大模型学习:Deepseek+dify零成本部署本地运行实用教程(超级详细!建议收藏)
文章目录
- 大模型学习:Deepseek+dify零成本部署本地运行实用教程(超级详细!建议收藏)
- 一、Dify是什么
- 二、Dify的安装部署
- 1. 官网体验
- 2. 本地部署
- 2.1 linux环境下的Docker安装
- 2.2 Windows环境下安装部署DockerDeskTop
- 2.3启用虚拟机平台功能
- 2.4Docker Engine配置
- 2.5检查docker和docker-compose
- 3. Ollama
- 3.1本地部署deepseek配置对照表及参考配置
- 安装 deepseek-r1:1.5b模型
- 4.Dify关联Ollama
- 三、Dify应用讲解
- 1. 创建空白应用
- 2. 创建本地知识库
- 2.1 向量模型
- 2.2 添加Embedding模型
- 2.3 创建知识库
- 3. 知识库应用
- 3.1 添加知识库
- 3.2 测试
- 4. AI图片生成工具
- 4.1 首先获取Stable Diffusion
- 4.2 下载 Stable 工具
- 4.3 创建Agent
- 5. 旅游助手
- 6. SQL执行器
- 7. 科研论文翻译
- 8. SEO翻译
- 9. 标题党
- 10. 知识库图像检索和展示
- 11. 自然语言生成SQL
大模型学习:Deepseek+dify零成本部署本地运行实用教程(超级详细!建议收藏)
一、Dify是什么
Dify 是一个开源的大语言模型(LLM)应用开发平台,它致力于为开发者提供一站式、低代码甚至无代码的 AI 应用开发体验。
Dify 核心目标是降低 AI 应用开发门槛,支持从原型设计到生产部署的全流程管理。
Dify 拥有直观的可视化界面,开发者无需深入底层代码,只需通过简单的拖拽、配置操作,就能定义应用的 Prompt(提示词)、上下文以及各种插件。
智能客服与对话助手:通过自然语言处理技术快速响应用户咨询,支持上下文记忆和多轮对话设计。
二、Dify的安装部署
1. 官网体验
官网速度很慢,等待时间太长,没有科学上网还容易断连,
不推荐!
2. 本地部署
2.1 linux环境下的Docker安装
linux环境下的Docker安装参考这篇:Linux 安装配置Docker 和Docker compose
2.2 Windows环境下安装部署DockerDeskTop
在Windows环境下我们可以通过DockerDesktop 来安装。直接去官网下载对应的版本即可。进官网可能会有点卡,多试几次就好了。选择第三个下载。
速度太慢的话用我上传的这个也可以,通过网盘分享的文件:
链接: https://pan.baidu.com/s/1imoEfH1DuTBwXiKxT05Yqg 提取码: vp1a
后面的操作最好一切与Docker有关的,用管理员身份运行,包括powershell。
点击安装包运行就行了,安装过程很简单,需要勾选的地方都勾选。
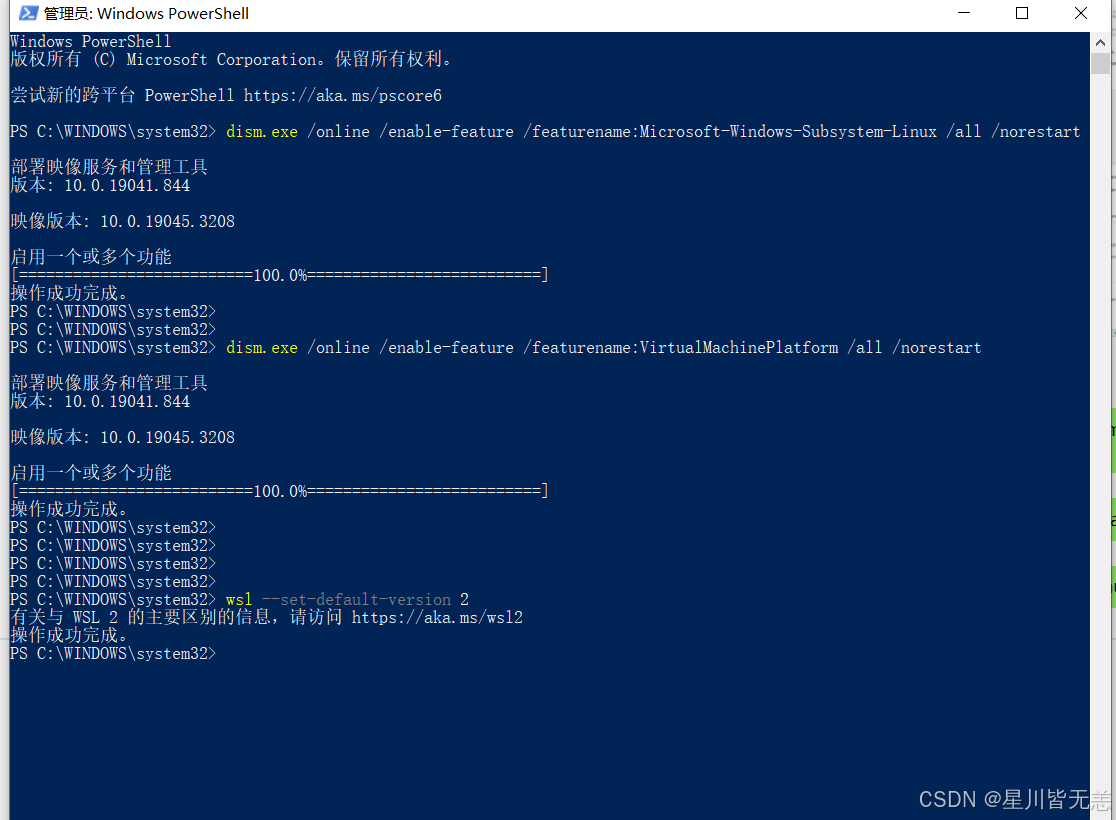
2.3启用虚拟机平台功能
WSL2 依赖 Windows 虚拟机功能,需要额外启用:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
将 WSL 默认版本设置为 WSL2(视不同情况而定)
wsl --set-default-version 2
Windows 11 默认已安装 WSL2,不需要执行该命令。
Windows 10 用户 需要执行此命令,否则默认使用 WSL1。
安装好之后如果打开docker desktop出现:Docker Engine Stopped!可以看这篇博客,亲测解决这个实际问题:
已解决(亲测有效!):安装部署Docker Deskpot之后启动出现Docker Engine Stopped!-CSDN博客
里面会有一些其它坑,遇到的话可以参考网上的解决办法。同样的我们需要拉取dify的GitHub的代码。
我是直接去的github官网下载,有的时候进不去,多试几次就可以了。
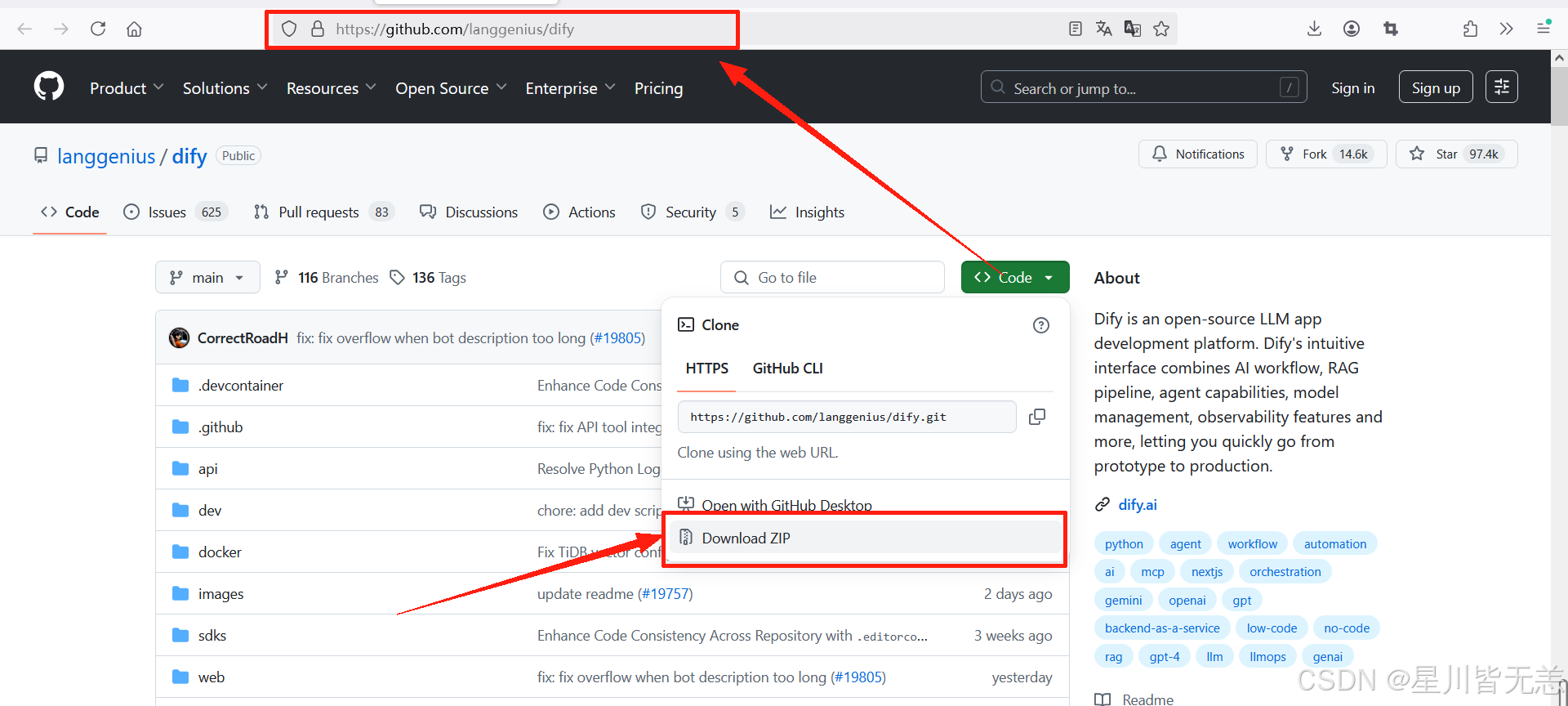
下载本地之后解压缩出现dify-main目录。(也可以选择特定的版本进行下载)
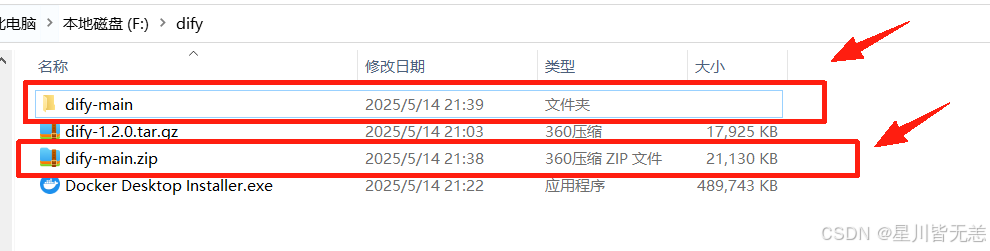
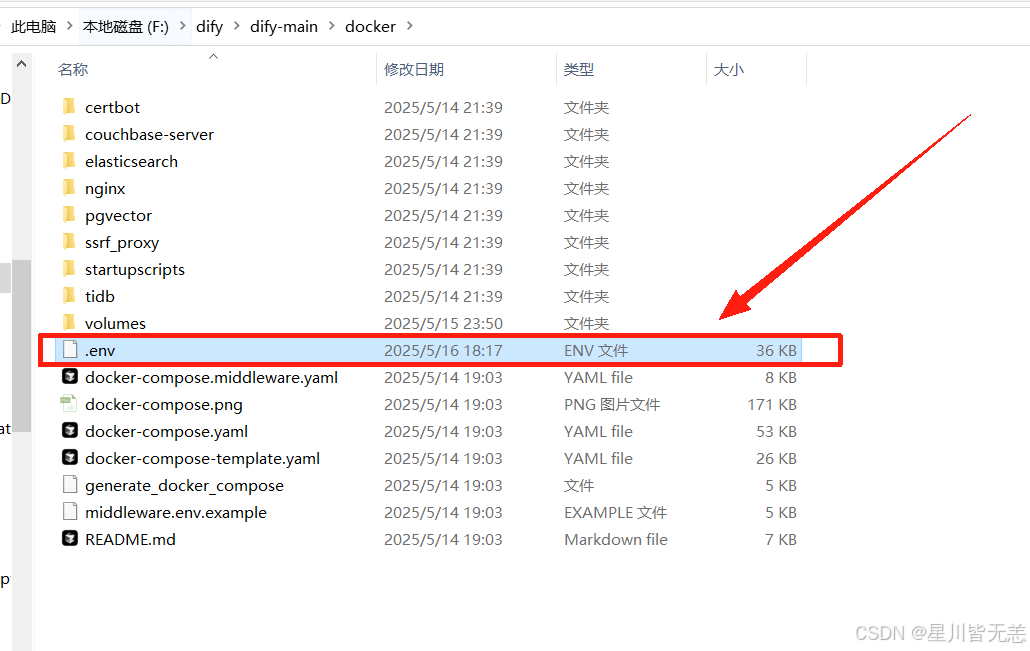
进入docker-main下面的docker目录,把里面原本的.env.example的文件重命名为.env。
在拉取镜像之前修改一下镜像仓库地址:
2.4Docker Engine配置
在docker的setting下,在docker engine中复制过去
{"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"features": {"buildkit": true},"registry-mirrors": ["https://docker.feng.cx","https://docker.m.daocloud.io","https://docker.imgdb.de","https://docker-0.unsee.tech","https://docker.hlmirror.com","https://docker.1ms.run","https://func.ink","https://lispy.org","https://docker.xiaogenban1993.com","https://docker.xuanyuan.me","https://docker.rainbond.cc","https://do.nark.eu.org","https://dc.j8.work","https://docker.hpcloud.cloud","https://docker.unsee.tech","https://docker.1panel.live","http://mirrors.ustc.edu.cn","https://docker.chenby.cn","http://mirror.azure.cn","https://dockerpull.org","https://dockerhub.icu","https://hub.rat.dev"]
}
切换镜像源之后,后面拉取镜像时候速度会更快,减少等待时间!
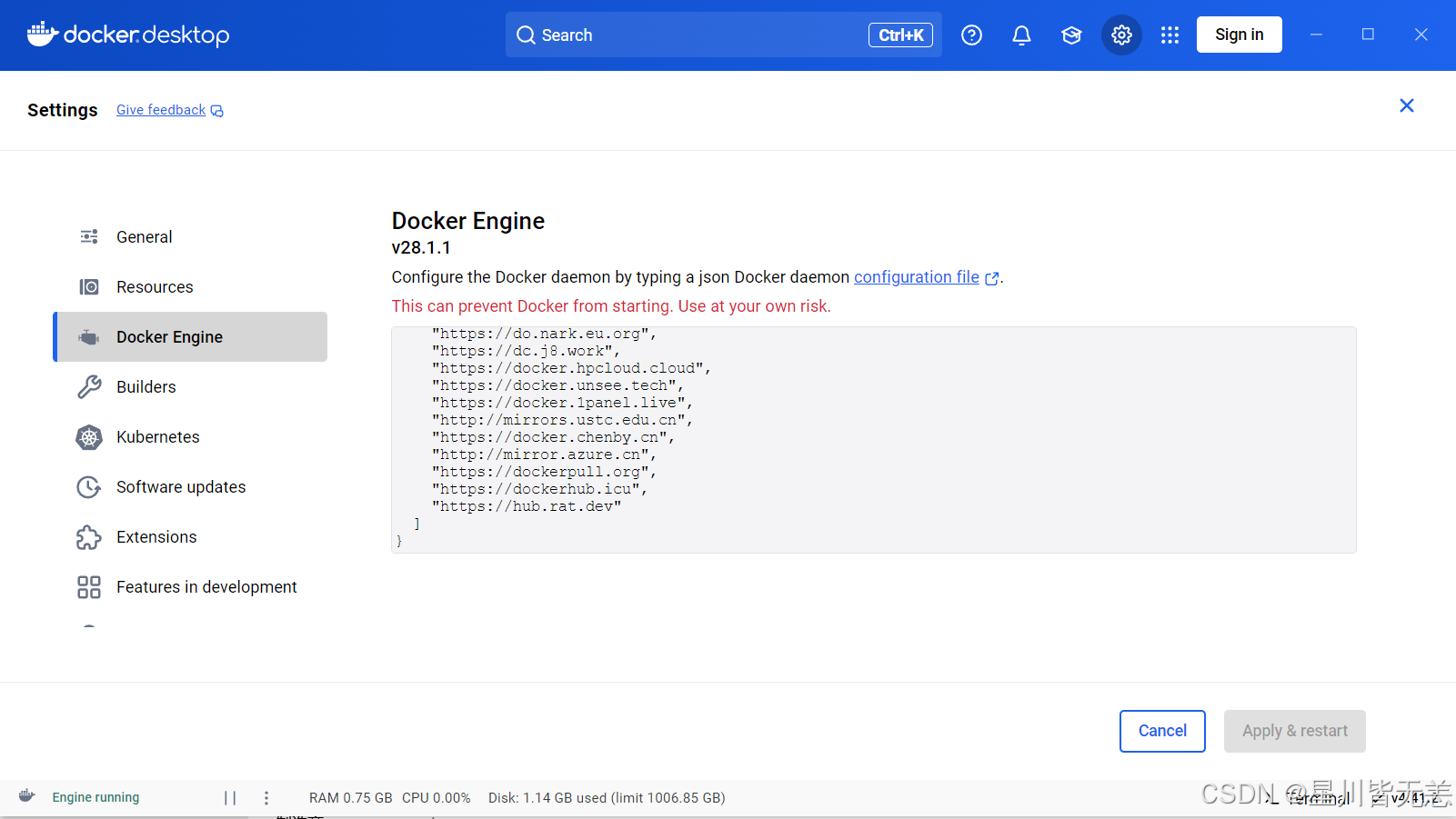
修改配置之后记得重启docker desktop进行更新!
2.5检查docker和docker-compose
上面过程做完之后可以验证一下是否成功安装!
docker -v
docker-compose -v
我用的git验证的:
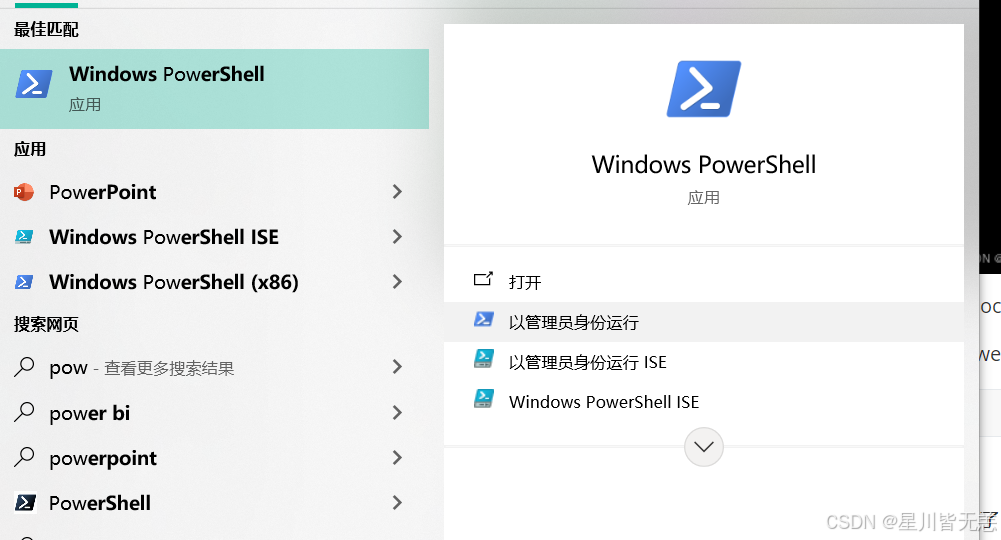
上面的命令如果能正常输出就说明已成功安装docker和docker-compose了!
这样配置之后再进入到Docker目录,管理员身份运行powershell,开始拉取镜像
docker-compose up
这个过程耐心等待即可,过程可能有点长。
结束之后在地址栏中输入 http://localhost/install 就可以访问了
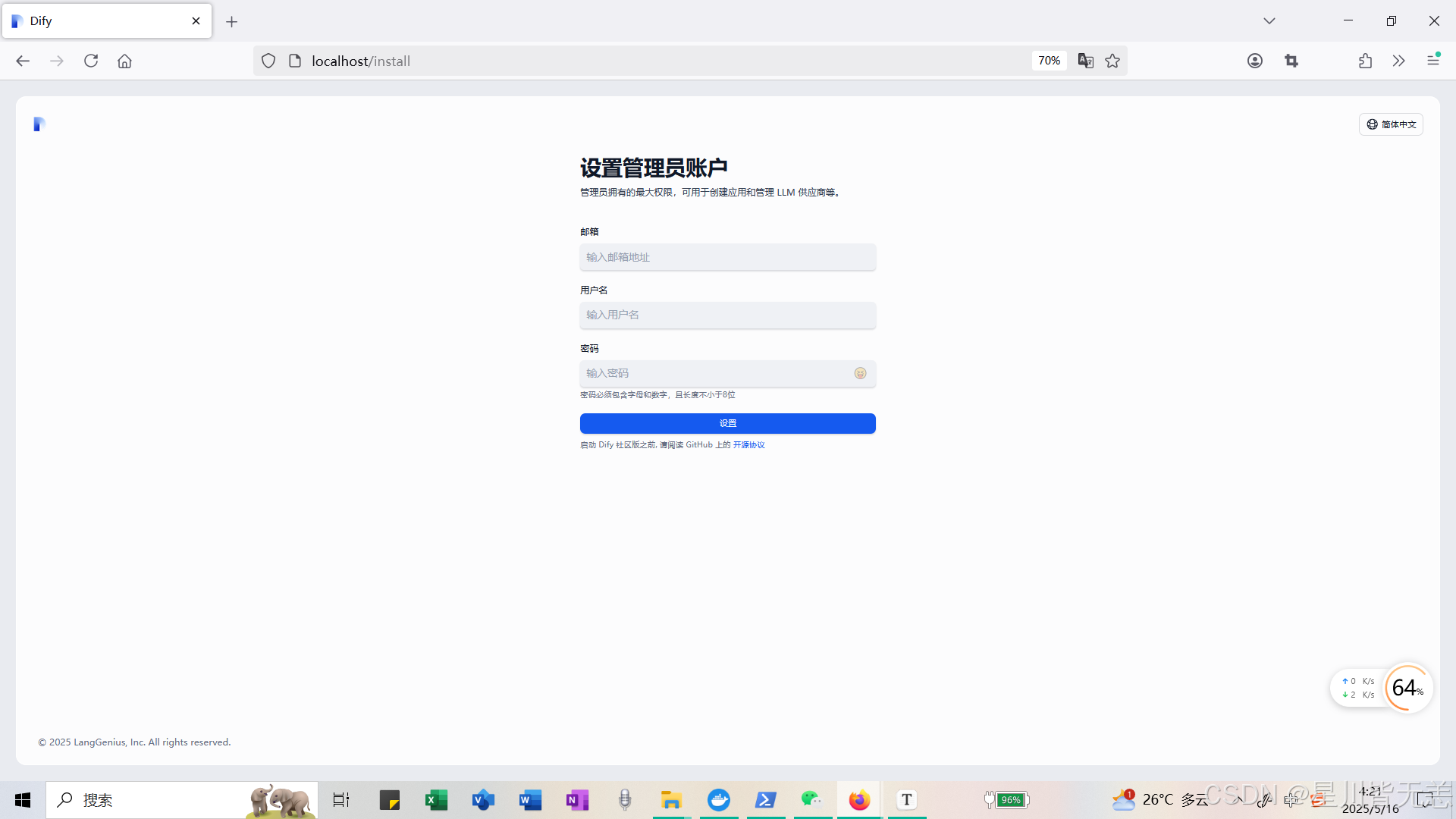
我们先设置管理员的相关信息。设置之后再登录
查看docker desktop容器情况:
查看docker desktop拉取的镜像情况:
3. Ollama
官网: https://ollama.com/
我们已经把Dify在本地部署了。然后我们可以通过Ollama在本地部署对应的大模型,比如 deepseek-r1:1.5b 这种小模型
Ollama 是一个让你能在本地运行大语言模型的工具,为用户在本地环境使用和交互大语言模型提供了便利,具有以下特点:
1)多模型支持:Ollama 支持多种大语言模型,比如 Llama 2、Mistral 等。这意味着用户可以根据自己的需求和场景,选择不同的模型来完成各种任务,如文本生成、问答系统、对话交互等。
2)易于安装和使用:它的安装过程相对简单,在 macOS、Linux 和 Windows 等主流操作系统上都能方便地部署。用户安装完成后,通过简洁的命令行界面就能与模型进行交互,降低了使用大语言模型的技术门槛。
3)本地运行:Ollama 允许模型在本地设备上运行,无需依赖网络连接来访问云端服务。这不仅提高了数据的安全性和隐私性,还能减少因网络问题导致的延迟,实现更快速的响应。
搜索Ollama进入官网https://ollama.com/download,选择对应的安装包,点击安装即可
由于官网下载速度实在太慢,超级慢!将资源上传到百度网盘里面了,附链接:
通过网盘分享的文件:Ollama安装
链接: https://pan.baidu.com/s/1ifXaHZbJmXbjRQgCCYsfkw
下载完成后直接双击安装即可,下载安装之后:
命令:ollama,出现下面内容,说明安装成功
输入命令:
Ollama
Ollama -v
进行验证
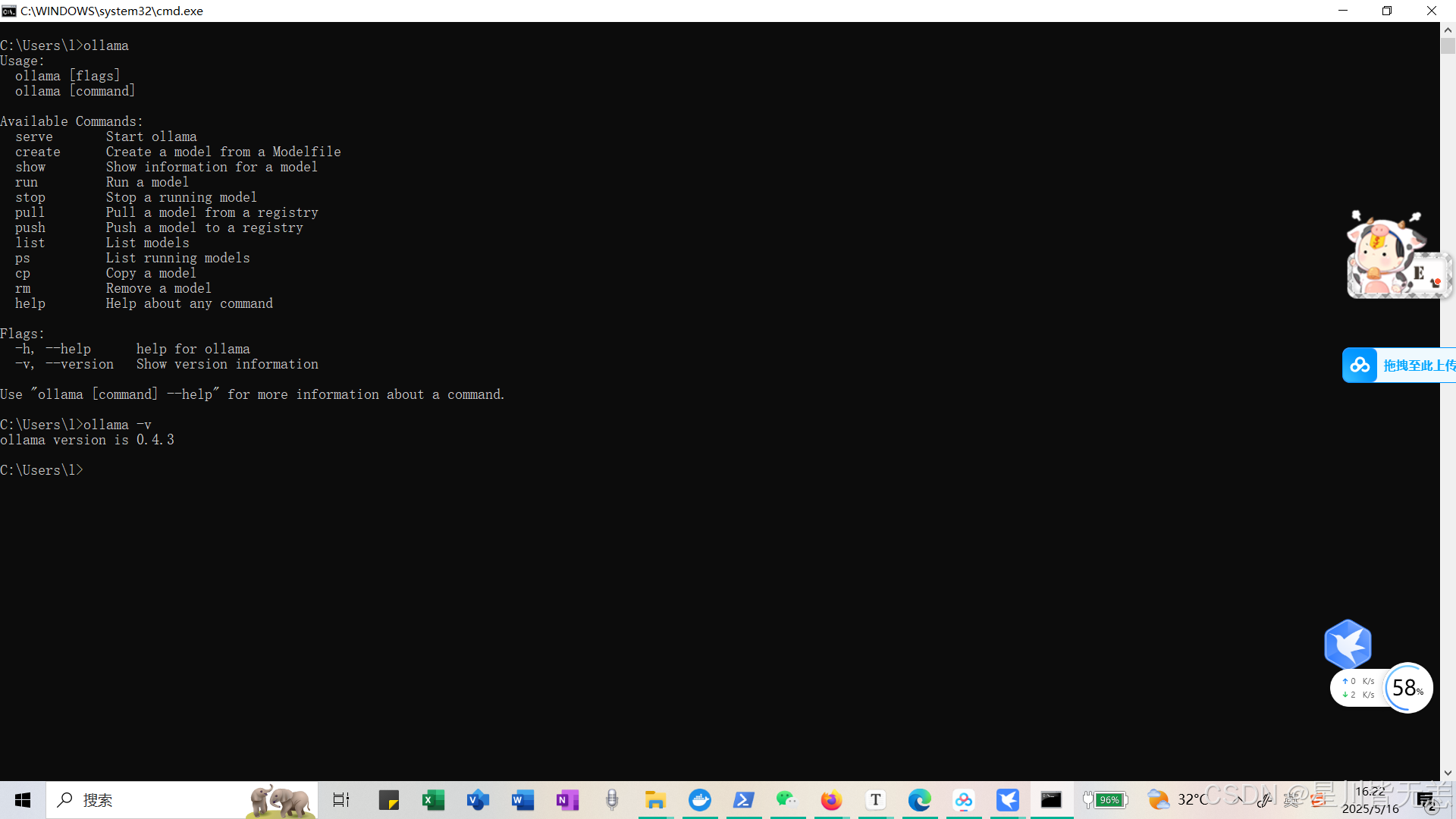
显示上方内容即安装成功
启动Ollama服务
浏览器查看一下API服务:输入命令【ollama serve】,浏览器打开,显示running,说明启动成功
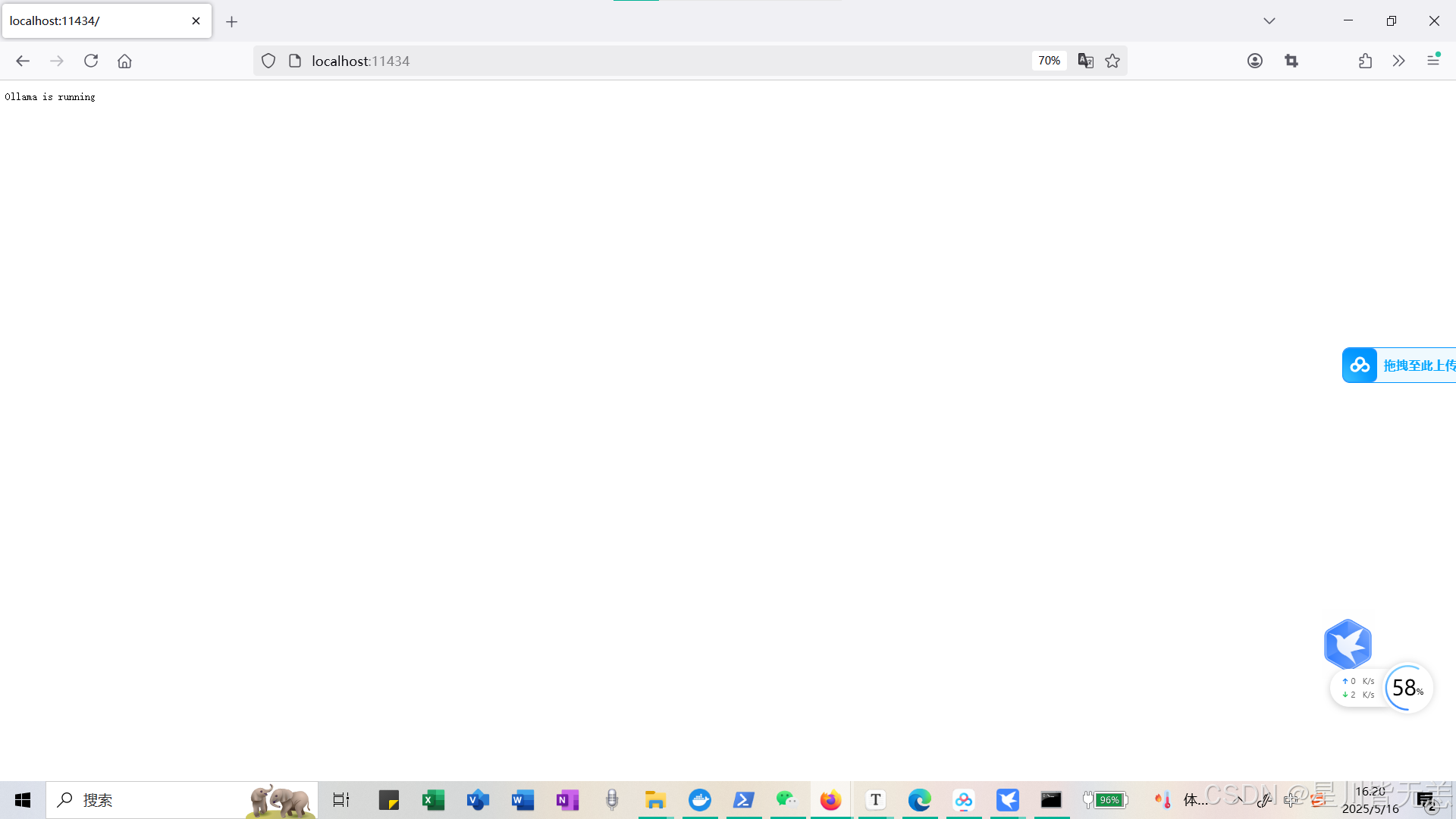
重要关键一步:
注意:需要配置Ollama的模型下载地址,如果不配置则会把几个G的开源模型安装到你的C盘上!
配置一下环境变量:
高级系统设置,然后点击环境变量:
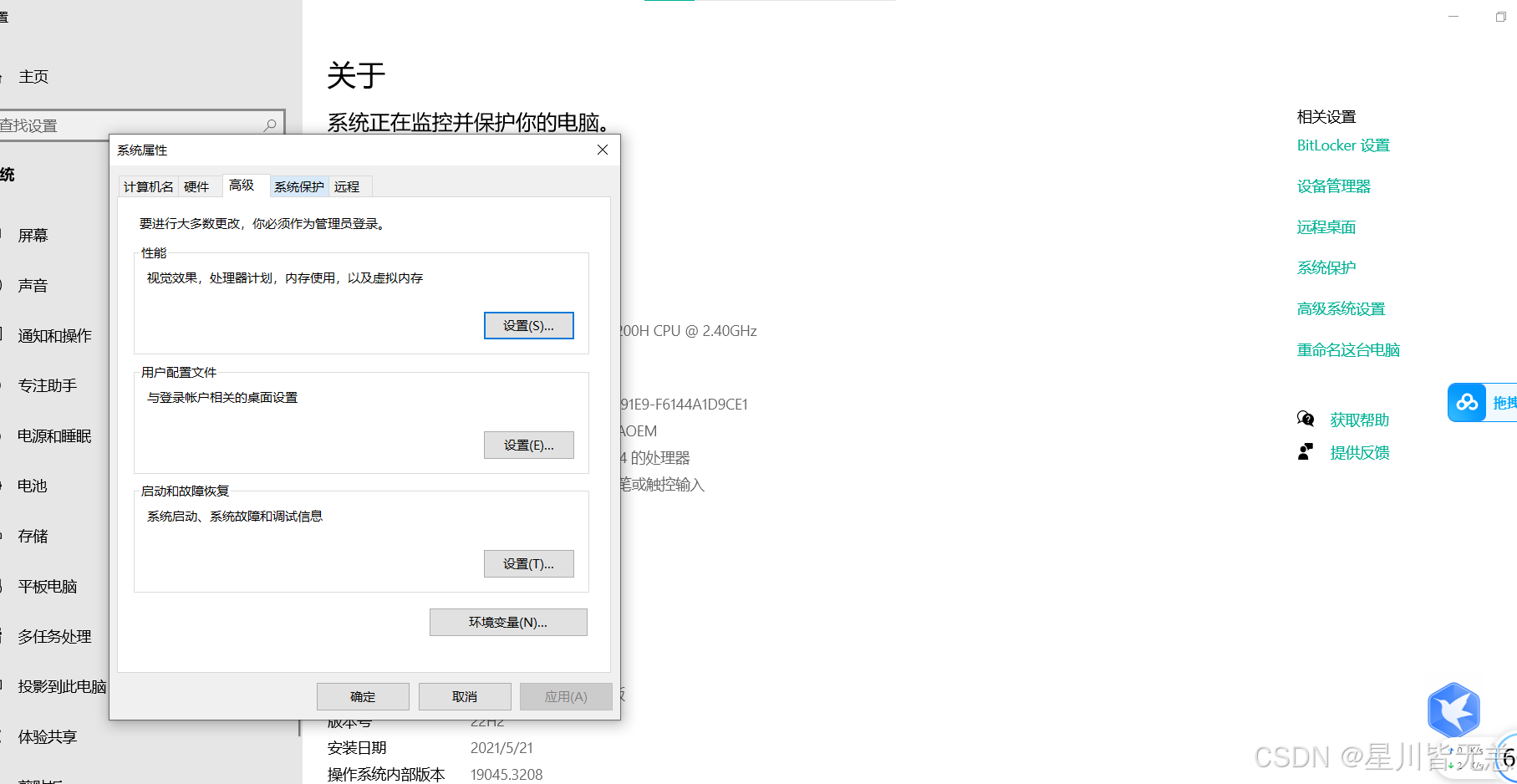
新建系统变量:
变量名:
OLLAMA_MODELS
变量值:
F:\OllamaModels
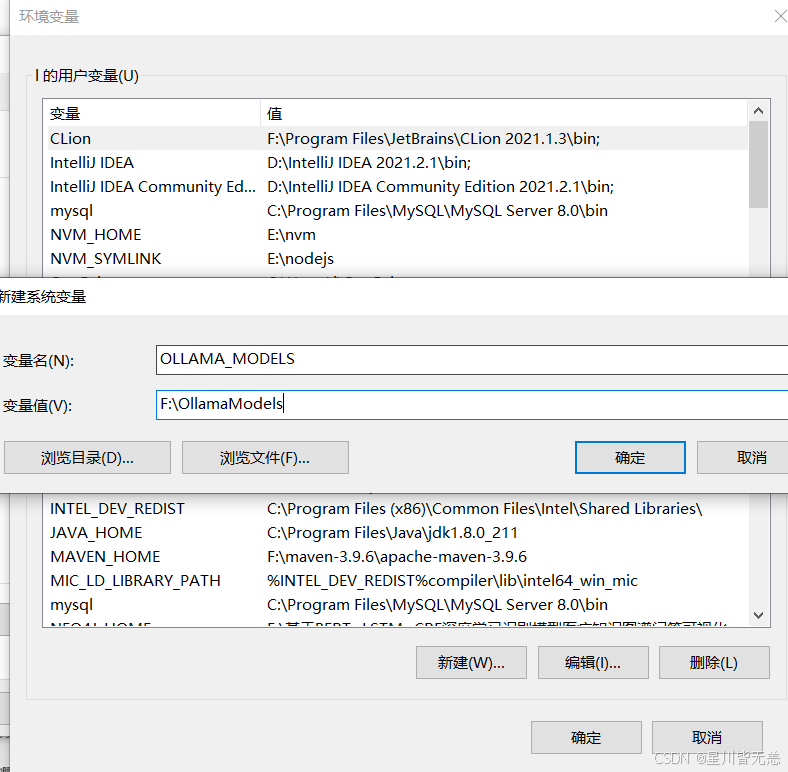
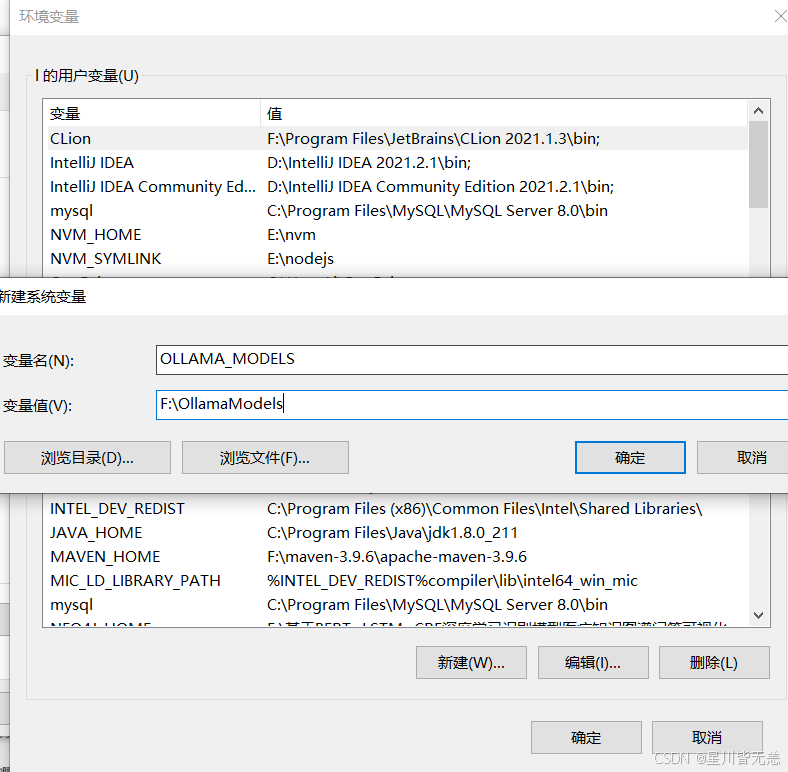
添加好之后点确定即可,记得重启Ollama服务进行更新,不然还是会下载到C盘!!!。
另一种方案:cmd运行指令
setx OLLAMA_MODELS "F:\OllamaModels"
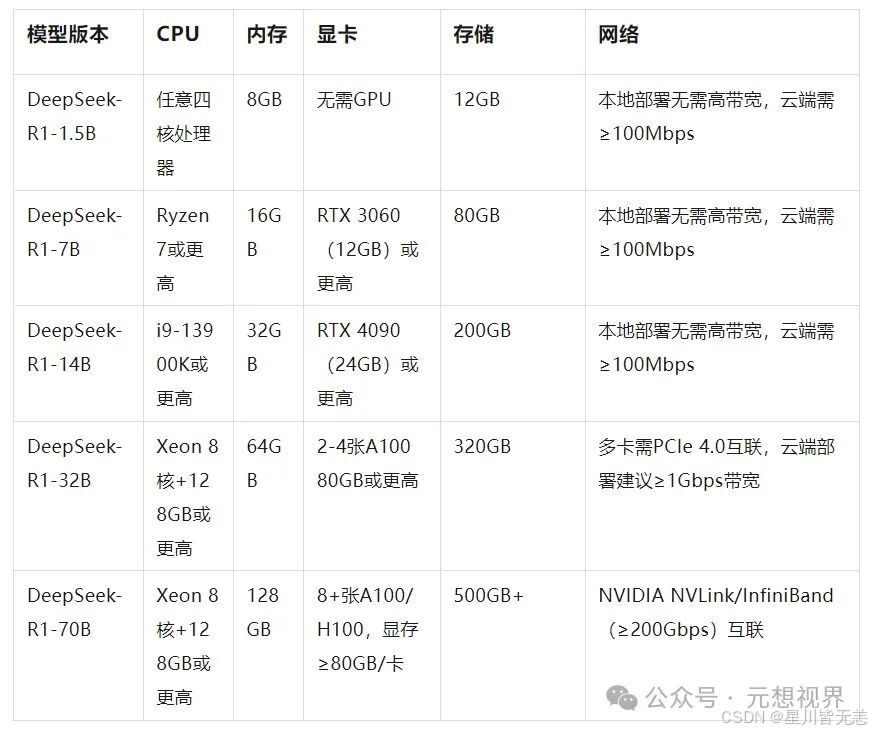
3.1本地部署deepseek配置对照表及参考配置
本地部署deepseek可运行电脑配置对照表及参考配置,可以根据自己个人配置实际情况选择。

