Datawhale PyPOTS时间序列5月第3次笔记
下游任务的两阶段(two-stage) 处理
下载数据并预处理的程序:
# -------------------------------
# 导入必要的库
# -------------------------------
import numpy as np
import torch
from benchpots.datasets import preprocess_physionet2012
from pypots.imputation import SAITS
from pypots.optim import Adam
from pypots.nn.functional import calc_mse
from pypots.data.saving import pickle_dump# -------------------------------
# 设备配置
# -------------------------------
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"# -------------------------------
# 预处理PhysioNet2012数据
# -------------------------------
physionet2012_dataset = preprocess_physionet2012(subset="set-a", pattern="point", rate=0.1,
)
print(physionet2012_dataset.keys())# -------------------------------
# 构建缺失掩码、替换NaN
# -------------------------------
physionet2012_dataset["test_X_indicating_mask"] = (np.isnan(physionet2012_dataset["test_X"]) ^ np.isnan(physionet2012_dataset["test_X_ori"])
)
physionet2012_dataset["test_X_ori"] = np.nan_to_num(physionet2012_dataset["test_X_ori"])# -------------------------------
# 构建训练、验证、测试集
# -------------------------------
train_set = {"X": physionet2012_dataset["train_X"]}
val_set = {"X": physionet2012_dataset["val_X"],"X_ori": physionet2012_dataset["val_X_ori"],
}
test_set = {"X": physionet2012_dataset["test_X"],"X_ori": physionet2012_dataset["test_X_ori"],
}# -------------------------------
# 初始化SAITS模型
# -------------------------------
saits = SAITS(n_steps=physionet2012_dataset['n_steps'],n_features=physionet2012_dataset['n_features'],n_layers=3,d_model=64,n_heads=4,d_k=16,d_v=16,d_ffn=128,dropout=0.1,ORT_weight=1,MIT_weight=1,batch_size=32,epochs=10,patience=3,optimizer=Adam(lr=1e-3),num_workers=0,device=DEVICE,saving_path="result_saving/imputation/saits",model_saving_strategy="best",
)# -------------------------------
# 模型训练
# -------------------------------
saits.fit(train_set, val_set)# -------------------------------
# 测试集预测 & 评估
# -------------------------------
test_set_imputation_results = saits.predict(test_set)test_MSE = calc_mse(test_set_imputation_results["imputation"],physionet2012_dataset["test_X_ori"],physionet2012_dataset["test_X_indicating_mask"],
)
print(f"SAITS test_MSE: {test_MSE}")# -------------------------------
# 保存插补结果和标签
# -------------------------------
train_set_imputation = saits.impute(train_set)
val_set_imputation = saits.impute(val_set)
test_set_imputation = test_set_imputation_results["imputation"]dict_to_save = {'train_set_imputation': train_set_imputation,'train_set_labels': physionet2012_dataset['train_y'],'val_set_imputation': val_set_imputation,'val_set_labels': physionet2012_dataset['val_y'],'test_set_imputation': test_set_imputation,'test_set_labels': physionet2012_dataset['test_y'],
}pickle_dump(dict_to_save, "result_saving/imputed_physionet2012.pkl")
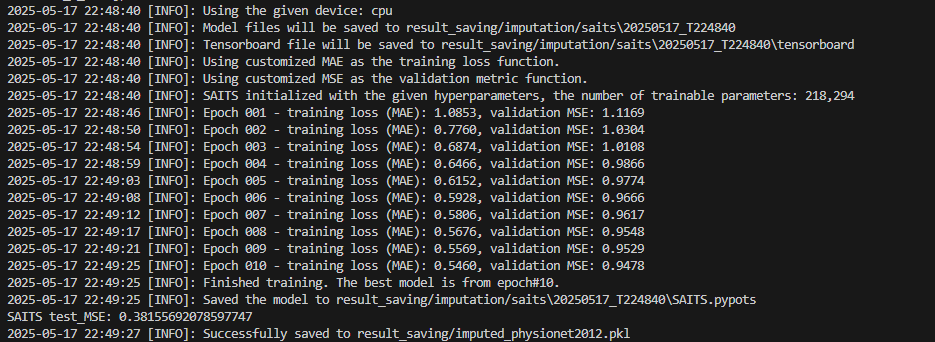
结果:
████████╗██╗███╗ ███╗███████╗ ███████╗███████╗██████╗ ██╗███████╗███████╗ █████╗ ██╗
╚══██╔══╝██║████╗ ████║██╔════╝ ██╔════╝██╔════╝██╔══██╗██║██╔════╝██╔════╝ ██╔══██╗██║
██║ ██║██╔████╔██║█████╗█████╗███████╗█████╗ ██████╔╝██║█████╗ ███████╗ ███████║██║
██║ ██║██║╚██╔╝██║██╔══╝╚════╝╚════██║██╔══╝ ██╔══██╗██║██╔══╝ ╚════██║ ██╔══██║██║
██║ ██║██║ ╚═╝ ██║███████╗ ███████║███████╗██║ ██║██║███████╗███████║██╗██║ ██║██║
╚═╝ ╚═╝╚═╝ ╚═╝╚══════╝ ╚══════╝╚══════╝╚═╝ ╚═╝╚═╝╚══════╝╚══════╝╚═╝╚═╝ ╚═╝╚═╝
ai4ts v0.0.3 - building AI for unified time-series analysis, https://time-series.ai2025-05-17 22:48:33 [INFO]: You're using dataset physionet_2012, please cite it properly in your work. You can find its reference information at the below link:
https://github.com/WenjieDu/TSDB/tree/main/dataset_profiles/physionet_2012
2025-05-17 22:48:33 [INFO]: Dataset physionet_2012 has already been downloaded. Processing directly...
2025-05-17 22:48:33 [INFO]: Dataset physionet_2012 has already been cached. Loading from cache directly...
2025-05-17 22:48:33 [INFO]: Loaded successfully!
2025-05-17 22:48:40 [WARNING]: Note that physionet_2012 has sparse observations in the time series, hence we don't add additional missing values to the training dataset.
2025-05-17 22:48:40 [INFO]: 23126 values masked out in the val set as ground truth, take 10.03% of the original observed values
2025-05-17 22:48:40 [INFO]: 28703 values masked out in the test set as ground truth, take 10.00% of the original observed values
2025-05-17 22:48:40 [INFO]: Total sample number: 3997
2025-05-17 22:48:40 [INFO]: Training set size: 2557 (63.97%)
2025-05-17 22:48:40 [INFO]: Validation set size: 640 (16.01%)
2025-05-17 22:48:40 [INFO]: Test set size: 800 (20.02%)
2025-05-17 22:48:40 [INFO]: Number of steps: 48
2025-05-17 22:48:40 [INFO]: Number of features: 37
2025-05-17 22:48:40 [INFO]: Train set missing rate: 79.70%
2025-05-17 22:48:40 [INFO]: Validating set missing rate: 81.74%
2025-05-17 22:48:40 [INFO]: Test set missing rate: 81.82%
dict_keys(['n_classes', 'n_steps', 'n_features', 'scaler', 'train_X', 'train_y', 'train_ICUType', 'val_X', 'val_y', 'val_ICUType', 'test_X', 'test_y', 'test_ICUType', 'val_X_ori', 'test_X_ori'])
2025-05-17 22:48:40 [INFO]: Using the given device: cpu
2025-05-17 22:48:40 [INFO]: Model files will be saved to result_saving/imputation/saits\20250517_T224840
2025-05-17 22:48:40 [INFO]: Tensorboard file will be saved to result_saving/imputation/saits\20250517_T224840\tensorboard
2025-05-17 22:48:40 [INFO]: Using customized MAE as the training loss function.
2025-05-17 22:48:40 [INFO]: Using customized MSE as the validation metric function.
2025-05-17 22:48:40 [INFO]: SAITS initialized with the given hyperparameters, the number of trainable parameters: 218,294
2025-05-17 22:48:46 [INFO]: Epoch 001 - training loss (MAE): 1.0853, validation MSE: 1.1169
2025-05-17 22:48:50 [INFO]: Epoch 002 - training loss (MAE): 0.7760, validation MSE: 1.0304
2025-05-17 22:48:54 [INFO]: Epoch 003 - training loss (MAE): 0.6874, validation MSE: 1.0108
2025-05-17 22:48:59 [INFO]: Epoch 004 - training loss (MAE): 0.6466, validation MSE: 0.9866
2025-05-17 22:49:03 [INFO]: Epoch 005 - training loss (MAE): 0.6152, validation MSE: 0.9774
2025-05-17 22:49:08 [INFO]: Epoch 006 - training loss (MAE): 0.5928, validation MSE: 0.9666
2025-05-17 22:49:12 [INFO]: Epoch 007 - training loss (MAE): 0.5806, validation MSE: 0.9617
2025-05-17 22:49:17 [INFO]: Epoch 008 - training loss (MAE): 0.5676, validation MSE: 0.9548
2025-05-17 22:49:21 [INFO]: Epoch 009 - training loss (MAE): 0.5569, validation MSE: 0.9529
2025-05-17 22:49:25 [INFO]: Epoch 010 - training loss (MAE): 0.5460, validation MSE: 0.9478
2025-05-17 22:49:25 [INFO]: Finished training. The best model is from epoch#10.
2025-05-17 22:49:25 [INFO]: Saved the model to result_saving/imputation/saits\20250517_T224840\SAITS.pypots
SAITS test_MSE: 0.38155692078597747
2025-05-17 22:49:27 [INFO]: Successfully saved to result_saving/imputed_physionet2012.pkl
(pypots-env) PS D:\Projects\pypots-experiments>
两阶段处理的脚本程序:
# 导入必要库
import numpy as np
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from copy import deepcopy
from pypots.data.saving import pickle_load
