【图像生成大模型】HunyuanVideo:大规模视频生成模型的系统性框架
HunyuanVideo:大规模视频生成模型的系统性框架
- 引言
- HunyuanVideo 项目概述
- 核心技术
- 1. 统一的图像和视频生成架构
- 2. 多模态大语言模型(MLLM)文本编码器
- 3. 3D VAE
- 4. 提示重写(Prompt Rewrite)
- 项目运行方式与执行步骤
- 1. 环境准备
- 2. 安装依赖
- 3. 下载预训练模型
- 4. 单 GPU 推理
- 使用命令行
- 运行 Gradio 服务器
- 5. 多 GPU 并行推理
- 6. FP8 推理
- 执行报错与问题解决
- 1. 显存不足
- 2. 环境依赖问题
- 3. 模型下载问题
- 相关论文与研究
- 1. 扩散模型(Diffusion Models)
- 2. Transformer 架构
- 3. 3D 变分自编码器(3D VAE)
- 4. 多模态大语言模型(MLLM)
- 总结
引言
随着人工智能技术的快速发展,视频生成领域正逐渐成为研究和应用的热点。视频生成技术能够根据文本描述生成相应的视频内容,广泛应用于视频创作、广告制作、教育娱乐等多个领域。腾讯的 HunyuanVideo 项目正是这一领域的前沿成果,它提供了一个系统性的框架,用于大规模视频生成模型的开发和应用。
HunyuanVideo 项目概述
HunyuanVideo 是一个开源的大规模视频生成模型框架,旨在推动视频生成技术的发展。该项目的核心目标是通过系统性的设计和优化,实现高效、高质量的视频生成。HunyuanVideo 的主要特点包括:
- 高性能:HunyuanVideo 在视频生成质量上达到了与领先闭源模型相当甚至更优的水平。
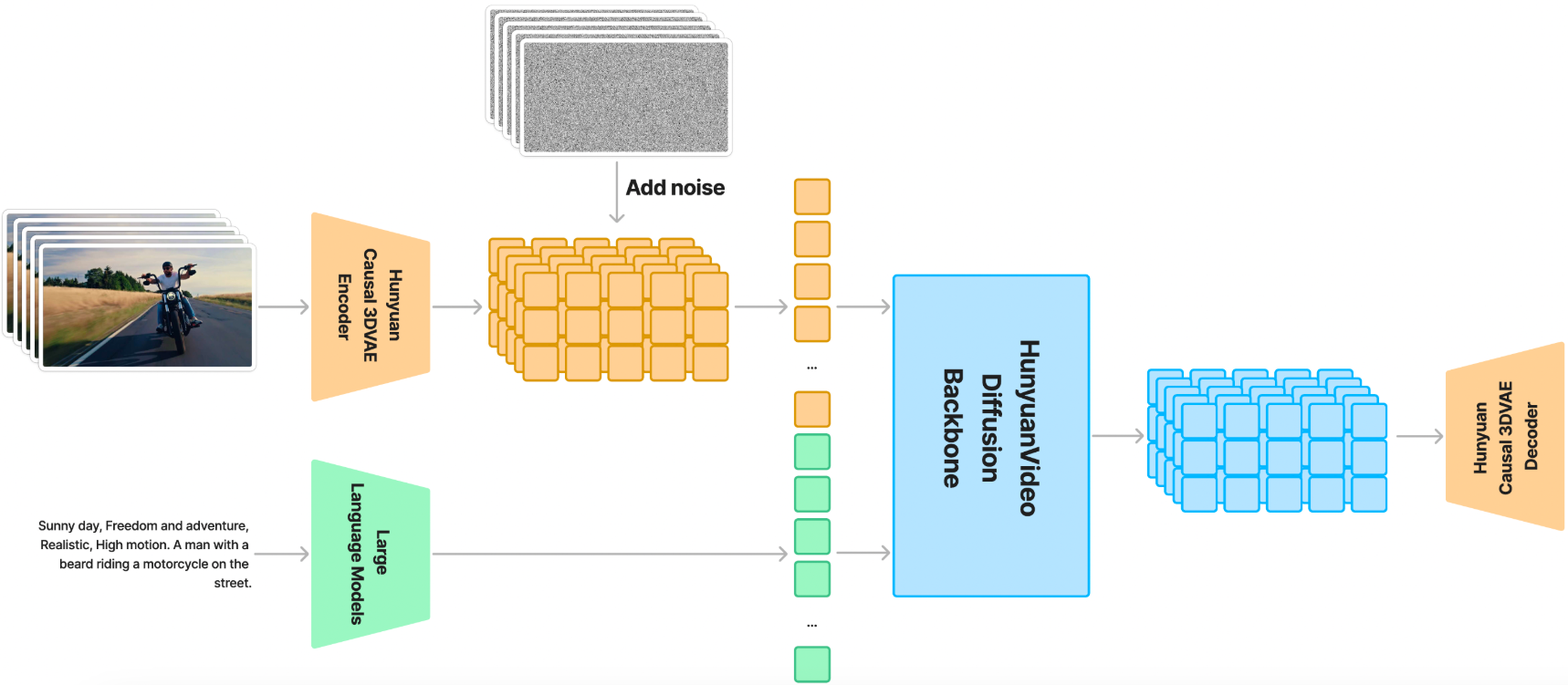
- 统一的图像和视频生成架构:通过 Transformer 设计和全注意力机制,实现图像和视频的统一生成。
- 多模态大语言模型(MLLM)文本编码器:使用预训练的 MLLM 作为文本编码器,提升文本特征的表达能力。
- 3D VAE:通过因果卷积 3D VAE 压缩视频和图像,显著减少后续扩散 Transformer 模型的 token 数量。
- 提示重写(Prompt Rewrite):通过提示重写模型,优化用户提供的文本提示,提升模型对用户意图的理解。
核心技术
1. 统一的图像和视频生成架构
HunyuanVideo 引入了 Transformer 设计,采用全注意力机制实现图像和视频的统一生成。具体来说,HunyuanVideo 采用了“双流到单流”(Dual-stream to Single-stream)的混合模型设计。在双流阶段,视频和文本 token 通过多个 Transformer 块独立处理,使每种模态都能学习到自己的调制机制,避免相互干扰。在单流阶段,将视频和文本 token 连接起来,输入后续的 Transformer 块,实现有效的多模态信息融合。这种设计能够捕捉视觉和语义信息之间的复杂交互,提升模型的整体性能。
2. 多模态大语言模型(MLLM)文本编码器
HunyuanVideo 使用预训练的多模态大语言模型(MLLM)作为文本编码器,与传统的 CLIP 和 T5-XXL 文本编码器相比,具有以下优势:
- 更好的图像-文本对齐:MLLM 在视觉指令微调后,能够更好地对齐图像和文本的特征空间,减轻扩散模型中指令遵循的难度。
- 更强的图像细节描述和复杂推理能力:MLLM 在图像细节描述和复杂推理方面表现出色,优于 CLIP。
- 零样本学习能力:MLLM 可以作为零样本学习器,通过在用户提示前添加系统指令,帮助文本特征更关注关键信息。
此外,MLLM 基于因果注意力,而 T5-XXL 使用双向注意力,这使得 MLLM 为扩散模型提供了更好的文本引导。因此,HunyuanVideo 引入了一个额外的双向 token 优化器来增强文本特征。
3. 3D VAE
HunyuanVideo 使用因果卷积 3D VAE 压缩像素空间的视频和图像,将其转换为紧凑的潜在空间。具体来说,视频长度、空间和通道的压缩比分别设置为 4、8 和 16。这种压缩可以显著减少后续扩散 Transformer 模型的 token 数量,使模型能够在原始分辨率和帧率下训练视频。
