique_centroids[j]) < 1e-5:is_unique = Falsebreakif is_unique:unique_centroids.append(centroids[i])return np.array(unique_centroids) # 返回最终的聚类中心# 生成数据集,这里使用make_blobs生成一个带有四个簇的数据集
data, _ = make_blobs(n_samples=300, centers=4, cluster_std=1.0, random_state=42)# 使用Mean Shift算法进行聚类,指定带宽参数为2
centroids = mean_shift(data, bandwidth=2)# 可视化结果
plt.scatter(data[:, 0], data[:, 1], s=30, color='blue', label='Data points') # 绘制原始数据点
plt.scatter(centroids[:, 0], centroids[:, 1], s=100, color='red', marker='X', label='Cluster Centers') # 绘制聚类中心点
plt.title('Mean-shift Clustering') # 设置标题
plt.legend() # 显示图例
plt.show() # 显示图形
功能说明
功能说明:
euclidean_distance函数计算两个点之间的欧氏距离;gaussian_kernel函数定义了高斯核函数,用于计算每个点的权重;mean_shift函数实现了Mean Shift算法,通过迭代更新每个点的位置,直到收敛为止;make_blobs函数生成了一个带有四个簇的数据集;- 最后,代码将原始的数据点和聚类中心点在二维坐标中以不同颜色进行了绘制。
效果展示
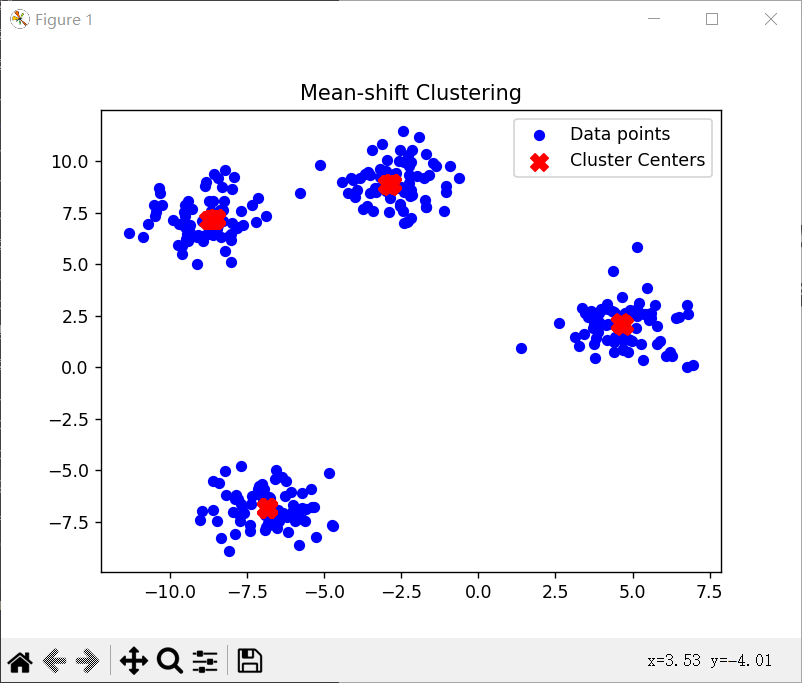
结论
基于生成的数据集和指定的带宽参数,Mean Shift算法对数据进行了聚类,并成功找到了聚类中心点。通过可视化结果可以清楚地看到每个簇的中心位置和数据点的分布情况。需要注意的是,聚类结果可能会受到带宽参数的影响,不同的参数可能会得到不同的聚类结果。在实际应用中,可以通过尝试不同的参数值来优化聚类效果。
相关文章:

OpenCV-图像分割
实验1 实验内容 上述代码通过使用OpenCV和Matplotlib库来执行以下操作: 读取名为’kt.jpg’的图像文件,并存储在变量img中。将图像img转换为灰度图像,将其存储在变量gray中。使用cv2.threshold函数对灰度图gray进行阈值化处理,…...

Vue-计算属性
计算属性 案例 输入姓、名, 全名称姓名 实现 插值语法 代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><title>计算属性与监视</title><!-- 引入Vue --><script type&…...

