基于Llama3的开发应用(二):大语言模型的工业部署
大语言模型的工业部署
- 0 前言
- 1 ollama部署大模型
- 1.1 ollama简介
- 1.2 ollama的安装
- 1.3 启动ollama服务
- 1.4 下载模型
- 1.5 通过API调用模型
- 2 vllm部署大模型
- 2.1 vllm简介
- 2.2 vllm的安装
- 2.3 启动vllm模型服务
- 2.4 API调用
- 3 LMDeploy部署大模型
- 3.1 LMDeploy简介
- 3.2 LMDeploy的安装
- 3.3 启动 LMDeploy 模型服务
- 3.4 API调用
- 4 使用streamlit+vllm部署模型
- 5 总结
0 前言
上篇文章讲了Llama3模型的简单部署,并且我们介绍了transformers调用大模型的通用格式,并且我们使用 streamlit 做了一个简易交互界面。但真实生产环境中,推理框架很少用transformers,这是因为该库的设计初衷是广泛兼容性和易用性,而不是专门针对特定硬件或大规模模型的性能优化。生产环境中主要用 vllm 和 LMDploy,另外,对于个人用户,ollama的使用也比较多,所以本文主要介绍这三种推理框架的使用。
1 ollama部署大模型
1.1 ollama简介
Ollama 是一个开源工具,旨在简化大型语言模型(LLMs)在本地计算机上的部署和运行。以下是其核心特点及功能的简要介绍:
核心功能
-
本地运行
允许用户在本地设备(如个人电脑)直接运行LLMs(如Meta的LLaMA、LLaMA 2等),无需依赖云服务,保障数据隐私并支持离线使用。 -
模型支持
• 提供预训练模型库,支持多种模型(如LLaMA 2、Mistral、Gemma等)及不同参数量版本(如7B、13B)。
• 通过简单命令(如ollama run llama2)即可下载和运行模型,类似Docker镜像管理。 -
跨平台兼容性
支持主流操作系统(Windows、macOS、Linux),并利用硬件加速(如CUDA、Metal)优化性能,提升推理速度。 -
用户友好性
主要提供命令行接口(CLI),简化模型交互流程。部分第三方工具(如Open WebUI)可扩展图形界面。
技术特点
• 量化优化:采用4位量化等技术减少模型内存占用,使其能在消费级硬件(如普通GPU/CPU)上流畅运行。
• 灵活扩展:支持导入自定义模型或适配Hugging Face等平台的模型,满足进阶开发需求。
使用场景
• 开发者测试:本地快速部署模型,进行原型开发或调试。
• 隐私敏感场景:处理敏感数据时避免依赖云端服务。
• 教育与研究:无网络环境下进行模型实验或教学演示。
与类似工具对比
相较于llama.cpp(专注于高效推理)或Hugging Face Transformers(需更多配置),Ollama强调开箱即用,降低使用门槛,适合非专业用户。
1.2 ollama的安装
进入ollama官网,点击Download:
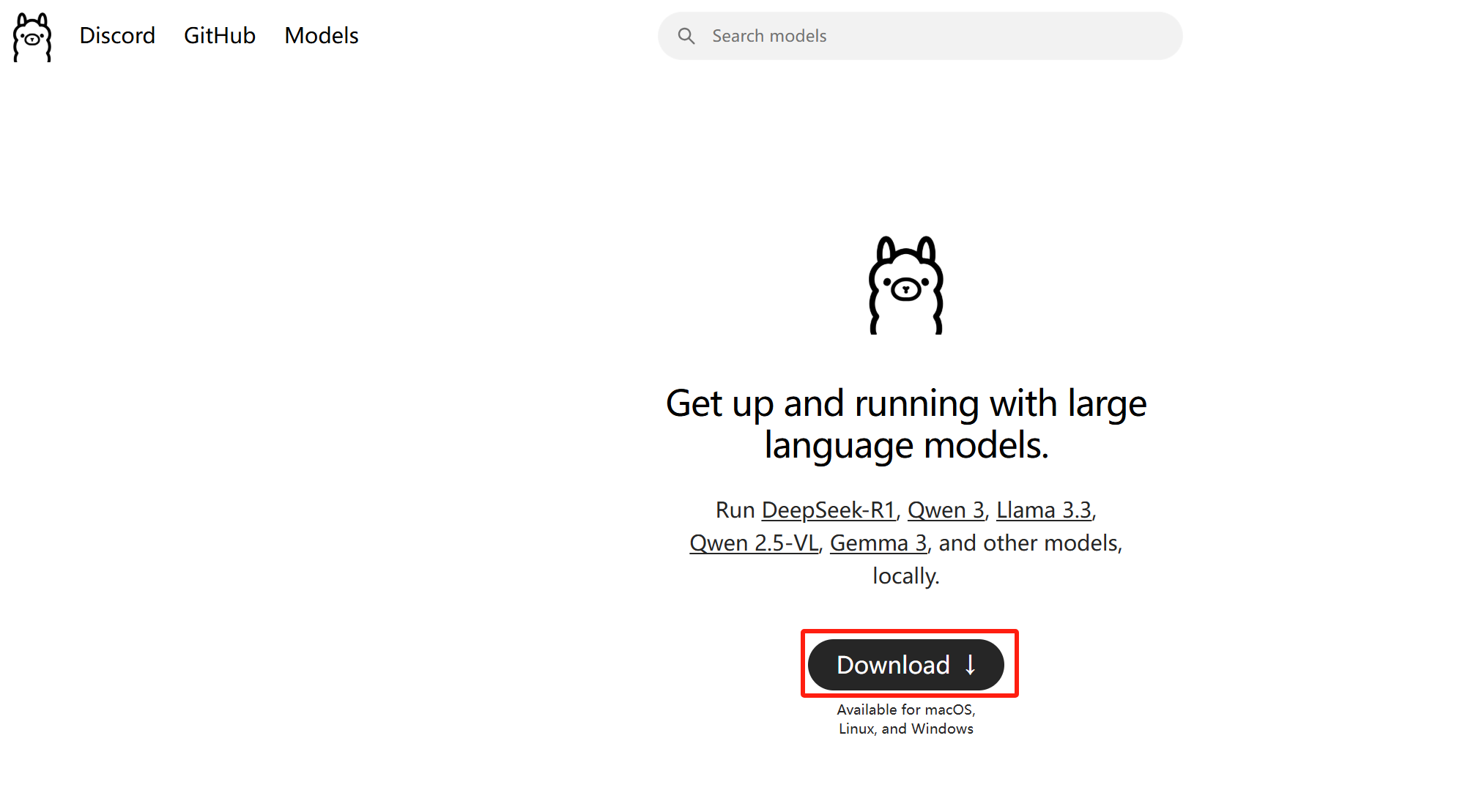
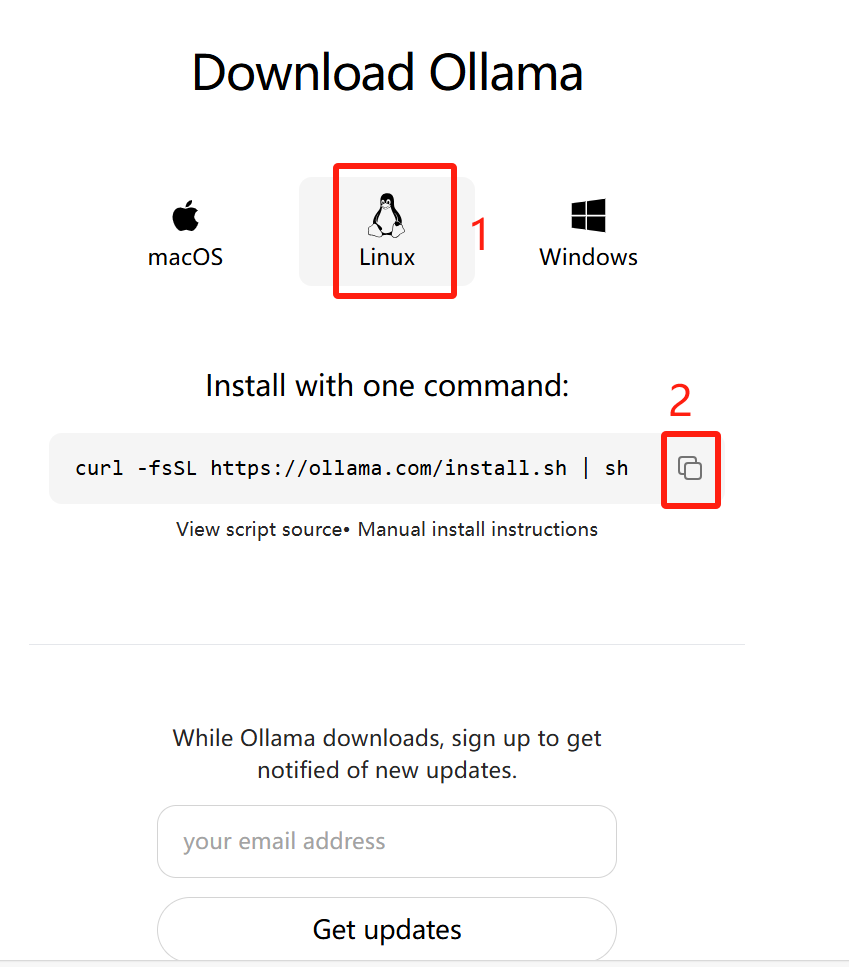
点击Linux,并获取安装命令
在服务器中新建一个conda环境,名字为ollama,此环境专门用于ollama推理:conda create -n ollama python==3.12
环境创建后,激活该环境,输入刚刚复制的安装指令安装,即:
curl -fsSL https://ollama.com/install.sh | sh
国内用户这一步经常会因为网络问题而安装失败,这一步在魔搭平台中有解决方案:
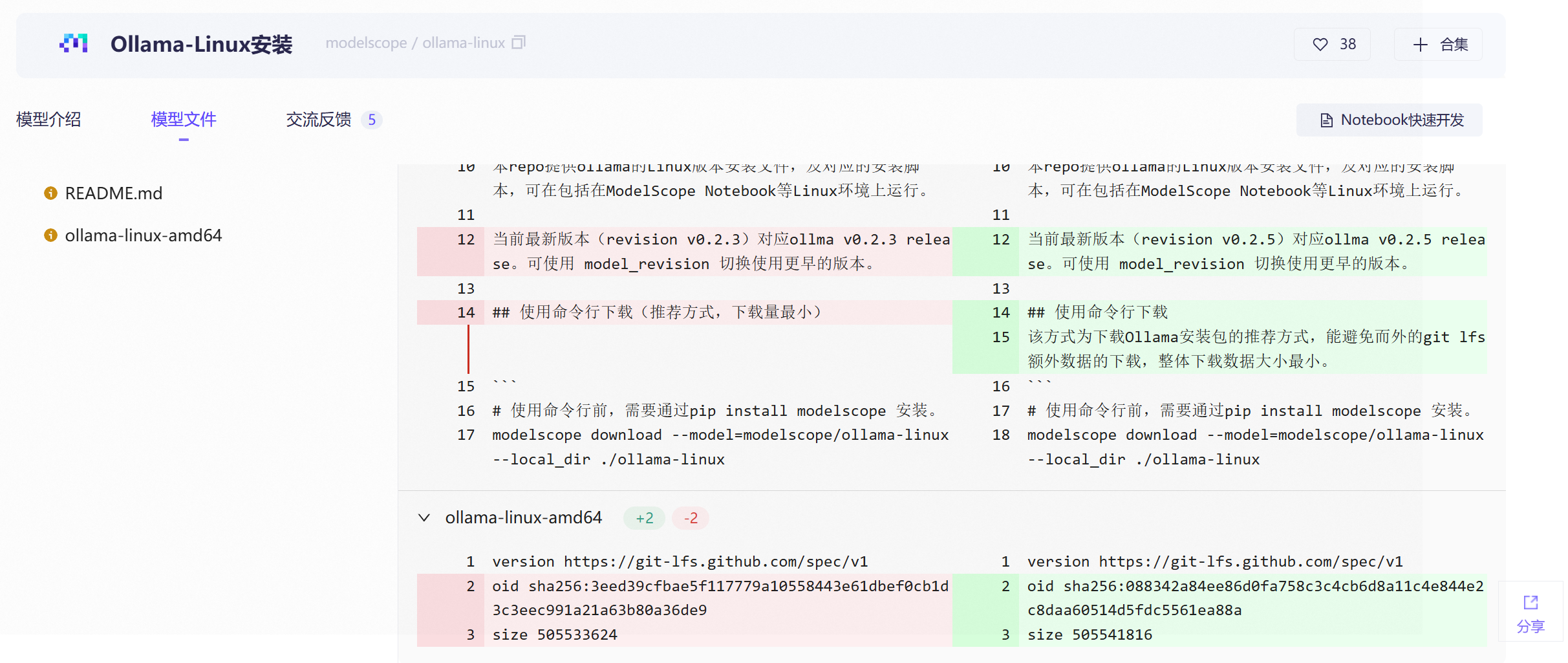
其实就是两条命令:
pip install modelscope
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux
以上命令执行后,ollama的安装文件将改从魔搭平台下载。
接下来是安装,执行下面两条命令:
cd ollama-linux/
sh ollama-linux/ollama-modelscope-install.sh
若出现以下信息,则说明安装成功:

