PyTorch音频处理技术及应用研究:从特征提取到相似度分析
文章目录
- 音频处理技术及应用
- 音频处理技术
- 音视频摘要技术
- 音频识别及应用
- 梅尔频率倒谱系数音频特征
- 尔频率倒谱系数简介及参数提取过程
- 音频处理
- 快速傅里叶变换(FFT)
- 能量谱处理
- 离散余弦转换
- 练习案例:音频建模
- 加载音频数据源
- 波形变换的类型
- 绘制波形频谱图
- 波形Mu-Law 编码
- 对比前后波形的比较
- 练习案例:音频相似度分析
- 案例说明
- 实现代码
- 结果分析
音频处理技术及应用
- 音频信号具有采集设备简单、存储空间小、处理速度快等优势,本节介绍其核心技术及应用场景。
音频处理技术
-
音频处理技术的商业化应用日益广泛。例如,微软于2021年收购智能语音公司Nuance,主要看中其在医疗领域的对话式AI和云端解决方案。Nuance的Dragon语音转录软件采用深度学习技术,持续提升识别精度,该技术已应用于苹果Siri等产品。
-
随着移动设备的普及和算力提升,现代智能终端普遍配备声音传感器和高效处理器,使音频处理技术广泛应用于以下领域: 多媒体数据检索 、环境检测与自适应调整 、视觉辅助系统(在视线受阻或光照不足时提供补充信息)
-
关键技术突破包括:
- 环境类别识别:设备可通过音频分析自动切换模式(如手机识别场景类型)
- 辅助功能增强:助听器等设备整合环境识别功能,提升用户体验
- 场景感知:系统能通过声音特征(如对话、背景音)判断环境类型(如区分餐厅和车辆)
-
音频场景建模主要解决两个问题: 特定场所的声学特征建模(如餐厅、车站) 场景内对象/事件的声学特征检测(如笑声、鸣笛声)。尽管已开发MFCC等特征提取方法,但由于声音信号的复杂性,建模分析仍面临挑战。
音视频摘要技术
该技术通过提取关键内容实现信息压缩:
- 音频摘要:识别重要转折点,生成时间缩短但保留核心内容的版本
- 视频摘要:浓缩长视频的关键片段,特别适用于监控录像分析
关键技术实现:
- 音频兴趣度量化:
- 分割音频为等长片段
- 提取MFCC特征并计算协方差矩阵
- 通过特征空间映射评估兴趣度(实验证明可有效识别笑声等特征音)
- 音视频融合分析:场景转换常伴随声音变化(如球赛进球时的欢呼声),可辅助关键帧提取
音频识别及应用
主要解决海量音频数据的高效检索问题,核心应用包括:
-
音频分类: 四大类别:语音、音乐、环境音、静音
- 处理流程: 静音检测(基于能量阈值) ,MFCC特征提取,基于MDL的高斯建模分割,分层分类(语音/音乐/环境音)
-
音乐情感分析: 情感模型:
- 类别模型(6种基础情感)
- 维度模型(情感空间坐标)
- 应用价值:实现多媒体内容的情绪化索引和检索
梅尔频率倒谱系数音频特征
- 在语音识别(SpeechRecognition)和说话者识别(SpeakerRecognition)方面,最常用到的语音特征就是梅尔频率倒谱系数(MFCC)。
尔频率倒谱系数简介及参数提取过程
- 梅尔频率倒谱系数(MFCC)是音频处理中常用的特征提取方法。它的设计模仿了人耳对声音的感知特点。
-
基本原理:人耳对低频声音更敏感(比如能更好地区分低音变化),高频区域的区分能力相对较弱
-
计算过程:
- 先设置一组三角滤波器(低频区域滤波器密集,高频区域稀疏)
- 让音频信号通过这些滤波器
- 记录每个滤波器输出的能量值
- 对这些能量值做进一步处理得到最终特征
- 主要优势:不受原始声音内容影响(适用于各种声音);抗噪能力强(在嘈杂环境中仍能准确提取特征);符合人耳听觉特性(提取的特征更贴近实际听感)
- 这种方法让机器能像人耳一样"听懂"声音的关键特征。
- MFCC参数的提取过程如图
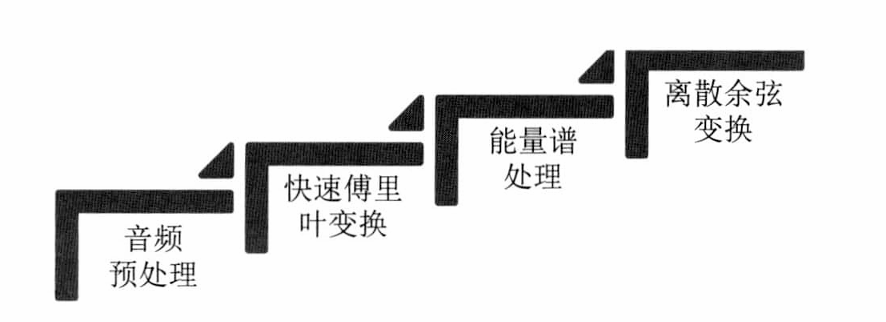
音频处理
- 信号预处理过程包括预加重,分侦,加载。预加重的过程即使将语音信号通过一个高通滤波器得到新的信号,如语音信号 s ( n ) s(n) s(n)通过高通滤波器 H ( z ) = l − α × ( z − l ) H(z)=l-α×(z-l) H(z)=l−α×(z−l)预加重后得到的信号为 s 2 ( n ) = s ( n ) − a × s ( n − l ) s_2(n)=s(n)-a×s(n-l) s2(n)=s(n)−a×s(n−l),其中,系数 a a a介于 0.9 0.9 0.9和 1.0 1.0 1.0之间。预加重的目的是补偿音频信号被隐藏的高频部分,从而凸显高频的共振峰。
- 预处理过程的第二个步骤是分帧,语音信号分帧的目的是将若干个取样点集合作为一个观测单位,即处理单位,一般认为 10 ~ 30 m s 10~30ms 10~30ms的语音信号是稳定的,比如采样率为 44.1 k H z 44.1kHz 44.1kHz的声音信号,取20ms长度为一个帧长,那么一个帧长由 44100 × 0.02 = 882 44100×0.02=882 44100×0.02=882个取样点组成。通常为了避免相邻两帧之间的变化过大,会在两相邻帧之间设置一段的重叠区域,重叠区域的长度一般是帧长的一半或 1 / 3 1/3 1/3。
- 在完成预加重和分帧之后,下一步是对每一帧应用汉明窗。通常,在处理语音信号时,“加窗”意味着一次只处理窗口内的数据。由于实际的语音信号往往很长,无法一次性全部处理。只需要每次分析一段数据即可。通过构造特定的函数实现,函数在处理区间内取非零值,在非处理区间内则为零。汉明窗就是这样一种函数,任何信号与汉明窗,任何信号与汉明窗相乘后,结果的一部分将是非零值,其余部分则为零。处理完一个窗口内的数据后,需要移动窗口,通常移动的步长是帧长的一半或三分之一以产生重叠。
- 汉明窗函数的形式
w ( n , a ) = ( 1 − a ) − a × c o s ( 2 π × n N − 1 ) 0 ≤ n ≤ N − 1 w(n,a)=(1-a)-a\times cos(2\pi \times \frac{n}{N-1}) 0\leq n\leq N-1 w(n,a)=(1−a)−a×cos(2π×N−1n)0≤n≤N−1 - N N N是处理数据点的个数(帧长),分帧是窗函数截取原音频信号形成的,一般a取值为0.46,汉明窗函数还可以写成如下形式:
KaTeX parse error: Undefined control sequence: \leqN at position 89: …{N-1}) 0\leq n \̲l̲e̲q̲N̲\\ 0\quad \te… - 加汉明窗后的声音信号如下:
s ( n ) = s ( n ) × w ( n ) n = 0 , 1 , . . . , N − 1 s(n)=s(n)\times \qquad w(n) n=0,1,...,N-1 s(n)=s(n)×w(n)n=0,1,...,N−1