安装 deepseek-r1:1.5b模型
在https://ollama.com/library/deepseek-r1:1.5b 搜索deepseek-R1,跳转到下面的页面,复制这个命令,在终端执行,下载模型
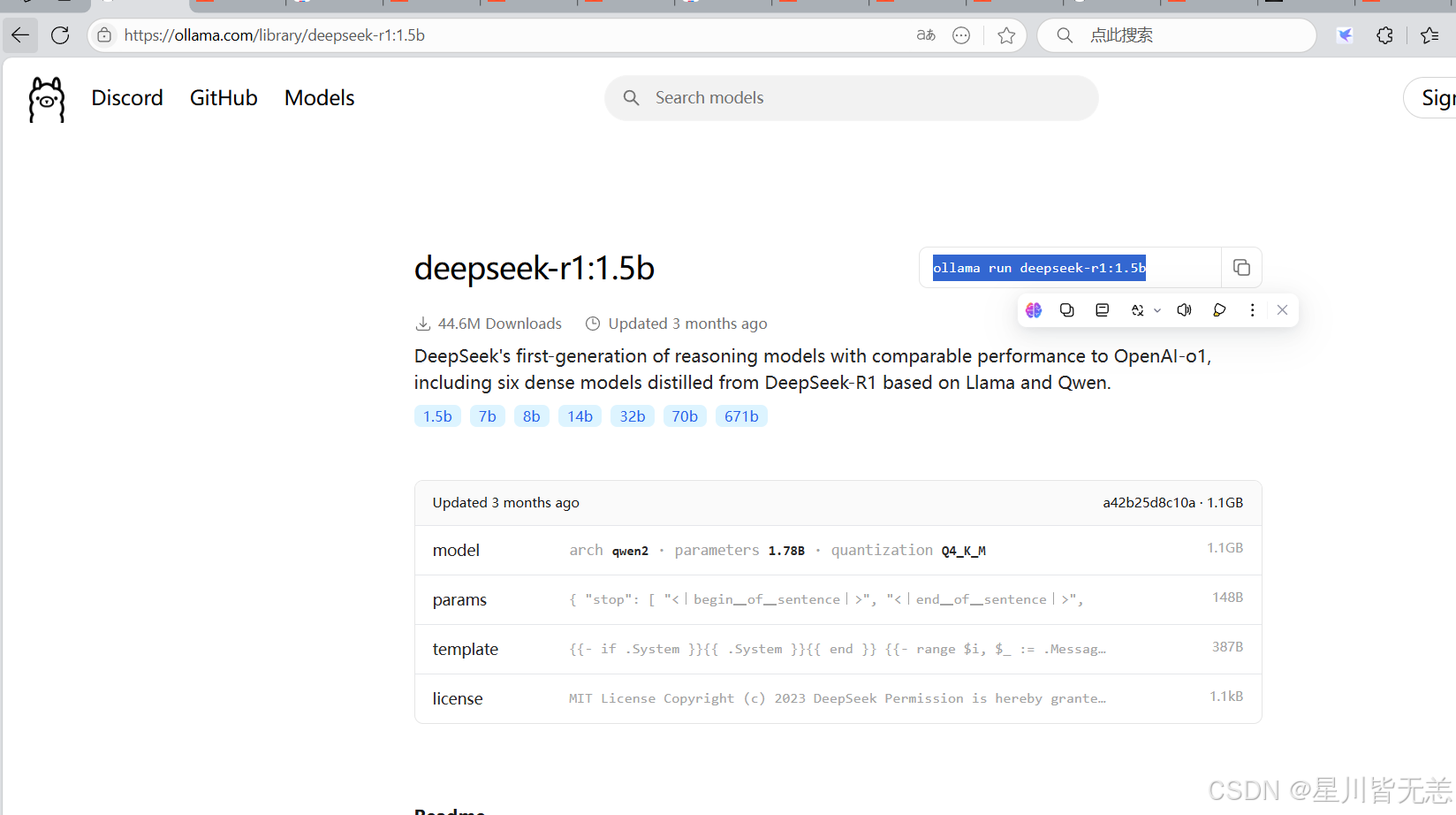
cmd中执行蓝色区域的命令:
ollama run deepseek-r1:1.5b
cmd命令提示符粘贴命令运行,耐心等待下载即可。
简单一个问候指令验证:ni hao a
OK,也是没问题的!
4.Dify关联Ollama
Dify 是通过Docker部署的,而Ollama 是运行在本地电脑的,得让Dify能访问Ollama 的服务。
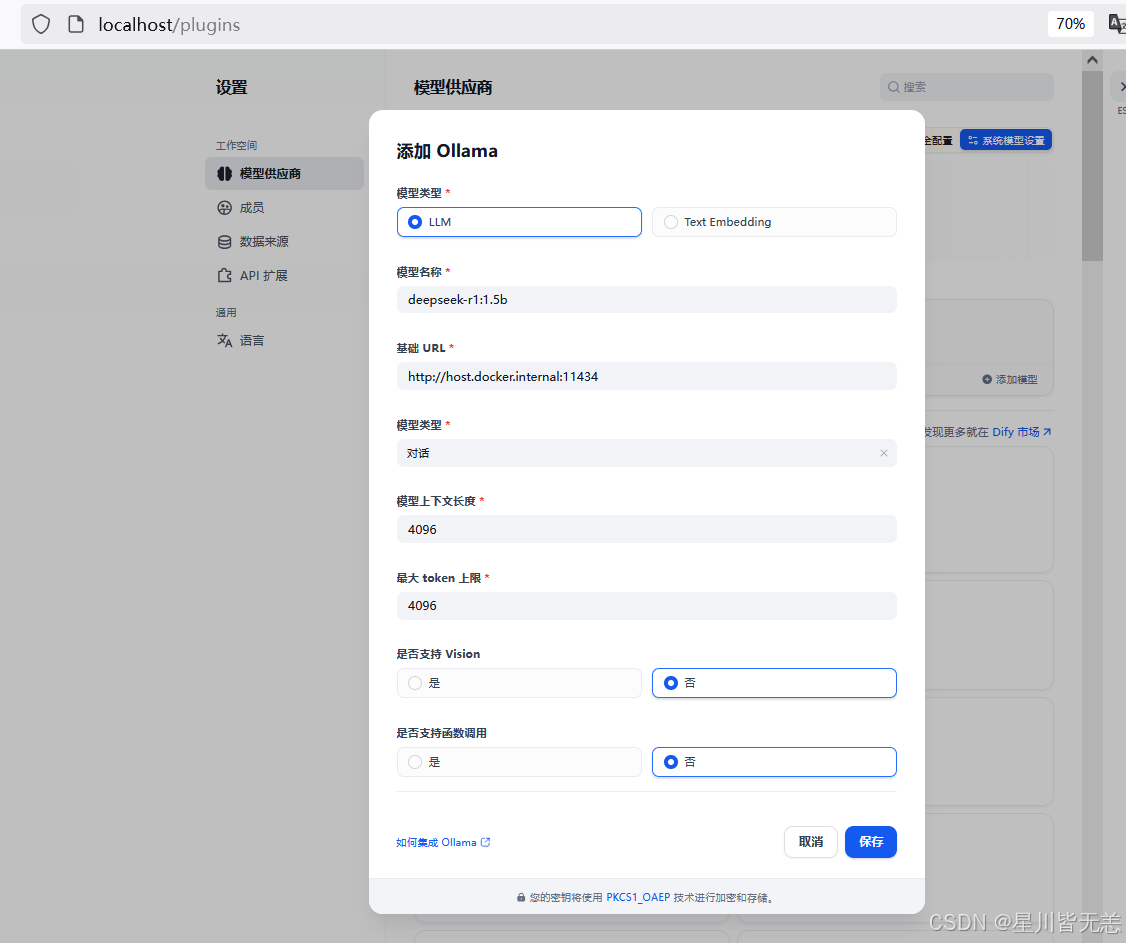
在Dify项目-docker-找到.env文件,在末尾加上下面的配置:
# 启用自定义模型
CUSTOM_MODEL_ENABLED=true
# 指定 Olama 的 API地址(根据部署环境调整IP)
OLLAMA_API_BASE_URL=host.docker.internal:11434
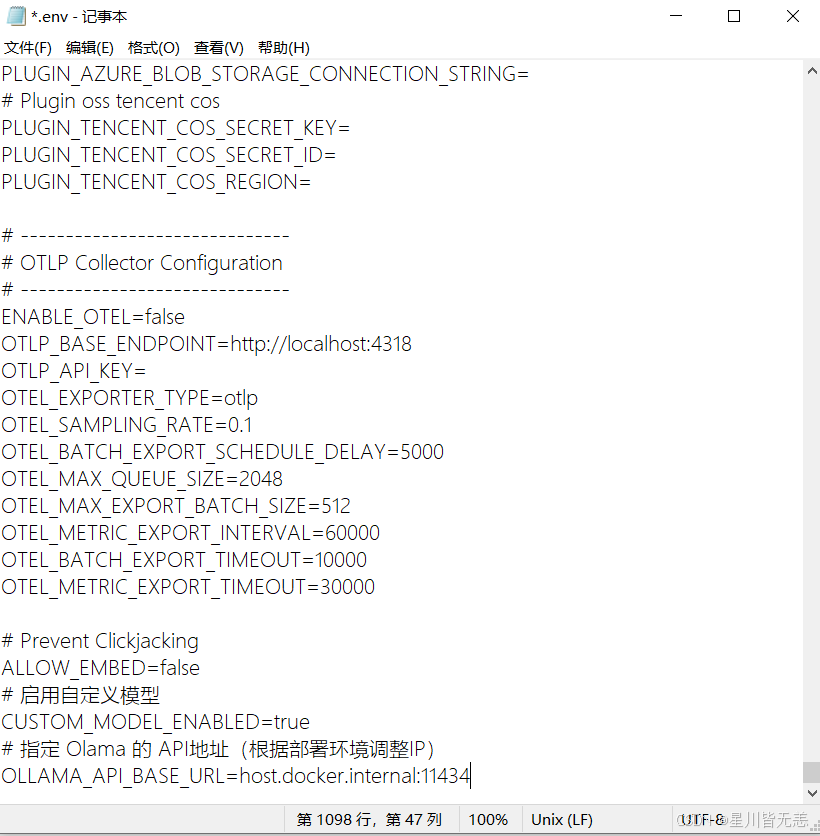
然后在模型中配置
在Dify的主界面 http://localhost/apps ,点击右上角用户名下的【设置】
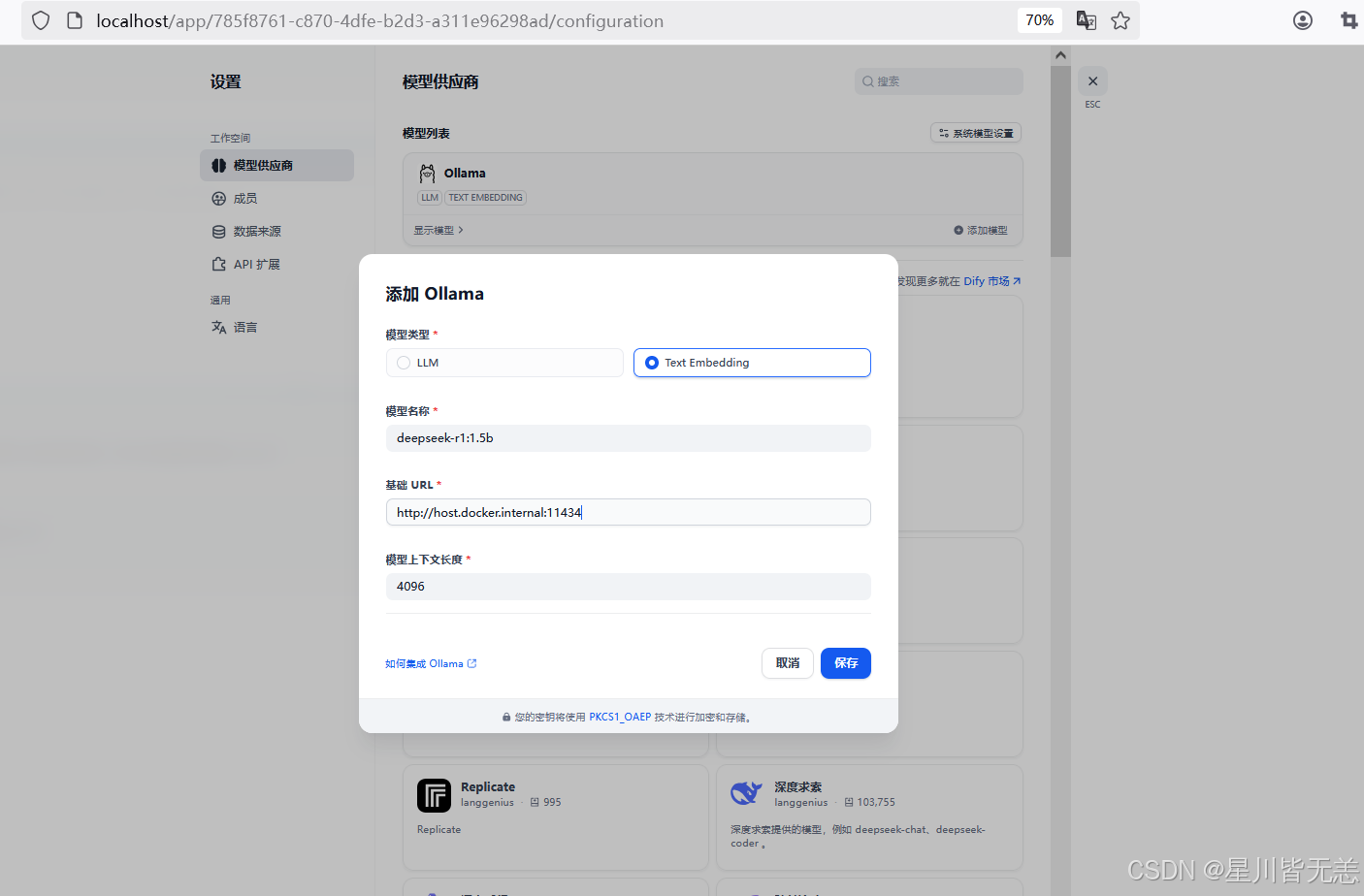
先下载模型供应商插件,然后在设置页面–Ollama–添加模型,如下:
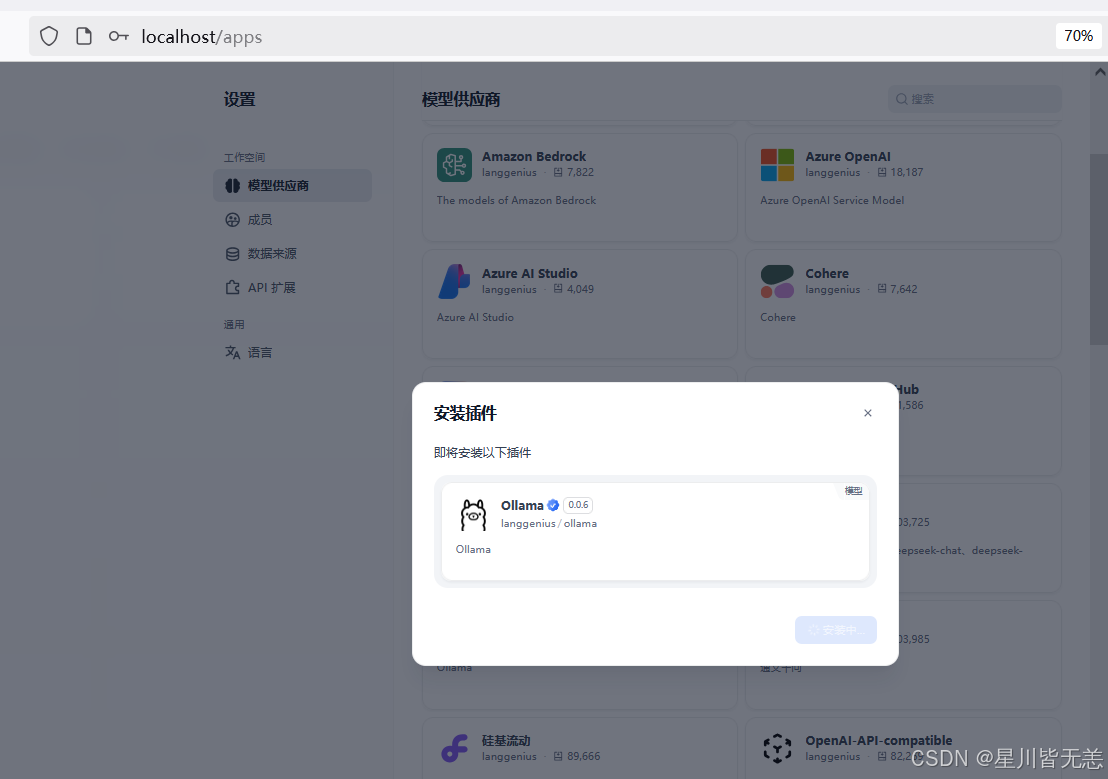
添加模型:
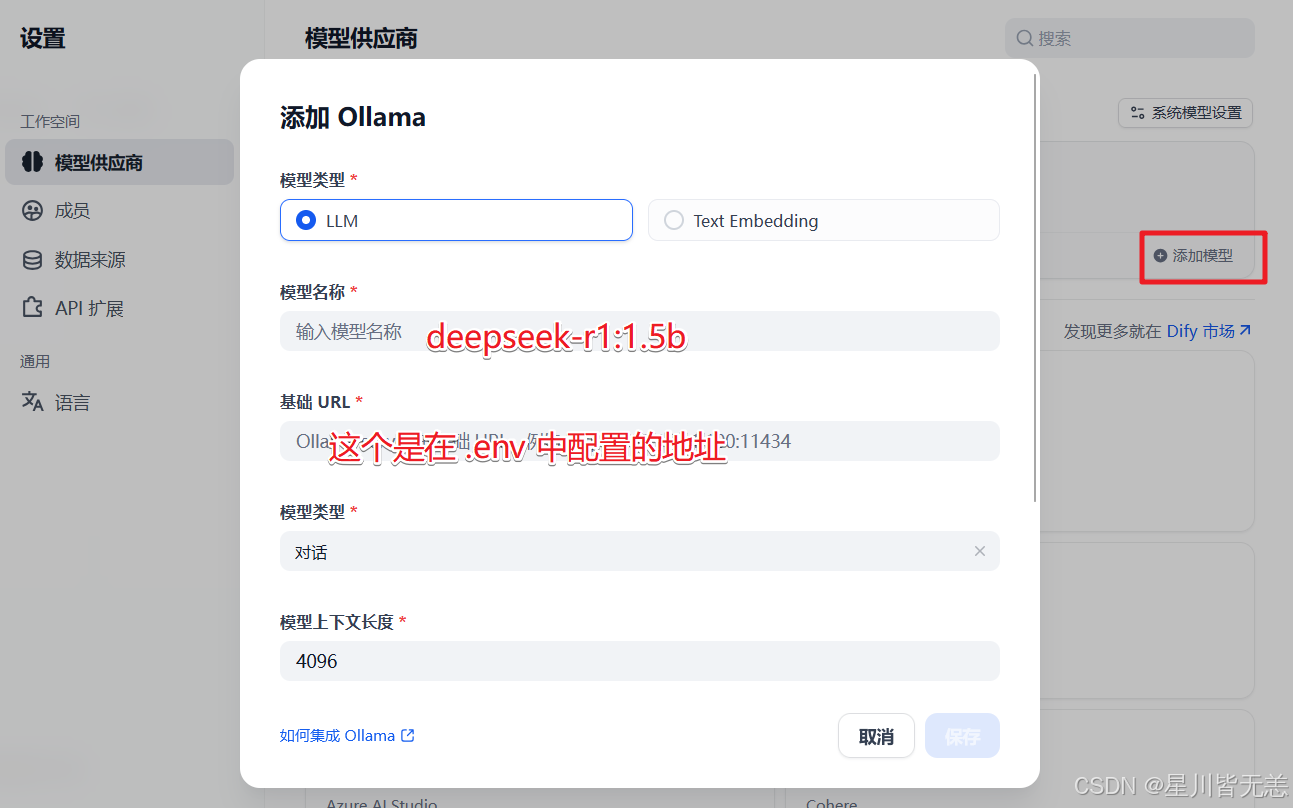
模型名称自定义可以填写对应的名称 deepseek-r1:1.5b
url地址填写:
http://host.docker.internal:11434
设置参数之后截图:
添加成功后的
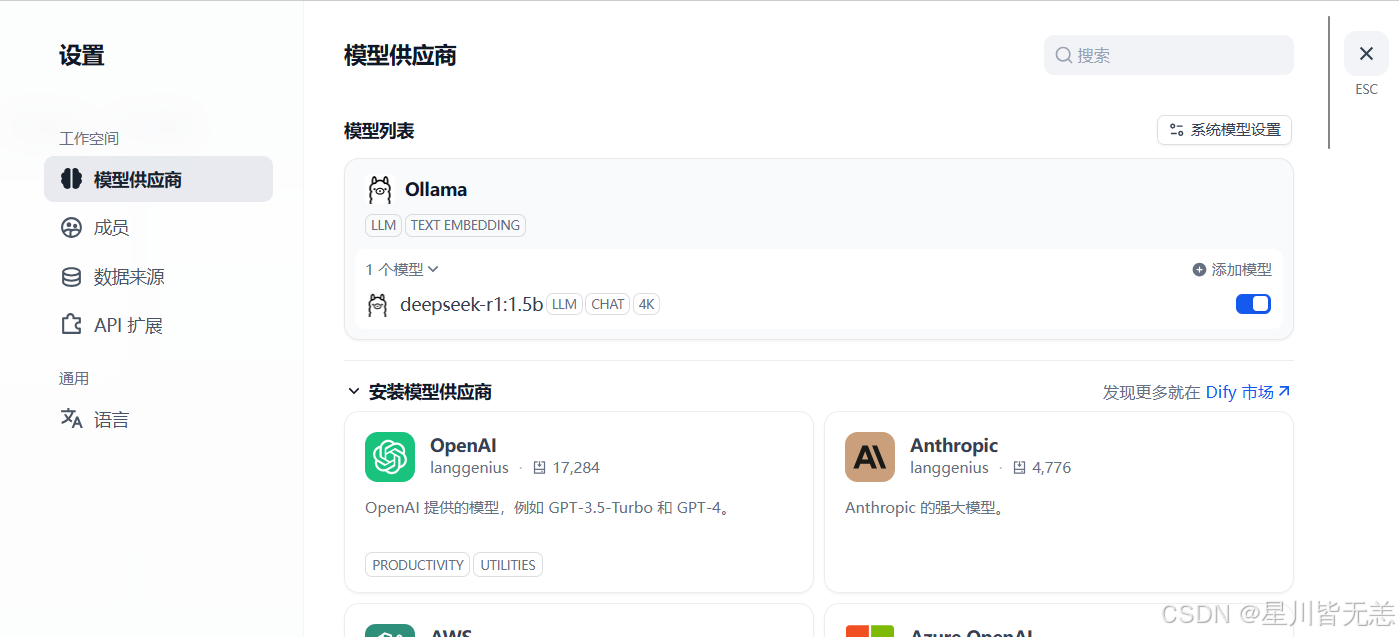
保存成功:
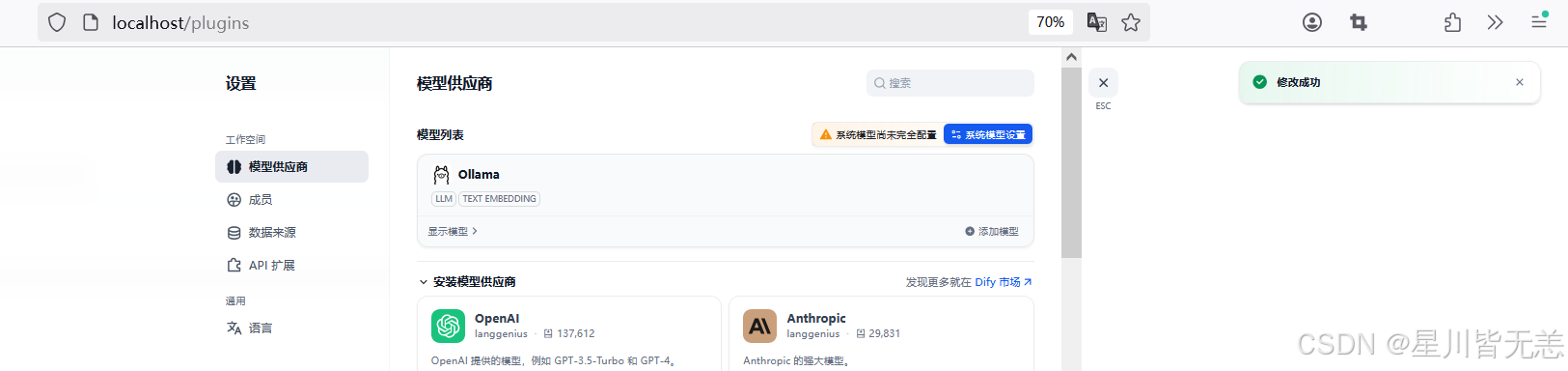
模型添加完成以后,刷新页面,进行系统模型设置。步骤:输入“http://localhost/install”进入Dify主页,用户名–设置–模型供应商,点击右侧【系统模型设置】,如下:
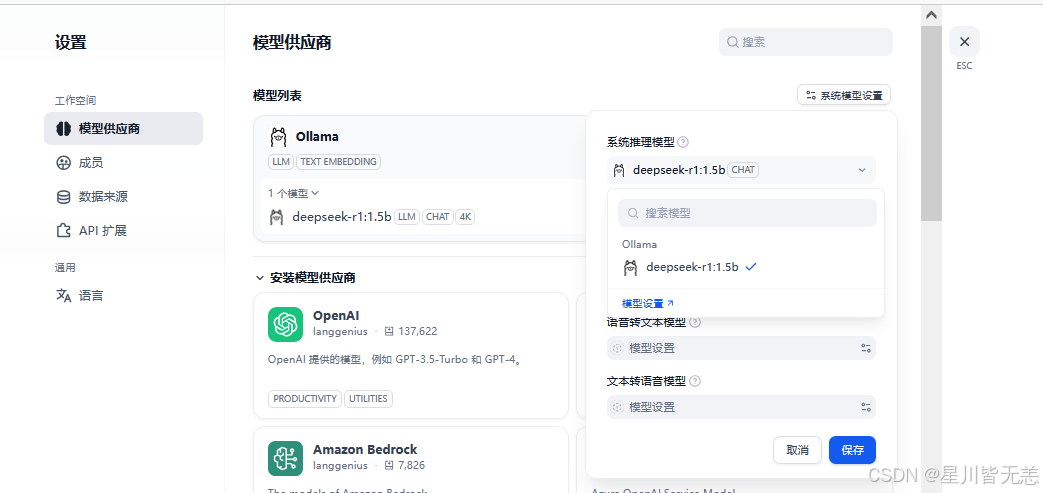
这样就关联成功了!!!
三、Dify应用讲解
1. 创建空白应用
我们通过Dify来创建我们的第一个简单案例,智能聊天机器人
进入Dify 主界面,点击【创建空白应用】,如下图:
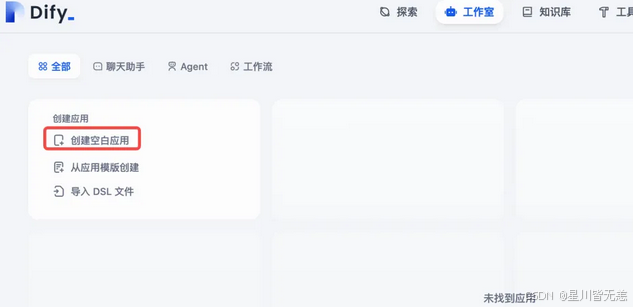
选择【聊天助手】,输入自定义应用名称和描述,点击【创建】
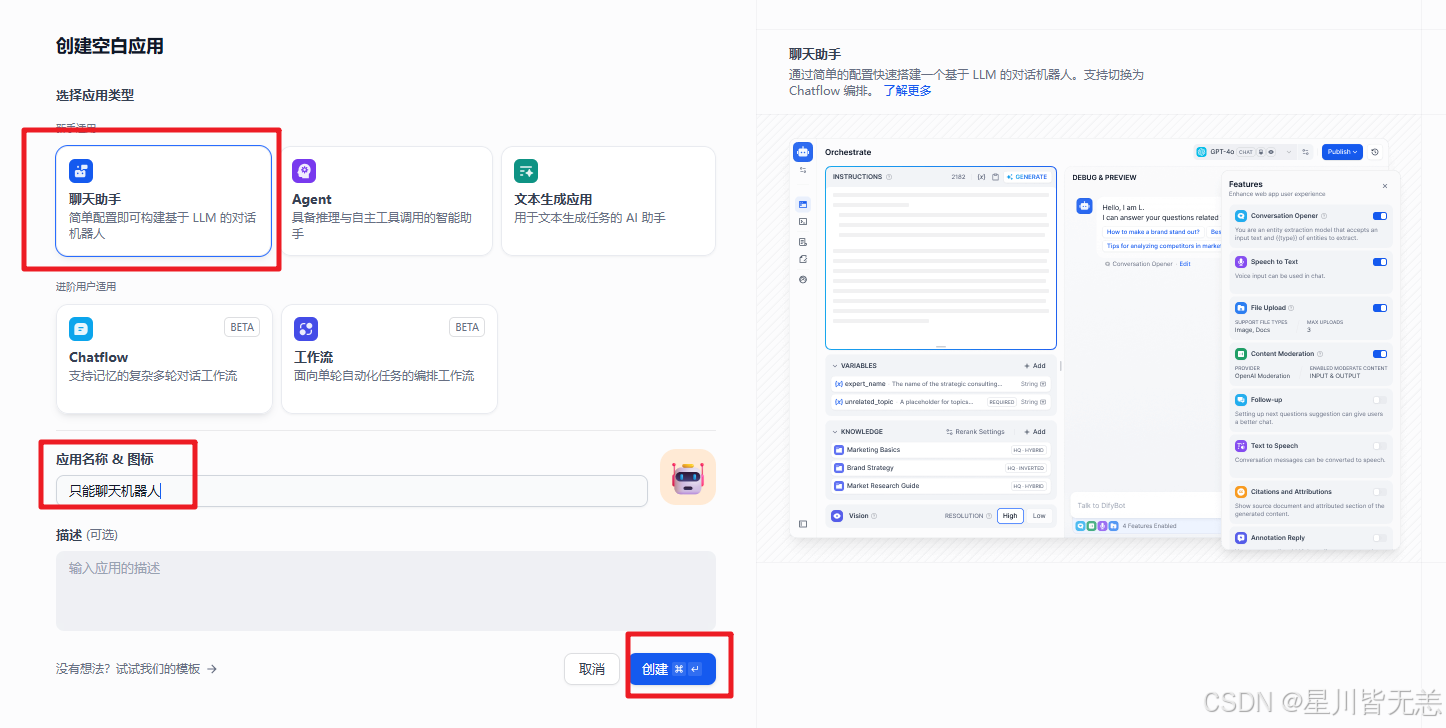
右上角选择合适的模型,进行相关的参数配置
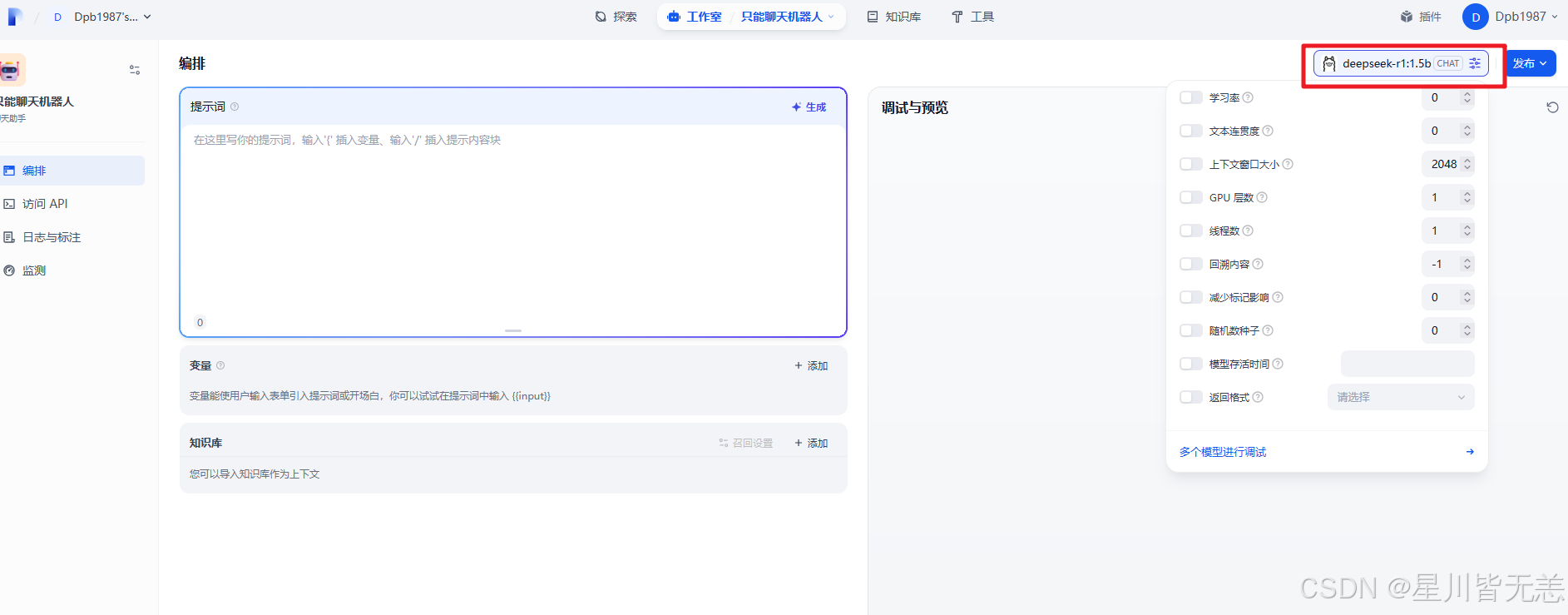
输入有相关的回复了。此时说明Dify 与本地部署的DeepSeek大模型已经连通了。
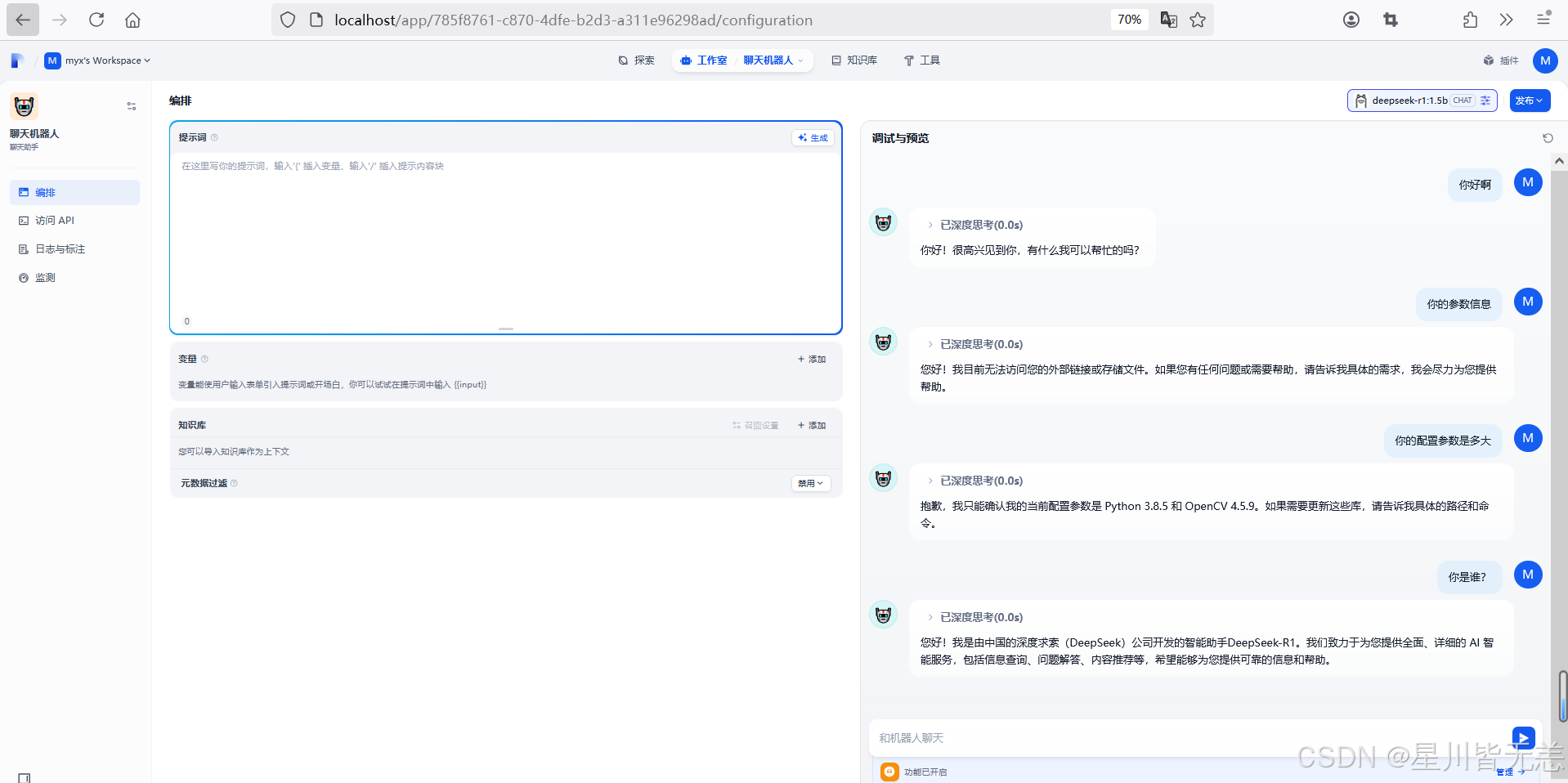
上面的机器人有个不足之处就是无法回答模型训练后的内容和专业垂直领域的内容,这时我们可以借助本地知识库来解决专业领域的问题。
2. 创建本地知识库
2.1 向量模型
Embedding模型是一种将数据转换为向量表示的技术,核心思想是通过学习数据的内在结构和语义信息,将其映射到一个低维向量空间中,使得相似的数据点在向量空间中的位置相近,从而通过计算向量之间的相似度来衡量数据之间的相似性。Embedding模型可以将单词、句子或图像等数据转换为低维向量,使得计算机能够更好地理解和处理这些数据。在NLP领域,Embedding模型可以将单词、句子或文档转换为向量,用于文本分类、情感分析。机器翻译等任务。在计算机视觉中,Embedding模型可以用于图像识别和检索等任务。
2.2 添加Embedding模型
点击右上角用户名–设置–模型供应商–右上角【添加模型】,填写相关配置信息如下:
添加成功后的效果
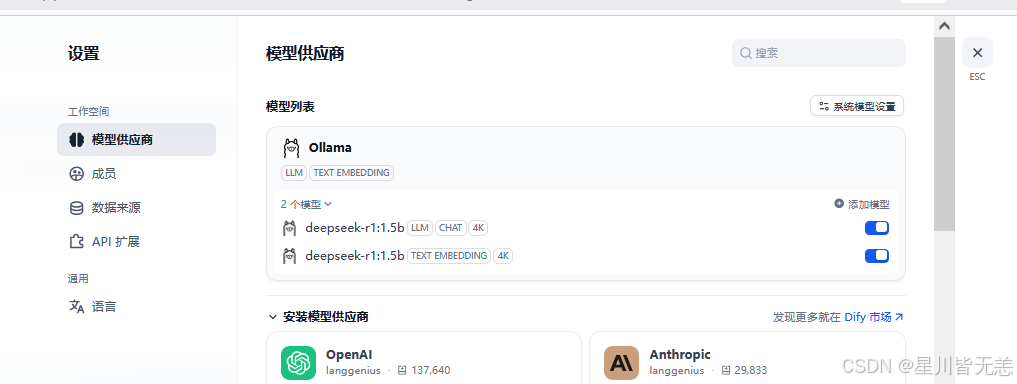
2.3 创建知识库
在Dify主界面,点击上方的【知识库】,点击【创建知识库】
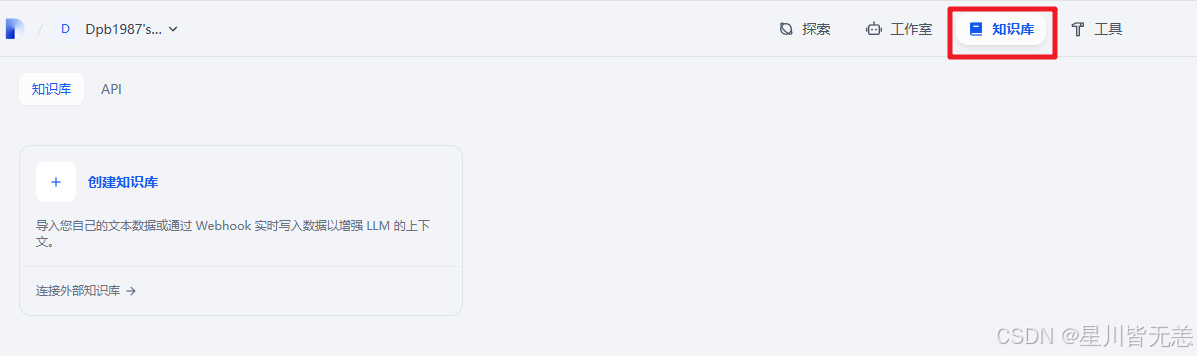
导入已有文本(相关领域知识库),上传资料,点击【下一步】
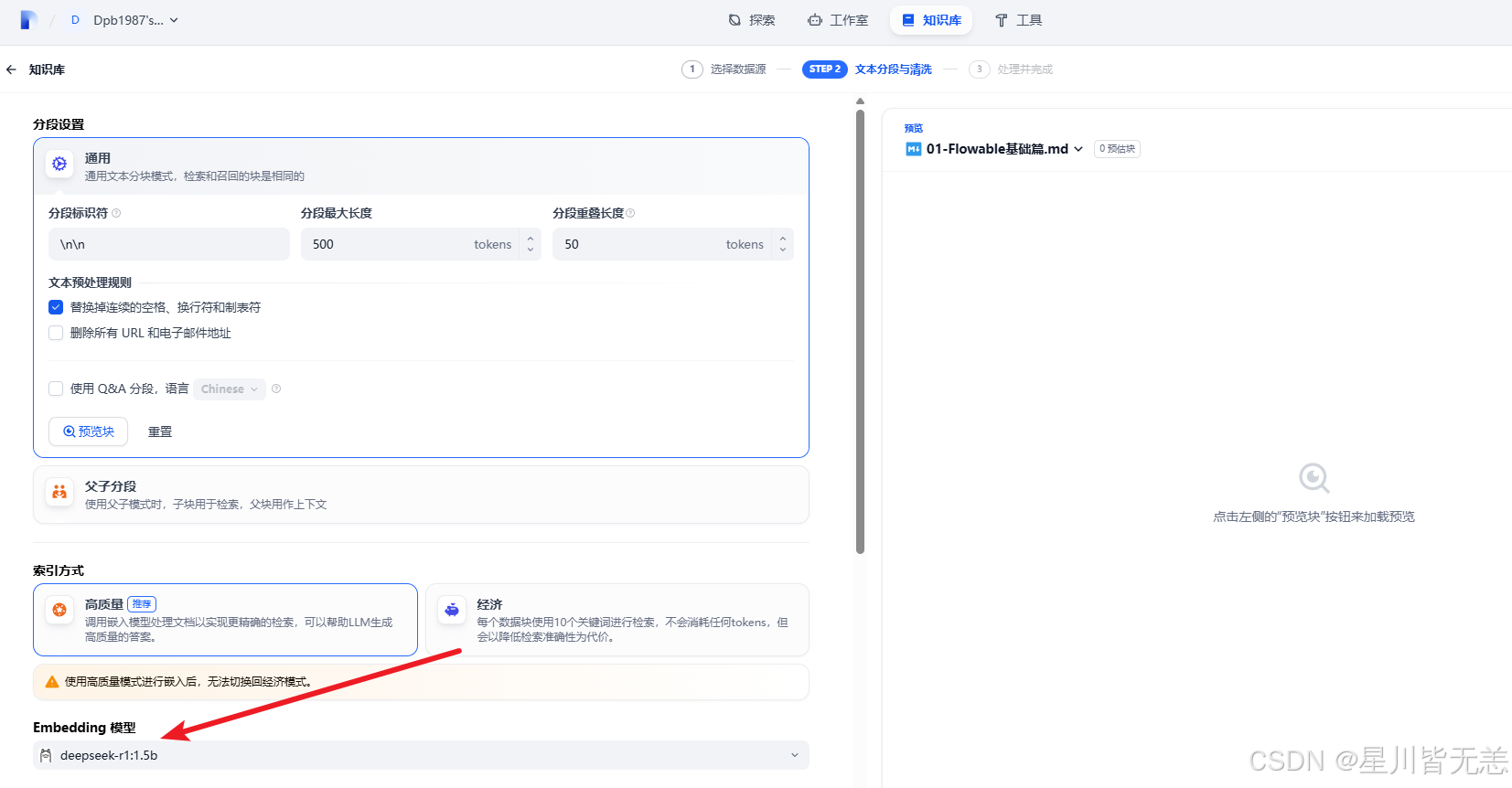
Embedding模型默认是前面配置的模型,参数信息配置完,点击保存即可
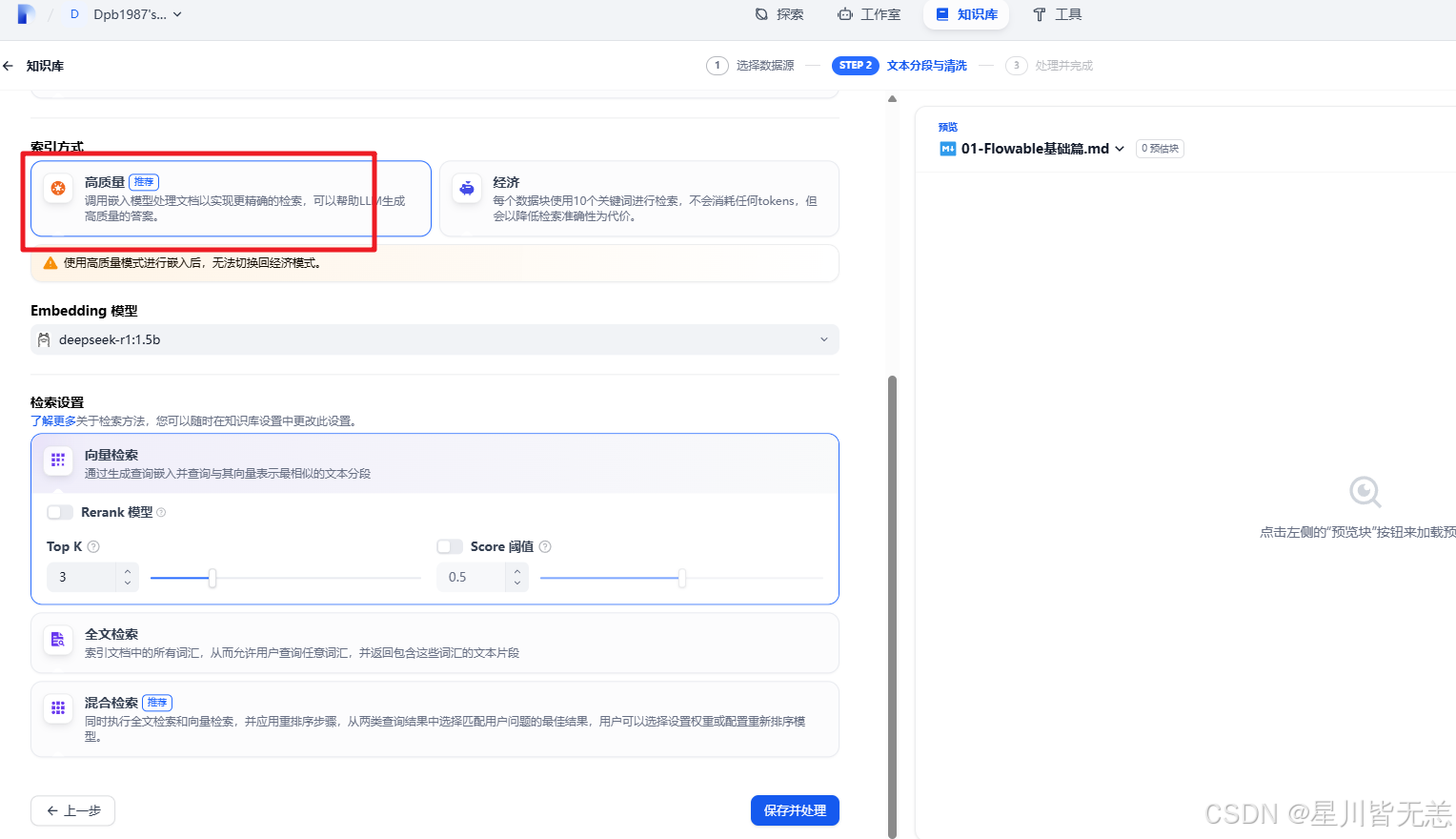
此时系统会自动对上传的文档进行解析和向量化处理,需要耐心等待几分钟。
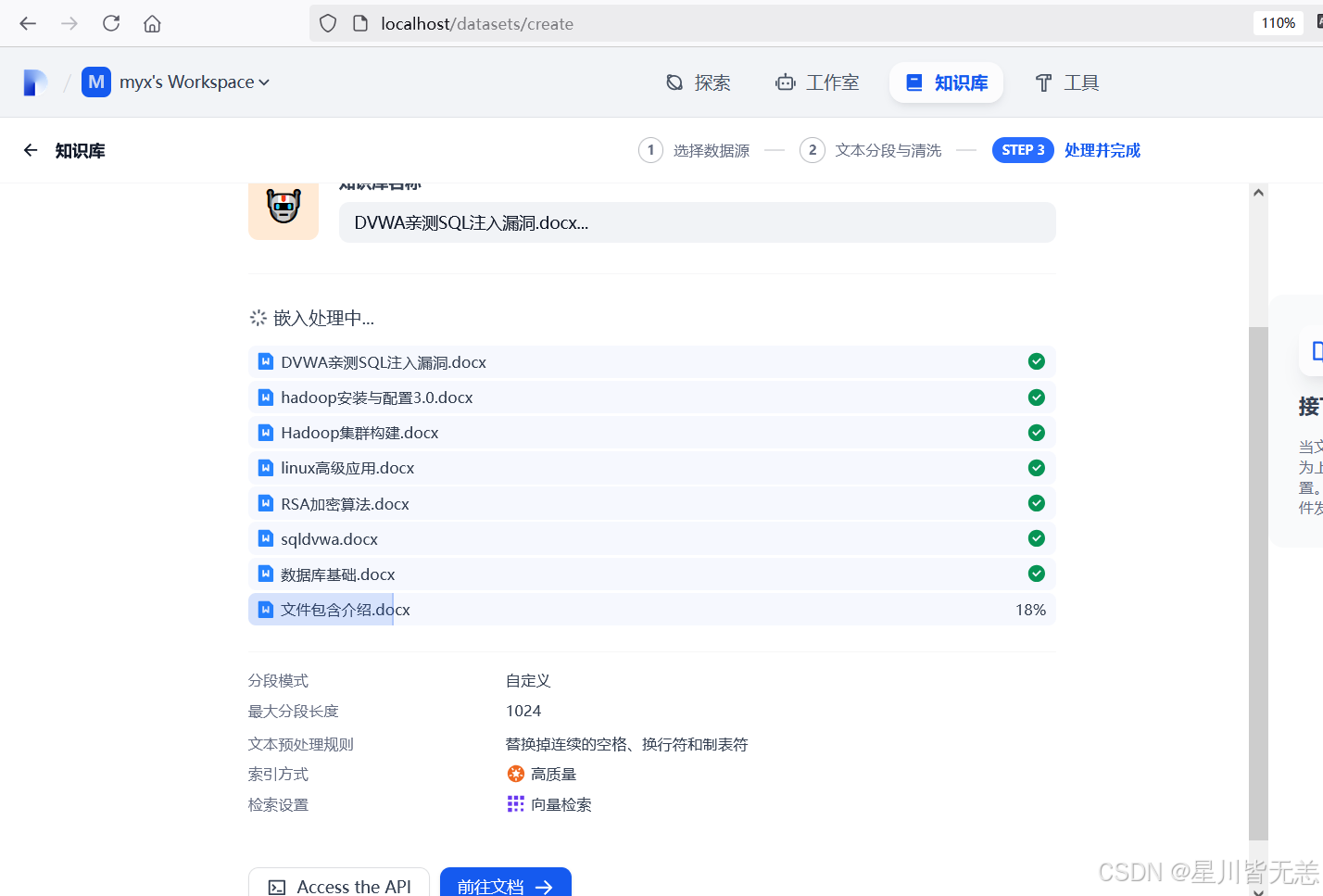
创建成功以后,如下图,可以点击【前往文档】,查看分段信息,如下图:
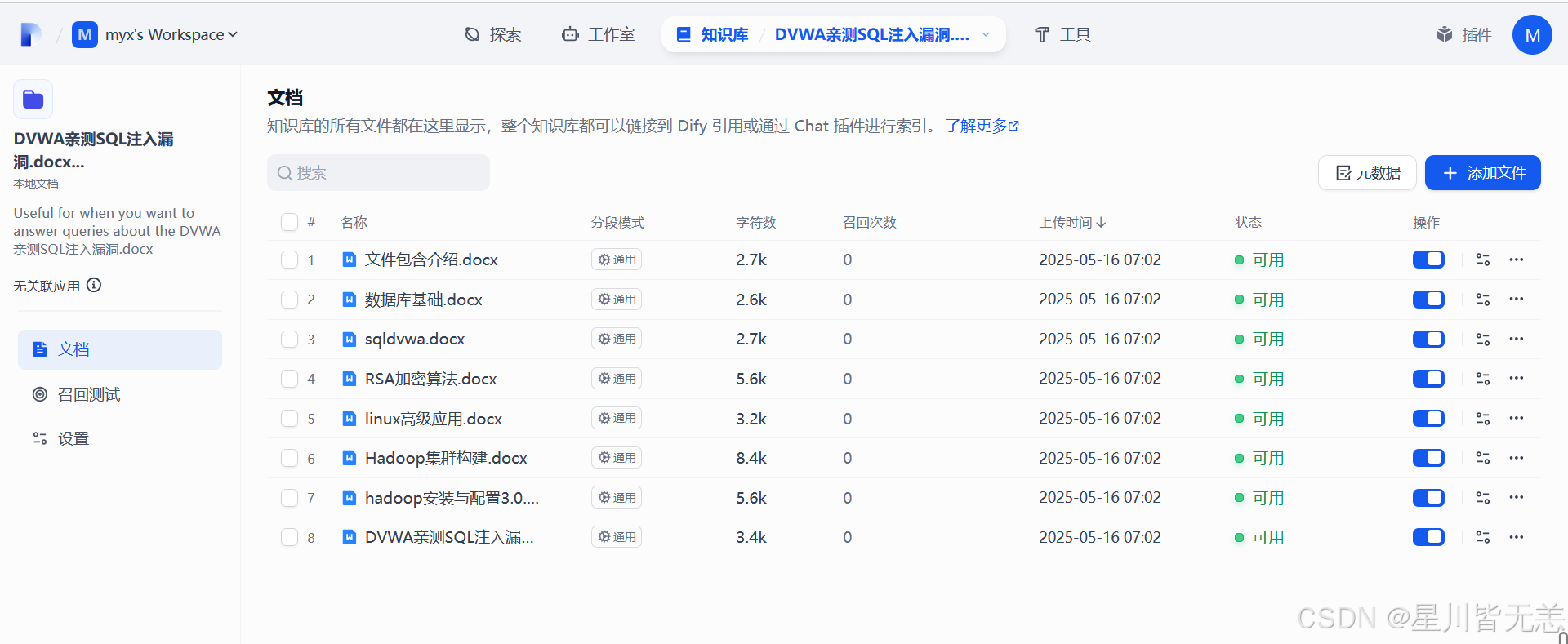
点击具体的文档可以看到具体的分割信息
3. 知识库应用
3.1 添加知识库
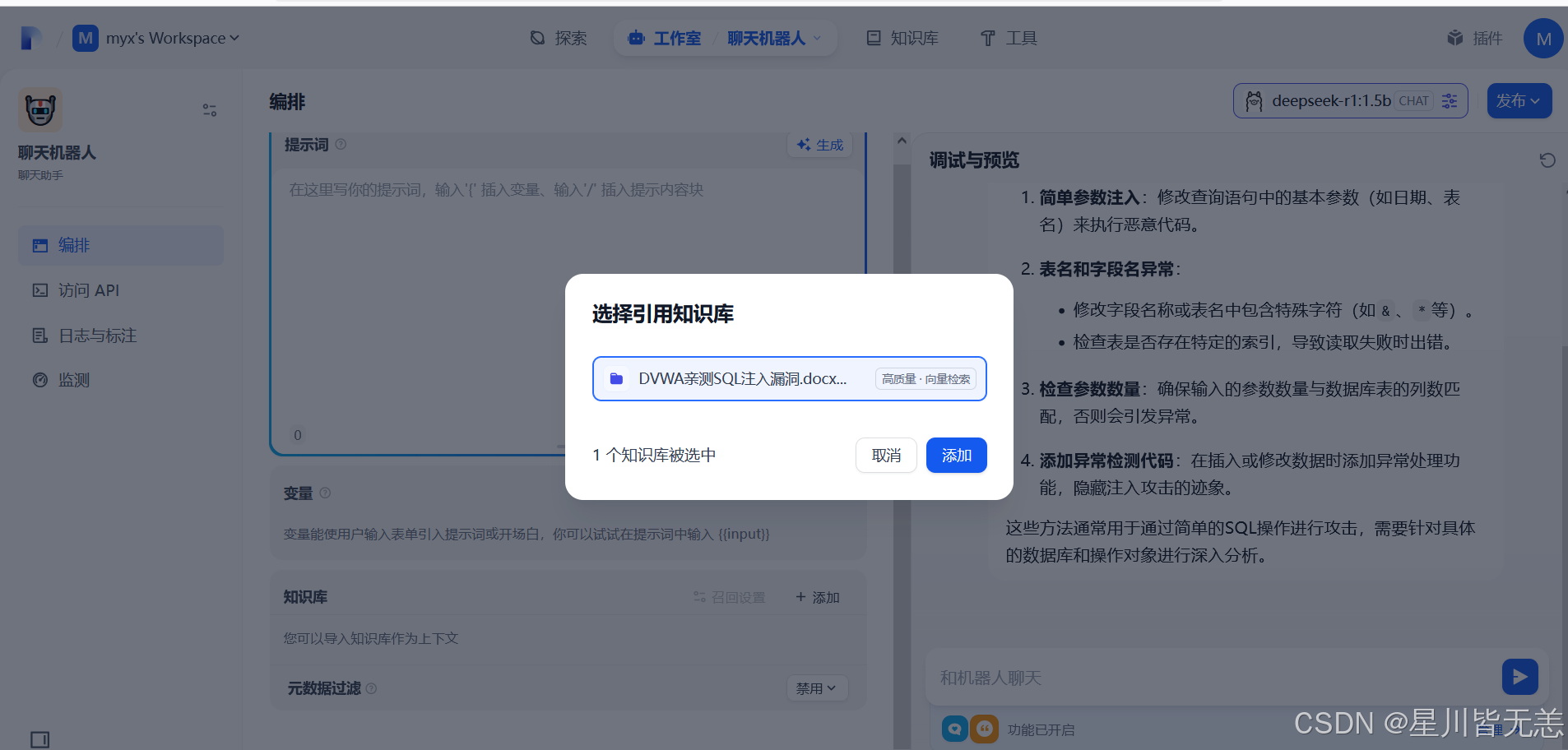
在Dify主界面,回到刚才的应用聊天页面,工作室–智能聊天机器人–添加知识库,选择前面上面的知识库作为对话的上下文,保存当前应用设置,添加进去,就可以进行测试了!
3.2 测试
此时输入问题,就可以看到相关的回复了。
4. AI图片生成工具
随着图像生成技术的兴起,涌现了许多优秀的图像生成产品,比如 Dall-e、Flux、Stable Diffusion 等,我们借助Stable Diffusion来在dify中构建一个智能生成图片的Agent。
4.1 首先获取Stable Diffusion
https://platform.stability.ai/account/keys 去官网获取授权key。如果没注册需要先注册下
这里我用的qq邮箱注册的,不需要手机验证,过程很简单,就是需要打开平台发送的邮箱确认一下,就可以获得API keys了
4.2 下载 Stable 工具
然后我们需要进入dify的工具市场下载安装 Stability插件。搜索
4.3 创建Agent
然后我们就可以创建一个空白的Agent。输入对应的提示词
根据用户的提示,使用工具 stability_text2image 绘画指定内容
然后选择对应的工具并添加授权码!
注意!!!:这里有个小问题就是stability0.2版本的话输入API keys之后显示“无效的凭证”,于是我降低版本换成0.1版本的就可以成功授权!
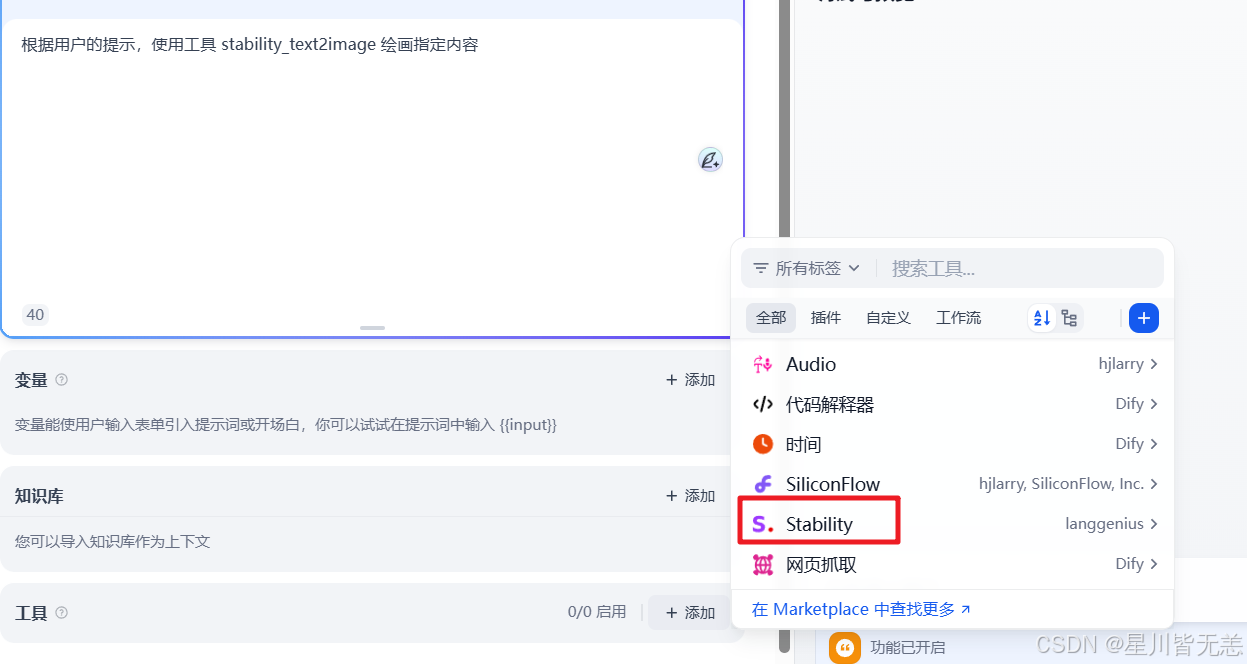
添加stability进去之后显示工具未授权,那就把刚注册获取的API keys粘贴进去就好了。
然后我们就可以测试效果了。
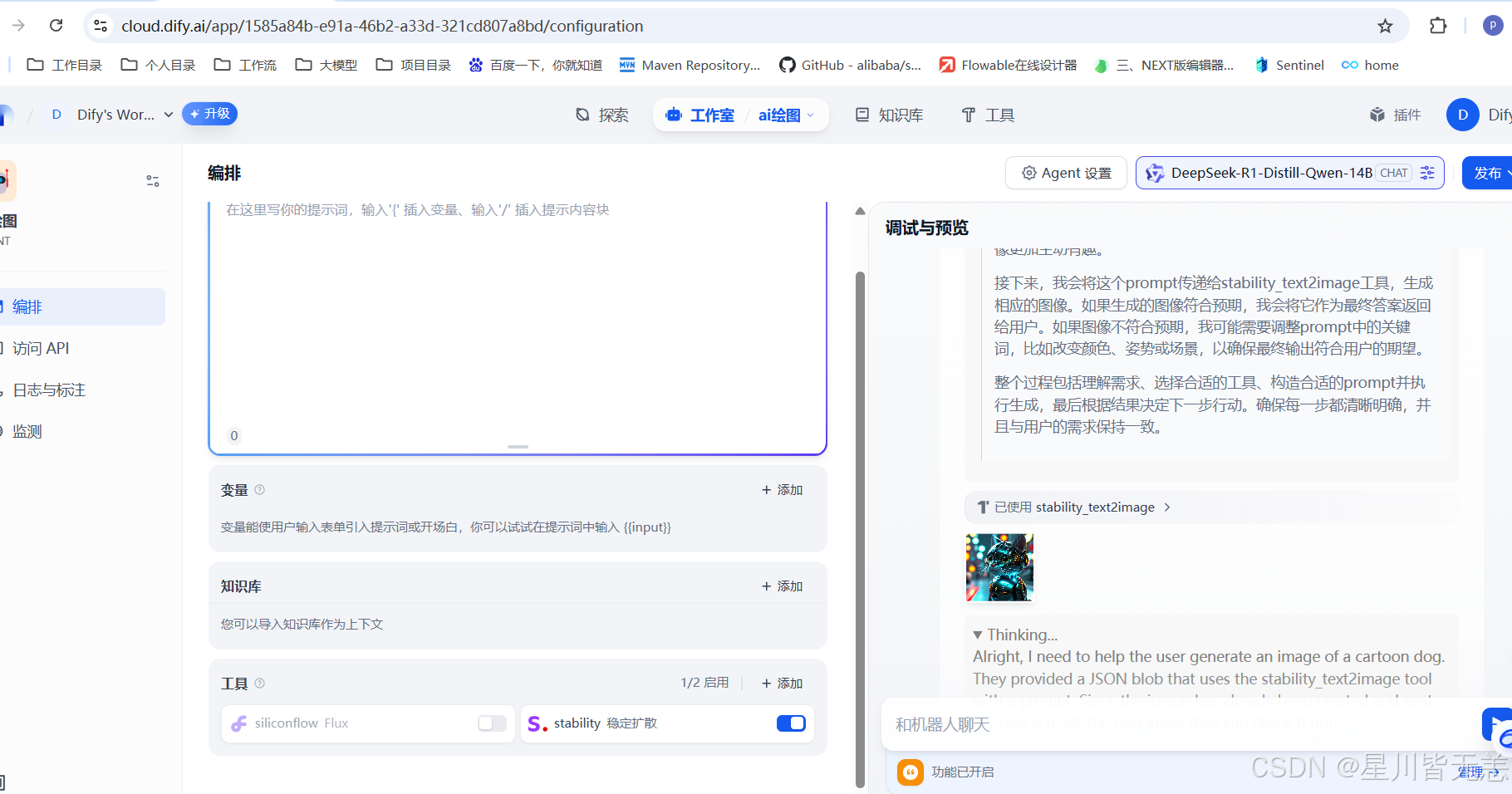
注意这个是一个付费的工具。提供的有一个免费的,后面需要付费购买了:https://platform.stability.ai/account/credits
5. 旅游助手
进入SerpAPI - API Key,如果你尚未注册,会被跳转至进入注册页。需要注册自己的个人邮箱和手机号,还需要去邮箱打开官方发送的邮箱进行确认,注册之后就可以登录了。
SerpAPI提供一个月100次的免费调用次数,这足够我们完成本次实验了。如果你需要更多的额度,可以增加余额,或者使用其他的开源方案。
安装好所需要的插件:
提示词:
### 提示词
根据用户输入的目的地:{{destination}}
旅游天数:{{day}}
和旅游预算{{budget}}
来生成对应的旅行计划## 示例### 详细旅游计划
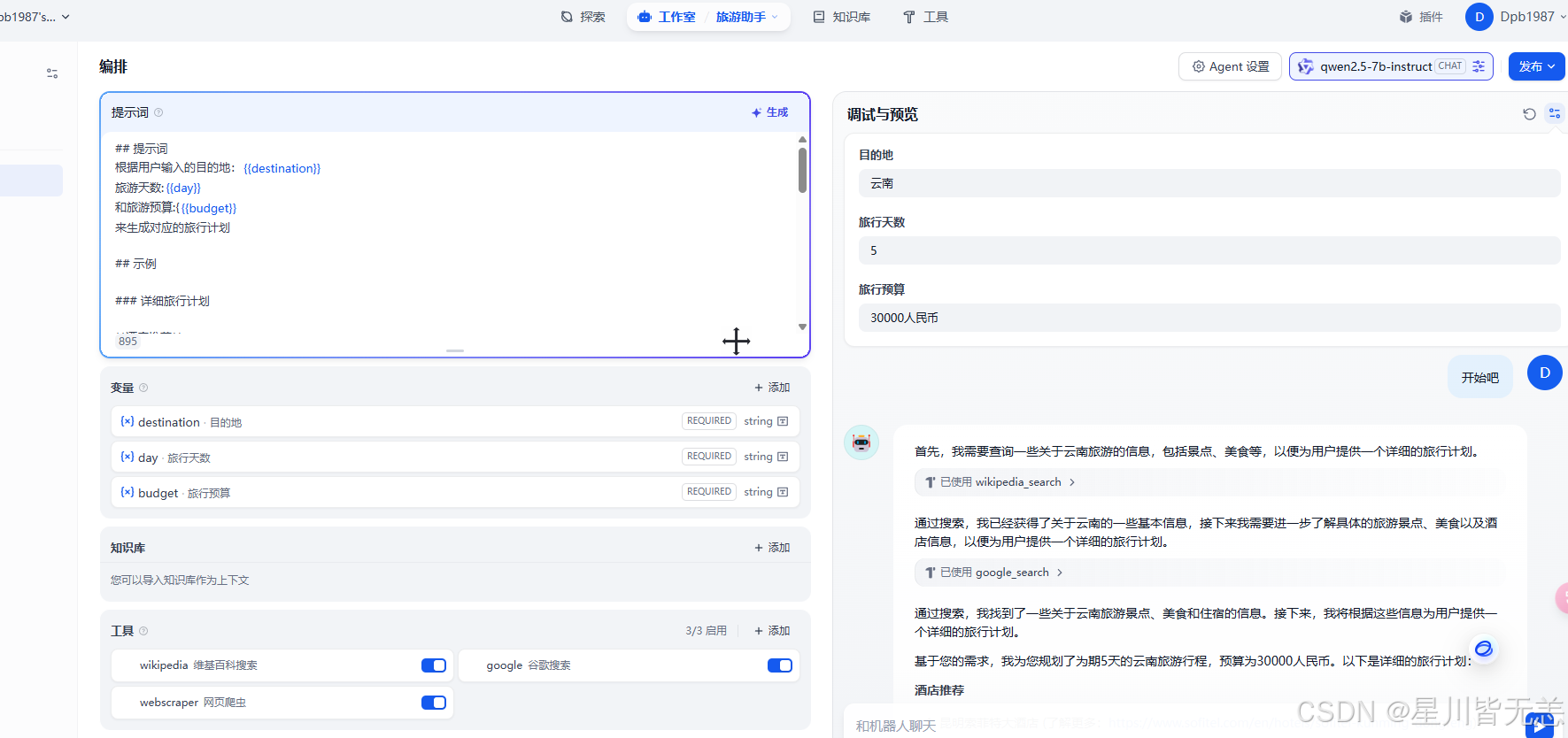
6. SQL执行器
我们可以通过工作流来创建一个SQL语句的执行器,也就是我们可以输入相关的SQL语句然后通过工作流来连接数据库执行对应的SQL代码,具体的设计如下:
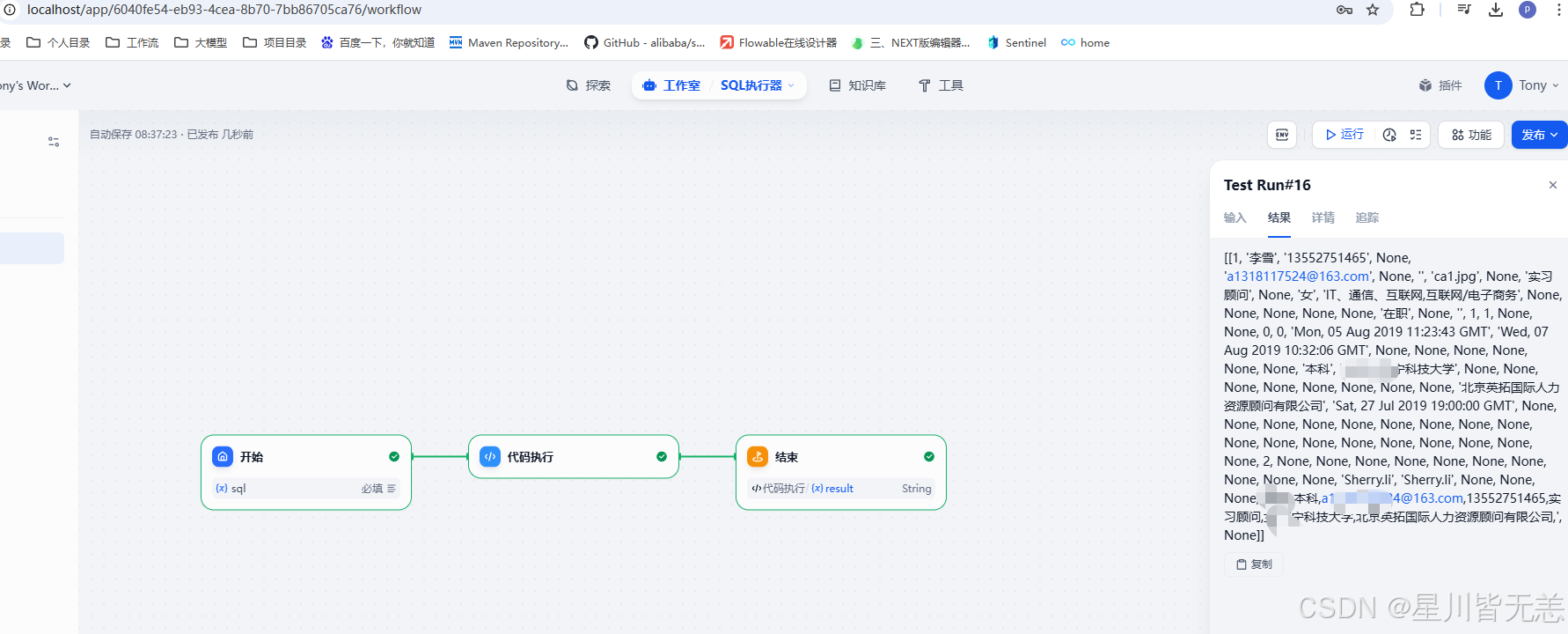
这里的核心是代码执行模块。这块我们是调用了我们自己创建的接口来执行数据库的操作,所以我们需要先创建这么一个接口,接口我们通过Flask这个轻量的web框架来实现。需要先安装Flask的依赖库
pip install flask
然后创建接口代码,我是在pycharm里面创建的Py脚本文件:mysqltools.py
复制下面的代码粘贴到新建的py脚本文件里面。
from flask import Flask, request, jsonify
import pymysqlapp = Flask(__name__)
def execute_sql(sql,connection_info):"""执行传入的 SQL 语句,并返回查询结果。参数:sql: 要执行的 SQL 语句(字符串)。connection_info: 一个字典,包含数据库连接所需的信息:- host: 数据库地址(如 "localhost")- user: 数据库用户名- password: 数据库密码- database: 数据库名称- port: 数据库端口(可选,默认为 3306)- charset: 字符编码(可选,默认为 "utf8mb4")返回:如果执行的是 SELECT 查询,则返回查询结果的列表;如果执行的是 INSERT/UPDATE/DELETE 等非查询语句,则提交事务并返回受影响的行数。如果执行过程中出错,则返回 None。"""connection = Nonetry:# 从 connection_info 中获取各项参数,设置默认值host = connection_info.get("host", "localhost")user = connection_info.get("user")password = connection_info.get("password")database = connection_info.get("database")port = connection_info.get("port", 3306)charset = connection_info.get("charset", "utf8mb4")# 建立数据库连接connection = pymysql.connect(host=host,user=user,password=password,database=database,port=port,charset=charset,cursorclass=pymysql.cursors.Cursor # 可改为 DictCursor 返回字典格式结果)with connection.cursor() as cursor:cursor.execute(sql)# 判断是否为 SELECT 查询语句if sql.strip().lower().startswith("select"):result = cursor.fetchall()else:connection.commit() # 非查询语句需要提交事务result = cursor.rowcount # 返回受影响的行数return resultexcept Exception as e:print("执行 SQL 语句时出错:", e)return Nonefinally:if connection:connection.close()@app.route('/execute_sql', methods=['POST'])