4. 提示重写(Prompt Rewrite)
为了应对用户提供的文本提示在语言风格和长度上的多样性,HunyuanVideo 使用 Hunyuan-Large 模型微调的提示重写模型,将原始用户提示适应为模型偏好的提示。HunyuanVideo 提供了两种重写模式:普通模式(Normal mode)和大师模式(Master mode)。普通模式旨在增强视频生成模型对用户意图的理解,而大师模式则增强了对构图、灯光和镜头运动的描述,倾向于生成视觉质量更高的视频。然而,这种强调有时可能会导致一些语义细节的丢失。
项目运行方式与执行步骤
1. 环境准备
在开始运行 HunyuanVideo 之前,需要确保你的开发环境已经准备好。以下是推荐的环境配置:
- 操作系统:推荐使用 Linux,Windows 用户可能需要额外配置 WSL 或虚拟机。
- Python 版本:建议使用 Python 3.10 或更高版本。
- CUDA 和 GPU:确保你的系统安装了 CUDA,并且 GPU 驱动程序是最新的。推荐使用具有 80GB 内存的 GPU 以获得更好的生成质量。
2. 安装依赖
首先,需要克隆项目仓库并安装依赖项:
git clone https://github.com/Tencent/HunyuanVideo.git
cd HunyuanVideo
创建并激活 Conda 环境:
conda create -n HunyuanVideo python==3.10.9
conda activate HunyuanVideo
安装 PyTorch 和其他依赖项:
# For CUDA 11.8
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia# For CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
安装 pip 依赖项:
python -m pip install -r requirements.txt
安装 Flash Attention v2 以加速推理:
python -m pip install ninja
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3
安装 xDiT 用于多 GPU 并行推理:
python -m pip install xfuser==0.4.0
3. 下载预训练模型
HunyuanVideo 提供了多种预训练模型,可以通过以下链接下载:
- HunyuanVideo 模型权重
- HunyuanVideo FP8 模型权重
4. 单 GPU 推理
使用命令行
以下是一个简单的命令,用于在单 GPU 上运行视频生成任务:
cd HunyuanVideopython3 sample_video.py \--video-size 720 1280 \--video-length 129 \--infer-steps 50 \--prompt "A cat walks on the grass, realistic style." \--flow-reverse \--use-cpu-offload \--save-path ./results
运行 Gradio 服务器
你也可以运行一个 Gradio 服务器,通过 Web 界面进行视频生成:
python3 gradio_server.py --flow-reverse
5. 多 GPU 并行推理
HunyuanVideo 支持使用 xDiT 在多 GPU 上进行并行推理。以下是一个使用 8 个 GPU 的命令示例:
cd HunyuanVideotorchrun --nproc_per_node=8 sample_video.py \--video-size 1280 720 \--video-length 129 \--infer-steps 50 \--prompt "A cat walks on the grass, realistic style." \--flow-reverse \--seed 42 \--ulysses-degree 8 \--ring-degree 1 \--save-path ./results