如果直接使用官网的安装教程安装ollama,那么通过 ollama run 命令从ollama官网中下载的模型会保存在/usr/share/ollama/.ollama/models中。
如果是从魔搭平台下载安装文件进行安装(即替代方案),则通过 ollama run 命令从ollama官网中下载的模型保存在~/.ollama/models中,最好重新设置模型保存路径。依次输入下面两条命令,修改保存路径:
echo 'export OLLAMA_MODELS="/data/coding/model_weights/ollama/models"' >> ~/.bashrc # 修改成你想保存的路径
source ~/.bashrc
1.3 启动ollama服务
只有开启服务后,才能下载并部署模型
ollama serve
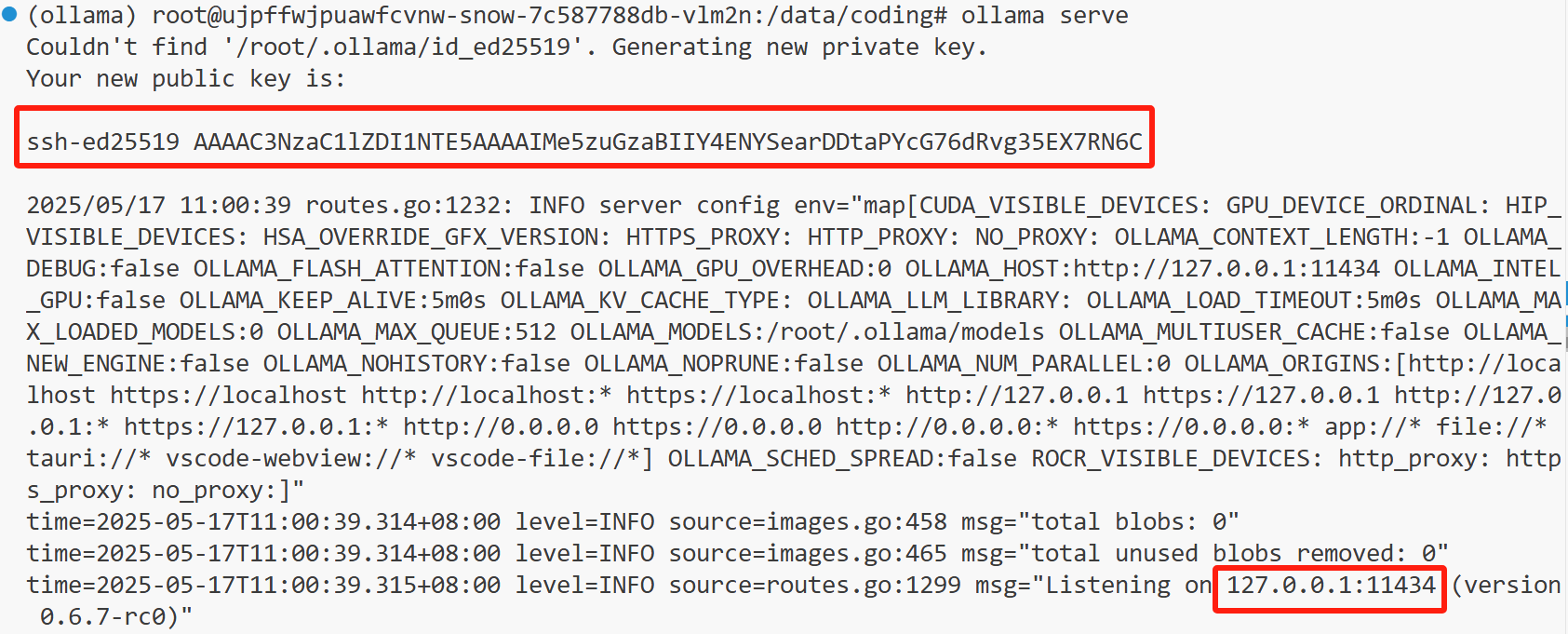
我们可以看到API Key,还有地址与端口号。
1.4 下载模型
ollama只能运行经过GGUF量化后的模型,相对于原模型效果略差。首次运行模型,如果本地没有,那么会从ollama官网拉取模型文件到本地。
在ollama主页中搜索模型名并按回车,我们这里输入qwen3(之所以不用llama3,是因为llama3最小的都是8B,llama3.2最小的是1B,下载起来很慢,而qwen3最小的是0.6B):
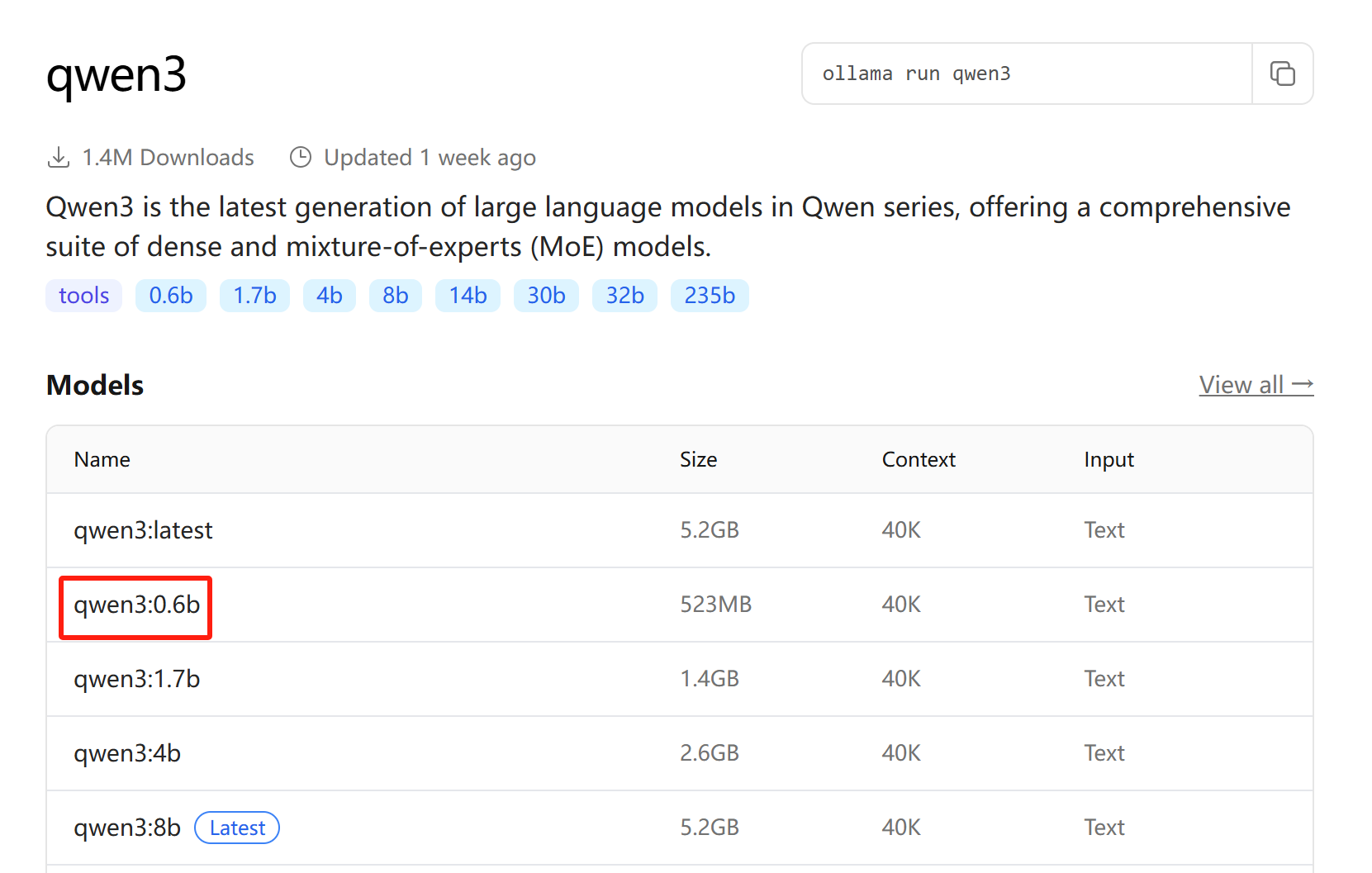
点击 qwen3:0.6b
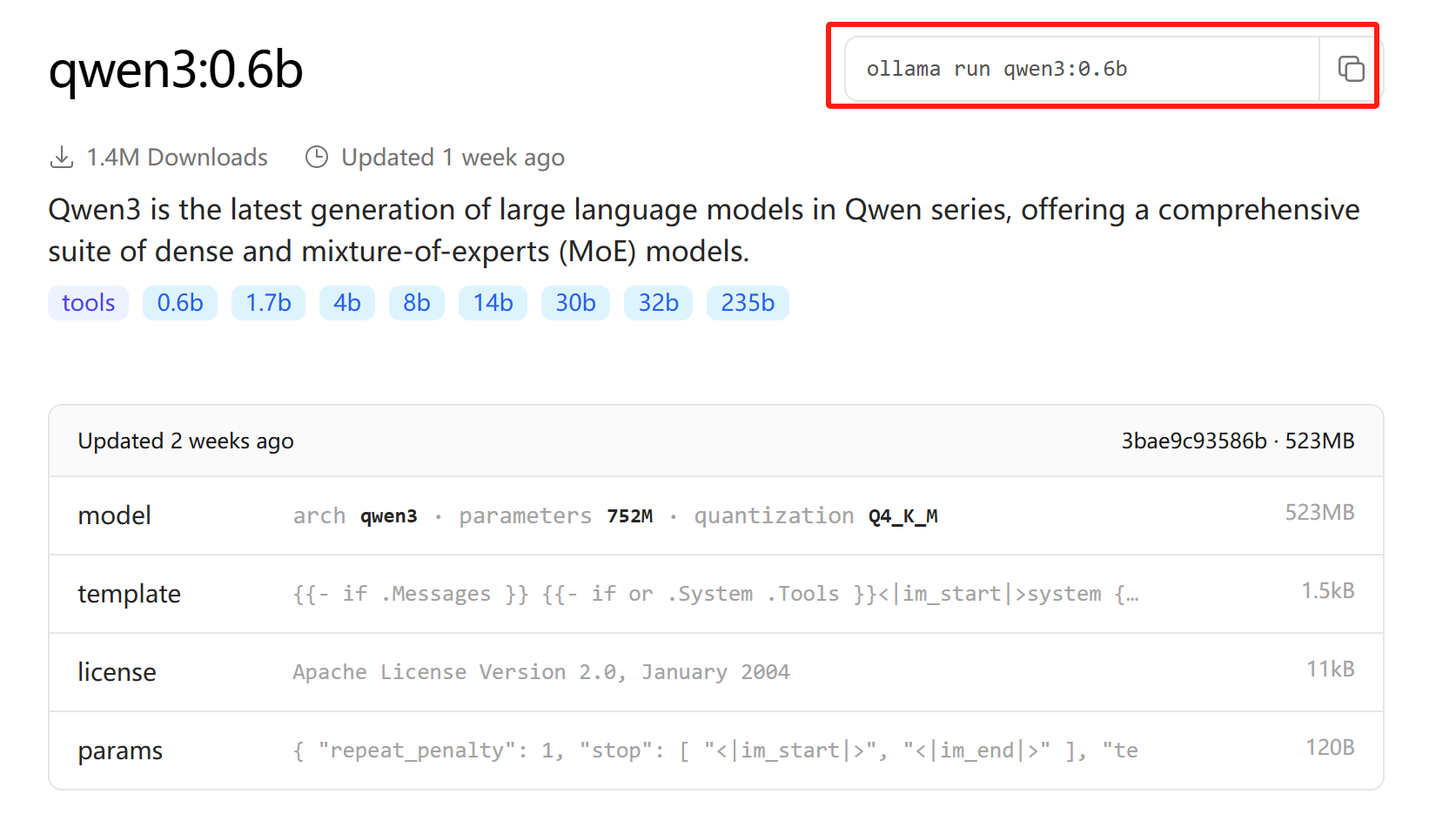
新建一个终端,并激活ollama环境,随后复制右上角的模型运行命令,即:
ollama run qwen3:0.6b
拉取完模型后(下载速度不用担心,在国内下载速度是可以的),会出现简单的交互界面:

可以看到,qwen3已经像deepseek一样,具有了深度思考大的功能。输入Ctrl + d 或者 /bye 退出交互界面。
可以在我们设置的路径下找到模型文件:
可以在终端输入 ollama list 查看能调用的模型,我这里输入的结果是:
NAME ID SIZE MODIFIED
qwen3:0.6b 3bae9c93586b 522 MB 48 minutes ago
1.5 通过API调用模型
启动服务的那一步,我们可以拿到API Key以及模型地址,接下来我们用OpenAI API 的风格调用模型。在此之前,需要安装OpenAI:
pip install openai
新建一个名为 ollama_test.py 的程序文件,内容如下:
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:11434/v1/", # /v1表示调用为OpenAI风格设计的接口api_key="AAAA" # 调用本机的服务,api_key可以随便写) #初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="qwen3:0.6b") # model只需要置为模型名就行#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()
Ollama 服务端在启动时,会监听多个路径:/api,原生 Ollama API(如生成、拉取模型);/v1:专为兼容 OpenAI API 设计的接口。
Ollama 的 OpenAI 风格接口仅在 /v1 路径下实现,因此 base_url="http://localhost:11434/v1/" 的 /v1 用于标识 OpenAI API 接口版本,这样可以保持原生 API 和 OpenAI 风格 API 的路径分离,避免冲突。
此外,由于调用本机的服务,无需真实密钥,密钥可以随便写,但不能没有。
在终端输入(以下命令无需在ollama环境中运行):
ollama_test.py
终端结果如下:

按Ctrl+C退出交互。
从上面的结果可以看到,qwen3:0.6b 的多轮对话能力不行,记不住前面回答的内容,一方面是模型太小,只有0.6b,另一方面是模型经过量化,效果变差。
2 vllm部署大模型
2.1 vllm简介
vLLM 是一个快速且易于使用的库,用于 LLM 推理和服务。vLLM 最初在加州大学伯克利分校的 Sky Computing Lab 开发,现已发展成为一个社区驱动的项目,汇集了学术界和工业界的贡献。
vLLM 速度快,具有:
- 最先进的服务吞吐量
- 使用 PagedAttention 高效管理注意力键和值内存
- 持续批处理传入请求
- 使用 CUDA/HIP 图快速模型执行
- 量化:GPTQ, AWQ, INT4, INT8 和 FP8
- 优化的 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成。
- 推测解码
- 分块预填充
vLLM 灵活且易于使用,具有:
- 与流行的 HuggingFace 模型无缝集成(ollama只能调用GUFF模型)
- 使用各种解码算法(包括并行采样、束搜索等)实现高吞吐量服务
- 张量并行和流水线并行支持分布式推理
- 流式输出
- OpenAI 兼容的 API 服务器
- 支持 NVIDIA GPU、AMD CPU 和 GPU、Intel CPU、Gaudi® 加速器和 GPU、IBM Power CPU、TPU 以及 AWS Trainium 和 Inferentia 加速器。
- 前缀缓存支持
- Multi-LoRA 支持
vllm有专门的中文文档。
2.2 vllm的安装
vllm目前只能在Linux系统安装,安装vllm的硬件环境,必须是算力不低于7.0的GPU,像P40、P100显卡就没法用(其实也可以,但比较麻烦,需要自己编译),CPU虽然也能装,但vllm一般是用于企业级用户,CPU无法满足算力要求。
不要在base环境中安装vllm,因为安装的时候,会安装与vllm配套的CUDA,如果原有的CUDA与vllm不匹配,则会卸载原有的CUDA,从而重新安装PyTorch,这样影响很大。
我们这里和ollama类似,新建一个环境,专门使用vllm部署:
conda create -n vllm1 python=3.12 # 我在新建环境时,环境名后面多敲了个1
然后安装vllm:
pip install vllm
安装的时候,会把相关的依赖也安装好,包括最新版本的 PyTorch。因为安装的依赖比较多,为了加速,最好把pip的镜像切换回国内的镜像源,例如可以用清华源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
2.3 启动vllm模型服务
终端输入:
vllm serve model_weights/LLM-Research/Meta-Llama-3-8B-Instruct
其实就是 vllm serve 加 模型路径。
出现以下信息,说明服务启动成功:
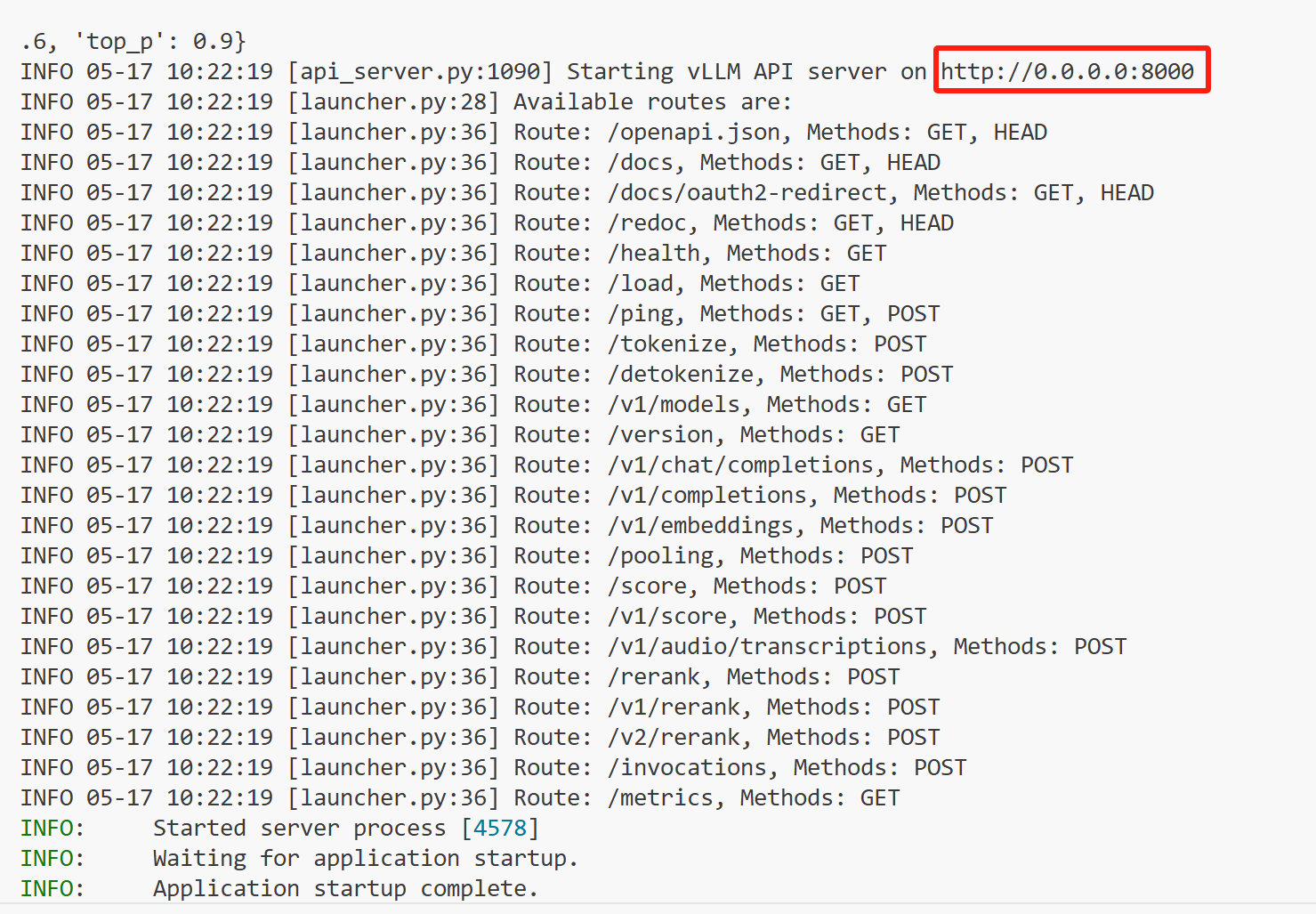
从上面的信息可以看到服务的路径和端口号。
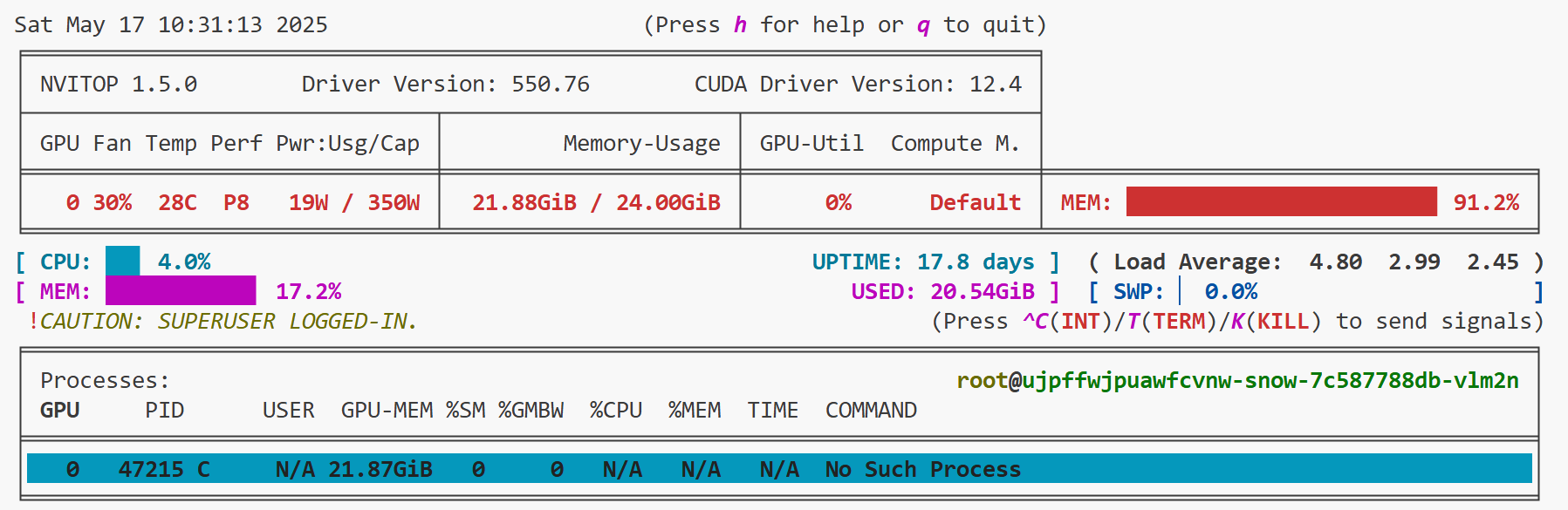
此时我们可以新建一个端口,输入nvitop查看显存使用情况:
2.4 API调用
新建一个名为 test03.py 的代码文件,内容如下:
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie") # 在本地调用,api_key可以任意,但不能没有#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="model_weights/LLM-Research/Meta-Llama-3-8B-Instruct")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()
注意,调用模型时,model需要指定为模型路径,代码的其他部分和 ollama_test.py 没差。
新建一个终端,切换到装有openai的环境,然后命令行执行:
python test03.py
然后在控制台进行交互:
按Ctrl+C退出交互。
3 LMDeploy部署大模型
3.1 LMDeploy简介
LMDeploy 是一个用于大型语言模型(LLMs)和视觉-语言模型(VLMs)压缩、部署和服务的 Python 库,由 MMDeploy 和 MMRazor 团队联合开发。 其核心推理引擎包括 TurboMind 引擎和 PyTorch 引擎。前者由 C++ 和 CUDA 开发,致力于推理性能的优化,而后者纯 Python 开发,旨在降低开发者的门槛。
LMDeploy 支持在 Linux 和 Windows 平台上部署 LLMs 和 VLMs,这个比vllm强一些,最低要求 CUDA 版本为 11.3。它和vllm一样,主要也是面向企业级用户,GPU算力同样必须在7.0或7.0以上。
LMDeploy 工具箱提供以下核心功能:
- 高效的推理: LMDeploy 开发了 Persistent Batch(即 Continuous Batch),Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算 kernel等重要特性。推理性能是 vLLM 的 1.8 倍
- 可靠的量化: LMDeploy 支持权重量化和 k/v 量化。4bit 模型推理效率是 FP16 下的 2.4 倍。量化模型的可靠性已通过 OpenCompass 评测得到充分验证。
- 便捷的服务: 通过请求分发服务,LMDeploy 支持多模型在多机、多卡上的推理服务。
- 有状态推理: 通过缓存多轮对话过程中 attention 的 k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率。
- 卓越的兼容性: LMDeploy 支持 KV Cache 量化, AWQ 和 Automatic Prefix Caching 同时使用。
LMDeploy的文档。
3.2 LMDeploy的安装
和前面一样,创建一个名为 lmdeploy 的环境,专门用于LLMDeploy部署模型:
conda create -n lmdeploy python==3.12
然后安装 lmdeploy:
pip install lmdeploy
这里同样会重新安装cuda,以及与之配套的最新版PyTorch。
3.3 启动 LMDeploy 模型服务
终端输入:
lmdeploy serve api_server model_weights/LLM-Research/Meta-Llama-3-8B-Instruct --max-batch-size 8
其实就是 vllm serve + 模型路径,如果显存够大的化,可以不加–max-batch-size参数(我最开始没加的,然后显存就爆了)。
当出现以下信息,说明服务启动成功:
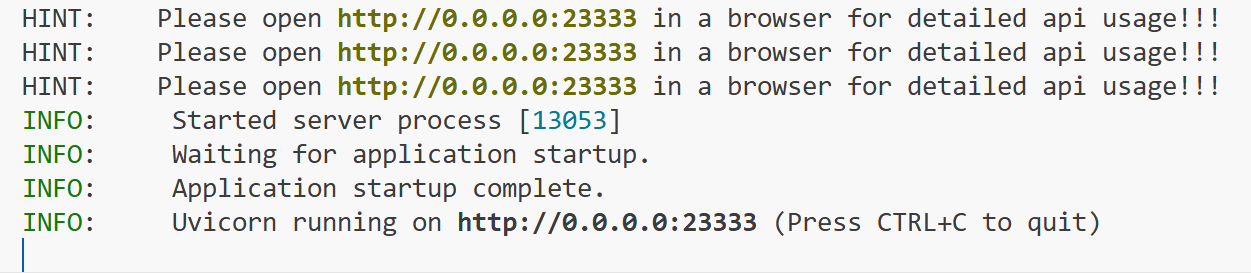
从打印的信息中,我们可以看到端口号。
新建一个端口,使用 nvitop 查看显存使用情况:
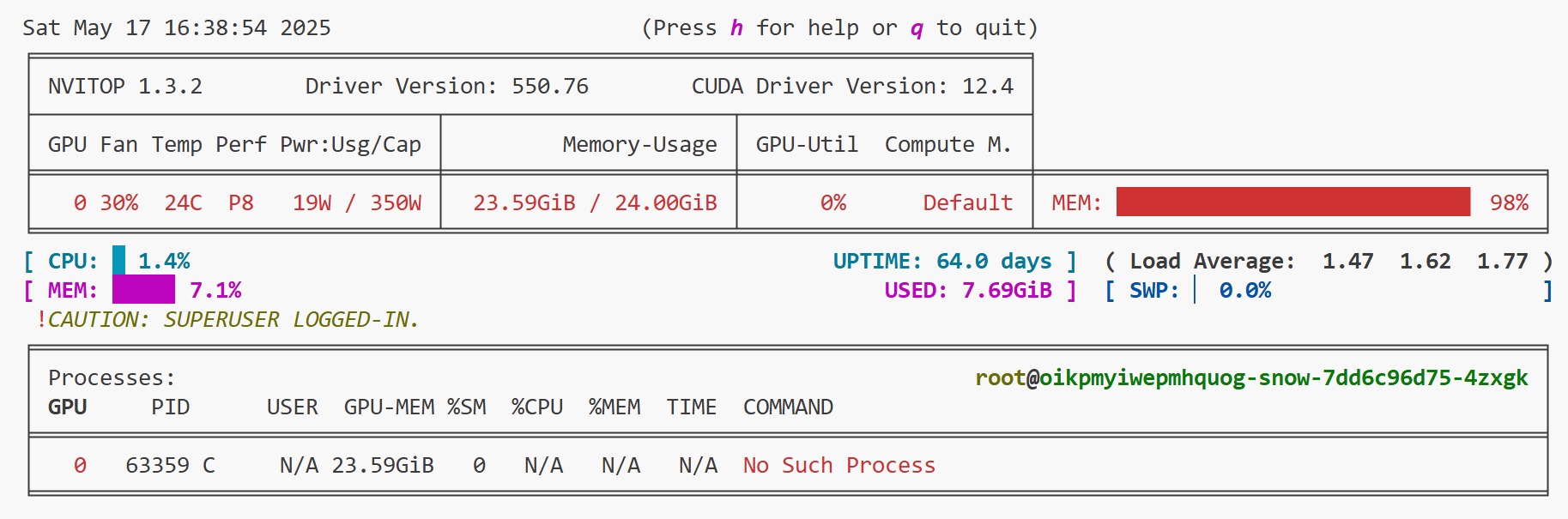
对比 vllm 可以发现,相同的模型,lmdeploy显存占用较高,当然,也有可能是我的参数设置不合理,可是我试了把 --max-batch-size 设置成1、2、4,显存占用都是98%。
3.4 API调用
创建一个名为 lmdeploy_test.py 的代码文件:
#多轮对话