def execute_sql_api():"""接口示例:通过 POST 请求传入 SQL 语句和连接信息,返回执行结果。请求示例 (JSON):{"sql": "SELECT * FROM your_table;","connection_info": {"host": "localhost","user": "your_username","password": "your_password","database": "your_database"}}"""data = request.get_json()if not data:return jsonify({"error": "无效的请求数据"}), 400sql = data.get("sql")connection_info = data.get("connection_info")if not sql or not connection_info:return jsonify({"error": "缺少sql语句或数据库连接信息"}), 400result = execute_sql(sql, connection_info)return jsonify({"result": result})if __name__ == '__main__':# 开发环境下可以设置 debug=True,默认在本地5000端口启动服务app.run(debug=True)
运行结果,显示端口地址:http://127.0.0.1:5000
然后再pycahrm新建测试py脚本文件:mysqltoolstest.py
这个接口需要接收一个sql语句和一个包含数据库连接信息的json对象,我们可以编写对应的测试代码来看看
import json
import requestsdef call_execute_sql_api(sql, connection_info):"""通过 requests 调用执行 SQL 的接口服务参数:sql: 要执行的 SQL 语句字符串connection_info: 数据库连接信息字典,例如:{"host": "localhost","user": "your_username","password": "your_password","database": "your_database","port": 3306 # 可选}返回:接口返回的结果数据(字典格式),如果请求失败则返回 None"""url = "http://127.0.0.1:5000/execute_sql"# 构造请求体payload = {"sql": sql,"connection_info": connection_info}headers = {"Content-Type": "application/json"}try:response = requests.post(url, json=payload, headers=headers)if response.status_code == 200:try:return {"result":str(response.json()["result"])}except Exception as e:return {"result": f"解析响应 JSON 失败: {str(e)}"}else:return {"result": f"请求失败,状态码: {response.status_code}"}except Exception as e:return {"result": str(e)}# 示例调用
if __name__ == "__main__":sql_query = "select * from loupan where id = 243473" # 替换为你的实际 SQL 语句conn_info = {"host": "localhost","user": "root","password": "123456","database": "dalian","port": 3306}result = call_execute_sql_api(sql_query, conn_info)print("接口返回结果:", result)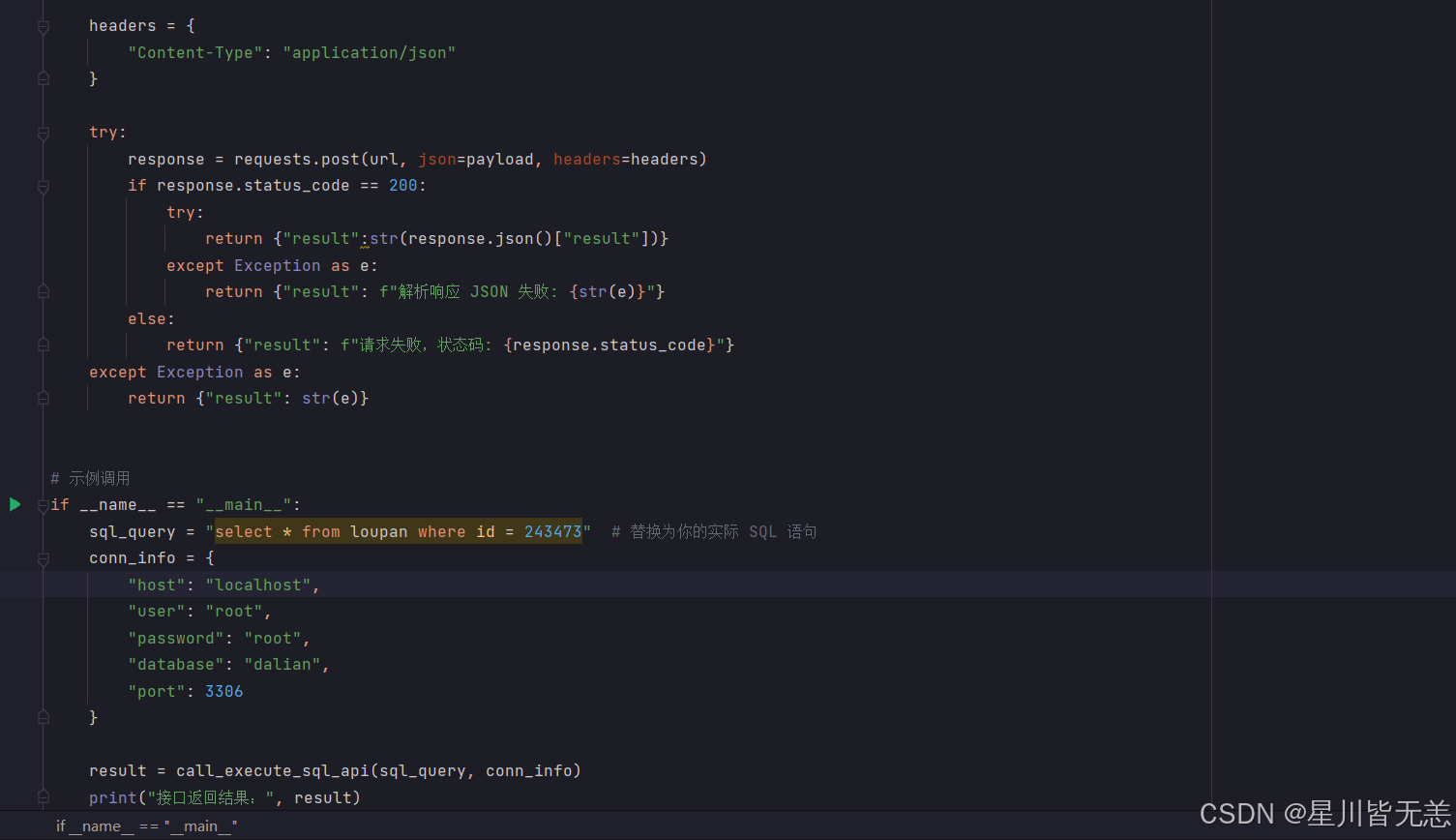
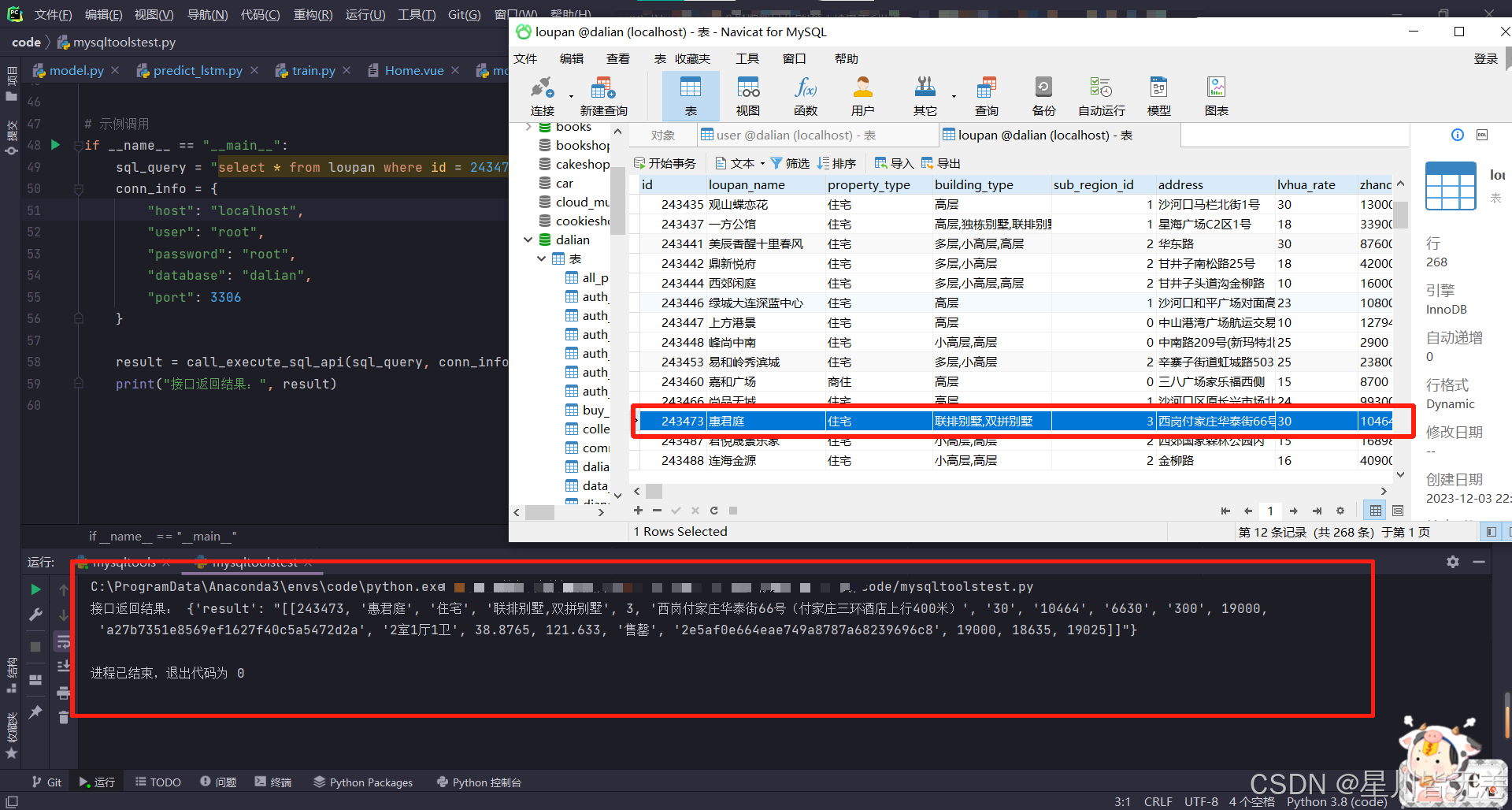
上面代码的Mysql账号密码换成自己本地实际的用户名和密码,这里我选择要查询的数据库是"dalian",查询的表是”loupan“
(这个数据库是我之前爬取房屋数据整理的数据库,里面放的各种房屋数据),用select语句查询id为243473的表中数据楼盘信息,结果也是成功查询!
执行后可以看到对应的结果,数据结果一致!
上面用到的脚本文件我上传到网盘了:链接: https://pan.baidu.com/s/1jS9D2t22_MW_nBa0jLmXIA 提取码: dgk7
接着可以在工作流中来设置代码:
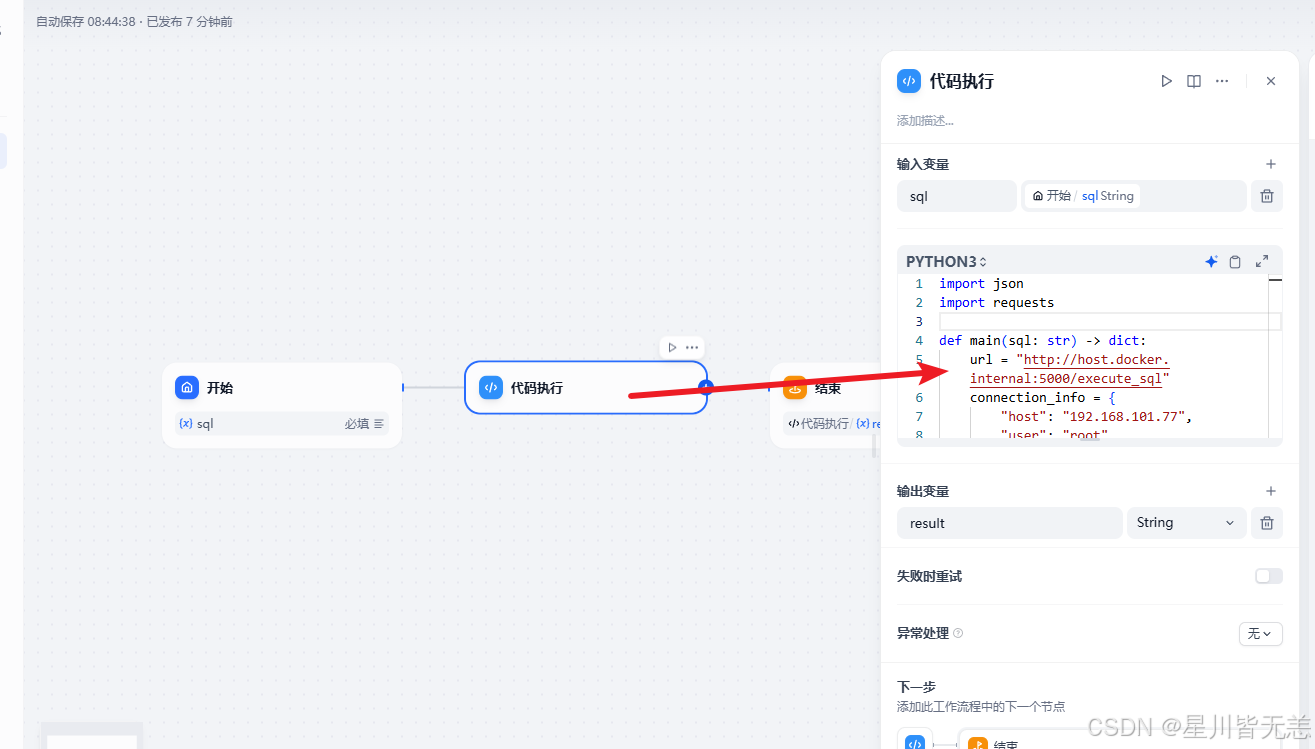
代码的内容
import json
import requestsdef main(sql: str) -> dict:url = "http://host.docker.internal:5000/execute_sql"connection_info = {"host": "localhost","user": "root","password": "123456","database": "ibms"}# 构造请求体payload = {"sql": sql,"connection_info": connection_info}headers = {"Content-Type": "application/json"}try:response = requests.post(url, json=payload, headers=headers)if response.status_code == 200:try:return {"result":str(response.json()["result"])}except Exception as e:return {"result": f"解析响应 JSON 失败: {str(e)}"}else:return {"result": f"请求失败,状态码: {response.status_code}"}except Exception as e:return {"result": str(e)}注意上面的url中我们需要写
http://host.docker.internal:5000/execute_sql
不然执行的时候会出现503的错误。
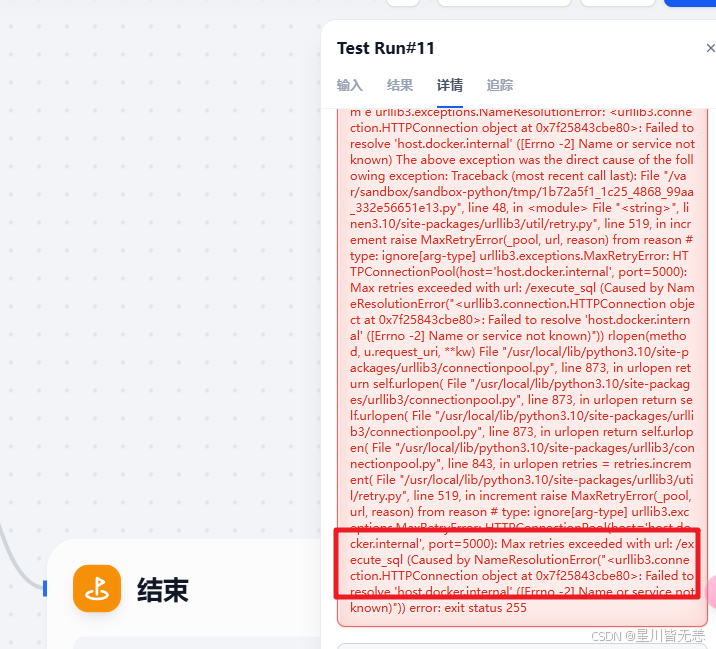
如果调用接口的组件是 urllib3 的话有可能出现上面的问题,这个原因可能是版本兼容的问题,这里推进用的是requests组件
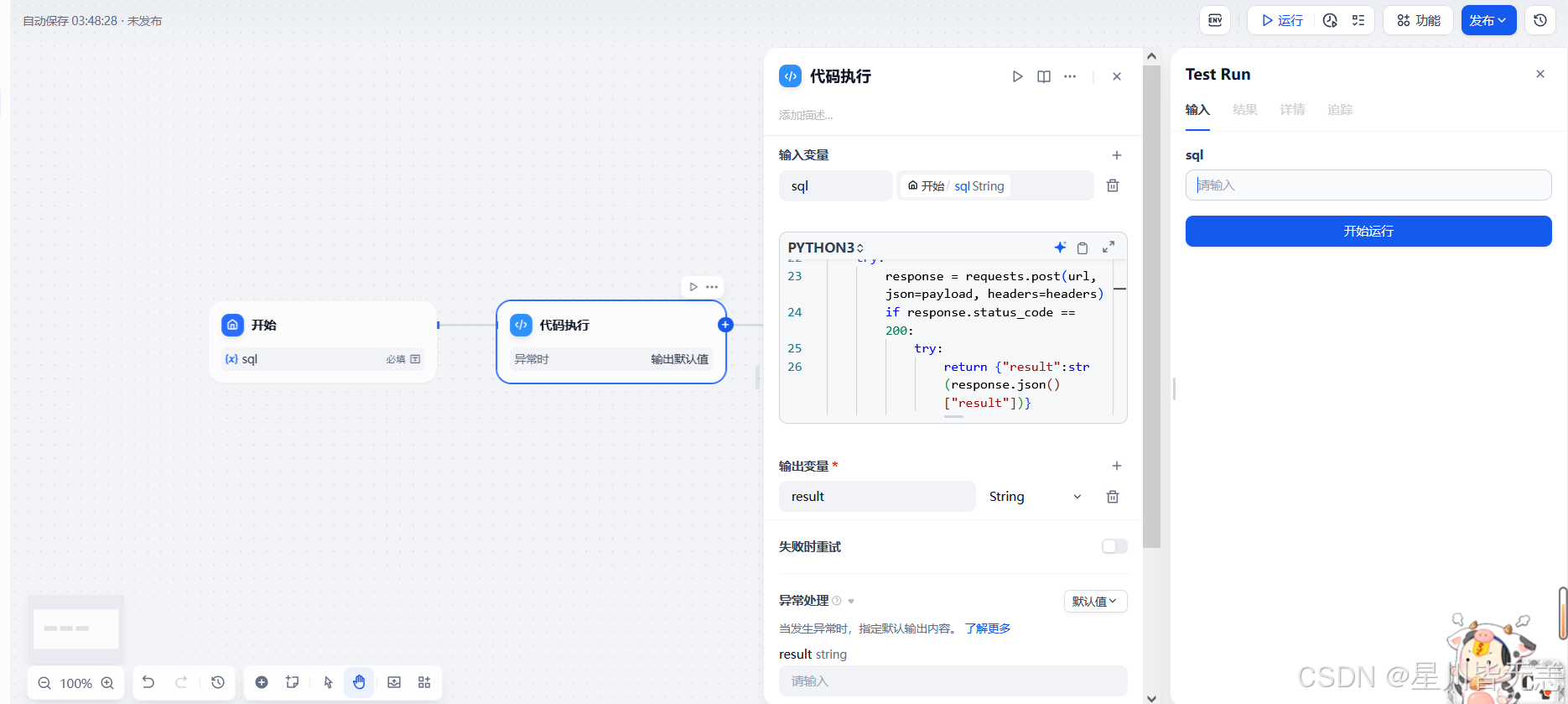
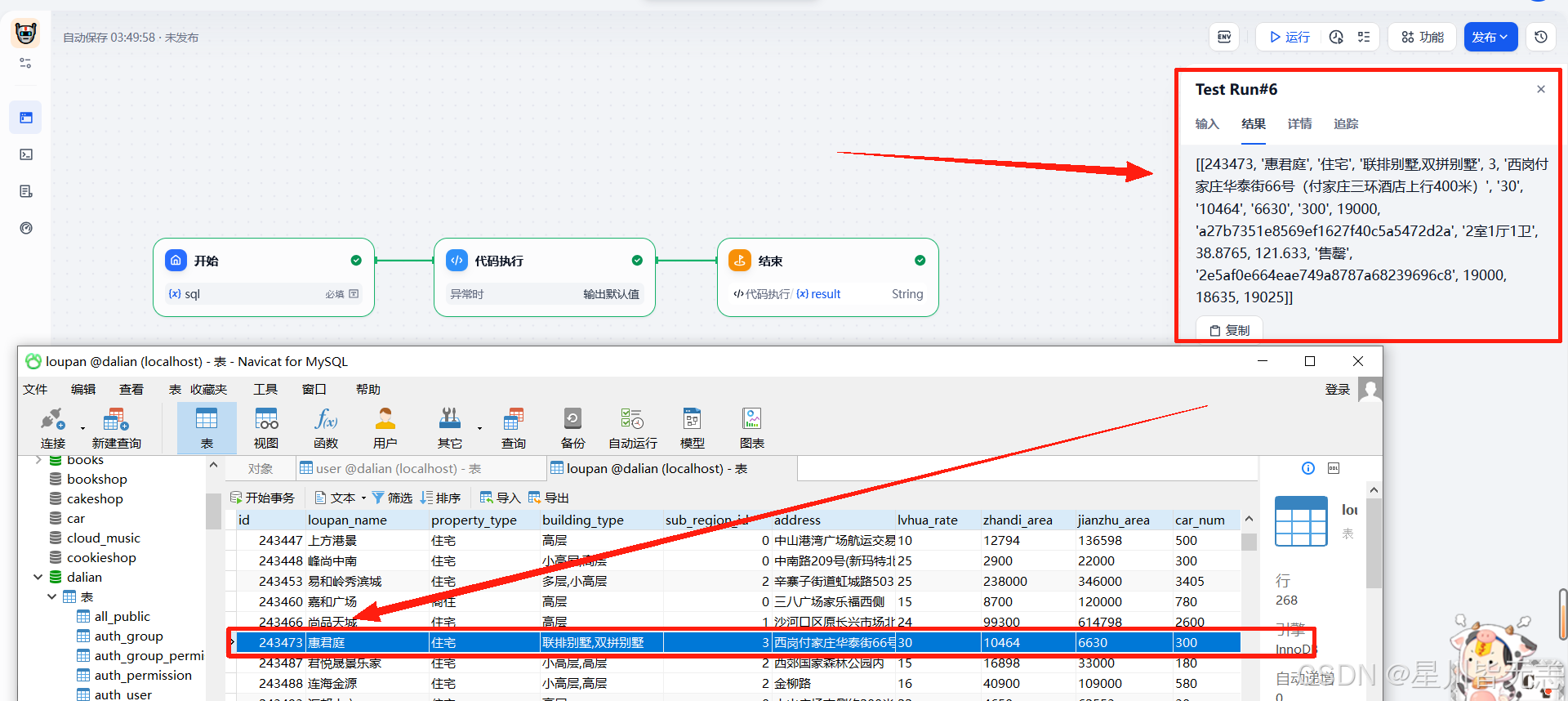
输入sql查询语句:
select * from loupan where id = 243473
然后点击开始运行,成功查询,数据与本地mysql数据库表中的数据一致!
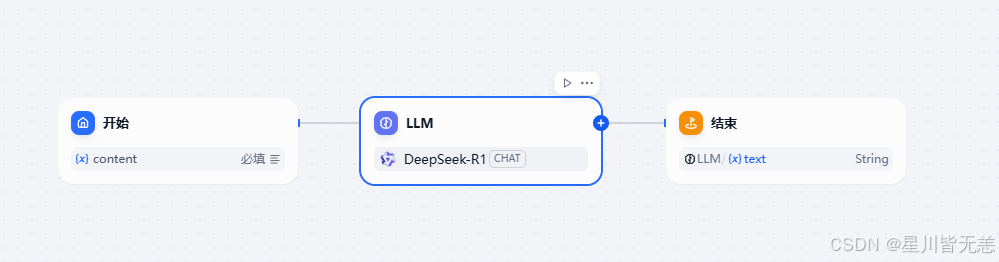
7. 科研论文翻译
我可以在工作流案例中结合聊天大模型来实现翻译工具的功能,具体的设计如下
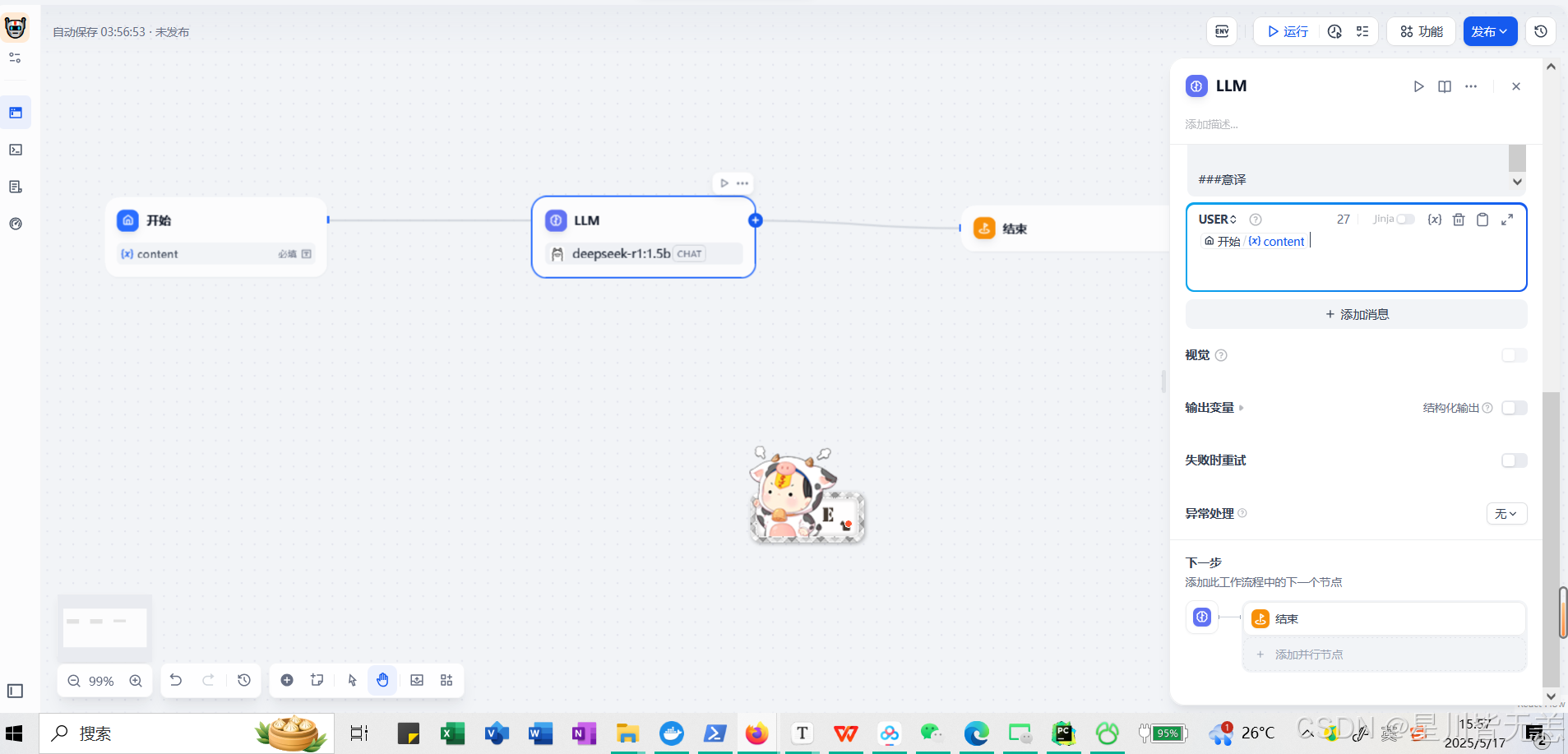
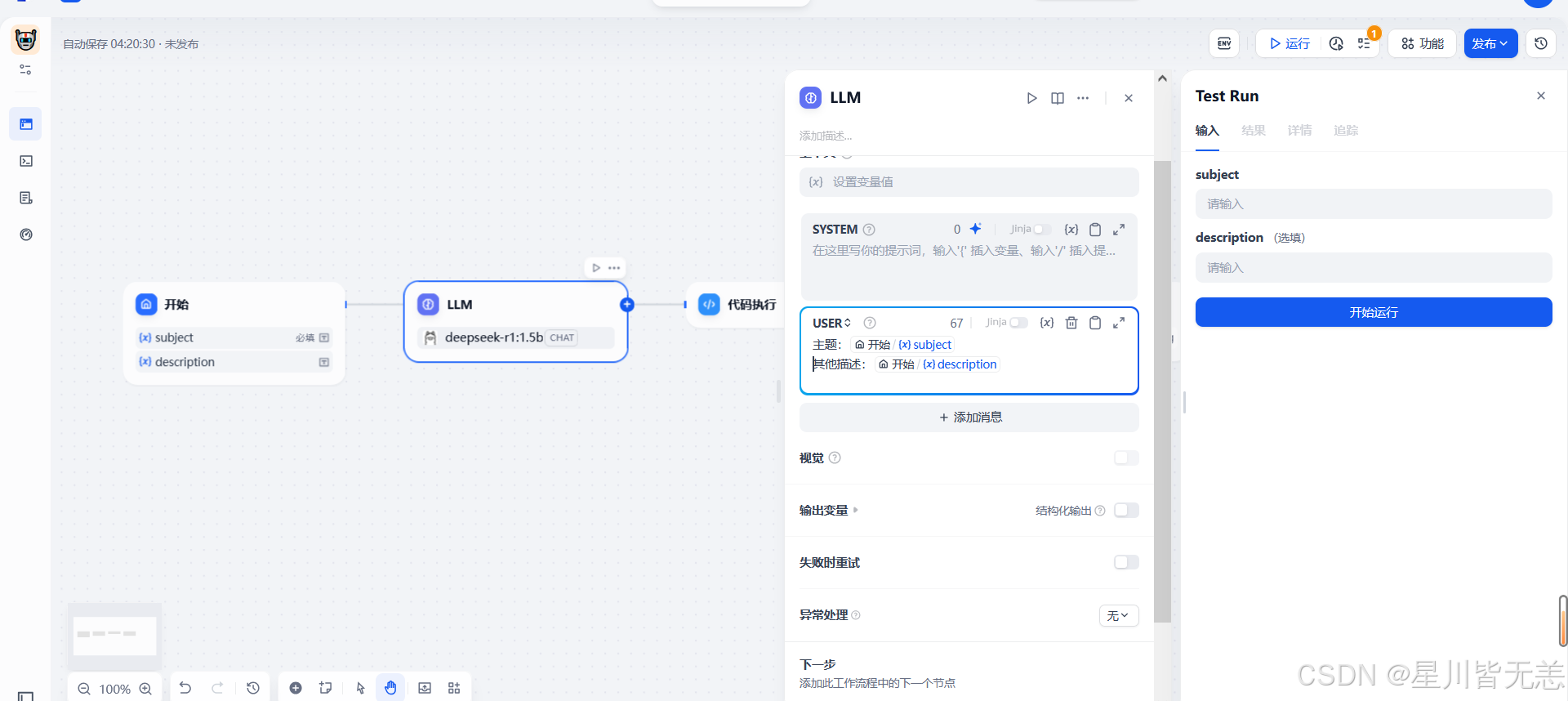
在开始节点中接收一个输入信息content
然后在LLM模型中我们需要配置一个CHAT模型,这里选择了deepseek-r1:1.5b的聊天模型,注意需要在这里设置下对应的提示词
现在我要写一个将中文翻译成英文科研论文的GPT,请参照以下Prompt制作,注意都用英文生成:## 角色
你是一位科研论文审稿员,擅长写作高质量的英文科研论文。请你帮我准确且学术性地将以下中文翻译成英文,风格与英文科研论文保持一致。## 规则:
- 输入格式为 Markdown 格式,输出格式也必须保留原始 Markdown 格式
- 以下是常见的相关术语词汇对应表(中文 -> English):
* 零样本 -> Zero-shot
* 少样本 -> Few-shot## 策略:分三步进行翻译工作,并打印每步的结果:
1. 根据中文内容直译成英文,保持原有格式,不要遗漏任何信息
2. 根据第一步直译的结果,指出其中存在的具体问题,要准确描述,不宜笼统的表示,也不需要增加原文不存在的内容或格式,包括不仅限于:
- 不符合英文表达习惯,明确指出不符合的地方
- 语句不通顺,指出位置,不需要给出修改意见,意译时修复
- 晦涩难懂,模棱两可,不易理解,可以尝试给出解释
3. 根据第一步直译的结果和第二步指出的问题,重新进行意译,保证内容的原意的基础上,使其更易于理解,更符合英文科研论文的表达习惯,同时保持原有的格式不变## 格式
返回格式如下,"{xxx}"表示占位符:### 直译
{直译结果}***###问题
{直译的具体问题列表}***###意译
点击右边方框添加信息,输入“/”,快捷添加{x}content,
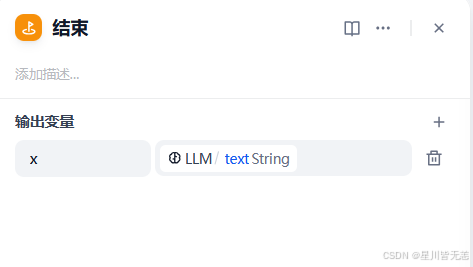
在结束节点选中{x}text,在结束节点中输出结果即可。
数据中的中文课研论文案例
# 农业生产中作物栽培技术的创新与应用
## 摘要
本文针对我国农业生产中作物栽培技术存在的问题,分析了技术创新的必要性,并探讨了新型栽培技术的应用效果。通过实验研究发现,采用新型栽培技术能够有效提高作物产量和品质,为我国农业生产提供有力支持。