from pypots.nn.functional.classification import calc_binary_classification_metrics# 设置设备
DEVICE = "cpu"# 数据集封装类
class LoadImputedDataAndLabel(Dataset):def __init__(self, imputed_data, labels):self.imputed_data = imputed_dataself.labels = labelsdef __len__(self):return len(self.labels)def __getitem__(self, idx):return (torch.from_numpy(self.imputed_data[idx]).to(torch.float32),torch.tensor(self.labels[idx]).to(torch.long),)# LSTM 分类器模型
class ClassificationLSTM(torch.nn.Module):def __init__(self, n_features, rnn_hidden_size, n_classes):super().__init__()self.rnn = torch.nn.LSTM(n_features,hidden_size=rnn_hidden_size,batch_first=True,)self.fcn = torch.nn.Linear(rnn_hidden_size, n_classes)def forward(self, data):hidden_states, _ = self.rnn(data)logits = self.fcn(hidden_states[:, -1, :])prediction_probabilities = torch.sigmoid(logits)return prediction_probabilities# 数据加载器生成函数
def get_dataloaders(train_X, train_y, val_X, val_y, test_X, test_y, batch_size=128):train_set = LoadImputedDataAndLabel(train_X, train_y)val_set = LoadImputedDataAndLabel(val_X, val_y)test_set = LoadImputedDataAndLabel(test_X, test_y)train_loader = DataLoader(train_set, batch_size, shuffle=True)val_loader = DataLoader(val_set, batch_size, shuffle=False)test_loader = DataLoader(test_set, batch_size, shuffle=False)return train_loader, val_loader, test_loader# 训练流程
def train(model, train_dataloader, val_dataloader, test_loader):n_epochs = 20patience = 5optimizer = torch.optim.Adam(model.parameters(), 1e-3)current_patience = patiencebest_loss = float("inf")for epoch in range(n_epochs):model.train()for idx, data in enumerate(train_dataloader):X, y = map(lambda x: x.to(DEVICE), data)optimizer.zero_grad()probabilities = model(X)loss = F.cross_entropy(probabilities, y.reshape(-1))loss.backward()optimizer.step()model.eval()loss_collector = []with torch.no_grad():for idx, data in enumerate(val_dataloader):X, y = map(lambda x: x.to(DEVICE), data)probabilities = model(X)loss = F.cross_entropy(probabilities, y.reshape(-1))loss_collector.append(loss.item())loss = np.asarray(loss_collector).mean()if best_loss > loss:current_patience = patiencebest_loss = lossbest_model = deepcopy(model.state_dict())else:current_patience -= 1if current_patience == 0:breakmodel.load_state_dict(best_model)model.eval()probability_collector = []for idx, data in enumerate(test_loader):X, y = map(lambda x: x.to(DEVICE), data)probabilities = model.forward(X)probability_collector += probabilities.cpu().tolist()probability_collector = np.asarray(probability_collector)return probability_collector# 加载插补后的数据
data = pickle_load('result_saving/imputed_physionet2012.pkl')
train_X, val_X, test_X = data['train_set_imputation'], data['val_set_imputation'], data['test_set_imputation']
train_y, val_y, test_y = data['train_set_labels'], data['val_set_labels'], data['test_set_labels']# 构建数据加载器
train_loader, val_loader, test_loader = get_dataloaders(train_X, train_y, val_X, val_y, test_X, test_y)# 初始化并训练分类器
rnn_classifier = ClassificationLSTM(n_features=37, rnn_hidden_size=128, n_classes=2)
proba_predictions = train(rnn_classifier, train_loader, val_loader, test_loader)# 输出测试集分类性能
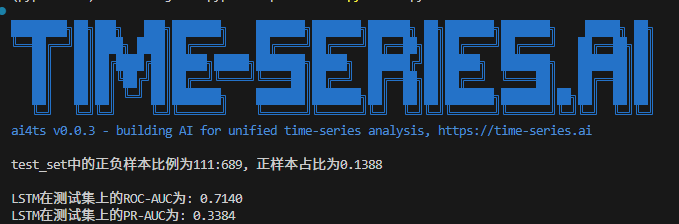
pos_num = test_y.sum()
neg_num = len(test_y) - pos_num
print(f'test_set中的正负样本比例为{pos_num}:{neg_num}, 正样本占比为{pos_num/len(test_y):.4f}\n')classification_metrics = calc_binary_classification_metrics(proba_predictions, test_y)
print(f"LSTM在测试集上的ROC-AUC为: {classification_metrics['roc_auc']:.4f}")
print(f"LSTM在测试集上的PR-AUC为: {classification_metrics['pr_auc']:.4f}")
结果如下:
相关文章:

Datawhale PyPOTS时间序列5月第3次笔记
下游任务的两阶段(two-stage) 处理 下载数据并预处理的程序: # ------------------------------- # 导入必要的库 # ------------------------------- import numpy as np import torch from benchpots.datasets import preprocess_physionet2012 from pypots.imp…...

初探Reforcement Learning强化学习【QLearning/Sarsa/DQN】
文章目录 一、Q-learning现实理解:举例:回顾: 二、Sarsa和Q-learning的区别 三、Deep Q-NetworkDeep Q-Network是如何工作的?前处理:Convolution NetworksExperience Replay 一、Q-learning 是RL中model-free、value-…...
(第2版)学习笔记 12.曲面细分)
计算机图形学编程(使用OpenGL和C++)(第2版)学习笔记 12.曲面细分
1. 曲面细分 曲面细分着色器(Tessellation Shader)是OpenGL 4.0及以上版本引入的一种可编程着色器阶段,用于在GPU上对几何体进行细分,将粗糙的多边形网格自动细分为更平滑、更精细的曲面。它主要用于实现高质量的曲面渲染&#x…...

8天Python从入门到精通【itheima】-14~16
目录 第二章学习内容总体预览: 14节-字面量: 1.学习目标:编辑 2.Python中6大常用数据类型: 3.实现:整数、浮点数、字符串类型的数据输出 4.字面量的定义: 5.小节总结 15节-注释: 1.le…...

Spring Boot 项目的计算机专业论文参考文献
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

linux线程基础
1. 什么是线程 进程是承担系统资源分配的基本实体,而线程(Thread)是进程内的一个执行单元,是CPU调度的基本单位。一个进程可以包含多个线程,这些线程共享进程的地址空间和资源(如文件描述符、全局变量等&a…...