from openai import OpenAI#定义多轮对话方法
def run_chat_session():#初始化客户端client = OpenAI(base_url="http://localhost:23333/v1/",api_key="suibianxie")#初始化对话历史chat_history = []#启动对话循环while True:#获取用户输入user_input = input("用户:")if user_input.lower() == "exit":print("退出对话。")break#更新对话历史(添加用户输入)chat_history.append({"role":"user","content":user_input})#调用模型回答try:chat_complition = client.chat.completions.create(messages=chat_history,model="model_weights/LLM-Research/Meta-Llama-3-8B-Instruct")#获取最新回答model_response = chat_complition.choices[0]print("AI:",model_response.message.content)#更新对话历史(添加AI模型的回复)chat_history.append({"role":"assistant","content":model_response.message.content})except Exception as e:print("发生错误:",e)break
if __name__ == '__main__':run_chat_session()
创建一个新的终端,输入:
python lmdeploy_test.py
然后在控制台交互:
4 使用streamlit+vllm部署模型
这个其实就是用vllm作为推理框架,然后再搭一个前端交互界面。
新建一个名为 demo_vllm_streamlit.py 的代码文件,内容如下:
import streamlit as st
from openai import OpenAI# 合并对话历史
def build_messages(prompt, history):messages = []system_message = {"role": "system", "content": "You are a helpful assistant."}messages.append(system_message)messages.extend(history)user_message = {"role": "user", "content": prompt}messages.append(user_message)return messages# 初始化客户端
@st.cache_resource
def get_client():# 如果没有 @st.cache_resource,那么每次在前端界面输入信息时,程序就会再次执行,导致模型重复导入client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie")return client# 在侧边栏中创建一个标题和一个链接
with st.sidebar:st.markdown("## LLaMA3 LLM")"[开源大模型食用指南 self-llm](https://github.com/datawhalechina/self-llm.git)"# 创建一个标题和一个副标题
st.title("💬 LLaMA3 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")# 如果session_state中没有"messages",则创建一个包含默认消息的列表
if "messages" not in st.session_state:st.session_state["messages"] = []# 遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:st.chat_message(msg["role"]).write(msg["content"])# 初始化客户端
client = get_client()#初始化消息列表(即对话历史)
chat_history = [{"role": "system", "content": "You are a helpful assistant."}]# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():# 在聊天界面上显示用户的输入st.chat_message("user").write(prompt)# 将当前提示词添加到消息列表messages = build_messages(prompt=prompt, history=st.session_state["messages"])#调用模型chat_complition = client.chat.completions.create(messages=messages,model="model_weights/LLM-Research/Meta-Llama-3-8B-Instruct")#获取回答model_response = chat_complition.choices[0]response_text = model_response.message.content# 将用户问题和模型的输出添加到session_state中的messages列表中st.session_state.messages.append({"role": "user", "content": prompt})st.session_state.messages.append({"role": "assistant", "content": response_text})# 在聊天界面上显示模型的输出st.chat_message("assistant").write(response_text)# 在终端中运行以下命令,启动streamlit服务,并将端口映射到本地,然后在浏览器中打开链接 http://localhost:6006/ ,即可看到聊天界面。
# ```bash
# streamlit run demo_vllm_streamlit.py --server.address 127.0.0.1 --server.port 6006
#
在终端中运行以下命令,启动streamlit服务,并将端口映射到本地,然后在浏览器中打开链接 http://localhost:6006/ ,即可看到聊天界面。
streamlit run demo_vllm_streamlit.py --server.address 127.0.0.1 --server.port 6006
5 总结
这篇文章看完之后,可以说只要显存够,所有的大模型都会部署了,后面的文章还会介绍量化和分布式部署。
相关文章:
:大语言模型的工业部署)
基于Llama3的开发应用(二):大语言模型的工业部署
大语言模型的工业部署 0 前言1 ollama部署大模型1.1 ollama简介1.2 ollama的安装1.3 启动ollama服务1.4 下载模型1.5 通过API调用模型 2 vllm部署大模型2.1 vllm简介2.2 vllm的安装2.3 启动vllm模型服务2.4 API调用 3 LMDeploy部署大模型3.1 LMDeploy简介3.2 LMDeploy的安装3.3…...