16. 通用配置文件开发.py
16. 通用配置文件开发.py 一、配置文件架构设计 1.1 模块化结构规划 #mermaid-svg-Iuex47psGWeZj6XQ {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-Iuex47psGWeZj6XQ .error-icon{fill:#552222;}#mermaid-svg-Iu…...

Python训练营打卡 Day29
复习日:类的装饰器 知识点回顾 类的装饰器:餐厅升级计划 假设你是一家餐厅的老板,餐厅已经运营了一段时间,但你希望提升服务质量,比如在每道菜上增加一些特别的服务(比如日志记录、额外的装饰等)…...

解决 Tailwind CSS 代码冗余问题
解决 Tailwind CSS 代码冗余问题 Tailwind CSS 确实可能导致 HTML 类名过长和冗余的问题,以下是几种有效的解决方案: 1. 使用 apply 指令提取重复样式 /* 在CSS文件中 */ .btn {apply px-4 py-2 rounded-md font-medium; }.card {apply p-6 bg-white …...

【藏经阁】加密机服务完整解决方案,包含客户端+服务端
前言 你是否存在这样的苦恼,数据需要安全存储,但是每个系统大家自己写,很浪费时间。 encryption-local 一个离线版本的金融敏感信息加解密工具,用于数据库敏感信息存储。 离线版本的加解密好处是非常的方便。不过缺点也比较明显…...

互联网大厂Java求职面试:AI与大模型应用集成及云原生挑战
互联网大厂Java求职面试:AI与大模型应用集成及云原生挑战 面试场景设定 郑薪苦是一位具有搞笑风格但技术潜力巨大的程序员,正在接受一位严肃专业的技术总监面试。 第一轮提问 面试官:在我们公司的短视频平台中,需要处理千万级…...

ffmpeg -vf subtitles添加字幕绝对路径问题的解决方法
今天遇到奇怪的问题,老是报 Unable to parse option value Error applying option original_size to filter subtitles: Invalid argument 踩坑很长时间,记录下 因subtitles需要指定绝对路径, 注意点: 外面要用单引号 不能…...

JetBrains IDEA,Android Studio,WebStorm 等IDE 字体出现异常时解决方法
JetBrains IDEA,Android Studio,WebStorm 等IDE 中文字体出现异常,很怪的时候,通常需要设置字体回退才能解决。 需要在 Font 中将字体连写打开,并且设置字体回退为 Microsoft YaHei Ul 只有这样 IDEA 在没有中文字体的样式下,会将…...

鸿蒙AI开发:10-多模态大模型与原子化服务的集成
鸿蒙AI开发:10-多模态大模型与原子化服务的集成 在鸿蒙生态中,多模态大模型与原子化服务的集成是一个重要课题。本文将介绍如何在鸿蒙平台上进行多模态大模型与原子化服务的集成,以及相关的技术细节和实际案例。 鸿蒙AI开发概述 什么是鸿蒙AI…...

信奥赛CSP动态规划入门-最大子段和
针对**“最大子段和”**问题的详细分步解析与程序实现,通过动态规划将大问题分解为小问题: 一、问题拆解步骤 1. 明确问题定义 大问题:在数组[-2,1,-3,4,-1,2,1]中,找到连续子数组的和的最大值。 小问题:以每个位置i结尾的子数组能得到的最大和。 2. 状态定义 定义数组…...

Python爬虫实战:通过PyExecJS库实现逆向解密
1. 核心定义 1.1 PyExecJS 库 PyExecJS 是 Python 的第三方库,通过调用 JavaScript 运行时环境(如 Node.js、PhantomJS),实现 Python 与 JavaScript 的无缝交互。其核心功能包括: JavaScript 代码编译与执行跨语言函数调用与数据传递多引擎支持与自动环境检测1.2 字段加…...

网络安全深度解析:21种常见网站漏洞及防御指南
一、高危漏洞TOP 10 1. SQL注入(SQLi) 原理:通过构造恶意SQL语句突破系统过滤机制 典型场景: - 联合查询注入: union select 1,version(),3--+ - 布尔盲注:and (select substr(user(),1,1)=r) - 时间盲注:;if(now()=sysdate(),sleep(5),0)/ 防御方案: - 严格参数化查…...

web系统安全管理
一、概述 认证、授权是JavaWeb项目的核心部分。 二、相关概念 1、认证Authentication 认证,简单来说,就是确认用户身份的过程,确认“你是谁”(验证身份)。 2、授权(Authorization) 授权&…...

