PrimeVul论文解读-如何构建高质量漏洞标签与数据集
目录
- 1. 引入
- 2. 现有漏洞识别方案的不足
- 2.1 数据集中label不准
- 2.2 数据重复
- 2.3 测评标准不够好
- 3. 现有漏洞识别数据集分析
- 3.1 关于现有数据集中label的准确率分析
- 3.2 关于现有数据集中数据泄露( Data Leakage)情况分析
- 4. 漏洞识别测评
- 5. PrimeVul数据集构建过程
- 5.1 数据合并
- 5.2 数据去重
- 5.3 数据打标
- 5.4 数据切分
- 6. 模型测评情况
- 6.1 对开源代码大模型进行微调后的测评
- 6.2 对GPT4和GPT3.5进行测评
- 7. 总结
- 8. 参考
1. 引入
参考1是2024年5月份发表在ICSE(47th IEEE/ACM International Conference on Software Engineering (ICSE 2025))上的一篇文章,文章题目是"Vulnerability Detection with Code Language Models: How Far Are We?"。它对现阶段的漏洞数据集进行了分析,指出了现有数据集label不准和数据重复的问题,现有根据ACC/F1来做漏洞识别模型评测的不足,并给出了作者构建的另一个高质量数据集PrimeVul,还用这个数据测评了现有的SOTA的一些模型,并得出了现有模型做漏洞识别能力都不足的结论。
下面详细解读其核心思想。
2. 现有漏洞识别方案的不足
2.1 数据集中label不准
- 大部分数据集,都是自动打标,比如根据漏洞修复的commit来对函数打标。但真实世界中,修复漏洞的同时,也会对其他代码做调整,这样打标就导致误标。
2.2 数据重复
- 数据重复:发现18.9%的样本在测试集和训练集中同时存在
2.3 测评标准不够好
- 漏洞检测任务不适合用accuracy来做评价,因为真实世界中漏洞很少,一直输出0就能得到很高的acc
- 真实世界中漏洞检测,防止误报很重要
3. 现有漏洞识别数据集分析
3.1 关于现有数据集中label的准确率分析
现有数据集分析:
(1)Juliet和SARD这种老数据集不能表示真实世界漏洞的复杂性;
(2)真实开源软件的漏洞:自动label的不准,手动label成本高。
手动label,成本高。比如SVEN数据集,虽然量少(1606个函数,半数都有洞),但质量高。