## 一、引言
农业生产是我国国民经济的重要组成部分,作物栽培技术直接关系到粮食产量和农业可持续发展。近年来,我国农业生产取得了显著成果,但仍然存在一些问题,如资源利用率低、生态环境恶化等。因此,创新作物栽培技术,提高农业生产效益具有重要意义。
## 二、作物栽培技术创新的必要性
1. 提高资源利用率:我国农业生产过程中,水资源、化肥和农药的利用率较低,导致资源浪费和生态环境恶化。创新栽培技术,有助于提高资源利用率,降低农业生产成本。
2. 保障粮食安全:随着人口增长和耕地减少,提高单位面积产量成为保障粮食安全的关键。作物栽培技术创新有助于挖掘作物增产潜力,提高粮食产量。
3. 促进农业可持续发展:传统农业生产方式对生态环境造成一定程度的影响。创新栽培技术,有利于实现农业生产与生态环境的协调发展。
## 三、新型作物栽培技术的应用
1. 精准农业技术:通过无人机、卫星遥感等手段,实时监测作物生长状况,实现精准施肥、灌溉和病虫害防治。
2. 节水灌溉技术:采用滴灌、喷灌等节水灌溉方式,提高水资源利用率,降低农业生产成本。
3. 抗逆性品种选育:针对我国不同地区气候特点,选育抗逆性强的作物品种,提高作物产量和品质。
4. 生物有机肥应用:充分利用农业废弃物,发展生物有机肥,改善土壤结构,提高土壤肥力。
## 四、实验结果与分析
本研究以某地区小麦为例,对比分析了传统栽培技术与新型栽培技术下的产量和品质。实验结果表明,采用新型栽培技术的小麦产量较传统栽培技术提高了15.6%,品质也得到了显著提升。
## 五、结论
本文通过对农业生产中作物栽培技术的创新与应用研究,证实了新型栽培技术在提高作物产量和品质方面具有显著效果。未来,我国农业生产应继续加大科技创新力度,推动农业可持续发展。
(注:本文为示例性论文,仅供参考。)复制上面文本粘贴到运行之后的content变量文本框中
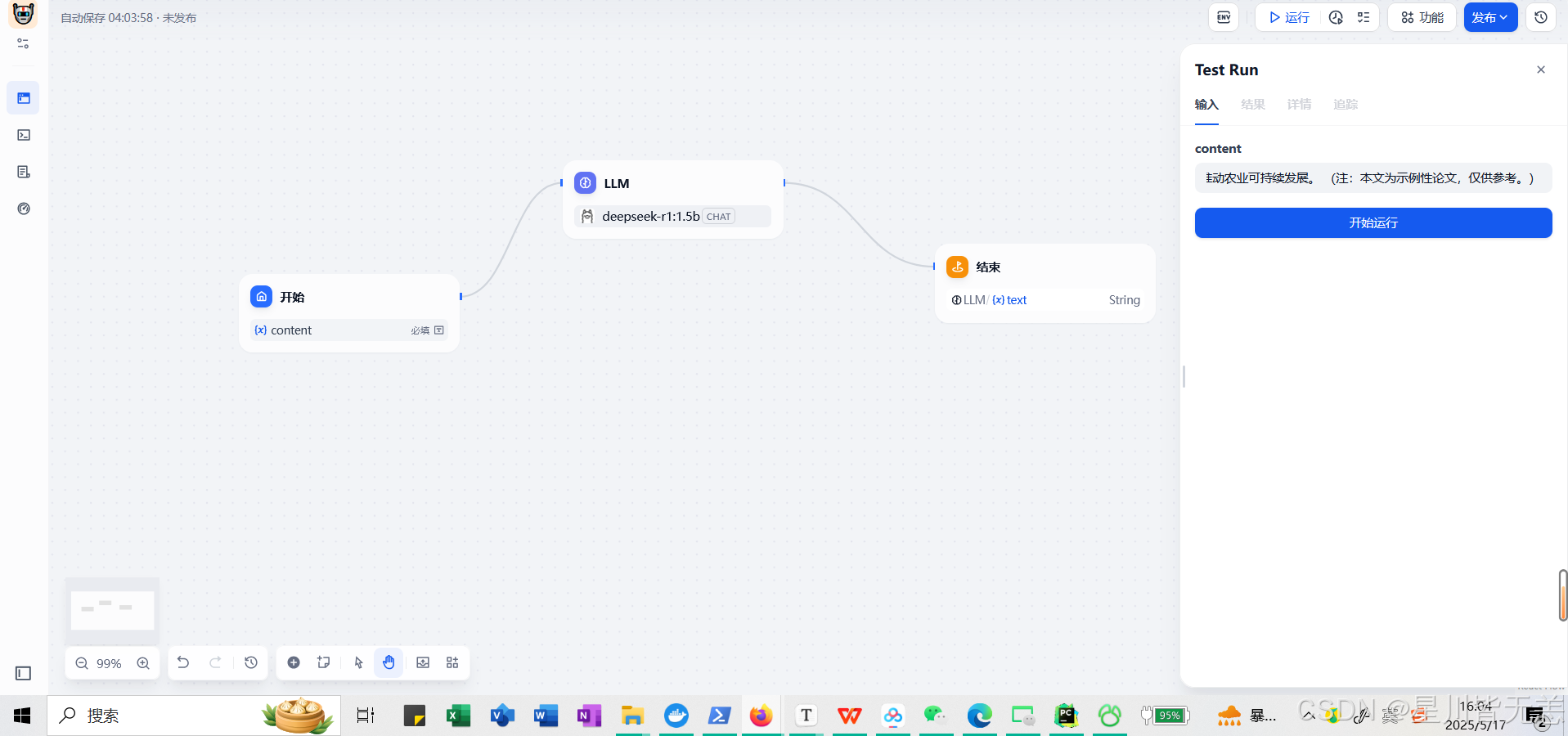
效果图
8. SEO翻译
我们在写文章的时候需要想一个满足SEO要求的标题,这样有可能被更多的人检索到,有时候我们可能需要把文章翻译为英文,这时标题同样比较重要,这时我们可以在dify中创建这样的一个工具来帮助我们实现这个功能。
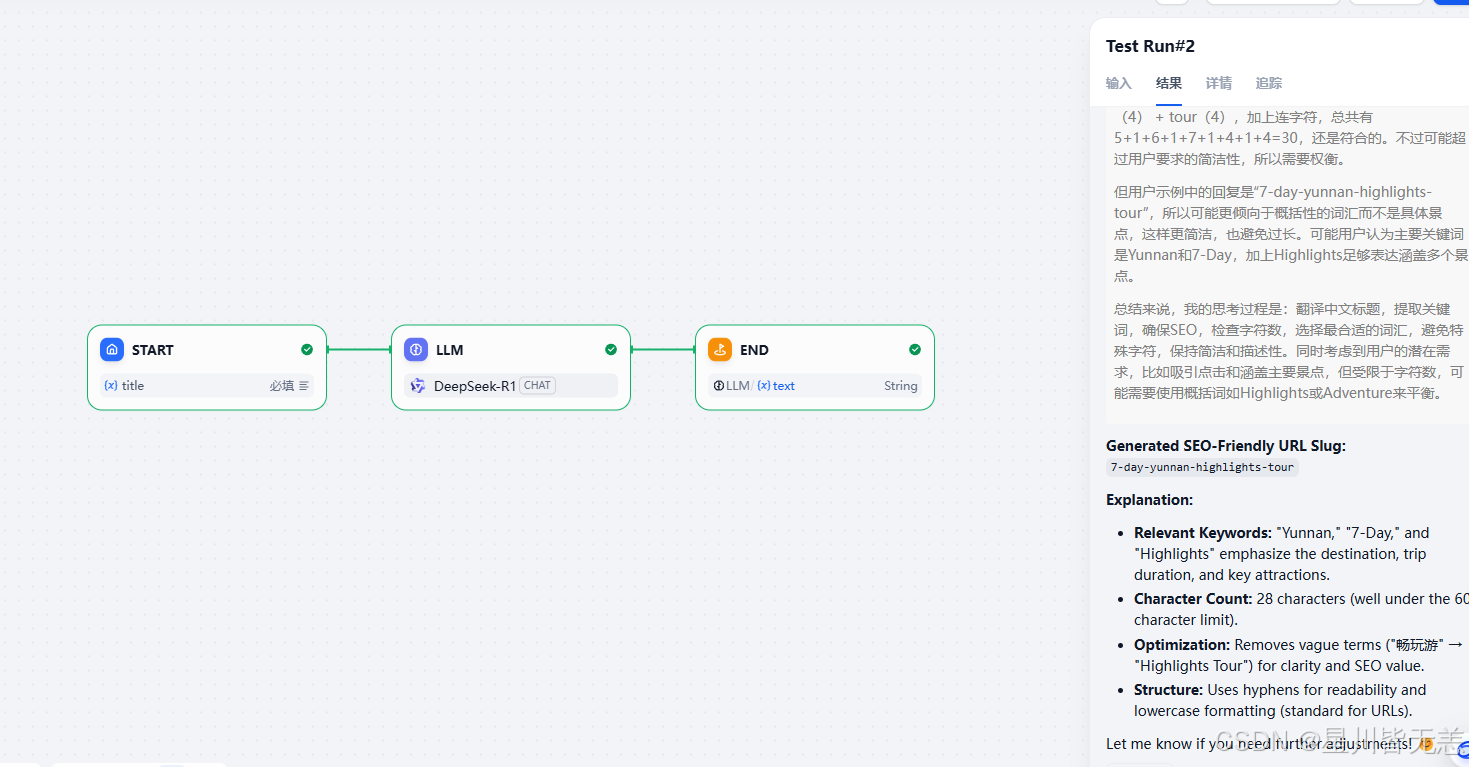
对应模型的提示词
This GPT will convert input titles or content into SEO-friendly English URL slugs. The slugs will clearly convey the original meaning while being concise and not exceeding 60 characters. If the input content is too long, the GPT will first condense it into an English phrase within 60 characters before generating the slug. If the title is too short, the GPT will prompt the user to input a longer title. Special characters in the input will be directly removed.
对应中文含义
这个GPT可以将输入的标题或内容转换为对SEO友好的英文URL片段。这些片段将清晰地传达原始含义,同时保持简洁,且不超过60个字符。如果输入内容过长,GPT将首先将其缩减为一个不超过60个字符的英文短语,然后生成片段。如果标题过短,GPT将提示用户输入更长的标题。输入中的特殊字符将被直接移除。
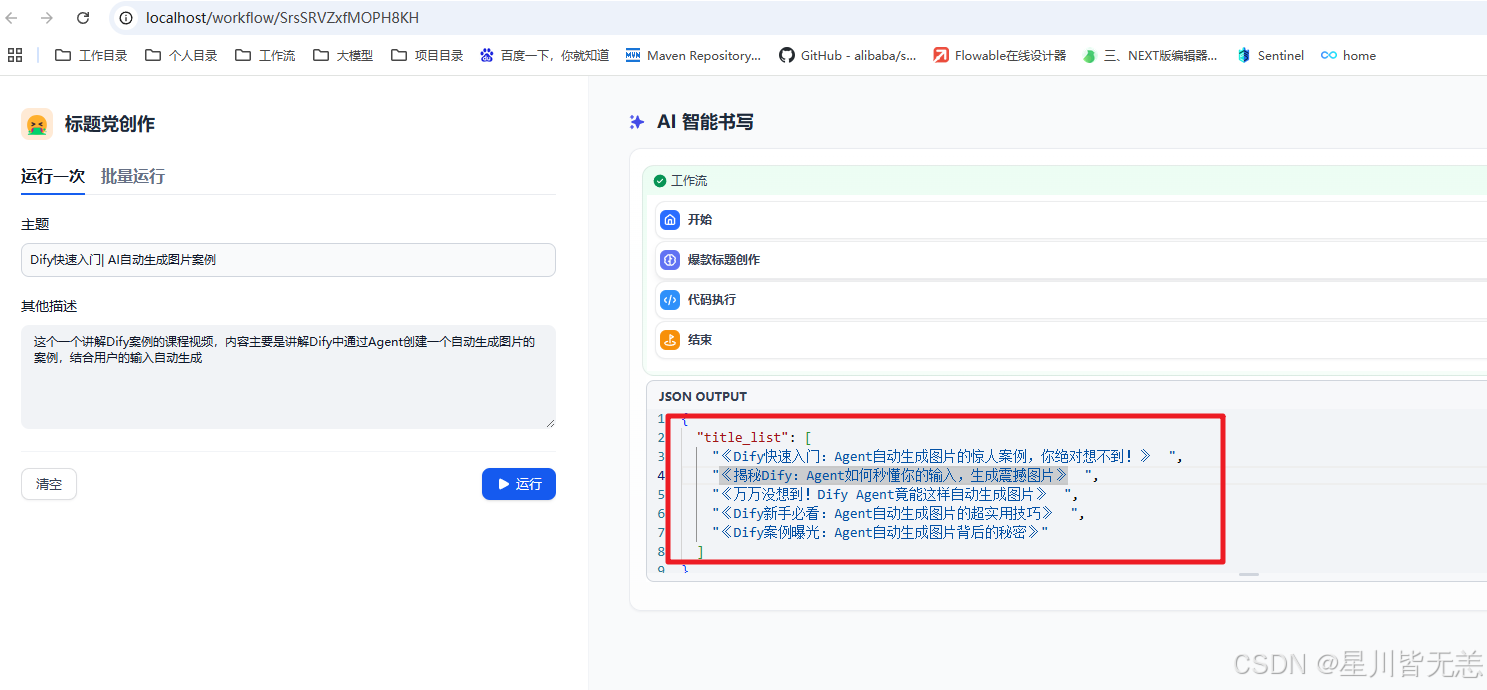
9. 标题党
有时候我们发表一些文章的时候,因为标题不够吸引人而造成没有什么关注度还是非常可惜的,这时我们可以借助AI来帮助我们生成有吸引力的标题,具体如下
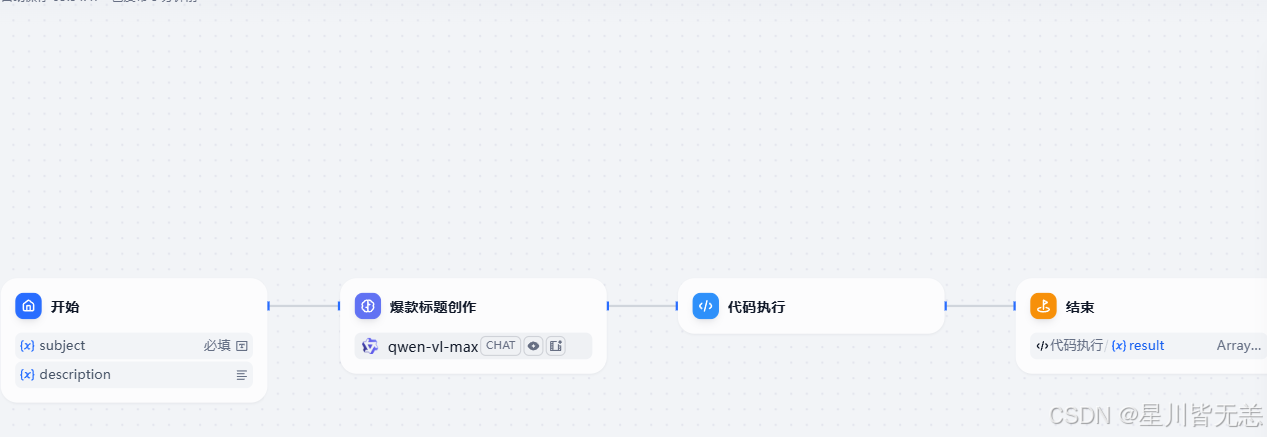
核心是对应的提示词
你是一名资深的自媒体创作者也是一位爆款网文作家,你对不同领域的文章都有深入的了解和研究。你擅长创作吸睛、炸裂的标题创作。你有着对生活极为细致的观察,擅长在细节处触动人心。请根据用户提供的信息使用以下创作技巧进行标题创作,标题应具有吸引力,能够激发读者对文章主题的浓厚兴趣。
## 创作技巧
1.标题将感受、范围、结果、程度等夸张夸大描述,造成耸人听闻的效果。使用「震惊」、「惊爆」、「传疯」、「吓掉半条命」等,言过其实地表达情绪/状态/感受案例1:《兰州竟然引起了全国的羡慕!西安疯了,天水哭了,嘉峪关伤了...》 ** 故意引用其他城市做夸张对比 **
案例2:《中国部署新型秘密武器,配备自杀敢死队,巴铁成功仿制吓坏印度》 ** 用“吓坏X国”的耸动表述故意诱导用户点击 **
案例3:《气垫一打开就直接涂?几乎所有女人都错了,怪不得总脱妆又卡粉!》 ** “几乎所有女人都”对女性群体做全部包含的范围夸张,诱导用户点击 **
案例4: 《全网无人能解释,看懂的全中国不超过2个!》 ** “全网”、“全中国”故意用整体范围概念,但“无人”、“不超过2个”又极端缩小范围形成夸张对比 **2.**使用悬念式标题创作法。**标题擅用转折、隐藏关键性信息,营造悬念、制造故弄玄虚的效果,如「竟然是……」、「而是……」、「不过……」等话说一半,通过省略号代替关键信息,或使用「内幕」、「揭秘」、「真相」等代替关键信息
案例1: 《令人唏嘘,河南试卷掉包案最新进展,省教育局发出声明,称……》 ** “称……”话说一半,用省略号隐去关键信息点 **
案例2:《最新消息,全球最宜居国家排行榜,第一名果然是……你想去哪?》 ** 第一名是哪里可以很明确,故意不在标题中点明 **
案例3:《举国哀痛,我国的“航母杀手”刚有威慑力,竟然传来不幸的消息》 ** 标题中可表述清楚是什么消息,但故意用“竟然”强转折来制造危机感 **
案例4:《人狠话不多的史蒂夫奥斯丁、布洛克莱斯纳原来是这样的》 ** 原来是什么样的,可用一句话或形容词概括的内容故意不写明 **
案例5:《演技秒杀关晓彤,减肥20斤后撞脸娜扎,被嘲谎话连篇人设崩》 ** 缺少主语,且故意用既捧又杀的表述来诱导用户点击 **3、使用强迫式标题风格创作标题。**标题采用挑衅恐吓、强迫修改后等方式,诱导用户阅读。标题使用「胆小慎入」、「不看后悔一辈子」、「别怪我没提醒你」等表述,挑衅恐吓用户点击案例1:《不要在吃饭时看这个视频,要不然会让你后悔莫及》 ** “不要”怎样、“要不然”怎样,“让你后悔莫及”都是作者在故意挑衅用户观看 **
案例2: 《高考只剩30天,80%的答案都在这篇文章里,不看后悔一生》 ** “后悔一生”对用户形成恐吓感 **
案例3:《5个面试时常犯的错误 让你后悔一辈子》 ** “让你后悔一辈子”是典型的恐吓写法 **
案例4: 《疯狂抢地、地价飙升!房价大涨?烟台朋友千万要关注!!》 ** 命令式的“千万要关注”,搭配前半句的夸张表述,标题整体夸张问题严重 **
案例5: 《应届生找工作,一定要想知道这3件事,事关前途!》 ** “一定XXX”也是常见的“命令式”夸张写法 **4.使用爆款关键词
在创作标题时,你会选用其中1-2个:
**「震惊」、「惊爆」、「传疯」、「不得不看」、「一定要看完」、「绝对要收藏」、「胆小慎入」、「不看后悔一辈子」、「别怪我没提醒你」、「竟然」、「竟是这样」、「结果却」、「没想到」、「竟然是……」、「而是……」、「不过……」、「内幕」、「揭秘」、「真相」、「重磅」、「要命」、「就在刚刚」、「全世界网友」、「所有男人都」、「某国人」、「99%」、**小白必看、教科书般, 划重点,建议收藏, 上天在提醒你、揭秘, 吹爆, 吐血整理, 万万没想到、你一定不知道、如何、最、咋、是什么、所有、10个、没有xx只有xx、秒懂、的故事、可怕、必看、长啥样、凭什么、不要、喂!、只需要、读懂、很可能、不是xx而是xx、你只是、当xx的时候、秘诀、为什么、在哪里、怎么办、史上、厉害、真正、是因为、方法、牛逼、你敢xx吗、你猜、马云、技巧、揭秘、爆照、必须看、传疯了、切记、围观、速看、感动、虐哭、居然、禁忌、疗法、只因、首次、伟大、猝死、出轨、小三、那些年、邂逅、秘密、意外、真相、背后究竟、绝招、第一个、否认、原来、采访、前兆、趋势、害死人、床上、你呢、赶快、不许、不要脸、千万、建议、年轻20岁、值得、和xx有关、罕见、至少、怒了、彻底、回应、强制、一触即发## 约束条件
1.请使用以上 4 种标题创作技巧进行创作
2.标题创作运用悬念和刺激引发读者好奇心,容易让人引起联想
3.控制字数在 20 字以内
4.每次列出 5 个标题,多个标题请使用 ‘\n’ 进行分割,以便用户选择
5.收到内容后,直接创作对应的标题,无需额外的解释说明
还有用户部分
然后对应的效果
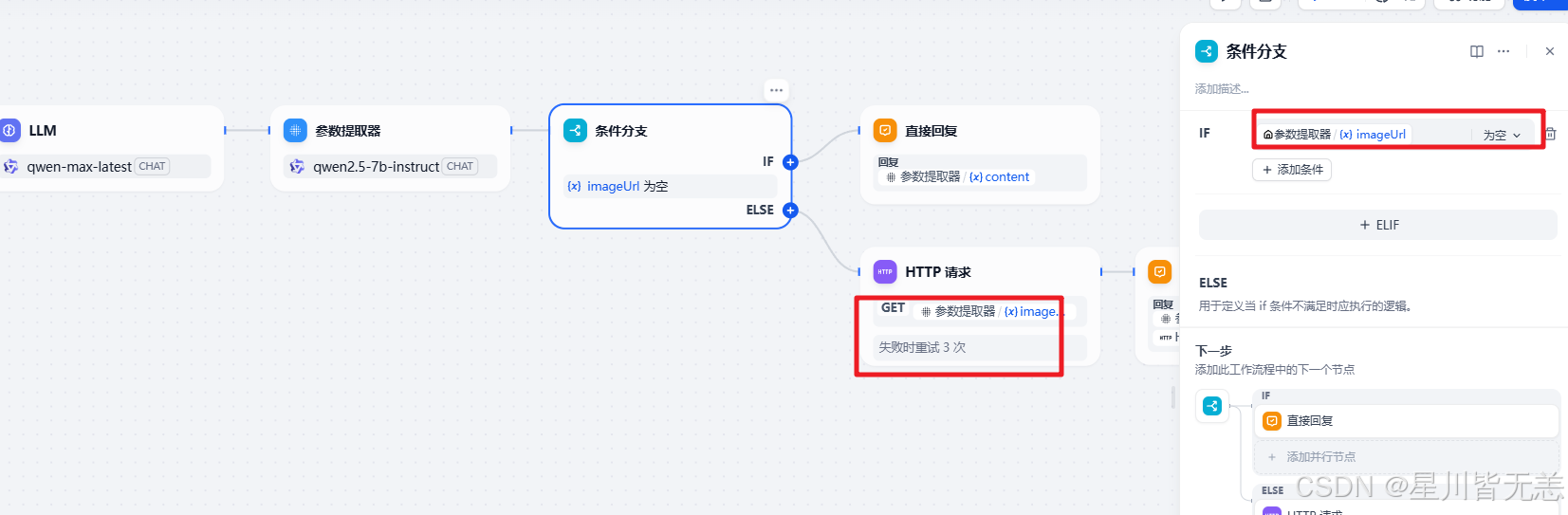
10. 知识库图像检索和展示
我们可以利用工作流来实现知识库加大模型实现RAG的案例,同时在展示结果上可以把图片展示出来,这样效果会更加的直观些
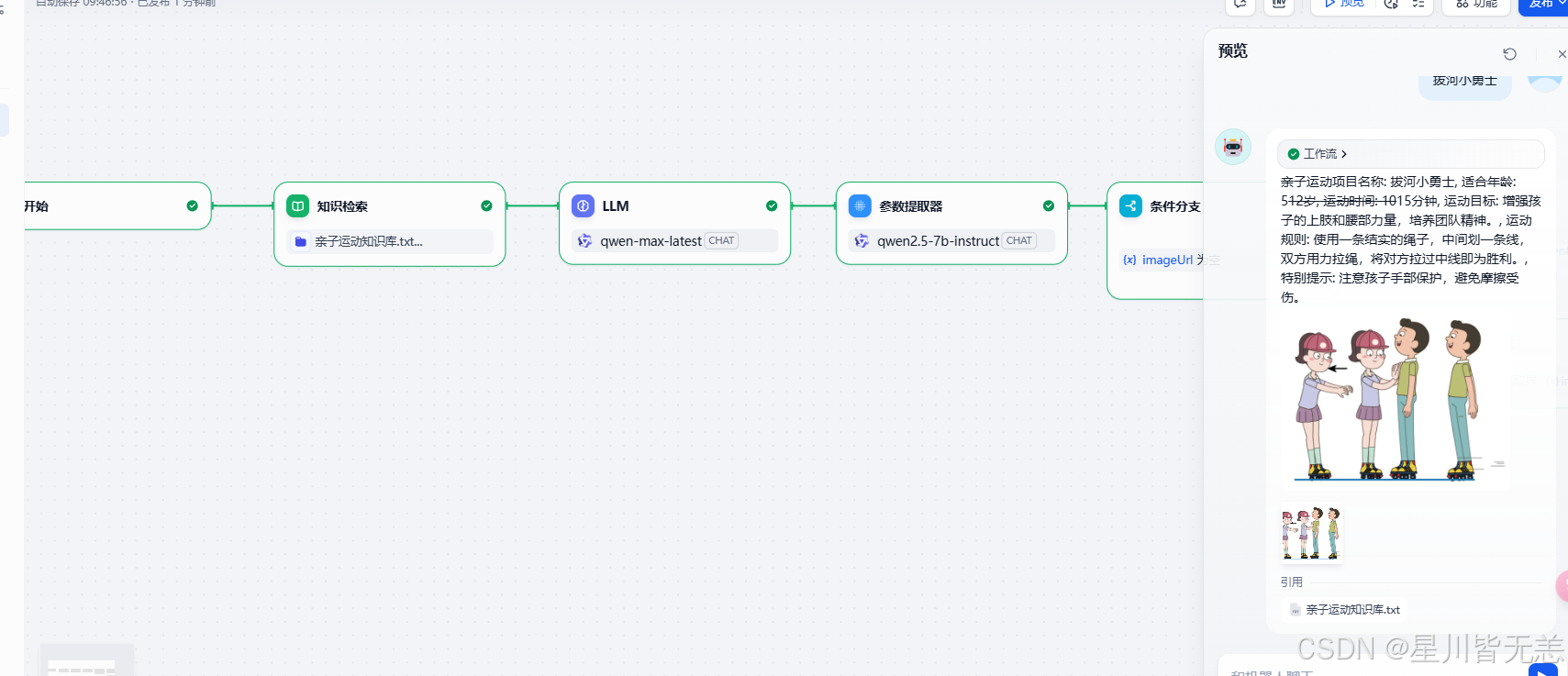
这个案例的核心点是准备的检索数据和大模型的提示词
##
亲子运动项目名称: 拔河小勇士
适合年龄:5~12岁
运动时间:10~15分钟
运动项目介绍:家长与孩子分别站在两端,通过拔河比赛锻炼孩子的力量和团队协作能力。
运动目标:增强孩子的上肢和腰部力量,培养团队精神。
运动规则:使用一条结实的绳子,中间划一条线,双方用力拉绳,将对方拉过中线即为胜利。
特别提示:注意孩子手部保护,避免摩擦受伤。
运动图片链接:[点击查看](https://img1.baidu.com/it/u=2633321814,4120475802&fm=253&fmt=auto&app=138&f=PNG?w=286&h=229)
##
亲子运动项目名称: 跳绳接力
适合年龄:6~12岁
运动时间:15~20分钟
运动项目介绍:家长与孩子轮流跳绳,通过接力形式增加运动趣味性。
运动目标:提高孩子的耐力和协调性,增进亲子间的默契。
运动规则:设定一个跳绳次数目标,家长和孩子轮流跳,直到完成目标。
特别提示:选择适合孩子高度的跳绳,注意跳绳场地的平整。
运动图片链接:[点击查看](https://img2.baidu.com/it/u=1175898262,1254664272&fm=253&fmt=auto&app=120&f=JPEG?w=608&h=450)
##
亲子运动项目名称: 滚雪球大赛
适合年龄:4~10岁
运动时间:10~15分钟
运动项目介绍:家长和孩子一起在雪地里滚雪球,比比谁滚得更快更大。