6. FP8 推理
HunyuanVideo 还提供了 FP8 量化权重,可以显著减少 GPU 内存占用。以下是一个使用 FP8 权重的命令示例:
cd HunyuanVideoDIT_CKPT_PATH={PATH_TO_FP8_WEIGHTS}/{WEIGHT_NAME}_fp8.ptpython3 sample_video.py \--dit-weight ${DIT_CKPT_PATH} \--video-size 1280 720 \--video-length 129 \--infer-steps 50 \--prompt "A cat walks on the grass, realistic style." \--seed 42 \--embedded-cfg-scale 6.0 \--flow-shift 7.0 \--flow-reverse \--use-cpu-offload \--use-fp8 \--save-path ./results
执行报错与问题解决
在运行 HunyuanVideo 项目时,可能会遇到一些常见的问题。以下是一些常见问题及其解决方法:
1. 显存不足
如果在运行时遇到显存不足的错误,可以尝试以下方法:
- 使用 CPU 卸载:通过
--use-cpu-offload参数将部分模型参数卸载到 CPU,减少 GPU 内存使用。 - 降低分辨率:降低生成视频的分辨率,例如从 720p 降低到 540p。
- 减少推理步数:通过调整
--infer-steps参数来减少推理步数。 - 使用 FP8 权重:使用 FP8 量化权重可以显著减少 GPU 内存占用。
2. 环境依赖问题
如果在安装依赖时遇到问题,可以尝试以下方法:
- 更新 pip 和 setuptools:确保 pip 和 setuptools 是最新版本。
- 手动安装依赖:对于某些依赖项,可以尝试手动安装,例如
torch和transformers。
3. 模型下载问题
如果在下载模型时遇到问题,可以尝试以下方法:
- 检查网络连接:确保你的网络连接正常,能够访问 Hugging Face。
- 手动下载模型:如果自动下载失败,可以手动下载模型文件并放置到指定目录。
相关论文与研究
HunyuanVideo 的开发基于多项前沿研究,其中一些关键的论文和技术包括:
1. 扩散模型(Diffusion Models)
扩散模型是一种基于噪声扩散和去噪过程的生成模型。其核心思想是通过逐步添加噪声将数据分布转换为先验分布,然后通过去噪过程恢复原始数据分布。HunyuanVideo 使用了扩散模型的框架,结合了 Flow Matching 技术,显著提高了生成视频的质量。
2. Transformer 架构
HunyuanVideo 的模型架构基于 Transformer,这种架构在自然语言处理和计算机视觉领域都取得了巨大成功。Transformer 的自注意力机制能够有效地捕捉长距离依赖关系,使其在视频生成任务中表现出色。
3. 3D 变分自编码器(3D VAE)
HunyuanVideo 使用因果卷积 3D VAE 压缩视频和图像,显著减少了后续扩散 Transformer 模型的 token 数量。这种压缩不仅加速了训练和推理过程,还与扩散过程对压缩表示的偏好相一致。
4. 多模态大语言模型(MLLM)
HunyuanVideo 使用预训练的多模态大语言模型(MLLM)作为文本编码器,显著提升了文本特征的表达能力。MLLM 在图像-文本对齐、图像细节描述和复杂推理方面表现出色,优于传统的 CLIP 和 T5-XXL 文本编码器。
总结
HunyuanVideo 项目以其卓越的性能、高效的实现方式和开源性,为视频生成领域提供了一个强大的工具。通过本文的详细介绍,读者可以全面了解 HunyuanVideo 的技术架构,并掌握如何在实际项目中应用这一模型。无论是研究人员还是开发者,都可以从 HunyuanVideo 中受益,推动视频生成技术的发展和应用。
未来,随着技术的不断进步,HunyuanVideo 有望在更多领域发挥更大的作用,为人类创造更加丰富多彩的视觉内容。
相关文章:

【图像生成大模型】HunyuanVideo:大规模视频生成模型的系统性框架
HunyuanVideo:大规模视频生成模型的系统性框架 引言HunyuanVideo 项目概述核心技术1. 统一的图像和视频生成架构2. 多模态大语言模型(MLLM)文本编码器3. 3D VAE4. 提示重写(Prompt Rewrite) 项目运行方式与执行步骤1. …...
)
Java IO流(超详细!!!)
Java IO流 文章目录 Java IO流1.文件相关基础普及1.1 常用文件操作1.3 目录的操作和文件删除 2.IO流原理及流的分类2.1 字节流2.1.1 InputStream:字节输入流2.1.2 OutputStream 2.2 字符流2.2.1 Reader2.2.1 Writer 2.3 节点流和处理流2.3.1节点流2.3.2 处理流2.3.2…...

规则联动引擎GoRules初探
背景说明 嵌入式设备随着物联网在生活和生产中不断渗透而渐渐多起来,数据的采集、处理、分析在设备侧的自定义配置越来越重要。一个可通过图形化配置的数据处理过程,对于加速嵌入式设备的功能开发愈发重要。作为一个嵌入式软件从业者,笔者一…...

Android开发-翻页类视图
在Android应用中,翻页类视图(Paging Views) 是一种非常直观且用户友好的方式来展示内容。无论是用于展示图片轮播、引导页还是分页加载数据列表,翻页效果都能极大地提升用户体验。本文将介绍几种实现翻页效果的常见组件和方法&…...