自动label的方法,一般是这样做的:收集漏洞修复commit,把修复前的作为有洞数据,修复后的作为无洞数据。随机取样分析,每个数据集随机抽样50个函数,3个人工检查,最终按投票决策,发现现有数据集label本身准确率较低,见表1。
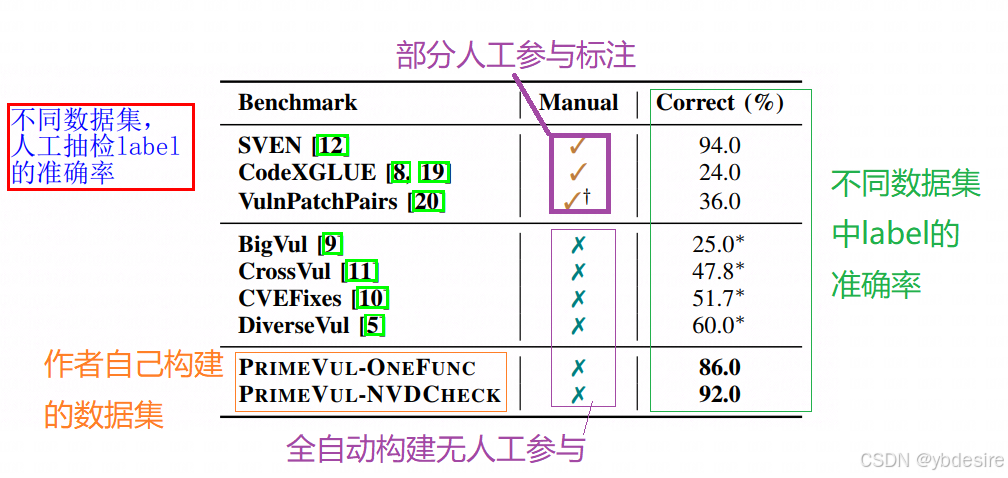
BigVul,CrossVul,CVEFixes,DiverseVul这四个都是比较知名的数据集,从表格中的数据看,准确率也都不行。
3.2 关于现有数据集中数据泄露( Data Leakage)情况分析
文中的 Data Leakage,指的是:测试集中含有训练集中的数据。作者认为,目前大部分已经存在的漏洞数据集中,造成数据泄露的两种情况是(1)数据复制(2)时间顺序错乱。
(1)数据复制
作者按照现有数据集来分析其训练集和测试集中函数的重复性,得到的结果如下图:
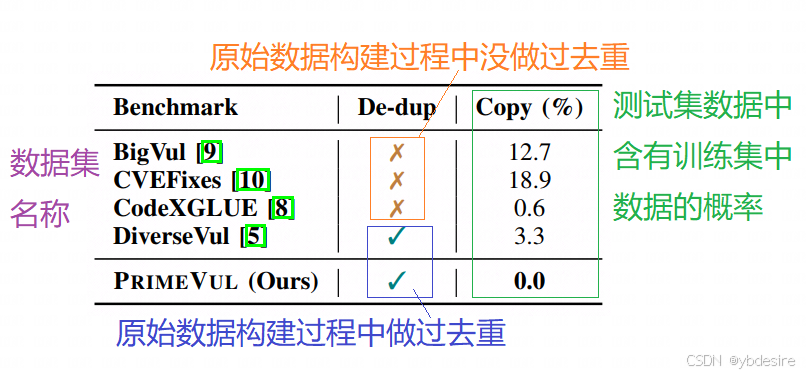
对于DiverseVul,它虽然做过hash去重,但还是有3.3%的重复率,因为它没有对格式化字符做归一化(比如空格的数量不同)。
(2)时间顺序错乱
大部分数据集构建时,采用随机切分数据集为训练集、测试集,这带来的问题:
随机划分函数到不同集合中,会导致训练和测试数据在时间顺序上不合理,出现数据时间顺序错乱的 “时间穿越” 现象,这种现象会使得模型训练和测试的结果不能真实反映模型在实际应用(用过去数据训练预测未来数据)中的性能 。
4. 漏洞识别测评
真实世界中的漏洞检测,开发者不关注F1和ACC,而是关注
(1)减少漏洞和误报;
(2)对于文本上相似的代码样本(包括有漏洞的样本和已修复补丁的样本)的区分能力,也就是模型能否准确地区分有漏洞的代码和已经修复了漏洞的代码,即使它们在文本内容上很相似。
漏报太多,会导致安全问题;误报太多,看不过来。所以漏报和误报要平衡折中。作者认为:
(1)漏报率FNR要越低越好;
(2)有一些误报FPR是可以接受的
作者提出的测评标准是Vulnerability Detection Score (VD-S)。公式为:FNR@(FPR≤r) ,其中 r∈[0%, 100%] 是可配置参数,文中选择 r = 0.5% 进行评估。如果一个漏洞检测模型的 VD-S 为 10%,意味着在误报率被控制在 0.5% 的情况下,仍有 10% 的真实漏洞可能被漏检。所以VD-S越低越好。
5. PrimeVul数据集构建过程