快速傅里叶变换(FFT)
- 快速傅里叶变换(FastFourierTransform,FFT)是一种高效计算离散傅里叶变换(DFT)的算法,在音频处理中有着广泛的应用。
- 原始音频信号在时域上难以直观体现特征,因此需要通过加汉明窗后进行快速傅里叶变换(FFT),将其转换到频域来观察声音的能量分布特征。
- FFT是对离散傅里叶变换(DiscreteFourierTransform,DFT)的改进算法,快速算法实现的基本思想是分析原有变换的计算特点以及某些子运算的特殊性,想办法减少乘法和加法操作次数,换一种方式实现原变换的效果。
- 语音信号的离散傅里叶变换如下
S a ( k ) = ∑ n = 0 N − 1 s ( n ) ∗ e − j 2 π k / N 0 ≤ k ≤ N S_a(k)=\sum_{n=0}^{N-1}s(n)*e^{-j2\pi k/N} \qquad 0\leq k \leq N Sa(k)=n=0∑N−1s(n)∗e−j2πk/N0≤k≤N - s ( n ) s(n) s(n)是加窗后的语音信号, N N N表示傅里叶变换的点数。
- FFT是利用分治策略和对称性来减少DFT计算中的冗余步骤,从而提高了计算效率。这种算法特别适合信号处理中的频谱分析,因为它可以快速地从时域信号中提取出频域信息。
能量谱处理
- 音频预处理后,就需要计算能量谱,即求频谱幅度的平方。其计算方法是,将能量谱输入一组Mel频率的三角带通滤波器组,三角滤波器的中心频率为 f ( m ) , m = 1 , 2 , . . . , M f(m),m=1,2,...,M f(m),m=1,2,...,M,f(m)的取值随m取值的减小而缩小,随着m取值的增大而变宽,Mel频率代表的是一般人耳对于频率的感受度,其与一般的频率间的关系如下。
m e l ( f ) = 2595 ∗ l g ( 1 + f 700 ) mel(f)=2595*lg(1+\frac{f}{700}) \\ mel(f)=2595∗lg(1+700f) - 或者
m e l ( f ) = 1125 ∗ l g ( 1 + f 700 ) mel(f)=1125*lg(1+\frac{f}{700}) mel(f)=1125∗lg(1+700f) - 人耳对频率的感受度是呈对数变化的,在高频部分人耳对声音的感受越来越粗糙,在低频部分则相对敏感。三角滤波器引入的目的是平滑化频谱,消除谐波的作用,并突出原始信号的共振峰,因此MFCC参数不能呈现原始语音的音调或音高,即提取声音信号的MFCC特征时,不受语音音调的影响。三角滤波器的频率响应定义如下所示,其中
∑ m = 0 M − 1 H m ( k ) = 1 \sum_{m=0}^{M-1}H_m(k)=1 m=0∑M−1Hm(k)=1
H m ( k ) = { 0 k < f ( m − 1 ) 2 ( k − f ( m − 1 ) ) ( f ( m + 1 ) − f ( m − 1 ) ) ( f ( m ) − f ( m − 1 ) ) f ( m − 1 ) ⩽ k ⩽ f ( m ) 2 ( f ( m + 1 ) − k ) ( f ( m + 1 ) − f ( m − 1 ) ) ( f ( m + 1 ) − f ( m ) ) f ( m ) ⩽ k ⩽ f ( m − 1 ) 0 k ⩾ f ( m + 1 ) \begin{equation} H _ { m } ( k ) = \left\{ \begin{array} { l l } { 0 } & { k < f ( m - 1 ) } \\ { \cfrac { 2 ( k - f ( m - 1 ) ) } { ( f ( m + 1 ) - f ( m - 1 ) ) ( f ( m ) - f ( m - 1 ) ) } } & { f ( m - 1 ) \leqslant k \leqslant f ( m ) } \\ { \cfrac { 2 ( f ( m + 1 ) - k ) } { ( f ( m + 1 ) - f ( m - 1 ) ) ( f ( m + 1 ) - f ( m ) ) } } & { f ( m ) \leqslant k \leqslant f ( m - 1 ) } \\ { 0 } & { k \geqslant f ( m + 1 ) } \end{array} \right. \end{equation} Hm(k)=⎩ ⎨ ⎧0(f(m+1)−f(m−1))(f(m)−f(m−1))2(k−f(m−1))(f(m+1)−f(m−1))(f(m+1)−f(m))2(f(m+1)−k)0k<f(m−1)f(m−1)⩽k⩽f(m)f(m)⩽k⩽f(m−1)k⩾f(m+1)
离散余弦转换
- 离散余弦转换是一种在数字信号处理中非常有用的工具,它通过将信号转换为频域表示,帮助分析和处理信号,尤其在图像和音频编码领域有着重要的应用。例如,我们对对数能量做离散余弦转换(DCT),得到的 C ( n ) C(n) C(n) 即为 M M M 阶的Mel倒谱参数,通常取前12个作为最终的MFCC特征。计算公式如下:
C ( n ) = ∑ m = 0 N − 1 S ( m ) cos ( π n ( m − 0.5 ) M ) 0 ≤ n < M C(n) = \sum_{m=0}^{N-1} S(m) \cos \left( \frac{\pi n (m - 0.5)}{M} \right) \quad 0 \leq n < M C(n)=m=0∑N−1S(m)cos(Mπn(m−0.5))0≤n<M
- 上式得到的倒谱参数只能反映语音信号的静态特性,如果要获得语音信号的动态特性需采用静态特性的差分谱描述,结合动态和静态的特征能更有效地提高对信号的识别性能,计算差分参数的公式如下:
d t = { C t + 1 − C t t < K ∑ k = 1 K k ( C t + k − C t − k ) 2 ∑ k = 1 K k 2 其他 C t − C t − 1 t ≥ Q − K d_t = \begin{cases} C_{t+1} - C_t & t < K \\ \frac{\sum_{k=1}^{K} k (C_{t+k} - C_{t-k})}{\sqrt{2 \sum_{k=1}^{K} k^2}} & \text{其他} \\ C_t - C_{t-1} & t \geq Q - K \end{cases} dt=⎩ ⎨ ⎧Ct+1−Ct2∑k=1Kk2∑k=1Kk(Ct+k−Ct−k)Ct−Ct−1t<K其他t≥Q−K