高能数造闪耀 CIBF 2025,以创新技术引领新能源智造新征程
在全球新能源产业加速发展的关键节点,CIBF 2025 展会成为行业技术与成果交流的重要平台。高能数造(西安)技术有限公司深度参与此次盛会,凭借在新能源电池智能制造领域的深厚积累与创新突破,为行业发展注入强劲动力&…...

数据结构与算法——栈和队列
栈和队列 栈概念与结构栈的实现栈的初始化栈的销毁判断栈是否为空入栈出栈取栈顶元素栈中有效元素个数 队列概念与结构队列的实现队列结点结构队列结构初始化队列队列判空销毁队列入队列,队尾出队列,队头取队头数据取队尾数据队列有效数据个数 栈 概念与…...

新电脑软件配置三 pycharm
快捷键放大和缩小字体 按住ctrl鼠标滚轮向上 缩小同理...
、ES2023(ES14)版本对比,及使用建议---ES6就够用(个人觉得))
浅入ES5、ES6(ES2015)、ES2023(ES14)版本对比,及使用建议---ES6就够用(个人觉得)
JavaScript(ECMAScript)的发展经历了多个版本,每个版本都引入了新特性和改进。以下仅是对三个常用版本(ES5、ES6(ES2015) 和 ES2023)的基本对比及使用建议: 目前常见项目中还是用ES6…...

【Odoo】Pycharm导入运行Odoo15
【Odoo】Pycharm导入运行Odoo15 前置准备1. Odoo-15项目下载解压2. PsrtgreSQL数据库 项目导入运行1. 项目导入2. 设置项目内虚拟环境3. 下载项目中依赖4. 修改配置文件odoo.conf 运行Pycharm快捷运行 前置准备 1. Odoo-15项目下载解压 将下载好的项目解压到开发目录下 2. …...

【运营商查询】批量手机号码归属地和手机运营商高速查询分类,按省份城市,按运营商移动联通电信快速分类导出Excel表格,基于WPF的实现方案
WPF手机号码归属地批量查询与分类导出方案 应用场景 市场营销:企业根据手机号码归属地进行精准营销,按城市或省份分类制定针对性推广策略客户管理:快速对客户手机号码进行归属地分类,便于后续客户关系管理数…...

中级统计师-统计学基础知识-第四章 假设检验
一、假设检验的基本原理 1. 基本思想 反证法:假设原假设成立,通过样本矛盾性进行反驳小概率原理:设定显著性水平 α \alpha α(通常取 0.05),若观测结果的概率 p ≤ α p \leq \alpha p≤α,…...

等于和绝对等于的区别
1. (等于) 特点:比较时会自动进行类型转换(隐式转换),尝试将两边的值转为相同类型后再比较。规则: 如果类型相同,直接比较值。如果类型不同,按以下规则转换: …...

家庭关系处理个人总结
首先要说到前面的是,每个家庭的成员背景环境经济状况不同,原生家庭差异,导致面临具体问题是不同的。就类似软件“没有银弹”的概念,没有一种方法可以解决每个人问题。 举个例子,面对婆媳矛盾 网上父辈的人 会说 百行孝…...

【Python训练营打卡】day29 @浙大疏锦行
DAY 29 复习日 知识点回顾 1. 类的装饰器 2. 装饰器思想的进一步理解:外部修改、动态 3. 类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,…...

React 19版本refs也支持清理函数了。
文章目录 前言一、refs 支持清理函数二、案例演示1.useEffect写法2.React 19改进 的ref写法 总结 前言 React 19版本发布了ref支持清理函数了,这样就可以达到useEffect一样的效果了。为啥需要清理函数呢,这是因为节约内存。 清理事件监听(避…...

uniapp的适配方式
文章目录 前言✅ 一、核心适配方式对比📏 二、rpx 单位:uni-app 的核心适配机制🧱 三、默认设计稿适配(750宽)🔁 四、字体 & 屏幕密度适配🛠 五、特殊平台适配(底部安全区、刘海…...