相机基础常识
相机基础常识 相机中颜色滤镜的作用🎨 1. **捕捉彩色图像**✅ 最常见的颜色滤镜阵列是 **拜耳滤镜(Bayer Filter)**: 🔍 2. **实现特定的图像效果或分析功能**✅ 常见的滤镜类型包括: 🛠️ 3. *…...

Python训练营打卡Day29
复习日:类的装饰器 知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 1. 类的装饰器 类的装饰器是一种特殊的函数,用于修改或扩展类的行为。它们在类定义时被应用,类似于函…...

不同版本 Linux 系统账号操作指令 ——rtkit 账号删除、普通账号的创建 / 删除 / 权限修改超详细大全
不同版本 Linux 系统账号操作指令 ——rtkit 账号删除、普通账号的创建 / 删除 / 权限修改超详细大全 安全提醒 先备份:/etc/passwd 、/etc/shadow 、/etc/group 、/etc/sudoers 以及 Home 目录。系统账户慎删:rtkit 属于实时调度守护进程 RealtimeKit&…...

基于 Zookeeper 部署 Kafka 集群
文章目录 1、前期准备2、安装 JDK 83、搭建 Zookeeper 集群3.1、下载3.2、调整配置3.3、标记节点3.4、启动集群 4、搭建 Kafka 集群4.1、下载4.2、调整配置4.3、启动集群 1、前期准备 本次集群搭建使用:3 Zookeeper 3 Kafka,所以我在阿里云租了3台ECS用…...

Listener method could not be invoked with the incoming message
问题描述 生产者方代码: private void rollbackOrder(long orderId, CorrelationData correlationData) {rabbitTemplate.convertAndSend("order-rollback-exchange","rollback.order",new QuotaRollbackTO(orderId,null,null),correlationData…...

VueUse/Core:提升Vue开发效率的实用工具库
文章目录 引言什么是VueUse/Core?为什么选择VueUse/Core?核心功能详解1. 状态管理2. 元素操作3. 实用工具函数4. 浏览器API封装5. 传感器相关 实战示例:构建一个拖拽上传组件性能优化技巧与原生实现对比常见问题解答总结 引言 在现代前端开发…...

记录一次win11本地部署deepseek的过程
20250518 win11 docker安装部署 ollama安装 ragflow部署 deepseek部署 文章目录 1 部署Ollama下载安装ollama配置环境变量通过ollama下载模型deepseek-r1:7b 2 部署docker2.1 官网下载amd版本安装2.2 配置wsl2.3 Docker配置:位置代理镜像源 3 部署RAGFlow更换ragfl…...

PrimeVul论文解读-如何构建高质量漏洞标签与数据集
目录 1. 引入2. 现有漏洞识别方案的不足2.1 数据集中label不准2.2 数据重复2.3 测评标准不够好 3. 现有漏洞识别数据集分析3.1 关于现有数据集中label的准确率分析3.2 关于现有数据集中数据泄露( Data Leakage)情况分析 4. 漏洞识别测评5. PrimeVul数据集…...

现代生活健康养生新视角
在科技飞速发展的今天,我们的生活方式发生巨大转变,健康养生也需要新视角。从光线、声音等生活细节入手,能为健康管理开辟新路径。 光线与健康密切相关。早晨接触自然光线,可调节生物钟,提升血清素水平,…...

开启健康生活的多元养生之道
健康养生是一门值得终身学习的学问,在追求健康的道路上,除了常见方法,还有许多容易被忽视却同样重要的角度。掌握这些多元养生之道,能让我们的生活更健康、更有品质。 室内环境的健康不容忽视。定期清洁空调滤网,避…...

Flink 并行度的设置
在 Apache Flink 中,并行度(Parallelism) 是控制任务并发执行的核心参数之一。Flink 提供了 多个层级设置并行度的方式,优先级从高到低如下: 🧩 一、Flink 并行度的四个设置层级 层级描述设置方式Operator…...

抖音视频怎么去掉抖音号水印
你是不是经常遇到这样的烦恼?看到喜欢的抖音视频,想保存下来分享给朋友或二次创作,却被抖音号水印挡住了画面?别着急,今天教你几种超简单的方法,轻松去除水印,高清无水印视频一键保存࿰…...