进阶-数据结构部分:3、常用查找算法
飞书文档https://x509p6c8to.feishu.cn/wiki/LRdnwfhNgihKeXka7DfcGuRPnZt 顺序查找 查找算法是指:从一些数据之中,找到一个特殊的数据的实现方法。查找算法与遍历有极高的相似性,唯一的不同就是查找算法可能并不一定会将每一个数据都进行访…...

JavaScript 中的 for...in 和 for...of 循环详解
在 JavaScript 中,for...in 和 for...of 是两种常用的循环结构,但它们有着不同的用途和行为。很多初学者容易混淆这两者,本文将详细解析它们的区别、适用场景以及注意事项。 目录 for…in 循环 基本用法遍历对象属性注意事项 for…of 循环 …...

【汇总】影视仓接口地址,影视仓最新配置接口【2025.5】
📦 TVBOX接口分类与制作加载指南 结合参考资料,整理TVBOX接口的核心分类、制作方法及加载技巧,助你快速上手! 🌐 一、接口分类 🌍 网络接口(远程URL) 特点:动态加载在线J…...

vue引用cesium,解决“Not allowed to load local resource”报错
vue引用cesium,解决“Not allowed to load local resource”报错TOC 工具 vscode node :v22.14.0npm :10.9.2vue:vue/cli 5.0.8 一、创建一个 Vue 3 项目 1.创建名为cesium_test的项目: vue create cesium_test2.…...

阿里云服务器跑模型教程
首先打开阿里云官网点击免费试用 选择250工时/月的免费仨月新人试用套餐 点击右上角主账号 选择人工智能平台PAI 然后选择交互式建模(DSW) 选择新建实例 起个名字 然后点击确定 点击打开 进入到命令行工具 下载MINIConda和对应的pytorch还有相关依赖库文件即可 然后上传…...

JavaScript入门【2】语法基础
1.JavaScript的引⼊⽅式(使用): 1.方式1:行内引用: 此种方式是将<font style"color:rgb(38,38,38);">JavaScript代码作为HTML标签的属性值使⽤,示例如下:</font><html lang"en"> <head><meta charset"UTF-8"><…...

调用DeepSeek系列模型问答时,输出只有</think>标签,而没有<think>标签
问题:调用DeepSeek系列模型问答时,输出结果缺少只有标签,而没有标签? DeepSeek官方有关说明 这里设置成这样是为了保证让模型的生成是以"<think>\n"开头的,然后开始思考过程,避免模型没…...

python:gimp 与 blender 两个软件如何协作?
GIMP(GNU Image Manipulation Program)和 Blender 是两个不同领域的开源工具,但它们在数字创作流程中常协同使用,以下是它们的主要联系和互补性: 1. 功能互补:2D 与 3D 的结合 GIMP 是专业的 2D 图像处理工…...

MMDetection环境安装配置
MMDetection 支持在 Linux,Windows 和 macOS 上运行。它需要 Python 3.7 以上,CUDA 9.2 以上和 PyTorch 1.8 及其以上。 MMDetection 至今也一直更新很多个版本了,但是对于最新的pytorch版本仍然不支持,我安装的时候仍然多次遇到m…...

【springboot+vue3的前后端分离项目实现支付宝的沙箱支付】
【springbootvue3的前后端分离项目实现支付宝的沙箱支付】 以下是基于SpringBoot Vue前后端分离项目实现支付宝沙箱支付的完整解决方案,包含关键代码和调试技巧 一、项目架构设计 二、后端实现(SpringBoot) 1. 添加依赖 <!-- pom.xml…...
:大语言模型的工业部署)
基于Llama3的开发应用(二):大语言模型的工业部署
大语言模型的工业部署 0 前言1 ollama部署大模型1.1 ollama简介1.2 ollama的安装1.3 启动ollama服务1.4 下载模型1.5 通过API调用模型 2 vllm部署大模型2.1 vllm简介2.2 vllm的安装2.3 启动vllm模型服务2.4 API调用 3 LMDeploy部署大模型3.1 LMDeploy简介3.2 LMDeploy的安装3.3…...