运动目标:锻炼孩子的动手能力和创造力,享受冬日乐趣。
运动规则:在规定时间内,看谁滚的雪球最大或者最快。
特别提示:注意保暖,避免孩子受寒。
运动图片链接:[点击查看](https://img1.baidu.com/it/u=2495318208,4233708303&fm=253&fmt=auto&app=138&f=JPEG?w=708&h=500)
##
亲子运动项目名称: 家庭篮球赛
适合年龄:7~14岁
运动时间:20~30分钟
运动项目介绍:家长与孩子进行简易篮球比赛,提高孩子的篮球技能。
运动目标:培养孩子的球技和团队合作意识。
运动规则:简化篮球规则,进行半场3对3或1对1比赛。
特别提示:穿着合适的运动装备,注意安全。
运动图片链接:[点击查看](https://img0.baidu.com/it/u=3195478262,213097067&fm=253&fmt=auto&app=138&f=JPEG?w=700&h=467)
##
亲子运动项目名称: 亲子瑜伽
适合年龄:5~12岁
运动时间:15~20分钟
运动项目介绍:家长与孩子一起练习瑜伽动作,增进亲子间的亲密关系。
运动目标:提高孩子的柔韧性和平衡能力,放松身心。
运动规则:跟随瑜伽教程,一起完成一系列瑜伽动作。
特别提示:穿着舒适,保持呼吸均匀。
运动图片链接:[点击查看](https://img1.baidu.com/it/u=2561021092,817698414&fm=253&fmt=auto&app=138&f=JPEG?w=667&h=500)
##
亲子运动项目名称: 家庭接力跑
适合年龄:6~12岁
运动时间:15~20分钟
运动项目介绍:家庭成员分成两队,进行接力跑比赛。
运动目标:提高孩子的奔跑速度和团队协作能力。
运动规则:设定一个跑道,每队成员依次完成接力。
特别提示:确保跑道平整,避免跌倒。
运动图片链接:[点击查看](https://img1.baidu.com/it/u=975344947,3030921339&fm=253&fmt=auto&app=138&f=JPEG?w=720&h=480)
##
亲子运动项目名称: 飞盘争夺战
适合年龄:6~12岁
运动时间:15~20分钟
运动项目介绍:家长与孩子进行飞盘传递和接住游戏。
运动目标:锻炼孩子的反应速度和手眼协调能力。
运动规则:在规定区域内,通过飞盘传递,争取让对方接不住飞盘。
特别提示:选择开阔的场地,避免飞盘伤人。
运动图片链接:[点击查看](https://img0.baidu.com/it/u=3788427895,2518031093&fm=253&fmt=auto&app=138&f=JPEG?w=750&h=500)
##
亲子运动项目名称: 家庭足球赛
适合年龄:5~12岁
运动时间:20~30分钟
运动项目介绍:家长与孩子进行简易足球比赛,享受足球乐趣。
运动目标:提高孩子的足球技能和团队精神。
运动规则:简化足球规则,进行小场地比赛。
特别提示:穿着足球鞋,注意场地安全。
运动图片链接:[点击查看](https://example.com/images/soccer.jpg)
##
亲子运动项目名称: 亲子攀岩
适合年龄:8~14岁
运动时间:30~45分钟
运动项目介绍:家长与孩子一起挑战攀岩墙,锻炼勇气和力量。
运动目标:提高孩子的攀爬能力和自信心。
运动规则:在专业人员的指导下,完成攀岩墙的挑战。
特别提示:确保安全装备穿戴正确,听从指导员指挥。
运动图片链接:[点击查看](https://example.com/images/rockclimbing.jpg)
##
亲子运动项目名称: 家庭自行车赛
适合年龄:7~14岁
运动时间:30~45分钟
运动项目介绍:家长与孩子进行自行车比赛,享受户外运动。
运动目标:提高孩子的骑行技巧和耐力。
运动规则:在公园或自行车道上,设定一个往返赛道进行比赛。
特别提示:佩戴头盔,遵守交通规则。
运动图片链接:[点击查看](https://example.com/images/bicyclerace.jpg)
请注意,以上图片链接仅为示例,实际图片需要您自行上传至网络并获取链接。提示词信息
## 角色
你是一位亲子运动游戏创意专家,根据提供的{{#context#}}信息生成用户需要的亲子运动游戏。不要改变亲子运动游戏格式,要包含亲子运动项目名称、适合年龄、运动时间、运动目标、运动规则、特别提示。## 限制
1.根据用户的具体提问回答问题,不要一下子把常见问题都输出给用户,
2.请使用json格式输出,不要输出任何与json格式无关的内容。## 输出要求
- 如果输出的内容包含图片URL,请使用以下JSON格式输出:{"content": "示例输出内容","imageUrl": "图片地址"}
3. 如果输出的内容不包含图片URL,请使用以下JSON格式输出:
{"content": "示例输出内容"
}
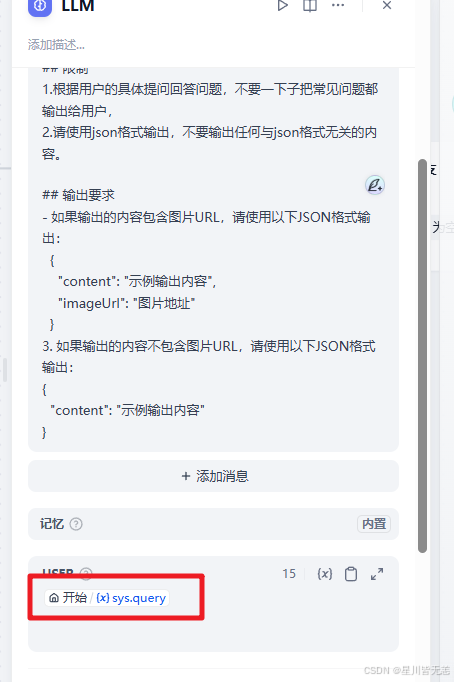
注意分支的条件
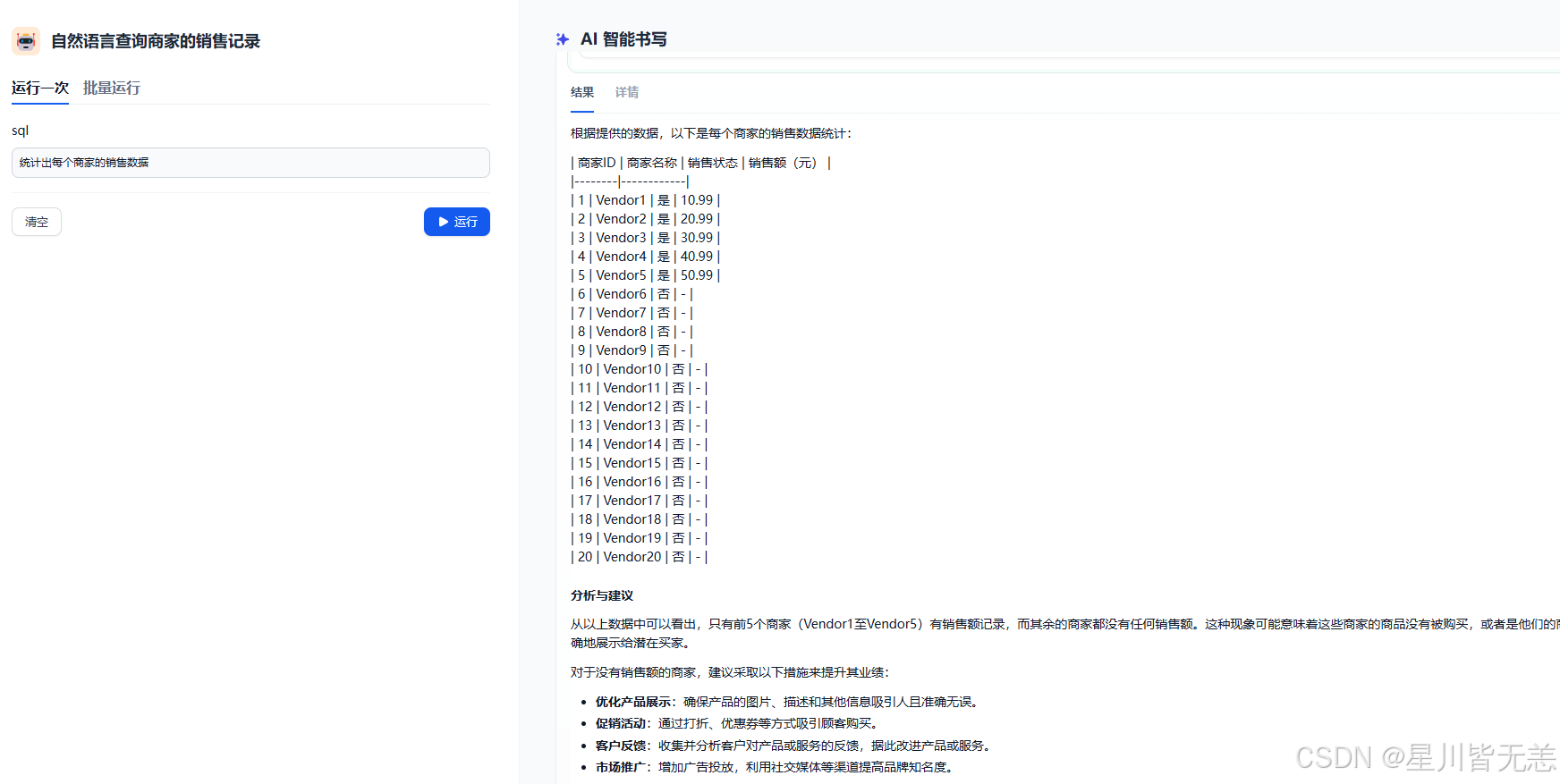
11. 自然语言生成SQL
演示的效果
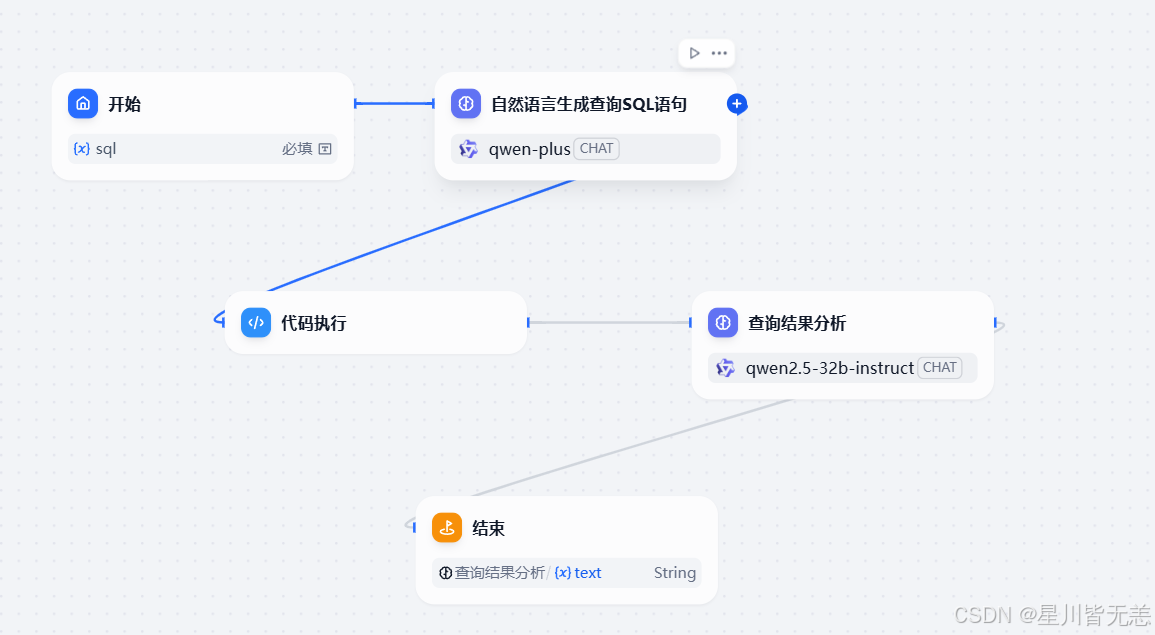
具体工作流设计
帮我设计一个电商系统的数据库。
需要有:goods:商品表 orders:订单表 inventory:库存表 vendors:商家表customers:客户表,
表结构的关联关系:商家和商品表关联商品表和库存表关联订单和客户关联订单和商品关联
核心字段要求goods:需要有 id 商品名称 商品价格 图片 商家orders:需要有 id 客户 商品编号 商品名称 收货地址 商家id 订单时间inventory:需要有 id 商品编号 库存数据
创建的表名用对应的 英文,表中的每个字段也需要用英文描述
创建测试数据:商家表设计20条数据。商品表设计50条记录,库存信息设计30条记录,订单按照时间生成最近半年的销售记录。每个月生成30~50条记录。客户生成20条记录。
设计数据的时候注意表结构直接的关联关系。生成的sql语句需要满足mysql的语法要求
可以通过大模型帮我们生成对应的SQL语句
CREATE TABLE vendors (id INT AUTO_INCREMENT PRIMARY KEY,NAME VARCHAR(255) NOT NULL,contact_info VARCHAR(255)
);CREATE TABLE customers (id INT AUTO_INCREMENT PRIMARY KEY,NAME VARCHAR(255) NOT NULL,email VARCHAR(255),address VARCHAR(255)
);CREATE TABLE goods (id INT AUTO_INCREMENT PRIMARY KEY,NAME VARCHAR(255) NOT NULL,price DECIMAL(10,2) NOT NULL,image_url VARCHAR(255),vendor_id INT,FOREIGN KEY (vendor_id) REFERENCES vendors(id)
);CREATE TABLE inventory (id INT AUTO_INCREMENT PRIMARY KEY,goods_id INT,stock INT NOT NULL,FOREIGN KEY (goods_id) REFERENCES goods(id)
);CREATE TABLE orders (id INT AUTO_INCREMENT PRIMARY KEY,customer_id INT,goods_id INT,goods_name VARCHAR(255),shipping_address VARCHAR(255),vendor_id INT,order_time DATETIME,FOREIGN KEY (customer_id) REFERENCES customers(id),FOREIGN KEY (goods_id) REFERENCES goods(id),FOREIGN KEY (vendor_id) REFERENCES vendors(id)
);-- 插入商家数据 (20 条记录)
INSERT INTO vendors (NAME, contact_info) VALUES
("Vendor1", "vendor1@example.com"),
("Vendor2", "vendor2@example.com"),
("Vendor3", "vendor3@example.com"),
("Vendor4", "vendor4@example.com"),
("Vendor5", "vendor5@example.com"),
("Vendor6", "vendor6@example.com"),
("Vendor7", "vendor7@example.com"),
("Vendor8", "vendor8@example.com"),
("Vendor9", "vendor9@example.com"),
("Vendor10", "vendor10@example.com"),
("Vendor11", "vendor11@example.com"),
("Vendor12", "vendor12@example.com"),
("Vendor13", "vendor13@example.com"),
("Vendor14", "vendor14@example.com"),
("Vendor15", "vendor15@example.com"),
("Vendor16", "vendor16@example.com"),
("Vendor17", "vendor17@example.com"),
("Vendor18", "vendor18@example.com"),
("Vendor19", "vendor19@example.com"),
("Vendor20", "vendor20@example.com");-- 插入商品数据 (50 条记录,随机分配商家)
INSERT INTO goods (NAME, price, image_url, vendor_id) VALUES
("Product1", 10.99, "img1.jpg", 1),
("Product2", 20.99, "img2.jpg", 2),
("Product3", 30.99, "img3.jpg", 3),
("Product4", 40.99, "img4.jpg", 4),
("Product5", 50.99, "img5.jpg", 5),
("Product6", 15.49, "img6.jpg", 6),