- 其中, Q Q Q 表示的是倒谱系数的阶数, d t d_t dt 表示第 t t t 个一阶差分, C t C_t Ct 表示第 t t t 个倒谱系数, K K K 表示的是一阶导数的时间差,取1或2。
练习案例:音频建模
加载音频数据源
import torchaudio
import matplotlib.pyplot as plt#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
# 显示波形
print("波形形状:{}".format(waveform.size()))
# 显示采样率
print("波形采样率:{}".format(sample_rate))
# 绘制波形图并添加标题和坐标轴标签
plt.figure()
plt.plot(waveform.t().numpy())
plt.title("Audio Waveform")
plt.xlabel("Sample Points")
plt.ylabel("Amplitude")
plt.show()
波形形状:torch.Size([2, 8935836])
波形采样率:44100
波形变换的类型
torchaudio库支持的波形转换类型如下。
| 功能名称 | 描述 |
|---|---|
| 重采样 (Resample) | 将波形重采样为其他采样率。 |
| 频谱图 (Spectrogram) | 从波形创建频谱图。 |
| GriffinLim | 使用Griffin-Lim转换从线性比例幅度谱图计算波形。 |
| ComputeDeltas | 计算张量(通常是声谱图)的增量系数。 |
| ComplexNorm | 计算复数张量的范数。 |
| MelScale | 使用转换矩阵将正常STFT转换为Mel频率STFT。 |
| AmplitudeToDB | 将频谱图从功率/振幅标度变为分贝标度。 |
| MFCC | 根据波形创建梅尔频率倒谱系数。 |
| MelSpectrogram | 使用PyTorch中的STFT功能从波形创建MEL频谱图。 |
| MuLawEncoding | 基于mu-law压扩对波形进行编码。 |
| MuLawDecoding | 解码mu-law编码的波形。 |
| TimeStretch | 在不更改给定速率的音高的情况下,及时拉伸频谱图。 |
| FrequencyMasking | 在频域中屏蔽频谱图应用。 |
| TimeMasking | 在时域中屏蔽频谱图应用。 |
绘制波形频谱图
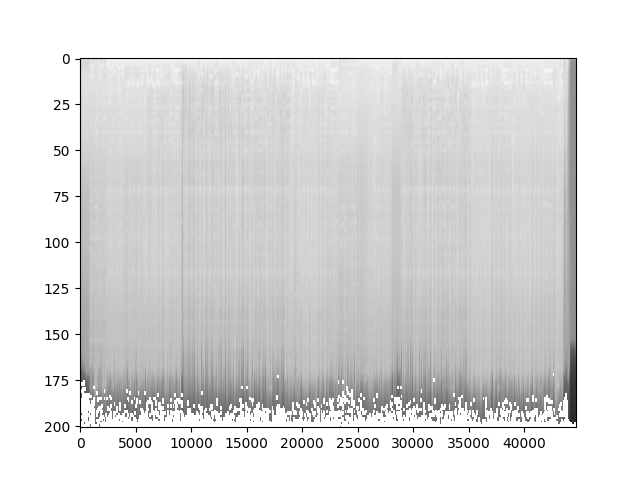
- 以对数刻度查看频谱图的对数。首先使用torchaudio库中的Spectrogram函数将波形数据转换为频谱图。然后打印出频谱图的形状,并使用Matplotlib库绘制并显示频谱图。通过观察频谱图,可以了解信号在不同频率上的能量分布情况。
import torchaudio
import matplotlib.pyplot as plt
#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
#对数刻度查看频谱图
spectrogram = torchaudio.transforms.Spectrogram()(waveform)
# 打印频谱图的形状,即频谱图的尺寸
print("频谱图形状:{}".format(spectrogram.size()))
plt.figure()
"""
# 显示频谱图的对数变换结果spectrogram.log2()[0,:,:].numpy()表示取频谱图的对数变换结果,并将其转换为NumPy 数组cmap='gray用于指定颜色映射为灰度色aspect="auto”表示自动调整图像的纵横比
"""
plt.imshow(spectrogram.log2()[0,:,:].numpy(),cmap='gray',aspect="auto")
plt.show()
频谱图形状:torch.Size([2, 201, 44680])
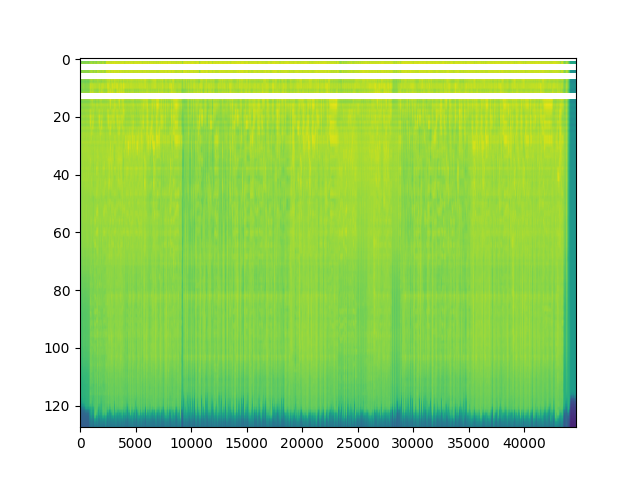
- 使用对数刻度查看梅尔频谱图。将波形数据转换为梅尔频谱图,并将其可视化显示出来,以便观察信号在梅尔频率尺度上的能量分布情况。使用MelSpectrogram函数来生成梅尔频谱图。梅尔频谱图是一种特殊的频谱表示,它基于梅尔频率尺度,常用于语音处理等领域。
import torchaudio
import matplotlib.pyplot as plt
#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
#对数刻度查看梅尔光谱图
spectrogram = torchaudio.transforms.MelSpectrogram()(waveform)
print("梅尔频谱图形状:{}".format(spectrogram.size()))
plt.figure()
# 显示梅尔频谱图的对数变换结果
p = plt.imshow(spectrogram.log2()[0,:,:].detach().numpy(),cmap='viridis',aspect="auto")
plt.show()
梅尔频谱图形状:torch.Size([2, 128, 44680])
- 重新采样波形,一次一个通道。重采样常用于改变波形的采样率,以便适应不同的需求或处理。
import torchaudio
import matplotlib.pyplot as plt
#加载声音文件,原始音频信号
filename = "恭喜发财.mp3"
# 加载音频文件并获取波形和采样率
waveform,sample_rate = torchaudio.load(filename)
# 计算新的采样率,将原始采样率除以15
new_sample_rate = sample_rate/15
# 选择要处理的通道,设置为0
channel = 0
# 使用Resample函数对波形进行重采样将原始采样率和新的采样率作为参数传递给函数,并将波形数据的指定通道转换为一维张量
transformed = torchaudio.transforms.Resample(sample_rate,new_sample_rate)(waveform[channel,:].view(1,-1))
# 打印变换后波形的形状,即尺寸信息
print("变换后波形形状:{}".format(transformed.size()))
plt.figure()
# 绘制变换后的波形 transformed[O,:]表示取变换后波形的第一个样本,并将其转换为NumPy数组进行绘图
plt.plot(transformed[0,:].numpy())