高质量数据集PrimeVul的构建过程:
5.1 数据合并
首先,对真实世界的数据集进行合并。作者将BigVul、CrossVul、CVEfixes和DiverseVul这些数据集中函数进行合并。作者没有使用Devign和CodeXGLUE数据,因为作者发现这两数据集中的内容的很大一部分与安全问题无关。
5.2 数据去重
去除空格、制表符(“\t”)、换行符(“\n”)和回车符(“\r”)等字符,对提交前后已更改的函数进行规范化处理。然后,我们计算已更改函数在提交前版本和提交后版本的 MD5 哈希值。如果一个函数的提交前版本和提交后版本产生相同的哈希值,我们就认为这个函数没有发生变化,并且将其舍弃。
5.3 数据打标
作者构建了两种数据打标策略,进一步提高label的正确率:
(1)PRIMEVUL-ONEFUNC
标注规则:如果某个函数是与安全相关的提交中唯一被更改的函数,那么就将这个函数视为存在漏洞的函数。
也就是说,在之前的标注方法中,当一个提交commit修改了多个函数时,可能会在判断哪个函数真正存在漏洞。而 PRIMEVUL-ONEFUNC 方法通过限定只有当某个函数是安全相关提交中唯一被改动的函数时才认定它有漏洞,避免了在多函数修改提交情况下标注的模糊性和错误,提供了一种更明确、更准确的标注方式来确定函数是否存在漏洞 ,从而提高了数据标注的质量,有助于后续漏洞检测模型的训练和评估。
(2)PRIMEVUL-NVDCHECK
**关联数据:**首先,我们将与安全相关的代码提交(commits)与其对应的 CVE 编号以及 NVD 数据库中的漏洞描述进行关联。
数据标注:
- NVD 的描述中明确指出了该函数存在漏洞。这意味着在 NVD 对某个 CVE 的详细描述中,直接提到了这个函数是有问题的,那么根据这个权威信息,我们就可以将该函数标记为存在漏洞。
- 当 NVD 的描述提到了某个函数所在的文件名,并且在这个文件中,这个函数是唯一因与安全相关的提交而被更改的函数时,该函数也会被认定为存在漏洞的函数。
5.4 数据切分
不是随机切分训练集、测试集。而是根据时间切分,老数据做训练集,新数据做测试集。
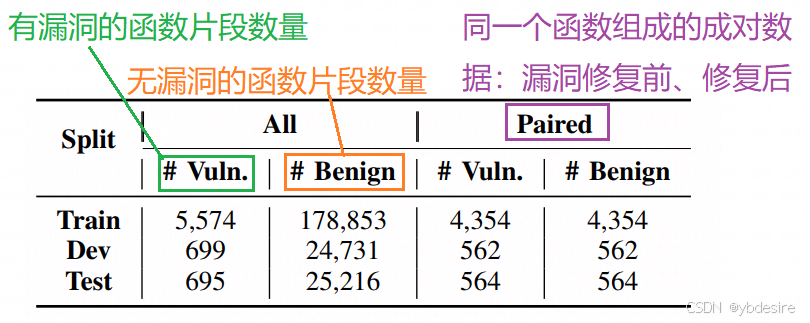
最终,得到的数据集PrimeVul如下:
6. 模型测评情况
作者对如下模型进行了测评
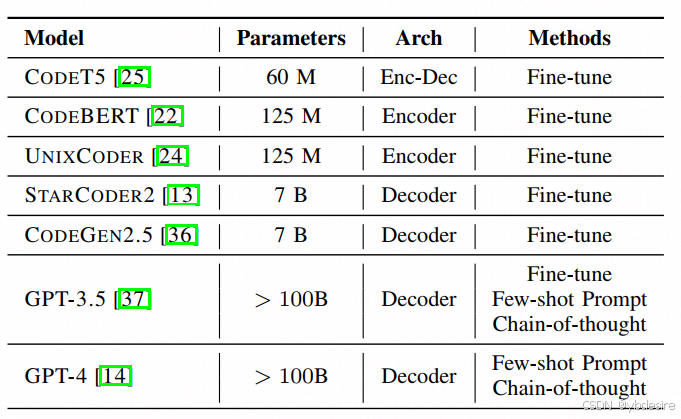