MySQL只操作同一条记录也会死锁吗?
大家好,我是锋哥。今天分享关于【MySQL只操作同一条记录也会死锁吗?】面试题。希望对大家有帮助; MySQL里where条件的顺序影响索引使用吗? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在MySQL中,死锁通常发生在多…...

Linux的静态库 共享库 进程 主函数的参数
1、库文件 库文件 库是一组预先编译好的方法的集合; Linux系统储存的位置一般在/lib和/usr/lib中 库的头文件放在/usr/include 库分类:静态库(libxxx.a)共享库(libxxx.so) 静态库 (1&#…...

软件设计师考试结构型设计模式考点全解析
结构型设计模式考点全解析 一、分值占比与考察趋势分析(75分制) 设计模式近5年平均分值考察频率趋势分析适配器模式3-5分高频保持稳定桥接模式2-3分中频略有上升组合模式4-6分高频持续重点装饰器模式3-4分高频稳定考察代理模式5-7分高频逐年增加外观模…...

Java-Objects类高效应用的全面指南
Java_Objects类高效应用的全面指南 前言一、Objects 类概述二、Objects 类的核心方法解析2.1 requireNonNull系列方法:空指针检查的利器2.2 equals方法:安全的对象比较2.3 hashCode方法:统一的哈希值生成2.4 toString方法:灵活的对…...

PostGIS实现栅格数据入库-raster2pgsql
raster2pgsql使用与最佳实践 一、工具概述 raster2pgsql是PostGIS提供的命令行工具,用于将GDAL支持的栅格格式(如GeoTIFF、JPEG、PNG等)导入PostgreSQL数据库,支持批量加载、分块切片、创建空间索引及金字塔概览,是栅格数据入库的核心工具。 二、核心功能与典型用法 1…...
)
专题四:综合练习(组合问题的决策树与回溯算法)
以leetode77题为例 题目分析: 给一个数字n,你可以在1到n中选k个数字进行组合,注意包括1和n,而且通过观察实例 1,2和2,1是一样的,所以我们画决策树的时候,只需要从当前位置往后列举…...

从神经架构到万物自动化的 AI 革命:解码深度学习驱动的智能自动化新范式
目录 一、深度学习与 AI 自动化概述 二、深度学习核心技术解析 2.1 常见深度学习架构 2.2 关键算法 三、AI 自动化实践案例 3.1 图像分类自动化 3.2 自然语言处理自动化 —— 文本情感分析 编辑 五、自动化系统设计与实现 5.1 端到端自动化框架 5.2 自动化测试框架…...

3.5/Q1,GBD数据库最新文章解读
文章题目:Burden, trends, projections, and spatial patterns of lip and oral cavity cancer in Iran: a time-series analysis from 1990 to 2040 DOI:10.1186/s12889-025-22202-8 中文标题:伊朗唇癌和口腔癌的负担、趋势、预测和空间模式…...
智能化专项汇报方案)
智慧校园(含实验室)智能化专项汇报方案
该方案聚焦智慧校园(含实验室)智能化建设,针对传统实验室在运营监管、环境监测、安全管控、排课考勤等方面的问题,依据《智慧校园总体框架》等标准,设计数字孪生平台、实验室综合管理平台、消安电一体化平台三大核心平台,涵盖通信、安防、建筑设备管理等设施,涉及 395 个…...

玩转 AI · 思考过程可视化
玩转 AI 思考过程可视化 我们在开发 AI 的思维链 / 处理流时,难免遇到耗时较长的流程,如果遇到处理过慢的,用户什么也看不到可能丧失使用兴趣,对于这种情况,一个巧妙的产品思维就是呈现处理进度。 示例 其实完成这个页…...