MySQL只操作同一条记录也会死锁吗?
大家好,我是锋哥。今天分享关于【MySQL只操作同一条记录也会死锁吗?】面试题。希望对大家有帮助; MySQL里where条件的顺序影响索引使用吗? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在MySQL中,死锁通常发生在多…...

Linux的静态库 共享库 进程 主函数的参数
1、库文件 库文件 库是一组预先编译好的方法的集合; Linux系统储存的位置一般在/lib和/usr/lib中 库的头文件放在/usr/include 库分类:静态库(libxxx.a)共享库(libxxx.so) 静态库 (1&#…...

软件设计师考试结构型设计模式考点全解析
结构型设计模式考点全解析 一、分值占比与考察趋势分析(75分制) 设计模式近5年平均分值考察频率趋势分析适配器模式3-5分高频保持稳定桥接模式2-3分中频略有上升组合模式4-6分高频持续重点装饰器模式3-4分高频稳定考察代理模式5-7分高频逐年增加外观模…...

Java-Objects类高效应用的全面指南
Java_Objects类高效应用的全面指南 前言一、Objects 类概述二、Objects 类的核心方法解析2.1 requireNonNull系列方法:空指针检查的利器2.2 equals方法:安全的对象比较2.3 hashCode方法:统一的哈希值生成2.4 toString方法:灵活的对…...