类的加载过程详解
类的加载过程详解 Java类的加载过程分为加载(Loading)、链接(Linking) 和 初始化(Initialization) 三个阶段。其中链接又分为验证(Verification)、准备(Preparation&…...

运行:MSI Afterburner报错:应用程序无法启动并行配置不正确
从日志中可以看出,MSI Afterburner 运行时因缺少关键依赖组件(Microsoft.VC90.MFC)导致激活上下文生成失败。这是典型的 Visual C 运行时库缺失/版本不匹配 问题,与您提到的 for %1 in (%windir%\system32\*.dll) do regsvr32.exe…...

基于智能家居项目 ESP8266 WiFi 模块通信过程与使用方法详解
一、ESP8266 简介 ESP8266 是由乐鑫科技(Espressif)推出的一款低功耗、高集成度的 WiFi SoC 芯片。它内置 TCP/IP 协议栈,支持 STA(Station)、AP(Access Point)和 STA+AP 混合模式,可以独立作为主控 MCU 或配合其它主控(如 STM32、Arduino)通过串口通信使用。 常见…...

字节跳动开源通用图像定制模型DreamO,支持风格转换、换衣、身份定制、多条件组合等多种功能~
项目背景分析 图像定制是一个快速发展的领域,包括身份(ID)、风格、服装试穿(Try-On)等多种任务。现有研究表明,大规模生成模型在这些任务上表现出色,但大多数方法是任务特定的,难以推…...

Cursor:简单三步提高生成效率
第一步:结构化提示词——像写需求文档一样对话 常见误区:“做个知识管理模块,用SpringBoot。” 问题:AI会陷入迷茫——需要哪些字段?分页怎么做?异常处理是否需要? 正确写法: Note C…...

第二章 苍穹外卖
开发环境搭建_后端环境搭建_熟悉项目结构 constant:存储的是定义好的常量类 context:存储与上下文相关的 enumeration:存储枚举类 exception:存储一些异常 json:处理一些json转换的类 properties:存储一些配置类 …...

【上位机——WPF】命名空间
概述 XAML命名空间实际上是XML命名空间概念的扩展。指定XAML命名空间的技术依赖于XML命名空间语法、使用URL作为命名空间标识符的约定,使用前缀提供从同一标记源中引用多个命名空间的方法,诸如此类,XML命名空间的XAML定义中增加的主要概念是…...

当AI自我纠错:一个简单的“Wait“提示如何让模型思考更深、推理更强
原论文:s1: Simple test-time scaling 作者:Niklas Muennighoff, Zitong Yang, Weijia Shi等(斯坦福大学、华盛顿大学、Allen AI研究所、Contextual AI) 论文链接:arXiv:2501.19393 代码仓库:GitHub - simp…...

【聚类】 K-means
K-means 文章目录 K-means1. 算法介绍2. 公式及原理3. 伪代码1. 算法介绍 背景与目标 K-means 是最经典、最常用的原型聚类(prototype-based clustering)算法之一,由 Stuart Lloyd 于1957年提出,1982年被广泛推广。其核心目标是: 将给定的 n n n 个数据点划分为 K K K 个…...

matlab分段函数
在 MATLAB 中,定义分段函数可以使用 piecewise 函数或者条件语句(如 if、else)来实现。以下是两种常见方法的示例: 1. 使用 piecewise 函数(适用于符号函数) syms x f piecewise(x < 0, x^2, x > …...

《Vite 报错》ReferenceError: module is not defined in ES module scope
trip): [ReferenceError] module is not defined in ES module scope 解决方案 postcss.config.js 要改为 postcss.config.cjs,也就是 .cjs 后缀。 原因解析 原因解析 下图提示,packages.json 中的属性 type 设置为 module。所有*.js文件现在都被解释…...
)
基于matlab/simulink锂电池算法学习集合(SOC、SOH、BMS)
一、引言概述。 锂电池是目前在各个能源密集型行业中用途广泛,例如新能源汽车、电力微网、航空航天等。电池模型的建立对研究电池的特性、SOC(state-of-charge)估计、SOH(state-of-health)估计、BMS算法开发以及电池系统的快速实时仿真有重要的意义。 等效电路建模…...