hysAnalyser 从MPEG-TS导出ES功能说明
摘要 hysAnalyser 是一款特色的 MPEG-TS 数据分析工具。本文主要介绍了 hysAnalyser 从MPEG-TS 中导出选定的 ES 或 PES 功能(版本v1.0.003),以便用户知悉和掌握这些功能,帮助分析和解决各种遇到ES或PES相关的实际问题。hysAnalyser 支持主流的MP1/MP2/…...
YOLO V3的介绍)
[YOLO模型](4)YOLO V3的介绍
文章目录 YOLO V3一、模型思想二、模型性能三、改进的地方1. 三种scale2. scale变换经典方法3. 残差连接4. 核心网络架构(1) 结构(2) 输出与先验框关系 5. Logistic分类器替代Softmax 四、总结 YOLO V3 一、模型思想 作者 Redmon 又在 YOLOv2 的基础上做了一些改进:…...
21/6=3.5)
期望是什么:(无数次的均值,结合概率)21/6=3.5
https://seeing-theory.brown.edu/basic-probability/cn.html 期望是什么:(无数次的均值,结合概率)21/6=3.5 一、期望(数学概念) 在概率论和统计学中,**期望(Expectation)**是一个核心概念,用于描述随机变量的长期平均取值,反映随机变量取值的集中趋势。 (一…...
:集成学习中的“超级英雄团队”)
Stacking(堆叠):集成学习中的“超级英雄团队”
在机器学习的世界里,如果要找一个类似漫威“复仇者联盟”的存在,那么**Stacking(堆叠)**无疑是最佳候选人。就像钢铁侠、美国队长和雷神各自拥有独特的能力,但只有当他们组队时才能发挥出惊人的战斗力,Stac…...
)
手写tomcat:基本功能实现(3)
TomcatRoute类 TomcatRoute类是Servlet容器,是Tomcat中最核心的部分,其本身是一个HashMap,其功能为:将路径和对象写入Servlet容器中。 package com.qcby.config;import com.qcby.Util.SearchClassUtil; import com.qcby.servlet…...

nt!MiRemovePageByColor函数分析之脱链和刷新颜色表
第0部分:背景 PFN_NUMBER FASTCALL MiRemoveZeroPage ( IN ULONG Color ) { ASSERT (Color < MmSecondaryColors); Page FreePagesByColor[Color].Flink; if (Page ! MM_EMPTY_LIST) { // // Remove the first entry on the zeroe…...

时间筛掉了不够坚定的东西
2025年5月17日,16~25℃,还好 待办: 《高等数学1》重修考试 《高等数学2》备课 《物理[2]》备课 《高等数学2》取消考试资格学生名单 《物理[2]》取消考试资格名单 职称申报材料 2024年税务申报 5月24日、25日监考报名 遇见:敲了一…...

3D个人简历网站 4.小岛
1.模型素材 在Sketchfab上下载狐狸岛模型,然后转换为素材资源asset,嫌麻烦直接在网盘链接下载素材, Fox’s islandshttps://sketchfab.com/3d-models/foxs-islands-163b68e09fcc47618450150be7785907https://gltf.pmnd.rs/ 素材夸克网盘&a…...

第十一课 蜗牛爬树
上次作业 同学们课后可以尝试找一下30以内,哪个整数有最多的因数呢? 这个整数有多少个因数呢? 最好使用程序来进行判断哦 int main() {int max_num 1; // 记录因数最多的数int max_count 1; // 记录最大因数个数for (int num 2; num <…...

字体样式集合
根据您提供的字体样式列表,以下是分类整理后的完整字体样式名称(不含数量统计): 基础样式 • Regular • Normal • Plain • Medium • Bold • Black • Light • Thin • Heavy • Ultra • Extra • Semi • Hai…...
?)
Spring MVC 如何处理文件上传? 需要哪些配置和依赖?如何在 Controller 中接收上传的文件 (MultipartFile)?
Spring MVC 处理文件上传主要依赖于 MultipartResolver 接口及其实现。最常用的实现是 CommonsMultipartResolver(基于 Apache Commons FileUpload)和 StandardServletMultipartResolver(基于 Servlet 3.0 API)。 以下是如何配置…...
成员函数的深度解读(中篇))
探索C++对象模型:(拷贝构造、运算符重载)成员函数的深度解读(中篇)
前引:在C的面向对象编程中,对象模型是理解语言行为的核心。无论是类的成员函数如何访问数据,还是资源管理如何自动化,其底层机制均围绕两个关键概念展开:拷贝复制、取地址重载成员函数。它们如同对象的“隐形守护者”&…...
)
[逆向工程]C++实现DLL注入:原理、实现与防御全解析(二十五)
[逆向工程]C实现DLL注入:原理、实现与防御全解析(二十五) 引言 DLL注入(DLL Injection)是Windows系统下实现进程间通信、功能扩展、监控调试的核心技术之一。本文将从原理分析、代码实现、实战调试到防御方案&#x…...