PostGIS实现栅格数据入库-raster2pgsql
raster2pgsql使用与最佳实践 一、工具概述 raster2pgsql是PostGIS提供的命令行工具,用于将GDAL支持的栅格格式(如GeoTIFF、JPEG、PNG等)导入PostgreSQL数据库,支持批量加载、分块切片、创建空间索引及金字塔概览,是栅格数据入库的核心工具。 二、核心功能与典型用法 1…...
)
专题四:综合练习(组合问题的决策树与回溯算法)
以leetode77题为例 题目分析: 给一个数字n,你可以在1到n中选k个数字进行组合,注意包括1和n,而且通过观察实例 1,2和2,1是一样的,所以我们画决策树的时候,只需要从当前位置往后列举…...

从神经架构到万物自动化的 AI 革命:解码深度学习驱动的智能自动化新范式
目录 一、深度学习与 AI 自动化概述 二、深度学习核心技术解析 2.1 常见深度学习架构 2.2 关键算法 三、AI 自动化实践案例 3.1 图像分类自动化 3.2 自然语言处理自动化 —— 文本情感分析 编辑 五、自动化系统设计与实现 5.1 端到端自动化框架 5.2 自动化测试框架…...

3.5/Q1,GBD数据库最新文章解读
文章题目:Burden, trends, projections, and spatial patterns of lip and oral cavity cancer in Iran: a time-series analysis from 1990 to 2040 DOI:10.1186/s12889-025-22202-8 中文标题:伊朗唇癌和口腔癌的负担、趋势、预测和空间模式…...
智能化专项汇报方案)
智慧校园(含实验室)智能化专项汇报方案
该方案聚焦智慧校园(含实验室)智能化建设,针对传统实验室在运营监管、环境监测、安全管控、排课考勤等方面的问题,依据《智慧校园总体框架》等标准,设计数字孪生平台、实验室综合管理平台、消安电一体化平台三大核心平台,涵盖通信、安防、建筑设备管理等设施,涉及 395 个…...

玩转 AI · 思考过程可视化
玩转 AI 思考过程可视化 我们在开发 AI 的思维链 / 处理流时,难免遇到耗时较长的流程,如果遇到处理过慢的,用户什么也看不到可能丧失使用兴趣,对于这种情况,一个巧妙的产品思维就是呈现处理进度。 示例 其实完成这个页…...

hysAnalyser 从MPEG-TS导出ES功能说明
摘要 hysAnalyser 是一款特色的 MPEG-TS 数据分析工具。本文主要介绍了 hysAnalyser 从MPEG-TS 中导出选定的 ES 或 PES 功能(版本v1.0.003),以便用户知悉和掌握这些功能,帮助分析和解决各种遇到ES或PES相关的实际问题。hysAnalyser 支持主流的MP1/MP2/…...
YOLO V3的介绍)
[YOLO模型](4)YOLO V3的介绍
文章目录 YOLO V3一、模型思想二、模型性能三、改进的地方1. 三种scale2. scale变换经典方法3. 残差连接4. 核心网络架构(1) 结构(2) 输出与先验框关系 5. Logistic分类器替代Softmax 四、总结 YOLO V3 一、模型思想 作者 Redmon 又在 YOLOv2 的基础上做了一些改进:…...
21/6=3.5)
期望是什么:(无数次的均值,结合概率)21/6=3.5
https://seeing-theory.brown.edu/basic-probability/cn.html 期望是什么:(无数次的均值,结合概率)21/6=3.5 一、期望(数学概念) 在概率论和统计学中,**期望(Expectation)**是一个核心概念,用于描述随机变量的长期平均取值,反映随机变量取值的集中趋势。 (一…...
:集成学习中的“超级英雄团队”)
Stacking(堆叠):集成学习中的“超级英雄团队”
在机器学习的世界里,如果要找一个类似漫威“复仇者联盟”的存在,那么**Stacking(堆叠)**无疑是最佳候选人。就像钢铁侠、美国队长和雷神各自拥有独特的能力,但只有当他们组队时才能发挥出惊人的战斗力,Stac…...
)
手写tomcat:基本功能实现(3)
TomcatRoute类 TomcatRoute类是Servlet容器,是Tomcat中最核心的部分,其本身是一个HashMap,其功能为:将路径和对象写入Servlet容器中。 package com.qcby.config;import com.qcby.Util.SearchClassUtil; import com.qcby.servlet…...

nt!MiRemovePageByColor函数分析之脱链和刷新颜色表
第0部分:背景 PFN_NUMBER FASTCALL MiRemoveZeroPage ( IN ULONG Color ) { ASSERT (Color < MmSecondaryColors); Page FreePagesByColor[Color].Flink; if (Page ! MM_EMPTY_LIST) { // // Remove the first entry on the zeroe…...

时间筛掉了不够坚定的东西
2025年5月17日,16~25℃,还好 待办: 《高等数学1》重修考试 《高等数学2》备课 《物理[2]》备课 《高等数学2》取消考试资格学生名单 《物理[2]》取消考试资格名单 职称申报材料 2024年税务申报 5月24日、25日监考报名 遇见:敲了一…...

3D个人简历网站 4.小岛
1.模型素材 在Sketchfab上下载狐狸岛模型,然后转换为素材资源asset,嫌麻烦直接在网盘链接下载素材, Fox’s islandshttps://sketchfab.com/3d-models/foxs-islands-163b68e09fcc47618450150be7785907https://gltf.pmnd.rs/ 素材夸克网盘&a…...

第十一课 蜗牛爬树
上次作业 同学们课后可以尝试找一下30以内,哪个整数有最多的因数呢? 这个整数有多少个因数呢? 最好使用程序来进行判断哦 int main() {int max_num 1; // 记录因数最多的数int max_count 1; // 记录最大因数个数for (int num 2; num <…...

字体样式集合
根据您提供的字体样式列表,以下是分类整理后的完整字体样式名称(不含数量统计): 基础样式 • Regular • Normal • Plain • Medium • Bold • Black • Light • Thin • Heavy • Ultra • Extra • Semi • Hai…...
?)
Spring MVC 如何处理文件上传? 需要哪些配置和依赖?如何在 Controller 中接收上传的文件 (MultipartFile)?
Spring MVC 处理文件上传主要依赖于 MultipartResolver 接口及其实现。最常用的实现是 CommonsMultipartResolver(基于 Apache Commons FileUpload)和 StandardServletMultipartResolver(基于 Servlet 3.0 API)。 以下是如何配置…...
成员函数的深度解读(中篇))
探索C++对象模型:(拷贝构造、运算符重载)成员函数的深度解读(中篇)
前引:在C的面向对象编程中,对象模型是理解语言行为的核心。无论是类的成员函数如何访问数据,还是资源管理如何自动化,其底层机制均围绕两个关键概念展开:拷贝复制、取地址重载成员函数。它们如同对象的“隐形守护者”&…...
)
[逆向工程]C++实现DLL注入:原理、实现与防御全解析(二十五)
[逆向工程]C实现DLL注入:原理、实现与防御全解析(二十五) 引言 DLL注入(DLL Injection)是Windows系统下实现进程间通信、功能扩展、监控调试的核心技术之一。本文将从原理分析、代码实现、实战调试到防御方案&#x…...

gcc/g++常用参数
1.介绍 gcc用于编译c语言,g用于编译c 源代码生成可执行文件过程,预处理-编译-汇编-链接。https://zhuanlan.zhihu.com/p/476697014 2.常用参数说明 2.1编译过程控制 参数作用-oOutput,指定输出名字-cCompile,编译源文件生成对…...

51单片机课设基于GM65模块的二维码加条形码识别
系统组成 主控单元:51单片机(如STC89C52)作为核心控制器,协调各模块工作。 扫描模块:GM65条码扫描头,支持二维码/条形码识别,通过串口(UART)与单片机通信。 显示模块&a…...

物联网赋能7×24H无人值守共享自习室系统设计与实践!
随着"全民学习"浪潮的兴起,共享自习室市场也欣欣向荣,今天就带大家了解下在物联网的加持下,无人共享自习室系统的设计与实际方法。 一、物联网系统整体架构 1.1 系统分层设计 层级技术组成核心功能用户端微信小程序/H5预约选座、…...
增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化)
基于多头自注意力机制(MHSA)增强的YOLOv11主干网络—面向高精度目标检测的结构创新与性能优化
深度学习在计算机视觉领域的快速发展推动了目标检测算法的持续进步。作为实时检测框架的典型代表,YOLO系列凭借其高效性与准确性备受关注。本文提出一种基于多头自注意力机制(Multi-Head Self-Attention, MHSA)增强的YOLOv11主干网络结构,旨在提升模型在…...