Java面试场景:从音视频到AI应用的技术探讨
面试场景:音视频与AI应用技术的碰撞 在某互联网大厂的面试中,面试官王先生与求职者明哥展开了一场关于音视频技术与AI应用的对话。 第一轮提问:音视频场景 面试官:明哥,你能谈谈在音视频场景中,Spring B…...

es聚合-词条统计
es语句 ---普通结构----"tags":{"type": "keyword","index": true},GET /knowledge_test/_search {"size": 0,"aggs": {"tag_count": {"terms": {"field": "tags",&quo…...

【沉浸式求职学习day43】【Java面试题精选3】
沉浸式求职学习 1.Java中this和super的区别2.为什么返回类型不算方法重载3.方法重写时需要注意什么问题4.深克隆和浅克隆有什么区别5.如何实现深克隆6.什么是动态代理7.静态代理和动态代理的区别8.如何实现动态代理?9.JDK Proxy 和 CGLib 有什么区别?10.…...

OpenAI推出Codex — ChatGPT内置的软件工程Agents
OpenAI继续让ChatGPT对开发者更加实用。 几天前,他们增加了连接GitHub仓库的支持,可以"Deep Research"并根据你自己的代码提问。 今天,该公司在ChatGPT中推出了Codex的研究预览版,这是迄今为止最强大的AI编码Agent。 它可以编写代码、修复错误、运行测试,并在…...

Win 11开始菜单图标变成白色怎么办?
在使用windows 11的过程中,有时候开始菜单的某些程序图标变成白色的文件形式,但是程序可以正常打开,这个如何解决呢? 这通常是由于快捷方式出了问题,下面跟着操作步骤来解决吧。 1、右键有问题的软件,打开…...

中级统计师-统计学基础知识-第三章 参数估计
统计学基础知识 第三章 参数估计 第一节 统计量与抽样分布 1.1 总体参数与统计量 总体参数:描述总体特征的未知量(如均值 μ \mu μ、方差 σ 2 \sigma^2 σ2、比例 π \pi π)。统计量:由样本数据计算的量(如样本…...

学习黑客HTTP 请求头
HTTP 请求头(Request Headers)是 HTTP 请求中非常重要的一部分,它们以键值对的形式向服务器传递关于请求的附加信息、客户端的能力或上下文。 理解请求头对于 Web 开发、API 交互、网络调试和安全都至关重要。下面我将常见的 HTTP 请求头字段…...

日志参数含义
一 学习率相关 base_lr:基础学习率,初始设定的学习率 -lr:当前实际使用的学习率,通常是 base_lr 经过学习率调整策略后的值,比如lrbase_lr*(1start_factor) 时间统计 time:每次迭代总时间,单位…...

[Linux]安装吧!我的软件包管理器!
一、常见安装方式 在 Linux 中,有 3 种常见的软件安装方式: (1)yam、apt (2).rpm 安装包安装 (3)源码安装 二、什么是软件包 在 Linux 下安装软件,通常的办法是下载…...

Flink 作业提交流程
Apache Flink 的 作业提交流程(Job Submission Process) 是指从用户编写完 Flink 应用程序,到最终在 Flink 集群上运行并执行任务的整个过程。它涉及多个组件之间的交互,包括客户端、JobManager、TaskManager 和 ResourceManager。…...

牛客网NC276110题解:小红的数组重排
牛客网NC276110题解:小红的数组重排 题目解析 算法思路 对数组进行排序(非降序)检查特殊情况: 如果存在三个连续相等的元素,则无解如果前两个元素都是0,则无解 若不存在特殊情况,则排序后的数…...