plt.show()
变换后波形形状:torch.Size([1, 595723])
波形Mu-Law 编码
- 基于Mu-Law编码对信号进行编码,需要信号在-1和1之间。由于张量只是一个常规的PyTorch张量,因此可以在其上应用标准运算符。
print("波形最小值:{}\n波形最大值:{}\n波形平均值:{}".format(waveform_.min(),waveform_.max(),waveform_.mean()))
波形最小值:-1.0179462432861328
波形最大值:0.9967186450958252
波形平均值:-1.8553495465312153e-05
- 对波形进行归一化,使其处于-1到1之间。
#波形的归一化
def normalize(tensor):tensor_minusmean = tensor - tensor.mean()return tensor_minusmean/tensor_minusmean.abs().max()waveform_normalize = normalize(waveform)print("波形最小值:{}\n波形最大值:{}\n波形平均值:{}".format(waveform_normalize.min(),waveform_normalize.max(),waveform_normalize.mean()))
波形最小值:-1.0
波形最大值:0.9791827201843262
波形平均值:1.3822981648203836e-09
- 应用编码波形,绘制波形图帮助理解变换后的波形特征。
#新波形Mu-Law编码
transformed = torchaudio.transforms.MuLawEncoding()(waveform_normalize)
print("变换后波形形状: {}".format(transformed.size()))plt.figure()
plt.plot(transformed[0,:].numpy())
plt.show()
- 解码并观察到解码后新波形的形状和特征。Mu-Law编码是Mu-Law编码的逆操作,用于将编码后的波形还原为原始波形的近似。绘制波形图可以帮助直观地理解解码后的波形特征。
#对新波形解码
reconstructed = torchaudio.transforms.MuLawDecoding()(transformed)
print("新波形形状: {}".format(reconstructed.size()))plt.figure()
plt.plot(reconstructed[0,:].numpy())
plt.show()
对比前后波形的比较
- 分析波形变换前后是否存在较大差异,可以将原始波形与归一化和Mu-Law变换后的波形进行比较。评估原始波形和重构波形之间的相似度或差异程度。
#比较原始波形与新波形
epsilon = 1e-8
err = ((waveform - reconstructed).abs() / (waveform.abs() + epsilon)).mean()
print("原始信号和重构信号之间的差异: {:.2%}".format(err))
原始信号和重构信号之间的差异: 27.08%
练习案例:音频相似度分析
案例说明
- 通过使用torchaudio库和余弦相似度研究两个音频之间的相似程度,从而根据用户喜欢的音频信号进行音乐等方面的推荐。
实现代码
import torch
import torchaudio
import soundfile
import matplotlib.pyplot as plt
# 支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题filename1 = "教程1.wav"
waveform1,sample_rate1 = torchaudio.load(filename1)
print("Shape of waveform:{}".format(waveform1.size())) #音频大小
print("sample rate of waveform:{}".format(sample_rate1))#采样率
plt.figure()
plt.plot(waveform1.t().numpy())
plt.title("教程1波形")
plt.show()filename2 = "教程2.wav"
waveform2,sample_rate2 = torchaudio.load(filename2)
print("Shape of waveform:{}".format(waveform2.size())) #音频大小print("sample rate of waveform:{}".format(sample_rate2))#采样率
plt.figure()
plt.plot(waveform2.t().numpy())
plt.title("教程2波形")
plt.show()similarity = torch.cosine_similarity(waveform1, waveform2, dim=0)
print('similarity', similarity)
# 输出平均差异值
print(similarity.mean())
# 输出中位数
print(similarity.median())
结果分析
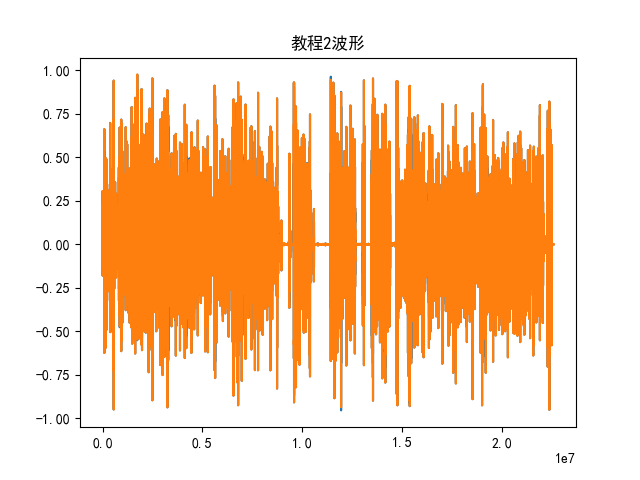
Shape of waveform:torch.Size([2, 22601250])
sample rate of waveform:44100
Shape of waveform:torch.Size([2, 22601250])
sample rate of waveform:44100
similarity tensor([0.0000, 0.0000, 0.0000, ..., 0.9701, 1.0000, 0.9487])
tensor(-6.3115e-05)
tensor(0.)
- 余弦相似度是一种常用的相似性度量,用于衡量两个向量之间的相似程度。这里用于比较两个波形之间的相似度运行结果为
similarity tensor([0.0000, 0.0000, 0.0000, ..., 0.9701, 1.0000, 0.9487]) - 相似度矩阵的均值
similarity.mean()计算相似度矩阵的均值。 - 相似度矩阵的中位数
similarity.median()接近于0,说明两个音频不相思。
相关文章:

PyTorch音频处理技术及应用研究:从特征提取到相似度分析
文章目录 音频处理技术及应用音频处理技术音视频摘要技术音频识别及应用 梅尔频率倒谱系数音频特征尔频率倒谱系数简介及参数提取过程音频处理快速傅里叶变换(FFT)能量谱处理离散余弦转换 练习案例:音频建模加载音频数据源波形变换的类型绘制波形频谱图波形Mu-Law 编…...

【IPMV】图像处理与机器视觉:Lec10 Edges and Lines
【IPMV】图像处理与机器视觉:Lec10 Edges and Lines 本系列为2025年同济大学自动化专业**图像处理与机器视觉**课程笔记 Lecturer: Rui Fan、Yanchao Dong Lec0 Course Description Lec3 Perspective Transformation Lec7 Image Filtering Lec8 Image Pyramid …...

Elasticsearch 初步认识
Elasticsearch 初步认识 1 索引(index) 索引是具有相同结构的文档集合。例如,可以有一个客户信息的索引,包括一个产品目录的索引,一个订单数据的索引。在系统上索引的名字全部小写,通过这个名字可以用来执…...

数据库DDL
数据库DDL(数据定义语言)全面解析 一、DDL定义 DDL(Data Definition Language,数据定义语言)是SQL语言的一个子集,专门用于定义和管理数据库结构。它允许数据库管理员和开发人员创建、修改和删除数据库对象…...