对CodeT5等开源代码大模型,用PrimeVul微调后做了测评。
6.1 对开源代码大模型进行微调后的测评
微调时,对StarCoder2和CodeGen2.5,epoch=4;对CodeT5和CodeBERT,epoch=10。微调后的模型测评结果如下:
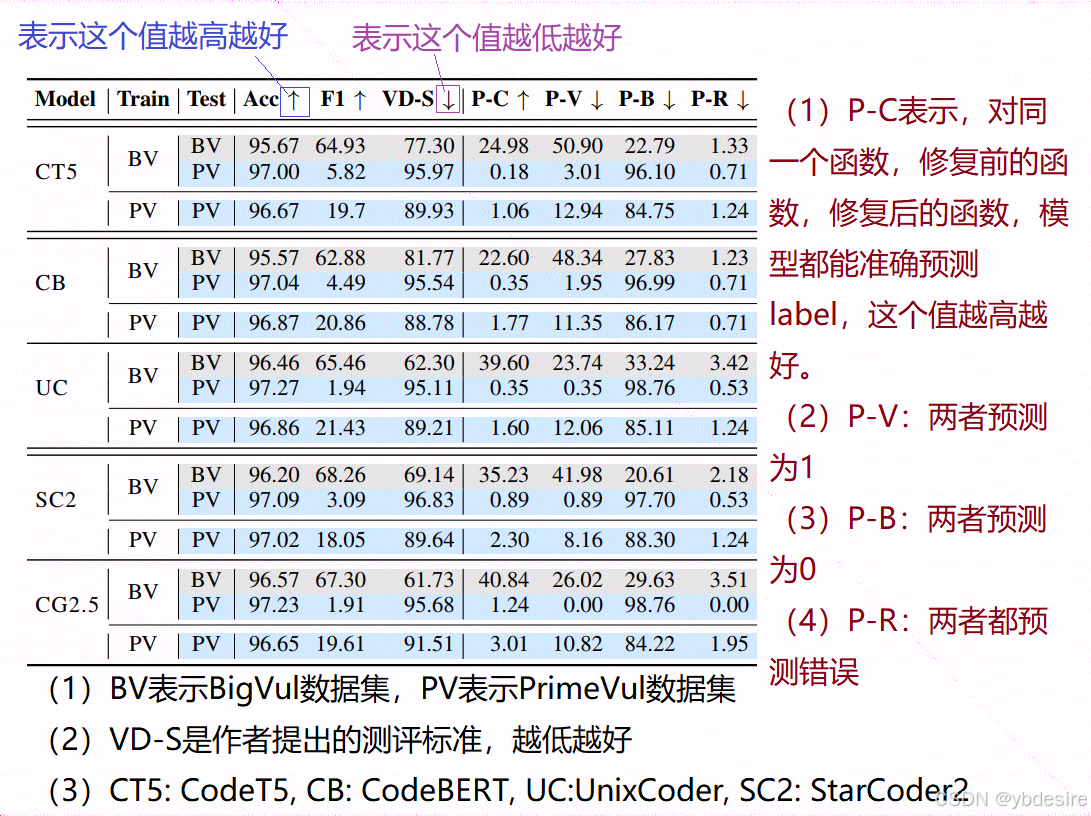
虽然 StarCoder2 模型在 BigVul 基准测试上表现出了值得称赞的 F1 分数(达到 68.26%),但在 PrimeVul 基准测试上,它的 F1 分数却急剧下降到了微不足道的 3.09%。这种大幅下降并非个例,而是在所有模型中都能观察到的一种趋势,这从观察到的漏报率中就可以得到例证。也就是说,之前基于 BigVul 等基准测试所认为的模型具有较好的漏洞检测能力,其实是不准确的,当使用更能反映现实漏洞复杂性的 PrimeVul 基准测试时,这些模型的真实表现很差,漏报率较高,无法有效地检测出漏洞。这表明之前的基准测试存在局限性,不能真实反映代码语言模型在实际漏洞检测任务中的性能。
作者还做了更复杂的训练,结果表明,用于二分类的先进训练技术,例如对比学习和类别权重,并不能显著提升代码语言模型在 PrimeVul 数据集上的性能,这突显了该任务在现实中的难度。
6.2 对GPT4和GPT3.5进行测评
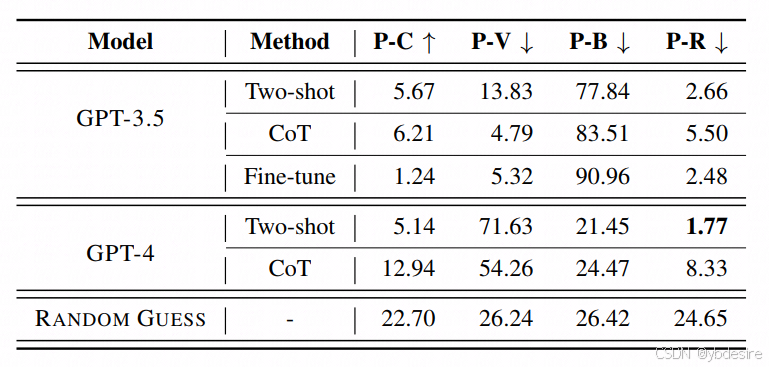
我们对 GPT-3.5 进行微调时,我们注意到该模型受到了漏洞样本与良性样本 1:3 比例的强烈影响,其表现甚至比使用提示方法时还要差。这是一个危险信号,表明即使是这样一个大型的语言模型(LLM),仍然无法捕捉到漏洞模式,而是选择了从数据中走捷径(即依赖数据中的表面特征而非真正理解漏洞模式)。
所以,作者认为,即使是最先进的 OpenAI 模型,在 PrimeVul 数据集上也无法取得可靠的性能表现,这就需要从根本上采用全新的方法来改进这项任务。
7. 总结
PrimeVul作者对现有漏洞数据集进行分析,指出了现有数据集label不准和数据重复的问题,现有根据ACC/F1来做漏洞识别模型评测的不足,并给出了作者构建的另一个高质量数据集PrimeVul,还用这个数据测评了现有的SOTA的一些模型,并得出了现有模型做漏洞识别能力都不足的结论。作者的分析方法和高质量数据集构建的思路非常值得借鉴。
8. 参考
- https://arxiv.org/abs/2403.18624
相关文章:

PrimeVul论文解读-如何构建高质量漏洞标签与数据集
目录 1. 引入2. 现有漏洞识别方案的不足2.1 数据集中label不准2.2 数据重复2.3 测评标准不够好 3. 现有漏洞识别数据集分析3.1 关于现有数据集中label的准确率分析3.2 关于现有数据集中数据泄露( Data Leakage)情况分析 4. 漏洞识别测评5. PrimeVul数据集…...

现代生活健康养生新视角
在科技飞速发展的今天,我们的生活方式发生巨大转变,健康养生也需要新视角。从光线、声音等生活细节入手,能为健康管理开辟新路径。 光线与健康密切相关。早晨接触自然光线,可调节生物钟,提升血清素水平,…...

开启健康生活的多元养生之道
健康养生是一门值得终身学习的学问,在追求健康的道路上,除了常见方法,还有许多容易被忽视却同样重要的角度。掌握这些多元养生之道,能让我们的生活更健康、更有品质。 室内环境的健康不容忽视。定期清洁空调滤网,避…...

Flink 并行度的设置
在 Apache Flink 中,并行度(Parallelism) 是控制任务并发执行的核心参数之一。Flink 提供了 多个层级设置并行度的方式,优先级从高到低如下: 🧩 一、Flink 并行度的四个设置层级 层级描述设置方式Operator…...

抖音视频怎么去掉抖音号水印
你是不是经常遇到这样的烦恼?看到喜欢的抖音视频,想保存下来分享给朋友或二次创作,却被抖音号水印挡住了画面?别着急,今天教你几种超简单的方法,轻松去除水印,高清无水印视频一键保存࿰…...

类的加载过程详解
类的加载过程详解 Java类的加载过程分为加载(Loading)、链接(Linking) 和 初始化(Initialization) 三个阶段。其中链接又分为验证(Verification)、准备(Preparation&…...

运行:MSI Afterburner报错:应用程序无法启动并行配置不正确
从日志中可以看出,MSI Afterburner 运行时因缺少关键依赖组件(Microsoft.VC90.MFC)导致激活上下文生成失败。这是典型的 Visual C 运行时库缺失/版本不匹配 问题,与您提到的 for %1 in (%windir%\system32\*.dll) do regsvr32.exe…...

基于智能家居项目 ESP8266 WiFi 模块通信过程与使用方法详解
一、ESP8266 简介 ESP8266 是由乐鑫科技(Espressif)推出的一款低功耗、高集成度的 WiFi SoC 芯片。它内置 TCP/IP 协议栈,支持 STA(Station)、AP(Access Point)和 STA+AP 混合模式,可以独立作为主控 MCU 或配合其它主控(如 STM32、Arduino)通过串口通信使用。 常见…...

字节跳动开源通用图像定制模型DreamO,支持风格转换、换衣、身份定制、多条件组合等多种功能~
项目背景分析 图像定制是一个快速发展的领域,包括身份(ID)、风格、服装试穿(Try-On)等多种任务。现有研究表明,大规模生成模型在这些任务上表现出色,但大多数方法是任务特定的,难以推…...

Cursor:简单三步提高生成效率
第一步:结构化提示词——像写需求文档一样对话 常见误区:“做个知识管理模块,用SpringBoot。” 问题:AI会陷入迷茫——需要哪些字段?分页怎么做?异常处理是否需要? 正确写法: Note C…...

第二章 苍穹外卖
开发环境搭建_后端环境搭建_熟悉项目结构 constant:存储的是定义好的常量类 context:存储与上下文相关的 enumeration:存储枚举类 exception:存储一些异常 json:处理一些json转换的类 properties:存储一些配置类 …...

【上位机——WPF】命名空间
概述 XAML命名空间实际上是XML命名空间概念的扩展。指定XAML命名空间的技术依赖于XML命名空间语法、使用URL作为命名空间标识符的约定,使用前缀提供从同一标记源中引用多个命名空间的方法,诸如此类,XML命名空间的XAML定义中增加的主要概念是…...