从零启动 Elasticsearch
elastic 有弹力的 ElaticSearch (ES)是一个基于 Lucene 的分布式全文检索引擎。可以做到近乎实时地存储、检索数据,并且本身具有良好的扩展性,可以扩展到上百台服务器,处理PB级别(1 Petabyte 1024TB&…...

nginx服务器实验
1.实验要求 1)在Nginx服务器上搭建LNMP服务,并且能够对外提供Discuz论坛服务。 在Web1、Web2服务器上搭建Tomcat 服务。 2)为nginx服务配置虚拟主机,新增两个域名 www.kgc.com 和 www.benet.com,使用http://www.kgc.…...
)
王树森推荐系统公开课 排序02:Multi-gate Mixture-of-Experts (MMoE)
专家模型 与上一节相同,模型的输入是一个向量,包含用户特征、物品特征、统计特征、场景特征,把向量输入三个神经网络,三个神经网络都是由很多全连接层组成,但是并不共享参数,三个神经网络各输出一个向量&a…...

【OpenCV基础 1】几何变换、形态学处理、阈值分割、区域提取和脱敏处理
目录 一、图像几何变化 1、对图片进行放大、缩小、水平放大和垂直放大 2、旋转、缩放、控制画布大小 二、图像形态学处理 1、梯度运算 2、闭运算 3、礼帽运算 4、黑帽运算 三、图像阈值分割 1、二值化处理 2、反二值化处理 3、截断阈值处理 4、超阈值零处理 5、低…...

代码随想录算法训练营 Day49 图论Ⅰ 深度优先与广度优先
图论 基础 图的概念 图的概念 概念清单有向图 (a)无向图 (b)有向/无向如图 a 所示每条边有指向如图 b 所示每条边没有箭头指向权值每条边的权值每条边的权值度-有几条边连到该节点 (eg V 2 V_2 V2 度为 3)入度/出度出度:从该节点出发的边个数入度:…...

LG P9844 [ICPC 2021 Nanjing R] Paimon Segment Tree Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),有 m m m 次修改 ( l , r , v ) (l,r,v) (l,r,v): 对每个 i ∈ [ l , r ] i\in[l,r] i∈[l,r],令 a i ← a i v a_i\gets a_iv ai←…...

PyTorch音频处理技术及应用研究:从特征提取到相似度分析
文章目录 音频处理技术及应用音频处理技术音视频摘要技术音频识别及应用 梅尔频率倒谱系数音频特征尔频率倒谱系数简介及参数提取过程音频处理快速傅里叶变换(FFT)能量谱处理离散余弦转换 练习案例:音频建模加载音频数据源波形变换的类型绘制波形频谱图波形Mu-Law 编…...

【IPMV】图像处理与机器视觉:Lec10 Edges and Lines
【IPMV】图像处理与机器视觉:Lec10 Edges and Lines 本系列为2025年同济大学自动化专业**图像处理与机器视觉**课程笔记 Lecturer: Rui Fan、Yanchao Dong Lec0 Course Description Lec3 Perspective Transformation Lec7 Image Filtering Lec8 Image Pyramid …...

Elasticsearch 初步认识
Elasticsearch 初步认识 1 索引(index) 索引是具有相同结构的文档集合。例如,可以有一个客户信息的索引,包括一个产品目录的索引,一个订单数据的索引。在系统上索引的名字全部小写,通过这个名字可以用来执…...

数据库DDL
数据库DDL(数据定义语言)全面解析 一、DDL定义 DDL(Data Definition Language,数据定义语言)是SQL语言的一个子集,专门用于定义和管理数据库结构。它允许数据库管理员和开发人员创建、修改和删除数据库对象…...

企业级小程序APP用户数据查询系统安全脆弱性分析及纵深防御体系构建
一、用户数据查询系统安全现状分析 1.1 业务场景风险建模 在企业小程序用户数据查询业务中,普遍存在以下安全风险点: ①输入验证缺失:未对姓名、身份证号等关键输入进行严格的格式校验与合法性检查 ②身份认证薄弱:仅依赖基础参数…...