企业级小程序APP用户数据查询系统安全脆弱性分析及纵深防御体系构建
一、用户数据查询系统安全现状分析 1.1 业务场景风险建模 在企业小程序用户数据查询业务中,普遍存在以下安全风险点: ①输入验证缺失:未对姓名、身份证号等关键输入进行严格的格式校验与合法性检查 ②身份认证薄弱:仅依赖基础参数…...

互联网大厂Java面试:从Spring Boot到微服务架构的技术深挖
场景描述 在某互联网大厂的面试会议室里,严肃的面试官老王正审视着面前的程序员明哥。这场面试以业务场景为切入点,围绕Java技术栈展开。 第一轮:基础知识与Spring生态 面试官老王: 明哥,你对Spring Boot的核心功能…...

23种设计模式解释+记忆
一、创建型模式(5种)—— “怎么造对象?” 单例模式(Singleton) 场景:公司的CEO只能有一个。 核心:确保一个类只有一个实例,全局访问。 关键词:唯一、全局访问。 工厂方…...

逻辑与非逻辑的弥聚
非逻辑弥聚与逻辑弥聚是复杂系统中两种不同的信息整合方式。逻辑弥聚侧重于通过明确的规则、规律和结构化方法,将分散的信息或功能进行有序的组织和集中处理,强调理性和确定性。而非逻辑弥聚则更多地涉及情感、直觉、经验等非线性、非结构化的因素&#…...

Python 从列表中删除值的多种实用方法详解
# Python 从列表中删除值的多种实用方法详解 在Python编程中,列表(List)是一种常用的数据结构,具有动态可变的特性。当我们需要从列表中删除元素时,根据不同的场景(如按值删除、按索引删除、批量删除等&…...

C++多线程数据错乱
C多线程数据错乱(也称为线程安全问题或数据竞争)主要是由于多个线程在没有正确同步的情况下,并发访问和修改共享数据导致的。其主要原因包括以下几个方面: 一、线程交替执行导致的非原子操作 线程在执行时,可能会在中途被挂起&a…...
)
StarRocks Community Monthly Newsletter (Apr)
版本动态 3.4.3 版本更新 核心功能升级 Routine Load和Stream Load新增Lambda表达式支持,支持复杂的列数据提取 增强JSON数据处理能力,支持将JSON Array/Object转为ARRAY/MAP类型 优化information_schema.task_runs视图查询,新增LIMIT支持…...

延时双删-争议与我的思路-001
目录 概括大概思路目的场景思路一退货时间差 思路2思路3 最后 概括 延时双删,是指在代码中删除两次缓存. 第一次自己访问,先删除.之后直接访问数据库获得数据 第二次是指 在第一步之后,在删除一次缓存的数据 大概思路 不进行延时双删的.寻找别的解决方法 目的 主要是为了…...

Tomcat简述介绍
文章目录 Web服务器Tomcat的作用Tomcat分析目录结构 Web服务器 Web服务器的作用是接收客户端的请求,给客户端作出响应。 知名Java Web服务器 Tomcat(Apache):用来开发学习使用;免费,开源JBoss࿰…...

掌握版本控制从本地到分布式
一、什么是版本控制? 版本控制是一种记录文件(尤其是源代码)在“时间轴”上变更的系统,主要功能包括: 历史回溯:随时恢复到任意版本的代码或文档;差异比较:查看两个版本之间的改动…...

Linux `touch` 命令深度解析与高阶应用指南
Linux `touch` 命令深度解析与高阶应用指南 一、核心功能解析1. 基本作用2. 与类似操作对比二、选项系统详解1. 基础选项说明2. 时间格式说明三、高阶应用技巧1. 时间戳控制2. 批量文件操作3. 特殊文件处理四、企业级应用场景1. 日志系统维护2. 持续集成系统3. 安全审计跟踪五、…...

Django学习
1:在PyCharm终端: # 查看已安装的Django版本 python -m django --version # 或 pip show django # 卸载当前Django pip uninstall django# 安装指定版本(例如Django 3.2.10) pip install django3.2.10 2. 检查Python版本兼容性 …...

Java IO框架
I/O框架 流 流的分类: 按方向: 输入流:将存储设备的内容读入到内存中 输出流:将内存的内容写入到存储设备中 按单位: 字节流:以字节为单位,可以读取所有数据 字符流:以字符为单…...

Spring AI Alibaba集成阿里云百炼大模型
1.准备工作 开发环境:JDK17、SpringBoot3.x 2.引入maven依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance&q…...