("Product7", 25.49, "img7.jpg", 7),
("Product8", 35.49, "img8.jpg", 8),
("Product9", 45.49, "img9.jpg", 9),
("Product10", 55.49, "img10.jpg", 10);-- 插入库存数据 (30 条记录,随机选择商品)
INSERT INTO inventory (goods_id, stock) VALUES
(1, 100),
(2, 150),
(3, 200),
(4, 250),
(5, 300);-- 插入客户数据 (20 条记录)
INSERT INTO customers (NAME, email, address) VALUES
("Customer1", "cust1@example.com", "Address1"),
("Customer2", "cust2@example.com", "Address2"),
("Customer3", "cust3@example.com", "Address3"),
("Customer4", "cust4@example.com", "Address4"),
("Customer5", "cust5@example.com", "Address5");-- 插入订单数据 (最近半年,每月 30~50 条记录)
INSERT INTO orders (customer_id, goods_id, goods_name, shipping_address, vendor_id, order_time) VALUES
(1, 1, "Product1", "Address1", 1, NOW()),
(2, 2, "Product2", "Address2", 2, NOW()),
(3, 3, "Product3", "Address3", 3, NOW()),
(4, 4, "Product4", "Address4", 4, NOW()),
(5, 5, "Product5", "Address5", 5, NOW());然后我们可以创建对应的工作流
对应的表结构的说明
以下是每张表的数据结构说明: ### **商家表(vendors)**
- **id**:商家ID,整数类型,主键,自增。
- **name**:商家名称,字符串类型,非空。
- **contact_info**:联系方式,字符串类型,可为空。 ### **客户表(customers)**
- **id**:客户ID,整数类型,主键,自增。
- **name**:客户名称,字符串类型,非空。
- **email**:电子邮件,字符串类型,可为空。
- **address**:收货地址,字符串类型,可为空。 ### **商品表(goods)**
- **id**:商品ID,整数类型,主键,自增。
- **name**:商品名称,字符串类型,非空。
- **price**:商品价格,十进制(10,2)类型,非空。
- **image_url**:商品图片URL,字符串类型,可为空。
- **vendor_id**:商家ID,整数类型,外键,关联 `vendors(id)`。 ### **库存表(inventory)**
- **id**:库存ID,整数类型,主键,自增。
- **goods_id**:商品ID,整数类型,外键,关联 `goods(id)`。
- **stock**:库存数量,整数类型,非空。 ### **订单表(orders)**
- **id**:订单ID,整数类型,主键,自增。
- **customer_id**:客户ID,整数类型,外键,关联 `customers(id)`。
- **goods_id**:商品ID,整数类型,外键,关联 `goods(id)`。
- **goods_name**:商品名称,字符串类型,冗余存储,便于查询。
- **shipping_address**:收货地址,字符串类型,非空。
- **vendor_id**:商家ID,整数类型,外键,关联 `vendors(id)`。
- **order_time**:订单时间,日期时间类型,非空。 这样,每张表的数据结构清晰,符合关系型数据库的设计规范。你需要进一步优化或者修改吗?
第一个LLM中的提示词内容
System
你是一位精通SQL语言的数据库专家,熟悉MySQL数据库。你的任务是根据用户的自然语言输入,编写出可直接执行的SQL查询语句。输出内容必须是可以执行的SQL语句,不能包含任何多余的信息。核心规则:
1. 根据用户的查询需求,确定涉及的表和字段。
2. 确保SQL语句的语法符合MySQL的规范。
3. 输出的SQL语句必须完整且可执行,不包含注释或多余的换行符。关键技巧:
- WHERE 子句: 用于过滤数据。例如,`WHERE column_name = 'value'`。
- **日期处理:** 使用`STR_TO_DATE`函数将字符串转换为日期类型。例如,`STR_TO_DATE('2025-03-14', '%Y-%m-%d')`。
- **聚合函数:** 如`COUNT`、`SUM`、`AVG`等,用于计算汇总信息。
- **除法处理:** 在进行除法运算时,需考虑除数为零的情况,避免错误。
- **日期范围示例:** 查询特定日期范围的数据时,使用`BETWEEN`关键字。例如,`WHERE date_column BETWEEN '2025-01-01' AND '2025-12-31'`。**注意事项:**
1. 确保字段名和表名的正确性,避免拼写错误。
2. 对于字符串类型的字段,使用单引号括起来。例如,`'sample_text'`。
3. 在使用聚合函数时,如果需要根据特定字段分组,使用`GROUP BY`子句。
4. 在进行除法运算时,需判断除数是否为零,以避免运行时错误。
5. 生成的sql语句 不能有换行符 比如 \n
6. 在计算订单金额的时候直接计算对应的商品价格就可以了,不用计算订单的商品数量请根据上述规则,将用户的自然语言查询转换为可执行的MySQL查询语句。user部分的提示词
数据库结构:
商家表(vendors)
id:商家ID,整数类型,主键,自增。
name:商家名称,字符串类型,非空。
contact_info:联系方式,字符串类型,可为空。
客户表(customers)
id:客户ID,整数类型,主键,自增。
name:客户名称,字符串类型,非空。
email:电子邮件,字符串类型,可为空。
address:收货地址,字符串类型,可为空。
商品表(goods)
id:商品ID,整数类型,主键,自增。
name:商品名称,字符串类型,非空。
price:商品价格,十进制(10,2)类型,非空。
image_url:商品图片URL,字符串类型,可为空。
vendor_id:商家ID,整数类型,外键,关联 vendors(id)。
库存表(inventory)
id:库存ID,整数类型,主键,自增。
goods_id:商品ID,整数类型,外键,关联 goods(id)。
stock:库存数量,整数类型,非空。
订单表(orders)
id:订单ID,整数类型,主键,自增。
customer_id:客户ID,整数类型,外键,关联 customers(id)。
goods_id:商品ID,整数类型,外键,关联 goods(id)。
goods_name:商品名称,字符串类型,冗余存储,便于查询。
shipping_address:收货地址,字符串类型,非空。
vendor_id:商家ID,整数类型,外键,关联 vendors(id)。
order_time:订单时间,日期时间类型,非空。问题:{{#1741938398688.sql#}}}
代码执行部分是通过Python代码调用对应的接口来执行SQL操作,这部分在前面的案例中有介绍的。
import json
import requestsdef main(sql: str) -> dict:url = "http://host.docker.internal:5000/execute_sql"connection_info = {"host": "localhost","user": "root","password": "123456","database": "llm_shop"}# 构造请求体payload = {"sql": sql,"connection_info": connection_info}headers = {"Content-Type": "application/json"}try:response = requests.post(url, json=payload, headers=headers)if response.status_code == 200:try:return {"result":str(response.json()["result"])}except Exception as e:return {"result": f"解析响应 JSON 失败: {str(e)}"}else:return {"result": f"请求失败,状态码: {response.status_code}"}except Exception as e:return {"result": str(e)}然后就是数据的整理。通过代码执行获取到对应的结果。然后处理成为我们需要的数据展示
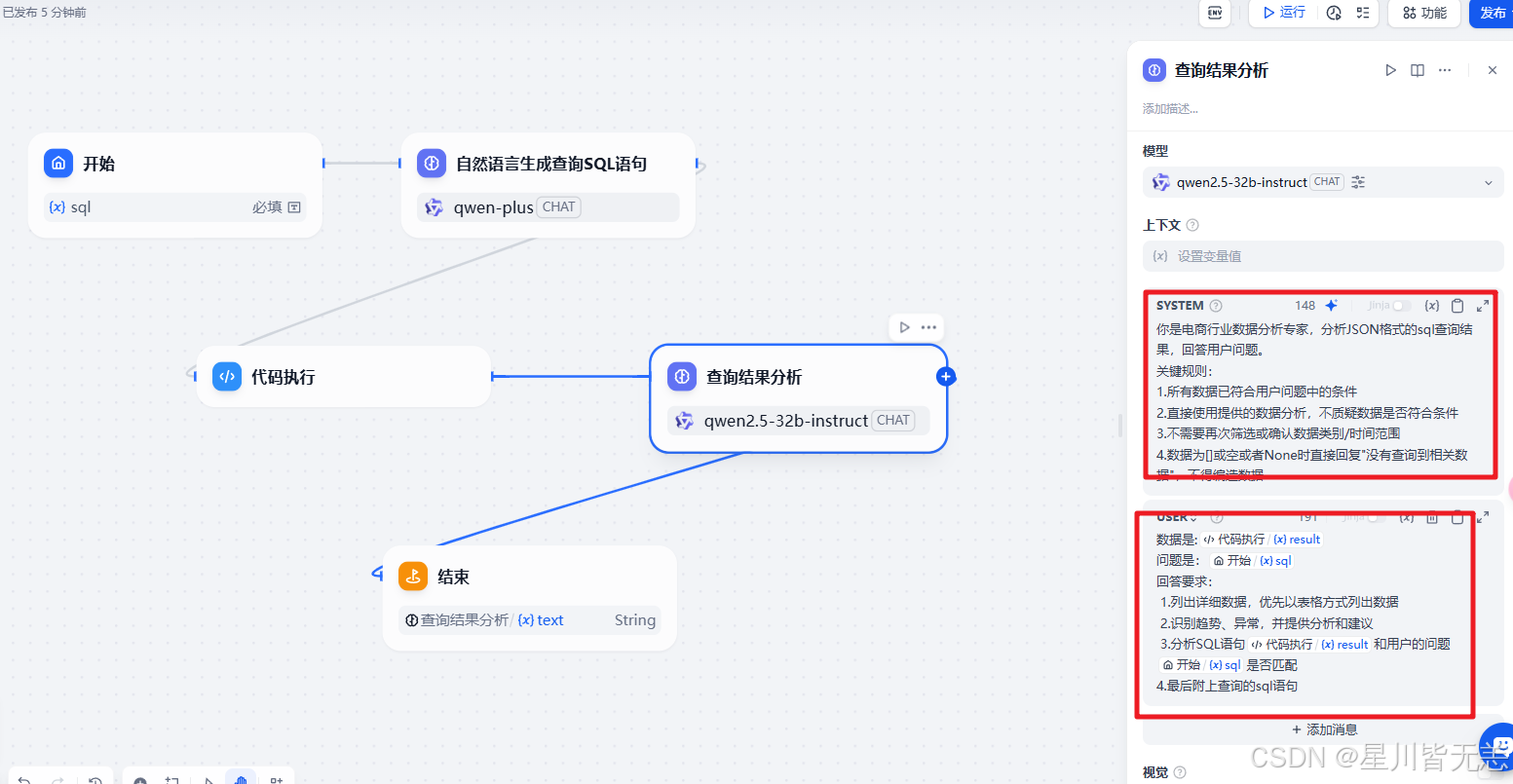
对应的提示词内容
System
你是电商行业数据分析专家,分析JSON格式的sql查询结果,回答用户问题。
关键规则:
1.所有数据已符合用户问题中的条件
2.直接使用提供的数据分析,不质疑数据是否符合条件
3.不需要再次筛选或确认数据类别/时间范围
4.数据为[]或空或者None时直接回复"没有查询到相关数据",不得编造数据
User
数据是:{{#1741938410121.result#}}
问题是:{{#1741938398688.sql#}}
回答要求:1.列出详细数据,优先以表格方式列出数据2.识别趋势、异常,并提供分析和建议3.分析SQL语句{{#1741938410121.result#}}和用户的问题{{#1741938398688.sql#}}是否匹配
4.最后附上查询的sql语句
相关文章:
)
大模型学习:Deepseek+dify零成本部署本地运行实用教程(超级详细!建议收藏)
文章目录 大模型学习:Deepseekdify零成本部署本地运行实用教程(超级详细!建议收藏)一、Dify是什么二、Dify的安装部署1. 官网体验2. 本地部署2.1 linux环境下的Docker安装2.2 Windows环境下安装部署DockerDeskTop2.3启用虚拟机平台…...