当AI自我纠错:一个简单的“Wait“提示如何让模型思考更深、推理更强
原论文:s1: Simple test-time scaling 作者:Niklas Muennighoff, Zitong Yang, Weijia Shi等(斯坦福大学、华盛顿大学、Allen AI研究所、Contextual AI) 论文链接:arXiv:2501.19393 代码仓库:GitHub - simp…...

【聚类】 K-means
K-means 文章目录 K-means1. 算法介绍2. 公式及原理3. 伪代码1. 算法介绍 背景与目标 K-means 是最经典、最常用的原型聚类(prototype-based clustering)算法之一,由 Stuart Lloyd 于1957年提出,1982年被广泛推广。其核心目标是: 将给定的 n n n 个数据点划分为 K K K 个…...

matlab分段函数
在 MATLAB 中,定义分段函数可以使用 piecewise 函数或者条件语句(如 if、else)来实现。以下是两种常见方法的示例: 1. 使用 piecewise 函数(适用于符号函数) syms x f piecewise(x < 0, x^2, x > …...

《Vite 报错》ReferenceError: module is not defined in ES module scope
trip): [ReferenceError] module is not defined in ES module scope 解决方案 postcss.config.js 要改为 postcss.config.cjs,也就是 .cjs 后缀。 原因解析 原因解析 下图提示,packages.json 中的属性 type 设置为 module。所有*.js文件现在都被解释…...
)
基于matlab/simulink锂电池算法学习集合(SOC、SOH、BMS)
一、引言概述。 锂电池是目前在各个能源密集型行业中用途广泛,例如新能源汽车、电力微网、航空航天等。电池模型的建立对研究电池的特性、SOC(state-of-charge)估计、SOH(state-of-health)估计、BMS算法开发以及电池系统的快速实时仿真有重要的意义。 等效电路建模…...

10.8 LangChain三大模块深度实战:从模型交互到企业级Agent工具链全解析
LangChain Community 项目:Model I/O, Retrieval, Agent Tooling 关键词:LangChain Model I/O, 检索增强生成, Agent 工具链, 多路召回策略, 工具调用协议 1. Model I/O 模块:大模型交互标准化接口 Model I/O 是 LangChain 生态中连接大模型的核心模块,定义了统一的输入输…...

408考研逐题详解:2009年第16题
2009年第16题 某机器字长为 16 位,主存按字节编址,转移指令采用相对寻址,由两个字节组成,第一个字节为操作码字段,第二个字节为相对位移量字段。假定取指令时,每取一个字节 PC 自动加 1。若某转移指令所在…...

python打卡day29@浙大疏锦行
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...

双紫擒龙紫紫红指标源码学习,2025升级版紫紫红指标公式-重点技术
VAR1:MA((LOWHIGHCLOSE)/3,5); VAR2:CLOSEHHV(C,4) AND REF(C,1)LLV(C,4); 双紫擒龙:REF(C,1)LLV(C,4) AND C>REF(C,2) OR REF(C,2)LLV(C,4) AND REF(C,1)<REF(C,3) AND REF(C,2)<REF(C,4) AND C>REF(C,1); VAR4:VAR1>REF(VAR1,1) AND REF(VAR1,1)<REF(VAR1,…...

Redis学习打卡-Day3-分布式ID生成策略、分布式锁
分布式 ID 当单机 MySQL 已经无法支撑系统的数据量时,就需要进行分库分表(推荐 Sharding-JDBC)。在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键全局唯一了。这个时候就需要生…...
是处理 HTTP 请求的核心组件)
在 ASP.NET 中,HTTP 处理程序(HttpHandler)是处理 HTTP 请求的核心组件
ASP.NET 中 HttpHandler 的用法详解 在 ASP.NET 中,HTTP 处理程序(HttpHandler)是处理 HTTP 请求的核心组件。根据你的配置文件,我将详细解释 <handlers> 节点的各种用法和配置选项。 1. HttpHandler 概述 HttpHandler 是…...

Word文档图片和图表自动添加序号
0 Preface/Foreword Word文档是办公常用的文档,里面经常会插入图片或者表格,当表格和图片数量过多时,如果有些图片需要删除或者添加,那么大概率需要修改大量图片的序号或者引用记录,如果通过手工一个一个修改…...

Android开发-列表类视图
在Android应用开发中,列表类视图(List View) 是展示数据集的重要UI组件之一。无论是显示联系人列表、新闻文章还是产品目录,列表类视图都能提供一个高效且用户友好的方式来呈现信息。本文将详细介绍如何使用 ListView 和更现代的 …...