5月18总结
一.算法题总结 1. 解题思路:对于这个题,我最开始想到就是二分,但是头痛的是有三个解,如果我在-100到100之间二分,那么只能得出一个解,然后我就想了一下,这个要求精度,那么0.01这么小…...
可视化理解:图形化思考)
动态规划(4)可视化理解:图形化思考
引言 动态规划作为一种强大的算法设计范式,其抽象性常常使初学者感到困惑。许多学习者在理解状态定义、状态转移方程和递归结构时遇到困难,这些困难往往源于动态规划问题的高度抽象性和复杂性。然而,人类的大脑天生擅长处理视觉信息,通过将抽象的动态规划概念转化为直观的…...
---java版--需2刷)
2025年- H31-Lc139- 242.回文链表(快慢指针)---java版--需2刷
1.题目描述 2.思路 (1)将链表取中位数,分为左右两部分。 (2)右半部分的元素进行反转链表,能达到O(1)的空间复杂度 (3)再判断左右部分的元素,是否…...
)
云原生安全:IaaS安全全解析(从基础到实践)
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念:IaaS的核心价值与安全边界 1.1 什么是IaaS? 基础设施即服务(Infrastructure as a Service)是云计算的基础层,提供虚拟机、存储、网络等基础资源。用户通过…...

【AGI】大模型微调数据集准备
【AGI】大模型微调数据集准备 (1)模型内置特殊字符及提示词模板(2)带有系统提示和Function calling微调数据集格式(3)带有思考过程的微调数据集结构(4)Qwen3混合推理模型构造微调数据…...

二分算法的介绍简单易懂
目录 1.概论 2.朴素的二分算法 3.求左端点的二分算法和求右端点的二分算法 4.总结 1.概论 要想了解什么是二分算法,我们就要知道什么是二分算法,二分算法是根据数组的规律,每次查找的数据原来的效率可能要O(n),而我…...

Trae IDE和VSCode Trae插件初探
Trae IDE初探 输入以下提示词: 生成一个to do list清单web页面,采用vue实现,可以在页面上进行todolist进行增删改查。 VSCode Trae插件初探 trae vscode插件初探 tips:如果还是提示找不到npm命令,重启vscode即可&am…...
红黑树)
数据结构 -- 树形查找(三)红黑树
红黑树 为什么要发明红黑树 平衡二叉树AVL:插入/删除很容易破坏平衡性,需要频繁调整树的形态。如:插入操作导致不平衡,则需要先计算平衡因子,找到最小不平衡子树(时间开销大),在进行…...

Mac 在恢复模式下出现 旋转地球图标 但进度非常缓慢
如果您的 Mac 在恢复模式下出现 旋转地球图标 但进度非常缓慢,可能是由于网络连接或系统恢复机制的问题。以下是详细的解决方案: 1. 检查网络连接 • Wi-Fi 信号:确保您的 Wi-Fi 信号稳定,建议靠近路由器或使用有线网络ÿ…...
格式转VOC(xml)格式数据集】以及【制作VOC格式数据集 】)
【YOLO(txt)格式转VOC(xml)格式数据集】以及【制作VOC格式数据集 】
1.txt—>xml转化代码 如果我们手里只有YOLO标签的数据集,我们要进行VOC格式数据集的制作首先要进行标签的转化,以下是标签转化的脚本。 其中picPath为图片所在文件夹路径; txtPath为你的YOLO标签对应的txt文件所在路径; xmlPa…...

【信息系统项目管理师】第8章:项目整合管理 - 39个经典题目及详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...

“Cloud Native English“云原生时代下的微服务架构设计:从理论到实战全解析
前引 :技术演进与架构变革的必然性 在数字经济高速发展的今天,软件系统的复杂度呈指数级增长。传统单体架构已无法满足高并发、弹性扩展和快速迭代的需求。根据Gartner预测,到2026年全球75%的企业将完成微服务架构改造。本文将深入探讨云原生…...
)
自由学习记录(61)
使用了 #pragma multi_compile_fwdbase 这条编译指令启用了 Unity 内部用于主光源阴影支持的一组关键词变体,如: SHADOWS_SCREEN(屏幕空间阴影贴图) SHADOWS_DEPTH(深度图阴影) SHADOWS_SOFT(…...
)
深入了解linux系统—— 基础IO(下)
前言 在基础IO(上)中,我们了解了文件相关的系统调用;以及文件描述符是什么,和操作系统是如何将被打开的文件管理起来的。 本篇文章来继续学习文件相关的知识 重定向 在了解重定向之前,我们先来看这样的…...

Flink Table SQL
Apache Flink 提供了强大的 Table API 和 SQL 接口,用于统一处理批数据和流数据。它们为开发者提供了类 SQL 的编程方式,简化了复杂的数据处理逻辑,并支持与外部系统集成。 🧩 一、Flink Table & SQL 核心概念 概念描述Table…...

【Git】基本操作
【简介】 Git是一种“版本控制器”, 可以用于记录每次的修改以及版本的迭代 其可以控制电脑上所有格式的文件,方便地查看文件的每个小修改版本都修改了什么内容,但前提条件是被管理的文件需要放在对应的git仓库(又名“版本库”&…...

【八股战神篇】MySQL高频面试题
目录 专栏简介 一 什么是索引 延伸 1 索引的底层使用的是什么数据结构? 2 MySQL 索引分类有哪些? 3 什么字段适合创建索引? 4 索引失效的场景 5 什么是最左匹配原则? 二 为什么 InnoDB 存储引擎选用 B 树而不是 B 树呢&a…...