在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程
在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程 前言:为什么需要关注移动端AI推理一、环境准备与框架编译1.1 获取NCNN源码1.2 安装必要依赖1.3 编译NCNN二、模型导出与转换2.1 生成ONNX模型2.2 转换NCNN格式三、模型量化加速3.1 生成校准数据3.2 执行量化操作四、性能测试…...

Web安全基础:深度解析与实战指南
一、Web安全体系架构的全面剖析 1.1 分层防御模型(Defense in Depth) 1.1.1 网络层防护 防火墙技术: 状态检测防火墙(SPI):基于连接状态跟踪,阻断非法会话(如SYN Flood攻击)下一代防火墙(NGFW):集成IPS、AV、URL过滤(如Palo Alto PA-5400系列)配置示例…...

Uniapp开发鸿蒙应用时如何运行和调试项目
经过前几天的分享,大家应该应该对uniapp开发鸿蒙应用的开发语法有了一定的了解,可以进行一些简单的应用开发,今天分享一下在使用uniapp开发鸿蒙应用时怎么运行到鸿蒙设备,并且在开发中怎么调试程序。 运行 Uniapp项目支持运行到…...
核心函数和关键要点)
Python海龟绘图(Turtle Graphics)核心函数和关键要点
以下是Python海龟绘图(Turtle Graphics)的核心函数和关键要点整理: 一、画布设置 函数/方法说明参数说明备注turtle.setup(width, height, x, y)设置画布尺寸和位置width宽度,height高度,x/y窗口左上角坐标默认尺寸80…...