使用Spring Boot与Spring Security构建安全的RESTful API
使用Spring Boot与Spring Security构建安全的RESTful API 引言 在现代Web应用开发中,安全性是不可忽视的重要环节。Spring Boot和Spring Security作为Java生态中的主流框架,为开发者提供了强大的工具来构建安全的RESTful API。本文将详细介绍如何结合S…...

小刚说C语言刷题—1230蝴蝶结
1.题目描述 请输出 n 行的蝴蝶结的形状,n 一定是一个奇数! 输入 一个整数 n ,代表图形的行数! 输出 n 行的图形。 样例 输入 9 输出 ***** **** *** ** * ** *** **** ***** 2.参考代码(C语言版)…...

利用SenseGlove触觉手套开发XR手术训练体验
VirtualiSurg和VR触觉 作为领先的培训平台,VirtualiSurg自2017年以来一直利用扩展现实 (XR) 和触觉技术,为全球医疗保健行业提供个性化、数据驱动的学习解决方案。该平台赋能医疗专业人员进行协作式学习和培训,提升他们的技能,使…...
—2D平行束投影公式)
CT重建笔记(五)—2D平行束投影公式
写的又回去了,因为我发现我理解不够透彻,反正想到啥写啥,尽量保证内容质量好简洁易懂 2D平行束投影公式 p ( s , θ ) ∫ ∫ f ( x , y ) δ ( x c o s θ y s i n θ − s ) d x d y p(s,\theta)\int \int f(x,y)\delta(x cos\theta ysi…...

【Java】应对高并发的思路
在Java中应对高并发场景需要结合多方面的技术手段和设计模式,从线程管理、数据结构、同步机制到异步处理、IO优化等,都需要合理设计和配置。以下是Java在高并发场景下的主要应对策略和最佳实践: 1. 线程管理 1.1 线程池(ThreadPo…...

从数据分析到数据可视化:揭开数据背后的故事
从数据分析到数据可视化:揭开数据背后的故事 大家好,今天咱们聊聊“从数据分析到数据可视化”的完整流程。说实话,数据分析和可视化这俩词听起来高大上,但咱们平时就是围绕这俩词打转——数据分析帮我们找故事,可视化则帮我们讲故事。没有它们,数据就是死的;有了它们,数…...

WPS JS宏实现去掉文档中的所有空行
WPS改造系列文章: 1.在WPS中通过JavaScript宏(JSA)调用本地DeepSeek API优化文档教程:在WPS中通过JavaScript宏(JSA)调用本地DeepSeek API优化文档教程_wps javascript-CSDN博客 2.在WPS中通过JavaScrip…...

【2025年软考中级】第一章1.6 安全性、可靠性、性能评价
文章目录 安全性、可靠性、性能评价计算机可靠性可靠性指标串并联系统可靠性并联系统可靠性N模元余系统 计算机系统性能评价信息安全加密技术对称(私钥)加密技术非对称加密技术(公钥)对称和非对称加密算法的区别数字信封原理数字签…...

MODBUS RTU通信协议详解与调试指南
一、MODBUS RTU简介 MODBUS RTU(Remote Terminal Unit)是一种基于串行通信(RS-485/RS-232)的工业标准协议,采用二进制数据格式,具有高效、可靠的特点,广泛应用于PLC、传感器、变频器等工业设备…...

【深度学习新浪潮】大模型时代,我们还需要学习传统机器学习么?
在大模型时代,AI 工程师仍需掌握传统机器学习知识,这不仅是技术互补的需求,更是应对复杂场景和职业发展的关键。以下从必要性和学习路径两方面展开分析: 一、传统机器学习在大模型时代的必要性 技术互补性 大模型(如GPT、BERT)擅长处理复杂语义和生成任务,但在数据量少…...

深入解析Spring Boot与Spring Security的集成实践
深入解析Spring Boot与Spring Security的集成实践 引言 在现代Web应用开发中,安全性是一个不可忽视的重要方面。Spring Security作为Spring生态中的安全框架,提供了强大的认证和授权功能。本文将结合Spring Boot,详细介绍如何集成Spring Se…...

嵌入式学习笔记 - STM32 使用一个外部触发同时启动两个定时器
一个定时器是同时可以设置成主模式跟从模式的, 下面例子中, 一 TM1首先被配置为主模式, 通过MMS001:使能 – 计数器使能信号CNT_EN被用于作为触发输出(TRGO)。见寄存器描述,此位默认为000,这时从模式状态…...

JWT令牌验证
一、JWT 验证方式详解 JWT(JSON Web Token)的验证核心是确保令牌未被篡改且符合业务规则,主要分为以下步骤: 1. 令牌解析与基础校验 收到客户端传递的 JWT 后,首先按 . 分割为三部分:Header、Payload、S…...

Go语言 GORM框架 使用指南
在 Go 语言社区中,数据库交互一直是开发者们关注的重点领域,不同开发者基于自身的需求和偏好,形成了两种主要的技术选型流派。一部分开发者钟情于像sqlx这类简洁的库,尽管其功能并非一应俱全,但它赋予开发者对 SQL 语句…...

c#车检车构客户管理系统软件车辆年审短信提醒软件
# CMS_VehicleInspection 车检车构客户管理系统软件车辆年审短信提醒软件 # 开发背景 软件是给泸州某公司开发的车检车构客户管理系统软件。用于在车检年审到期前一个月给客户发送车检短信提醒 # 功能描述 主要功能:车辆年审前一个月给客户发年审短信提醒…...
-《Go语言实战指南》原创)
匿名函数与闭包(Anonymous Functions and Closures)-《Go语言实战指南》原创
Go 支持将函数当作值来使用,也允许定义匿名函数,并通过闭包实现对外部变量的捕获与持续访问。这一特性使函数式编程风格在 Go 中成为可能。 一、什么是匿名函数? 匿名函数是没有名字的函数,可以定义后立即调用,或赋值…...

兰亭妙微:用系统化思维重构智能座舱 UI 体验
兰亭妙微设计专注于以产品逻辑驱动的界面体验优化,服务领域覆盖AI交互、智能穿戴、IoT设备、智慧出行等多个技术密集型产业。我们倡导以“系统性设计”为方法论,在用户需求与技术边界之间找到最优解。 此次智能驾驶项目,我们为某车载平台提供…...

Flowbite 和 daisyUI 那个好用?
Flowbite 和 daisyUI 都是基于 Tailwind CSS 的组件库,它们各有特色,选哪个更好用,取决于你的项目需求和设计偏好。 简要结论 对比项daisyUIFlowbite上手难度简单,类名即组件略复杂(多用 HTML 结构)Vue 支…...

中间网络工程师知识点5
1.PKI证书主要用于确保主体公钥的合法性 2.VLAN帧的最小帧长是64字节,其中表示帧优先级的字是PRI 3.WIFI6是2.4GHZ和5GHZ频段的,理论吞吐量最高可达9.6Gbps,遵从协议802.11ax,支持完整版的MU-MIMO 4.在大型无线网络中,AP通过DHCP option43端口来获取AC的IP地址 5.项目…...

二、数据模型
二、数据模型 数据模型回顾 数据模型(Data Model) 是信息领域采用的模型将现实世界的各种事物以及事物之间的联系,表示为数据以及数据之间的联系是对现实世界数据特征的抽象和模拟用来描述数据、组织数据和操作数是数据库系统的核心和基础 …...

获取淘宝店铺所有商品信息接口数据指南
在电商运营和数据分析中,获取淘宝店铺的商品信息是常见的需求。淘宝开放平台提供了丰富的 API 接口,方便开发者获取商品的详细信息,包括商品列表、商品详情、销量等。本文将详细介绍如何从零开始获取淘宝店铺的所有商品信息,包括注…...

目标检测工作原理:从滑动窗口到Haar特征检测的完整实现
目标检测探索指南 🔍 目标检测就像是一位细心的侦探!我们需要在图像中寻找并定位特定的目标,就像侦探在现场搜寻线索一样。让我们一起来探索这个充满挑战的图像处理领域吧! 目录 1. 什么是目标检测?2. 滑动窗口检测3.…...