服务器防文件上传手写waf
一、waf的目录结构,根据自己目录情况进行修改 二、创建文件夹以及文件 sudo mkdir -p /www/server/waf-monitor sudo mkdir -p /www/server/waf-monitor/quarantine #创建文件夹 chmod 755 /www/server/waf-monitor #赋权cd /www/server/waf-monitor/touch waf-m…...

ElasticSearch-集群
本篇文章依据ElasticSearch权威指南进行实操和记录 1,空集群 即不包含任何节点的集群 集群大多数分为两类,主节点和数据节点 主节点 职责:主节点负责管理集群的状态,例如分配分片、添加和删除节点、监控节点故障等。它们不直接…...

Android开发——原生渲染方案实现 PDF 预览功能
Android开发——原生渲染方案实现 PDF 预览功能 1. 引言2. 原生渲染方案核心设计:从数据到视图3. 混合文档容器:ViewPager2 与适配器设计1. 引言 在移动应用开发中,PDF 预览是文档处理场景的核心需求之一。Android 生态提供了多元化的技术方案,从系统级简版预览到原生渲染…...

Java求职者面试:从Spring Boot到微服务的技术点解析
Java求职者面试:从Spring Boot到微服务的技术点解析 场景:互联网医疗-预约挂号系统 面试官: “小明,我们今天的场景是一个互联网医疗的预约挂号系统。我们需要支持高并发的用户预约操作,同时保证数据一致性和系统的高…...

操作系统听课笔记之进程的概念
引入新的概念,为什么不能叫程序 内存中进程Image实例: stack: 局部变量(函数弹出来没有了) data: 全局变量(共享) 静态变量 heap: malloc分配的内存 从数据结构和算法角度解决问题: 设计相应的数据结构和设计算法 数据结构: 进程PCB 算法:创建进程和进程通信各种操作在线内…...

【基于Spring Boot 的图书购买系统】深度讲解 用户注册的前后端交互,Mapper操作MySQL数据库进行用户持久化
引言 在现代Web应用中,用户注册功能是用户与应用交互的入口。一个高效、安全且用户友好的注册系统不仅能吸引用户,还能为后续功能(如个性化服务)奠定基础。本博客将通过一个实际案例,展示如何使用HTML、JavaScript、j…...

Spark,连接MySQL数据库,添加数据,读取数据
以下是使用 Spark/SparkSQL 连接 MySQL 数据库、添加数据和读取数据的完整示例(需提前准备 MySQL 驱动包): 一、环境准备 1. 下载 MySQL 驱动 - 下载 mysql-connector-java-8.0.33.jar (或对应版本),放…...

ubuntu的虚拟机上的网络图标没有了
非正常的关机导致虚拟机连接xshell连接不上,ping也ping不通。网络的图标也没有了。 记录一下解决步骤 1、重启服务 sudo systemctl restart NetworkManager 2、图标显示 sudo nmcli network off sudo nmcli network on 3、sudo dhclient ens33 //(网卡) …...

Linux系统:ext2文件系统的核心概念和结构
本节重点 块、块组、分区的引入块组的构成inode与inode Table路径解析与路径缓存机制目录与文件名在文件系统中的存储分区的初始化与挂载 一、ext2文件系统 1.1 “块”的引入 在前言部分我们说扇区是磁盘硬件的最小读写单位,通常为512字节,但是在操作…...

Python 装饰器详解
装饰器是 Python 中一种强大的语法特性,它允许在不修改原函数代码的情况下动态地扩展函数的功能。装饰器本质上是一个高阶函数,它接受一个函数作为参数并返回一个新的函数。 基本装饰器 1. 简单装饰器示例 def my_decorator(func):def wrapper():prin…...

Docker配置容器开机自启或服务重启后自启
要将一个 Docker 容器设置为开机自启,你可以使用 docker update 命令或配置 Docker 服务来实现。以下是两种常见的方法: 方法 1:使用 docker update 设置容器自动重启 使用 docker update 设置容器为开机自启 你可以使用以下命令,…...

20250518 黎曼在三维空间中总结的一维二维的规律,推广到高维度合适吗?有没有人提出反对意见
黎曼在三维空间中总结的一维二维的规律,推广到高维度合适吗?有没有人提出反对意见 黎曼几何在数学物理中的广泛应用,尤其是在广义相对论和高维空间理论中,确实是建立在黎曼在三维空间中的推广基础上的。不过,这种推广…...

使用AI 生成PPT 最佳实践方案对比
文章大纲 一、专业AI生成工具(推荐新手)**1. 推荐工具详解****2. 操作流程优化****3. 优势与局限**二、代码生成方案(开发者推荐)**1. Python-pptx进阶用法****2. GitHub推荐**三、混合工作流(平衡效率与定制)**1. 工具链升级****2. 示例Markdown结构**四、网页转换方案(…...
集群)
【Docker】Docker Compose方式搭建分布式协调服务(Zookeeper)集群
开发分布式应用时,往往需要高度可靠的分布式协调,Apache ZooKeeper 致力于开发和维护开源服务器,以实现高度可靠的分布式协调。具体内容见zookeeper官网。现代应用往往使用云原生技术进行搭建,如何用Docker搭建Zookeeper集群,这里介绍使用Docker Compose方式搭建分布…...
)
R for Data Science(3)
R for Data Science以下是关于网页内容的详细笔记: 1. 章节概览 章节主题:数据转换(Data Transformation)核心内容:介绍如何使用 R 中的 dplyr 包进行数据转换,包括对数据框的行、列和组的操作࿰…...