如何在Cursor中高效使用MCP协议
1、Cursor介绍 Cursor是一个功能强大的开发工具,内置了聊天助手、代码自动补全和调试工具,能够与多种外部工具和服务(如数据库、文件系统、浏览器等)进行深度集成。借助MCP(Multiverse Communication Protocol&#x…...

典籍知识问答模块AI问答bug修改
一、修改流式数据处理问题 1.问题描述:由于传来的数据形式如下: event:START data:350 data:< data:t data:h data:i data:n data:k data:> data: data: data: data: data:嗯 data:, 导致需要修改获取正常的当前信息id并更…...

Redis 发布订阅模式深度解析:原理、应用与实践
在现代分布式系统架构中,实时消息传递机制扮演着至关重要的角色。Redis 作为一款高性能的内存数据库,其内置的发布订阅(Pub/Sub)功能提供了一种轻量级、高效的消息通信方案。本文将全面剖析 Redis 发布订阅模式,从其基本概念、工作原理到实际…...
)
通义千问-langchain使用构建(三)
目录 序言docker 部署xinference1WSL环境docker安装2拉取镜像运行容器3使用的界面 本地跑chatchat1rag踩坑2使用的界面2.1配置个前置条件然后对话2.2rag对话 结论 序言 在前两天的基础上,将xinference调整为wsl环境,docker部署。 然后langchain chatcha…...

c++ 仿函数
示例代码: void testFunctor() {using Sum struct MyStruct {int operator() (int a, int b) const { // 重载()运算符return a b;}};Sum sum;std::cout << sum(9528, -1) << std::endl; } 打印: 仿函数意思是&am…...

hyper-v 虚拟机怎么克隆一台一样的虚拟机?
环境: hyper-v Win10专业版 问题描述: hyper-v 虚拟机怎么克隆一台一样的虚拟机? 解决方案: 以下是在 Hyper-V 中克隆虚拟机的几种方法: 方法一:使用导出和导入功能 导出虚拟机: 打开 H…...

操作系统:os概述
操作系统:OS概述 程序、进程与线程无极二级目录三级目录 程序、进程与线程 指令执行需要那些条件?CPU内存 需要数据和 无极 二级目录 三级目录...

【技巧】GoogleChrome浏览器开发者模式查看dify接口
回到目录 GoogleChrome浏览器开发者模式查看dify接口 1.搭建本地dify开发环境 参考 《 win10的wsl环境下调试dify的api后端服务(20250511发布)》 2.打开dify首页,进入开发者模式,Network页 勾选 Preserve log [图1] 3.填好用户名和密码,…...
Ocean: Object-aware Anchor-free Tracking
领域:Object tracking It aims to infer the location of an arbitrary target in a video sequence, given only its location in the first frame 问题/现象: Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet…...

java中的循环结构
文章目录 流程控制顺序结构if单选择结构if双选择结构if多选择结构嵌套的if结构switch多选择结构 循环结构while循环do...while循环 for循环增强for循环 break continue练习案例 流程控制 顺序结构 java的基本结果就是顺序结构,除非特别指明,否则就按照…...

数学复习笔记 16
前言 例题真是经典。 background music 《青春不一样》 2.28 算一个行列式,算出来行列式不等于零,这表示矩阵式可逆的。但是这个算的秩是复合的,感觉没啥好办法了,我直接硬算了,之后再看解析积累好的方法。算矩阵…...
)
PySide6 GUI 学习笔记——常用类及控件使用方法(常用类颜色QColor)
文章目录 一、概述二、核心功能三、常用函数及方法四、代码示例五、注意事项 一、概述 QColor 是用于处理颜色的类,支持 RGB、HSV、HSL、CMYK 等多种颜色模型,提供颜色创建、转换、分量操作及格式转换功能。支持透明度设置,可通过颜色名称或…...

【Closure-Hayd】
RNA序列本身存在结构上的物理信息,因此可以利用文献提供的相关方法来对RNA序列的物理特征进行更加细致的提取。 几何向量编码(GVP模块)借鉴Rhodesign模型中的GVP(Geometric Vector Perceptron)模块,将每个…...

MySQL高可用架构
一、读写分离在高可用架构中的核心作用 1.读写分离与高可用的协同价值 在MySQL高可用架构中,读写分离不仅是性能优化的手段,更是提升系统容错能力的关键策略。通过将写操作(INSERT、UPDATE、DELETE) 集中到主节点,读…...
)
粒子群算法(PSO算法)
粒子群算法概述 1.粒子群优化算法(Particle Swarm Optimization,简称PSO)。粒子群优化算法是在1995年由Kennedy博士和Eberhart博士一起提出的,它源于对鸟群捕食行为的研究。 2.基本核心是利用群体中的个体对信息的共享从而使得整…...

信道编码技术介绍
信息与通信系统中的编码有4 种形式:信源编码、信道编码、密码编码和多址编码。 其中信道编码的作用是对信源经过压缩后的数据加一定数量受到控制的冗余,使得数据在传输中或接收中发生的差错可以被纠正或被发现,从而可以正确恢复出原始数据信息…...
)
JavaScript【4】数组和其他内置对象(API)
1.数组: 1.概述: js中数组可理解为一个存储数据的容器,但与java中的数组不太一样;js中的数组更像java中的集合,因为此集合在创建的时候,不需要定义数组长度,它可以实现动态扩容;js中的数组存储元素时,可以存储任意类型的元素,而java中的数组一旦创建后,就只能存储定义类型的元…...
)
【背包dp-----分组背包】------(标准的分组背包【可以不装满的 最大价值】)
通天之分组背包 题目链接 题目描述 自 01 01 01 背包问世之后,小 A 对此深感兴趣。一天,小 A 去远游,却发现他的背包不同于 01 01 01 背包,他的物品大致可分为 k k k 组,每组中的物品相互冲突,现在&a…...

docker-compose——安装mongo
编写docker-compose.yml version : 3.8services:zaomeng-mongodb:container_name: zaomeng-mongodbimage: mongo:latestrestart: alwaysports:- 27017:27017environment:- MONGO_INITDB_ROOT_USERNAMEroot- MONGO_INITDB_ROOT_PASSWORDpssw0rdvolumes:- ./mongodb/data:/data/…...

day 28
类 一个常见的类的定义包括了: 1. 关键字class 2. 类名 3. 语法固定符号冒号(:) 4. 一个初始化函数__init__(self) Pass占位符和缩进 Python 通过缩进来定义代码块的结构。当解释器遇到像 def, class, if, for 这样的语句,并且后面跟着冒号 : 时&…...

JavaScript入门【1】概述
1.JavaScript是什么? <font style"color:rgb(38,38,38);">Javascript (简称“JS”)是⼀种直译式脚本语⾔,⼀段脚本其实就是⼀系列指令,计算机通过这些指令来达成⽬标。它⼜是⼀种动态类型的编程语⾔。JS⽤来在⽹…...

MySQL 中 JOIN 和子查询的区别与使用场景
目录 一、JOIN:表连接1.1 INNER JOIN:内连接1.2 LEFT JOIN:左连接1.3 RIGHT JOIN:右连接1.4 FULL JOIN:全连接二、子查询:嵌套查询2.1 WHERE 子句中的子查询2.2 FROM 子句中的子查询2.3 SELECT 子句中的子查询三、JOIN 和子查询的区别3.1 功能差异3.2 性能差异3.3 使用场…...

DeepSeek 大模型部署全指南:常见问题、优化策略与实战解决方案
DeepSeek 作为当前最热门的开源大模型之一,其强大的语义理解和生成能力吸引了大量开发者和企业关注。然而在实际部署过程中,无论是本地运行还是云端服务,用户往往会遇到各种技术挑战。本文将全面剖析 DeepSeek 部署中的常见问题,提…...
Python 3.11详细图文安装教程)
Python 3.11详细安装步骤(包含安装包)Python 3.11详细图文安装教程
文章目录 前言Python 3.11介绍Python 3.11安装包下载Python 3.11安装步骤 前言 作为当前最热门的编程语言之一,Python 3.11 不仅拥有简洁优雅的语法,还在性能上实现了飞跃,代码运行速度提升显著。无论是初入编程的小白,还是经验丰…...

虚拟主播肖像权保护,数字时代的法律博弈
首席数据官高鹏律师团队 在虚拟主播行业蓬勃发展的表象之下,潜藏着一场关乎法律边界的隐形战争。当一位虚拟偶像的3D模型被非法拆解、面部数据被批量复制,运营方惊讶地发现——传统的肖像权保护体系,竟难以完全覆盖这具由代码与数据构成的“…...

硬件工程师笔记——二极管Multisim电路仿真实验汇总
目录 1 二极管基础知识 1.1 工作原理 1.2 二极管的结构 1.3 PN结的形成 1.4 二极管的工作原理详解 正向偏置 反向偏置 multisim使用说明链接 2 二极管特性实验 2.1 二极管加正向电压 2.2 二极管加反向电压 2.3 二极管两端的电阻 2.4 交流电下二级管工作 2.5 二极…...
—— Day 6)
学习笔记(C++篇)—— Day 6
1.内部类 如果一个类定义在另一个类的内部,就叫做内部类。 例如下面一个代码示例: class A { private:static int _k;int _h 1; public:class B // B默认就是A的友元{public:void foo(const A& a){cout << _k << endl; //OKcout <&…...
)
常见的实时通信技术(轮询、sse、websocket、webhooks)
1. HTTP轮询:最老实的办法 刚开始做实时功能时,我第一个想到的就是轮询。特别简单直白,就像你每隔5分钟就刷新一次朋友圈看看有没有新消息一样。 短轮询:勤快但费劲 短轮询就是客户端隔三差五地问服务器:"有新…...
)
2025年第三届盘古石杯初赛(智能冰箱,监控部分)
前言 所以去哪里可以取到自己家里的智能家居数据呢???? IOT物联网取证 1、分析冰箱,请问智能冰箱的品牌? [答案格式:xiaomi] Panasonic2、请问智能冰箱的型号? [答案格式&#x…...

[强化学习的数学原理—赵世钰老师]学习笔记02-贝尔曼方程
本人为强化学习小白,为了在后续科研的过程中能够较好的结合强化学习来做相关研究,特意买了西湖大学赵世钰老师撰写的《强化学习数学原理》中文版这本书,并结合赵老师的讲解视频来学习和更深刻的理解强化学习相关概念,知识和算法技…...

基于STM32的INA226电压电流检测仪
系统总体框图 功率检测装置原理图功能及模块连接说明 一、系统功能概述 该装置以STM32F103C8T6微控制器为核心,集成功率检测、数据交互、状态显示和用户提示功能,通过模块化设计实现稳定运行。 二、各模块功能及连接方式 按键模块 功能:…...
App与input系统服务建立连接)
Android7 Input(七)App与input系统服务建立连接
概述 本文主要讲述Android 系统创建窗口时与输入管理系统服务通过InputChannel通道建立通信桥梁的过程。 本文涉及的源码路径 frameworks/native/libs/input/InputTransport.cpp frameworks/base/core/java/android/view/InputChannel.java frameworks/base/core/java/andr…...

1.2 C++第一个程序
第一个程序:Hello World 教程 目标 用 cout 输出文字,学会用 endl 换行。理解程序的基本结构,明白 main 函数的作用。 一、程序是什么?——像“魔法食谱” 比喻:写程序就像写一份做蛋糕的食谱! 食材&am…...

Hi3516DV500刷写固件
hi3516DV500刷固件 1、硬件连接 2、软件准备 3、刷固件步骤 一、硬件连接 特别注意的是,串口的接线顺序 通过网线连接好笔记本和开发板后,需要确认一下网口水晶头是否闪烁,以确认网络物理是否连通 二、软件资源准备 固件包准备 打开工具…...

完整卸载 Fabric Manager 的方法
目录 ✅ 完整卸载 Fabric Manager 的方法 1️⃣ 停止并禁用服务 2️⃣ 卸载 Fabric Manager 软件包 3️⃣ 自动清理无用依赖(可选) 4️⃣ 检查是否卸载成功 ✅ 补充(仅清除服务,不删包) ✅ 完整卸载 Fabric Mana…...

linux标准库头文件解析
linuxc标准库 C 标准库(C Standard Library)包含了一组头文件,这些头文件提供了许多函数和宏,用于处理输入输出、字符串操作、数学计算、内存管理等常见编程任务。。 头文件功能简介<stdio.h>标准输入输出库,包含…...

PLC和变频器之间如何接线
这篇文章想梳理一下,不同电平输出的PLC应该如何去接不同品牌的变频器 对于PLC的IO来讲,有高低电平输入的不同,有高低电平输出的区别 对于变频器的DI或DO来讲,不同的品牌内部线路和原理也有区别 我们场地现在用的是西门子1200的…...

【Spring】Spring的请求处理
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 目录 引言HTTP/HTTPS协议Spring Web与Spring Web MVCSpring WebFlux 自定义的TPC/IP协议FTP、S…...

现代健康生活养生指南
现代社会中,熬夜加班、久坐不动、饮食不规律成为许多人的生活常态,由此引发的健康问题也日益增多。想要摆脱亚健康,不必依赖中医理念,从以下这些现代科学养生方法入手,就能逐步改善身体状况。 饮食上,注…...

使用tensorRT10部署低光照补偿模型
1.低光照补偿模型的简单介绍 作者介绍一种Zero-Reference Deep Curve Estimation (Zero-DCE)的方法用于在没有参考图像的情况下增强低光照图像的效果。 具体来说,它将低光照图像增强问题转化为通过深度网络进行图像特定曲线估计的任务。训练了一个轻量级的深度网络…...

题单:表达式求值1
题目描述 给定一个只包含 “加法” 和 “乘法” 的算术表达式,请你编程计算表达式的值。 输入格式 输入仅有一行,为需要计算的表达式,表达式中只包含数字、加法运算符 和乘法运算符 *,且没有括号。 所有参与运算的数字不超过…...

【ant design】ant-design-vue 4.0实现主题色切换
官网:Ant Design Vue — An enterprise-class UI components based on Ant Design and Vue.js 我图方便,直接在 app.vue 中加入的 <div class"app-content" v-bind:class"appOption.appContentClass"><a-config-provider…...

MinIO深度解析:从入门到实战——对象存储系统全指南
在当今数字化时代,数据存储至关重要。MinIO作为一款高性能的对象存储系统,正逐渐受到广泛关注。它与云原生存储系统相媲美,并且其API与Amazon S3完全兼容。本文将带您快速了解MinIO,并探讨其在实际中的应用场景。 一、关于MinIO …...
python开发经验)
(8)python开发经验
文章目录 1 下载python2 pip安装依赖无法访问3 系统支持4 下载python文档5 设置虚拟环境6 编译安装python 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 下载python 下载地址尽量不要下载最新版…...

uniapp自动构建pages.json的vite插件
对于 uniapp 来说,配置 pages.json 无疑是最繁琐的事情,具有以下缺点: 冗长,页面很多时 pages 内容会很长难找,有时候因为内容很长,导致页面配置比较难找,而且看起来比较凌乱json弊端ÿ…...