如何使用 Apple 提供的 benchmark 工具
目录 🧭 Apple 提供的 benchmark 工具有哪些? ✅ 方式一:使用 Core ML Benchmark Tool(推理性能测试) 🔧 安装方式(推荐用 Python 工具) ✅ 方式二:使用 Instruments…...

第11章 JDBC与MySQL数据库
11.1 MySQL数据库管理系统 11.2 启动MySQL数据库服务器 在MySQL安装目录的bin子目录下键入mysqld或mysqld -nt 启动MySQL数据库服务器。 11.3 MySQL客户端管理工具 11.4 JDBC 对于JDK8版本,可以数据库连接器到JDK的扩展目录中(即JAVA_HOME环境变量指…...

Python 向量化操作如何实现多条件筛选
在处理大量数据时,高效的数据筛选是数据分析和科学计算中的关键环节。Python 的 numpy 库以其强大的向量化操作功能,能够帮助我们快速、高效地实现多条件筛选,避免使用低效的循环结构。 NumPy 向量化操作与布尔筛选基础 NumPy 是 Python 中用…...
)
内容社区系统开发文档(下)
目录 4 系统测试 4.1 数据库测试设计 测试流程图 测试策略矩阵 4.2 数据库测试内容 测试点 1:数据项增删改查(CRUD)操作 和 数据一致性测试 一、基础数据初始化 二、用户表测试(users) 1. 新增用户 2. 更新…...
什么是迁移学习(Transfer Learning)?
什么是迁移学习(Transfer Learning)? 一句话概括 迁移学习研究如何把一个源领域(source domain)/源任务(source task)中获得的知识迁移到目标领域(target domain)/目标任…...

CMake调试与详细输出选项解析
在使用 CMake 进行项目构建和编译时,--debug-output 和 --verbose 的作用如下: 1. --debug-output 适用阶段:CMake 配置阶段(运行 cmake 命令生成构建系统时)。作用: 启用 CMake 内部的调试输出࿰…...

Elasticsearch进阶篇-DSL
目录 DSL查询 1 快速入门 2 DSL 查询分类 2.1 叶子查询 2.1.1 全文检索查询 语法 举例 2.1.2 精准查询 term 语法 term 示例 range 语法 range 示例 2.2 复合查询 2.2.1 bool查询 举例 2.3 排序 语法 示例 2.4 分页 2.4.1 基础分页 示例 2.4.2 深度分页 …...
)
2025年全国青少年信息素养大赛初赛真题(算法创意实践挑战赛C++初中组:文末附答案)
2025年全国青少年信息素养大赛初赛真题(算法创意实践挑战赛C++初中组:文末附答案) 一、单项选择题(每题 5 分) C++ 程序流程控制的基本结构不包括以下哪项? A. 分支结构 B. 数据结构 C. 循环结构 D. 顺序结构 以下哪段代码能将数组 int a[4] = {2, 4, 6, 8}; 的所有元素变…...

C++ 二分查找:解锁高效搜索的密码
一、引言 在 C 编程的广阔领域中,数据处理和查找是日常开发中极为常见的操作。想象一下,你有一个包含数百万个数据的有序数组,需要从中快速找到特定的元素,如果采用逐个遍历的方式,效率之低可想而知,而二分…...
模块 降低模型复杂度,提升复杂场景下的目标定位与分类精度)
YOLO12改进-模块-引入Channel Reduction Attention (CRA)模块 降低模型复杂度,提升复杂场景下的目标定位与分类精度
在语义分割任务中,基于 Transformer 的解码器需要捕获全局上下文信息,但传统自注意力机制(如 SRA)因高分辨率特征图导致计算成本高昂。现有方法多通过降低空间分辨率减少计算量,但未充分优化通道维度。为平衡全局上下文…...

sparkSQL读入csv文件写入mysql
思路 示例 (年龄>18改成>20) mysql的字符集问题 把user改成person “让字符集认识中文”...

如何确定自己的职业发展方向?
引言 确定职业发展方向是一个需要深度自我探索和外部信息结合的过程。以下是系统化的思考框架和行动步骤,帮助你逐步清晰方向: 一、核心问题:职业方向的本质是什么? 职业方向的核心是找到 “你能做什么”(能力&…...
【LLIE专题】基于Retinex理论的transformer暗光增强
Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement(2023,ICCV) 专题介绍一、研究背景二、Retinexformer方法1. 通用Retinex理论2. 作者建立的Retinex理论3. ORF(one stage Retinex-based Framework)4. 网…...