gcc/g++常用参数
1.介绍 gcc用于编译c语言,g用于编译c 源代码生成可执行文件过程,预处理-编译-汇编-链接。https://zhuanlan.zhihu.com/p/476697014 2.常用参数说明 2.1编译过程控制 参数作用-oOutput,指定输出名字-cCompile,编译源文件生成对…...

51单片机课设基于GM65模块的二维码加条形码识别
系统组成 主控单元:51单片机(如STC89C52)作为核心控制器,协调各模块工作。 扫描模块:GM65条码扫描头,支持二维码/条形码识别,通过串口(UART)与单片机通信。 显示模块&a…...

物联网赋能7×24H无人值守共享自习室系统设计与实践!
随着"全民学习"浪潮的兴起,共享自习室市场也欣欣向荣,今天就带大家了解下在物联网的加持下,无人共享自习室系统的设计与实际方法。 一、物联网系统整体架构 1.1 系统分层设计 层级技术组成核心功能用户端微信小程序/H5预约选座、…...
增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化)
基于多头自注意力机制(MHSA)增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化
深度学习在计算机视觉领域的快速发展推动了目标检测算法的持续进步。作为实时检测框架的典型代表,YOLO系列凭借其高效性与准确性备受关注。本文提出一种基于多头自注意力机制(Multi-Head Self-Attention, MHSA)增强的YOLOv11主干网络结构,旨在提升模型在…...

使用Spring Boot与Spring Security构建安全的RESTful API
使用Spring Boot与Spring Security构建安全的RESTful API 引言 在现代Web应用开发中,安全性是不可忽视的重要环节。Spring Boot和Spring Security作为Java生态中的主流框架,为开发者提供了强大的工具来构建安全的RESTful API。本文将详细介绍如何结合S…...

小刚说C语言刷题—1230蝴蝶结
1.题目描述 请输出 n 行的蝴蝶结的形状,n 一定是一个奇数! 输入 一个整数 n ,代表图形的行数! 输出 n 行的图形。 样例 输入 9 输出 ***** **** *** ** * ** *** **** ***** 2.参考代码(C语言版)…...

利用SenseGlove触觉手套开发XR手术训练体验
VirtualiSurg和VR触觉 作为领先的培训平台,VirtualiSurg自2017年以来一直利用扩展现实 (XR) 和触觉技术,为全球医疗保健行业提供个性化、数据驱动的学习解决方案。该平台赋能医疗专业人员进行协作式学习和培训,提升他们的技能,使…...
—2D平行束投影公式)
CT重建笔记(五)—2D平行束投影公式
写的又回去了,因为我发现我理解不够透彻,反正想到啥写啥,尽量保证内容质量好简洁易懂 2D平行束投影公式 p ( s , θ ) ∫ ∫ f ( x , y ) δ ( x c o s θ y s i n θ − s ) d x d y p(s,\theta)\int \int f(x,y)\delta(x cos\theta ysi…...

【Java】应对高并发的思路
在Java中应对高并发场景需要结合多方面的技术手段和设计模式,从线程管理、数据结构、同步机制到异步处理、IO优化等,都需要合理设计和配置。以下是Java在高并发场景下的主要应对策略和最佳实践: 1. 线程管理 1.1 线程池(ThreadPo…...

从数据分析到数据可视化:揭开数据背后的故事
从数据分析到数据可视化:揭开数据背后的故事 大家好,今天咱们聊聊“从数据分析到数据可视化”的完整流程。说实话,数据分析和可视化这俩词听起来高大上,但咱们平时就是围绕这俩词打转——数据分析帮我们找故事,可视化则帮我们讲故事。没有它们,数据就是死的;有了它们,数…...