互联网大厂Java面试:从Spring Boot到微服务架构的技术深挖
场景描述 在某互联网大厂的面试会议室里,严肃的面试官老王正审视着面前的程序员明哥。这场面试以业务场景为切入点,围绕Java技术栈展开。 第一轮:基础知识与Spring生态 面试官老王: 明哥,你对Spring Boot的核心功能…...

23种设计模式解释+记忆
一、创建型模式(5种)—— “怎么造对象?” 单例模式(Singleton) 场景:公司的CEO只能有一个。 核心:确保一个类只有一个实例,全局访问。 关键词:唯一、全局访问。 工厂方…...

逻辑与非逻辑的弥聚
非逻辑弥聚与逻辑弥聚是复杂系统中两种不同的信息整合方式。逻辑弥聚侧重于通过明确的规则、规律和结构化方法,将分散的信息或功能进行有序的组织和集中处理,强调理性和确定性。而非逻辑弥聚则更多地涉及情感、直觉、经验等非线性、非结构化的因素&#…...

Python 从列表中删除值的多种实用方法详解
# Python 从列表中删除值的多种实用方法详解 在Python编程中,列表(List)是一种常用的数据结构,具有动态可变的特性。当我们需要从列表中删除元素时,根据不同的场景(如按值删除、按索引删除、批量删除等&…...

C++多线程数据错乱
C多线程数据错乱(也称为线程安全问题或数据竞争)主要是由于多个线程在没有正确同步的情况下,并发访问和修改共享数据导致的。其主要原因包括以下几个方面: 一、线程交替执行导致的非原子操作 线程在执行时,可能会在中途被挂起&a…...
)
StarRocks Community Monthly Newsletter (Apr)
版本动态 3.4.3 版本更新 核心功能升级 Routine Load和Stream Load新增Lambda表达式支持,支持复杂的列数据提取 增强JSON数据处理能力,支持将JSON Array/Object转为ARRAY/MAP类型 优化information_schema.task_runs视图查询,新增LIMIT支持…...

延时双删-争议与我的思路-001
目录 概括大概思路目的场景思路一退货时间差 思路2思路3 最后 概括 延时双删,是指在代码中删除两次缓存. 第一次自己访问,先删除.之后直接访问数据库获得数据 第二次是指 在第一步之后,在删除一次缓存的数据 大概思路 不进行延时双删的.寻找别的解决方法 目的 主要是为了…...

Tomcat简述介绍
文章目录 Web服务器Tomcat的作用Tomcat分析目录结构 Web服务器 Web服务器的作用是接收客户端的请求,给客户端作出响应。 知名Java Web服务器 Tomcat(Apache):用来开发学习使用;免费,开源JBoss࿰…...

掌握版本控制从本地到分布式
一、什么是版本控制? 版本控制是一种记录文件(尤其是源代码)在“时间轴”上变更的系统,主要功能包括: 历史回溯:随时恢复到任意版本的代码或文档;差异比较:查看两个版本之间的改动…...

Linux `touch` 命令深度解析与高阶应用指南
Linux `touch` 命令深度解析与高阶应用指南 一、核心功能解析1. 基本作用2. 与类似操作对比二、选项系统详解1. 基础选项说明2. 时间格式说明三、高阶应用技巧1. 时间戳控制2. 批量文件操作3. 特殊文件处理四、企业级应用场景1. 日志系统维护2. 持续集成系统3. 安全审计跟踪五、…...

Django学习
1:在PyCharm终端: # 查看已安装的Django版本 python -m django --version # 或 pip show django # 卸载当前Django pip uninstall django# 安装指定版本(例如Django 3.2.10) pip install django3.2.10 2. 检查Python版本兼容性 …...

Java IO框架
I/O框架 流 流的分类: 按方向: 输入流:将存储设备的内容读入到内存中 输出流:将内存的内容写入到存储设备中 按单位: 字节流:以字节为单位,可以读取所有数据 字符流:以字符为单…...