10.8 LangChain三大模块深度实战:从模型交互到企业级Agent工具链全解析
LangChain Community 项目:Model I/O, Retrieval, Agent Tooling 关键词:LangChain Model I/O, 检索增强生成, Agent 工具链, 多路召回策略, 工具调用协议 1. Model I/O 模块:大模型交互标准化接口 Model I/O 是 LangChain 生态中连接大模型的核心模块,定义了统一的输入输…...

408考研逐题详解:2009年第16题
2009年第16题 某机器字长为 16 位,主存按字节编址,转移指令采用相对寻址,由两个字节组成,第一个字节为操作码字段,第二个字节为相对位移量字段。假定取指令时,每取一个字节 PC 自动加 1。若某转移指令所在…...

python打卡day29@浙大疏锦行
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...

双紫擒龙紫紫红指标源码学习,2025升级版紫紫红指标公式-重点技术
VAR1:MA((LOWHIGHCLOSE)/3,5); VAR2:CLOSEHHV(C,4) AND REF(C,1)LLV(C,4); 双紫擒龙:REF(C,1)LLV(C,4) AND C>REF(C,2) OR REF(C,2)LLV(C,4) AND REF(C,1)<REF(C,3) AND REF(C,2)<REF(C,4) AND C>REF(C,1); VAR4:VAR1>REF(VAR1,1) AND REF(VAR1,1)<REF(VAR1,…...

Redis学习打卡-Day3-分布式ID生成策略、分布式锁
分布式 ID 当单机 MySQL 已经无法支撑系统的数据量时,就需要进行分库分表(推荐 Sharding-JDBC)。在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键全局唯一了。这个时候就需要生…...
是处理 HTTP 请求的核心组件)
在 ASP.NET 中,HTTP 处理程序(HttpHandler)是处理 HTTP 请求的核心组件
ASP.NET 中 HttpHandler 的用法详解 在 ASP.NET 中,HTTP 处理程序(HttpHandler)是处理 HTTP 请求的核心组件。根据你的配置文件,我将详细解释 <handlers> 节点的各种用法和配置选项。 1. HttpHandler 概述 HttpHandler 是…...

Word文档图片和图表自动添加序号
0 Preface/Foreword Word文档是办公常用的文档,里面经常会插入图片或者表格,当表格和图片数量过多时,如果有些图片需要删除或者添加,那么大概率需要修改大量图片的序号或者引用记录,如果通过手工一个一个修改…...

Android开发-列表类视图
在Android应用开发中,列表类视图(List View) 是展示数据集的重要UI组件之一。无论是显示联系人列表、新闻文章还是产品目录,列表类视图都能提供一个高效且用户友好的方式来呈现信息。本文将详细介绍如何使用 ListView 和更现代的 …...

如何使用 Apple 提供的 benchmark 工具
目录 🧭 Apple 提供的 benchmark 工具有哪些? ✅ 方式一:使用 Core ML Benchmark Tool(推理性能测试) 🔧 安装方式(推荐用 Python 工具) ✅ 方式二:使用 Instruments…...

第11章 JDBC与MySQL数据库
11.1 MySQL数据库管理系统 11.2 启动MySQL数据库服务器 在MySQL安装目录的bin子目录下键入mysqld或mysqld -nt 启动MySQL数据库服务器。 11.3 MySQL客户端管理工具 11.4 JDBC 对于JDK8版本,可以数据库连接器到JDK的扩展目录中(即JAVA_HOME环境变量指…...

Python 向量化操作如何实现多条件筛选
在处理大量数据时,高效的数据筛选是数据分析和科学计算中的关键环节。Python 的 numpy 库以其强大的向量化操作功能,能够帮助我们快速、高效地实现多条件筛选,避免使用低效的循环结构。 NumPy 向量化操作与布尔筛选基础 NumPy 是 Python 中用…...
)
内容社区系统开发文档(下)
目录 4 系统测试 4.1 数据库测试设计 测试流程图 测试策略矩阵 4.2 数据库测试内容 测试点 1:数据项增删改查(CRUD)操作 和 数据一致性测试 一、基础数据初始化 二、用户表测试(users) 1. 新增用户 2. 更新…...