C++多态与虚函数详解——从入门到精通
C多态与虚函数详解——从入门到精通 引言 在C面向对象编程中,多态是一个核心概念,它赋予了程序极大的灵活性和扩展性。本文将通过六个精心设计的实例,深入浅出地讲解C中的多态、虚函数、继承和抽象类等概念,帮助初学者快速理解这…...

自适应Prompt技术:让LLM精准理解用户意图的进阶策略
开发|界面|引擎|交付|副驾——重写全栈法则:AI原生的倍速造应用流 来自全栈程序员 nine 的探索与实践,持续迭代中。 欢迎关注评论私信交流~ 一、核心挑战:传统Prompt的局限性 传统静态Prompt&…...

Java文件读写程序
1.引言 在日常的软件开发中,文件操作是常见的功能之一。不仅要了解如何读写文件,更要知道如何安全地操作文件以避免程序崩溃或数据丢失。这篇文章将深入分析一个简单的 Java 文件读写程序 Top.java,包括其基本实现、潜在问题以及改进建议&am…...
——使用Digital软件绘制脉冲触发的触发器)
数字电子技术基础(六十)——使用Digital软件绘制脉冲触发的触发器
目录 1 使用Digital软件来绘制脉冲触发的触发器 1.1 使用Digital软件来绘制脉冲触发的SR触发器 1.2 使用Digitial软件绘制脉冲触发的JK触发器 1.3 使用Digital软件绘制脉冲触发D触发器 1 使用Digital软件来绘制脉冲触发的触发器 1.1 使用Digital软件来绘制脉冲触发的SR触发…...
基础)
C++学习:六个月从基础到就业——C++20:范围(Ranges)基础
C学习:六个月从基础到就业——C20:范围(Ranges)基础 本文是我C学习之旅系列的第五十一篇技术文章,也是第三阶段"现代C特性"的第十三篇,介绍C20引入的范围(Ranges)库的基础知识。查看完整系列目录了解更多内容。 引言 S…...

【AGI】模型性能评估框架EvalScope
【AGI】模型性能评估框架EvalScope 项目地址:https://github.com/modelscope/evalscope EvalScope 是由阿里巴巴魔搭社区(ModelScope)推出的一款开源模型评估框架,旨在为大语言模型(LLM)和多模态模型提供…...

【老马】离线版金融敏感信息加解密组件开源项目 encryption-local
前言 你是否存在这样的苦恼,数据需要安全存储,但是每个系统大家自己写,很浪费时间。。 每一个子项目各自为政,加解密搞得也无法统一。也许下面这个开源项目可以帮助你。 encryption-local 一个离线版本的金融敏感信息加解密工具…...

利用systemd启动部署在服务器上的web应用
0.背景 系统环境: Ubuntu 22.04 web应用情况: 前后端分类,前端采用react,后端采用fastapi 1.具体配置 1.1 前端配置 开发态运行(启动命令是npm run dev),创建systemd服务文件 sudo nano /etc/systemd/…...

YOLOv5目标构建与损失计算
YOLOv5目标构建与损失计算 YOLOv5目标构建与损失计算构建目标关键步骤解析: 计算损失关键实现细节解析各损失分量说明 YOLOv5目标构建与损失计算 YOLOv5作为单阶段目标检测的经典算法,其高效的检测性能离不开精心设计的训练目标构建和损失计算策略。本文…...

【Linux】ELF与动静态库的“暗黑兵法”:程序是如何跑起来的?
目录 一、什么是库? 1. C标准库(libc) 2. C标准库(libstdc) 二、静态库 1. 静态库的生成 2. 静态库的使用 三、动态库 1. 动态库的生成 2. 动态库的使用 3. 库运行的搜索路径。 (1)原因…...

【图书管理系统】用户注册系统实现详解
引言 本系统允许用户输入用户名和密码,前端通过AJAX请求将数据发送到后端,后端验证并存储用户信息,同时为每个用户创建一个专属图书表。尽管这是一个基础实现,但它展示了前后端分离开发的核心思想。博客还将讨论潜在的优化点&…...
)
FastDFS分布式文件系统架构学习(一)
FastDFS分布式文件系统架构学习 1. FastDFS简介 FastDFS是一个开源的轻量级分布式文件系统,由淘宝资深架构师余庆设计并开发。它专为互联网应用量身定制,特别适合以中小文件(如图片、文档、音视频等)为载体的在线服务。FastDFS不…...